diff --git a/docs/about-the-author/dog-that-copies-other-people-essay.md b/docs/about-the-author/dog-that-copies-other-people-essay.md
index cf849132..653b616e 100644
--- a/docs/about-the-author/dog-that-copies-other-people-essay.md
+++ b/docs/about-the-author/dog-that-copies-other-people-essay.md
@@ -9,23 +9,23 @@ tag:
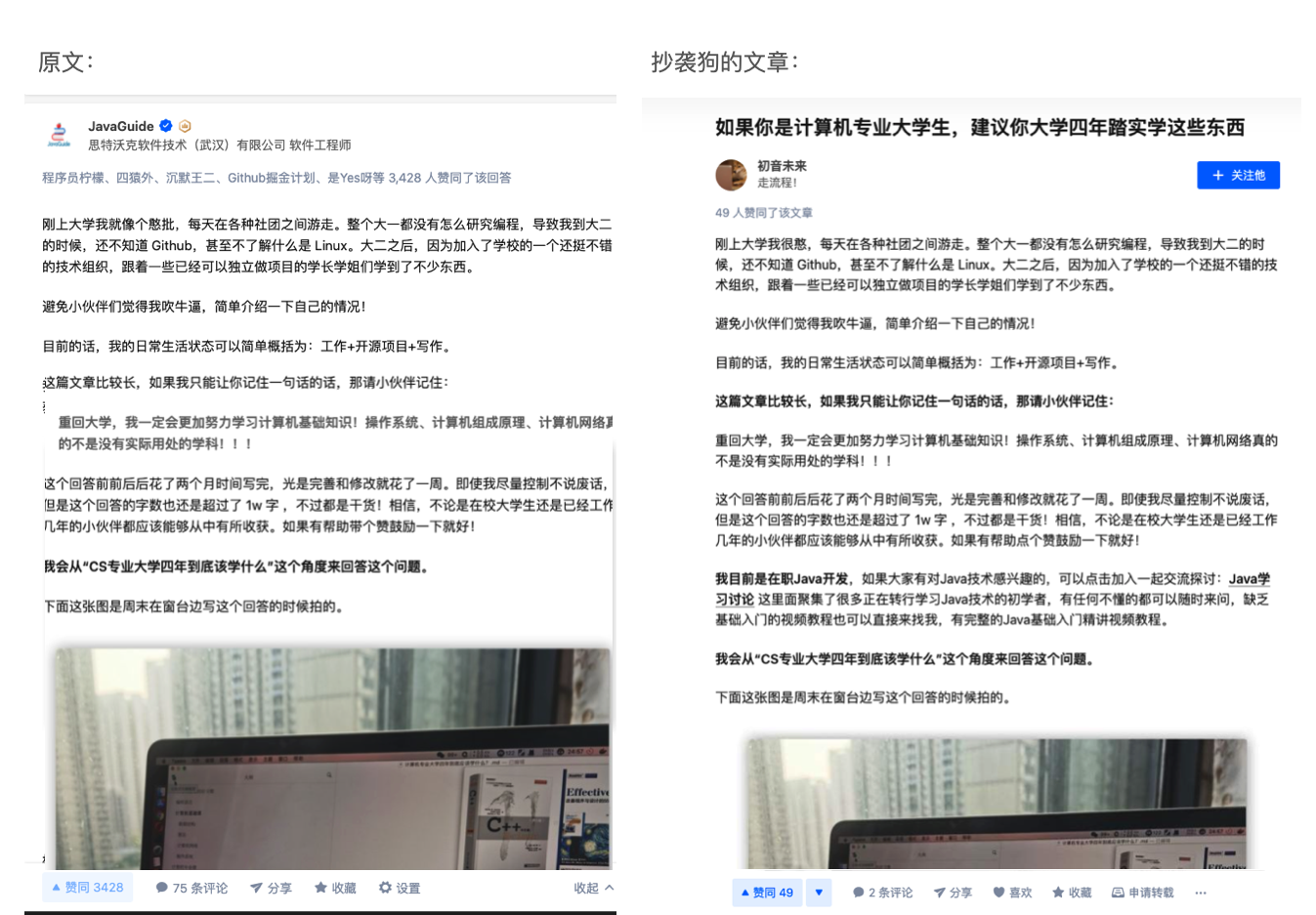
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
-
+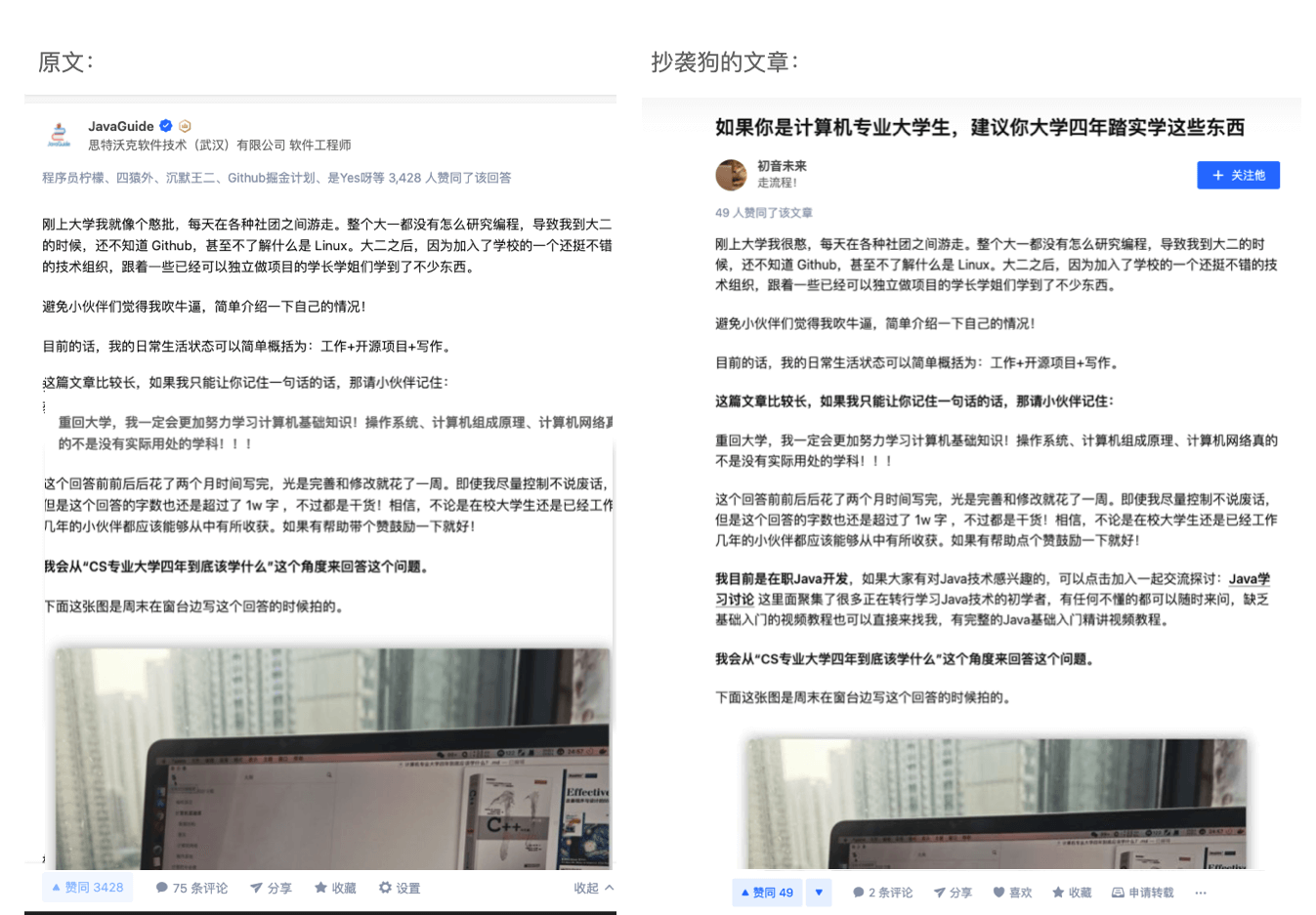
而且!!!这还不是最气的。
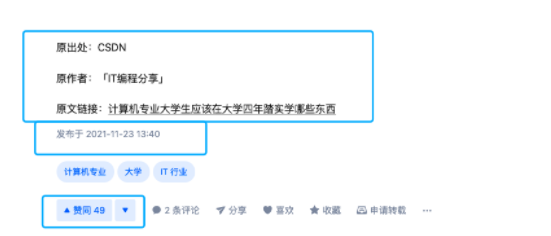
这人还在文末注明的原出处还不是我的。。。
-
+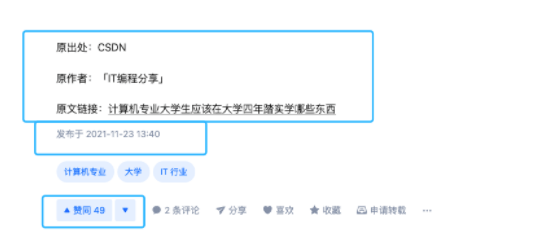
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
真可谓离谱他妈给离谱开门,离谱到家了。
-
+
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
-
+
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
@@ -33,7 +33,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
-
+
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
@@ -43,7 +43,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
-
+
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
@@ -51,6 +51,6 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
-
+
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
diff --git a/docs/about-the-author/readme.md b/docs/about-the-author/readme.md
index a16e882c..54e14e2e 100644
--- a/docs/about-the-author/readme.md
+++ b/docs/about-the-author/readme.md
@@ -33,7 +33,7 @@ category: 走近作者
下面这张是我大一下学期办补习班的时候拍的(离开前的最后一顿饭):
-
+
下面这张是我大三去三亚的时候拍的:
@@ -55,7 +55,7 @@ category: 走近作者
我早期写文章用的笔名是 SnailClimb 。很多人不知道这个名字是啥意思,给大家拆解一下就清楚了。SnailClimb=Snail(蜗牛)+Climb(攀登)。我从小就非常喜欢听周杰伦的歌曲,特别是他的《蜗牛》🐌 这首歌曲,另外,当年我高考发挥的算是比较失常,上了大学之后还算是比较“奋青”,所以,我就给自己起的笔名叫做 SnailClimb ,寓意自己要不断向上攀登,嘿嘿 😁
-
+
## 后记
diff --git a/docs/books/search-engine.md b/docs/books/search-engine.md
index aa59a1a7..84124efa 100644
--- a/docs/books/search-engine.md
+++ b/docs/books/search-engine.md
@@ -20,8 +20,8 @@ Elasticsearch 在 Apache Lucene 的基础上开发而成,学习 ES 之前,
如果你想看书的话,可以考虑一下 **[《Elasticsearch 实战》](https://book.douban.com/subject/30380439/)** 这本书。不过,需要说明的是,这本书中的 Elasticsearch 版本比较老,你可以将其作为一个参考书籍来看,有一些原理性的东西可以在上面找找答案。
-
+
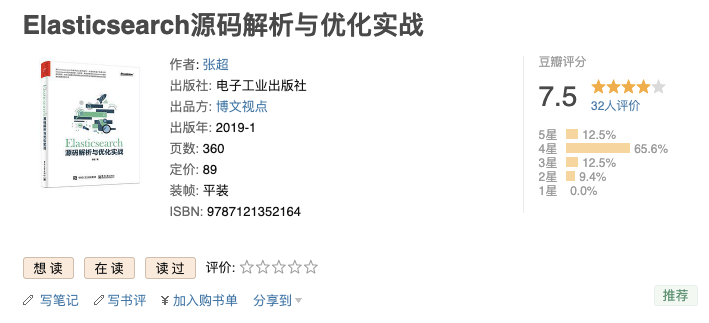
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的 **[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)** 这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
-
+
diff --git a/docs/cs-basics/algorithms/the-sword-refers-to-offer.md b/docs/cs-basics/algorithms/the-sword-refers-to-offer.md
index 182bc138..03ae1444 100644
--- a/docs/cs-basics/algorithms/the-sword-refers-to-offer.md
+++ b/docs/cs-basics/algorithms/the-sword-refers-to-offer.md
@@ -423,7 +423,7 @@ public class Solution {
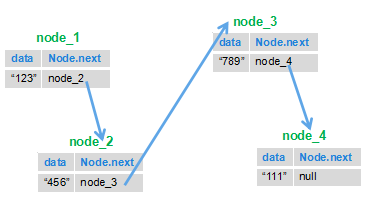
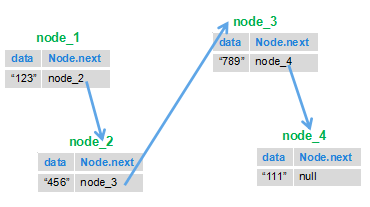
思路就是我们根据链表的特点,前一个节点指向下一个节点的特点,把后面的节点移到前面来。
就比如下图:我们把 1 节点和 2 节点互换位置,然后再将 3 节点指向 2 节点,4 节点指向 3 节点,这样以来下面的链表就被反转了。
-
+
**考察内容:**
diff --git a/docs/cs-basics/network/computer-network-xiexiren-summary.md b/docs/cs-basics/network/computer-network-xiexiren-summary.md
index 8874a06e..216cbdc2 100644
--- a/docs/cs-basics/network/computer-network-xiexiren-summary.md
+++ b/docs/cs-basics/network/computer-network-xiexiren-summary.md
@@ -7,7 +7,7 @@ tag:
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
-
+
