mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
docs: add linter
This commit is contained in:
parent
893c673f1c
commit
6bdc809e2f
19
.markdownlint.json
Normal file
19
.markdownlint.json
Normal file
@ -0,0 +1,19 @@
|
|||||||
|
{
|
||||||
|
"default": true,
|
||||||
|
"MD003": {
|
||||||
|
"style": "atx"
|
||||||
|
},
|
||||||
|
"MD004": {
|
||||||
|
"style": "dash"
|
||||||
|
},
|
||||||
|
"MD013": false,
|
||||||
|
"MD024": {
|
||||||
|
"allow_different_nesting": true
|
||||||
|
},
|
||||||
|
"MD035": {
|
||||||
|
"style": "---"
|
||||||
|
},
|
||||||
|
"MD040": false,
|
||||||
|
"MD046": false,
|
||||||
|
"MD049": false
|
||||||
|
}
|
||||||
4
.markdownlintignore
Normal file
4
.markdownlintignore
Normal file
@ -0,0 +1,4 @@
|
|||||||
|
**/node_modules/**
|
||||||
|
|
||||||
|
# markdown snippets
|
||||||
|
*.snippet.md
|
||||||
15
.prettierignore
Normal file
15
.prettierignore
Normal file
@ -0,0 +1,15 @@
|
|||||||
|
# Vuepress Cache
|
||||||
|
**/.vuepress/.cache/**
|
||||||
|
# Vuepress Temp
|
||||||
|
**/.vuepress/.temp/**
|
||||||
|
# Vuepress Output
|
||||||
|
dist/
|
||||||
|
|
||||||
|
# Node modules
|
||||||
|
node_modules/
|
||||||
|
|
||||||
|
# pnpm lock file
|
||||||
|
pnpm-lock.yaml
|
||||||
|
|
||||||
|
index.html
|
||||||
|
sw.js
|
||||||
@ -2,7 +2,11 @@ import { navbar } from "vuepress-theme-hope";
|
|||||||
|
|
||||||
export default navbar([
|
export default navbar([
|
||||||
{ text: "面试指南", icon: "java", link: "/home.md" },
|
{ text: "面试指南", icon: "java", link: "/home.md" },
|
||||||
{ text: "知识星球", icon: "code", link: "/about-the-author/zhishixingqiu-two-years.md" },
|
{
|
||||||
|
text: "知识星球",
|
||||||
|
icon: "code",
|
||||||
|
link: "/about-the-author/zhishixingqiu-two-years.md",
|
||||||
|
},
|
||||||
{ text: "开源项目", icon: "github", link: "/open-source-project/" },
|
{ text: "开源项目", icon: "github", link: "/open-source-project/" },
|
||||||
{ text: "技术书籍", icon: "book", link: "/books/" },
|
{ text: "技术书籍", icon: "book", link: "/books/" },
|
||||||
{
|
{
|
||||||
|
|||||||
@ -76,8 +76,8 @@ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
|
|||||||
|
|
||||||
## 2. 翻转链表
|
## 2. 翻转链表
|
||||||
|
|
||||||
|
|
||||||
### 题目描述
|
### 题目描述
|
||||||
|
|
||||||
> 剑指 offer:输入一个链表,反转链表后,输出链表的所有元素。
|
> 剑指 offer:输入一个链表,反转链表后,输出链表的所有元素。
|
||||||
|
|
||||||
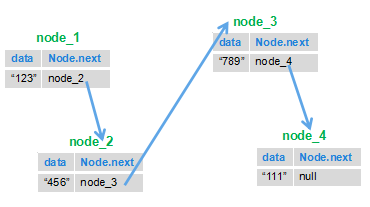
|

|
||||||
@ -88,7 +88,6 @@ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
|
|||||||
|
|
||||||
### Solution
|
### Solution
|
||||||
|
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public class ListNode {
|
public class ListNode {
|
||||||
int val;
|
int val;
|
||||||
@ -174,7 +173,6 @@ public class Solution {
|
|||||||
|
|
||||||
首先两个节点/指针,一个节点 node1 先开始跑,指针 node1 跑到 k-1 个节点后,另一个节点 node2 开始跑,当 node1 跑到最后时,node2 所指的节点就是倒数第 k 个节点也就是正数第(L-K+1)个节点。
|
首先两个节点/指针,一个节点 node1 先开始跑,指针 node1 跑到 k-1 个节点后,另一个节点 node2 开始跑,当 node1 跑到最后时,node2 所指的节点就是倒数第 k 个节点也就是正数第(L-K+1)个节点。
|
||||||
|
|
||||||
|
|
||||||
### Solution
|
### Solution
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ -221,10 +219,8 @@ public class Solution {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
## 4. 删除链表的倒数第 N 个节点
|
## 4. 删除链表的倒数第 N 个节点
|
||||||
|
|
||||||
|
|
||||||
> Leetcode:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
|
> Leetcode:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
|
||||||
|
|
||||||
**示例:**
|
**示例:**
|
||||||
@ -248,7 +244,6 @@ public class Solution {
|
|||||||
|
|
||||||
### 问题分析
|
### 问题分析
|
||||||
|
|
||||||
|
|
||||||
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)个结点,其中 L 是列表的长度。只要我们找到列表的长度 L,这个问题就很容易解决。
|
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)个结点,其中 L 是列表的长度。只要我们找到列表的长度 L,这个问题就很容易解决。
|
||||||
|
|
||||||
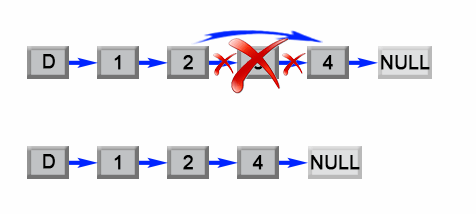
|

|
||||||
@ -301,11 +296,8 @@ public class Solution {
|
|||||||
- **时间复杂度 O(L)** :该算法对列表进行了两次遍历,首先计算了列表的长度 LL 其次找到第 (L - n)(L−n) 个结点。 操作执行了 2L-n2L−n 步,时间复杂度为 O(L)O(L)。
|
- **时间复杂度 O(L)** :该算法对列表进行了两次遍历,首先计算了列表的长度 LL 其次找到第 (L - n)(L−n) 个结点。 操作执行了 2L-n2L−n 步,时间复杂度为 O(L)O(L)。
|
||||||
- **空间复杂度 O(1)** :我们只用了常量级的额外空间。
|
- **空间复杂度 O(1)** :我们只用了常量级的额外空间。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**进阶——一次遍历法:**
|
**进阶——一次遍历法:**
|
||||||
|
|
||||||
|
|
||||||
> 链表中倒数第 N 个节点也就是正数第(L-N+1)个节点。
|
> 链表中倒数第 N 个节点也就是正数第(L-N+1)个节点。
|
||||||
|
|
||||||
其实这种方法就和我们上面第四题找“链表中倒数第 k 个节点”所用的思想是一样的。**基本思路就是:** 定义两个节点 node1、node2;node1 节点先跑,node1 节点 跑到第 n+1 个节点的时候,node2 节点开始跑.当 node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点(L 代表总链表长度,也就是倒数第 n+1 个节点)
|
其实这种方法就和我们上面第四题找“链表中倒数第 k 个节点”所用的思想是一样的。**基本思路就是:** 定义两个节点 node1、node2;node1 节点先跑,node1 节点 跑到第 n+1 个节点的时候,node2 节点开始跑.当 node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点(L 代表总链表长度,也就是倒数第 n+1 个节点)
|
||||||
@ -345,10 +337,6 @@ public class Solution {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 5. 合并两个排序的链表
|
## 5. 合并两个排序的链表
|
||||||
|
|
||||||
### 题目描述
|
### 题目描述
|
||||||
@ -400,4 +388,3 @@ public ListNode Merge(ListNode list1,ListNode list2) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -116,7 +116,7 @@ int jumpFloor(int number) {
|
|||||||
所以在 n>=2 的情况下:
|
所以在 n>=2 的情况下:
|
||||||
f(n)=f(n-1)+f(n-2)+...+f(1)
|
f(n)=f(n-1)+f(n-2)+...+f(1)
|
||||||
因为 f(n-1)=f(n-2)+f(n-3)+...+f(1)
|
因为 f(n-1)=f(n-2)+f(n-3)+...+f(1)
|
||||||
所以f(n)=2*f(n-1) 又f(1)=1,所以可得**f(n)=2^(number-1)**
|
所以 f(n)=2\*f(n-1) 又 f(1)=1,所以可得**f(n)=2^(number-1)**
|
||||||
|
|
||||||
**示例代码:**
|
**示例代码:**
|
||||||
|
|
||||||
@ -140,7 +140,6 @@ int b = a << 2;//左移2,等同于16 * 2的2次方,也就是16 * 4
|
|||||||
int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
|
int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
## 二维数组查找
|
## 二维数组查找
|
||||||
|
|
||||||
**题目描述:**
|
**题目描述:**
|
||||||
@ -228,12 +227,9 @@ public String replaceSpace(StringBuffer str) {
|
|||||||
**问题解析:**
|
**问题解析:**
|
||||||
|
|
||||||
这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
|
这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
|
||||||
更具剑指offer书中细节,该题的解题思路如下:
|
更具剑指 offer 书中细节,该题的解题思路如下: 1.当底数为 0 且指数<0 时,会出现对 0 求倒数的情况,需进行错误处理,设置一个全局变量; 2.判断底数是否等于 0,由于 base 为 double 型,所以不能直接用==判断 3.优化求幂函数(二分幂)。
|
||||||
1.当底数为0且指数<0时,会出现对0求倒数的情况,需进行错误处理,设置一个全局变量;
|
当 n 为偶数,a^n =(a^n/2)_(a^n/2);
|
||||||
2.判断底数是否等于0,由于base为double型,所以不能直接用==判断
|
当 n 为奇数,a^n = a^[(n-1)/2] _ a^[(n-1)/2] \* a。时间复杂度 O(logn)
|
||||||
3.优化求幂函数(二分幂)。
|
|
||||||
当n为偶数,a^n =(a^n/2)*(a^n/2);
|
|
||||||
当n为奇数,a^n = a^[(n-1)/2] * a^[(n-1)/2] * a。时间复杂度O(logn)
|
|
||||||
|
|
||||||
**时间复杂度**:O(logn)
|
**时间复杂度**:O(logn)
|
||||||
|
|
||||||
|
|||||||
@ -57,7 +57,6 @@ tag:
|
|||||||
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
|
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
|
||||||
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
|
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
|
||||||
|
|
||||||
|
|
||||||
## 编码实战
|
## 编码实战
|
||||||
|
|
||||||
### 通过 Java 编程手动实现布隆过滤器
|
### 通过 Java 编程手动实现布隆过滤器
|
||||||
@ -245,9 +244,9 @@ Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Red
|
|||||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
|
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
|
||||||
其他还有:
|
其他还有:
|
||||||
|
|
||||||
* redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||||
* pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
|
- pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
|
||||||
* ......
|
- ......
|
||||||
|
|
||||||
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
|
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
|
||||||
|
|
||||||
@ -287,7 +286,7 @@ root@21396d02c252:/data# redis-cli
|
|||||||
|
|
||||||
可选参数:
|
可选参数:
|
||||||
|
|
||||||
* expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以`expansion`。默认扩展值为 2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
|
- expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以`expansion`。默认扩展值为 2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
|
||||||
|
|
||||||
### 实际使用
|
### 实际使用
|
||||||
|
|
||||||
|
|||||||
@ -25,21 +25,25 @@ tag:
|
|||||||
## 图的基本概念
|
## 图的基本概念
|
||||||
|
|
||||||
### 顶点
|
### 顶点
|
||||||
|
|
||||||
图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)
|
图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)
|
||||||
|
|
||||||
对应到好友关系图,每一个用户就代表一个顶点。
|
对应到好友关系图,每一个用户就代表一个顶点。
|
||||||
|
|
||||||
### 边
|
### 边
|
||||||
|
|
||||||
顶点之间的关系用边表示。
|
顶点之间的关系用边表示。
|
||||||
|
|
||||||
对应到好友关系图,两个用户是好友的话,那两者之间就存在一条边。
|
对应到好友关系图,两个用户是好友的话,那两者之间就存在一条边。
|
||||||
|
|
||||||
### 度
|
### 度
|
||||||
|
|
||||||
度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。
|
度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。
|
||||||
|
|
||||||
对应到好友关系图,度就代表了某个人的好友数量。
|
对应到好友关系图,度就代表了某个人的好友数量。
|
||||||
|
|
||||||
### 无向图和有向图
|
### 无向图和有向图
|
||||||
|
|
||||||
边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A 是 B 的同学,那么 B 也肯定是 A 的同学,那么在表示 A 和 B 的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
|
边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A 是 B 的同学,那么 B 也肯定是 A 的同学,那么在表示 A 和 B 的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
|
||||||
|
|
||||||
有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A 是 B 的爸爸,但 B 肯定不是 A 的爸爸,A 关注 B,B 不一定关注 A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
|
有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A 是 B 的爸爸,但 B 肯定不是 A 的爸爸,A 关注 B,B 不一定关注 A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
|
||||||
@ -55,7 +59,9 @@ tag:
|
|||||||
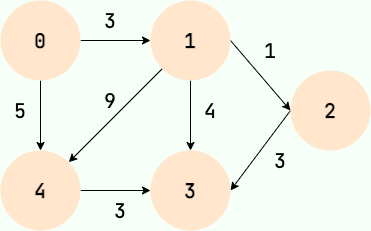
|

