mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-06-16 18:10:13 +08:00
commit
7bc7370d4b
@ -88,6 +88,8 @@
|
||||
|
||||
**重要知识点详解**:
|
||||
|
||||
- [乐观锁和悲观锁详解](./docs/java/concurrent/jmm.md)
|
||||
- [CAS 详解](./docs/java/concurrent/cas.md)
|
||||
- [JMM(Java 内存模型)详解](./docs/java/concurrent/jmm.md)
|
||||
- **线程池**:[Java 线程池详解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./docs/java/concurrent/java-thread-pool-best-practices.md)
|
||||
- [ThreadLocal 详解](./docs/java/concurrent/threadlocal.md)
|
||||
|
||||
@ -34,6 +34,7 @@ export const highQualityTechnicalArticles = arraySidebar([
|
||||
prefix: "programmer/",
|
||||
collapsible: false,
|
||||
children: [
|
||||
"high-value-certifications-for-programmers",
|
||||
"how-do-programmers-publish-a-technical-book",
|
||||
"efficient-book-publishing-and-practice-guide",
|
||||
],
|
||||
|
||||
@ -112,6 +112,7 @@ export default sidebar({
|
||||
collapsible: true,
|
||||
children: [
|
||||
"optimistic-lock-and-pessimistic-lock",
|
||||
"cas",
|
||||
"jmm",
|
||||
"java-thread-pool-summary",
|
||||
"java-thread-pool-best-practices",
|
||||
|
||||
@ -48,14 +48,14 @@ export default hopeTheme({
|
||||
notice: [
|
||||
{
|
||||
path: "/",
|
||||
title: "2023技术年货汇总",
|
||||
title: "PDF面试资料(2024版)",
|
||||
showOnce: true,
|
||||
content:
|
||||
"抽空整理了一些优秀的技术团队公众号 2023 年的优质技术文章汇总,质量都挺高的,强烈建议打开这篇文章看看。",
|
||||
"2024最新版原创PDF面试资料来啦!涵盖 Java 核心、数据库、缓存、分布式、设计模式、智力题等内容,非常全面!",
|
||||
actions: [
|
||||
{
|
||||
text: "开始阅读",
|
||||
link: "https://www.yuque.com/snailclimb/dr6cvl/nt5qc467p3t6s13k?singleDoc# 《2023技术年货》",
|
||||
text: "点击领取",
|
||||
link: "https://oss.javaguide.cn/backend-notekbook/official-account-traffic-backend-notebook-with-data-screenshot.png",
|
||||
type: "primary",
|
||||
},
|
||||
],
|
||||
|
||||
@ -61,6 +61,10 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
|
||||
|
||||
我的最终军衔停留在了两个钻石,玩过的小伙伴应该清楚这在当时要玩多少把(现在升级比较简单)。
|
||||
|
||||
|
||||
|
||||
ps: 回坑 CF 快一年了,目前的军衔是到了两颗星中校 3 了。
|
||||
|
||||
那时候成绩挺差的。这样说吧!我当时在很普通的一个县级市的高中,全年级有 500 来人,我基本都是在 280 名左右。而且,整个初二我都没有学物理,上物理课就睡觉,考试就交白卷。
|
||||
|
||||
为什么对物理这么抵触呢?这是因为开学不久的一次物理课,物理老师误会我在上课吃东西还狡辩,扇了我一巴掌。那时候心里一直记仇到大学,想着以后自己早晚有时间把这个物理老师暴打一顿。
|
||||
@ -109,8 +113,6 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
|
||||
|
||||
于是,我便开始牟足劲学习,每天都沉迷学习无法自拔(豪不夸张),乐在其中。虽然晚自习上完回到家已经差不多 11 点了,但也并不感觉累,反而感觉很快乐,很充实。
|
||||
|
||||

|
||||
|
||||
**我的付出也很快得到了回报,我顺利返回了奥赛班。** 当时,理科平行班大概有 7 个,每次考试都是平行班之间会单独排一个名次,小班和奥赛班不和我们一起排名次。后面的话,自己基本每次都能在平行班得第一,并且很多时候都是领先第二名 30 来分。由于成绩还算亮眼,高三上学期快结束的时候,我就向年级主任申请去了奥赛班。
|
||||
|
||||
## 高考前的失眠
|
||||
@ -125,9 +127,11 @@ QQ 飞车这款戏当时还挺火的,很多 90 后的小伙伴应该比较熟
|
||||
|
||||

|
||||
|
||||
高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,身上还起了一些小痘痘。
|
||||
高考那几天的失眠,我觉得可能和我喝了老师推荐的安神补脑液有关系,又或者是我自己太过于紧张了。因为那几天睡觉总会感觉有很多蚂蚁在身上爬一样,身上还起了一些小痘痘(有点像是过敏)。
|
||||
|
||||
然后,这里要格外说明一点,避免引起误导:**睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
|
||||
这里要格外说明一点,避免引起误导:**睡不着本身就是自身的问题,上述言论并没有责怪这个补脑液的意思。** 另外, 这款安神补脑液我去各个平台都查了一下,发现大家对他的评价都挺好,和我们老师当时推荐的理由差不多。如果大家需要改善睡眠的话,可以咨询相关医生之后尝试一下。
|
||||
|
||||
高考也确实没发挥好,整个人在考场都是懵的状态。高考成绩出来之后,比我自己预估的还低了几十分,最后只上了一个双非一本。不过,好在专业选的好,吃了一些计算机专业的红利,大学期间也挺努力的。
|
||||
|
||||
## 大学生活
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 我的知识星球快 3 岁了!
|
||||
title: 我的知识星球 4 岁了!
|
||||
category: 知识星球
|
||||
star: 2
|
||||
---
|
||||
|
||||
@ -148,7 +148,7 @@ public class MyBloomFilter {
|
||||
*/
|
||||
public int hash(Object value) {
|
||||
int h;
|
||||
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
|
||||
return (value == null) ? 0 : Math.abs((cap - 1) & seed * ((h = value.hashCode()) ^ (h >>> 16)));
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@ -50,7 +50,7 @@ tag:
|
||||
|
||||
### 完全二叉树
|
||||
|
||||
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 **完全二叉树** 。
|
||||
除最后一层外,若其余层都是满的,并且最后一层是满的或者是在右边缺少连续若干节点,则这个二叉树就是 **完全二叉树** 。
|
||||
|
||||
大家可以想象为一棵树从根结点开始扩展,扩展完左子节点才能开始扩展右子节点,每扩展完一层,才能继续扩展下一层。如下图所示:
|
||||
|
||||
|
||||
@ -102,7 +102,7 @@ FTP 是基于客户—服务器(C/S)模型而设计的,在客户端与 FTP
|
||||
|
||||
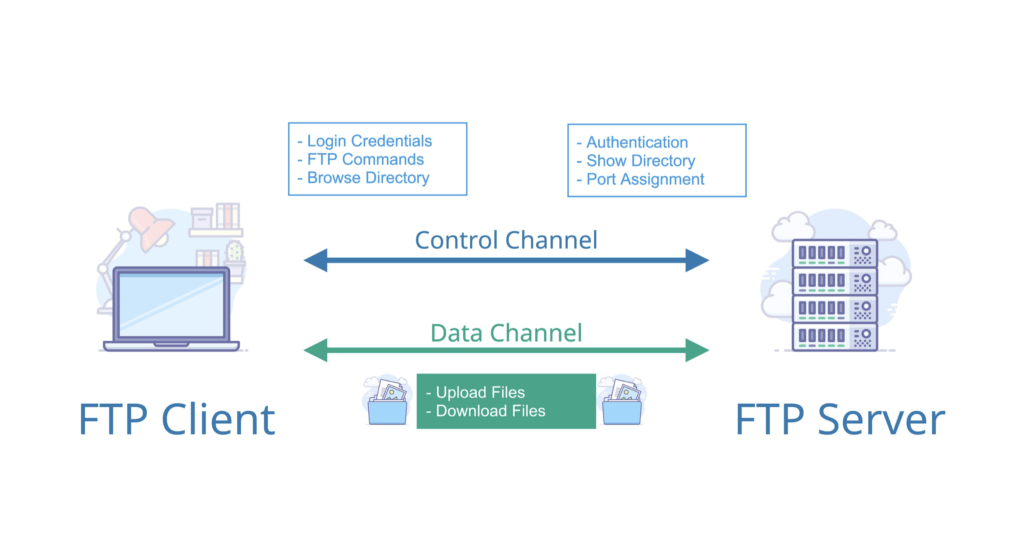
|
||||
|
||||
注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。因此,FTP 传输的文件可能会被窃听或篡改。建议在传输敏感数据时使用更安全的协议,如 SFTP(一种基于 SSH 协议的安全文件传输协议,用于在网络上安全地传输文件)。
|
||||
注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。因此,FTP 传输的文件可能会被窃听或篡改。建议在传输敏感数据时使用更安全的协议,如 SFTP(SSH File Transfer Protocol,一种基于 SSH 协议的安全文件传输协议,用于在网络上安全地传输文件)。
|
||||
|
||||
## Telnet:远程登陆协议
|
||||
|
||||
@ -114,10 +114,12 @@ FTP 是基于客户—服务器(C/S)模型而设计的,在客户端与 FTP
|
||||
|
||||
**SSH(Secure Shell)** 基于 TCP 协议,通过加密和认证机制实现安全的访问和文件传输等业务。
|
||||
|
||||
SSH 的经典用途是登录到远程电脑中执行命令。除此之外,SSH 也支持隧道协议、端口映射和 X11 连接。借助 SFTP 或 SCP 协议,SSH 还可以传输文件。
|
||||
SSH 的经典用途是登录到远程电脑中执行命令。除此之外,SSH 也支持隧道协议、端口映射和 X11 连接(允许用户在本地运行远程服务器上的图形应用程序)。借助 SFTP(SSH File Transfer Protocol) 或 SCP(Secure Copy Protocol) 协议,SSH 还可以安全传输文件。
|
||||
|
||||
SSH 使用客户端-服务器模型,默认端口是 22。SSH 是一个守护进程,负责实时监听客户端请求,并进行处理。大多数现代操作系统都提供了 SSH。
|
||||
|
||||
如下图所示,SSH Client(SSH 客户端)和 SSH Server(SSH 服务器)通过公钥交换生成共享的对称加密密钥,用于后续的加密通信。
|
||||
|
||||
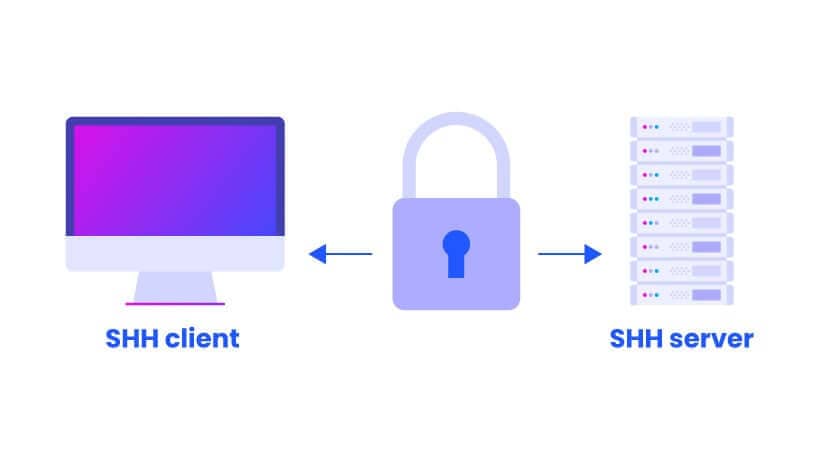
|
||||
|
||||
## RTP:实时传输协议
|
||||
|
||||
@ -94,7 +94,7 @@ tag:
|
||||
- **ARP(Address Resolution Protocol,地址解析协议)**:ARP 协议解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||
- **ICMP(Internet Control Message Protocol,互联网控制报文协议)**:一种用于传输网络状态和错误消息的协议,常用于网络诊断和故障排除。例如,Ping 工具就使用了 ICMP 协议来测试网络连通性。
|
||||
- **NAT(Network Address Translation,网络地址转换协议)**:NAT 协议的应用场景如同它的名称——网络地址转换,应用于内部网到外部网的地址转换过程中。具体地说,在一个小的子网(局域网,LAN)内,各主机使用的是同一个 LAN 下的 IP 地址,但在该 LAN 以外,在广域网(WAN)中,需要一个统一的 IP 地址来标识该 LAN 在整个 Internet 上的位置。
|
||||
- **OSPF(Open Shortest Path First,开放式最短路径优先)** ):一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
|
||||
- **OSPF(Open Shortest Path First,开放式最短路径优先)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是广泛使用的一种动态路由协议,基于链路状态算法,考虑了链路的带宽、延迟等因素来选择最佳路径。
|
||||
- **RIP(Routing Information Protocol,路由信息协议)**:一种内部网关协议(Interior Gateway Protocol,IGP),也是一种动态路由协议,基于距离向量算法,使用固定的跳数作为度量标准,选择跳数最少的路径作为最佳路径。
|
||||
- **BGP(Border Gateway Protocol,边界网关协议)**:一种用来在路由选择域之间交换网络层可达性信息(Network Layer Reachability Information,NLRI)的路由选择协议,具有高度的灵活性和可扩展性。
|
||||
|
||||
@ -132,40 +132,40 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
||||
|
||||
### HTTP Header 中常见的字段有哪些?
|
||||
|
||||
| 请求头字段名 | 说明 | 示例 |
|
||||
| :------------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :----------------------------------------------------------------------------------------- |
|
||||
| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
|
||||
| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
|
||||
| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
|
||||
| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
|
||||
| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
|
||||
| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
|
||||
| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
|
||||
| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive Connection: Upgrade |
|
||||
| Content-Length | 以 八位字节数组 (8 位的字节)表示的请求体的长度 | Content-Length: 348 |
|
||||
| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
|
||||
| Content-Type | 请求体的 多媒体类型 (用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
|
||||
| Cookie | 之前由服务器通过 Set- Cookie (下文详述)发送的一个 超文本传输协议 Cookie | Cookie: \$Version=1; Skin=new; |
|
||||
| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
|
||||
| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
|
||||
| From | 发起此请求的用户的邮件地址 | From: [user@example.com](mailto:user@example.com) |
|
||||
| Host | 服务器的域名(用于虚拟主机 ),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org:80 |
|
||||
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用时,用作像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
|
||||
| If-Modified-Since | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
|
||||
| If-None-Match | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ) | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
|
||||
| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: “737060cd8c284d8af7ad3082f209582d” |
|
||||
| If-Unmodified-Since | 仅当该实体自某个特定时间已来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
|
||||
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
|
||||
| Origin | 发起一个针对 跨来源资源共享 的请求。 | Origin: [http://www.example-social-network.com](http://www.example-social-network.com/) |
|
||||
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
|
||||
| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
|
||||
| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
|
||||
| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | Referer: [http://en.wikipedia.org/wiki/Main_Page](https://en.wikipedia.org/wiki/Main_Page) |
|
||||
| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
|
||||
| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
|
||||
| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
|
||||
| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
|
||||
| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
|
||||
| 请求头字段名 | 说明 | 示例 |
|
||||
| :------------------ | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :-------------------------------------------------------------------------------------- |
|
||||
| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
|
||||
| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
|
||||
| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
|
||||
| Accept-Encoding | 能够接受的编码方式列表。参考 HTTP 压缩。 | Accept-Encoding: gzip, deflate |
|
||||
| Accept-Language | 能够接受的回应内容的自然语言列表。 | Accept-Language: en-US |
|
||||
| Authorization | 用于超文本传输协议的认证的认证信息 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
|
||||
| Cache-Control | 用来指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令 | Cache-Control: no-cache |
|
||||
| Connection | 该浏览器想要优先使用的连接类型 | Connection: keep-alive |
|
||||
| Content-Length | 以八位字节数组(8 位的字节)表示的请求体的长度 | Content-Length: 348 |
|
||||
| Content-MD5 | 请求体的内容的二进制 MD5 散列值,以 Base64 编码的结果 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
|
||||
| Content-Type | 请求体的多媒体类型(用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded |
|
||||
| Cookie | 之前由服务器通过 Set-Cookie(下文详述)发送的一个超文本传输协议 Cookie | Cookie: $Version=1; Skin=new; |
|
||||
| Date | 发送该消息的日期和时间(按照 RFC 7231 中定义的"超文本传输协议日期"格式来发送) | Date: Tue, 15 Nov 1994 08:12:31 GMT |
|
||||
| Expect | 表明客户端要求服务器做出特定的行为 | Expect: 100-continue |
|
||||
| From | 发起此请求的用户的邮件地址 | From: [user@example.com](mailto:user@example.com) |
|
||||
| Host | 服务器的域名(用于虚拟主机),以及服务器所监听的传输控制协议端口号。如果所请求的端口是对应的服务的标准端口,则端口号可被省略。 | Host: en.wikipedia.org |
|
||||
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要作用是用于像 PUT 这样的方法中,仅当从用户上次更新某个资源以来,该资源未被修改的情况下,才更新该资源。 | If-Match: "737060cd8c284d8af7ad3082f209582d" |
|
||||
| If-Modified-Since | 允许服务器在请求的资源自指定的日期以来未被修改的情况下返回 `304 Not Modified` 状态码 | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
|
||||
| If-None-Match | 允许服务器在请求的资源的 ETag 未发生变化的情况下返回 `304 Not Modified` 状态码 | If-None-Match: "737060cd8c284d8af7ad3082f209582d" |
|
||||
| If-Range | 如果该实体未被修改过,则向我发送我所缺少的那一个或多个部分;否则,发送整个新的实体 | If-Range: "737060cd8c284d8af7ad3082f209582d" |
|
||||
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
|
||||
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 |
|
||||
| Origin | 发起一个针对跨来源资源共享的请求。 | Origin: [http://www.example-social-network.com](http://www.example-social-network.com/) |
|
||||
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生多种效果。 | Pragma: no-cache |
|
||||
| Proxy-Authorization | 用来向代理进行认证的认证信息。 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
|
||||
| Range | 仅请求某个实体的一部分。字节偏移以 0 开始。参见字节服务。 | Range: bytes=500-999 |
|
||||
| Referer | 表示浏览器所访问的前一个页面,正是那个页面上的某个链接将浏览器带到了当前所请求的这个页面。 | Referer: http://en.wikipedia.org/wiki/Main_Page |
|
||||
| TE | 浏览器预期接受的传输编码方式:可使用回应协议头 Transfer-Encoding 字段中的值; | TE: trailers, deflate |
|
||||
| Upgrade | 要求服务器升级到另一个协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
|
||||
| User-Agent | 浏览器的浏览器身份标识字符串 | User-Agent: Mozilla/5.0 (X11; Linux x86_64; rv:12.0) Gecko/20100101 Firefox/21.0 |
|
||||
| Via | 向服务器告知,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 example.com (Apache/1.1) |
|
||||
| Warning | 一个一般性的警告,告知,在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning |
|
||||
|
||||
### HTTP 和 HTTPS 有什么区别?(重要)
|
||||
|
||||
@ -211,14 +211,25 @@ HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://b
|
||||
|
||||
- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
|
||||
- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
|
||||
- **头部压缩**:HTTP/2.0 使用 HPACK 算法进行头部压缩,而 HTTP/3.0 使用更高效的 QPACK 头压缩算法。
|
||||
- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
|
||||
- **连接迁移**:HTTP/3.0 支持连接迁移,因为 QUIC 使用 64 位 ID 标识连接,只要 ID 不变就不会中断,网络环境改变时(如从 Wi-Fi 切换到移动数据)也能保持连接。而 TCP 连接是由(源 IP,源端口,目的 IP,目的端口)组成,这个四元组中一旦有一项值发生改变,这个连接也就不能用了。
|
||||
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
|
||||
- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
|
||||
- **安全性**:HTTP/2.0 和 HTTP/3.0 都支持加密通信,但实现方式不同。HTTP/2.0 依赖 TLS 协议加密,而 HTTP/3.0 基于 QUIC 协议,QUIC 内置了 TLS 1.3,能更快建立连接,并减少网络报头信息暴露,提升了安全性和隐私性。
|
||||
|
||||
HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
|
||||
|
||||

|
||||
|
||||
下图是一个更详细的 HTTP/2.0 和 HTTP/3.0 对比图:
|
||||
|
||||
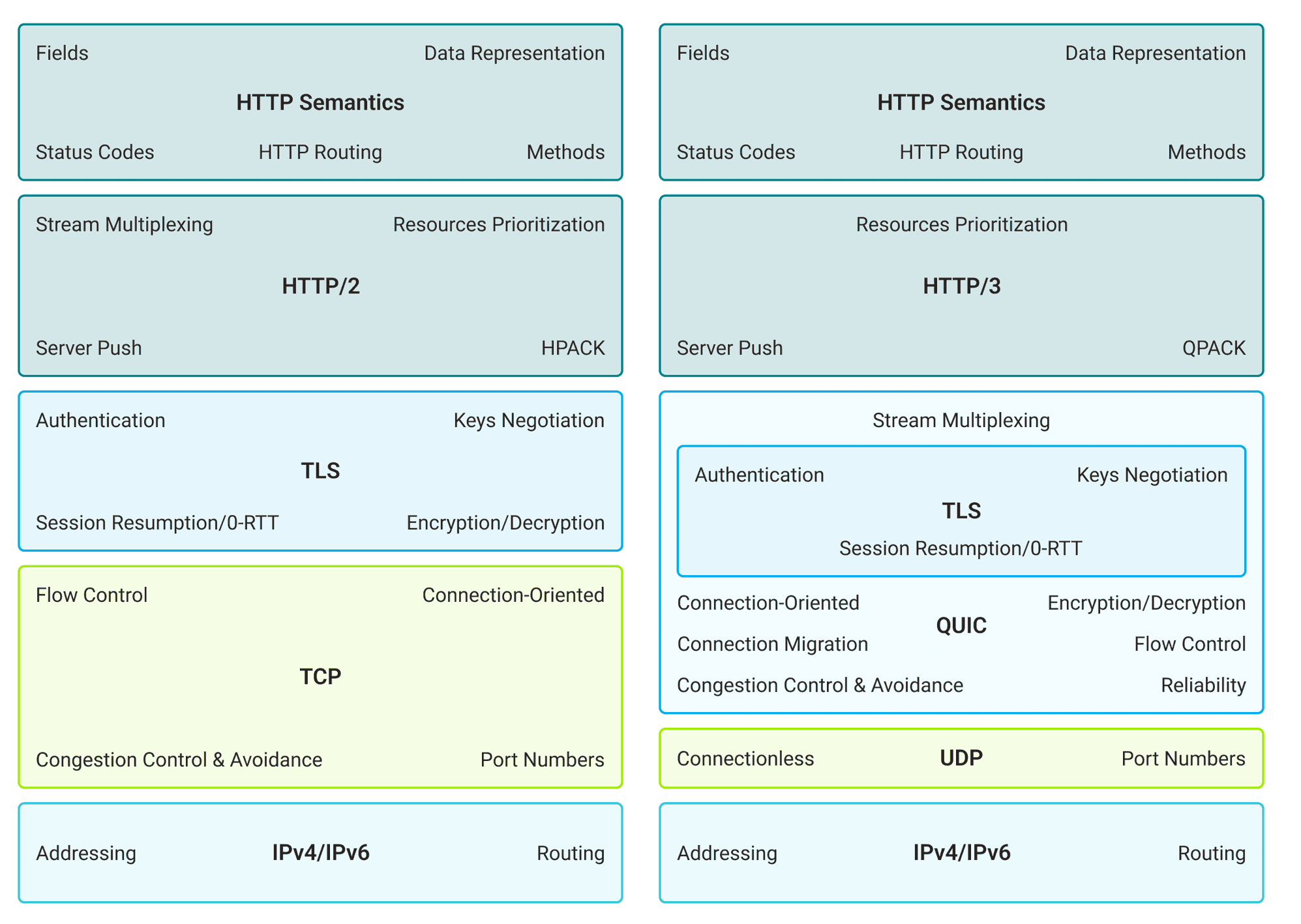
|
||||
|
||||
从上图可以看出:
|
||||
|
||||
- **HTTP/2.0**:使用 TCP 作为传输协议、使用 HPACK 进行头部压缩、依赖 TLS 进行加密。
|
||||
- **HTTP/3.0**:使用基于 UDP 的 QUIC 协议、使用更高效的 QPACK 进行头部压缩、在 QUIC 中直接集成了 TLS。QUIC 协议具备连接迁移、拥塞控制与避免、流量控制等特性。
|
||||
|
||||
关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
|
||||
|
||||
### HTTP 是不保存状态的协议, 如何保存用户状态?
|
||||
@ -317,7 +328,7 @@ SSE 与 WebSocket 作用相似,都可以建立服务端与浏览器之间的
|
||||
|
||||
SSE 好像一直不被大家所熟知,一部分原因是出现了 WebSocket,这个提供了更丰富的协议来执行双向、全双工通信。对于游戏、即时通信以及需要双向近乎实时更新的场景,拥有双向通道更具吸引力。
|
||||
|
||||
但是,在某些情况下,不需要从客户端发送数据。而你只需要一些服务器操作的更新。比如:站内信、未读消息数、状态更新、股票行情、监控数量等场景,SEE 不管是从实现的难易和成本上都更加有优势。此外,SSE 具有 WebSocket 在设计上缺乏的多种功能,例如:自动重新连接、事件 ID 和发送任意事件的能力。
|
||||
但是,在某些情况下,不需要从客户端发送数据。而你只需要一些服务器操作的更新。比如:站内信、未读消息数、状态更新、股票行情、监控数量等场景,SSE 不管是从实现的难易和成本上都更加有优势。此外,SSE 具有 WebSocket 在设计上缺乏的多种功能,例如:自动重新连接、事件 ID 和发送任意事件的能力。
|
||||
|
||||
## PING
|
||||
|
||||
|
||||
@ -282,7 +282,7 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
|
||||
|
||||
|
||||
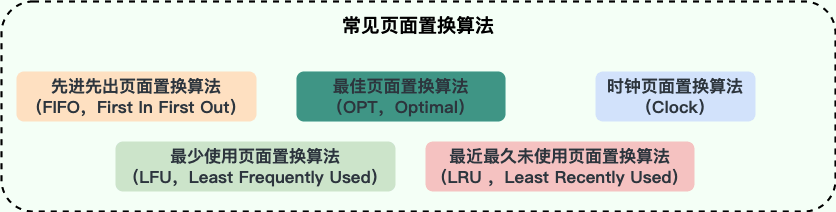
1. **最佳页面置换算法(OPT,Optimal)**:优先选择淘汰的页面是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若干页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现,只是理论最优的页面置换算法,可以作为衡量其他置换算法优劣的标准。
|
||||
2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可需求。不过,它的性能并不是很好。
|
||||
2. **先进先出页面置换算法(FIFO,First In First Out)** : 最简单的一种页面置换算法,总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。该算法易于实现和理解,一般只需要通过一个 FIFO 队列即可满足需求。不过,它的性能并不是很好。
|
||||
3. **最近最久未使用页面置换算法(LRU ,Least Recently Used)**:LRU 算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。LRU 算法是根据各页之前的访问情况来实现,因此是易于实现的。OPT 算法是根据各页未来的访问情况来实现,因此是不可实现的。
|
||||
4. **最少使用页面置换算法(LFU,Least Frequently Used)** : 和 LRU 算法比较像,不过该置换算法选择的是之前一段时间内使用最少的页面作为淘汰页。
|
||||
5. **时钟页面置换算法(Clock)**:可以认为是一种最近未使用算法,即逐出的页面都是最近没有使用的那个。
|
||||
|
||||
@ -87,7 +87,7 @@ ER 图由下面 3 个要素组成:
|
||||
为什么不要用外键呢?大部分人可能会这样回答:
|
||||
|
||||
1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
|
||||
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗数据库资源。如果在应用层面去维护的话,可以减小数据库压力;
|
||||
3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
|
||||
4. ……
|
||||
|
||||
|
||||
@ -88,7 +88,7 @@ SELECT * FROM tb1 WHERE id < 500;
|
||||
|
||||
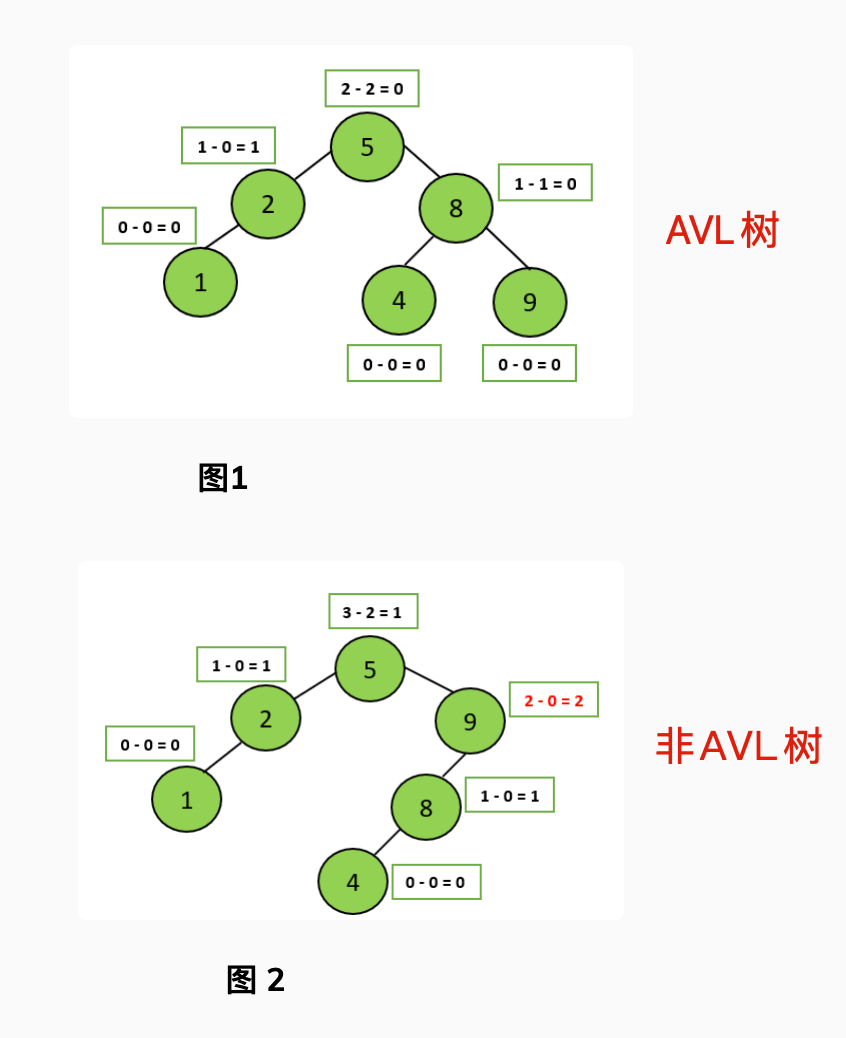
AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
|
||||
|
||||
|
||||

|
||||
|
||||
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
|
||||
|
||||
@ -385,6 +385,14 @@ EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk'
|
||||
SELECT * FROM student WHERE class = 'lIrm08RYVk';
|
||||
```
|
||||
|
||||
再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1`会走索引么?`c=1` 呢?`b=1 AND c=1`呢?
|
||||
|
||||
先不要往下看答案,给自己 3 分钟时间想一想。
|
||||
|
||||
1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
|
||||
2. 查询 `c=1` :由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
|
||||
3. 查询`b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
|
||||
|
||||
MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
|
||||
|
||||
## 索引下推
|
||||
|
||||
@ -249,7 +249,11 @@ mysql> SHOW VARIABLES LIKE '%storage_engine%';
|
||||
|
||||
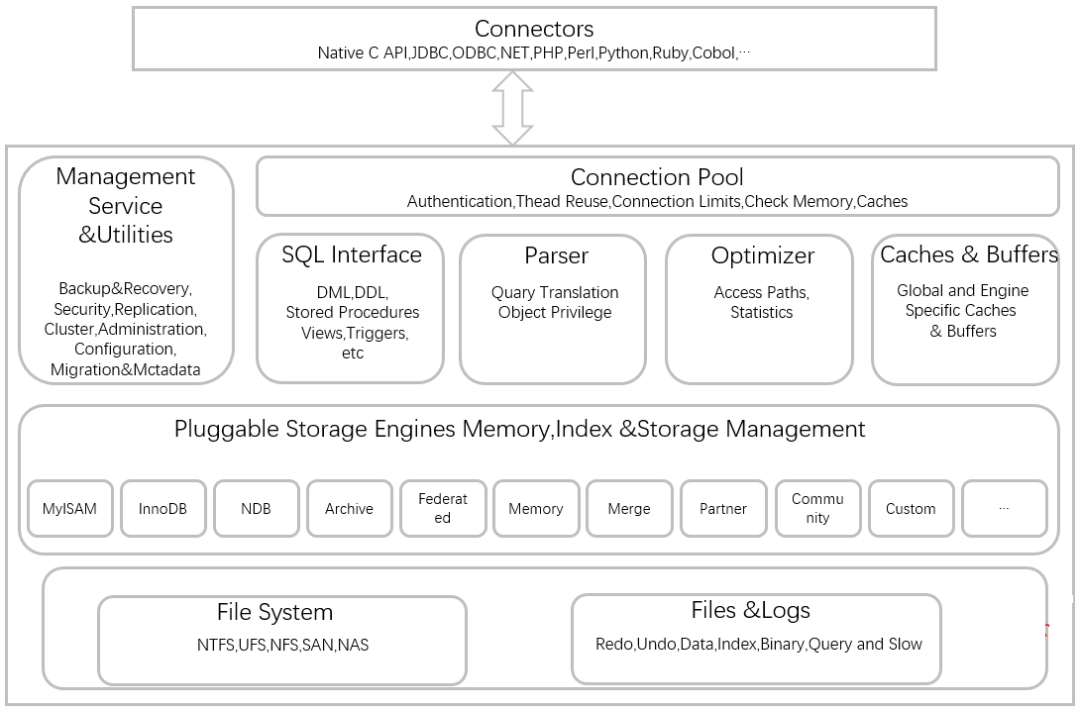
MySQL 存储引擎采用的是 **插件式架构** ,支持多种存储引擎,我们甚至可以为不同的数据库表设置不同的存储引擎以适应不同场景的需要。**存储引擎是基于表的,而不是数据库。**
|
||||
|
||||
并且,你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
|
||||
下图展示了具有可插拔存储引擎的 MySQL 架构():
|
||||
|
||||
|
||||
|
||||
你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
|
||||
|
||||
MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址:<https://dev.mysql.com/doc/internals/en/custom-engine.html> 。
|
||||
|
||||
@ -337,15 +341,13 @@ InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使
|
||||
|
||||
### MyISAM 和 InnoDB 如何选择?
|
||||
|
||||
大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊!)。
|
||||
大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊)。
|
||||
|
||||
《MySQL 高性能》上面有一句话这样写到:
|
||||
|
||||
> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
|
||||
|
||||
一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择 MyISAM 也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
|
||||
|
||||
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
|
||||
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
|
||||
|
||||
## MySQL 索引
|
||||
|
||||
@ -353,7 +355,7 @@ MySQL 索引相关的问题比较多,对于面试和工作都比较重要,
|
||||
|
||||
## MySQL 查询缓存
|
||||
|
||||
执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
|
||||
MySQL 查询缓存是查询结果缓存。执行查询语句的时候,会先查询缓存,如果缓存中有对应的查询结果,就会直接返回。
|
||||
|
||||
`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
|
||||
|
||||
@ -369,7 +371,7 @@ set global query_cache_type=1;
|
||||
set global query_cache_size=600000;
|
||||
```
|
||||
|
||||
如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。
|
||||
查询缓存会在同样的查询条件和数据情况下,直接返回缓存中的结果。但需要注意的是,查询缓存的匹配条件非常严格,任何细微的差异都会导致缓存无法命中。这里的查询条件包括查询语句本身、当前使用的数据库、以及其他可能影响结果的因素,如客户端协议版本号等。
|
||||
|
||||
**查询缓存不命中的情况:**
|
||||
|
||||
@ -377,12 +379,16 @@ set global query_cache_size=600000;
|
||||
2. 如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
|
||||
3. 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
||||
|
||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,**还可以通过 `sql_cache` 和 `sql_no_cache` 来控制某个查询语句是否需要缓存:**
|
||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,还可以通过 `sql_cache` 和 `sql_no_cache` 来控制某个查询语句是否需要缓存:
|
||||
|
||||
```sql
|
||||
SELECT sql_no_cache COUNT(*) FROM usr;
|
||||
```
|
||||
|
||||
MySQL 5.6 开始,查询缓存已默认禁用。MySQL 8.0 开始,已经不再支持查询缓存了(具体可以参考这篇文章:[MySQL 8.0: Retiring Support for the Query Cache](https://dev.mysql.com/blog-archive/mysql-8-0-retiring-support-for-the-query-cache/))。
|
||||
|
||||

