mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Update redis-data-structures.md
This commit is contained in:
parent
eaf56cbe49
commit
752fc401cb
@ -10,11 +10,13 @@
|
||||
|
||||
#### 介绍
|
||||
|
||||
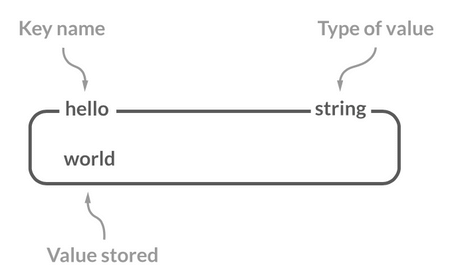
String 是 Redis 中最简单同时也是最常用的一个数据结构。它是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
|
||||
String 是 Redis 中最简单同时也是最常用的一个数据结构。
|
||||
|
||||

|
||||
String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
|
||||
|
||||
虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(simple dynamic string,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
|
||||
|
||||
|
||||
虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(Simple Dynamic String,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
|
||||
|
||||
#### 常用命令
|
||||
|
||||
@ -89,9 +91,19 @@ OK
|
||||
|
||||
#### 应用场景
|
||||
|
||||
**需要存储数据的场景**
|
||||
|
||||
- 举例 :缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 相关命令 : `SET`、`GET`。
|
||||
|
||||
**需要计数的场景**
|
||||
|
||||
比如用户的访问次数、热点文章的点赞转发数量等等。
|
||||
- 举例 :用户单位时间的请求数(简单限流可以用到)、
|
||||
- 相关命令 :`SET`、`GET`、 `INCR`、`DECR` 。
|
||||
|
||||
**分布式锁**
|
||||
|
||||
利用 `SETNX key value` 命令可以实现一个最简易的分布式锁(存在一些缺陷,通常不建议这样实现分布式锁)。
|
||||
|
||||
### List(列表)
|
||||
|
||||
@ -101,7 +113,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
|
||||
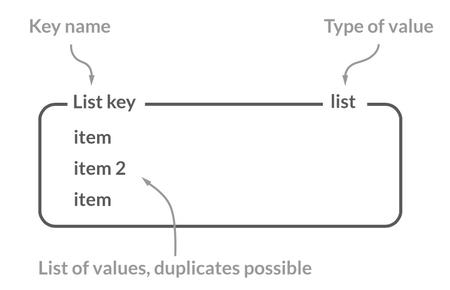
许多高级编程语言都内置了链表的实现比如 Java 中的 `LinkedList`,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 常用命令
|
||||
|
||||
@ -172,18 +184,17 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
|
||||
#### 应用场景
|
||||
|
||||
**Timeline 信息流展示**
|
||||
|
||||
Timeline 信息流中内存都是按照时间来排序,比较典型的产品有微信朋友圈、QQ 空间、微博关注者动态、Twitter 最新推文。
|
||||
|
||||
像这种场景,Redis List 就非常适合用来作为存储数据结构了。
|
||||
|
||||
**消息队列**
|
||||
|
||||
Redis List 数据结构可以用来做消息队列,只是功能过于简单,不建议这样做。
|
||||
|
||||
相对来说,Redis 5.0 新增加的一个数据结构 `Stream` 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
|
||||
|
||||
**信息流展示**
|
||||
|
||||
- 举例 :最新文章、最新动态。
|
||||
- 相关命令 : `LPUSH`、`LRANGE`。
|
||||
|
||||
### Hash(哈希)
|
||||
|
||||
#### 介绍
|
||||
@ -192,7 +203,7 @@ Hash 是一个 String 类型的 field 和 value 的映射表,特别适合用
|
||||
|
||||
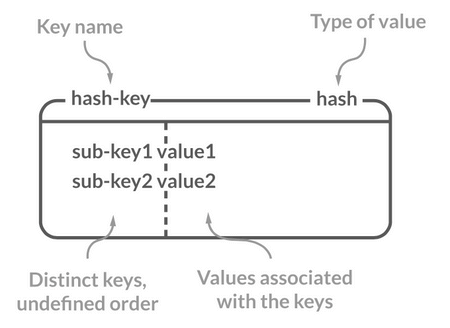
Hash 类似于 JDK1.8 前的 `HashMap`,内部实现也差不多(数组 + 链表)。不过,Redis 的 Hash 做了更多优化。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 常用命令
|
||||
|
||||
@ -235,19 +246,36 @@ OK
|
||||
|
||||
#### 应用场景
|
||||
|
||||
对象数据的存储。
|
||||
**对象数据存储场景**
|
||||
|
||||
- 举例 :用户信息、商品信息、文章信息、购物车信息。
|
||||
- 相关命令 :`HSET` (设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
|
||||
|
||||
String 存储还是 Hash 存储对象数据更好呢?
