mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-06-20 22:17:09 +08:00
Update:optimize content
This commit is contained in:
parent
40cda295ce
commit
7a7b6a4b6b
@ -41,28 +41,28 @@
|
||||
|
||||
## Arraylist 与 LinkedList 区别?
|
||||
|
||||
- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
|
||||
- **1. 是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
|
||||
|
||||
- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
|
||||
- **2. 底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
|
||||
|
||||
- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
|
||||
- **3. 插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
|
||||
|
||||
- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
|
||||
- **4. 是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
|
||||
|
||||
- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
||||
|
||||
### **补充内容:RandomAccess接口**
|
||||
|
||||
```
|
||||
```java
|
||||
public interface RandomAccess {
|
||||
}
|
||||
```
|
||||
|
||||
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
|
||||
查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
|
||||
|
||||
在binarySearch()方法中,它要判断传入的list 是否RamdomAccess的实例,如果是,调用indexedBinarySearch()方法,如果不是,那么调用iteratorBinarySearch()方法
|
||||
在 `binarySearch(`)方法中,它要判断传入的list 是否 `RamdomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
|
||||
|
||||
```
|
||||
```java
|
||||
public static <T>
|
||||
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
|
||||
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
|
||||
@ -72,12 +72,12 @@ public interface RandomAccess {
|
||||
}
|
||||
```
|
||||
|
||||
ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArrayList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArrayList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArrayList 实现 RandomAccess 接口才具有快速随机访问功能的!
|
||||
`ArrayList` 实现了 `RandomAccess` 接口, 而 `LinkedList` 没有实现。为什么呢?我觉得还是和底层数据结构有关!`ArrayList` 底层是数组,而 `LinkedList` 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,`ArrayList` 实现了 `RandomAccess` 接口,就表明了他具有快速随机访问功能。 `RandomAccess` 接口只是标识,并不是说 `ArrayList` 实现 `RandomAccess` 接口才具有快速随机访问功能的!
|
||||
|
||||
**下面再总结一下 list 的遍历方式选择:**
|
||||
|
||||
- 实现了RandomAccess接口的list,优先选择普通for循环 ,其次foreach,
|
||||
- 未实现RandomAccess接口的list,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
|
||||
- 实现了 `RandomAccess` 接口的list,优先选择普通 for 循环 ,其次 foreach,
|
||||
- 未实现 `RandomAccess`接口的list,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的,),大size的数据,千万不要使用普通for循环
|
||||
|
||||
### 补充内容:双向链表和双向循环链表
|
||||
|
||||
@ -91,9 +91,9 @@ ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什
|
||||
|
||||
## ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?
|
||||
|
||||
Vector类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
|
||||
`Vector`类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
|
||||
|
||||
Arraylist不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
|
||||
`Arraylist`不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
|
||||
|
||||
## 说一说 ArrayList 的扩容机制吧
|
||||
|
||||
@ -146,7 +146,7 @@ Arraylist不是同步的,所以在不需要保证线程安全时时建议使
|
||||
|
||||
## HashMap 和 HashSet区别
|
||||
|
||||
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 `clone() `、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
