Merge remote-tracking branch 'upstream/master'
236
HomePage.md
Normal file
@ -0,0 +1,236 @@
|
||||
点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
|
||||
|
||||
<h1 align="center">Java 学习/面试指南</h1>
|
||||
<p align="center">
|
||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3/logo - 副本.png" width=""/>
|
||||
</a>
|
||||
|
||||
## 目录
|
||||
|
||||
- [Java](#java)
|
||||
- [基础](#基础)
|
||||
- [容器](#容器)
|
||||
- [并发](#并发)
|
||||
- [JVM](#jvm)
|
||||
- [I/O](#io)
|
||||
- [Java 8](#java-8)
|
||||
- [编程规范](#编程规范)
|
||||
- [网络](#网络)
|
||||
- [操作系统](#操作系统)
|
||||
- [Linux相关](#linux相关)
|
||||
- [数据结构与算法](#数据结构与算法)
|
||||
- [数据结构](#数据结构)
|
||||
- [算法](#算法)
|
||||
- [数据库](#数据库)
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [系统设计](#系统设计)
|
||||
- [设计模式(工厂模式、单例模式 ... )](#设计模式)
|
||||
- [常用框架(Spring、Zookeeper ... )](#常用框架)
|
||||
- [数据通信(消息队列、Dubbo ... )](#数据通信)
|
||||
- [网站架构](#网站架构)
|
||||
- [面试指南](#面试指南)
|
||||
- [备战面试](#备战面试)
|
||||
- [常见面试题总结](#常见面试题总结)
|
||||
- [面经](#面经)
|
||||
- [工具](#工具)
|
||||
- [Git](#git)
|
||||
- [Docker](#Docker)
|
||||
- [资料](#资料)
|
||||
- [书单](#书单)
|
||||
- [Github榜单](#Github榜单)
|
||||
- [待办](#待办)
|
||||
- [说明](#说明)
|
||||
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
|
||||
* [Java 基础知识回顾](java/Java基础知识.md)
|
||||
* [Java 基础知识疑难点总结](java/Java疑难点.md)
|
||||
* [J2EE 基础知识回顾](java/J2EE基础知识.md)
|
||||
|
||||
### 容器
|
||||
|
||||
* [Java容器常见面试题/知识点总结](java/collection/Java集合框架常见面试题.md)
|
||||
* [ArrayList 源码学习](java/collection/ArrayList.md)
|
||||
* [LinkedList 源码学习](java/collection/LinkedList.md)
|
||||
* [HashMap(JDK1.8)源码学习](java/collection/HashMap.md)
|
||||
|
||||
### 并发
|
||||
|
||||
* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
|
||||
* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
|
||||
* [并发容器总结](java/Multithread/并发容器总结.md)
|
||||
* [乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
||||
* [JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
|
||||
* [AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
|
||||
|
||||
### JVM
|
||||
* [一 Java内存区域](java/jvm/Java内存区域.md)
|
||||
* [二 JVM垃圾回收](java/jvm/JVM垃圾回收.md)
|
||||
* [三 JDK 监控和故障处理工具](java/jvm/JDK监控和故障处理工具总结.md)
|
||||
* [四 类文件结构](java/jvm/类文件结构.md)
|
||||
* [五 类加载过程](java/jvm/类加载过程.md)
|
||||
* [六 类加载器](java/jvm/类加载器.md)
|
||||
|
||||
### I/O
|
||||
|
||||
* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
|
||||
* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
|
||||
|
||||
### Java 8
|
||||
|
||||
* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
|
||||
### 编程规范
|
||||
|
||||
- [Java 编程规范](java/Java编程规范.md)
|
||||
|
||||
## 网络
|
||||
|
||||
* [计算机网络常见面试题](network/计算机网络.md)
|
||||
* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
|
||||
* [HTTPS中的TLS](network/HTTPS中的TLS.md)
|
||||
|
||||
## 操作系统
|
||||
|
||||
### Linux相关
|
||||
|
||||
* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
|
||||
* [Shell 编程入门](operating-system/Shell.md)
|
||||
|
||||
## 数据结构与算法
|
||||
|
||||
### 数据结构
|
||||
|
||||
- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
|
||||
|
||||
### 算法
|
||||
|
||||
- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
|
||||
- [几道常见的字符串算法题总结 ](dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的链表算法题总结 ](dataStructures-algorithms/几道常见的链表算法题.md)
|
||||
- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
|
||||
- [公司真题](dataStructures-algorithms/公司真题.md)
|
||||
- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
|
||||
|
||||
## 数据库
|
||||
|
||||
### MySQL
|
||||
|
||||
* [MySQL 学习与面试](database/MySQL.md)
|
||||
* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
|
||||
* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
|
||||
* [数据库索引总结](database/MySQL%20Index.md)
|
||||
* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
|
||||
* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
|
||||
|
||||
### Redis
|
||||
|
||||
* [Redis 总结](database/Redis/Redis.md)
|
||||
* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
|
||||
* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 设计模式
|
||||
|
||||
- [设计模式系列文章](system-design/设计模式.md)
|
||||
|
||||
### 常用框架
|
||||
|
||||
#### Spring
|
||||
|
||||
- [Spring 学习与面试](system-design/framework/spring/Spring.md)
|
||||
- [Spring 常见问题总结](system-design/framework/spring/SpringInterviewQuestions.md)
|
||||
- [Spring中bean的作用域与生命周期](system-design/framework/spring/SpringBean.md)
|
||||
- [SpringMVC 工作原理详解](system-design/framework/spring/SpringMVC-Principle.md)
|
||||
- [Spring中都用到了那些设计模式?](system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
|
||||
#### ZooKeeper
|
||||
|
||||
- [ZooKeeper 相关概念总结](system-design/framework/ZooKeeper.md)
|
||||
- [ZooKeeper 数据模型和常见命令](system-design/framework/ZooKeeper数据模型和常见命令.md)
|
||||
|
||||
### 数据通信
|
||||
|
||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/summary.md)
|
||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
|
||||
- [消息队列总结](system-design/data-communication/message-queue.md)
|
||||
- [RabbitMQ 入门](system-design/data-communication/rabbitmq.md)
|
||||
- [RocketMQ的几个简单问题与答案](system-design/data-communication/RocketMQ-Questions.md)
|
||||
|
||||
### 网站架构
|
||||
|
||||
- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
|
||||
- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
## 面试指南
|
||||
|
||||
### 备战面试
|
||||
|
||||
* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
|
||||
* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
|
||||
* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
|
||||
* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
|
||||
* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
|
||||
* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
|
||||
|
||||
### 常见面试题总结
|
||||
|
||||
* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
|
||||
* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
|
||||
* [第三周(2018-08-22)](java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
|
||||
* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
|
||||
|
||||
### 面经
|
||||
|
||||
- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
|
||||
- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
|
||||
- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
|
||||
|
||||
## 工具
|
||||
|
||||
### Git
|
||||
|
||||
* [Git入门](tools/Git.md)
|
||||
|
||||
### Docker
|
||||
|
||||
* [Docker 入门](tools/Docker.md)
|
||||
* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
|
||||
|
||||
## 资料
|
||||
|
||||
### 书单
|
||||
|
||||
- [Java程序员必备书单](data/java-recommended-books.md)
|
||||
|
||||
### Github榜单
|
||||
|
||||
- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
|
||||
|
||||
***
|
||||
|
||||
## 待办
|
||||
|
||||
- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
- [ ] Java 多线程类别知识重构(---正在进行中---)
|
||||
- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
|
||||
- [ ] Netty 总结(---正在进行中---)
|
||||
- [ ] 数据结构总结重构(---正在进行中---)
|
||||
|
||||
## 公众号
|
||||
|
||||
- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
|
||||
- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-gold-cdn.xitu.io/2018/11/28/167598cd2e17b8ec?w=258&h=258&f=jpeg&s=27334" width=""/>
|
||||
</p>
|
||||
110
README.md
@ -1,4 +1,10 @@
|
||||
点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/docs/9BJjNsNg7S4dCnz3/)
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
作者的其他开源项目推荐:
|
||||
|
||||
1. [springboot-guide](https://github.com/Snailclimb/springboot-guide) : 适合新手入门以及有经验的开发人员查阅的 Spring Boot 教程(业余时间维护中,欢迎一起维护)。
|
||||
2. [programmer-advancement](https://github.com/Snailclimb/programmer-advancement) : 我觉得技术人员应该有的一些好习惯!
|
||||
3. [spring-security-jwt-guide](https://github.com/Snailclimb/spring-security-jwt-guide) :从零入门 !Spring Security With JWT(含权限验证)后端部分代码。
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||
@ -12,17 +18,7 @@
|
||||
<a href="#公众号"><img src="https://img.shields.io/badge/%E5%85%AC%E4%BC%97%E5%8F%B7-JavaGuide-lightgrey.svg" alt="公众号"></a>
|
||||
<a href="#公众号"><img src="https://img.shields.io/badge/PDF-Java面试突击-important.svg" alt="公众号"></a>
|
||||
<a href="#投稿"><img src="https://img.shields.io/badge/support-投稿-critical.svg" alt="投稿"></a>
|
||||
</p>
|
||||
|
||||
<h2 align="center">Special Sponsors</h2>
|
||||
|
||||
<p align="center">
|
||||
<a href="https://www.aliyun.com/acts/hi618/index?userCode=hf47liqn" target="_blank">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-6/阿里云外投-1600-300.png" width="390px" height="70px" alt="阿里云618 2折起!"/>
|
||||
</a>
|
||||
<a href="https://coding.net/?utm_source=JavaGuide" target="_blank">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-6/006rNwoDgy1g2dw5gau7nj30eg02vwfr.jpg" alt="零成本开启敏捷研发" height="70px" width="390px"/>
|
||||
</a>
|
||||
<a href="https://xiaozhuanlan.com/javainterview?rel=javaguide"><img src="https://img.shields.io/badge/Java-面试指南-important" alt="投稿"></a>
|
||||
</p>
|
||||
|
||||
推荐使用 https://snailclimb.top/JavaGuide/ 在线阅读(访问速度慢的话,请使用 https://snailclimb.gitee.io/javaguide ),在线阅读内容本仓库同步一致。这种方式阅读的优势在于:有侧边栏阅读体验更好,Gitee pages 的访问速度相对来说也比较快。
|
||||
@ -47,8 +43,9 @@
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [系统设计](#系统设计)
|
||||
- [常用框架(Spring/SpringBoot、Zookeeper ... )](#常用框架)
|
||||
- [权限认证](#权限认证)
|
||||
- [设计模式(工厂模式、单例模式 ... )](#设计模式)
|
||||
- [常用框架(Spring、Zookeeper ... )](#常用框架)
|
||||
- [数据通信(消息队列、Dubbo ... )](#数据通信)
|
||||
- [网站架构](#网站架构)
|
||||
- [面试指南](#面试指南)
|
||||
@ -58,7 +55,7 @@
|
||||
- [工具](#工具)
|
||||
- [Git](#git)
|
||||
- [Docker](#Docker)
|
||||
- [资料](#资料)
|
||||
- [资源](#资源)
|
||||
- [书单](#书单)
|
||||
- [Github榜单](#Github榜单)
|
||||
- [待办](#待办)
|
||||
@ -68,20 +65,22 @@
|
||||
|
||||
### 基础
|
||||
|
||||
* [Java 基础知识回顾](docs/java/Java基础知识.md)
|
||||
* **[Java 基础知识回顾](docs/java/Java基础知识.md)**
|
||||
* **[Java 基础知识疑难点/易错点](docs/java/Java疑难点.md)**
|
||||
* **[一些重要的Java程序设计题](docs/java/Java程序设计题.md)**
|
||||
* [J2EE 基础知识回顾](docs/java/J2EE基础知识.md)
|
||||
|
||||
### 容器
|
||||
|
||||
* [Java容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)
|
||||
* **[Java容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)**
|
||||
* [ArrayList 源码学习](docs/java/collection/ArrayList.md)
|
||||
* [LinkedList 源码学习](docs/java/collection/LinkedList.md)
|
||||
* [HashMap(JDK1.8)源码学习](docs/java/collection/HashMap.md)
|
||||
|
||||
### 并发
|
||||
|
||||
* [Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
|
||||
* [Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
|
||||
* **[Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)**
|
||||
* **[Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)**
|
||||
* [并发容器总结](docs/java/Multithread/并发容器总结.md)
|
||||
* [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
||||
* [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
|
||||
@ -89,11 +88,11 @@
|
||||
|
||||
### JVM
|
||||
|
||||
* [一 Java内存区域](docs/java/jvm/Java内存区域.md)
|
||||
* [二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)
|
||||
* **[一 Java内存区域](docs/java/jvm/Java内存区域.md)**
|
||||
* **[二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)**
|
||||
* [三 JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
|
||||
* [四 类文件结构](docs/java/jvm/类文件结构.md)
|
||||
* [五 类加载过程](docs/java/jvm/类加载过程.md)
|
||||
* **[五 类加载过程](docs/java/jvm/类加载过程.md)**
|
||||
* [六 类加载器](docs/java/jvm/类加载器.md)
|
||||
|
||||
### I/O
|
||||
@ -105,6 +104,7 @@
|
||||
|
||||
* [Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
* [Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
* [Java8 forEach 指南](docs/java/What's%20New%20in%20JDK8/Java8foreach指南.md)
|
||||
|
||||
### 编程规范
|
||||
|
||||
@ -121,7 +121,7 @@
|
||||
### Linux相关
|
||||
|
||||
* [后端程序员必备的 Linux 基础知识](docs/operating-system/后端程序员必备的Linux基础知识.md)
|
||||
* [Shell 编程入门](docs/operating-system/Shell.md)
|
||||
* [Shell 编程入门](docs/operating-system/Shell.md)
|
||||
|
||||
## 数据结构与算法
|
||||
|
||||
@ -132,7 +132,7 @@
|
||||
### 算法
|
||||
|
||||
- [算法学习资源推荐](docs/dataStructures-algorithms/算法学习资源推荐.md)
|
||||
- [几道常见的子符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的字符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的链表算法题总结 ](docs/dataStructures-algorithms/几道常见的链表算法题.md)
|
||||
- [剑指offer部分编程题](docs/dataStructures-algorithms/剑指offer部分编程题.md)
|
||||
- [公司真题](docs/dataStructures-algorithms/公司真题.md)
|
||||
@ -142,10 +142,10 @@
|
||||
|
||||
### MySQL
|
||||
|
||||
* [MySQL 学习与面试](docs/database/MySQL.md)
|
||||
* [一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)
|
||||
* **[MySQL 学习与面试](docs/database/MySQL.md)**
|
||||
* **[一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)**
|
||||
* [MySQL高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
|
||||
* [搞定数据库索引就是这么简单](docs/database/MySQL%20Index.md)
|
||||
* [数据库索引总结](docs/database/MySQL%20Index.md)
|
||||
* [事务隔离级别(图文详解)](docs/database/事务隔离级别(图文详解).md)
|
||||
* [一条SQL语句在MySQL中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
|
||||
|
||||
@ -157,16 +157,13 @@
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 设计模式
|
||||
|
||||
- [设计模式系列文章](docs/system-design/设计模式.md)
|
||||
|
||||
### 常用框架
|
||||
|
||||
#### Spring
|
||||
#### Spring/SpringBoot
|
||||
|
||||
- [Spring 学习与面试](docs/system-design/framework/spring/Spring.md)
|
||||
- [Spring 常见问题总结](docs/system-design/framework/spring/SpringInterviewQuestions.md)
|
||||
- **[Spring 常见问题总结](docs/system-design/framework/spring/SpringInterviewQuestions.md)**
|
||||
- **[SpringBoot 指南/常见面试题总结](https://github.com/Snailclimb/springboot-guide)**
|
||||
- [Spring中bean的作用域与生命周期](docs/system-design/framework/spring/SpringBean.md)
|
||||
- [SpringMVC 工作原理详解](docs/system-design/framework/spring/SpringMVC-Principle.md)
|
||||
- [Spring中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
@ -176,13 +173,25 @@
|
||||
- [ZooKeeper 相关概念总结](docs/system-design/framework/ZooKeeper.md)
|
||||
- [ZooKeeper 数据模型和常见命令](docs/system-design/framework/ZooKeeper数据模型和常见命令.md)
|
||||
|
||||
### 权限认证
|
||||
|
||||
- **[权限认证基础:区分Authentication,Authorization以及Cookie、Session、Token](docs/system-design/authority-certification/basis-of-authority-certification.md)**
|
||||
- **[JWT 优缺点分析以及常见问题解决方案](docs/system-design/authority-certification/JWT-advantages-and-disadvantages.md)**
|
||||
- **[适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)**
|
||||
|
||||
### 设计模式
|
||||
|
||||
- [设计模式系列文章](docs/system-design/设计模式.md)
|
||||
|
||||
### 数据通信
|
||||
|
||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
|
||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
|
||||
- [消息队列总结](docs/system-design/data-communication/message-queue.md)
|
||||
- [RabbitMQ 入门](docs/system-design/data-communication/RabbitMQ.md)
|
||||
- [RabbitMQ 入门](docs/system-design/data-communication/rabbitmq.md)
|
||||
- [RocketMQ的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
|
||||
- [Kafka入门看这一篇就够了](docs/system-design/data-communication/Kafka入门看这一篇就够了.md)
|
||||
- [Kafka系统设计开篇-面试看这篇就够了](docs/system-design/data-communication/Kafka系统设计开篇-面试看这篇就够了.md)
|
||||
|
||||
### 网站架构
|
||||
|
||||
@ -194,12 +203,12 @@
|
||||
|
||||
### 备战面试
|
||||
|
||||
* [【备战面试1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
|
||||
* [【备战面试2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
|
||||
* [【备战面试3】7个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
|
||||
* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
|
||||
* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
|
||||
* [【备战面试6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
|
||||
* **[【备战面试1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)**
|
||||
* **[【备战面试2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)**
|
||||
* **[【备战面试3】7个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)**
|
||||
* **[【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)**
|
||||
* **[【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/如果面试官问你"你有什么问题问我吗?"时,你该如何回答.md)**
|
||||
* **[【备战面试6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)**
|
||||
|
||||
### 常见面试题总结
|
||||
|
||||
@ -225,13 +234,18 @@
|
||||
* [Docker 入门](docs/tools/Docker.md)
|
||||
* [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
||||
|
||||
## 资料
|
||||
## 资源
|
||||
|
||||
### 书单
|
||||
|
||||
- [Java程序员必备书单](docs/data/java-recommended-books.md)
|
||||
|
||||
### Github榜单
|
||||
### 实战项目推荐
|
||||
|
||||
- [onemall](https://github.com/YunaiV/onemall) : mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
|
||||
-
|
||||
|
||||
### Github 历史榜单
|
||||
|
||||
- [Java 项目月榜单](docs/github-trending/JavaGithubTrending.md)
|
||||
|
||||
@ -239,10 +253,7 @@
|
||||
|
||||
## 待办
|
||||
|
||||
- [x] [Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
- [x] [Java 8 新特性详解](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
- [ ] Java 多线程类别知识重构(---正在进行中---)
|
||||
- [x] [BIO,NIO,AIO 总结 ](docs/java/BIO-NIO-AIO.md)
|
||||
- [ ] Netty 总结(---正在进行中---)
|
||||
- [ ] 数据结构总结重构(---正在进行中---)
|
||||
|
||||
@ -280,7 +291,7 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
|
||||
|
||||
添加我的微信备注“Github”,回复关键字 **“加群”** 即可入群。
|
||||
|
||||

|
||||

|
||||
|
||||
### Contributor
|
||||
|
||||
@ -288,7 +299,10 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
|
||||
|
||||
<a href="https://github.com/fanofxiaofeng">
|
||||
<img src="https://avatars0.githubusercontent.com/u/3983683?s=460&v=4" width="45px"></a>
|
||||
<a href="https://github.com/dongzl">
|
||||
<a href="https://github.com/fanchenggang">
|
||||
<img src="https://avatars2.githubusercontent.com/u/8225921?s=460&v=4" width="45px">
|
||||
</a>
|
||||
<a href="https://github.com/ipofss">
|
||||
<img src="https://avatars1.githubusercontent.com/u/5917359?s=460&v=4" width="45px"></a>
|
||||
<a href="https://github.com/Gene1994">
|
||||
<img src="https://avatars3.githubusercontent.com/u/24930369?s=460&v=4" width="45px">
|
||||
@ -335,6 +349,6 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
@ -8,3 +8,6 @@
|
||||
[GitHub](<https://github.com/Snailclimb/JavaGuide>)
|
||||
[开始阅读](#java)
|
||||
|
||||

|
||||
|
||||
|
||||
204
docs/HomePage.md
@ -1,204 +0,0 @@
|
||||
点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
|
||||
|
||||
<h1 align="center">Java 学习/面试指南</h1>
|
||||
<p align="center">
|
||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3/logo - 副本.png" width=""/>
|
||||
</a>
|
||||
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
|
||||
* [Java 基础知识回顾](./java/Java基础知识.md)
|
||||
* [J2EE 基础知识回顾](./java/J2EE基础知识.md)
|
||||
|
||||
### 容器
|
||||
|
||||
* [常见面试题](./java/collection/Java集合框架常见面试题.md)
|
||||
* [ArrayList 源码学习](./java/collection/ArrayList.md)
|
||||
* [LinkedList 源码学习](./java/collection/LinkedList.md)
|
||||
* [HashMap(JDK1.8)源码学习](./java/collection/HashMap.md)
|
||||
|
||||
### 并发
|
||||
|
||||
* [Java 并发基础常见面试题总结](./java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
|
||||
* [Java 并发进阶常见面试题总结](./java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
|
||||
* [并发容器总结](./java/Multithread/并发容器总结.md)
|
||||
* [乐观锁与悲观锁](./essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
||||
* [JUC 中的 Atomic 原子类总结](./java/Multithread/Atomic.md)
|
||||
* [AQS 原理以及 AQS 同步组件总结](./java/Multithread/AQS.md)
|
||||
|
||||
### JVM
|
||||
|
||||
* [一 Java内存区域](./java/jvm/Java内存区域.md)
|
||||
* [二 JVM垃圾回收](./java/jvm/JVM垃圾回收.md)
|
||||
* [三 JDK 监控和故障处理工具](./java/jvm/JDK监控和故障处理工具总结.md)
|
||||
* [四 类文件结构](./java/jvm/类文件结构.md)
|
||||
* [五 类加载过程](./java/jvm/类加载过程.md)
|
||||
* [六 类加载器](./java/jvm/类加载器.md)
|
||||
|
||||
### I/O
|
||||
|
||||
* [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
|
||||
* [Java IO 与 NIO系列文章](./java/Java%20IO与NIO.md)
|
||||
|
||||
### Java 8
|
||||
|
||||
* [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
* [Java 8 学习资源推荐](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
|
||||
### 编程规范
|
||||
|
||||
- [Java 编程规范](./java/Java编程规范.md)
|
||||
|
||||
## 网络
|
||||
|
||||
* [计算机网络常见面试题](./network/计算机网络.md)
|
||||
* [计算机网络基础知识总结](./network/干货:计算机网络知识总结.md)
|
||||
* [HTTPS中的TLS](./network/HTTPS中的TLS.md)
|
||||
|
||||
## 操作系统
|
||||
|
||||
### Linux相关
|
||||
|
||||
* [后端程序员必备的 Linux 基础知识](./operating-system/后端程序员必备的Linux基础知识.md)
|
||||
* [Shell 编程入门](./operating-system/Shell.md)
|
||||
|
||||
## 数据结构与算法
|
||||
|
||||
### 数据结构
|
||||
|
||||
- [数据结构知识学习与面试](./dataStructures-algorithms/数据结构.md)
|
||||
|
||||
### 算法
|
||||
|
||||
- [算法学习资源推荐](./dataStructures-algorithms/算法学习资源推荐.md)
|
||||
- [几道常见的子符串算法题总结 ](./dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的链表算法题总结 ](./dataStructures-algorithms/几道常见的链表算法题.md)
|
||||
- [剑指offer部分编程题](./dataStructures-algorithms/剑指offer部分编程题.md)
|
||||
- [公司真题](./dataStructures-algorithms/公司真题.md)
|
||||
- [回溯算法经典案例之N皇后问题](./dataStructures-algorithms/Backtracking-NQueens.md)
|
||||
|
||||
## 数据库
|
||||
|
||||
### MySQL
|
||||
|
||||
* [MySQL 学习与面试](./database/MySQL.md)
|
||||
* [一千行MySQL学习笔记](./database/一千行MySQL命令.md)
|
||||
* [MySQL高性能优化规范建议](./database/MySQL高性能优化规范建议.md)
|
||||
* [搞定数据库索引就是这么简单](./database/MySQL%20Index.md)
|
||||
* [事务隔离级别(图文详解)](./database/事务隔离级别(图文详解).md)
|
||||
* [一条SQL语句在MySQL中如何执行的](./database/一条sql语句在mysql中如何执行的.md)
|
||||
|
||||
### Redis
|
||||
|
||||
* [Redis 总结](./database/Redis/Redis.md)
|
||||
* [Redlock分布式锁](./database/Redis/Redlock分布式锁.md)
|
||||
* [如何做可靠的分布式锁,Redlock真的可行么](./database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 设计模式
|
||||
|
||||
- [设计模式系列文章](./system-design/设计模式.md)
|
||||
|
||||
### 常用框架
|
||||
|
||||
#### Spring
|
||||
|
||||
- [Spring 学习与面试](./system-design/framework/spring/Spring.md)
|
||||
- [Spring中bean的作用域与生命周期](./system-design/framework/spring/SpringBean.md)
|
||||
- [SpringMVC 工作原理详解](./system-design/framework/spring/SpringMVC-Principle.md)
|
||||
- [Spring中都用到了那些设计模式?](./system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
|
||||
#### ZooKeeper
|
||||
|
||||
- [ZooKeeper 相关概念总结](./system-design/framework/ZooKeeper.md)
|
||||
- [ZooKeeper 数据模型和常见命令](./system-design/framework/ZooKeeper数据模型和常见命令.md)
|
||||
|
||||
### 数据通信
|
||||
|
||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](./system-design/data-communication/summary.md)
|
||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](./system-design/data-communication/dubbo.md)
|
||||
- [消息队列总结](./system-design/data-communication/message-queue.md)
|
||||
- [RabbitMQ 入门](./system-design/data-communication/RabbitMQ.md)
|
||||
- [RocketMQ的几个简单问题与答案](./system-design/data-communication/RocketMQ-Questions.md)
|
||||
|
||||
### 网站架构
|
||||
|
||||
- [一文读懂分布式应该学什么](./system-design/website-architecture/分布式.md)
|
||||
- [8 张图读懂大型网站技术架构](./system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](./system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
## 面试指南
|
||||
|
||||
### 备战面试
|
||||
|
||||
* [【备战面试1】程序员的简历就该这样写](./essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
|
||||
* [【备战面试2】初出茅庐的程序员该如何准备面试?](./essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
|
||||
* [【备战面试3】7个大部分程序员在面试前很关心的问题](./essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
|
||||
* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](./essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
|
||||
* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](./essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
|
||||
* [【备战面试6】美团面试常见问题总结(附详解答案)](./essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
|
||||
|
||||
### 常见面试题总结
|
||||
|
||||
* [第一周(2018-8-7)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
|
||||
* [第二周(2018-8-13)](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
|
||||
* [第三周(2018-08-22)](./java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
|
||||
* [第四周(2018-8-30).md](./essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
|
||||
|
||||
### 面经
|
||||
|
||||
- [5面阿里,终获offer(2018年秋招)](./essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
|
||||
- [蚂蚁金服2019实习生面经总结(已拿口头offer)](./essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
|
||||
- [2019年蚂蚁金服、头条、拼多多的面试总结](./essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
|
||||
|
||||
## 工具
|
||||
|
||||
### Git
|
||||
|
||||
* [Git入门](./tools/Git.md)
|
||||
|
||||
### Docker
|
||||
|
||||
* [Docker 入门](./tools/Docker.md)
|
||||
* [一文搞懂 Docker 镜像的常用操作!](./tools/Docker-Image.md)
|
||||
|
||||
## 资料
|
||||
|
||||
### 书单
|
||||
|
||||
- [Java程序员必备书单](./data/java-recommended-books.md)
|
||||
|
||||
### Github榜单
|
||||
|
||||
- [Java 项目月榜单](./github-trending/JavaGithubTrending.md)
|
||||
|
||||
***
|
||||
|
||||
## 待办
|
||||
|
||||
- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
- [ ] Java 多线程类别知识重构(---正在进行中---)
|
||||
- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
|
||||
- [ ] Netty 总结(---正在进行中---)
|
||||
- [ ] 数据结构总结重构(---正在进行中---)
|
||||
|
||||
## 联系我
|
||||
|
||||
添加我的微信备注“Github”,回复关键字 **“加群”** 即可入群。
|
||||
|
||||

|
||||
|
||||
## 公众号
|
||||
|
||||
- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
|
||||
- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||
<p align="center">
|
||||
<img src="https://user-gold-cdn.xitu.io/2018/11/28/167598cd2e17b8ec?w=258&h=258&f=jpeg&s=27334" width=""/>
|
||||
</p>
|
||||
@ -135,17 +135,21 @@ public class Main {
|
||||
|
||||
}
|
||||
|
||||
private static boolean checkStrs(String[] strs) {
|
||||
if (strs != null) {
|
||||
// 遍历strs检查元素值
|
||||
for (int i = 0; i < strs.length; i++) {
|
||||
if (strs[i] == null || strs[i].length() == 0) {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
}
|
||||
return true;
|
||||
}
|
||||
private static boolean chechStrs(String[] strs) {
|
||||
boolean flag = false;
|
||||
if (strs != null) {
|
||||
// 遍历strs检查元素值
|
||||
for (int i = 0; i < strs.length; i++) {
|
||||
if (strs[i] != null && strs[i].length() != 0) {
|
||||
flag = true;
|
||||
} else {
|
||||
flag = false;
|
||||
break;
|
||||
}
|
||||
}
|
||||
}
|
||||
return flag;
|
||||
}
|
||||
|
||||
// 测试
|
||||
public static void main(String[] args) {
|
||||
@ -459,7 +463,7 @@ public class Main {
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
return flag == 1 ? res : -res;
|
||||
return flag != 2 ? res : -res;
|
||||
|
||||
}
|
||||
|
||||
|
||||
@ -47,7 +47,7 @@ Queue 用来存放 等待处理元素 的集合,这种场景一般用于缓冲
|
||||
### 什么是 Set
|
||||
Set 继承于 Collection 接口,是一个不允许出现重复元素,并且无序的集合,主要 HashSet 和 TreeSet 两大实现类。
|
||||
|
||||
在判断重复元素的时候,Set 集合会调用 hashCode()和 equal()方法来实现。
|
||||
在判断重复元素的时候,HashSet 集合会调用 hashCode()和 equal()方法来实现;TreeSet 集合会调用compareTo方法来实现。
|
||||
|
||||
### 补充:有序集合与无序集合说明
|
||||
- 有序集合:集合里的元素可以根据 key 或 index 访问 (List、Map)
|
||||
@ -83,8 +83,8 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
|
||||
|
||||
### ArrayList 和 LinkedList 源码学习
|
||||
|
||||
- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/ArrayList.md)
|
||||
- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/LinkedList.md)
|
||||
- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList.md)
|
||||
- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/LinkedList.md)
|
||||
|
||||
### 推荐阅读
|
||||
|
||||
@ -104,7 +104,7 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
|
||||
|
||||
(1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
|
||||
|
||||
(2)[满二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
|
||||
(2)[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
|
||||
|
||||
(3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
|
||||
|
||||
|
||||
@ -70,7 +70,7 @@ select * from user where city=xx ; // 无法命中索引
|
||||
|
||||
冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
||||
|
||||
MySQLS.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
|
||||
MySQL 5.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
|
||||
|
||||
### Mysql如何为表字段添加索引???
|
||||
|
||||
|
||||
@ -1,9 +1,31 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [书籍推荐](#书籍推荐)
|
||||
- [文字教程推荐](#文字教程推荐)
|
||||
- [视频教程推荐](#视频教程推荐)
|
||||
- [常见问题总结](#常见问题总结)
|
||||
- [什么是MySQL?](#什么是mysql)
|
||||
- [存储引擎](#存储引擎)
|
||||
- [一些常用命令](#一些常用命令)
|
||||
- [MyISAM和InnoDB区别](#myisam和innodb区别)
|
||||
- [字符集及校对规则](#字符集及校对规则)
|
||||
- [索引](#索引)
|
||||
- [查询缓存的使用](#查询缓存的使用)
|
||||
- [什么是事务?](#什么是事务)
|
||||
- [事物的四大特性(ACID)](#事物的四大特性acid)
|
||||
- [并发事务带来哪些问题?](#并发事务带来哪些问题)
|
||||
- [事务隔离级别有哪些?MySQL的默认隔离级别是?](#事务隔离级别有哪些mysql的默认隔离级别是)
|
||||
- [锁机制与InnoDB锁算法](#锁机制与innodb锁算法)
|
||||
- [大表优化](#大表优化)
|
||||
- [1. 限定数据的范围](#1-限定数据的范围)
|
||||
- [2. 读/写分离](#2-读写分离)
|
||||
- [3. 垂直分区](#3-垂直分区)
|
||||
- [4. 水平分区](#4-水平分区)
|
||||
- [一条SQL语句在MySQL中如何执行的](#一条sql语句在mysql中如何执行的)
|
||||
- [MySQL高性能优化规范建议](#mysql高性能优化规范建议)
|
||||
- [一条SQL语句执行得很慢的原因有哪些?](#一条sql语句执行得很慢的原因有哪些)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
@ -14,161 +36,276 @@
|
||||
|
||||
## 文字教程推荐
|
||||
|
||||
[MySQL 教程(菜鸟教程)](http://www.runoob.com/mysql/mysql-tutorial.html)
|
||||
- [SQL Tutorial](https://www.w3schools.com/sql/default.asp) (SQL语句学习,英文)、[SQL Tutorial](https://www.w3school.com.cn/sql/index.asp)(SQL语句学习,中文)、[SQL语句在线练习](https://www.w3schools.com/sql/exercise.asp) (非常不错)
|
||||
- [Github-MySQL入门教程(MySQL tutorial book)](https://github.com/jaywcjlove/mysql-tutorial) (从零开始学习MySQL,主要是面向MySQL数据库管理系统初学者)
|
||||
- [官方教程](https://dev.mysql.com/doc/refman/5.7/)
|
||||
- [MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
|
||||
|
||||
[MySQL教程(易百教程)](https://www.yiibai.com/mysql/)
|
||||
## 相关资源推荐
|
||||
|
||||
- [中国5级行政区域mysql库](https://github.com/kakuilan/china_area_mysql)
|
||||
|
||||
## 视频教程推荐
|
||||
|
||||
**基础入门:** [与MySQL的零距离接触-慕课网](https://www.imooc.com/learn/122)
|
||||
|
||||
**Mysql开发技巧:** [MySQL开发技巧(一)](https://www.imooc.com/learn/398) [MySQL开发技巧(二)](https://www.imooc.com/learn/427) [MySQL开发技巧(三)](https://www.imooc.com/learn/449)
|
||||
**MySQL开发技巧:** [MySQL开发技巧(一)](https://www.imooc.com/learn/398) [MySQL开发技巧(二)](https://www.imooc.com/learn/427) [MySQL开发技巧(三)](https://www.imooc.com/learn/449)
|
||||
|
||||
**Mysql5.7新特性及相关优化技巧:** [MySQL5.7版本新特性](https://www.imooc.com/learn/533) [性能优化之MySQL优化](https://www.imooc.com/learn/194)
|
||||
**MySQL5.7新特性及相关优化技巧:** [MySQL5.7版本新特性](https://www.imooc.com/learn/533) [性能优化之MySQL优化](https://www.imooc.com/learn/194)
|
||||
|
||||
[MySQL集群(PXC)入门](https://www.imooc.com/learn/993) [MyCAT入门及应用](https://www.imooc.com/learn/951)
|
||||
|
||||
## 常见问题总结
|
||||
|
||||
- ### ①存储引擎
|
||||
### 什么是MySQL?
|
||||
|
||||
[MySQL常见的两种存储引擎:MyISAM与InnoDB的爱恨情仇](https://juejin.im/post/5b1685bef265da6e5c3c1c34)
|
||||
|
||||
- ### ②字符集及校对规则
|
||||
MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是**3306**。
|
||||
|
||||
字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。Mysql中每一种字符集都会对应一系列的校对规则。
|
||||
### 存储引擎
|
||||
|
||||
Mysql采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集) PS:整理自《Java工程师修炼之道》
|
||||
|
||||
详细内容可以参考: [MySQL字符集及校对规则的理解](https://www.cnblogs.com/geaozhang/p/6724393.html#mysqlyuzifuji)
|
||||
#### 一些常用命令
|
||||
|
||||
- ### ③索引相关的内容(数据库使用中非常关键的技术,合理正确的使用索引可以大大提高数据库的查询性能)
|
||||
|
||||
Mysql索引使用的数据结构主要有**BTree索引** 和 **哈希索引** 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
|
||||
|
||||
Mysql的BTree索引使用的是B数中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
|
||||
**查看MySQL提供的所有存储引擎**
|
||||
|
||||
**MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
|
||||
**InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
|
||||
|
||||
详细内容可以参考:
|
||||
|
||||
[干货:mysql索引的数据结构](https://www.jianshu.com/p/1775b4ff123a)
|
||||
|
||||
[MySQL优化系列(三)--索引的使用、原理和设计优化](https://blog.csdn.net/Jack__Frost/article/details/72571540)
|
||||
|
||||
[数据库两大神器【索引和锁】](https://juejin.im/post/5b55b842f265da0f9e589e79#comment)
|
||||
|
||||
- ### ④查询缓存的使用
|
||||
```sql
|
||||
mysql> show engines;
|
||||
```
|
||||
|
||||
my.cnf加入以下配置,重启Mysql开启查询缓存
|
||||
```
|
||||
query_cache_type=1
|
||||
query_cache_size=600000
|
||||
```
|
||||
|
||||
Mysql执行以下命令也可以开启查询缓存
|
||||
|
||||
```
|
||||
set global query_cache_type=1;
|
||||
set global query_cache_size=600000;
|
||||
```
|
||||
如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、Mysql库中的系统表,其查询结果也不会被缓存。
|
||||
|
||||
缓存建立之后,Mysql的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
||||
|
||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
|
||||
```
|
||||
select sql_no_cache count(*) from usr;
|
||||
```
|
||||
|
||||
- ### ⑤事务机制
|
||||
|
||||
**关系性数据库需要遵循ACID规则,具体内容如下:**
|
||||
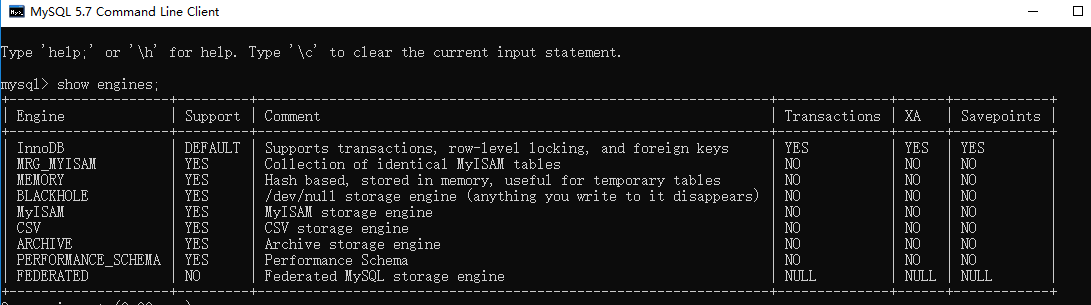
|
||||
|
||||

|
||||
从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
|
||||
|
||||
1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性:** 执行事务前后,数据库从一个一致性状态转换到另一个一致性状态。
|
||||
3. **隔离性:** 并发访问数据库时,一个用户的事物不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库 发生故障也不应该对其有任何影响。
|
||||
|
||||
**为了达到上述事务特性,数据库定义了几种不同的事务隔离级别:**
|
||||
**查看MySQL当前默认的存储引擎**
|
||||
|
||||
- **READ_UNCOMMITTED(未提交读):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
|
||||
- **READ_COMMITTED(提交读):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
|
||||
- **REPEATABLE_READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
|
||||
- **SERIALIZABLE(串行):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
|
||||
我们也可以通过下面的命令查看默认的存储引擎。
|
||||
|
||||
这里需要注意的是:**Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.**
|
||||
```sql
|
||||
mysql> show variables like '%storage_engine%';
|
||||
```
|
||||
|
||||
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVCC(多版本并发控制),通过行的创建时间和行的过期时间来支持并发一致性读和回滚等特性。
|
||||
**查看表的存储引擎**
|
||||
|
||||
详细内容可以参考: [可能是最漂亮的Spring事务管理详解](https://blog.csdn.net/qq_34337272/article/details/80394121)
|
||||
```sql
|
||||
show table status like "table_name" ;
|
||||
```
|
||||
|
||||
- ### ⑥锁机制与InnoDB锁算法
|
||||
**MyISAM和InnoDB存储引擎使用的锁:**
|
||||

|
||||
|
||||
- MyISAM采用表级锁(table-level locking)。
|
||||
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
|
||||
#### MyISAM和InnoDB区别
|
||||
|
||||
**表级锁和行级锁对比:**
|
||||
MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,而且提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。
|
||||
|
||||
- **表级锁:** Mysql中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
|
||||
- **行级锁:** Mysql中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
|
||||
大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下。(如果你不介意 MyISAM 崩溃恢复问题的话)。
|
||||
|
||||
详细内容可以参考:
|
||||
[Mysql锁机制简单了解一下](https://blog.csdn.net/qq_34337272/article/details/80611486)
|
||||
|
||||
**InnoDB存储引擎的锁的算法有三种:**
|
||||
- Record lock:单个行记录上的锁
|
||||
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
|
||||
- Next-key lock:record+gap 锁定一个范围,包含记录本身
|
||||
|
||||
**相关知识点:**
|
||||
1. innodb对于行的查询使用next-key lock
|
||||
2. Next-locking keying为了解决Phantom Problem幻读问题
|
||||
3. 当查询的索引含有唯一属性时,将next-key lock降级为record key
|
||||
4. Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
|
||||
5. 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
|
||||
**两者的对比:**
|
||||
|
||||
- ### ⑦大表优化
|
||||
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
|
||||
2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
|
||||
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
|
||||
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
|
||||
5. ......
|
||||
|
||||
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
|
||||
|
||||
1. **限定数据的范围:** 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
|
||||
2. **读/写分离:** 经典的数据库拆分方案,主库负责写,从库负责读;
|
||||
3 . **垂直分区:**
|
||||
|
||||
**根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
|
||||
《MySQL高性能》上面有一句话这样写到:
|
||||
|
||||
**简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。
|
||||

|
||||
|
||||
**垂直拆分的优点:** 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
|
||||
> 不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
|
||||
|
||||
**垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
|
||||
一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
|
||||
|
||||
4. **水平分区:**
|
||||
|
||||
|
||||
**保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
|
||||
|
||||
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
|
||||
|
||||