|
||||
|
||||
- String 存储的是序列化后的对象数据,存放的是整个对象。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
|
||||
- String 存储相对来说更加节省内存,缓存相同数量的对象数据,String 消耗的内存约是 Hash 的一半。并且,存储具有多层嵌套的对象时也方便很多。如果系统对性能和资源消耗非常敏感的话,String 就非常适合。
|
||||
|
||||
在绝大部分情况,我们建议使用 String 来存储对象数据即可!
|
||||
|
||||
那购物车信息用 String 存储还是 Hash 存储更好呢?
|
||||
|
||||
购物车信息建议使用 Hash 存储:
|
||||
|
||||
- 用户 id 为 key
|
||||
- 商品 id 为 field,商品数量为 value
|
||||
|
||||
由于购物车中的商品频繁修改和变动,这个时候 Hash 就非常适合了!
|
||||
|
||||
### Set(集合)
|
||||
|
||||
#### 介绍
|
||||
|
||||
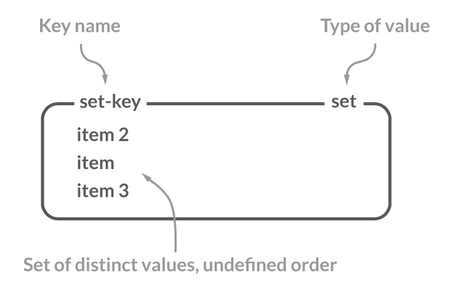
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于Java 中的 `HashSet` 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
|
||||
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
|
||||
|
||||
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
|
||||
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
#### 常用命令
|
||||
|
||||
@ -263,6 +291,8 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
| SUNIONSTORE destination key1 key2 ... | 将给定所有集合的并集存储在 destination 中 |
|
||||
| SDIFF key1 key2 ... | 获取给定所有集合的差集 |
|
||||
| SDIFFSTORE destination key1 key2 ... | 将给定所有集合的差集存储在 destination 中 |
|
||||
| SPOP key | 随机移除并获取指定集合中一个或多个元素 |
|
||||
| SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
|
||||
|
||||
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=set 。
|
||||
|
||||
@ -285,7 +315,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
```
|
||||
|
||||
- `mySet` : `value1`、`value2` 。
|
||||
- `mySet2 ` : `value2` 、`value3` 。
|
||||
- `mySet2` : `value2` 、`value3` 。
|
||||
|
||||
**求交集** :
|
||||
|
||||
@ -314,7 +344,24 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
|
||||
#### 应用场景
|
||||
|
||||
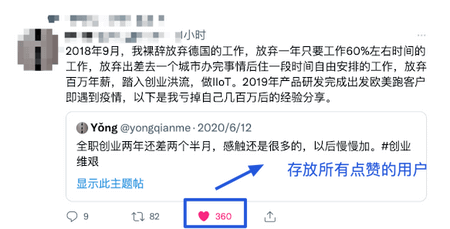
当我们需要存放的数据不能重复,并且需要获取多个数据源交集、并集和差集的时候(比如共同好友) Set 就非常适合。
|
||||
**需要存放的数据不能重复的场景**
|
||||
|
||||
- 举例:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog`更适合一些)、文章点赞、动态点赞等场景。
|
||||
- 相关命令:`SCARD`(获取集合数量) 。
|
||||
|
||||
|
||||
|
||||
**需要获取多个数据源交集、并集和差集的场景**
|
||||
|
||||
- 举例 :共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集) 、订阅号推荐(差集+交集) 等场景。
|
||||
- 相关命令:`SINTER`(交集)、`SINTERSTORE` (交集)、`SUNION` (并集)、`SUNIONSTORE`(并集)、`SDIFF`(交集)、`SDIFFSTORE` (交集)。
|
||||
|
||||