相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
@@ -20,11 +20,11 @@ tag:
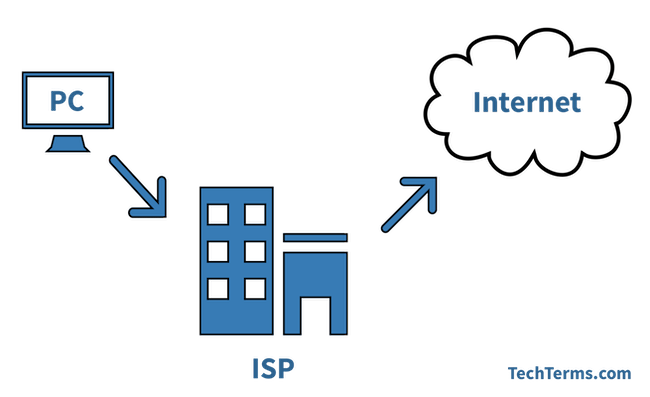
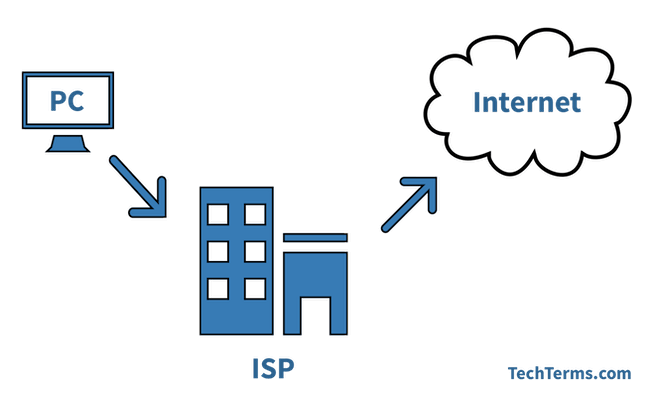
3. **主机(host)**:连接在因特网上的计算机。
4. **ISP(Internet Service Provider)**:因特网服务提供者(提供商)。
-
+
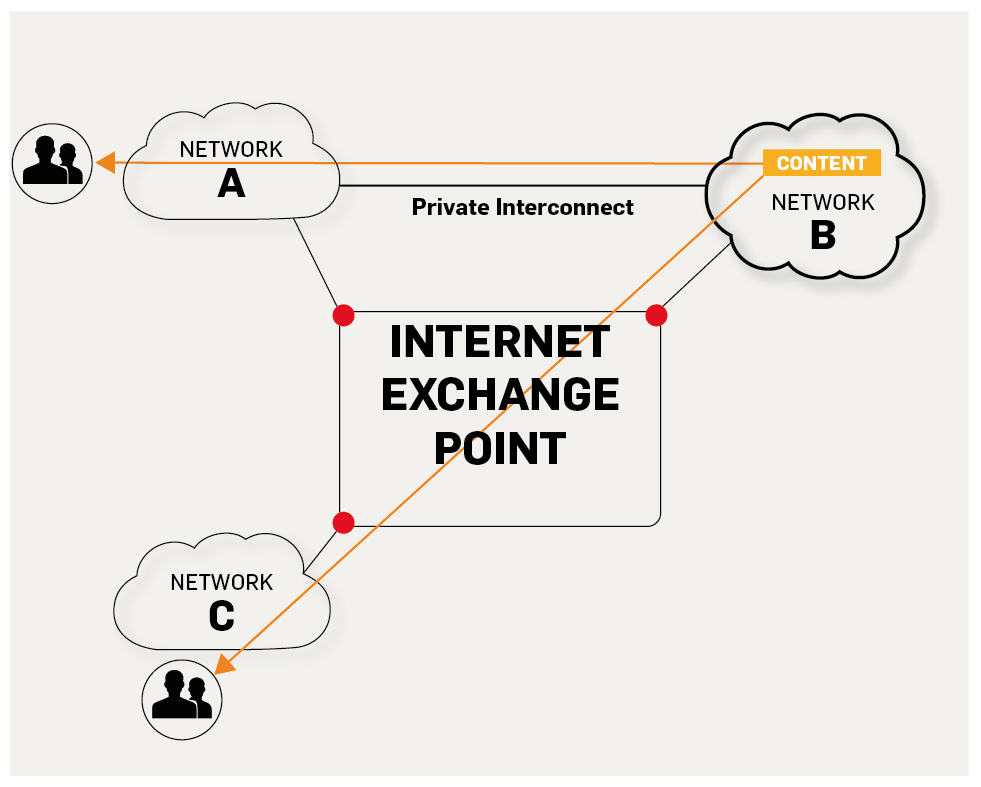
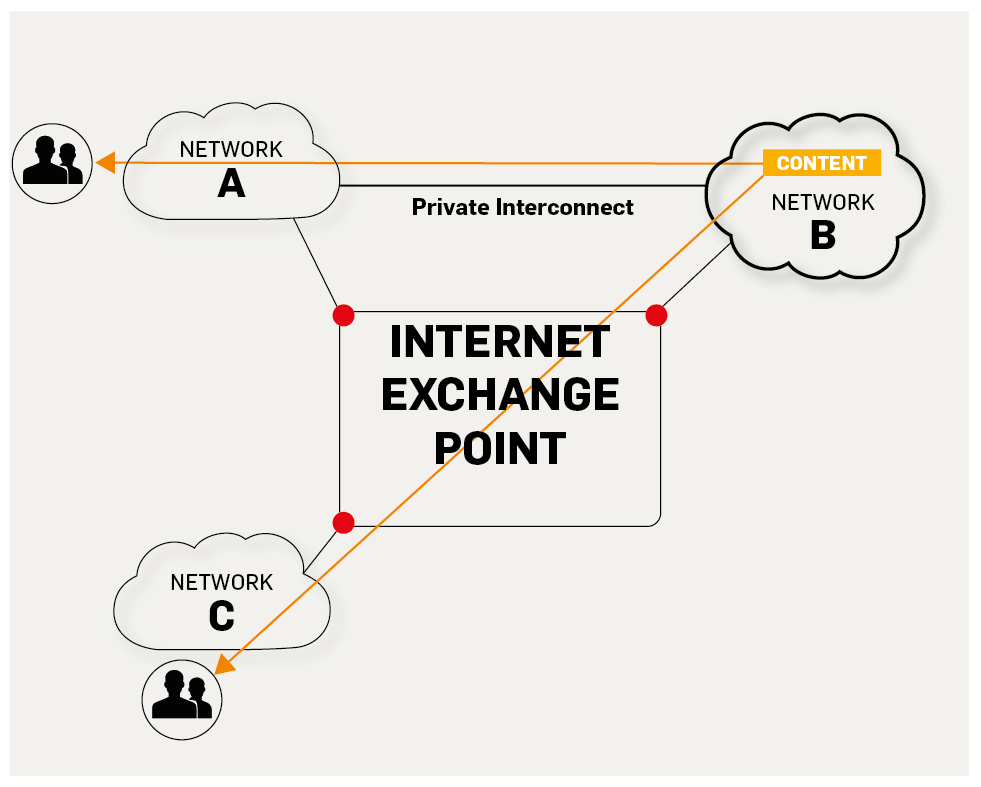
5. **IXP(Internet eXchange Point)**:互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
-
+
https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive
@@ -33,20 +33,20 @@ tag:
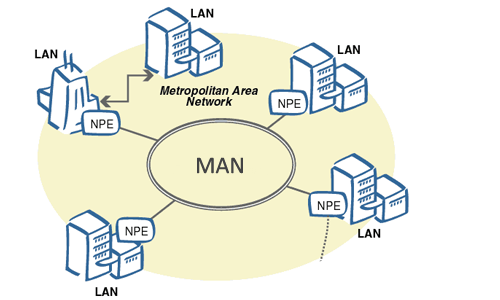
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
9. **局域网 LAN(Local Area Network)**:学校或企业大多拥有多个互连的局域网。
-
+
http://conexionesmanwman.blogspot.com/
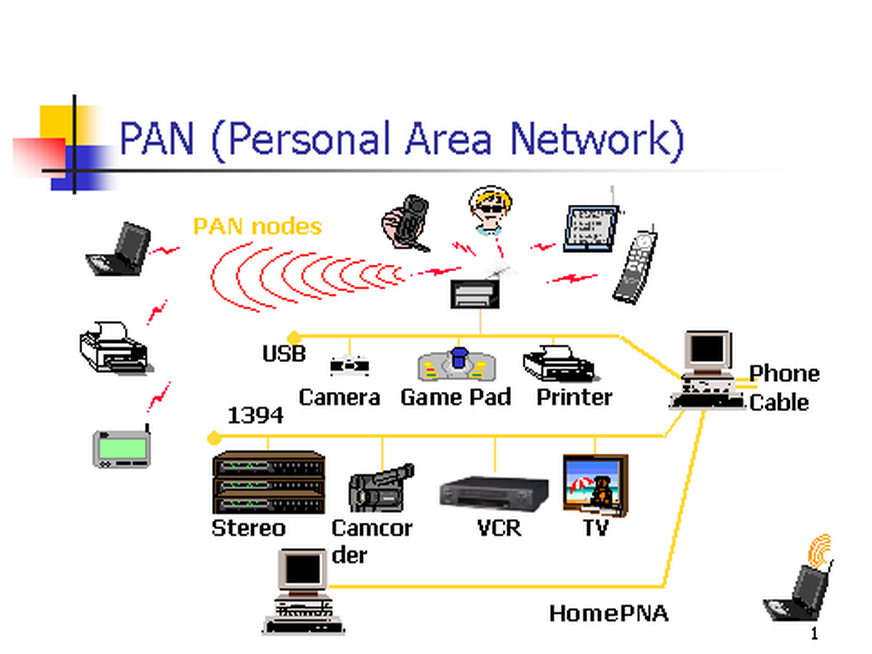
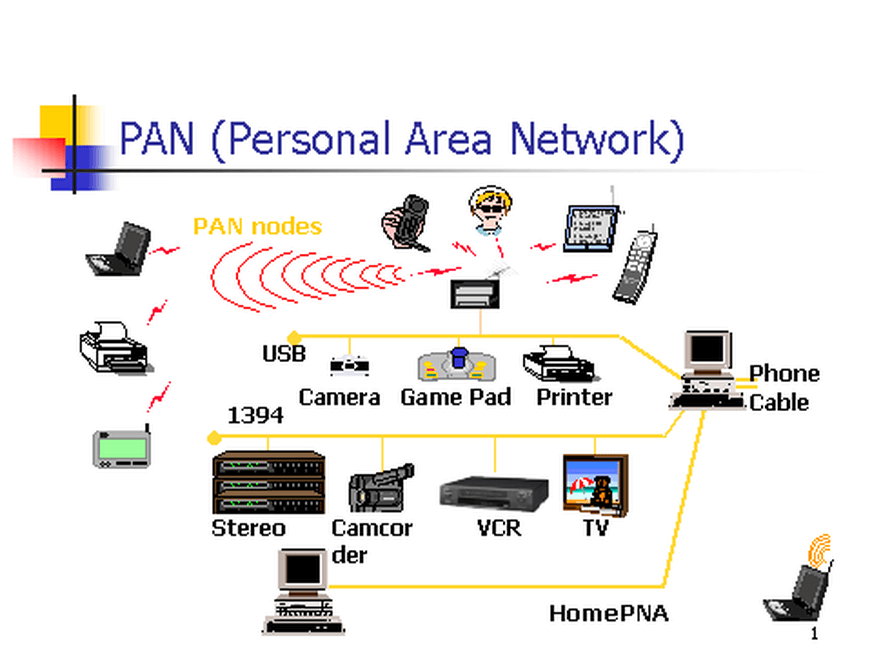
10. **个人区域网 PAN(Personal Area Network)**:在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
-
+
https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/
12. **分组(packet )**:因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
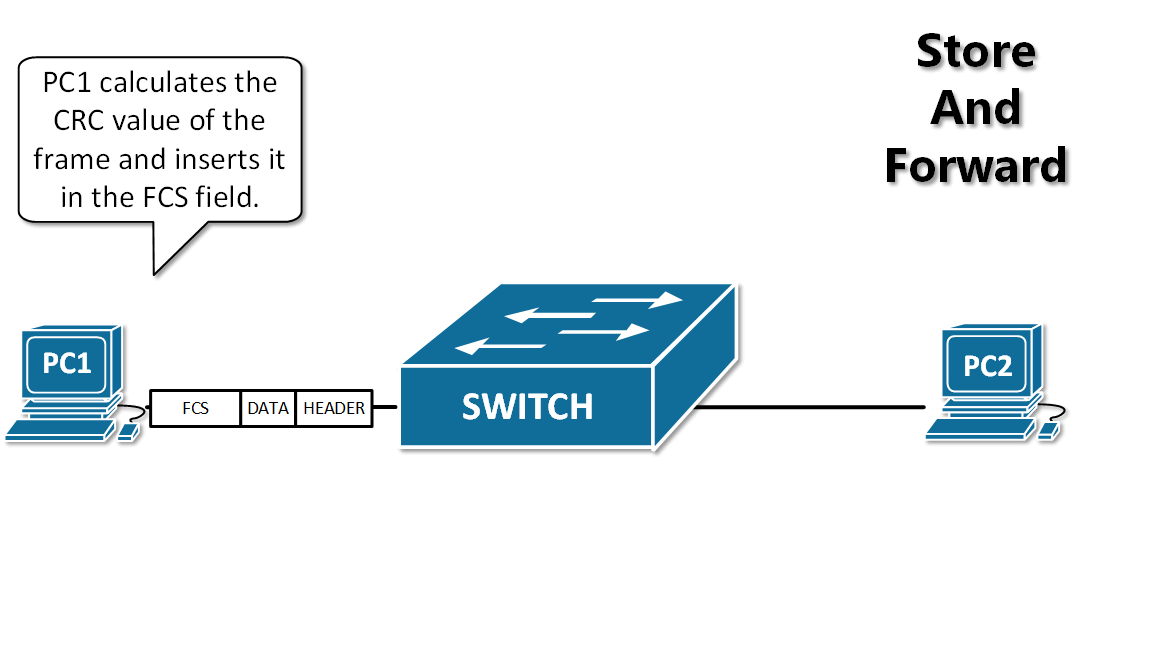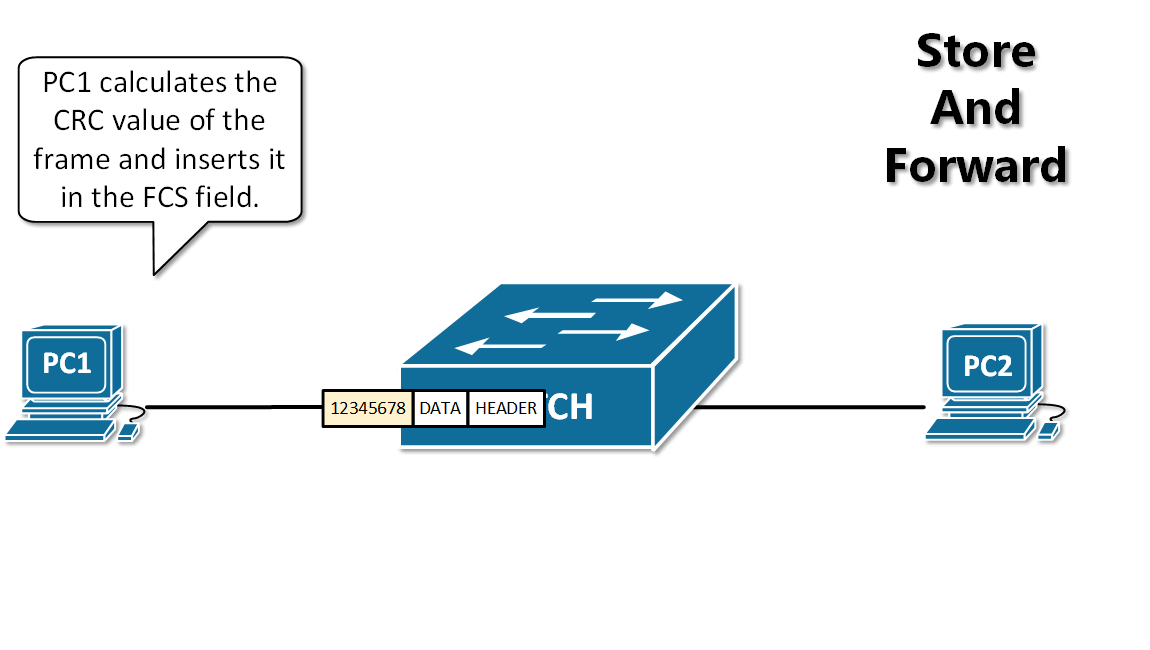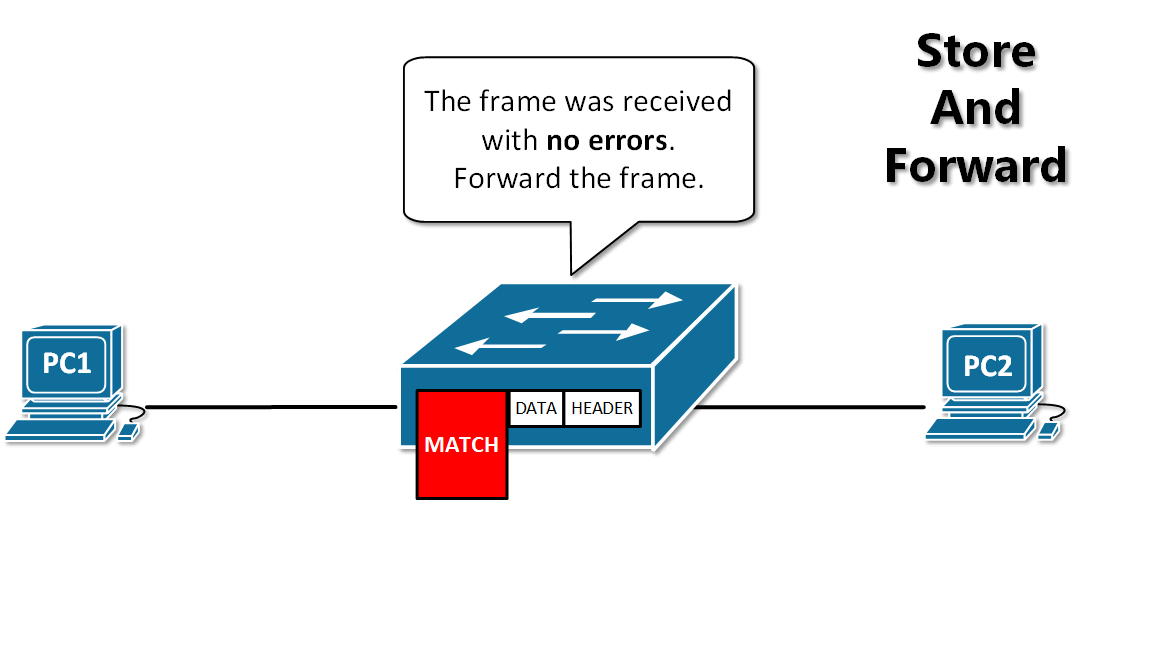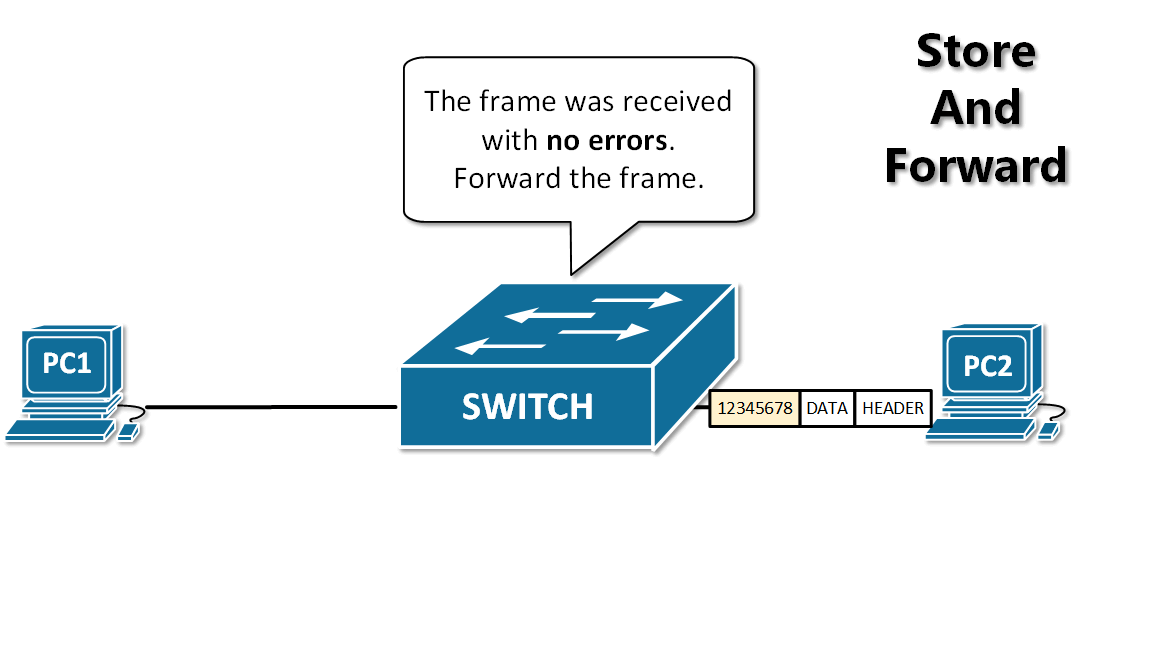
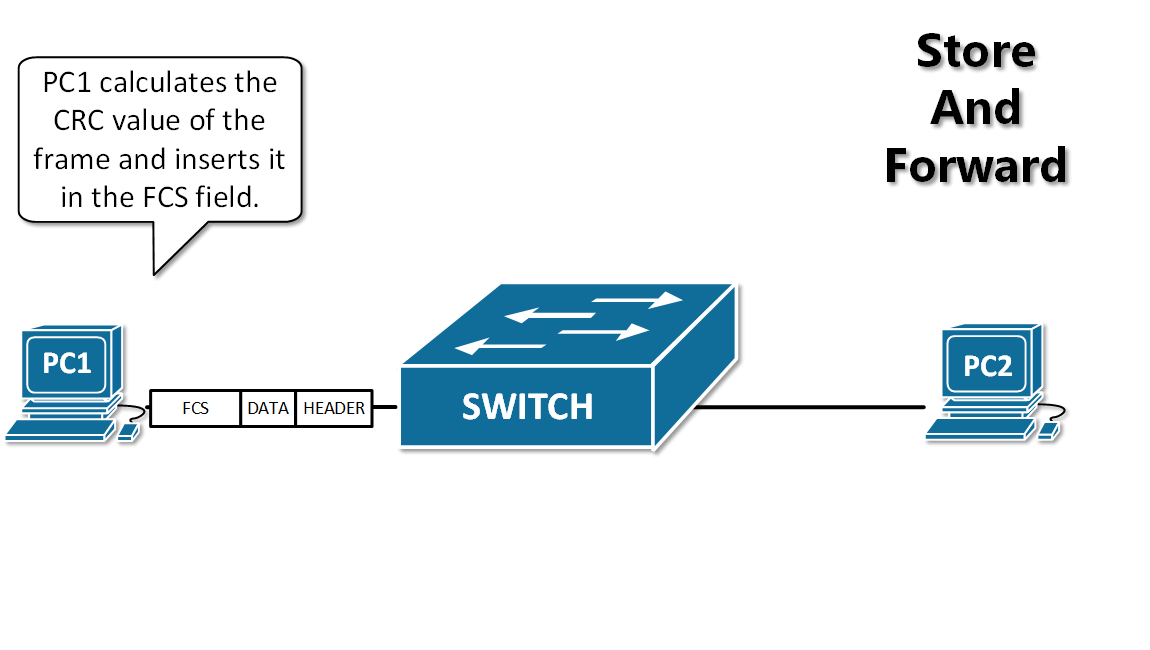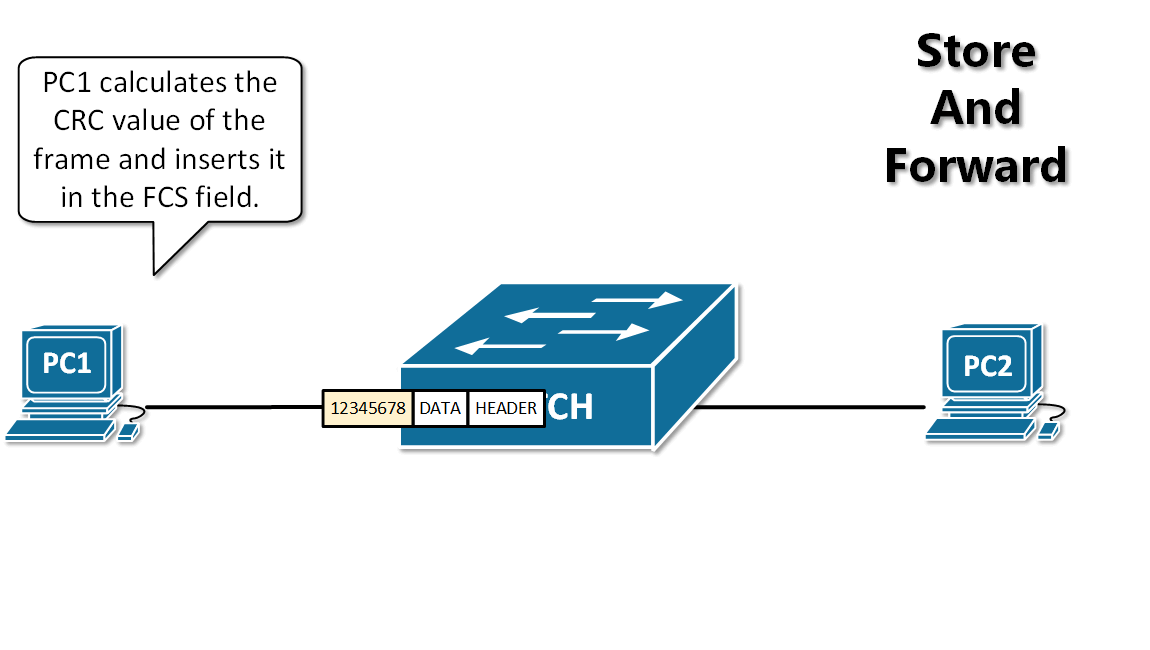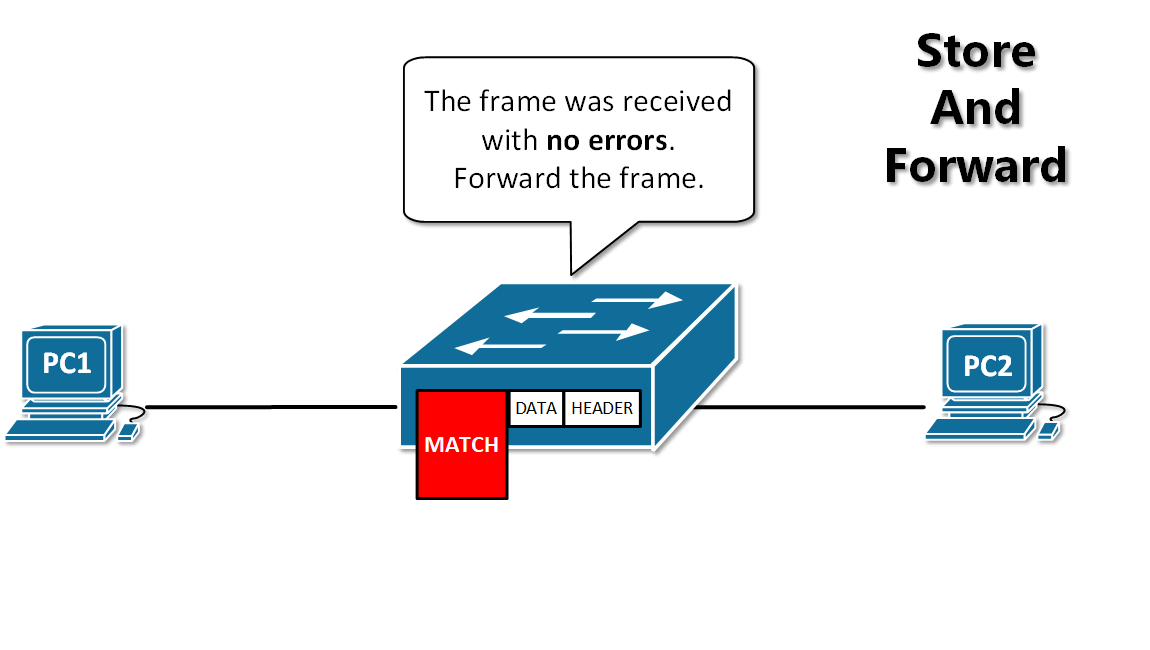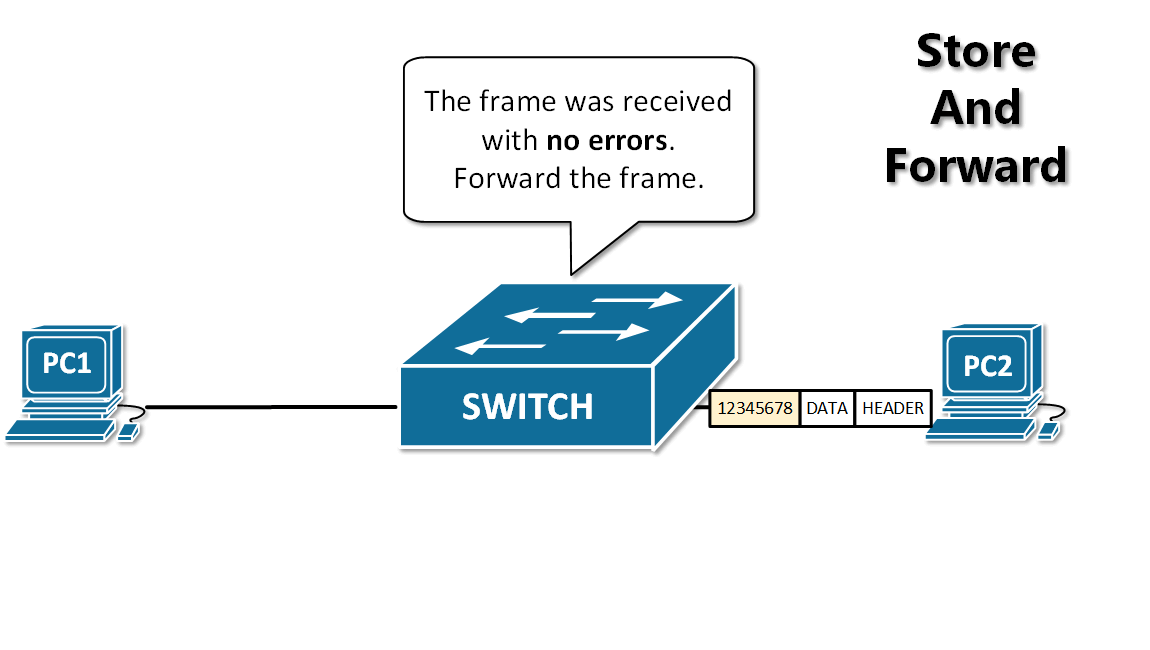
13. **存储转发(store and forward )**:路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
-
+
14. **带宽(bandwidth)**:在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
15. **吞吐量(throughput )**:表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
@@ -64,13 +64,13 @@ tag:
9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
-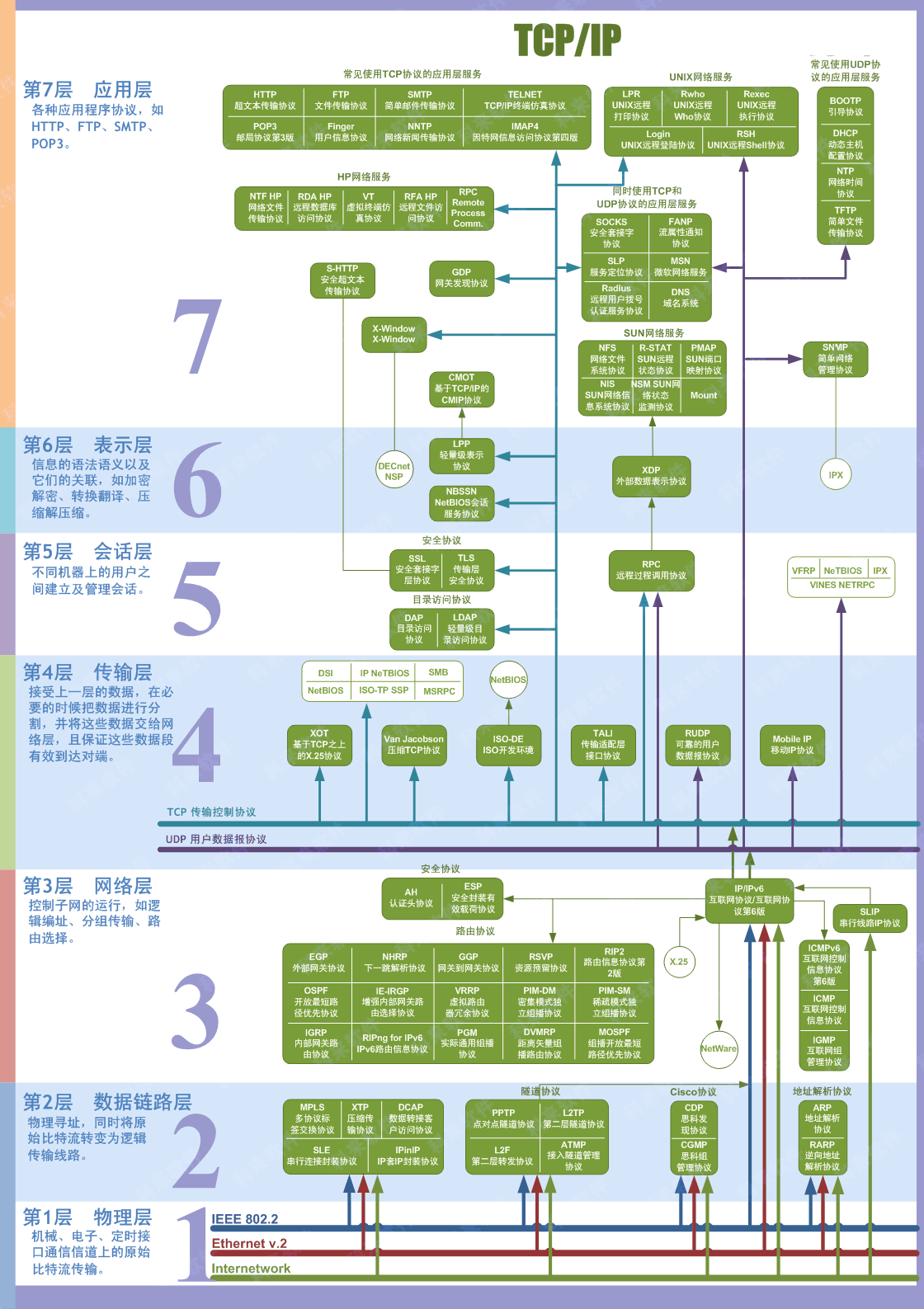
+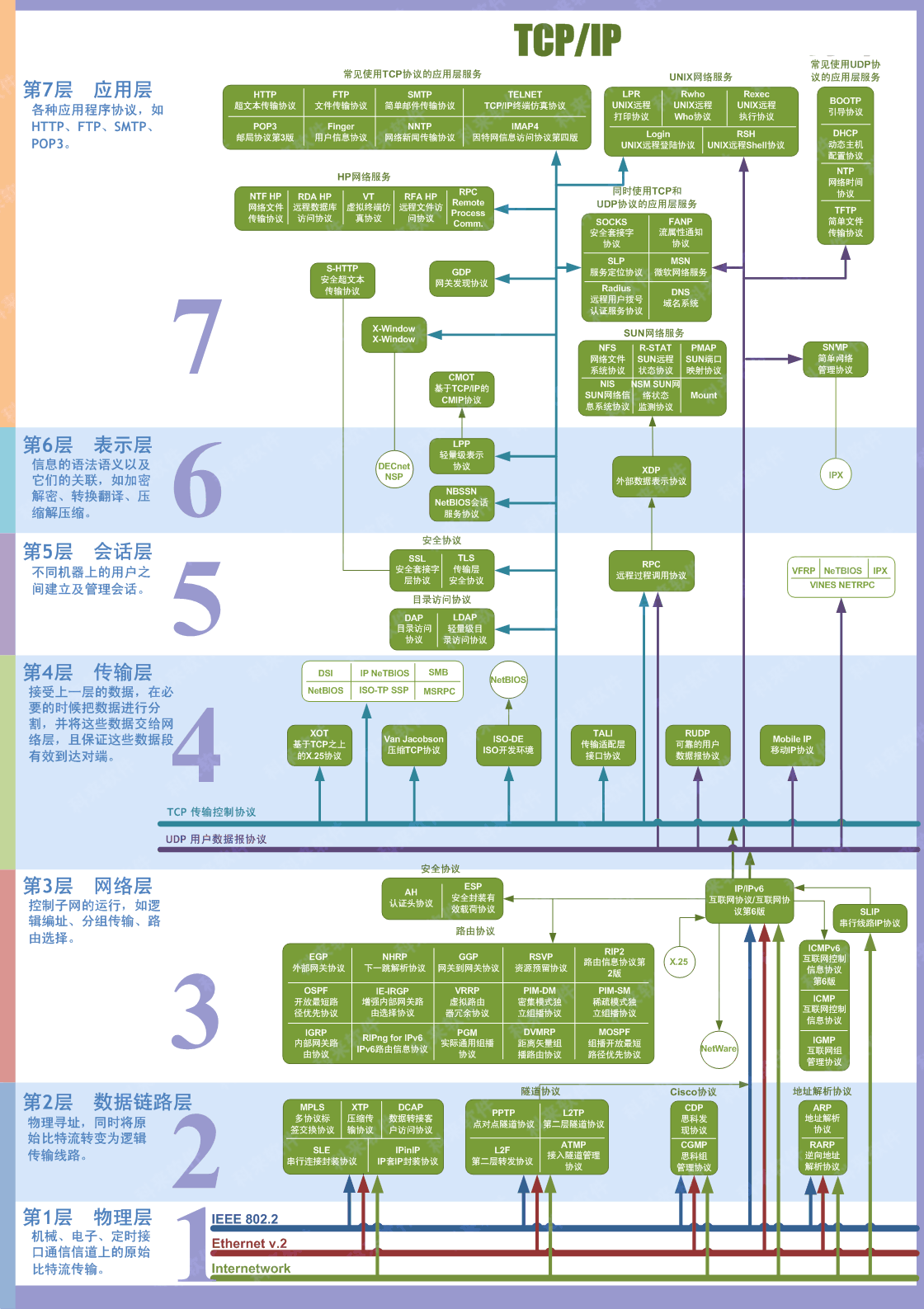
下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
## 2. 物理层(Physical Layer)
-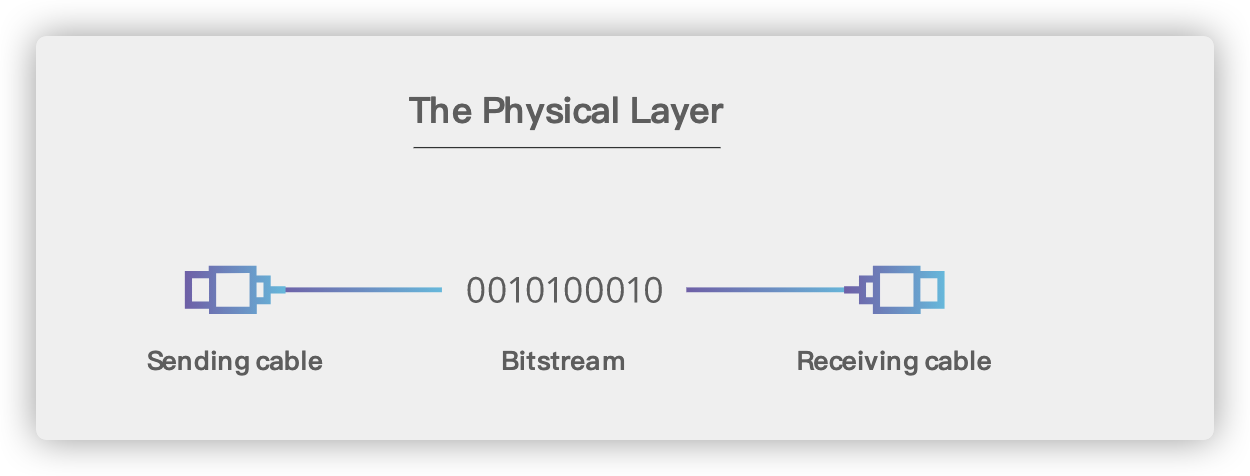
+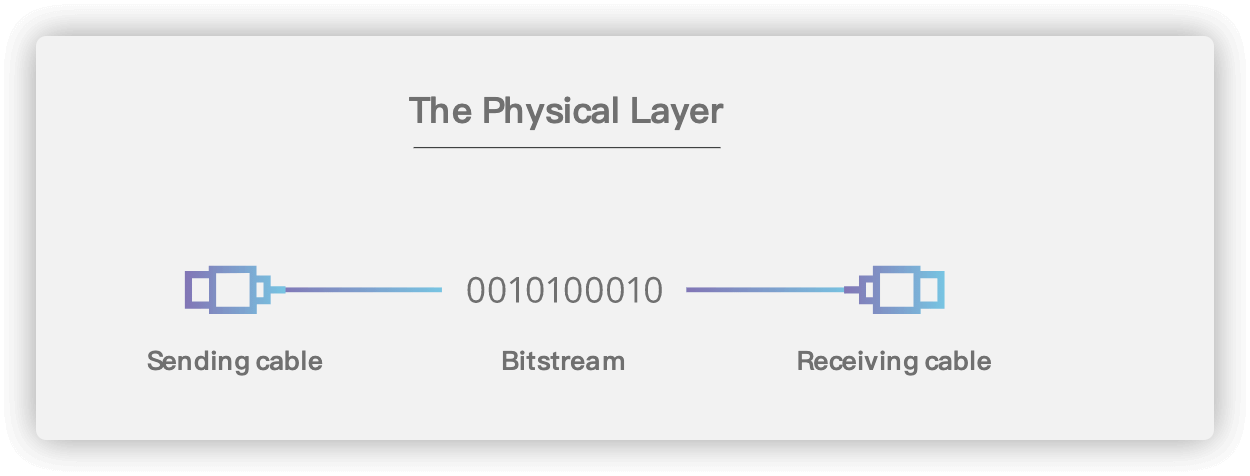
### 2.1. 基本术语
@@ -81,11 +81,11 @@ tag:
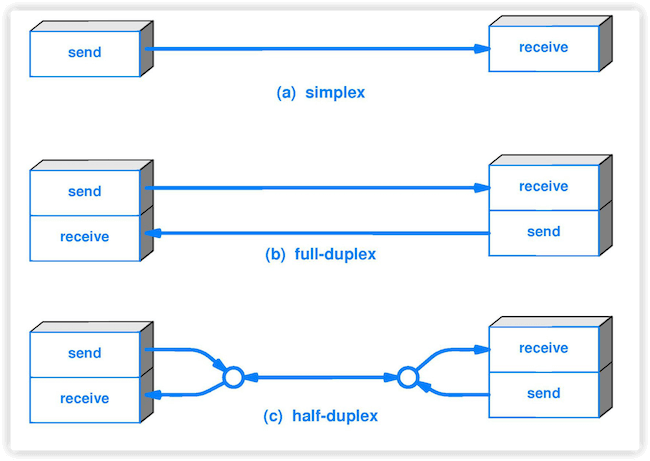
5. **半双工(half duplex )**:通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
-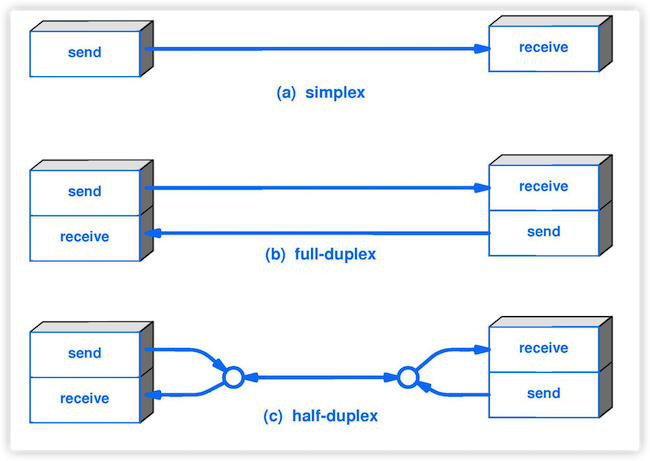
+
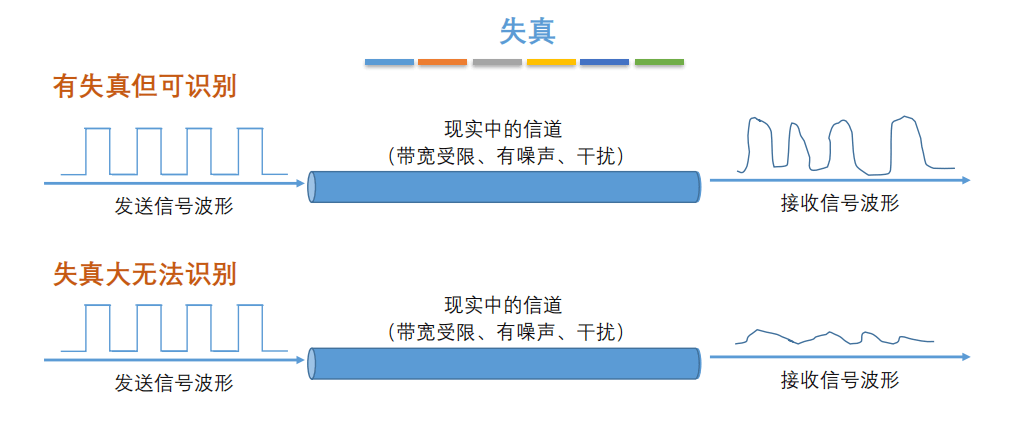
7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
-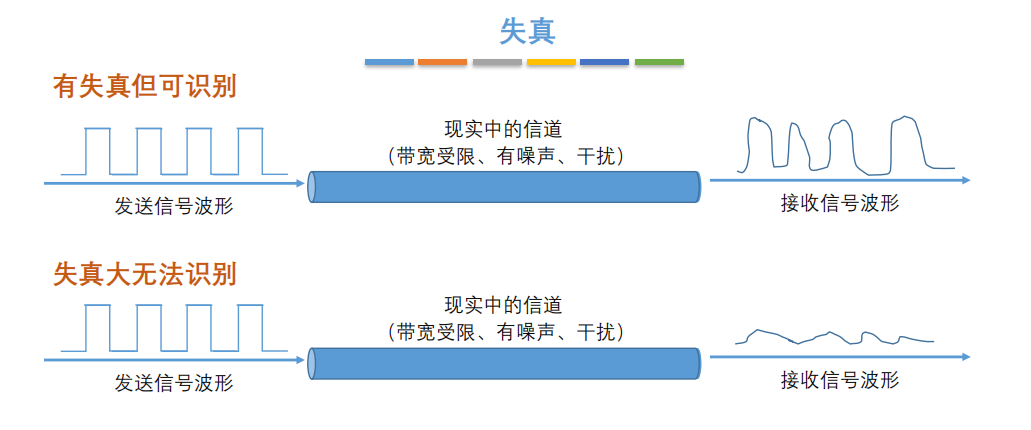
+
8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
9. **香农定理**:在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
@@ -95,7 +95,7 @@ tag:
13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
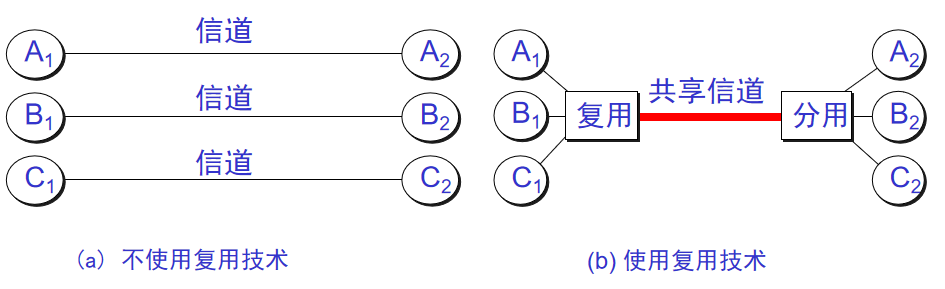
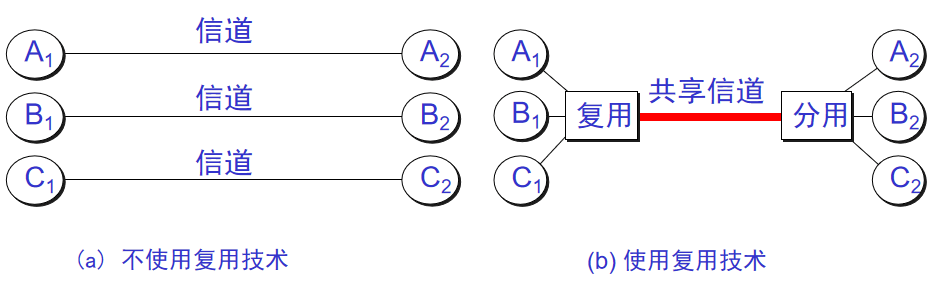
14. **信道复用(channel multiplexing )**:指多个用户共享同一个信道。(并不一定是同时)。
-
+
15. **比特率(bit rate )**:单位时间(每秒)内传送的比特数。
16. **波特率(baud rate)**:单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
@@ -137,7 +137,7 @@ tag:
## 3. 数据链路层(Data Link Layer)
-
+
### 3.1. 基本术语
@@ -148,10 +148,10 @@ tag:
5. **MTU(Maximum Transfer Uint )**:最大传送单元。帧的数据部分的的长度上限。
6. **误码率 BER(Bit Error Rate )**:在一段时间内,传输错误的比特占所传输比特总数的比率。
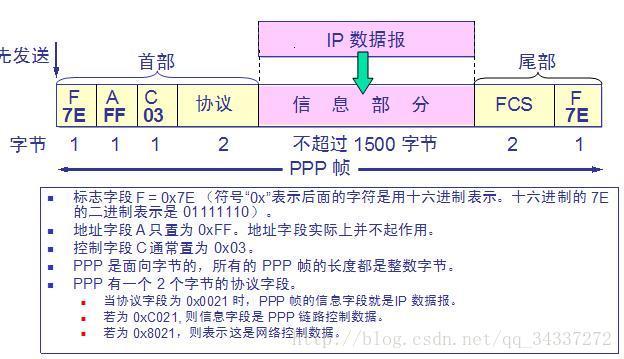
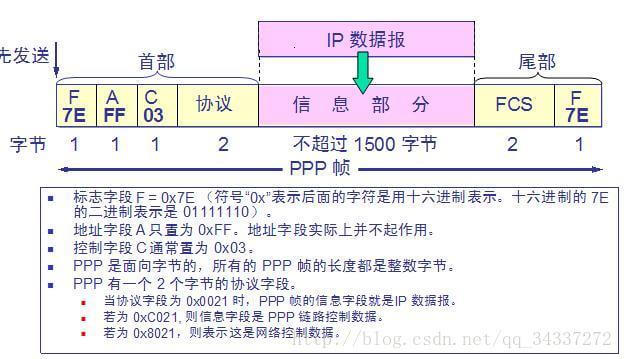
7. **PPP(Point-to-Point Protocol )**:点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
- 
+ 
8. **MAC 地址(Media Access Control 或者 Medium Access Control)**:意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