|
||||||
|
|
||||||
## 图的存储
|
## 图的存储
|
||||||
|
|
||||||
### 邻接矩阵存储
|
### 邻接矩阵存储
|
||||||
|
|
||||||
邻接矩阵将图用二维矩阵存储,是一种较为直观的表示方式。
|
邻接矩阵将图用二维矩阵存储,是一种较为直观的表示方式。
|
||||||
|
|
||||||
如果第 i 个顶点和第 j 个顶点之间有关系,且关系权值为 n,则 `A[i][j]=n` 。
|
如果第 i 个顶点和第 j 个顶点之间有关系,且关系权值为 n,则 `A[i][j]=n` 。
|
||||||
@ -86,7 +92,9 @@ tag:
|
|||||||
- 在有向图中,邻接表元素个数等于边的条数,如右图所示的有向图中,边的条数为 8,邻接表存储的元素个数为 8。
|
- 在有向图中,邻接表元素个数等于边的条数,如右图所示的有向图中,边的条数为 8,邻接表存储的元素个数为 8。
|
||||||
|
|
||||||
## 图的搜索
|
## 图的搜索
|
||||||
|
|
||||||
### 广度优先搜索
|
### 广度优先搜索
|
||||||
|
|
||||||
广度优先搜索就像水面上的波纹一样一层一层向外扩展,如下图所示:
|
广度优先搜索就像水面上的波纹一样一层一层向外扩展,如下图所示:
|
||||||
|
|
||||||
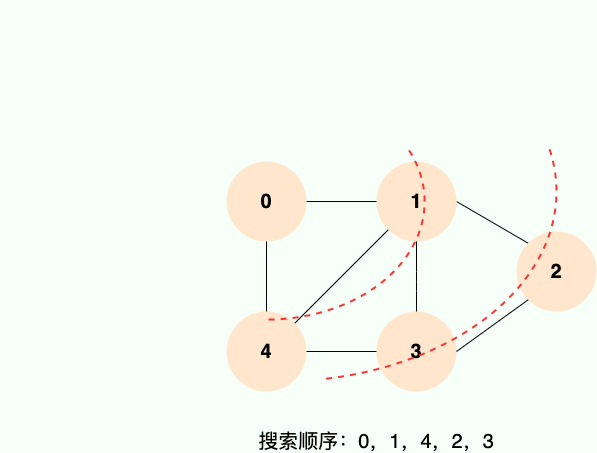
|

|
||||||
@ -123,7 +131,6 @@ tag:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
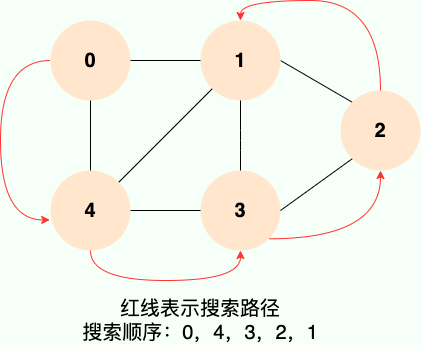
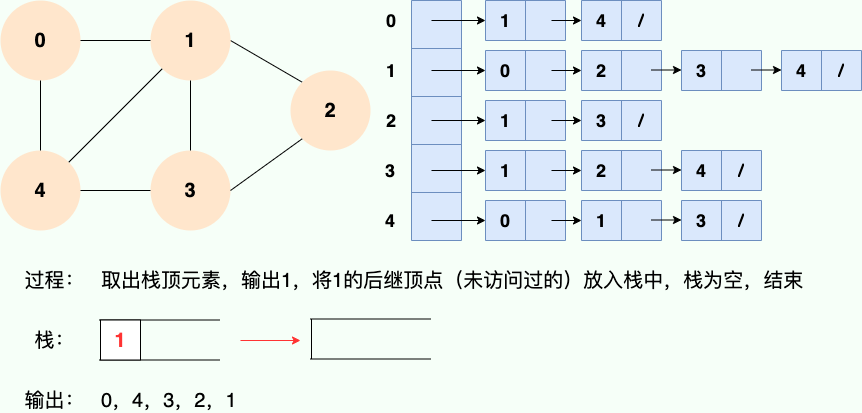
**和广度优先搜索类似,深度优先搜索的具体实现用到了另一种线性数据结构——栈** 。具体过程如下图所示:
|
**和广度优先搜索类似,深度优先搜索的具体实现用到了另一种线性数据结构——栈** 。具体过程如下图所示:
|
||||||
|
|
||||||
**第 1 步:**
|
**第 1 步:**
|
||||||
@ -149,4 +156,3 @@ tag:
|
|||||||
**第 6 步:**
|
**第 6 步:**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
@ -28,6 +28,7 @@ tag:
|
|||||||
第 3 个不是,第三个中,根结点 1 比 2 和 15 小,而 15 却比 3 大,19 比 5 大,不满足堆的性质。
|
第 3 个不是,第三个中,根结点 1 比 2 和 15 小,而 15 却比 3 大,19 比 5 大,不满足堆的性质。
|
||||||
|
|
||||||
## 堆的用途
|
## 堆的用途
|
||||||
|
|
||||||
当我们只关心所有数据中的最大值或者最小值,存在多次获取最大值或者最小值,多次插入或删除数据时,就可以使用堆。
|
当我们只关心所有数据中的最大值或者最小值,存在多次获取最大值或者最小值,多次插入或删除数据时,就可以使用堆。
|
||||||
|
|
||||||
有小伙伴可能会想到用有序数组,初始化一个有序数组时间复杂度是 `O(nlog(n))`,查找最大值或者最小值时间复杂度都是 `O(1)`,但是,涉及到更新(插入或删除)数据时,时间复杂度为 `O(n)`,即使是使用复杂度为 `O(log(n))` 的二分法找到要插入或者删除的数据,在移动数据时也需要 `O(n)` 的时间复杂度。
|
有小伙伴可能会想到用有序数组,初始化一个有序数组时间复杂度是 `O(nlog(n))`,查找最大值或者最小值时间复杂度都是 `O(1)`,但是,涉及到更新(插入或删除)数据时,时间复杂度为 `O(n)`,即使是使用复杂度为 `O(log(n))` 的二分法找到要插入或者删除的数据,在移动数据时也需要 `O(n)` 的时间复杂度。
|
||||||
@ -39,6 +40,7 @@ tag:
|
|||||||
## 堆的分类
|
## 堆的分类
|
||||||
|
|
||||||
堆分为 **最大堆** 和 **最小堆**。二者的区别在于节点的排序方式。
|
堆分为 **最大堆** 和 **最小堆**。二者的区别在于节点的排序方式。
|
||||||
|
|
||||||
- **最大堆** :堆中的每一个节点的值都大于等于子树中所有节点的值
|
- **最大堆** :堆中的每一个节点的值都大于等于子树中所有节点的值
|
||||||
- **最小堆** :堆中的每一个节点的值都小于等于子树中所有节点的值
|
- **最小堆** :堆中的每一个节点的值都小于等于子树中所有节点的值
|
||||||
|
|
||||||
@ -46,8 +48,8 @@ tag:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
## 堆的存储
|
## 堆的存储
|
||||||
|
|
||||||
之前介绍树的时候说过,由于完全二叉树的优秀性质,利用数组存储二叉树即节省空间,又方便索引(若根结点的序号为 1,那么对于树中任意节点 i,其左子节点序号为 `2*i`,右子节点序号为 `2*i+1`)。
|
之前介绍树的时候说过,由于完全二叉树的优秀性质,利用数组存储二叉树即节省空间,又方便索引(若根结点的序号为 1,那么对于树中任意节点 i,其左子节点序号为 `2*i`,右子节点序号为 `2*i+1`)。
|
||||||
|
|
||||||
为了方便存储和索引,(二叉)堆可以用完全二叉树的形式进行存储。存储的方式如下图所示:
|
为了方便存储和索引,(二叉)堆可以用完全二叉树的形式进行存储。存储的方式如下图所示:
|
||||||
@ -55,9 +57,13 @@ tag:
|
|||||||