|
||||
|
||||
**需要随机获取数据源中的元素的场景**
|
||||
|
||||
- 举例 :抽奖系统、随机。
|
||||
- 相关命令:`SPOP`(随机获取集合中的元素并移除,适合不允许重复中奖的场景)、`SRANDMEMBER`(随机获取集合中的元素,适合允许重复中奖的场景)。
|
||||
|
||||
### Sorted Set(有序集合)
|
||||
|
||||
@ -322,20 +369,20 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
|
||||
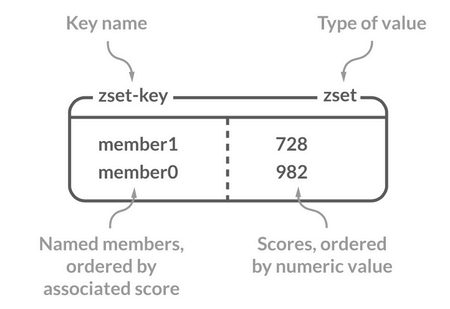
Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重参数 `score`,使得集合中的元素能够按 `score` 进行有序排列,还可以通过 `score` 的范围来获取元素的列表。有点像是 Java 中 `HashMap` 和 `TreeSet` 的结合体。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| --------------------------------------------- | ------------------------------------------------------------ |
|
||||
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
||||
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
||||
| ZCARD KEY | 获取指定有序集合的元素数量 |
|
||||
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
|
||||
| ZINTERSTORE destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
|
||||
| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
|
||||
| ZDIFF destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
|
||||
| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素 |
|
||||
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score从高到底) |
|
||||
| ZDIFF destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
|
||||
| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
|
||||
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
|
||||
| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
|
||||
|
||||
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:https://redis.io/commands/?group=sorted-set 。
|
||||
@ -361,7 +408,7 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
||||
```
|
||||
|
||||
- `myZset` : `value1`(2.0)、`value2`(1.0) 。
|
||||
- ` myZset2 ` : `value2` (4.0)、`value3`(3.0) 。
|
||||
- `myZset2` : `value2` (4.0)、`value3`(3.0) 。
|
||||
|
||||
**获取指定元素的排名** :
|
||||
|
||||
@ -406,23 +453,33 @@ value1
|
||||
|
||||
#### 应用场景
|
||||
|
||||
需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
|
||||
**需要随机获取数据源中的元素根据某个权重进行排序的场景**
|
||||
|
||||
- 举例 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
- 相关命令 :`ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
|
||||

|
||||
|
||||
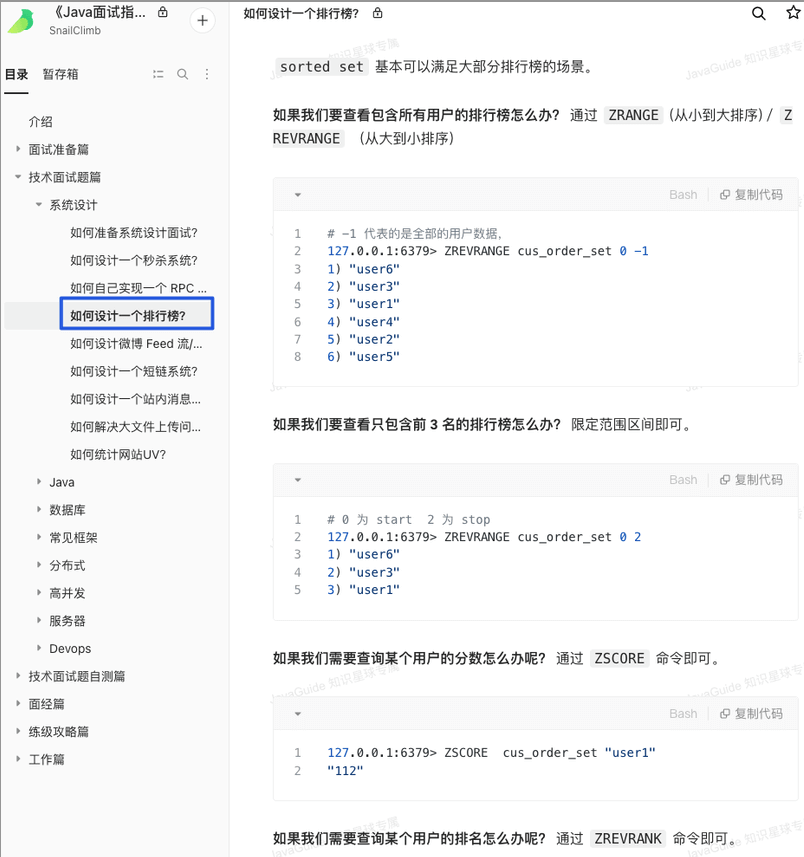