|
||||
|
||||
水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。
|
||||
|
||||
水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨节点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
|
||||
|
||||
**下面补充一下数据库分片的两种常见方案:**
|
||||
- **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
|
||||
- **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
|
||||
|
||||
|
||||
详细内容可以参考:
|
||||
[MySQL大表优化方案](https://segmentfault.com/a/1190000006158186)
|
||||
|
||||
### 字符集及校对规则
|
||||
|
||||
字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。MySQL中每一种字符集都会对应一系列的校对规则。
|
||||
|
||||
MySQL采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集) PS:整理自《Java工程师修炼之道》
|
||||
|
||||
详细内容可以参考: [MySQL字符集及校对规则的理解](https://www.cnblogs.com/geaozhang/p/6724393.html#MySQLyuzifuji)
|
||||
|
||||
### 索引
|
||||
|
||||
MySQL索引使用的数据结构主要有**BTree索引** 和 **哈希索引** 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
|
||||
|
||||
MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
|
||||
|
||||
- **MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
- **InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
|
||||
|
||||
**更多关于索引的内容可以查看文档首页MySQL目录下关于索引的详细总结。**
|
||||
|
||||
### 查询缓存的使用
|
||||
|
||||
> 执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
|
||||
|
||||
my.cnf加入以下配置,重启MySQL开启查询缓存
|
||||
```properties
|
||||
query_cache_type=1
|
||||
query_cache_size=600000
|
||||
```
|
||||
|
||||
MySQL执行以下命令也可以开启查询缓存
|
||||
|
||||
```properties
|
||||
set global query_cache_type=1;
|
||||
set global query_cache_size=600000;
|
||||
```
|
||||
如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果也不会被缓存。
|
||||
|
||||
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
||||
|
||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
|
||||
```sql
|
||||
select sql_no_cache count(*) from usr;
|
||||
```
|
||||
|
||||
### 什么是事务?
|
||||
|
||||
**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
|
||||
|
||||
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
|
||||
|
||||
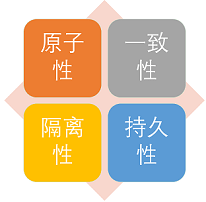
### 事物的四大特性(ACID)
|
||||
|
||||
|
||||
|
||||
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
|
||||
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
### 并发事务带来哪些问题?
|
||||
|
||||
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
|
||||
|
||||
- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
|
||||
- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
|
||||
- **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
|
||||
- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
|
||||
|
||||
**不可重复读和幻读区别:**
|
||||
|
||||
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
|
||||
|
||||
### 事务隔离级别有哪些?MySQL的默认隔离级别是?
|
||||
|
||||
**SQL 标准定义了四个隔离级别:**
|
||||
|
||||
- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
|
||||
- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
|
||||
- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
|
||||
- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
|
||||
|
||||
------
|
||||
|
||||
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|
||||
| :--------------: | :--: | :--------: | :----: |
|
||||
| READ-UNCOMMITTED | √ | √ | √ |
|
||||
| READ-COMMITTED | × | √ | √ |
|
||||
| REPEATABLE-READ | × | × | √ |
|
||||
| SERIALIZABLE | × | × | × |
|
||||
|
||||
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看
|
||||
|
||||
```sql
|
||||
mysql> SELECT @@tx_isolation;
|
||||
+-----------------+
|
||||
| @@tx_isolation |
|
||||
+-----------------+
|
||||
| REPEATABLE-READ |
|
||||
+-----------------+
|
||||
```
|
||||
|
||||
这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)**
|
||||
事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)
|
||||
是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了
|
||||
SQL标准的 **SERIALIZABLE(可串行化)** 隔离级别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
|
||||
|
||||
InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
|
||||
|
||||
### 锁机制与InnoDB锁算法
|
||||
|
||||
**MyISAM和InnoDB存储引擎使用的锁:**
|
||||
|
||||
- MyISAM采用表级锁(table-level locking)。
|
||||
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
|
||||
|
||||
**表级锁和行级锁对比:**
|
||||
|
||||
- **表级锁:** MySQL中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
|
||||
- **行级锁:** MySQL中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
|
||||
|
||||
详细内容可以参考: MySQL锁机制简单了解一下:[https://blog.csdn.net/qq_34337272/article/details/80611486](https://blog.csdn.net/qq_34337272/article/details/80611486)
|
||||
|
||||
**InnoDB存储引擎的锁的算法有三种:**
|
||||
|
||||
- Record lock:单个行记录上的锁
|
||||
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
|
||||
- Next-key lock:record+gap 锁定一个范围,包含记录本身
|
||||
|
||||
**相关知识点:**
|
||||
|
||||
1. innodb对于行的查询使用next-key lock
|
||||
2. Next-locking keying为了解决Phantom Problem幻读问题
|
||||
3. 当查询的索引含有唯一属性时,将next-key lock降级为record key
|
||||
4. Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
|
||||
5. 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
|
||||
|
||||
### 大表优化
|
||||
|
||||
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
|
||||
|
||||
#### 1. 限定数据的范围
|
||||
|
||||
务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
|
||||
|
||||
#### 2. 读/写分离
|
||||
|
||||
经典的数据库拆分方案,主库负责写,从库负责读;
|
||||
|
||||
#### 3. 垂直分区
|
||||
|
||||
**根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
|
||||
|
||||
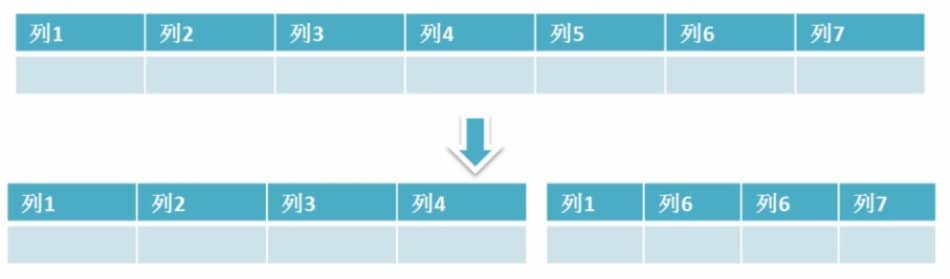
**简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。
|
||||
|
||||
|
||||
- **垂直拆分的优点:** 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
|
||||
- **垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
|
||||
|
||||
#### 4. 水平分区
|
||||
|
||||
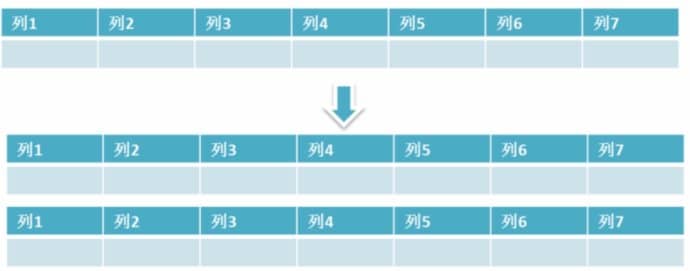
**保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
|
||||
|
||||
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
|
||||
|
||||
|
||||
|
||||
水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。
|
||||
|
||||
水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨节点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
|
||||
|
||||
**下面补充一下数据库分片的两种常见方案:**
|
||||
|
||||
- **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
|
||||
- **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
|
||||
|
||||
详细内容可以参考: MySQL大表优化方案: [https://segmentfault.com/a/1190000006158186](https://segmentfault.com/a/1190000006158186)
|
||||
|
||||
### 一条SQL语句在MySQL中如何执行的
|
||||
|
||||
[一条SQL语句在MySQL中如何执行的](<https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485097&idx=1&sn=84c89da477b1338bdf3e9fcd65514ac1&chksm=cea24962f9d5c074d8d3ff1ab04ee8f0d6486e3d015cfd783503685986485c11738ccb542ba7&token=79317275&lang=zh_CN#rd>)
|
||||
|
||||
### MySQL高性能优化规范建议
|
||||
|
||||
[MySQL高性能优化规范建议](<https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485117&idx=1&sn=92361755b7c3de488b415ec4c5f46d73&chksm=cea24976f9d5c060babe50c3747616cce63df5d50947903a262704988143c2eeb4069ae45420&token=79317275&lang=zh_CN#rd>)
|
||||
|
||||
### 一条SQL语句执行得很慢的原因有哪些?
|
||||
|
||||
[腾讯面试:一条SQL语句执行得很慢的原因有哪些?---不看后悔系列](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485185&idx=1&sn=66ef08b4ab6af5757792223a83fc0d45&chksm=cea248caf9d5c1dc72ec8a281ec16aa3ec3e8066dbb252e27362438a26c33fbe842b0e0adf47&token=79317275&lang=zh_CN#rd)
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
@ -18,7 +19,6 @@
|
||||
- [缓存雪崩和缓存穿透问题解决方案](#缓存雪崩和缓存穿透问题解决方案)
|
||||
- [如何解决 Redis 的并发竞争 Key 问题](#如何解决-redis-的并发竞争-key-问题)
|
||||
- [如何保证缓存与数据库双写时的数据一致性?](#如何保证缓存与数据库双写时的数据一致性)
|
||||
- [参考:](#参考)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
|
||||
**高性能:**
|
||||
|
||||
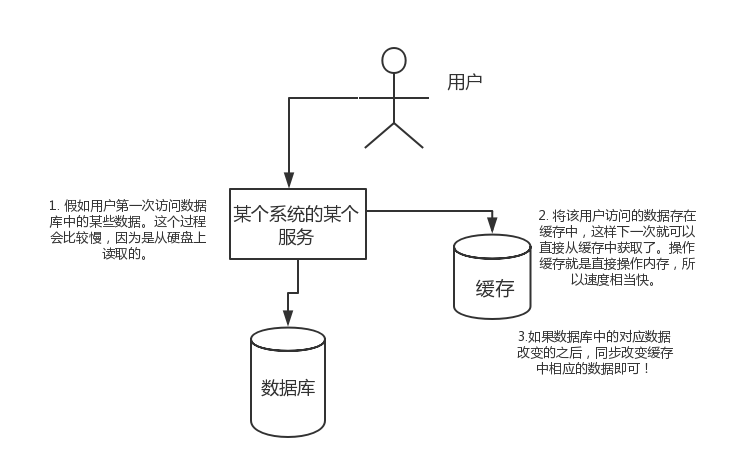
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
|
||||
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
|
||||
|
||||
|
||||
|
||||
@ -54,6 +54,21 @@
|
||||
|
||||
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
|
||||
|
||||
### redis 的线程模型
|
||||
|
||||
> 参考地址:https://www.javazhiyin.com/22943.html
|
||||
|
||||
redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
|
||||
|
||||
文件事件处理器的结构包含 4 个部分:
|
||||
|
||||
- 多个 socket
|
||||
- IO 多路复用程序
|
||||
- 文件事件分派器
|
||||
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
||||
|
||||
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
|
||||
|
||||
|
||||
### redis 和 memcached 的区别
|
||||
|
||||
@ -149,8 +164,6 @@ Redis中有个设置时间过期的功能,即对存储在 redis 数据库中
|
||||
|
||||
但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢? **redis 内存淘汰机制。**
|
||||
|
||||
|
||||
|
||||
### redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
|
||||
|
||||
redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大家可以自行查阅或者通过这个网址查看: [http://download.redis.io/redis-stable/redis.conf](http://download.redis.io/redis-stable/redis.conf)
|
||||
@ -169,8 +182,6 @@ redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大
|
||||
7. **volatile-lfu**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
|
||||
8. **allkeys-lfu**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
|
||||
|
||||
|
||||
|
||||
**备注: 关于 redis 设置过期时间以及内存淘汰机制,我这里只是简单的总结一下,后面会专门写一篇文章来总结!**
|
||||
|
||||
|
||||
@ -240,6 +251,10 @@ Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。
|
||||
|
||||
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
|
||||
|
||||
补充内容:
|
||||
|
||||
> 1. redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。(来自[issue:关于Redis事务不是原子性问题](https://github.com/Snailclimb/JavaGuide/issues/452) )
|
||||
|
||||
### 缓存雪崩和缓存穿透问题解决方案
|
||||
|
||||
**缓存雪崩**
|
||||
@ -287,13 +302,14 @@ Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。
|
||||
|
||||
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
|
||||
|
||||
**参考:**
|
||||
**参考:** Java工程师面试突击第1季(可能是史上最好的Java面试突击课程)-中华石杉老师!公众号后台回复关键字“1”即可获取该视频内容。
|
||||
|
||||
- Java工程师面试突击第1季(可能是史上最好的Java面试突击课程)-中华石杉老师。视频地址见下面!
|
||||
- 链接: https://pan.baidu.com/s/18pp6g1xKVGCfUATf_nMrOA
|
||||
- 密码:5i58
|
||||
## 公众号
|
||||
|
||||
### 参考:
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
- redis设计与实现(第二版)
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
@ -104,7 +104,7 @@ SHOW VARIABLES -- 显示系统变量信息
|
||||
-- 查看所有表
|
||||
SHOW TABLES[ LIKE 'pattern']
|
||||
SHOW TABLES FROM 库名
|
||||
-- 查看表机构
|
||||
-- 查看表结构
|
||||
SHOW CREATE TABLE 表名 (信息更详细)
|
||||
DESC 表名 / DESCRIBE 表名 / EXPLAIN 表名 / SHOW COLUMNS FROM 表名 [LIKE 'PATTERN']
|
||||
SHOW TABLE STATUS [FROM db_name] [LIKE 'pattern']
|
||||
@ -363,7 +363,7 @@ set(val1, val2, val3...)
|
||||
字段不能再分,就满足第一范式。
|
||||
-- 2NF, 第二范式
|
||||
满足第一范式的前提下,不能出现部分依赖。
|
||||
消除符合主键就可以避免部分依赖。增加单列关键字。
|
||||
消除复合主键就可以避免部分依赖。增加单列关键字。
|
||||
-- 3NF, 第三范式
|
||||
满足第二范式的前提下,不能出现传递依赖。
|
||||
某个字段依赖于主键,而有其他字段依赖于该字段。这就是传递依赖。
|
||||
@ -590,7 +590,7 @@ CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}] VIEW view_name
|
||||
```mysql
|
||||
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败。
|
||||
- 支持连续SQL的集体成功或集体撤销。
|
||||
- 事务是数据库在数据晚自习方面的一个功能。
|
||||
- 事务是数据库在数据完整性方面的一个功能。
|
||||
- 需要利用 InnoDB 或 BDB 存储引擎,对自动提交的特性支持完成。
|
||||
- InnoDB被称为事务安全型引擎。
|
||||
-- 事务开启
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
|
||||
- [事务隔离级别(图文详解)](#事务隔离级别图文详解)
|
||||
- [什么是事务?](#什么是事务)
|
||||
- [事物的特性(ACID)](#事物的特性acid)
|
||||
- [事务的特性(ACID)](#事务的特性acid)
|
||||
- [并发事务带来的问题](#并发事务带来的问题)
|
||||
- [事务隔离级别](#事务隔离级别)
|
||||
- [实际情况演示](#实际情况演示)
|
||||
@ -24,9 +24,9 @@
|
||||
|
||||
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
|
||||
|
||||
### 事物的特性(ACID)
|
||||
### 事务的特性(ACID)
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
@ -69,7 +69,7 @@
|
||||
| REPEATABLE-READ | × | × | √ |
|
||||
| SERIALIZABLE | × | × | × |
|
||||
|
||||
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看
|
||||
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
|
||||
|
||||
```sql
|
||||
mysql> SELECT @@tx_isolation;
|
||||
|
||||
@ -1,78 +1,89 @@
|
||||
最近浏览 Github ,收藏了一些还算不错的 Java面试/学习相关的仓库,分享给大家,希望对你有帮助。我暂且按照目前的 Star 数量来排序。
|
||||
昨天我整理了公众号历史所有和面试相关的我觉得还不错的文章:[整理了一些有助于你拿Offer的文章](<https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485434&idx=1&sn=f6bdf19d2594bf719e149e48d1384340&chksm=cea24831f9d5c1278617d347238f65f0481f36291675f05fabb382b69ea0ff3adae7ee6e6524&token=1452779379&lang=zh_CN#rd>) 。今天分享一下最近逛Github看到了一些我觉得对于Java面试以及学习有帮助的仓库,这些仓库涉及Java核心知识点整理、Java常见面试题、算法、基础知识点比如网络和操作系统等等。
|
||||
|
||||
本文由 SnailClimb 整理,如需转载请联系作者。
|
||||
## 知识点相关
|
||||
|
||||
### 1. interviews
|
||||
|
||||
- Github地址: [https://github.com/kdn251/interviews/blob/master/README-zh-cn.md](https://github.com/kdn251/interviews/blob/master/README-zh-cn.md)
|
||||
- star: 31k
|
||||
- 介绍: 软件工程技术面试个人指南。
|
||||
- 概览:
|
||||
|
||||
|
||||
|
||||
### 2. JCSprout
|
||||
|
||||
- Github地址:[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
|
||||
- star: 17.7k
|
||||
- 介绍: Java Core Sprout:处于萌芽阶段的 Java 核心知识库。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 3. JavaGuide
|
||||
### 1.JavaGuide
|
||||
|
||||
- Github地址: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- star: 17.4k
|
||||
- star: 64.0k
|
||||
- 介绍: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
|
||||
- 概览:
|
||||
|
||||

|
||||
### 2.CS-Notes
|
||||
|
||||
### 4. technology-talk
|
||||
- Github 地址:<https://github.com/CyC2018/CS-Notes>
|
||||
- Star: 68.3k
|
||||
- 介绍: 技术面试必备基础知识、Leetcode 题解、后端面试、Java 面试、春招、秋招、操作系统、计算机网络、系统设计。
|
||||
|
||||
- Github地址: [https://github.com/aalansehaiyang/technology-talk](https://github.com/aalansehaiyang/technology-talk)
|
||||
- star: 4.2k
|
||||
- 介绍: 汇总java生态圈常用技术框架、开源中间件,系统架构、项目管理、经典架构案例、数据库、常用三方库、线上运维等知识。
|
||||
|
||||
### 5. fullstack-tutorial
|
||||
|
||||
- Github地址: [https://github.com/frank-lam/fullstack-tutorial](https://github.com/frank-lam/fullstack-tutorial)
|
||||
- star: 2.8k
|
||||
- 介绍: Full Stack Developer Tutorial,后台技术栈/全栈开发/架构师之路,秋招/春招/校招/面试。 from zero to hero。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 6. java-bible
|
||||
|
||||
- Github地址:[https://github.com/biezhi/java-bible](https://github.com/biezhi/java-bible)
|
||||
- star: 1.9k
|
||||
- 介绍: 这里记录了一些技术摘要,部分文章来自网络,本项目的目的力求分享精品技术干货,以Java为主。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 7. EasyJob
|
||||
|
||||
- Github地址:[https://github.com/it-interview/EasyJob](https://github.com/it-interview/EasyJob)
|
||||
- star: 1.9k
|
||||
- 介绍: 互联网求职面试题、知识点和面经整理。
|
||||
|
||||
### 8. advanced-java
|
||||
### 3. advanced-java
|
||||
|
||||
- Github地址:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- star: 1k
|
||||
- 介绍: 互联网 Java 工程师进阶知识完全扫盲
|
||||
- star: 23.4k
|
||||
- 介绍: 互联网 Java 工程师进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务等领域知识,后端同学必看,前端同学也可学习。
|
||||
|
||||
### 9. 3y
|
||||
### 4.JCSprout
|
||||
|
||||
- Github地址:[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
|
||||
- star: 21.2k
|
||||
- 介绍: Java Core Sprout:处于萌芽阶段的 Java 核心知识库。
|
||||
|
||||
### 5.toBeTopJavaer
|
||||
|
||||
- Github地址:[https://github.com/hollischuang/toBeTopJavaer](https://github.com/hollischuang/toBeTopJavaer)
|
||||
- star: 4.0 k
|
||||
- 介绍: Java工程师成神之路。
|
||||
|
||||
### 6.architect-awesome
|
||||
|
||||
- Github地址:[https://github.com/xingshaocheng/architect-awesome](https://github.com/xingshaocheng/architect-awesome)
|
||||
- star: 34.4 k
|
||||
- 介绍:后端架构师技术图谱。
|
||||
|
||||
### 7.technology-talk
|
||||
|
||||
- Github地址: [https://github.com/aalansehaiyang/technology-talk](https://github.com/aalansehaiyang/technology-talk)
|
||||
- star: 6.1k
|
||||
- 介绍: 汇总java生态圈常用技术框架、开源中间件,系统架构、项目管理、经典架构案例、数据库、常用三方库、线上运维等知识。
|
||||
|
||||
### 8.fullstack-tutorial
|
||||
|
||||
- Github地址: [https://github.com/frank-lam/fullstack-tutorial](https://github.com/frank-lam/fullstack-tutorial)
|
||||
- star: 4.0k
|
||||
- 介绍: fullstack tutorial 2019,后台技术栈/架构师之路/全栈开发社区,春招/秋招/校招/面试。
|
||||
|
||||
### 9.3y
|
||||
|
||||
- Github地址:[https://github.com/ZhongFuCheng3y/3y](https://github.com/ZhongFuCheng3y/3y)
|
||||
- star: 0.4 k
|
||||
- star: 1.9 k
|
||||
- 介绍: Java 知识整合。
|
||||
|
||||
除了这九个仓库,再推荐几个不错的学习方向的仓库给大家。
|
||||
### 10.java-bible
|
||||
|
||||
1. Star 数高达 4w+的 CS 笔记-CS-Notes:[https://github.com/CyC2018/CS-Notes](https://github.com/CyC2018/CS-Notes)
|
||||
2. 后端(尤其是Java)程序员的 Linux 学习仓库-Linux-Tutorial:[https://github.com/judasn/Linux-Tutorial](https://github.com/judasn/Linux-Tutorial)( Star:4.6k)
|
||||
3. 两个算法相关的仓库,刷 Leetcode 的小伙伴必备:①awesome-java-leetcode:[https://github.com/Blankj/awesome-java-leetcode](https://github.com/Blankj/awesome-java-leetcode);②LintCode:[https://github.com/awangdev/LintCode](https://github.com/awangdev/LintCode)
|
||||
- Github地址:[https://github.com/biezhi/java-bible](https://github.com/biezhi/java-bible)
|
||||
- star: 2.3k
|
||||
- 介绍: 这里记录了一些技术摘要,部分文章来自网络,本项目的目的力求分享精品技术干货,以Java为主。
|
||||
|
||||
### 11.interviews
|
||||
|
||||
- Github地址: [https://github.com/kdn251/interviews/blob/master/README-zh-cn.md](https://github.com/kdn251/interviews/blob/master/README-zh-cn.md)
|
||||
- star: 35.3k
|
||||
- 介绍: 软件工程技术面试个人指南(国外的一个项目,虽然有翻译版,但是不太推荐,因为很多内容并不适用于国内)。
|
||||
|
||||
## 算法相关
|
||||
|
||||
### 1.LeetCodeAnimation
|
||||
|
||||
- Github 地址: <https://github.com/MisterBooo/LeetCodeAnimation>
|
||||
- Star: 33.4k
|
||||
- 介绍: Demonstrate all the questions on LeetCode in the form of animation.(用动画的形式呈现解LeetCode题目的思路)。
|
||||
|
||||
### 2.awesome-java-leetcode
|
||||
|
||||
- Github地址:[https://github.com/Blankj/awesome-java-leetcode](https://github.com/Blankj/awesome-java-leetcode)
|
||||
- star: 6.1k
|
||||
- 介绍: LeetCode 上 Facebook 的面试题目。
|
||||
|
||||
### 3.leetcode
|
||||
|
||||
- Github地址:[https://github.com/azl397985856/leetcode](https://github.com/azl397985856/leetcode)
|
||||
- star: 12.0k
|
||||
- 介绍: LeetCode Solutions: A Record of My Problem Solving Journey.( leetcode题解,记录自己的leetcode解题之路。)
|
||||
@ -102,7 +102,7 @@
|
||||
## 排版注意事项
|
||||
|
||||
1. 尽量简洁,不要太花里胡哨;
|
||||
2. 一些技术名词不要弄错了大小写比如MySQL不要写成mysql,Java不要写成Java。这个在我看来还是比较忌讳的,所以一定要注意这个细节;
|
||||
2. 一些技术名词不要弄错了大小写比如MySQL不要写成mysql,Java不要写成java。这个在我看来还是比较忌讳的,所以一定要注意这个细节;
|
||||
3. 中文和数字英文之间加上空格的话看起来会舒服一点;
|
||||
|
||||
## 其他的一些小tips
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
- [2.1 两者的对比](#21-两者的对比)
|
||||
- [2.2 关于两者的总结](#22-关于两者的总结)
|
||||
- [3 聊聊 Java 中的集合吧!](#3-聊聊-java-中的集合吧)
|
||||
- [3.1 Arraylist 与 LinkedList 有什么不同?\(注意加上从数据结构分析的内容\)](#31-arraylist-与-linkedlist-有什么不同注意加上从数据结构分析的内容)
|
||||
- [3.1 ArrayList 与 LinkedList 有什么不同?\(注意加上从数据结构分析的内容\)](#31-arraylist-与-linkedlist-有什么不同注意加上从数据结构分析的内容)
|
||||
- [3.2 HashMap的底层实现](#32-hashmap的底层实现)
|
||||
- [1)JDK1.8之前](#1jdk18之前)
|
||||
- [2)JDK1.8之后](#2jdk18之后)
|
||||
@ -108,7 +108,7 @@
|
||||
request.getRequestDispatcher("login_success.jsp").forward(request, response);
|
||||
```
|
||||
|
||||
**重定向(Redirect)** 是利用服务器返回的状态吗来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过HttpServletRequestResponse的setStatus(int status)方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
|
||||
**重定向(Redirect)** 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过HttpServletRequestResponse的setStatus(int status)方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
|
||||
|
||||
1. **从地址栏显示来说**:forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器。浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址。redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址。所以地址栏显示的是新的URL。
|
||||
2. **从数据共享来说**:forward:转发页面和转发到的页面可以共享request里面的数据。redirect:不能共享数据。
|
||||
@ -484,7 +484,7 @@ TransactionDefinition 接口中定义了五个表示隔离级别的常量:
|
||||
|
||||
### 2.2 关于两者的总结
|
||||
|
||||
MyISAM更适合读密集的表,而InnoDB更适合写密集的的表。 在数据库做主从分离的情况下,经常选择MyISAM作为主库的存储引擎。
|
||||
MyISAM更适合读密集的表,而InnoDB更适合写密集的表。 在数据库做主从分离的情况下,经常选择MyISAM作为主库的存储引擎。
|
||||
|
||||
一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB是不错的选择。如果你的数据量很大(MyISAM支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM是最好的选择。
|
||||
|
||||
|
||||
119
docs/github-trending/2019-6.md
Normal file
@ -0,0 +1,119 @@
|
||||
### 1.CS-Notes
|
||||
|
||||
- **Github 地址**:https://github.com/CyC2018/CS-Notes
|
||||
- **Star**: 69.8k
|
||||
- **介绍**: 技术面试必备基础知识、Leetcode 题解、后端面试、Java 面试、春招、秋招、操作系统、计算机网络、系统设计。
|
||||
|
||||
### 2.toBeTopJavaer
|
||||
|
||||
- **Github 地址:**[https://github.com/hollischuang/toBeTopJavaer](https://github.com/hollischuang/toBeTopJavaer)
|
||||
- **Star**: 4.7k
|
||||
- **介绍**: To Be Top Javaer - Java工程师成神之路。
|
||||
|
||||
### 3.p3c
|
||||
|
||||
- **Github 地址:** [https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
||||
- **Star**: 16.6k
|
||||
- **介绍**: Alibaba Java Coding Guidelines pmd implements and IDE plugin。Eclipse 和 IDEA 上都有该插件,推荐使用!
|
||||
|
||||
### 4.SpringCloudLearning
|
||||
|
||||
- **Github 地址:** [https://github.com/forezp/SpringCloudLearning](https://github.com/forezp/SpringCloudLearning)
|
||||
- **Star**: 8.7k
|
||||
- **介绍**: 史上最简单的Spring Cloud教程源码。
|
||||
|
||||
### 5.dubbo
|
||||
|
||||
- **Github地址**:<https://github.com/apache/dubbo>
|
||||
- **star**: 27.6 k
|
||||
- **介绍**: Apache Dubbo是一个基于Java的高性能开源RPC框架。
|
||||
|
||||
### 6.jeecg-boot
|
||||
|
||||
- **Github地址**: [https://github.com/zhangdaiscott/jeecg-boot](https://github.com/zhangdaiscott/jeecg-boot)
|
||||
- **star**: 3.3 k
|
||||
- **介绍**: 一款基于代码生成器的JAVA快速开发平台!全新架构前后端分离:SpringBoot 2.x,Ant Design&Vue,Mybatis,Shiro,JWT。强大的代码生成器让前后端代码一键生成,无需写任何代码,绝对是全栈开发福音!! JeecgBoot的宗旨是提高UI能力的同时,降低前后分离的开发成本,JeecgBoot还独创在线开发模式,No代码概念,一系列在线智能开发:在线配置表单、在线配置报表、在线设计流程等等。
|
||||
|
||||
### 7.advanced-java
|
||||
|
||||
- **Github 地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**: 24.2k
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务等领域知识,后端同学必看,前端同学也可学习。
|
||||
|
||||
### 8.FEBS-Shiro
|
||||
|
||||
- **Github 地址**:[https://github.com/wuyouzhuguli/FEBS-Shiro](https://github.com/wuyouzhuguli/FEBS-Shiro)
|
||||
- **Star**: 2.6k
|
||||
- **介绍**: Spring Boot 2.1.3,Shiro1.4.0 & Layui 2.5.4 权限管理系统。预览地址:http://49.234.20.223:8080/login。
|
||||
|
||||
### 9.SpringAll
|
||||
|
||||
- **Github 地址**: [https://github.com/wuyouzhuguli/SpringAll](https://github.com/wuyouzhuguli/SpringAll)
|
||||
- **Star**: 5.4k
|
||||
- **介绍**: 循序渐进,学习Spring Boot、Spring Boot & Shiro、Spring Cloud、Spring Security & Spring Security OAuth2,博客Spring系列源码。
|
||||
|
||||
### 10.JavaGuide
|
||||
|
||||
- **Github 地址**:<https://github.com/Snailclimb/JavaGuide>
|
||||
- **Star**: 47.2k
|
||||
- **介绍**: 【Java 学习+面试指南】 一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
|
||||
### 11.vhr
|
||||
|
||||
- **Github 地址**:[https://github.com/lenve/vhr](https://github.com/lenve/vhr)
|
||||
- **Star**: 4.9k
|
||||
- **介绍**: 微人事是一个前后端分离的人力资源管理系统,项目采用SpringBoot+Vue开发。
|
||||
|
||||
### 12. tutorials
|
||||
|
||||
- **Github 地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
|
||||
- **star**: 15.4 k
|
||||
- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖 Java 生态系统中单一且定义明确的开发领域。 当然,它们的重点是 Spring Framework - Spring,Spring Boot 和 Spring Securiyt。 除了 Spring 之外,还有以下技术:核心 Java,Jackson,HttpClient,Guava。
|
||||
|
||||
### 13.EasyScheduler
|
||||
|
||||
- **Github 地址**:[https://github.com/analysys/EasyScheduler](https://github.com/analysys/EasyScheduler)
|
||||
- **star**: 1.1 k
|
||||
- **介绍**: Easy Scheduler是一个分布式工作流任务调度系统,主要解决“复杂任务依赖但无法直接监控任务健康状态”的问题。Easy Scheduler以DAG方式组装任务,可以实时监控任务的运行状态。同时,它支持重试,重新运行等操作... 。https://analysys.github.io/easyscheduler_docs_cn/
|
||||
|
||||
### 14.thingsboard
|
||||
|
||||
- **Github 地址**:[https://github.com/thingsboard/thingsboard](https://github.com/thingsboard/thingsboard)
|
||||
- **star**: 3.7 k
|
||||
- **介绍**: 开源物联网平台 - 设备管理,数据收集,处理和可视化。 [https://thingsboard.io](https://thingsboard.io/)
|
||||
|
||||
### 15.mall-learning
|
||||
|
||||
- **Github 地址**: [https://github.com/macrozheng/mall-learning](https://github.com/macrozheng/mall-learning)
|
||||
- **star**: 0.6 k
|
||||
- **介绍**: mall学习教程,架构、业务、技术要点全方位解析。mall项目(16k+star)是一套电商系统,使用现阶段主流技术实现。 涵盖了SpringBoot2.1.3、MyBatis3.4.6、Elasticsearch6.2.2、RabbitMQ3.7.15、Redis3.2、Mongodb3.2、Mysql5.7等技术,采用Docker容器化部署。 https://github.com/macrozheng/mall
|
||||
|
||||
### 16. flink
|
||||
|
||||
- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
|
||||
- **star**: 9.3 k
|
||||
- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
|
||||
|
||||
### 17.spring-cloud-kubernetes
|
||||
|
||||
- **Github地址**:[https://github.com/spring-cloud/spring-cloud-kubernetes](https://github.com/spring-cloud/spring-cloud-kubernetes)
|
||||
- **star**: 1.4 k
|
||||
- **介绍**: Kubernetes 集成 Spring Cloud Discovery Client, Configuration, etc...
|
||||
|
||||
### 18.springboot-learning-example
|
||||
|
||||
- **Github地址**:[https://github.com/JeffLi1993/springboot-learning-example](https://github.com/JeffLi1993/springboot-learning-example)
|
||||
- **star**: 10.0 k
|
||||
- **介绍**: spring boot 实践学习案例,是 spring boot 初学者及核心技术巩固的最佳实践。
|
||||
|
||||
### 19.canal
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/canal](https://github.com/alibaba/canal)
|
||||
- **star**: 9.3 k
|
||||
- **介绍**: 阿里巴巴 MySQL binlog 增量订阅&消费组件。
|
||||
|
||||
### 20.react-native-device-info
|
||||
|
||||
- **Github地址**:[https://github.com/react-native-community/react-native-device-info](https://github.com/react-native-community/react-native-device-info)
|
||||
- **star**: 4.0 k
|
||||
- **介绍**: React Native iOS和Android的设备信息。
|
||||
@ -3,3 +3,6 @@
|
||||
- [2019 年 2 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-2.md)
|
||||
- [2019 年 3 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-3.md)
|
||||
- [2019 年 4 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-4.md)
|
||||
- [2019 年 5 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-5.md)
|
||||
- [2019 年 6 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-6.md)
|
||||
|
||||
|
||||
@ -202,13 +202,13 @@ NIO 通过Channel(通道) 进行读写。
|
||||
|
||||
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
|
||||
|
||||
#### 4)Selectors(选择器)
|
||||
#### 4)Selector (选择器)
|
||||
|
||||
NIO有选择器,而IO没有。
|
||||
|
||||
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
|
||||
|
||||
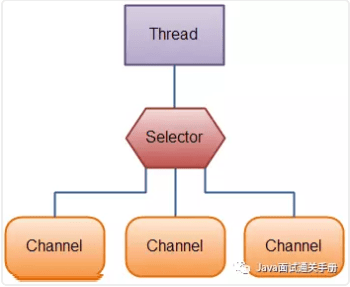
|
||||

|
||||
|
||||
### 2.3 NIO 读数据和写数据方式
|
||||
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
|
||||
@ -273,8 +273,7 @@ public class NIOServer {
|
||||
|
||||
if (key.isAcceptable()) {
|
||||
try {
|
||||
// (1)
|
||||
// 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
|
||||
// (1) 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
|
||||
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
|
||||
clientChannel.configureBlocking(false);
|
||||
clientChannel.register(clientSelector, SelectionKey.OP_READ);
|
||||
|
||||
@ -59,7 +59,7 @@ Servlet接口定义了5个方法,其中**前三个方法与Servlet生命周期
|
||||
|
||||
- `void init(ServletConfig config) throws ServletException`
|
||||
- `void service(ServletRequest req, ServletResponse resp) throws ServletException, java.io.IOException`
|
||||
- `void destory()`
|
||||
- `void destroy()`
|
||||
- `java.lang.String getServletInfo()`
|
||||
- `ServletConfig getServletConfig()`
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
- [4. Oracle JDK 和 OpenJDK 的对比](#4-oracle-jdk-和-openjdk-的对比)
|
||||
- [5. Java和C++的区别?](#5-java和c的区别)
|
||||
- [6. 什么是 Java 程序的主类 应用程序和小程序的主类有何不同?](#6-什么是-java-程序的主类-应用程序和小程序的主类有何不同)
|
||||
- [7. Java 应用程序与小程序之间有那些差别?](#7-java-应用程序与小程序之间有那些差别)
|
||||
- [7. Java 应用程序与小程序之间有哪些差别?](#7-java-应用程序与小程序之间有哪些差别)
|
||||
- [8. 字符型常量和字符串常量的区别?](#8-字符型常量和字符串常量的区别)
|
||||
- [9. 构造器 Constructor 是否可被 override?](#9-构造器-constructor-是否可被-override)
|
||||
- [10. 重载和重写的区别](#10-重载和重写的区别)
|
||||
@ -26,7 +26,7 @@
|
||||
- [15. 在 Java 中定义一个不做事且没有参数的构造方法的作用](#15-在-java-中定义一个不做事且没有参数的构造方法的作用)
|
||||
- [16. import java和javax有什么区别?](#16-import-java和javax有什么区别)
|
||||
- [17. 接口和抽象类的区别是什么?](#17-接口和抽象类的区别是什么)
|
||||
- [18. 成员变量与局部变量的区别有那些?](#18-成员变量与局部变量的区别有那些)
|
||||
- [18. 成员变量与局部变量的区别有哪些?](#18-成员变量与局部变量的区别有哪些)
|
||||
- [19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?](#19-创建一个对象用什么运算符对象实体与对象引用有何不同)
|
||||
- [20. 什么是方法的返回值?返回值在类的方法里的作用是什么?](#20-什么是方法的返回值返回值在类的方法里的作用是什么)
|
||||
- [21. 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?](#21-一个类的构造方法的作用是什么-若一个类没有声明构造方法该程序能正确执行吗-为什么)
|
||||
@ -48,7 +48,7 @@
|
||||
- [Throwable类常用方法](#throwable类常用方法)
|
||||
- [异常处理总结](#异常处理总结)
|
||||
- [33 Java序列化中如果有些字段不想进行序列化,怎么办?](#33-java序列化中如果有些字段不想进行序列化怎么办)
|
||||
- [34 获取用键盘输入常用的的两种方法](#34-获取用键盘输入常用的的两种方法)
|
||||
- [34 获取用键盘输入常用的两种方法](#34-获取用键盘输入常用的两种方法)
|
||||
- [35 Java 中 IO 流分为几种?BIO,NIO,AIO 有什么区别?](#35-java-中-io-流分为几种bionioaio-有什么区别)
|
||||
- [java 中 IO 流分为几种?](#java-中-io-流分为几种)
|
||||
- [BIO,NIO,AIO 有什么区别?](#bionioaio-有什么区别)
|
||||
@ -61,8 +61,14 @@
|
||||
|
||||
## 1. 面向对象和面向过程的区别
|
||||
|
||||
- **面向过程** :**面向过程性能比面向对象高。** 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发。但是,**面向过程没有面向对象易维护、易复用、易扩展。**
|
||||
- **面向对象** :**面向对象易维护、易复用、易扩展。** 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,**面向过程性能比面向过程低**。
|
||||
- **面向过程** :**面向过程性能比面向对象高。** 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix等一般采用面向过程开发。但是,**面向过程没有面向对象易维护、易复用、易扩展。**
|
||||
- **面向对象** :**面向对象易维护、易复用、易扩展。** 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,**面向对象性能比面向过程低**。
|
||||
|
||||
参见 issue : [面向过程 :面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431)
|
||||
|
||||
> 这个并不是根本原因,面向过程也需要分配内存,计算内存偏移量,Java性能差的主要原因并不是因为它是面向对象语言,而是Java是半编译语言,最终的执行代码并不是可以直接被CPU执行的二进制机械码。
|
||||
>
|
||||
> 而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比Java好。
|
||||
|
||||
## 2. Java 语言有哪些特点?
|
||||
|
||||
@ -117,7 +123,7 @@ JRE 是 Java运行时环境。它是运行已编译 Java 程序所需的所有
|
||||
|
||||
**总结:**
|
||||
|
||||
1. Oracle JDK版本将每三年发布一次,而OpenJDK版本每三个月发布一次;
|
||||
1. Oracle JDK大概每6个月发一次主要版本,而OpenJDK版本大概每三个月发布一次。但这不是固定的,我觉得了解这个没啥用处。详情参见:https://blogs.oracle.com/java-platform-group/update-and-faq-on-the-java-se-release-cadence。
|
||||
2. OpenJDK 是一个参考模型并且是完全开源的,而Oracle JDK是OpenJDK的一个实现,并不是完全开源的;
|
||||
3. Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎相同,但Oracle JDK有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到Oracle JDK就可以解决问题;
|
||||
4. 在响应性和JVM性能方面,Oracle JDK与OpenJDK相比提供了更好的性能;
|
||||
@ -138,7 +144,7 @@ JRE 是 Java运行时环境。它是运行已编译 Java 程序所需的所有
|
||||
|
||||
一个程序中可以有多个类,但只能有一个类是主类。在 Java 应用程序中,这个主类是指包含 main()方法的类。而在 Java 小程序中,这个主类是一个继承自系统类 JApplet 或 Applet 的子类。应用程序的主类不一定要求是 public 类,但小程序的主类要求必须是 public 类。主类是 Java 程序执行的入口点。
|
||||
|
||||
## 7. Java 应用程序与小程序之间有那些差别?
|
||||
## 7. Java 应用程序与小程序之间有哪些差别?
|
||||
|
||||
简单说应用程序是从主线程启动(也就是 `main()` 方法)。applet 小程序没有 `main()` 方法,主要是嵌在浏览器页面上运行(调用`init()`或者`run()`来启动),嵌入浏览器这点跟 flash 的小游戏类似。
|
||||
|
||||
@ -247,12 +253,12 @@ Java 程序在执行子类的构造方法之前,如果没有用 `super() `来
|
||||
|
||||
备注:在JDK8中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,则必须重写,不然会报错。(详见issue:[https://github.com/Snailclimb/JavaGuide/issues/146](https://github.com/Snailclimb/JavaGuide/issues/146))
|
||||
|
||||
## 18. 成员变量与局部变量的区别有那些?
|
||||
## 18. 成员变量与局部变量的区别有哪些?
|
||||
|
||||
1. 从语法形式上看:成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
|
||||
2. 从变量在内存中的存储方式来看:如果成员变量是使用`static`修饰的,那么这个成员变量是属于类的,如果没有使用`static`修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
|
||||
3. 从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
|
||||
4. 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外被 final 修饰的成员变量也必须显示地赋值),而局部变量则不会自动赋值。
|
||||
4. 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
|
||||
|
||||
## 19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
|
||||
|
||||
@ -359,7 +365,7 @@ hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返
|
||||
|
||||
**程序**是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
|
||||
|
||||
**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
|
||||
**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
|
||||
线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
|
||||
|
||||
## 30. 线程有哪些基本状态?
|
||||
@ -408,7 +414,7 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
**Exception(异常):是程序本身可以处理的异常**。</font>Exception 类有一个重要的子类 **RuntimeException**。RuntimeException 异常由Java虚拟机抛出。**NullPointerException**(要访问的变量没有引用任何对象时,抛出该异常)、**ArithmeticException**(算术运算异常,一个整数除以0时,抛出该异常)和 **ArrayIndexOutOfBoundsException** (下标越界异常)。
|
||||
|
||||
**注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。**
|
||||
**注意:异常和错误的区别:异常能被程序本身处理,错误是无法处理。**
|
||||
|
||||
### Throwable类常用方法
|
||||
|
||||
@ -419,9 +425,10 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
### 异常处理总结
|
||||
|
||||
- **try 块:**用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
|
||||
- **catch 块:**用于处理try捕获到的异常。
|
||||
- **finally 块:**无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return语句时,finally语句块将在方法返回之前被执行。
|
||||
- **try 块:** 用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
|
||||
- **catch 块:** 用于处理try捕获到的异常。
|
||||
- **finally 块:** 无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return
|
||||
语句时,finally语句块将在方法返回之前被执行。
|
||||
|
||||
**在以下4种特殊情况下,finally块不会被执行:**
|
||||
|
||||
@ -432,15 +439,21 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
下面这部分内容来自issue:<https://github.com/Snailclimb/JavaGuide/issues/190>。
|
||||
|
||||
**关于返回值:**
|
||||
**注意:** 当try语句和finally语句中都有return语句时,在方法返回之前,finally语句的内容将被执行,并且finally语句的返回值将会覆盖原始的返回值。如下:
|
||||
|
||||
如果try语句里有return,返回的是try语句块中变量值。
|
||||
详细执行过程如下:
|
||||
```java
|
||||
public static int f(int value) {
|
||||
try {
|
||||
return value * value;
|
||||
} finally {
|
||||
if (value == 2) {
|
||||
return 0;
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
1. 如果有返回值,就把返回值保存到局部变量中;
|
||||
2. 执行jsr指令跳到finally语句里执行;
|
||||
3. 执行完finally语句后,返回之前保存在局部变量表里的值。
|
||||
4. 如果try,finally语句里均有return,忽略try的return,而使用finally的return.
|
||||
如果调用 `f(2)`,返回值将是0,因为finally语句的返回值覆盖了try语句块的返回值。
|
||||
|
||||
## 33 Java序列化中如果有些字段不想进行序列化,怎么办?
|
||||
|
||||
@ -448,7 +461,7 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
transient关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
|
||||
|
||||
## 34 获取用键盘输入常用的的两种方法
|
||||
## 34 获取用键盘输入常用的两种方法
|
||||
|
||||
方法1:通过 Scanner
|
||||
|
||||
|
||||
373
docs/java/Java疑难点.md
Normal file
@ -0,0 +1,373 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [1. 基础](#1-基础)
|
||||
- [1.1. 正确使用 equals 方法](#11-正确使用-equals-方法)
|
||||
- [1.2. 整型包装类值的比较](#12-整型包装类值的比较)
|
||||
- [1.3. BigDecimal](#13-bigdecimal)
|
||||
- [1.3.1. BigDecimal 的用处](#131-bigdecimal-的用处)
|
||||
- [1.3.2. BigDecimal 的大小比较](#132-bigdecimal-的大小比较)
|
||||
- [1.3.3. BigDecimal 保留几位小数](#133-bigdecimal-保留几位小数)
|
||||
- [1.3.4. BigDecimal 的使用注意事项](#134-bigdecimal-的使用注意事项)
|
||||
- [1.3.5. 总结](#135-总结)
|
||||
- [1.4. 基本数据类型与包装数据类型的使用标准](#14-基本数据类型与包装数据类型的使用标准)
|
||||
- [2. 集合](#2-集合)
|
||||
- [2.1. Arrays.asList()使用指南](#21-arraysaslist使用指南)
|
||||
- [2.1.1. 简介](#211-简介)
|
||||
- [2.1.2. 《阿里巴巴Java 开发手册》对其的描述](#212-阿里巴巴java-开发手册对其的描述)
|
||||
- [2.1.3. 使用时的注意事项总结](#213-使用时的注意事项总结)
|
||||
- [2.1.4. 如何正确的将数组转换为ArrayList?](#214-如何正确的将数组转换为arraylist)
|
||||
- [2.2. Collection.toArray()方法使用的坑&如何反转数组](#22-collectiontoarray方法使用的坑如何反转数组)
|
||||
- [2.3. 不要在 foreach 循环里进行元素的 remove/add 操作](#23-不要在-foreach-循环里进行元素的-removeadd-操作)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
# 1. 基础
|
||||
|
||||
## 1.1. 正确使用 equals 方法
|
||||
|
||||
Object的equals方法容易抛空指针异常,应使用常量或确定有值的对象来调用 equals。
|
||||
|
||||
举个例子:
|
||||
|
||||
```java
|
||||
// 不能使用一个值为null的引用类型变量来调用非静态方法,否则会抛出异常
|
||||
String str = null;
|
||||
if (str.equals("SnailClimb")) {
|
||||
...
|
||||
} else {
|
||||
..
|
||||
}
|
||||
```
|
||||
|
||||
运行上面的程序会抛出空指针异常,但是我们把第二行的条件判断语句改为下面这样的话,就不会抛出空指针异常,else 语句块得到执行。:
|
||||
|
||||
```java
|
||||
"SnailClimb".equals(str);// false
|
||||
```
|
||||
不过更推荐使用 `java.util.Objects#equals`(JDK7 引入的工具类)。
|
||||
|
||||
```java
|
||||
Objects.equals(null,"SnailClimb");// false
|
||||
```
|
||||
我们看一下`java.util.Objects#equals`的源码就知道原因了。
|
||||
```java
|
||||
public static boolean equals(Object a, Object b) {
|
||||
// 可以避免空指针异常。如果a==null的话此时a.equals(b)就不会得到执行,避免出现空指针异常。
|
||||
return (a == b) || (a != null && a.equals(b));
|
||||
}
|
||||
```
|
||||
|
||||
**注意:**
|
||||
|
||||
Reference:[Java中equals方法造成空指针异常的原因及解决方案](https://blog.csdn.net/tick_tock97/article/details/72824894)
|
||||
|
||||
- 每种原始类型都有默认值一样,如int默认值为 0,boolean 的默认值为 false,null 是任何引用类型的默认值,不严格的说是所有 Object 类型的默认值。
|
||||
- 可以使用 == 或者 != 操作来比较null值,但是不能使用其他算法或者逻辑操作。在Java中`null == null`将返回true。
|
||||
- 不能使用一个值为null的引用类型变量来调用非静态方法,否则会抛出异常
|
||||
|
||||
## 1.2. 整型包装类值的比较
|
||||
|
||||
所有整型包装类对象值的比较必须使用equals方法。
|
||||
|
||||
先看下面这个例子:
|
||||
|
||||
```java
|
||||
Integer x = 3;
|
||||
Integer y = 3;
|
||||
System.out.println(x == y);// true
|
||||
Integer a = new Integer(3);
|
||||
Integer b = new Integer(3);
|
||||
System.out.println(a == b);//false
|
||||
System.out.println(a.equals(b));//true
|
||||
```
|
||||
|
||||
当使用自动装箱方式创建一个Integer对象时,当数值在-128 ~127时,会将创建的 Integer 对象缓存起来,当下次再出现该数值时,直接从缓存中取出对应的Integer对象。所以上述代码中,x和y引用的是相同的Integer对象。
|
||||
|
||||
**注意:**如果你的IDE(IDEA/Eclipse)上安装了阿里巴巴的p3c插件,这个插件如果检测到你用 ==的话会报错提示,推荐安装一个这个插件,很不错。
|
||||
|
||||
## 1.3. BigDecimal
|
||||
|
||||
### 1.3.1. BigDecimal 的用处
|
||||
|
||||
《阿里巴巴Java开发手册》中提到:**浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用 equals 来判断。** 具体原理和浮点数的编码方式有关,这里就不多提了,我们下面直接上实例:
|
||||
|
||||
```java
|
||||
float a = 1.0f - 0.9f;
|
||||
float b = 0.9f - 0.8f;
|
||||
System.out.println(a);// 0.100000024
|
||||
System.out.println(b);// 0.099999964
|
||||
System.out.println(a == b);// false
|
||||
```
|
||||
具有基本数学知识的我们很清楚的知道输出并不是我们想要的结果(**精度丢失**),我们如何解决这个问题呢?一种很常用的方法是:**使用使用 BigDecimal 来定义浮点数的值,再进行浮点数的运算操作。**
|
||||
|
||||
```java
|
||||
BigDecimal a = new BigDecimal("1.0");
|
||||
BigDecimal b = new BigDecimal("0.9");
|
||||
BigDecimal c = new BigDecimal("0.8");
|
||||
BigDecimal x = a.subtract(b);// 0.1
|
||||
BigDecimal y = b.subtract(c);// 0.1
|
||||
System.out.println(x.equals(y));// true
|
||||
```
|
||||
|
||||
### 1.3.2. BigDecimal 的大小比较
|
||||
|
||||
`a.compareTo(b)` : 返回 -1 表示小于,0 表示 等于, 1表示 大于。
|
||||
|
||||
```java
|
||||
BigDecimal a = new BigDecimal("1.0");
|
||||
BigDecimal b = new BigDecimal("0.9");
|
||||
System.out.println(a.compareTo(b));// 1
|
||||
```
|
||||
### 1.3.3. BigDecimal 保留几位小数
|
||||
|
||||
通过 `setScale`方法设置保留几位小数以及保留规则。保留规则有挺多种,不需要记,IDEA会提示。
|
||||
|
||||
```java
|
||||
BigDecimal m = new BigDecimal("1.255433");
|
||||
BigDecimal n = m.setScale(3,BigDecimal.ROUND_HALF_DOWN);
|
||||
System.out.println(n);// 1.255
|
||||
```
|
||||
|
||||
### 1.3.4. BigDecimal 的使用注意事项
|
||||
|
||||
注意:我们在使用BigDecimal时,为了防止精度丢失,推荐使用它的 **BigDecimal(String)** 构造方法来创建对象。《阿里巴巴Java开发手册》对这部分内容也有提到如下图所示。
|
||||
|
||||

