mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
74fc413bcc
@ -694,12 +694,12 @@ System.out.println(s);
|
||||
**字符串常量池** 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
|
||||
|
||||
```java
|
||||
// 在堆中创建字符串对象”ab“
|
||||
// 将字符串对象”ab“的引用保存在字符串常量池中
|
||||
// 在字符串常量池中创建字符串对象 ”ab“
|
||||
// 将字符串对象 ”ab“ 的引用赋值给 aa
|
||||
String aa = "ab";
|
||||
// 直接返回字符串常量池中字符串对象”ab“的引用
|
||||
// 直接返回字符串常量池中字符串对象 ”ab“,赋值给引用 bb
|
||||
String bb = "ab";
|
||||
System.out.println(aa==bb);// true
|
||||
System.out.println(aa==bb); // true
|
||||
```
|
||||
|
||||
更多关于字符串常量池的介绍可以看一下 [Java 内存区域详解](https://javaguide.cn/java/jvm/memory-area.html) 这篇文章。
|
||||
@ -708,7 +708,7 @@ System.out.println(aa==bb);// true
|
||||
|
||||
会创建 1 或 2 个字符串对象。
|
||||
|
||||
1、如果字符串常量池中不存在字符串对象“abc”的引用,那么它会在堆上创建两个字符串对象,其中一个字符串对象的引用会被保存在字符串常量池中。
|
||||
1、如果字符串常量池中不存在字符串对象 “abc”,那么它首先会在字符串常量池中创建字符串对象 "abc",然后在堆内存中再创建其中一个字符串对象 "abc"
|
||||
|
||||
示例代码(JDK 1.8):
|
||||
|
||||
@ -720,14 +720,14 @@ String s1 = new String("abc");
|
||||
|
||||
|
||||
|
||||
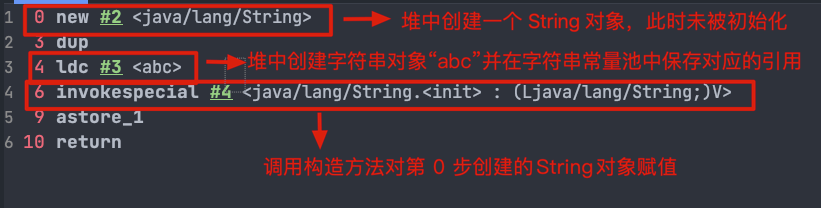
`ldc` 命令用于判断字符串常量池中是否保存了对应的字符串对象的引用,如果保存了的话直接返回,如果没有保存的话,会在堆中创建对应的字符串对象并将该字符串对象的引用保存到字符串常量池中。
|
||||
`ldc (load constant)` 指令的作用是从常量池中加载常量,包括字符串常量、整数常量、浮点数常量、或者类引用。这里用于判断字符串常量池中是否保存了对应的字符串对象,如果保存了的话会将它的引用加载到操作数栈,如果没有保存的话,会在字符串常量池中创建对应的字符串对象,并将其引用加载到操作数栈中。
|
||||
|
||||
2、如果字符串常量池中已存在字符串对象“abc”的引用,则只会在堆中创建 1 个字符串对象“abc”。
|
||||
2、如果字符串常量池中已存在字符串对象“abc”,则只会在堆中创建 1 个字符串对象“abc”。
|
||||
|
||||
示例代码(JDK 1.8):
|
||||
|
||||
```java
|
||||
// 字符串常量池中已存在字符串对象“abc”的引用
|
||||
// 字符串常量池中已存在字符串对象“abc”
|
||||
String s1 = "abc";
|
||||
// 下面这段代码只会在堆中创建 1 个字符串对象“abc”
|
||||
String s2 = new String("abc");
|
||||
|
||||
@ -451,8 +451,8 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
|
||||
|
||||
简单来说:
|
||||
|
||||
- **序列化**:将数据结构或对象转换成二进制字节流的过程
|
||||
- **反序列化**:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
|
||||
- **序列化**:将数据结构或对象转换成可以存储或传输的形式,通常是二进制字节流,也可以是 JSON, XML 等文本格式
|
||||
- **反序列化**:将在序列化过程中所生成的数据转换为原始数据结构或者对象的过程
|
||||
|
||||
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
|
||||
|
||||
|
||||
@ -11,8 +11,8 @@ tag:
|
||||
|
||||
简单来说:
|
||||
|
||||
- **序列化**:将数据结构或对象转换成二进制字节流的过程
|
||||
- **反序列化**:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
|
||||
- **序列化**:将数据结构或对象转换成可以存储或传输的形式,通常是二进制字节流,也可以是 JSON, XML 等文本格式
|
||||
- **反序列化**:将在序列化过程中所生成的数据转换为原始数据结构或者对象的过程
|
||||
|
||||
对于 Java 这种面向对象编程语言来说,我们序列化的都是对象(Object)也就是实例化后的类(Class),但是在 C++这种半面向对象的语言中,struct(结构体)定义的是数据结构类型,而 class 对应的是对象类型。
|
||||
|
||||
|
||||
@ -353,7 +353,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
||||
|
||||
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 Java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
|
||||
|
||||
比如在新生代中,每次收集都会有大量对象死去,所以可以选择“标记-复制”算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
|
||||
比如在新生代中,每次收集都会有大量对象死去,所以可以选择“复制”算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。
|
||||
|
||||
**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
|
||||
|
||||
|
||||
@ -242,12 +242,12 @@ Class 文件中除了有类的版本、字段、方法、接口等描述信息
|
||||
**字符串常量池** 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
|
||||
|
||||
```java
|
||||
// 在堆中创建字符串对象”ab“
|
||||
// 将字符串对象”ab“的引用保存在字符串常量池中
|
||||
// 在字符串常量池中创建字符串对象 ”ab“
|
||||
// 将字符串对象 ”ab“ 的引用赋值给给 aa
|
||||
String aa = "ab";
|
||||
// 直接返回字符串常量池中字符串对象”ab“的引用
|
||||
// 直接返回字符串常量池中字符串对象 ”ab“,赋值给引用 bb
|
||||
String bb = "ab";
|
||||
System.out.println(aa==bb);// true
|
||||
System.out.println(aa==bb); // true
|
||||
```
|
||||
|
||||
HotSpot 虚拟机中字符串常量池的实现是 `src/hotspot/share/classfile/stringTable.cpp` ,`StringTable` 可以简单理解为一个固定大小的`HashTable` ,容量为 `StringTableSize`(可以通过 `-XX:StringTableSize` 参数来设置),保存的是字符串(key)和 字符串对象的引用(value)的映射关系,字符串对象的引用指向堆中的字符串对象。
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user