-
+
9. **网桥(bridge)**:一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
10. **交换机(switch )**:广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
@@ -180,7 +180,7 @@ tag:
## 4. 网络层(Network Layer)
-
+
### 4.1. 基本术语
@@ -208,7 +208,7 @@ tag:
## 5. 传输层(Transport Layer)
-
+
### 5.1. 基本术语
@@ -218,7 +218,7 @@ tag:
4. **TCP(Transmission Control Protocol)**:传输控制协议。
5. **UDP(User Datagram Protocol)**:用户数据报协议。
-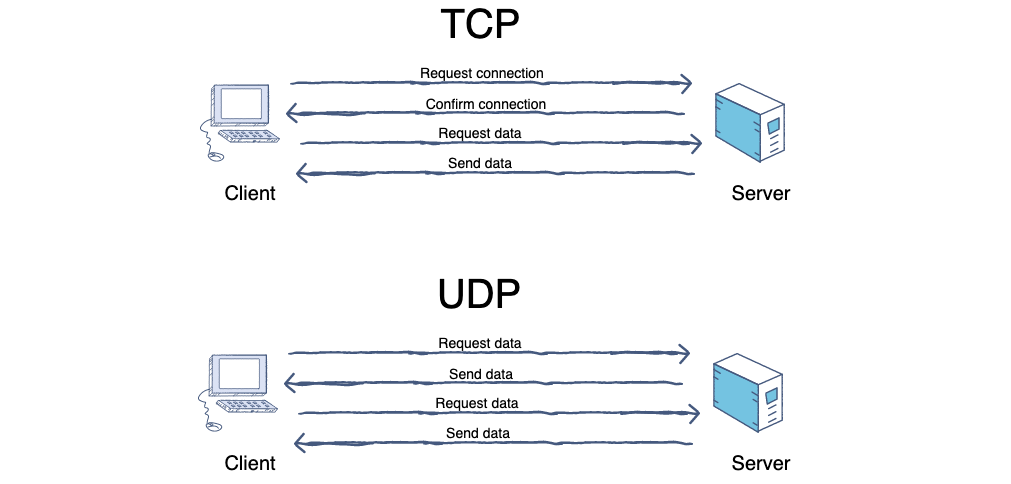
+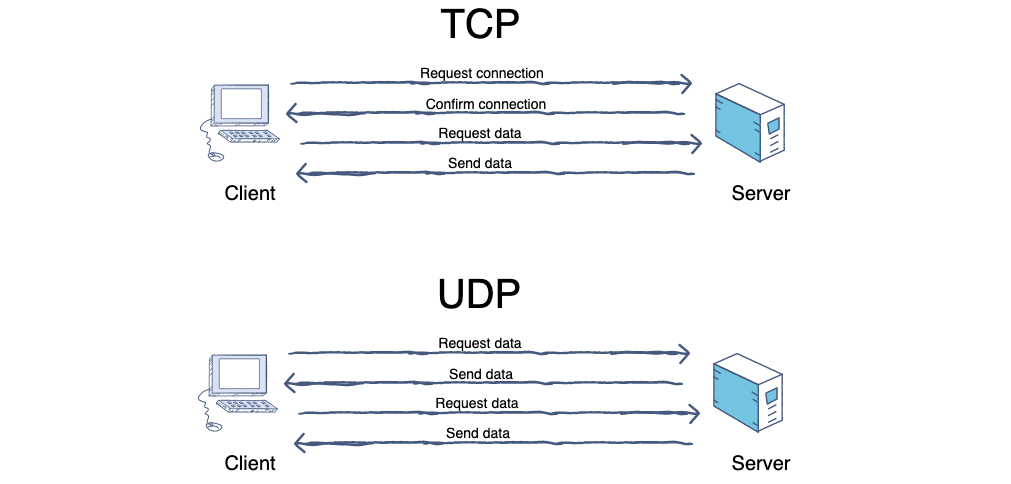
6. **端口(port)**:端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
7. **停止等待协议(stop-and-wait)**:指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
@@ -261,45 +261,43 @@ tag:
## 6. 应用层(Application Layer)
-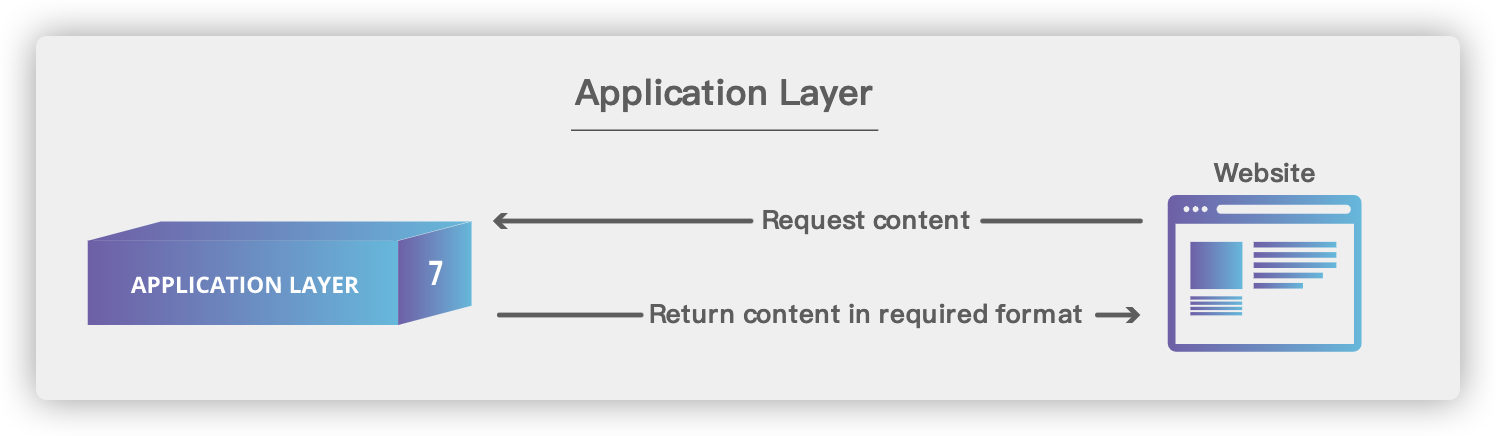
+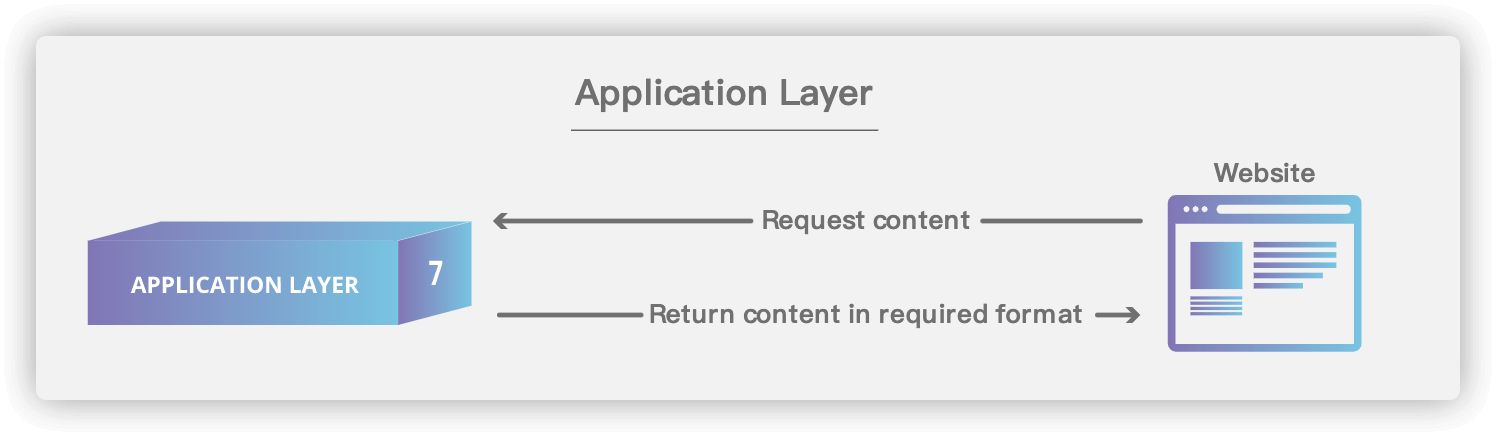
### 6.1. 基本术语
1. **域名系统(DNS)**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
-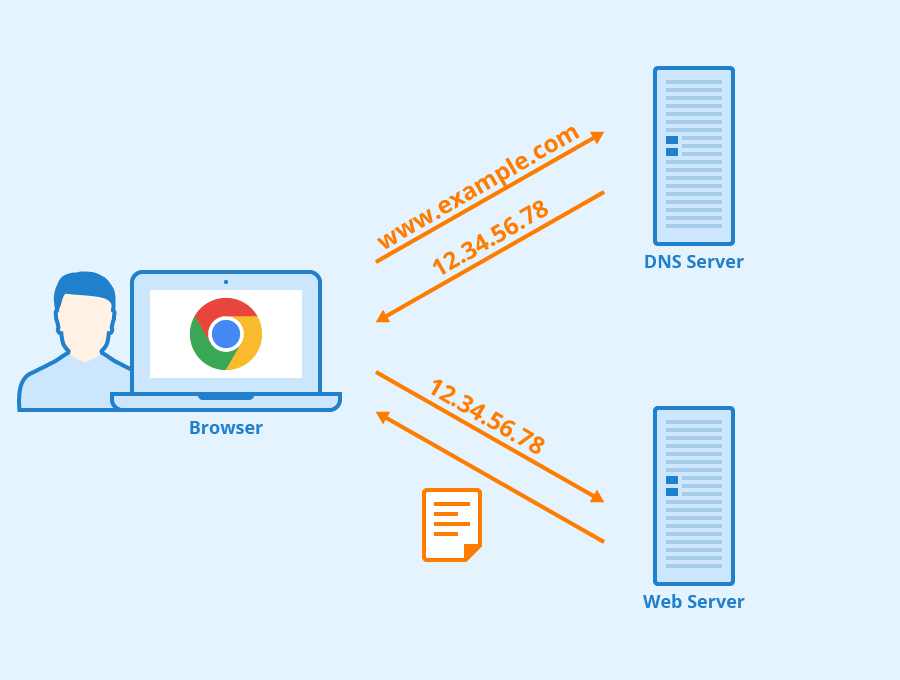
+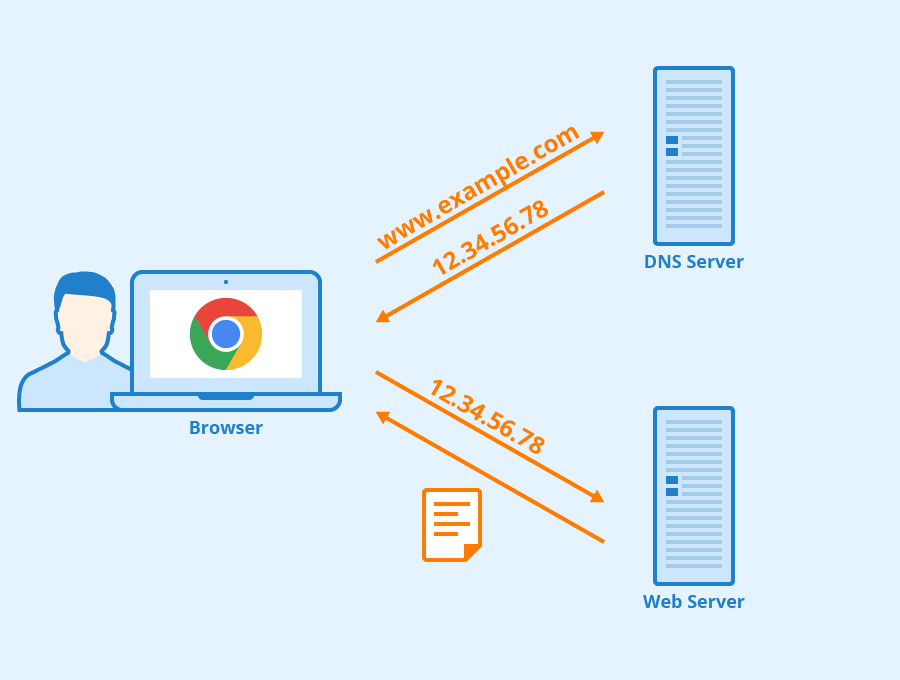
https://www.seobility.net/en/wiki/HTTP_headers
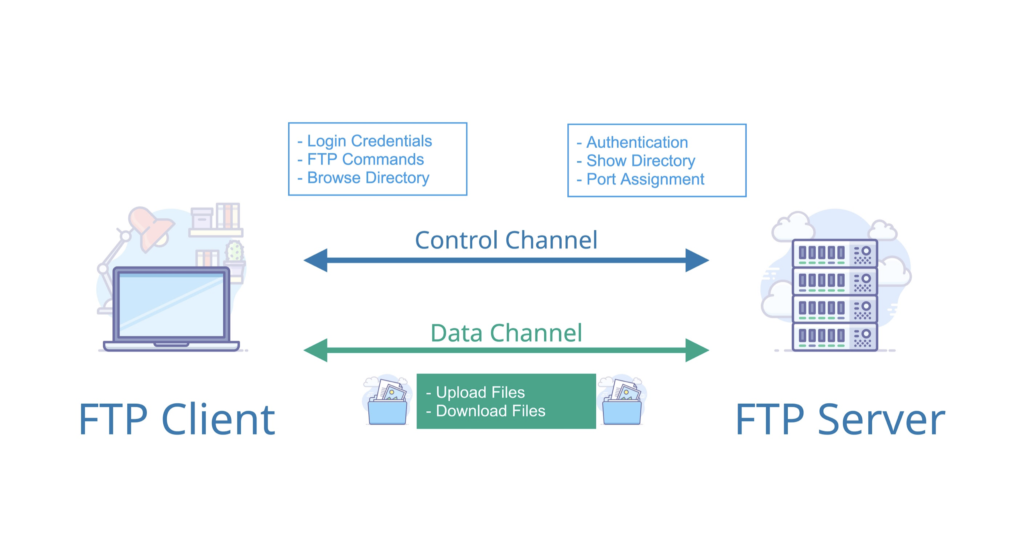
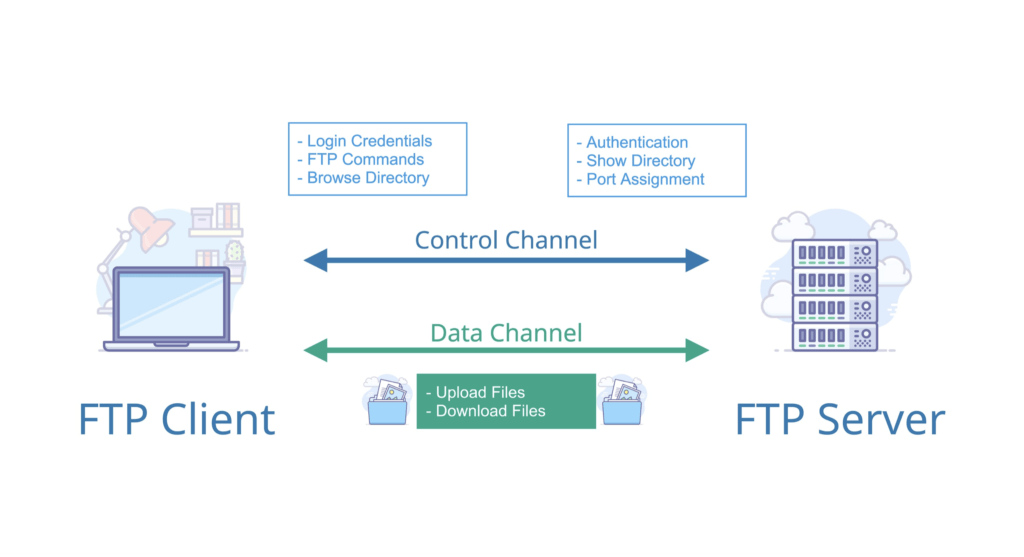
2. **文件传输协议(FTP)**:FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
-
+
3. **简单文件传输协议(TFTP)**:TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
4. **远程终端协议(TELNET)**:Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
5. **万维网(WWW)**:WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
6. **万维网的大致工作工程:**
-
+
7. **统一资源定位符(URL)**:统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
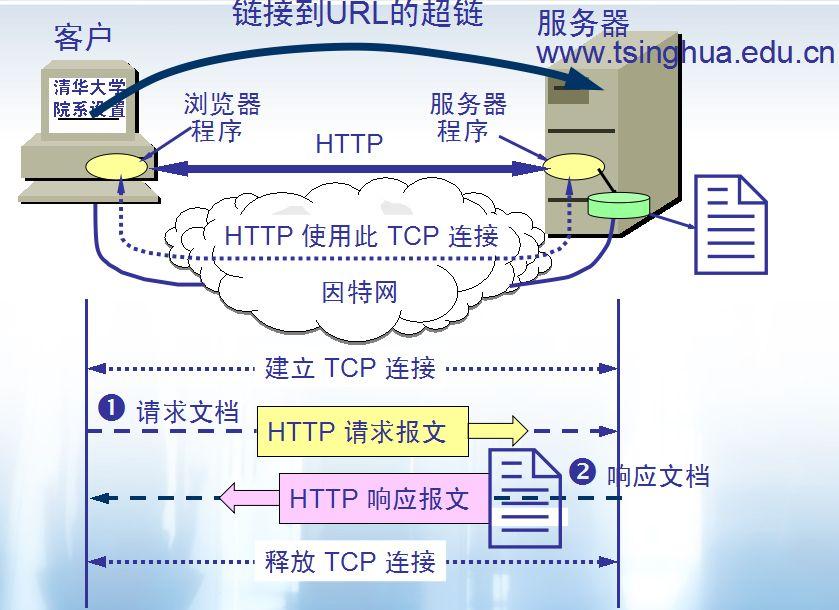
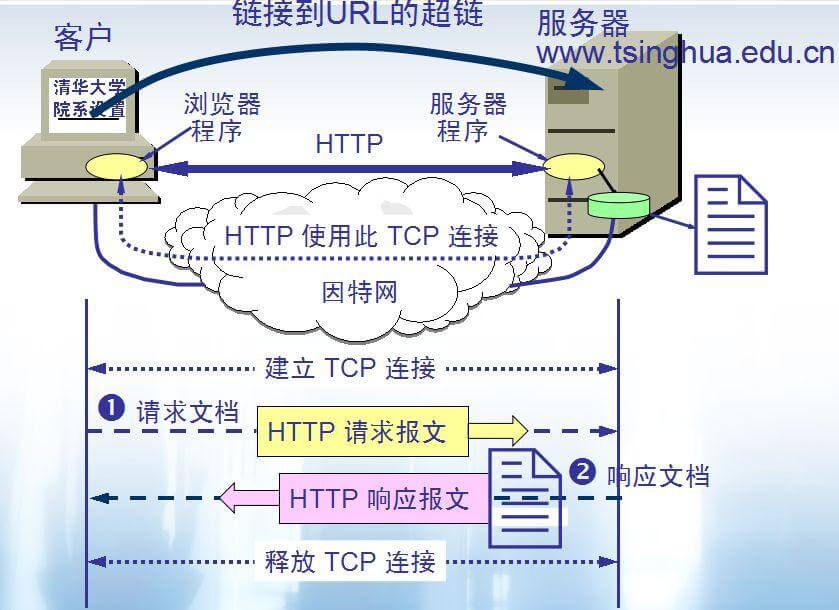
8. **超文本传输协议(HTTP)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
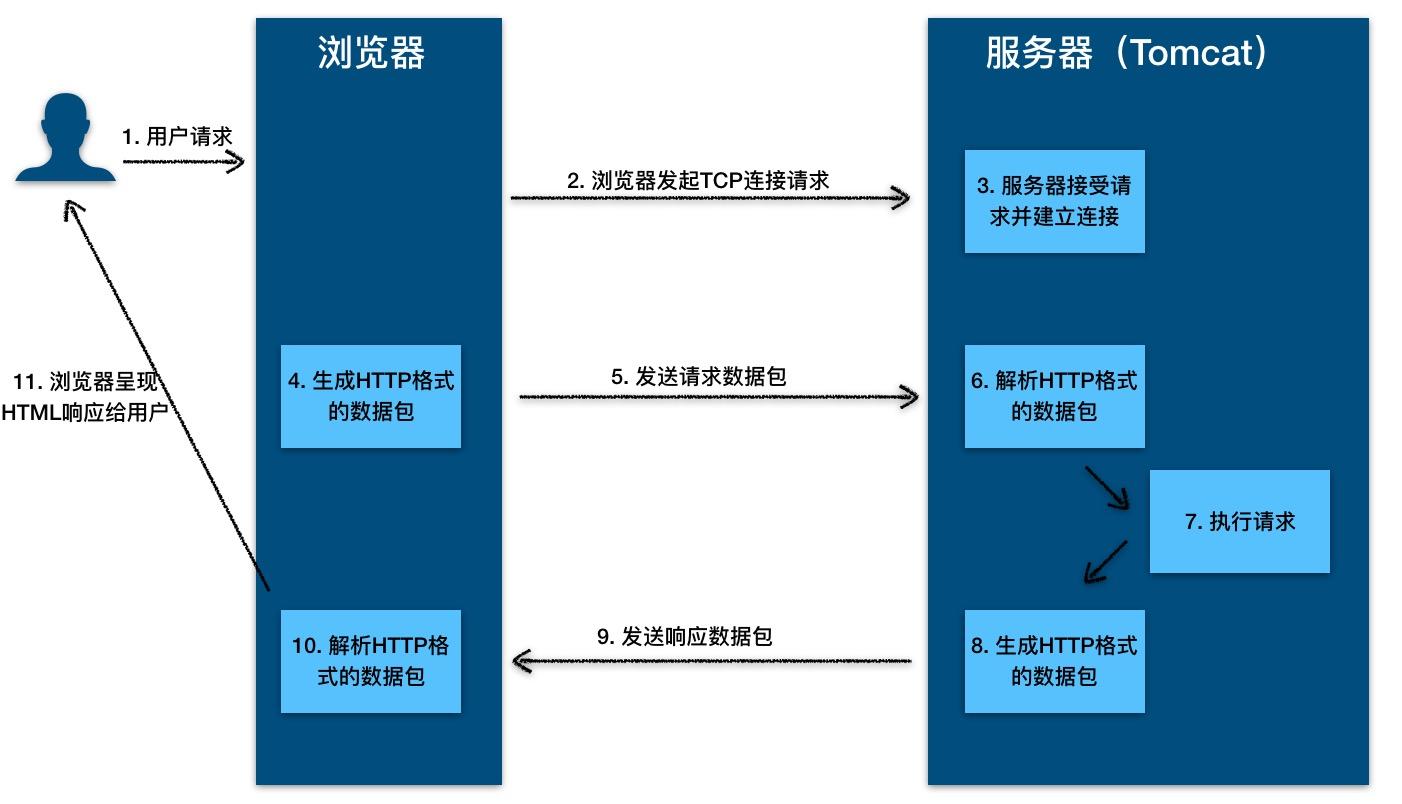
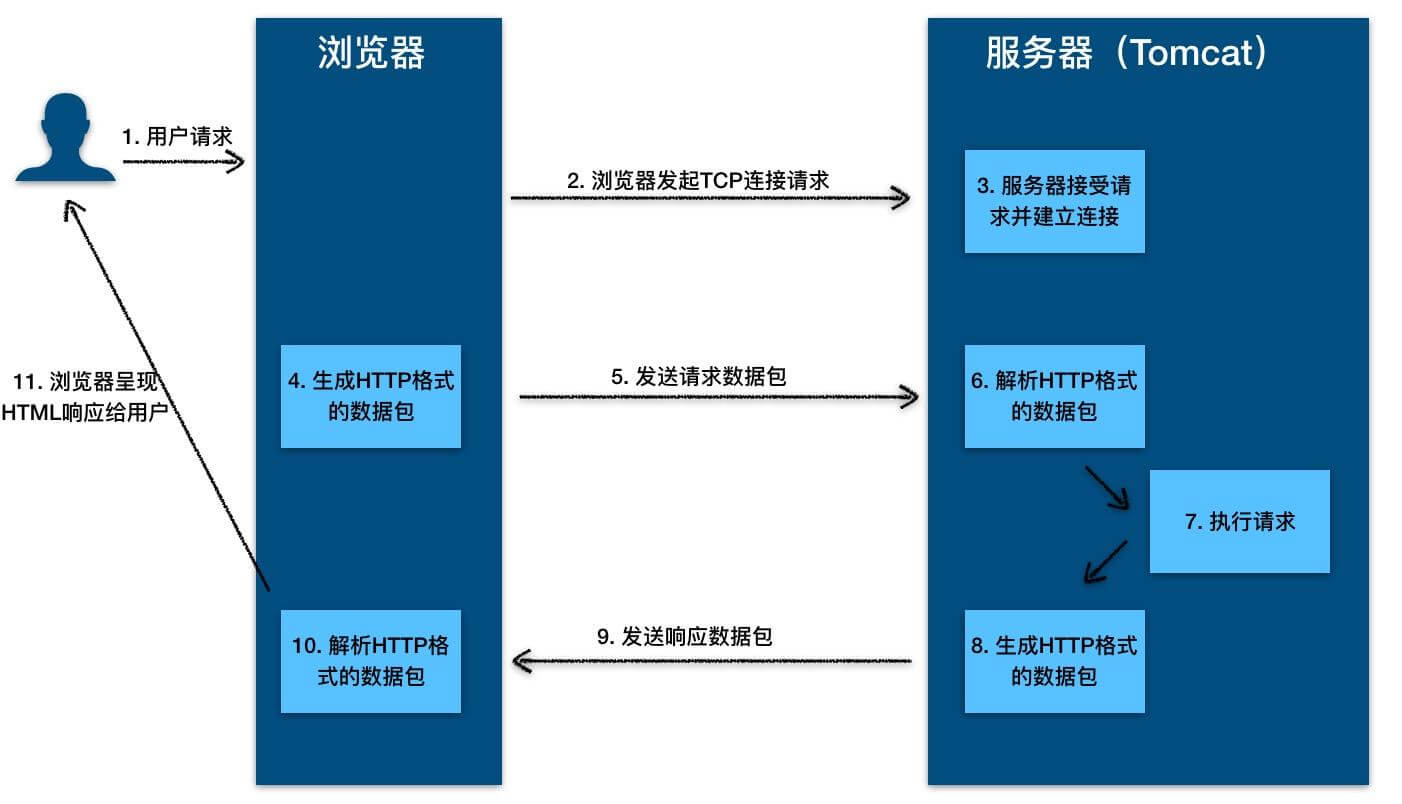
HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
-
+
10. **代理服务器(Proxy Server)**:代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
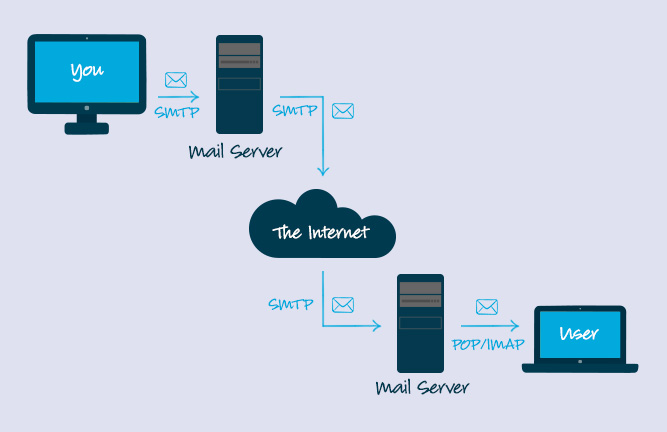
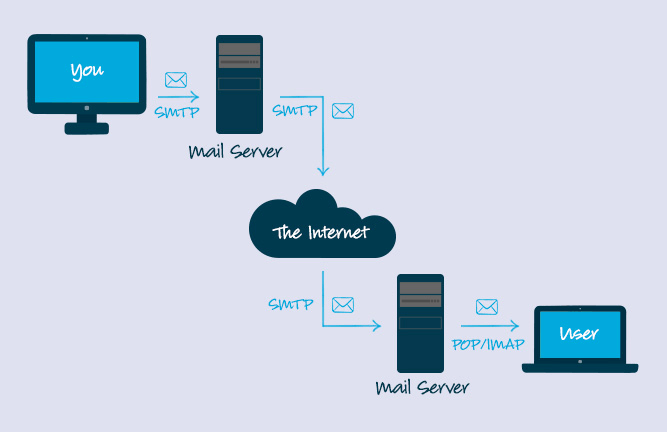
11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
-
+
https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/
11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
-
-
12. **垂直搜索引擎**:垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
14. **目录索引**:目录索引( search index/directory),顾名思义就是将网站分门别类地存放在相应的目录中,因此用户在查询信息时,可选择关键词搜索,也可按分类目录逐层查找。
diff --git a/docs/cs-basics/network/network-attack-means.md b/docs/cs-basics/network/network-attack-means.md
index 6d482503..f3e785cc 100644
--- a/docs/cs-basics/network/network-attack-means.md
+++ b/docs/cs-basics/network/network-attack-means.md
@@ -21,7 +21,7 @@ tag:
**IP 头部格式** :
-
+
### IP 欺骗技术是什么?
@@ -33,7 +33,7 @@ IP 欺骗技术就是**伪造**某台主机的 IP 地址的技术。通过 IP
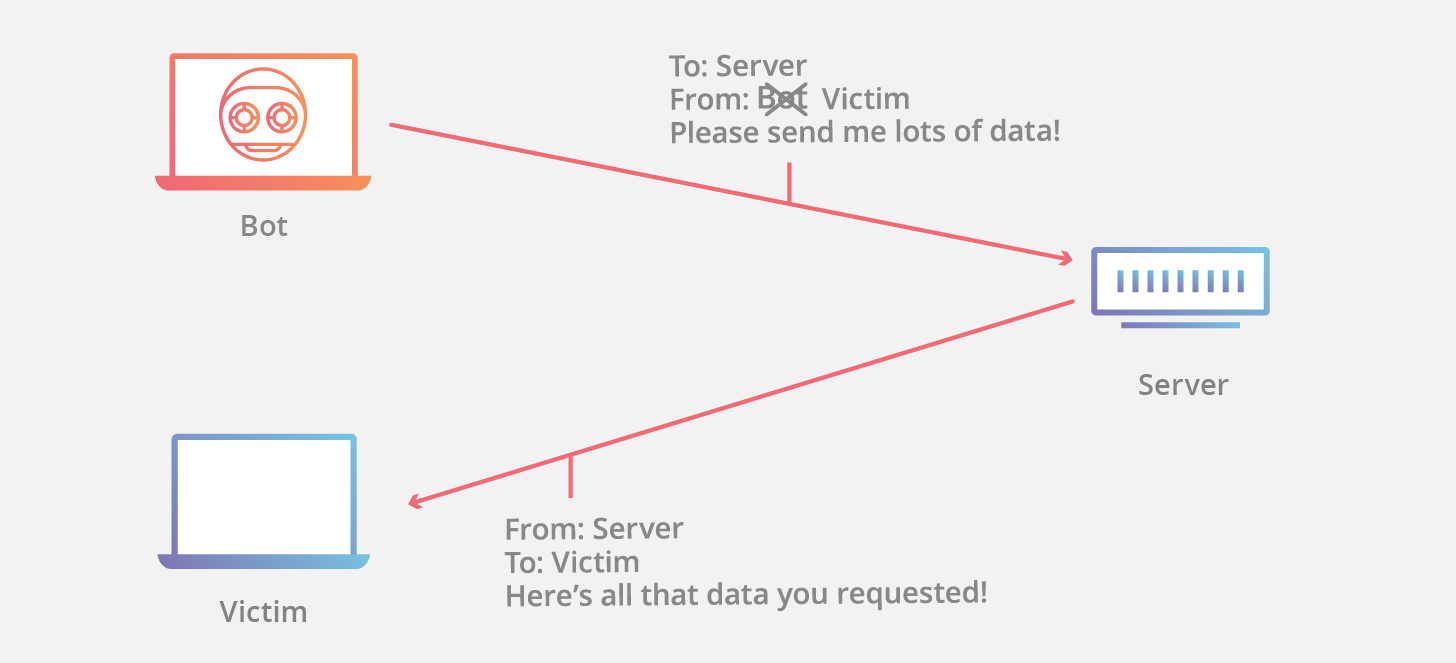
这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
-
+
### 如何缓解 IP 欺骗?
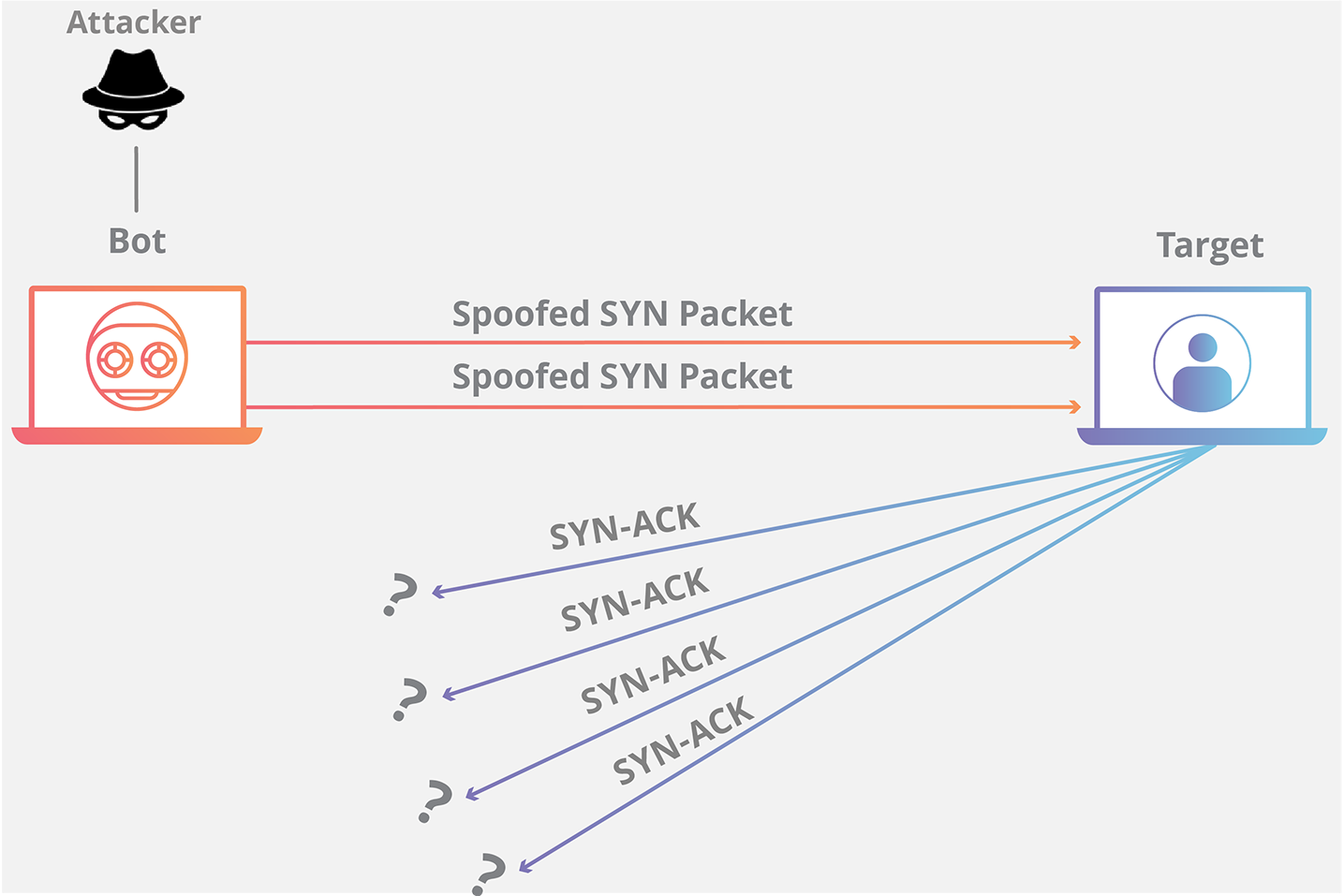
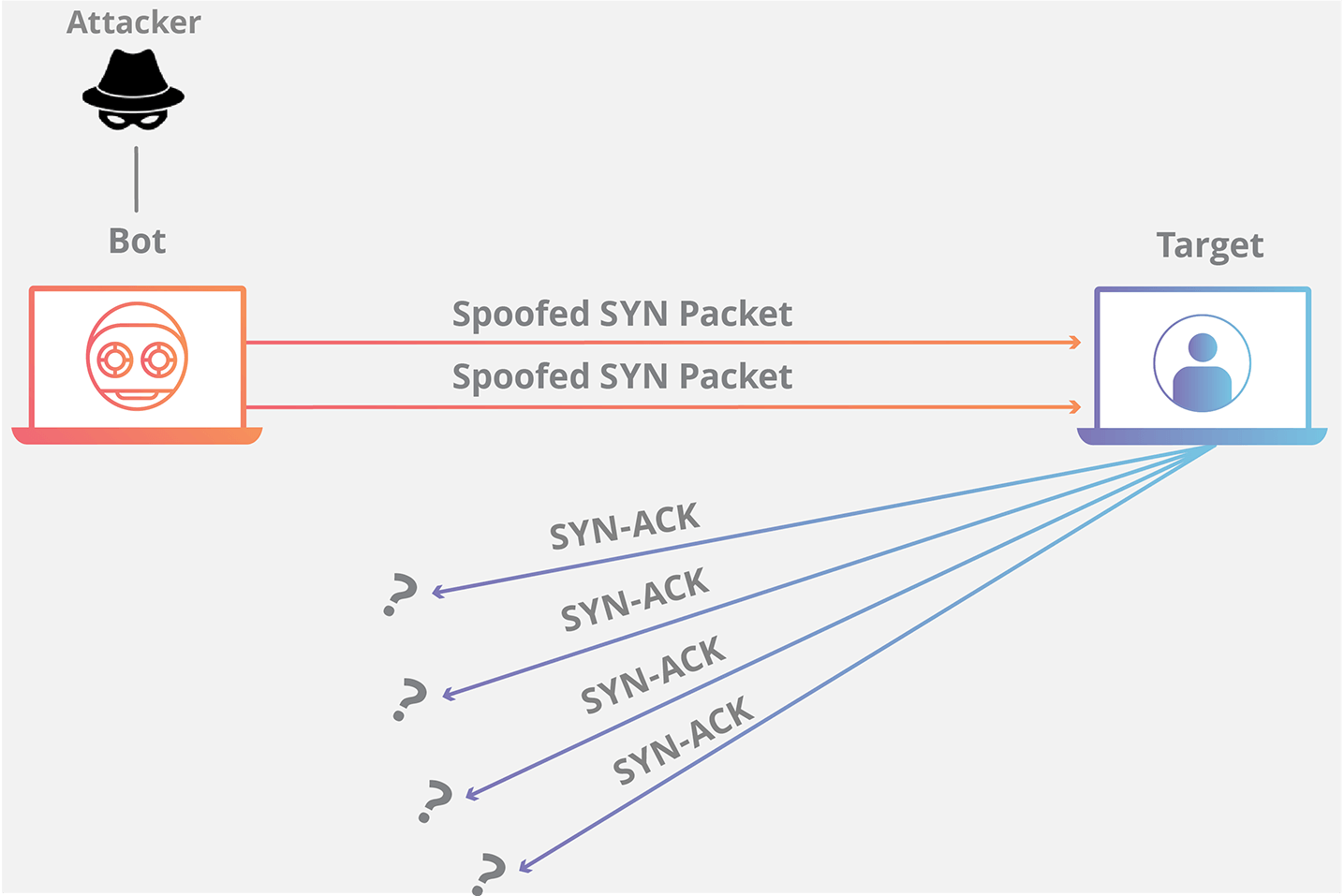
@@ -48,13 +48,13 @@ SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of S
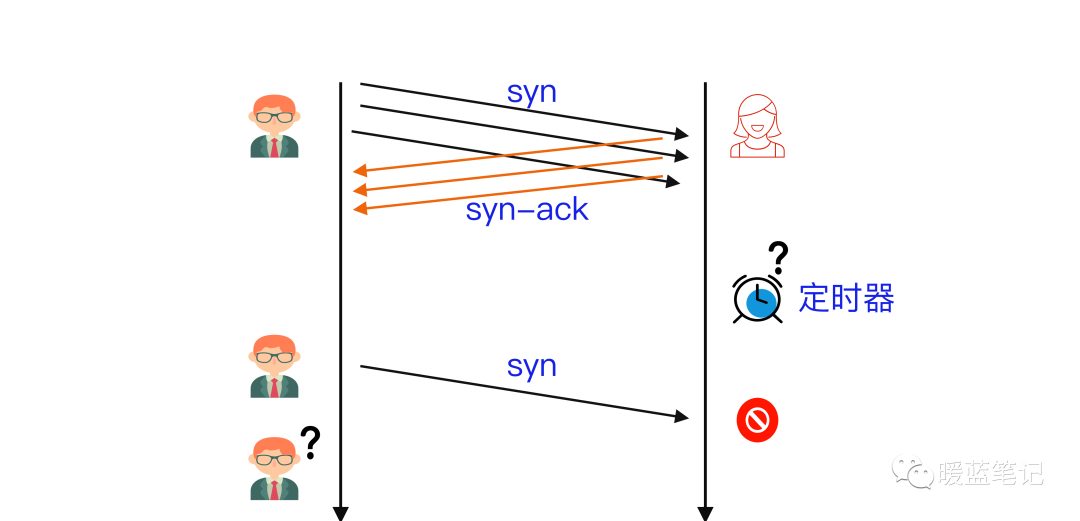
SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
增加服务器性能,提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪,防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