|
||||
|
||||
### 1.3.5. 总结
|
||||
|
||||
BigDecimal 主要用来操作(大)浮点数,BigInteger 主要用来操作大整数(超过 long 类型)。
|
||||
|
||||
BigDecimal 的实现利用到了 BigInteger, 所不同的是 BigDecimal 加入了小数位的概念
|
||||
|
||||
## 1.4. 基本数据类型与包装数据类型的使用标准
|
||||
|
||||
Reference:《阿里巴巴Java开发手册》
|
||||
|
||||
- 【强制】所有的 POJO 类属性必须使用包装数据类型。
|
||||
- 【强制】RPC 方法的返回值和参数必须使用包装数据类型。
|
||||
- 【推荐】所有的局部变量使用基本数据类型。
|
||||
|
||||
比如我们如果自定义了一个Student类,其中有一个属性是成绩score,如果用Integer而不用int定义,一次考试,学生可能没考,值是null,也可能考了,但考了0分,值是0,这两个表达的状态明显不一样.
|
||||
|
||||
**说明** :POJO 类属性没有初值是提醒使用者在需要使用时,必须自己显式地进行赋值,任何 NPE 问题,或者入库检查,都由使用者来保证。
|
||||
|
||||
**正例** : 数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险。
|
||||
|
||||
**反例** : 比如显示成交总额涨跌情况,即正负 x%,x 为基本数据类型,调用的 RPC 服务,调用不成功时,返回的是默认值,页面显示为 0%,这是不合理的,应该显示成中划线。所以包装数据类型的 null 值,能够表示额外的信息,如:远程调用失败,异常退出。
|
||||
|
||||
# 2. 集合
|
||||
|
||||
## 2.1. Arrays.asList()使用指南
|
||||
|
||||
最近使用`Arrays.asList()`遇到了一些坑,然后在网上看到这篇文章:[Java Array to List Examples](http://javadevnotes.com/java-array-to-list-examples) 感觉挺不错的,但是还不是特别全面。所以,自己对于这块小知识点进行了简单的总结。
|
||||
|
||||
### 2.1.1. 简介
|
||||
|
||||
`Arrays.asList()`在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个List集合。
|
||||
|
||||
```java
|
||||
String[] myArray = { "Apple", "Banana", "Orange" };
|
||||
List<String> myList = Arrays.asList(myArray);
|
||||
//上面两个语句等价于下面一条语句
|
||||
List<String> myList = Arrays.asList("Apple","Banana", "Orange");
|
||||
```
|
||||
|
||||
JDK 源码对于这个方法的说明:
|
||||
|
||||
```java
|
||||
/**
|
||||
*返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
|
||||
*/
|
||||
public static <T> List<T> asList(T... a) {
|
||||
return new ArrayList<>(a);
|
||||
}
|
||||
```
|
||||
|
||||
### 2.1.2. 《阿里巴巴Java 开发手册》对其的描述
|
||||
|
||||
`Arrays.asList()`将数组转换为集合后,底层其实还是数组,《阿里巴巴Java 开发手册》对于这个方法有如下描述:
|
||||
|
||||
方法.png)
|
||||
|
||||
### 2.1.3. 使用时的注意事项总结
|
||||
|
||||
**传递的数组必须是对象数组,而不是基本类型。**
|
||||
|
||||
`Arrays.asList()`是泛型方法,传入的对象必须是对象数组。
|
||||
|
||||
```java
|
||||
int[] myArray = { 1, 2, 3 };
|
||||
List myList = Arrays.asList(myArray);
|
||||
System.out.println(myList.size());//1
|
||||
System.out.println(myList.get(0));//数组地址值
|
||||
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
|
||||
int [] array=(int[]) myList.get(0);
|
||||
System.out.println(array[0]);//1
|
||||
```
|
||||
当传入一个原生数据类型数组时,`Arrays.asList()` 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时List 的唯一元素就是这个数组,这也就解释了上面的代码。
|
||||
|
||||
我们使用包装类型数组就可以解决这个问题。
|
||||
|
||||
```java
|
||||
Integer[] myArray = { 1, 2, 3 };
|
||||
```
|
||||
|
||||
**使用集合的修改方法:`add()`、`remove()`、`clear()`会抛出异常。**
|
||||
|
||||
```java
|
||||
List myList = Arrays.asList(1, 2, 3);
|
||||
myList.add(4);//运行时报错:UnsupportedOperationException
|
||||
myList.remove(1);//运行时报错:UnsupportedOperationException
|
||||
myList.clear();//运行时报错:UnsupportedOperationException
|
||||
```
|
||||
|
||||
`Arrays.asList()` 方法返回的并不是 `java.util.ArrayList` ,而是 `java.util.Arrays` 的一个内部类,这个内部类并没有实现集合的修改方法或者说并没有重写这些方法。
|
||||
|
||||
```java
|
||||
List myList = Arrays.asList(1, 2, 3);
|
||||
System.out.println(myList.getClass());//class java.util.Arrays$ArrayList
|
||||
```
|
||||
|
||||
下图是`java.util.Arrays$ArrayList`的简易源码,我们可以看到这个类重写的方法有哪些。
|
||||
|
||||
```java
|
||||
private static class ArrayList<E> extends AbstractList<E>
|
||||
implements RandomAccess, java.io.Serializable
|
||||
{
|
||||
...
|
||||
|
||||
@Override
|
||||
public E get(int index) {
|
||||
...
|
||||
}
|
||||
|
||||
@Override
|
||||
public E set(int index, E element) {
|
||||
...
|
||||
}
|
||||
|
||||
@Override
|
||||
public int indexOf(Object o) {
|
||||
...
|
||||
}
|
||||
|
||||
@Override
|
||||
public boolean contains(Object o) {
|
||||
...
|
||||
}
|
||||
|
||||
@Override
|
||||
public void forEach(Consumer<? super E> action) {
|
||||
...
|
||||
}
|
||||
|
||||
@Override
|
||||
public void replaceAll(UnaryOperator<E> operator) {
|
||||
...
|
||||
}
|
||||
|
||||
@Override
|
||||
public void sort(Comparator<? super E> c) {
|
||||
...
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
我们再看一下`java.util.AbstractList`的`remove()`方法,这样我们就明白为啥会抛出`UnsupportedOperationException`。
|
||||
|
||||
```java
|
||||
public E remove(int index) {
|
||||
throw new UnsupportedOperationException();
|
||||
}
|
||||
```
|
||||
|
||||
### 2.1.4. 如何正确的将数组转换为ArrayList?
|
||||
|
||||
stackoverflow:https://dwz.cn/vcBkTiTW
|
||||
|
||||
**1. 自己动手实现(教育目的)**
|
||||
|
||||
```java
|
||||
//JDK1.5+
|
||||
static <T> List<T> arrayToList(final T[] array) {
|
||||
final List<T> l = new ArrayList<T>(array.length);
|
||||
|
||||
for (final T s : array) {
|
||||
l.add(s);
|
||||
}
|
||||
return (l);
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
Integer [] myArray = { 1, 2, 3 };
|
||||
System.out.println(arrayToList(myArray).getClass());//class java.util.ArrayList
|
||||
```
|
||||
|
||||
**2. 最简便的方法(推荐)**
|
||||
|
||||
```java
|
||||
List list = new ArrayList<>(Arrays.asList("a", "b", "c"))
|
||||
```
|
||||
|
||||
**3. 使用 Java8 的Stream(推荐)**
|
||||
|
||||
```java
|
||||
Integer [] myArray = { 1, 2, 3 };
|
||||
List myList = Arrays.stream(myArray).collect(Collectors.toList());
|
||||
//基本类型也可以实现转换(依赖boxed的装箱操作)
|
||||
int [] myArray2 = { 1, 2, 3 };
|
||||
List myList = Arrays.stream(myArray2).boxed().collect(Collectors.toList());
|
||||
```
|
||||
|
||||
**4. 使用 Guava(推荐)**
|
||||
|
||||
对于不可变集合,你可以使用[`ImmutableList`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/ImmutableList.java)类及其[`of()`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/ImmutableList.java#L101)与[`copyOf()`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/ImmutableList.java#L225)工厂方法:(参数不能为空)
|
||||
|
||||
```java
|
||||
List<String> il = ImmutableList.of("string", "elements"); // from varargs
|
||||
List<String> il = ImmutableList.copyOf(aStringArray); // from array
|
||||
```
|
||||
对于可变集合,你可以使用[`Lists`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/Lists.java)类及其[`newArrayList()`](https://github.com/google/guava/blob/master/guava/src/com/google/common/collect/Lists.java#L87)工厂方法:
|
||||
|
||||
```java
|
||||
List<String> l1 = Lists.newArrayList(anotherListOrCollection); // from collection
|
||||
List<String> l2 = Lists.newArrayList(aStringArray); // from array
|
||||
List<String> l3 = Lists.newArrayList("or", "string", "elements"); // from varargs
|
||||
```
|
||||
|
||||
**5. 使用 Apache Commons Collections**
|
||||
|
||||
```java
|
||||
List<String> list = new ArrayList<String>();
|
||||
CollectionUtils.addAll(list, str);
|
||||
```
|
||||
|
||||
## 2.2. Collection.toArray()方法使用的坑&如何反转数组
|
||||
|
||||
该方法是一个泛型方法:`<T> T[] toArray(T[] a);` 如果`toArray`方法中没有传递任何参数的话返回的是`Object`类型数组。
|
||||
|
||||
```java
|
||||
String [] s= new String[]{
|
||||
"dog", "lazy", "a", "over", "jumps", "fox", "brown", "quick", "A"
|
||||
};
|
||||
List<String> list = Arrays.asList(s);
|
||||
Collections.reverse(list);
|
||||
s=list.toArray(new String[0]);//没有指定类型的话会报错
|
||||
```
|
||||
|
||||
由于JVM优化,`new String[0]`作为`Collection.toArray()`方法的参数现在使用更好,`new String[0]`就是起一个模板的作用,指定了返回数组的类型,0是为了节省空间,因为它只是为了说明返回的类型。详见:<https://shipilev.net/blog/2016/arrays-wisdom-ancients/>
|
||||
|
||||
## 2.3. 不要在 foreach 循环里进行元素的 remove/add 操作
|
||||
|
||||
如果要进行`remove`操作,可以调用迭代器的 `remove `方法而不是集合类的 remove 方法。因为如果列表在任何时间从结构上修改创建迭代器之后,以任何方式除非通过迭代器自身`remove/add`方法,迭代器都将抛出一个`ConcurrentModificationException`,这就是单线程状态下产生的 **fail-fast 机制**。
|
||||
|
||||
> **fail-fast 机制** :多个线程对 fail-fast 集合进行修改的时,可能会抛出ConcurrentModificationException,单线程下也会出现这种情况,上面已经提到过。
|
||||
|
||||
`java.util`包下面的所有的集合类都是fail-fast的,而`java.util.concurrent`包下面的所有的类都是fail-safe的。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
125
docs/java/Java程序设计题.md
Normal file
@ -0,0 +1,125 @@
|
||||
## 泛型的实际应用
|
||||
|
||||
### 实现最小值函数
|
||||
|
||||
自己设计一个泛型的获取数组最小值的函数.并且这个方法只能接受Number的子类并且实现了Comparable接口。
|
||||
|
||||
```java
|
||||
//注意:Number并没有实现Comparable
|
||||
private static <T extends Number & Comparable<? super T>> T min(T[] values) {
|
||||
if (values == null || values.length == 0) return null;
|
||||
T min = values[0];
|
||||
for (int i = 1; i < values.length; i++) {
|
||||
if (min.compareTo(values[i]) > 0) min = values[i];
|
||||
}
|
||||
return min;
|
||||
}
|
||||
```
|
||||
|
||||
测试:
|
||||
|
||||
```java
|
||||
int minInteger = min(new Integer[]{1, 2, 3});//result:1
|
||||
double minDouble = min(new Double[]{1.2, 2.2, -1d});//result:-1d
|
||||
String typeError = min(new String[]{"1","3"});//报错
|
||||
```
|
||||
|
||||
## 数据结构
|
||||
|
||||
### 使用数组实现栈
|
||||
|
||||
**自己实现一个栈,要求这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。**
|
||||
|
||||
提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用`Arrays.copyOf()`进行扩容;
|
||||
|
||||
```java
|
||||
public class MyStack {
|
||||
private int[] storage;//存放栈中元素的数组
|
||||
private int capacity;//栈的容量
|
||||
private int count;//栈中元素数量
|
||||
private static final int GROW_FACTOR = 2;
|
||||
|
||||
//TODO:不带初始容量的构造方法。默认容量为8
|
||||
public MyStack() {
|
||||
this.capacity = 8;
|
||||
this.storage=new int[8];
|
||||
this.count = 0;
|
||||
}
|
||||
|
||||
//TODO:带初始容量的构造方法
|
||||
public MyStack(int initialCapacity) {
|
||||
if (initialCapacity < 1)
|
||||
throw new IllegalArgumentException("Capacity too small.");
|
||||
|
||||
this.capacity = initialCapacity;
|
||||
this.storage = new int[initialCapacity];
|
||||
this.count = 0;
|
||||
}
|
||||
|
||||
//TODO:入栈
|
||||
public void push(int value) {
|
||||
if (count == capacity) {
|
||||
ensureCapacity();
|
||||
}
|
||||
storage[count++] = value;
|
||||
}
|
||||
|
||||
//TODO:确保容量大小
|
||||
private void ensureCapacity() {
|
||||
int newCapacity = capacity * GROW_FACTOR;
|
||||
storage = Arrays.copyOf(storage, newCapacity);
|
||||
capacity = newCapacity;
|
||||
}
|
||||
|
||||
//TODO:返回栈顶元素并出栈
|
||||
private int pop() {
|
||||
count--;
|
||||
if (count == -1)
|
||||
throw new IllegalArgumentException("Stack is empty.");
|
||||
|
||||
return storage[count];
|
||||
}
|
||||
|
||||
//TODO:返回栈顶元素不出栈
|
||||
private int peek() {
|
||||
if (count == 0){
|
||||
throw new IllegalArgumentException("Stack is empty.");
|
||||
}else {
|
||||
return storage[count-1];
|
||||
}
|
||||
}
|
||||
|
||||
//TODO:判断栈是否为空
|
||||
private boolean isEmpty() {
|
||||
return count == 0;
|
||||
}
|
||||
|
||||
//TODO:返回栈中元素的个数
|
||||
private int size() {
|
||||
return count;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
验证
|
||||
|
||||
```java
|
||||
MyStack myStack = new MyStack(3);
|
||||
myStack.push(1);
|
||||
myStack.push(2);
|
||||
myStack.push(3);
|
||||
myStack.push(4);
|
||||
myStack.push(5);
|
||||
myStack.push(6);
|
||||
myStack.push(7);
|
||||
myStack.push(8);
|
||||
System.out.println(myStack.peek());//8
|
||||
System.out.println(myStack.size());//8
|
||||
for (int i = 0; i < 8; i++) {
|
||||
System.out.println(myStack.pop());
|
||||
}
|
||||
System.out.println(myStack.isEmpty());//true
|
||||
myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
|
||||
```
|
||||
@ -2,8 +2,8 @@
|
||||
|
||||
### 团队
|
||||
|
||||
- **阿里巴巴Java开发手册(详尽版)** <https://github.com/alibaba/p3c/blob/master/阿里巴巴Java开发手册(详尽版).pdf>
|
||||
- **Google Java编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
|
||||
- **阿里巴巴Java开发手册(详尽版)** <https://github.com/alibaba/p3c/blob/master/阿里巴巴Java开发手册(华山版).pdf>
|
||||
- **Google Java编程风格指南:** <http://hawstein.com/2014/01/20/google-java-style/>
|
||||
|
||||
### 个人
|
||||
|
||||
|
||||
@ -33,7 +33,7 @@ AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效
|
||||
|
||||
### 2 AQS 原理
|
||||
|
||||
> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
|
||||
> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参考,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
|
||||
|
||||
下面大部分内容其实在AQS类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
|
||||
|
||||
@ -124,7 +124,7 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
|
||||
### 3 Semaphore(信号量)-允许多个线程同时访问
|
||||
|
||||
**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。**示例代码如下:
|
||||
**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。** 示例代码如下:
|
||||
|
||||
```java
|
||||
/**
|
||||
|
||||
@ -56,7 +56,7 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
**引用类型**
|
||||
|
||||
- AtomicReference:引用类型原子类
|
||||
- AtomicStampedReference:原子更新引用类型里的字段原子类
|
||||
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
|
||||
- AtomicMarkableReference :原子更新带有标记位的引用类型
|
||||
|
||||
**对象的属性修改类型**
|
||||
@ -553,4 +553,4 @@ class User {
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
@ -321,9 +321,9 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
}
|
||||
```
|
||||
|
||||
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。**
|
||||
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
|
||||
|
||||
**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为key的键值对。这里解释了为什么每个线程访问同一个`ThreadLocal`,得到的确是不同的数值。另外,`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。**
|
||||
**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。这也就解释了 ThreadLocal 声明的变量为什么在每一个线程都有自己的专属本地变量。
|
||||
|
||||
`ThreadLocalMap`是`ThreadLocal`的静态内部类。
|
||||
|
||||
@ -514,7 +514,7 @@ AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效
|
||||
|
||||
AQS 原理这部分参考了部分博客,在5.2节末尾放了链接。
|
||||
|
||||
> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要假如自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
|
||||
> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
|
||||
|
||||
下面大部分内容其实在AQS类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
|
||||
|
||||
|
||||
@ -104,8 +104,8 @@ public class MultiThread {
|
||||
|
||||
### 2.3. 虚拟机栈和本地方法栈为什么是私有的?
|
||||
|
||||
- **虚拟机栈:**每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
|
||||
- **本地方法栈:**和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
|
||||
- **虚拟机栈:** 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
|
||||
- **本地方法栈:** 和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
|
||||
|
||||
所以,为了**保证线程中的局部变量不被别的线程访问到**,虚拟机栈和本地方法栈是线程私有的。
|
||||
|
||||
@ -152,7 +152,7 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
|
||||
|
||||