|
||||
|
||||
## MySQL 日志
|
||||
|
||||
MySQL 日志常见的面试题有:
|
||||
@ -642,7 +648,7 @@ SELECT ... FOR UPDATE;
|
||||
- **意向共享锁(Intention Shared Lock,IS 锁)**:事务有意向对表中的某些记录加共享锁(S 锁),加共享锁前必须先取得该表的 IS 锁。
|
||||
- **意向排他锁(Intention Exclusive Lock,IX 锁)**:事务有意向对表中的某些记录加排他锁(X 锁),加排他锁之前必须先取得该表的 IX 锁。
|
||||
|
||||
**意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InooDB 会先获取该数据行所在在数据表的对应意向锁。**
|
||||
**意向锁是由数据引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享/排他锁之前,InnoDB 会先获取该数据行所在在数据表的对应意向锁。**
|
||||
|
||||
意向锁之间是互相兼容的。
|
||||
|
||||
|
||||
@ -640,11 +640,11 @@ void bioKillThreads(void);
|
||||
|
||||
## Redis 内存管理
|
||||
|
||||
### Redis 给缓存数据设置过期时间有啥用?
|
||||
### Redis 给缓存数据设置过期时间有什么用?
|
||||
|
||||
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
|
||||
|
||||
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
|
||||
内存是有限且珍贵的,如果不对缓存数据设置过期时间,那内存占用就会一直增长,最终可能会导致 OOM 问题。通过设置合理的过期时间,Redis 会自动删除暂时不需要的数据,为新的缓存数据腾出空间。
|
||||
|
||||
Redis 自带了给缓存数据设置过期时间的功能,比如:
|
||||
|
||||
@ -657,7 +657,7 @@ OK
|
||||
(integer) 56
|
||||
```
|
||||
|
||||
注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间。**
|
||||
注意 ⚠️:Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间。
|
||||
|
||||
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
|
||||
|
||||
@ -689,7 +689,7 @@ typedef struct redisDb {
|
||||
|
||||
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
|
||||
|
||||
常用的过期数据的删除策略就下面这几种(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
||||
常用的过期数据的删除策略就下面这几种:
|
||||
|
||||
1. **惰性删除**:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
||||
2. **定期删除**:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
|
||||
|
||||
@ -1095,13 +1095,14 @@ WHERE b.prod_id = 'BR01'
|
||||
|
||||
```sql
|
||||
# 写法 1:子查询
|
||||
SELECT o.cust_id AS cust_id, tb.total_ordered AS total_ordered
|
||||
FROM (SELECT order_num, Sum(item_price * quantity) AS total_ordered
|
||||
SELECT o.cust_id, SUM(tb.total_ordered) AS `total_ordered`
|
||||
FROM (SELECT order_num, SUM(item_price * quantity) AS total_ordered
|
||||
FROM OrderItems
|
||||
GROUP BY order_num) AS tb,
|
||||
Orders o
|
||||
WHERE tb.order_num = o.order_num
|
||||
ORDER BY total_ordered DESC
|
||||
GROUP BY o.cust_id
|
||||
ORDER BY total_ordered DESC;
|
||||
|
||||
# 写法 2:连接表
|
||||
SELECT b.cust_id, Sum(a.quantity * a.item_price) AS total_ordered
|
||||
@ -1111,6 +1112,8 @@ GROUP BY cust_id
|
||||
ORDER BY total_ordered DESC
|
||||
```
|
||||
|
||||
关于写法一详细介绍可以参考: [issue#2402:写法 1 存在的错误以及修改方法](https://github.com/Snailclimb/JavaGuide/issues/2402)。
|
||||
|
||||
### 从 Products 表中检索所有的产品名称以及对应的销售总数
|
||||
|
||||
`Products` 表中检索所有的产品名称:`prod_name`、产品 id:`prod_id`
|
||||
@ -1653,12 +1656,12 @@ ORDER BY prod_name
|
||||
注意:`vend_id` 列会显示在多个表中,因此在每次引用它时都需要完全限定它。
|
||||
|
||||
```sql
|
||||
SELECT vend_id, COUNT(prod_id) AS prod_id
|
||||
FROM Vendors
|
||||
LEFT JOIN Products
|
||||
SELECT v.vend_id, COUNT(prod_id) AS prod_id
|
||||
FROM Vendors v
|
||||
LEFT JOIN Products p
|
||||
USING(vend_id)
|
||||
GROUP BY vend_id
|
||||
ORDER BY vend_id
|
||||
GROUP BY v.vend_id
|
||||
ORDER BY v.vend_id
|
||||
```
|
||||
|
||||
## 组合查询
|
||||
|
||||
@ -216,9 +216,9 @@ WHERE info.exam_id = record.exam_id
|
||||
|
||||
| total_pv | complete_pv | complete_exam_cnt |
|
||||
| -------- | ----------- | ----------------- |
|
||||
| 11 | 7 | 2 |
|
||||
| 10 | 7 | 2 |
|
||||
|
||||
解释:表示截止当前,有 11 次试卷作答记录,已完成的作答次数为 7 次(中途退出的为未完成状态,其交卷时间和份数为 NULL),已完成的试卷有 9001 和 9002 两份。
|
||||
解释:表示截止当前,有 10 次试卷作答记录,已完成的作答次数为 7 次(中途退出的为未完成状态,其交卷时间和份数为 NULL),已完成的试卷有 9001 和 9002 两份。
|
||||
|
||||
**思路**: 这题一看到统计次数,肯定第一时间就要想到用`COUNT`这个函数来解决,问题是要统计不同的记录,该怎么来写?使用子查询就能解决这个题目(这题用 case when 也能写出来,解法类似,逻辑不同而已);首先在做这个题之前,让我们先来了解一下`COUNT`的基本用法;
|
||||
|
||||
|
||||
@ -148,7 +148,7 @@ WHERE username = 'root';
|
||||
### 删除数据
|
||||
|
||||
- `DELETE` 语句用于删除表中的记录。
|
||||
- `TRUNCATE TABLE` 可以清空表,也就是删除所有行。
|
||||
- `TRUNCATE TABLE` 可以清空表,也就是删除所有行。说明:`TRUNCATE` 语句不属于 DML 语法而是 DDL 语法。
|
||||
|
||||
**删除表中的指定数据**
|
||||
|
||||
@ -257,11 +257,11 @@ ORDER BY cust_name DESC;
|
||||
**使用 WHERE 和 HAVING 过滤数据**
|
||||
|
||||
```sql
|
||||
SELECT cust_name, COUNT(*) AS num
|
||||
SELECT cust_name, COUNT(*) AS NumberOfOrders
|
||||
FROM Customers
|
||||
WHERE cust_email IS NOT NULL
|
||||
GROUP BY cust_name
|
||||
HAVING COUNT(*) >= 1;
|
||||
HAVING COUNT(*) > 1;
|
||||
```
|
||||
|
||||
**`having` vs `where`**:
|
||||
@ -396,7 +396,7 @@ WHERE prod_price BETWEEN 3 AND 5;
|
||||
|
||||
**AND 示例**
|
||||
|
||||
```ini
|
||||
```sql
|
||||
SELECT prod_id, prod_name, prod_price
|
||||
FROM products
|
||||
WHERE vend_id = 'DLL01' AND prod_price <= 4;
|
||||
|
||||
@ -202,13 +202,11 @@ Redlock 是直接操作 Redis 节点的,并不是通过 Redis 集群操作的
|
||||
|
||||
Redlock 实现比较复杂,性能比较差,发生时钟变迁的情况下还存在安全性隐患。《数据密集型应用系统设计》一书的作者 Martin Kleppmann 曾经专门发文([How to do distributed locking - Martin Kleppmann - 2016](https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html))怼过 Redlock,他认为这是一个很差的分布式锁实现。感兴趣的朋友可以看看[Redis 锁从面试连环炮聊到神仙打架](https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505097&idx=1&sn=5c03cb769c4458350f4d4a321ad51f5a&source=41#wechat_redirect)这篇文章,有详细介绍到 antirez 和 Martin Kleppmann 关于 Redlock 的激烈辩论。
|
||||
|
||||
实际项目中不建议使用 Redlock 算法,成本和收益不成正比。
|
||||
|
||||
如果不是非要实现绝对可靠的分布式锁的话,其实单机版 Redis 就完全够了,实现简单,性能也非常高。如果你必须要实现一个绝对可靠的分布式锁的话,可以基于 ZooKeeper 来做,只是性能会差一些。
|
||||
实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
|
||||
|
||||
## 基于 ZooKeeper 实现分布式锁
|
||||
|
||||
Redis 实现分布式锁性能较高,ZooKeeper 实现分布式锁可靠性更高。实际项目中,我们应该根据业务的具体需求来选择。
|
||||
ZooKeeper 相比于 Redis 实现分布式锁,除了提供相对更高的可靠性之外,在功能层面还有一个非常有用的特性:**Watch 机制**。这个机制可以用来实现公平的分布式锁。不过,使用 ZooKeeper 实现的分布式锁在性能方面相对较差,因此如果对性能要求比较高的话,ZooKeeper 可能就不太适合了。
|
||||
|
||||
### 如何基于 ZooKeeper 实现分布式锁?
|
||||
|
||||
@ -365,14 +363,19 @@ private static class LockData
|
||||
|
||||
## 总结
|
||||
|
||||
在这篇文章中,我介绍了实现分布式锁的两种常见方式: Redis 和 ZooKeeper。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。
|
||||
在这篇文章中,我介绍了实现分布式锁的两种常见方式:**Redis** 和 **ZooKeeper**。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要根据业务的具体需求来决定。
|
||||
|
||||
- 如果对性能要求比较高的话,建议使用 Redis 实现分布式锁(优先选择 Redisson 提供的现成的分布式锁,而不是自己实现)。
|
||||
- 如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁(推荐基于 Curator 框架实现)。不过,现在很多项目都不会用到 ZooKeeper,如果单纯是因为分布式锁而引入 ZooKeeper 的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
|
||||
- 如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。推荐优先选择 **Redisson** 提供的现成分布式锁,而不是自己实现。实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
|
||||
- 如果对可靠性要求比较高,建议使用 ZooKeeper 实现分布式锁,推荐基于 **Curator** 框架来实现。不过,现在很多项目都不会用到 ZooKeeper,如果单纯是因为分布式锁而引入 ZooKeeper 的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
|
||||
|
||||
最后,再分享两篇我觉得写的还不错的文章:
|
||||
需要注意的是,无论选择哪种方式实现分布式锁,包括 Redis、ZooKeeper 或 Etcd(本文没介绍,但也经常用来实现分布式锁),都无法保证 100% 的安全性,特别是在遇到进程垃圾回收(GC)、网络延迟等异常情况下。
|
||||
|
||||
为了进一步提高系统的可靠性,建议引入一个兜底机制。例如,可以通过 **版本号(Fencing Token)机制** 来避免并发冲突。
|
||||
|
||||
最后,再分享几篇我觉得写的还不错的文章:
|
||||
|
||||
- [分布式锁实现原理与最佳实践 - 阿里云开发者](https://mp.weixin.qq.com/s/JzCHpIOiFVmBoAko58ZuGw)
|
||||
- [聊聊分布式锁 - 字节跳动技术团队](https://mp.weixin.qq.com/s/-N4x6EkxwAYDGdJhwvmZLw)
|
||||
- [Redis、ZooKeeper、Etcd,谁有最好用的分布式锁? - 腾讯云开发者](https://mp.weixin.qq.com/s/yZC6VJGxt1ANZkn0SljZBg)
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
@ -8,15 +8,15 @@ icon: et-performance
|
||||
|
||||
这篇文章是我会结合自己的实际经历以及在测试这里取的经所得,除此之外,我还借鉴了一些优秀书籍,希望对你有帮助。
|
||||
|
||||
## 一 不同角色看网站性能
|
||||
## 不同角色看网站性能
|
||||
|
||||
### 1.1 用户
|
||||
### 用户
|
||||
|
||||
当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
|
||||
|
||||
所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
|
||||
|
||||
### 1.2 开发人员
|
||||
### 开发人员
|
||||
|
||||
用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。
|
||||
|
||||
@ -31,7 +31,7 @@ icon: et-performance
|
||||
7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
|
||||
8. ……
|
||||
|
||||
### 1.3 测试人员
|
||||
### 测试人员
|
||||
|
||||
测试人员一般会根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:
|
||||
|
||||
@ -40,63 +40,87 @@ icon: et-performance
|
||||
3. 吞吐量;
|
||||
4. ……
|
||||
|
||||
### 1.4 运维人员
|
||||
### 运维人员
|
||||
|
||||
运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
|
||||
|
||||
## 二 性能测试需要注意的点
|
||||
## 性能测试需要注意的点
|
||||
|
||||
几乎没有文章在讲性能测试的时候提到这个问题,大家都会讲如何去性能测试,有哪些性能测试指标这些东西。
|
||||
|
||||
### 2.1 了解系统的业务场景
|
||||
### 了解系统的业务场景
|
||||
|
||||
**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
|
||||
|
||||
### 2.2 历史数据非常有用
|
||||
### 历史数据非常有用
|
||||
|
||||
当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些 service 承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
|
||||
当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些服务承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
|
||||
|
||||
另外,这些地方也就像这个系统的一个短板一样,优化好了这些地方会为我们的系统带来质的提升。
|
||||
|
||||
### 三 性能测试的指标
|
||||
## 常见性能指标
|
||||
|
||||
### 3.1 响应时间
|
||||
### 响应时间
|
||||
|
||||
**响应时间就是用户发出请求到用户收到系统处理结果所需要的时间。** 重要吗?实在太重要!
|
||||
**响应时间 RT(Response-time)就是用户发出请求到用户收到系统处理结果所需要的时间。**
|
||||
|
||||
比较出名的 2-5-8 原则是这样描述的:通常来说,2 到 5 秒,页面体验会比较好,5 到 8 秒还可以接受,8 秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
|
||||
RT 是一个非常重要且直观的指标,RT 数值大小直接反应了系统处理用户请求速度的快慢。
|
||||
|
||||
但是,在某些场景下我们也并不需要太看重 2-5-8 原则 ,比如我觉得系统导出导入大数据量这种就不需要,系统生成系统报告这种也不需要。
|
||||
### 并发数
|
||||
|
||||
### 3.2 并发数
|
||||
**并发数可以简单理解为系统能够同时供多少人访问使用也就是说系统同时能处理的请求数量。**
|
||||
|
||||
**并发数是系统能同时处理请求的数目即同时提交请求的用户数目。**
|
||||
并发数反应了系统的负载能力。
|
||||
|
||||
不得不说,高并发是现在后端架构中非常非常火热的一个词了,这个与当前的互联网环境以及中国整体的互联网用户量都有很大关系。一般情况下,你的系统并发量越大,说明你的产品做的就越大。但是,并不是每个系统都需要达到像淘宝、12306 这种亿级并发量的。
|
||||
### QPS 和 TPS
|
||||
|
||||
### 3.3 吞吐量
|
||||
|
||||
吞吐量指的是系统单位时间内系统处理的请求数量。衡量吞吐量有几个重要的参数:QPS(TPS)、并发数、响应时间。
|
||||
|
||||
1. QPS(Query Per Second):服务器每秒可以执行的查询次数;
|
||||
2. TPS(Transaction Per Second):服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
|
||||
3. 并发数;系统能同时处理请求的数目即同时提交请求的用户数目。
|
||||
4. 响应时间:一般取多次请求的平均响应时间
|
||||
|
||||
理清他们的概念,就很容易搞清楚他们之间的关系了。
|
||||
|
||||
- **QPS(TPS)** = 并发数/平均响应时间
|
||||
- **并发数** = QPS\*平均响应时间
|
||||
- **QPS(Query Per Second)** :服务器每秒可以执行的查询次数;
|
||||
- **TPS(Transaction Per Second)** :服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
|
||||
|
||||
书中是这样描述 QPS 和 TPS 的区别的。
|
||||
|
||||
> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
|
||||
|
||||
### 3.4 性能计数器
|
||||
### 吞吐量
|
||||
|
||||
**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU 使用、磁盘与网络 I/O 等情况。**
|
||||
**吞吐量指的是系统单位时间内系统处理的请求数量。**
|
||||
|
||||
### 四 几种常见的性能测试
|
||||
一个系统的吞吐量与请求对系统的资源消耗等紧密关联。请求对系统资源消耗越多,系统吞吐能力越低,反之则越高。
|
||||
|
||||
TPS、QPS 都是吞吐量的常用量化指标。
|
||||
|
||||
- **QPS(TPS)** = 并发数/平均响应时间(RT)
|
||||
- **并发数** = QPS \* 平均响应时间(RT)
|
||||
|
||||
## 系统活跃度指标
|
||||
|
||||
### PV(Page View)
|
||||
|
||||
访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。UV 从网页打开的数量/刷新的次数的角度来统计的。
|
||||
|
||||
### UV(Unique Visitor)
|
||||
|
||||
独立访客,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。
|
||||
|
||||
### DAU(Daily Active User)
|
||||
|
||||
日活跃用户数量。
|
||||
|
||||
### MAU(monthly active users)
|
||||
|
||||
月活跃用户人数。
|
||||
|
||||
举例:某网站 DAU 为 1200w, 用户日均使用时长 1 小时,RT 为 0.5s,求并发量和 QPS。
|
||||
|
||||
平均并发量 = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数(86400)=1200w/24 = 50w
|
||||
|
||||
真实并发量(考虑到某些时间段使用人数比较少) = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数-访问量比较小的时间段假设为 8 小时(57600)=1200w/16 = 75w
|
||||
|
||||
峰值并发量 = 平均并发量 \* 6 = 300w
|
||||
|
||||
QPS = 真实并发量/RT = 75W/0.5=150w/s
|
||||
|
||||
## 性能测试分类
|
||||
|
||||
### 性能测试
|
||||
|
||||
@ -118,25 +142,27 @@ icon: et-performance
|
||||
|
||||
模拟真实场景,给系统一定压力,看看业务是否能稳定运行。
|
||||
|
||||
## 五 常用性能测试工具
|
||||
## 常用性能测试工具
|
||||
|
||||
这里就不多扩展了,有时间的话会单独拎一个熟悉的说一下。
|
||||
### 后端常用
|
||||
|
||||
### 5.1 后端常用
|
||||
既然系统设计涉及到系统性能方面的问题,那在面试的时候,面试官就很可能会问:**你是如何进行性能测试的?**
|
||||
|
||||
没记错的话,除了 LoadRunner 其他几款性能测试工具都是开源免费的。
|
||||
推荐 4 个比较常用的性能测试工具:
|
||||
|
||||
1. Jmeter:Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
2. LoadRunner:一款商业的性能测试工具。
|
||||
3. Galtling:一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. ab:全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
1. **Jmeter** :Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
2. **LoadRunner**:一款商业的性能测试工具。
|
||||
3. **Galtling** :一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. **ab** :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
|
||||
### 5.2 前端常用
|
||||
没记错的话,除了 **LoadRunner** 其他几款性能测试工具都是开源免费的。
|
||||
|
||||
1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
|
||||
2. HttpWatch: 可用于录制 HTTP 请求信息的工具。
|
||||
### 前端常用
|
||||
|
||||
## 六 常见的性能优化策略
|
||||
1. **Fiddler**:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
|
||||
2. **HttpWatch**: 可用于录制 HTTP 请求信息的工具。
|
||||
|
||||
## 常见的性能优化策略
|
||||
|
||||
性能优化之前我们需要对请求经历的各个环节进行分析,排查出可能出现性能瓶颈的地方,定位问题。
|
||||
|
||||
|
||||
@ -23,7 +23,7 @@ head:
|
||||
1. **时间维度区分**:按照数据的创建时间、更新时间、过期时间等,将一定时间段内的数据视为热数据,超过该时间段的数据视为冷数据。例如,订单系统可以将 1 年前的订单数据作为冷数据,1 年内的订单数据作为热数据。这种方法适用于数据的访问频率和时间有较强的相关性的场景。
|
||||
2. **访问频率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统可以将浏览量非常低的文章作为冷数据,浏览量较高的文章作为热数据。这种方法需要记录数据的访问频率,成本较高,适合访问频率和数据本身有较强的相关性的场景。
|
||||
|
||||
几年前的数据并不一定都是热数据,例如一些优质文章发表几年后依然有很多人访问,大部分普通用户新发表的文章却基本没什么人访问。
|
||||
几年前的数据并不一定都是冷数据,例如一些优质文章发表几年后依然有很多人访问,大部分普通用户新发表的文章却基本没什么人访问。
|
||||
|
||||
这两种区分冷热数据的方法各有优劣,实际项目中,可以将两者结合使用。
|
||||
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 48 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 23 KiB |
@ -23,9 +23,9 @@ tag:
|
||||
|
||||
参与消息传递的双方称为 **生产者** 和 **消费者** ,生产者负责发送消息,消费者负责处理消息。
|
||||
|
||||

|
||||
|
||||
|
||||
我们知道操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
|
||||
操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
|
||||
|
||||
维基百科是这样介绍中间件的:
|
||||
|
||||
@ -43,7 +43,7 @@ tag:
|
||||
|
||||
通常来说,使用消息队列主要能为我们的系统带来下面三点好处:
|
||||
|
||||
1. 通过异步处理提高系统性能(减少响应所需时间)
|
||||
1. 异步处理
|
||||
2. 削峰/限流
|
||||
3. 降低系统耦合性
|
||||
|
||||
@ -51,11 +51,11 @@ tag:
|
||||
|
||||
如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
|
||||
|
||||
### 通过异步处理提高系统性能(减少响应时间)
|
||||
### 异步处理
|
||||
|
||||
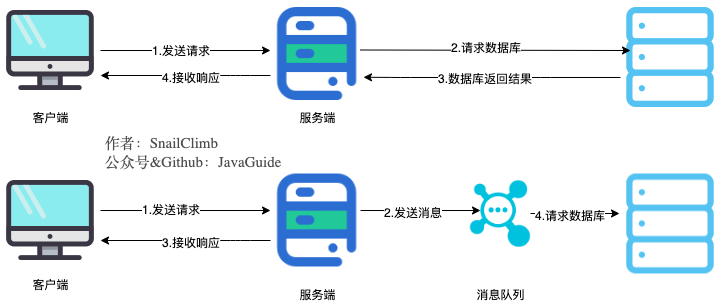
|
||||
|
||||
将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
|
||||
将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
|
||||
|
||||
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,**使用消息队列进行异步处理之后,需要适当修改业务流程进行配合**,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
|
||||
|
||||
@ -69,11 +69,11 @@ tag:
|
||||
|
||||
### 降低系统耦合性
|
||||
|
||||
使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
|
||||
使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
|
||||
|
||||
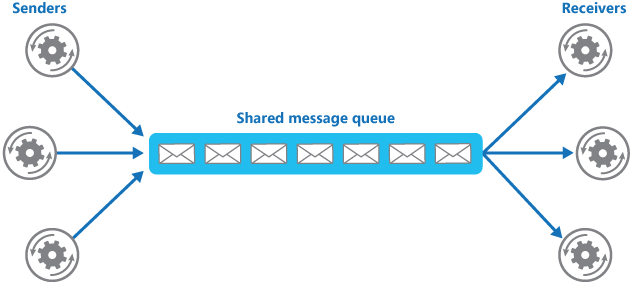
|
||||
生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
|
||||
|
||||
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
|
||||

|
||||
|
||||
**消息队列使用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
|
||||
|
||||
@ -87,7 +87,7 @@ tag:
|
||||
|
||||
### 实现分布式事务
|
||||
|
||||
我们知道分布式事务的解决方案之一就是 MQ 事务。
|
||||
分布式事务的解决方案之一就是 MQ 事务。
|
||||
|
||||
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
|
||||
|
||||
@ -103,6 +103,14 @@ RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允
|
||||
|
||||
消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持定时/延时消息。
|
||||
|
||||
|
||||
|
||||
### 即时通讯
|
||||
|
||||
MQTT(消息队列遥测传输协议)是一种轻量级的通讯协议,采用发布/订阅模式,非常适合于物联网(IoT)等需要在低带宽、高延迟或不可靠网络环境下工作的应用。它支持即时消息传递,即使在网络条件较差的情况下也能保持通信的稳定性。
|
||||
|
||||
RabbitMQ 内置了 MQTT 插件用于实现 MQTT 功能(默认不启用,需要手动开启)。
|
||||
|
||||
### 数据流处理
|
||||
|
||||
针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
|
||||
@ -133,13 +141,13 @@ JMS 定义了五种不同的消息正文格式以及调用的消息类型,允
|
||||
|
||||
#### 点到点(P2P)模型
|
||||
|
||||

|
||||
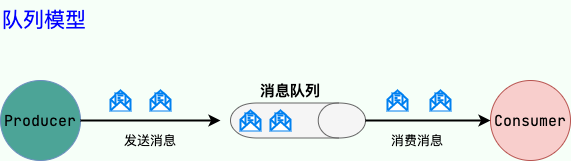
|
||||
|
||||
使用**队列(Queue)**作为消息通信载体;满足**生产者与消费者模式**,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
|
||||
|
||||
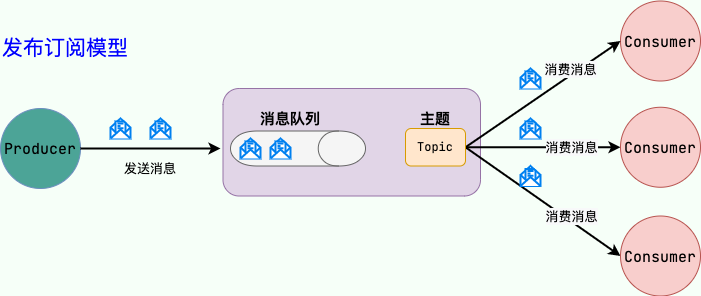
#### 发布/订阅(Pub/Sub)模型
|
||||
|
||||

|
||||

|
||||
|
||||
发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者。
|
||||
|
||||
|
||||
@ -0,0 +1,114 @@
|
||||
---
|
||||
title: 程序员最该拿的几种高含金量证书
|
||||
category: 技术文章精选集
|
||||
tag:
|
||||
- 程序员
|
||||
---
|
||||
|
||||
证书是能有效证明自己能力的好东西,它就是你实力的象征。在短短的面试时间内,证书可以为你加不少分。通过考证来提升自己,是一种性价比很高的办法。不过,相比金融、建筑、医疗等行业,IT 行业的职业资格证书并没有那么多。
|
||||
|
||||
下面我总结了一下程序员可以考的一些常见证书。
|
||||
|
||||
## 软考
|
||||
|
||||
全国计算机技术与软件专业技术资格(水平)考试,简称“软考”,是国内认可度较高的一项计算机技术资格认证。尽管一些人吐槽其实际价值,但在特定领域和情况下,它还是非常有用的,例如软考证书在国企和事业单位中具有较高的认可度、在某些城市软考证书可以用于积分落户、可用于个税补贴。
|
||||
|
||||
软考有初、中、高三个级别,建议直接考高级。相比于 PMP(项目管理专业人士认证),软考高项的难度更大,特别是论文部分,绝大部分人都挂在了论文部分。过了软考高项,在一些单位可以内部挂证,每个月多拿几百。
|
||||
|
||||

|
||||
|
||||
官网地址:<https://www.ruankao.org.cn/>。
|
||||
|
||||
备考建议:[2024 年上半年,一次通过软考高级架构师考试的备考秘诀 - 阿里云开发者](https://mp.weixin.qq.com/s/9aUXHJ7dXgrHuT19jRhCnw)
|
||||
|
||||
## PAT
|
||||
|
||||
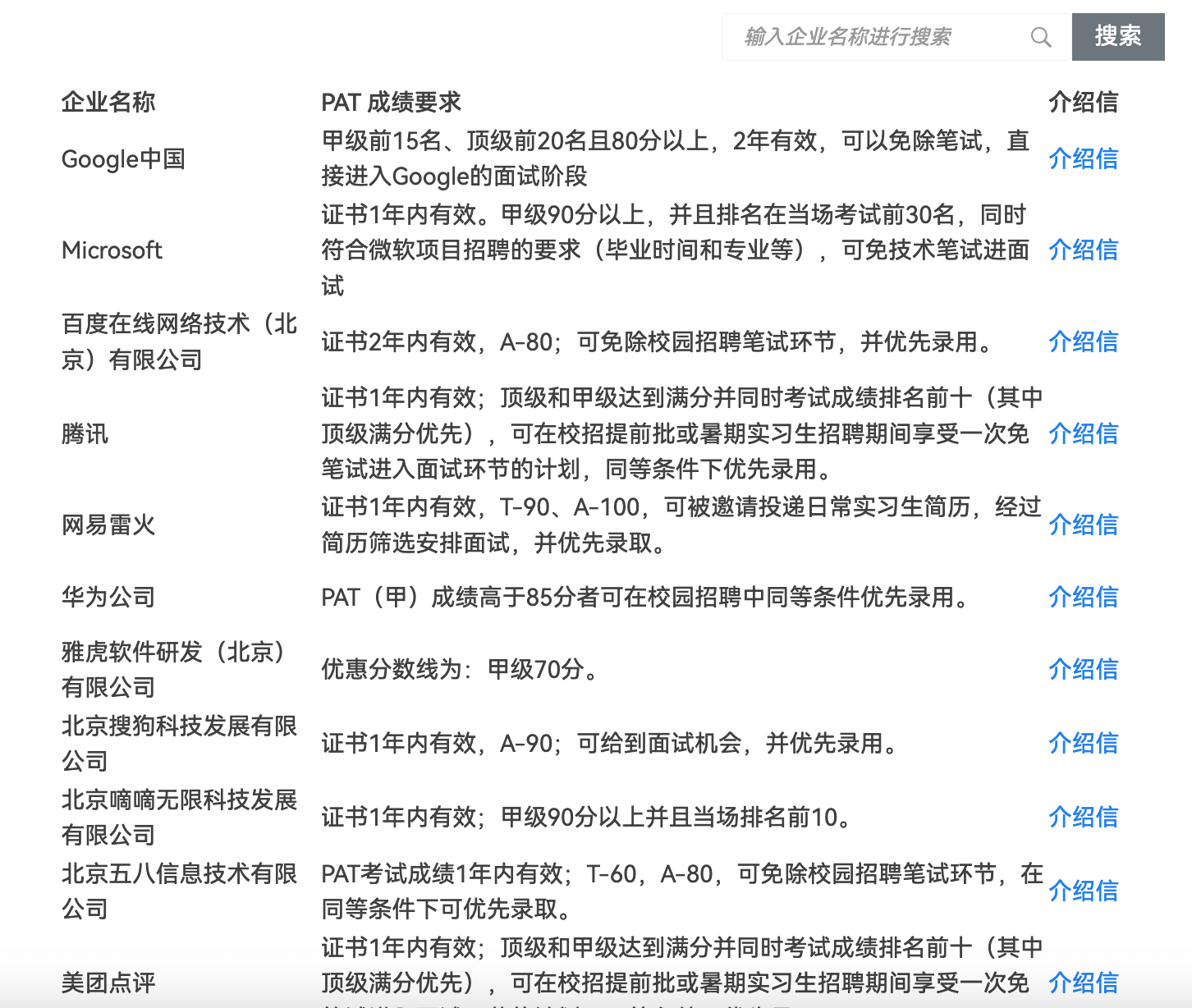
攀拓计算机能力测评(PAT)是一个专注于考察算法能力的测评体系,由浙江大学主办。该测评分为四个级别:基础级、乙级、甲级和顶级。
|
||||
|
||||
通过 PAT 测评并达到联盟企业规定的相应评级和分数,可以跳过学历门槛,免除筛选简历和笔试环节,直接获得面试机会。具体有哪些公司可以去官网看看:<https://www.patest.cn/company> 。
|
||||
|
||||
对于考研浙江大学的同学来说,PAT(甲级)成绩在一年内可以作为硕士研究生招生考试上机复试成绩。
|
||||
|
||||
|
||||
|
||||
## PMP
|
||||
|
||||
PMP(Project Management Professional)认证由美国项目管理协会(PMI)提供,是全球范围内认可度最高的项目管理专业人士资格认证。PMP 认证旨在提升项目管理专业人士的知识和技能,确保项目顺利完成。
|
||||
|
||||

|
||||
|
||||
PMP 是“一证在手,全球通用”的资格认证,对项目管理人士来说,PMP 证书含金量还是比较高的。放眼全球,很多成功企业都会将 PMP 认证作为项目经理的入职标准。
|
||||
|
||||
但是!真正有价值的不是 PMP 证书,而是《PMBOK》 那套项目管理体系,在《PMBOK》(PMP 考试指定用书)中也包含了非常多商业活动、实业项目、组织规划、建筑行业等各个领域的项目案例。
|
||||
|
||||
另外,PMP 证书不是一个高大上的证书,而是一个基础的证书。
|
||||
|
||||
## ACP
|
||||
|
||||
ACP(Agile Certified Practitioner)认证同样由美国项目管理协会(PMI)提供,是项目管理领域的另一个重要认证。与 PMP(Project Management Professional)注重传统的瀑布方法论不同,ACP 专注于敏捷项目管理方法论,如 Scrum、Kanban、Lean、Extreme Programming(XP)等。
|
||||
|
||||
## OCP
|
||||
|
||||
Oracle Certified Professional(OCP)是 Oracle 公司提供的一项专业认证,专注于 Oracle 数据库及相关技术。这个认证旨在验证和认证个人在使用和管理 Oracle 数据库方面的专业知识和技能。
|
||||
|
||||
下图展示了 Oracle 认证的不同路径和相应的认证级别,分别是核心路径(Core Track)和专业路径(Speciality Track)。
|
||||
|
||||

|
||||
|
||||
## 阿里云认证
|
||||
|
||||
阿里云(Alibaba Cloud)提供的专业认证,认证方向包括云计算、大数据、人工智能、Devops 等。职业认证分为 ACA、ACP、ACE 三个等级,除了职业认证之外,还有一个开发者 Clouder 认证,这是专门为开发者设立的专项技能认证。
|
||||
|
||||

|
||||
|
||||
官网地址:<https://edu.aliyun.com/certification/>。
|
||||
|
||||
## 华为认证
|
||||
|
||||
华为认证是由华为技术有限公司提供的面向 ICT(信息与通信技术)领域的专业认证,认证方向包括网络、存储、云计算、大数据、人工智能等,非常庞大的认证体系。
|
||||
|
||||

|
||||
|
||||
## AWS 认证
|
||||
|
||||
AWS 云认证考试是 AWS 云计算服务的官方认证考试,旨在验证 IT 专业人士在设计、部署和管理 AWS 基础架构方面的技能。
|
||||
|
||||
AWS 认证分为多个级别,包括基础级、从业者级、助理级、专业级和专家级(Specialty),涵盖多个角色和技能:
|
||||
|
||||
- **基础级别**:AWS Certified Cloud Practitioner,适合初学者,验证对 AWS 基础知识的理解,是最简单的入门认证。
|
||||
- **助理级别**:包括 AWS Certified Solutions Architect – Associate、AWS Certified Developer – Associate 和 AWS Certified SysOps Administrator – Associate,适合中级专业人士,验证其设计、开发和管理 AWS 应用的能力。
|
||||
- **专业级别**:包括 AWS Certified Solutions Architect – Professional 和 AWS Certified DevOps Engineer – Professional,适合高级专业人士,验证其在复杂和大规模 AWS 环境中的能力。
|
||||
- **专家级别**:包括 AWS Certified Advanced Networking – Specialty、AWS Certified Big Data – Specialty 等,专注于特定技术领域的深度知识和技能。
|
||||
|
||||
备考建议:[小白入门云计算的最佳方式,是去考一张 AWS 的证书(附备考经验)](https://mp.weixin.qq.com/s/xAqNOnfZ05GDRuUbAiMHIA)
|
||||
|
||||
## Google Cloud 认证
|
||||
|
||||
与 AWS 认证不同,Google Cloud 认证只有一门助理级认证(Associate Cloud Engineer),其他大部分为专业级(专家级)认证。
|
||||
|
||||
备考建议:[如何备考谷歌云认证](https://mp.weixin.qq.com/s/Vw5LGPI_akA7TQl1FMygWw)
|
||||
|
||||
官网地址:<https://cloud.google.com/certification>
|
||||
|
||||
## 微软认证
|
||||
|
||||
微软的认证体系主要针对其 Azure 云平台,分为基础级别、助理级别和专家级别,认证方向包括云计算、数据管理、开发、生产力工具等。
|
||||
|
||||
|
||||
|
||||
## Elastic 认证
|
||||
|
||||
Elastic 认证是由 Elastic 公司提供的一系列专业认证,旨在验证个人在使用 Elastic Stack(包括 Elasticsearch、Logstash、Kibana 、Beats 等)方面的技能和知识。
|
||||
|
||||
如果你在日常开发核心工作是负责 ElasticSearch 相关业务的话,还是比较建议考的,含金量挺高。
|
||||
|
||||
目前 Elastic 认证证书分为四类:Elastic Certified Engineer、Elastic Certified Analyst、Elastic Certified Observability Engineer、Elastic Certified SIEM Specialist。
|
||||
|
||||
比较建议考 **Elastic Certified Engineer**,这个是 Elastic Stack 的基础认证,考察安装、配置、管理和维护 Elasticsearch 集群等核心技能。
|
||||
|
||||

|
||||
|
||||
## 其他
|
||||
|
||||
- PostgreSQL 认证:国内的 PostgreSQL 认证分为专员级(PCA)、专家级(PCP)和大师级(PCM),主要考查 PostgreSQL 数据库管理和优化,价格略贵,不是很推荐。
|
||||
- Kubernetes 认证:Cloud Native Computing Foundation (CNCF) 提供了几个官方认证,例如 Certified Kubernetes Administrator (CKA)、Certified Kubernetes Application Developer (CKAD),主要考察 Kubernetes 方面的技能和知识。
|
||||
@ -23,6 +23,7 @@
|
||||
|
||||
## 程序员
|
||||
|
||||
- [程序员最该拿的几种高含金量证书](./programmer/high-value-certifications-for-programmers.md)
|
||||
- [程序员怎样出版一本技术书](./programmer/how-do-programmers-publish-a-technical-book.md)
|
||||
- [程序员高效出书避坑和实践指南](./programmer/efficient-book-publishing-and-practice-guide.md)
|
||||
|
||||
|
||||
@ -72,6 +72,8 @@ title: JavaGuide(Java学习&面试指南)
|
||||
|
||||
**重要知识点详解**:
|
||||
|
||||
- [乐观锁和悲观锁详解](./java/concurrent/jmm.md)
|
||||
- [CAS 详解](./java/concurrent/cas.md)
|
||||
- [JMM(Java 内存模型)详解](./java/concurrent/jmm.md)
|
||||
- **线程池**:[Java 线程池详解](./java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./java/concurrent/java-thread-pool-best-practices.md)
|
||||
- [ThreadLocal 详解](./java/concurrent/threadlocal.md)
|
||||
|
||||
@ -25,6 +25,6 @@ icon: experience
|
||||
有很多同学要说了:“为什么不直接给出具体答案呢?”。主要原因有如下两点:
|
||||
|
||||
1. 参考资料解释的要更详细一些,还可以顺便让你把相关的知识点复习一下。
|
||||
2. 给出的参考资料基本都是我的原创,假如后续我想对面试问题的答案进行完善,就不需要挨个把之前的面经写的答案给修改了(面试中的很多问题都是比较类似的)。当然了,我的原创文章也不太可能覆盖到面试的每个点,部面试问题的答案,我是精选的其他技术博主写的优质文章,文章质量都很高。
|
||||
2. 给出的参考资料基本都是我的原创,假如后续我想对面试问题的答案进行完善,就不需要挨个把之前的面经写的答案给修改了(面试中的很多问题都是比较类似的)。当然了,我的原创文章也不太可能覆盖到面试的每个点,部分面试问题的答案,我是精选的其他技术博主写的优质文章,文章质量都很高。
|
||||
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -10,16 +10,17 @@ icon: star
|
||||
|
||||
## Java 后端面试哪些知识点是重点?
|
||||
|
||||
**准备面试的时候,具体哪些知识点是重点呢?**
|
||||
**准备面试的时候,具体哪些知识点是重点呢?如何把握重点?**
|
||||
|
||||
给你几点靠谱的建议:
|
||||
|
||||
1. Java 基础、集合、并发、MySQL、Redis、Spring、Spring Boot 这些 Java 后端开发必备的知识点。大厂以及中小厂的面试问的比较多的就是这些知识点(不信的话,你可以去多找一些面经看看)。我这里没有提到计算机基础相关的内容,这个会在下面提到。
|
||||
2. 你的项目经历涉及到的知识点,有水平的面试官都是会根据你的项目经历来问的。举个例子,你的项目经历使用了 Redis 来做限流,那 Redis 相关的八股文(比如 Redis 常见数据结构)以及限流相关的八股文(比如常见的限流算法)你就应该多花更多心思来搞懂!吃透!你把项目经历上的知识点吃透之后,再把你简历上哪些写熟练掌握的技术给吃透。最后,再去花时间准备其他知识点。
|
||||
3. 针对自身找工作的需求,你又可以适当地调整复习的重点。像中小厂一般问计算机基础比较少一些,有些大厂比如字节比较重视计算机基础尤其是算法。这样的话,如果你的目标是中小厂的话,计算机基础就准备面试来说不是那么重要了。如果复习时间不够的话,可以暂时先放放。
|
||||
1. Java 基础、集合、并发、MySQL、Redis 、Spring、Spring Boot 这些 Java 后端开发必备的知识点(MySQL + Redis >= Java > Spring + Spring Boot)。大厂以及中小厂的面试问的比较多的就是这些知识点。Spring 和 Spring Boot 这俩框架类的知识点相对前面的知识点来说重要性要稍低一些,但一般面试也会问一些,尤其是中小厂。并发知识一般中大厂提问更多也更难,尤其是大厂喜欢深挖底层,很容易把人问倒。计算机基础相关的内容会在下面提到。
|
||||
2. 你的项目经历涉及到的知识点是重中之重,有水平的面试官都是会根据你的项目经历来问的。举个例子,你的项目经历使用了 Redis 来做限流,那 Redis 相关的八股文(比如 Redis 常见数据结构)以及限流相关的八股文(比如常见的限流算法)你就应该多花更多心思来搞懂吃透!你把项目经历上的知识点吃透之后,再把你简历上哪些写熟练掌握的技术给吃透,最后再去花时间准备其他知识点。
|
||||
3. 针对自身找工作的需求,你又可以适当地调整复习的重点。像中小厂一般问计算机基础比较少一些,有些大厂比如字节比较重视计算机基础尤其是算法。这样的话,如果你的目标是中小厂的话,计算机基础就准备面试来说不是那么重要了。如果复习时间不够的话,可以暂时先放放,腾出时间给其他重要的知识点。
|
||||
4. 一般校招的面试不会强制要求你会分布式/微服务、高并发的知识(不排除个别岗位有这方面的硬性要求),所以到底要不要掌握还是要看你个人当前的实际情况。如果你会这方面的知识的话,对面试相对来说还是会更有利一些(想要让项目经历有亮点,还是得会一些性能优化的知识。性能优化的知识这也算是高并发知识的一个小分支了)。如果你的技能介绍或者项目经历涉及到分布式/微服务、高并发的知识,那建议你尽量也要抽时间去认真准备一下,面试中很可能会被问到,尤其是项目经历用到的时候。不过,也还是主要准备写在简历上的那些知识点就好。
|
||||
5. JVM 相关的知识点,一般是大厂才会问到,面试中小厂就没必要准备了。JVM 面试中比较常问的是 [Java 内存区域](https://javaguide.cn/java/jvm/memory-area.html)、[JVM 垃圾回收](https://javaguide.cn/java/jvm/jvm-garbage-collection.html)、[类加载器和双亲委派模型](https://javaguide.cn/java/jvm/classloader.html) 以及 JVM 调优和问题排查(我之前分享过一些[常见的线上问题案例](https://t.zsxq.com/0bsAac47U),里面就有 JVM 相关的)。
|
||||
5. JVM 相关的知识点,一般是大厂(例如美团、阿里)和一些不错的中厂(例如携程、顺丰、招银网络)才会问到,面试国企、差一点的中厂和小厂就没必要准备了。JVM 面试中比较常问的是 [Java 内存区域](https://javaguide.cn/java/jvm/memory-area.html)、[JVM 垃圾回收](https://javaguide.cn/java/jvm/jvm-garbage-collection.html)、[类加载器和双亲委派模型](https://javaguide.cn/java/jvm/classloader.html) 以及 JVM 调优和问题排查(我之前分享过一些[常见的线上问题案例](https://t.zsxq.com/0bsAac47U),里面就有 JVM 相关的)。
|
||||
6. 不同的大厂面试侧重点也会不同。比如说你要去阿里这种公司的话,项目和八股文就是重点,阿里笔试一般会有代码题,进入面试后就很少问代码题了,但是对原理性的问题问的比较深,经常会问一些你对技术的思考。再比如说你要面试字节这种公司,那计算机基础,尤其是算法是重点,字节的面试十分注重代码功底,有时候开始面试就会直接甩给你一道代码题,写出来再谈别的。也会问面试八股文,以及项目,不过,相对来说要少很多。建议你看一下这篇文章 [为了解开互联网大厂秋招内幕,我把他们全面了一遍](https://mp.weixin.qq.com/s/pBsGQNxvRupZeWt4qZReIA),了解一下常见大厂的面试题侧重点。
|
||||
7. 多去找一些面经看看,尤其你目标公司或者类似公司对应岗位的面经。这样可以实现针对性的复习,还能顺便自测一波,检查一下自己的掌握情况。
|
||||
|
||||
看似 Java 后端八股文很多,实际把复习范围一缩小,重要的东西就是那些。考虑到时间问题,你不可能连一些比较冷门的知识点也给准备了。这没必要,主要精力先放在那些重要的知识点即可。
|
||||
|
||||
@ -31,8 +32,12 @@ icon: star
|
||||
|
||||
举个例子:你的项目中需要用到 Redis 来做缓存,你对照着官网简单了解并实践了简单使用 Redis 之后,你去看了 Redis 对应的八股文。你发现 Redis 可以用来做限流、分布式锁,于是你去在项目中实践了一下并掌握了对应的八股文。紧接着,你又发现 Redis 内存不够用的情况下,还能使用 Redis Cluster 来解决,于是你就又去实践了一下并掌握了对应的八股文。
|
||||
|
||||
**一定要记住你的主要目标是理解和记关键词,而不是像背课文一样一字一句地记下来!**
|
||||
**一定要记住你的主要目标是理解和记关键词,而不是像背课文一样一字一句地记下来,这样毫无意义!效率最低,对自身帮助也最小!**
|
||||
|
||||
另外,记录博客或者用自己的理解把对应的知识点讲给别人听也是一个不错的选择。
|
||||
还要注意适当“投机取巧”,不要单纯死记八股,有些技术方案的实现有很多种,例如分布式 ID、分布式锁、幂等设计,想要完全记住所有方案不太现实,你就重点记忆你项目的实现方案以及选择该种实现方案的原因就好了。当然,其他方案还是建议你简单了解一下,不然也没办法和你选择的方案进行对比。
|
||||
|
||||
想要检测自己是否搞懂或者加深印象,记录博客或者用自己的理解把对应的知识点讲给别人听也是一个不错的选择。
|
||||
|
||||
另外,准备八股文的过程中,强烈建议你花个几个小时去根据你的简历(主要是项目经历部分)思考一下哪些地方可能被深挖,然后把你自己的思考以面试问题的形式体现出来。面试之后,你还要根据当下的面试情况复盘一波,对之前自己整理的面试问题进行完善补充。这个过程对于个人进一步熟悉自己的简历(尤其是项目经历)部分,非常非常有用。这些问题你也一定要多花一些时间搞懂吃透,能够流畅地表达出来。面试问题可以参考 [Java 面试常见问题总结(2024 最新版)](https://t.zsxq.com/0eRq7EJPy),记得根据自己项目经历去深入拓展即可!
|
||||
|
||||
最后,准备技术面试的同学一定要定期复习(自测的方式非常好),不然确实会遗忘的。
|
||||
|
||||
@ -50,6 +50,8 @@ head:
|
||||
|
||||
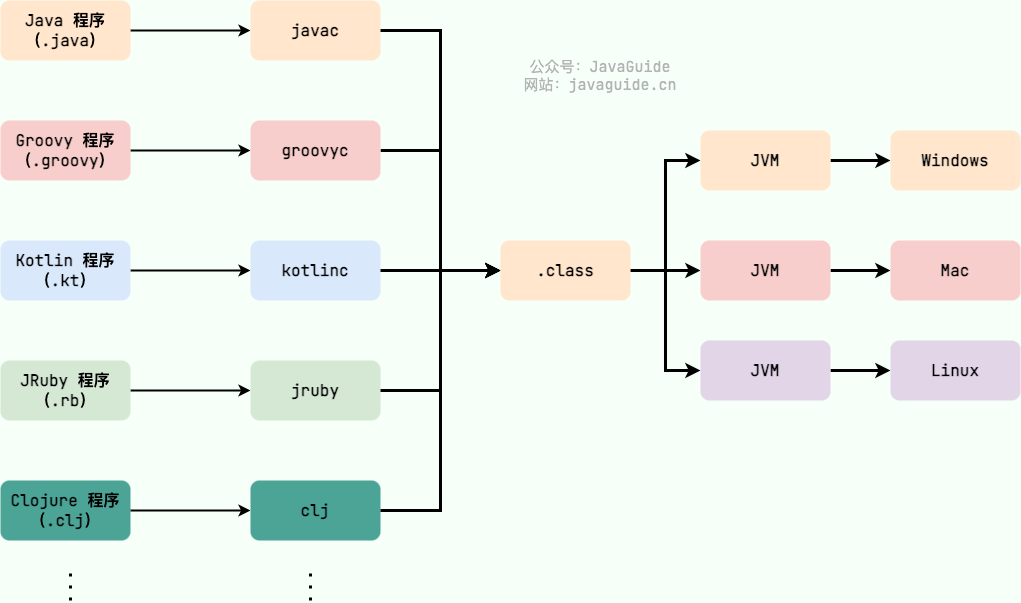
Java 虚拟机(Java Virtual Machine, JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
|
||||
|
||||
如下图所示,不同编程语言(Java、Groovy、Kotlin、JRuby、Clojure ...)通过各自的编译器编译成 `.class` 文件,并最终通过 JVM 在不同平台(Windows、Mac、Linux)上运行。
|
||||
|
||||
|
||||
|
||||
**JVM 并不是只有一种!只要满足 JVM 规范,每个公司、组织或者个人都可以开发自己的专属 JVM。** 也就是说我们平时接触到的 HotSpot VM 仅仅是是 JVM 规范的一种实现而已。
|
||||
@ -60,13 +62,20 @@ Java 虚拟机(Java Virtual Machine, JVM)是运行 Java 字节码的虚拟
|
||||
|
||||
#### JDK 和 JRE
|
||||
|
||||
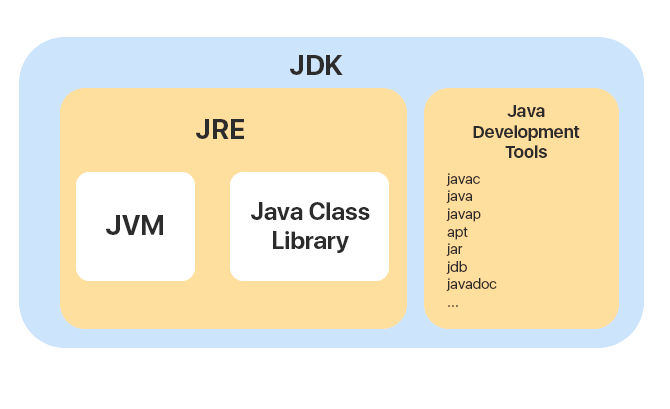
JDK(Java Development Kit),它是功能齐全的 Java SDK,是提供给开发者使用,能够创建和编译 Java 程序的开发套件。它包含了 JRE,同时还包含了编译 java 源码的编译器 javac 以及一些其他工具比如 javadoc(文档注释工具)、jdb(调试器)、jconsole(基于 JMX 的可视化监控⼯具)、javap(反编译工具)等等。
|
||||
JDK(Java Development Kit)是一个功能齐全的 Java 开发工具包,供开发者使用,用于创建和编译 Java 程序。它包含了 JRE(Java Runtime Environment),以及编译器 javac 和其他工具,如 javadoc(文档生成器)、jdb(调试器)、jconsole(监控工具)、javap(反编译工具)等。
|
||||
|
||||
JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,主要包括 Java 虚拟机(JVM)、Java 基础类库(Class Library)。
|
||||
JRE 是运行已编译 Java 程序所需的环境,主要包含以下两个部分:
|
||||
|
||||
也就是说,JRE 是 Java 运行时环境,仅包含 Java 应用程序的运行时环境和必要的类库。而 JDK 则包含了 JRE,同时还包括了 javac、javadoc、jdb、jconsole、javap 等工具,可以用于 Java 应用程序的开发和调试。如果需要进行 Java 编程工作,比如编写和编译 Java 程序、使用 Java API 文档等,就需要安装 JDK。而对于某些需要使用 Java 特性的应用程序,如 JSP 转换为 Java Servlet、使用反射等,也需要 JDK 来编译和运行 Java 代码。因此,即使不打算进行 Java 应用程序的开发工作,也有可能需要安装 JDK。
|
||||
1. **JVM** : 也就是我们上面提到的 Java 虚拟机。
|
||||
2. **Java 基础类库(Class Library)**:一组标准的类库,提供常用的功能和 API(如 I/O 操作、网络通信、数据结构等)。
|
||||
|
||||
|
||||
简单来说,JRE 只包含运行 Java 程序所需的环境和类库,而 JDK 不仅包含 JRE,还包括用于开发和调试 Java 程序的工具。
|
||||
|
||||
如果需要编写、编译 Java 程序或使用 Java API 文档,就需要安装 JDK。某些需要 Java 特性的应用程序(如 JSP 转换为 Servlet 或使用反射)也可能需要 JDK 来编译和运行 Java 代码。因此,即使不进行 Java 开发工作,有时也可能需要安装 JDK。
|
||||
|
||||
下图清晰展示了 JDK、JRE 和 JVM 的关系。
|
||||
|
||||

|
||||
|
||||
不过,从 JDK 9 开始,就不需要区分 JDK 和 JRE 的关系了,取而代之的是模块系统(JDK 被重新组织成 94 个模块)+ [jlink](http://openjdk.java.net/jeps/282) 工具 (随 Java 9 一起发布的新命令行工具,用于生成自定义 Java 运行时映像,该映像仅包含给定应用程序所需的模块) 。并且,从 JDK 11 开始,Oracle 不再提供单独的 JRE 下载。
|
||||
|
||||
@ -129,7 +138,7 @@ JDK 9 引入了一种新的编译模式 **AOT(Ahead of Time Compilation)** 。
|
||||
|
||||
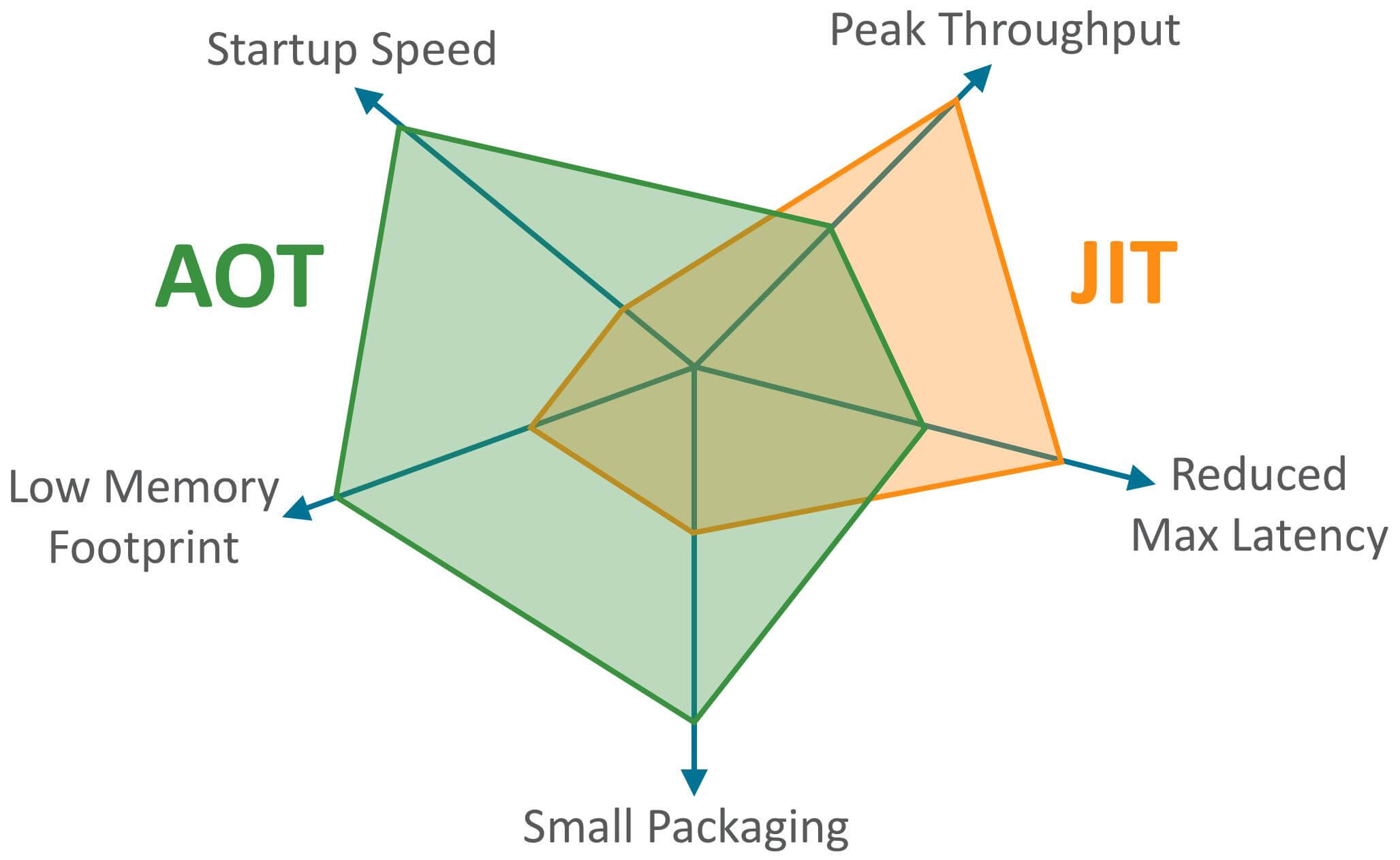
**JIT 与 AOT 两者的关键指标对比**:
|
||||
|
||||
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/java/basis/jit-vs-aot.png" alt="JIT vs AOT" style="zoom: 25%;" />
|
||||
|
||||
可以看出,AOT 的主要优势在于启动时间、内存占用和打包体积。JIT 的主要优势在于具备更高的极限处理能力,可以降低请求的最大延迟。
|
||||
|
||||
@ -203,8 +212,6 @@ JDK 9 引入了一种新的编译模式 **AOT(Ahead of Time Compilation)** 。
|
||||
|
||||
Java 中的注释有三种:
|
||||
|
||||

|
||||
|
||||
1. **单行注释**:通常用于解释方法内某单行代码的作用。
|
||||
|
||||
2. **多行注释**:通常用于解释一段代码的作用。
|
||||
@ -274,9 +281,26 @@ Java 中的注释有三种:
|
||||
|
||||
### 自增自减运算符
|
||||
|
||||
在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1,Java 提供了一种特殊的运算符,用于这种表达式,叫做自增运算符(++)和自减运算符(--)。
|
||||
在写代码的过程中,常见的一种情况是需要某个整数类型变量增加 1 或减少 1。Java 提供了自增运算符 (`++`) 和自减运算符 (`--`) 来简化这种操作。
|
||||
|
||||
++ 和 -- 运算符可以放在变量之前,也可以放在变量之后,当运算符放在变量之前时(前缀),先自增/减,再赋值;当运算符放在变量之后时(后缀),先赋值,再自增/减。例如,当 `b = ++a` 时,先自增(自己增加 1),再赋值(赋值给 b);当 `b = a++` 时,先赋值(赋值给 b),再自增(自己增加 1)。也就是,++a 输出的是 a+1 的值,a++输出的是 a 值。用一句口诀就是:“符号在前就先加/减,符号在后就后加/减”。
|
||||
`++` 和 `--` 运算符可以放在变量之前,也可以放在变量之后:
|
||||
|
||||
- **前缀形式**(例如 `++a` 或 `--a`):先自增/自减变量的值,然后再使用该变量,例如,`b = ++a` 先将 `a` 增加 1,然后把增加后的值赋给 `b`。
|
||||
- **后缀形式**(例如 `a++` 或 `a--`):先使用变量的当前值,然后再自增/自减变量的值。例如,`b = a++` 先将 `a` 的当前值赋给 `b`,然后再将 `a` 增加 1。
|
||||
|
||||
为了方便记忆,可以使用下面的口诀:**符号在前就先加/减,符号在后就后加/减**。
|
||||
|
||||
下面来看一个考察自增自减运算符的高频笔试题:执行下面的代码后,`a` 、`b` 、 `c` 、`d`和`e`的值是?
|
||||
|
||||
```java
|
||||
int a = 9;
|
||||
int b = a++;
|
||||
int c = ++a;
|
||||
int d = c--;
|
||||
int e = --d;
|
||||
```
|
||||
|
||||
答案:`a = 11` 、`b = 9` 、 `c = 10` 、 `d = 10` 、 `e = 10`。
|
||||
|
||||
### 移位运算符
|
||||
|
||||
@ -295,18 +319,29 @@ static final int hash(Object key) {
|
||||
|
||||
```
|
||||
|
||||
在 Java 代码里使用 `<<`、 `>>` 和`>>>`转换成的指令码运行起来会更高效些。
|
||||
**使用移位运算符的主要原因**:
|
||||
|
||||
1. **高效**:移位运算符直接对应于处理器的移位指令。现代处理器具有专门的硬件指令来执行这些移位操作,这些指令通常在一个时钟周期内完成。相比之下,乘法和除法等算术运算在硬件层面上需要更多的时钟周期来完成。
|
||||
2. **节省内存**:通过移位操作,可以使用一个整数(如 `int` 或 `long`)来存储多个布尔值或标志位,从而节省内存。
|
||||
|
||||
移位运算符最常用于快速乘以或除以 2 的幂次方。除此之外,它还在以下方面发挥着重要作用:
|
||||
|
||||
- **位字段管理**:例如存储和操作多个布尔值。
|
||||
- **哈希算法和加密解密**:通过移位和与、或等操作来混淆数据。
|
||||
- **数据压缩**:例如霍夫曼编码通过移位运算符可以快速处理和操作二进制数据,以生成紧凑的压缩格式。
|
||||
- **数据校验**:例如 CRC(循环冗余校验)通过移位和多项式除法生成和校验数据完整性。。
|
||||
- **内存对齐**:通过移位操作,可以轻松计算和调整数据的对齐地址。
|
||||
|
||||
掌握最基本的移位运算符知识还是很有必要的,这不光可以帮助我们在代码中使用,还可以帮助我们理解源码中涉及到移位运算符的代码。
|
||||
|
||||
Java 中有三种移位运算符:
|
||||
|
||||