[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
|
||||
|
||||
|
||||
|
||||
**需要存储的数据有优先级或者重要程度的场景** 比如优先级任务队列。
|
||||
|
||||
- 举例 :优先级任务队列。
|
||||
- 相关命令 :`ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
|
||||
## 特殊数据结构
|
||||
|
||||
### Bitmap
|
||||
|
||||
#### 介绍
|
||||
|
||||
### sorted set
|
||||
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
|
||||
|
||||
#### 常用命令
|
||||
|
||||
|
||||
|
||||
|
||||
### bitmap
|
||||
|
||||
1. **介绍:** bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
|
||||
2. **常用命令:** `setbit` 、`getbit` 、`bitcount`、`bitop`
|
||||
3. **应用场景:** 适合需要保存状态信息(比如是否签到、是否登录...)并需要进一步对这些信息进行分析的场景。比如用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
|
||||
`setbit` 、`getbit` 、`bitcount`、`bitop`
|
||||
|
||||
```bash
|
||||
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
|
||||
@ -441,9 +498,11 @@ value1
|
||||
(integer) 2
|
||||
```
|
||||
|
||||
针对上面提到的一些场景,这里进行进一步说明。
|
||||
#### 应用场景
|
||||
|
||||
**使用场景一:用户行为分析**
|
||||
适合需要保存状态信息(比如是否签到、是否登录...)并需要进一步对这些信息进行分析的场景。比如用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)
|
||||
|
||||
**用户行为分析**
|
||||
很多网站为了分析你的喜好,需要研究你点赞过的内容。
|
||||
|
||||
```bash
|
||||
@ -451,7 +510,7 @@ value1
|
||||
> setbit beauty_girl_001 uid 1
|
||||
```
|
||||
|
||||
**使用场景二:统计活跃用户**
|
||||
**统计活跃用户**
|
||||
|
||||
使用时间作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1
|
||||
|
||||
@ -492,13 +551,19 @@ BITOP operation destkey key [key ...]
|
||||
(integer) 2
|
||||
```
|
||||
|
||||
**使用场景三:用户在线状态**
|
||||
**用户在线状态**
|
||||
|
||||
对于获取或者统计用户在线状态,使用 bitmap 是一个节约空间且效率又高的一种方法。
|
||||
对于获取或者统计用户在线状态,使用 Bitmap 是一个节约空间且效率又高的一种方法。
|
||||
|
||||
只需要一个 key,然后用户 ID 为 offset,如果在线就设置为 1,不在线就设置为 0。
|
||||
|
||||
### HyperLogLog
|
||||
|
||||
### Stream
|
||||
|
||||
## 参考
|
||||
|
||||
- Redis Data Structures :https://redis.com/redis-enterprise/data-structures/ 。
|
||||
- Redis Commands : https://redis.io/commands/ 。
|
||||
- Redis Commands : https://redis.io/commands/ 。
|
||||
- Redis Data types tutorial:https://redis.io/docs/manual/data-types/data-types-tutorial/ 。
|
||||
- Redis 存储对象信息是用 Hash 还是 String : https://segmentfault.com/a/1190000040032006
|
||||
Loading…
x
Reference in New Issue
Block a user