|
||||
|
||||
当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)**状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的` run() `方法之后将会进入到 **TERMINATED(终止)** 状态。
|
||||
当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)** 状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的` run() `方法之后将会进入到 **TERMINATED(终止)** 状态。
|
||||
|
||||
## 7. 什么是上下文切换?
|
||||
|
||||
@ -294,7 +294,8 @@ Process finished with exit code 0
|
||||
- 两者最主要的区别在于:**sleep 方法没有释放锁,而 wait 方法释放了锁** 。
|
||||
- 两者都可以暂停线程的执行。
|
||||
- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
|
||||
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。
|
||||
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用wait(long timeout)超时后线程会自动苏醒。
|
||||
|
||||
|
||||
## 10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
|
||||
|
||||
|
||||
@ -129,7 +129,19 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
|
||||
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。**
|
||||
|
||||
**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为key的键值对。这里解释了为什么每个线程访问同一个`ThreadLocal`,得到的确是不同的数值。另外,`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。**
|
||||
**每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。这也就解释了ThreadLocal声明的变量为什么在每一个线程都有自己的专属本地变量。
|
||||
|
||||
```java
|
||||
public class Thread implements Runnable {
|
||||
......
|
||||
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
|
||||
ThreadLocal.ThreadLocalMap threadLocals = null;
|
||||
|
||||
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
|
||||
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
......
|
||||
}
|
||||
```
|
||||
|
||||
`ThreadLocalMap`是`ThreadLocal`的静态内部类。
|
||||
|
||||
|
||||
@ -38,12 +38,10 @@ JDK提供的这些容器大部分在 `java.util.concurrent` 包中。
|
||||
|
||||
所以就有了 HashMap 的线程安全版本—— ConcurrentHashMap 的诞生。在ConcurrentHashMap中,无论是读操作还是写操作都能保证很高的性能:在进行读操作时(几乎)不需要加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其它段的访问。
|
||||
|
||||
关于 ConcurrentHashMap 相关问题,我在 [《这几道Java集合框架面试题几乎必问》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93.md) 这篇文章中已经提到过。下面梳理一下关于 ConcurrentHashMap 比较重要的问题:
|
||||
|
||||
- [ConcurrentHashMap 和 Hashtable 的区别](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/%E8%BF%99%E5%87%A0%E9%81%93Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E9%9D%A2%E8%AF%95%E9%A2%98%E5%87%A0%E4%B9%8E%E5%BF%85%E9%97%AE.md#concurrenthashmap-%E5%92%8C-hashtable-%E7%9A%84%E5%8C%BA%E5%88%AB)
|
||||
- [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/%E8%BF%99%E5%87%A0%E9%81%93Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E9%9D%A2%E8%AF%95%E9%A2%98%E5%87%A0%E4%B9%8E%E5%BF%85%E9%97%AE.md#concurrenthashmap%E7%BA%BF%E7%A8%8B%E5%AE%89%E5%85%A8%E7%9A%84%E5%85%B7%E4%BD%93%E5%AE%9E%E7%8E%B0%E6%96%B9%E5%BC%8F%E5%BA%95%E5%B1%82%E5%85%B7%E4%BD%93%E5%AE%9E%E7%8E%B0)
|
||||
|
||||
关于 ConcurrentHashMap 相关问题,我在 [Java集合框架常见面试题](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98.md) 这篇文章中已经提到过。下面梳理一下关于 ConcurrentHashMap 比较重要的问题:
|
||||
|
||||
- [ConcurrentHashMap 和 Hashtable 的区别](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98.md#concurrenthashmap-%E5%92%8C-hashtable-%E7%9A%84%E5%8C%BA%E5%88%AB)
|
||||
- [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98.md#concurrenthashmap%E7%BA%BF%E7%A8%8B%E5%AE%89%E5%85%A8%E7%9A%84%E5%85%B7%E4%BD%93%E5%AE%9E%E7%8E%B0%E6%96%B9%E5%BC%8F%E5%BA%95%E5%B1%82%E5%85%B7%E4%BD%93%E5%AE%9E%E7%8E%B0)
|
||||
|
||||
## 三 CopyOnWriteArrayList
|
||||
|
||||
@ -229,4 +227,4 @@ PriorityBlockingQueue 并发控制采用的是 **ReentrantLock**,队列为无
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
@ -340,7 +340,7 @@ Thread[线程 2,5,main]waiting get resource1
|
||||
1. 不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
|
||||
1. 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
|
||||
|
||||
### 如何避免线程死锁?
|
||||
### 如何预防线程死锁?
|
||||
|
||||
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
|
||||
|
||||
@ -1,163 +0,0 @@
|
||||
JDK8接口规范
|
||||
===
|
||||
在JDK8中引入了lambda表达式,出现了函数式接口的概念,为了在扩展接口时保持向前兼容性(比如泛型也是为了保持兼容性而失去了在一些别的语言泛型拥有的功能),Java接口规范发生了一些改变。。
|
||||
---
|
||||
## 1.JDK8以前的接口规范
|
||||
- JDK8以前接口可以定义的变量和方法
|
||||
- 所有变量(Field)不论是否<i>显式</i> 的声明为```public static final```,它实际上都是```public static final```的。
|
||||
- 所有方法(Method)不论是否<i>显示</i> 的声明为```public abstract```,它实际上都是```public abstract```的。
|
||||
```java
|
||||
public interface AInterfaceBeforeJDK8 {
|
||||
int FIELD = 0;
|
||||
void simpleMethod();
|
||||
}
|
||||
```
|
||||
以上接口信息反编译以后可以看到字节码信息里Filed是public static final的,而方法是public abstract的,即是你没有显示的去声明它。
|
||||
```java
|
||||
{
|
||||
public static final int FIELD;
|
||||
descriptor: I
|
||||
flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
|
||||
ConstantValue: int 0
|
||||
|
||||
public abstract void simpleMethod();
|
||||
descriptor: ()V
|
||||
flags: (0x0401) ACC_PUBLIC, ACC_ABSTRACT
|
||||
}
|
||||
```
|
||||
## 2.JDK8之后的接口规范
|
||||
- JDK8之后接口可以定义的变量和方法
|
||||
- 变量(Field)仍然必须是 ```java public static final```的
|
||||
- 方法(Method)除了可以是public abstract之外,还可以是public static或者是default(相当于仅public修饰的实例方法)的。
|
||||
从以上改变不难看出,修改接口的规范主要是为了能在扩展接口时保持向前兼容。
|
||||
<br>下面是一个JDK8之后的接口例子
|
||||
```java
|
||||
public interface AInterfaceInJDK8 {
|
||||
int simpleFiled = 0;
|
||||
static int staticField = 1;
|
||||
|
||||
public static void main(String[] args) {
|
||||
}
|
||||
static void staticMethod(){}
|
||||
|
||||
default void defaultMethod(){}
|
||||
|
||||
void simpleMethod() throws IOException;
|
||||
|
||||
}
|
||||
```
|
||||
进行反编译(去除了一些没用信息)
|
||||
```java
|
||||
{
|
||||
public static final int simpleFiled;
|
||||
flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
|
||||
|
||||
public static final int staticField;
|
||||
flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
|
||||
|
||||
public static void main(java.lang.String[]);
|
||||
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
|
||||
|
||||
public static void staticMethod();
|
||||
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
|
||||
|
||||
public void defaultMethod();
|
||||
flags: (0x0001) ACC_PUBLIC
|
||||
|
||||
public abstract void simpleMethod() throws java.io.IOException;
|
||||
flags: (0x0401) ACC_PUBLIC, ACC_ABSTRACT
|
||||
Exceptions:
|
||||
throws java.io.IOException
|
||||
}
|
||||
```
|
||||
可以看到 default关键字修饰的方法是像实例方法一样定义的,所以我们来定义一个只有default的方法并且实现一下试一试。
|
||||
```java
|
||||
interface Default {
|
||||
default int defaultMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
|
||||
public class DefaultMethod implements Default {
|
||||
public static void main(String[] args) {
|
||||
DefaultMethod defaultMethod = new DefaultMethod();
|
||||
System.out.println(defaultMethod.defaultMethod());
|
||||
//compile error : Non-static method 'defaultMethod()' cannot be referenced from a static context
|
||||
//! DefaultMethod.defaultMethod();
|
||||
}
|
||||
}
|
||||
```
|
||||
可以看到default方法确实像实例方法一样,必须有实例对象才能调用,并且子类在实现接口时,可以不用实现default方法,也可以覆盖该方法。
|
||||
这有点像子类继承父类实例方法。
|
||||
<br>
|
||||
接口静态方法就像是类静态方法,唯一的区别是**接口静态方法只能通过接口名调用,而类静态方法既可以通过类名调用也可以通过实例调用**
|
||||
```java
|
||||
interface Static {
|
||||
static int staticMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
... main(String...args)
|
||||
//!compile error: Static method may be invoked on containing interface class only
|
||||
//!aInstanceOfStatic.staticMethod();
|
||||
...
|
||||
```
|
||||
另一个问题是多继承问题,大家知道Java中类是不支持多继承的,但是接口是多继承和多实现(implements后跟多个接口)的,
|
||||
那么如果一个接口继承另一个接口,两个接口都有同名的default方法会怎么样呢?答案是会像类继承一样覆写(@Override),以下代码在IDE中可以顺利编译
|
||||
```java
|
||||
interface Default {
|
||||
default int defaultMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
interface Default2 extends Default {
|
||||
@Override
|
||||
default int defaultMethod() {
|
||||
return 9527;
|
||||
}
|
||||
}
|
||||
public class DefaultMethod implements Default,Default2 {
|
||||
public static void main(String[] args) {
|
||||
DefaultMethod defaultMethod = new DefaultMethod();
|
||||
System.out.println(defaultMethod.defaultMethod());
|
||||
}
|
||||
}
|
||||
|
||||
输出 : 9527
|
||||
```
|
||||
出现上面的情况时,会优先找继承树上近的方法,类似于“短路优先”。
|
||||
<br>
|
||||
那么如果一个类实现了两个没有继承关系的接口,且这两个接口有同名方法的话会怎么样呢?IDE会要求你重写这个冲突的方法,让你自己选择去执行哪个方法,因为IDE它
|
||||
还没智能到你不告诉它,它就知道你想执行哪个方法。可以通过```java 接口名.super```指针来访问接口中定义的实例(default)方法。
|
||||
```java
|
||||
interface Default {
|
||||
default int defaultMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
|
||||
interface Default2 {
|
||||
default int defaultMethod() {
|
||||
return 9527;
|
||||
}
|
||||
}
|
||||
//如果不重写
|
||||
//compile error : defaults.DefaultMethod inherits unrelated defaults for defaultMethod() from types defaults.Default and defaults.Default2
|
||||
public class DefaultMethod implements Default,Default2 {
|
||||
@Override
|
||||
public int defaultMethod() {
|
||||
System.out.println(Default.super.defaultMethod());
|
||||
System.out.println(Default2.super.defaultMethod());
|
||||
return 996;
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
DefaultMethod defaultMethod = new DefaultMethod();
|
||||
System.out.println(defaultMethod.defaultMethod());
|
||||
}
|
||||
}
|
||||
|
||||
运行输出 :
|
||||
4396
|
||||
9527
|
||||
996
|
||||
```
|
||||
@ -494,7 +494,7 @@ forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda
|
||||
|
||||
中间操作 map 会将元素根据指定的 Function 接口来依次将元素转成另外的对象。
|
||||
|
||||
下面的示例展示了将字符串转换为大写字符串。你也可以通过map来讲对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
|
||||
下面的示例展示了将字符串转换为大写字符串。你也可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
|
||||
|
||||
```java
|
||||
// 测试 Map 操作
|
||||
@ -930,4 +930,4 @@ System.out.println(hints2.length); // 2
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
139
docs/java/What's New in JDK8/Java8foreach指南.md
Normal file
@ -0,0 +1,139 @@
|
||||
> 本文由 JavaGuide 翻译,原文地址:https://www.baeldung.com/foreach-java
|
||||
|
||||
## 1 概述
|
||||
|
||||
在Java 8中引入的*forEach*循环为程序员提供了一种新的,简洁而有趣的迭代集合的方式。
|
||||
|
||||
在本文中,我们将看到如何将*forEach*与集合*一起*使用,它采用何种参数以及此循环与增强的*for*循环的不同之处。
|
||||
|
||||
## 2 基础知识
|
||||
|
||||
```Java
|
||||
public interface Collection<E> extends Iterable<E>
|
||||
```
|
||||
|
||||
Collection 接口实现了 Iterable 接口,而 Iterable 接口在 Java 8开始具有一个新的 API:
|
||||
|
||||
```java
|
||||
void forEach(Consumer<? super T> action)//对 Iterable的每个元素执行给定的操作,直到所有元素都被处理或动作引发异常。
|
||||
```
|
||||
|
||||
使用*forEach*,我们可以迭代一个集合并对每个元素执行给定的操作,就像任何其他*迭代器一样。*
|
||||
|
||||
例如,迭代和打印字符串集合*的*for循环版本:
|
||||
|
||||
```java
|
||||
for (String name : names) {
|
||||
System.out.println(name);
|
||||
}
|
||||
```
|
||||
|
||||
我们可以使用*forEach*写这个 :
|
||||
|
||||
```java
|
||||
names.forEach(name -> {
|
||||
System.out.println(name);
|
||||
});
|
||||
```
|
||||
|
||||
## 3.使用forEach方法
|
||||
|
||||
### 3.1 匿名类
|
||||
|
||||
我们使用 *forEach*迭代集合并对每个元素执行特定操作。**要执行的操作包含在实现Consumer接口的类中,并作为参数传递给forEach 。**
|
||||
|
||||
所述*消费者*接口是一个功能接口(具有单个抽象方法的接口)。它接受输入并且不返回任何结果。
|
||||
|
||||
Consumer 接口定义如下:
|
||||
|
||||
```java
|
||||
@FunctionalInterface
|
||||
public interface Consumer {
|
||||
void accept(T t);
|
||||
}
|
||||
```
|
||||
任何实现,例如,只是打印字符串的消费者:
|
||||
|
||||
```java
|
||||
Consumer<String> printConsumer = new Consumer<String>() {
|
||||
public void accept(String name) {
|
||||
System.out.println(name);
|
||||
};
|
||||
};
|
||||
```
|
||||
|
||||
可以作为参数传递给*forEach*:
|
||||
|
||||
```java
|
||||
names.forEach(printConsumer);
|
||||
```
|
||||
|
||||
但这不是通过消费者和使用*forEach* API 创建操作的唯一方法。让我们看看我们将使用*forEach*方法的另外2种最流行的方式:
|
||||
|
||||
### 3.2 Lambda表达式
|
||||
|
||||
Java 8功能接口的主要优点是我们可以使用Lambda表达式来实例化它们,并避免使用庞大的匿名类实现。
|
||||
|
||||
由于 Consumer 接口属于函数式接口,我们可以通过以下形式在Lambda中表达它:
|
||||
|
||||
```java
|
||||
(argument) -> { body }
|
||||
name -> System.out.println(name)
|
||||
names.forEach(name -> System.out.println(name));
|
||||
```
|
||||
|
||||
### 3.3 方法参考
|
||||
|
||||
我们可以使用方法引用语法而不是普通的Lambda语法,其中已存在一个方法来对类执行操作:
|
||||
|
||||
```java
|
||||
names.forEach(System.out::println);
|
||||
```
|
||||
|
||||
## 4.forEach在集合中的使用
|
||||
|
||||
### 4.1.迭代集合
|
||||
|
||||
**任何类型Collection的可迭代 - 列表,集合,队列 等都具有使用forEach的相同语法。**
|
||||
|
||||
因此,正如我们已经看到的,迭代列表的元素:
|
||||
|
||||
```java
|
||||
List<String> names = Arrays.asList("Larry", "Steve", "James");
|
||||
|
||||
names.forEach(System.out::println);
|
||||
```
|
||||
|
||||
同样对于一组:
|
||||
|
||||
```java
|
||||
Set<String> uniqueNames = new HashSet<>(Arrays.asList("Larry", "Steve", "James"));
|
||||
|
||||
uniqueNames.forEach(System.out::println);
|
||||
```
|
||||
|
||||
或者让我们说一个*队列*也是一个*集合*:
|
||||
|
||||
```java
|
||||
Queue<String> namesQueue = new ArrayDeque<>(Arrays.asList("Larry", "Steve", "James"));
|
||||
|
||||
namesQueue.forEach(System.out::println);
|
||||
```
|
||||
|
||||
### 4.2.迭代Map - 使用Map的forEach
|
||||
|
||||
Map没有实现Iterable接口,但它**提供了自己的forEach 变体,它接受BiConsumer**。*
|
||||
|
||||
```java
|
||||
Map<Integer, String> namesMap = new HashMap<>();
|
||||
namesMap.put(1, "Larry");
|
||||
namesMap.put(2, "Steve");
|
||||
namesMap.put(3, "James");
|
||||
namesMap.forEach((key, value) -> System.out.println(key + " " + value));
|
||||
```
|
||||
|
||||
### 4.3.迭代一个Map - 通过迭代entrySet
|
||||
|
||||
```java
|
||||
namesMap.entrySet().forEach(entry -> System.out.println(entry.getKey() + " " + entry.getValue()));
|
||||
```
|
||||
@ -1,235 +0,0 @@
|
||||
JDK8--Lambda表达式
|
||||
===
|
||||
## 1.什么是Lambda表达式
|
||||
**Lambda表达式实质上是一个可传递的代码块,Lambda又称为闭包或者匿名函数,是函数式编程语法,让方法可以像普通参数一样传递**
|
||||
|
||||
## 2.Lambda表达式语法
|
||||
```(参数列表) -> {执行代码块}```
|
||||
<br>参数列表可以为空```()->{}```
|
||||
<br>可以加类型声明比如```(String para1, int para2) -> {return para1 + para2;}```我们可以看到,lambda同样可以有返回值.
|
||||
<br>在编译器可以推断出类型的时候,可以将类型声明省略,比如```(para1, para2) -> {return para1 + para2;}```
|
||||
<br>(lambda有点像动态类型语言语法。lambda在字节码层面是用invokedynamic实现的,而这条指令就是为了让JVM更好的支持运行在其上的动态类型语言)
|
||||
|
||||
## 3.函数式接口
|
||||
在了解Lambda表达式之前,有必要先了解什么是函数式接口```(@FunctionalInterface)```<br>
|
||||
**函数式接口指的是有且只有一个抽象(abstract)方法的接口**<br>
|
||||
当需要一个函数式接口的对象时,就可以用Lambda表达式来实现,举个常用的例子:
|
||||
<br>
|
||||
```java
|
||||
Thread thread = new Thread(() -> {
|
||||
System.out.println("This is JDK8's Lambda!");
|
||||
});
|
||||
```
|
||||
这段代码和函数式接口有啥关系?我们回忆一下,Thread类的构造函数里是不是有一个以Runnable接口为参数的?
|
||||
```java
|
||||
public Thread(Runnable target) {...}
|
||||
|
||||
/**
|
||||
* Runnable Interface
|
||||
*/
|
||||
@FunctionalInterface
|
||||
public interface Runnable {
|
||||
public abstract void run();
|
||||
}
|
||||
```
|
||||
到这里大家可能已经明白了,**Lambda表达式相当于一个匿名类或者说是一个匿名方法**。上面Thread的例子相当于
|
||||
```java
|
||||
Thread thread = new Thread(new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("Anonymous class");
|
||||
}
|
||||
});
|
||||
```
|
||||
也就是说,上面的lambda表达式相当于实现了这个run()方法,然后当做参数传入(个人感觉可以这么理解,lambda表达式就是一个函数,只不过它的返回值、参数列表都
|
||||
由编译器帮我们推断,因此可以减少很多代码量)。
|
||||
<br>Lambda也可以这样用 :
|
||||
```java
|
||||
Runnable runnable = () -> {...};
|
||||
```
|
||||
其实这和上面的用法没有什么本质上的区别。
|
||||
<br>至此大家应该明白什么是函数式接口以及函数式接口和lambda表达式之间的关系了。在JDK8中修改了接口的规范,
|
||||
目的是为了在给接口添加新的功能时保持向前兼容(个人理解),比如一个已经定义了的函数式接口,某天我们想给它添加新功能,那么就不能保持向前兼容了,
|
||||
因为在旧的接口规范下,添加新功能必定会破坏这个函数式接口[(JDK8中接口规范)]()
|
||||
<br>
|
||||
除了上面说的Runnable接口之外,JDK中已经存在了很多函数式接口
|
||||
比如(当然不止这些):
|
||||
- ```java.util.concurrent.Callable```
|
||||
- ```java.util.Comparator```
|
||||
- ```java.io.FileFilter```
|
||||
<br>**关于JDK中的预定义的函数式接口**
|
||||
|
||||
- JDK在```java.util.function```下预定义了很多函数式接口
|
||||
- ```Function<T, R> {R apply(T t);}``` 接受一个T对象,然后返回一个R对象,就像普通的函数。
|
||||
- ```Consumer<T> {void accept(T t);}``` 消费者 接受一个T对象,没有返回值。
|
||||
- ```Predicate<T> {boolean test(T t);}``` 判断,接受一个T对象,返回一个布尔值。
|
||||
- ```Supplier<T> {T get();} 提供者(工厂)``` 返回一个T对象。
|
||||
- 其他的跟上面的相似,大家可以看一下function包下的具体接口。
|
||||
## 4.变量作用域
|
||||
```java
|
||||
public class VaraibleHide {
|
||||
@FunctionalInterface
|
||||
interface IInner {
|
||||
void printInt(int x);
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
int x = 20;
|
||||
IInner inner = new IInner() {
|
||||
int x = 10;
|
||||
@Override
|
||||
public void printInt(int x) {
|
||||
System.out.println(x);
|
||||
}
|
||||
};
|
||||
inner.printInt(30);
|
||||
|
||||
inner = (s) -> {
|
||||
//Variable used in lambda expression should be final or effectively final
|
||||
//!int x = 10;
|
||||
//!x= 50; error
|
||||
System.out.print(x);
|
||||
};
|
||||
inner.printInt(30);
|
||||
}
|
||||
}
|
||||
输出 :
|
||||
30
|
||||
20
|
||||
```
|
||||
对于lambda表达式```java inner = (s) -> {System.out.print(x);};```,变量x并不是在lambda表达式中定义的,像这样并不是在lambda中定义或者通过lambda的参数列表()获取的变量成为自由变量,它是被lambda表达式捕获的。
|
||||
<br>lambda表达式和内部类一样,对外部自由变量捕获时,外部自由变量必须为final或者是最终变量(effectively final)的,也就是说这个变量初始化后就不能为它赋新值,
|
||||
同时lambda不像内部类/匿名类,lambda表达式与外围嵌套块有着相同的作用域,因此对变量命名的有关规则对lambda同样适用。大家阅读上面的代码对这些概念应该
|
||||
不难理解。
|
||||
## 5.方法引用
|
||||
**只需要提供方法的名字,具体的调用过程由Lambda和函数式接口来确定,这样的方法调用成为方法引用。**
|
||||
<br>下面的例子会打印list中的每个元素:
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 0; i < 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.forEach(System.out::println);
|
||||
```
|
||||
其中```System.out::println```这个就是一个方法引用,等价于Lambda表达式 ```(para)->{System.out.println(para);}```
|
||||
<br>我们看一下List#forEach方法 ```default void forEach(Consumer<? super T> action)```可以看到它的参数是一个Consumer接口,该接口是一个函数式接口
|
||||
```java
|
||||
@FunctionalInterface
|
||||
public interface Consumer<T> {
|
||||
void accept(T t);
|
||||
```
|
||||
大家能发现这个函数接口的方法和```System.out::println```有什么相似的么?没错,它们有着相似的参数列表和返回值。
|
||||
<br>我们自己定义一个方法,看看能不能像标准输出的打印函数一样被调用
|
||||
```java
|
||||
public class MethodReference {
|
||||
public static void main(String[] args) {
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 0; i < 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.forEach(MethodReference::myPrint);
|
||||
}
|
||||
|
||||
static void myPrint(int i) {
|
||||
System.out.print(i + ", ");
|
||||
}
|
||||
}
|
||||
|
||||
输出: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
|
||||
```
|
||||
可以看到,我们自己定义的方法也可以当做方法引用。
|
||||
<br>到这里大家多少对方法引用有了一定的了解,我们再来说一下方法引用的形式。
|
||||
- 方法引用
|
||||
- 类名::静态方法名
|
||||
- 类名::实例方法名
|
||||
- 类名::new (构造方法引用)
|
||||
- 实例名::实例方法名
|
||||
可以看出,方法引用是通过(方法归属名)::(方法名)来调用的。通过上面的例子已经讲解了一个`类名::静态方法名`的使用方法了,下面再依次介绍其余的几种
|
||||
方法引用的使用方法。<br>
|
||||
**类名::实例方法名**<br>
|
||||
先来看一段代码
|
||||
```java
|
||||
String[] strings = new String[10];
|
||||
Arrays.sort(strings, String::compareToIgnoreCase);
|
||||
```
|
||||
**上面的String::compareToIgnoreCase等价于(x, y) -> {return x.compareToIgnoreCase(y);}**<br>
|
||||
我们看一下`Arrays#sort`方法`public static <T> void sort(T[] a, Comparator<? super T> c)`,
|
||||
可以看到第二个参数是一个Comparator接口,该接口也是一个函数式接口,其中的抽象方法是`int compare(T o1, T o2);`,再看一下
|
||||
`String#compareToIgnoreCase`方法,`public int compareToIgnoreCase(String str)`,这个方法好像和上面讲方法引用中`类名::静态方法名`不大一样啊,它
|
||||
的参数列表和函数式接口的参数列表不一样啊,虽然它的返回值一样?
|
||||
<br>是的,确实不一样但是别忘了,String类的这个方法是个实例方法,而不是静态方法,也就是说,这个方法是需要有一个接收者的。所谓接收者就是
|
||||
instance.method(x)中的instance,
|
||||
它是某个类的实例,有的朋友可能已经明白了。上面函数式接口的`compare(T o1, T o2)`中的第一个参数作为了实例方法的接收者,而第二个参数作为了实例方法的
|
||||
参数。我们再举一个自己实现的例子:
|
||||
```java
|
||||
public class MethodReference {
|
||||
static Random random = new Random(47);
|
||||
public static void main(String[] args) {
|
||||
MethodReference[] methodReferences = new MethodReference[10];
|
||||
Arrays.sort(methodReferences, MethodReference::myCompare);
|
||||
}
|
||||
int myCompare(MethodReference o) {
|
||||
return random.nextInt(2) - 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
上面的例子可以在IDE里通过编译,大家有兴趣的可以模仿上面的例子自己写一个程序,打印出排序后的结果。
|
||||
<br>**构造器引用**<br>
|
||||
构造器引用仍然需要与特定的函数式接口配合使用,并不能像下面这样直接使用。IDE会提示String不是一个函数式接口
|
||||
```java
|
||||
//compile error : String is not a functional interface
|
||||
String str = String::new;
|
||||
```
|
||||
下面是一个使用构造器引用的例子,可以看出构造器引用可以和这种工厂型的函数式接口一起使用的。
|
||||
```java
|
||||
interface IFunctional<T> {
|
||||
T func();
|
||||
}
|
||||
|
||||
public class ConstructorReference {
|
||||
|
||||
public ConstructorReference() {
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Supplier<ConstructorReference> supplier0 = () -> new ConstructorReference();
|
||||
Supplier<ConstructorReference> supplier1 = ConstructorReference::new;
|
||||
IFunctional<ConstructorReference> functional = () -> new ConstructorReference();
|
||||
IFunctional<ConstructorReference> functional1 = ConstructorReference::new;
|
||||
}
|
||||
}
|
||||
```
|
||||
下面是一个JDK官方的例子
|
||||
```java
|
||||
public static <T, SOURCE extends Collection<T>, DEST extends Collection<T>>
|
||||
DEST transferElements(
|
||||
SOURCE sourceCollection,
|
||||
Supplier<DEST> collectionFactory) {
|
||||
|
||||
DEST result = collectionFactory.get();
|
||||
for (T t : sourceCollection) {
|
||||
result.add(t);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
...
|
||||
|
||||
Set<Person> rosterSet = transferElements(
|
||||
roster, HashSet::new);
|
||||
```
|
||||
|
||||
**实例::实例方法**
|
||||
<br>
|
||||
其实开始那个例子就是一个实例::实例方法的引用
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 0; i < 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.forEach(System.out::println);
|
||||
```
|
||||
其中System.out就是一个实例,println是一个实例方法。相信不用再给大家做解释了。
|
||||
## 总结
|
||||
Lambda表达式是JDK8引入Java的函数式编程语法,使用Lambda需要直接或者间接的与函数式接口配合,在开发中使用Lambda可以减少代码量,
|
||||
但是并不是说必须要使用Lambda(虽然它是一个很酷的东西)。有些情况下使用Lambda会使代码的可读性急剧下降,并且也节省不了多少代码,
|
||||
所以在实际开发中还是需要仔细斟酌是否要使用Lambda。和Lambda相似的还有JDK10中加入的var类型推断,同样对于这个特性需要斟酌使用。
|
||||
@ -1,556 +0,0 @@
|
||||
JDK8新特性总结
|
||||
======
|
||||
总结了部分JDK8新特性,另外一些新特性可以通过Oracle的官方文档查看,毕竟是官方文档,各种新特性都会介绍,有兴趣的可以去看。<br>
|
||||
[Oracle官方文档:What's New in JDK8](https://www.oracle.com/technetwork/java/javase/8-whats-new-2157071.html)
|
||||
-----
|
||||
- [Java语言特性](#JavaProgrammingLanguage)
|
||||
- [Lambda表达式是一个新的语言特性,已经在JDK8中加入。它是一个可以传递的代码块,你也可以把它们当做方法参数。
|
||||
Lambda表达式允许您更紧凑地创建单虚方法接口(称为功能接口)的实例。](#LambdaExpressions)
|
||||
|
||||
- [方法引用为已经存在的具名方法提供易于阅读的Lambda表达式](#MethodReferences)
|
||||
|
||||
- [默认方法允许将新功能添加到库的接口,并确保与为这些接口的旧版本编写的代码的二进制兼容性。](#DefaultMethods)
|
||||
|
||||
- [改进的类型推断。](#ImprovedTypeInference)
|
||||
|
||||
- [方法参数反射(通过反射获得方法参数信息)](#MethodParameterReflection)
|
||||
|
||||
- [流(stream)](#stream)
|
||||
- [新java.util.stream包中的类提供Stream API以支持对元素流的功能样式操作。流(stream)和I/O里的流不是同一个概念
|
||||
,使用stream API可以更方便的操作集合。]()
|
||||
|
||||
- [国际化]()
|
||||
- 待办
|
||||
- 待办
|
||||
___
|
||||
<!-- ---------------------------------------------------Lambda表达式-------------------------------------------------------- -->
|
||||
<!-- 标题与跳转-->
|
||||
<span id="JavaProgrammingLanguage"></span>
|
||||
<span id="LambdaExpressions"></span>
|
||||
<!-- 标题与跳转结束-->
|
||||
<!-- 正文-->
|
||||
|
||||
## Lambda表达式
|
||||
### 1.什么是Lambda表达式
|
||||
**Lambda表达式实质上是一个可传递的代码块,Lambda又称为闭包或者匿名函数,是函数式编程语法,让方法可以像普通参数一样传递**
|
||||
|
||||
### 2.Lambda表达式语法
|
||||
```(参数列表) -> {执行代码块}```
|
||||
<br>参数列表可以为空```()->{}```
|
||||
<br>可以加类型声明比如```(String para1, int para2) -> {return para1 + para2;}```我们可以看到,lambda同样可以有返回值.
|
||||
<br>在编译器可以推断出类型的时候,可以将类型声明省略,比如```(para1, para2) -> {return para1 + para2;}```
|
||||
<br>(lambda有点像动态类型语言语法。lambda在字节码层面是用invokedynamic实现的,而这条指令就是为了让JVM更好的支持运行在其上的动态类型语言)
|
||||
|
||||
### 3.函数式接口
|
||||
在了解Lambda表达式之前,有必要先了解什么是函数式接口```(@FunctionalInterface)```<br>
|
||||
**函数式接口指的是有且只有一个抽象(abstract)方法的接口**<br>
|
||||
当需要一个函数式接口的对象时,就可以用Lambda表达式来实现,举个常用的例子:
|
||||
<br>
|
||||
```java
|
||||
Thread thread = new Thread(() -> {
|
||||
System.out.println("This is JDK8's Lambda!");
|
||||
});
|
||||
```
|
||||
这段代码和函数式接口有啥关系?我们回忆一下,Thread类的构造函数里是不是有一个以Runnable接口为参数的?
|
||||
```java
|
||||
public Thread(Runnable target) {...}
|
||||
|
||||
/**
|
||||
* Runnable Interface
|
||||
*/
|
||||
@FunctionalInterface
|
||||
public interface Runnable {
|
||||
public abstract void run();
|
||||
}
|
||||
```
|
||||
到这里大家可能已经明白了,**Lambda表达式相当于一个匿名类或者说是一个匿名方法**。上面Thread的例子相当于
|
||||
```java
|
||||
Thread thread = new Thread(new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("Anonymous class");
|
||||
}
|
||||
});
|
||||
```
|
||||
也就是说,上面的lambda表达式相当于实现了这个run()方法,然后当做参数传入(个人感觉可以这么理解,lambda表达式就是一个函数,只不过它的返回值、参数列表都
|
||||
由编译器帮我们推断,因此可以减少很多代码量)。
|
||||
<br>Lambda也可以这样用 :
|
||||
```java
|
||||
Runnable runnable = () -> {...};
|
||||
```
|
||||
其实这和上面的用法没有什么本质上的区别。
|
||||
<br>至此大家应该明白什么是函数式接口以及函数式接口和lambda表达式之间的关系了。在JDK8中修改了接口的规范,
|
||||
目的是为了在给接口添加新的功能时保持向前兼容(个人理解),比如一个已经定义了的函数式接口,某天我们想给它添加新功能,那么就不能保持向前兼容了,
|
||||
因为在旧的接口规范下,添加新功能必定会破坏这个函数式接口[(JDK8中接口规范)]()
|
||||
<br>
|
||||
除了上面说的Runnable接口之外,JDK中已经存在了很多函数式接口
|
||||
比如(当然不止这些):
|
||||
- ```java.util.concurrent.Callable```
|
||||
- ```java.util.Comparator```
|
||||
- ```java.io.FileFilter```
|
||||
<br>**关于JDK中的预定义的函数式接口**
|
||||
|
||||
- JDK在```java.util.function```下预定义了很多函数式接口
|
||||
- ```Function<T, R> {R apply(T t);}``` 接受一个T对象,然后返回一个R对象,就像普通的函数。
|
||||
- ```Consumer<T> {void accept(T t);}``` 消费者 接受一个T对象,没有返回值。
|
||||
- ```Predicate<T> {boolean test(T t);}``` 判断,接受一个T对象,返回一个布尔值。
|
||||
- ```Supplier<T> {T get();} 提供者(工厂)``` 返回一个T对象。
|
||||
- 其他的跟上面的相似,大家可以看一下function包下的具体接口。
|
||||
### 4.变量作用域
|
||||
```java
|
||||
public class VaraibleHide {
|
||||
@FunctionalInterface
|
||||
interface IInner {
|
||||
void printInt(int x);
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
int x = 20;
|
||||
IInner inner = new IInner() {
|
||||
int x = 10;
|
||||
@Override
|
||||
public void printInt(int x) {
|
||||
System.out.println(x);
|
||||
}
|
||||
};
|
||||
inner.printInt(30);
|
||||
|
||||
inner = (s) -> {
|
||||
//Variable used in lambda expression should be final or effectively final
|
||||
//!int x = 10;
|
||||
//!x= 50; error
|
||||
System.out.print(x);
|
||||
};
|
||||
inner.printInt(30);
|
||||
}
|
||||
}
|
||||
输出 :
|
||||
30
|
||||
20
|
||||
```
|
||||
对于lambda表达式```java inner = (s) -> {System.out.print(x);};```,变量x并不是在lambda表达式中定义的,像这样并不是在lambda中定义或者通过lambda
|
||||
的参数列表()获取的变量成为自由变量,它是被lambda表达式捕获的。
|
||||
<br>lambda表达式和内部类一样,对外部自由变量捕获时,外部自由变量必须为final或者是最终变量(effectively final)的,也就是说这个变量初始化后就不能为它赋新值,同时lambda不像内部类/匿名类,lambda表达式与外围嵌套块有着相同的作用域,因此对变量命名的有关规则对lambda同样适用。大家阅读上面的代码对这些概念应该不难理解。
|
||||
<span id="MethodReferences"></span>
|
||||
### 5.方法引用
|
||||
**只需要提供方法的名字,具体的调用过程由Lambda和函数式接口来确定,这样的方法调用成为方法引用。**
|
||||
<br>下面的例子会打印list中的每个元素:
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 0; i < 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.forEach(System.out::println);
|
||||
```
|
||||
其中```System.out::println```这个就是一个方法引用,等价于Lambda表达式 ```(para)->{System.out.println(para);}```
|
||||
<br>我们看一下List#forEach方法 ```default void forEach(Consumer<? super T> action)```可以看到它的参数是一个Consumer接口,该接口是一个函数式接口
|
||||
```java
|
||||
@FunctionalInterface
|
||||
public interface Consumer<T> {
|
||||
void accept(T t);
|
||||
```
|
||||
大家能发现这个函数接口的方法和```System.out::println```有什么相似的么?没错,它们有着相似的参数列表和返回值。
|
||||
<br>我们自己定义一个方法,看看能不能像标准输出的打印函数一样被调用
|
||||
```java
|
||||
public class MethodReference {
|
||||
public static void main(String[] args) {
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 0; i < 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.forEach(MethodReference::myPrint);
|
||||
}
|
||||
|
||||
static void myPrint(int i) {
|
||||
System.out.print(i + ", ");
|
||||
}
|
||||
}
|
||||
|
||||
输出: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9,
|
||||
```
|
||||
可以看到,我们自己定义的方法也可以当做方法引用。
|
||||
<br>到这里大家多少对方法引用有了一定的了解,我们再来说一下方法引用的形式。
|
||||
- 方法引用
|
||||
- 类名::静态方法名
|
||||
- 类名::实例方法名
|
||||
- 类名::new (构造方法引用)
|
||||
- 实例名::实例方法名
|
||||
可以看出,方法引用是通过(方法归属名)::(方法名)来调用的。通过上面的例子已经讲解了一个`类名::静态方法名`的使用方法了,下面再依次介绍其余的几种
|
||||
方法引用的使用方法。<br>
|
||||
**类名::实例方法名**<br>
|
||||
先来看一段代码
|
||||
```java
|
||||
String[] strings = new String[10];
|
||||
Arrays.sort(strings, String::compareToIgnoreCase);
|
||||
```
|
||||
**上面的String::compareToIgnoreCase等价于(x, y) -> {return x.compareToIgnoreCase(y);}**<br>
|
||||
我们看一下`Arrays#sort`方法`public static <T> void sort(T[] a, Comparator<? super T> c)`,
|
||||
可以看到第二个参数是一个Comparator接口,该接口也是一个函数式接口,其中的抽象方法是`int compare(T o1, T o2);`,再看一下
|
||||
`String#compareToIgnoreCase`方法,`public int compareToIgnoreCase(String str)`,这个方法好像和上面讲方法引用中`类名::静态方法名`不大一样啊,它
|
||||
的参数列表和函数式接口的参数列表不一样啊,虽然它的返回值一样?
|
||||
<br>是的,确实不一样但是别忘了,String类的这个方法是个实例方法,而不是静态方法,也就是说,这个方法是需要有一个接收者的。所谓接收者就是
|
||||
instance.method(x)中的instance,
|
||||
它是某个类的实例,有的朋友可能已经明白了。上面函数式接口的`compare(T o1, T o2)`中的第一个参数作为了实例方法的接收者,而第二个参数作为了实例方法的
|
||||
参数。我们再举一个自己实现的例子:
|
||||
```java
|
||||
public class MethodReference {
|
||||
static Random random = new Random(47);
|
||||
public static void main(String[] args) {
|
||||
MethodReference[] methodReferences = new MethodReference[10];
|
||||
Arrays.sort(methodReferences, MethodReference::myCompare);
|
||||
}
|
||||
int myCompare(MethodReference o) {
|
||||
return random.nextInt(2) - 1;
|
||||
}
|
||||
}
|
||||
```
|
||||
上面的例子可以在IDE里通过编译,大家有兴趣的可以模仿上面的例子自己写一个程序,打印出排序后的结果。
|
||||
<br>**构造器引用**<br>
|
||||
构造器引用仍然需要与特定的函数式接口配合使用,并不能像下面这样直接使用。IDE会提示String不是一个函数式接口
|
||||
```java
|
||||
//compile error : String is not a functional interface
|
||||
String str = String::new;
|
||||
```
|
||||
下面是一个使用构造器引用的例子,可以看出构造器引用可以和这种工厂型的函数式接口一起使用的。
|
||||
```java
|
||||
interface IFunctional<T> {
|
||||
T func();
|
||||
}
|
||||
|
||||
public class ConstructorReference {
|
||||
|
||||
public ConstructorReference() {
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
Supplier<ConstructorReference> supplier0 = () -> new ConstructorReference();
|
||||
Supplier<ConstructorReference> supplier1 = ConstructorReference::new;
|
||||
IFunctional<ConstructorReference> functional = () -> new ConstructorReference();
|
||||
IFunctional<ConstructorReference> functional1 = ConstructorReference::new;
|
||||
}
|
||||
}
|
||||
```
|
||||
下面是一个JDK官方的例子
|
||||
```java
|
||||
public static <T, SOURCE extends Collection<T>, DEST extends Collection<T>>
|
||||
DEST transferElements(
|
||||
SOURCE sourceCollection,
|
||||
Supplier<DEST> collectionFactory) {
|
||||
|
||||
DEST result = collectionFactory.get();
|
||||
for (T t : sourceCollection) {
|
||||
result.add(t);
|
||||
}
|
||||
return result;
|
||||
}
|
||||
|
||||
...
|
||||
|
||||
Set<Person> rosterSet = transferElements(
|
||||
roster, HashSet::new);
|
||||
```
|
||||
|
||||
**实例::实例方法**
|
||||
<br>
|
||||
其实开始那个例子就是一个实例::实例方法的引用
|
||||
```java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 0; i < 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.forEach(System.out::println);
|
||||
```
|
||||
其中System.out就是一个实例,println是一个实例方法。相信不用再给大家做解释了。
|
||||
### 总结
|
||||
Lambda表达式是JDK8引入Java的函数式编程语法,使用Lambda需要直接或者间接的与函数式接口配合,在开发中使用Lambda可以减少代码量,
|
||||
但是并不是说必须要使用Lambda(虽然它是一个很酷的东西)。有些情况下使用Lambda会使代码的可读性急剧下降,并且也节省不了多少代码,
|
||||
所以在实际开发中还是需要仔细斟酌是否要使用Lambda。和Lambda相似的还有JDK10中加入的var类型推断,同样对于这个特性需要斟酌使用。
|
||||
|
||||
<!-- ---------------------------------------------------Lambda表达式结束---------------------------------------------------- -->
|
||||
___
|
||||
<!-- ---------------------------------------------------接口默认方法-------------------------------------------------------- -->
|
||||
<span id="DefaultMethods"></span>
|
||||
## JDK8接口规范
|
||||
### 在JDK8中引入了lambda表达式,出现了函数式接口的概念,为了在扩展接口时保持向前兼容性(JDK8之前扩展接口会使得实现了该接口的类必须实现添加的方法,否则会报错。为了保持兼容性而做出妥协的特性还有泛型,泛型也是为了保持兼容性而失去了在一些别的语言泛型拥有的功能),Java接口规范发生了一些改变。
|
||||
### 1.JDK8以前的接口规范
|
||||
- JDK8以前接口可以定义的变量和方法
|
||||
- 所有变量(Field)不论是否<i>显式</i> 的声明为```public static final```,它实际上都是```public static final```的。
|
||||
- 所有方法(Method)不论是否<i>显示</i> 的声明为```public abstract```,它实际上都是```public abstract```的。
|
||||
```java
|
||||
public interface AInterfaceBeforeJDK8 {
|
||||
int FIELD = 0;
|
||||
void simpleMethod();
|
||||
}
|
||||
```
|
||||
以上接口信息反编译以后可以看到字节码信息里Filed是public static final的,而方法是public abstract的,即是你没有显示的去声明它。
|
||||
```java
|
||||
{
|
||||
public static final int FIELD;
|
||||
descriptor: I
|
||||
flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
|
||||
ConstantValue: int 0
|
||||
|
||||
public abstract void simpleMethod();
|
||||
descriptor: ()V
|
||||
flags: (0x0401) ACC_PUBLIC, ACC_ABSTRACT
|
||||
}
|
||||
```
|
||||
### 2.JDK8之后的接口规范
|
||||
- JDK8之后接口可以定义的变量和方法
|
||||
- 变量(Field)仍然必须是 ```java public static final```的
|
||||
- 方法(Method)除了可以是public abstract之外,还可以是public static或者是default(相当于仅public修饰的实例方法)的。
|
||||
从以上改变不难看出,修改接口的规范主要是为了能在扩展接口时保持向前兼容。
|
||||
<br>下面是一个JDK8之后的接口例子
|
||||
```java
|
||||
public interface AInterfaceInJDK8 {
|
||||
int simpleFiled = 0;
|
||||
static int staticField = 1;
|
||||
|
||||
public static void main(String[] args) {
|
||||
}
|
||||
static void staticMethod(){}
|
||||
|
||||
default void defaultMethod(){}
|
||||
|
||||
void simpleMethod() throws IOException;
|
||||
|
||||
}
|
||||
```
|
||||
进行反编译(去除了一些没用信息)
|
||||
```java
|
||||
{
|
||||
public static final int simpleFiled;
|
||||
flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
|
||||
|
||||
public static final int staticField;
|
||||
flags: (0x0019) ACC_PUBLIC, ACC_STATIC, ACC_FINAL
|
||||
|
||||
public static void main(java.lang.String[]);
|
||||
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
|
||||
|
||||
public static void staticMethod();
|
||||
flags: (0x0009) ACC_PUBLIC, ACC_STATIC
|
||||
|
||||
public void defaultMethod();
|
||||
flags: (0x0001) ACC_PUBLIC
|
||||
|
||||
public abstract void simpleMethod() throws java.io.IOException;
|
||||
flags: (0x0401) ACC_PUBLIC, ACC_ABSTRACT
|
||||
Exceptions:
|
||||
throws java.io.IOException
|
||||
}
|
||||
```
|
||||
可以看到 default关键字修饰的方法是像实例方法(就是普通类中定义的普通方法)一样定义的,所以我们来定义一个只有default方法的接口并且实现一下这个接口试一
|
||||
试。
|
||||
```java
|
||||
interface Default {
|
||||
default int defaultMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
|
||||
public class DefaultMethod implements Default {
|
||||
public static void main(String[] args) {
|
||||
DefaultMethod defaultMethod = new DefaultMethod();
|
||||
System.out.println(defaultMethod.defaultMethod());
|
||||
//compile error : Non-static method 'defaultMethod()' cannot be referenced from a static context
|
||||
//! DefaultMethod.defaultMethod();
|
||||
}
|
||||
}
|
||||
```
|
||||
可以看到default方法确实像实例方法一样,必须有实例对象才能调用,并且子类在实现接口时,可以不用实现default方法,也可以选择覆盖该方法。
|
||||
这有点像子类继承父类实例方法。
|
||||
<br>
|
||||
接口静态方法就像是类静态方法,唯一的区别是**接口静态方法只能通过接口名调用,而类静态方法既可以通过类名调用也可以通过实例调用**
|
||||
```java
|
||||
interface Static {
|
||||
static int staticMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
... main(String...args)
|
||||
//!compile error: Static method may be invoked on containing interface class only
|
||||
//!aInstanceOfStatic.staticMethod();
|
||||
...
|
||||
```
|
||||
另一个问题是多继承问题,大家知道Java中类是不支持多继承的,但是接口是多继承和多实现(implements后跟多个接口)的,
|
||||
那么如果一个接口继承另一个接口,两个接口都有同名的default方法会怎么样呢?答案是会像类继承一样覆写(@Override),以下代码在IDE中可以顺利编译
|
||||
```java
|
||||
interface Default {
|
||||
default int defaultMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
interface Default2 extends Default {
|
||||
@Override
|
||||
default int defaultMethod() {
|
||||
return 9527;
|
||||
}
|
||||
}
|
||||
public class DefaultMethod implements Default,Default2 {
|
||||
public static void main(String[] args) {
|
||||
DefaultMethod defaultMethod = new DefaultMethod();
|
||||
System.out.println(defaultMethod.defaultMethod());
|
||||
}
|
||||
}
|
||||
|
||||
输出 : 9527
|
||||
```
|
||||
出现上面的情况时,会优先找继承树上近的方法,类似于“短路优先”。
|
||||
<br>
|
||||
那么如果一个类实现了两个没有继承关系的接口,且这两个接口有同名方法的话会怎么样呢?IDE会要求你重写这个冲突的方法,让你自己选择去执行哪个方法,因为IDE它还没智能到你不告诉它,它就知道你想执行哪个方法。可以通过```java 接口名.super```指针来访问接口中定义的实例(default)方法。
|
||||
```java
|
||||
interface Default {
|
||||
default int defaultMethod() {
|
||||
return 4396;
|
||||
}
|
||||
}
|
||||
|
||||
interface Default2 {
|
||||
default int defaultMethod() {
|
||||
return 9527;
|
||||
}
|
||||
}
|
||||
//如果不重写
|
||||
//compile error : defaults.DefaultMethod inherits unrelated defaults for defaultMethod() from types defaults.Default and defaults.Default2
|
||||
public class DefaultMethod implements Default,Default2 {
|
||||
@Override
|
||||
public int defaultMethod() {
|
||||
System.out.println(Default.super.defaultMethod());
|
||||
System.out.println(Default2.super.defaultMethod());
|
||||
return 996;
|
||||
}
|
||||
public static void main(String[] args) {
|
||||
DefaultMethod defaultMethod = new DefaultMethod();
|
||||
System.out.println(defaultMethod.defaultMethod());
|
||||
}
|
||||
}
|
||||
|
||||
运行输出 :
|
||||
4396
|
||||
9527
|
||||
996
|
||||
```
|
||||
|
||||
<!-- ---------------------------------------------------接口默认方法结束---------------------------------------------------- -->
|
||||
___
|
||||
<!-- --------------------------------------------------- 改进的类型推断 ---------------------------------------------------- -->
|
||||
<span id="ImprovedTypeInference"></span>
|
||||
## 改进的类型推断
|
||||
### 1.什么是类型推断
|
||||
类型推断就像它的字面意思一样,编译器根据<b><i>你显示声明的已知的信息</i></b> 推断出你没有显示声明的类型,这就是类型推断。
|
||||
看过《Java编程思想 第四版》的朋友可能还记得里面讲解泛型一章的时候,里面很多例子是下面这样的:
|
||||
```java
|
||||
Map<String, Object> map = new Map<String, Object>();
|
||||
```
|
||||
而我们平常写的都是这样的:
|
||||
```java
|
||||
Map<String, Object> map = new Map<>();
|
||||
```
|
||||
这就是类型推断,《Java编程思想 第四版》这本书出书的时候最新的JDK只有1.6(JDK7推出的类型推断),在Java编程思想里Bruce Eckel大叔还提到过这个问题
|
||||
(可能JDK的官方人员看了Bruce Eckel大叔的Thinking in Java才加的类型推断,☺),在JDK7中推出了上面这样的类型推断,可以减少一些无用的代码。
|
||||
(Java编程思想到现在还只有第四版,是不是因为Bruce Eckel大叔觉得Java新推出的语言特性“然并卵”呢?/滑稽)
|
||||
<br>
|
||||
在JDK7中,类型推断只有上面例子的那样的能力,即只有在使用**赋值语句**时才能自动推断出泛型参数信息(即<>里的信息),下面的官方文档里的例子在JDK7里会编译
|
||||
错误
|
||||
```java
|
||||
List<String> stringList = new ArrayList<>();
|
||||
stringList.add("A");
|
||||
//error : addAll(java.util.Collection<? extends java.lang.String>)in List cannot be applied to (java.util.List<java.lang.Object>)
|
||||
stringList.addAll(Arrays.asList());
|
||||
```
|
||||
但是上面的代码在JDK8里可以通过,也就说,JDK8里,类型推断不仅可以用于赋值语句,而且可以根据代码中上下文里的信息推断出更多的信息,因此我们需要些的代码
|
||||
会更少。加强的类型推断还有一个就是用于Lambda表达式了。
|
||||
<br>
|
||||
大家其实不必细究类型推断,在日常使用中IDE会自动判断,当IDE自己无法推断出足够的信息时,就需要我们额外做一下工作,比如在<>里添加更多的类型信息,
|
||||
相信随着Java的进化,这些便利的功能会越来越强大。
|
||||
|
||||
<!-- --------------------------------------------------- 改进的类型推断结束------------------------------------------------- -->
|
||||
____
|
||||
<!-- --------------------------------------------------- 反射获得方法参数信息------------------------------------------------- -->
|
||||
<span id="MethodParameterReflection"></span>
|
||||
## 通过反射获得方法的参数信息
|
||||
JDK8之前 .class文件是不会存储方法参数信息的,因此也就无法通过反射获取该信息(想想反射获取类信息的入口是什么?当然就是Class类了)。即是是在JDK11里
|
||||
也不会默认生成这些信息,可以通过在javac加上-parameters参数来让javac生成这些信息(javac就是java编译器,可以把java文件编译成.class文件)。生成额外
|
||||
的信息(运行时非必须信息)会消耗内存并且有可能公布敏感信息(某些方法参数比如password,JDK文档里这么说的),并且确实很多信息javac并不会为我们生成,比如
|
||||
LocalVariableTable,javac就不会默认生成,需要你加上 -g:vars来强制让编译器生成,同样的,方法参数信息也需要加上
|
||||
-parameters来让javac为你在.class文件中生成这些信息,否则运行时反射是无法获取到这些信息的。在讲解Java语言层面的方法之前,先看一下javac加上该
|
||||
参数和不加生成的信息有什么区别(不感兴趣想直接看运行代码的可以跳过这段)。下面是随便写的一个类。
|
||||
```java
|
||||
public class ByteCodeParameters {
|
||||
public String simpleMethod(String canUGetMyName, Object yesICan) {
|
||||
return "9527";
|
||||
}
|
||||
}
|
||||
```
|
||||
先来不加参数编译和反编译一下这个类javac ByteCodeParameters.java , javap -v ByteCodeParameters:
|
||||
```java
|
||||
//只截取了部分信息
|
||||
public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
|
||||
descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
|
||||
flags: (0x0001) ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=3, args_size=3
|
||||
0: ldc #2 // String 9527
|
||||
2: areturn
|
||||
LineNumberTable:
|
||||
line 5: 0
|
||||
//这个方法的描述到这里就结束了
|
||||
```
|
||||
接下来我们加上参数javac -parameters ByteCodeParameters.java 再来看反编译的信息:
|
||||
```java
|
||||
public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
|
||||
descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
|
||||
flags: (0x0001) ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=3, args_size=3
|
||||
0: ldc #2 // String 9527
|
||||
2: areturn
|
||||
LineNumberTable:
|
||||
line 8: 0
|
||||
MethodParameters:
|
||||
Name Flags
|
||||
canUGetMyName
|
||||
yesICan
|
||||
```
|
||||
可以看到.class文件里多了一个MethodParameters信息,这就是参数的名字,可以看到默认是不保存的。
|
||||
<br>下面看一下在Intelj Idea里运行的这个例子,我们试一下通过反射获取方法名 :
|
||||
```java
|
||||
public class ByteCodeParameters {
|
||||
public String simpleMethod(String canUGetMyName, Object yesICan) {
|
||||
return "9527";
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws NoSuchMethodException {
|
||||
Class<?> clazz = ByteCodeParameters.class;
|
||||
Method simple = clazz.getDeclaredMethod("simpleMethod", String.class, Object.class);
|
||||
Parameter[] parameters = simple.getParameters();
|
||||
for (Parameter p : parameters) {
|
||||
System.out.println(p.getName());
|
||||
}
|
||||
}
|
||||
}
|
||||
输出 :
|
||||
arg0
|
||||
arg1
|
||||
```
|
||||
???说好的方法名呢????别急,哈哈。前面说了,默认是不生成参数名信息的,因此我们需要做一些配置,我们找到IDEA的settings里的Java Compiler选项,在
|
||||
Additional command line parameters:一行加上-parameters(Eclipse 也是找到Java Compiler选中Stoer information about method parameters),或者自
|
||||
己编译一个.class文件放在IDEA的out下,然后再来运行 :
|
||||
```java
|
||||
输出 :
|
||||
canUGetMyName
|
||||
yesICan
|
||||
```
|
||||
这样我们就通过反射获取到参数信息了。想要了解更多的同学可以自己研究一下 [官方文档]
|
||||
(https://docs.oracle.com/javase/tutorial/reflect/member/methodparameterreflection.html)
|
||||
<br>
|
||||
## 总结与补充
|
||||
在JDK8之后,可以通过-parameters参数来让编译器生成参数信息然后在运行时通过反射获取方法参数信息,其实在SpringFramework
|
||||
里面也有一个LocalVariableTableParameterNameDiscoverer对象可以获取方法参数名信息,有兴趣的同学可以自行百度(这个类在打印日志时可能会比较有用吧,个人感觉)。
|
||||
<!-- --------------------------------------------------- 反射获得方法参数信息结束------------------------------------------------- -->
|
||||
____
|
||||
<!-- --------------------------------------------------- JDK8流库------------------------------------------------------------- -->
|
||||
<span id="stream"></span>
|
||||
|
||||
<!-- --------------------------------------------------- JDK8流库结束------------------------------------------------- -->
|
||||
___
|
||||
@ -1,75 +0,0 @@
|
||||
Stream API 旨在让编码更高效率、干净、简洁。
|
||||
|
||||
### 从迭代器到Stream操作
|
||||
|
||||
当使用 `Stream` 时,我们一般会通过三个阶段建立一个流水线:
|
||||
|
||||
1. 创建一个 `Stream`;
|
||||
2. 进行一个或多个中间操作;
|
||||
3. 使用终止操作产生一个结果,`Stream` 就不会再被使用了。
|
||||
|
||||
**案例1:统计 List 中的单词长度大于6的个数**
|
||||
|
||||
```java
|
||||
/**
|
||||
* 案例1:统计 List 中的单词长度大于6的个数
|
||||
*/
|
||||
ArrayList<String> wordsList = new ArrayList<String>();
|
||||
wordsList.add("Charles");
|
||||
wordsList.add("Vincent");
|
||||
wordsList.add("William");
|
||||
wordsList.add("Joseph");
|
||||
wordsList.add("Henry");
|
||||
wordsList.add("Bill");
|
||||
wordsList.add("Joan");
|
||||
wordsList.add("Linda");
|
||||
int count = 0;
|
||||
```
|
||||
Java8之前我们通常用迭代方法来完成上面的需求:
|
||||
|
||||
```java
|
||||
//迭代(Java8之前的常用方法)
|
||||
//迭代不好的地方:1. 代码多;2 很难被并行运算。
|
||||
for (String word : wordsList) {
|
||||
if (word.length() > 6) {
|
||||
count++;
|
||||
}
|
||||
}
|
||||
System.out.println(count);//3
|
||||
```
|
||||
Java8之前我们使用 `Stream` 一行代码就能解决了,而且可以瞬间转换为并行执行的效果:
|
||||
|
||||
```java
|
||||
//Stream
|
||||
//将stream()改为parallelStream()就可以瞬间将代码编程并行执行的效果
|
||||
long count2=wordsList.stream()
|
||||
.filter(w->w.length()>6)
|
||||
.count();
|
||||
long count3=wordsList.parallelStream()
|
||||
.filter(w->w.length()>6)
|
||||
.count();
|
||||
System.out.println(count2);
|
||||
System.out.println(count3);
|
||||
```
|
||||
|
||||
### `distinct()`
|
||||
|
||||
去除 List 中重复的 String
|
||||
|
||||
```java
|
||||
List<String> list = list.stream()
|
||||
.distinct()
|
||||
.collect(Collectors.toList());
|
||||
```
|
||||
|
||||
### `map`
|
||||
|
||||
map 方法用于映射每个元素到对应的结果,以下代码片段使用 map 输出了元素对应的平方数:
|
||||
|
||||
```java
|
||||
List<Integer> numbers = Arrays.asList(3, 2, 2, 3, 7, 3, 5);
|
||||
// 获取 List 中每个元素对应的平方数并去重
|
||||
List<Integer> squaresList = numbers.stream().map( i -> i*i).distinct().collect(Collectors.toList());
|
||||
System.out.println(squaresList.toString());//[9, 4, 49, 25]
|
||||
```
|
||||
|
||||
@ -1,30 +0,0 @@
|
||||
## 改进的类型推断
|
||||
### 1.什么是类型推断
|
||||
类型推断就像它的字面意思一样,编译器根据<b><i>你显示声明的已知的信息</i></b> 推断出你没有显示声明的类型,这就是类型推断。
|
||||
看过《Java编程思想 第四版》的朋友可能还记得里面讲解泛型一章的时候,里面很多例子是下面这样的:
|
||||
```java
|
||||
Map<String, Object> map = new Map<String, Object>();
|
||||
```
|
||||
而我们平常写的都是这样的:
|
||||
```java
|
||||
Map<String, Object> map = new Map<>();
|
||||
```
|
||||
这就是类型推断,《Java编程思想 第四版》这本书出书的时候最新的JDK只有1.6(JDK7推出的类型推断),在Java编程思想里Bruce Eckel大叔还提到过这个问题
|
||||
(可能JDK的官方人员看了Bruce Eckel大叔的Thinking in Java才加的类型推断,☺),在JDK7中推出了上面这样的类型推断,可以减少一些无用的代码。
|
||||
(Java编程思想到现在还只有第四版,是不是因为Bruce Eckel大叔觉得Java新推出的语言特性“然并卵”呢?/滑稽)
|
||||
<br>
|
||||
在JDK7中,类型推断只有上面例子的那样的能力,即只有在使用**赋值语句**时才能自动推断出泛型参数信息(即<>里的信息),下面的官方文档里的例子在JDK7里会编译
|
||||
错误
|
||||
```java
|
||||
List<String> stringList = new ArrayList<>();
|
||||
stringList.add("A");
|
||||
//error : addAll(java.util.Collection<? extends java.lang.String>)in List cannot be applied to (java.util.List<java.lang.Object>)
|
||||
stringList.addAll(Arrays.asList());
|
||||
```
|
||||
但是上面的代码在JDK8里可以通过,也就说,JDK8里,类型推断不仅可以用于赋值语句,而且可以根据代码中上下文里的信息推断出更多的信息,因此我们需要些的代码
|
||||
会更少。加强的类型推断还有一个就是用于Lambda表达式了。
|
||||
<br>
|
||||
大家其实不必细究类型推断,在日常使用中IDE会自动判断,当IDE自己无法推断出足够的信息时,就需要我们额外做一下工作,比如在<>里添加更多的类型信息,
|
||||
相信随着Java的进化,这些便利的功能会越来越强大。
|
||||
|
||||
<!-- --------------------------------------------------- 改进的类型推断结束------------------------------------------------- -->
|
||||
@ -1,79 +0,0 @@
|
||||
## 通过反射获得方法的参数信息
|
||||
JDK8之前 .class文件是不会存储方法参数信息的,因此也就无法通过反射获取该信息(想想反射获取类信息的入口是什么?当然就是Class类了)。即是是在JDK11里
|
||||
也不会默认生成这些信息,可以通过在javac加上-parameters参数来让javac生成这些信息(javac就是java编译器,可以把java文件编译成.class文件)。生成额外
|
||||
的信息(运行时非必须信息)会消耗内存并且有可能公布敏感信息(某些方法参数比如password,JDK文档里这么说的),并且确实很多信息javac并不会为我们生成,比如
|
||||
LocalVariableTable,javac就不会默认生成,需要你加上 -g:vars来强制让编译器生成,同样的,方法参数信息也需要加上
|
||||
-parameters来让javac为你在.class文件中生成这些信息,否则运行时反射是无法获取到这些信息的。在讲解Java语言层面的方法之前,先看一下javac加上该
|
||||
参数和不加生成的信息有什么区别(不感兴趣想直接看运行代码的可以跳过这段)。下面是随便写的一个类。
|
||||
```java
|
||||
public class ByteCodeParameters {
|
||||
public String simpleMethod(String canUGetMyName, Object yesICan) {
|
||||
return "9527";
|
||||
}
|
||||
}
|
||||
```
|
||||
先来不加参数编译和反编译一下这个类javac ByteCodeParameters.java , javap -v ByteCodeParameters:
|
||||
```java
|
||||
//只截取了部分信息
|
||||
public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
|
||||
descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
|
||||
flags: (0x0001) ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=3, args_size=3
|
||||
0: ldc #2 // String 9527
|
||||
2: areturn
|
||||
LineNumberTable:
|
||||
line 5: 0
|
||||
//这个方法的描述到这里就结束了
|
||||
```
|
||||
接下来我们加上参数javac -parameters ByteCodeParameters.java 再来看反编译的信息:
|
||||
```java
|
||||
public java.lang.String simpleMethod(java.lang.String, java.lang.Object);
|
||||
descriptor: (Ljava/lang/String;Ljava/lang/Object;)Ljava/lang/String;
|
||||
flags: (0x0001) ACC_PUBLIC
|
||||
Code:
|
||||
stack=1, locals=3, args_size=3
|
||||
0: ldc #2 // String 9527
|
||||
2: areturn
|
||||
LineNumberTable:
|
||||
line 8: 0
|
||||
MethodParameters:
|
||||
Name Flags
|
||||
canUGetMyName
|
||||
yesICan
|
||||
```
|
||||
可以看到.class文件里多了一个MethodParameters信息,这就是参数的名字,可以看到默认是不保存的。
|
||||
<br>下面看一下在Intelj Idea里运行的这个例子,我们试一下通过反射获取方法名 :
|
||||
```java
|
||||
public class ByteCodeParameters {
|
||||
public String simpleMethod(String canUGetMyName, Object yesICan) {
|
||||
return "9527";
|
||||
}
|
||||
|
||||
public static void main(String[] args) throws NoSuchMethodException {
|
||||
Class<?> clazz = ByteCodeParameters.class;
|
||||
Method simple = clazz.getDeclaredMethod("simpleMethod", String.class, Object.class);
|
||||
Parameter[] parameters = simple.getParameters();
|
||||
for (Parameter p : parameters) {
|
||||
System.out.println(p.getName());
|
||||
}
|
||||
}
|
||||
}
|
||||
输出 :
|
||||
arg0
|
||||
arg1
|
||||
```
|
||||
???说好的方法名呢????别急,哈哈。前面说了,默认是不生成参数名信息的,因此我们需要做一些配置,我们找到IDEA的settings里的Java Compiler选项,在
|
||||
Additional command line parameters:一行加上-parameters(Eclipse 也是找到Java Compiler选中Stoer information about method parameters),或者自
|
||||
己编译一个.class文件放在IDEA的out下,然后再来运行 :
|
||||
```java
|
||||
输出 :
|
||||
canUGetMyName
|
||||
yesICan
|
||||
```
|
||||
这样我们就通过反射获取到参数信息了。想要了解更多的同学可以自己研究一下 [官方文档]
|
||||
(https://docs.oracle.com/javase/tutorial/reflect/member/methodparameterreflection.html)
|
||||
<br>
|
||||
## 总结与补充
|
||||
在JDK8之后,可以通过-parameters参数来让编译器生成参数信息然后在运行时通过反射获取方法参数信息,其实在SpringFramework
|
||||
里面也有一个LocalVariableTableParameterNameDiscoverer对象可以获取方法参数名信息,有兴趣的同学可以自行百度(这个类在打印日志时可能会比较有用吧,个人感觉)。
|
||||
@ -660,7 +660,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
(3)private class SubList extends AbstractList<E> implements RandomAccess
|
||||
(4)static final class ArrayListSpliterator<E> implements Spliterator<E>
|
||||
```
|
||||
ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**,**next()**,**remove()**等方法;其中的**ListItr**继承**Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**,**nextIndex()**,**previousIndex()**,**previous()**,**set(E e)**,**add(E e)**等方法,所以这也可以看出了 **Iterator和ListIterator的区别:**ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
|
||||
ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**, **next()**, **remove()** 等方法;其中的**ListItr** 继承 **Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**, **nextIndex()**, **previousIndex()**, **previous()**, **set(E e)**, **add(E e)** 等方法,所以这也可以看出了 **Iterator和ListIterator的区别:** ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
|
||||
### <font face="楷体" id="6"> ArrayList经典Demo</font>
|
||||
|
||||
```java
|
||||
|
||||
@ -56,7 +56,7 @@ static int hash(int h) {
|
||||
|
||||
所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
|
||||
|
||||

|
||||
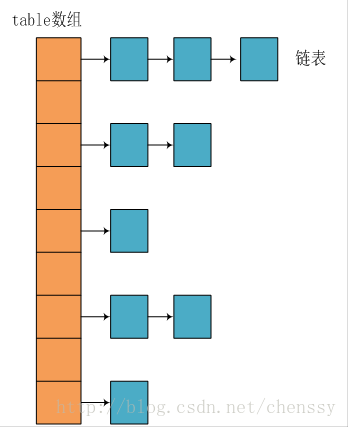
|
||||
|
||||
### JDK1.8之后
|
||||
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
|
||||
@ -170,7 +170,9 @@ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
|
||||
```
|
||||
## HashMap源码分析
|
||||
### 构造方法
|
||||

|
||||
|
||||
HashMap 中有四个构造方法,它们分别如下:
|
||||
|
||||
```java
|
||||
// 默认构造函数。
|
||||
public HashMap() {
|
||||
@ -237,9 +239,7 @@ HashMap只提供了put用于添加元素,putVal方法只是给put方法调用
|
||||
- ①如果定位到的数组位置没有元素 就直接插入。
|
||||
- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用`e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
|
||||
|
||||
|
||||
|
||||

|
||||
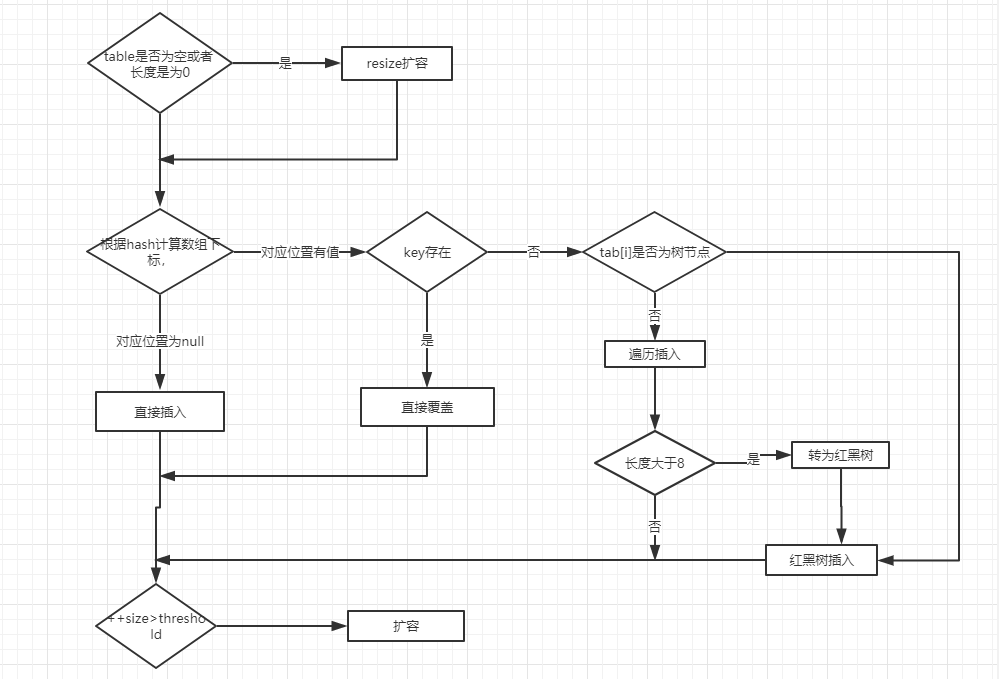
|
||||
|
||||
```java
|
||||
public V put(K key, V value) {
|
||||
|
||||
@ -83,11 +83,11 @@ public interface RandomAccess {
|
||||
|
||||
### 补充内容:双向链表和双向循环链表
|
||||
|
||||
**双向链表:** 包含两个指针,一个prev指向前一个节点,一个next指向后一个节点。
|
||||
**双向链表:** 包含两个指针,一个prev指向前一个节点,一个next指向后一个节点。
|
||||
|
||||
|
||||
|
||||
**双向循环链表:** 最后一个节点的 next 指向head,而 head 的prev指向最后一个节点,构成一个环。
|
||||
**双向循环链表:** 最后一个节点的 next 指向head,而 head 的prev指向最后一个节点,构成一个环。
|
||||
|
||||
|
||||
|
||||
@ -95,11 +95,11 @@ public interface RandomAccess {
|
||||
|
||||
`Vector`类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
|
||||
|
||||
`Arraylist`不是同步的,所以在不需要保证线程安全时时建议使用Arraylist。
|
||||
`Arraylist`不是同步的,所以在不需要保证线程安全时建议使用Arraylist。
|
||||
|
||||
## 说一说 ArrayList 的扩容机制吧
|
||||
|
||||
详见笔主的这篇文章:[通过源码一步一步分析ArrayList 扩容机制](ArrayList-Grow.md)
|
||||
详见笔主的这篇文章:[通过源码一步一步分析ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList-Grow.md)
|
||||
|
||||
## HashMap 和 Hashtable 的区别
|
||||
|
||||
@ -109,7 +109,7 @@ public interface RandomAccess {
|
||||
4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
|
||||
5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
|
||||
|
||||
**HasMap 中带有初始容量的构造函数:**
|
||||
**HashMap 中带有初始容量的构造函数:**
|
||||
|
||||
```java
|
||||
public HashMap(int initialCapacity, float loadFactor) {
|
||||
@ -253,7 +253,7 @@ ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方
|
||||
|
||||
图片来源:<http://www.cnblogs.com/chengxiao/p/6842045.html>
|
||||
|
||||
**HashTable:**
|
||||
**HashTable:**
|
||||
|
||||
|
||||
|
||||
@ -263,7 +263,7 @@ ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方
|
||||
|
||||
**JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):**
|
||||
|
||||

|
||||
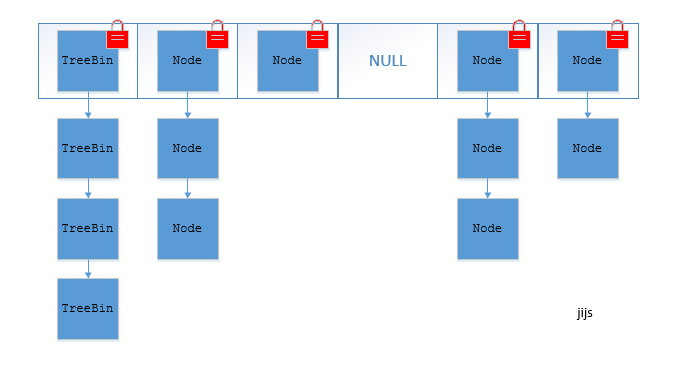
|
||||
|
||||
## ConcurrentHashMap线程安全的具体实现方式/底层具体实现
|
||||
|
||||
@ -284,7 +284,7 @@ static class Segment<K,V> extends ReentrantLock implements Serializable {
|
||||
|
||||
### JDK1.8 (上面有示意图)
|
||||
|
||||
ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))
|
||||
ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(log(N)))
|
||||
|
||||
synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
|
||||
|
||||
@ -431,8 +431,8 @@ Output:
|
||||
#### 2. Set
|
||||
|
||||
- **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
|
||||
- **LinkedHashSet:** LinkedHashSet 继承与 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 Hashmap 实现一样,不过还是有一点点区别的。
|
||||
- **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树。)
|
||||
- **LinkedHashSet:** LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的
|
||||
- **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树)
|
||||
|
||||
### Map
|
||||
|
||||
@ -451,6 +451,6 @@ Output:
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
|
||||
@ -56,7 +56,7 @@
|
||||
|
||||
|
||||
|
||||
当需要排查各种 内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
|
||||
当需要排查各种内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
|
||||
|
||||
## 1 揭开 JVM 内存分配与回收的神秘面纱
|
||||
|
||||
@ -194,9 +194,9 @@ JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数
|
||||
|
||||
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
|
||||
|
||||
**1.强引用**
|
||||
**1.强引用(StrongReference)**
|
||||
|
||||
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空 间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
|
||||
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
|
||||
|
||||
**2.软引用(SoftReference)**
|
||||
|
||||
@ -206,7 +206,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
||||
|
||||
**3.弱引用(WeakReference)**
|
||||
|
||||
如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
|
||||
如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
|
||||
|
||||
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
|
||||
|
||||
@ -216,7 +216,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
||||
|
||||
**虚引用主要用来跟踪对象被垃圾回收的活动**。
|
||||
|
||||
**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃 圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是 否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
|
||||
**虚引用与软引用和弱引用的一个区别在于:** 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
|
||||
|
||||
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为**软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生**。
|
||||
|
||||
@ -267,7 +267,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
||||
<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-8-27/90984624.jpg" alt="公众号" width="500px">
|
||||
|
||||
### 3.3 标记-整理算法
|
||||
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
|
||||
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
|
||||
|
||||
|
||||
|
||||
@ -287,7 +287,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
||||
|
||||
**如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。**
|
||||
|
||||
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为知道现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
|
||||
虽然我们对各个收集器进行比较,但并非要挑选出一个最好的收集器。因为直到现在为止还没有最好的垃圾收集器出现,更加没有万能的垃圾收集器,**我们能做的就是根据具体应用场景选择适合自己的垃圾收集器**。试想一下:如果有一种四海之内、任何场景下都适用的完美收集器存在,那么我们的 HotSpot 虚拟机就不会实现那么多不同的垃圾收集器了。
|
||||
|
||||
|
||||
### 4.1 Serial 收集器
|
||||
@ -317,7 +317,7 @@ Serial(串行)收集器收集器是最基本、历史最悠久的垃圾收
|
||||
|
||||
### 4.3 Parallel Scavenge 收集器
|
||||
|
||||
Parallel Scavenge 收集器类似于 ParNew 收集器。 **那么它有什么特别之处呢?**
|
||||
Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和ParNew都一样。 **那么它有什么特别之处呢?**
|
||||
|
||||
```
|
||||
-XX:+UseParallelGC
|
||||
@ -330,10 +330,10 @@ Parallel Scavenge 收集器类似于 ParNew 收集器。 **那么它有什么特
|
||||
|
||||
```
|
||||
|
||||
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
|
||||
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
|
||||
|
||||
**新生代采用复制算法,老年代采用标记-整理算法。**
|
||||

|
||||

|
||||
|
||||
|
||||
### 4.4.Serial Old 收集器
|
||||
@ -344,7 +344,7 @@ Parallel Scavenge 收集器类似于 ParNew 收集器。 **那么它有什么特
|
||||
|
||||
### 4.6 CMS 收集器
|
||||
|
||||
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
|
||||
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。**
|
||||
|
||||
**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
|
||||
|
||||
|
||||
@ -54,7 +54,7 @@
|
||||
|
||||
## 一 概述
|
||||
|
||||
对于 Java 程序员来说,在虚拟机自动内存管理机制下,不再需要像 C/C++程序开发程序员这样为内一个 new 操作去写对应的 delete/free 操作,不容易出现内存泄漏和内存溢出问题。正是因为 Java 程序员把内存控制权利交给 Java 虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那么排查错误将会是一个非常艰巨的任务。
|
||||
对于 Java 程序员来说,在虚拟机自动内存管理机制下,不再需要像 C/C++程序开发程序员这样为每一个 new 操作去写对应的 delete/free 操作,不容易出现内存泄漏和内存溢出问题。正是因为 Java 程序员把内存控制权利交给 Java 虚拟机,一旦出现内存泄漏和溢出方面的问题,如果不了解虚拟机是怎样使用内存的,那么排查错误将会是一个非常艰巨的任务。
|
||||
|
||||
## 二 运行时数据区域
|
||||
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。JDK. 1.8 和之前的版本略有不同,下面会介绍到。
|
||||
@ -84,7 +84,7 @@ Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成
|
||||
- 直接内存 (非运行时数据区的一部分)
|
||||
|
||||
### 2.1 程序计数器
|
||||
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。**字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完。**
|
||||
程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。**字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完成。**
|
||||
|
||||
另外,**为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。**
|
||||
|
||||
@ -149,7 +149,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
|
||||
|
||||
#### 2.5.1 方法区和永久代的关系
|
||||
|
||||
> 《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 **方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。** 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久带这一说法。
|
||||
> 《Java 虚拟机规范》只是规定了有方法区这么个概念和它的作用,并没有规定如何去实现它。那么,在不同的 JVM 上方法区的实现肯定是不同的了。 **方法区和永久代的关系很像 Java 中接口和类的关系,类实现了接口,而永久代就是 HotSpot 虚拟机对虚拟机规范中方法区的一种实现方式。** 也就是说,永久代是 HotSpot 的概念,方法区是 Java 虚拟机规范中的定义,是一种规范,而永久代是一种实现,一个是标准一个是实现,其他的虚拟机实现并没有永久代这一说法。
|
||||
|
||||
#### 2.5.2 常用参数
|
||||
|
||||
@ -160,7 +160,7 @@ JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参
|
||||
-XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
|
||||
```
|
||||
|
||||
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。**
|
||||
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
|
||||
|
||||
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。
|
||||
|
||||
@ -175,7 +175,7 @@ JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1
|
||||
|
||||
#### 2.5.3 为什么要将永久代 (PermGen) 替换为元空间 (MetaSpace) 呢?
|
||||
|
||||
整个永久代有一个 JVM 本身设置固定大小上线,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,并且永远不会得到 java.lang.OutOfMemoryError。你可以使用 `-XX:MaxMetaspaceSize` 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。`-XX:MetaspaceSize` 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
|
||||
整个永久代有一个 JVM 本身设置固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,并且永远不会得到 java.lang.OutOfMemoryError。你可以使用 `-XX:MaxMetaspaceSize` 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。`-XX:MetaspaceSize` 调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
|
||||
|
||||
当然这只是其中一个原因,还有很多底层的原因,这里就不提了。
|
||||
|
||||
@ -183,7 +183,7 @@ JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1
|
||||
|
||||
运行时常量池是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有常量池信息(用于存放编译期生成的各种字面量和符号引用)
|
||||
|
||||
既然运行时常量池时方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
|
||||
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 异常。
|
||||
|
||||
**JDK1.7 及之后版本的 JVM 已经将运行时常量池从方法区中移了出来,在 Java 堆(Heap)中开辟了一块区域存放运行时常量池。**
|
||||
|
||||
@ -197,7 +197,7 @@ JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1
|
||||
|
||||
JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)** 与**缓存区(Buffer)** 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
|
||||
|
||||
本机直接内存的分配不会收到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
||||
本机直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
||||
|
||||
|
||||
## 三 HotSpot 虚拟机对象探秘
|
||||
@ -253,7 +253,7 @@ JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**
|
||||
**对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。** 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
|
||||
|
||||
### 3.3 对象的访问定位
|
||||
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式有虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
|
||||
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
|
||||
|
||||
1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
|
||||
|
||||
@ -294,7 +294,7 @@ System.out.println(str2==str3);//false
|
||||
**String 类型的常量池比较特殊。它的主要使用方法有两种:**
|
||||
|
||||
- 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
|
||||
- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方法。String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
|
||||
- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方法。String.intern() 是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7之前(不包含1.7)的处理方式是在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7以及之后的处理方式是在常量池中记录此字符串的引用,并返回该引用。
|
||||
|
||||
```java
|
||||
String s1 = new String("计算机");
|
||||
@ -322,7 +322,7 @@ System.out.println(str2==str3);//false
|
||||
尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
|
||||
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
|
||||
|
||||
**将创建 1 或 2 个字符串。如果池中已存在字符串文字“abc”,则池中只会创建一个字符串“s1”。如果池中没有字符串文字“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。**
|
||||
**将创建 1 或 2 个字符串。如果池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。如果池中没有字符串常量“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。**
|
||||
|
||||
**验证:**
|
||||
|
||||
@ -342,7 +342,7 @@ true
|
||||
|
||||
### 4.3 8 种基本类型的包装类和常量池
|
||||
|
||||
- **Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;这 5 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。**
|
||||
- **Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;这 5 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。** 为啥把缓存设置为[-128,127]区间?([参见issue/461](https://github.com/Snailclimb/JavaGuide/issues/461))性能和资源之间的权衡。
|
||||
- **两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。**
|
||||
|
||||
```java
|
||||
@ -421,6 +421,7 @@ i4=i5+i6 true
|
||||
- <http://www.pointsoftware.ch/en/under-the-hood-runtime-data-areas-javas-memory-model/>
|
||||
- <https://dzone.com/articles/jvm-permgen-%E2%80%93-where-art-thou>
|
||||
- <https://stackoverflow.com/questions/9095748/method-area-and-permgen>
|
||||
- 深入解析String#intern<https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html>
|
||||
|
||||
## 公众号
|
||||
|
||||
@ -430,4 +431,4 @@ i4=i5+i6 true
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
@ -38,7 +38,7 @@ JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他
|
||||
|
||||
### 双亲委派模型介绍
|
||||
|
||||
每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 **双亲委派模型** 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。**加载的时候,首先会把该请求委派该父类加载器的 `loadClass()` 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 `BootstrapClassLoader` 中。当父类加载器无法处理时,才由自己来处理。**当父类加载器为null时,会使用启动类加载器 `BootstrapClassLoader` 作为父类加载器。
|
||||
每一个类都有一个对应它的类加载器。系统中的 ClassLoder 在协同工作的时候会默认使用 **双亲委派模型** 。即在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。加载的时候,首先会把该请求委派该父类加载器的 `loadClass()` 处理,因此所有的请求最终都应该传送到顶层的启动类加载器 `BootstrapClassLoader` 中。当父类加载器无法处理时,才由自己来处理。当父类加载器为null时,会使用启动类加载器 `BootstrapClassLoader` 作为父类加载器。
|
||||
|
||||