|
||||
|
||||
- `<<` :左移运算符,向左移若干位,高位丢弃,低位补零。`x << 1`,相当于 x 乘以 2(不溢出的情况下)。
|
||||
- `>>` :带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。`x >> 1`,相当于 x 除以 2。
|
||||
- `<<` :左移运算符,向左移若干位,高位丢弃,低位补零。`x << n`,相当于 x 乘以 2 的 n 次方(不溢出的情况下)。
|
||||
- `>>` :带符号右移,向右移若干位,高位补符号位,低位丢弃。正数高位补 0,负数高位补 1。`x >> n`,相当于 x 除以 2 的 n 次方。
|
||||
- `>>>` :无符号右移,忽略符号位,空位都以 0 补齐。
|
||||
|
||||
虽然移位运算本质上可以分为左移和右移,但在实际应用中,右移操作需要考虑符号位的处理方式。
|
||||
|
||||
由于 `double`,`float` 在二进制中的表现比较特殊,因此不能来进行移位操作。
|
||||
|
||||
移位操作符实际上支持的类型只有`int`和`long`,编译器在对`short`、`byte`、`char`类型进行移位前,都会将其转换为`int`类型再操作。
|
||||
@ -365,31 +400,31 @@ System.out.println("左移 10 位后的数据对应的二进制字符 " + Intege
|
||||
思考一下:下列语句的运行结果是什么?
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
boolean flag = false;
|
||||
for (int i = 0; i <= 3; i++) {
|
||||
if (i == 0) {
|
||||
System.out.println("0");
|
||||
} else if (i == 1) {
|
||||
System.out.println("1");
|
||||
continue;
|
||||
} else if (i == 2) {
|
||||
System.out.println("2");
|
||||
flag = true;
|
||||
} else if (i == 3) {
|
||||
System.out.println("3");
|
||||
break;
|
||||
} else if (i == 4) {
|
||||
System.out.println("4");
|
||||
}
|
||||
System.out.println("xixi");
|
||||
public static void main(String[] args) {
|
||||
boolean flag = false;
|
||||
for (int i = 0; i <= 3; i++) {
|
||||
if (i == 0) {
|
||||
System.out.println("0");
|
||||
} else if (i == 1) {
|
||||
System.out.println("1");
|
||||
continue;
|
||||
} else if (i == 2) {
|
||||
System.out.println("2");
|
||||
flag = true;
|
||||
} else if (i == 3) {
|
||||
System.out.println("3");
|
||||
break;
|
||||
} else if (i == 4) {
|
||||
System.out.println("4");
|
||||
}
|
||||
if (flag) {
|
||||
System.out.println("haha");
|
||||
return;
|
||||
}
|
||||
System.out.println("heihei");
|
||||
System.out.println("xixi");
|
||||
}
|
||||
if (flag) {
|
||||
System.out.println("haha");
|
||||
return;
|
||||
}
|
||||
System.out.println("heihei");
|
||||
}
|
||||
```
|
||||
|
||||
运行结果:
|
||||
@ -438,14 +473,13 @@ Java 中有 8 种基本数据类型,分别为:
|
||||
**注意:**
|
||||
|
||||
1. Java 里使用 `long` 类型的数据一定要在数值后面加上 **L**,否则将作为整型解析。
|
||||
2. `char a = 'h'`char :单引号,`String a = "hello"` :双引号。
|
||||
2. Java 里使用 `float` 类型的数据一定要在数值后面加上 **f 或 F**,否则将无法通过编译。
|
||||
3. `char a = 'h'`char :单引号,`String a = "hello"` :双引号。
|
||||
|
||||
这八种基本类型都有对应的包装类分别为:`Byte`、`Short`、`Integer`、`Long`、`Float`、`Double`、`Character`、`Boolean` 。
|
||||
|
||||
### 基本类型和包装类型的区别?
|
||||
|
||||

|
||||
|
||||
- **用途**:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
|
||||
- **存储方式**:基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 `static` 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
|
||||
- **占用空间**:相比于包装类型(对象类型), 基本数据类型占用的空间往往非常小。
|
||||
@ -661,15 +695,18 @@ System.out.println(a == b);// false
|
||||
|
||||
```java
|
||||
BigDecimal a = new BigDecimal("1.0");
|
||||
BigDecimal b = new BigDecimal("0.9");
|
||||
BigDecimal b = new BigDecimal("1.00");
|
||||
BigDecimal c = new BigDecimal("0.8");
|
||||
|
||||
BigDecimal x = a.subtract(b);
|
||||
BigDecimal x = a.subtract(c);
|
||||
BigDecimal y = b.subtract(c);
|
||||
|
||||
System.out.println(x); /* 0.1 */
|
||||
System.out.println(y); /* 0.1 */
|
||||
System.out.println(Objects.equals(x, y)); /* true */
|
||||
System.out.println(x); /* 0.2 */
|
||||
System.out.println(y); /* 0.20 */
|
||||
// 比较内容,不是比较值
|
||||
System.out.println(Objects.equals(x, y)); /* false */
|
||||
// 比较值相等用相等compareTo,相等返回0
|
||||
System.out.println(0 == x.compareTo(y)); /* true */
|
||||
```
|
||||
|
||||
关于 `BigDecimal` 的详细介绍,可以看看我写的这篇文章:[BigDecimal 详解](https://javaguide.cn/java/basis/bigdecimal.html)。
|
||||
@ -694,8 +731,6 @@ System.out.println(l + 1 == Long.MIN_VALUE); // true
|
||||
|
||||
### 成员变量与局部变量的区别?
|
||||
|
||||

|
||||
|
||||
- **语法形式**:从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 `public`,`private`,`static` 等修饰符所修饰,而局部变量不能被访问控制修饰符及 `static` 所修饰;但是,成员变量和局部变量都能被 `final` 所修饰。
|
||||
- **存储方式**:从变量在内存中的存储方式来看,如果成员变量是使用 `static` 修饰的,那么这个成员变量是属于类的,如果没有使用 `static` 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
|
||||
- **生存时间**:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
|
||||
@ -976,6 +1011,7 @@ public class SuperMan extends Hero{
|
||||
}
|
||||
|
||||
public class SuperSuperMan extends SuperMan {
|
||||
@Override
|
||||
public String name() {
|
||||
return "超级超级英雄";
|
||||
}
|
||||
|
||||
@ -18,14 +18,26 @@ head:
|
||||
|
||||
### 面向对象和面向过程的区别
|
||||
|
||||
两者的主要区别在于解决问题的方式不同:
|
||||
面向过程编程(Procedural-Oriented Programming,POP)和面向对象编程(Object-Oriented Programming,OOP)是两种常见的编程范式,两者的主要区别在于解决问题的方式不同:
|
||||
|
||||
- 面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
|
||||
- 面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。
|
||||
- **面向过程编程(POP)**:面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
|
||||
- **面向对象编程(OOP)**:面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。
|
||||
|
||||
另外,面向对象开发的程序一般更易维护、易复用、易扩展。
|
||||
相比较于 POP,OOP 开发的程序一般具有下面这些优点:
|
||||
|
||||
相关 issue : [面向过程:面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431) 。
|
||||
- **易维护**:由于良好的结构和封装性,OOP 程序通常更容易维护。
|
||||
- **易复用**:通过继承和多态,OOP 设计使得代码更具复用性,方便扩展功能。
|
||||
- **易扩展**:模块化设计使得系统扩展变得更加容易和灵活。
|
||||
|
||||
POP 的编程方式通常更为简单和直接,适合处理一些较简单的任务。
|
||||
|
||||
POP 和 OOP 的性能差异主要取决于它们的运行机制,而不仅仅是编程范式本身。因此,简单地比较两者的性能是一个常见的误区(相关 issue : [面向过程:面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431) )。
|
||||
|
||||
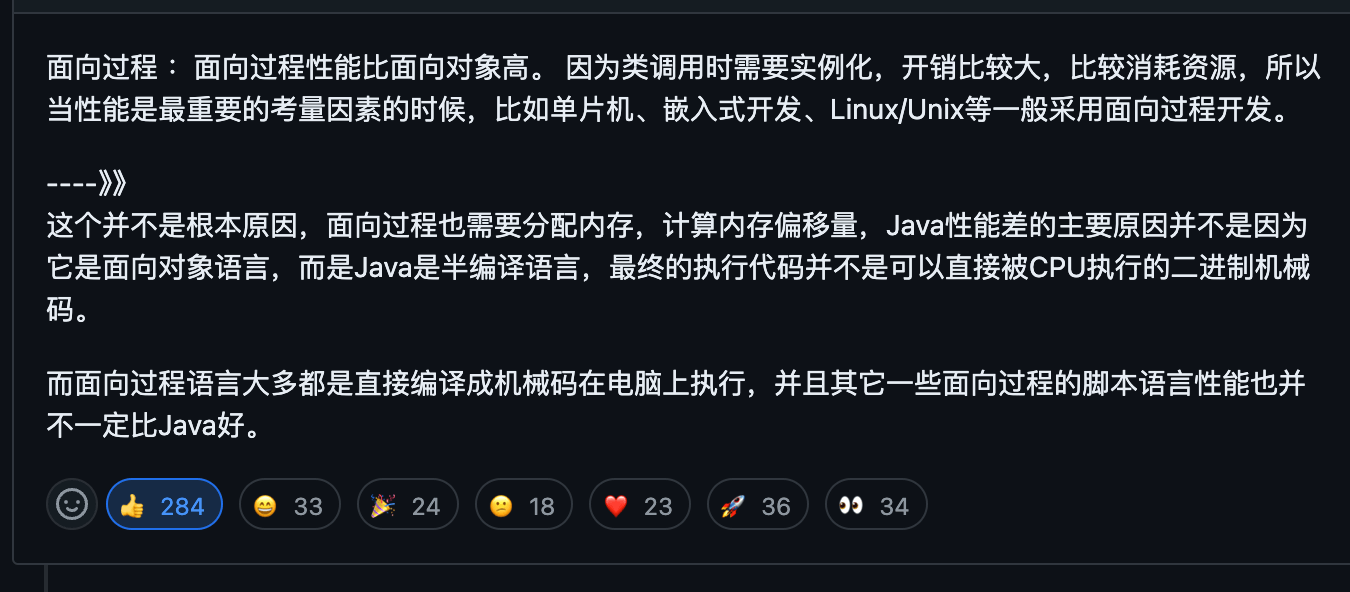
|
||||
|
||||
在选择编程范式时,性能并不是唯一的考虑因素。代码的可维护性、可扩展性和开发效率同样重要。
|
||||
|
||||
现代编程语言基本都支持多种编程范式,既可以用来进行面向过程编程,也可以进行面向对象编程。
|
||||
|
||||
下面是一个求圆的面积和周长的示例,简单分别展示了面向对象和面向过程两种不同的解决方案。
|
||||
|
||||
@ -136,13 +148,13 @@ true
|
||||
|
||||
### 构造方法有哪些特点?是否可被 override?
|
||||
|
||||
构造方法特点如下:
|
||||
构造方法具有以下特点:
|
||||
|
||||
- 名字与类名相同。
|
||||
- 没有返回值,但不能用 void 声明构造函数。
|
||||
- 生成类的对象时自动执行,无需调用。
|
||||
- **名称与类名相同**:构造方法的名称必须与类名完全一致。
|
||||
- **没有返回值**:构造方法没有返回类型,且不能使用 `void` 声明。
|
||||
- **自动执行**:在生成类的对象时,构造方法会自动执行,无需显式调用。
|
||||
|
||||
构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
|
||||
构造方法**不能被重写(override)**,但**可以被重载(overload)**。因此,一个类中可以有多个构造方法,这些构造方法可以具有不同的参数列表,以提供不同的对象初始化方式。
|
||||
|
||||
### 面向对象三大特征
|
||||
|
||||
@ -200,17 +212,67 @@ public class Student {
|
||||
|
||||
### 接口和抽象类有什么共同点和区别?
|
||||
|
||||
**共同点**:
|
||||
#### 接口和抽象类的共同点
|
||||
|
||||
- 都不能被实例化。
|
||||
- 都可以包含抽象方法。
|
||||
- 都可以有默认实现的方法(Java 8 可以用 `default` 关键字在接口中定义默认方法)。
|
||||
- **实例化**:接口和抽象类都不能直接实例化,只能被实现(接口)或继承(抽象类)后才能创建具体的对象。
|
||||
- **抽象方法**:接口和抽象类都可以包含抽象方法。抽象方法没有方法体,必须在子类或实现类中实现。
|
||||
|
||||
**区别**:
|
||||
#### 接口和抽象类的区别
|
||||
|
||||
- 接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
|
||||
- 一个类只能继承一个类,但是可以实现多个接口。
|
||||
- 接口中的成员变量只能是 `public static final` 类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default,可在子类中被重新定义,也可被重新赋值。
|
||||
- **设计目的**:接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
|
||||
- **继承和实现**:一个类只能继承一个类(包括抽象类),因为 Java 不支持多继承。但一个类可以实现多个接口,一个接口也可以继承多个其他接口。
|
||||
- **成员变量**:接口中的成员变量只能是 `public static final` 类型的,不能被修改且必须有初始值。抽象类的成员变量可以有任何修饰符(`private`, `protected`, `public`),可以在子类中被重新定义或赋值。
|
||||
- **方法**:
|
||||
- Java 8 之前,接口中的方法默认是 `public abstract` ,也就是只能有方法声明。自 Java 8 起,可以在接口中定义 `default`(默认) 方法和 `static` (静态)方法。 自 Java 9 起,接口可以包含 `private` 方法。
|
||||
- 抽象类可以包含抽象方法和非抽象方法。抽象方法没有方法体,必须在子类中实现。非抽象方法有具体实现,可以直接在抽象类中使用或在子类中重写。
|
||||
|
||||
在 Java 8 及以上版本中,接口引入了新的方法类型:`default` 方法、`static` 方法和 `private` 方法。这些方法让接口的使用更加灵活。
|
||||
|
||||
Java 8 引入的`default` 方法用于提供接口方法的默认实现,可以在实现类中被覆盖。这样就可以在不修改实现类的情况下向现有接口添加新功能,从而增强接口的扩展性和向后兼容性。
|
||||
|
||||
```java
|
||||
public interface MyInterface {
|
||||
default void defaultMethod() {
|
||||
System.out.println("This is a default method.");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Java 8 引入的`static` 方法无法在实现类中被覆盖,只能通过接口名直接调用( `MyInterface.staticMethod()`),类似于类中的静态方法。`static` 方法通常用于定义一些通用的、与接口相关的工具方法,一般很少用。
|
||||
|
||||
```java
|
||||
public interface MyInterface {
|
||||
static void staticMethod() {
|
||||
System.out.println("This is a static method in the interface.");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Java 9 允许在接口中使用 `private` 方法。`private`方法可以用于在接口内部共享代码,不对外暴露。
|
||||
|
||||
```java
|
||||
public interface MyInterface {
|
||||
// default 方法
|
||||
default void defaultMethod() {
|
||||
commonMethod();
|
||||
}
|
||||
|
||||
// static 方法
|
||||
static void staticMethod() {
|
||||
commonMethod();
|
||||
}
|
||||
|
||||
// 私有静态方法,可以被 static 和 default 方法调用
|
||||
private static void commonMethod() {
|
||||
System.out.println("This is a private method used internally.");
|
||||
}
|
||||
|
||||
// 实例私有方法,只能被 default 方法调用。
|
||||
private void instanceCommonMethod() {
|
||||
System.out.println("This is a private instance method used internally.");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### 深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
|
||||
|
||||
@ -299,13 +361,13 @@ System.out.println(person1.getAddress() == person1Copy.getAddress());
|
||||
|
||||
我专门画了一张图来描述浅拷贝、深拷贝、引用拷贝:
|
||||
|
||||
|
||||