-
+
### TCP SYN Flood 攻击原理是什么?
**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
-
+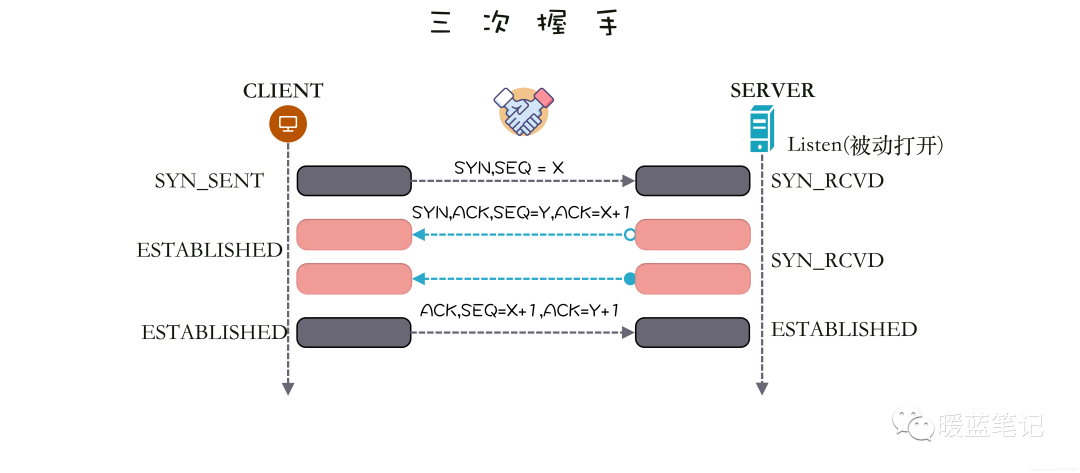
A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
@@ -71,7 +71,7 @@ A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收
假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
-
+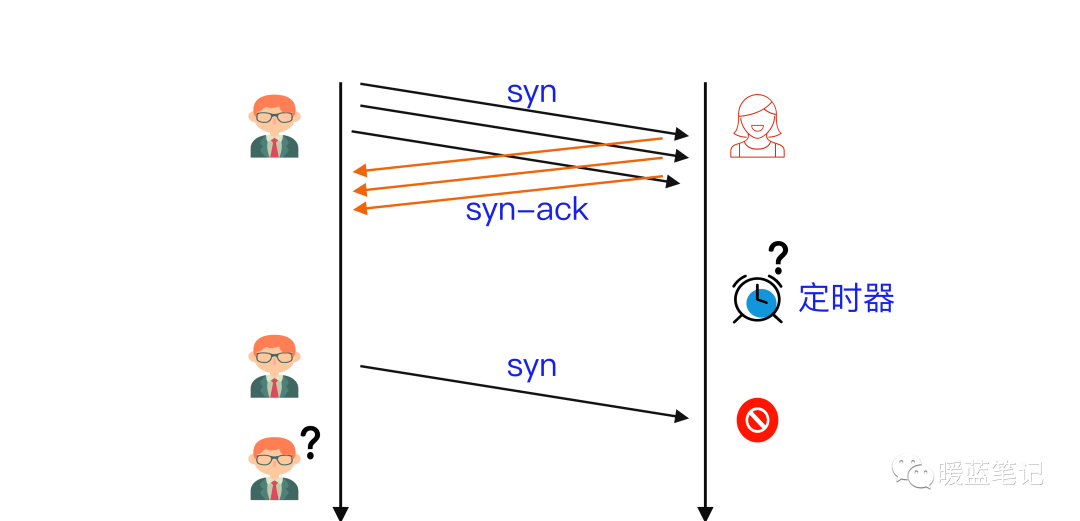
B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
@@ -118,7 +118,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
-
+
### 如何缓解 UDP Flooding?
@@ -130,7 +130,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
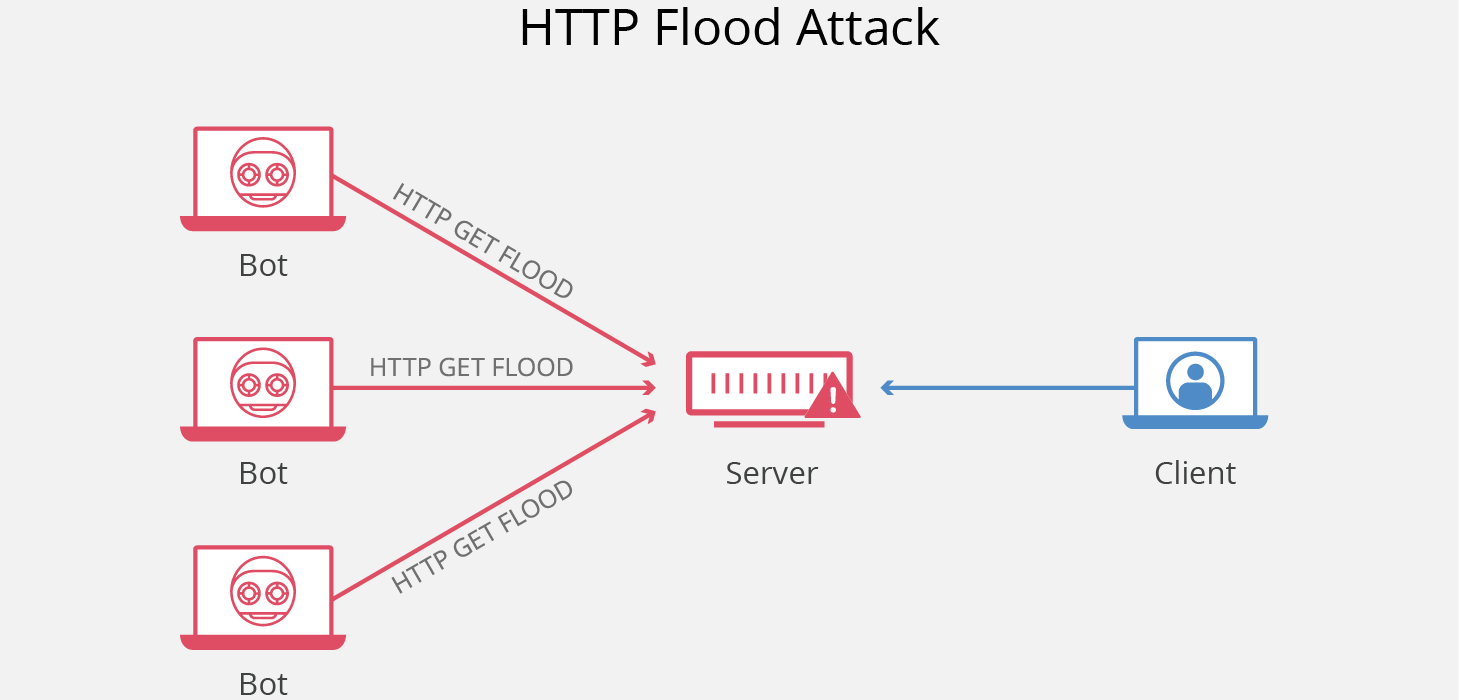
HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
-
+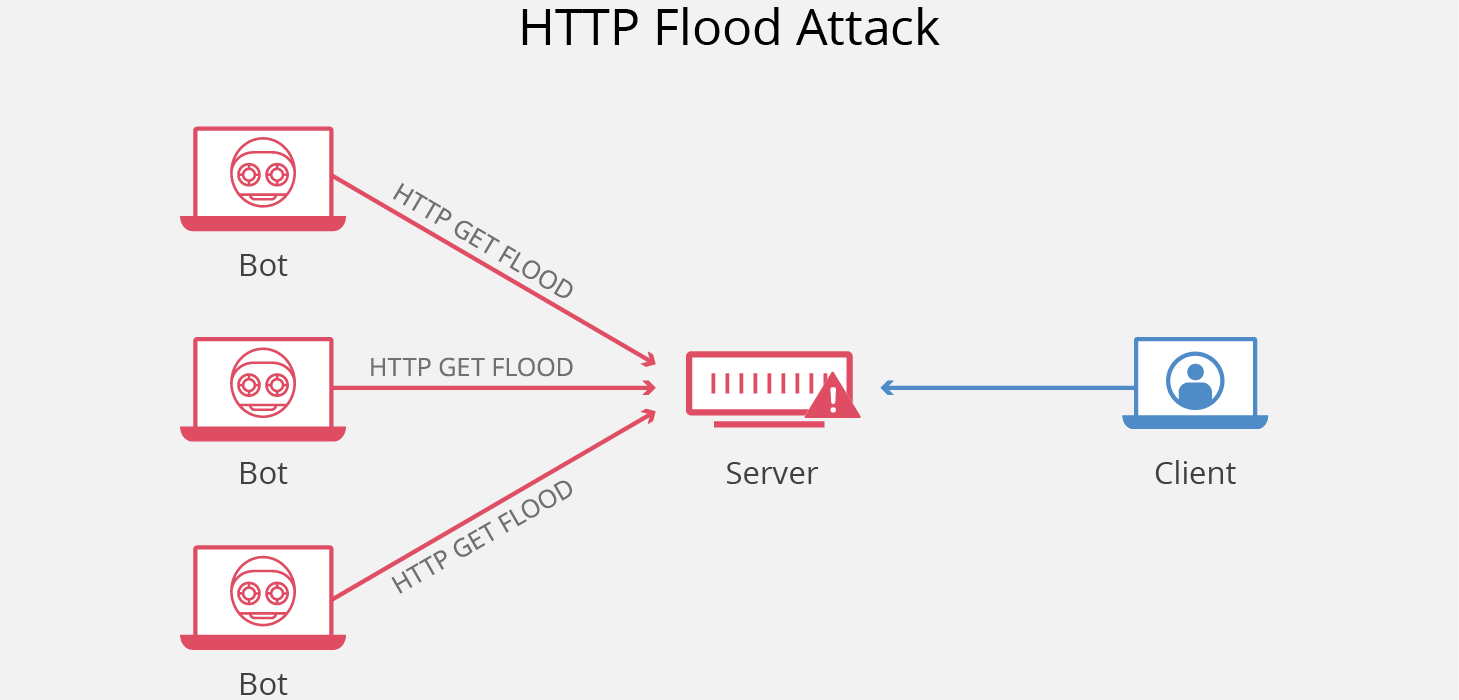
### HTTP Flood 的攻击原理是什么?
@@ -157,7 +157,7 @@ HTTP 洪水攻击有两种:
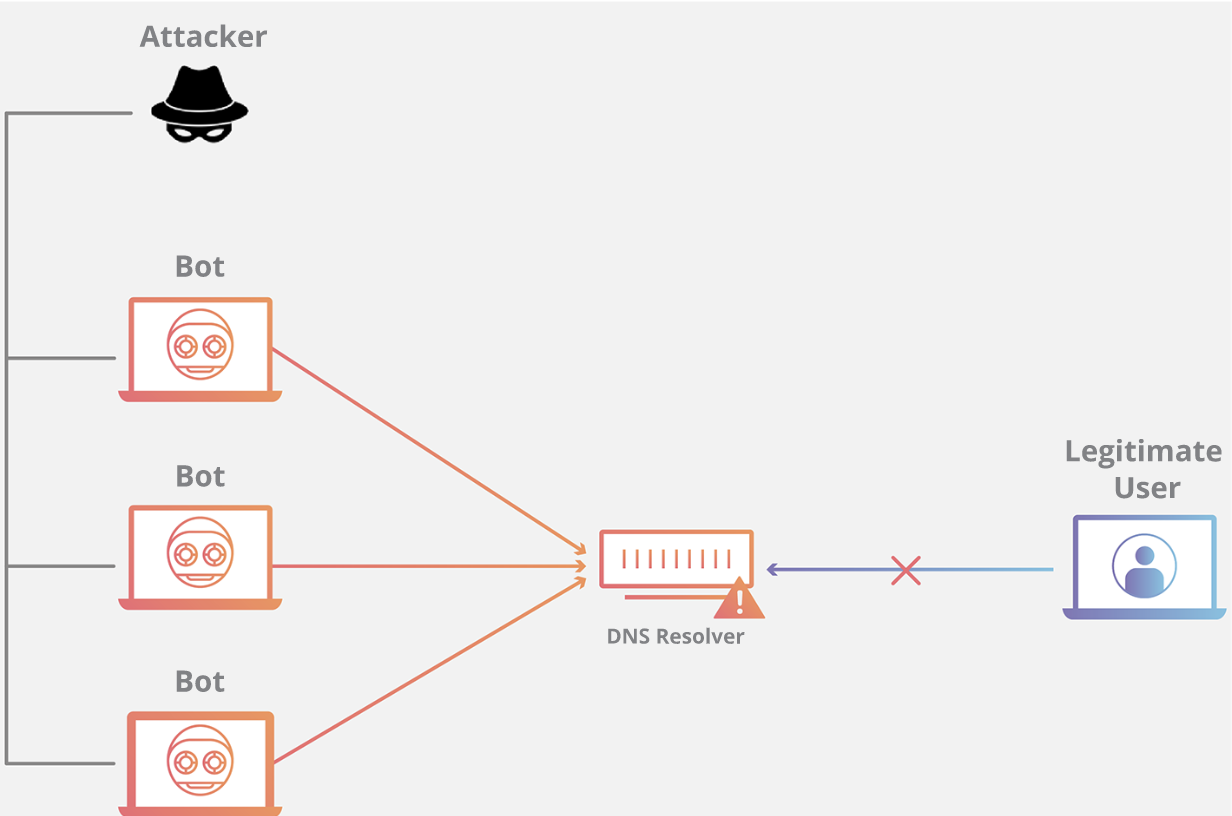
### DNS Flood 的攻击原理是什么?
-
+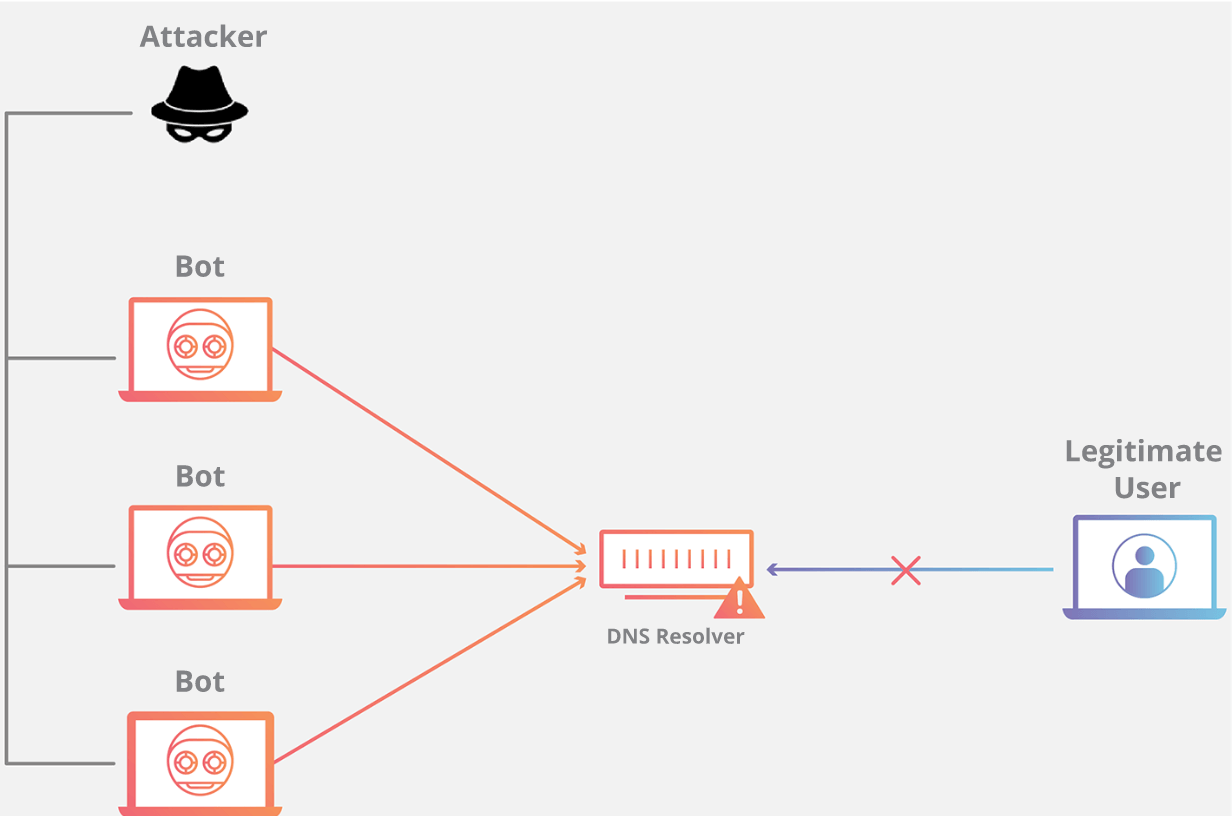
域名系统的功能是将易于记忆的名称(例如 example.com)转换成难以记住的网站服务器地址(例如 192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood 攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood 攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
@@ -210,13 +210,13 @@ $ nc 127.0.0.1 8000
该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
-
+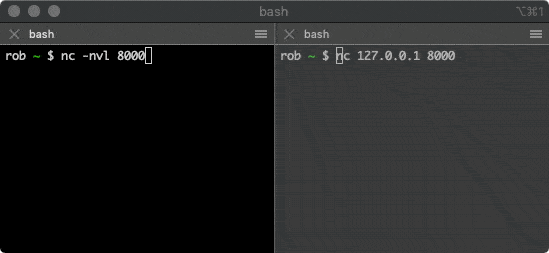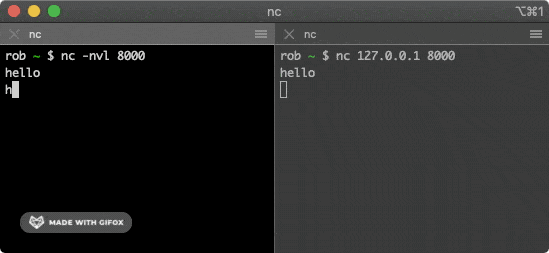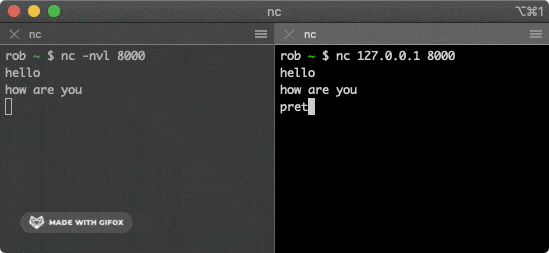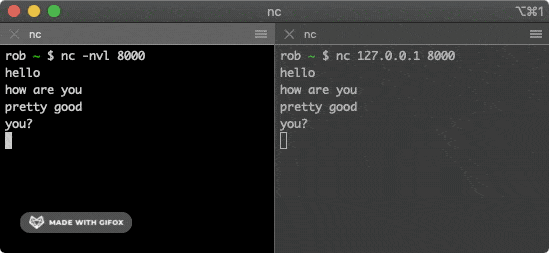
> 嗅探流量
编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
-
+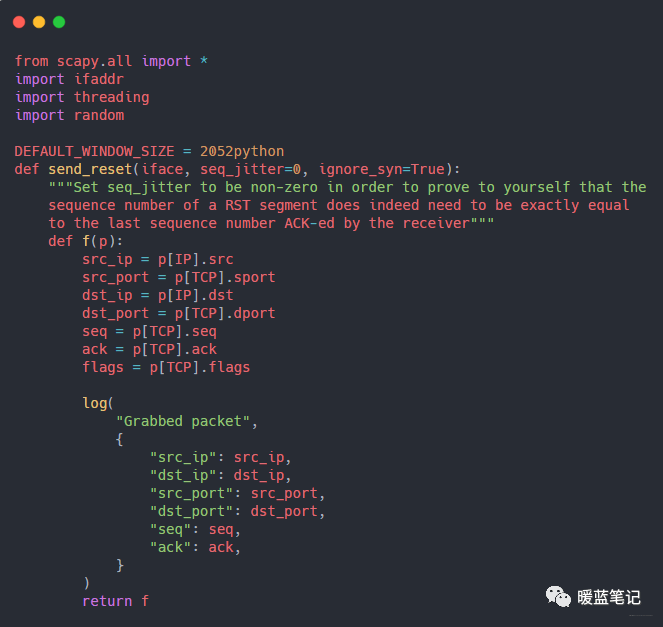
这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
@@ -252,7 +252,7 @@ $ nc 127.0.0.1 8000
攻击中间人攻击英文名叫 Man-in-the-MiddleAttack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
-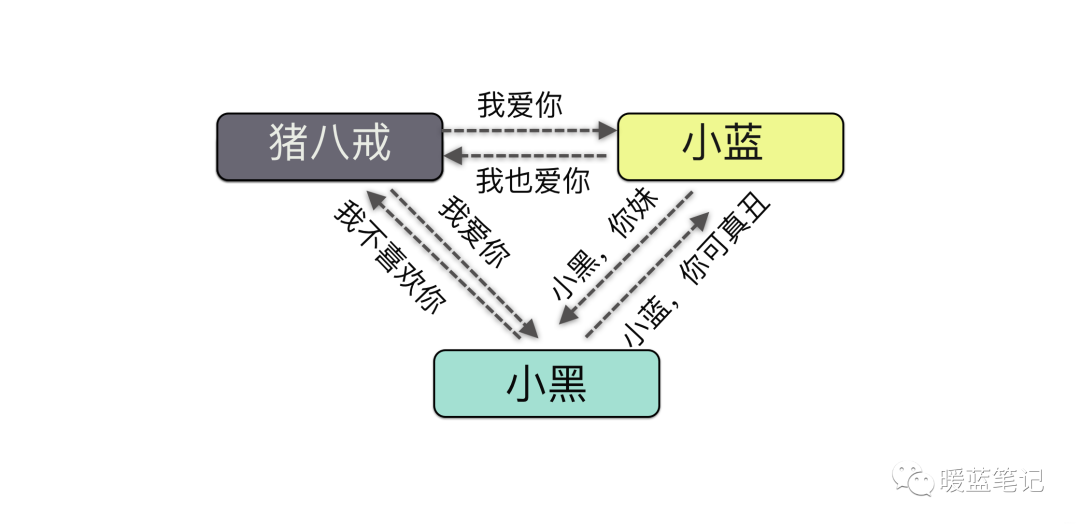
+
从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
@@ -292,7 +292,7 @@ $ nc 127.0.0.1 8000
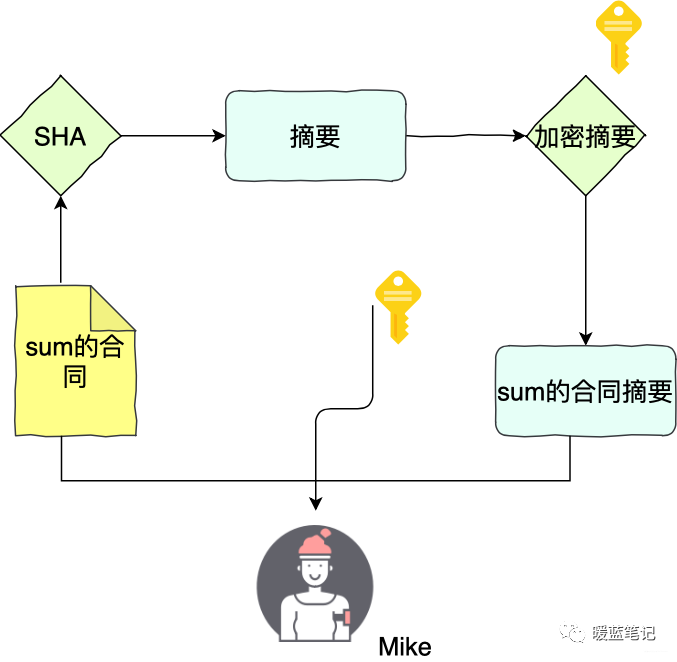
同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
-
+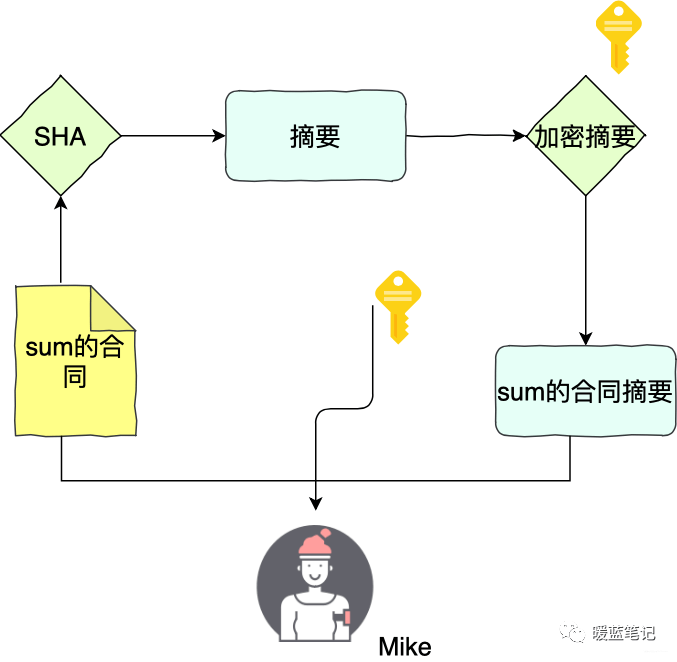
如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
@@ -308,7 +308,7 @@ $ nc 127.0.0.1 8000
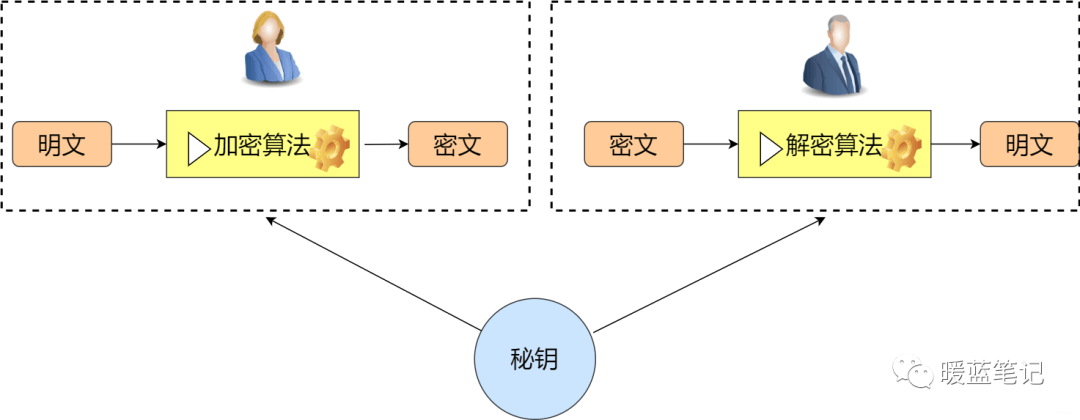
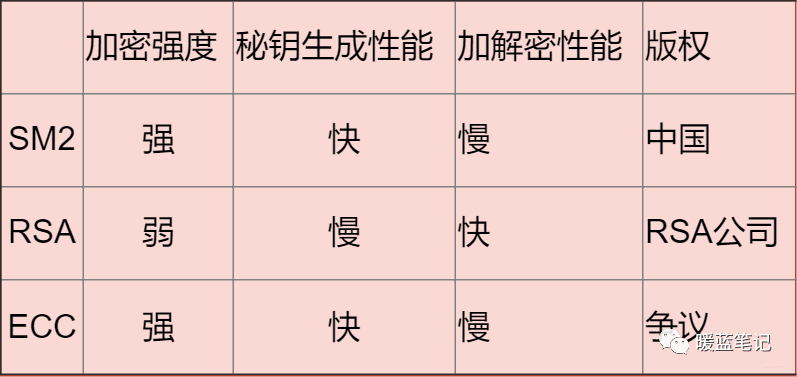
对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
-
+
#### 常见的对称加密算法有哪些?
@@ -316,7 +316,7 @@ $ nc 127.0.0.1 8000
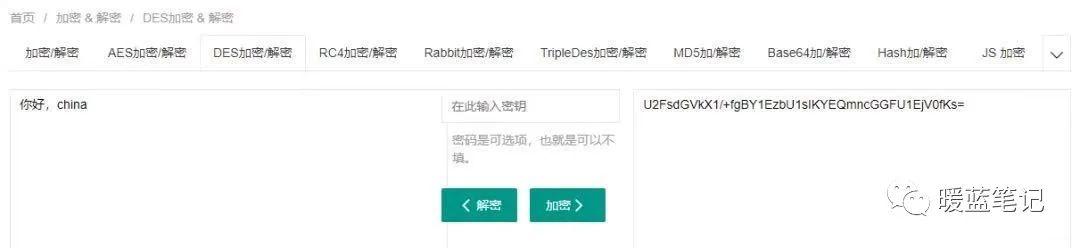
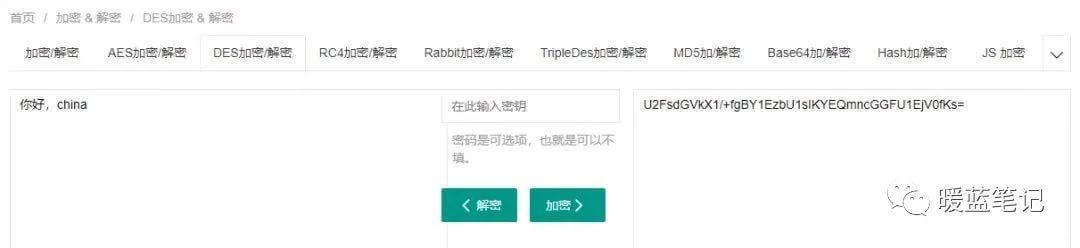
DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
-
+
**IDEA**
@@ -332,13 +332,13 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
**总结**:
-
+
#### 常见的非对称加密算法有哪些?
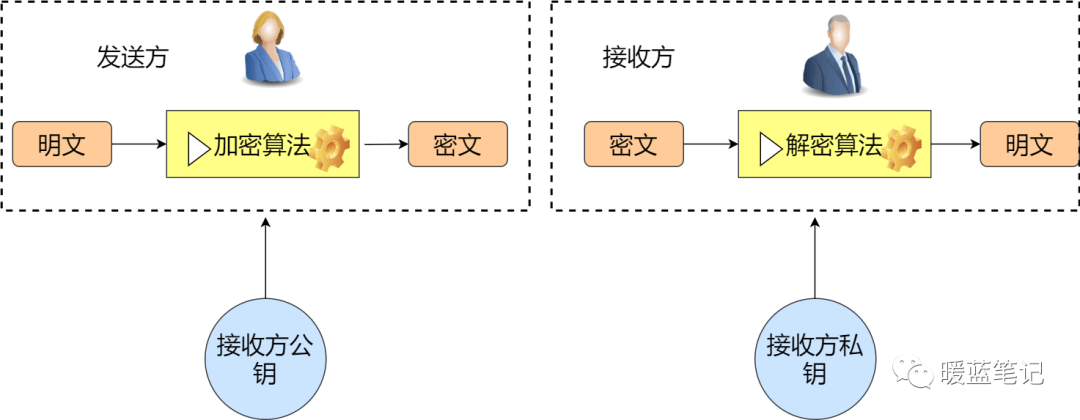
在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
-
+
其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 docker 集群也会使用相关非对称加密算法。
@@ -351,7 +351,7 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
总结:
-
+
#### 常见的散列算法有哪些?
@@ -371,7 +371,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
**总结**:
-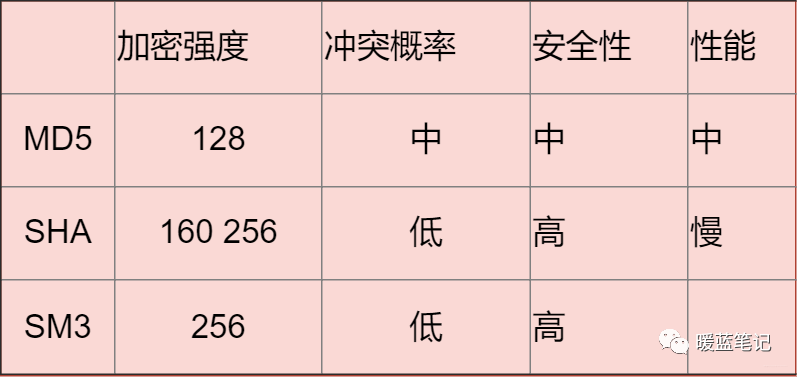
+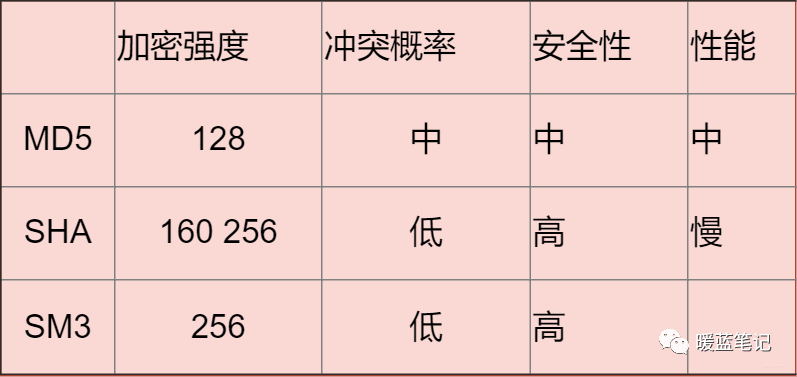
**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则散列算法。** 因为这段时间有这方面需求,就看了一些这方面的资料,入坑信息安全,就怕以后洗发水都不用买。谢谢大家查看!
@@ -383,7 +383,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike ,而是提供由第三方机构,含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那 ik,信任关系成立
-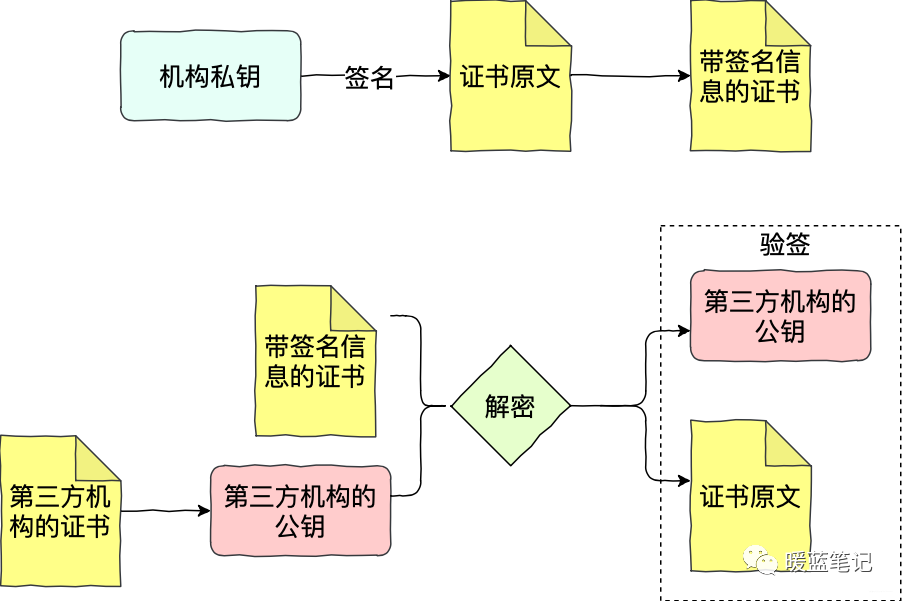
+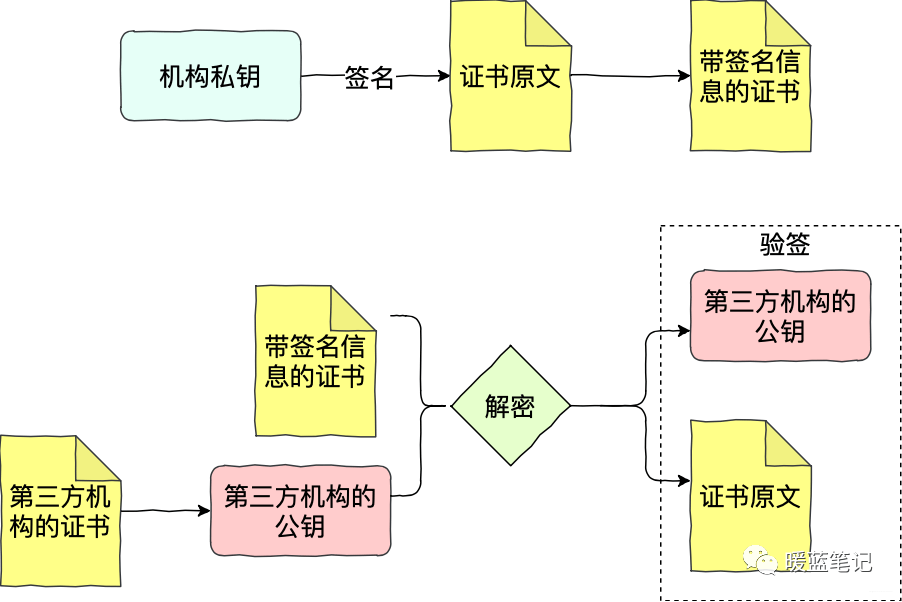
如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
@@ -391,7 +391,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险
-
+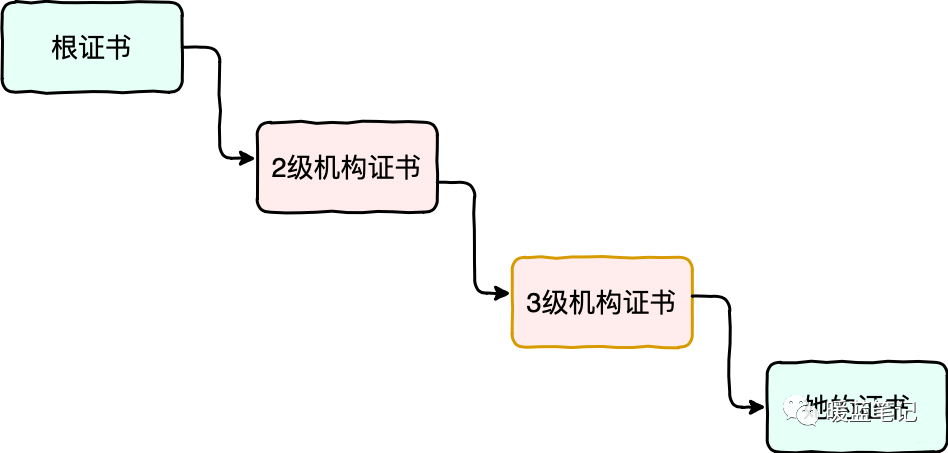
上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
@@ -407,7 +407,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
-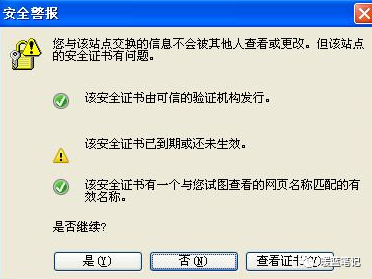
+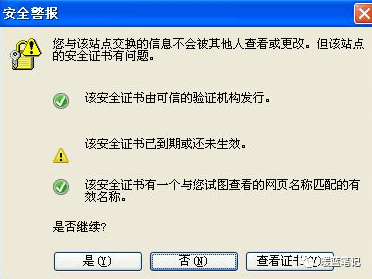
出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
diff --git a/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md b/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md
index 92c0ad13..92ecdf84 100644
--- a/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md
+++ b/docs/database/mysql/mysql-auto-increment-primary-key-continuous.md
@@ -16,17 +16,17 @@ tag:
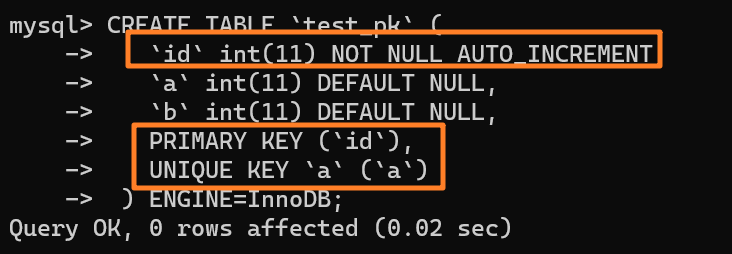
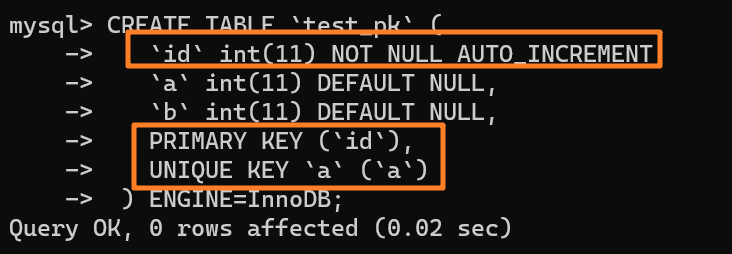
下面举个例子来看下,如下所示创建一张表:
-
+
## 自增值保存在哪里?
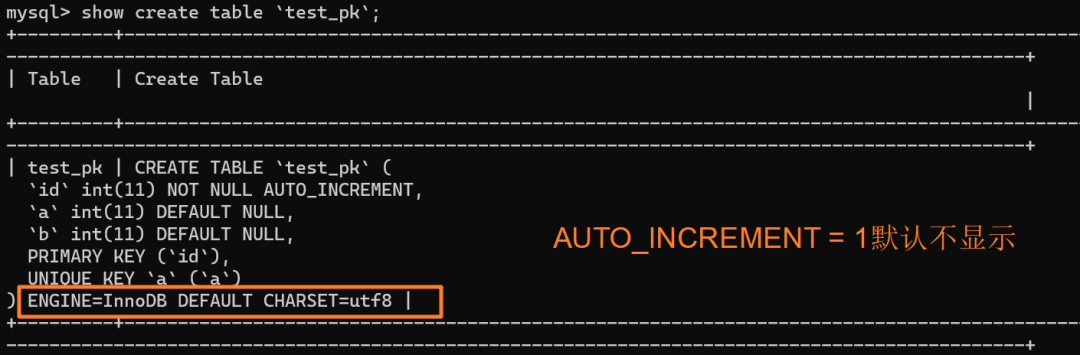
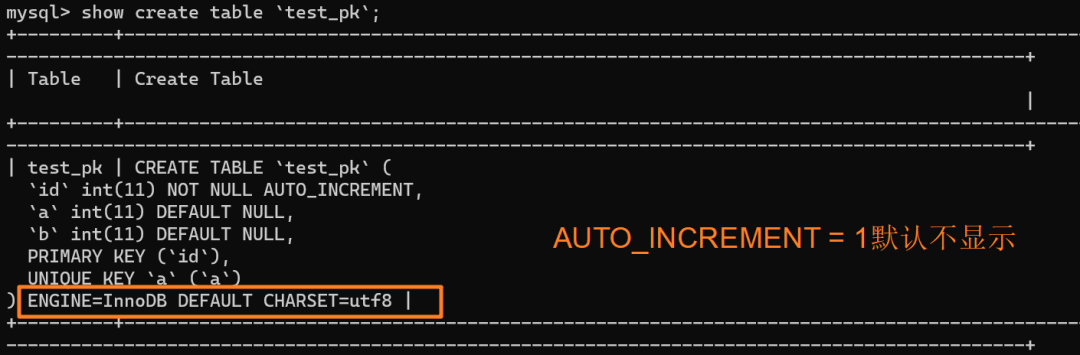
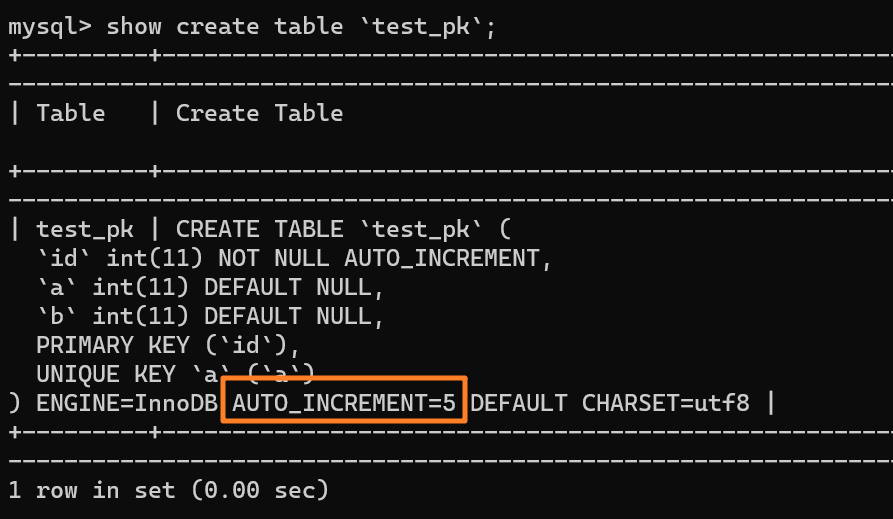
使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
-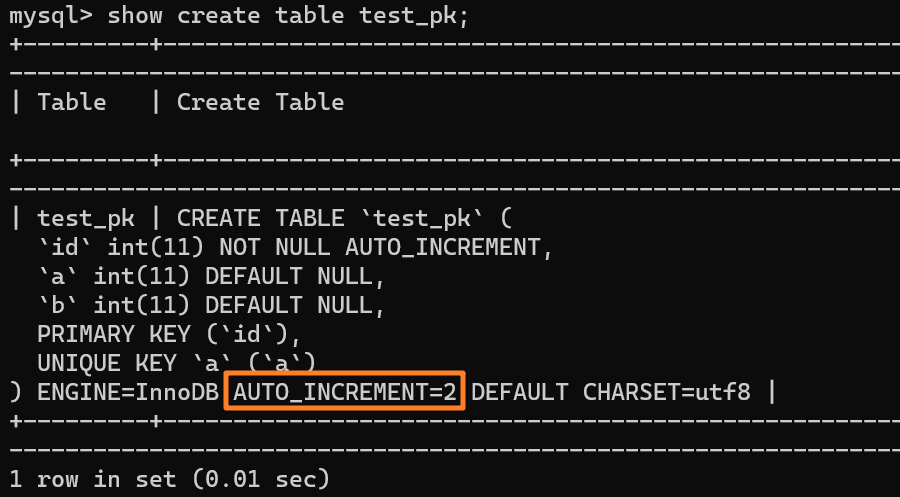
+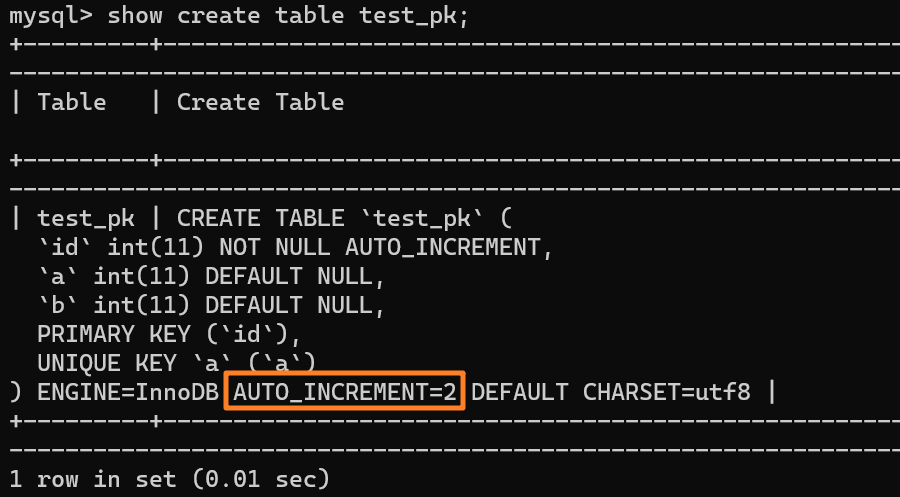
上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
-
+
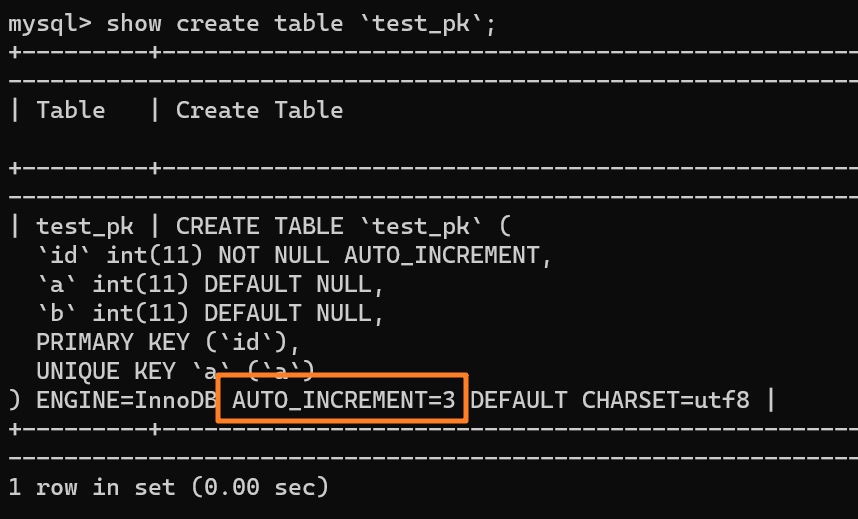
从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
@@ -38,13 +38,13 @@ tag:
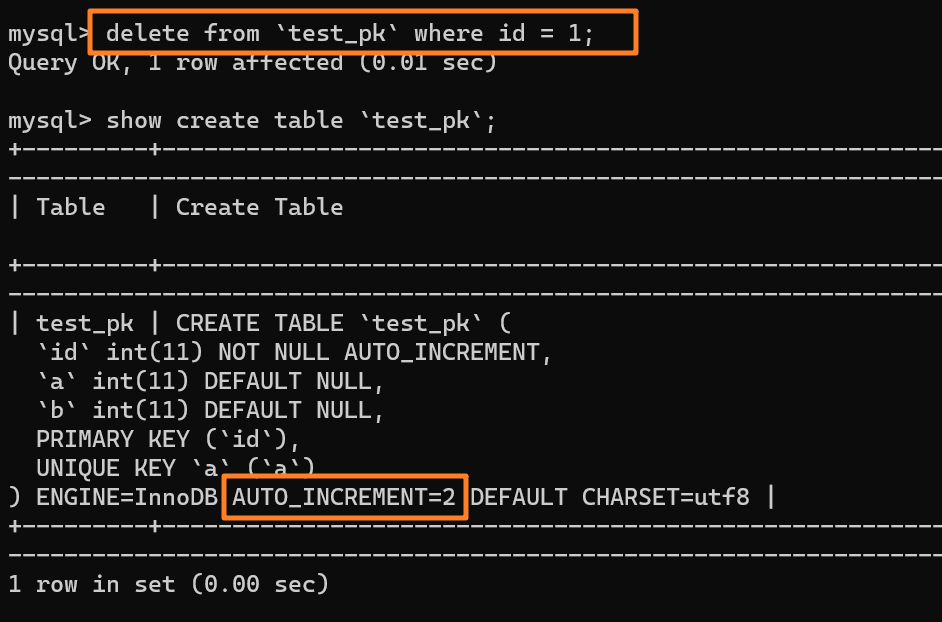
举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
-
+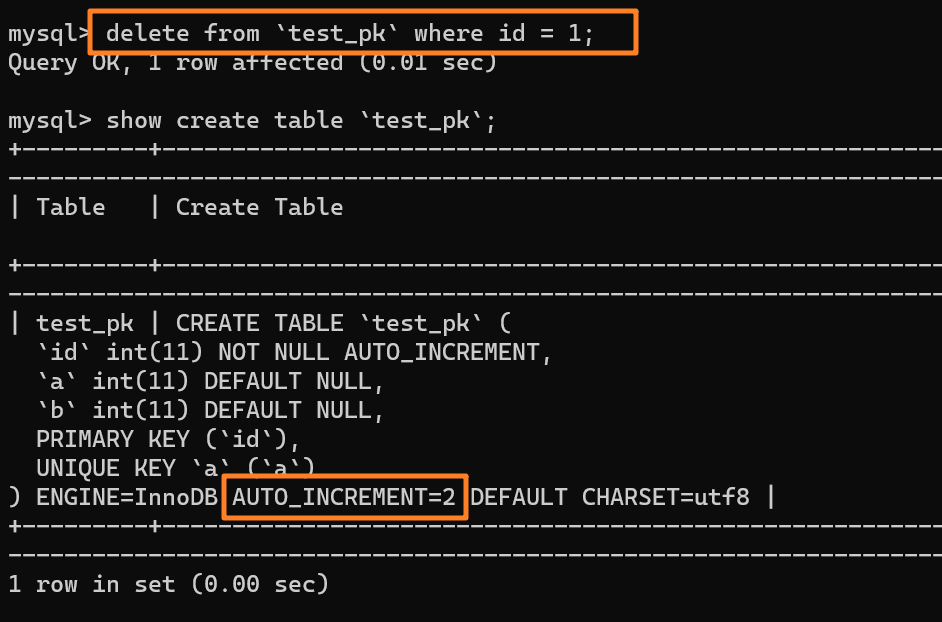
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。 也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
-
+
-
+
以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
@@ -86,11 +86,11 @@ tag:
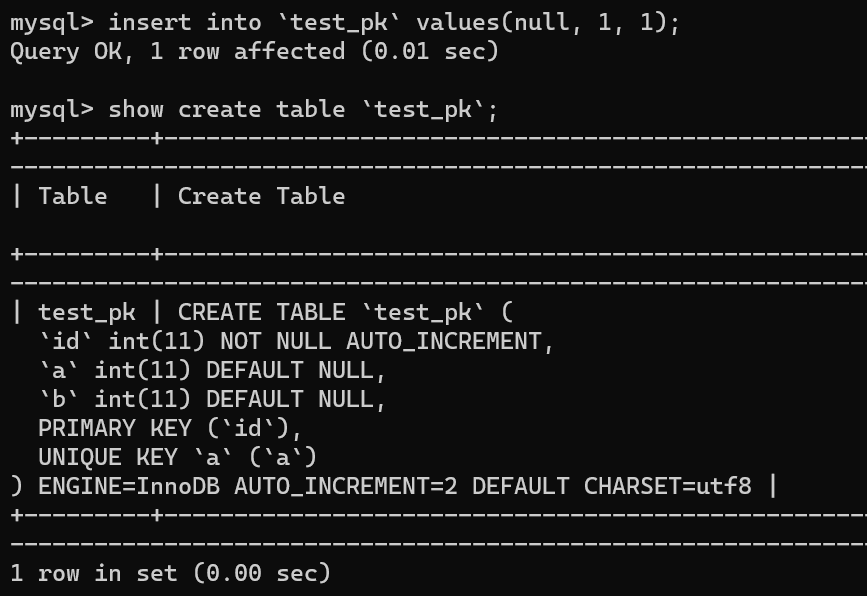
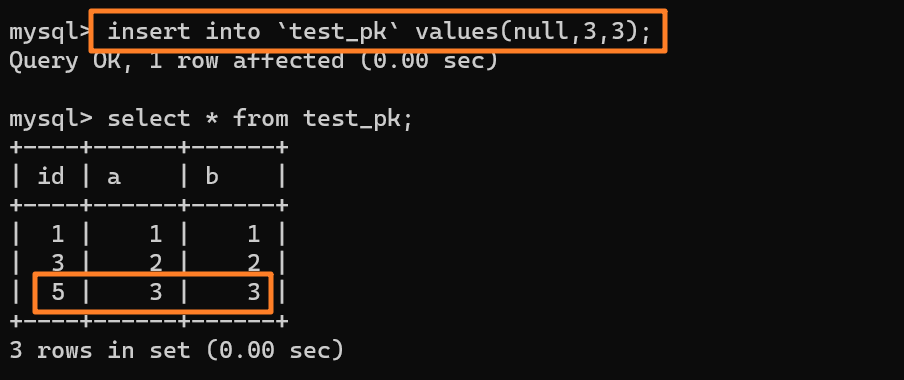
举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
-
+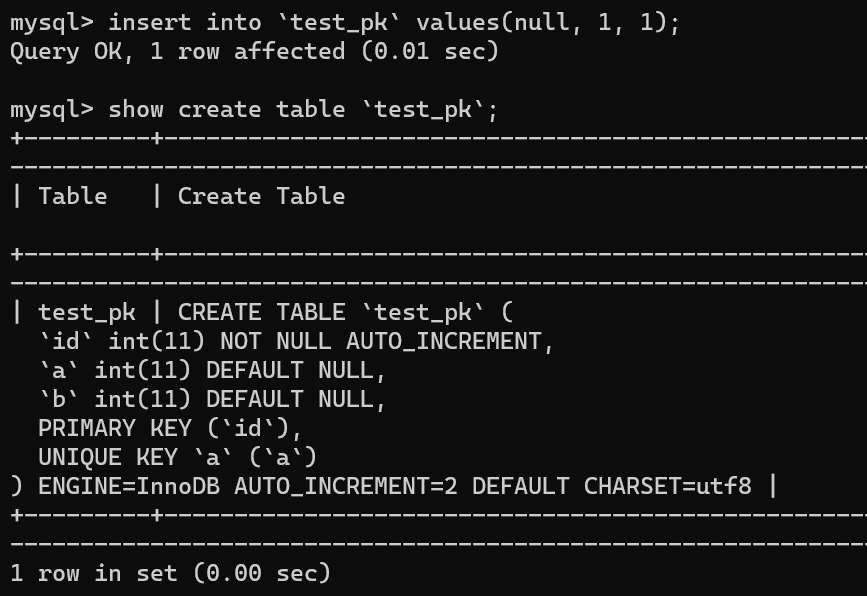
这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
-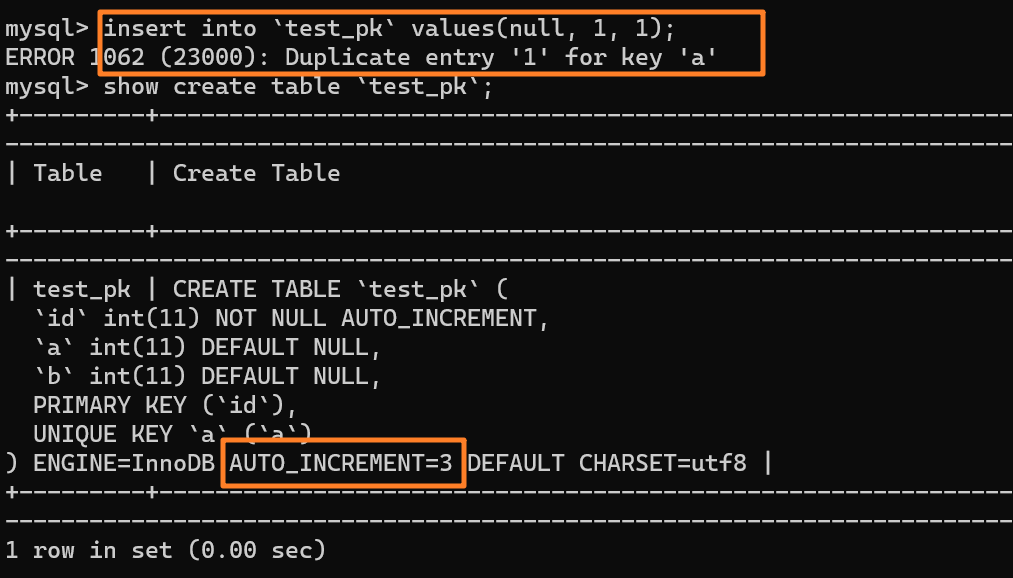
+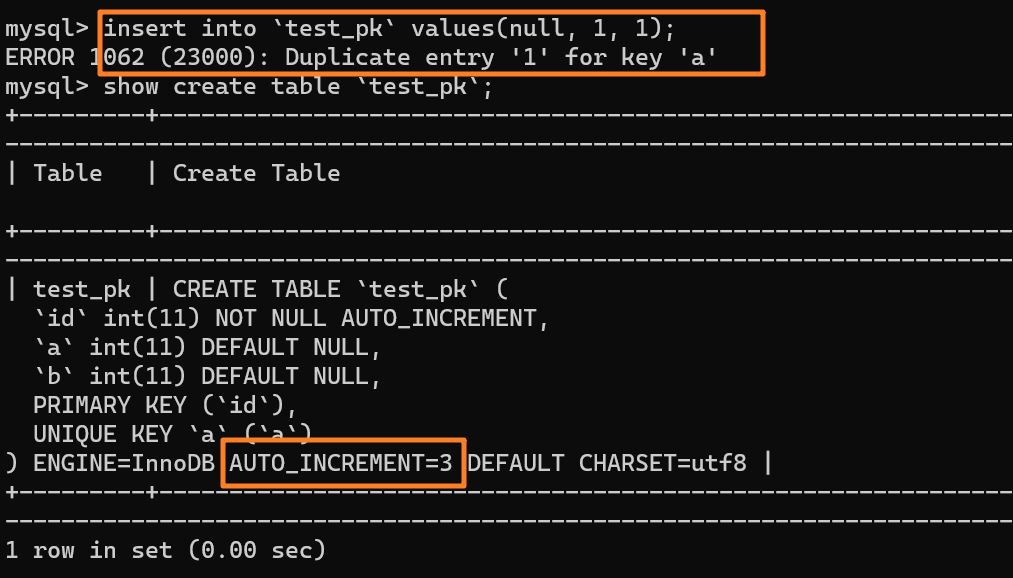
但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
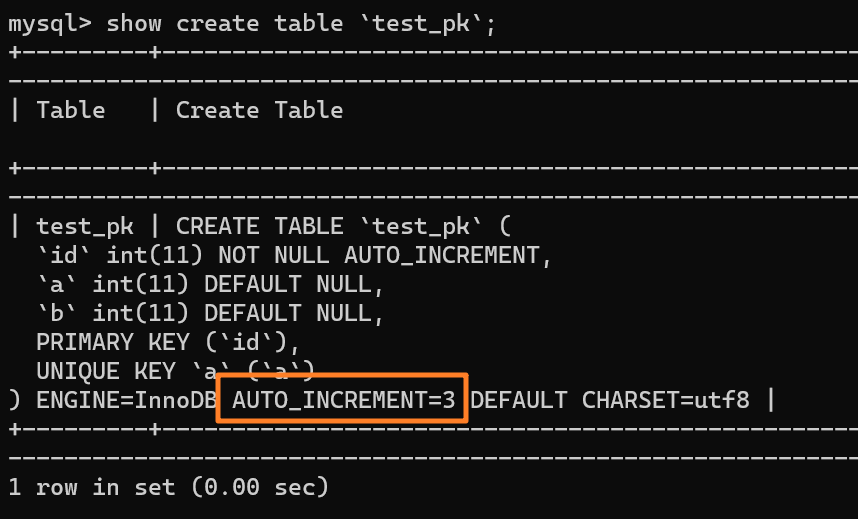
@@ -119,27 +119,27 @@ tag:
我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
-
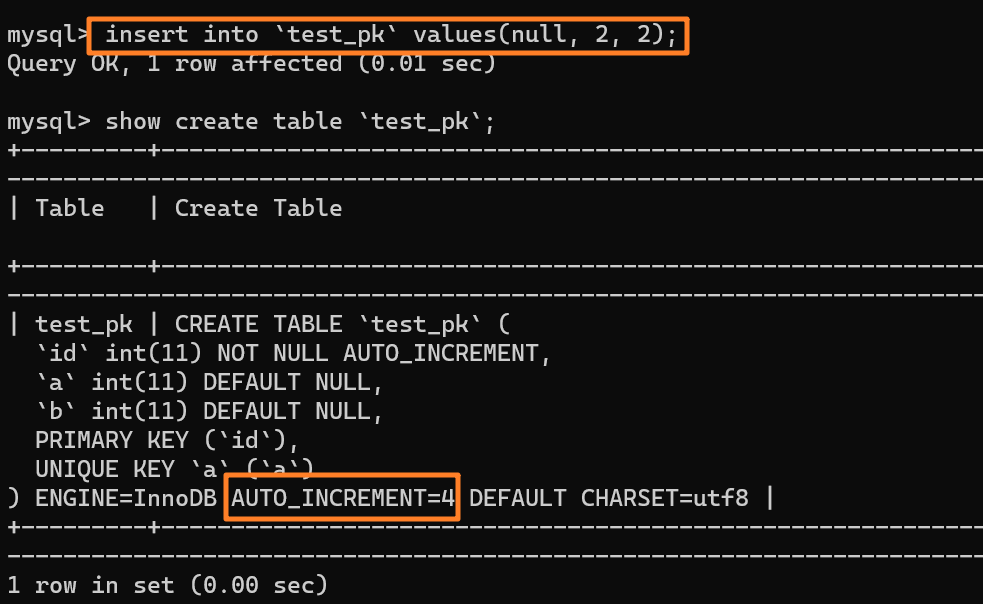
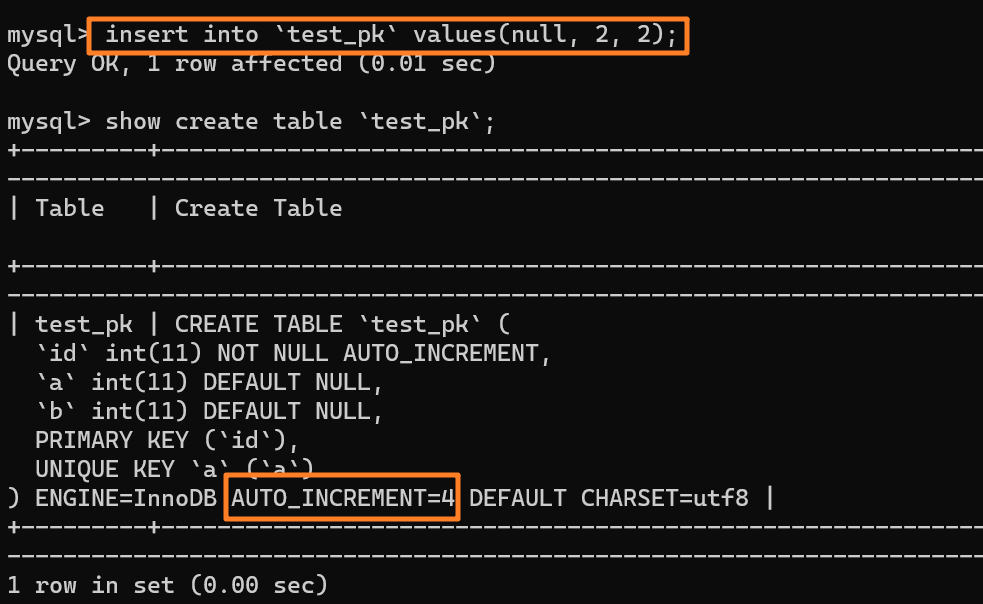
+
我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
-
+
再去执行这样一段 SQL:
-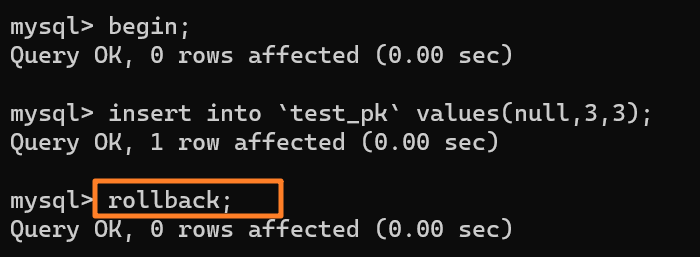
+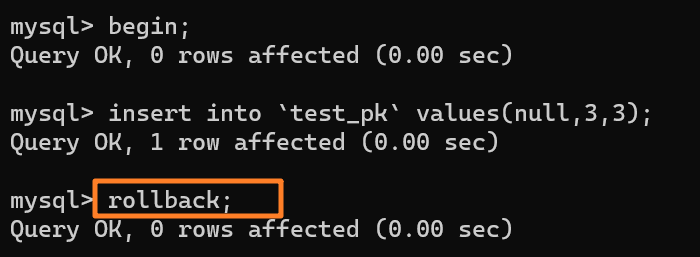
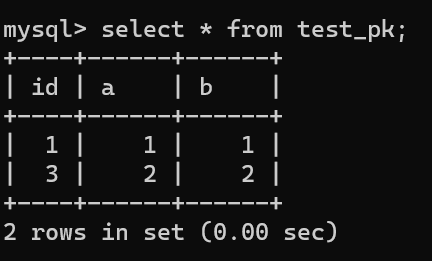
虽然我们插入了一条 (null, 3, 3) 记录,但是使用 rollback 进行回滚了,所以数据库中是没有这条记录的:
-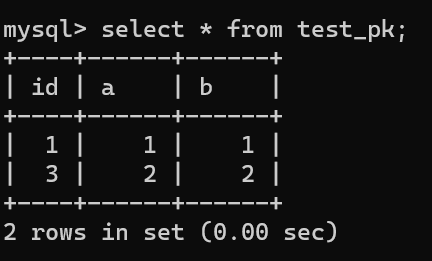
+
在这种事务回滚的情况下,自增值并没有同样发生回滚!如下图所示,自增值仍然固执地从 4 增加到了 5:
-
+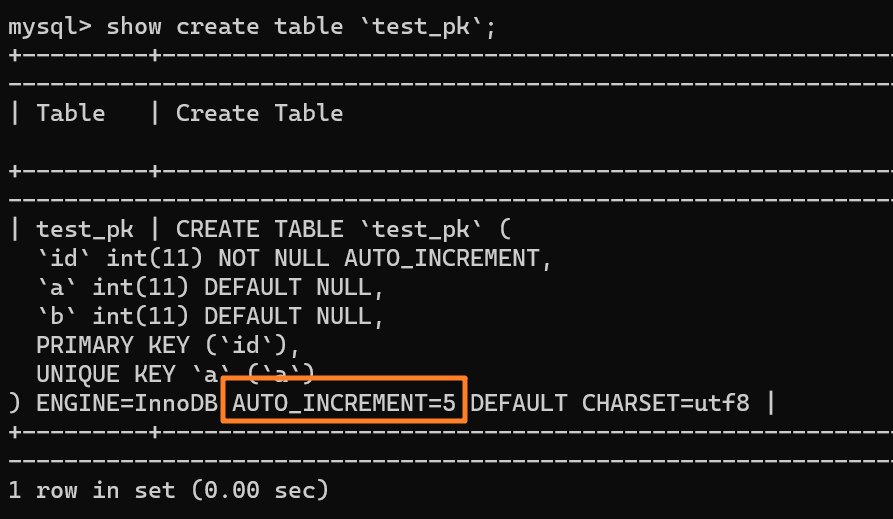
所以这时候我们再去插入一条数据(null, 3, 3)的时候,主键 id 就会被自动赋为 `5` 了:
-
+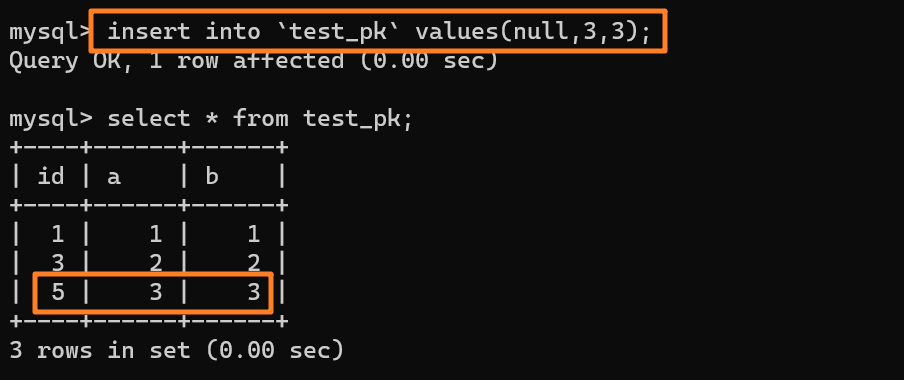
那么,为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表的自增值改回去呢?回退回去的话不就不会发生自增 id 不连续了吗?