|

|
||||||
|
|
||||||
## 堆的操作
|
## 堆的操作
|
||||||
|
|
||||||
堆的更新操作主要包括两种 : **插入元素** 和 **删除堆顶元素**。操作过程需要着重掌握和理解。
|
堆的更新操作主要包括两种 : **插入元素** 和 **删除堆顶元素**。操作过程需要着重掌握和理解。
|
||||||
|
|
||||||
> 在进入正题之前,再重申一遍,堆是一个公平的公司,有能力的人自然会走到与他能力所匹配的位置
|
> 在进入正题之前,再重申一遍,堆是一个公平的公司,有能力的人自然会走到与他能力所匹配的位置
|
||||||
|
|
||||||
### 插入元素
|
### 插入元素
|
||||||
|
|
||||||
> 插入元素,作为一个新入职的员工,初来乍到,这个员工需要从基层做起
|
> 插入元素,作为一个新入职的员工,初来乍到,这个员工需要从基层做起
|
||||||
|
|
||||||
**1.将要插入的元素放到最后**
|
**1.将要插入的元素放到最后**
|
||||||
@ -87,18 +93,14 @@ tag:
|
|||||||
|
|
||||||
首先删除堆顶元素,使得数组中下标为 1 的位置空出。
|
首先删除堆顶元素,使得数组中下标为 1 的位置空出。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
> 那么他的位置由谁来接替呢,当然是他的直接下属了,谁能力强就让谁上呗
|
> 那么他的位置由谁来接替呢,当然是他的直接下属了,谁能力强就让谁上呗
|
||||||
|
|
||||||
比较根结点的左子节点和右子节点,也就是下标为 2,3 的数组元素,将较大的元素填充到根结点(下标为 1)的位置。
|
比较根结点的左子节点和右子节点,也就是下标为 2,3 的数组元素,将较大的元素填充到根结点(下标为 1)的位置。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
> 这个时候又空出一个位置了,老规矩,谁有能力谁上
|
> 这个时候又空出一个位置了,老规矩,谁有能力谁上
|
||||||
|
|
||||||
一直循环比较空出位置的左右子节点,并将较大者移至空位,直到堆的最底部
|
一直循环比较空出位置的左右子节点,并将较大者移至空位,直到堆的最底部
|
||||||
@ -108,6 +110,7 @@ tag:
|
|||||||
这个时候已经完成了自底向上的堆化,没有元素可以填补空缺了,但是,我们可以看到数组中出现了“气泡”,这会导致存储空间的浪费。接下来我们试试自顶向下堆化。
|
这个时候已经完成了自底向上的堆化,没有元素可以填补空缺了,但是,我们可以看到数组中出现了“气泡”,这会导致存储空间的浪费。接下来我们试试自顶向下堆化。
|
||||||
|
|
||||||
#### 自顶向下堆化
|
#### 自顶向下堆化
|
||||||
|
|
||||||
自顶向下的堆化用一个词形容就是“石沉大海”,那么第一件事情,就是把石头抬起来,从海面扔下去。这个石头就是堆的最后一个元素,我们将最后一个元素移动到堆顶。
|
自顶向下的堆化用一个词形容就是“石沉大海”,那么第一件事情,就是把石头抬起来,从海面扔下去。这个石头就是堆的最后一个元素,我们将最后一个元素移动到堆顶。
|
||||||
|
|
||||||

|

|
||||||
@ -118,14 +121,11 @@ tag:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 堆的操作总结
|
### 堆的操作总结
|
||||||
|
|
||||||
- **插入元素** :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
|
- **插入元素** :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
|
||||||
- **删除堆顶元素** :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
|
- **删除堆顶元素** :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
|
||||||
|
|
||||||
|
|
||||||
## 堆排序
|
## 堆排序
|
||||||
|
|
||||||
堆排序的过程分为两步:
|
堆排序的过程分为两步:
|
||||||
|
|||||||
@ -19,4 +19,3 @@ tag:
|
|||||||
**为什么要用红黑树?** 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
**为什么要用红黑树?** 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||||
|
|
||||||
**相关阅读** :[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
**相关阅读** :[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||||
|
|
||||||
|
|||||||
@ -38,7 +38,7 @@ tag:
|
|||||||
|
|
||||||
**二叉树** 的分支通常被称作“**左子树**”或“**右子树**”。并且,**二叉树** 的分支具有左右次序,不能随意颠倒。
|
**二叉树** 的分支通常被称作“**左子树**”或“**右子树**”。并且,**二叉树** 的分支具有左右次序,不能随意颠倒。
|
||||||
|
|
||||||
**二叉树** 的第 i 层至多拥有 `2^(i-1)` 个节点,深度为 k 的二叉树至多总共有 `2^(k+1)-1` 个节点(满二叉树的情况),至少有 2^(k) 个节点(关于节点的深度的定义国内争议比较多,我个人比较认可维基百科对[节点深度的定义](https://zh.wikipedia.org/wiki/%E6%A0%91_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)#/%E6%9C%AF%E8%AF%AD))。
|
**二叉树** 的第 i 层至多拥有 `2^(i-1)` 个节点,深度为 k 的二叉树至多总共有 `2^(k+1)-1` 个节点(满二叉树的情况),至少有 2^(k) 个节点(关于节点的深度的定义国内争议比较多,我个人比较认可维基百科对[节点深度的定义](<https://zh.wikipedia.org/wiki/%E6%A0%91_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)#/%E6%9C%AF%E8%AF%AD>))。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -48,8 +48,6 @@ tag:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 完全二叉树
|
### 完全二叉树
|
||||||
|
|
||||||
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 **完全二叉树** 。
|
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 **完全二叉树** 。
|
||||||
|
|||||||
@ -5,8 +5,6 @@ tag:
|
|||||||
- 计算机网络
|
- 计算机网络
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## HTTP:超文本传输协议
|
## HTTP:超文本传输协议
|
||||||
|
|
||||||
**超文本传输协议(HTTP,HyperText Transfer Protocol)** 是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
**超文本传输协议(HTTP,HyperText Transfer Protocol)** 是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- 计算机网络
|
- 计算机网络
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
|
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
|
||||||
|
|
||||||

|

|
||||||
|
|||||||
@ -138,6 +138,3 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
|
|||||||
- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
|
- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
|
||||||
- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
||||||
- **安全性和资源消耗** : HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
- **安全性和资源消耗** : HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -68,4 +68,3 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被
|
|||||||
- https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
|
- https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
|
||||||
- https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
|
- https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
|
||||||
- https://segmentfault.com/a/1190000018264501
|
- https://segmentfault.com/a/1190000018264501
|
||||||
|
|
||||||
|
|||||||
@ -133,7 +133,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||||||
### HTTP Header 中常见的字段有哪些?
|
### HTTP Header 中常见的字段有哪些?
|
||||||
|
|
||||||
| 请求头字段名 | 说明 | 示例 |
|
| 请求头字段名 | 说明 | 示例 |
|
||||||
| :------------------ | :----------------------------------------------------------- | :----------------------------------------------------------- |
|
| :------------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :----------------------------------------------------------------------------------------- |
|
||||||
| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
|
| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
|
||||||
| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
|
| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
|
||||||
| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
|
| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
|
||||||
|
|||||||
@ -104,8 +104,6 @@ tag:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 什么是 IP 地址过滤?
|
### 什么是 IP 地址过滤?
|
||||||
|
|
||||||
**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
|
**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- 计算机网络
|
- 计算机网络
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
|
为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
|
||||||
|
|
||||||
## 建立连接-TCP 三次握手
|
## 建立连接-TCP 三次握手
|
||||||
@ -14,7 +13,6 @@ tag:
|
|||||||
|
|
||||||
建立一个 TCP 连接需要“三次握手”,缺一不可 :
|
建立一个 TCP 连接需要“三次握手”,缺一不可 :
|
||||||
|
|
||||||
|
|
||||||
- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
|
- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
|
||||||
- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
|
- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
|
||||||
- **三次握手**:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务器端都进入**ESTABLISHED** 状态,完成 TCP 三次握手。
|
- **三次握手**:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务器端都进入**ESTABLISHED** 状态,完成 TCP 三次握手。
|
||||||
@ -24,6 +22,7 @@ tag:
|
|||||||
### 为什么要三次握手?
|
### 为什么要三次握手?
|
||||||
|
|
||||||
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
|
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
|
||||||
|
|
||||||
1. **第一次握手** :Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
|
1. **第一次握手** :Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
|
||||||
2. **第二次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
|
2. **第二次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
|
||||||
3. **第三次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
3. **第三次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
||||||
@ -64,28 +63,22 @@ TCP是全双工通信,可以双向传输数据。任何一方都可以在数
|
|||||||
|
|
||||||
### 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
|
### 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
|
||||||
|
|
||||||
|
|
||||||
因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务器到客户端的数据传送。
|
因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务器到客户端的数据传送。
|
||||||
|
|
||||||
### 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
|
### 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
|
||||||
|
|
||||||
|
|
||||||
客户端没有收到 ACK 确认,会重新发送 FIN 请求。
|
客户端没有收到 ACK 确认,会重新发送 FIN 请求。
|
||||||
|
|
||||||
### 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
|
### 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
|
||||||
|
|
||||||
|
|
||||||
第四次挥手时,客户端发送给服务器的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2\*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
|
第四次挥手时,客户端发送给服务器的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2\*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
|
||||||
|
|
||||||
> **MSL(Maximum Segment Lifetime)** : 一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
|
> **MSL(Maximum Segment Lifetime)** : 一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
|
|
||||||
- 《计算机网络(第 7 版)》
|
- 《计算机网络(第 7 版)》
|
||||||
|
|
||||||
- 《图解 HTTP》
|
- 《图解 HTTP》
|
||||||
|
|
||||||
- TCP and UDP Tutorial:https://www.9tut.com/tcp-and-udp-tutorial
|
- TCP and UDP Tutorial:https://www.9tut.com/tcp-and-udp-tutorial
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -60,7 +60,6 @@ TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客
|
|||||||
|
|
||||||
## TCP 的拥塞控制是怎么实现的?
|
## TCP 的拥塞控制是怎么实现的?
|
||||||
|
|
||||||
|
|
||||||
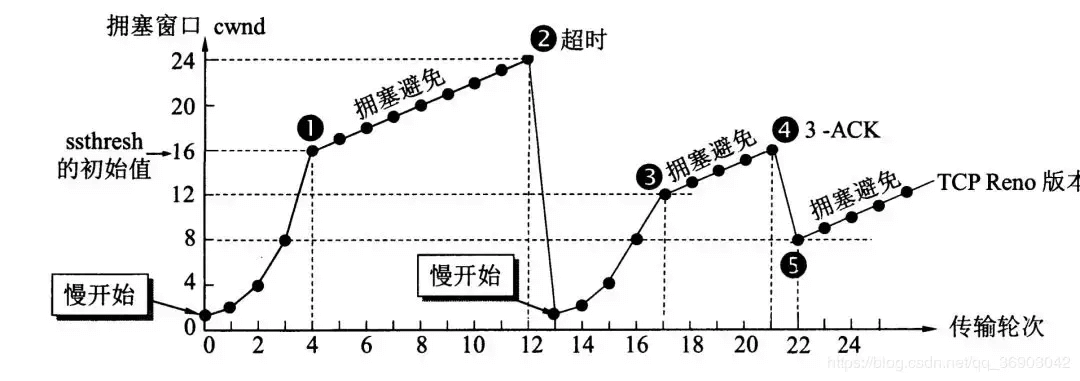
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
|
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
|
||||||
|
|
||||||
|