|
||||
|
||||
## Object
|
||||
|
||||
### Object 类的常见方法有哪些?
|
||||
|
||||
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
|
||||
Object 类是一个特殊的类,是所有类的父类,主要提供了以下 11 个方法:
|
||||
|
||||
```java
|
||||
/**
|
||||
@ -621,7 +683,7 @@ System.out.println(s);
|
||||
|
||||
如果你使用 IDEA 的话,IDEA 自带的代码检查机制也会提示你修改代码。
|
||||
|
||||
不过,使用 “+” 进行字符串拼接会产生大量的临时对象的问题在 JDK9 中得到了解决。在 JDK9 当中,字符串相加 “+” 改为了用动态方法 `makeConcatWithConstants()` 来实现,而不是大量的 `StringBuilder` 了。这个改进是 JDK9 的 [JEP 280](https://openjdk.org/jeps/280) 提出的,这也意味着 JDK 9 之后,你可以放心使用“+” 进行字符串拼接了。关于这部分改进的详细介绍,推荐阅读这篇文章:还在无脑用 [StringBuilder?来重温一下字符串拼接吧](https://juejin.cn/post/7182872058743750715) 。
|
||||
在 JDK 9 中,字符串相加“+”改为用动态方法 `makeConcatWithConstants()` 来实现,通过提前分配空间从而减少了部分临时对象的创建。然而这种优化主要针对简单的字符串拼接,如: `a+b+c` 。对于循环中的大量拼接操作,仍然会逐个动态分配内存(类似于两个两个 append 的概念),并不如手动使用 StringBuilder 来进行拼接效率高。这个改进是 JDK9 的 [JEP 280](https://openjdk.org/jeps/280) 提出的,关于这部分改进的详细介绍,推荐阅读这篇文章:还在无脑用 [StringBuilder?来重温一下字符串拼接吧](https://juejin.cn/post/7182872058743750715) 以及参考 [issue#2442](https://github.com/Snailclimb/JavaGuide/issues/2442)。
|
||||
|
||||
### String#equals() 和 Object#equals() 有何区别?
|
||||
|
||||
|
||||
@ -286,7 +286,7 @@ class GeneratorImpl<T> implements Generator<T>{
|
||||
实现泛型接口,指定类型:
|
||||
|
||||
```java
|
||||
class GeneratorImpl<T> implements Generator<String>{
|
||||
class GeneratorImpl implements Generator<String> {
|
||||
@Override
|
||||
public String method() {
|
||||
return "hello";
|
||||
@ -417,21 +417,20 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
|
||||
|
||||
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
|
||||
|
||||

|
||||
<img src="https://oss.javaguide.cn/github/javaguide/java/basis/spi/22e1830e0b0e4115a882751f6c417857tplv-k3u1fbpfcp-zoom-1.jpeg" style="zoom:50%;" />
|
||||
|
||||
### SPI 和 API 有什么区别?
|
||||
|
||||
**那 SPI 和 API 有啥区别?**
|
||||
|
||||
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
|
||||
说到 SPI 就不得不说一下 API(Application Programming Interface) 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
|
||||
|
||||
|
||||
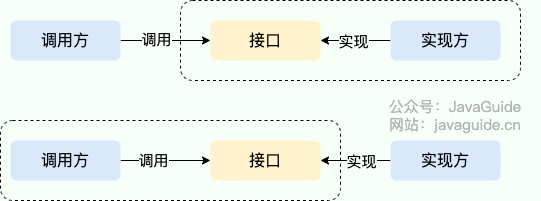
|
||||
|
||||
一般模块之间都是通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
|
||||
一般模块之间都是通过接口进行通讯,因此我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
|
||||
|
||||
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
|
||||
|
||||
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
|
||||
- 当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 **API**。这种情况下,接口和实现都是放在实现方的包中。调用方通过接口调用实现方的功能,而不需要关心具体的实现细节。
|
||||
- 当接口存在于调用方这边时,这就是 **SPI ** 。由接口调用方确定接口规则,然后由不同的厂商根据这个规则对这个接口进行实现,从而提供服务。
|
||||
|
||||
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
|
||||
|
||||
|
||||
@ -28,21 +28,20 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
|
||||
|
||||
很多框架都使用了 Java 的 SPI 机制,比如:Spring 框架、数据库加载驱动、日志接口、以及 Dubbo 的扩展实现等等。
|
||||
|
||||

|
||||
<img src="https://oss.javaguide.cn/github/javaguide/java/basis/spi/22e1830e0b0e4115a882751f6c417857tplv-k3u1fbpfcp-zoom-1.jpeg" style="zoom:50%;" />
|
||||
|
||||
### SPI 和 API 有什么区别?
|
||||
|
||||
**那 SPI 和 API 有啥区别?**
|
||||
|
||||
说到 SPI 就不得不说一下 API 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
|
||||
说到 SPI 就不得不说一下 API(Application Programming Interface) 了,从广义上来说它们都属于接口,而且很容易混淆。下面先用一张图说明一下:
|
||||
|
||||

|
||||

|
||||
|
||||
一般模块之间都是通过接口进行通讯,那我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
|
||||
一般模块之间都是通过接口进行通讯,因此我们在服务调用方和服务实现方(也称服务提供者)之间引入一个“接口”。
|
||||
|
||||
当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 API ,这种接口和实现都是放在实现方的。
|
||||
|
||||
当接口存在于调用方这边时,就是 SPI ,由接口调用方确定接口规则,然后由不同的厂商去根据这个规则对这个接口进行实现,从而提供服务。
|
||||
- 当实现方提供了接口和实现,我们可以通过调用实现方的接口从而拥有实现方给我们提供的能力,这就是 **API**。这种情况下,接口和实现都是放在实现方的包中。调用方通过接口调用实现方的功能,而不需要关心具体的实现细节。
|
||||
- 当接口存在于调用方这边时,这就是 **SPI ** 。由接口调用方确定接口规则,然后由不同的厂商根据这个规则对这个接口进行实现,从而提供服务。
|
||||
|
||||
举个通俗易懂的例子:公司 H 是一家科技公司,新设计了一款芯片,然后现在需要量产了,而市面上有好几家芯片制造业公司,这个时候,只要 H 公司指定好了这芯片生产的标准(定义好了接口标准),那么这些合作的芯片公司(服务提供者)就按照标准交付自家特色的芯片(提供不同方案的实现,但是给出来的结果是一样的)。
|
||||
|
||||
|
||||
@ -421,7 +421,7 @@ public void objTest() throws Exception{
|
||||
|
||||
#### 典型应用
|
||||
|
||||
- **常规对象实例化方式**:我们通常所用到的创建对象的方式,从本质上来讲,都是通过 new 机制来实现对象的创建。但是,new 机制有个特点就是当类只提供有参的构造函数且无显示声明无参构造函数时,则必须使用有参构造函数进行对象构造,而使用有参构造函数时,必须传递相应个数的参数才能完成对象实例化。
|
||||
- **常规对象实例化方式**:我们通常所用到的创建对象的方式,从本质上来讲,都是通过 new 机制来实现对象的创建。但是,new 机制有个特点就是当类只提供有参的构造函数且无显式声明无参构造函数时,则必须使用有参构造函数进行对象构造,而使用有参构造函数时,必须传递相应个数的参数才能完成对象实例化。
|
||||
- **非常规的实例化方式**:而 Unsafe 中提供 allocateInstance 方法,仅通过 Class 对象就可以创建此类的实例对象,而且不需要调用其构造函数、初始化代码、JVM 安全检查等。它抑制修饰符检测,也就是即使构造器是 private 修饰的也能通过此方法实例化,只需提类对象即可创建相应的对象。由于这种特性,allocateInstance 在 java.lang.invoke、Objenesis(提供绕过类构造器的对象生成方式)、Gson(反序列化时用到)中都有相应的应用。
|
||||
|
||||
### 数组操作
|
||||
|
||||
@ -305,8 +305,11 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
|
||||
/**
|
||||
* 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
|
||||
* 返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
|
||||
* 因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
|
||||
* 返回的数组将是“安全的”,因为该列表不保留对它的引用。
|
||||
* (换句话说,这个方法必须分配一个新的数组)。
|
||||
* 因此,调用者可以自由地修改返回的数组结构。
|
||||
* 注意:如果元素是引用类型,修改元素的内容会影响到原列表中的对象。
|
||||
* 此方法充当基于数组和基于集合的API之间的桥梁。
|
||||
*/
|
||||
public Object[] toArray() {
|
||||
return Arrays.copyOf(elementData, size);
|
||||
@ -729,7 +732,7 @@ private void grow(int minCapacity) {
|
||||
**我们再来通过例子探究一下`grow()` 方法:**
|
||||
|
||||
- 当 `add` 第 1 个元素时,`oldCapacity` 为 0,经比较后第一个 if 判断成立,`newCapacity = minCapacity`(为 10)。但是第二个 if 判断不会成立,即 `newCapacity` 不比 `MAX_ARRAY_SIZE` 大,则不会进入 `hugeCapacity` 方法。数组容量为 10,`add` 方法中 return true,size 增为 1。
|
||||
- 当 `add` 第 11 个元素进入 `grow` 方法时,`newCapacity` 为 15,比 `minCapacity`(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 huge`C`apacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
|
||||
- 当 `add` 第 11 个元素进入 `grow` 方法时,`newCapacity` 为 15,比 `minCapacity`(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 `hugeCapacity` 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
|
||||
- 以此类推······
|
||||
|
||||
**这里补充一点比较重要,但是容易被忽视掉的知识点:**
|
||||
|
||||
@ -23,6 +23,7 @@ head:
|
||||
- **对 Null key 和 Null value 的支持:** `HashMap` 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;Hashtable 不允许有 null 键和 null 值,否则会抛出 `NullPointerException`。
|
||||
- **初始容量大小和每次扩充容量大小的不同:** ① 创建时如果不指定容量初始值,`Hashtable` 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。`HashMap` 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 `Hashtable` 会直接使用你给定的大小,而 `HashMap` 会将其扩充为 2 的幂次方大小(`HashMap` 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 `HashMap` 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
|
||||
- **底层数据结构:** JDK1.8 以后的 `HashMap` 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间(后文中我会结合源码对这一过程进行分析)。`Hashtable` 没有这样的机制。
|
||||
- **哈希函数的实现**:`HashMap` 对哈希值进行了高位和低位的混合扰动处理以减少冲突,而 `Hashtable` 直接使用键的 `hashCode()` 值。
|
||||
|
||||
**`HashMap` 中带有初始容量的构造函数:**
|
||||
|
||||
@ -47,18 +48,18 @@ head:
|
||||
下面这个方法保证了 `HashMap` 总是使用 2 的幂作为哈希表的大小。
|
||||
|
||||
```java
|
||||
/**
|
||||
* Returns a power of two size for the given target capacity.
|
||||
*/
|
||||
static final int tableSizeFor(int cap) {
|
||||
int n = cap - 1;
|
||||
n |= n >>> 1;
|
||||
n |= n >>> 2;
|
||||
n |= n >>> 4;
|
||||
n |= n >>> 8;
|
||||
n |= n >>> 16;
|
||||
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
|
||||
}
|
||||
/**
|
||||
* Returns a power of two size for the given target capacity.
|
||||
*/
|
||||
static final int tableSizeFor(int cap) {
|
||||
int n = cap - 1;
|
||||
n |= n >>> 1;
|
||||
n |= n >>> 2;
|
||||
n |= n >>> 4;
|
||||
n |= n >>> 8;
|
||||
n |= n >>> 16;
|
||||
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
|
||||
}
|
||||
```
|
||||
|
||||
### HashMap 和 HashSet 区别
|
||||
@ -82,7 +83,7 @@ head:
|
||||
|
||||
`NavigableMap` 接口提供了丰富的方法来探索和操作键值对:
|
||||
|
||||
1. **定向搜索**: `ceilingEntry()`, `floorEntry()`, `higherEntry()`和 `lowerEntry()` 等方法可以用于定位大于、小于、大于等于、小于等于给定键的最接近的键值对。
|
||||
1. **定向搜索**: `ceilingEntry()`, `floorEntry()`, `higherEntry()`和 `lowerEntry()` 等方法可以用于定位大于等于、小于等于、严格大于、严格小于给定键的最接近的键值对。
|
||||
2. **子集操作**: `subMap()`, `headMap()`和 `tailMap()` 方法可以高效地创建原集合的子集视图,而无需复制整个集合。
|
||||
3. **逆序视图**:`descendingMap()` 方法返回一个逆序的 `NavigableMap` 视图,使得可以反向迭代整个 `TreeMap`。
|
||||
4. **边界操作**: `firstEntry()`, `lastEntry()`, `pollFirstEntry()`和 `pollLastEntry()` 等方法可以方便地访问和移除元素。
|
||||
@ -184,7 +185,7 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
|
||||
|
||||
JDK1.8 之前 `HashMap` 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。HashMap 通过 key 的 `hashcode` 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
|
||||
|
||||
所谓扰动函数指的就是 HashMap 的 `hash` 方法。使用 `hash` 方法也就是扰动函数是为了防止一些实现比较差的 `hashCode()` 方法 换句话说使用扰动函数之后可以减少碰撞。
|
||||
`HashMap` 中的扰动函数(`hash` 方法)是用来优化哈希值的分布。通过对原始的 `hashCode()` 进行额外处理,扰动函数可以减小由于糟糕的 `hashCode()` 实现导致的碰撞,从而提高数据的分布均匀性。
|
||||
|
||||
**JDK 1.8 HashMap 的 hash 方法源码:**
|
||||
|
||||
@ -239,7 +240,7 @@ for (int binCount = 0; ; ++binCount) {
|
||||
// 遍历到链表最后一个节点
|
||||
if ((e = p.next) == null) {
|
||||
p.next = newNode(hash, key, value, null);
|
||||
// 如果链表元素个数大于等于TREEIFY_THRESHOLD(8)
|
||||
// 如果链表元素个数大于TREEIFY_THRESHOLD(8)
|
||||
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
|
||||
// 红黑树转换(并不会直接转换成红黑树)
|
||||
treeifyBin(tab, hash);
|
||||
@ -285,11 +286,55 @@ final void treeifyBin(Node<K,V>[] tab, int hash) {
|
||||
|
||||
### HashMap 的长度为什么是 2 的幂次方
|
||||
|
||||
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
|
||||
为了让 `HashMap` 存取高效并减少碰撞,我们需要确保数据尽量均匀分布。哈希值在 Java 中通常使用 `int` 表示,其范围是 `-2147483648 ~ 2147483647`前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但是,问题是一个 40 亿长度的数组,内存是放不下的。所以,这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。
|
||||
|
||||
**这个算法应该如何设计呢?**
|
||||
|
||||
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。**
|
||||
我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了:“**取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作**(也就是说 `hash%length==hash&(length-1)` 的前提是 length 是 2 的 n 次方)。” 并且,**采用二进制位操作 & 相对于 % 能够提高运算效率**。
|
||||
|
||||
除了上面所说的位运算比取余效率高之外,我觉得更重要的一个原因是:**长度是 2 的幂次方,可以让 `HashMap` 在扩容的时候更均匀**。例如:
|
||||
|
||||
- length = 8 时,length - 1 = 7 的二进制位`0111`
|
||||
- length = 16 时,length - 1 = 15 的二进制位`1111`
|
||||
|
||||
这时候原本存在 `HashMap` 中的元素计算新的数组位置时 `hash&(length-1)`,取决 hash 的第四个二进制位(从右数),会出现两种情况:
|
||||
|
||||
1. 第四个二进制位为 0,数组位置不变,也就是说当前元素在新数组和旧数组的位置相同。
|
||||
2. 第四个二进制位为 1,数组位置在新数组扩容之后的那一部分。
|
||||
|
||||
这里列举一个例子:
|
||||
|
||||
```plain
|
||||
假设有一个元素的哈希值为 10101100
|
||||
|
||||
旧数组元素位置计算:
|
||||
hash = 10101100
|
||||
length - 1 = 00000111
|
||||
& -----------------
|
||||
index = 00000100 (4)
|
||||
|
||||
新数组元素位置计算:
|
||||
hash = 10101100
|
||||
length - 1 = 00001111
|
||||
& -----------------
|
||||
index = 00001100 (12)
|
||||
|
||||
看第四位(从右数):
|
||||
1.高位为 0:位置不变。
|
||||
2.高位为 1:移动到新位置(原索引位置+原容量)。
|
||||
```
|
||||
|
||||
⚠️注意:这里列举的场景看的是第四个二进制位,更准确点来说看的是高位(从右数),例如 `length = 32` 时,`length - 1 = 31`,二进制为 `11111`,这里看的就是第五个二进制位。
|
||||
|
||||
也就是说扩容之后,在旧数组元素 hash 值比较均匀(至于 hash 值均不均匀,取决于前面讲的对象的 `hashcode()` 方法和扰动函数)的情况下,新数组元素也会被分配的比较均匀,最好的情况是会有一半在新数组的前半部分,一半在新数组后半部分。
|
||||
|
||||
这样也使得扩容机制变得简单和高效,扩容后只需检查哈希值高位的变化来决定元素的新位置,要么位置不变(高位为 0),要么就是移动到新位置(高位为 1,原索引位置+原容量)。
|
||||
|
||||
最后,简单总结一下 `HashMap` 的长度是 2 的幂次方的原因:
|
||||
|
||||
1. 位运算效率更高:位运算(&)比取余运算(%)更高效。当长度为 2 的幂次方时,`hash % length` 等价于 `hash & (length - 1)`。
|
||||
2. 可以更好地保证哈希值的均匀分布:扩容之后,在旧数组元素 hash 值比较均匀的情况下,新数组元素也会被分配的比较均匀,最好的情况是会有一半在新数组的前半部分,一半在新数组后半部分。
|
||||
3. 扩容机制变得简单和高效:扩容后只需检查哈希值高位的变化来决定元素的新位置,要么位置不变(高位为 0),要么就是移动到新位置(高位为 1,原索引位置+原容量)。
|
||||
|
||||
### HashMap 多线程操作导致死循环问题
|
||||
|
||||
|
||||
@ -272,7 +272,7 @@ void afterNodeAccess(Node < K, V > e) { // move node to last
|
||||
if (b == null)
|
||||
head = a;
|
||||
else
|
||||
//如果后继节点不为空,则让前驱节点指向后继节点
|
||||
//如果前驱节点不为空,则让前驱节点指向后继节点
|
||||
b.after = a;
|
||||
|
||||
//如果后继节点不为空,则让后继节点指向前驱节点
|
||||
@ -372,10 +372,10 @@ void afterNodeRemoval(Node<K,V> e) { // unlink
|
||||
|
||||
从源码可以看出, `afterNodeRemoval` 方法的整体操作就是让当前节点 p 和前驱节点、后继节点断开联系,等待 gc 回收,整体步骤为:
|
||||
|
||||
1. 获取当前节点 p、以及 e 的前驱节点 b 和后继节点 a。
|
||||
1. 获取当前节点 p、以及 p 的前驱节点 b 和后继节点 a。
|
||||
2. 让当前节点 p 和其前驱、后继节点断开联系。
|
||||
3. 尝试让前驱节点 b 指向后继节点 a,若 b 为空则说明当前节点 p 在链表首部,我们直接将 head 指向后继节点 a 即可。
|
||||
4. 尝试让后继节点 a 指向前驱节点 b,若 a 为空则说明当前节点 p 在链表末端,所以直接让 tail 指针指向前驱节点 a 即可。
|
||||
4. 尝试让后继节点 a 指向前驱节点 b,若 a 为空则说明当前节点 p 在链表末端,所以直接让 tail 指针指向前驱节点 b 即可。
|
||||
|
||||
可以结合这张图理解,展示了 key 为 13 的元素被删除,也就是从链表中移除了这个元素。
|
||||
|
||||
|
||||
@ -151,8 +151,9 @@ void linkBefore(E e, Node<E> succ) {
|
||||
final Node<E> newNode = new Node<>(pred, e, succ);
|
||||
// 将 succ 节点前驱引用 prev 指向新节点
|
||||
succ.prev = newNode;
|
||||
// 判断尾节点是否为空,为空表示当前链表还没有节点
|
||||
// 判断前驱节点是否为空,为空表示 succ 是第一个节点
|
||||
if (pred == null)
|
||||
// 新节点成为第一个节点
|
||||
first = newNode;
|
||||
else
|
||||
// succ 节点前驱的后继引用指向新节点
|
||||
|
||||
@ -7,17 +7,21 @@ tag:
|
||||
|
||||
## Atomic 原子类介绍
|
||||
|
||||
Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
|
||||
`Atomic` 翻译成中文是“原子”的意思。在化学上,原子是构成物质的最小单位,在化学反应中不可分割。在编程中,`Atomic` 指的是一个操作具有原子性,即该操作不可分割、不可中断。即使在多个线程同时执行时,该操作要么全部执行完成,要么不执行,不会被其他线程看到部分完成的状态。
|
||||
|
||||
所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
|
||||
原子类简单来说就是具有原子性操作特征的类。
|
||||
|
||||
并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
|
||||
`java.util.concurrent.atomic` 包中的 `Atomic` 原子类提供了一种线程安全的方式来操作单个变量。
|
||||
|
||||
`Atomic` 类依赖于 CAS(Compare-And-Swap,比较并交换)乐观锁来保证其方法的原子性,而不需要使用传统的锁机制(如 `synchronized` 块或 `ReentrantLock`)。
|
||||
|
||||
这篇文章我们只介绍 Atomic 原子类的概念,具体实现原理可以阅读笔者写的这篇文章:[CAS 详解](./cas.md)。
|
||||
|
||||
|
||||
|
||||
根据操作的数据类型,可以将 JUC 包中的原子类分为 4 类
|
||||
根据操作的数据类型,可以将 JUC 包中的原子类分为 4 类:
|
||||
|
||||
**基本类型**
|
||||
**1、基本类型**
|
||||
|
||||
使用原子的方式更新基本类型
|
||||
|
||||
@ -25,7 +29,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
- `AtomicLong`:长整型原子类
|
||||
- `AtomicBoolean`:布尔型原子类
|
||||
|
||||
**数组类型**
|
||||
**2、数组类型**
|
||||
|
||||
使用原子的方式更新数组里的某个元素
|
||||
|
||||
@ -33,7 +37,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
- `AtomicLongArray`:长整型数组原子类
|
||||
- `AtomicReferenceArray`:引用类型数组原子类
|
||||
|
||||
**引用类型**
|
||||
**3、引用类型**
|
||||
|
||||
- `AtomicReference`:引用类型原子类
|
||||
- `AtomicMarkableReference`:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题~~。
|
||||
@ -41,7 +45,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
|
||||
**🐛 修正(参见:[issue#626](https://github.com/Snailclimb/JavaGuide/issues/626))** : `AtomicMarkableReference` 不能解决 ABA 问题。
|
||||
|
||||
**对象的属性修改类型**
|
||||
**4、对象的属性修改类型**
|
||||
|
||||
- `AtomicIntegerFieldUpdater`:原子更新整型字段的更新器
|
||||
- `AtomicLongFieldUpdater`:原子更新长整型字段的更新器
|
||||
@ -57,7 +61,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
|
||||
上面三个类提供的方法几乎相同,所以我们这里以 `AtomicInteger` 为例子来介绍。
|
||||
|
||||
**AtomicInteger 类常用方法**
|
||||
**`AtomicInteger` 类常用方法** :
|
||||
|
||||
```java
|
||||
public final int get() //获取当前的值
|
||||
@ -66,90 +70,51 @@ public final int getAndIncrement()//获取当前的值,并自增
|
||||
public final int getAndDecrement() //获取当前的值,并自减
|
||||
public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
|
||||
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
|
||||
public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
|
||||
public final void lazySet(int newValue)//最终设置为newValue, lazySet 提供了一种比 set 方法更弱的语义,可能导致其他线程在之后的一小段时间内还是可以读到旧的值,但可能更高效。
|
||||
```
|
||||
|
||||
**`AtomicInteger` 类使用示例** :
|
||||
|
||||
```java
|
||||
import java.util.concurrent.atomic.AtomicInteger;
|
||||
// 初始化 AtomicInteger 对象,初始值为 0
|
||||
AtomicInteger atomicInt = new AtomicInteger(0);
|
||||
|
||||
public class AtomicIntegerTest {
|
||||
// 使用 getAndSet 方法获取当前值,并设置新值为 3
|
||||
int tempValue = atomicInt.getAndSet(3);
|
||||
System.out.println("tempValue: " + tempValue + "; atomicInt: " + atomicInt);
|
||||
|
||||
public static void main(String[] args) {
|
||||
int temvalue = 0;
|
||||
AtomicInteger i = new AtomicInteger(0);
|
||||
temvalue = i.getAndSet(3);
|
||||
System.out.println("temvalue:" + temvalue + "; i:" + i); //temvalue:0; i:3
|
||||
temvalue = i.getAndIncrement();
|
||||
System.out.println("temvalue:" + temvalue + "; i:" + i); //temvalue:3; i:4
|
||||
temvalue = i.getAndAdd(5);
|
||||
System.out.println("temvalue:" + temvalue + "; i:" + i); //temvalue:4; i:9
|
||||
}
|
||||
// 使用 getAndIncrement 方法获取当前值,并自增 1
|
||||
tempValue = atomicInt.getAndIncrement();
|
||||
System.out.println("tempValue: " + tempValue + "; atomicInt: " + atomicInt);
|
||||
|
||||
}
|
||||
// 使用 getAndAdd 方法获取当前值,并增加指定值 5
|
||||
tempValue = atomicInt.getAndAdd(5);
|
||||
System.out.println("tempValue: " + tempValue + "; atomicInt: " + atomicInt);
|
||||
|
||||
// 使用 compareAndSet 方法进行原子性条件更新,期望值为 9,更新值为 10
|
||||
boolean updateSuccess = atomicInt.compareAndSet(9, 10);
|
||||
System.out.println("Update Success: " + updateSuccess + "; atomicInt: " + atomicInt);
|
||||
|
||||
// 获取当前值
|
||||
int currentValue = atomicInt.get();
|
||||
System.out.println("Current value: " + currentValue);
|
||||
|
||||
// 使用 lazySet 方法设置新值为 15
|
||||
atomicInt.lazySet(15);
|
||||
System.out.println("After lazySet, atomicInt: " + atomicInt);
|
||||
```
|
||||
|
||||
### 基本数据类型原子类的优势
|
||||
|
||||
通过一个简单例子带大家看一下基本数据类型原子类的优势
|
||||
|
||||
**1、多线程环境不使用原子类保证线程安全(基本数据类型)**
|
||||
输出:
|
||||
|
||||
```java
|
||||
class Test {
|
||||
private volatile int count = 0;
|
||||
//若要线程安全执行执行count++,需要加锁
|
||||
public synchronized void increment() {
|
||||
count++;
|
||||
}
|
||||
|
||||
public int getCount() {
|
||||
return count;
|
||||
}
|
||||
}
|
||||
tempValue: 0; atomicInt: 3
|
||||
tempValue: 3; atomicInt: 4
|
||||
tempValue: 4; atomicInt: 9
|
||||
Update Success: true; atomicInt: 10
|
||||
Current value: 10
|
||||
After lazySet, atomicInt: 15
|
||||
```
|
||||
|
||||
**2、多线程环境使用原子类保证线程安全(基本数据类型)**
|
||||
|
||||
```java
|
||||
class Test2 {
|
||||
private AtomicInteger count = new AtomicInteger();
|
||||
|
||||
public void increment() {
|
||||
count.incrementAndGet();
|
||||
}
|
||||
//使用AtomicInteger之后,不需要加锁,也可以实现线程安全。
|
||||
public int getCount() {
|
||||
return count.get();
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### AtomicInteger 线程安全原理简单分析
|
||||
|
||||
`AtomicInteger` 类的部分源码:
|
||||
|
||||
```java
|
||||
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
|
||||
private static final Unsafe unsafe = Unsafe.getUnsafe();
|
||||
private static final long valueOffset;
|
||||
|
||||
static {
|
||||
try {
|
||||
valueOffset = unsafe.objectFieldOffset
|
||||
(AtomicInteger.class.getDeclaredField("value"));
|
||||
} catch (Exception ex) { throw new Error(ex); }
|
||||
}
|
||||
|
||||
private volatile int value;
|
||||
```
|
||||
|
||||
`AtomicInteger` 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
|
||||
|
||||
CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 `objectFieldOffset()` 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
|
||||
|
||||
## 数组类型原子类
|
||||
|
||||
使用原子的方式更新数组里的某个元素
|
||||
@ -175,26 +140,55 @@ public final void lazySet(int i, int newValue)//最终 将index=i 位置的元
|
||||
**`AtomicIntegerArray` 类使用示例** :
|
||||
|
||||
```java
|
||||
import java.util.concurrent.atomic.AtomicIntegerArray;
|
||||
|
||||
public class AtomicIntegerArrayTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
int temvalue = 0;
|
||||
int[] nums = { 1, 2, 3, 4, 5, 6 };
|
||||
AtomicIntegerArray i = new AtomicIntegerArray(nums);
|
||||
for (int j = 0; j < nums.length; j++) {
|
||||
System.out.println(i.get(j));
|
||||
}
|
||||
temvalue = i.getAndSet(0, 2);
|
||||
System.out.println("temvalue:" + temvalue + "; i:" + i);
|
||||
temvalue = i.getAndIncrement(0);
|
||||
System.out.println("temvalue:" + temvalue + "; i:" + i);
|
||||
temvalue = i.getAndAdd(0, 5);
|
||||
System.out.println("temvalue:" + temvalue + "; i:" + i);
|
||||
}
|
||||
int[] nums = {1, 2, 3, 4, 5, 6};
|
||||
// 创建 AtomicIntegerArray
|
||||
AtomicIntegerArray atomicArray = new AtomicIntegerArray(nums);
|
||||
|
||||
// 打印 AtomicIntegerArray 中的初始值
|
||||
System.out.println("Initial values in AtomicIntegerArray:");
|
||||
for (int j = 0; j < nums.length; j++) {
|
||||
System.out.print("Index " + j + ": " + atomicArray.get(j) + " ");
|
||||
}
|
||||
|
||||
// 使用 getAndSet 方法将索引 0 处的值设置为 2,并返回旧值
|
||||
int tempValue = atomicArray.getAndSet(0, 2);
|
||||
System.out.println("\nAfter getAndSet(0, 2):");
|
||||
System.out.println("Returned value: " + tempValue);
|
||||
for (int j = 0; j < atomicArray.length(); j++) {
|
||||
System.out.print("Index " + j + ": " + atomicArray.get(j) + " ");
|
||||
}
|
||||
|
||||
// 使用 getAndIncrement 方法将索引 0 处的值加 1,并返回旧值
|
||||
tempValue = atomicArray.getAndIncrement(0);
|
||||
System.out.println("\nAfter getAndIncrement(0):");
|
||||
System.out.println("Returned value: " + tempValue);
|
||||
for (int j = 0; j < atomicArray.length(); j++) {
|
||||
System.out.print("Index " + j + ": " + atomicArray.get(j) + " ");
|
||||
}
|
||||
|
||||
// 使用 getAndAdd 方法将索引 0 处的值增加 5,并返回旧值
|
||||
tempValue = atomicArray.getAndAdd(0, 5);
|
||||
System.out.println("\nAfter getAndAdd(0, 5):");
|
||||
System.out.println("Returned value: " + tempValue);
|
||||
for (int j = 0; j < atomicArray.length(); j++) {
|
||||
System.out.print("Index " + j + ": " + atomicArray.get(j) + " ");
|
||||
}
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```plain
|
||||
Initial values in AtomicIntegerArray:
|
||||
Index 0: 1 Index 1: 2 Index 2: 3 Index 3: 4 Index 4: 5 Index 5: 6
|
||||
After getAndSet(0, 2):
|
||||
Returned value: 1
|
||||
Index 0: 2 Index 1: 2 Index 2: 3 Index 3: 4 Index 4: 5 Index 5: 6
|
||||
After getAndIncrement(0):
|
||||
Returned value: 2
|
||||
Index 0: 3 Index 1: 2 Index 2: 3 Index 3: 4 Index 4: 5 Index 5: 6
|
||||
After getAndAdd(0, 5):
|
||||
Returned value: 3
|
||||
Index 0: 8 Index 1: 2 Index 2: 3 Index 3: 4 Index 4: 5 Index 5: 6
|
||||
```
|
||||
|
||||
## 引用类型原子类
|
||||
@ -210,174 +204,133 @@ public class AtomicIntegerArrayTest {
|
||||
**`AtomicReference` 类使用示例** :
|
||||
|
||||
```java
|
||||
import java.util.concurrent.atomic.AtomicReference;
|
||||
|
||||
public class AtomicReferenceTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
AtomicReference < Person > ar = new AtomicReference < Person > ();
|
||||
Person person = new Person("SnailClimb", 22);
|
||||
ar.set(person);
|
||||
Person updatePerson = new Person("Daisy", 20);
|
||||
ar.compareAndSet(person, updatePerson);
|
||||
|
||||
System.out.println(ar.get().getName());
|
||||
System.out.println(ar.get().getAge());
|
||||
}
|
||||
}
|
||||
|
||||
// Person 类
|
||||
class Person {
|
||||
private String name;
|
||||
private int age;
|
||||
|
||||
public Person(String name, int age) {
|
||||
super();
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
public int getAge() {
|
||||
return age;
|
||||
}
|
||||
|
||||
public void setAge(int age) {
|
||||
this.age = age;
|
||||
}
|
||||
|
||||
//省略getter/setter和toString
|
||||
}
|
||||
|
||||
|
||||
// 创建 AtomicReference 对象并设置初始值
|
||||
AtomicReference<Person> ar = new AtomicReference<>(new Person("SnailClimb", 22));
|
||||
|
||||
// 打印初始值
|
||||
System.out.println("Initial Person: " + ar.get().toString());
|
||||
|
||||
// 更新值
|
||||
Person updatePerson = new Person("Daisy", 20);
|
||||
ar.compareAndSet(ar.get(), updatePerson);
|
||||
|
||||
// 打印更新后的值
|
||||
System.out.println("Updated Person: " + ar.get().toString());
|
||||
|
||||
// 尝试再次更新
|
||||
Person anotherUpdatePerson = new Person("John", 30);
|
||||
boolean isUpdated = ar.compareAndSet(updatePerson, anotherUpdatePerson);
|
||||
|
||||
// 打印是否更新成功及最终值
|
||||
System.out.println("Second Update Success: " + isUpdated);
|
||||
System.out.println("Final Person: " + ar.get().toString());
|
||||
```
|
||||
|
||||
上述代码首先创建了一个 `Person` 对象,然后把 `Person` 对象设置进 `AtomicReference` 对象中,然后调用 `compareAndSet` 方法,该方法就是通过 CAS 操作设置 ar。如果 ar 的值为 `person` 的话,则将其设置为 `updatePerson`。实现原理与 `AtomicInteger` 类中的 `compareAndSet` 方法相同。运行上面的代码后的输出结果如下:
|
||||
输出:
|
||||
|
||||
```plain
|
||||
Daisy
|
||||
20
|
||||
Initial Person: Person{name='SnailClimb', age=22}
|
||||
Updated Person: Person{name='Daisy', age=20}
|
||||
Second Update Success: true
|
||||
Final Person: Person{name='John', age=30}
|
||||
```
|
||||
|
||||
**`AtomicStampedReference` 类使用示例** :
|
||||
|
||||
```java
|
||||
import java.util.concurrent.atomic.AtomicStampedReference;
|
||||
// 创建一个 AtomicStampedReference 对象,初始值为 "SnailClimb",初始版本号为 1
|
||||
AtomicStampedReference<String> asr = new AtomicStampedReference<>("SnailClimb", 1);
|
||||
|
||||
public class AtomicStampedReferenceDemo {
|
||||
public static void main(String[] args) {
|
||||
// 实例化、取当前值和 stamp 值
|
||||
final Integer initialRef = 0, initialStamp = 0;
|
||||
final AtomicStampedReference<Integer> asr = new AtomicStampedReference<>(initialRef, initialStamp);
|
||||
System.out.println("currentValue=" + asr.getReference() + ", currentStamp=" + asr.getStamp());
|
||||
// 打印初始值和版本号
|
||||
int[] initialStamp = new int[1];
|
||||
String initialRef = asr.get(initialStamp);
|
||||
System.out.println("Initial Reference: " + initialRef + ", Initial Stamp: " + initialStamp[0]);
|
||||
|
||||
// compare and set
|
||||
final Integer newReference = 666, newStamp = 999;
|
||||
final boolean casResult = asr.compareAndSet(initialRef, newReference, initialStamp, newStamp);
|
||||
System.out.println("currentValue=" + asr.getReference()
|
||||
+ ", currentStamp=" + asr.getStamp()
|
||||
+ ", casResult=" + casResult);
|
||||
// 更新值和版本号
|
||||
int oldStamp = initialStamp[0];
|
||||
String oldRef = initialRef;
|
||||
String newRef = "Daisy";
|
||||
int newStamp = oldStamp + 1;
|
||||
|
||||
// 获取当前的值和当前的 stamp 值
|
||||
int[] arr = new int[1];
|
||||
final Integer currentValue = asr.get(arr);
|
||||
final int currentStamp = arr[0];
|
||||
System.out.println("currentValue=" + currentValue + ", currentStamp=" + currentStamp);
|
||||
boolean isUpdated = asr.compareAndSet(oldRef, newRef, oldStamp, newStamp);
|
||||
System.out.println("Update Success: " + isUpdated);
|
||||
|
||||
// 单独设置 stamp 值
|
||||
final boolean attemptStampResult = asr.attemptStamp(newReference, 88);
|
||||
System.out.println("currentValue=" + asr.getReference()
|
||||
+ ", currentStamp=" + asr.getStamp()
|
||||
+ ", attemptStampResult=" + attemptStampResult);
|
||||
// 打印更新后的值和版本号
|
||||
int[] updatedStamp = new int[1];
|
||||
String updatedRef = asr.get(updatedStamp);
|
||||
System.out.println("Updated Reference: " + updatedRef + ", Updated Stamp: " + updatedStamp[0]);
|
||||
|
||||
// 重新设置当前值和 stamp 值
|
||||
asr.set(initialRef, initialStamp);
|
||||
System.out.println("currentValue=" + asr.getReference() + ", currentStamp=" + asr.getStamp());
|
||||
// 尝试用错误的版本号更新
|
||||
boolean isUpdatedWithWrongStamp = asr.compareAndSet(newRef, "John", oldStamp, newStamp + 1);
|
||||
System.out.println("Update with Wrong Stamp Success: " + isUpdatedWithWrongStamp);
|
||||
|
||||
// [不推荐使用,除非搞清楚注释的意思了] weak compare and set
|
||||
// 困惑!weakCompareAndSet 这个方法最终还是调用 compareAndSet 方法。[版本: jdk-8u191]
|
||||
// 但是注释上写着 "May fail spuriously and does not provide ordering guarantees,
|
||||
// so is only rarely an appropriate alternative to compareAndSet."
|
||||
// todo 感觉有可能是 jvm 通过方法名在 native 方法里面做了转发
|
||||
final boolean wCasResult = asr.weakCompareAndSet(initialRef, newReference, initialStamp, newStamp);
|
||||
System.out.println("currentValue=" + asr.getReference()
|
||||
+ ", currentStamp=" + asr.getStamp()
|
||||
+ ", wCasResult=" + wCasResult);
|
||||
}
|
||||
}
|
||||
// 打印最终的值和版本号
|
||||
int[] finalStamp = new int[1];
|
||||
String finalRef = asr.get(finalStamp);
|
||||
System.out.println("Final Reference: " + finalRef + ", Final Stamp: " + finalStamp[0]);
|
||||
```
|
||||
|
||||
输出结果如下:
|
||||
|
||||
```plain
|
||||
currentValue=0, currentStamp=0
|
||||
currentValue=666, currentStamp=999, casResult=true
|
||||
currentValue=666, currentStamp=999
|
||||
currentValue=666, currentStamp=88, attemptStampResult=true
|
||||
currentValue=0, currentStamp=0
|
||||
currentValue=666, currentStamp=999, wCasResult=true
|
||||
Initial Reference: SnailClimb, Initial Stamp: 1
|
||||
Update Success: true
|
||||
Updated Reference: Daisy, Updated Stamp: 2
|
||||
Update with Wrong Stamp Success: false
|
||||
Final Reference: Daisy, Final Stamp: 2
|
||||
```
|
||||
|
||||
**`AtomicMarkableReference` 类使用示例** :
|
||||
|
||||
```java
|
||||
import java.util.concurrent.atomic.AtomicMarkableReference;
|
||||
// 创建一个 AtomicMarkableReference 对象,初始值为 "SnailClimb",初始标记为 false
|
||||
AtomicMarkableReference<String> amr = new AtomicMarkableReference<>("SnailClimb", false);
|
||||
|
||||
public class AtomicMarkableReferenceDemo {
|
||||
public static void main(String[] args) {
|
||||
// 实例化、取当前值和 mark 值
|
||||
final Boolean initialRef = null, initialMark = false;
|
||||
final AtomicMarkableReference<Boolean> amr = new AtomicMarkableReference<>(initialRef, initialMark);
|
||||
System.out.println("currentValue=" + amr.getReference() + ", currentMark=" + amr.isMarked());
|
||||
// 打印初始值和标记
|
||||
boolean[] initialMark = new boolean[1];
|
||||
String initialRef = amr.get(initialMark);
|
||||
System.out.println("Initial Reference: " + initialRef + ", Initial Mark: " + initialMark[0]);
|
||||
|
||||
// compare and set
|
||||
final Boolean newReference1 = true, newMark1 = true;
|
||||
final boolean casResult = amr.compareAndSet(initialRef, newReference1, initialMark, newMark1);
|
||||
System.out.println("currentValue=" + amr.getReference()
|
||||
+ ", currentMark=" + amr.isMarked()
|
||||
+ ", casResult=" + casResult);
|
||||
// 更新值和标记
|
||||
String oldRef = initialRef;
|
||||
String newRef = "Daisy";
|
||||
boolean oldMark = initialMark[0];
|
||||
boolean newMark = true;
|
||||
|
||||
// 获取当前的值和当前的 mark 值
|
||||
boolean[] arr = new boolean[1];
|
||||
final Boolean currentValue = amr.get(arr);
|
||||
final boolean currentMark = arr[0];
|
||||
System.out.println("currentValue=" + currentValue + ", currentMark=" + currentMark);
|
||||
boolean isUpdated = amr.compareAndSet(oldRef, newRef, oldMark, newMark);
|
||||
System.out.println("Update Success: " + isUpdated);
|
||||
|
||||
// 单独设置 mark 值
|
||||
final boolean attemptMarkResult = amr.attemptMark(newReference1, false);
|
||||
System.out.println("currentValue=" + amr.getReference()
|
||||
+ ", currentMark=" + amr.isMarked()
|
||||
+ ", attemptMarkResult=" + attemptMarkResult);
|
||||
// 打印更新后的值和标记
|
||||
boolean[] updatedMark = new boolean[1];
|
||||
String updatedRef = amr.get(updatedMark);
|
||||
System.out.println("Updated Reference: " + updatedRef + ", Updated Mark: " + updatedMark[0]);
|
||||
|
||||
// 重新设置当前值和 mark 值
|
||||
amr.set(initialRef, initialMark);
|
||||
System.out.println("currentValue=" + amr.getReference() + ", currentMark=" + amr.isMarked());
|
||||
// 尝试用错误的标记更新
|
||||
boolean isUpdatedWithWrongMark = amr.compareAndSet(newRef, "John", oldMark, !newMark);
|
||||
System.out.println("Update with Wrong Mark Success: " + isUpdatedWithWrongMark);
|
||||
|
||||
// [不推荐使用,除非搞清楚注释的意思了] weak compare and set
|
||||
// 困惑!weakCompareAndSet 这个方法最终还是调用 compareAndSet 方法。[版本: jdk-8u191]
|
||||
// 但是注释上写着 "May fail spuriously and does not provide ordering guarantees,
|
||||
// so is only rarely an appropriate alternative to compareAndSet."
|
||||
// todo 感觉有可能是 jvm 通过方法名在 native 方法里面做了转发
|
||||
final boolean wCasResult = amr.weakCompareAndSet(initialRef, newReference1, initialMark, newMark1);
|
||||
System.out.println("currentValue=" + amr.getReference()
|
||||
+ ", currentMark=" + amr.isMarked()
|
||||
+ ", wCasResult=" + wCasResult);
|
||||
}
|
||||
}
|
||||
// 打印最终的值和标记
|
||||
boolean[] finalMark = new boolean[1];
|
||||
String finalRef = amr.get(finalMark);
|
||||
System.out.println("Final Reference: " + finalRef + ", Final Mark: " + finalMark[0]);
|
||||
```
|
||||
|
||||
输出结果如下:
|
||||
|
||||
```plain
|
||||
currentValue=null, currentMark=false
|
||||
currentValue=true, currentMark=true, casResult=true
|
||||
currentValue=true, currentMark=true
|
||||
currentValue=true, currentMark=false, attemptMarkResult=true
|
||||
currentValue=null, currentMark=false
|
||||
currentValue=true, currentMark=true, wCasResult=true
|
||||
Initial Reference: SnailClimb, Initial Mark: false
|
||||
Update Success: true
|
||||
Updated Reference: Daisy, Updated Mark: true
|
||||
Update with Wrong Mark Success: false
|
||||
Final Reference: Daisy, Final Mark: true
|
||||
```
|
||||
|
||||
## 对象的属性修改类型原子类
|
||||
@ -395,52 +348,48 @@ currentValue=true, currentMark=true, wCasResult=true
|
||||
**`AtomicIntegerFieldUpdater` 类使用示例** :
|
||||
|
||||
```java
|
||||
import java.util.concurrent.atomic.AtomicIntegerFieldUpdater;
|
||||
|
||||
public class AtomicIntegerFieldUpdaterTest {
|
||||
public static void main(String[] args) {
|
||||
AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater.newUpdater(User.class, "age");
|
||||
|
||||
User user = new User("Java", 22);
|
||||
System.out.println(a.getAndIncrement(user));// 22
|
||||
System.out.println(a.get(user));// 23
|
||||
}
|
||||
// Person 类
|
||||
class Person {
|
||||
private String name;
|
||||
// 要使用 AtomicIntegerFieldUpdater,字段必须是 public volatile
|
||||
private volatile int age;
|
||||
//省略getter/setter和toString
|
||||
}
|
||||
|
||||
class User {
|
||||
private String name;
|
||||
public volatile int age;
|
||||
// 创建 AtomicIntegerFieldUpdater 对象
|
||||
AtomicIntegerFieldUpdater<Person> ageUpdater = AtomicIntegerFieldUpdater.newUpdater(Person.class, "age");
|
||||
|
||||
public User(String name, int age) {
|
||||
super();
|
||||
this.name = name;
|
||||
this.age = age;
|
||||
}
|
||||
// 创建 Person 对象
|
||||
Person person = new Person("SnailClimb", 22);
|
||||
|
||||
public String getName() {
|
||||
return name;
|
||||
}
|
||||
// 打印初始值
|
||||
System.out.println("Initial Person: " + person);
|
||||
|
||||
public void setName(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
// 更新 age 字段
|
||||
ageUpdater.incrementAndGet(person); // 自增
|
||||
System.out.println("After Increment: " + person);
|
||||
|
||||
public int getAge() {
|
||||
return age;
|
||||
}
|
||||
ageUpdater.addAndGet(person, 5); // 增加 5
|
||||
System.out.println("After Adding 5: " + person);
|
||||
|
||||
public void setAge(int age) {
|
||||
this.age = age;
|
||||
}
|
||||
ageUpdater.compareAndSet(person, 28, 30); // 如果当前值是 28,则设置为 30
|
||||
System.out.println("After Compare and Set (28 to 30): " + person);
|
||||
|
||||
}
|
||||
// 尝试使用错误的比较值进行更新
|
||||
boolean isUpdated = ageUpdater.compareAndSet(person, 28, 35); // 这次应该失败
|
||||
System.out.println("Compare and Set (28 to 35) Success: " + isUpdated);
|
||||
System.out.println("Final Person: " + person);
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```plain
|
||||
22
|
||||
23
|
||||
Initial Person: Name: SnailClimb, Age: 22
|
||||
After Increment: Name: SnailClimb, Age: 23
|
||||
After Adding 5: Name: SnailClimb, Age: 28
|
||||
After Compare and Set (28 to 30): Name: SnailClimb, Age: 30
|
||||
Compare and Set (28 to 35) Success: false
|
||||
Final Person: Name: SnailClimb, Age: 30
|
||||
```
|
||||
|
||||
## 参考
|
||||
|
||||
162
docs/java/concurrent/cas.md
Normal file
162
docs/java/concurrent/cas.md
Normal file
@ -0,0 +1,162 @@
|
||||
---
|
||||
title: CAS 详解
|
||||
category: Java
|
||||
tag:
|
||||
- Java并发
|
||||
---
|
||||
|
||||
乐观锁和悲观锁的介绍以及乐观锁常见实现方式可以阅读笔者写的这篇文章:[乐观锁和悲观锁详解](https://javaguide.cn/java/concurrent/optimistic-lock-and-pessimistic-lock.html)。
|
||||
|
||||
这篇文章主要介绍 :Java 中 CAS 的实现以及 CAS 存在的一些问题。
|
||||
|
||||
## Java 中 CAS 是如何实现的?
|
||||
|
||||
在 Java 中,实现 CAS(Compare-And-Swap, 比较并交换)操作的一个关键类是`Unsafe`。
|
||||
|
||||
`Unsafe`类位于`sun.misc`包下,是一个提供低级别、不安全操作的类。由于其强大的功能和潜在的危险性,它通常用于 JVM 内部或一些需要极高性能和底层访问的库中,而不推荐普通开发者在应用程序中使用。关于 `Unsafe`类的详细介绍,可以阅读这篇文章:📌[Java 魔法类 Unsafe 详解](https://javaguide.cn/java/basis/unsafe.html)。
|
||||
|
||||
`sun.misc`包下的`Unsafe`类提供了`compareAndSwapObject`、`compareAndSwapInt`、`compareAndSwapLong`方法来实现的对`Object`、`int`、`long`类型的 CAS 操作:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 以原子方式更新对象字段的值。
|
||||
*
|
||||
* @param o 要操作的对象
|
||||
* @param offset 对象字段的内存偏移量
|
||||
* @param expected 期望的旧值
|
||||
* @param x 要设置的新值
|
||||
* @return 如果值被成功更新,则返回 true;否则返回 false
|
||||
*/
|
||||
boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
|
||||
|
||||
/**
|
||||
* 以原子方式更新 int 类型的对象字段的值。
|
||||
*/
|
||||
boolean compareAndSwapInt(Object o, long offset, int expected, int x);
|
||||
|
||||
/**
|
||||
* 以原子方式更新 long 类型的对象字段的值。
|
||||
*/
|
||||
boolean compareAndSwapLong(Object o, long offset, long expected, long x);
|
||||
```
|
||||
|
||||
`Unsafe`类中的 CAS 方法是`native`方法。`native`关键字表明这些方法是用本地代码(通常是 C 或 C++)实现的,而不是用 Java 实现的。这些方法直接调用底层的硬件指令来实现原子操作。也就是说,Java 语言并没有直接用 Java 实现 CAS。
|
||||
|
||||
更准确点来说,Java 中 CAS 是 C++ 内联汇编的形式实现的,通过 JNI(Java Native Interface) 调用。因此,CAS 的具体实现与操作系统以及 CPU 密切相关。
|
||||
|
||||
`java.util.concurrent.atomic` 包提供了一些用于原子操作的类。
|
||||
|
||||