@@ -153,7 +153,7 @@ tag:
2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。
3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。
-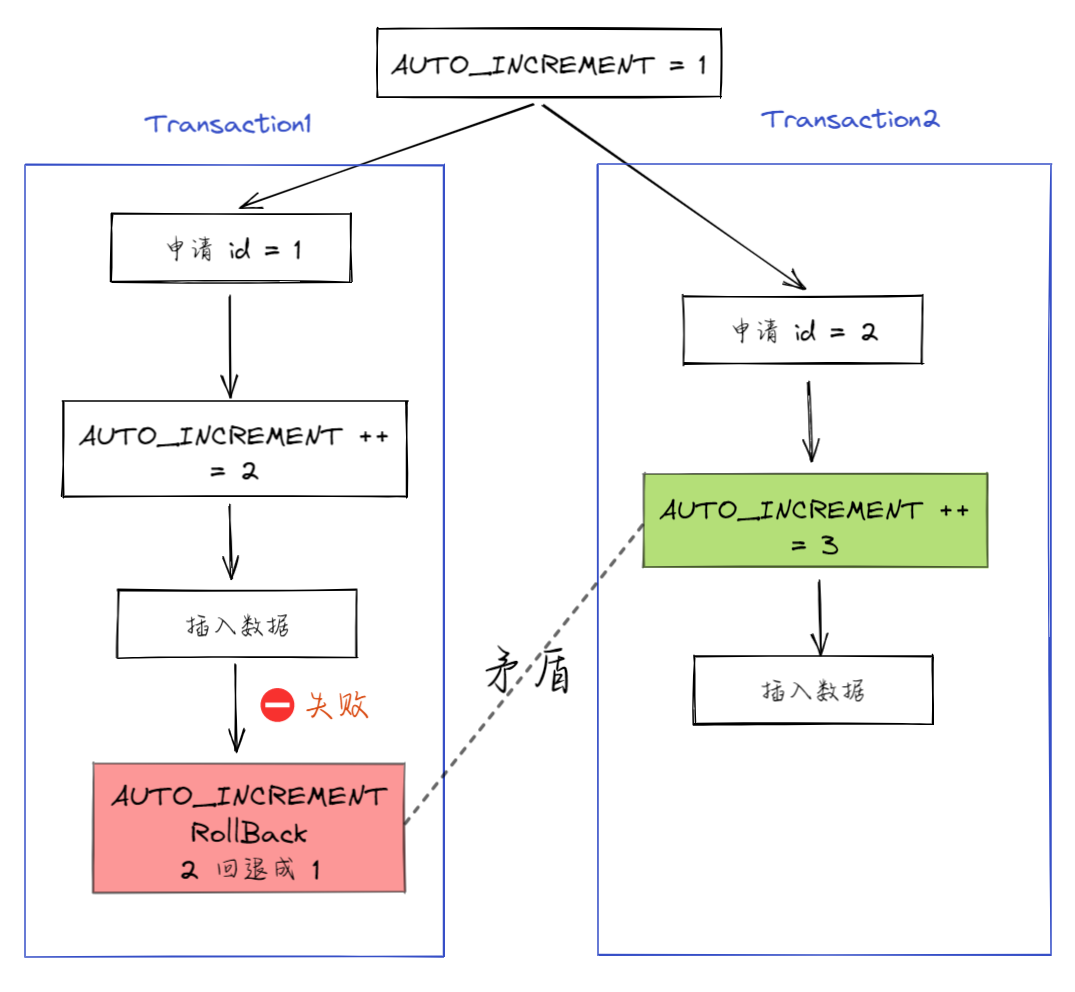
+
而为了解决这个主键冲突,有两种方法:
@@ -181,21 +181,21 @@ tag:
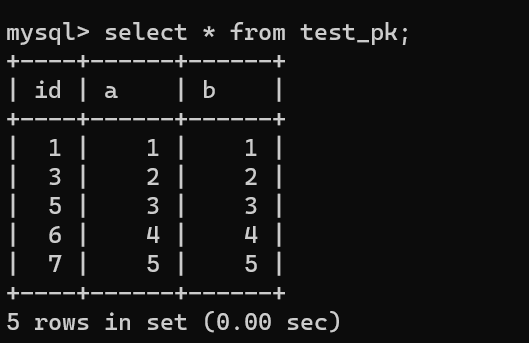
举个例子,假设我们现在这个表有下面这些数据:
-
+
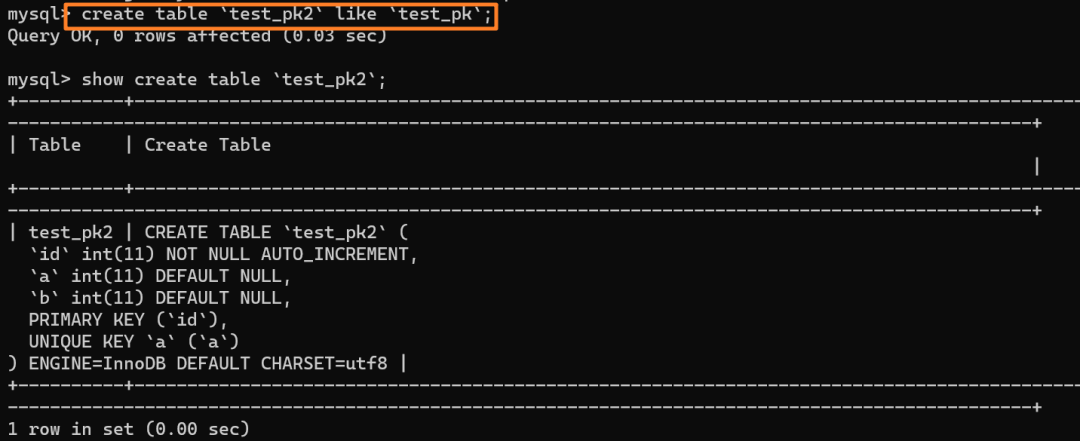
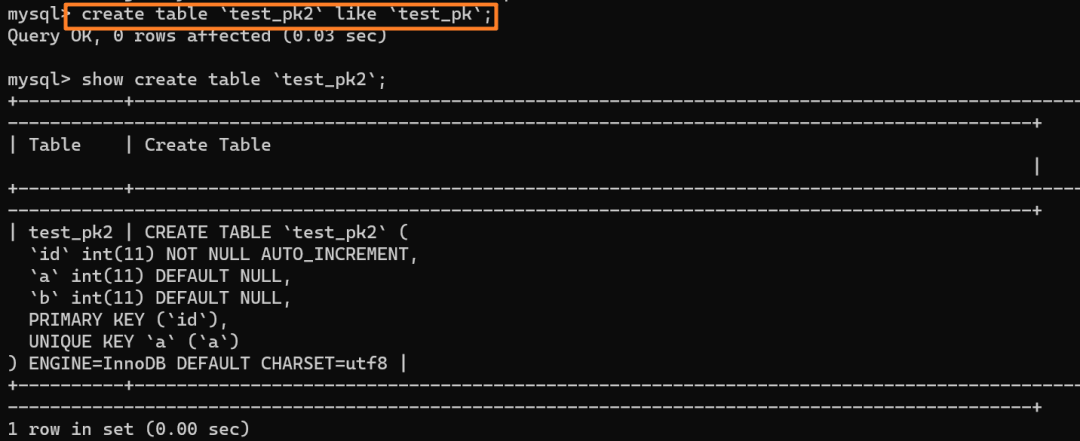
我们创建一个和当前表 `test_pk` 有相同结构定义的表 `test_pk2`:
-
+
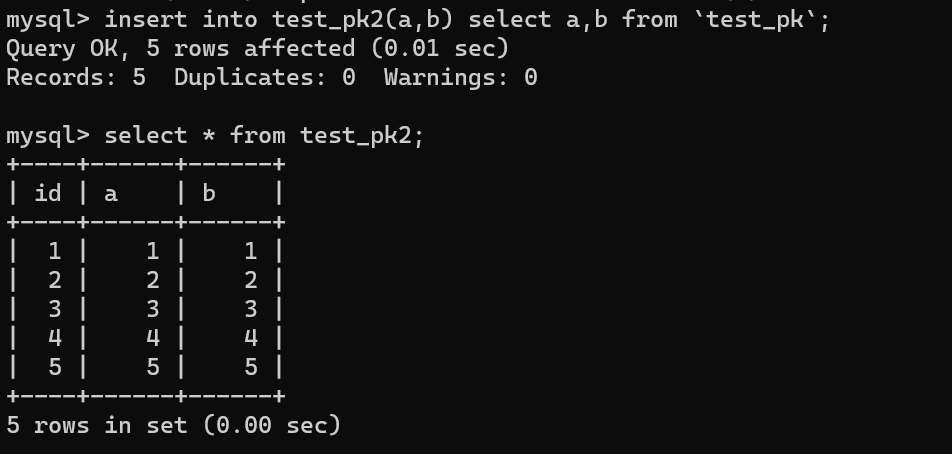
然后使用 `insert...select` 往 `teset_pk2` 表中批量插入数据:
-
+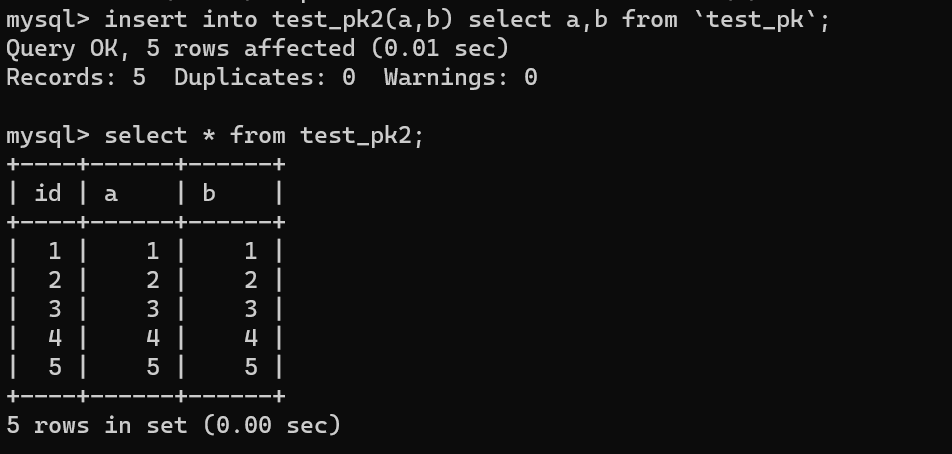
可以看到,成功导入了数据。
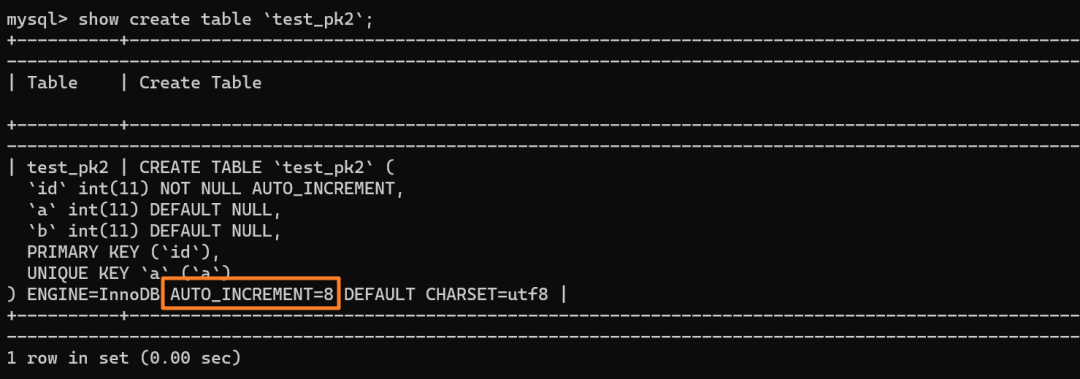
再来看下 `test_pk2` 的自增值是多少:
-
+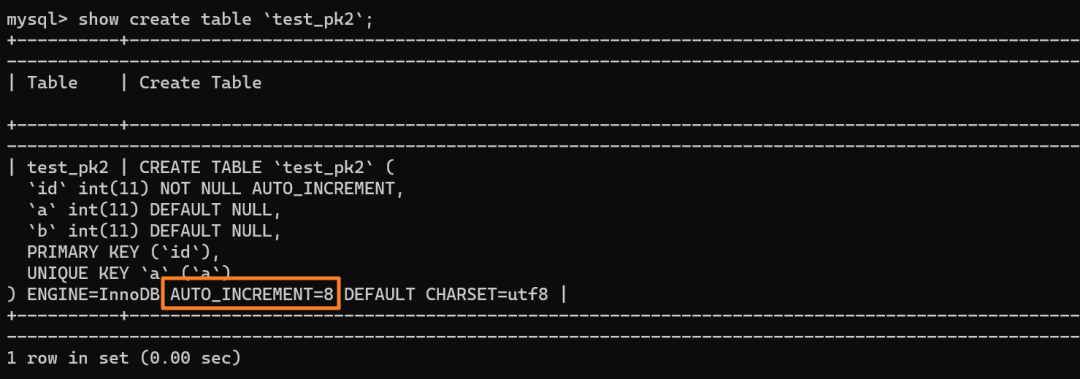
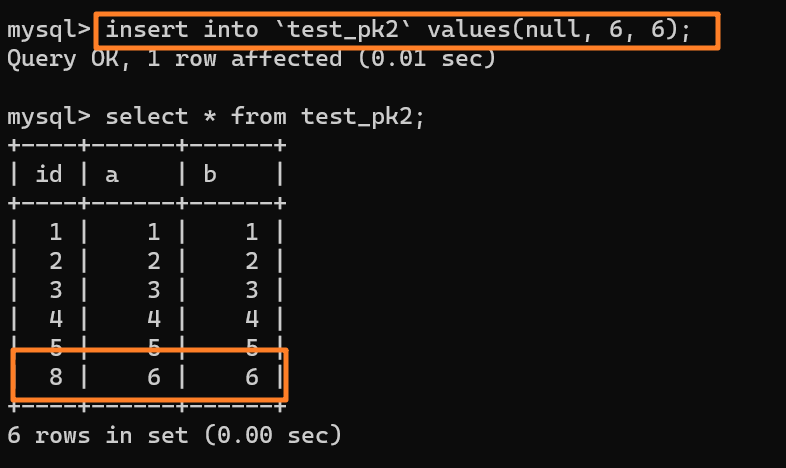
如上分析,是 8 而不是 6
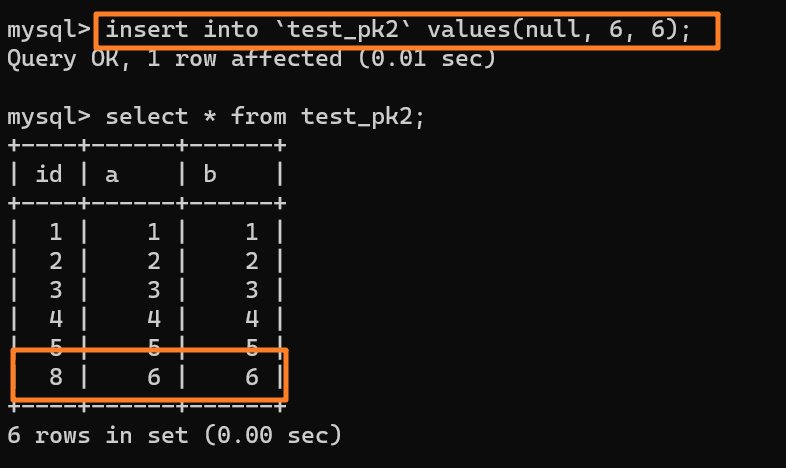
@@ -207,7 +207,7 @@ tag:
由于这条语句实际只用上了 5 个 id,所以 id=6 和 id=7 就被浪费掉了。之后,再执行 `insert into test_pk2 values(null,6,6)`,实际上插入的数据就是(8,6,6):
-
+
## 小结
diff --git a/docs/database/redis/redis-data-structures-01.md b/docs/database/redis/redis-data-structures-01.md
index 9a9ec231..c0fd83cb 100644
--- a/docs/database/redis/redis-data-structures-01.md
+++ b/docs/database/redis/redis-data-structures-01.md
@@ -178,7 +178,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
```bash
> RPUSH myList2 value1 value2 value3
(integer) 3
-> RPOP myList2 # 将 list的头部(最右边)元素取出
+> RPOP myList2 # 将 list的最右边的元素取出
"value3"
```
@@ -483,6 +483,16 @@ value1
- 举例:优先级任务队列。
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
+## 总结
+
+| 数据类型 | 说明 |
+| -------------------------------- | ------------------------------------------------- |
+| String | 一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
+| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
+| Set | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
+| Hash | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。 |
+| Zset | 和 Set 相比,Sorted Set 增加了一个权重参数 `score`,使得集合中的元素能够按 `score` 进行有序排列,还可以通过 `score` 的范围来获取元素的列表。有点像是 Java 中 `HashMap` 和 `TreeSet` 的结合体。 |
+
## 参考
- Redis Data Structures: 。
diff --git a/docs/database/redis/redis-data-structures-02.md b/docs/database/redis/redis-data-structures-02.md
index 4a1c5ad1..7b090c7d 100644
--- a/docs/database/redis/redis-data-structures-02.md
+++ b/docs/database/redis/redis-data-structures-02.md
@@ -74,7 +74,7 @@ Redis 官方文档中有对应的详细说明:

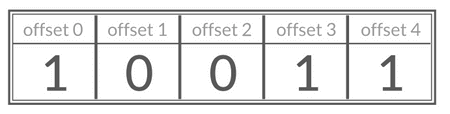
-基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` 。)。
+基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。
@@ -201,6 +201,14 @@ user2
- 举例:附近的人。
- 相关命令: `GEOADD`、`GEORADIUS`、`GEORADIUSBYMEMBER` 。
+## 总结
+
+| 数据类型 | 说明 |
+| ---------------- | ------------------------------------------------------------ |
+| Bitmap | 你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
+| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。 |
+| Geospatial index | Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。 |
+
## 参考
- Redis Data Structures:https://redis.com/redis-enterprise/data-structures/ 。
diff --git a/docs/database/sql/sql-syntax-summary.md b/docs/database/sql/sql-syntax-summary.md
index cc51b15f..6879abcd 100644
--- a/docs/database/sql/sql-syntax-summary.md
+++ b/docs/database/sql/sql-syntax-summary.md
@@ -28,7 +28,7 @@ SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,
#### SQL 语法结构
-
+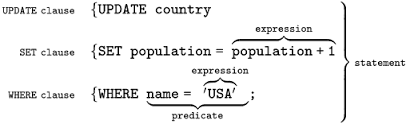
SQL 语法结构包括:
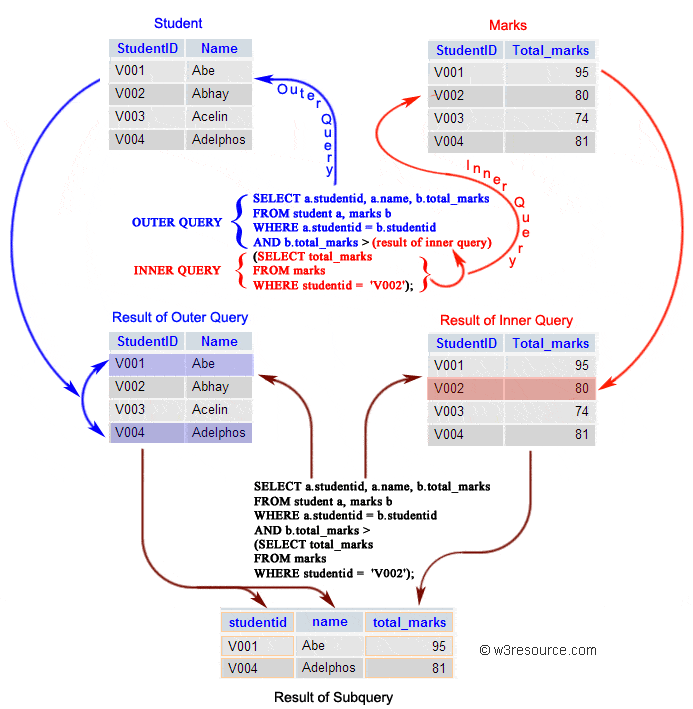
@@ -322,7 +322,7 @@ WHERE cust_id IN (SELECT cust_id
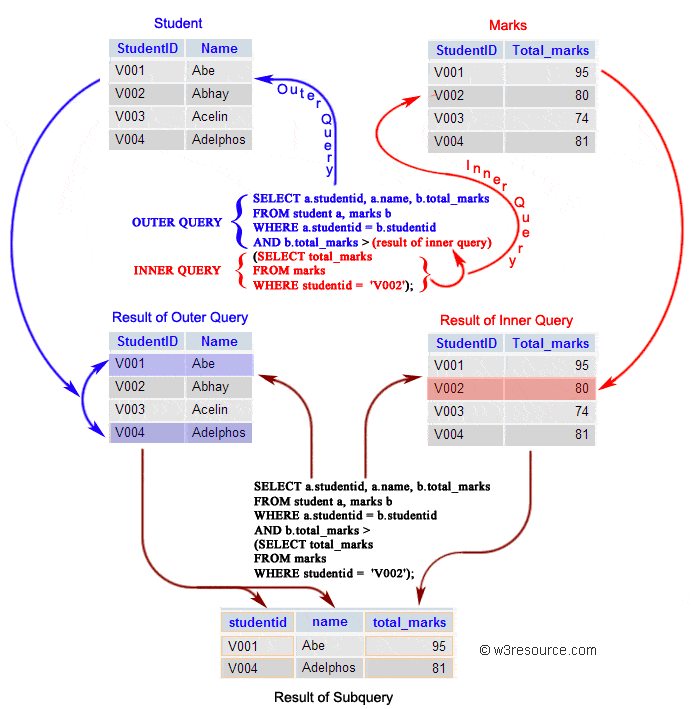
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
-
+
### WHERE
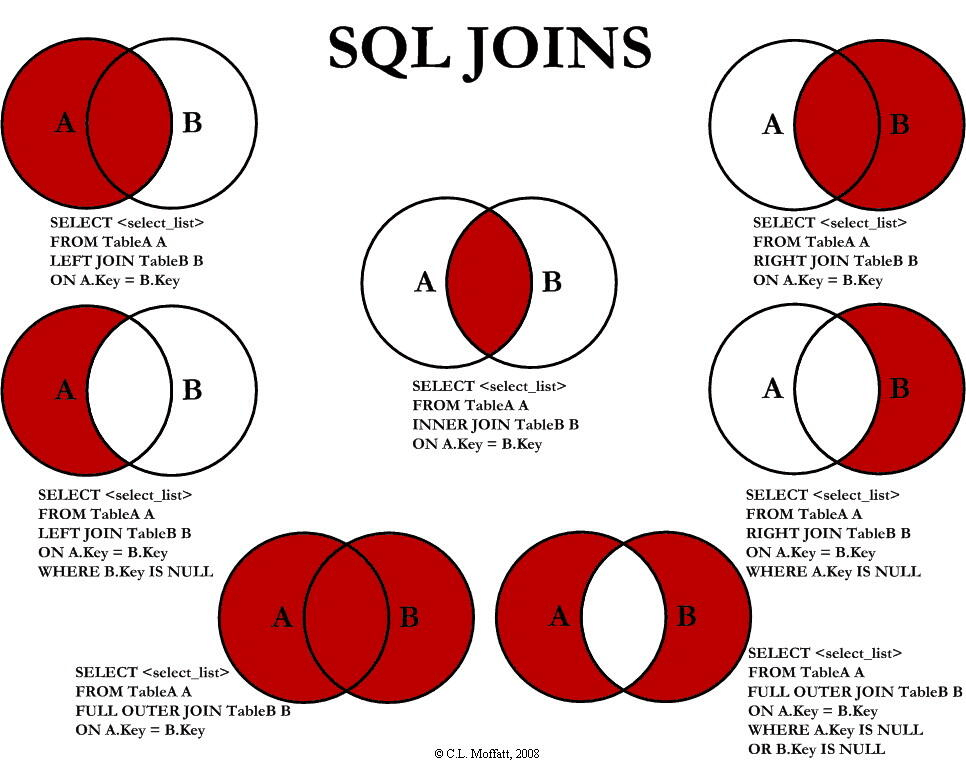
@@ -500,7 +500,7 @@ SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
-
+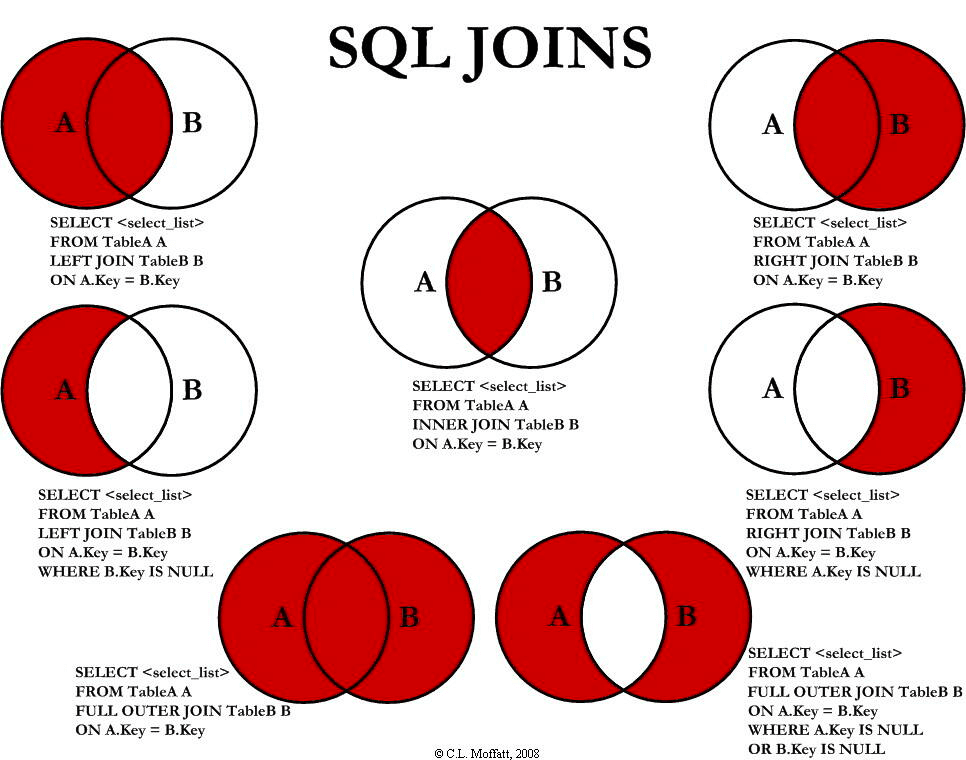
如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIIN`
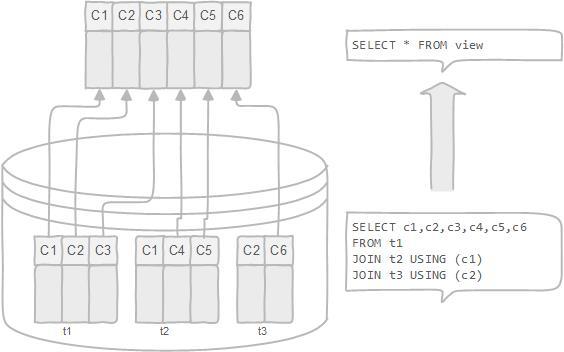
@@ -728,7 +728,7 @@ DROP PRIMARY KEY;
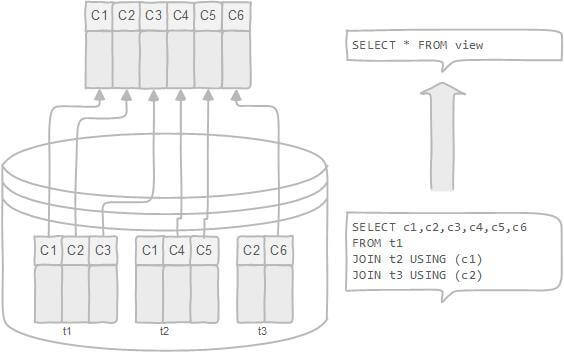
- 通过只给用户访问视图的权限,保证数据的安全性;
- 更改数据格式和表示。
-
+
#### 创建视图
@@ -1001,7 +1001,7 @@ SET PASSWORD FOR myuser = 'mypass';
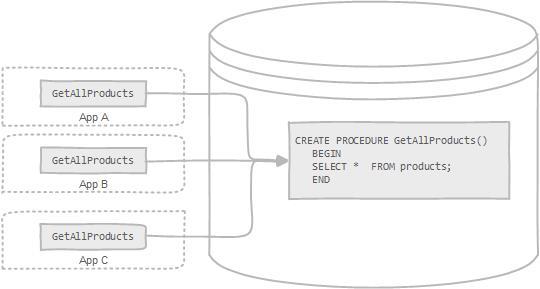
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
-
+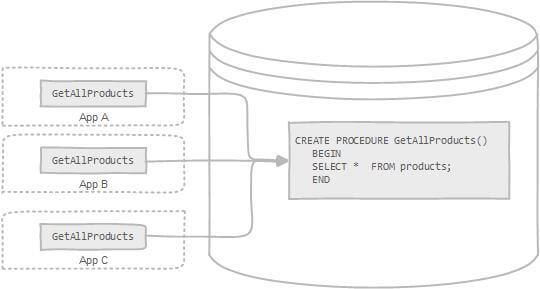
使用存储过程的好处:
@@ -1018,7 +1018,7 @@ SET PASSWORD FOR myuser = 'mypass';
需要注意的是:**阿里巴巴《Java 开发手册》强制禁止使用存储过程。因为存储过程难以调试和扩展,更没有移植性。**
-
+
至于到底要不要在项目中使用,还是要看项目实际需求,权衡好利弊即可!