|
||||
|
||||
@ -63,9 +63,9 @@ The GrandParent of ClassLodarDemo's ClassLoader is null
|
||||
```
|
||||
|
||||
`AppClassLoader`的父类加载器为`ExtClassLoader`
|
||||
`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `Bootstrap ClassLoader`** 。
|
||||
`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `BootstrapClassLoader`** 。
|
||||
|
||||
其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mather ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
|
||||
其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mother ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
|
||||
|
||||
>The Java platform uses a delegation model for loading classes. **The basic idea is that every class loader has a "parent" class loader.** When loading a class, a class loader first "delegates" the search for the class to its parent class loader before attempting to find the class itself.
|
||||
|
||||
@ -114,7 +114,7 @@ protected Class<?> loadClass(String name, boolean resolve)
|
||||
|
||||
### 双亲委派模型的好处
|
||||
|
||||
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果不用没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
|
||||
双亲委派模型保证了Java程序的稳定运行,可以避免类的重复加载(JVM 区分不同类的方式不仅仅根据类名,相同的类文件被不同的类加载器加载产生的是两个不同的类),也保证了 Java 的核心 API 不被篡改。如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 `java.lang.Object` 类的话,那么程序运行的时候,系统就会出现多个不同的 `Object` 类。
|
||||
|
||||
### 如果我们不想用双亲委派模型怎么办?
|
||||
|
||||
|
||||
@ -23,7 +23,7 @@
|
||||
|
||||
在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
||||
|
||||
Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行在 Java 虚拟机之上。下图展示了不同的语言被不同的编译器编异常`.class`文件最终运行在 Java 虚拟机之上。`.class`文件的二进制格式可以使用 [WinHex](https://www.x-ways.net/winhex/) 查看。
|
||||
Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行在 Java 虚拟机之上。下图展示了不同的语言被不同的编译器编译成`.class`文件最终运行在 Java 虚拟机之上。`.class`文件的二进制格式可以使用 [WinHex](https://www.x-ways.net/winhex/) 查看。
|
||||
|
||||

|
||||
|
||||
|
||||
@ -38,7 +38,7 @@
|
||||
#### <font color="#99CC33"> 分组(packet ):
|
||||
因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
|
||||
#### <font color="#99CC33"> 存储转发(store and forward ):
|
||||
路由器收到一个分组,先存储下来,再检查气首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
|
||||
路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
|
||||
#### <font color="#99CC33"> 带宽(bandwidth):
|
||||
在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
|
||||
#### <font color="#99CC33"> 吞吐量(throughput ):
|
||||
@ -54,13 +54,13 @@
|
||||
|
||||
<font color="#999999">3,路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
|
||||
|
||||
<font color="#999999">4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由西组成边缘部分,其作用是提供连通性和交换。
|
||||
<font color="#999999">4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
|
||||
|
||||
<font color="#999999">5,计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S方式)和对等连接方式(P2P方式)。
|
||||
|
||||
<font color="#999999">6,客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
|
||||
|
||||
<font color="#999999">7,按照作用范围的不同,计算机网络分为广域网WAN,城域网MAN,局域网LAN,个人区域网PAN。
|
||||
<font color="#999999">7,按照作用范围的不同,计算机网络分为广域网WAN,城域网MAN,局域网LAN,个人区域网PAN。
|
||||
|
||||
<font color="#999999">8,计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。
|
||||
|
||||
@ -193,7 +193,7 @@
|
||||
|
||||
<font color="#999999">12,以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。</font>
|
||||
|
||||
<font color="#999999">13,使用集线器可以在物理层扩展以太网(扩展后的以太网任然是一个网络)</font>
|
||||
<font color="#999999">13,使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)</font>
|
||||
### <font color="#003333">(3),最重要的知识点<font>
|
||||
#### ① <font color="#999999">数据链路层的点对点信道和广播信道的特点,以及这两种信道所使用的协议(PPP协议以及CSMA/CD协议)的特点<font>
|
||||
#### ② <font color="#999999">数据链路层的三个基本问题:**封装成帧**,**透明传输**,**差错检测**<font>
|
||||
|
||||
@ -38,7 +38,7 @@
|
||||
|
||||
学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
|
||||
|
||||

|
||||

|
||||
|
||||
结合互联网的情况,自上而下地,非常简要的介绍一下各层的作用。
|
||||
|
||||
@ -77,7 +77,7 @@
|
||||
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
|
||||
|
||||
### 1.4 数据链路层
|
||||
**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装程帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
|
||||
**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装成帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
|
||||
|
||||
在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结束。这样,数据链路层在收到一个帧后,就可从中提出数据部分,上交给网络层。
|
||||
控制信息还使接收端能够检测到所收到的帧中有误差错。如果发现差错,数据链路层就简单地丢弃这个出了差错的帧,以避免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在链路层传输时出现差错(这就是说,数据链路层不仅要检错,而且还要纠错),那么就要采用可靠性传输协议来纠正出现的差错。这种方法会使链路层的协议复杂些。
|
||||
@ -91,7 +91,8 @@
|
||||
### 1.6 总结一下
|
||||
|
||||
上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下。图片来源:https://blog.csdn.net/yaopeng_2005/article/details/7064869
|
||||

|
||||
|
||||

|
||||
|
||||
## 二 TCP 三次握手和四次挥手(面试常客)
|
||||
|
||||
@ -100,10 +101,10 @@
|
||||
### 2.1 TCP 三次握手漫画图解
|
||||
|
||||
如下图所示,下面的两个机器人通过3次握手确定了对方能正确接收和发送消息(图片来源:《图解HTTP》)。
|
||||

|
||||
|
||||
|
||||
**简单示意图:**
|
||||

|
||||
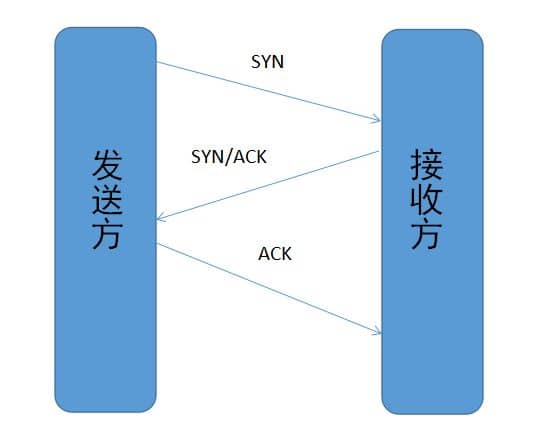
|
||||
|
||||
- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
|
||||
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
|
||||
@ -113,9 +114,9 @@
|
||||
|
||||
**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
|
||||
|
||||
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常
|
||||
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
|
||||
|
||||
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
|
||||
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
|
||||
|
||||
第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
||||
|
||||
@ -131,7 +132,7 @@
|
||||
|
||||
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
|
||||
|
||||

|
||||
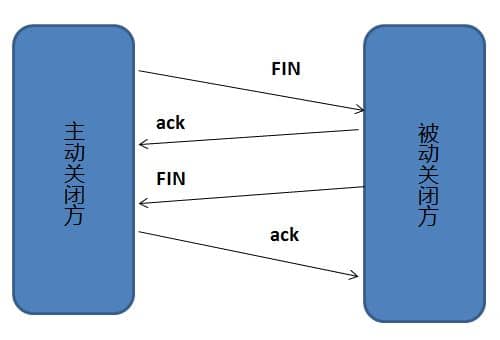
|
||||
|
||||
断开一个 TCP 连接则需要“四次挥手”:
|
||||
|
||||
@ -178,30 +179,18 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
|
||||
|
||||
**缺点:** 信道利用率低,等待时间长
|
||||
|
||||
|
||||
**1) 无差错情况:**
|
||||
|
||||

|
||||
|
||||
发送方发送分组,接收方在规定时间内收到,并且回复确认.发送方再次发送。
|
||||
|
||||
**2) 出现差错情况(超时重传):**
|
||||

|
||||
|
||||
停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重传时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为 **自动重传请求 ARQ** 。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。**连续 ARQ 协议** 可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
|
||||
|
||||
**3) 确认丢失和确认迟到**
|
||||
|
||||
- **确认丢失**:确认消息在传输过程丢失
|
||||

|
||||
当A发送M1消息,B收到后,B向A发送了一个M1确认消息,但却在传输过程中丢失。而A并不知道,在超时计时过后,A重传M1消息,B再次收到该消息后采取以下两点措施:
|
||||
|
||||
1. 丢弃这个重复的M1消息,不向上层交付。
|
||||
2. 向A发送确认消息。(不会认为已经发送过了,就不再发送。A能重传,就证明B的确认消息丢失)。
|
||||
- **确认迟到** :确认消息在传输过程中迟到
|
||||

|
||||
A发送M1消息,B收到并发送确认。在超时时间内没有收到确认消息,A重传M1消息,B仍然收到并继续发送确认消息(B收到了2份M1)。此时A收到了B第二次发送的确认消息。接着发送其他数据。过了一会,A收到了B第一次发送的对M1的确认消息(A也收到了2份确认消息)。处理如下:
|
||||
1. A收到重复的确认后,直接丢弃。
|
||||
2. B收到重复的M1后,也直接丢弃重复的M1。
|
||||
- **确认丢失** :确认消息在传输过程丢失。当A发送M1消息,B收到后,B向A发送了一个M1确认消息,但却在传输过程中丢失。而A并不知道,在超时计时过后,A重传M1消息,B再次收到该消息后采取以下两点措施:1. 丢弃这个重复的M1消息,不向上层交付。 2. 向A发送确认消息。(不会认为已经发送过了,就不再发送。A能重传,就证明B的确认消息丢失)。
|
||||
- **确认迟到** :确认消息在传输过程中迟到。A发送M1消息,B收到并发送确认。在超时时间内没有收到确认消息,A重传M1消息,B仍然收到并继续发送确认消息(B收到了2份M1)。此时A收到了B第二次发送的确认消息。接着发送其他数据。过了一会,A收到了B第一次发送的对M1的确认消息(A也收到了2份确认消息)。处理如下:1. A收到重复的确认后,直接丢弃。2. B收到重复的M1后,也直接丢弃重复的M1。
|
||||
|
||||
#### 连续ARQ协议
|
||||
|
||||
@ -224,12 +213,9 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
|
||||
TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免** 、**快重传** 和 **快恢复**。在网络层也可以使路由器采用适当的分组丢弃策略(如主动队列管理 AQM),以减少网络拥塞的发生。
|
||||
|
||||
- **慢开始:** 慢开始算法的思路是当主机开始发送数据时,如果立即把大量数据字节注入到网络,那么可能会引起网络阻塞,因为现在还不知道网络的符合情况。经验表明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是由小到大逐渐增大拥塞窗口数值。cwnd初始值为1,每经过一个传播轮次,cwnd加倍。
|
||||

|
||||
- **拥塞避免:** 拥塞避免算法的思路是让拥塞窗口cwnd缓慢增大,即每经过一个往返时间RTT就把发送放的cwnd加1.
|
||||
- **快重传与快恢复:**
|
||||
在 TCP/IP 中,快速重传和恢复(fast retransmit and recovery,FRR)是一种拥塞控制算法,它能快速恢复丢失的数据包。没有 FRR,如果数据包丢失了,TCP 将会使用定时器来要求传输暂停。在暂停的这段时间内,没有新的或复制的数据包被发送。有了 FRR,如果接收机接收到一个不按顺序的数据段,它会立即给发送机发送一个重复确认。如果发送机接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。有了 FRR,就不会因为重传时要求的暂停被耽误。 当有单独的数据包丢失时,快速重传和恢复(FRR)能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
|
||||
|
||||

|
||||
|
||||
|
||||
## 五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)
|
||||
@ -255,7 +241,7 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
|
||||
|
||||
## 六 状态码
|
||||
|
||||

|
||||
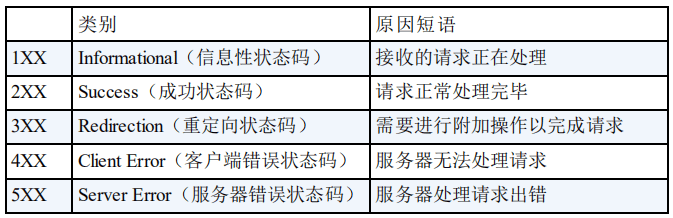
|
||||
|
||||
|
||||
## 七 各种协议与HTTP协议之间的关系
|
||||
@ -263,7 +249,7 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
|
||||
|
||||
图片来源:《图解HTTP》
|
||||
|
||||

|
||||
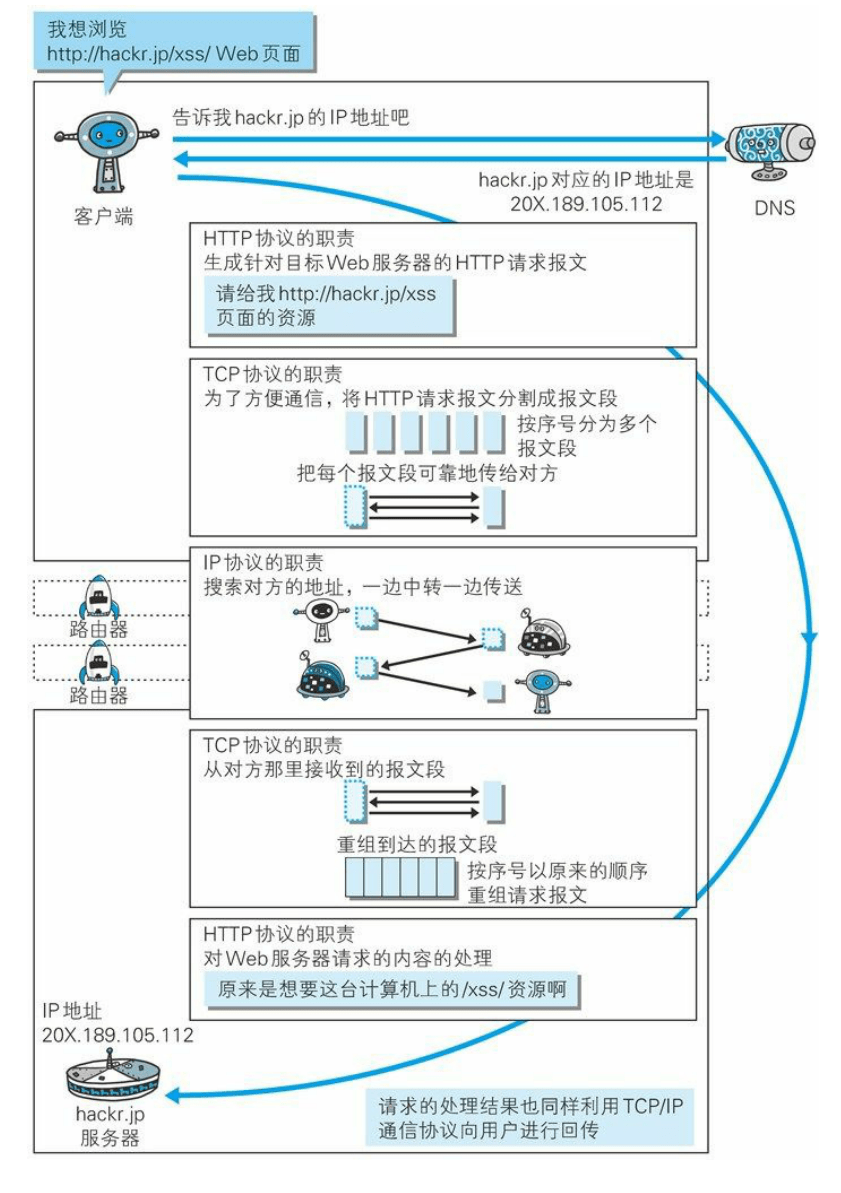
|
||||
|
||||
## 八 HTTP长连接,短连接
|
||||
|
||||
@ -316,8 +302,8 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
|
||||
|
||||
## 十二 URI和URL的区别是什么?
|
||||
|
||||
- URI(Uniform Resource Identifier) 是同一资源标志符,可以唯一标识一个资源。
|
||||
- URL(Uniform Resource Location) 是同一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
|
||||
- URI(Uniform Resource Identifier) 是统一资源标志符,可以唯一标识一个资源。
|
||||
- URL(Uniform Resource Location) 是统一资源定位符,可以提供该资源的路径。它是一种具体的 URI,即 URL 可以用来标识一个资源,而且还指明了如何 locate 这个资源。
|
||||
|
||||
URI的作用像身份证号一样,URL的作用更像家庭住址一样。URL是一种具体的URI,它不仅唯一标识资源,而且还提供了定位该资源的信息。
|
||||
|
||||
|
||||
@ -78,7 +78,7 @@ echo "helloworld!"
|
||||
shell中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在linux中,除了bash shell以外,还有很多版本的shell, 例如zsh、dash等等...不过bash shell还是我们使用最多的。**
|
||||
|
||||
|
||||
(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
|
||||
(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 helloworld.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
|
||||
|
||||

|
||||
|
||||
@ -260,7 +260,7 @@ echo $length #输出:5
|
||||
echo $length2 #输出:5
|
||||
# 输出数组第三个元素
|
||||
echo ${array[2]} #输出:3
|
||||
unset array[1]# 删除下表为1的元素也就是删除第二个元素
|
||||
unset array[1]# 删除下标为1的元素也就是删除第二个元素
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,输出: 1 3 4 5
|
||||
unset arr_number; # 删除数组中的所有元素
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
|
||||
@ -272,7 +272,7 @@ for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没
|
||||
> 说明:图片来自《菜鸟教程》
|
||||
|
||||
Shell 编程支持下面几种运算符
|
||||
|
||||
|
||||
- 算数运算符
|
||||
- 关系运算符
|
||||
- 布尔运算符
|
||||
@ -283,14 +283,14 @@ for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没
|
||||
|
||||
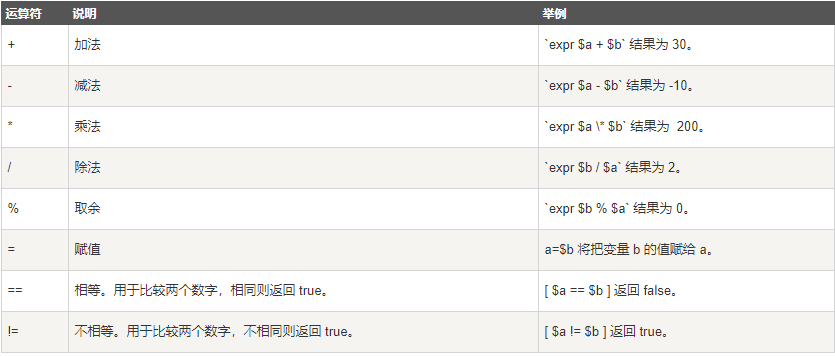
|
||||
|
||||
我以加法运算符做一个简单的示例:
|
||||
我以加法运算符做一个简单的示例(注意:不是单引号,是反引号):
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
a=3;b=3;
|
||||
val=`expr $a + $b`
|
||||
#输出:Total value : 6
|
||||
echo "Total value : $val
|
||||
echo "Total value : $val"
|
||||
```
|
||||
|
||||
|
||||
@ -380,10 +380,10 @@ a 不等于 b
|
||||
#!/bin/bash
|
||||
a=3;
|
||||
b=9;
|
||||
if [ $a = $b ]
|
||||
if [ $a -eq $b ]
|
||||
then
|
||||
echo "a 等于 b"
|
||||
elif [ $a > $b ]
|
||||
elif [ $a -gt $b ]
|
||||
then
|
||||
echo "a 大于 b"
|
||||
else
|
||||
@ -394,7 +394,7 @@ fi
|
||||
输出结果:
|
||||
|
||||
```
|
||||
a 大于 b
|
||||
a 小于 b
|
||||
```
|
||||
|
||||
相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
|
||||
@ -467,7 +467,7 @@ done
|
||||
是的!变形金刚 是一个好电影
|
||||
```
|
||||
|
||||
**无线循环:**
|
||||
**无限循环:**
|
||||
|
||||
```shell
|
||||
while true
|
||||
@ -482,16 +482,20 @@ done
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
function(){
|
||||
hello(){
|
||||
echo "这是我的第一个 shell 函数!"
|
||||
}
|
||||
function
|
||||
echo "-----函数开始执行-----"
|
||||
hello
|
||||
echo "-----函数执行完毕-----"
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
-----函数开始执行-----
|
||||
这是我的第一个 shell 函数!
|
||||
-----函数执行完毕-----
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [一 从认识操作系统开始](#一-从认识操作系统开始)
|
||||
@ -22,12 +24,15 @@
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
推荐一个Github开源的Linux学习指南(Java工程师向):<https://github.com/judasn/Linux-Tutorial>
|
||||
|
||||
> 学习Linux之前,我们先来简单的认识一下操作系统。
|
||||
|
||||
## 一 从认识操作系统开始
|
||||
|
||||
### 1.1 操作系统简介
|
||||
|
||||
我通过以下四点介绍什么操作系统:
|
||||
我通过以下四点介绍什么是操作系统:
|
||||
|
||||
- **操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;**
|
||||
- **操作系统本质上是运行在计算机上的软件程序 ;**
|
||||
@ -160,7 +165,7 @@ Linux命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
|
||||
|
||||
注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
|
||||
3. **`vim 文件`:** 修改文件的内容(改)
|
||||
|
||||
|
||||
vim编辑器是Linux中的强大组件,是vi编辑器的加强版,vim编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用vim编辑修改文件的方式基本会使用就可以了。
|
||||
|
||||
**在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:**
|
||||
@ -181,14 +186,14 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
其中:
|
||||
|
||||
z:调用gzip压缩命令进行压缩
|
||||
|
||||
|
||||
c:打包文件
|
||||
|
||||
|
||||
v:显示运行过程
|
||||
|
||||
|
||||
f:指定文件名
|
||||
|
||||
比如:加入test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
|
||||
比如:假如test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
|
||||
|
||||
|
||||
**2)解压压缩包:**
|
||||
@ -201,7 +206,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
|
||||
1 将/test下的test.tar.gz解压到当前目录下可以使用命令:**`tar -xvf test.tar.gz`**
|
||||
|
||||
2 将/test下的test.tar.gz解压到根目录/usr下:**`tar -xvf xxx.tar.gz -C /usr`**(- C代表指定解压的位置)
|
||||
2 将/test下的test.tar.gz解压到根目录/usr下:**`tar -xvf test.tar.gz -C /usr`**(- C代表指定解压的位置)
|
||||
|
||||
|
||||
### 4.5 Linux的权限命令
|
||||
@ -235,21 +240,21 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
**文件和目录权限的区别:**
|
||||
|
||||
对文件和目录而言,读写执行表示不同的意义。
|
||||
|
||||
|
||||
对于文件:
|
||||
|
||||
| 权限名称 | 可执行操作 |
|
||||
| 权限名称 | 可执行操作 |
|
||||
| :-------- | --------:|
|
||||
| r | 可以使用cat查看文件的内容 |
|
||||
|w | 可以修改文件的内容 |
|
||||
| r | 可以使用cat查看文件的内容 |
|
||||
|w | 可以修改文件的内容 |
|
||||
| x | 可以将其运行为二进制文件 |
|
||||
|
||||
对于目录:
|
||||
|
||||
| 权限名称 | 可执行操作 |
|
||||
| 权限名称 | 可执行操作 |
|
||||
| :-------- | --------:|
|
||||
| r | 可以查看目录下列表 |
|
||||
|w | 可以创建和删除目录下文件 |
|
||||
| r | 可以查看目录下列表 |
|
||||
|w | 可以创建和删除目录下文件 |
|
||||
| x | 可以使用cd进入目录 |
|
||||
|
||||
|
||||
@ -260,7 +265,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
|
||||
一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用ls ‐ahl命令可以看到文件的所有者 也可以使用chown 用户名 文件名来修改文件的所有者 。
|
||||
- **文件所在组**
|
||||
|
||||
|
||||
当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组 用ls ‐ahl命令可以看到文件的所有组 也可以使用chgrp 组名 文件名来修改文件所在的组。
|
||||
- **其它组**
|
||||
|
||||
@ -341,10 +346,16 @@ passwd命令用于设置用户的认证信息,包括用户密码、密码过
|
||||
`net-tools`起源于BSD的TCP/IP工具箱,后来成为老版本Linux内核中配置网络功能的工具。但自2001年起,Linux社区已经对其停止维护。同时,一些Linux发行版比如Arch Linux和CentOS/RHEL 7则已经完全抛弃了net-tools,只支持`iproute2`。linux ip命令类似于ifconfig,但功能更强大,旨在替代它。更多详情请阅读[如何在Linux中使用IP命令和示例](https://linoxide.com/linux-command/use-ip-command-linux)
|
||||
- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定5分钟后关机,同时送出警告信息给登入用户。
|
||||
- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,93 @@
|
||||
# JWT 身份认证优缺点分析以及常见问题解决方案
|
||||
|
||||
之前分享了一个使用 Spring Security 实现 JWT 身份认证的 Demo,文章地址:[适合初学者入门 Spring Security With JWT 的 Demo](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485622&idx=1&sn=e9750ed63c47457ba1896db8dfceac6a&chksm=cea2477df9d5ce6b7af20e582c6c60b7408a6459b05b849394c45f04664d1651510bdee029f7&token=684071313&lang=zh_CN&scene=21#wechat_redirect)。 Demo 非常简单,没有介绍到 JWT 存在的一些问题。所以,单独抽了一篇文章出来介绍。为了完成这篇文章,我查阅了很多资料和文献,我觉得应该对大家有帮助。
|
||||
|
||||
相关阅读:
|
||||
|
||||
- [《一问带你区分清楚Authentication,Authorization以及Cookie、Session、Token》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485626&idx=1&sn=3247aa9000693dd692de8a04ccffeec1&chksm=cea24771f9d5ce675ea0203633a95b68bfe412dc6a9d05f22d221161147b76161d1b470d54b3&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [适合初学者入门 Spring Security With JWT 的 Demo](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485622&idx=1&sn=e9750ed63c47457ba1896db8dfceac6a&chksm=cea2477df9d5ce6b7af20e582c6c60b7408a6459b05b849394c45f04664d1651510bdee029f7&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [Spring Boot 使用 JWT 进行身份和权限验证](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485640&idx=1&sn=0ff147808318d53b371f16bb730c96ef&chksm=cea24703f9d5ce156ba67662f6f3f482330e8e6ebd9d44c61bf623083e9b941d8a180db6b0ea&token=1533246333&lang=zh_CN#rd)
|
||||
|
||||
## Token 认证的优势
|
||||
|
||||
相比于 Session 认证的方式来说,使用 token 进行身份认证主要有下面三个优势:
|
||||
|
||||
### 1.无状态
|
||||
|
||||
token 自身包含了身份验证所需要的所有信息,使得我们的服务器不需要存储 Session 信息,这显然增加了系统的可用性和伸缩性,大大减轻了服务端的压力。但是,也正是由于 token 的无状态,也导致了它最大的缺点:当后端在token 有效期内废弃一个 token 或者更改它的权限的话,不会立即生效,一般需要等到有效期过后才可以。另外,当用户 Logout 的话,token 也还有效。除非,我们在后端增加额外的处理逻辑。
|
||||
|
||||
### 2.有效避免了CSRF 攻击
|
||||
|
||||
**CSRF(Cross Site Request Forgery)**一般被翻译为 **跨站请求伪造**,属于网络攻击领域范围。相比于 SQL 脚本注入、XSS等等安全攻击方式,CSRF 的知名度并没有它们高。但是,它的确是每个系统都要考虑的安全隐患,就连技术帝国 Google 的 Gmail 在早些年也被曝出过存在 CSRF 漏洞,这给 Gmail 的用户造成了很大的损失。
|
||||
|
||||
那么究竟什么是 **跨站请求伪造** 呢?说简单用你的身份去发送一些对你不友好的请求。举个简单的例子:
|
||||
|
||||
小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了10000元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
|
||||
|
||||
```html
|
||||
<a src=http://www.mybank.com/Transfer?bankId=11&money=10000>科学理财,年盈利率过万</>
|
||||
```
|
||||
|
||||
导致这个问题很大的原因就是: Session 认证中 Cookie 中的 session_id 是由浏览器发送到服务端的,借助这个特性,攻击者就可以通过让用户误点攻击链接,达到攻击效果。
|
||||
|
||||
**那为什么 token 不会存在这种问题呢?**
|
||||
|
||||
我是这样理解的:一般情况下我们使用 JWT 的话,在我们登录成功获得 token 之后,一般会选择存放在 local storage 中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 token,这样就不会出现 CSRF 漏洞的问题。因为,即使有个你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 token 的,所以这个请求将是非法的。
|
||||
|
||||
但是这样会存在 XSS 攻击中被盗的风险,为了避免 XSS 攻击,你可以选择将 token 存储在标记为`httpOnly` 的cookie 中。但是,这样又导致了你必须自己提供CSRF保护。
|
||||
|
||||
具体采用上面哪两种方式存储 token 呢,大部分情况下存放在 local storage 下都是最好的选择,某些情况下可能需要存放在标记为`httpOnly` 的cookie 中会更好。
|
||||
|
||||
### 3.适合移动端应用
|
||||
|
||||
使用 Session 进行身份认证的话,需要保存一份信息在服务器端,而且这种方式会依赖到 Cookie(需要 Cookie 保存 SessionId),所以不适合移动端。
|
||||
|
||||
但是,使用 token 进行身份认证就不会存在这种问题,因为只要 token 可以被客户端存储就能够使用,而且 token 还可以跨语言使用。
|
||||
|
||||
### 4.单点登录友好
|
||||
|
||||
使用 Session 进行身份认证的话,实现单点登录,需要我们把用户的 Session 信息保存在一台电脑上,并且还会遇到常见的 Cookie 跨域的问题。但是,使用 token 进行认证的话, token 被保存在客户端,不会存在这些问题。
|
||||
|
||||
## Token 认证常见问题以及解决办法
|
||||
|
||||
### 1.注销登录等场景下 token 还有效
|
||||
|
||||
与之类似的具体相关场景有:
|
||||
|
||||
1. 退出登录;
|
||||
2. 修改密码;
|
||||
3. 服务端修改了某个用户具有的权限或者角色;
|
||||
4. 用户的帐户被删除/暂停。
|
||||
5. 用户由管理员注销;
|
||||
|
||||
这个问题不存在于 Session 认证方式中,因为在 Session 认证方式中,遇到这种情况的话服务端删除对应的 Session 记录即可。但是,使用 token 认证的方式就不好解决了。我们也说过了,token 一旦派发出去,如果后端不增加其他逻辑的话,它在失效之前都是有效的。那么,我们如何解决这个问题呢?查阅了很多资料,总结了下面几种方案:
|
||||
|
||||
- **将 token 存入内存数据库**:将 token 存入 DB 中,redis 内存数据库在这里是是不错的选择。如果需要让某个 token 失效就直接从 redis 中删除这个 token 即可。但是,这样会导致每次使用 token 发送请求都要先从 DB 中查询 token 是否存在的步骤,而且违背了 JWT 的无状态原则。
|
||||
- **黑名单机制**:和上面的方式类似,使用内存数据库比如 redis 维护一个黑名单,如果想让某个 token 失效的话就直接将这个 token 加入到 **黑名单** 即可。然后,每次使用 token 进行请求的话都会先判断这个 token 是否存在于黑名单中。
|
||||
- **修改密钥 (Secret)** : 我们为每个用户都创建一个专属密钥,如果我们想让某个 token 失效,我们直接修改对应用户的密钥即可。但是,这样相比于前两种引入内存数据库带来了危害更大,比如:1⃣️如果服务是分布式的,则每次发出新的 token 时都必须在多台机器同步密钥。为此,你需要将必须将机密存储在数据库或其他外部服务中,这样和 Session 认证就没太大区别了。2⃣️如果用户同时在两个浏览器打开系统,或者在手机端也打开了系统,如果它从一个地方将账号退出,那么其他地方都要重新进行登录,这是不可取的。
|
||||
- **保持令牌的有效期限短并经常轮换** :很简单的一种方式。但是,会导致用户登录状态不会被持久记录,而且需要用户经常登录。
|
||||
|
||||
对于修改密码后 token 还有效问题的解决还是比较容易的,说一种我觉得比较好的方式:**使用用户的密码的哈希值对 token 进行签名。因此,如果密码更改,则任何先前的令牌将自动无法验证。**
|
||||
|
||||
### 2.token 的续签问题
|
||||
|
||||
token 有效期一般都建议设置的不太长,那么 token 过期后如何认证,如何实现动态刷新 token,避免用户经常需要重新登录?
|
||||
|
||||
我们先来看看在 Session 认证中一般的做法:**假如 session 的有效期30分钟,如果 30 分钟内用户有访问,就把 session 有效期被延长30分钟。**
|
||||
|
||||
1. **类似于 Session 认证中的做法**:这种方案满足于大部分场景。假设服务端给的 token 有效期设置为30分钟,服务端每次进行校验时,如果发现 token 的有效期马上快过期了,服务端就重新生成 token 给客户端。客户端每次请求都检查新旧token,如果不一致,则更新本地的token。这种做法的问题是仅仅在快过期的时候请求才会更新 token ,对客户端不是很友好。
|
||||
2. **每次请求都返回新 token** :这种方案的的思路很简单,但是,很明显,开销会比较大。
|
||||
3. **token 有效期设置到半夜** :这种方案是一种折衷的方案,保证了大部分用户白天可以正常登录,适用于对安全性要求不高的系统。
|
||||
4. **用户登录返回两个 token** :第一个是 acessToken ,它的过期时间 token 本身的过期时间比如半个小时,另外一个是 refreshToken 它的过期时间更长一点比如为1天。客户端登录后,将 accessToken和refreshToken 保存在本地,每次访问将 accessToken 传给服务端。服务端校验 accessToken 的有效性,如果过期的话,就将 refreshToken 传给服务端。如果有效,服务端就生成新的 accessToken 给客户端。否则,客户端就重新登录即可。该方案的不足是:1⃣️需要客户端来配合;2⃣️用户注销的时候需要同时保证两个 token 都无效;3⃣️重新请求获取 token 的过程中会有短暂 token 不可用的情况(可以通过在客户端设置定时器,当accessToken 快过期的时候,提前去通过 refreshToken 获取新的accessToken)。
|
||||
|
||||
## 总结
|
||||
|
||||
JWT 最适合的场景是不需要服务端保存用户状态的场景,比如如果考虑到 token 注销和 token 续签的场景话,没有特别好的解决方案,大部分解决方案都给 token 加上了状态,这就有点类似 Session 认证了。
|
||||
|
||||
## Reference
|
||||
|
||||
- [JWT 超详细分析](https://learnku.com/articles/17883?order_by=vote_count&)
|
||||
- https://medium.com/devgorilla/how-to-log-out-when-using-jwt-a8c7823e8a6
|
||||
- https://medium.com/@agungsantoso/csrf-protection-with-json-web-tokens-83e0f2fcbcc
|
||||
- [Invalidating JSON Web Tokens](https://stackoverflow.com/questions/21978658/invalidating-json-web-tokens)
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
## 1. 认证 (Authentication) 和授权 (Authorization)的区别是什么?
|
||||
|
||||
这是一个绝大多数人都会混淆的问题。首先先从读音上来认识这两个名词,很多人都会把它俩的读音搞混,所以我建议你先先去查一查这两个单词到底该怎么读,他们的具体含义是什么。
|
||||
|
||||
说简单点就是:
|
||||
|
||||
- **认证 (Authentication):** 你是谁。
|
||||
- **授权 (Authorization):** 你有权限干什么。
|
||||
|
||||
稍微正式点(啰嗦点)的说法就是:
|
||||
|
||||
- **Authentication(认证)** 是验证您的身份的凭据(例如用户名/用户ID和密码),通过这个凭据,系统得以知道你就是你,也就是说系统存在你这个用户。所以,Authentication 被称为身份/用户验证。
|
||||
- **Authorization(授权)** 发生在 **Authentication(认证)**之后。授权嘛,光看意思大家应该就明白,它主要掌管我们访问系统的权限。比如有些特定资源只能具有特定权限的人才能访问比如admin,有些对系统资源操作比如删除、添加、更新只能特定人才具有。
|
||||
|
||||
这两个一般在我们的系统中被结合在一起使用,目的就是为了保护我们系统的安全性。
|
||||
|
||||
## 2. 什么是Cookie ? Cookie的作用是什么?如何在服务端使用 Cookie ?
|
||||
|
||||
### 2.1 什么是Cookie ? Cookie的作用是什么?
|
||||
|
||||
Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但是两者的应用场景不太一样。
|
||||
|
||||
维基百科是这样定义 Cookie 的:Cookies是某些网站为了辨别用户身份而储存在用户本地终端上的数据(通常经过加密)。简单来说: **Cookie 存放在客户端,一般用来保存用户信息**。
|
||||
|
||||
下面是 Cookie 的一些应用案例:
|
||||
|
||||
1. 我们在 Cookie 中保存已经登录过得用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了。除此之外,Cookie 还能保存用户首选项,主题和其他设置信息。
|
||||
2. 使用Cookie 保存 session 或者 token ,向后端发送请求的时候带上 Cookie,这样后端就能取到session或者token了。这样就能记录用户当前的状态了,因为 HTTP 协议是无状态的。
|
||||
3. Cookie 还可以用来记录和分析用户行为。举个简单的例子你在网上购物的时候,因为HTTP协议是没有状态的,如果服务器想要获取你在某个页面的停留状态或者看了哪些商品,一种常用的实现方式就是将这些信息存放在Cookie
|
||||
|
||||
### 2.2 如何能在 服务端使用 Cookie 呢?
|
||||
|
||||
这部分内容参考:https://attacomsian.com/blog/cookies-spring-boot,更多如何在Spring Boot中使用Cookie 的内容可以查看这篇文章。
|
||||
|
||||
**1)设置cookie返回给客户端**
|
||||
|
||||
```java
|
||||
@GetMapping("/change-username")
|
||||
public String setCookie(HttpServletResponse response) {
|
||||
// 创建一个 cookie
|
||||
Cookie cookie = new Cookie("username", "Jovan");
|
||||
//设置 cookie过期时间
|
||||
cookie.setMaxAge(7 * 24 * 60 * 60); // expires in 7 days
|
||||
//添加到 response 中
|
||||
response.addCookie(cookie);
|
||||
|
||||
return "Username is changed!";
|
||||
}
|
||||
```
|
||||
|
||||
**2) 使用Spring框架提供的`@CookieValue`注解获取特定的 cookie的值**
|
||||
|
||||
```java
|
||||
@GetMapping("/")
|
||||
public String readCookie(@CookieValue(value = "username", defaultValue = "Atta") String username) {
|
||||
return "Hey! My username is " + username;
|
||||
}
|
||||
```
|
||||
|
||||
**3) 读取所有的 Cookie 值**
|
||||
|
||||
```java
|
||||
@GetMapping("/all-cookies")
|
||||
public String readAllCookies(HttpServletRequest request) {
|
||||
|
||||
Cookie[] cookies = request.getCookies();
|
||||
if (cookies != null) {
|
||||
return Arrays.stream(cookies)
|
||||
.map(c -> c.getName() + "=" + c.getValue()).collect(Collectors.joining(", "));
|
||||
}
|
||||
|
||||
return "No cookies";
|
||||
}
|
||||
```
|
||||
|
||||
## 3. Cookie 和 Session 有什么区别?如何使用Session进行身份验证?
|
||||
|
||||
**Session 的主要作用就是通过服务端记录用户的状态。** 典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了。
|
||||
|
||||
**Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。**
|
||||
|
||||
**那么,如何使用Session进行身份验证?**
|
||||
|
||||
很多时候我们都是通过 SessionID 来实现特定的用户,SessionID 一般会选择存放在 Redis 中。举个例子:用户成功登陆系统,然后返回给客户端具有 SessionID 的 Cookie,当用户向后端发起请求的时候会把 SessionID 带上,这样后端就知道你的身份状态了。关于这种认证方式更详细的过程如下:
|
||||
|
||||
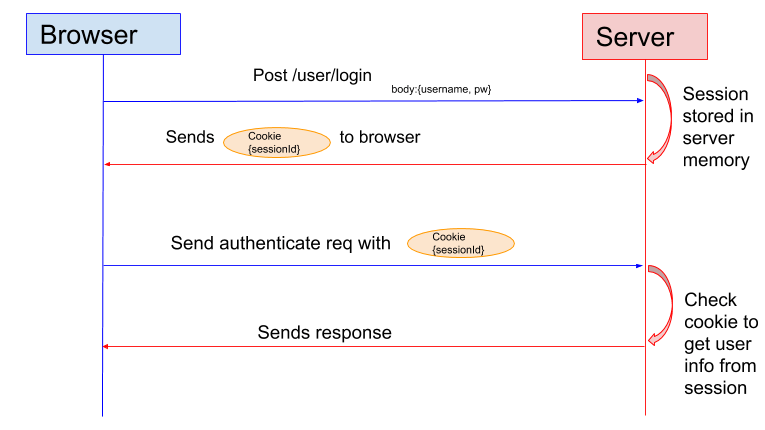
|
||||
|
||||
1. 用户向服务器发送用户名和密码用于登陆系统。
|
||||
2. 服务器验证通过后,服务器为用户创建一个 Session,并将 Session信息存储 起来。
|
||||
3. 服务器向用户返回一个 SessionID,写入用户的 Cookie。
|
||||
4. 当用户保持登录状态时,Cookie 将与每个后续请求一起被发送出去。
|
||||
5. 服务器可以将存储在 Cookie 上的 Session ID 与存储在内存中或者数据库中的 Session 信息进行比较,以验证用户的身份,返回给用户客户端响应信息的时候会附带用户当前的状态。
|
||||
|
||||
另外,Spring Session提供了一种跨多个应用程序或实例管理用户会话信息的机制。如果想详细了解可以查看下面几篇很不错的文章:
|
||||
|
||||
- [Getting Started with Spring Session](https://codeboje.de/spring-session-tutorial/)
|
||||
- [Guide to Spring Session](https://www.baeldung.com/spring-session)
|
||||
- [Sticky Sessions with Spring Session & Redis](https://medium.com/@gvnix/sticky-sessions-with-spring-session-redis-bdc6f7438cc3)
|
||||
|
||||
## 4. 什么是 Token?什么是 JWT?如何基于Token进行身份验证?
|
||||
|
||||
我们在上一个问题中探讨了使用 Session 来鉴别用户的身份,并且给出了几个 Spring Session 的案例分享。 我们知道 Session 信息需要保存一份在服务器端。这种方式会带来一些麻烦,比如需要我们保证保存 Session 信息服务器的可用性、不适合移动端(依赖Cookie)等等。
|
||||
|
||||
有没有一种不需要自己存放 Session 信息就能实现身份验证的方式呢?使用 Token 即可!JWT (JSON Web Token) 就是这种方式的实现,通过这种方式服务器端就不需要保存 Session 数据了,只用在客户端保存服务端返回给客户的 Token 就可以了,扩展性得到提升。
|
||||
|
||||
**JWT 本质上就一段签名的 JSON 格式的数据。由于它是带有签名的,因此接收者便可以验证它的真实性。**
|
||||
|
||||
下面是 [RFC 7519](https://link.juejin.im/?target=https%3A%2F%2Ftools.ietf.org%2Fhtml%2Frfc7519) 对 JWT 做的较为正式的定义。
|
||||
|
||||
> JSON Web Token (JWT) is a compact, URL-safe means of representing claims to be transferred between two parties. The claims in a JWT are encoded as a JSON object that is used as the payload of a JSON Web Signature (JWS) structure or as the plaintext of a JSON Web Encryption (JWE) structure, enabling the claims to be digitally signed or integrity protected with a Message Authentication Code (MAC) and/or encrypted. ——[JSON Web Token (JWT)](https://tools.ietf.org/html/rfc7519)
|
||||
|
||||
JWT 由 3 部分构成:
|
||||
|
||||
1. Header :描述 JWT 的元数据。定义了生成签名的算法以及 Token 的类型。
|
||||
2. Payload(负载):用来存放实际需要传递的数据
|
||||
3. Signature(签名):服务器通过`Payload`、`Header`和一个密钥(`secret`)使用 Header 里面指定的签名算法(默认是 HMAC SHA256)生成。
|
||||
|
||||
在基于 Token 进行身份验证的的应用程序中,服务器通过`Payload`、`Header`和一个密钥(`secret`)创建令牌(`Token`)并将 `Token` 发送给客户端,客户端将 `Token` 保存在 Cookie 或者 localStorage 里面,以后客户端发出的所有请求都会携带这个令牌。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP Header 的 Authorization字段中:` Authorization: Bearer Token`。
|
||||
|
||||
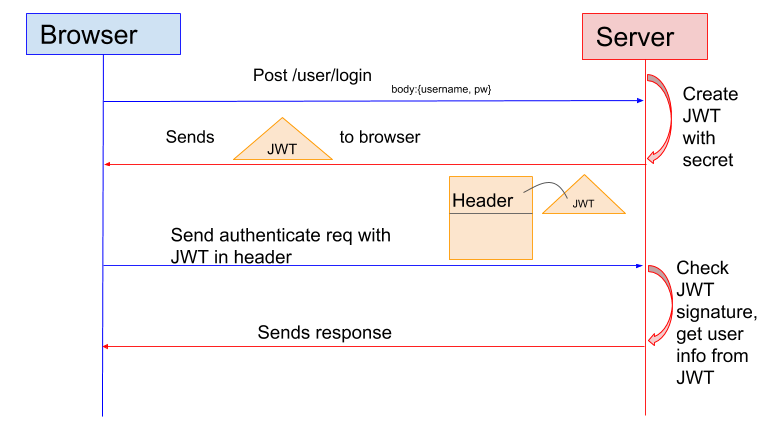
|
||||
|
||||
1. 用户向服务器发送用户名和密码用于登陆系统。
|
||||
2. 身份验证服务响应并返回了签名的 JWT,上面包含了用户是谁的内容。
|
||||
3. 用户以后每次向后端发请求都在Header中带上 JWT。
|
||||
4. 服务端检查 JWT 并从中获取用户相关信息。
|
||||
|
||||
|
||||
推荐阅读:
|
||||
|
||||
- [JWT (JSON Web Tokens) Are Better Than Session Cookies](https://dzone.com/articles/jwtjson-web-tokens-are-better-than-session-cookies)
|
||||
- [JSON Web Tokens (JWT) 与 Sessions](https://juejin.im/entry/577b7b56a3413100618c2938)
|
||||
- [JSON Web Token 入门教程](https://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html)
|
||||
- [彻底理解Cookie,Session,Token](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485603&idx=1&sn=c8d324f44d6102e7b44554733da10bb7&chksm=cea24768f9d5ce7efe7291ddabce02b68db34073c7e7d9a7dc9a7f01c5a80cebe33ac75248df&token=844918801&lang=zh_CN#rd)
|
||||
|
||||
## 5 什么是OAuth 2.0?
|
||||
|
||||
OAuth 是一个行业的标准授权协议,主要用来授权第三方应用获取有限的权限。而 OAuth 2.0是对 OAuth 1.0 的完全重新设计,OAuth 2.0更快,更容易实现,OAuth 1.0 已经被废弃。详情请见:[rfc6749](https://tools.ietf.org/html/rfc6749)。
|
||||
|
||||
实际上它就是一种授权机制,它的最终目的是为第三方应用颁发一个有时效性的令牌 token,使得第三方应用能够通过该令牌获取相关的资源。
|
||||
|
||||
OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了第三方登录的时候一般就是使用的 OAuth 2.0 协议。
|
||||
|
||||
推荐阅读:
|
||||
|
||||
- [OAuth 2.0 的一个简单解释](http://www.ruanyifeng.com/blog/2019/04/oauth_design.html)
|
||||
- [10 分钟理解什么是 OAuth 2.0 协议](https://deepzz.com/post/what-is-oauth2-protocol.html)
|
||||
- [OAuth 2.0 的四种方式](http://www.ruanyifeng.com/blog/2019/04/oauth-grant-types.html)
|
||||
- [GitHub OAuth 第三方登录示例教程](http://www.ruanyifeng.com/blog/2019/04/github-oauth.html)
|
||||
|
||||
## 参考
|
||||
|
||||
- https://medium.com/@sherryhsu/session-vs-token-based-authentication-11a6c5ac45e4
|
||||
- https://www.varonis.com/blog/what-is-oauth/
|
||||
- https://tools.ietf.org/html/rfc6749
|
||||
321
docs/system-design/data-communication/Kafka入门看这一篇就够了.md
Normal file
@ -0,0 +1,321 @@
|
||||
> 本文由 JavaGuide 读者推荐,JavaGuide 对文章进行了整理排版!原文地址:https://www.wmyskxz.com/2019/07/17/kafka-ru-men-jiu-zhe-yi-pian/ , 作者:我没有三颗心脏。
|
||||
|
||||
# 一、Kafka 简介
|
||||
|
||||
------
|
||||
|
||||
## Kafka 创建背景
|
||||
|
||||
**Kafka** 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被[多家不同类型的公司](https://cwiki.apache.org/confluence/display/KAFKA/Powered+By) 作为多种类型的数据管道和消息系统使用。
|
||||
|
||||
**活动流数据**是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。**运营数据**指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
|
||||
|
||||
近年来,活动和运营数据处理已经成为了网站软件产品特性中一个至关重要的组成部分,这就需要一套稍微更加复杂的基础设施对其提供支持。
|
||||
|
||||
## Kafka 简介
|
||||
|
||||
**Kafka 是一种分布式的,基于发布 / 订阅的消息系统。**
|
||||
|
||||
主要设计目标如下:
|
||||
|
||||
- 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
|
||||
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
|
||||
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
|
||||
- 同时支持离线数据处理和实时数据处理。
|
||||
- Scale out:支持在线水平扩展。
|
||||
|
||||
## Kafka 基础概念
|
||||
|
||||
### 概念一:生产者与消费者
|
||||
|
||||