|
||||
|
||||
关于这些 Atomic 原子类的介绍和使用,可以阅读这篇文章:[Atomic 原子类总结](https://javaguide.cn/java/concurrent/atomic-classes.html)。
|
||||
|
||||
Atomic 类依赖于 CAS 乐观锁来保证其方法的原子性,而不需要使用传统的锁机制(如 `synchronized` 块或 `ReentrantLock`)。
|
||||
|
||||
`AtomicInteger`是 Java 的原子类之一,主要用于对 `int` 类型的变量进行原子操作,它利用`Unsafe`类提供的低级别原子操作方法实现无锁的线程安全性。
|
||||
|
||||
下面,我们通过解读`AtomicInteger`的核心源码(JDK1.8),来说明 Java 如何使用`Unsafe`类的方法来实现原子操作。
|
||||
|
||||
`AtomicInteger`核心源码如下:
|
||||
|
||||
```java
|
||||
// 获取 Unsafe 实例
|
||||
private static final Unsafe unsafe = Unsafe.getUnsafe();
|
||||
private static final long valueOffset;
|
||||
|
||||
static {
|
||||
try {
|
||||
// 获取“value”字段在AtomicInteger类中的内存偏移量
|
||||
valueOffset = unsafe.objectFieldOffset
|
||||
(AtomicInteger.class.getDeclaredField("value"));
|
||||
} catch (Exception ex) { throw new Error(ex); }
|
||||
}
|
||||
// 确保“value”字段的可见性
|
||||
private volatile int value;
|
||||
|
||||
// 如果当前值等于预期值,则原子地将值设置为newValue
|
||||
// 使用 Unsafe#compareAndSwapInt 方法进行CAS操作
|
||||
public final boolean compareAndSet(int expect, int update) {
|
||||
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
|
||||
}
|
||||
|
||||
// 原子地将当前值加 delta 并返回旧值
|
||||
public final int getAndAdd(int delta) {
|
||||
return unsafe.getAndAddInt(this, valueOffset, delta);
|
||||
}
|
||||
|
||||
// 原子地将当前值加 1 并返回加之前的值(旧值)
|
||||
// 使用 Unsafe#getAndAddInt 方法进行CAS操作。
|
||||
public final int getAndIncrement() {
|
||||
return unsafe.getAndAddInt(this, valueOffset, 1);
|
||||
}
|
||||
|
||||
// 原子地将当前值减 1 并返回减之前的值(旧值)
|
||||
public final int getAndDecrement() {
|
||||
return unsafe.getAndAddInt(this, valueOffset, -1);
|
||||
}
|
||||
```
|
||||
|
||||
`Unsafe#getAndAddInt`源码:
|
||||
|
||||
```java
|
||||
// 原子地获取并增加整数值
|
||||
public final int getAndAddInt(Object o, long offset, int delta) {
|
||||
int v;
|
||||
do {
|
||||
// 以 volatile 方式获取对象 o 在内存偏移量 offset 处的整数值
|
||||
v = getIntVolatile(o, offset);
|
||||
} while (!compareAndSwapInt(o, offset, v, v + delta));
|
||||
// 返回旧值
|
||||
return v;
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,`getAndAddInt` 使用了 `do-while` 循环:在`compareAndSwapInt`操作失败时,会不断重试直到成功。也就是说,`getAndAddInt`方法会通过 `compareAndSwapInt` 方法来尝试更新 `value` 的值,如果更新失败(当前值在此期间被其他线程修改),它会重新获取当前值并再次尝试更新,直到操作成功。
|
||||
|
||||
由于 CAS 操作可能会因为并发冲突而失败,因此通常会与`while`循环搭配使用,在失败后不断重试,直到操作成功。这就是 **自旋锁机制** 。
|
||||
|
||||
## CAS 算法存在哪些问题?
|
||||
|
||||
ABA 问题是 CAS 算法最常见的问题。
|
||||
|
||||
### ABA 问题
|
||||
|
||||
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 **"ABA"问题。**
|
||||
|
||||
ABA 问题的解决思路是在变量前面追加上**版本号或者时间戳**。JDK 1.5 以后的 `AtomicStampedReference` 类就是用来解决 ABA 问题的,其中的 `compareAndSet()` 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
|
||||
|
||||
```java
|
||||
public boolean compareAndSet(V expectedReference,
|
||||
V newReference,
|
||||
int expectedStamp,
|
||||
int newStamp) {
|
||||
Pair<V> current = pair;
|
||||
return
|
||||
expectedReference == current.reference &&
|
||||
expectedStamp == current.stamp &&
|
||||
((newReference == current.reference &&
|
||||
newStamp == current.stamp) ||
|
||||
casPair(current, Pair.of(newReference, newStamp)));
|
||||
}
|
||||
```
|
||||
|
||||
### 循环时间长开销大
|
||||
|
||||
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
|
||||
|
||||
如果 JVM 能够支持处理器提供的`pause`指令,那么自旋操作的效率将有所提升。`pause`指令有两个重要作用:
|
||||
|
||||
1. **延迟流水线执行指令**:`pause`指令可以延迟指令的执行,从而减少 CPU 的资源消耗。具体的延迟时间取决于处理器的实现版本,在某些处理器上,延迟时间可能为零。
|
||||
2. **避免内存顺序冲突**:在退出循环时,`pause`指令可以避免由于内存顺序冲突而导致的 CPU 流水线被清空,从而提高 CPU 的执行效率。
|
||||
|
||||
### 只能保证一个共享变量的原子操作
|
||||
|
||||
CAS 操作仅能对单个共享变量有效。当需要操作多个共享变量时,CAS 就显得无能为力。不过,从 JDK 1.5 开始,Java 提供了`AtomicReference`类,这使得我们能够保证引用对象之间的原子性。通过将多个变量封装在一个对象中,我们可以使用`AtomicReference`来执行 CAS 操作。
|
||||
|
||||
除了 `AtomicReference` 这种方式之外,还可以利用加锁来保证。
|
||||
|
||||
## 总结
|
||||
|
||||
在 Java 中,CAS 通过 `Unsafe` 类中的 `native` 方法实现,这些方法调用底层的硬件指令来完成原子操作。由于其实现依赖于 C++ 内联汇编和 JNI 调用,因此 CAS 的具体实现与操作系统以及 CPU 密切相关。
|
||||
|
||||
CAS 虽然具有高效的无锁特性,但也需要注意 ABA 、循环时间长开销大等问题。
|
||||
@ -5,19 +5,25 @@ tag:
|
||||
- Java并发
|
||||
---
|
||||
|
||||
一个接口可能需要调用 N 个其他服务的接口,这在项目开发中还是挺常见的。举个例子:用户请求获取订单信息,可能需要调用用户信息、商品详情、物流信息、商品推荐等接口,最后再汇总数据统一返回。
|
||||
实际项目中,一个接口可能需要同时获取多种不同的数据,然后再汇总返回,这种场景还是挺常见的。举个例子:用户请求获取订单信息,可能需要同时获取用户信息、商品详情、物流信息、商品推荐等数据。
|
||||
|
||||
如果是串行(按顺序依次执行每个任务)执行的话,接口的响应速度会非常慢。考虑到这些接口之间有大部分都是 **无前后顺序关联** 的,可以 **并行执行** ,就比如说调用获取商品详情的时候,可以同时调用获取物流信息。通过并行执行多个任务的方式,接口的响应速度会得到大幅优化。
|
||||
如果是串行(按顺序依次执行每个任务)执行的话,接口的响应速度会非常慢。考虑到这些任务之间有大部分都是 **无前后顺序关联** 的,可以 **并行执行** ,就比如说调用获取商品详情的时候,可以同时调用获取物流信息。通过并行执行多个任务的方式,接口的响应速度会得到大幅优化。
|
||||
|
||||

|
||||

|
||||
|
||||
对于存在前后顺序关系的接口调用,可以进行编排,如下图所示。
|
||||
对于存在前后调用顺序关系的任务,可以进行任务编排。
|
||||
|
||||
|
||||
|
||||
1. 获取用户信息之后,才能调用商品详情和物流信息接口。
|
||||
2. 成功获取商品详情和物流信息之后,才能调用商品推荐接口。
|
||||
|
||||
可能会用到多线程异步任务编排的场景(这里只是举例,数据不一定是一次返回,可能会对接口进行拆分):
|
||||
|
||||
1. 首页:例如技术社区的首页可能需要同时获取文章推荐列表、广告栏、文章排行榜、热门话题等信息。
|
||||
2. 详情页:例如技术社区的文章详情页可能需要同时获取作者信息、文章详情、文章评论等信息。
|
||||
3. 统计模块:例如技术社区的后台统计模块可能需要同时获取粉丝数汇总、文章数据(阅读量、评论量、收藏量)汇总等信息。
|
||||
|
||||
对于 Java 程序来说,Java 8 才被引入的 `CompletableFuture` 可以帮助我们来做多个任务的编排,功能非常强大。
|
||||
|
||||
这篇文章是 `CompletableFuture` 的简单入门,带大家看看 `CompletableFuture` 常用的 API。
|
||||
|
||||
@ -84,8 +84,6 @@ JDK 1.2 之前,Java 线程是基于绿色线程(Green Threads)实现的,
|
||||
|
||||
在 Windows 和 Linux 等主流操作系统中,Java 线程采用的是一对一的线程模型,也就是一个 Java 线程对应一个系统内核线程。Solaris 系统是一个特例(Solaris 系统本身就支持多对多的线程模型),HotSpot VM 在 Solaris 上支持多对多和一对一。具体可以参考 R 大的回答: [JVM 中的线程模型是用户级的么?](https://www.zhihu.com/question/23096638/answer/29617153)。
|
||||
|
||||
虚拟线程在 JDK 21 顺利转正,关于虚拟线程、平台线程(也就是我们上面提到的 Java 线程)和内核线程三者的关系可以阅读我写的这篇文章:[Java 20 新特性概览](../new-features/java20.md)。
|
||||
|
||||
### 请简要描述线程与进程的关系,区别及优缺点?
|
||||
|
||||
下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。
|
||||
@ -230,6 +228,30 @@ new 一个 `Thread`,线程进入了新建状态。调用 `start()`方法,会
|
||||
- **单核时代**:在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
|
||||
- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 核心上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
|
||||
|
||||
### 单核 CPU 支持 Java 多线程吗?
|
||||
|
||||
单核 CPU 是支持 Java 多线程的。操作系统通过时间片轮转的方式,将 CPU 的时间分配给不同的线程。尽管单核 CPU 一次只能执行一个任务,但通过快速在多个线程之间切换,可以让用户感觉多个任务是同时进行的。
|
||||
|
||||
这里顺带提一下 Java 使用的线程调度方式。
|
||||
|
||||
操作系统主要通过两种线程调度方式来管理多线程的执行:
|
||||
|
||||
- **抢占式调度(Preemptive Scheduling)**:操作系统决定何时暂停当前正在运行的线程,并切换到另一个线程执行。这种切换通常是由系统时钟中断(时间片轮转)或其他高优先级事件(如 I/O 操作完成)触发的。这种方式存在上下文切换开销,但公平性和 CPU 资源利用率较好,不易阻塞。
|
||||
- **协同式调度(Cooperative Scheduling)**:线程执行完毕后,主动通知系统切换到另一个线程。这种方式可以减少上下文切换带来的性能开销,但公平性较差,容易阻塞。
|
||||
|
||||
Java 使用的线程调度是抢占式的。也就是说,JVM 本身不负责线程的调度,而是将线程的调度委托给操作系统。操作系统通常会基于线程优先级和时间片来调度线程的执行,高优先级的线程通常获得 CPU 时间片的机会更多。
|
||||
|
||||
### 单核 CPU 上运行多个线程效率一定会高吗?
|
||||
|
||||
单核 CPU 同时运行多个线程的效率是否会高,取决于线程的类型和任务的性质。一般来说,有两种类型的线程:
|
||||
|
||||
1. **CPU 密集型**:CPU 密集型的线程主要进行计算和逻辑处理,需要占用大量的 CPU 资源。
|
||||
2. **IO 密集型**:IO 密集型的线程主要进行输入输出操作,如读写文件、网络通信等,需要等待 IO 设备的响应,而不占用太多的 CPU 资源。
|
||||
|
||||
在单核 CPU 上,同一时刻只能有一个线程在运行,其他线程需要等待 CPU 的时间片分配。如果线程是 CPU 密集型的,那么多个线程同时运行会导致频繁的线程切换,增加了系统的开销,降低了效率。如果线程是 IO 密集型的,那么多个线程同时运行可以利用 CPU 在等待 IO 时的空闲时间,提高了效率。
|
||||
|
||||
因此,对于单核 CPU 来说,如果任务是 CPU 密集型的,那么开很多线程会影响效率;如果任务是 IO 密集型的,那么开很多线程会提高效率。当然,这里的“很多”也要适度,不能超过系统能够承受的上限。
|
||||
|
||||
### 使用多线程可能带来什么问题?
|
||||
|
||||
并发编程的目的就是为了能提高程序的执行效率进而提高程序的运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
|
||||
@ -241,14 +263,6 @@ new 一个 `Thread`,线程进入了新建状态。调用 `start()`方法,会
|
||||
- 线程安全指的是在多线程环境下,对于同一份数据,不管有多少个线程同时访问,都能保证这份数据的正确性和一致性。
|
||||
- 线程不安全则表示在多线程环境下,对于同一份数据,多个线程同时访问时可能会导致数据混乱、错误或者丢失。
|
||||
|
||||
### 单核 CPU 上运行多个线程效率一定会高吗?
|
||||
|
||||
单核 CPU 同时运行多个线程的效率是否会高,取决于线程的类型和任务的性质。一般来说,有两种类型的线程:CPU 密集型和 IO 密集型。CPU 密集型的线程主要进行计算和逻辑处理,需要占用大量的 CPU 资源。IO 密集型的线程主要进行输入输出操作,如读写文件、网络通信等,需要等待 IO 设备的响应,而不占用太多的 CPU 资源。
|
||||
|
||||
在单核 CPU 上,同一时刻只能有一个线程在运行,其他线程需要等待 CPU 的时间片分配。如果线程是 CPU 密集型的,那么多个线程同时运行会导致频繁的线程切换,增加了系统的开销,降低了效率。如果线程是 IO 密集型的,那么多个线程同时运行可以利用 CPU 在等待 IO 时的空闲时间,提高了效率。
|
||||
|
||||
因此,对于单核 CPU 来说,如果任务是 CPU 密集型的,那么开很多线程会影响效率;如果任务是 IO 密集型的,那么开很多线程会提高效率。当然,这里的“很多”也要适度,不能超过系统能够承受的上限。
|
||||
|
||||
## 死锁
|
||||
|
||||
### 什么是线程死锁?
|
||||
@ -391,4 +405,14 @@ Process finished with exit code 0
|
||||
|
||||
线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了。然后线程 1 再去获取 resource2 的监视器锁,可以获取到。然后线程 1 释放了对 resource1、resource2 的监视器锁的占用,线程 2 获取到就可以执行了。这样就破坏了破坏循环等待条件,因此避免了死锁。
|
||||
|
||||
## 虚拟线程
|
||||
|
||||
虚拟线程在 Java 21 正式发布,这是一项重量级的更新。我写了一篇文章来总结虚拟线程常见的问题:[虚拟线程常见问题总结](./virtual-thread.md),包含下面这些问题:
|
||||
|
||||
1. 什么是虚拟线程?
|
||||
2. 虚拟线程和平台线程有什么关系?
|
||||
3. 虚拟线程有什么优点和缺点?
|
||||
4. 如何创建虚拟线程?
|
||||
5. 虚拟线程的底层原理是什么?
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
@ -285,6 +285,108 @@ public final native boolean compareAndSwapLong(Object o, long offset, long expec
|
||||
|
||||
关于 `Unsafe` 类的详细介绍可以看这篇文章:[Java 魔法类 Unsafe 详解 - JavaGuide - 2022](https://javaguide.cn/java/basis/unsafe.html) 。
|
||||
|
||||
### Java 中 CAS 是如何实现的?
|
||||
|
||||
在 Java 中,实现 CAS(Compare-And-Swap, 比较并交换)操作的一个关键类是`Unsafe`。
|
||||
|
||||
`Unsafe`类位于`sun.misc`包下,是一个提供低级别、不安全操作的类。由于其强大的功能和潜在的危险性,它通常用于 JVM 内部或一些需要极高性能和底层访问的库中,而不推荐普通开发者在应用程序中使用。关于 `Unsafe`类的详细介绍,可以阅读这篇文章:📌[Java 魔法类 Unsafe 详解](https://javaguide.cn/java/basis/unsafe.html)。
|
||||
|
||||
`sun.misc`包下的`Unsafe`类提供了`compareAndSwapObject`、`compareAndSwapInt`、`compareAndSwapLong`方法来实现的对`Object`、`int`、`long`类型的 CAS 操作:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 以原子方式更新对象字段的值。
|
||||
*
|
||||
* @param o 要操作的对象
|
||||
* @param offset 对象字段的内存偏移量
|
||||
* @param expected 期望的旧值
|
||||
* @param x 要设置的新值
|
||||
* @return 如果值被成功更新,则返回 true;否则返回 false
|
||||
*/
|
||||
boolean compareAndSwapObject(Object o, long offset, Object expected, Object x);
|
||||
|
||||
/**
|
||||
* 以原子方式更新 int 类型的对象字段的值。
|
||||
*/
|
||||
boolean compareAndSwapInt(Object o, long offset, int expected, int x);
|
||||
|
||||
/**
|
||||
* 以原子方式更新 long 类型的对象字段的值。
|
||||
*/
|
||||
boolean compareAndSwapLong(Object o, long offset, long expected, long x);
|
||||
```
|
||||
|
||||
`Unsafe`类中的 CAS 方法是`native`方法。`native`关键字表明这些方法是用本地代码(通常是 C 或 C++)实现的,而不是用 Java 实现的。这些方法直接调用底层的硬件指令来实现原子操作。也就是说,Java 语言并没有直接用 Java 实现 CAS,而是通过 C++ 内联汇编的形式实现的(通过 JNI 调用)。因此,CAS 的具体实现与操作系统以及 CPU 密切相关。
|
||||
|
||||
`java.util.concurrent.atomic` 包提供了一些用于原子操作的类。这些类利用底层的原子指令,确保在多线程环境下的操作是线程安全的。
|
||||
|
||||