|
||||||
@ -100,7 +99,6 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
|||||||
|
|
||||||
### 连续 ARQ 协议
|
### 连续 ARQ 协议
|
||||||
|
|
||||||
|
|
||||||
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
|
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
|
||||||
|
|
||||||
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
||||||
@ -109,7 +107,6 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
|||||||
|
|
||||||
## Reference
|
## Reference
|
||||||
|
|
||||||
|
|
||||||
1. 《计算机网络(第 7 版)》
|
1. 《计算机网络(第 7 版)》
|
||||||
2. 《图解 HTTP》
|
2. 《图解 HTTP》
|
||||||
3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
|
3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
|
||||||
|
|||||||
@ -45,8 +45,6 @@ head:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
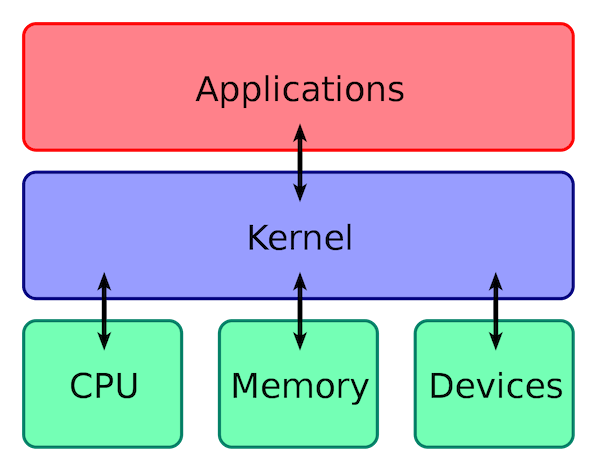
### 操作系统主要有哪些功能?
|
### 操作系统主要有哪些功能?
|
||||||
|
|
||||||
从资源管理的角度来看,操作系统有 6 大功能:
|
从资源管理的角度来看,操作系统有 6 大功能:
|
||||||
|
|||||||
@ -29,7 +29,7 @@ MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三
|
|||||||
**SQL 与 MongoDB 常见术语对比** :
|
**SQL 与 MongoDB 常见术语对比** :
|
||||||
|
|
||||||
| SQL | MongoDB |
|
| SQL | MongoDB |
|
||||||
| ----------------------- | ------------------------------ |
|
| ------------------------ | ------------------------------- |
|
||||||
| 表(Table) | 集合(Collection) |
|
| 表(Table) | 集合(Collection) |
|
||||||
| 行(Row) | 文档(Document) |
|
| 行(Row) | 文档(Document) |
|
||||||
| 列(Col) | 字段(Field) |
|
| 列(Col) | 字段(Field) |
|
||||||
@ -197,7 +197,7 @@ MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时
|
|||||||
**常用阶段操作符** :
|
**常用阶段操作符** :
|
||||||
|
|
||||||
| 操作符 | 简述 |
|
| 操作符 | 简述 |
|
||||||
| --------- | ------------------------------------------------------------ |
|
| --------- | ---------------------------------------------------------------------------------------------------- |
|
||||||
| \$match | 匹配操作符,用于对文档集合进行筛选 |
|
| \$match | 匹配操作符,用于对文档集合进行筛选 |
|
||||||
| \$project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
|
| \$project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
|
||||||
| \$sort | 排序操作符,用于根据一个或多个字段对文档进行排序 |
|
| \$sort | 排序操作符,用于根据一个或多个字段对文档进行排序 |
|
||||||
|
|||||||
@ -953,4 +953,3 @@ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
|
|||||||
6. SQL对大小写不敏感
|
6. SQL对大小写不敏感
|
||||||
7. 清除已有语句:\c
|
7. 清除已有语句:\c
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -84,15 +84,16 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
|||||||
|
|
||||||
结合上面的说明,我们分析下这个语句的执行流程:
|
结合上面的说明,我们分析下这个语句的执行流程:
|
||||||
|
|
||||||
* 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
||||||
* 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
- 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
||||||
* 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
|
- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
|
||||||
|
|
||||||
a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
|
a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
|
||||||
b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
|
b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
|
||||||
|
|
||||||
那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
|
那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
|
||||||
|
|
||||||
* 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
|
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
|
||||||
|
|
||||||
### 2.2 更新语句
|
### 2.2 更新语句
|
||||||
|
|
||||||
@ -101,12 +102,13 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
|||||||
```
|
```
|
||||||
update tb_student A set A.age='19' where A.name=' 张三 ';
|
update tb_student A set A.age='19' where A.name=' 张三 ';
|
||||||
```
|
```
|
||||||
|
|
||||||
我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
|
我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
|
||||||
|
|
||||||
* 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
|
- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
|
||||||
* 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
|
- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
|
||||||
* 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
|
- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
|
||||||
* 更新完成。
|
- 更新完成。
|
||||||
|
|
||||||
**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
|
**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
|
||||||
|
|
||||||
@ -114,25 +116,25 @@ update tb_student A set A.age='19' where A.name=' 张三 ';
|
|||||||
|
|
||||||
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
|
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
|
||||||
|
|
||||||
* **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
|
- **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
|
||||||
* **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
|
- **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
|
||||||
|
|
||||||
如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢?
|
如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢?
|
||||||
这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
|
这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
|
||||||
|
|
||||||
* 判断 redo log 是否完整,如果判断是完整的,就立即提交。
|
- 判断 redo log 是否完整,如果判断是完整的,就立即提交。
|
||||||
* 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
|
- 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
|
||||||
|
|
||||||
这样就解决了数据一致性的问题。
|
这样就解决了数据一致性的问题。
|
||||||
|
|
||||||
## 三 总结
|
## 三 总结
|
||||||
|
|
||||||
* MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
|
- MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
|
||||||
* 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
|
- 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
|
||||||
* 查询语句的执行流程如下:权限校验(如果命中缓存)--->查询缓存--->分析器--->优化器--->权限校验--->执行器--->引擎
|
- 查询语句的执行流程如下:权限校验(如果命中缓存)--->查询缓存--->分析器--->优化器--->权限校验--->执行器--->引擎
|
||||||
* 更新语句执行流程如下:分析器---->权限校验---->执行器--->引擎---redo log(prepare 状态)--->binlog--->redo log(commit状态)
|
- 更新语句执行流程如下:分析器---->权限校验---->执行器--->引擎---redo log(prepare 状态)--->binlog--->redo log(commit 状态)
|
||||||
|
|
||||||
## 四 参考
|
## 四 参考
|
||||||
|
|
||||||
* 《MySQL 实战45讲》
|
- 《MySQL 实战 45 讲》
|
||||||
* MySQL 5.6参考手册:<https://dev.MySQL.com/doc/refman/5.6/en/>
|
- MySQL 5.6 参考手册:<https://dev.MySQL.com/doc/refman/5.6/en/>
|
||||||
|
|||||||
@ -89,8 +89,7 @@ id 如果相同,从上往下依次执行。id 不同,id 值越大,执行
|
|||||||
查询用到的表名,每行都有对应的表名,表名除了正常的表之外,也可能是以下列出的值:
|
查询用到的表名,每行都有对应的表名,表名除了正常的表之外,也可能是以下列出的值:
|
||||||
|
|
||||||
- **`<unionM,N>`** : 本行引用了 id 为 M 和 N 的行的 UNION 结果;
|
- **`<unionM,N>`** : 本行引用了 id 为 M 和 N 的行的 UNION 结果;
|
||||||
- **`<derivedN>`** : 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。
|
- **`<derivedN>`** : 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。 -**`<subqueryN>`** : 本行引用了 id 为 N 的表所产生的的物化子查询结果。
|
||||||
-**`<subqueryN>`** : 本行引用了 id 为 N 的表所产生的的物化子查询结果。
|
|
||||||
|
|
||||||
### type(重要)
|
### type(重要)
|
||||||
|
|
||||||
|
|||||||
@ -73,7 +73,7 @@ SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTE
|
|||||||
|
|
||||||
### 脏读(读未提交)
|
### 脏读(读未提交)
|
||||||
|
|
||||||
%E5%AE%9E%E4%BE%8B.jpg)
|
%E5%AE%9E%E4%BE%8B.jpg>)
|
||||||
|
|
||||||
### 避免脏读(读已提交)
|
### 避免脏读(读已提交)
|
||||||
|
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- Redis
|
- Redis
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
|
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
|
||||||
|
|
||||||
在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单了写一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
|
在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单了写一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
|
||||||
|
|||||||
@ -9,7 +9,6 @@ tag:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn) 的补充完善,两者可以配合使用。
|
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn) 的补充完善,两者可以配合使用。
|
||||||
|
|
||||||