|
||||
|
||||
对于 Kafka 来说客户端有两种基本类型:
|
||||
|
||||
1. **生产者(Producer)**
|
||||
2. **消费者(Consumer)**。
|
||||
|
||||
除此之外,还有用来做数据集成的 Kafka Connect API 和流式处理的 Kafka Streams 等高阶客户端,但这些高阶客户端底层仍然是生产者和消费者API,它们只不过是在上层做了封装。
|
||||
|
||||
这很容易理解,生产者(也称为发布者)创建消息,而消费者(也称为订阅者)负责消费or读取消息。
|
||||
|
||||
### 概念二:主题(Topic)与分区(Partition)
|
||||
|
||||

|
||||
|
||||
在 Kafka 中,消息以**主题(Topic)**来分类,每一个主题都对应一个 **「消息队列」**,这有点儿类似于数据库中的表。但是如果我们把所有同类的消息都塞入到一个“中心”队列中,势必缺少可伸缩性,无论是生产者/消费者数目的增加,还是消息数量的增加,都可能耗尽系统的性能或存储。
|
||||
|
||||
我们使用一个生活中的例子来说明:现在 A 城市生产的某商品需要运输到 B 城市,走的是公路,那么单通道的高速公路不论是在「A 城市商品增多」还是「现在 C 城市也要往 B 城市运输东西」这样的情况下都会出现「吞吐量不足」的问题。所以我们现在引入**分区(Partition)**的概念,类似“允许多修几条道”的方式对我们的主题完成了水平扩展。
|
||||
|
||||
### 概念三:Broker 和集群(Cluster)
|
||||
|
||||
一个 Kafka 服务器也称为 Broker,它接受生产者发送的消息并存入磁盘;Broker 同时服务消费者拉取分区消息的请求,返回目前已经提交的消息。使用特定的机器硬件,一个 Broker 每秒可以处理成千上万的分区和百万量级的消息。(现在动不动就百万量级..我特地去查了一把,好像确实集群的情况下吞吐量挺高的..嗯..)
|
||||
|
||||
若干个 Broker 组成一个集群(Cluster),其中集群内某个 Broker 会成为集群控制器(Cluster Controller),它负责管理集群,包括分配分区到 Broker、监控 Broker 故障等。在集群内,一个分区由一个 Broker 负责,这个 Broker 也称为这个分区的 Leader;当然一个分区可以被复制到多个 Broker 上来实现冗余,这样当存在 Broker 故障时可以将其分区重新分配到其他 Broker 来负责。下图是一个样例:
|
||||
|
||||

|
||||
|
||||
Kafka 的一个关键性质是日志保留(retention),我们可以配置主题的消息保留策略,譬如只保留一段时间的日志或者只保留特定大小的日志。当超过这些限制时,老的消息会被删除。我们也可以针对某个主题单独设置消息过期策略,这样对于不同应用可以实现个性化。
|
||||
|
||||
### 概念四:多集群
|
||||
|
||||
随着业务发展,我们往往需要多集群,通常处于下面几个原因:
|
||||
|
||||
- 基于数据的隔离;
|
||||
- 基于安全的隔离;
|
||||
- 多数据中心(容灾)
|
||||
|
||||
当构建多个数据中心时,往往需要实现消息互通。举个例子,假如用户修改了个人资料,那么后续的请求无论被哪个数据中心处理,这个更新需要反映出来。又或者,多个数据中心的数据需要汇总到一个总控中心来做数据分析。
|
||||
|
||||
上面说的分区复制冗余机制只适用于同一个 Kafka 集群内部,对于多个 Kafka 集群消息同步可以使用 Kafka 提供的 MirrorMaker 工具。本质上来说,MirrorMaker 只是一个 Kafka 消费者和生产者,并使用一个队列连接起来而已。它从一个集群中消费消息,然后往另一个集群生产消息。
|
||||
|
||||
|
||||
# 二、Kafka 的设计与实现
|
||||
|
||||
------
|
||||
|
||||
上面我们知道了 Kafka 中的一些基本概念,但作为一个成熟的「消息队列」中间件,其中有许多有意思的设计值得我们思考,下面我们简单列举一些。
|
||||
|
||||
## 讨论一:Kafka 存储在文件系统上
|
||||
|
||||
是的,**您首先应该知道 Kafka 的消息是存在于文件系统之上的**。Kafka 高度依赖文件系统来存储和缓存消息,一般的人认为 “磁盘是缓慢的”,所以对这样的设计持有怀疑态度。实际上,磁盘比人们预想的快很多也慢很多,这取决于它们如何被使用;一个好的磁盘结构设计可以使之跟网络速度一样快。
|
||||
|
||||
现代的操作系统针对磁盘的读写已经做了一些优化方案来加快磁盘的访问速度。比如,**预读**会提前将一个比较大的磁盘快读入内存。**后写**会将很多小的逻辑写操作合并起来组合成一个大的物理写操作。并且,操作系统还会将主内存剩余的所有空闲内存空间都用作**磁盘缓存**,所有的磁盘读写操作都会经过统一的磁盘缓存(除了直接 I/O 会绕过磁盘缓存)。综合这几点优化特点,**如果是针对磁盘的顺序访问,某些情况下它可能比随机的内存访问都要快,甚至可以和网络的速度相差无几。**
|
||||
|
||||
**上述的 Topic 其实是逻辑上的概念,面相消费者和生产者,物理上存储的其实是 Partition**,每一个 Partition 最终对应一个目录,里面存储所有的消息和索引文件。默认情况下,每一个 Topic 在创建时如果不指定 Partition 数量时只会创建 1 个 Partition。比如,我创建了一个 Topic 名字为 test ,没有指定 Partition 的数量,那么会默认创建一个 test-0 的文件夹,这里的命名规则是:`<topic_name>-<partition_id>`。
|
||||
|
||||

|
||||
|
||||
任何发布到 Partition 的消息都会被追加到 Partition 数据文件的尾部,这样的顺序写磁盘操作让 Kafka 的效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是 Kafka 高吞吐率的一个很重要的保证)。
|
||||
|
||||
每一条消息被发送到 Broker 中,会根据 Partition 规则选择被存储到哪一个 Partition。如果 Partition 规则设置的合理,所有消息可以均匀分布到不同的 Partition中。
|
||||
|
||||
## 讨论二:Kafka 中的底层存储设计
|
||||
|
||||
假设我们现在 Kafka 集群只有一个 Broker,我们创建 2 个 Topic 名称分别为:「topic1」和「topic2」,Partition 数量分别为 1、2,那么我们的根目录下就会创建如下三个文件夹:
|
||||
|
||||
```shell
|
||||
| --topic1-0
|
||||
| --topic2-0
|
||||
| --topic2-1
|
||||
```
|
||||
|
||||
在 Kafka 的文件存储中,同一个 Topic 下有多个不同的 Partition,每个 Partition 都为一个目录,而每一个目录又被平均分配成多个大小相等的 **Segment File** 中,Segment File 又由 index file 和 data file 组成,他们总是成对出现,后缀 “.index” 和 “.log” 分表表示 Segment 索引文件和数据文件。
|
||||
|
||||
现在假设我们设置每个 Segment 大小为 500 MB,并启动生产者向 topic1 中写入大量数据,topic1-0 文件夹中就会产生类似如下的一些文件:
|
||||
|
||||
```shell
|
||||
| --topic1-0
|
||||
| --00000000000000000000.index
|
||||
| --00000000000000000000.log
|
||||
| --00000000000000368769.index
|
||||
| --00000000000000368769.log
|
||||
| --00000000000000737337.index
|
||||
| --00000000000000737337.log
|
||||
| --00000000000001105814.index | --00000000000001105814.log
|
||||
| --topic2-0
|
||||
| --topic2-1
|
||||
|
||||
```
|
||||
|
||||
**Segment 是 Kafka 文件存储的最小单位。**Segment 文件命名规则:Partition 全局的第一个 Segment 从 0 开始,后续每个 Segment 文件名为上一个 Segment 文件最后一条消息的 offset 值。数值最大为 64 位 long 大小,19 位数字字符长度,没有数字用0填充。如 00000000000000368769.index 和 00000000000000368769.log。
|
||||
|
||||
以上面的一对 Segment File 为例,说明一下索引文件和数据文件对应关系:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
其中以索引文件中元数据 `<3, 497>` 为例,依次在数据文件中表示第 3 个 message(在全局 Partition 表示第 368769 + 3 = 368772 个 message)以及该消息的物理偏移地址为 497。
|
||||
|
||||
注意该 index 文件并不是从0开始,也不是每次递增1的,这是因为 Kafka 采取稀疏索引存储的方式,每隔一定字节的数据建立一条索引,它减少了索引文件大小,使得能够把 index 映射到内存,降低了查询时的磁盘 IO 开销,同时也并没有给查询带来太多的时间消耗。
|
||||
|
||||
因为其文件名为上一个 Segment 最后一条消息的 offset ,所以当需要查找一个指定 offset 的 message 时,通过在所有 segment 的文件名中进行二分查找就能找到它归属的 segment ,再在其 index 文件中找到其对应到文件上的物理位置,就能拿出该 message 。
|
||||
|
||||
由于消息在 Partition 的 Segment 数据文件中是顺序读写的,且消息消费后不会删除(删除策略是针对过期的 Segment 文件),这种顺序磁盘 IO 存储设计师 Kafka 高性能很重要的原因。
|
||||
|
||||
> Kafka 是如何准确的知道 message 的偏移的呢?这是因为在 Kafka 定义了标准的数据存储结构,在 Partition 中的每一条 message 都包含了以下三个属性:
|
||||
>
|
||||
> - offset:表示 message 在当前 Partition 中的偏移量,是一个逻辑上的值,唯一确定了 Partition 中的一条 message,可以简单的认为是一个 id;
|
||||
> - MessageSize:表示 message 内容 data 的大小;
|
||||
> - data:message 的具体内容
|
||||
|
||||
## 讨论三:生产者设计概要
|
||||
|
||||
当我们发送消息之前,先问几个问题:每条消息都是很关键且不能容忍丢失么?偶尔重复消息可以么?我们关注的是消息延迟还是写入消息的吞吐量?
|
||||
|
||||
举个例子,有一个信用卡交易处理系统,当交易发生时会发送一条消息到 Kafka,另一个服务来读取消息并根据规则引擎来检查交易是否通过,将结果通过 Kafka 返回。对于这样的业务,消息既不能丢失也不能重复,由于交易量大因此吞吐量需要尽可能大,延迟可以稍微高一点。
|
||||
|
||||
再举个例子,假如我们需要收集用户在网页上的点击数据,对于这样的场景,少量消息丢失或者重复是可以容忍的,延迟多大都不重要只要不影响用户体验,吞吐则根据实时用户数来决定。
|
||||
|
||||
不同的业务需要使用不同的写入方式和配置。具体的方式我们在这里不做讨论,现在先看下生产者写消息的基本流程:
|
||||
|
||||

|
||||
|
||||
图片来源:[http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/12/kafka-producer.html](http://www.dengshenyu.com/分布式系统/2017/11/12/kafka-producer.html)
|
||||
|
||||
流程如下:
|
||||
|
||||
1. 首先,我们需要创建一个ProducerRecord,这个对象需要包含消息的主题(topic)和值(value),可以选择性指定一个键值(key)或者分区(partition)。
|
||||
2. 发送消息时,生产者会对键值和值序列化成字节数组,然后发送到分配器(partitioner)。
|
||||
3. 如果我们指定了分区,那么分配器返回该分区即可;否则,分配器将会基于键值来选择一个分区并返回。
|
||||
4. 选择完分区后,生产者知道了消息所属的主题和分区,它将这条记录添加到相同主题和分区的批量消息中,另一个线程负责发送这些批量消息到对应的Kafka broker。
|
||||
5. 当broker接收到消息后,如果成功写入则返回一个包含消息的主题、分区及位移的RecordMetadata对象,否则返回异常。
|
||||
6. 生产者接收到结果后,对于异常可能会进行重试。
|
||||
|
||||
|
||||
|
||||
## 讨论四:消费者设计概要
|
||||
|
||||
### 消费者与消费组
|
||||
|
||||
假设这么个场景:我们从Kafka中读取消息,并且进行检查,最后产生结果数据。我们可以创建一个消费者实例去做这件事情,但如果生产者写入消息的速度比消费者读取的速度快怎么办呢?这样随着时间增长,消息堆积越来越严重。对于这种场景,我们需要增加多个消费者来进行水平扩展。
|
||||
|
||||
Kafka消费者是**消费组**的一部分,当多个消费者形成一个消费组来消费主题时,每个消费者会收到不同分区的消息。假设有一个T1主题,该主题有4个分区;同时我们有一个消费组G1,这个消费组只有一个消费者C1。那么消费者C1将会收到这4个分区的消息,如下所示:
|
||||
|
||||

|
||||
如果我们增加新的消费者C2到消费组G1,那么每个消费者将会分别收到两个分区的消息,如下所示:
|
||||
|
||||

|
||||
|
||||
如果增加到4个消费者,那么每个消费者将会分别收到一个分区的消息,如下所示:
|
||||
|
||||

|
||||
|
||||
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息:
|
||||
|
||||

|
||||
|
||||
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
|
||||
|
||||
**Kafka一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。**换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。对于上面的例子,假如我们新增了一个新的消费组G2,而这个消费组有两个消费者,那么会是这样的:
|
||||
|
||||

|
||||
|
||||
在这个场景中,消费组G1和消费组G2都能收到T1主题的全量消息,在逻辑意义上来说它们属于不同的应用。
|
||||
|
||||
最后,总结起来就是:如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
|
||||
|
||||
### 消费组与分区重平衡
|
||||
|
||||
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为**重平衡(rebalance)**。重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。**不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。**而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。后面我们会讨论如何安全的进行重平衡以及如何尽可能避免。
|
||||
|
||||
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的 broker 来保持在消费组内存活。这个 broker 不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
|
||||
|
||||
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
|
||||
|
||||
在 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
|
||||
|
||||
### Partition 与消费模型
|
||||
|
||||
上面提到,Kafka 中一个 topic 中的消息是被打散分配在多个 Partition(分区) 中存储的, Consumer Group 在消费时需要从不同的 Partition 获取消息,那最终如何重建出 Topic 中消息的顺序呢?
|
||||
|
||||
答案是:没有办法。Kafka 只会保证在 Partition 内消息是有序的,而不管全局的情况。
|
||||
|
||||
下一个问题是:Partition 中的消息可以被(不同的 Consumer Group)多次消费,那 Partition中被消费的消息是何时删除的? Partition 又是如何知道一个 Consumer Group 当前消费的位置呢?
|
||||
|
||||
无论消息是否被消费,除非消息到期 Partition 从不删除消息。例如设置保留时间为 2 天,则消息发布 2 天内任何 Group 都可以消费,2 天后,消息自动被删除。
|
||||
Partition 会为每个 Consumer Group 保存一个偏移量,记录 Group 消费到的位置。 如下图:
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
### 为什么 Kafka 是 pull 模型
|
||||
|
||||
消费者应该向 Broker 要数据(pull)还是 Broker 向消费者推送数据(push)?作为一个消息系统,Kafka 遵循了传统的方式,选择由 Producer 向 broker push 消息并由 Consumer 从 broker pull 消息。一些 logging-centric system,比如 Facebook 的[Scribe](https://github.com/facebookarchive/scribe)和 Cloudera 的[Flume](https://flume.apache.org/),采用 push 模式。事实上,push 模式和 pull 模式各有优劣。
|
||||
|
||||
**push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。**push 模式的目标是尽可能以最快速度传递消息,但是这样很容易造成 Consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。**而 pull 模式则可以根据 Consumer 的消费能力以适当的速率消费消息。**
|
||||
|
||||
**对于 Kafka 而言,pull 模式更合适。**pull 模式可简化 broker 的设计,Consumer 可自主控制消费消息的速率,同时 Consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
|
||||
|
||||
## 讨论五:Kafka 如何保证可靠性
|
||||
|
||||
当我们讨论**可靠性**的时候,我们总会提到*保证**这个词语。可靠性保证是基础,我们基于这些基础之上构建我们的应用。比如关系型数据库的可靠性保证是ACID,也就是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
|
||||
|
||||
Kafka 中的可靠性保证有如下四点:
|
||||
|
||||
- 对于一个分区来说,它的消息是有序的。如果一个生产者向一个分区先写入消息A,然后写入消息B,那么消费者会先读取消息A再读取消息B。
|
||||
- 当消息写入所有in-sync状态的副本后,消息才会认为**已提交(committed)**。这里的写入有可能只是写入到文件系统的缓存,不一定刷新到磁盘。生产者可以等待不同时机的确认,比如等待分区主副本写入即返回,后者等待所有in-sync状态副本写入才返回。
|
||||
- 一旦消息已提交,那么只要有一个副本存活,数据不会丢失。
|
||||
- 消费者只能读取到已提交的消息。
|
||||
|
||||
使用这些基础保证,我们构建一个可靠的系统,这时候需要考虑一个问题:究竟我们的应用需要多大程度的可靠性?可靠性不是无偿的,它与系统可用性、吞吐量、延迟和硬件价格息息相关,得此失彼。因此,我们往往需要做权衡,一味的追求可靠性并不实际。
|
||||
|
||||
> 想了解更多戳这里:http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/21/kafka-data-delivery.html
|
||||
|
||||
# 三、动手搭一个 Kafka
|
||||
|
||||
通过上面的描述,我们已经大致了解到了「Kafka」是何方神圣了,现在我们开始尝试自己动手本地搭一个来实际体验一把。
|
||||
|
||||
## 第一步:下载 Kafka
|
||||
|
||||
这里以 Mac OS 为例,在安装了 Homebrew 的情况下执行下列代码:
|
||||
|
||||
```shell
|
||||
brew install kafka
|
||||
```
|
||||
|
||||
由于 Kafka 依赖了 Zookeeper,所以在下载的时候会自动下载。
|
||||
|
||||
## 第二步:启动服务
|
||||
|
||||
我们在启动之前首先需要修改 Kafka 的监听地址和端口为 `localhost:9092`:
|
||||
|
||||
```shell
|
||||
vi /usr/local/etc/kafka/server.properties
|
||||
```
|
||||
|
||||
|
||||
然后修改成下图的样子:
|
||||
|
||||

|
||||
依次启动 Zookeeper 和 Kafka:
|
||||
|
||||
```shell
|
||||
brew services start zookeeper
|
||||
brew services start kafka
|
||||
```
|
||||
|
||||
然后执行下列语句来创建一个名字为 “test” 的 Topic:
|
||||
|
||||
```shell
|
||||
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
|
||||
```
|
||||
|
||||
我们可以通过下列的命令查看我们的 Topic 列表:
|
||||
|
||||
```shell
|
||||
kafka-topics --list --zookeeper localhost:2181
|
||||
```
|
||||
|
||||
## 第三步:发送消息
|
||||
|
||||
然后我们新建一个控制台,运行下列命令创建一个消费者关注刚才创建的 Topic:
|
||||
|
||||
```shell
|
||||
kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning
|
||||
```
|
||||
|
||||
用控制台往刚才创建的 Topic 中添加消息,并观察刚才创建的消费者窗口:
|
||||
|
||||
```shel
|
||||
kafka-console-producer --broker-list localhost:9092 --topic test
|
||||
```
|
||||
|
||||
能通过消费者窗口观察到正确的消息:
|
||||
|
||||

|
||||
|
||||
# 参考资料
|
||||
|
||||
------
|
||||
|
||||
1. https://www.infoq.cn/article/kafka-analysis-part-1 - Kafka 设计解析(一):Kafka 背景及架构介绍
|
||||
2. [http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/06/kafka-Meet-Kafka.html](http://www.dengshenyu.com/分布式系统/2017/11/06/kafka-Meet-Kafka.html) - Kafka系列(一)初识Kafka
|
||||
3. https://lotabout.me/2018/kafka-introduction/ - Kafka 入门介绍
|
||||
4. https://www.zhihu.com/question/28925721 - Kafka 中的 Topic 为什么要进行分区? - 知乎
|
||||
5. https://blog.joway.io/posts/kafka-design-practice/ - Kafka 的设计与实践思考
|
||||
6. [http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/21/kafka-data-delivery.html](http://www.dengshenyu.com/分布式系统/2017/11/21/kafka-data-delivery.html) - Kafka系列(六)可靠的数据传输
|
||||
|
||||
|
||||
281
docs/system-design/data-communication/Kafka系统设计开篇-面试看这篇就够了.md
Normal file
@ -0,0 +1,281 @@
|
||||
> 原文链接:https://mp.weixin.qq.com/s/zxPz_aFEMrshApZQ727h4g
|
||||
|
||||
## 引言
|
||||
|
||||
MQ(消息队列)是跨进程通信的方式之一,可理解为异步rpc,上游系统对调用结果的态度往往是重要不紧急。使用消息队列有以下好处:业务解耦、流量削峰、灵活扩展。接下来介绍消息中间件Kafka。
|
||||
|
||||
## Kafka是什么?
|
||||
|
||||
Kafka是一个分布式的消息引擎。具有以下特征
|
||||
|
||||
能够发布和订阅消息流(类似于消息队列)
|
||||
以容错的、持久的方式存储消息流
|
||||
多分区概念,提高了并行能力
|
||||
|
||||
## Kafka架构总览
|
||||
|
||||
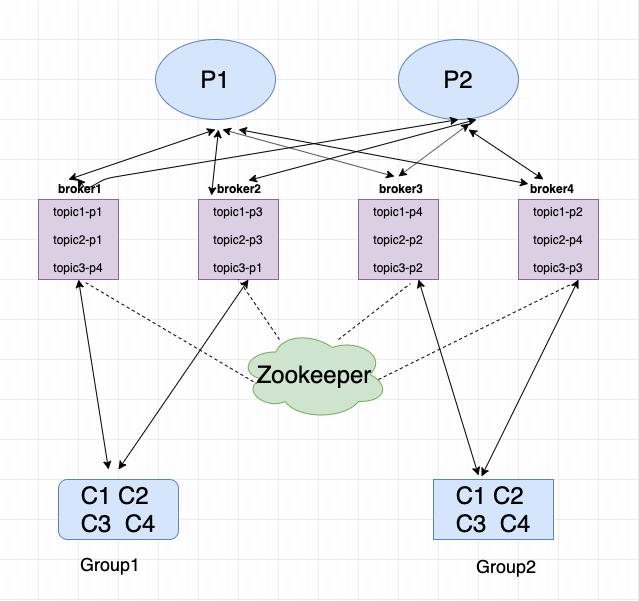
|
||||
|
||||
## Topic
|
||||
|
||||
消息的主题、队列,每一个消息都有它的topic,Kafka通过topic对消息进行归类。Kafka中可以将Topic从物理上划分成一个或多个分区(Partition),每个分区在物理上对应一个文件夹,以”topicName_partitionIndex”的命名方式命名,该dir包含了这个分区的所有消息(.log)和索引文件(.index),这使得Kafka的吞吐率可以水平扩展。
|
||||
|
||||
## Partition
|
||||
|
||||
每个分区都是一个 顺序的、不可变的消息队列, 并且可以持续的添加;分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。
|
||||
producer在发布消息的时候,可以为每条消息指定Key,这样消息被发送到broker时,会根据分区算法把消息存储到对应的分区中(一个分区存储多个消息),如果分区规则设置的合理,那么所有的消息将会被均匀的分布到不同的分区中,这样就实现了负载均衡。
|
||||
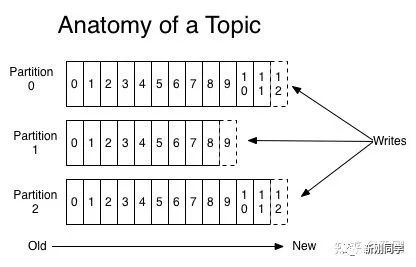
|
||||
|
||||
## Broker
|
||||
|
||||
Kafka server,用来存储消息,Kafka集群中的每一个服务器都是一个Broker,消费者将从broker拉取订阅的消息
|
||||
Producer
|
||||
向Kafka发送消息,生产者会根据topic分发消息。生产者也负责把消息关联到Topic上的哪一个分区。最简单的方式从分区列表中轮流选择。也可以根据某种算法依照权重选择分区。算法可由开发者定义。
|
||||
|
||||
## Cousumer
|
||||
|
||||
Consermer实例可以是独立的进程,负责订阅和消费消息。消费者用consumerGroup来标识自己。同一个消费组可以并发地消费多个分区的消息,同一个partition也可以由多个consumerGroup并发消费,但是在consumerGroup中一个partition只能由一个consumer消费
|
||||
|
||||
## CousumerGroup
|
||||
|
||||
Consumer Group:同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer
|
||||
|
||||
# Kafka producer 设计原理
|
||||
|
||||
## 发送消息的流程
|
||||
|
||||
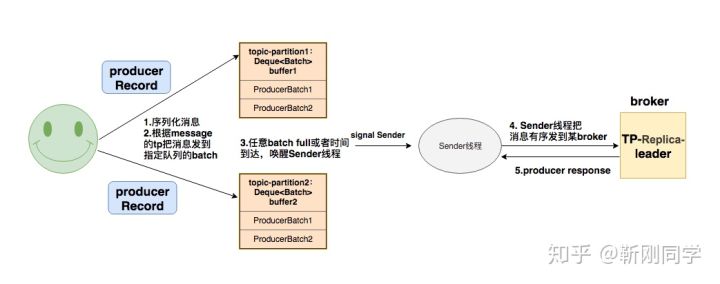
|
||||
**1.序列化消息&&.计算partition**
|
||||
根据key和value的配置对消息进行序列化,然后计算partition:
|
||||
ProducerRecord对象中如果指定了partition,就使用这个partition。否则根据key和topic的partition数目取余,如果key也没有的话就随机生成一个counter,使用这个counter来和partition数目取余。这个counter每次使用的时候递增。
|
||||
|
||||
**2发送到batch&&唤醒Sender 线程**
|
||||
根据topic-partition获取对应的batchs(Dueue<ProducerBatch>),然后将消息append到batch中.如果有batch满了则唤醒Sender 线程。队列的操作是加锁执行,所以batch内消息时有序的。后续的Sender操作当前方法异步操作。
|
||||
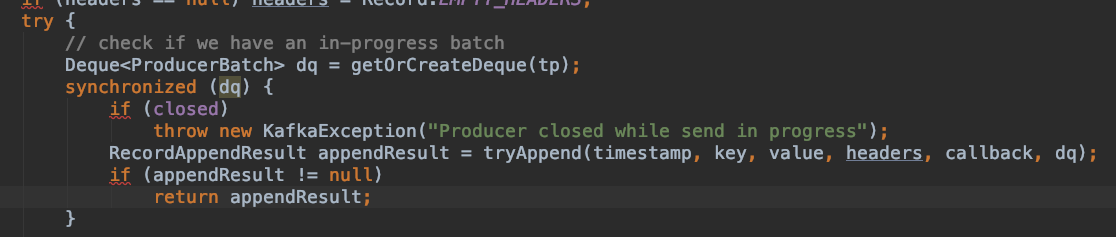
|
||||
|
||||
|
||||
|
||||
**3.Sender把消息有序发到 broker(tp replia leader)**
|
||||
**3.1 确定tp relica leader 所在的broker**
|
||||
|
||||
Kafka中 每台broker都保存了kafka集群的metadata信息,metadata信息里包括了每个topic的所有partition的信息: leader, leader_epoch, controller_epoch, isr, replicas等;Kafka客户端从任一broker都可以获取到需要的metadata信息;sender线程通过metadata信息可以知道tp leader的brokerId
|
||||
producer也保存了metada信息,同时根据metadata更新策略(定期更新metadata.max.age.ms、失效检测,强制更新:检查到metadata失效以后,调用metadata.requestUpdate()强制更新
|
||||
|
||||
```
|
||||
public class PartitionInfo {
|
||||
private final String topic; private final int partition;
|
||||
private final Node leader; private final Node[] replicas;
|
||||
private final Node[] inSyncReplicas; private final Node[] offlineReplicas;
|
||||
}
|
||||
```
|
||||
|
||||
**3.2 幂等性发送**
|
||||
|
||||
为实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。对于每个PID,该Producer发送消息的每个<Topic, Partition>都对应一个单调递增的Sequence Number。同样,Broker端也会为每个<PID, Topic, Partition>维护一个序号,并且每Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号)大一,则Broker会接受它,否则将其丢弃:
|
||||
|
||||
如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
|
||||
如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
|
||||
Sender发送失败后会重试,这样可以保证每个消息都被发送到broker
|
||||
|
||||
**4. Sender处理broker发来的produce response**
|
||||
一旦broker处理完Sender的produce请求,就会发送produce response给Sender,此时producer将执行我们为send()设置的回调函数。至此producer的send执行完毕。
|
||||
|
||||
## 吞吐性&&延时:
|
||||
|
||||
buffer.memory:buffer设置大了有助于提升吞吐性,但是batch太大会增大延迟,可搭配linger_ms参数使用
|
||||
linger_ms:如果batch太大,或者producer qps不高,batch添加的会很慢,我们可以强制在linger_ms时间后发送batch数据
|
||||
ack:producer收到多少broker的答复才算真的发送成功
|
||||
0表示producer无需等待leader的确认(吞吐最高、数据可靠性最差)
|
||||
1代表需要leader确认写入它的本地log并立即确认
|
||||
-1/all 代表所有的ISR都完成后确认(吞吐最低、数据可靠性最高)
|
||||
|
||||
## Sender线程和长连接
|
||||
|
||||
每初始化一个producer实例,都会初始化一个Sender实例,新增到broker的长连接。
|
||||
代码角度:每初始化一次KafkaProducer,都赋一个空的client
|
||||
|
||||
```
|
||||
public KafkaProducer(final Map<String, Object> configs) {
|
||||
this(configs, null, null, null, null, null, Time.SYSTEM);
|
||||
}
|
||||
```
|
||||
|
||||
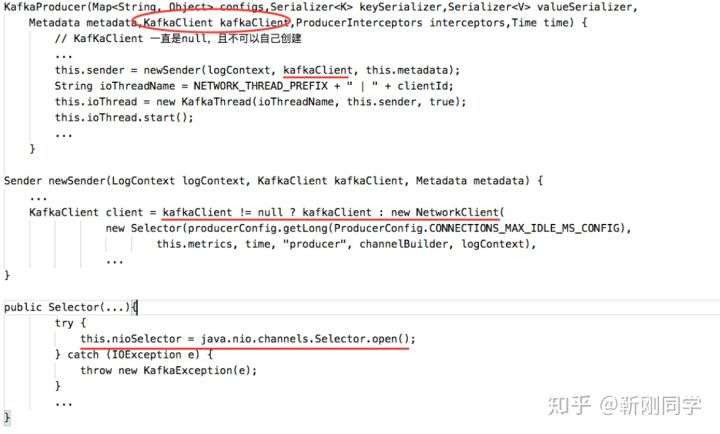
|
||||
|
||||
终端查看TCP连接数:
|
||||
lsof -p portNum -np | grep TCP
|
||||
|
||||
# Consumer设计原理
|
||||
|
||||
## poll消息
|
||||
|
||||
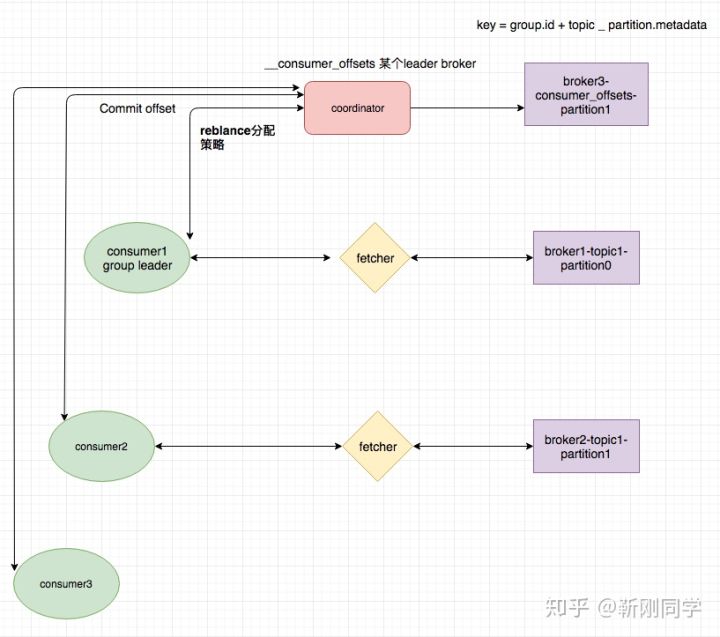
|
||||
|
||||
- 消费者通过fetch线程拉消息(单线程)
|
||||
- 消费者通过心跳线程来与broker发送心跳。超时会认为挂掉
|
||||
- 每个consumer
|
||||
group在broker上都有一个coordnator来管理,消费者加入和退出,以及消费消息的位移都由coordnator处理。
|
||||
|
||||
## 位移管理
|
||||
|
||||
consumer的消息位移代表了当前group对topic-partition的消费进度,consumer宕机重启后可以继续从该offset开始消费。
|
||||
在kafka0.8之前,位移信息存放在zookeeper上,由于zookeeper不适合高并发的读写,新版本Kafka把位移信息当成消息,发往__consumers_offsets 这个topic所在的broker,__consumers_offsets默认有50个分区。
|
||||
消息的key 是groupId+topic_partition,value 是offset.
|
||||
|
||||
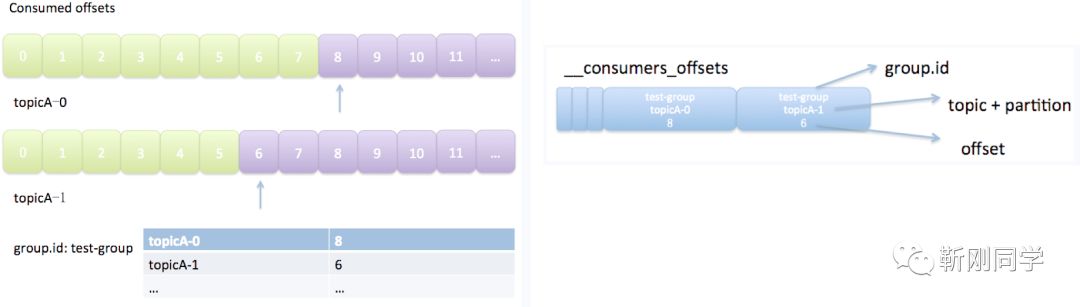
|
||||
|
||||
|
||||
|
||||
## Kafka Group 状态
|
||||
|
||||
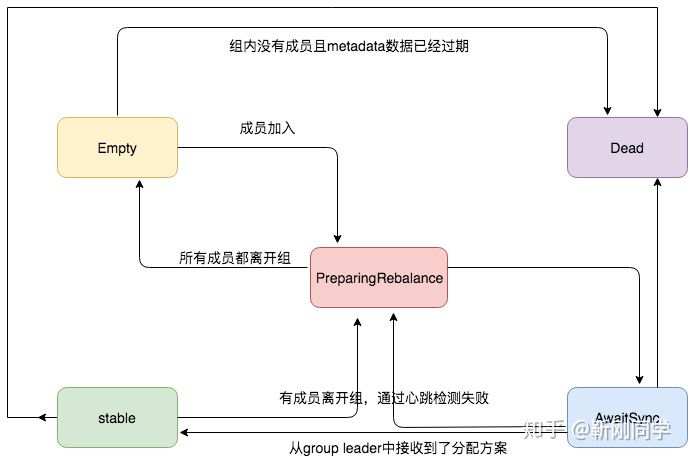
|
||||
|
||||
- Empty:初始状态,Group 没有任何成员,如果所有的 offsets 都过期的话就会变成 Dead
|
||||
- PreparingRebalance:Group 正在准备进行 Rebalance
|
||||
- AwaitingSync:Group 正在等待来 group leader 的 分配方案
|
||||
- Stable:稳定的状态(Group is stable);
|
||||
- Dead:Group 内已经没有成员,并且它的 Metadata 已经被移除
|
||||
|
||||
## 重平衡reblance
|
||||
|
||||
当一些原因导致consumer对partition消费不再均匀时,kafka会自动执行reblance,使得consumer对partition的消费再次平衡。
|
||||
什么时候发生rebalance?:
|
||||
|
||||
- 组订阅topic数变更
|
||||
- topic partition数变更
|
||||
- consumer成员变更
|
||||
- consumer 加入群组或者离开群组的时候
|
||||
- consumer被检测为崩溃的时候
|
||||
|
||||
## reblance过程
|
||||
|
||||
举例1 consumer被检测为崩溃引起的reblance
|
||||
比如心跳线程在timeout时间内没和broker发送心跳,此时coordnator认为该group应该进行reblance。接下来其他consumer发来fetch请求后,coordnator将回复他们进行reblance通知。当consumer成员收到请求后,只有leader会根据分配策略进行分配,然后把各自的分配结果返回给coordnator。这个时候只有consumer leader返回的是实质数据,其他返回的都为空。收到分配方法后,consumer将会把分配策略同步给各consumer
|
||||
|
||||
举例2 consumer加入引起的reblance
|
||||
|
||||
使用join协议,表示有consumer 要加入到group中
|
||||
使用sync 协议,根据分配规则进行分配
|
||||
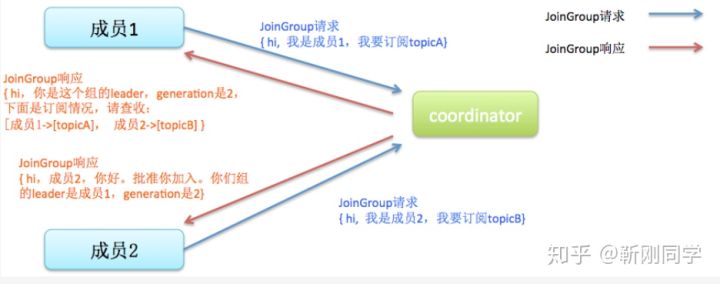
|
||||
|
||||
(上图图片摘自网络)
|
||||
|
||||
## 引申:以上reblance机制存在的问题
|
||||
|
||||
在大型系统中,一个topic可能对应数百个consumer实例。这些consumer陆续加入到一个空消费组将导致多次的rebalance;此外consumer 实例启动的时间不可控,很有可能超出coordinator确定的rebalance timeout(即max.poll.interval.ms),将会再次触发rebalance,而每次rebalance的代价又相当地大,因为很多状态都需要在rebalance前被持久化,而在rebalance后被重新初始化。
|
||||
|
||||
## 新版本改进
|
||||
|
||||
**通过延迟进入PreparingRebalance状态减少reblance次数**
|
||||
|
||||
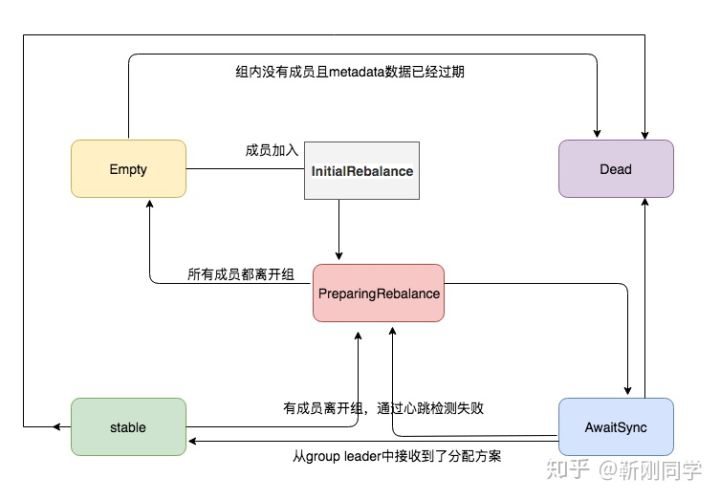
|
||||
|
||||
新版本新增了group.initial.rebalance.delay.ms参数。空消费组接受到成员加入请求时,不立即转化到PreparingRebalance状态来开启reblance。当时间超过group.initial.rebalance.delay.ms后,再把group状态改为PreparingRebalance(开启reblance)。实现机制是在coordinator底层新增一个group状态:InitialReblance。假设此时有多个consumer陆续启动,那么group状态先转化为InitialReblance,待group.initial.rebalance.delay.ms时间后,再转换为PreparingRebalance(开启reblance)
|
||||
|
||||
|
||||
|
||||
# Broker设计原理
|
||||
|
||||
Broker 是Kafka 集群中的节点。负责处理生产者发送过来的消息,消费者消费的请求。以及集群节点的管理等。由于涉及内容较多,先简单介绍,后续专门抽出一篇文章分享
|
||||
|
||||
## broker zk注册
|
||||
|
||||
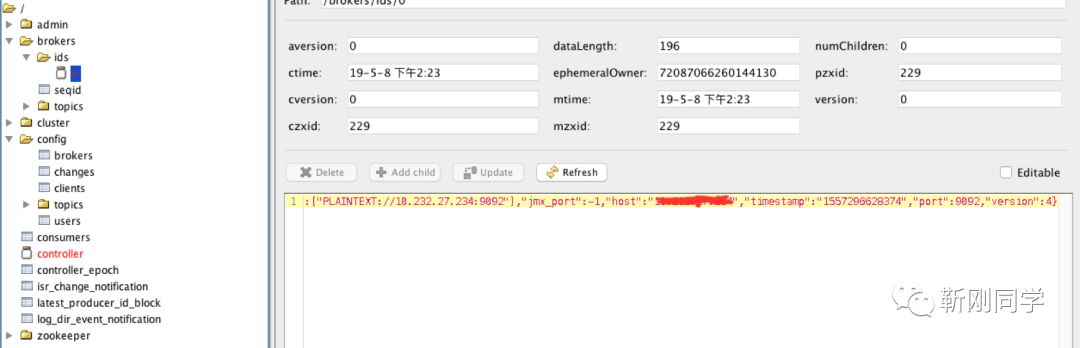
|
||||
|
||||
## broker消息存储
|
||||
|
||||
Kafka的消息以二进制的方式紧凑地存储,节省了很大空间
|
||||
此外消息存在ByteBuffer而不是堆,这样broker进程挂掉时,数据不会丢失,同时避免了gc问题
|
||||
通过零拷贝和顺序寻址,让消息存储和读取速度都非常快
|
||||
处理fetch请求的时候通过zero-copy 加快速度
|
||||
|
||||
## broker状态数据
|
||||
|
||||
broker设计中,每台机器都保存了相同的状态数据。主要包括以下:
|
||||
|
||||
controller所在的broker ID,即保存了当前集群中controller是哪台broker
|
||||
集群中所有broker的信息:比如每台broker的ID、机架信息以及配置的若干组连接信息
|
||||
集群中所有节点的信息:严格来说,它和上一个有些重复,不过此项是按照broker ID和***类型进行分组的。对于超大集群来说,使用这一项缓存可以快速地定位和查找给定节点信息,而无需遍历上一项中的内容,算是一个优化吧
|
||||
集群中所有分区的信息:所谓分区信息指的是分区的leader、ISR和AR信息以及当前处于offline状态的副本集合。这部分数据按照topic-partitionID进行分组,可以快速地查找到每个分区的当前状态。(注:AR表示assigned replicas,即创建topic时为该分区分配的副本集合)
|
||||
|
||||
## broker负载均衡
|
||||
|
||||
**分区数量负载**:各台broker的partition数量应该均匀
|
||||
partition Replica分配算法如下:
|
||||
|
||||
将所有Broker(假设共n个Broker)和待分配的Partition排序
|
||||
将第i个Partition分配到第(i mod n)个Broker上
|
||||
将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
|
||||
|
||||
**容量大小负载:**每台broker的硬盘占用大小应该均匀
|
||||
在kafka1.1之前,Kafka能够保证各台broker上partition数量均匀,但由于每个partition内的消息数不同,可能存在不同硬盘之间内存占用差异大的情况。在Kafka1.1中增加了副本跨路径迁移功能kafka-reassign-partitions.sh,我们可以结合它和监控系统,实现自动化的负载均衡
|
||||
|
||||
# Kafka高可用
|
||||
|
||||
在介绍kafka高可用之前先介绍几个概念
|
||||
|
||||
同步复制:要求所有能工作的Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率
|
||||
异步复制:Follower异步的从Leader pull数据,data只要被Leader写入log认为已经commit,这种情况下如果Follower落后于Leader的比较多,如果Leader突然宕机,会丢失数据
|
||||
|
||||
## Isr
|
||||
|
||||
Kafka结合同步复制和异步复制,使用ISR(与Partition Leader保持同步的Replica列表)的方式在确保数据不丢失和吞吐率之间做了平衡。Producer只需把消息发送到Partition Leader,Leader将消息写入本地Log。Follower则从Leader pull数据。Follower在收到该消息向Leader发送ACK。一旦Leader收到了ISR中所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。这样如果leader挂了,只要Isr中有一个replica存活,就不会丢数据。
|
||||
|
||||
## Isr动态更新
|
||||
|
||||
Leader会跟踪ISR,如果ISR中一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader后的条数超过预定值(replica.lag.max.messages)或者Follower超过一定时间(replica.lag.time.max.ms)未向Leader发送fetch请求。
|
||||
|
||||
broker Nodes In Zookeeper
|
||||
/brokers/topics/[topic]/partitions/[partition]/state 保存了topic-partition的leader和Isr等信息
|
||||
|
||||
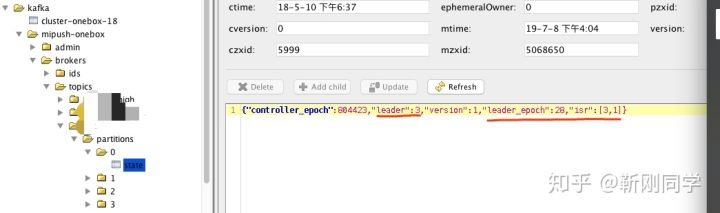
|
||||
|
||||
## Controller负责broker故障检查&&故障转移(fail/recover)
|
||||
|
||||
1. Controller在Zookeeper上注册Watch,一旦有Broker宕机,其在Zookeeper对应的znode会自动被删除,Zookeeper会触发
|
||||
Controller注册的watch,Controller读取最新的Broker信息
|
||||
2. Controller确定set_p,该集合包含了宕机的所有Broker上的所有Partition
|
||||
3. 对set_p中的每一个Partition,选举出新的leader、Isr,并更新结果。
|
||||
|
||||
3.1 从/brokers/topics/[topic]/partitions/[partition]/state读取该Partition当前的ISR
|
||||
|
||||
3.2 决定该Partition的新Leader和Isr。如果当前ISR中有至少一个Replica还幸存,则选择其中一个作为新Leader,新的ISR则包含当前ISR中所有幸存的Replica。否则选择该Partition中任意一个幸存的Replica作为新的Leader以及ISR(该场景下可能会有潜在的数据丢失)
|
||||
|
||||
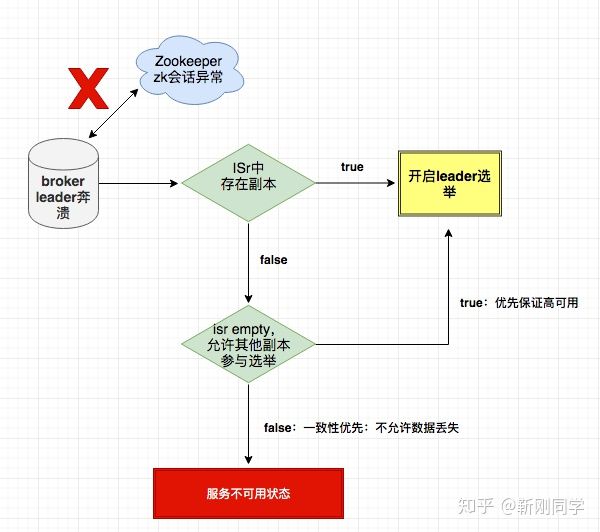
|
||||
3.3 更新Leader、ISR、leader_epoch、controller_epoch:写入/brokers/topics/[topic]/partitions/[partition]/state
|
||||
|
||||
4. 直接通过RPC向set_p相关的Broker发送LeaderAndISRRequest命令。Controller可以在一个RPC操作中发送多个命令从而提高效率。
|
||||
|
||||
## Controller挂掉
|
||||
|
||||
每个 broker 都会在 zookeeper 的临时节点 "/controller" 注册 watcher,当 controller 宕机时 "/controller" 会消失,触发broker的watch,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
|
||||
|
||||
# 使用Kafka如何保证幂等性
|
||||
|
||||
不丢消息
|
||||
|
||||
首先kafka保证了对已提交消息的at least保证
|
||||
Sender有重试机制
|
||||
producer业务方在使用producer发送消息时,注册回调函数。在onError方法中重发消息
|
||||
consumer 拉取到消息后,处理完毕再commit,保证commit的消息一定被处理完毕
|
||||
|
||||
不重复
|
||||
|
||||
consumer拉取到消息先保存,commit成功后删除缓存数据
|
||||
|
||||
# Kafka高性能
|
||||
|
||||
partition提升了并发
|
||||
zero-copy
|
||||
顺序写入
|
||||
消息聚集batch
|
||||
页缓存
|
||||
业务方对 Kafka producer的优化
|
||||
|
||||
增大producer数量
|
||||
ack配置
|
||||
batch
|
||||
|
||||
如果喜欢我的文章,欢迎扫码关注
|
||||
|
||||