|
||||
|
||||
关于这些 Atomic 原子类的介绍和使用,可以阅读这篇文章:[Atomic 原子类总结](https://javaguide.cn/java/concurrent/atomic-classes.html)。
|
||||
|
||||
`AtomicInteger`是 Java 的原子类之一,主要用于对 `int` 类型的变量进行原子操作,它利用`Unsafe`类提供的低级别原子操作方法实现无锁的线程安全性。
|
||||
|
||||
下面,我们通过解读`AtomicInteger`的核心源码(JDK1.8),来说明 Java 如何使用`Unsafe`类的方法来实现原子操作。
|
||||
|
||||
`AtomicInteger`核心源码如下:
|
||||
|
||||
```java
|
||||
// 获取 Unsafe 实例
|
||||
private static final Unsafe unsafe = Unsafe.getUnsafe();
|
||||
private static final long valueOffset;
|
||||
|
||||
static {
|
||||
try {
|
||||
// 获取“value”字段在AtomicInteger类中的内存偏移量
|
||||
valueOffset = unsafe.objectFieldOffset
|
||||
(AtomicInteger.class.getDeclaredField("value"));
|
||||
} catch (Exception ex) { throw new Error(ex); }
|
||||
}
|
||||
// 确保“value”字段的可见性
|
||||
private volatile int value;
|
||||
|
||||
// 如果当前值等于预期值,则原子地将值设置为newValue
|
||||
// 使用 Unsafe#compareAndSwapInt 方法进行CAS操作
|
||||
public final boolean compareAndSet(int expect, int update) {
|
||||
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
|
||||
}
|
||||
|
||||
// 原子地将当前值加 delta 并返回旧值
|
||||
public final int getAndAdd(int delta) {
|
||||
return unsafe.getAndAddInt(this, valueOffset, delta);
|
||||
}
|
||||
|
||||
// 原子地将当前值加 1 并返回加之前的值(旧值)
|
||||
// 使用 Unsafe#getAndAddInt 方法进行CAS操作。
|
||||
public final int getAndIncrement() {
|
||||
return unsafe.getAndAddInt(this, valueOffset, 1);
|
||||
}
|
||||
|
||||
// 原子地将当前值减 1 并返回减之前的值(旧值)
|
||||
public final int getAndDecrement() {
|
||||
return unsafe.getAndAddInt(this, valueOffset, -1);
|
||||
}
|
||||
```
|
||||
|
||||
`Unsafe#getAndAddInt`源码:
|
||||
|
||||
```java
|
||||
// 原子地获取并增加整数值
|
||||
public final int getAndAddInt(Object o, long offset, int delta) {
|
||||
int v;
|
||||
do {
|
||||
// 以 volatile 方式获取对象 o 在内存偏移量 offset 处的整数值
|
||||
v = getIntVolatile(o, offset);
|
||||
} while (!compareAndSwapInt(o, offset, v, v + delta));
|
||||
// 返回旧值
|
||||
return v;
|
||||
}
|
||||
```
|
||||
|
||||
可以看到,`getAndAddInt` 使用了 `do-while` 循环:在`compareAndSwapInt`操作失败时,会不断重试直到成功。也就是说,`getAndAddInt`方法会通过 `compareAndSwapInt` 方法来尝试更新 `value` 的值,如果更新失败(当前值在此期间被其他线程修改),它会重新获取当前值并再次尝试更新,直到操作成功。
|
||||
|
||||
由于 CAS 操作可能会因为并发冲突而失败,因此通常会与`while`循环搭配使用,在失败后不断重试,直到操作成功。这就是 **自旋锁机制** 。
|
||||
|
||||
### CAS 算法存在哪些问题?
|
||||
|
||||
ABA 问题是 CAS 算法最常见的问题。
|
||||
@ -314,15 +416,19 @@ public boolean compareAndSet(V expectedReference,
|
||||
|
||||
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
|
||||
|
||||
如果 JVM 能支持处理器提供的 pause 指令那么效率会有一定的提升,pause 指令有两个作用:
|
||||
如果 JVM 能够支持处理器提供的`pause`指令,那么自旋操作的效率将有所提升。`pause`指令有两个重要作用:
|
||||
|
||||
1. 可以延迟流水线执行指令,使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。
|
||||
2. 可以避免在退出循环的时候因内存顺序冲突而引起 CPU 流水线被清空,从而提高 CPU 的执行效率。
|
||||
1. **延迟流水线执行指令**:`pause`指令可以延迟指令的执行,从而减少 CPU 的资源消耗。具体的延迟时间取决于处理器的实现版本,在某些处理器上,延迟时间可能为零。
|
||||
2. **避免内存顺序冲突**:在退出循环时,`pause`指令可以避免由于内存顺序冲突而导致的 CPU 流水线被清空,从而提高 CPU 的执行效率。
|
||||
|
||||
#### 只能保证一个共享变量的原子操作
|
||||
|
||||
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了`AtomicReference`类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference`类把多个共享变量合并成一个共享变量来操作。
|
||||
|
||||
CAS 操作仅能对单个共享变量有效。当需要操作多个共享变量时,CAS 就显得无能为力。不过,从 JDK 1.5 开始,Java 提供了`AtomicReference`类,这使得我们能够保证引用对象之间的原子性。通过将多个变量封装在一个对象中,我们可以使用`AtomicReference`来执行 CAS 操作。
|
||||
|
||||
除了 `AtomicReference` 这种方式之外,还可以利用加锁来保证。
|
||||
|
||||
## synchronized 关键字
|
||||
|
||||
### synchronized 是什么?有什么用?
|
||||
|
||||
@ -234,12 +234,12 @@ static class Entry extends WeakReference<ThreadLocal<?>> {
|
||||
|
||||
`Executors` 返回线程池对象的弊端如下:
|
||||
|
||||
- `FixedThreadPool` 和 `SingleThreadExecutor`:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
- `FixedThreadPool` 和 `SingleThreadExecutor`:使用的是有界阻塞队列是 `LinkedBlockingQueue` ,其任务队列的最大长度为 `Integer.MAX_VALUE` ,可能堆积大量的请求,从而导致 OOM。
|
||||
- `CachedThreadPool`:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。
|
||||
- `ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`:使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
- `ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` :使用的无界的延迟阻塞队列 `DelayedWorkQueue` ,任务队列最大长度为 `Integer.MAX_VALUE` ,可能堆积大量的请求,从而导致 OOM。
|
||||
|
||||
```java
|
||||
// 无界队列 LinkedBlockingQueue
|
||||
// 有界队列 LinkedBlockingQueue
|
||||
public static ExecutorService newFixedThreadPool(int nThreads) {
|
||||
|
||||
return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>());
|
||||
@ -317,6 +317,15 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
||||
|
||||
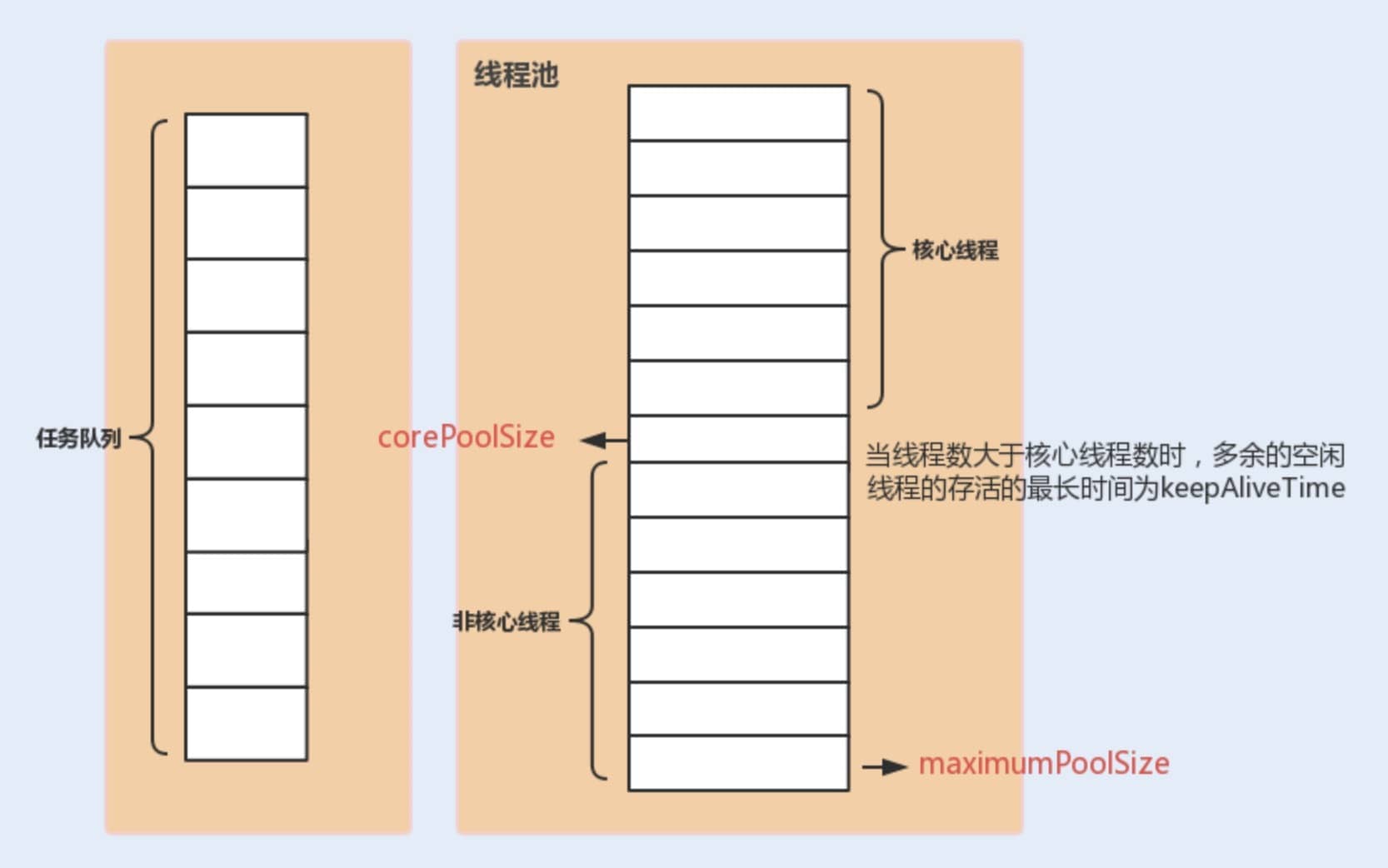
|
||||
|
||||
### 线程池的核心线程会被回收吗?
|
||||
|
||||
`ThreadPoolExecutor` 默认不会回收核心线程,即使它们已经空闲了。这是为了减少创建线程的开销,因为核心线程通常是要长期保持活跃的。但是,如果线程池是被用于周期性使用的场景,且频率不高(周期之间有明显的空闲时间),可以考虑将 `allowCoreThreadTimeOut(boolean value)` 方法的参数设置为 `true`,这样就会回收空闲(时间间隔由 `keepAliveTime` 指定)的核心线程了。
|
||||
|
||||
```java
|
||||
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(4, 6, 6, TimeUnit.SECONDS, new SynchronousQueue<>());
|
||||
threadPoolExecutor.allowCoreThreadTimeOut(true);
|
||||
```
|
||||
|
||||
### 线程池的拒绝策略有哪些?
|
||||
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||
@ -372,48 +381,58 @@ public static class CallerRunsPolicy implements RejectedExecutionHandler {
|
||||
|
||||
不过,如果走到`CallerRunsPolicy`的任务是个非常耗时的任务,且处理提交任务的线程是主线程,可能会导致主线程阻塞,影响程序的正常运行。
|
||||
|
||||
这里简单举一个例子,该线程池限定了最大线程数为 2,还阻塞队列大小为 1(这意味着第 4 个任务就会走到拒绝策略),`ThreadUtil`为 Hutool 提供的工具类:
|
||||
这里简单举一个例子,该线程池限定了最大线程数为 2,阻塞队列大小为 1(这意味着第 4 个任务就会走到拒绝策略),`ThreadUtil`为 Hutool 提供的工具类:
|
||||
|
||||
```java
|
||||
Logger log = LoggerFactory.getLogger(ThreadPoolTest.class);
|
||||
// 创建一个线程池,核心线程数为1,最大线程数为2
|
||||
// 当线程数大于核心线程数时,多余的空闲线程存活的最长时间为60秒,
|
||||
// 任务队列为容量为1的ArrayBlockingQueue,饱和策略为CallerRunsPolicy。
|
||||
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,
|
||||
2,
|
||||
60,
|
||||
TimeUnit.SECONDS,
|
||||
new ArrayBlockingQueue<>(1),
|
||||
new ThreadPoolExecutor.CallerRunsPolicy());
|
||||
public class ThreadPoolTest {
|
||||
|
||||
// 提交第一个任务,由核心线程执行
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("核心线程执行第一个任务");
|
||||
ThreadUtil.sleep(1, TimeUnit.MINUTES);
|
||||
});
|
||||
private static final Logger log = LoggerFactory.getLogger(ThreadPoolTest.class);
|
||||
|
||||
// 提交第二个任务,由于核心线程被占用,任务将进入队列等待
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("非核心线程处理入队的第二个任务");
|
||||
ThreadUtil.sleep(1, TimeUnit.MINUTES);
|
||||
});
|
||||
public static void main(String[] args) {
|
||||
// 创建一个线程池,核心线程数为1,最大线程数为2
|
||||
// 当线程数大于核心线程数时,多余的空闲线程存活的最长时间为60秒,
|
||||
// 任务队列为容量为1的ArrayBlockingQueue,饱和策略为CallerRunsPolicy。
|
||||
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,
|
||||
2,
|
||||
60,
|
||||
TimeUnit.SECONDS,
|
||||
new ArrayBlockingQueue<>(1),
|
||||
new ThreadPoolExecutor.CallerRunsPolicy());
|
||||
|
||||
// 提交第三个任务,由于核心线程被占用且队列已满,创建非核心线程处理
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("非核心线程处理第三个任务");
|
||||
ThreadUtil.sleep(1, TimeUnit.MINUTES);
|
||||
});
|
||||
// 提交第一个任务,由核心线程执行
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("核心线程执行第一个任务");
|
||||
ThreadUtil.sleep(1, TimeUnit.MINUTES);
|
||||
});
|
||||
|
||||
// 提交第四个任务,由于核心线程和非核心线程都被占用,队列也满了,根据CallerRunsPolicy策略,任务将由提交任务的线程(即主线程)来执行
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("主线程处理第四个任务");
|
||||
ThreadUtil.sleep(2, TimeUnit.MINUTES);
|
||||
});
|
||||
// 提交第二个任务,由于核心线程被占用,任务将进入队列等待
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("非核心线程处理入队的第二个任务");
|
||||
ThreadUtil.sleep(1, TimeUnit.MINUTES);
|
||||
});
|
||||
|
||||
// 提交第三个任务,由于核心线程被占用且队列已满,创建非核心线程处理
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("非核心线程处理第三个任务");
|
||||
ThreadUtil.sleep(1, TimeUnit.MINUTES);
|
||||
});
|
||||
|
||||
// 提交第四个任务,由于核心线程和非核心线程都被占用,队列也满了,根据CallerRunsPolicy策略,任务将由提交任务的线程(即主线程)来执行
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("主线程处理第四个任务");
|
||||
ThreadUtil.sleep(2, TimeUnit.MINUTES);
|
||||
});
|
||||
|
||||
// 提交第五个任务,主线程被第四个任务卡住,该任务必须等到主线程执行完才能提交
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("核心线程执行第五个任务");
|
||||
});
|
||||
|
||||
// 关闭线程池
|
||||
threadPoolExecutor.shutdown();
|
||||
}
|
||||
}
|
||||
|
||||
// 提交第五个任务,主线程被第四个任务卡住,该任务必须等到主线程执行完才能提交
|
||||
threadPoolExecutor.execute(() -> {
|
||||
log.info("核心线程执行第五个任务");
|
||||
});
|
||||
```
|
||||
|
||||
输出:
|
||||
@ -438,14 +457,14 @@ threadPoolExecutor.execute(() -> {
|
||||
|
||||
这里提供的一种**任务持久化**的思路,这里所谓的任务持久化,包括但不限于:
|
||||
|
||||
1. 设计一张任务表间任务存储到 MySQL 数据库中。
|
||||
2. `Redis`缓存任务。
|
||||
1. 设计一张任务表将任务存储到 MySQL 数据库中。
|
||||
2. Redis 缓存任务。
|
||||
3. 将任务提交到消息队列中。
|
||||
|
||||
这里以方案一为例,简单介绍一下实现逻辑:
|
||||
|
||||
1. 实现`RejectedExecutionHandler`接口自定义拒绝策略,自定义拒绝策略负责将线程池暂时无法处理(此时阻塞队列已满)的任务入库(保存到 MySQL 中)。注意:线程池暂时无法处理的任务会先被放在阻塞队列中,阻塞队列满了才会触发拒绝策略。
|
||||
2. 继承`BlockingQueue`实现一个混合式阻塞队列,该队列包含`JDK`自带的`ArrayBlockingQueue`。另外,该混合式阻塞队列需要修改取任务处理的逻辑,也就是重写`take()`方法,取任务时优先从数据库中读取最早的任务,数据库中无任务时再从 `ArrayBlockingQueue`中去取任务。
|
||||
2. 继承`BlockingQueue`实现一个混合式阻塞队列,该队列包含 JDK 自带的`ArrayBlockingQueue`。另外,该混合式阻塞队列需要修改取任务处理的逻辑,也就是重写`take()`方法,取任务时优先从数据库中读取最早的任务,数据库中无任务时再从 `ArrayBlockingQueue`中去取任务。
|
||||
|
||||
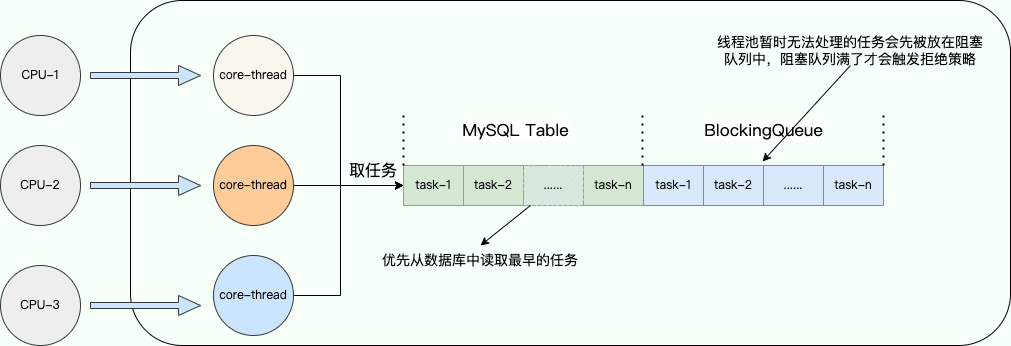
|
||||
|
||||
@ -494,9 +513,10 @@ new RejectedExecutionHandler() {
|
||||
|
||||
不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。
|
||||
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。`FixedThreadPool`最多只能创建核心线程数的线程(核心线程数和最大线程数相等),`SingleThreadExector`只能创建一个线程(核心线程数和最大线程数都是 1),二者的任务队列永远不会被放满。
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(有界阻塞队列):`FixedThreadPool` 和 `SingleThreadExecutor` 。`FixedThreadPool`最多只能创建核心线程数的线程(核心线程数和最大线程数相等),`SingleThreadExecutor`只能创建一个线程(核心线程数和最大线程数都是 1),二者的任务队列永远不会被放满。
|
||||
- `SynchronousQueue`(同步队列):`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
|
||||
- `DelayedWorkQueue`(延迟阻塞队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
|
||||
- `DelayedWorkQueue`(延迟队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容,增加原来容量的 50%,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
|
||||
- `ArrayBlockingQueue`(有界阻塞队列):底层由数组实现,容量一旦创建,就不能修改。
|
||||
|
||||
### 线程池处理任务的流程了解吗?
|
||||
|
||||
@ -507,9 +527,16 @@ new RejectedExecutionHandler() {
|
||||
3. 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
|
||||
4. 如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,拒绝策略会调用`RejectedExecutionHandler.rejectedExecution()`方法。
|
||||
|
||||
再提一个有意思的小问题:**线程池在提交任务前,可以提前创建线程吗?**
|
||||
|
||||
答案是可以的!`ThreadPoolExecutor` 提供了两个方法帮助我们在提交任务之前,完成核心线程的创建,从而实现线程池预热的效果:
|
||||
|
||||
- `prestartCoreThread()`:启动一个线程,等待任务,如果已达到核心线程数,这个方法返回 false,否则返回 true;
|
||||
- `prestartAllCoreThreads()`:启动所有的核心线程,并返回启动成功的核心线程数。
|
||||
|
||||
### 线程池中线程异常后,销毁还是复用?
|
||||
|
||||
先说结论,需要分两种情况:
|
||||
直接说结论,需要分两种情况:
|
||||
|
||||
- **使用`execute()`提交任务**:当任务通过`execute()`提交到线程池并在执行过程中抛出异常时,如果这个异常没有在任务内被捕获,那么该异常会导致当前线程终止,并且异常会被打印到控制台或日志文件中。线程池会检测到这种线程终止,并创建一个新线程来替换它,从而保持配置的线程数不变。
|
||||
- **使用`submit()`提交任务**:对于通过`submit()`提交的任务,如果在任务执行中发生异常,这个异常不会直接打印出来。相反,异常会被封装在由`submit()`返回的`Future`对象中。当调用`Future.get()`方法时,可以捕获到一个`ExecutionException`。在这种情况下,线程不会因为异常而终止,它会继续存在于线程池中,准备执行后续的任务。
|
||||
@ -644,7 +671,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
||||
|
||||
这是一个常见的面试问题,本质其实还是在考察求职者对于线程池以及阻塞队列的掌握。
|
||||
|
||||
我们上面也提到了,不同的线程池会选用不同的阻塞队列作为任务队列,比如`FixedThreadPool` 使用的是`LinkedBlockingQueue`(无界队列),由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程。
|
||||
我们上面也提到了,不同的线程池会选用不同的阻塞队列作为任务队列,比如`FixedThreadPool` 使用的是`LinkedBlockingQueue`(有界队列),默认构造器初始的队列长度为 `Integer.MAX_VALUE` ,由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程。
|
||||
|
||||
假如我们需要实现一个优先级任务线程池的话,那可以考虑使用 `PriorityBlockingQueue` (优先级阻塞队列)作为任务队列(`ThreadPoolExecutor` 的构造函数有一个 `workQueue` 参数可以传入任务队列)。
|
||||
|
||||
@ -1140,6 +1167,7 @@ public int await() throws InterruptedException, BrokenBarrierException {
|
||||
|
||||
- 《深入理解 Java 虚拟机》
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- Java 线程池的实现原理及其在业务中的最佳实践:阿里云开发者:<https://mp.weixin.qq.com/s/icrrxEsbABBvEU0Gym7D5Q>
|
||||
- 带你了解下 SynchronousQueue(并发队列专题):<https://juejin.cn/post/7031196740128768037>
|
||||
- 阻塞队列 — DelayedWorkQueue 源码分析:<https://zhuanlan.zhihu.com/p/310621485>
|
||||
- Java 多线程(三)——FutureTask/CompletableFuture:<https://www.cnblogs.com/iwehdio/p/14285282.html>
|
||||
|
||||
@ -13,9 +13,9 @@ tag:
|
||||
|
||||
`Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
|
||||
|
||||
- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
|
||||
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`** : 使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是有界阻塞队列 `LinkedBlockingQueue`,任务队列的默认长度和最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`,允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
|
||||
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`** : 使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
|
||||
说白了就是:**使用有界队列,控制线程创建数量。**
|
||||
|
||||
@ -227,7 +227,7 @@ try {
|
||||
|
||||
线程池本身的目的是为了提高任务执行效率,避免因频繁创建和销毁线程而带来的性能开销。如果将耗时任务提交到线程池中执行,可能会导致线程池中的线程被长时间占用,无法及时响应其他任务,甚至会导致线程池崩溃或者程序假死。
|
||||
|
||||
因此,在使用线程池时,我们应该尽量避免将耗时任务提交到线程池中执行。对于一些比较耗时的操作,如网络请求、文件读写等,可以采用异步操作的方式来处理,以避免阻塞线程池中的线程。
|
||||
因此,在使用线程池时,我们应该尽量避免将耗时任务提交到线程池中执行。对于一些比较耗时的操作,如网络请求、文件读写等,可以采用 `CompletableFuture` 等其他异步操作的方式来处理,以避免阻塞线程池中的线程。
|
||||
|
||||
## 8、线程池使用的一些小坑
|
||||
|
||||
|
||||
@ -534,7 +534,7 @@ Finished all threads // 任务全部执行完了才会跳出来,因为executo
|
||||
|
||||
#### `Runnable` vs `Callable`
|
||||
|
||||
`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是 **`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
|
||||
`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。`Runnable` 接口不会返回结果或抛出检查异常,但是 `Callable` 接口可以。所以,如果任务不需要返回结果或抛出异常推荐使用 `Runnable` 接口,这样代码看起来会更加简洁。
|
||||
|
||||
工具类 `Executors` 可以实现将 `Runnable` 对象转换成 `Callable` 对象。(`Executors.callable(Runnable task)` 或 `Executors.callable(Runnable task, Object result)`)。
|
||||
|
||||
@ -567,14 +567,15 @@ public interface Callable<V> {
|
||||
|
||||
#### `execute()` vs `submit()`
|
||||
|
||||
- `execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;
|
||||
- `submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法的话,如果在 `timeout` 时间内任务还没有执行完,就会抛出 `java.util.concurrent.TimeoutException`。
|
||||
`execute()` 和 `submit()`是两种提交任务到线程池的方法,有一些区别:
|
||||
|
||||
这里只是为了演示使用,推荐使用 `ThreadPoolExecutor` 构造方法来创建线程池。
|
||||
- **返回值**:`execute()` 方法用于提交不需要返回值的任务。通常用于执行 `Runnable` 任务,无法判断任务是否被线程池成功执行。`submit()` 方法用于提交需要返回值的任务。可以提交 `Runnable` 或 `Callable` 任务。`submit()` 方法返回一个 `Future` 对象,通过这个 `Future` 对象可以判断任务是否执行成功,并获取任务的返回值(`get()`方法会阻塞当前线程直到任务完成, `get(long timeout,TimeUnit unit)`多了一个超时时间,如果在 `timeout` 时间内任务还没有执行完,就会抛出 `java.util.concurrent.TimeoutException`)。
|
||||
- **异常处理**:在使用 `submit()` 方法时,可以通过 `Future` 对象处理任务执行过程中抛出的异常;而在使用 `execute()` 方法时,异常处理需要通过自定义的 `ThreadFactory` (在线程工厂创建线程的时候设置`UncaughtExceptionHandler`对象来 处理异常)或 `ThreadPoolExecutor` 的 `afterExecute()` 方法来处理
|
||||
|
||||
示例 1:使用 `get()`方法获取返回值。
|
||||
|
||||
```java
|
||||
// 这里只是为了演示使用,推荐使用 `ThreadPoolExecutor` 构造方法来创建线程池。
|
||||
ExecutorService executorService = Executors.newFixedThreadPool(3);
|
||||
|
||||
Future<String> submit = executorService.submit(() -> {
|
||||
|
||||
@ -7,8 +7,6 @@ tag:
|
||||
|
||||
如果将悲观锁(Pessimistic Lock)和乐观锁(PessimisticLock 或 OptimisticLock)对应到现实生活中来。悲观锁有点像是一位比较悲观(也可以说是未雨绸缪)的人,总是会假设最坏的情况,避免出现问题。乐观锁有点像是一位比较乐观的人,总是会假设最好的情况,在要出现问题之前快速解决问题。
|
||||
|
||||
在程序世界中,乐观锁和悲观锁的最终目的都是为了保证线程安全,避免在并发场景下的资源竞争问题。但是,相比于乐观锁,悲观锁对性能的影响更大!
|
||||
|
||||
## 什么是悲观锁?
|
||||
|
||||
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
|
||||
@ -31,34 +29,30 @@ try {
|
||||
}
|
||||
```
|
||||
|
||||
高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。
|
||||
高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题(线程获得锁的顺序不当时),影响代码的正常运行。
|
||||
|
||||
## 什么是乐观锁?
|
||||
|
||||
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了(具体方法可以使用版本号机制或 CAS 算法)。
|
||||
|
||||
像 Java 中`java.util.concurrent.atomic`包下面的原子变量类(比如`AtomicInteger`、`LongAdder`)就是使用了乐观锁的一种实现方式 **CAS** 实现的。
|
||||
|
||||
|
||||
在 Java 中`java.util.concurrent.atomic`包下面的原子变量类(比如`AtomicInteger`、`LongAdder`)就是使用了乐观锁的一种实现方式 **CAS** 实现的。
|
||||
|
||||
|
||||
```java
|
||||
// LongAdder 在高并发场景下会比 AtomicInteger 和 AtomicLong 的性能更好
|
||||
// 代价就是会消耗更多的内存空间(空间换时间)
|
||||
LongAdder longAdder = new LongAdder();
|
||||
// 自增
|
||||
longAdder.increment();
|
||||
// 获取结果
|
||||
longAdder.sum();
|
||||
LongAdder sum = new LongAdder();
|
||||
sum.increment();
|
||||
```
|
||||
|
||||
高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。但是,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试(悲观锁的开销是固定的),这样同样会非常影响性能,导致 CPU 飙升。
|
||||
高并发的场景下,乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁问题,在性能上往往会更胜一筹。但是,如果冲突频繁发生(写占比非常多的情况),会频繁失败并重试,这样同样会非常影响性能,导致 CPU 飙升。
|
||||
|
||||
不过,大量失败重试的问题也是可以解决的,像我们前面提到的 `LongAdder`以空间换时间的方式就解决了这个问题。
|
||||
|
||||
理论上来说:
|
||||
|
||||
- 悲观锁通常多用于写比较多的情况下(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如`LongAdder`),也是可以考虑使用乐观锁的,要视实际情况而定。
|
||||
- 乐观锁通常多于写比较少的情况下(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考`java.util.concurrent.atomic`包下面的原子变量类)。
|
||||
- 悲观锁通常多用于写比较多的情况(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如`LongAdder`),也是可以考虑使用乐观锁的,要视实际情况而定。
|
||||
- 乐观锁通常多用于写比较少的情况(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考`java.util.concurrent.atomic`包下面的原子变量类)。
|
||||
|
||||
## 如何实现乐观锁?
|
||||
|
||||
@ -100,77 +94,21 @@ CAS 涉及到三个操作数:
|
||||
|
||||
当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
|
||||
|
||||
Java 语言并没有直接实现 CAS,CAS 相关的实现是通过 C++ 内联汇编的形式实现的(JNI 调用)。因此, CAS 的具体实现和操作系统以及 CPU 都有关系。
|
||||
|
||||
`sun.misc`包下的`Unsafe`类提供了`compareAndSwapObject`、`compareAndSwapInt`、`compareAndSwapLong`方法来实现的对`Object`、`int`、`long`类型的 CAS 操作
|
||||
|
||||
```java
|
||||
/**
|
||||
* CAS
|
||||
* @param o 包含要修改field的对象
|
||||
* @param offset 对象中某field的偏移量
|
||||
* @param expected 期望值
|
||||
* @param update 更新值
|
||||
* @return true | false
|
||||
*/
|
||||
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
|
||||
|
||||
public final native boolean compareAndSwapInt(Object o, long offset, int expected,int update);
|
||||
|
||||
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long update);
|
||||
```
|
||||
|
||||
关于 `Unsafe` 类的详细介绍可以看这篇文章:[Java 魔法类 Unsafe 详解 - JavaGuide - 2022](https://javaguide.cn/java/basis/unsafe.html) 。
|
||||
|
||||
## CAS 算法存在哪些问题?
|
||||
|
||||
ABA 问题是 CAS 算法最常见的问题。
|
||||
|
||||
### ABA 问题
|
||||
|
||||
如果一个变量 V 初次读取的时候是 A 值,并且在准备赋值的时候检查到它仍然是 A 值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回 A,那 CAS 操作就会误认为它从来没有被修改过。这个问题被称为 CAS 操作的 **"ABA"问题。**
|
||||
|
||||
ABA 问题的解决思路是在变量前面追加上**版本号或者时间戳**。JDK 1.5 以后的 `AtomicStampedReference` 类就是用来解决 ABA 问题的,其中的 `compareAndSet()` 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
|
||||
|
||||
```java
|
||||
public boolean compareAndSet(V expectedReference,
|
||||
V newReference,
|
||||
int expectedStamp,
|
||||
int newStamp) {
|
||||
Pair<V> current = pair;
|
||||
return
|
||||
expectedReference == current.reference &&
|
||||
expectedStamp == current.stamp &&
|
||||
((newReference == current.reference &&
|
||||
newStamp == current.stamp) ||
|
||||
casPair(current, Pair.of(newReference, newStamp)));
|
||||
}
|
||||
```
|
||||
|
||||
### 循环时间长开销大
|
||||
|
||||
CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循环执行直到成功。如果长时间不成功,会给 CPU 带来非常大的执行开销。
|
||||
|
||||
如果 JVM 能支持处理器提供的 pause 指令那么效率会有一定的提升,pause 指令有两个作用:
|
||||
|
||||
1. 可以延迟流水线执行指令,使 CPU 不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。
|
||||
2. 可以避免在退出循环的时候因内存顺序冲突而引起 CPU 流水线被清空,从而提高 CPU 的执行效率。
|
||||
|
||||
### 只能保证一个共享变量的原子操作
|
||||
|
||||
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了`AtomicReference`类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference`类把多个共享变量合并成一个共享变量来操作。
|
||||
关于 CAS 的进一步介绍,可以阅读读者写的这篇文章:[CAS 详解](./cas.md),其中详细提到了 Java 中 CAS 的实现以及 CAS 存在的一些问题。
|
||||
|
||||
## 总结
|
||||
|
||||
- 高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。并且,悲观锁还可能会存在死锁问题,影响代码的正常运行。乐观锁相比悲观锁来说,不存在锁竞争造成线程阻塞,也不会有死锁的问题,在性能上往往会更胜一筹。不过,如果冲突频繁发生(写占比非常多的情况),会频繁失败和重试,这样同样会非常影响性能,导致 CPU 飙升。
|
||||
- 乐观锁一般会使用版本号机制或 CAS 算法实现,CAS 算法相对来说更多一些,这里需要格外注意。
|
||||
- CAS 的全称是 **Compare And Swap(比较与交换)** ,用于实现乐观锁,被广泛应用于各大框架中。CAS 的思想很简单,就是用一个预期值和要更新的变量值进行比较,两值相等才会进行更新。
|
||||
- CAS 算法的问题:ABA 问题、循环时间长开销大、只能保证一个共享变量的原子操作。
|
||||
本文详细介绍了乐观锁和悲观锁的概念以及乐观锁常见实现方式:
|
||||
|
||||
- 悲观锁基于悲观的假设,认为共享资源在每次访问时都会发生冲突,因此在每次操作时都会加锁。这种锁机制会导致其他线程阻塞,直到锁被释放。Java 中的 `synchronized` 和 `ReentrantLock` 是悲观锁的典型实现方式。虽然悲观锁能有效避免数据竞争,但在高并发场景下会导致线程阻塞、上下文切换频繁,从而影响系统性能,并且还可能引发死锁问题。
|
||||
- 乐观锁基于乐观的假设,认为共享资源在每次访问时不会发生冲突,因此无须加锁,只需在提交修改时验证数据是否被其他线程修改。Java 中的 `AtomicInteger` 和 `LongAdder` 等类通过 CAS(Compare-And-Swap)算法实现了乐观锁。乐观锁避免了线程阻塞和死锁问题,在读多写少的场景中性能优越。但在写操作频繁的情况下,可能会导致大量重试和失败,从而影响性能。
|
||||
- 乐观锁主要通过版本号机制或 CAS 算法实现。版本号机制通过比较版本号确保数据一致性,而 CAS 通过硬件指令实现原子操作,直接比较和交换变量值。
|
||||
|
||||
悲观锁和乐观锁各有优缺点,适用于不同的应用场景。在实际开发中,选择合适的锁机制能够有效提升系统的并发性能和稳定性。
|
||||
|
||||
## 参考
|
||||
|
||||
- 《Java 并发编程核心 78 讲》
|
||||
- 通俗易懂 悲观锁、乐观锁、可重入锁、自旋锁、偏向锁、轻量/重量级锁、读写锁、各种锁及其 Java 实现!:<https://zhuanlan.zhihu.com/p/71156910>
|
||||
- 一文彻底搞懂 CAS 实现原理 & 深入到 CPU 指令:<https://zhuanlan.zhihu.com/p/94976168>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 虚拟线程极简入门
|
||||
title: 虚拟线程常见问题总结
|
||||
category: Java
|
||||
tag:
|
||||
- Java并发
|
||||
@ -27,26 +27,25 @@ tag:
|
||||
|
||||
### 优点
|
||||
|
||||
- 非常轻量级:可以在单个线程中创建成百上千个虚拟线程而不会导致过多的线程创建和上下文切换。
|
||||
- 简化异步编程: 虚拟线程可以简化异步编程,使代码更易于理解和维护。它可以将异步代码编写得更像同步代码,避免了回调地狱(Callback Hell)。
|
||||
- 减少资源开销: 相比于操作系统线程,虚拟线程的资源开销更小。本质上是提高了线程的执行效率,从而减少线程资源的创建和上下文切换。
|
||||
- **非常轻量级**:可以在单个线程中创建成百上千个虚拟线程而不会导致过多的线程创建和上下文切换。
|
||||
- **简化异步编程**: 虚拟线程可以简化异步编程,使代码更易于理解和维护。它可以将异步代码编写得更像同步代码,避免了回调地狱(Callback Hell)。
|
||||
- **减少资源开销**: 由于虚拟线程是由 JVM 实现的,它能够更高效地利用底层资源,例如 CPU 和内存。虚拟线程的上下文切换比平台线程更轻量,因此能够更好地支持高并发场景。
|
||||
|
||||
### 缺点
|
||||
|
||||
- 不适用于计算密集型任务: 虚拟线程适用于 I/O 密集型任务,但不适用于计算密集型任务,因为密集型计算始终需要 CPU 资源作为支持。
|
||||
- 依赖于语言或库的支持: 协程需要编程语言或库提供支持。不是所有编程语言都原生支持协程。比如 Java 实现的虚拟线程。
|
||||
- **不适用于计算密集型任务**: 虚拟线程适用于 I/O 密集型任务,但不适用于计算密集型任务,因为密集型计算始终需要 CPU 资源作为支持。
|
||||
- **与某些第三方库不兼容**: 虽然虚拟线程设计时考虑了与现有代码的兼容性,但某些依赖平台线程特性的第三方库可能不完全兼容虚拟线程。
|
||||
|
||||
## 四种创建虚拟线程的方法
|
||||
|
||||
Java 21 已经正式支持虚拟线程,大家可以在官网下载使用,在使用上官方为了降低使用门槛,尽量复用原有的 `Thread` 类,让大家可以更加平滑的使用。
|
||||
## 如何创建虚拟线程?
|
||||
|
||||
官方提供了以下四种方式创建虚拟线程:
|
||||
|
||||
1. 使用 `Thread.startVirtualThread()` 创建
|
||||
2. 使用 `Thread.ofVirtual()` 创建
|
||||
3. 使用 `ThreadFactory` 创建
|
||||
4. 使用 `Executors.newVirtualThreadPerTaskExecutor()`创建
|
||||
|
||||
#### 使用 Thread.startVirtualThread()创建
|
||||
**1、使用 `Thread.startVirtualThread()` 创建**
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
@ -64,7 +63,7 @@ static class CustomThread implements Runnable {
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用 Thread.ofVirtual()创建
|
||||
**2、使用 `Thread.ofVirtual()` 创建**
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
@ -85,7 +84,7 @@ static class CustomThread implements Runnable {
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用 ThreadFactory 创建
|
||||
**3、使用 `ThreadFactory` 创建**
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
@ -105,7 +104,7 @@ static class CustomThread implements Runnable {
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用 Executors.newVirtualThreadPerTaskExecutor()创建
|
||||
**4、使用`Executors.newVirtualThreadPerTaskExecutor()`创建**
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
@ -227,6 +226,11 @@ totalMillis:2865ms
|
||||
|
||||
- 可以看到在密集 IO 的场景下,需要创建大量的平台线程异步处理才能达到虚拟线程的处理速度。
|
||||
- 因此,在密集 IO 的场景,虚拟线程可以大幅提高线程的执行效率,减少线程资源的创建以及上下文切换。
|
||||
- 吐槽:虽然虚拟线程我很想用,但是我 Java8 有机会升级到 Java21 吗?呜呜
|
||||
|
||||
**注意**:有段时间 JDK 一直致力于 Reactor 响应式编程来提高 Java 性能,但响应式编程难以理解、调试、使用,最终又回到了同步编程,最终虚拟线程诞生。
|
||||
|
||||
## 虚拟线程的底层原理是什么?
|
||||
|
||||
如果你想要详细了解虚拟线程实现原理,推荐一篇文章:[虚拟线程 - VirtualThread 源码透视](https://www.cnblogs.com/throwable/p/16758997.html)。
|
||||
|
||||
面试一般是不会问到这个问题的,仅供学有余力的同学进一步研究学习。
|
||||
|
||||
@ -342,7 +342,7 @@ public class NioSelectorExample {
|
||||
|
||||
零拷贝是提升 IO 操作性能的一个常用手段,像 ActiveMQ、Kafka 、RocketMQ、QMQ、Netty 等顶级开源项目都用到了零拷贝。
|
||||
|
||||
零拷贝是指计算机执行 IO 操作时,CPU 不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及 CPU 的拷贝时间。也就是说,零拷贝主主要解决操作系统在处理 I/O 操作时频繁复制数据的问题。零拷贝的常见实现技术有: `mmap+write`、`sendfile`和 `sendfile + DMA gather copy` 。
|
||||
零拷贝是指计算机执行 IO 操作时,CPU 不需要将数据从一个存储区域复制到另一个存储区域,从而可以减少上下文切换以及 CPU 的拷贝时间。也就是说,零拷贝主要解决操作系统在处理 I/O 操作时频繁复制数据的问题。零拷贝的常见实现技术有: `mmap+write`、`sendfile`和 `sendfile + DMA gather copy` 。
|
||||
|
||||
下图展示了各种零拷贝技术的对比图:
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ tag:
|
||||
|
||||
## 类的生命周期
|
||||
|
||||
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段::加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。其中,验证、准备和解析这三个阶段可以统称为连接(Linking)。
|
||||
类从被加载到虚拟机内存中开始到卸载出内存为止,它的整个生命周期可以简单概括为 7 个阶段:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)。其中,验证、准备和解析这三个阶段可以统称为连接(Linking)。
|
||||
|
||||
这 7 个阶段的顺序如下图所示:
|
||||
|
||||
@ -49,7 +49,7 @@ tag:
|
||||
|
||||
验证阶段这一步在整个类加载过程中耗费的资源还是相对较多的,但很有必要,可以有效防止恶意代码的执行。任何时候,程序安全都是第一位。
|
||||
|
||||
不过,验证阶段也不是必须要执行的阶段。如果程序运行的全部代码(包括自己编写的、第三方包中的、从外部加载的、动态生成的等所有代码)都已经被反复使用和验证过,在生产环境的实施阶段就可以考虑使用 `-Xverify:none` 参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。
|
||||
不过,验证阶段也不是必须要执行的阶段。如果程序运行的全部代码(包括自己编写的、第三方包中的、从外部加载的、动态生成的等所有代码)都已经被反复使用和验证过,在生产环境的实施阶段就可以考虑使用 `-Xverify:none` 参数来关闭大部分的类验证措施,以缩短虚拟机类加载的时间。但是需要注意的是 `-Xverify:none` 和 `-noverify` 在 JDK 13 中被标记为 deprecated ,在未来版本的 JDK 中可能会被移除。
|
||||
|
||||
验证阶段主要由四个检验阶段组成:
|
||||
|
||||
|
||||
@ -131,7 +131,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
||||
MaxTenuringThreshold of 20 is invalid; must be between 0 and 15
|
||||
```
|
||||
|
||||
**为什么年龄只能是 0-15? **
|
||||
**为什么年龄只能是 0-15?**
|
||||
|
||||
因为记录年龄的区域在对象头中,这个区域的大小通常是 4 位。这 4 位可以表示的最大二进制数字是 1111,即十进制的 15。因此,对象的年龄被限制为 0 到 15。
|
||||
|
||||
|
||||
@ -595,7 +595,7 @@ System.out.println(String.format("parallel sort took: %d ms", millis));
|
||||
|
||||
```java
|
||||
1000000
|
||||
parallel sort took: 475 ms//串行排序所用的时间
|
||||
parallel sort took: 475 ms//并行排序所用的时间
|
||||
```
|
||||
|
||||
上面两个代码几乎是一样的,但是并行版的快了 50% 左右,唯一需要做的改动就是将 `stream()` 改为`parallelStream()`。
|
||||
|
||||
@ -59,7 +59,6 @@ icon: "xitongsheji"
|
||||
- [Retrofit](https://github.com/square/retrofit):适用于 Android 和 Java 的类型安全的 HTTP 客户端。Retrofit 的 HTTP 请求使用的是 [OkHttp](https://square.github.io/okhttp/) 库(一款被广泛使用网络框架)。
|
||||
- [Forest](https://gitee.com/dromara/forest):轻量级 HTTP 客户端 API 框架,让 Java 发送 HTTP/HTTPS 请求不再难。它比 OkHttp 和 HttpClient 更高层,是封装调用第三方 restful api client 接口的好帮手,是 retrofit 和 feign 之外另一个选择。
|
||||
- [netty-websocket-spring-boot-starter](https://github.com/YeautyYE/netty-websocket-spring-boot-starter) :帮助你在 Spring Boot 中使用 Netty 来开发 WebSocket 服务器,并像 spring-websocket 的注解开发一样简单。
|
||||
- [SMS4J](https://github.com/dromara/SMS4J):短信聚合框架,解决接入多个短信 SDK 的繁琐流程。
|
||||
|
||||
## 数据库
|
||||
|
||||
@ -72,6 +71,7 @@ icon: "xitongsheji"
|
||||
|
||||
- [MyBatis-Plus](https://github.com/baomidou/mybatis-plus) : [MyBatis](http://www.mybatis.org/mybatis-3/) 增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
|
||||
- [MyBatis-Flex](https://gitee.com/mybatis-flex/mybatis-flex):一个优雅的 MyBatis 增强框架,无其他任何第三方依赖,支持 CRUD、分页查询、多表查询、批量操作。
|
||||
- [jOOQ](https://github.com/jOOQ/jOOQ):用 Java 编写 SQL 的最佳方式。
|
||||
- [Redisson](https://github.com/redisson/redisson "redisson"):Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid),支持超过 30 个对象和服务:`Set`,`SortedSet`, `Map`, `List`, `Queue`, `Deque` ……,并且提供了多种分布式锁的实现。更多介绍请看:[《Redisson 项目介绍》](https://github.com/redisson/redisson/wiki/Redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D "Redisson项目介绍")。
|
||||
|
||||
### 数据同步
|
||||
@ -125,9 +125,8 @@ icon: "xitongsheji"
|
||||
- [Quartz](https://github.com/quartz-scheduler/quartz):一个很火的开源任务调度框架,Java 定时任务领域的老大哥或者说参考标准, 很多其他任务调度框架都是基于 `quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案
|
||||
- [XXL-JOB](https://github.com/xuxueli/xxl-job) :XXL-JOB 是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
|
||||
- [Elastic-Job](http://elasticjob.io/index_zh.html):Elastic-Job 是当当网开源的一个基于 Quartz 和 Zookeeper 的分布式调度解决方案,由两个相互独立的子项目 Elastic-Job-Lite 和 Elastic-Job-Cloud 组成,一般我们只要使用 Elastic-Job-Lite 就好。
|
||||
- [EasyScheduler](https://github.com/analysys/EasyScheduler "EasyScheduler") (已经更名为 DolphinScheduler,已经成为 Apache 孵化器项目):Easy Scheduler 是一个分布式工作流任务调度系统,主要解决“复杂任务依赖但无法直接监控任务健康状态”的问题。Easy Scheduler 以 DAG 方式组装任务,可以实时监控任务的运行状态。同时,它支持重试,重新运行等操作... 。
|
||||
- [EasyScheduler](https://github.com/analysys/EasyScheduler "EasyScheduler") (已经更名为 DolphinScheduler,已经成为 Apache 孵化器项目):分布式易扩展的可视化工作流任务调度平台,主要解决“复杂任务依赖但无法直接监控任务健康状态”的问题。
|
||||
- [PowerJob](https://gitee.com/KFCFans/PowerJob):新一代分布式任务调度与计算框架,支持 CRON、API、固定频率、固定延迟等调度策略,提供工作流来编排任务解决依赖关系,使用简单,功能强大,文档齐全,欢迎各位接入使用!<http://www.powerjob.tech/> 。
|
||||
- [DolphinScheduler](https://github.com/apache/dolphinscheduler):分布式易扩展的可视化工作流任务调度平台。
|
||||
|
||||
## 分布式
|
||||
|
||||
|
||||
@ -9,11 +9,6 @@ icon: codelibrary-fill
|
||||
- [lombok](https://github.com/rzwitserloot/lombok) :使用 Lombok 我们可以简化我们的 Java 代码,比如使用它之后我们通过注释就可以实现 getter/setter、equals 等方法。
|
||||
- [guava](https://github.com/google/guava "guava"):Guava 是一组核心库,其中包括新的集合类型(例如 multimap 和 multiset),不可变集合,图形库以及用于并发、I / O、哈希、原始类型、字符串等的实用程序!
|
||||
- [hutool](https://github.com/looly/hutool "hutool") : Hutool 是一个 Java 工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让 Java 语言也可以“甜甜的”。
|
||||
- [p3c](https://github.com/alibaba/p3c "p3c"):Alibaba Java Coding Guidelines pmd implements and IDE plugin。Eclipse 和 IDEA 上都有该插件,推荐使用!
|
||||
- [sonarqube](https://github.com/SonarSource/sonarqube "sonarqube"):SonarQube 支持所有开发人员编写更干净,更安全的代码。
|
||||
- [checkstyle](https://github.com/checkstyle/checkstyle "checkstyle") :Checkstyle 是一种开发工具,可帮助程序员编写符合编码标准的 Java 代码。它使检查 Java 代码的过程自动化,从而使人们不必执行这项无聊(但很重要)的任务。这使其成为想要实施编码标准的项目的理想选择。
|
||||
- [pmd](https://github.com/pmd/pmd "pmd") : 可扩展的多语言静态代码分析器。
|
||||
- [spotbugs](https://github.com/spotbugs/spotbugs "spotbugs") :SpotBugs 是 FindBugs 的继任者。静态分析工具,用于查找 Java 代码中的错误。
|
||||
|
||||
## 问题排查和性能优化
|
||||
|
||||
@ -24,6 +19,10 @@ icon: codelibrary-fill
|
||||
|
||||
## 文档处理
|
||||
|
||||
### 文档解析
|
||||
|
||||
- [Tika](https://github.com/apache/tika):Apache Tika 工具包能够检测并提取来自超过一千种不同文件类型(如 PPT、XLS 和 PDF)的元数据和文本内容。
|
||||
|
||||
### Excel
|
||||
|
||||
- [easyexcel](https://github.com/alibaba/easyexcel) :快速、简单避免 OOM 的 Java 处理 Excel 工具。
|
||||
@ -43,8 +42,8 @@ icon: codelibrary-fill
|
||||
- [x-easypdf](https://gitee.com/dromara/x-easypdf):一个用搭积木的方式构建 PDF 的框架(基于 pdfbox/fop),支持 PDF 导出和编辑。
|
||||
- [pdfbox](https://github.com/apache/pdfbox) :用于处理 PDF 文档的开放源码 Java 工具。该项目允许创建新的 PDF 文档、对现有文档进行操作以及从文档中提取内容。PDFBox 还包括几个命令行实用程序。PDFBox 是在 Apache 2.0 版许可下发布的。
|
||||
- [OpenPDF](https://github.com/LibrePDF/OpenPDF):OpenPDF 是一个免费的 Java 库,用于使用 LGPL 和 MPL 开源许可创建和编辑 PDF 文件。OpenPDF 基于 iText 的一个分支。
|
||||
- [itext7](https://github.com/itext/itext7):iText 7 代表了想要利用利用好 PDF 的开发人员的更高级别的 sdk。iText 7 配备了更好的文档引擎、高级和低级编程功能以及创建、编辑和增强 PDF 文档的能力,几乎对每个工作流都有好处。
|
||||
- [FOP](https://xmlgraphics.apache.org/fop/) :Apache FOP 项目的主要的输出目标是 PDF。
|
||||
- [itext7](https://github.com/itext/itext7):一个用于创建、编辑和增强 PDF 文档的 Java 库。
|
||||
- [FOP](https://xmlgraphics.apache.org/fop/) : Apache FOP 用于将 XSL-FO(Extensible Stylesheet Language Formatting Objects)格式化对象转换为多种输出格式,最常见的是 PDF。
|
||||
|
||||
## 图片处理
|
||||
|
||||
@ -57,6 +56,11 @@ icon: codelibrary-fill
|
||||
- [AJ-Captcha](https://gitee.com/anji-plus/captcha):行为验证码(滑动拼图、点选文字),前后端(java)交互。
|
||||
- [tianai-captcha](https://gitee.com/tianai/tianai-captcha):好看又好用的滑块验证码。
|
||||
|
||||
## 短信&邮件
|
||||
|
||||
- [SMS4J](https://github.com/dromara/SMS4J):短信聚合框架,解决接入多个短信 SDK 的繁琐流程。
|
||||
- [Simple Java Mail](https://github.com/bbottema/simple-java-mail):最简单的 Java 轻量级邮件库,同时能够发送复杂的电子邮件。
|
||||
|
||||
## 在线支付
|
||||
|
||||
- [jeepay](https://gitee.com/jeequan/jeepay):一套适合互联网企业使用的开源支付系统,已实现交易、退款、转账、分账等接口,支持服务商特约商户和普通商户接口。已对接微信,支付宝,云闪付官方接口,支持聚合码支付。
|
||||
|
||||
@ -4,6 +4,15 @@ category: 开源项目
|
||||
icon: tool
|
||||
---
|
||||
|
||||
## 代码质量
|
||||
|
||||
- [SonarQube](https://github.com/SonarSource/sonarqube "sonarqube"):静态代码检查工具,,帮助检查代码缺陷,可以快速的定位代码中潜在的或者明显的错误,改善代码质量,提高开发速度。
|
||||
- [Spotless](https://github.com/diffplug/spotless):Spotless 是支持多种语言的代码格式化工具,支持 Maven 和 Gradle 以 Plugin 的形式构建。
|
||||
- [CheckStyle](https://github.com/checkstyle/checkstyle "checkstyle") : 类似于 Spotless,可帮助程序员编写符合编码标准的 Java 代码。
|
||||
- [PMD](https://github.com/pmd/pmd "pmd") : 可扩展的多语言静态代码分析器。
|
||||
- [SpotBugs](https://github.com/spotbugs/spotbugs "spotbugs") : FindBugs 的继任者。静态分析工具,用于查找 Java 代码中的错误。
|
||||
- [P3C](https://github.com/alibaba/p3c "p3c"):Alibaba Java Coding Guidelines pmd implements and IDE plugin。Eclipse 和 IDEA 上都有该插件。
|
||||
|
||||
## 项目构建
|
||||
|
||||
- [Maven](https://maven.apache.org/):一个软件项目管理和理解工具。基于项目对象模型 (Project Object Model,POM) 的概念,Maven 可以从一条中心信息管理项目的构建、报告和文档。详细介绍:[Maven 核心概念总结](https://javaguide.cn/tools/maven/maven-core-concepts.html)。
|
||||
|
||||
@ -18,9 +18,9 @@ footer: |-
|
||||
|
||||
## 关于网站
|
||||
|
||||
JavaGuide 已经持续维护 5 年多了,累计提交了 **5000+** commit ,共有 **440** 多位朋友参与维护。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
|
||||
JavaGuide 已经持续维护 6 年多了,累计提交了 **5500+** commit ,共有 **520+** 多位贡献者共同参与维护和完善。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
|
||||
|
||||
如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,你觉得内容不错再点赞就好),这是对我最大的鼓励,感谢各位一起同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
|
||||
如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收货再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
|
||||
|
||||
- [项目介绍](./javaguide/intro.md)
|
||||
- [贡献指南](./javaguide/contribution-guideline.md)
|
||||
|
||||
@ -14,11 +14,11 @@
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍:[JavaGuide 知识星球详细介绍](../about-the-author/zhishixingqiu-two-years.md) 。
|
||||
|
||||
这里再送一个 **30** 元的星球专属优惠券,数量有限(价格即将上调。老用户续费半价 ,微信扫码即可续费)!
|
||||
这里再送一张 **30** 元的星球专属优惠券,数量有限(价格即将上调。老用户续费半价 ,微信扫码即可续费)!
|
||||
|
||||