|
||||
如果你看过 `HashSet` 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 `clone() `、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
|
||||
|
||||
| HashMap | HashSet |
|
||||
| :------------------------------: | :----------------------------------------------------------: |
|
||||
@ -157,7 +157,7 @@ Arraylist不是同步的,所以在不需要保证线程安全时时建议使
|
||||
|
||||
## HashSet如何检查重复
|
||||
|
||||
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
|
||||
当你把对象加入`HashSet`时,HashSet会先计算对象的`hashcode`值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用`equals()`方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
|
||||
|
||||
**hashCode()与equals()的相关规定:**
|
||||
|
||||
@ -177,7 +177,7 @@ Arraylist不是同步的,所以在不需要保证线程安全时时建议使
|
||||
|
||||
### JDK1.8之前
|
||||
|
||||
JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
|
||||
JDK1.8 之前 `HashMap` 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
|
||||
|
||||
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
|
||||
|
||||
@ -185,7 +185,7 @@ JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就
|
||||
|
||||
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
|
||||
|
||||
```
|
||||
```java
|
||||
static final int hash(Object key) {
|
||||
int h;
|
||||
// key.hashCode():返回散列值也就是hashcode
|
||||
@ -197,7 +197,7 @@ JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理
|
||||
|
||||
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
|
||||
|
||||
```
|
||||
```java
|
||||
static int hash(int h) {
|
||||
// This function ensures that hashCodes that differ only by
|
||||
// constant multiples at each bit position have a bounded
|
||||
@ -212,13 +212,13 @@ static int hash(int h) {
|
||||
|
||||
所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
|
||||
|
||||
[](https://camo.githubusercontent.com/eec1c575aa5ff57906dd9c9130ec7a82e212c96a/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f332f32302f313632343064626363333033643837323f773d33343826683d34323726663d706e6726733d3130393931)
|
||||
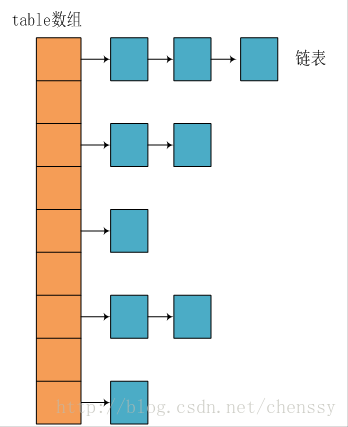
|
||||
|
||||
### JDK1.8之后
|
||||
|
||||
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
|
||||
|
||||
[](https://camo.githubusercontent.com/20de7e465cac279842851258ec4d1ec1c4d3d7d1/687474703a2f2f6d792d626c6f672d746f2d7573652e6f73732d636e2d6265696a696e672e616c6979756e63732e636f6d2f31382d382d32322f36373233333736342e6a7067)
|
||||
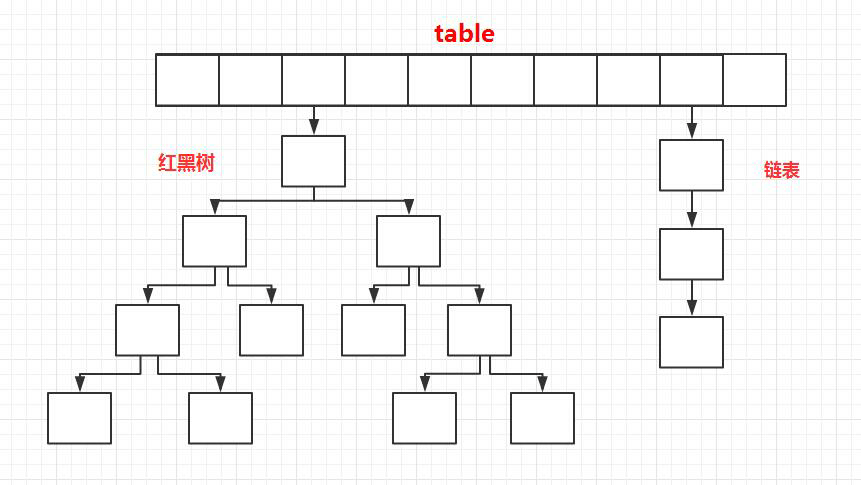
|
||||
|
||||
> TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
|
||||
|
||||
@ -273,7 +273,7 @@ ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方
|
||||
|
||||
Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
|
||||
|
||||
```
|
||||
```java
|
||||
static class Segment<K,V> extends ReentrantLock implements Serializable {
|
||||
}
|
||||
```
|
||||
@ -424,7 +424,7 @@ Output:
|
||||
|
||||
- **Arraylist:** Object数组
|
||||
- **Vector:** Object数组
|
||||
- **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环) 详细可阅读[JDK1.7-LinkedList循环链表优化](https://www.cnblogs.com/xingele0917/p/3696593.html)
|
||||
- **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
|
||||
|
||||
#### 2. Set
|
||||
|
||||
@ -451,4 +451,4 @@ Output:
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user