|
||||
@ -123,7 +123,7 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
|
||||
|
||||
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
|
||||
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
|
||||
- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“.”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
|
||||
- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
|
||||
|
||||
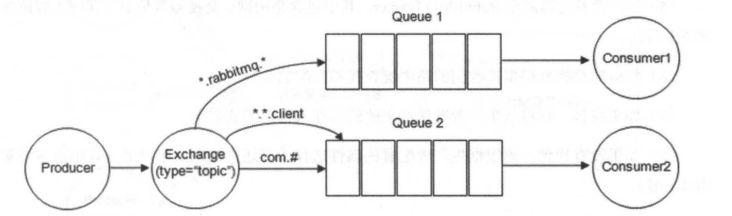
|
||||
|
||||
@ -177,7 +177,7 @@ erlang 官网下载:[http://www.erlang.org/downloads](http://www.erlang.org/do
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]#yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
|
||||
```
|
||||
```
|
||||
|
||||
**5 进入erlang 安装包解压文件对 erlang 进行安装环境的配置**
|
||||
|
||||
|
||||
@ -47,8 +47,6 @@ ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在
|
||||
|
||||
综上,何必增加那一个不必要的zookeeper呢?
|
||||
|
||||
|
||||
|
||||
## 二 关于 ZooKeeper 的一些重要概念
|
||||
|
||||
### 2.1 重要概念总结
|
||||
|
||||
@ -26,9 +26,7 @@ ZNode(数据节点)是 ZooKeeper 中数据的最小单元,每个ZNode上
|
||||
|
||||
提到 ZooKeeper 数据模型,还有一个不得不得提的东西就是 **事务 ID** 。事务的ACID(Atomic:原子性;Consistency:一致性;Isolation:隔离性;Durability:持久性)四大特性我在这里就不多说了,相信大家也已经挺腻了。
|
||||
|
||||
在Zookeeper中,事务是指能够改变 ZooKeeper 服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,**ZooKeeper 都会为其分配一个全局唯一的事务ID,用 ZXID 来表示**,通常是一个64位的数字。每一个ZXID对应一次更新操作,**从这些 ZXID 中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序**。
|
||||
|
||||
|
||||
在Zookeeper中,事务是指能够改变 ZooKeeper 服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。**对于每一个事务请求,ZooKeeper 都会为其分配一个全局唯一的事务ID,用 ZXID 来表示**,通常是一个64位的数字。每一个ZXID对应一次更新操作,**从这些 ZXID 中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序**。
|
||||
|
||||
### ZNode(数据节点)的结构
|
||||
|
||||
|
||||
@ -4,9 +4,8 @@
|
||||
|
||||
### 官网相关
|
||||
|
||||
- [Spring官网](https://spring.io/)
|
||||
- [Spring系列主要项目](https://spring.io/projects)
|
||||
- [Spring官网指南](https://spring.io/guides)
|
||||
- [Spring官网](https://spring.io/)、[Spring系列主要项目](https://spring.io/projects)、[Spring官网指南](https://spring.io/guides)、[官方文档](https://spring.io/docs/reference)
|
||||
- [spring-framework-reference](https://docs.spring.io/spring/docs/5.0.14.RELEASE/spring-framework-reference/index.html)
|
||||
- [Spring Framework 4.3.17.RELEASE API](https://docs.spring.io/spring/docs/4.3.17.RELEASE/javadoc-api/)
|
||||
|
||||
## 系统学习教程
|
||||
@ -72,7 +71,7 @@ Spring IOC的初始化过程:
|
||||
|
||||
### Spring源码阅读
|
||||
|
||||
阅读源码不仅可以加深我们对Spring设计思想的理解,提高自己的编码水品,还可以让自己在面试中如鱼得水。下面的是Github上的一个开源的Spring源码阅读,大家有时间可以看一下,当然你如果有时间也可以自己慢慢研究源码。
|
||||
阅读源码不仅可以加深我们对Spring设计思想的理解,提高自己的编码水平,还可以让自己在面试中如鱼得水。下面的是Github上的一个开源的Spring源码阅读,大家有时间可以看一下,当然你如果有时间也可以自己慢慢研究源码。
|
||||
|
||||
- [spring-core](https://github.com/seaswalker/Spring/blob/master/note/Spring.md)
|
||||
- [spring-aop](https://github.com/seaswalker/Spring/blob/master/note/spring-aop.md)
|
||||
|
||||
@ -1,27 +1,6 @@
|
||||
<!-- TOC -->
|
||||
这篇文章主要是想通过一些问题,加深大家对于 Spring 的理解,所以不会涉及太多的代码!这篇文章整理了挺长时间,下面的很多问题我自己在使用 Spring 的过程中也并没有注意,自己也是临时查阅了很多资料和书籍补上的。网上也有一些很多关于 Spring 常见问题/面试题整理的文章,我感觉大部分都是互相 copy,而且很多问题也不是很好,有些回答也存在问题。所以,自己花了一周的业余时间整理了一下,希望对大家有帮助。
|
||||
|
||||
- [什么是 Spring 框架?](#什么是-spring-框架)
|
||||
- [列举一些重要的Spring模块?](#列举一些重要的spring模块)
|
||||
- [谈谈自己对于 Spring IoC 和 AOP 的理解](#谈谈自己对于-spring-ioc-和-aop-的理解)
|
||||
- [Spring AOP 和 AspectJ AOP 有什么区别?](#spring-aop-和-aspectj-aop-有什么区别)
|
||||
- [Spring 中的 bean 的作用域有哪些?](#spring-中的-bean-的作用域有哪些)
|
||||
- [Spring 中的单例 bean 的线程安全问题了解吗?](#spring-中的单例-bean-的线程安全问题了解吗)
|
||||
- [Spring 中的 bean 生命周期?](#spring-中的-bean-生命周期)
|
||||
- [说说自己对于 Spring MVC 了解?](#说说自己对于-spring-mvc-了解)
|
||||
- [SpringMVC 工作原理了解吗?](#springmvc-工作原理了解吗)
|
||||
- [Spring 框架中用到了哪些设计模式?](#spring-框架中用到了哪些设计模式)
|
||||
- [@Component 和 @Bean 的区别是什么?](#component-和-bean-的区别是什么)
|
||||
- [将一个类声明为Spring的 bean 的注解有哪些?](#将一个类声明为spring的-bean-的注解有哪些)
|
||||
- [Spring 管理事务的方式有几种?](#spring-管理事务的方式有几种)
|
||||
- [Spring 事务中的隔离级别有哪几种?](#spring-事务中的隔离级别有哪几种)
|
||||
- [Spring 事务中哪几种事务传播行为?](#spring-事务中哪几种事务传播行为)
|
||||
- [参考](#参考)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
这篇文章主要是想通过一些问题,加深大家对于 Spring 的理解,所以不会涉及太多的代码!这篇文章整理了挺长时间,下面的很多问题我自己在使用 Spring 的过程中也并没有注意,自己也是临时查阅了很多资料和书籍补上的。网上也有一些很多关于 Spring 常见问题/面试题整理的文章,我感觉大部分都是互相 copy,而且很多问题也不是很汗,有些回答也存在问题。所以,自己花了一周的业余时间整理了一下,希望对大家有帮助。
|
||||
|
||||
## 什么是 Spring 框架?
|
||||
## 1. 什么是 Spring 框架?
|
||||
|
||||
Spring 是一种轻量级开发框架,旨在提高开发人员的开发效率以及系统的可维护性。Spring 官网:<https://spring.io/>。
|
||||
|
||||
@ -36,41 +15,71 @@ Spring 官网列出的 Spring 的 6 个特征:
|
||||
- **集成** :远程处理,JMS,JCA,JMX,电子邮件,任务,调度,缓存。
|
||||
- **语言** :Kotlin,Groovy,动态语言。
|
||||
|
||||
## 列举一些重要的Spring模块?
|
||||
## 2. 列举一些重要的Spring模块?
|
||||
|
||||
下图对应的是 Spring4.x 版本。目前最新的5.x版本中 Web 模块的 Portlet 组件已经被废弃掉,同时增加了用于异步响应式处理的 WebFlux 组件。
|
||||
|
||||

|
||||
|
||||
- **Spring Core:** 基础,可以说 Spring 其他所有的功能都需要依赖于该类库。主要提供 IOC 依赖注入功能。
|
||||
- **Spring Aspects ** : 该模块为与AspectJ的集成提供支持。
|
||||
- **Spring AOP** :提供了面向方面的编程实现。
|
||||
- **Spring Core:** 基础,可以说 Spring 其他所有的功能都需要依赖于该类库。主要提供 IoC 依赖注入功能。
|
||||
- **Spring Aspects** : 该模块为与AspectJ的集成提供支持。
|
||||
- **Spring AOP** :提供了面向切面的编程实现。
|
||||
- **Spring JDBC** : Java数据库连接。
|
||||
- **Spring JMS** :Java消息服务。
|
||||
- **Spring ORM** : 用于支持Hibernate等ORM工具。
|
||||
- **Spring Web** : 为创建Web应用程序提供支持。
|
||||
- **Spring Test** : 提供了对 JUnit 和 TestNG 测试的支持。
|
||||
|
||||
## 谈谈自己对于 Spring IoC 和 AOP 的理解
|
||||
## 3. @RestController vs @Controller
|
||||
|
||||
### IoC
|
||||
**`Controller` 返回一个页面**
|
||||
|
||||
单独使用 `@Controller` 不加 `@ResponseBody`的话一般使用在要返回一个视图的情况,这种情况属于比较传统的Spring MVC 的应用,对应于前后端不分离的情况。
|
||||
|
||||

|
||||
|
||||
**`@RestController` 返回JSON 或 XML 形式数据**
|
||||
|
||||
但`@RestController`只返回对象,对象数据直接以 JSON 或 XML 形式写入 HTTP 响应(Response)中,这种情况属于 RESTful Web服务,这也是目前日常开发所接触的最常用的情况(前后端分离)。
|
||||
|
||||
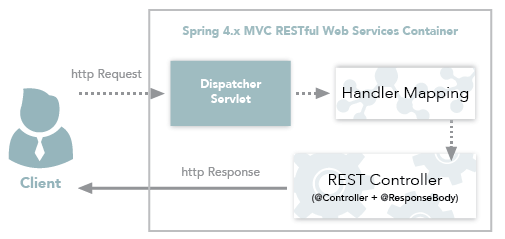
|
||||
|
||||
**`@Controller +@ResponseBody` 返回JSON 或 XML 形式数据**
|
||||
|
||||
如果你需要在Spring4之前开发 RESTful Web服务的话,你需要使用`@Controller` 并结合`@ResponseBody`注解,也就是说`@Controller` +`@ResponseBody`= `@RestController`(Spring 4 之后新加的注解)。
|
||||
|
||||
> `@ResponseBody` 注解的作用是将 `Controller` 的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到HTTP 响应(Response)对象的 body 中,通常用来返回 JSON 或者 XML 数据,返回 JSON 数据的情况比较多。
|
||||
|
||||

|
||||
|
||||
Reference:
|
||||
|
||||
- https://dzone.com/articles/spring-framework-restcontroller-vs-controller(图片来源)
|
||||
- https://javarevisited.blogspot.com/2017/08/difference-between-restcontroller-and-controller-annotations-spring-mvc-rest.html?m=1
|
||||
|
||||
## 4. Spring IOC & AOP
|
||||
|
||||
### 4.1 谈谈自己对于 Spring IoC 和 AOP 的理解
|
||||
|
||||
#### IoC
|
||||
|
||||
IoC(Inverse of Control:控制反转)是一种**设计思想**,就是 **将原本在程序中手动创建对象的控制权,交由Spring框架来管理。** IoC 在其他语言中也有应用,并非 Spirng 特有。 **IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个Map(key,value),Map 中存放的是各种对象。**
|
||||
|
||||
将对象之间的相互依赖关系交给 IOC 容器来管理,并由 IOC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 **IOC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。** 在实际项目中一个 Service 类可能有几百甚至上千个类作为它的底层,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IOC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
|
||||
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 **IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。** 在实际项目中一个 Service 类可能有几百甚至上千个类作为它的底层,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
|
||||
|
||||
Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉得 XML 文件来配置不太好,于是 SpringBoot 注解配置就慢慢开始流行起来。
|
||||
|
||||
推荐阅读:https://www.zhihu.com/question/23277575/answer/169698662
|
||||
|
||||
**Spring IOC的初始化过程:**
|
||||

|
||||
**Spring IoC的初始化过程:**
|
||||
|
||||
IOC源码阅读
|
||||

|
||||
|
||||
IoC源码阅读
|
||||
|
||||
- https://javadoop.com/post/spring-ioc
|
||||
|
||||
### AOP
|
||||
#### AOP
|
||||
|
||||
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,**却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来**,便于**减少系统的重复代码**,**降低模块间的耦合度**,并**有利于未来的可拓展性和可维护性**。
|
||||
|
||||
@ -82,7 +91,7 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
|
||||
|
||||
使用 AOP 之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
|
||||
|
||||
## Spring AOP 和 AspectJ AOP 有什么区别?
|
||||
### 4.2 Spring AOP 和 AspectJ AOP 有什么区别?
|
||||
|
||||
**Spring AOP 属于运行时增强,而 AspectJ 是编译时增强。** Spring AOP 基于代理(Proxying),而 AspectJ 基于字节码操作(Bytecode Manipulation)。
|
||||
|
||||
@ -90,7 +99,9 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
|
||||
|
||||
如果我们的切面比较少,那么两者性能差异不大。但是,当切面太多的话,最好选择 AspectJ ,它比Spring AOP 快很多。
|
||||
|
||||
## Spring 中的 bean 的作用域有哪些?
|
||||
## 5. Spring bean
|
||||
|
||||
### 5.1 Spring 中的 bean 的作用域有哪些?
|
||||
|
||||
- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
|
||||
- prototype : 每次请求都会创建一个新的 bean 实例。
|
||||
@ -98,7 +109,7 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
|
||||
- session : 每一次HTTP请求都会产生一个新的 bean,该bean仅在当前 HTTP session 内有效。
|
||||
- global-session: 全局session作用域,仅仅在基于portlet的web应用中才有意义,Spring5已经没有了。Portlet是能够生成语义代码(例如:HTML)片段的小型Java Web插件。它们基于portlet容器,可以像servlet一样处理HTTP请求。但是,与 servlet 不同,每个 portlet 都有不同的会话
|
||||
|
||||
## Spring 中的单例 bean 的线程安全问题了解吗?
|
||||
### 5.2 Spring 中的单例 bean 的线程安全问题了解吗?
|
||||
|
||||
大部分时候我们并没有在系统中使用多线程,所以很少有人会关注这个问题。单例 bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
|
||||
|
||||
@ -108,79 +119,8 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
|
||||
|
||||
2. 在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在 ThreadLocal 中(推荐的一种方式)。
|
||||
|
||||
## Spring 中的 bean 生命周期?
|
||||
|
||||
这部分网上有很多文章都讲到了,下面的内容整理自:<https://yemengying.com/2016/07/14/spring-bean-life-cycle/> ,除了这篇文章,再推荐一篇很不错的文章 :<https://www.cnblogs.com/zrtqsk/p/3735273.html> 。
|
||||
|
||||
- Bean 容器找到配置文件中 Spring Bean 的定义。
|
||||
- Bean 容器利用 Java Reflection API 创建一个Bean的实例。
|
||||
- 如果涉及到一些属性值 利用 `set()`方法设置一些属性值。
|
||||
- 如果 Bean 实现了 `BeanNameAware` 接口,调用 `setBeanName()`方法,传入Bean的名字。
|
||||
- 如果 Bean 实现了 `BeanClassLoaderAware` 接口,调用 `setBeanClassLoader()`方法,传入 `ClassLoader`对象的实例。
|
||||
- 如果Bean实现了 `BeanFactoryAware` 接口,调用 `setBeanClassLoader()`方法,传入 `ClassLoade` r对象的实例。
|
||||
- 与上面的类似,如果实现了其他 `*.Aware`接口,就调用相应的方法。
|
||||
- 如果有和加载这个 Bean 的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessBeforeInitialization()` 方法
|
||||
- 如果Bean实现了`InitializingBean`接口,执行`afterPropertiesSet()`方法。
|
||||
- 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
|
||||
- 如果有和加载这个 Bean的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessAfterInitialization()` 方法
|
||||
- 当要销毁 Bean 的时候,如果 Bean 实现了 `DisposableBean` 接口,执行 `destroy()` 方法。
|
||||
- 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
|
||||
|
||||
图示:
|
||||
|
||||
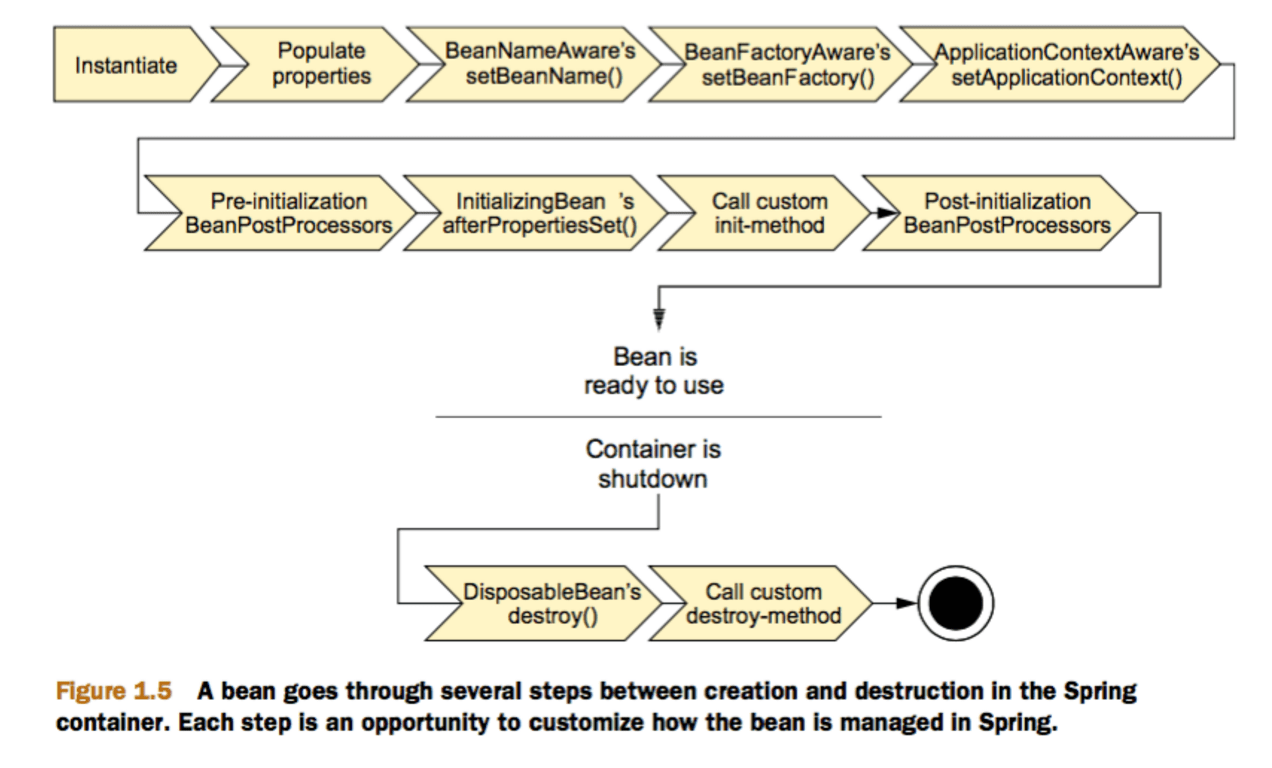
|
||||
|
||||
与之比较类似的中文版本:
|
||||
|
||||
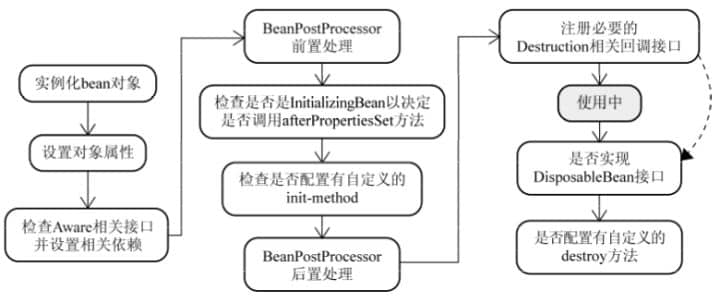
|
||||
|
||||
## 说说自己对于 Spring MVC 了解?
|
||||
|
||||
谈到这个问题,我们不得不提提之前 Model1 和 Model2 这两个没有 Spring MVC 的时代。
|
||||
|
||||
- **Model1 时代** : 很多学 Java 后端比较晚的朋友可能并没有接触过 Model1 模式下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。这个模式下 JSP 即是控制层又是表现层。显而易见,这种模式存在很多问题。比如①将控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;②前端和后端相互依赖,难以进行测试并且开发效率极低;
|
||||
- **Model2 时代** :学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+ JSP(View,)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。Model:系统涉及的数据,也就是 dao 和 bean。View:展示模型中的数据,只是用来展示。Controller:处理用户请求都发送给 ,返回数据给 JSP 并展示给用户。
|
||||
|
||||
Model2 模式下还存在很多问题,Model2的抽象和封装程度还远远不够,使用Model2进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和复用性。于是很多JavaWeb开发相关的 MVC 框架营运而生比如Struts2,但是 Struts2 比较笨重。随着 Spring 轻量级开发框架的流行,Spring 生态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相比于 Struts2 , Spring MVC 使用更加简单和方便,开发效率更高,并且 Spring MVC 运行速度更快。
|
||||
|
||||
MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring MVC 可以帮助我们进行更简洁的Web层的开发,并且它天生与 Spring 框架集成。Spring MVC 下我们一般把后端项目分为 Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台页面)。
|
||||
|
||||
**Spring MVC 的简单原理图如下:**
|
||||
|
||||
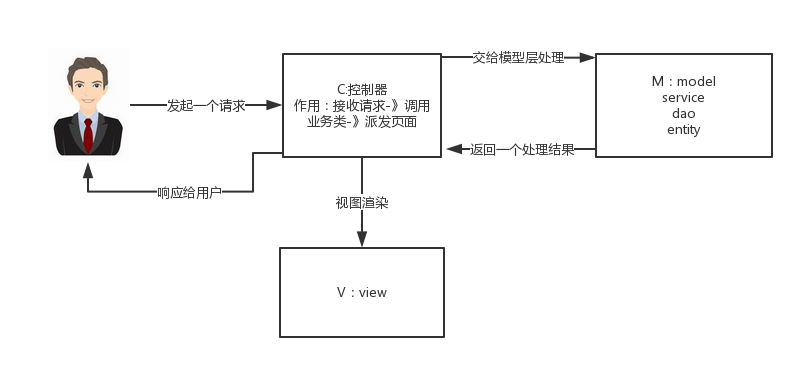
|
||||
|
||||
## SpringMVC 工作原理了解吗?
|
||||
|
||||
**原理如下图所示:**
|
||||
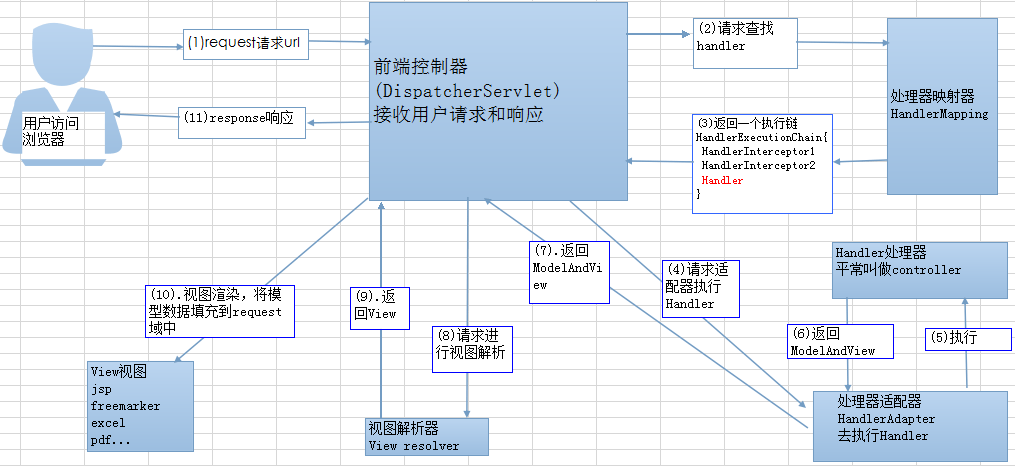
|
||||
|
||||
上图的一个笔误的小问题:Spring MVC 的入口函数也就是前端控制器 `DispatcherServlet` 的作用是接收请求,响应结果。
|
||||
|
||||
**流程说明(重要):**
|
||||
|
||||
1. 客户端(浏览器)发送请求,直接请求到 `DispatcherServlet`。
|
||||
2. `DispatcherServlet` 根据请求信息调用 `HandlerMapping`,解析请求对应的 `Handler`。
|
||||
3. 解析到对应的 `Handler`(也就是我们平常说的 `Controller` 控制器)后,开始由 `HandlerAdapter` 适配器处理。
|
||||
4. `HandlerAdapter` 会根据 `Handler `来调用真正的处理器开处理请求,并处理相应的业务逻辑。
|
||||
5. 处理器处理完业务后,会返回一个 `ModelAndView` 对象,`Model` 是返回的数据对象,`View` 是个逻辑上的 `View`。
|
||||
6. `ViewResolver` 会根据逻辑 `View` 查找实际的 `View`。
|
||||
7. `DispaterServlet` 把返回的 `Model` 传给 `View`(视图渲染)。
|
||||
8. 把 `View` 返回给请求者(浏览器)
|
||||
|
||||
## Spring 框架中用到了哪些设计模式?
|
||||
|
||||
关于下面一些设计模式的详细介绍,可以看笔主前段时间的原创文章[《面试官:“谈谈Spring中都用到了那些设计模式?”。》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485303&idx=1&sn=9e4626a1e3f001f9b0d84a6fa0cff04a&chksm=cea248bcf9d5c1aaf48b67cc52bac74eb29d6037848d6cf213b0e5466f2d1fda970db700ba41&token=255050878&lang=zh_CN#rd) 。
|
||||
|
||||
- **工厂设计模式** : Spring使用工厂模式通过 `BeanFactory`、`ApplicationContext` 创建 bean 对象。
|
||||
- **代理设计模式** : Spring AOP 功能的实现。
|
||||
- **单例设计模式** : Spring 中的 Bean 默认都是单例的。
|
||||
- **模板方法模式** : Spring 中 `jdbcTemplate`、`hibernateTemplate` 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
|
||||
- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
|
||||
- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
|
||||
- **适配器模式** :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
|
||||
- ......
|
||||
|
||||
## @Component 和 @Bean 的区别是什么?
|
||||
### 5.3 @Component 和 @Bean 的区别是什么?
|
||||
|
||||
1. 作用对象不同: `@Component` 注解作用于类,而`@Bean`注解作用于方法。
|
||||
2. `@Component`通常是通过类路径扫描来自动侦测以及自动装配到Spring容器中(我们可以使用 `@ComponentScan` 注解定义要扫描的路径从中找出标识了需要装配的类自动装配到 Spring 的 bean 容器中)。`@Bean` 注解通常是我们在标有该注解的方法中定义产生这个 bean,`@Bean`告诉了Spring这是某个类的示例,当我需要用它的时候还给我。
|
||||
@ -223,16 +163,92 @@ public OneService getService(status) {
|
||||
}
|
||||
```
|
||||
|
||||
## 将一个类声明为Spring的 bean 的注解有哪些?
|
||||
### 5.4 将一个类声明为Spring的 bean 的注解有哪些?
|
||||
|
||||
我们一般使用 `@Autowired` 注解自动装配 bean,要想把类标识成可用于 `@Autowired` 注解自动装配的 bean 的类,采用以下注解可实现:
|
||||
|
||||
- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于拿个层,可以使用`@Component` 注解标注。
|
||||
- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于哪个层,可以使用`@Component` 注解标注。
|
||||
- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
|
||||
- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao层。
|
||||
- `@Controller` : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
|
||||
|
||||
## Spring 管理事务的方式有几种?
|
||||
### 5.5 Spring 中的 bean 生命周期?
|
||||
|
||||
这部分网上有很多文章都讲到了,下面的内容整理自:<https://yemengying.com/2016/07/14/spring-bean-life-cycle/> ,除了这篇文章,再推荐一篇很不错的文章 :<https://www.cnblogs.com/zrtqsk/p/3735273.html> 。
|
||||
|
||||
- Bean 容器找到配置文件中 Spring Bean 的定义。
|
||||
- Bean 容器利用 Java Reflection API 创建一个Bean的实例。
|
||||
- 如果涉及到一些属性值 利用 `set()`方法设置一些属性值。
|
||||
- 如果 Bean 实现了 `BeanNameAware` 接口,调用 `setBeanName()`方法,传入Bean的名字。
|
||||
- 如果 Bean 实现了 `BeanClassLoaderAware` 接口,调用 `setBeanClassLoader()`方法,传入 `ClassLoader`对象的实例。
|
||||
- 如果Bean实现了 `BeanFactoryAware` 接口,调用 `setBeanClassLoader()`方法,传入 `ClassLoade` r对象的实例。
|
||||
- 与上面的类似,如果实现了其他 `*.Aware`接口,就调用相应的方法。
|
||||
- 如果有和加载这个 Bean 的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessBeforeInitialization()` 方法
|
||||
- 如果Bean实现了`InitializingBean`接口,执行`afterPropertiesSet()`方法。
|
||||
- 如果 Bean 在配置文件中的定义包含 init-method 属性,执行指定的方法。
|
||||
- 如果有和加载这个 Bean的 Spring 容器相关的 `BeanPostProcessor` 对象,执行`postProcessAfterInitialization()` 方法
|
||||
- 当要销毁 Bean 的时候,如果 Bean 实现了 `DisposableBean` 接口,执行 `destroy()` 方法。
|
||||
- 当要销毁 Bean 的时候,如果 Bean 在配置文件中的定义包含 destroy-method 属性,执行指定的方法。
|
||||
|
||||
图示:
|
||||
|
||||

|
||||
|
||||
与之比较类似的中文版本:
|
||||
|
||||

|
||||
|
||||
## 6. Spring MVC
|
||||
|
||||
### 6.1 说说自己对于 Spring MVC 了解?
|
||||
|
||||
谈到这个问题,我们不得不提提之前 Model1 和 Model2 这两个没有 Spring MVC 的时代。
|
||||
|
||||
- **Model1 时代** : 很多学 Java 后端比较晚的朋友可能并没有接触过 Model1 模式下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。这个模式下 JSP 即是控制层又是表现层。显而易见,这种模式存在很多问题。比如①将控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;②前端和后端相互依赖,难以进行测试并且开发效率极低;
|
||||
- **Model2 时代** :学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+ JSP(View,)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。Model:系统涉及的数据,也就是 dao 和 bean。View:展示模型中的数据,只是用来展示。Controller:处理用户请求都发送给 ,返回数据给 JSP 并展示给用户。
|
||||
|
||||
Model2 模式下还存在很多问题,Model2的抽象和封装程度还远远不够,使用Model2进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和复用性。于是很多JavaWeb开发相关的 MVC 框架应运而生比如Struts2,但是 Struts2 比较笨重。随着 Spring 轻量级开发框架的流行,Spring 生态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相比于 Struts2 , Spring MVC 使用更加简单和方便,开发效率更高,并且 Spring MVC 运行速度更快。
|
||||
|
||||
MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring MVC 可以帮助我们进行更简洁的Web层的开发,并且它天生与 Spring 框架集成。Spring MVC 下我们一般把后端项目分为 Service层(处理业务)、Dao层(数据库操作)、Entity层(实体类)、Controller层(控制层,返回数据给前台页面)。
|
||||
|
||||
**Spring MVC 的简单原理图如下:**
|
||||
|
||||

|
||||
|
||||
### 6.2 SpringMVC 工作原理了解吗?
|
||||
|
||||
**原理如下图所示:**
|
||||

|
||||
|
||||
上图的一个笔误的小问题:Spring MVC 的入口函数也就是前端控制器 `DispatcherServlet` 的作用是接收请求,响应结果。
|
||||
|
||||
**流程说明(重要):**
|
||||
|
||||
1. 客户端(浏览器)发送请求,直接请求到 `DispatcherServlet`。
|
||||
2. `DispatcherServlet` 根据请求信息调用 `HandlerMapping`,解析请求对应的 `Handler`。
|
||||
3. 解析到对应的 `Handler`(也就是我们平常说的 `Controller` 控制器)后,开始由 `HandlerAdapter` 适配器处理。
|
||||
4. `HandlerAdapter` 会根据 `Handler `来调用真正的处理器开处理请求,并处理相应的业务逻辑。
|
||||
5. 处理器处理完业务后,会返回一个 `ModelAndView` 对象,`Model` 是返回的数据对象,`View` 是个逻辑上的 `View`。
|
||||
6. `ViewResolver` 会根据逻辑 `View` 查找实际的 `View`。
|
||||
7. `DispaterServlet` 把返回的 `Model` 传给 `View`(视图渲染)。
|
||||
8. 把 `View` 返回给请求者(浏览器)
|
||||
|
||||
## 7. Spring 框架中用到了哪些设计模式?
|
||||
|
||||
关于下面一些设计模式的详细介绍,可以看笔主前段时间的原创文章[《面试官:“谈谈Spring中都用到了那些设计模式?”。》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485303&idx=1&sn=9e4626a1e3f001f9b0d84a6fa0cff04a&chksm=cea248bcf9d5c1aaf48b67cc52bac74eb29d6037848d6cf213b0e5466f2d1fda970db700ba41&token=255050878&lang=zh_CN#rd) 。
|
||||
|
||||
- **工厂设计模式** : Spring使用工厂模式通过 `BeanFactory`、`ApplicationContext` 创建 bean 对象。
|
||||
- **代理设计模式** : Spring AOP 功能的实现。
|
||||
- **单例设计模式** : Spring 中的 Bean 默认都是单例的。
|
||||
- **模板方法模式** : Spring 中 `jdbcTemplate`、`hibernateTemplate` 等以 Template 结尾的对数据库操作的类,它们就使用到了模板模式。
|
||||
- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
|
||||
- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
|
||||
- **适配器模式** :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
|
||||
- ......
|
||||
|
||||
## 8. Spring 事务
|
||||
|
||||
### 8.1 Spring 管理事务的方式有几种?
|
||||
|
||||
1. 编程式事务,在代码中硬编码。(不推荐使用)
|
||||
2. 声明式事务,在配置文件中配置(推荐使用)
|
||||
@ -242,7 +258,7 @@ public OneService getService(status) {
|
||||
1. 基于XML的声明式事务
|
||||
2. 基于注解的声明式事务
|
||||
|
||||
## Spring 事务中的隔离级别有哪几种?
|
||||
### 8.2 Spring 事务中的隔离级别有哪几种?
|
||||
|
||||
**TransactionDefinition 接口中定义了五个表示隔离级别的常量:**
|
||||
|
||||
@ -252,7 +268,7 @@ public OneService getService(status) {
|
||||
- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
|
||||
- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
|
||||
|
||||
## Spring 事务中哪几种事务传播行为?
|
||||
### 8.3 Spring 事务中哪几种事务传播行为?
|
||||
|
||||
**支持当前事务的情况:**
|
||||
|
||||
@ -270,17 +286,65 @@ public OneService getService(status) {
|
||||
|
||||
- **TransactionDefinition.PROPAGATION_NESTED:** 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
|
||||
|
||||
### 8.4 @Transactional(rollbackFor = Exception.class)注解了解吗?
|
||||
|
||||
我们知道:Exception分为运行时异常RuntimeException和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
|
||||
|
||||
当`@Transactional`注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
|
||||
|
||||
在`@Transactional`注解中如果不配置`rollbackFor`属性,那么事物只会在遇到`RuntimeException`的时候才会回滚,加上`rollbackFor=Exception.class`,可以让事物在遇到非运行时异常时也回滚。
|
||||
|
||||
## 9. JPA
|
||||
|
||||
### 9.1 如何使用JPA在数据库中非持久化一个字段?
|
||||
|
||||
假如我们有有下面一个类:
|
||||
|
||||
```java
|
||||
Entity(name="USER")
|
||||
public class User {
|
||||
|
||||
@Id
|
||||
@GeneratedValue(strategy = GenerationType.AUTO)
|
||||
@Column(name = "ID")
|
||||
private Long id;
|
||||
|
||||
@Column(name="USER_NAME")
|
||||
private String userName;
|
||||
|
||||
@Column(name="PASSWORD")
|
||||
private String password;
|
||||
|
||||
private String secrect;
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
如果我们想让`secrect` 这个字段不被持久化,也就是不被数据库存储怎么办?我们可以采用下面几种方法:
|
||||
|
||||
```java
|
||||
static String transient1; // not persistent because of static
|
||||
final String transient2 = “Satish”; // not persistent because of final
|
||||
transient String transient3; // not persistent because of transient
|
||||
@Transient
|
||||
String transient4; // not persistent because of @Transient
|
||||
```
|
||||
|
||||
一般使用后面两种方式比较多,我个人使用注解的方式比较多。
|
||||
|
||||
|
||||
## 参考
|
||||
|
||||
- 《Spring 技术内幕》
|
||||
- <http://www.cnblogs.com/wmyskxz/p/8820371.html>
|
||||
- <https://www.journaldev.com/2696/spring-interview-questions-and-answers>
|
||||
- <https://www.edureka.co/blog/interview-questions/spring-interview-questions/>
|
||||
- https://www.cnblogs.com/clwydjgs/p/9317849.html
|
||||
- <https://howtodoinjava.com/interview-questions/top-spring-interview-questions-with-answers/>
|
||||
- <http://www.tomaszezula.com/2014/02/09/spring-series-part-5-component-vs-bean/>
|
||||
- <https://stackoverflow.com/questions/34172888/difference-between-bean-and-autowired>
|
||||
|
||||
### 公众号
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
@ -288,4 +352,4 @@ public OneService getService(status) {
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
|
||||
110
docs/system-design/framework/spring/springboot-questions.md
Normal file
@ -0,0 +1,110 @@
|
||||
|
||||
|
||||
> 本文由JavaGuide整理翻译自(做了适当删减和修改):
|
||||
>
|
||||
> - https://www.javaguides.net/2018/11/spring-boot-interview-questions-and-answers.html
|
||||
> - https://www.algrim.co/posts/101-spring-boot-interview-questions
|
||||
|
||||
### 1. 什么是 Spring Boot?
|
||||
|
||||
首先,重要的是要理解 Spring Boot 并不是一个框架,它是一种创建独立应用程序的更简单方法,只需要很少或没有配置(相比于 Spring 来说)。Spring Boot最好的特性之一是它利用现有的 Spring 项目和第三方项目来开发适合生产的应用程序。
|
||||
|
||||
### 2. 说出使用Spring Boot的主要优点
|
||||
|
||||
1. 开发基于 Spring 的应用程序很容易。
|
||||
2. Spring Boot 项目所需的开发或工程时间明显减少,通常会提高整体生产力。
|
||||
3. Spring Boot不需要编写大量样板代码、XML配置和注释。
|
||||
4. Spring引导应用程序可以很容易地与Spring生态系统集成,如Spring JDBC、Spring ORM、Spring Data、Spring Security等。
|
||||
5. Spring Boot遵循“固执己见的默认配置”,以减少开发工作(默认配置可以修改)。
|
||||
6. Spring Boot 应用程序提供嵌入式HTTP服务器,如Tomcat和Jetty,可以轻松地开发和测试web应用程序。(这点很赞!普通运行Java程序的方式就能运行基于Spring Boot web 项目,省事很多)
|
||||
7. Spring Boot提供命令行接口(CLI)工具,用于开发和测试Spring Boot应用程序,如Java或Groovy。
|
||||
8. Spring Boot提供了多种插件,可以使用内置工具(如Maven和Gradle)开发和测试Spring Boot应用程序。
|
||||
|
||||
### 3. 为什么需要Spring Boot?
|
||||
|
||||
Spring Framework旨在简化J2EE企业应用程序开发。Spring Boot Framework旨在简化Spring开发。
|
||||
|
||||
|
||||
|
||||
### 4. 什么是 Spring Boot Starters?
|
||||
|
||||
Spring Boot Starters 是一系列依赖关系的集合,因为它的存在,项目的依赖之间的关系对我们来说变的更加简单了。举个例子:在没有Spring Boot Starters之前,我们开发REST服务或Web应用程序时; 我们需要使用像Spring MVC,Tomcat和Jackson这样的库,这些依赖我们需要手动一个一个添加。但是,有了 Spring Boot Starters 我们只需要一个只需添加一个**spring-boot-starter-web**一个依赖就可以了,这个依赖包含的字依赖中包含了我们开发REST 服务需要的所有依赖。
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### 如何在Spring Boot应用程序中使用Jetty而不是Tomcat?
|
||||
|
||||
Spring Boot Web starter使用Tomcat作为默认的嵌入式servlet容器, 如果你想使用 Jetty 的话只需要修改pom.xml(Maven)或者build.gradle(Gradle)就可以了。
|
||||
|
||||
**Maven:**
|
||||
|
||||
```xml
|
||||
<!--从Web启动器依赖中排除Tomcat-->
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-web</artifactId>
|
||||
<exclusions>
|
||||
<exclusion>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-tomcat</artifactId>
|
||||
</exclusion>
|
||||
</exclusions>
|
||||
</dependency>
|
||||
<!--添加Jetty依赖-->
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-jetty</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
**Gradle:**
|
||||
|
||||
```groovy
|
||||
compile("org.springframework.boot:spring-boot-starter-web") {
|
||||
exclude group: 'org.springframework.boot', module: 'spring-boot-starter-tomcat'
|
||||
}
|
||||
compile("org.springframework.boot:spring-boot-starter-jetty")
|
||||
```
|
||||
|
||||
说个题外话,从上面可以看出使用 Gradle 更加简洁明了,但是国内目前还是 Maven 使用的多一点,我个人觉得 Gradle 在很多方面都要好很多。
|
||||
|
||||
### 介绍一下@SpringBootApplication注解
|
||||
|
||||
```java
|
||||
package org.springframework.boot.autoconfigure;
|
||||
@Target(ElementType.TYPE)
|
||||
@Retention(RetentionPolicy.RUNTIME)
|
||||
@Documented
|
||||
@Inherited
|
||||
@SpringBootConfiguration
|
||||
@EnableAutoConfiguration
|
||||
@ComponentScan(excludeFilters = {
|
||||
@Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
|
||||
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
|
||||
public @interface SpringBootApplication {
|
||||
......
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
package org.springframework.boot;
|
||||
@Target(ElementType.TYPE)
|
||||
@Retention(RetentionPolicy.RUNTIME)
|
||||
@Documented
|
||||
@Configuration
|
||||
public @interface SpringBootConfiguration {
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
可以看出大概可以把 `@SpringBootApplication `看作是 `@Configuration`、`@EnableAutoConfiguration`、`@ComponentScan ` 注解的集合。根据 SpringBoot官网,这三个注解的作用分别是:
|
||||
|
||||
- `@EnableAutoConfiguration`:启用 SpringBoot 的自动配置机制
|
||||
- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的bean,注解默认会扫描该类所在的包下所有的类。
|
||||
- `@Configuration`:允许在上下文中注册额外的bean或导入其他配置类
|
||||
|
||||
@ -3,30 +3,30 @@
|
||||
[分布式系统的经典基础理论](https://blog.csdn.net/qq_34337272/article/details/80444032)
|
||||
|
||||
本文主要是简单的介绍了三个常见的概念: **分布式系统设计理念** 、 **CAP定理** 、 **BASE理论** ,关于分布式系统的还有很多很多东西。
|
||||