|
||||
|
||||
进入星球之后,记得查看 **[星球使用指南](https://t.zsxq.com/0d18KSarv)** (一定要看!!!) 和 **[星球优质主题汇总](https://t.zsxq.com/12uSKgTIm)**,干货多多!
|
||||
进入星球之后,记得查看 **[星球使用指南](https://t.zsxq.com/0d18KSarv)** (一定要看!!!) 和 **[星球优质主题汇总](https://t.zsxq.com/12uSKgTIm)** ,干货多多!
|
||||
|
||||
**无任何套路,无任何潜在收费项。用心做内容,不割韭菜!**
|
||||
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
## 星球限时优惠
|
||||
|
||||
这里再送一个 **30** 元的星球专属优惠券,数量有限(价格即将上调。老用户续费半价 ,微信扫码即可续费)!
|
||||
这里再送一张 **30** 元的星球专属优惠券,数量有限(价格即将上调。老用户续费半价 ,微信扫码即可续费)!
|
||||
|
||||

|
||||
|
||||
|
||||
@ -57,7 +57,7 @@ IoC 的思想就是两方之间不互相依赖,由第三方容器来管理相
|
||||
|
||||
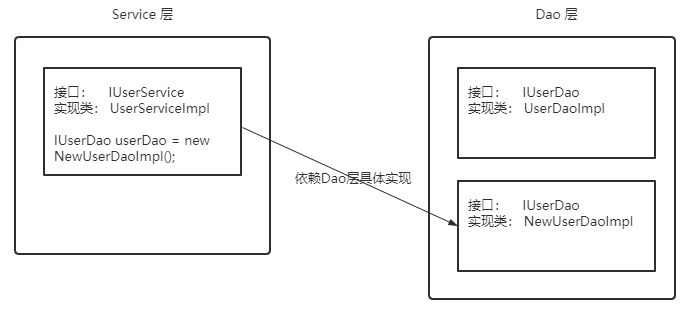
|
||||
|
||||
使用 IoC 的思想,我们将对象的控制权(创建、管理)交有 IoC 容器去管理,我们在使用的时候直接向 IoC 容器 “要” 就可以了
|
||||
使用 IoC 的思想,我们将对象的控制权(创建、管理)交由 IoC 容器去管理,我们在使用的时候直接向 IoC 容器 “要” 就可以了
|
||||
|
||||
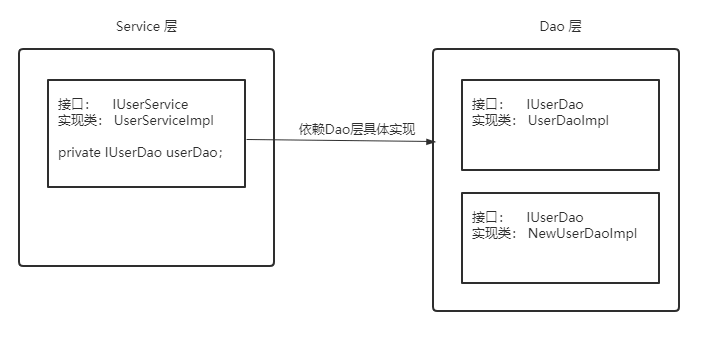
|
||||
|
||||
@ -94,7 +94,7 @@ AOP 之所以叫面向切面编程,是因为它的核心思想就是将横切
|
||||
- **连接点(JoinPoint)**:连接点是方法调用或者方法执行时的某个特定时刻(如方法调用、异常抛出等)。
|
||||
- **通知(Advice)**:通知就是切面在某个连接点要执行的操作。通知有五种类型,分别是前置通知(Before)、后置通知(After)、返回通知(AfterReturning)、异常通知(AfterThrowing)和环绕通知(Around)。前四种通知都是在目标方法的前后执行,而环绕通知可以控制目标方法的执行过程。
|
||||
- **切点(Pointcut)**:一个切点是一个表达式,它用来匹配哪些连接点需要被切面所增强。切点可以通过注解、正则表达式、逻辑运算等方式来定义。比如 `execution(* com.xyz.service..*(..))`匹配 `com.xyz.service` 包及其子包下的类或接口。
|
||||
- **织入(Weaving)**:织入是将切面和目标对象连接起来的过程,也就是将通知应用到切点匹配的连接点上。常见的织入时机有两种,分别是编译期织入(AspectJ)和运行期织入(AspectJ)。
|
||||
- **织入(Weaving)**:织入是将切面和目标对象连接起来的过程,也就是将通知应用到切点匹配的连接点上。常见的织入时机有两种,分别是编译期织入(Compile-Time Weaving 如:AspectJ)和运行期织入(Runtime Weaving 如:AspectJ、Spring AOP)。
|
||||
|
||||
### AOP 解决了什么问题?
|
||||
|
||||
|
||||
@ -5,15 +5,11 @@ tag:
|
||||
- 安全
|
||||
---
|
||||
|
||||
在 [JWT 基本概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)这篇文章中,我介绍了:
|
||||
校招面试中,遇到大部分的候选者认证登录这块用的都是 JWT。提问 JWT 的概念性问题以及使用 JWT 的原因,基本都能回答一些,但当问到 JWT 存在的一些问题和解决方案时,只有一小部分候选者回答的还可以。
|
||||
|
||||
- 什么是 JWT?
|
||||
- JWT 由哪些部分组成?
|
||||
- 如何基于 JWT 进行身份验证?
|
||||
- JWT 如何防止 Token 被篡改?
|
||||
- 如何加强 JWT 的安全性?
|
||||
JWT 不是银弹,也有很多缺陷,很多时候并不是最优的选择。这篇文章,我们一起探讨一下 JWT 身份认证的优缺点以及常见问题的解决办法,来看看为什么很多人不再推荐使用 JWT 了。
|
||||
|
||||
这篇文章,我们一起探讨一下 JWT 身份认证的优缺点以及常见问题的解决办法。
|
||||
关于 JWT 的基本概念介绍请看我写的这篇文章: [JWT 基本概念详解](https://javaguide.cn/system-design/security/jwt-intro.html)。
|
||||
|
||||
## JWT 的优势
|
||||
|
||||
@ -170,15 +166,35 @@ JWT 认证的话,我们应该如何解决续签问题呢?查阅了很多资
|
||||
- 重新请求获取 JWT 的过程中会有短暂 JWT 不可用的情况(可以通过在客户端设置定时器,当 accessJWT 快过期的时候,提前去通过 refreshJWT 获取新的 accessJWT);
|
||||
- 存在安全问题,只要拿到了未过期的 refreshJWT 就一直可以获取到 accessJWT。不过,由于 refreshJWT 只用来获取 accessJWT,不容易被泄露。
|
||||
|
||||
### JWT 体积太大
|
||||
|
||||
JWT 结构复杂(Header、Payload 和 Signature),包含了更多额外的信息,还需要进行 Base64Url 编码,这会使得 JWT 体积较大,增加了网络传输的开销。
|
||||
|
||||
JWT 组成:
|
||||
|
||||
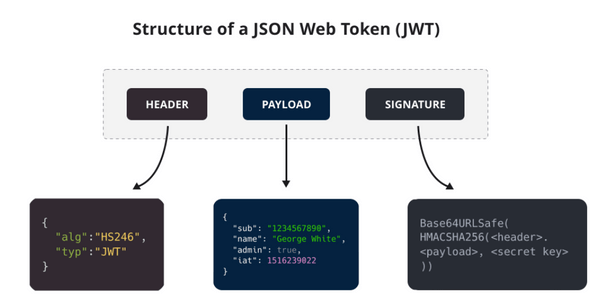
|
||||
|
||||
JWT 示例:
|
||||
|
||||
```plain
|
||||
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
|
||||
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.
|
||||
SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
|
||||
```
|
||||
|
||||
解决办法:
|
||||
|
||||
- 尽量减少 JWT Payload(载荷)中的信息,只保留必要的用户和权限信息。
|
||||
- 在传输 JWT 之前,使用压缩算法(如 GZIP)对 JWT 进行压缩以减少体积。
|
||||
- 在某些情况下,使用传统的 Token 可能更合适。传统的 Token 通常只是一个唯一标识符,对应的信息(例如用户 ID、Token 过期时间、权限信息)存储在服务端,通常会通过 Redis 保存。
|
||||
|
||||
## 总结
|
||||
|
||||
JWT 其中一个很重要的优势是无状态,但实际上,我们想要在实际项目中合理使用 JWT 的话,也还是需要保存 JWT 信息。
|
||||
JWT 其中一个很重要的优势是无状态,但实际上,我们想要在实际项目中合理使用 JWT 做认证登录的话,也还是需要保存 JWT 信息。
|
||||
|
||||
JWT 也不是银弹,也有很多缺陷,具体是选择 JWT 还是 Session 方案还是要看项目的具体需求。万万不可尬吹 JWT,而看不起其他身份认证方案。
|
||||
|
||||
另外,不用 JWT 直接使用普通的 Token(随机生成,不包含具体的信息) 结合 Redis 来做身份认证也是可以的。我在 [「优质开源项目推荐」](https://javaguide.cn/open-source-project/)的第 8 期推荐过的 [Sa-Token](https://github.com/dromara/sa-token) 这个项目是一个比较完善的 基于 JWT 的身份认证解决方案,支持自动续签、踢人下线、账号封禁、同端互斥登录等功能,感兴趣的朋友可以看看。
|
||||
|
||||