|

|
||||||
|
|||||||
@ -388,7 +388,7 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
|||||||
### 常用命令
|
### 常用命令
|
||||||
|
|
||||||
| 命令 | 介绍 |
|
| 命令 | 介绍 |
|
||||||
| --------------------------------------------- | ------------------------------------------------------------ |
|
| --------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
|
||||||
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
||||||
| ZCARD KEY | 获取指定有序集合的元素数量 |
|
| ZCARD KEY | 获取指定有序集合的元素数量 |
|
||||||
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
|
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
|
||||||
|
|||||||
@ -27,7 +27,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
|||||||
### 常用命令
|
### 常用命令
|
||||||
|
|
||||||
| 命令 | 介绍 |
|
| 命令 | 介绍 |
|
||||||
| ------------------------------------- | ------------------------------------------------------------ |
|
| ------------------------------------- | ---------------------------------------------------------------- |
|
||||||
| SETBIT key offset value | 设置指定 offset 位置的值 |
|
| SETBIT key offset value | 设置指定 offset 位置的值 |
|
||||||
| GETBIT key offset | 获取指定 offset 位置的值 |
|
| GETBIT key offset | 获取指定 offset 位置的值 |
|
||||||
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
|
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
|
||||||
@ -87,7 +87,7 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
|
|||||||
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
||||||
|
|
||||||
| 命令 | 介绍 |
|
| 命令 | 介绍 |
|
||||||
| ----------------------------------------- | ------------------------------------------------------------ |
|
| ----------------------------------------- | -------------------------------------------------------------------------------- |
|
||||||
| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
|
| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
|
||||||
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
|
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
|
||||||
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
|
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
|
||||||
@ -133,7 +133,7 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
|
|||||||
### 常用命令
|
### 常用命令
|
||||||
|
|
||||||
| 命令 | 介绍 |
|
| 命令 | 介绍 |
|
||||||
| ------------------------------------------------ | ------------------------------------------------------------ |
|
| ------------------------------------------------ | ---------------------------------------------------------------------------------------------------- |
|
||||||
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
|
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
|
||||||
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
|
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
|
||||||
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
|
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
|
||||||
|
|||||||
@ -248,7 +248,7 @@ struct __attribute__ ((__packed__)) sdshdr64 {
|
|||||||
通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
|
通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
|
||||||
|
|
||||||
| 类型 | 字节 | 位 |
|
| 类型 | 字节 | 位 |
|
||||||
| -------- | ---- | ---- |
|
| -------- | ---- | --- |
|
||||||
| sdshdr5 | < 1 | <8 |
|
| sdshdr5 | < 1 | <8 |
|
||||||
| sdshdr8 | 1 | 8 |
|
| sdshdr8 | 1 | 8 |
|
||||||
| sdshdr16 | 2 | 16 |
|
| sdshdr16 | 2 | 16 |
|
||||||
@ -593,4 +593,3 @@ Redis 提供 6 种数据淘汰策略:
|
|||||||
- 《Redis 设计与实现》
|
- 《Redis 设计与实现》
|
||||||
- Redis 命令手册:https://www.redis.com.cn/commands.html
|
- Redis 命令手册:https://www.redis.com.cn/commands.html
|
||||||
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
||||||
|
|
||||||
|
|||||||
@ -1204,7 +1204,7 @@ ORDER BY c.cust_name
|
|||||||
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
||||||
|
|
||||||
| 连接类型 | 说明 |
|
| 连接类型 | 说明 |
|
||||||
| ---------------------------------------- | ------------------------------------------------------------ |
|
| ---------------------------------------- | --------------------------------------------------------------------------------------------- |
|
||||||
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
||||||
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
||||||
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
||||||
|
|||||||
@ -490,7 +490,7 @@ order by c.cust_name;
|
|||||||
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
||||||
|
|
||||||
| 连接类型 | 说明 |
|
| 连接类型 | 说明 |
|
||||||
| ---------------------------------------- | ------------------------------------------------------------ |
|
| ---------------------------------------- | --------------------------------------------------------------------------------------------- |
|
||||||
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
||||||
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
||||||
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
||||||
@ -919,7 +919,7 @@ SELECT user FROM user;
|
|||||||
下表说明了可用于`GRANT`和`REVOKE`语句的所有允许权限:
|
下表说明了可用于`GRANT`和`REVOKE`语句的所有允许权限:
|
||||||
|
|
||||||
| **特权** | **说明** | **级别** | | | | | |
|
| **特权** | **说明** | **级别** | | | | | |
|
||||||
| ----------------------- | ------------------------------------------------------------ | -------- | ------ | -------- | -------- | ---- | ---- |
|
| ----------------------- | ------------------------------------------------------------------------------------------------------- | -------- | ------ | -------- | -------- | --- | --- |
|
||||||
| **全局** | 数据库 | **表** | **列** | **程序** | **代理** | | |
|
| **全局** | 数据库 | **表** | **列** | **程序** | **代理** | | |
|
||||||
| ALL [PRIVILEGES] | 授予除 GRANT OPTION 之外的指定访问级别的所有权限 | | | | | | |
|
| ALL [PRIVILEGES] | 授予除 GRANT OPTION 之外的指定访问级别的所有权限 | | | | | | |
|
||||||
| ALTER | 允许用户使用 ALTER TABLE 语句 | X | X | X | | | |
|
| ALTER | 允许用户使用 ALTER TABLE 语句 | X | X | X | | | |
|
||||||
|
|||||||
@ -293,8 +293,3 @@ zkClient.setData().forPath("/node1/00001","c++".getBytes());//更新节点数据
|
|||||||
```java
|
```java
|
||||||
List<String> childrenPaths = zkClient.getChildren().forPath("/node1");
|
List<String> childrenPaths = zkClient.getChildren().forPath("/node1");
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -125,7 +125,7 @@ Stat 类中包含了一个数据节点的所有状态信息的字段,包括事
|
|||||||
下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ) :
|
下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ) :
|
||||||
|
|
||||||
| znode 状态信息 | 解释 |
|
| znode 状态信息 | 解释 |
|
||||||
| -------------- | ------------------------------------------------------------ |
|
| -------------- | --------------------------------------------------------------------------------------------------- |
|
||||||
| cZxid | create ZXID,即该数据节点被创建时的事务 id |
|
| cZxid | create ZXID,即该数据节点被创建时的事务 id |
|
||||||
| ctime | create time,即该节点的创建时间 |
|
| ctime | create time,即该节点的创建时间 |
|
||||||
| mZxid | modified ZXID,即该节点最终一次更新时的事务 id |
|
| mZxid | modified ZXID,即该节点最终一次更新时的事务 id |
|
||||||
@ -202,7 +202,7 @@ Session 有一个属性叫做:`sessionTimeout` ,`sessionTimeout` 代表会
|
|||||||
ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定一台称为 “**Leader**” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,**Follower** 和 **Observer** 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
|
ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定一台称为 “**Leader**” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,**Follower** 和 **Observer** 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
|
||||||
|
|
||||||
| 角色 | 说明 |
|
| 角色 | 说明 |
|
||||||
| -------- | ------------------------------------------------------------ |
|
| -------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||||
| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
|
| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
|
||||||
| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
|
| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
|
||||||
| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
|
| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
|
||||||
|
|||||||
@ -79,9 +79,9 @@ tag:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
* **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
|
- **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
|
||||||
* **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
|
- **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
|
||||||
* **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
|
- **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
|
||||||
|
|
||||||
### 3PC(三阶段提交)
|
### 3PC(三阶段提交)
|
||||||
|
|
||||||
@ -109,8 +109,8 @@ tag:
|
|||||||
|
|
||||||
#### prepare 阶段
|
#### prepare 阶段
|
||||||
|
|
||||||
* `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
|
- `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号 N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
|
||||||
* `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号N记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
|
- `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
|
||||||
|
|
||||||
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
|
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
|
||||||
|
|
||||||
@ -156,9 +156,9 @@ tag:
|
|||||||
|
|
||||||
和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
|
和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
|
||||||
|
|
||||||
* `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
|
- `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
|
||||||
* `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
|
- `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
|
||||||
* `Observer` :就是没有选举权和被选举权的 `Follower` 。
|
- `Observer` :就是没有选举权和被选举权的 `Follower` 。
|
||||||
|
|
||||||
在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
|
在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
|
||||||
|
|
||||||
@ -242,24 +242,24 @@ tag:
|
|||||||
|
|
||||||
其中节点类型可以分为 **持久节点**、**持久顺序节点**、**临时节点** 和 **临时顺序节点**。
|
其中节点类型可以分为 **持久节点**、**持久顺序节点**、**临时节点** 和 **临时顺序节点**。
|
||||||
|
|
||||||
* 持久节点:一旦创建就一直存在,直到将其删除。
|
- 持久节点:一旦创建就一直存在,直到将其删除。
|
||||||
* 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
|
- 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
|
||||||
* 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
|
- 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||||
* 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
|
- 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
|
||||||
|
|
||||||
节点状态中包含了很多节点的属性比如 `czxid` 、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
|
节点状态中包含了很多节点的属性比如 `czxid` 、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
|
||||||
|
|
||||||
* `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务ID。
|
- `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务 ID。
|
||||||
* `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务ID。
|
- `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务 ID。
|
||||||
* `ctime`:`Created Time`,该节点被创建的时间。
|
- `ctime`:`Created Time`,该节点被创建的时间。
|
||||||
* `mtime`: `Modified Time`,该节点最后一次被修改的时间。
|
- `mtime`: `Modified Time`,该节点最后一次被修改的时间。
|
||||||
* `version`:节点的版本号。
|
- `version`:节点的版本号。
|
||||||
* `cversion`:**子节点** 的版本号。
|
- `cversion`:**子节点** 的版本号。
|
||||||
* `aversion`:节点的 `ACL` 版本号。
|
- `aversion`:节点的 `ACL` 版本号。
|
||||||
* `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为0。
|
- `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为 0。
|
||||||
* `dataLength`:节点数据内容的长度。
|
- `dataLength`:节点数据内容的长度。
|
||||||
* `numChildre`:该节点的子节点个数,如果为临时节点为0。
|
- `numChildre`:该节点的子节点个数,如果为临时节点为 0。
|
||||||
* `pzxid`:该节点子节点列表最后一次被修改时的事务ID,注意是子节点的 **列表** ,不是内容。
|
- `pzxid`:该节点子节点列表最后一次被修改时的事务 ID,注意是子节点的 **列表** ,不是内容。
|
||||||
|
|
||||||
### 会话
|
### 会话
|
||||||
|
|
||||||
@ -271,11 +271,11 @@ tag:
|
|||||||
|
|
||||||
`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
|
`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
|
||||||
|
|
||||||
* `CREATE` :创建子节点的权限。
|
- `CREATE` :创建子节点的权限。
|
||||||
* `READ`:获取节点数据和子节点列表的权限。
|
- `READ`:获取节点数据和子节点列表的权限。
|
||||||
* `WRITE`:更新节点数据的权限。
|
- `WRITE`:更新节点数据的权限。
|
||||||
* `DELETE`:删除子节点的权限。
|
- `DELETE`:删除子节点的权限。
|
||||||
* `ADMIN`:设置节点 ACL 的权限。
|
- `ADMIN`:设置节点 ACL 的权限。
|
||||||
|
|
||||||
### Watcher 机制
|
### Watcher 机制
|
||||||
|
|
||||||
@ -357,14 +357,14 @@ tag:
|
|||||||
|
|
||||||
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
|
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
|
||||||
|
|
||||||
* 分布式与集群的区别
|
- 分布式与集群的区别
|
||||||
|
|
||||||
* `2PC` 、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
|
- `2PC` 、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
|
||||||
|
|
||||||
* `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
|
- `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
|
||||||
|
|
||||||
* `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
|
- `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
|
||||||
|
|
||||||
* `zookeeper` 的典型应用场景,比如选主,注册中心等等。
|
- `zookeeper` 的典型应用场景,比如选主,注册中心等等。
|
||||||
|
|
||||||
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出 🤝🤝🤝。
|
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出 🤝🤝🤝。
|
||||||
|
|||||||
@ -210,7 +210,6 @@ Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来
|
|||||||
|
|
||||||
不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
|
不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
|
||||||
|
|
||||||
|
|
||||||
## Dubbo 的负载均衡策略
|
## Dubbo 的负载均衡策略
|
||||||
|
|
||||||
### 什么是负载均衡?
|
### 什么是负载均衡?
|
||||||
@ -411,8 +410,6 @@ public class RpcStatus {
|
|||||||
|
|
||||||
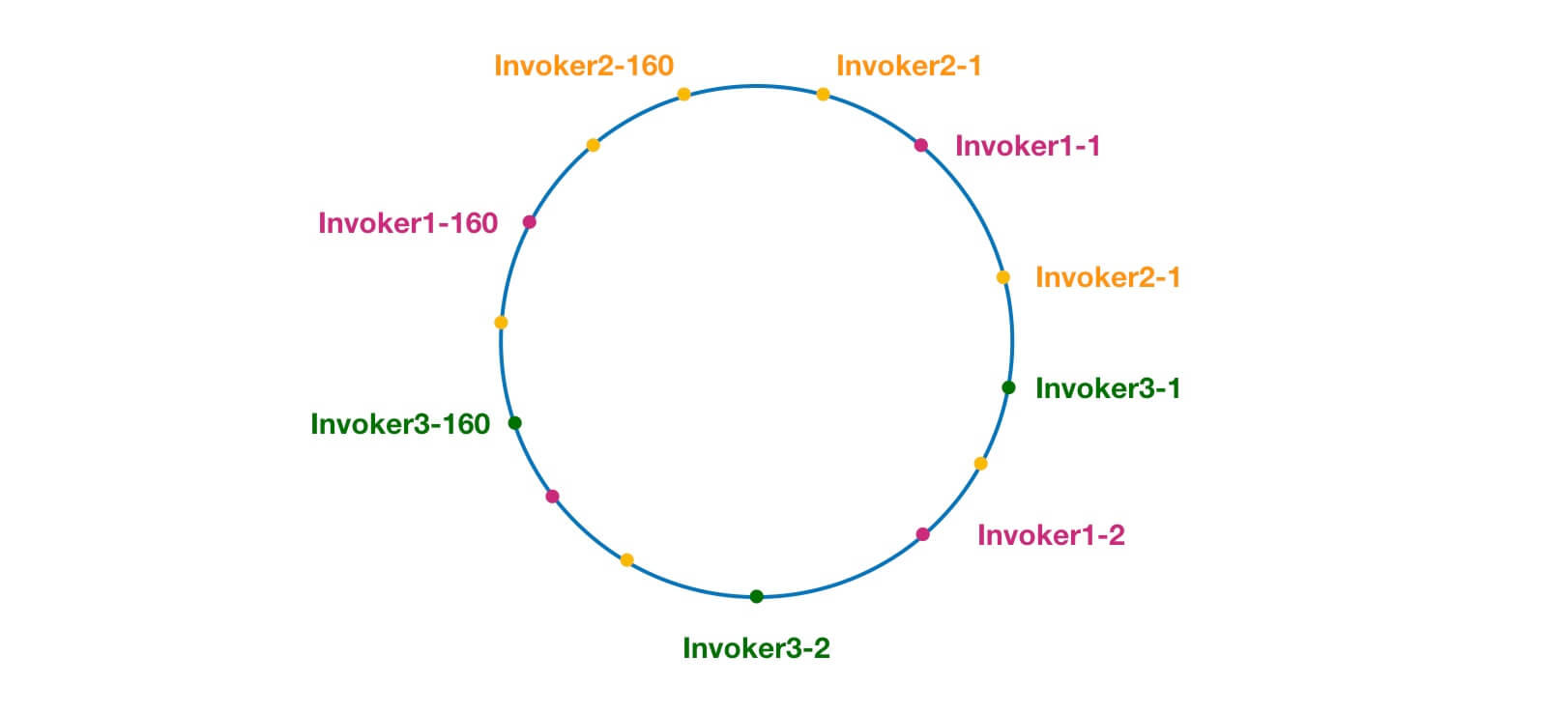
另外,Dubbo 为了避免数据倾斜问题(节点不够分散,大量请求落到同一节点),还引入了虚拟节点的概念。通过虚拟节点可以让节点更加分散,有效均衡各个节点的请求量。
|
另外,Dubbo 为了避免数据倾斜问题(节点不够分散,大量请求落到同一节点),还引入了虚拟节点的概念。通过虚拟节点可以让节点更加分散,有效均衡各个节点的请求量。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
官方有详细的源码分析:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance) 。这里还有一个相关的 [PR#5440](https://github.com/apache/dubbo/pull/5440) 来修复老版本中 ConsistentHashLoadBalance 存在的一些 Bug。感兴趣的小伙伴,可以多花点时间研究一下。我这里不多分析了,这个作业留给你们!
|
官方有详细的源码分析:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance) 。这里还有一个相关的 [PR#5440](https://github.com/apache/dubbo/pull/5440) 来修复老版本中 ConsistentHashLoadBalance 存在的一些 Bug。感兴趣的小伙伴,可以多花点时间研究一下。我这里不多分析了,这个作业留给你们!
|
||||||
@ -457,4 +454,3 @@ Kryo和FST这两种序列化方式是 Dubbo 后来才引入的,性能非常好
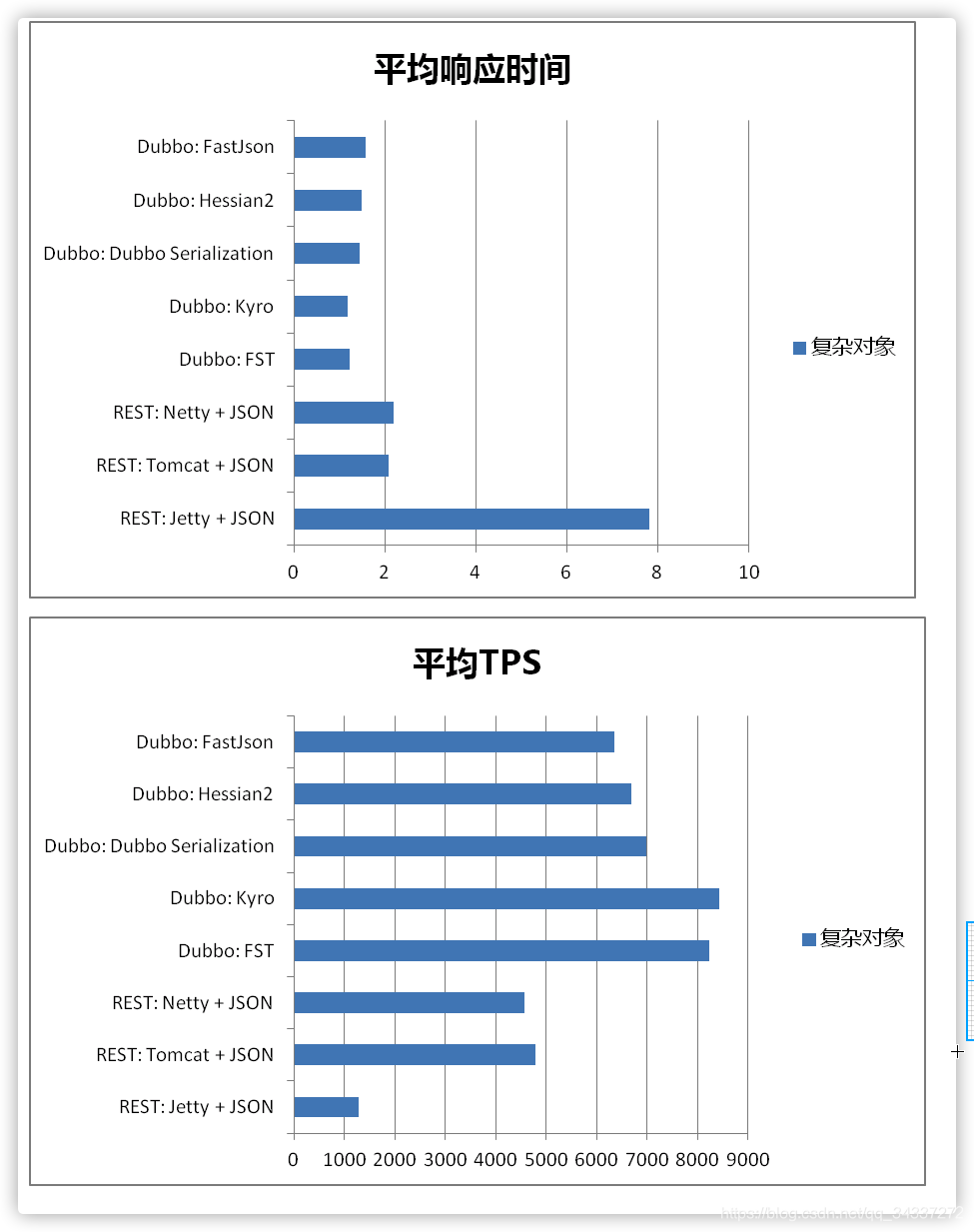
|
|||||||
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
|
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
@ -13,10 +13,8 @@ tag:
|
|||||||
|
|
||||||
**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
|
**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
|
||||||
|
|
||||||
|
|
||||||
**RPC 能帮助我们做什么呢?** 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
|
**RPC 能帮助我们做什么呢?** 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
|
||||||
|
|
||||||
|
|
||||||
举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
|
举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
|
||||||
|
|
||||||
一言蔽之:**RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。**
|
一言蔽之:**RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。**
|
||||||
@ -25,7 +23,6 @@ tag:
|
|||||||
|
|
||||||
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
|
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
|
||||||
|
|
||||||
|
|
||||||
1. **客户端(服务消费端)** :调用远程方法的一端。
|
1. **客户端(服务消费端)** :调用远程方法的一端。
|
||||||
1. **客户端 Stub(桩)** : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
|
1. **客户端 Stub(桩)** : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
|
||||||
1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
|
1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
|
||||||
@ -34,7 +31,6 @@ tag:
|
|||||||
|
|
||||||
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
|
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
|
||||||
|
|
||||||
|
|
||||||
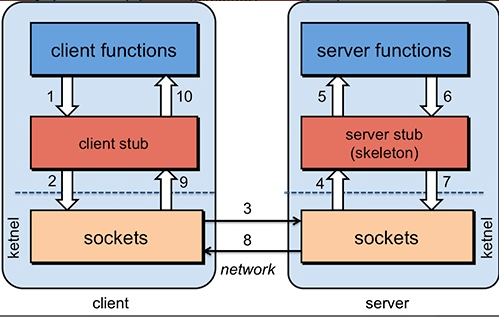
|