diff --git a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
index f046e189..f7cbea5a 100644
--- a/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
+++ b/docs/distributed-system/distributed-process-coordination/zookeeper/zookeeper-plus.md
@@ -11,23 +11,21 @@ tag:
`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
-
-
简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
其实解释到分布式这个概念的时候,我发现有些同学并不是能把 **分布式和集群** 这两个概念很好的理解透。前段时间有同学和我探讨起分布式的东西,他说分布式不就是加机器吗?一台机器不够用再加一台抗压呗。当然加机器这种说法也无可厚非,你一个分布式系统必定涉及到多个机器,但是你别忘了,计算机学科中还有一个相似的概念—— `Cluster` ,集群不也是加机器吗?但是 集群 和 分布式 其实就是两个完全不同的概念。
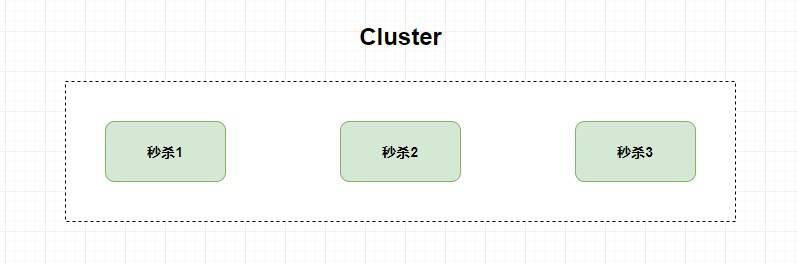
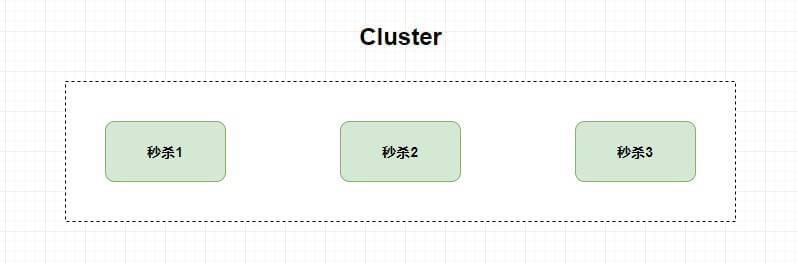
比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
-
+
但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
-
+
而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
-
+
比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
@@ -37,7 +35,7 @@ tag:
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
-
+
而上述前者就是 `Eureka` 的处理方式,它保证了 AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了 CP(数据一致性)。
@@ -47,7 +45,7 @@ tag:
这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
-
+
这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
@@ -73,11 +71,11 @@ tag:
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
-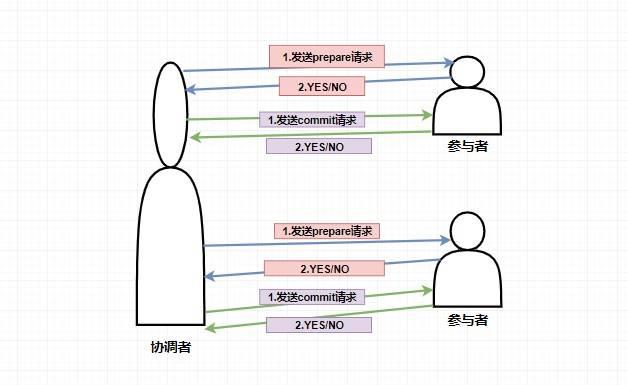
+
个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
-
+
- **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
- **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
@@ -93,7 +91,7 @@ tag:
2. **PreCommit 阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
3. **DoCommit 阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
-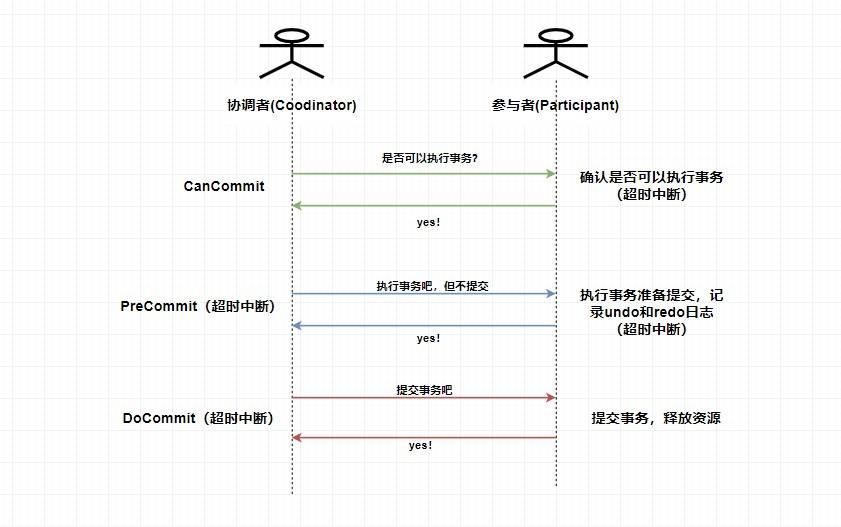
+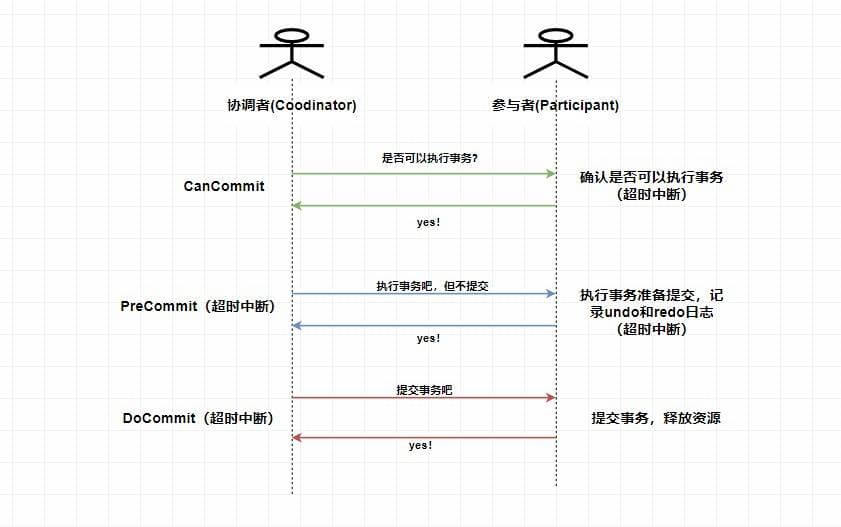
> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内未收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
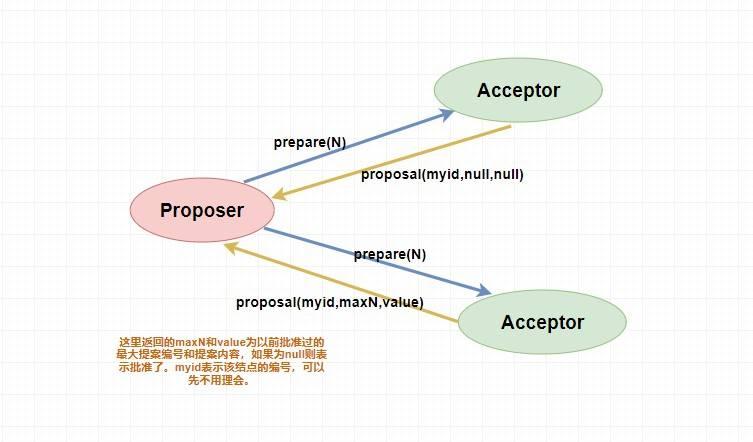
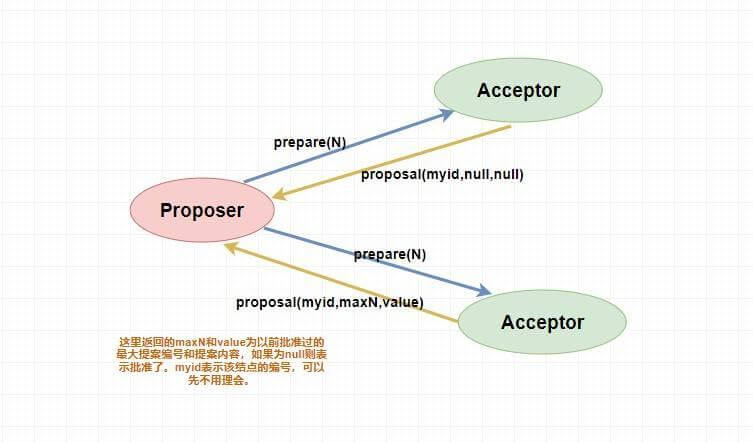
@@ -114,7 +112,7 @@ tag:
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
-
+
#### accept 阶段
@@ -122,11 +120,11 @@ tag:
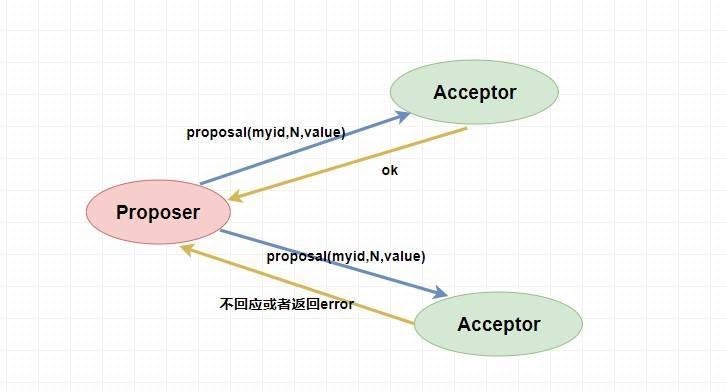
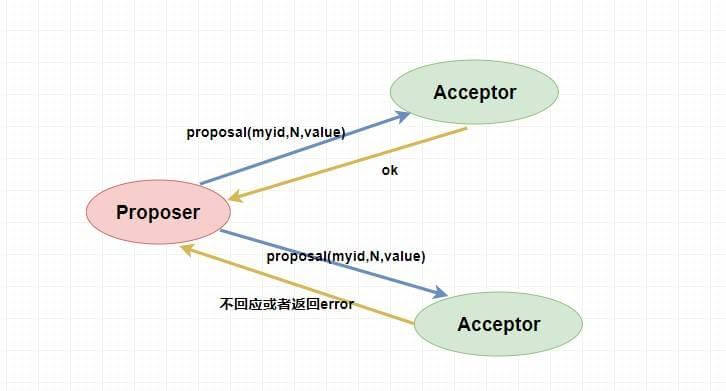
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
-
+
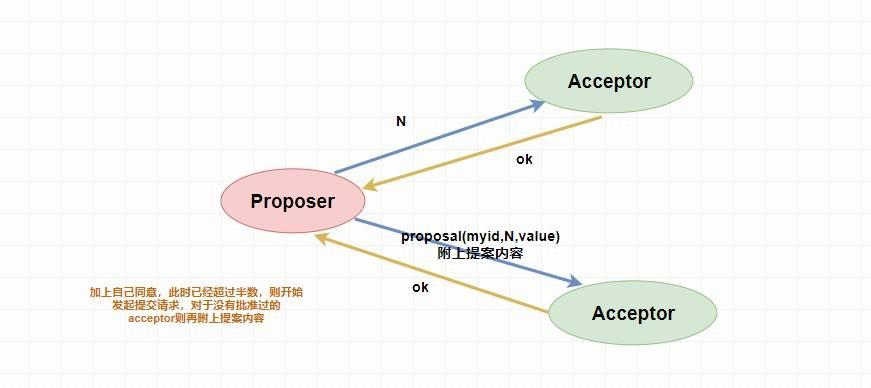
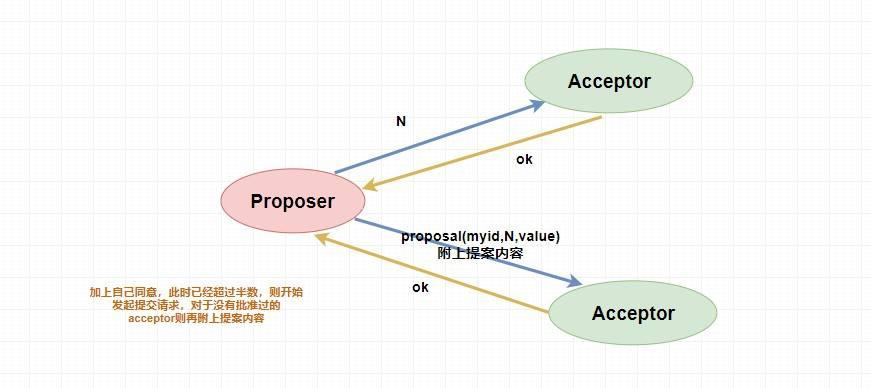
当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
-
+
而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
@@ -140,7 +138,7 @@ tag:
就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
-
+
那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
@@ -150,7 +148,7 @@ tag:
作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
-
+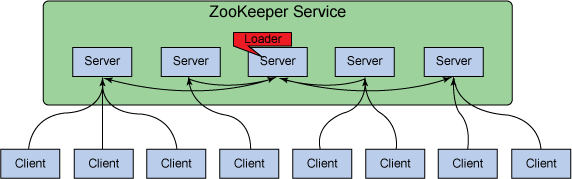
### ZAB 中的三个角色
@@ -168,11 +166,9 @@ tag:
不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
-
-
废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
-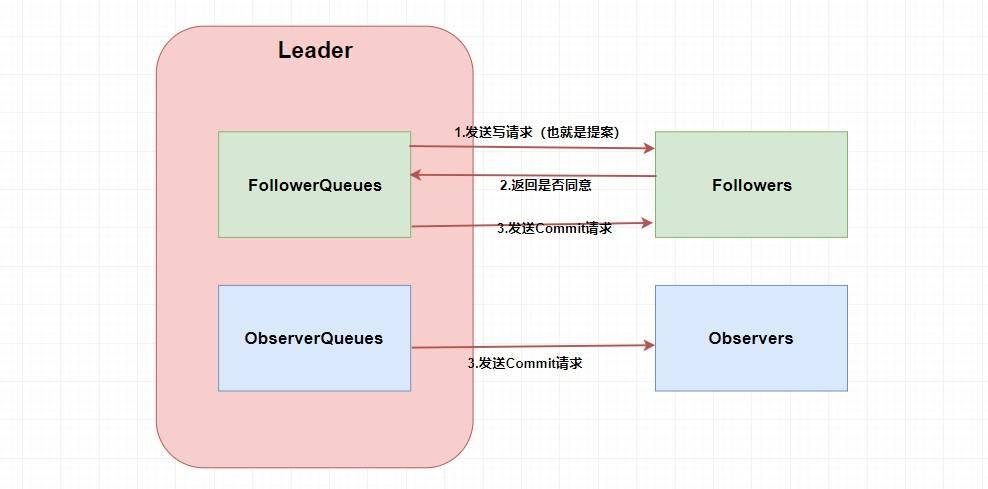
+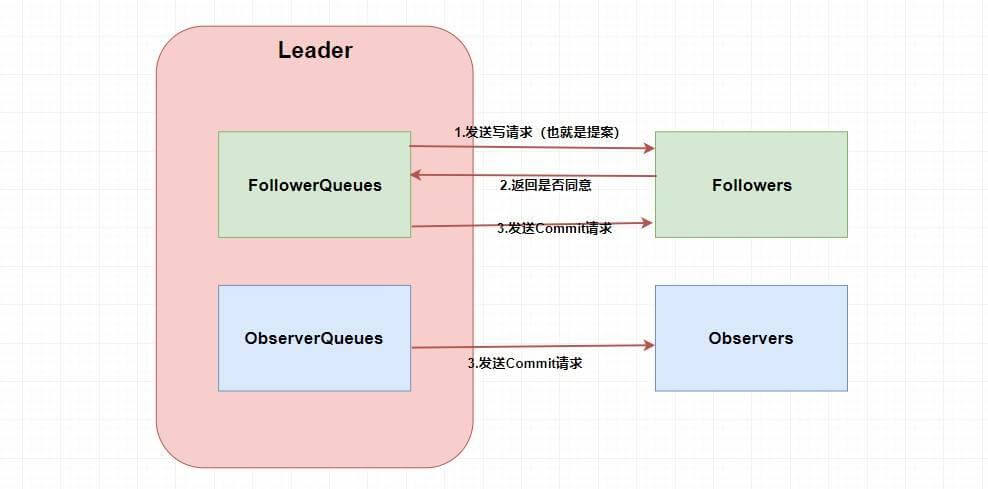
嗯。。。看起来很简单,貌似懂了 🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求 A,此时 `Leader` 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1 因为网络原因没有收到,而 `Leader` 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
@@ -214,7 +210,7 @@ tag:
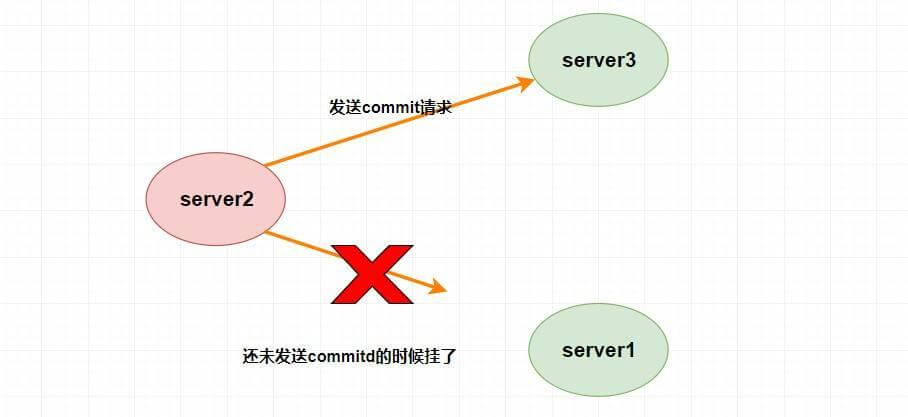
假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
-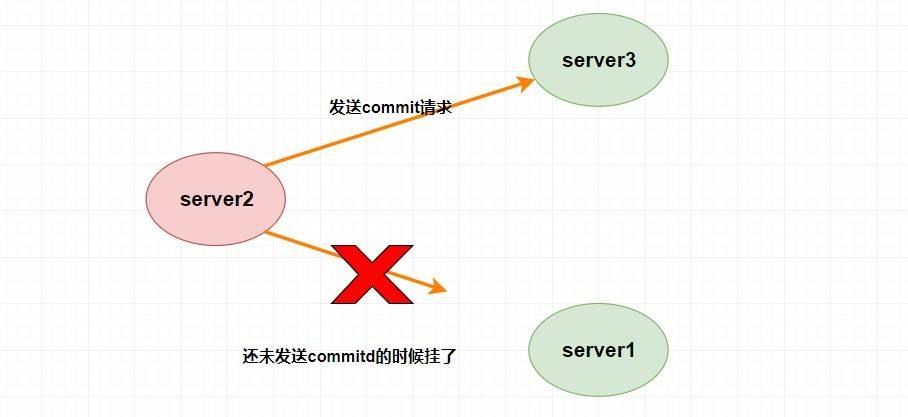
+
那怎么解决呢?
@@ -224,7 +220,7 @@ tag:
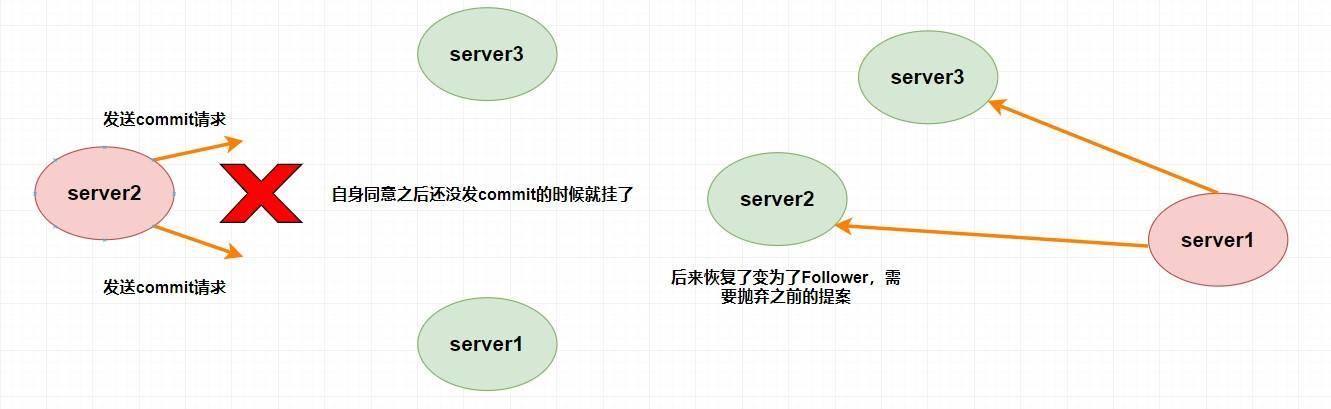
假设 `Leader (server2)` 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案 N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 **该提案 N1 最终需要被抛弃掉** 。
-
+
## Zookeeper 的几个理论知识
@@ -236,7 +232,7 @@ tag:
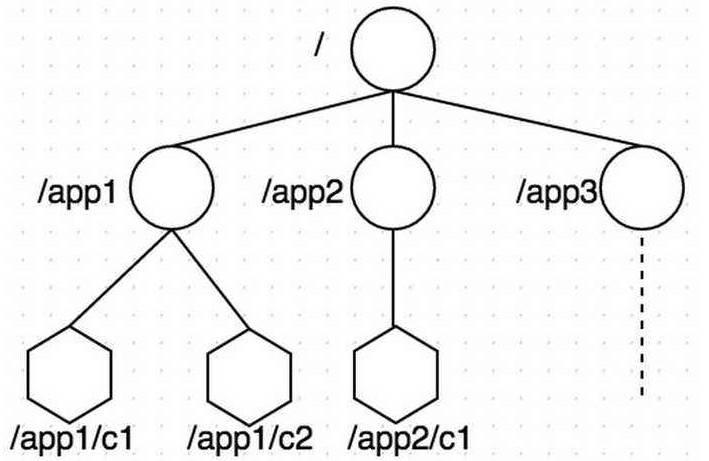
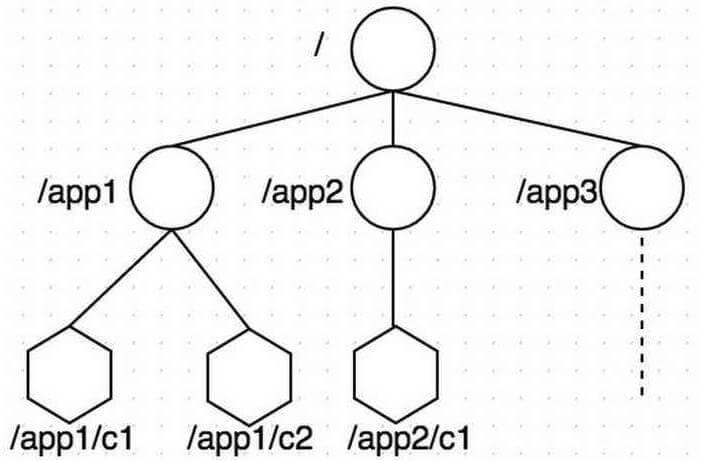
`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
-
+
每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
@@ -281,13 +277,13 @@ tag:
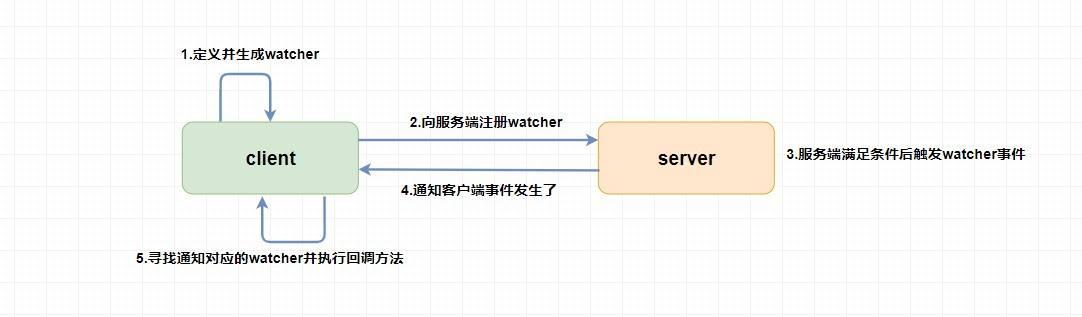
`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
-
+
## Zookeeper 的几个典型应用场景
前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
-
+
### 选主
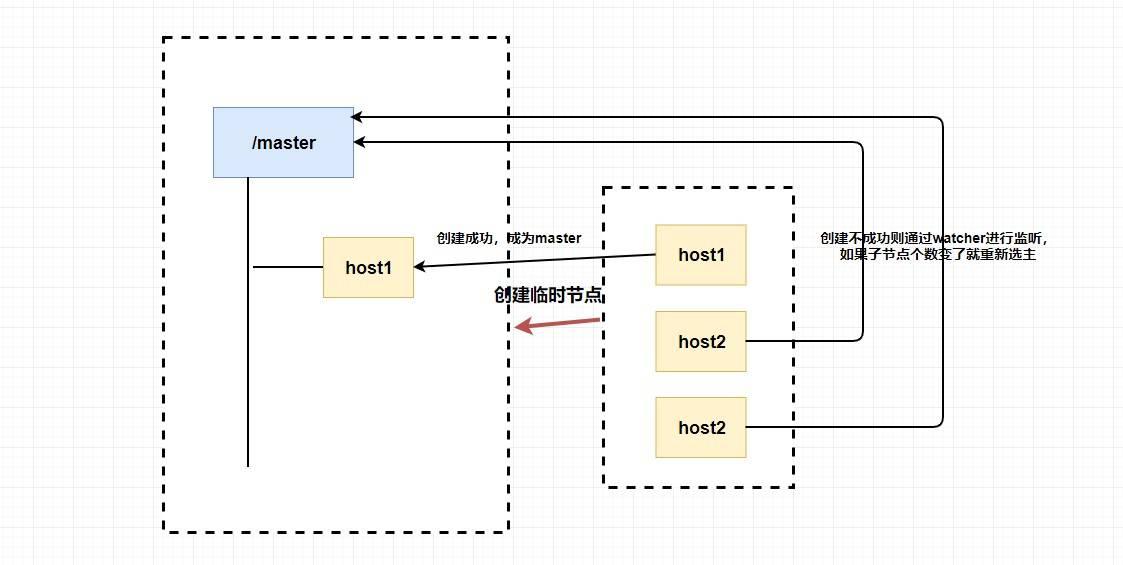
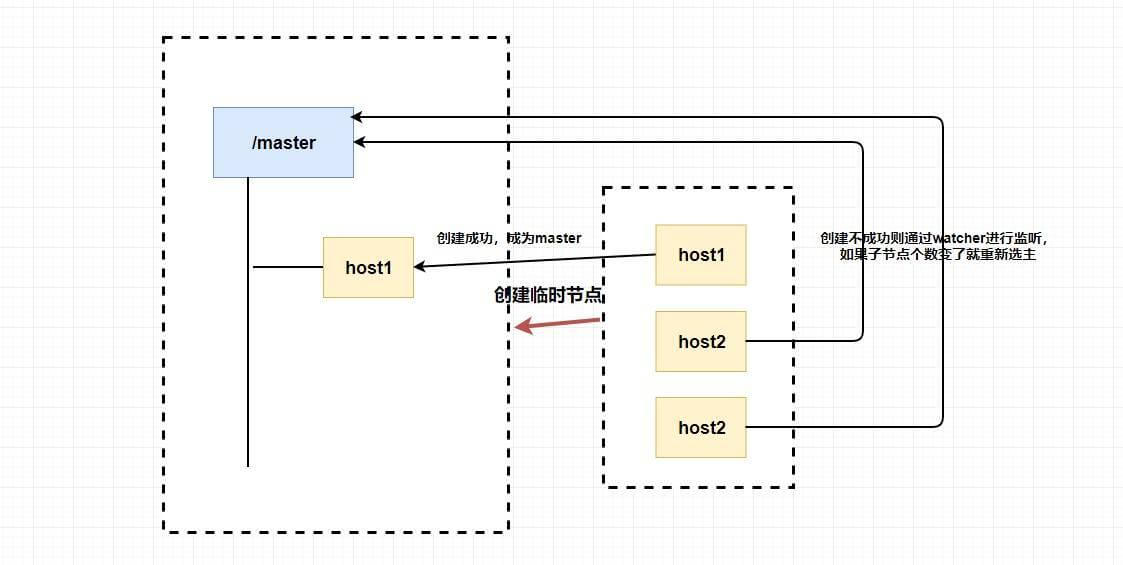
@@ -299,7 +295,7 @@ tag:
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
-
+
总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
@@ -341,19 +337,19 @@ tag:
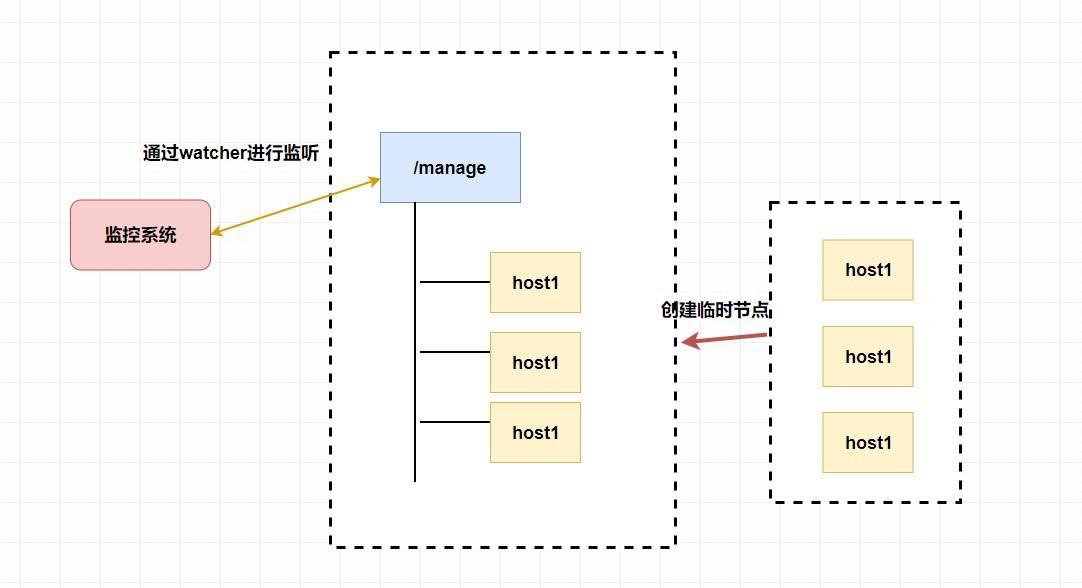
而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
-
+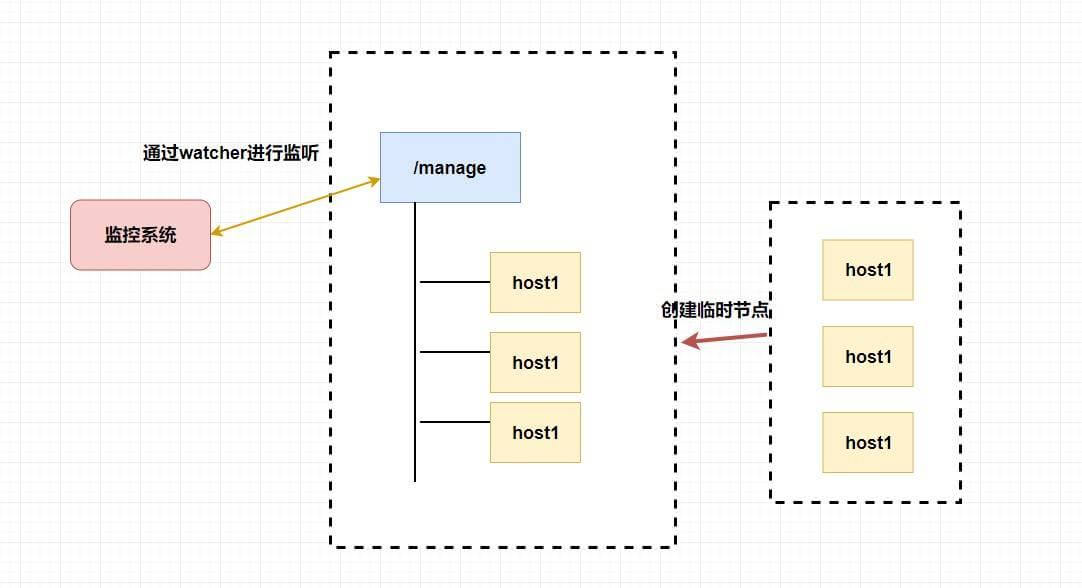
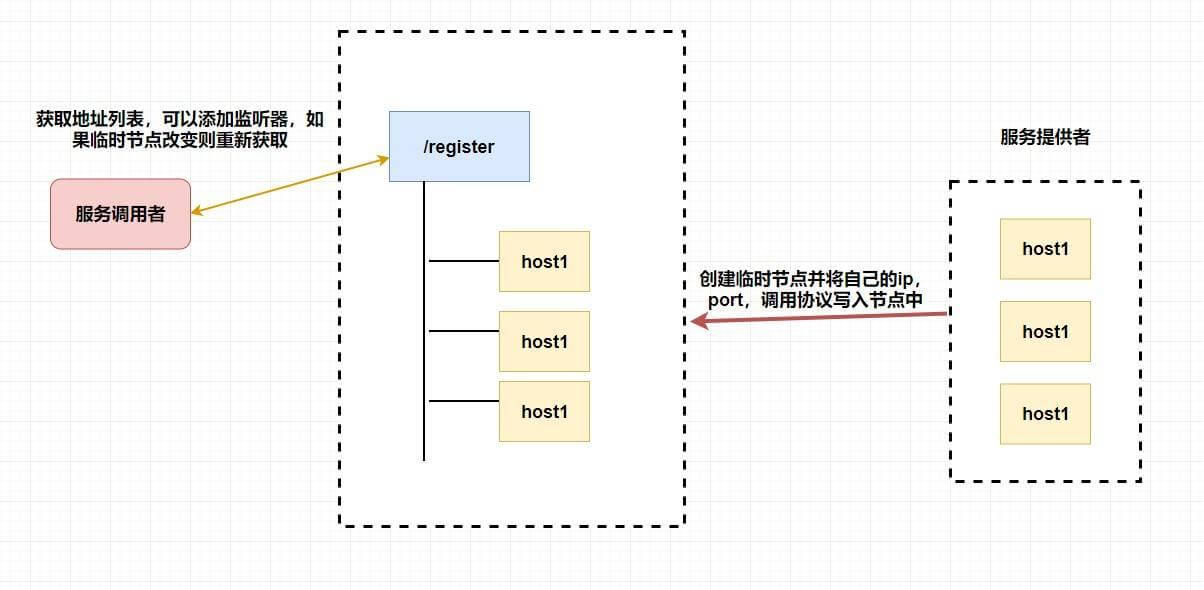
至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP 端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
-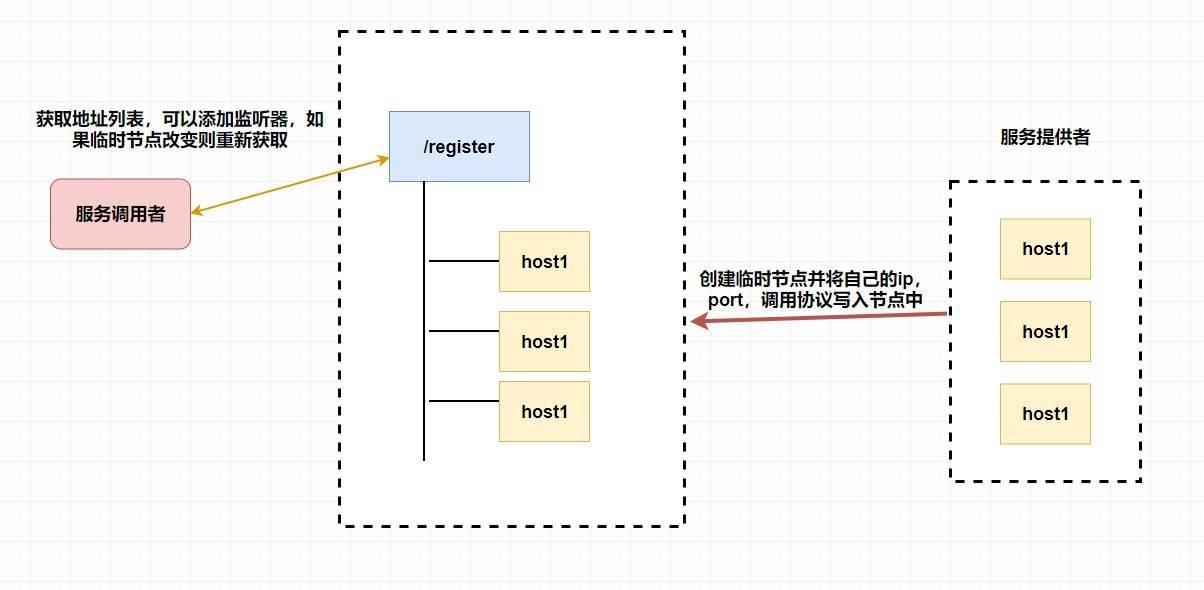
+
## 总结
看到这里的同学实在是太有耐心了 👍👍👍 不知道大家是否还记得我讲了什么 😒。
-
+
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
diff --git a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
index 19822da6..2565f5f5 100644
--- a/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
+++ b/docs/high-quality-technical-articles/advanced-programmer/the-growth-strategy-of-the-technological-giant.md
@@ -148,7 +148,7 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
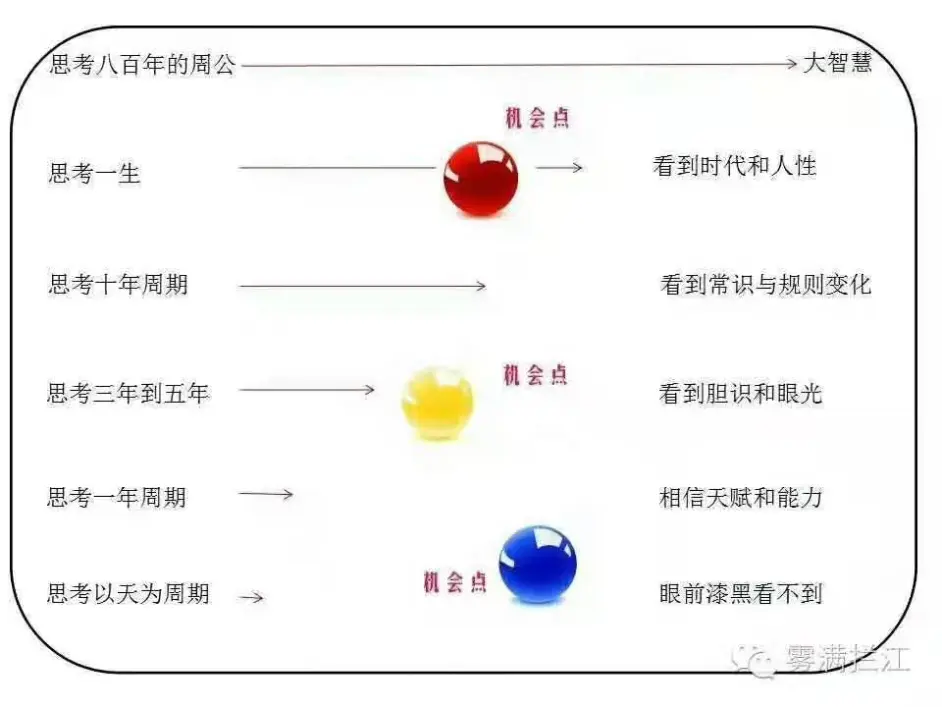
## 四、战略思维的诞生
-
+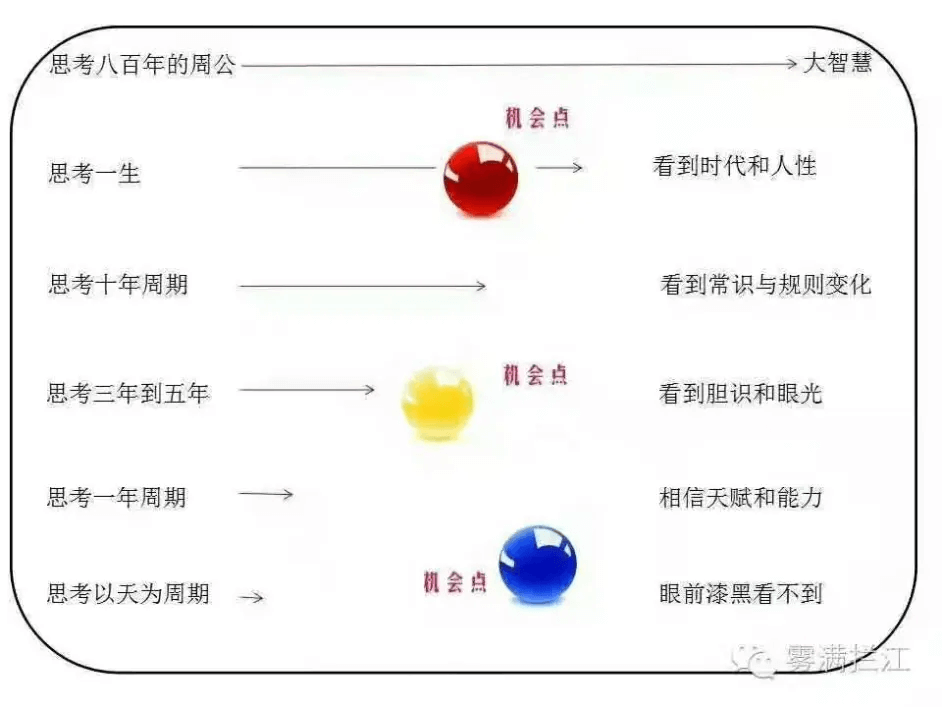
一般毕业生刚进入企业工作的时候,思考大都是以天/星期/月为单位的,基本上都是今天学个什么技术,明天学个什么语言,很少会去思考一年甚至更长的目标。这是个眼前漆黑看不到的懵懂时期,捕捉到机会点的能力和概率都非常小。
@@ -203,5 +203,3 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
> 译文:
>
> 实现战略目标,就像种树一样。刚开始只是一个小根芽,树干还没有长出来;树干长出来了,枝叶才能慢慢长出来;树枝长出来,然后才能开花和结果。刚开始种树的时候,只管栽培灌溉,别老是纠结枝什么时候长出来,花什么时候开,果实什么时候结出来。纠结有什么好处呢?只要你坚持投入栽培,还怕没有枝叶花实吗?