|
||||
另外,不用 JWT 直接使用普通的 Token(随机生成的 ID,不包含具体的信息) 结合 Redis 来做身份认证也是可以的。
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
@ -368,38 +368,43 @@ FastJSON 实现数据脱敏的方式主要有两种:
|
||||
- 基于注解 `@JSONField` 实现:需要自定义一个用于脱敏的序列化的类,然后在需要脱敏的字段上通过 `@JSONField` 中的 `serializeUsing` 指定为我们自定义的序列化类型即可。
|
||||
- 基于序列化过滤器:需要实现 `ValueFilter` 接口,重写 `process` 方法完成自定义脱敏,然后在 JSON 转换时使用自定义的转换策略。具体实现可参考这篇文章: <https://juejin.cn/post/7067916686141161479>。
|
||||
|
||||
### Mybatis-mate
|
||||
### Mybatis-Mate
|
||||
|
||||
MybatisPlus 也提供了数据脱敏模块 mybatis-mate。mybatis-mate 为 MybatisPlus 企业级模块,使用之前需要配置授权码(付费),旨在更敏捷优雅处理数据。
|
||||
先介绍一下 MyBatis、MyBatis-Plus 和 Mybatis-Mate 这三者的关系:
|
||||
|
||||
配置内容如下所示:
|
||||
- MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。
|
||||
- MyBatis-Plus 是一个 MyBatis 的增强工具,能够极大地简化持久层的开发工作。
|
||||
- Mybatis-Mate 是为 MyBatis-Plus 提供的企业级模块,旨在更敏捷优雅处理数据。不过,使用之前需要配置授权码(付费)。
|
||||
|
||||
```yaml
|
||||
# Mybatis Mate 配置
|
||||
mybatis-mate:
|
||||
cert:
|
||||
grant: jxftsdfggggx
|
||||
license: GKXP9r4MCJhGID/DTGigcBcLmZjb1YZGjE4GXaAoxbtGsPC20sxpEtiUr2F7Nb1ANTUekvF6Syo6DzraA4M4oacwoLVTglzfvaEfadfsd232485eLJK1QsskrSJmreMnEaNh9lsV7Lpbxy9JeGCeM0HPEbRvq8Y+8dUt5bQYLklsa3ZIBexir+4XykZY15uqn1pYIp4pEK0+aINTa57xjJNoWuBIqm7BdFIb4l1TAcPYMTsMXhF5hfMmKD2h391HxWTshJ6jbt4YqdKD167AgeoM+B+DE1jxlLjcpskY+kFs9piOS7RCcmKBBUOgX2BD/JxhR2gQ==
|
||||
Mybatis-Mate 支持敏感词脱敏,内置手机号、邮箱、银行卡号等 9 种常用脱敏规则。
|
||||
|
||||
```java
|
||||
@FieldSensitive("testStrategy")
|
||||
private String username;
|
||||
|
||||
@Configuration
|
||||
public class SensitiveStrategyConfig {
|
||||
|
||||
/**
|
||||
* 注入脱敏策略
|
||||
*/
|
||||
@Bean
|
||||
public ISensitiveStrategy sensitiveStrategy() {
|
||||
// 自定义 testStrategy 类型脱敏处理
|
||||
return new SensitiveStrategy().addStrategy("testStrategy", t -> t + "***test***");
|
||||
}
|
||||
}
|
||||
|
||||
// 跳过脱密处理,用于编辑场景
|
||||
RequestDataTransfer.skipSensitive();
|
||||
```
|
||||
|
||||
具体实现可参考 baomidou 提供的如下代码:<https://gitee.com/baomidou/mybatis-mate-examples> 。
|
||||
|
||||
### MyBatis-Flex
|
||||
|
||||
类似于 MybatisPlus,MyBatis-Flex 也是一个 MyBatis 增强框架。MyBatis-Flex 同样提供了数据脱敏功能,并且是可以免费使用的。
|
||||
|
||||
MyBatis-Flex 提供了 `@ColumnMask()` 注解,以及内置的 9 种脱敏规则,开箱即用:
|
||||
|
||||
- 用户名脱敏
|
||||
- 手机号脱敏
|
||||
- 固定电话脱敏
|
||||
- 身份证号脱敏
|
||||
- 车牌号脱敏
|
||||
- 地址脱敏
|
||||
- 邮件脱敏
|
||||
- 密码脱敏
|
||||
- 银行卡号脱敏
|
||||
|
||||
```java
|
||||
/**
|
||||
* 内置的数据脱敏方式
|
||||
@ -465,14 +470,57 @@ public class Account {
|
||||
|
||||
如果这些内置的脱敏规则不满足你的要求的话,你还可以自定义脱敏规则。
|
||||
|
||||
1、通过 `MaskManager` 注册新的脱敏规则:
|
||||
|
||||
```java
|
||||
MaskManager.registerMaskProcessor("自定义规则名称"
|
||||
, data -> {
|
||||
return data;
|
||||
})
|
||||
```
|
||||
|
||||
2、使用自定义的脱敏规则
|
||||
|
||||
```java
|
||||
@Table("tb_account")
|
||||
public class Account {
|
||||
|
||||
@Id(keyType = KeyType.Auto)
|
||||
private Long id;
|
||||
|
||||
@ColumnMask("自定义规则名称")
|
||||
private String userName;
|
||||
}
|
||||
```
|
||||
|
||||
并且,对于需要跳过脱密处理的场景,例如进入编辑页面编辑用户数据,MyBatis-Flex 也提供了对应的支持:
|
||||
|
||||
1. **`MaskManager#execWithoutMask`**(推荐):该方法使用了模版方法设计模式,保障跳过脱敏处理并执行相关逻辑后自动恢复脱敏处理。
|
||||
2. **`MaskManager#skipMask`**:跳过脱敏处理。
|
||||
3. **`MaskManager#restoreMask`**:恢复脱敏处理,确保后续的操作继续使用脱敏逻辑。
|
||||
|
||||
`MaskManager#execWithoutMask`方法实现如下:
|
||||
|
||||
```java
|
||||
public static <T> T execWithoutMask(Supplier<T> supplier) {
|
||||
try {
|
||||
skipMask();
|
||||
return supplier.get();
|
||||
} finally {
|
||||
restoreMask();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`MaskManager` 的`skipMask`和`restoreMask`方法一般配套使用,推荐`try{...}finally{...}`模式。
|
||||
|
||||
## 总结
|
||||
|
||||
本文主要介绍了数据脱敏的相关内容,首先介绍了数据脱敏的概念,在此基础上介绍了常用的数据脱敏规则;随后介绍了本文的重点 Hutool 工具及其使用方法,在此基础上进行了实操,分别演示了使用 DesensitizedUtil 工具类、配合 Jackson 通过注解的方式完成数据脱敏;最后,介绍了一些常见的数据脱敏方法,并附上了对应的教程链接供大家参考,本文内容如有不当之处,还请大家批评指正。
|
||||
这篇文章主要介绍了:
|
||||
|
||||
## 推荐阅读
|
||||
|
||||
- [Spring Boot 日志、配置文件、接口数据如何脱敏?老鸟们都是这样玩的!](https://mp.weixin.qq.com/s/59osrnjyPJ7BV070x6ABwQ)
|
||||
- [大厂也在用的 6 种数据脱敏方案,严防泄露数据的“内鬼”](https://mp.weixin.qq.com/s/_Dgekk1AJsIx0TTlnH6kUA)
|
||||
- 数据脱敏的定义:数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。
|
||||
- 常用的脱敏规则:替换、删除、重排、加噪和加密。
|
||||
- 常用的脱敏工具:Hutool、Apache ShardingSphere、FastJSON、Mybatis-Mate 和 MyBatis-Flex。
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
@ -25,13 +25,13 @@ JWT 自身包含了身份验证所需要的所有信息,因此,我们的服
|
||||
|
||||
## JWT 由哪些部分组成?
|
||||
|
||||

|
||||

|
||||
|
||||
JWT 本质上就是一组字串,通过(`.`)切分成三个为 Base64 编码的部分:
|
||||
|
||||
- **Header** : 描述 JWT 的元数据,定义了生成签名的算法以及 `Token` 的类型。
|
||||
- **Payload** : 用来存放实际需要传递的数据
|
||||
- **Signature(签名)**:服务器通过 Payload、Header 和一个密钥(Secret)使用 Header 里面指定的签名算法(默认是 HMAC SHA256)生成。
|
||||
- **Header(头部)** : 描述 JWT 的元数据,定义了生成签名的算法以及 `Token` 的类型。Header 被 Base64Url 编码后成为 JWT 的第一部分。
|
||||
- **Payload(载荷)** : 用来存放实际需要传递的数据,包含声明(Claims),如`sub`(subject,主题)、`jti`(JWT ID)。Payload 被 Base64Url 编码后成为 JWT 的第二部分。
|
||||
- **Signature(签名)**:服务器通过 Payload、Header 和一个密钥(Secret)使用 Header 里面指定的签名算法(默认是 HMAC SHA256)生成。生成的签名会成为 JWT 的第三部分。
|
||||
|
||||
JWT 通常是这样的:`xxxxx.yyyyy.zzzzz`。
|
||||
|
||||
|
||||
@ -5,13 +5,13 @@ tag:
|
||||
- Docker
|
||||
---
|
||||
|
||||
**本文只是对 Docker 的概念做了较为详细的介绍,并不涉及一些像 Docker 环境的安装以及 Docker 的一些常见操作和命令。**
|
||||
本文只是对 Docker 的概念做了较为详细的介绍,并不涉及一些像 Docker 环境的安装以及 Docker 的一些常见操作和命令。
|
||||
|
||||
## 一 认识容器
|
||||
## 容器介绍
|
||||
|
||||
**Docker 是世界领先的软件容器平台**,所以想要搞懂 Docker 的概念我们必须先从容器开始说起。
|
||||
|
||||
### 1.1 什么是容器?
|
||||
### 什么是容器?
|
||||
|
||||
#### 先来看看容器较为官方的解释
|
||||
|
||||
@ -23,11 +23,11 @@ tag:
|
||||
|
||||
#### 再来看看容器较为通俗的解释
|
||||
|
||||
**如果需要通俗地描述容器的话,我觉得容器就是一个存放东西的地方,就像书包可以装各种文具、衣柜可以放各种衣服、鞋架可以放各种鞋子一样。我们现在所说的容器存放的东西可能更偏向于应用比如网站、程序甚至是系统环境。**
|
||||
如果需要通俗地描述容器的话,我觉得容器就是一个存放东西的地方,就像书包可以装各种文具、衣柜可以放各种衣服、鞋架可以放各种鞋子一样。我们现在所说的容器存放的东西可能更偏向于应用比如网站、程序甚至是系统环境。
|
||||
|
||||
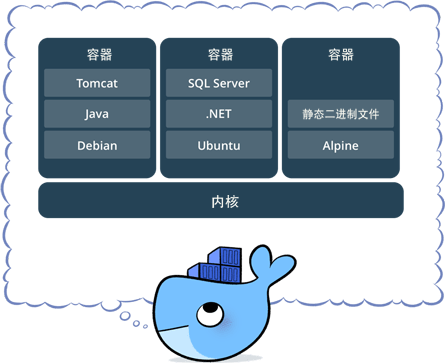
|
||||
|
||||
### 1.2 图解物理机,虚拟机与容器
|
||||
### 图解物理机,虚拟机与容器
|
||||
|
||||
关于虚拟机与容器的对比在后面会详细介绍到,这里只是通过网上的图片加深大家对于物理机、虚拟机与容器这三者的理解(下面的图片来源于网络)。
|
||||
|
||||
@ -45,87 +45,73 @@ tag:
|
||||
|
||||
通过上面这三张抽象图,我们可以大概通过类比概括出:**容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。因此容器的隔离级别会稍低一些。**
|
||||
|
||||
---
|
||||
### 容器 VS 虚拟机
|
||||
|
||||
**相信通过上面的解释大家对于容器这个既陌生又熟悉的概念有了一个初步的认识,下面我们就来谈谈 Docker 的一些概念。**
|
||||
|
||||
## 二 再来谈谈 Docker 的一些概念
|
||||
|
||||
### 2.1 什么是 Docker?
|
||||
|
||||
说实话关于 Docker 是什么并太好说,下面我通过四点向你说明 Docker 到底是个什么东西。
|
||||
|
||||
- **Docker 是世界领先的软件容器平台。**
|
||||
- **Docker** 使用 Google 公司推出的 **Go 语言** 进行开发实现,基于 **Linux 内核** 提供的 CGroup 功能和 namespace 来实现的,以及 AUFS 类的 **UnionFS** 等技术,**对进程进行封装隔离,属于操作系统层面的虚拟化技术。** 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
|
||||
- **Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。**
|
||||
- **用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。**
|
||||
|
||||
### 2.2 Docker 思想
|
||||
|
||||
- **集装箱**
|
||||
- **标准化:** ① 运输方式 ② 存储方式 ③ API 接口
|
||||
- **隔离**
|
||||
|
||||
### 2.3 Docker 容器的特点
|
||||
|
||||
- **轻量** : 在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
|
||||
- **标准** : Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
|
||||
- **安全** : Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
|
||||
|
||||
### 2.4 为什么要用 Docker ?
|
||||
|
||||
- **Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 “这段代码在我机器上没问题啊” 这类问题;——一致的运行环境**
|
||||
- **可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。——更快速的启动时间**
|
||||
- **避免公用的服务器,资源会容易受到其他用户的影响。——隔离性**
|
||||
- **善于处理集中爆发的服务器使用压力;——弹性伸缩,快速扩展**
|
||||
- **可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。——迁移方便**
|
||||
- **使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。——持续交付和部署**
|
||||
|
||||
---
|
||||
|
||||
## 三 容器 VS 虚拟机
|
||||
|
||||
**每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。**
|
||||
每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
|
||||
|
||||
简单来说:**容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。**
|
||||
|
||||
### 3.1 两者对比图
|
||||
|
||||
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便。
|
||||
|
||||

|
||||
|
||||
### 3.2 容器与虚拟机总结
|
||||
**容器和虚拟机的对比**:
|
||||
|
||||
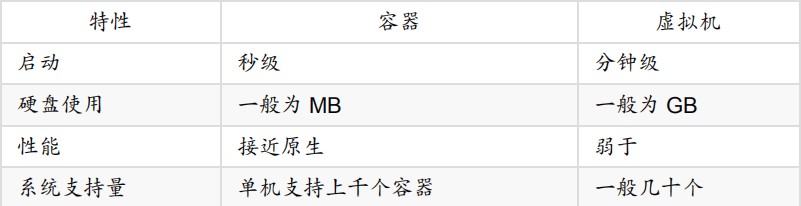
|
||||
|
||||
- **容器是一个应用层抽象,用于将代码和依赖资源打包在一起。** **多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行** 。与虚拟机相比, **容器占用的空间较少**(容器镜像大小通常只有几十兆),**瞬间就能完成启动** 。
|
||||
- 容器是一个应用层抽象,用于将代码和依赖资源打包在一起。 多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行 。与虚拟机相比, **容器占用的空间较少**(容器镜像大小通常只有几十兆),**瞬间就能完成启动** 。
|
||||
|
||||
- **虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。** 管理程序允许多个 VM 在一台机器上运行。每个 VM 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 **占用大量空间** 。而且 VM **启动也十分缓慢** 。
|
||||
- 虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。管理程序允许多个 VM 在一台机器上运行。每个 VM 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 **占用大量空间** 。而且 VM **启动也十分缓慢** 。
|
||||
|
||||
通过 Docker 官网,我们知道了这么多 Docker 的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。**虚拟机更擅长于彻底隔离整个运行环境**。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 **Docker 通常用于隔离不同的应用** ,例如前端,后端以及数据库。
|
||||
|
||||
### 3.3 容器与虚拟机两者是可以共存的
|
||||
|
||||
就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
|
||||
|
||||
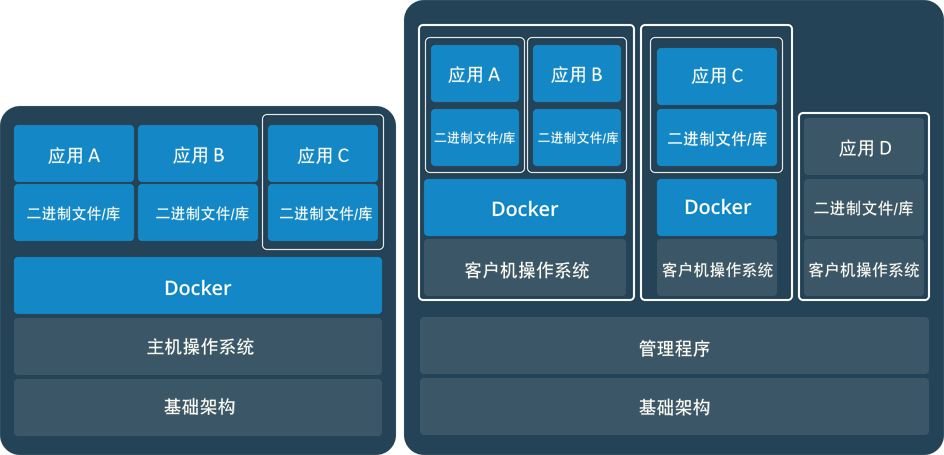
|
||||
|
||||
## Docker 介绍
|
||||
|
||||
### 什么是 Docker?
|
||||
|
||||
说实话关于 Docker 是什么并不太好说,下面我通过四点向你说明 Docker 到底是个什么东西。
|
||||
|
||||
- **Docker 是世界领先的软件容器平台。**
|
||||
- **Docker** 使用 Google 公司推出的 **Go 语言** 进行开发实现,基于 **Linux 内核** 提供的 CGroup 功能和 namespace 来实现的,以及 AUFS 类的 **UnionFS** 等技术,**对进程进行封装隔离,属于操作系统层面的虚拟化技术。** 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
|
||||
- Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。
|
||||
- 用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。
|
||||
|
||||
**Docker 思想**:
|
||||
|
||||
- **集装箱**:就像海运中的集装箱一样,Docker 容器包含了应用程序及其所有依赖项,确保在任何环境中都能以相同的方式运行。
|
||||
- **标准化:**运输方式、存储方式、API 接口。
|
||||
- **隔离**:每个 Docker 容器都在自己的隔离环境中运行,与宿主机和其他容器隔离。
|
||||
|
||||
### Docker 容器的特点
|
||||
|
||||
- **轻量** : 在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
|
||||
- **标准** : Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
|
||||
- **安全** : Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
|
||||
|
||||
### 为什么要用 Docker ?
|
||||
|
||||
- Docker 的镜像提供了除内核外完整的运行时环境,确保了应用运行环境一致性,从而不会再出现 “这段代码在我机器上没问题啊” 这类问题;——一致的运行环境
|
||||
- 可以做到秒级、甚至毫秒级的启动时间。大大的节约了开发、测试、部署的时间。——更快速的启动时间
|
||||
- 避免公用的服务器,资源会容易受到其他用户的影响。——隔离性
|
||||
- 善于处理集中爆发的服务器使用压力;——弹性伸缩,快速扩展
|
||||
- 可以很轻易的将在一个平台上运行的应用,迁移到另一个平台上,而不用担心运行环境的变化导致应用无法正常运行的情况。——迁移方便
|
||||
- 使用 Docker 可以通过定制应用镜像来实现持续集成、持续交付、部署。——持续交付和部署
|
||||
|
||||
---
|
||||
|
||||
## 四 Docker 基本概念
|
||||
## Docker 基本概念
|
||||
|
||||
**Docker 中有非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。**
|
||||
Docker 中有非常重要的三个基本概念:镜像(Image)、容器(Container)和仓库(Repository)。
|
||||
|
||||
- **镜像(Image)**
|
||||
- **容器(Container)**
|
||||
- **仓库(Repository)**
|
||||
理解了这三个概念,就理解了 Docker 的整个生命周期。
|
||||
|
||||
理解了这三个概念,就理解了 Docker 的整个生命周期
|
||||
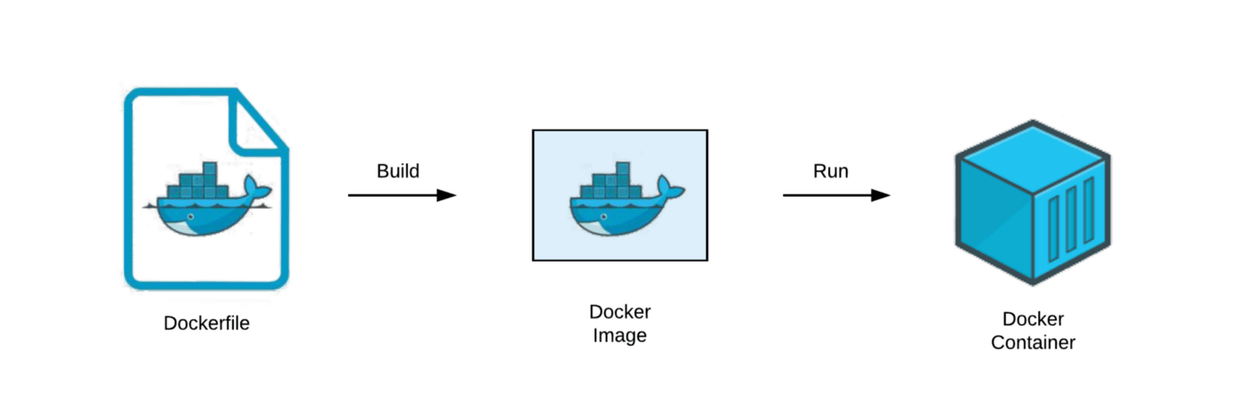
|
||||
|
||||
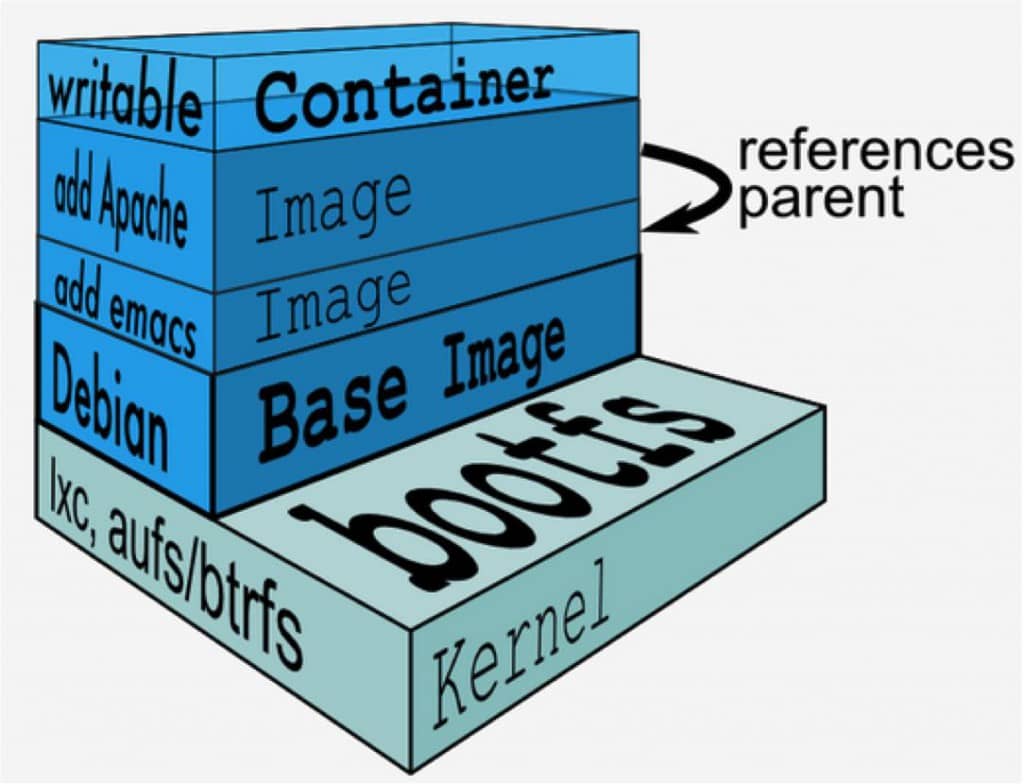
|
||||
|
||||
### 4.1 镜像(Image):一个特殊的文件系统
|
||||
### 镜像(Image):一个特殊的文件系统
|
||||
|
||||
**操作系统分为内核和用户空间**。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。
|
||||
|
||||
@ -137,7 +123,7 @@ Docker 设计时,就充分利用 **Union FS** 的技术,将其设计为**分
|
||||
|
||||
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
|
||||
|
||||
### 4.2 容器(Container):镜像运行时的实体
|
||||
### 容器(Container):镜像运行时的实体
|
||||
|
||||
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,**容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等** 。
|
||||
|
||||
@ -147,7 +133,7 @@ Docker 设计时,就充分利用 **Union FS** 的技术,将其设计为**分
|
||||
|
||||
按照 Docker 最佳实践的要求,**容器不应该向其存储层内写入任何数据** ,容器存储层要保持无状态化。**所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录**,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, **使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。**
|
||||
|
||||
### 4.3 仓库(Repository):集中存放镜像文件的地方
|
||||
### 仓库(Repository):集中存放镜像文件的地方
|
||||
|
||||
镜像构建完成后,可以很容易的在当前宿主上运行,但是, **如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。**
|
||||
|
||||
@ -183,15 +169,40 @@ mariadb MariaDB is a community-developed fork of MyS
|
||||
mysql/mysql-server Optimized MySQL Server Docker images. Create… 650 [OK]
|
||||
```
|
||||
|
||||
在国内访问**Docker Hub** 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [时速云镜像库](https://www.tenxcloud.com/ "时速云镜像库")、[网易云镜像服务](https://www.163yun.com/product/repo "网易云镜像服务")、[DaoCloud 镜像市场](https://www.daocloud.io/ "DaoCloud 镜像市场")、[阿里云镜像库](https://www.aliyun.com/product/containerservice?utm_content=se_1292836 "阿里云镜像库")等。
|
||||
在国内访问 **Docker Hub** 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [时速云镜像库](https://www.tenxcloud.com/ "时速云镜像库")、[网易云镜像服务](https://www.163yun.com/product/repo "网易云镜像服务")、[DaoCloud 镜像市场](https://www.daocloud.io/ "DaoCloud 镜像市场")、[阿里云镜像库](https://www.aliyun.com/product/containerservice?utm_content=se_1292836 "阿里云镜像库")等。
|
||||
|
||||
除了使用公开服务外,用户还可以在 **本地搭建私有 Docker Registry** 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
|
||||
除了使用公开服务外,用户还可以在 **本地搭建私有 Docker Registry** 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 Docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
|
||||
|
||||
---
|
||||
### Image、Container 和 Repository 的关系
|
||||
|
||||
## 五 常见命令
|
||||
下面这一张图很形象地展示了 Image、Container、Repository 和 Registry/Hub 这四者的关系:
|
||||
|
||||
### 5.1 基本命令
|
||||
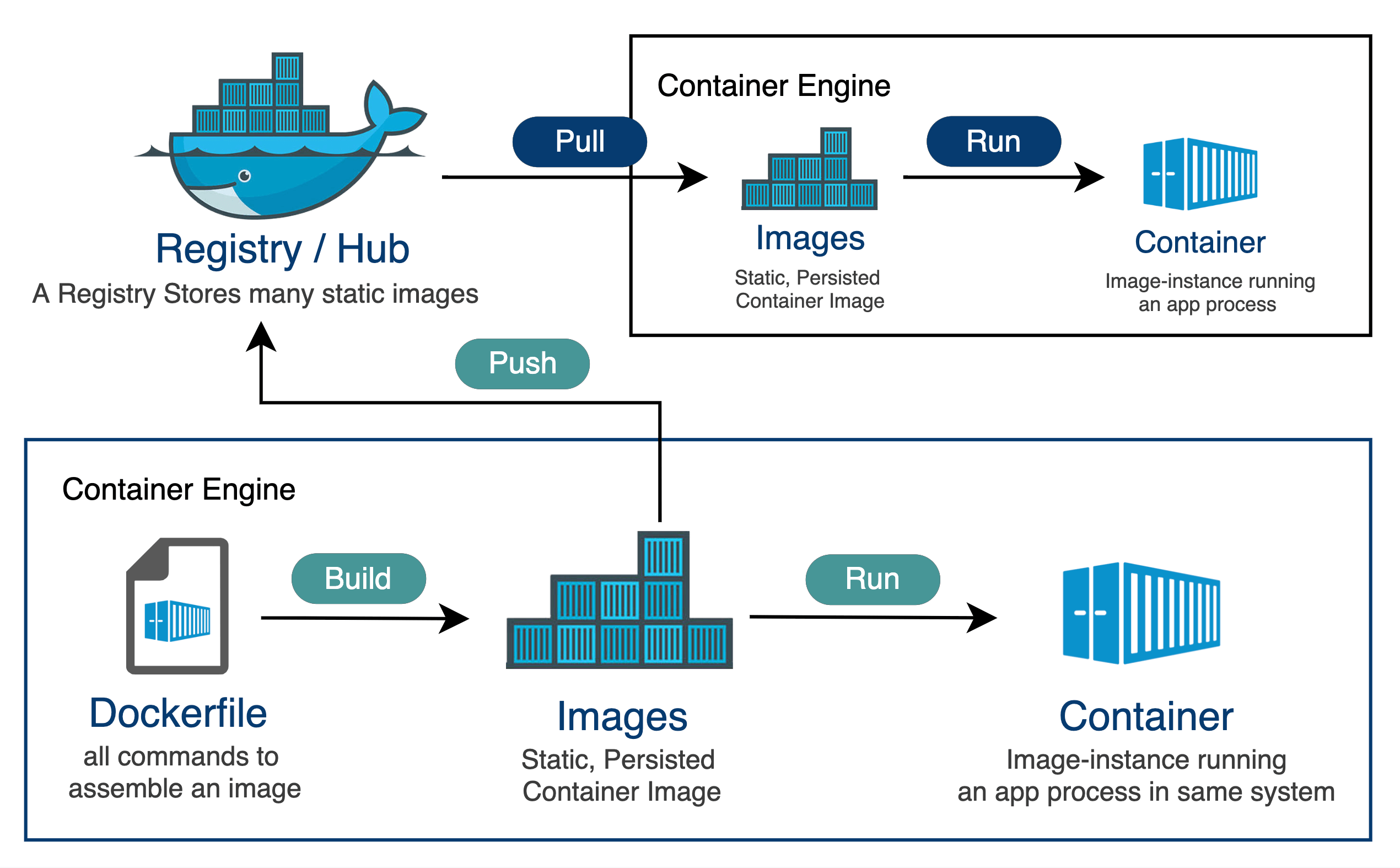
|
||||
|
||||
- Dockerfile 是一个文本文件,包含了一系列的指令和参数,用于定义如何构建一个 Docker 镜像。运行 `docker build`命令并指定一个 Dockerfile 时,Docker 会读取 Dockerfile 中的指令,逐步构建一个新的镜像,并将其保存在本地。
|
||||
- `docker pull` 命令可以从指定的 Registry/Hub 下载一个镜像到本地,默认使用 Docker Hub。
|
||||
- `docker run` 命令可以从本地镜像创建一个新的容器并启动它。如果本地没有镜像,Docker 会先尝试从 Registry/Hub 拉取镜像。
|
||||
- `docker push` 命令可以将本地的 Docker 镜像上传到指定的 Registry/Hub。
|
||||
|
||||
上面涉及到了一些 Docker 的基本命令,后面会详细介绍大。
|
||||
|
||||
### Build Ship and Run
|
||||
|
||||
Docker 的概念基本上已经讲完,我们再来谈谈:Build, Ship, and Run。
|
||||
|
||||
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||
|
||||
|
||||
|
||||
- **Build(构建镜像)**:镜像就像是集装箱包括文件以及运行环境等等资源。
|
||||
- **Ship(运输镜像)**:主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||
- **Run (运行镜像)**:运行的镜像就是一个容器,容器就是运行程序的地方。
|
||||
|
||||
Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。
|
||||
|
||||
## Docker 常见命令
|
||||
|
||||
### 基本命令
|
||||
|
||||
```bash
|
||||
docker version # 查看docker版本
|
||||
@ -201,7 +212,9 @@ docker ps #查看正在运行的容器
|
||||
docker image prune # 清理临时的、没有被使用的镜像文件。-a, --all: 删除所有没有用的镜像,而不仅仅是临时文件;
|
||||
```
|
||||
|
||||
### 5.2 拉取镜像
|
||||
### 拉取镜像
|
||||
|
||||
`docker pull` 命令默认使用的 Registry/Hub 是 Docker Hub。当你执行 docker pull 命令而没有指定任何 Registry/Hub 的地址时,Docker 会从 Docker Hub 拉取镜像。
|
||||
|
||||
```bash
|
||||
docker search mysql # 查看mysql相关镜像
|
||||
@ -209,7 +222,19 @@ docker pull mysql:5.7 # 拉取mysql镜像
|
||||
docker image ls # 查看所有已下载镜像
|
||||
```
|
||||
|
||||
### 5.3 删除镜像
|
||||
### 构建镜像
|
||||
|
||||
运行 `docker build`命令并指定一个 Dockerfile 时,Docker 会读取 Dockerfile 中的指令,逐步构建一个新的镜像,并将其保存在本地。
|
||||
|
||||
```bash
|
||||
#
|
||||
# imageName 是镜像名称,1.0.0 是镜像的版本号或标签
|
||||
docker build -t imageName:1.0.0 .
|
||||
```
|
||||
|
||||
需要注意:Dockerfile 的文件名不必须为 Dockerfile,也不一定要放在构建上下文的根目录中。使用 `-f` 或 `--file` 选项,可以指定任何位置的任何文件作为 Dockerfile。当然,一般大家习惯性的会使用默认的文件名 `Dockerfile`,以及会将其置于镜像构建上下文目录中。
|
||||
|
||||
### 删除镜像
|
||||
|
||||
比如我们要删除我们下载的 mysql 镜像。
|
||||
|
||||
@ -237,32 +262,195 @@ mysql 5.7 f6509bac4980 3 months ago
|
||||
docker rmi f6509bac4980 # 或者 docker rmi mysql
|
||||
```
|
||||
|
||||
## 六 Build Ship and Run
|
||||
### 镜像推送
|
||||
|
||||
**Docker 的概念以及常见命令基本上已经讲完,我们再来谈谈:Build, Ship, and Run。**
|
||||
`docker push` 命令用于将本地的 Docker 镜像上传到指定的 Registry/Hub。
|
||||
|
||||
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||
```bash
|
||||
# 将镜像推送到私有镜像仓库 Harbor
|
||||
# harbor.example.com是私有镜像仓库的地址,ubuntu是镜像的名称,18.04是镜像的版本标签
|
||||
docker push harbor.example.com/ubuntu:18.04
|
||||
```
|
||||
|
||||

|
||||
镜像推送之前,要确保本地已经构建好需要推送的 Docker 镜像。另外,务必先登录到对应的镜像仓库。
|
||||
|
||||
- **Build(构建镜像)**:镜像就像是集装箱包括文件以及运行环境等等资源。
|
||||
- **Ship(运输镜像)**:主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||
- **Run (运行镜像)**:运行的镜像就是一个容器,容器就是运行程序的地方。
|
||||
## Docker 数据管理
|
||||
|
||||
**Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。**
|
||||
在容器中管理数据主要有两种方式:
|
||||
|
||||
## 七 简单了解一下 Docker 底层原理
|
||||
1. 数据卷(Volumes)
|
||||
2. 挂载主机目录 (Bind mounts)
|
||||
|
||||
### 7.1 虚拟化技术
|
||||
|
||||
|
||||
首先,Docker **容器虚拟化**技术为基础的软件,那么什么是虚拟化技术呢?
|
||||
数据卷是由 Docker 管理的数据存储区域,有如下这些特点:
|
||||
|
||||
- 可以在容器之间共享和重用。
|
||||
- 即使容器被删除,数据卷中的数据也不会被自动删除,从而确保数据的持久性。
|
||||
- 对数据卷的修改会立马生效。
|
||||
- 对数据卷的更新,不会影响镜像。
|
||||
|
||||
```bash
|
||||
# 创建一个数据卷
|
||||
docker volume create my-vol
|
||||
# 查看所有的数据卷
|
||||
docker volume ls
|
||||
# 查看数据卷的具体信息
|
||||
docker inspect web
|
||||
# 删除指定的数据卷
|
||||
docker volume rm my-vol
|
||||
```
|
||||
|
||||
在用 `docker run` 命令的时候,使用 `--mount` 标记来将一个或多个数据卷挂载到容器里。
|
||||
|
||||
还可以通过 `--mount` 标记将宿主机上的文件或目录挂载到容器中,这使得容器可以直接访问宿主机的文件系统。Docker 挂载主机目录的默认权限是读写,用户也可以通过增加 `readonly` 指定为只读。
|
||||
|
||||
## Docker Compose
|
||||
|
||||
### 什么是 Docker Compose?有什么用?
|
||||
|
||||
Docker Compose 是 Docker 官方编排(Orchestration)项目之一,基于 Python 编写,负责实现对 Docker 容器集群的快速编排。通过 Docker Compose,开发者可以使用 YAML 文件来配置应用的所有服务,然后只需一个简单的命令即可创建和启动所有服务。
|
||||
|
||||
Docker Compose 是开源项目,地址:<https://github.com/docker/compose>。
|
||||
|
||||
Docker Compose 的核心功能:
|
||||
|
||||
- **多容器管理**:允许用户在一个 YAML 文件中定义和管理多个容器。
|
||||
- **服务编排**:配置容器间的网络和依赖关系。
|
||||
- **一键部署**:通过简单的命令,如`docker-compose up`和`docker-compose down`,可以轻松地启动和停止整个应用程序。
|
||||
|
||||
Docker Compose 简化了多容器应用程序的开发、测试和部署过程,提高了开发团队的生产力,同时降低了应用程序的部署复杂度和管理成本。
|
||||
|
||||
### Docker Compose 文件基本结构
|
||||
|
||||
Docker Compose 文件是 Docker Compose 工具的核心,用于定义和配置多容器 Docker 应用。这个文件通常命名为 `docker-compose.yml`,采用 YAML(YAML Ain't Markup Language)格式编写。
|
||||
|
||||
Docker Compose 文件基本结构如下:
|
||||
|
||||
- **版本(version):** 指定 Compose 文件格式的版本。版本决定了可用的配置选项。
|
||||
- **服务(services):** 定义了应用中的每个容器(服务)。每个服务可以使用不同的镜像、环境设置和依赖关系。
|
||||
- **镜像(image):** 从指定的镜像中启动容器,可以是存储仓库、标签以及镜像 ID。
|
||||
- **命令(command):** 可选,覆盖容器启动后默认执行的命令。在启动服务时运行特定的命令或脚本,常用于启动应用程序、执行初始化脚本等。
|
||||
- **端口(ports):** 可选,映射容器和宿主机的端口。
|
||||
- **依赖(depends_on):** 依赖配置的选项,意思是如果服务启动是如果有依赖于其他服务的,先启动被依赖的服务,启动完成后在启动该服务。
|
||||
- **环境变量(environment):** 可选,设置服务运行所需的环境变量。
|
||||
- **重启(restart):** 可选,控制容器的重启策略。在容器退出时,根据指定的策略自动重启容器。
|
||||
- **服务卷(volumes):** 可选,定义服务使用的卷,用于数据持久化或在容器之间共享数据。
|
||||
- **构建(build):** 指定构建镜像的 dockerfile 的上下文路径,或者详细配置对象。
|
||||
- **网络(networks):** 定义了容器间的网络连接。
|
||||
- **卷(volumes):** 用于数据持久化和共享的数据卷定义。常用于数据库存储、配置文件、日志等数据的持久化。
|
||||
|
||||
```yaml
|
||||
version: "3.8" # 定义版本, 表示当前使用的 docker-compose 语法的版本
|
||||
services: # 服务,可以存在多个
|
||||
servicename1: # 服务名字,它也是内部 bridge 网络可以使用的 DNS name,如果不是集群模式相当于 docker run 的时候指定的一个名称,
|
||||
#集群(Swarm)模式是多个容器的逻辑抽象
|
||||
image: # 镜像的名字
|
||||
command: # 可选,如果设置,则会覆盖默认镜像里的 CMD 命令
|
||||
environment: # 可选,等价于 docker container run 里的 --env 选项设置环境变量
|
||||
volumes: # 可选,等价于 docker container run 里的 -v 选项 绑定数据卷
|
||||
networks: # 可选,等价于 docker container run 里的 --network 选项指定网络
|
||||
ports: # 可选,等价于 docker container run 里的 -p 选项指定端口映射
|
||||
restart: # 可选,控制容器的重启策略
|
||||
build: #构建目录
|
||||
depends_on: #服务依赖配置
|
||||
servicename2:
|
||||
image:
|
||||
command:
|
||||
networks:
|
||||
ports:
|
||||
servicename3:
|
||||
#...
|
||||
volumes: # 可选,需要创建的数据卷,类似 docker volume create
|
||||
db_data:
|
||||
networks: # 可选,等价于 docker network create
|
||||
```
|
||||
|
||||
### Docker Compose 常见命令
|
||||
|
||||
#### 启动
|
||||
|
||||
`docker-compose up`会根据 `docker-compose.yml` 文件中定义的服务来创建和启动容器,并将它们连接到默认的网络中。
|
||||
|
||||
```bash
|
||||
# 在当前目录下寻找 docker-compose.yml 文件,并根据其中定义的服务启动应用程序
|
||||
docker-compose up
|
||||
# 后台启动
|
||||
docker-compose up -d
|
||||
# 强制重新创建所有容器,即使它们已经存在
|
||||
docker-compose up --force-recreate
|
||||
# 重新构建镜像
|
||||
docker-compose up --build
|
||||
# 指定要启动的服务名称,而不是启动所有服务
|
||||
# 可以同时指定多个服务,用空格分隔。
|
||||
docker-compose up service_name
|
||||
```
|
||||
|
||||
另外,如果 Compose 文件名称不是 `docker-compose.yml` 也没问题,可以通过 `-f` 参数指定。
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.prod.yml up
|
||||
```
|
||||
|
||||
#### 暂停
|
||||
|
||||
`docker-compose down`用于停止并移除通过 `docker-compose up` 启动的容器和网络。
|
||||
|
||||
```bash
|
||||
# 在当前目录下寻找 docker-compose.yml 文件
|
||||
# 根据其中定义移除启动的所有容器,网络和卷。
|
||||
docker-compose down
|
||||
# 停止容器但不移除
|
||||
docker-compose down --stop
|
||||
# 指定要停止和移除的特定服务,而不是停止和移除所有服务
|
||||
# 可以同时指定多个服务,用空格分隔。
|
||||
docker-compose down service_name
|
||||
```
|
||||
|
||||
同样地,如果 Compose 文件名称不是 `docker-compose.yml` 也没问题,可以通过 `-f` 参数指定。
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.prod.yml down
|
||||
```
|
||||
|
||||
#### 查看
|
||||
|
||||
`docker-compose ps`用于查看通过 `docker-compose up` 启动的所有容器的状态信息。
|
||||
|
||||
```bash
|
||||
# 查看所有容器的状态信息
|
||||
docker-compose ps
|
||||
# 只显示服务名称
|
||||
docker-compose ps --services
|
||||
# 查看指定服务的容器
|
||||
docker-compose ps service_name
|
||||
```
|
||||
|
||||
#### 其他
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------ | ---------------------- |
|
||||
| `docker-compose version` | 查看版本 |
|
||||
| `docker-compose images` | 列出所有容器使用的镜像 |
|
||||
| `docker-compose kill` | 强制停止服务的容器 |
|
||||
| `docker-compose exec` | 在容器中执行命令 |
|
||||
| `docker-compose logs` | 查看日志 |
|
||||
| `docker-compose pause` | 暂停服务 |
|
||||
| `docker-compose unpause` | 恢复服务 |
|
||||
| `docker-compose push` | 推送服务镜像 |
|
||||
| `docker-compose start` | 启动当前停止的某个容器 |
|
||||
| `docker-compose stop` | 停止当前运行的某个容器 |
|
||||
| `docker-compose rm` | 删除服务停止的容器 |
|
||||
| `docker-compose top` | 查看进程 |
|
||||
|
||||
## Docker 底层原理
|
||||
|
||||
首先,Docker 是基于轻量级虚拟化技术的软件,那什么是虚拟化技术呢?
|
||||
|
||||
简单点来说,虚拟化技术可以这样定义:
|
||||
|
||||
> 虚拟化技术是一种资源管理技术,是将计算机的各种[实体资源](https://zh.wikipedia.org/wiki/計算機科學 "实体资源"))([CPU](https://zh.wikipedia.org/wiki/CPU "CPU")、[内存](https://zh.wikipedia.org/wiki/内存 "内存")、[磁盘空间](https://zh.wikipedia.org/wiki/磁盘空间 "磁盘空间")、[网络适配器](https://zh.wikipedia.org/wiki/網路適配器 "网络适配器")等),予以抽象、转换后呈现出来并可供分割、组合为一个或多个电脑配置环境。由此,打破实体结构间的不可切割的障碍,使用户可以比原本的配置更好的方式来应用这些电脑硬件资源。这些资源的新虚拟部分是不受现有资源的架设方式,地域或物理配置所限制。一般所指的虚拟化资源包括计算能力和数据存储。
|
||||
|
||||
### 7.2 Docker 基于 LXC 虚拟容器技术
|
||||
|
||||
Docker 技术是基于 LXC(Linux container- Linux 容器)虚拟容器技术的。
|
||||
|
||||
> LXC,其名称来自 Linux 软件容器(Linux Containers)的缩写,一种操作系统层虚拟化(Operating system–level virtualization)技术,为 Linux 内核容器功能的一个用户空间接口。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。通过统一的名字空间和共用 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
|
||||
@ -283,17 +471,17 @@ LXC 技术主要是借助 Linux 内核中提供的 CGroup 功能和 namespace
|
||||
|
||||
两者都是将进程进行分组,但是两者的作用还是有本质区别。namespace 是为了隔离进程组之间的资源,而 cgroup 是为了对一组进程进行统一的资源监控和限制。
|
||||
|
||||
## 八 总结
|
||||
## 总结
|
||||
|
||||
本文主要把 Docker 中的一些常见概念做了详细的阐述,但是并不涉及 Docker 的安装、镜像的使用、容器的操作等内容。这部分东西,希望读者自己可以通过阅读书籍与官方文档的形式掌握。如果觉得官方文档阅读起来很费力的话,这里推荐一本书籍《Docker 技术入门与实战第二版》。
|
||||
本文主要把 Docker 中的一些常见概念和命令做了详细的阐述。从零到上手实战可以看[Docker 从入门到上手干事](https://javaguide.cn/tools/docker/docker-in-action.html)这篇文章,内容非常详细!
|
||||
|
||||
## 九 推荐阅读
|
||||
另外,再给大家推荐一本质量非常高的开源书籍[《Docker 从入门到实践》](https://yeasy.gitbook.io/docker_practice/introduction/why "《Docker 从入门到实践》") ,这本书的内容非常新,毕竟书籍的内容是开源的,可以随时改进。
|
||||
|
||||
- [10 分钟看懂 Docker 和 K8S](https://zhuanlan.zhihu.com/p/53260098 "10分钟看懂Docker和K8S")
|
||||
- [从零开始入门 K8s:详解 K8s 容器基本概念](https://www.infoq.cn/article/te70FlSyxhltL1Cr7gzM "从零开始入门 K8s:详解 K8s 容器基本概念")
|
||||
|
||||
|
||||
## 十 参考
|
||||
## 参考
|
||||
|
||||
- [Docker Compose:从零基础到实战应用的全面指南](https://juejin.cn/post/7306756690727747610)
|
||||
- [Linux Namespace 和 Cgroup](https://segmentfault.com/a/1190000009732550 "Linux Namespace和Cgroup")
|
||||
- [LXC vs Docker: Why Docker is Better](https://www.upguard.com/articles/docker-vs-lxc "LXC vs Docker: Why Docker is Better")
|
||||
- [CGroup 介绍、应用实例及原理描述](https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html "CGroup 介绍、应用实例及原理描述")
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user