|
||||||
|
|
||||||
1. 服务消费端(client)以本地调用的方式调用远程服务;
|
1. 服务消费端(client)以本地调用的方式调用远程服务;
|
||||||
@ -141,4 +137,3 @@ Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
|
|||||||
## 既然有了 HTTP 协议,为什么还要有 RPC ?
|
## 既然有了 HTTP 协议,为什么还要有 RPC ?
|
||||||
|
|
||||||
[HTTP 和 RPC 详细对比](http&rpc.md) 。
|
[HTTP 和 RPC 详细对比](http&rpc.md) 。
|
||||||
|
|
||||||
|
|||||||
@ -167,4 +167,3 @@ raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为
|
|||||||
- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
|
- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
|
||||||
- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
|
- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
|
||||||
- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
|
- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
|
||||||
|
|
||||||
|
|||||||
@ -95,8 +95,6 @@ Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这
|
|||||||
|
|
||||||
> **要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。** 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
|
> **要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。** 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
|
下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
|
||||||
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zookeeper-kafka.jpg" style="zoom:50%;" />
|
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zookeeper-kafka.jpg" style="zoom:50%;" />
|
||||||
@ -158,11 +156,11 @@ if (sendResult.getRecordMetadata() != null) {
|
|||||||
|
|
||||||
但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
|
但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
|
||||||
|
|
||||||
````java
|
```java
|
||||||
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
|
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
|
||||||
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
|
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
|
||||||
ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
|
ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
|
||||||
````
|
```
|
||||||
|
|
||||||
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
|
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
|
||||||
|
|
||||||
@ -217,8 +215,8 @@ acks 的默认值即为1,代表我们的消息被leader副本接收之后就
|
|||||||
|
|
||||||
- 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
|
- 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
|
||||||
- 将 **`enable.auto.commit`** 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:**什么时候提交 offset 合适?**
|
- 将 **`enable.auto.commit`** 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:**什么时候提交 offset 合适?**
|
||||||
* 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
|
- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
|
||||||
* 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
|
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
|
||||||
|
|
||||||
### Reference
|
### Reference
|
||||||
|
|
||||||
|
|||||||
@ -130,7 +130,7 @@ AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的
|
|||||||
### JMS vs AMQP
|
### JMS vs AMQP
|
||||||
|
|
||||||
| 对比方向 | JMS | AMQP |
|
| 对比方向 | JMS | AMQP |
|
||||||
| :----------: | :-------------------------------------- | :----------------------------------------------------------- |
|
| :----------: | :-------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||||
| 定义 | Java API | 协议 |
|
| 定义 | Java API | 协议 |
|
||||||
| 跨语言 | 否 | 是 |
|
| 跨语言 | 否 | 是 |
|
||||||
| 跨平台 | 否 | 是 |
|
| 跨平台 | 否 | 是 |
|
||||||
@ -260,7 +260,7 @@ Pulsar 更新记录(可以直观看到项目是否还在维护):https://gi
|
|||||||
> 参考《Java 工程师面试突击第 1 季-中华石杉老师》
|
> 参考《Java 工程师面试突击第 1 季-中华石杉老师》
|
||||||
|
|
||||||
| 对比方向 | 概要 |
|
| 对比方向 | 概要 |
|
||||||
| -------- | ------------------------------------------------------------ |
|
| -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||||
| 吞吐量 | 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。 |
|
| 吞吐量 | 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。 |
|
||||||
| 可用性 | 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 Kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
|
| 可用性 | 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 Kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
|
||||||
| 时效性 | RabbitMQ 基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级,其他几个都是 ms 级。 |
|
| 时效性 | RabbitMQ 基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级,其他几个都是 ms 级。 |
|
||||||
|
|||||||
@ -191,11 +191,13 @@ make && make install
|
|||||||
```shell
|
```shell
|
||||||
[root@SnailClimb otp_src_19.3]# ./bin/erl
|
[root@SnailClimb otp_src_19.3]# ./bin/erl
|
||||||
```
|
```
|
||||||
|
|
||||||
运行下面的语句输出“hello world”
|
运行下面的语句输出“hello world”
|
||||||
|
|
||||||
```erlang
|
```erlang
|
||||||
io:format("hello world~n", []).
|
io:format("hello world~n", []).
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
大功告成,我们的 erlang 已经安装完成。
|
大功告成,我们的 erlang 已经安装完成。
|
||||||
@ -236,6 +238,7 @@ export ERL_HOME PATH
|
|||||||
```shell
|
```shell
|
||||||
wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
||||||
```
|
```
|
||||||
|
|
||||||
或者直接在官网下载
|
或者直接在官网下载
|
||||||
|
|
||||||
[https://www.rabbitmq.com/install-rpm.html](https://www.rabbitmq.com/install-rpm.html)
|
[https://www.rabbitmq.com/install-rpm.html](https://www.rabbitmq.com/install-rpm.html)
|
||||||
@ -245,11 +248,13 @@ wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.
|
|||||||
```shell
|
```shell
|
||||||
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
|
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
|
||||||
```
|
```
|
||||||
|
|
||||||
紧接着执行:
|
紧接着执行:
|
||||||
|
|
||||||
```shell
|
```shell
|
||||||
yum install rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
yum install rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
||||||
```
|
```
|
||||||
|
|
||||||
中途需要你输入"y"才能继续安装。
|
中途需要你输入"y"才能继续安装。
|
||||||
|
|
||||||
**3 开启 web 管理插件**
|
**3 开启 web 管理插件**
|
||||||
@ -305,4 +310,3 @@ Setting permissions for user "root" in vhost "/" ...
|
|||||||
再次访问:http://你的 ip 地址:15672/ ,输入用户名和密码:root root
|
再次访问:http://你的 ip 地址:15672/ ,输入用户名和密码:root root
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
@ -419,7 +419,7 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
|||||||
|
|
||||||
而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
|
而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
|
||||||
|
|
||||||
所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号*索引固定⻓度20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
|
所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号\*索引固定⻓度 20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
|
||||||
|
|
||||||
讲到这里,你可能对 `RockeMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
|
讲到这里,你可能对 `RockeMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
|
||||||
|
|
||||||
|
|||||||
@ -110,6 +110,7 @@ class Broker {
|
|||||||
```
|
```
|
||||||
|
|
||||||
问题:
|
问题:
|
||||||
|
|
||||||
1. 没有实现真正执行消息存储落盘
|
1. 没有实现真正执行消息存储落盘
|
||||||
2. 没有实现 NameServer 去作为注册中心,定位服务
|
2. 没有实现 NameServer 去作为注册中心,定位服务
|
||||||
3. 使用 LinkedBlockingQueue 作为消息队列,注意,参数是无限大,在真正 RocketMQ 也是如此是无限大,理论上不会出现对进来的数据进行抛弃,但是会有内存泄漏问题(阿里巴巴开发手册也因为这个问题,建议我们使用自制线程池)
|
3. 使用 LinkedBlockingQueue 作为消息队列,注意,参数是无限大,在真正 RocketMQ 也是如此是无限大,理论上不会出现对进来的数据进行抛弃,但是会有内存泄漏问题(阿里巴巴开发手册也因为这个问题,建议我们使用自制线程池)
|
||||||
@ -186,6 +187,7 @@ class Broker {
|
|||||||
|