|
||||

|
||||
|
||||
- ### 二 分布式事务
|
||||
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。以上是百度百科的解释,简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
|
||||
* [深入理解分布式事务](http://www.codeceo.com/article/distributed-transaction.html)
|
||||
* [分布式事务?No, 最终一致性](https://zhuanlan.zhihu.com/p/25933039)
|
||||
* [聊聊分布式事务,再说说解决方案](https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html)
|
||||
|
||||
|
||||
|
||||
- ### 三 分布式系统一致性
|
||||
[分布式服务化系统一致性的“最佳实干”](https://www.jianshu.com/p/1156151e20c8)
|
||||
|
||||
- ### 四 一致性协议/算法
|
||||
早在1898年就诞生了著名的 **Paxos经典算法** (**Zookeeper就采用了Paxos算法的近亲兄弟Zab算法**),但由于Paxos算法非常难以理解、实现、排错。所以不断有人尝试简化这一算法,直到2013年才有了重大突破:斯坦福的Diego Ongaro、John Ousterhout以易懂性为目标设计了新的一致性算法—— **Raft算法** ,并发布了对应的论文《In Search of an Understandable Consensus Algorithm》,到现在有十多种语言实现的Raft算法框架,较为出名的有以Go语言实现的Etcd,它的功能类似于Zookeeper,但采用了更为主流的Rest接口。
|
||||
* [图解 Paxos 一致性协议](http://blog.xiaohansong.com/2016/09/30/Paxos/)
|
||||
* [图解 Paxos 一致性协议](https://mp.weixin.qq.com/s?__biz=MzI0NDI0MTgyOA==&mid=2652037784&idx=1&sn=d8c4f31a9cfb49ee91d05bb374e5cdd5&chksm=f2868653c5f10f45fc4a64d15a5f4163c3e66c00ed2ad334fa93edb46671f42db6752001f6c0#rd)
|
||||
* [图解分布式协议-RAFT](http://ifeve.com/raft/)
|
||||
* [Zookeeper ZAB 协议分析](http://blog.xiaohansong.com/2016/08/25/zab/)
|
||||
* [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
|
||||
|
||||
- ### 五 分布式存储
|
||||
|
||||
**分布式存储系统将数据分散存储在多台独立的设备上**。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
|
||||
|
||||
* [分布式存储系统概要](http://witchiman.top/2017/05/05/distributed-system/)
|
||||
|
||||
|
||||
- ### 六 分布式计算
|
||||
|
||||
**所谓分布式计算是一门计算机科学,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。**
|
||||
|
||||
@ -112,7 +112,7 @@ Git 有三种状态,你的文件可能处于其中之一:
|
||||
2. **已修改(modified)**:已修改表示修改了文件,但还没保存到数据库中。
|
||||
3. **已暂存(staged)**:表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
|
||||
|
||||
由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directoty) **、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
|
||||
由此引入 Git 项目的三个工作区域的概念:**Git 仓库(.git directoty)**、**工作目录(Working Directory)** 以及 **暂存区域(Staging Area)** 。
|
||||
|
||||
<div align="center">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3areas.png" width="500px"/>
|
||||
@ -256,3 +256,4 @@ git push origin
|
||||
- [图解Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
|
||||
- [猴子都能懂得Git入门](https://backlog.com/git-tutorial/cn/intro/intro1_1.html)
|
||||
- https://git-scm.com/book/en/v2
|
||||
- [Generating a new SSH key and adding it to the ssh-agent](https://help.github.com/en/articles/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent)
|
||||
|
||||
209
docs/公众号历史文章汇总.md
Normal file
@ -0,0 +1,209 @@
|
||||
## 热文
|
||||
|
||||
|
||||
|
||||
- [盘点阿里巴巴 15 款开发者工具](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485159&idx=1&sn=c97c087c45ad6dfc0ef61d80a9d0f702&scene=21#wechat_redirect)
|
||||
- [蚂蚁金服2019实习生面经总结(已拿口头offer)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485147&idx=1&sn=90e525a83a451d8c20298a7ef2d35ab9&scene=21#wechat_redirect)
|
||||
- [一千行 MySQL 学习笔记](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485025&idx=1&sn=1f4e19fc77af28f6795feff6ce7465b9&scene=21#wechat_redirect)
|
||||
- [可能是把Java内存区域讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485068&idx=1&sn=c37267fe59978dbfcd6a9a54eee1c502&scene=21#wechat_redirect)
|
||||
- [搞定 JVM 垃圾回收就是这么简单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484877&idx=1&sn=f54d41b68f0cd6cc7c0348a2fddbda9f&chksm=cea24a06f9d5c3102bfef946ba6c7cc5df9a503ccb14b9b141c54e179617e4923c260c0b0a01&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [【原创】Java学习路线以及方法推荐](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485290&idx=1&sn=569fa9724aae83bff3a353aefc5b7f1c&scene=21#wechat_redirect)
|
||||
- [技术面试复习大纲](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485505&idx=1&sn=f7d916334c078bc3fdc2933f889b5016&chksm=cea2478af9d5ce9cafcfe9a053e49e84296d8b1929f79844bba59c8c3d8b56753f34a2c2f6a9&token=1701499214&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
## Java
|
||||
|
||||
### 必看书籍
|
||||
|
||||
- [Java学习必备书籍推荐终极版!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485113&idx=1&sn=e4dd1bb22778e4e9139bf29d98a7492b&chksm=cea24972f9d5c064e5b454b84b9bc0d42f4aec007f20f79b564398e6dec7c0cdcda0e64193b5&token=1482344439&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
### 基础
|
||||
|
||||
- [关于Java基础你不得不会的34个问题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485015&idx=1&sn=5daa243c3359b88fc88b951f9d08b273&chksm=cea2499cf9d5c08a7698559a2fc27078c6b35856bc2d3588172bf64708c115d4b35d3de80cd9&token=1913747689&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [剖析面试最常见问题之 Java 基础知识](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485173&idx=1&sn=9605f89ed0893b674d14b0c8cf4dc942&chksm=cea2493ef9d5c028a969bb89b53f48fbdd72b975319a844319e3111b15d5dbbc350d91ea5b5a&token=1667678311&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
### Java8新特性
|
||||
|
||||
- [Java 8 新特性最佳指南](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484744&idx=1&sn=9db31dca13d327678845054af75efb74&chksm=cea24a83f9d5c3956f4feb9956b068624ab2fdd6c4a75fe52d5df5dca356a016577301399548&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [看完这篇文章,别说自己不会用Lambda表达式了!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485425&idx=1&sn=3cc01bc7c42549b6b6aa62b3656e02d1&chksm=cea2483af9d5c12cd10174dac4465a631b14a6d6a09495b018a98e01c698e86368d26b3be03d&token=1667678311&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
### JVM
|
||||
|
||||
- [Java内存区域](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485068&idx=1&sn=c37267fe59978dbfcd6a9a54eee1c502&scene=21#wechat_redirect)
|
||||
- [垃圾回收](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484877&idx=1&sn=f54d41b68f0cd6cc7c0348a2fddbda9f&chksm=cea24a06f9d5c3102bfef946ba6c7cc5df9a503ccb14b9b141c54e179617e4923c260c0b0a01&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [谈Java类文件结构](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485250&idx=2&sn=33793bcce3f2ff31b83cf2f9c32df153&scene=21#wechat_redirect)
|
||||
- [类加载过程](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485264&idx=2&sn=8c97f7e7d7ad36bc50e713572dbd1529&scene=21#wechat_redirect)
|
||||
|
||||
### 并发编程
|
||||
|
||||
- [并发编程面试必备:JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484834&idx=1&sn=7d3835091af8125c13fc6db765f4c5bd&chksm=cea24a69f9d5c37ff88a8328214cb48b06afb9dc82e46cd924d2595f109ea28922212f9e653c&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484832&idx=1&sn=f902febd050eac59d67fc0804d7e1ad5&chksm=cea24a6bf9d5c37d6b505fe1d43e4fb709729149f1f77344b4a0f5956cab5020a2e102f2adf2&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [BATJ都爱问的多线程面试题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484831&idx=1&sn=e22d2832a436dbb94233272429d4c4c4&chksm=cea24a54f9d5c3420e96aa94e3d893f4cf825852fff0b4a7e4e241cc229f4666f3dc4d53955e&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [通俗易懂,JDK 并发容器总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484797&idx=1&sn=e28462eec497e38053d9fb9ba17ff022&chksm=cea24ab6f9d5c3a05b5ad36111e93d824ce964442366bc8add1cd77cb432057e4995592c8024&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
### 代码质量
|
||||
|
||||
- [八点建议助您写出优雅的Java代码](https://mp.weixin.qq.com/s/o3BGTdAa8VufcIKU0ScBqA)
|
||||
- [十分钟搞懂Java效率工具Lombok使用与原理](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=1667678311&lang=zh_CN#rd)
|
||||
- [如何写出让同事无法维护的代码?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485413&idx=2&sn=70336d94018ad93d67cfacb4aeceb01b&chksm=cea2482ef9d5c1382d8a009e2ecd680c3b6ac3c7c02810af8901970e69c431273113ca7e4447&token=1667678311&lang=zh_CN#rd)
|
||||
- [Code Review最佳实践](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485494&idx=1&sn=c7f160fd1bb13a20b887493003acbbf9&chksm=cea247fdf9d5ceebf3b98bd7c524d0ecc672d4bcb10a70fae90390abd862538aa3283c93375b&token=1701499214&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [后端开发必备的 RestFul API 知识](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485510&idx=1&sn=e9273322ae638c8465a606737109ab97&chksm=cea2478df9d5ce9b58b9ff1f1e2ecca99e961b911adcec3d5a579b41e01151160cfb2891d91b&token=1701499214&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
## 网络
|
||||
|
||||
- [搞定计算机网络面试,看这篇就够了(补充版)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484889&idx=1&sn=5f9e6f5c29f9514701c246573d15d9fa&chksm=cea24a12f9d5c3041efd5cf864eb69b76aea6ef9c000a72b16d54794aab97d4fb53515a77147&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
## 系统设计
|
||||
|
||||
### Spring
|
||||
|
||||
- [Spring常见问题总结(补充版)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485576&idx=1&sn=f993349f12650a68904e1d99d2465131&chksm=cea24743f9d5ce55ffe543a0feaf2c566382024b625b59283482da6ab0cbcf2a3c9dc5b64a53&token=2133161636&lang=zh_CN#rd)
|
||||
- [面试官:“谈谈Spring中都用到了那些设计模式?”。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485303&idx=1&sn=9e4626a1e3f001f9b0d84a6fa0cff04a&chksm=cea248bcf9d5c1aaf48b67cc52bac74eb29d6037848d6cf213b0e5466f2d1fda970db700ba41&token=1667678311&lang=zh_CN#rd)
|
||||
- [可能是最漂亮的Spring事务管理详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484943&idx=1&sn=46b9082af4ec223137df7d1c8303ca24&chksm=cea249c4f9d5c0d2b8212a17252cbfb74e5fbe5488b76d829827421c53332326d1ec360f5d63&token=1082669959&lang=zh_CN#rd)
|
||||
- [SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484846&idx=1&sn=490014ea65669c1a1e73e25d7b9fa569&chksm=cea24a65f9d5c373d31d6cdd61297db21de63462c1c03c34b7025a0d0b93f1182b2ad7e33cab&token=1082669959&lang=zh_CN#rd)
|
||||
- [Spring编程式和声明式事务实例讲解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484942&idx=1&sn=b0d9e6f1af243bbf7f34ede5a6d2277d&chksm=cea249c5f9d5c0d3da9206b753bb7734d47d8d8b43edcc02bdf6f139e34e1db512cf5ed32217&token=1082669959&lang=zh_CN#rd)
|
||||
- [一文轻松搞懂Spring中bean的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484865&idx=2&sn=178c6e64e6c12172e77efdd669eb86a7&chksm=cea24a0af9d5c31c389ae7817613a336f00c330021f73c90afe383c8caf6ea07a9e1f949c68d&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
### SpringBoot
|
||||
|
||||
- [超详细,新手都能看懂 !使用SpringBoot+Dubbo 搭建一个简单的分布式服务](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484809&idx=1&sn=a789eba40404e6501d51b24345b28906&chksm=cea24a42f9d5c3544babde7f33790fc54f02ebc2f589ce9fa116bbb9c7b0c0cfb1bc314d17de&token=1082669959&lang=zh_CN#rd)
|
||||
- [基于 SpringBoot2.0+优雅整合 SpringBoot+Mybatis](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484805&idx=2&sn=0e148af5baebae53b3fd365cff689046&chksm=cea24a4ef9d5c35862efc9c67b0619f7e8ade4b75e1001189ededccd8fd35ca5cd19fda074b9&token=1082669959&lang=zh_CN#rd)
|
||||
- [新手也能实现,基于SpirngBoot2.0+ 的 SpringBoot+Mybatis 多数据源配置](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484803&idx=1&sn=9179890db39721a59bb815b7f985ec2d&chksm=cea24a48f9d5c35e73d3df4b29d340e1a4c76d43b220c0f9535e77b43a74ff049ee7b89a4a38&token=1082669959&lang=zh_CN#rd)
|
||||
- [SpringBoot 整合 阿里云OSS 存储服务,快来免费搭建一个自己的图床](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484801&idx=1&sn=22d97f9c963d45820559d7226874e33f&chksm=cea24a4af9d5c35cac3177921801287b1ad983eabb6e18cf30302fc235b7f699401510ea2a59&token=1082669959&lang=zh_CN#rd)
|
||||
- [Spring Boot 实现热部署的一种简单方式](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485586&idx=2&sn=01788bf8c64de91d085a01c1f4f5159d&chksm=cea24759f9d5ce4fe914aa43e517f16b7f4066de3096be09d01500596ca63ad9f1eef4b8fffa&token=2133161636&lang=zh_CN#rd)
|
||||
- [SpringBoot 处理异常的几种常见姿势](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485568&idx=2&sn=c5ba880fd0c5d82e39531fa42cb036ac&chksm=cea2474bf9d5ce5dcbc6a5f6580198fdce4bc92ef577579183a729cb5d1430e4994720d59b34&token=2133161636&lang=zh_CN#rd)
|
||||
- [5分钟搞懂如何在Spring Boot中Schedule Tasks](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485563&idx=1&sn=7419341f04036a10b141b74624a3f8c9&chksm=cea247b0f9d5cea6440759e6d49b4e77d06f4c99470243a10c1463834e873ca90266413fbc92&token=2133161636&lang=zh_CN#rd)
|
||||
|
||||
### MyBatis
|
||||
|
||||
- [面试官:“谈谈MyBatis中都用到了那些设计模式?”。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485369&idx=1&sn=a493d646e126cd1c19ce9f1fc9c724c9&chksm=cea24872f9d5c16462d82f033699d7ad3177964100f8c8958ce9b8e0872e246f552ae6ac423f&token=1667678311&lang=zh_CN#rd)
|
||||
|
||||
## 数据库
|
||||
|
||||
### MySQL
|
||||
|
||||
- [MySQL知识点总结[修订版]](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485390&idx=1&sn=43511395093d2e0deb64f89c8af1805e&chksm=cea24805f9d5c113026292c7681238b1c65c09958588aa5c70e37249e384f5c965f87ef438ad&token=1667678311&lang=zh_CN#rd)
|
||||
- [【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484848&idx=1&sn=77a0e6e82944ec385f5df17e91ce3bf2&chksm=cea24a7bf9d5c36d4b289cccb017292f9f36da9f3c887fd2b93ecd6af021fcf30121ba09799f&token=1082669959&lang=zh_CN#rd)
|
||||
- [一条SQL语句在MySQL中如何执行的](https://mp.weixin.qq.com/s/QU4-RSqVC88xRyMA31khMg)
|
||||
- [一文带你轻松搞懂事务隔离级别(图文详解)](https://mp.weixin.qq.com/s/WhK3SrkMDTj1_o2zp64ArQ)
|
||||
- [详记一次MySQL千万级大表优化过程!](https://mp.weixin.qq.com/s/SbpM_q_-nIKJn7_TSmrW8A)
|
||||
|
||||
### Redis
|
||||
|
||||
- [史上最全Redis高可用技术解决方案大全](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484850&idx=1&sn=3238360bfa8105cf758dcf7354af2814&chksm=cea24a79f9d5c36fb2399aafa91d7fb2699b5006d8d037fe8aaf2e5577ff20ae322868b04a87&token=1082669959&lang=zh_CN#rd)
|
||||
- [redis 总结——重构版](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484858&idx=1&sn=8e222ea6115e0b69cac91af14d2caf36&chksm=cea24a71f9d5c367148dccec3d5ddecf5ecd8ea096b5c5ec32f22080e66ac3c343e99151c9e0&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
## 面试相关
|
||||
|
||||
- [面试中常见的几道智力题 来看看你会做几道?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484923&idx=1&sn=e1fd890a1a7290f996dc8d7ca4b2d599&chksm=cea24a30f9d5c326f5498929decb7b2d9e39d8806b74c823ccf46fe9fba778d5d9aa644292db&token=1082669959&lang=zh_CN#rd)
|
||||
- [面试中常见的几道智力题 来看看你会做几道(2)?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484917&idx=1&sn=8587b384b42927618067c0e3a56083a9&chksm=cea24a3ef9d5c328a5fd97441de1ccfaf42f9296e5f491b1fa4be9422431d6f26dac36a75e16&token=1082669959&lang=zh_CN#rd)
|
||||
- [[算法总结] 搞定 BAT 面试——几道常见的子符串算法题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484869&idx=1&sn=785d0dce653aa1abdbc542007da830e8&chksm=cea24a0ef9d5c31853ae1114844041f12daf88ef753fb019980e466f32922c50d332e1d1fc2c&token=1082669959&lang=zh_CN#rd)
|
||||
- [[BAT面试必备] ——几道常见的链表算法题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484862&idx=1&sn=015a4eb2f66978010d68c1305a46cfb5&chksm=cea24a75f9d5c363683aadf3ac434b8baf9ff5be8d2939d7875ebb3a742780b568a0926a2cc4&token=1082669959&lang=zh_CN#rd)
|
||||
- [如何判断一个元素在亿级数据中是否存在?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484796&idx=1&sn=25c190a95ac53b81063f7acda936c994&chksm=cea24ab7f9d5c3a1819605008bfc92834eddf37ca3ad24b913fab558b5d00ed5306c5d6aab55&token=1082669959&lang=zh_CN#rd)
|
||||
- [可能是一份最适合你的后端面试指南(部分内容前端同样适用)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484840&idx=1&sn=cf4611ac290ae3cbb381fe52aa76b60b&chksm=cea24a63f9d5c375215f7539ff0f3d6320f091d5f8b73e95c724ec9a31d3b5baa98c3f5a1012&token=1082669959&lang=zh_CN#rd)
|
||||
- [GitHub 上四万 Star 大佬的求职回忆](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484802&idx=1&sn=58e204718559f6cf94d3d9cd9614ebc2&chksm=cea24a49f9d5c35f8d53f79801aea21fdd3c06ff4b6c16167e8211f627eea8c5a0ce334fd240&token=1082669959&lang=zh_CN#rd)
|
||||
- [这7个问题,可能大部分Java程序员都比较关心吧!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484786&idx=1&sn=4f61c62c0213602a106ce20db7768a93&chksm=cea24ab9f9d5c3afe7b5c90f6a8782adef93e916a46685aa8c46b752fddadf88273748c7f1ab&token=1082669959&lang=zh_CN#rd)
|
||||
- [2018年BATJ面试题精选](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484774&idx=1&sn=2aaaafcecd2bc6b519a11fa0fc1f66fa&chksm=cea24aadf9d5c3bb69359b0973930387885de75b444837df4f34ac14eebbabe498605660ae48&token=1082669959&lang=zh_CN#rd)
|
||||
- [一位大佬的亲身经历总结:简历和面试的技巧](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485409&idx=1&sn=47b09ec432929306d39762b13364b04b&chksm=cea2482af9d5c13cc91e8e679f0b823e667b616866519af1523d1d8b4e550cfdaa2f57b21bf3&token=1667678311&lang=zh_CN#rd)
|
||||
- [包装严重的IT行业,作为面试官,我是如何甄别应聘者的包装程度](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485404&idx=1&sn=b0c5b9e55bb6f7e71585c1b2e769fd87&chksm=cea24817f9d5c101cfa45a5d2707445030259f030d91f48c068450c5a280457ee25fa51b3f24&token=1667678311&lang=zh_CN#rd)
|
||||
- [面试官:你是如何使用JDK来实现自己的缓存(支持高并发)?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485347&idx=1&sn=8da3919089909d39dbf0745225ca0dad&chksm=cea24868f9d5c17eaec7eba2a4a3b63ed46dff87cb08b3f5d491e96890d8f375735cfcc77562&token=1667678311&lang=zh_CN#rd)
|
||||
|
||||
### 面经
|
||||
|
||||
- [5面阿里,终获offer](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484747&idx=1&sn=bff601fd1d314f670cb44171ea1925dd&chksm=cea24a80f9d5c396619acaa9f77207019f72d43749559b5a401359915e01b51598a687c48203&token=1082669959&lang=zh_CN#rd)
|
||||
- [记一次蚂蚁金服的面试经历](https://mp.weixin.qq.com/s/LIhtyspty9Kz1qRg1b8N-w)
|
||||
- [2019年蚂蚁金服、头条、拼多多的面试总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485167&idx=1&sn=a35fad235a6bb2b6e31f1ff37e72bfd7&chksm=cea24924f9d5c032cbbeffc87cd366e9aa7b209897a26ad5c7f7b1b766b3c34a2c9b6870006c&token=1667678311&lang=zh_CN#rd)
|
||||
- [蚂蚁金服2019实习生面经总结(已拿口头offer)](https://mp.weixin.qq.com/s/ktq2UOvi5qI1FymWIgp8jw)
|
||||
- [2019年蚂蚁金服面经(已拿Offer)!附答案!!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485251&idx=1&sn=21e5da0d76dd71d165f19015ebeba780&chksm=cea24888f9d5c19e041a145e6da3d4fa94f63b34c71d43f10c29340c7d51a4a23971904d19b5&token=1667678311&lang=zh_CN#rd)
|
||||
|
||||
### 备战面试系列
|
||||
|
||||
- [【备战春招/秋招系列】程序员的简历就该这样写](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484830&idx=1&sn=2e868311f79f4a52a0f3be383050c810&source=41#wechat_redirect)
|
||||
- [【备战春招/秋招系列】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484829&idx=1&sn=29e0e08d9da0f343f14c16bb3ac92beb&chksm=cea24a56f9d5c340ecb67a186b3c8fb5ef30ff481bfbdec3249f2145b3f376fd2d6dc19fbefc&token=1082669959&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】Java程序员必备书单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484826&idx=1&sn=cf015aca00e420d476c3cb456a11d994&chksm=cea24a51f9d5c34730dcdb538c99cb58d23496ebe8c51fb191dd629ab28c802f97662aef3366&token=1082669959&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】面试官问你“有什么问题问我吗?”,你该如何回答?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484755&idx=1&sn=4a09256062642c714f83ed03cb083846&chksm=cea24a98f9d5c38e8e040c332bf58ccac48a93190e059b9f39e4249eae579b8d32238cea88dd&token=1082669959&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】美团面经总结基础篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484825&idx=1&sn=a0ec65a5f2b268a6f4d22c3bb9790126&chksm=cea24a52f9d5c344922e4dcd4b9650d63ad5c4d843208e3fb7f21bcffa144a6bab0d748cdfbb&token=1082669959&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】美团面经总结进阶篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484822&idx=1&sn=efefe8a5a1ff9a54a57601edab134a04&chksm=cea24a5df9d5c34b36e8b12beb574ca31ae771de3881237c4f02be61b52e38f763d2d6137dd3&token=1082669959&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】美团Java面经总结终结篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484815&idx=1&sn=4dd1a280fb95c59366c73897c77049fb&chksm=cea24a44f9d5c3524b301ecf313382ea78b6ac821b4d5e9f9cf51346fc10839c1e234e7cb3ed&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
### 面试现场
|
||||
|
||||
- [【面试现场】如何实现可以获取最小值的栈?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484863&idx=2&sn=ac674bb0cf29b782aa0e6e9365defa4b&chksm=cea24a74f9d5c362b22459ceda77e635366a17175cd30bbdce14bc729e5417b137175a90331b&token=1082669959&lang=zh_CN#rd)
|
||||
- [【面试现场】为什么要分稳定排序和非稳定排序?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484856&idx=2&sn=af47a53a913b42b064a6e158d165fd2f&chksm=cea24a73f9d5c365084c65d30372f1ae35893ad3ec751da71e14ce5fda07b17ab5f0da90f663&token=1082669959&lang=zh_CN#rd)
|
||||
- [【面试现场】如何找到字符串中的最长回文子串?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484855&idx=1&sn=e75a06c56fe3b8802f18b04ef4df1c43&chksm=cea24a7cf9d5c36ab8090506442fa131a3d332343e953567c5f78dbef5aed0b6ed317b25af9f&token=1082669959&lang=zh_CN#rd)
|
||||
- [【面试现场】如何在10亿数中找出前1000大的数](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484845&idx=1&sn=6a235c6181c0f46630a9a22ef762a23b&chksm=cea24a66f9d5c3709e9618a1e418535d467053273123b81fda3897b4431a02a105703fd22644&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
## 算法
|
||||
|
||||
- [【算法技巧】位运算装逼指南](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485292&idx=1&sn=330e7f8c972bd7ed368aca7ccb434493&chksm=cea248a7f9d5c1b1f5387adbda961f0aa02c6f575fd9367937b9c15be1b241222b340f61dc5e&token=1667678311&lang=zh_CN#rd)
|
||||
|
||||
## Github 热门Java项目推荐
|
||||
|
||||
- [近几个月Github上最热门的Java项目一览](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484908&idx=1&sn=a95d37194f03b7e4aae1612e1785bf44&chksm=cea24a27f9d5c331d818fa1b2b564f9d5e9ff245a969a50e98944b909d6e45c0ebde544f982e&token=1082669959&lang=zh_CN#rd)(2018-07-20)
|
||||
- [推荐10个Java方向最热门的开源项目(8月)](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484876&idx=1&sn=3cab92ee5bda6b47bf7232724461f6a3&chksm=cea24a07f9d5c31106d0806b1bd8bae8821511b0a32879fb4f4b3bec7823db1f62e23821b07b&token=1082669959&lang=zh_CN#rd)( 2018-08-28)
|
||||
- [Github上 Star 数相加超过 7w+ 的三个面试相关的仓库推荐](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484819&idx=1&sn=6d83101ee504a6ab19ef07fb32650876&chksm=cea24a58f9d5c34ef9f3a7374c5147b1ff85e18ca4e59e21c4edf7d63bc1bd8c5c241e0c532b&token=1082669959&lang=zh_CN#rd)( 2018-11-17)
|
||||
- [11月 Github Trending 榜最热门的 10 个 Java 项目](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484805&idx=1&sn=acee5bd6c3f861c65be3a2fb8843e1f5&chksm=cea24a4ef9d5c358c263cb4605acc6b6254635c28c496a9a10aee0dc80293f457a9af2e90d1c&token=1082669959&lang=zh_CN#rd)( 2018-12-01)
|
||||
- [盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484789&idx=1&sn=2ad9fabb8fc7fae3bd3756ea05594344&chksm=cea24abef9d5c3a889b6cb8e00cb18abbb694d189c84a24fa1ed337ad4c56194cd39316dc6a5&token=1082669959&lang=zh_CN#rd)( 2018-12-24)
|
||||
- [12月GithubTrending榜Java项目总结,多了几个新面孔](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484784&idx=1&sn=3c98b2e6aa97014a8fb4bf837be40f52&chksm=cea24abbf9d5c3ad3ab779749f6a75ed9bc4321986056a65f5f04033c9cc626a382ebe597278&token=1082669959&lang=zh_CN#rd)(2019-01-02)
|
||||
- [1月份Github上收获最多star的10个项目](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484761&idx=1&sn=db6441c08f5ae8d75978384108cc852d&chksm=cea24a92f9d5c3846858a91aa7dc6b258f91407e2a22a1c7b2e46a8e5dd4d9a9ef443eed3b0e&token=1082669959&lang=zh_CN#rd)(2019-02-01)
|
||||
- [2019年2月份Github上收获最多Star的10个Java项目](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484749&idx=1&sn=a66a1e3707839454539d93499dcadfad&chksm=cea24a86f9d5c3902d07fc4614347606200536ddf9ee7464fe12bbbce5c1bd186ad9894f13e3&token=1082669959&lang=zh_CN#rd)(2019-03-05)
|
||||
- [3月Github最热门的10个Java开源项目](https://mp.weixin.qq.com/s/HYXFWeko2tGPCWhy-yrtEw)
|
||||
- [五一假期充电指南:4月Github最热门的Java项目推荐](https://mp.weixin.qq.com/s/3485Z0cbD1FvcWZMQTnRsw)
|
||||
|
||||
## 架构
|
||||
|
||||
- [8 张图读懂大型网站技术架构](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484863&idx=1&sn=8b7c8ce77f5927564d69587688114c79&chksm=cea24a74f9d5c362b7140d18bfc198e7f39572b938e597d1725e4dcf541a12b33d8db6ac1b45&token=1082669959&lang=zh_CN#rd)
|
||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484760&idx=1&sn=c41df36f538ab3d8907e23bf8f6d2cd5&chksm=cea24a93f9d5c3851f8a699fdf068f767e3571c38e1b2995297a3e5725f9ad024c6de2bcb100&token=1082669959&lang=zh_CN#rd)
|
||||
- [分布式系统的经典基础理论](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484941&idx=1&sn=e0812a9ccfde06550e24c23c4bb5ef1d&chksm=cea249c6f9d5c0d0bd16fc26c7af606c775868f1f06d81fbff2f8093d2a686c3b3befe9b971c&token=1082669959&lang=zh_CN#rd)
|
||||
- [软件开发的七条原则](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484938&idx=1&sn=597b1aec42d22caad051b3694816fb27&chksm=cea249c1f9d5c0d73bcedc02499cb44822f6b5ab9dcccd7f1a03f830aed158a1b9abec416efc&token=1082669959&lang=zh_CN#rd)
|
||||
- [关于分布式计算的一些概念](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484935&idx=2&sn=2394583a73b41cca431e392a28b0b4cb&chksm=cea249ccf9d5c0da5d1d4b8cf2dffb00ae1b6b605afe6da426112f3208898c2cca6249865146&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
## 工具
|
||||
|
||||
- [Git入门看这一篇就够了!](https://mp.weixin.qq.com/s/ylyHOuEPX4tDvOc7-SxMmw)
|
||||
- [团队开发中的 Git 实践](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485550&idx=1&sn=a0fa847b009c3c8c60c20773f0870dbf&chksm=cea247a5f9d5ceb317906f37d7dfbd44aebbe2206764cd8b50a25110c3125c7be3507ce3729e&token=2133161636&lang=zh_CN#rd)
|
||||
- [IDEA中的Git操作,看这一篇就够了!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485578&idx=1&sn=8f8ab9d597e1448053e5da380fff3e54&chksm=cea24741f9d5ce5791722dd3da12dfa3de5aa9d742e0cc78d0b72a89d75a48e6d84512265c30&token=2133161636&lang=zh_CN#rd)
|
||||
- [一文搞懂如何在Intellij IDEA中使用Debug,超级详细!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485250&idx=1&sn=9e1f270996441094104a06fc909c60f5&chksm=cea24889f9d5c19fbc6024779ca476a3ee141efa457fc86cc8c33a8f06a1c2b1e7b4922426c2&token=1667678311&lang=zh_CN#rd)
|
||||
- [十分钟搞懂Java效率工具Lombok使用与原理](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=913106598&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
## 效率
|
||||
|
||||
- [推荐几个可以提升工作效率的Chrome插件](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485315&idx=1&sn=f5e91a9386a6911acbff4d7721065563&chksm=cea24848f9d5c15ec3bc0efab93351ca7481a609e901d9c9c07816a7a9737cdcdc1b5f6497db&token=1667678311&lang=zh_CN#rd)
|
||||
|
||||
## 思维开阔
|
||||
|
||||
- [不就是个短信登录API嘛,有这么复杂吗?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485181&idx=1&sn=7a7a7ce0671e8c5456add8da098501c2&chksm=cea24936f9d5c020fa1e339a819a17e7ae6099f1c5072d9ea235cf9fca45437d96cb117f7f10&token=1667678311&lang=zh_CN#rd)
|
||||
|
||||
## 进阶
|
||||
|
||||
- [可能是把Docker的概念讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484921&idx=1&sn=d40518712a04b3c37d7c8fcd3e696e90&chksm=cea24a32f9d5c3243db78a227ba4e77618e679bbc856cf1974fccbd474c44847672f21658147&token=1082669959&lang=zh_CN#rd)
|
||||
- [后端必备——数据通信知识(RPC、消息队列)一站式总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484920&idx=1&sn=c7167df0b36522935896565973d02cc9&chksm=cea24a33f9d5c325fc663c95ebc221060ae2d5eeee254472558a99fdfc2837b31d3b9ae51a12&token=1082669959&lang=zh_CN#rd)
|
||||
- [可能是全网把 ZooKeeper 概念讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484868&idx=1&sn=af1e49c5f7dc89355255a4d46bafc005&chksm=cea24a0ff9d5c3195a690d2c85f09cd8901717674f52e10b0e6fd588d69de15de76b8184307d&token=1082669959&lang=zh_CN#rd)
|
||||
- [外行人都能看懂的SpringCloud,错过了血亏!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484813&idx=1&sn=d87c01aff031f35be6b88a61f5782da5&chksm=cea24a46f9d5c35023a54e20fa1319b4cd31c33b094e2fd161bb8667ab77b8b403af62cfb3b5&token=1082669959&lang=zh_CN#rd)
|
||||
- [关于 Dubbo 的重要入门知识点总结](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484753&idx=1&sn=32d987bf9f6208e30326877b111cad61&chksm=cea24a9af9d5c38cc7eb4d9bfeaa07e72003a1bf304a0fedc3fabb2a87f01c98b5a7d1c80d53&token=1082669959&lang=zh_CN#rd)
|
||||
- [Java 工程师成神之路 | 2019正式版](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484759&idx=1&sn=5a706091c1db2b585f0a93c75bca14da&chksm=cea24a9cf9d5c38a245bdc63a0c90934b02f582c34a8dfb4ef01cd149d4829d799cb9e9bd464&token=1082669959&lang=zh_CN#rd)
|
||||
- [聊一聊开发常用小工具](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484769&idx=1&sn=0968ce79f4d31d982b9f1ce24b051432&chksm=cea24aaaf9d5c3bc5feb0ef4e814990c9e108b72a0691193b1dda29642ee2ff74da5026016f6&token=1082669959&lang=zh_CN#rd)
|
||||
- [新手也能看懂,消息队列其实很简单](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484794&idx=1&sn=61585fe69eedb3654ee2f9c9cd67e1a1&chksm=cea24ab1f9d5c3a7fd07dd49244f69fc85a5a523ee5353fc9e442dcad2ca0dd1137ed563fcbe&token=1082669959&lang=zh_CN#rd)
|
||||
|
||||
## 杂文闲记
|
||||
|
||||
- [一只准准程序员的唠叨](http://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484932&idx=1&sn=a4f3057ecd4412cb8b18e92058b29680&chksm=cea249cff9d5c0d97580310f6666a4e0c42cfd1ba13dd759850e489c9386dce8c5c35b0a1a95&token=1082669959&lang=zh_CN#rd)(2018-06-09)
|
||||
- [说几件近期的小事](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484900&idx=1&sn=745e8f6027da369ef5f8e349cb5d6657&chksm=cea24a2ff9d5c339c925322ffacdc72dd37bda63238dfb3452540085c1695681e2e79070e2a7&token=1082669959&lang=zh_CN#rd)(2018-08-02)
|
||||
- [选择技术方向都要考虑哪些因素](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484898&idx=1&sn=fd2ebf9ffd37ab5de1de09cd3272ac0a&chksm=cea24a29f9d5c33fa48f5a57de864cd9382a730578fb18d78b7f06b45504aede18b235b9bc9e&token=1082669959&lang=zh_CN#rd)(2018-08-04)
|
||||
- [结束了我短暂的秋招,说点自己的感受](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484842&idx=1&sn=4489dfab0ef2479122b71407855afc71&chksm=cea24a61f9d5c3774a8ed67c5fcc3234cb0741fbe831152986e5d1c8fb4f36a003f4fb2f247e&token=1082669959&lang=zh_CN#rd)(2018-10-22)
|
||||
- [【周日闲谈】最近想说的几件小事](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484818&idx=1&sn=e14b0a08537456eb15ba49cf5e70ff74&chksm=cea24a59f9d5c34fe0a9e0567d867b85a81d1f19b0ea8e6a3c14161e436508de9adfeb2a5e6a&token=1082669959&lang=zh_CN#rd)(2018-11-18)
|
||||
- [做公众号这一年的经历和一件“大事”](http://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484746&idx=1&sn=a519a9e3d638bff5c65008f7de167e4b&chksm=cea24a81f9d5c397ca9ac5668ba6cb18b38065e0e282a34ebc077a2dea98de3f1eb285ea5f09&token=1082669959&lang=zh_CN#rd)(2019-03-10)
|
||||
- [几经周折,公众号终于留言功能啦!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485007&idx=1&sn=096a436cd6a9251c23b8effc3cfa5076&chksm=cea24984f9d5c092d1f7740d1c3e0ea347562ba0aa597507ce275c5bdf1c8bd608328ee756ba&token=1082669959&lang=zh_CN#rd)(2019-03-15)
|
||||
- [写在毕业季的大学总结!细数一下大学干过的“傻事”。](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485358&idx=1&sn=3aaf1163fe13351e06c76b70f2bd33bd&chksm=cea24865f9d5c1735b51c707c8f5ade16af7eca304540205ab0fb1284f99034d418b9858d7db&token=1667678311&lang=zh_CN#rd) (2019-06-11)
|
||||
- [入职一个月的职场小白,谈谈自己这段时间的感受](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485540&idx=1&sn=4492eece8f7738e99350118040e14a79&chksm=cea247aff9d5ceb9e7c67f418d8a8518c550fd7dd269bf2c9bdef83309502273b4b9f1e7021f&token=1333232257&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
## 其他好文推荐
|
||||
|
||||
- [谈恋爱也要懂https](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484821&idx=1&sn=e6ce4ec607a6c9b20edbd64fbeb0f6c5&chksm=cea24a5ef9d5c3480d3de284fc1038b51c2464152e25a350960efd81acd21f71d7e0eeb78c77&token=1082669959&lang=zh_CN#rd)
|
||||
- [快速入门大厂后端面试必备的 Shell 编程](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484810&idx=1&sn=0b622ae617b863ef1cc3a32c17b8b755&chksm=cea24a41f9d5c357199073c1e4692b7da7dcbd1809cf634a6cfec8c64c12250efc5274992f06&token=1082669959&lang=zh_CN#rd)
|
||||
- [为什么阿里巴巴禁止工程师直接使用日志系统(Log4j、Logback)中的 API](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484808&idx=1&sn=4774ecc18069e4ddc85f68877cff1ae3&chksm=cea24a43f9d5c35520a454d51e72c6084d38f505969835011f4dd36f76c78303af46780802c9&token=1082669959&lang=zh_CN#rd)
|
||||
- [一文搞懂 RabbitMQ 的重要概念以及安装](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484792&idx=1&sn=d34fdbb6cb21c231361038a7317ac2a4&chksm=cea24ab3f9d5c3a5c742de10cd0f7c77425b2144c86d2515d3e5d2011f4d16af12110c2de986&token=1082669959&lang=zh_CN#rd)
|
||||
- [漫话:如何给女朋友解释什么是RPC](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484795&idx=1&sn=64eb2dcac07cf6904ca79b14f408df9e&chksm=cea24ab0f9d5c3a6970c3fbbdcaa16d5230b51abed9bacd1cd2ea3192cccea4aba0ef2d1a9de&token=1082669959&lang=zh_CN#rd)
|
||||
- [Java人才市场年度盘点:转折与终局](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484779&idx=1&sn=a930b09a1783bca68e927cbe7d7a54a6&chksm=cea24aa0f9d5c3b6864ab3585a4cc5de1fa89ffc07538f2c55382776bfee0c369d7d74af7c79&token=1082669959&lang=zh_CN#rd)
|
||||
- [Github 上日获 800多 star 的阿里微服务架构分布式事务解决方案 FESCAR开源啦](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484776&idx=2&sn=bcd1cf6d72653bfff83724f1dbae0425&chksm=cea24aa3f9d5c3b5e9667f1e15f295d323efb3b2c8da6c9059f5e8b5e176b9cb1bf80cd1a78f&token=1082669959&lang=zh_CN#rd)
|
||||
- [Cloud Toolkit新版本发布,开发效率 “biu” 起来了](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484771&idx=2&sn=0eef929baacca950099ea8651f0e5cb2&chksm=cea24aa8f9d5c3bed5f359e6da981ac950dca8f31a93f1fe321d7de7908d843855604e79a4da&token=1082669959&lang=zh_CN#rd)
|
||||
- [我觉得技术人员该有的提问方式](https://mp.weixin.qq.com/s/eTEah5WOdfC3EAPbhpOKBA)
|
||||
@ -16,7 +16,6 @@
|
||||
name: 'JavaGuide',
|
||||
repo: 'https://github.com/Snailclimb/JavaGuide',
|
||||
maxLevel: 3,//最大支持渲染的标题层级
|
||||
homepage: 'HomePage.md',
|
||||
coverpage: true,//封面,_coverpage.md
|
||||
auto2top: true,//切换页面后是否自动跳转到页面顶部
|
||||
//ga: 'UA-138586553-1',
|
||||
BIN
media/pictures/kafaka/Broker和集群.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 134 KiB |
BIN
media/pictures/kafaka/Partition与消费模型.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
media/pictures/kafaka/kafka存在文件系统上.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 91 KiB |
BIN
media/pictures/kafaka/segment是kafka文件存储的最小单位.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 89 KiB |
BIN
media/pictures/kafaka/主题与分区.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 71 KiB |
BIN
media/pictures/kafaka/发送消息.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 135 KiB |
BIN
media/pictures/kafaka/启动服务.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 496 KiB |
BIN
media/pictures/kafaka/消费者设计概要1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 41 KiB |
BIN
media/pictures/kafaka/消费者设计概要2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
BIN
media/pictures/kafaka/消费者设计概要3.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 73 KiB |
BIN
media/pictures/kafaka/消费者设计概要4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 53 KiB |
BIN
media/pictures/kafaka/消费者设计概要5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 73 KiB |
BIN
media/pictures/kafaka/生产者和消费者.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 50 KiB |
BIN
media/pictures/kafaka/生产者设计概要.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 83 KiB |
BIN
media/pictures/rostyslav-savchyn-5joK905gcGc-unsplash.jpg
Executable file
{kind=link}
|
After Width: | Height: | Size: 2.0 MiB |