-
-
diff --git a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
index 17644017..1d4ca463 100644
--- a/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
+++ b/docs/high-quality-technical-articles/interview/summary-of-spring-recruitment.md
@@ -57,7 +57,7 @@ tag:
更多书籍推荐建议大家看 [JavaGuide](https://javaguide.cn/books/) 这个网站上的书籍推荐,比较全面。
-
+
### 教程推荐
diff --git a/docs/java/concurrent/java-concurrent-questions-03.md b/docs/java/concurrent/java-concurrent-questions-03.md
index 5f189376..91a5e442 100644
--- a/docs/java/concurrent/java-concurrent-questions-03.md
+++ b/docs/java/concurrent/java-concurrent-questions-03.md
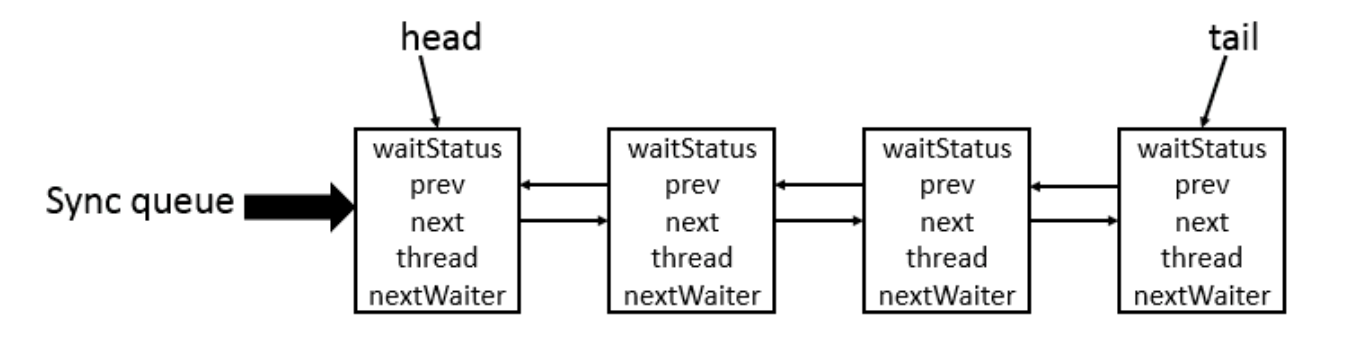
@@ -600,7 +600,7 @@ CLH(Craig,Landin,and Hagersten) 队列是一个虚拟的双向队列(虚拟的
CLH 队列结构如下图所示:
-
+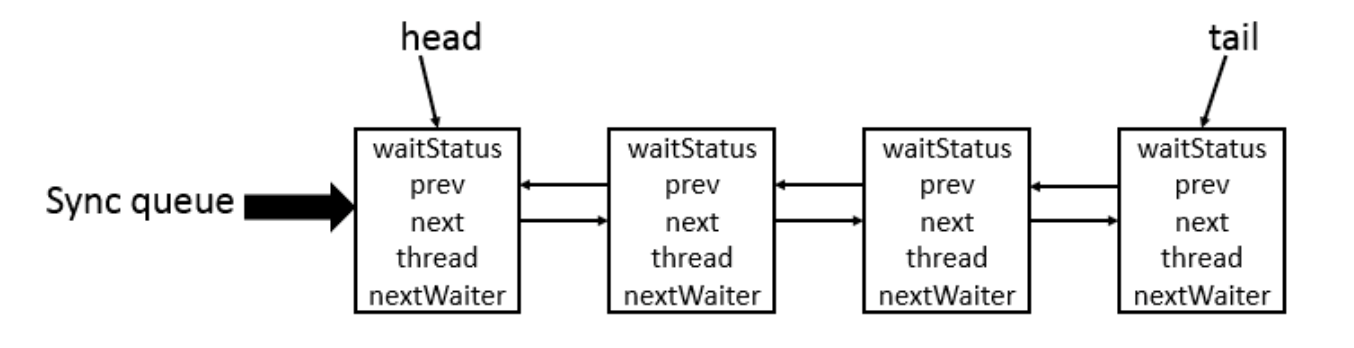
AQS(`AbstractQueuedSynchronizer`)的核心原理图(图源[Java 并发之 AQS 详解](https://www.cnblogs.com/waterystone/p/4920797.html))如下:
diff --git a/docs/java/io/io-model.md b/docs/java/io/io-model.md
index 9c37d760..03ca308e 100644
--- a/docs/java/io/io-model.md
+++ b/docs/java/io/io-model.md
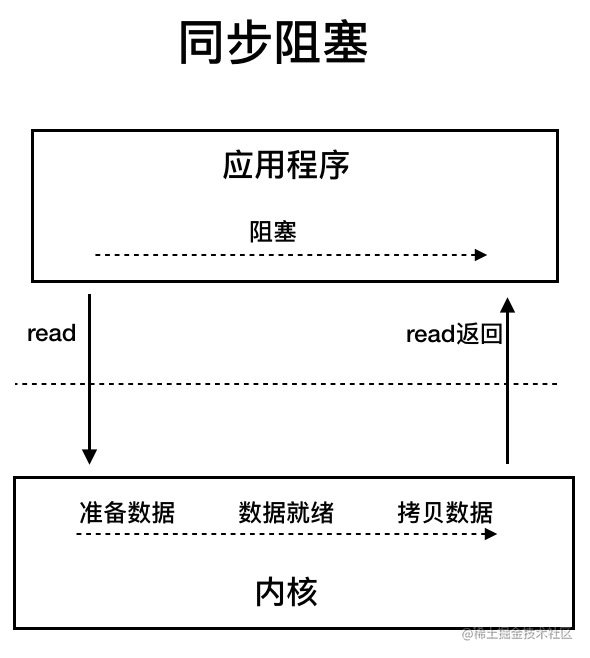
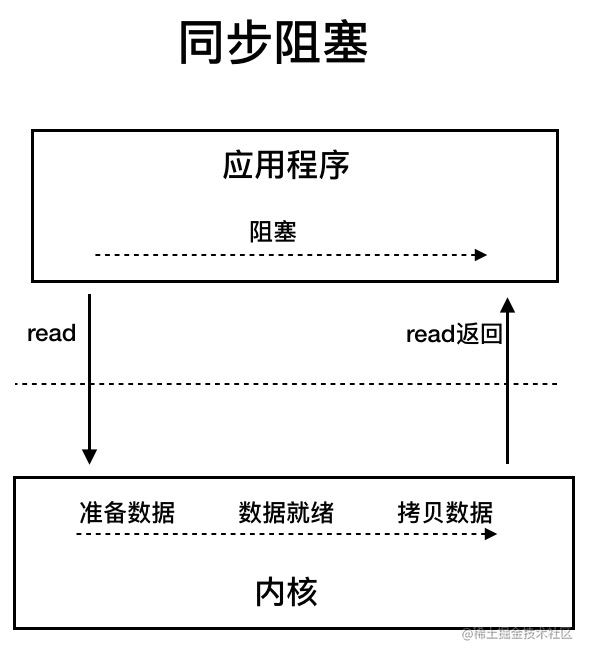
@@ -67,7 +67,7 @@ UNIX 系统下, IO 模型一共有 5 种:**同步阻塞 I/O**、**同步非
同步阻塞 IO 模型中,应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。
-
+
在客户端连接数量不高的情况下,是没问题的。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
@@ -81,7 +81,7 @@ Java 中的 NIO 可以看作是 **I/O 多路复用模型**。也有很多人认
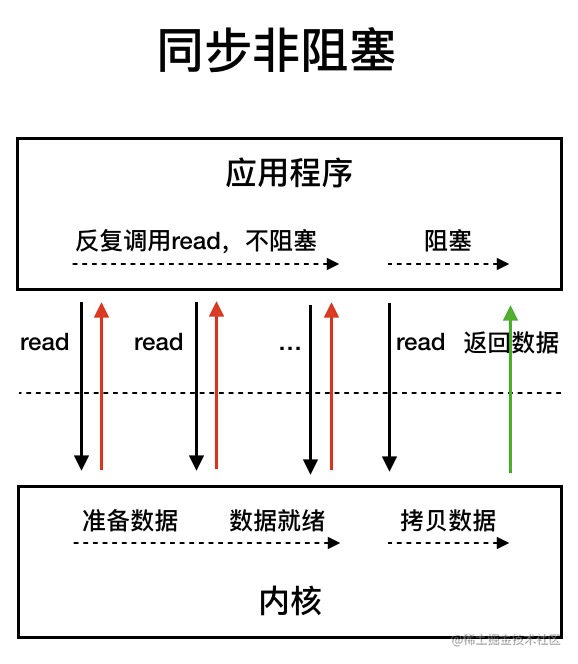
我们先来看看 **同步非阻塞 IO 模型**。
-
+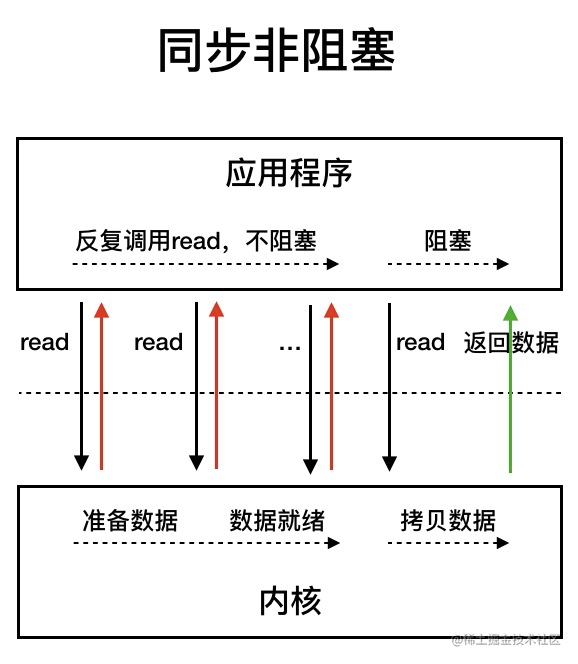
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
diff --git a/docs/java/io/nio-basis.md b/docs/java/io/nio-basis.md
index a3ae07a3..e4e79ddc 100644
--- a/docs/java/io/nio-basis.md
+++ b/docs/java/io/nio-basis.md
@@ -191,8 +191,8 @@ Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中
Channel 最核心的两个方法:
-1. `read` :用于从 Buffer 中读取数据;
-2. `write` :向 Buffer 中写入数据。
+1. `read` :读取数据并写入到 Buffer 中。
+2. `write` :将 Buffer 中的数据写入到 Channel 中。
这里我们以 `FileChannel` 为例演示一下是读取文件数据的。
diff --git a/docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md b/docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md
index 08dc8625..7a982850 100644
--- a/docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md
+++ b/docs/system-design/framework/spring/spring-boot-auto-assembly-principles.md
@@ -125,7 +125,7 @@ public @interface SpringBootConfiguration {
- `@Configuration`:允许在上下文中注册额外的 bean 或导入其他配置类
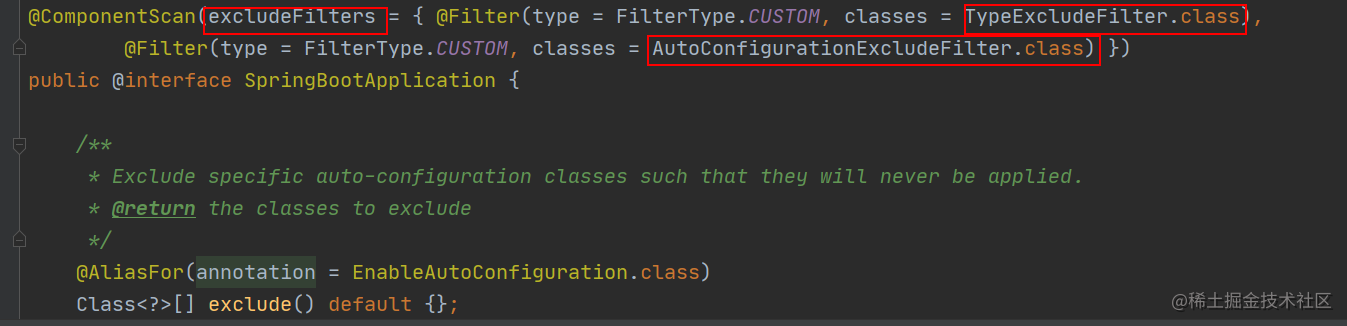
- `@ComponentScan`:扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除`TypeExcludeFilter`和`AutoConfigurationExcludeFilter`。
-
+
`@EnableAutoConfiguration` 是实现自动装配的重要注解,我们以这个注解入手。
@@ -223,13 +223,13 @@ AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoC
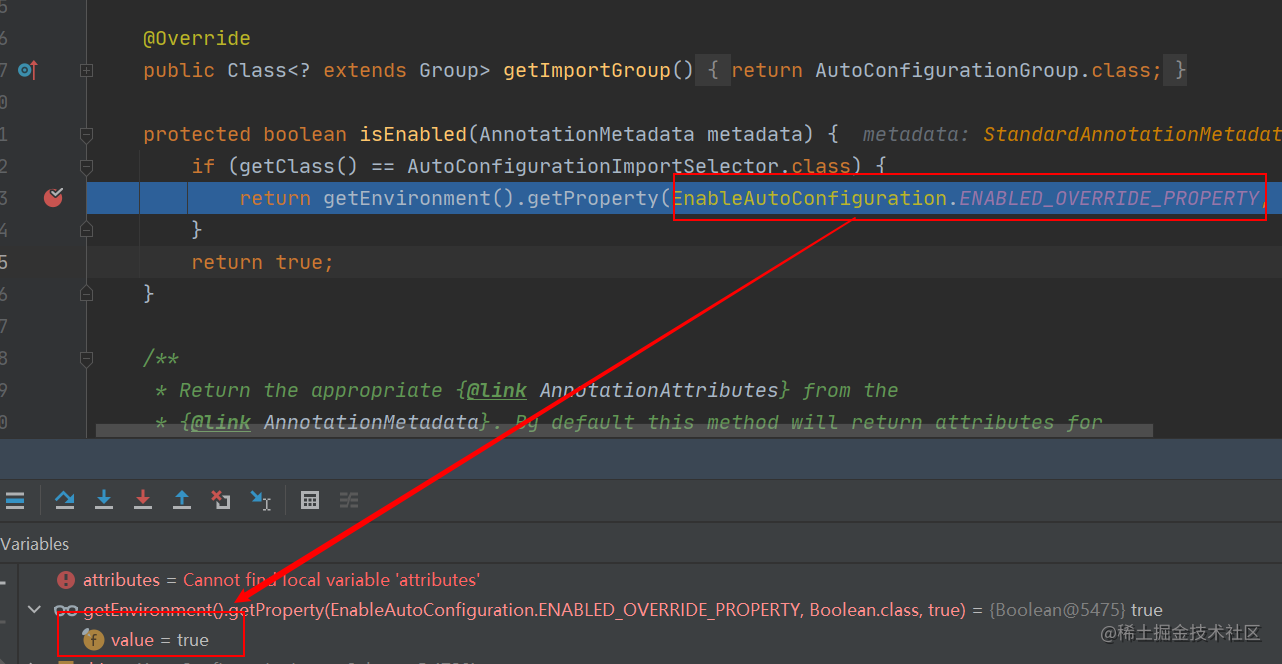
判断自动装配开关是否打开。默认`spring.boot.enableautoconfiguration=true`,可在 `application.properties` 或 `application.yml` 中设置
-
+
**第 2 步**:
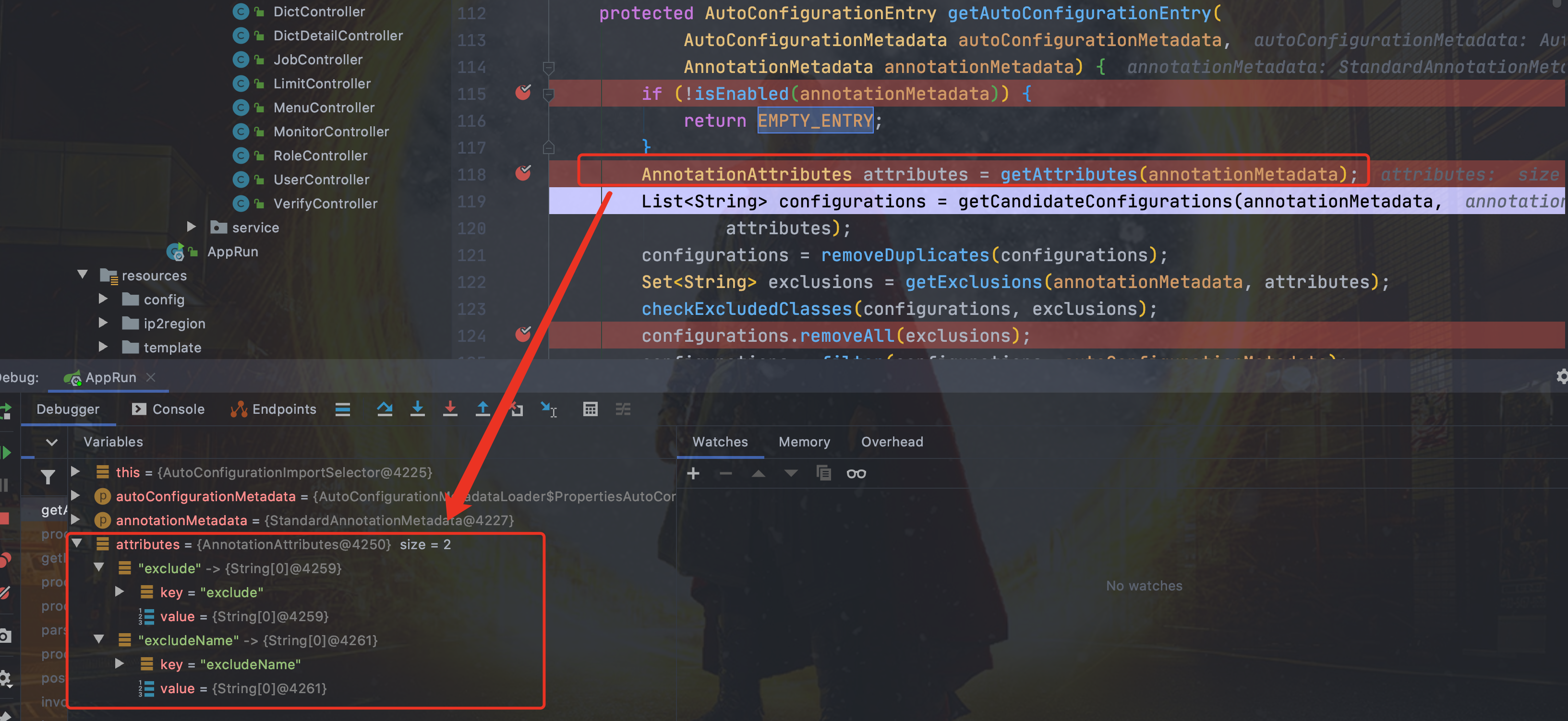
用于获取`EnableAutoConfiguration`注解中的 `exclude` 和 `excludeName`。
-
+
**第 3 步**
@@ -243,7 +243,7 @@ spring-boot/spring-boot-project/spring-boot-autoconfigure/src/main/resources/MET
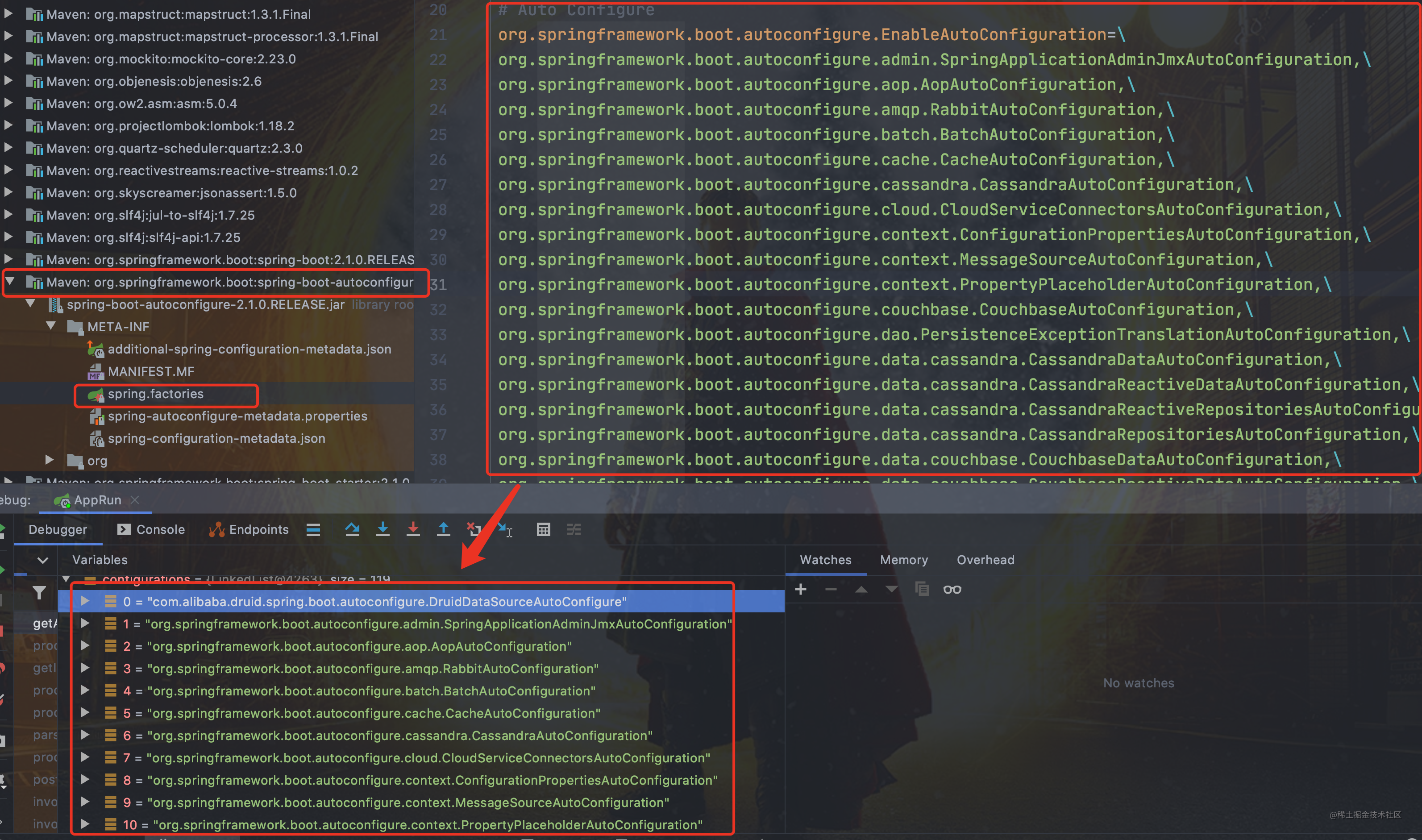
从下图可以看到这个文件的配置内容都被我们读取到了。`XXXAutoConfiguration`的作用就是按需加载组件。
-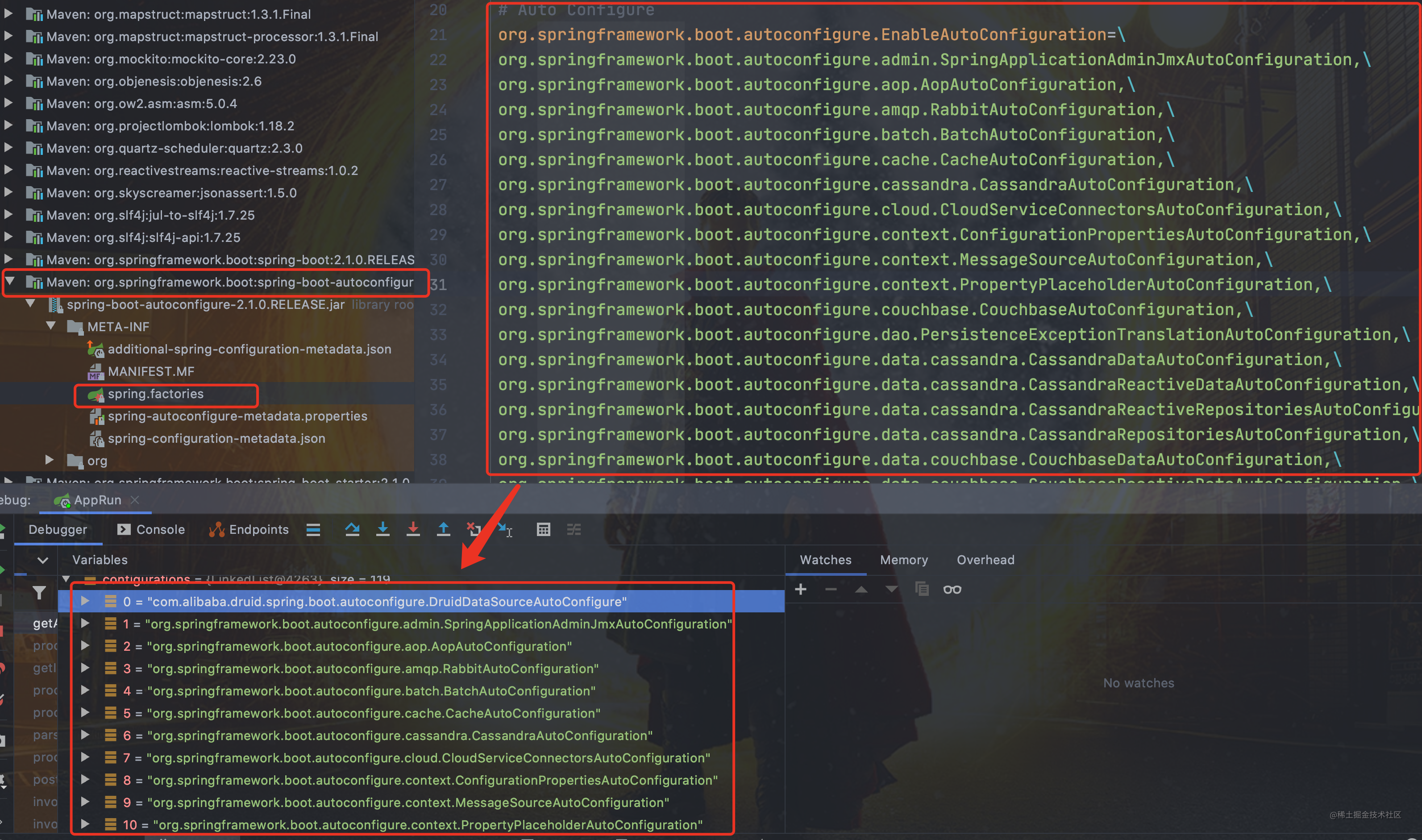
+
不光是这个依赖下的`META-INF/spring.factories`被读取到,所有 Spring Boot Starter 下的`META-INF/spring.factories`都会被读取到。
@@ -311,7 +311,7 @@ public class RabbitAutoConfiguration {
最后新建工程引入`threadpool-spring-boot-starter`
-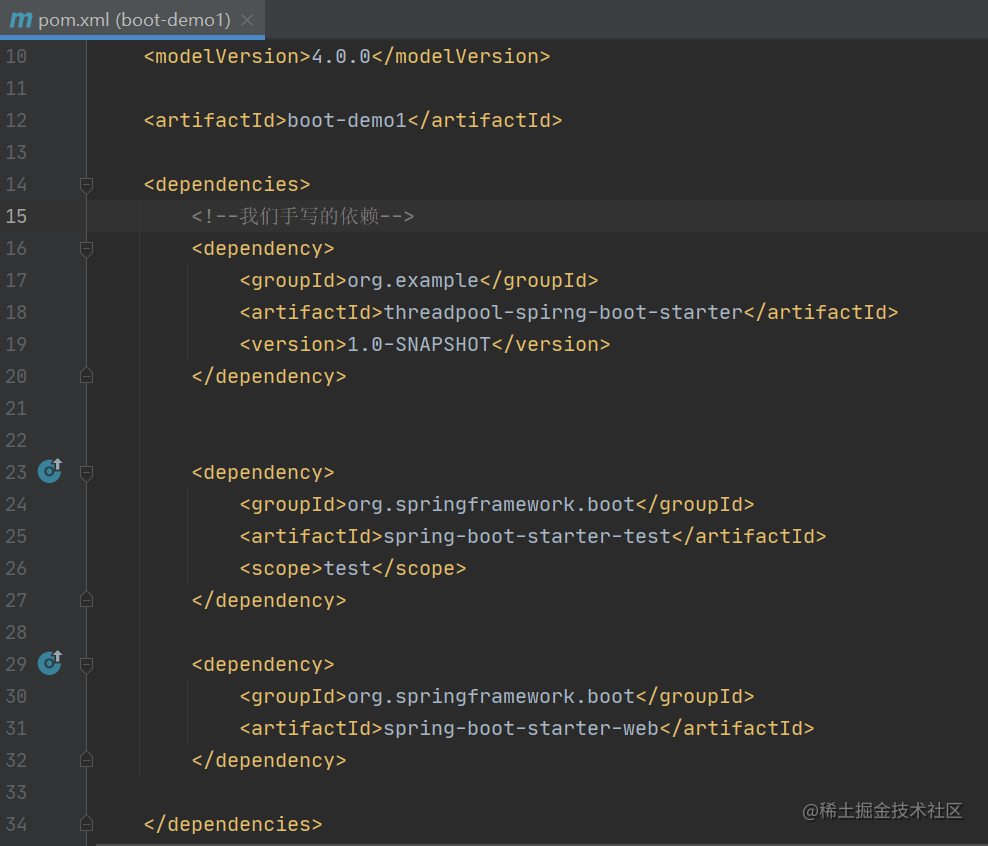
+
测试通过!!!