|
||||||
|
|
||||||
加分项咯
|
加分项咯
|
||||||
|
|
||||||
1. 包括组件通信间使用 Netty 的自定义协议
|
1. 包括组件通信间使用 Netty 的自定义协议
|
||||||
2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
|
2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
|
||||||
3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时,在 Broker 端就使用过滤服务器进行过滤)
|
3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时,在 Broker 端就使用过滤服务器进行过滤)
|
||||||
@ -195,7 +197,7 @@ class Broker {
|
|||||||
## 3 参考
|
## 3 参考
|
||||||
|
|
||||||
1. 《RocketMQ 技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
|
1. 《RocketMQ 技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
|
||||||
3. 十分钟入门RocketMQ:https://developer.aliyun.com/article/66101
|
2. 十分钟入门 RocketMQ:https://developer.aliyun.com/article/66101
|
||||||
4. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
|
3. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
|
||||||
5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
|
4. 滴滴出行基于 RocketMQ 构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
|
||||||
6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
|
5. 基于《RocketMQ 技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
|
||||||
|
|||||||
@ -12,7 +12,7 @@ tag:
|
|||||||
>
|
>
|
||||||
> **原文地址:** https://mp.weixin.qq.com/s/6hUU6SZsxGPWAIIByq93Rw
|
> **原文地址:** https://mp.weixin.qq.com/s/6hUU6SZsxGPWAIIByq93Rw
|
||||||
|
|
||||||
我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别****人沟通,都显得特别专业**。每次遇到这类人,我都在想,他们到底是怎么做到的?
|
我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别\*\***人沟通,都显得特别专业\*\*。每次遇到这类人,我都在想,他们到底是怎么做到的?
|
||||||
|
|
||||||
随着工作时间的增长,渐渐地我也总结出一些经验,他们身上都保持着一些看似很微小的优秀习惯,但正是因为这些习惯,体现出了一个优秀程序员的基本素养。
|
随着工作时间的增长,渐渐地我也总结出一些经验,他们身上都保持着一些看似很微小的优秀习惯,但正是因为这些习惯,体现出了一个优秀程序员的基本素养。
|
||||||
|
|
||||||
|
|||||||
@ -12,7 +12,7 @@ tag:
|
|||||||
>
|
>
|
||||||
> **原文地址** :https://www.cnblogs.com/scada/p/14259332.html
|
> **原文地址** :https://www.cnblogs.com/scada/p/14259332.html
|
||||||
|
|
||||||
------
|
---
|
||||||
|
|
||||||
## 前言
|
## 前言
|
||||||
|
|
||||||
@ -20,7 +20,7 @@ tag:
|
|||||||
|
|
||||||
近 8 年有些事情做对了,也有更多事情做错了,在这里记录一下,希望能够给后人一些帮助吧,也欢迎私信交流。文笔不好,见谅,有些细节记不清了,如果有出入,就当是我编的这个故事吧。
|
近 8 年有些事情做对了,也有更多事情做错了,在这里记录一下,希望能够给后人一些帮助吧,也欢迎私信交流。文笔不好,见谅,有些细节记不清了,如果有出入,就当是我编的这个故事吧。
|
||||||
|
|
||||||
*PS:有几个问题先在这里解释一下,评论就不一一回复了*
|
_PS:有几个问题先在这里解释一下,评论就不一一回复了_
|
||||||
|
|
||||||
1. 关于差生,我本人在科大时确实成绩偏下,差生主要讲这一点,没其他意思。
|
1. 关于差生,我本人在科大时确实成绩偏下,差生主要讲这一点,没其他意思。
|
||||||
2. 因为买房是我人生中的大事,我认为需要记录和总结一下,本文中会有买房,房价之类的信息出现,您如果对房价,炒房等反感的话,请您停止阅读,并且我再这里为浪费您的时间先道个歉。
|
2. 因为买房是我人生中的大事,我认为需要记录和总结一下,本文中会有买房,房价之类的信息出现,您如果对房价,炒房等反感的话,请您停止阅读,并且我再这里为浪费您的时间先道个歉。
|
||||||
|
|||||||
@ -825,8 +825,6 @@ public class Example {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 静态方法和实例方法有何不同?
|
### 静态方法和实例方法有何不同?
|
||||||
|
|
||||||
**1、调用方式**
|
**1、调用方式**
|
||||||
@ -898,7 +896,7 @@ public class Person {
|
|||||||
综上:**重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。**
|
综上:**重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。**
|
||||||
|
|
||||||
| 区别点 | 重载方法 | 重写方法 |
|
| 区别点 | 重载方法 | 重写方法 |
|
||||||
| :--------- | :------- | :----------------------------------------------------------- |
|
| :--------- | :------- | :--------------------------------------------------------------- |
|
||||||
| 发生范围 | 同一个类 | 子类 |
|
| 发生范围 | 同一个类 | 子类 |
|
||||||
| 参数列表 | 必须修改 | 一定不能修改 |
|
| 参数列表 | 必须修改 | 一定不能修改 |
|
||||||
| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
|
| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
|
||||||
|
|||||||
@ -569,8 +569,3 @@ for (String s : strs) {
|
|||||||
Java 中最常用的语法糖主要有泛型、自动拆装箱、变长参数、枚举、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等。
|
Java 中最常用的语法糖主要有泛型、自动拆装箱、变长参数、枚举、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等。
|
||||||
|
|
||||||
关于这些语法糖的详细解读,请看这篇文章 [Java 语法糖详解](./syntactic-sugar.md) 。
|
关于这些语法糖的详细解读,请看这篇文章 [Java 语法糖详解](./syntactic-sugar.md) 。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -250,7 +250,7 @@ bar.method2();
|
|||||||
不同点: 静态代码块在非静态代码块之前执行(静态代码块 -> 非静态代码块 -> 构造方法)。静态代码块只在第一次 new 执行一次,之后不再执行,而非静态代码块在每 new 一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
|
不同点: 静态代码块在非静态代码块之前执行(静态代码块 -> 非静态代码块 -> 构造方法)。静态代码块只在第一次 new 执行一次,之后不再执行,而非静态代码块在每 new 一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
|
||||||
|
|
||||||
> **🐛 修正(参见: [issue #677](https://github.com/Snailclimb/JavaGuide/issues/677))** :静态代码块可能在第一次 new 对象的时候执行,但不一定只在第一次 new 的时候执行。比如通过 `Class.forName("ClassDemo")`创建 Class 对象的时候也会执行,即 new 或者 `Class.forName("ClassDemo")` 都会执行静态代码块。
|
> **🐛 修正(参见: [issue #677](https://github.com/Snailclimb/JavaGuide/issues/677))** :静态代码块可能在第一次 new 对象的时候执行,但不一定只在第一次 new 的时候执行。比如通过 `Class.forName("ClassDemo")`创建 Class 对象的时候也会执行,即 new 或者 `Class.forName("ClassDemo")` 都会执行静态代码块。
|
||||||
一般情况下,如果有些代码比如一些项目最常用的变量或对象必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的。如果我们想要设计不需要创建对象就可以调用类中的方法,例如:`Arrays` 类,`Character` 类,`String` 类等,就需要使用静态方法, 两者的区别是 静态代码块是自动执行的而静态方法是被调用的时候才执行的.
|
> 一般情况下,如果有些代码比如一些项目最常用的变量或对象必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的。如果我们想要设计不需要创建对象就可以调用类中的方法,例如:`Arrays` 类,`Character` 类,`String` 类等,就需要使用静态方法, 两者的区别是 静态代码块是自动执行的而静态方法是被调用的时候才执行的.
|
||||||
|
|
||||||
Example:
|
Example:
|
||||||
|
|
||||||
|
|||||||
@ -400,4 +400,3 @@ after method send
|
|||||||
这篇文章中主要介绍了代理模式的两种实现:静态代理以及动态代理。涵盖了静态代理和动态代理实战、静态代理和动态代理的区别、JDK 动态代理和 Cglib 动态代理区别等内容。
|
这篇文章中主要介绍了代理模式的两种实现:静态代理以及动态代理。涵盖了静态代理和动态代理实战、静态代理和动态代理的区别、JDK 动态代理和 Cglib 动态代理区别等内容。
|
||||||
|
|
||||||
文中涉及到的所有源码,你可以在这里找到:[https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy](https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy) 。
|
文中涉及到的所有源码,你可以在这里找到:[https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy](https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy) 。
|
||||||
|
|
||||||
|
|||||||
@ -182,4 +182,3 @@ value is JavaGuide
|
|||||||
```java
|
```java
|
||||||
Class<?> targetClass = Class.forName("cn.javaguide.TargetObject");
|
Class<?> targetClass = Class.forName("cn.javaguide.TargetObject");
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -15,7 +15,6 @@ head:
|
|||||||
> 作者:Hollis
|
> 作者:Hollis
|
||||||
>
|
>
|
||||||
> 原文:https://mp.weixin.qq.com/s/o4XdEMq1DL-nBS-f8Za5Aw
|
> 原文:https://mp.weixin.qq.com/s/o4XdEMq1DL-nBS-f8Za5Aw
|
||||||
>
|
|
||||||
|
|
||||||
语法糖是大厂 Java 面试常问的一个知识点。
|
语法糖是大厂 Java 面试常问的一个知识点。
|
||||||
|
|
||||||
|
|||||||
@ -183,6 +183,7 @@ int main()
|
|||||||
```
|
```
|
||||||
|
|
||||||
输出结果:
|
输出结果:
|
||||||
|
|
||||||
```
|
```
|
||||||
invoke before: 10
|
invoke before: 10
|
||||||
incr before: 10
|
incr before: 10
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- Java集合
|
- Java集合
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
## ArrayList 简介
|
## ArrayList 简介
|
||||||
|
|
||||||
`ArrayList` 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 `ArrayList` 实例的容量。这可以减少递增式再分配的数量。
|
`ArrayList` 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 `ArrayList` 实例的容量。这可以减少递增式再分配的数量。
|
||||||
@ -603,7 +602,7 @@ public class ArrayList<E> extends AbstractList<E>
|
|||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
细心的同学一定会发现 :**以无参数构造方法创建 ``ArrayList`` 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
|
细心的同学一定会发现 :**以无参数构造方法创建 `ArrayList` 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
|
||||||
|
|
||||||
> 补充:JDK6 new 无参构造的 `ArrayList` 对象时,直接创建了长度是 10 的 `Object[]` 数组 elementData 。
|
> 补充:JDK6 new 无参构造的 `ArrayList` 对象时,直接创建了长度是 10 的 `Object[]` 数组 elementData 。
|
||||||
|
|
||||||
@ -940,6 +939,3 @@ public class EnsureCapacityTest {
|
|||||||
```
|
```
|
||||||
|
|
||||||
通过运行结果,我们可以看出向 `ArrayList` 添加大量元素之前使用`ensureCapacity` 方法可以提升性能。不过,这个性能差距几乎可以忽略不计。而且,实际项目根本也不可能往 `ArrayList` 里面添加这么多元素。
|
通过运行结果,我们可以看出向 `ArrayList` 添加大量元素之前使用`ensureCapacity` 方法可以提升性能。不过,这个性能差距几乎可以忽略不计。而且,实际项目根本也不可能往 `ArrayList` 里面添加这么多元素。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- Java集合
|
- Java集合
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
|
> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
|
||||||
|
|
||||||
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap ` 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
|
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap ` 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
|
||||||
@ -103,7 +102,7 @@ public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLe
|
|||||||
3. 寻找并发级别 `concurrencyLevel` 之上最近的 **2 的幂次方**值,作为初始化容量大小,**默认是 16**。
|
3. 寻找并发级别 `concurrencyLevel` 之上最近的 **2 的幂次方**值,作为初始化容量大小,**默认是 16**。
|
||||||
4. 记录 `segmentShift` 偏移量,这个值为【容量 = 2 的 N 次方】中的 N,在后面 Put 时计算位置时会用到。**默认是 32 - sshift = 28**.
|
4. 记录 `segmentShift` 偏移量,这个值为【容量 = 2 的 N 次方】中的 N,在后面 Put 时计算位置时会用到。**默认是 32 - sshift = 28**.
|
||||||
5. 记录 `segmentMask`,默认是 ssize - 1 = 16 -1 = 15.
|
5. 记录 `segmentMask`,默认是 ssize - 1 = 16 -1 = 15.
|
||||||
6. **初始化 `segments[0]`**,**默认大小为 2**,**负载因子 0.75**,**扩容阀值是 2*0.75=1.5**,插入第二个值时才会进行扩容。
|
6. **初始化 `segments[0]`**,**默认大小为 2**,**负载因子 0.75**,**扩容阀值是 2\*0.75=1.5**,插入第二个值时才会进行扩容。
|
||||||
|
|
||||||
### 3. put
|
### 3. put
|
||||||
|
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- Java集合
|
- Java集合
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
> 感谢 [changfubai](https://github.com/changfubai) 对本文的改进做出的贡献!
|
> 感谢 [changfubai](https://github.com/changfubai) 对本文的改进做出的贡献!
|
||||||
|
|
||||||
## HashMap 简介
|
## HashMap 简介
|
||||||
|
|||||||
@ -22,7 +22,6 @@ Java 集合框架如下图所示:
|
|||||||
|
|
||||||
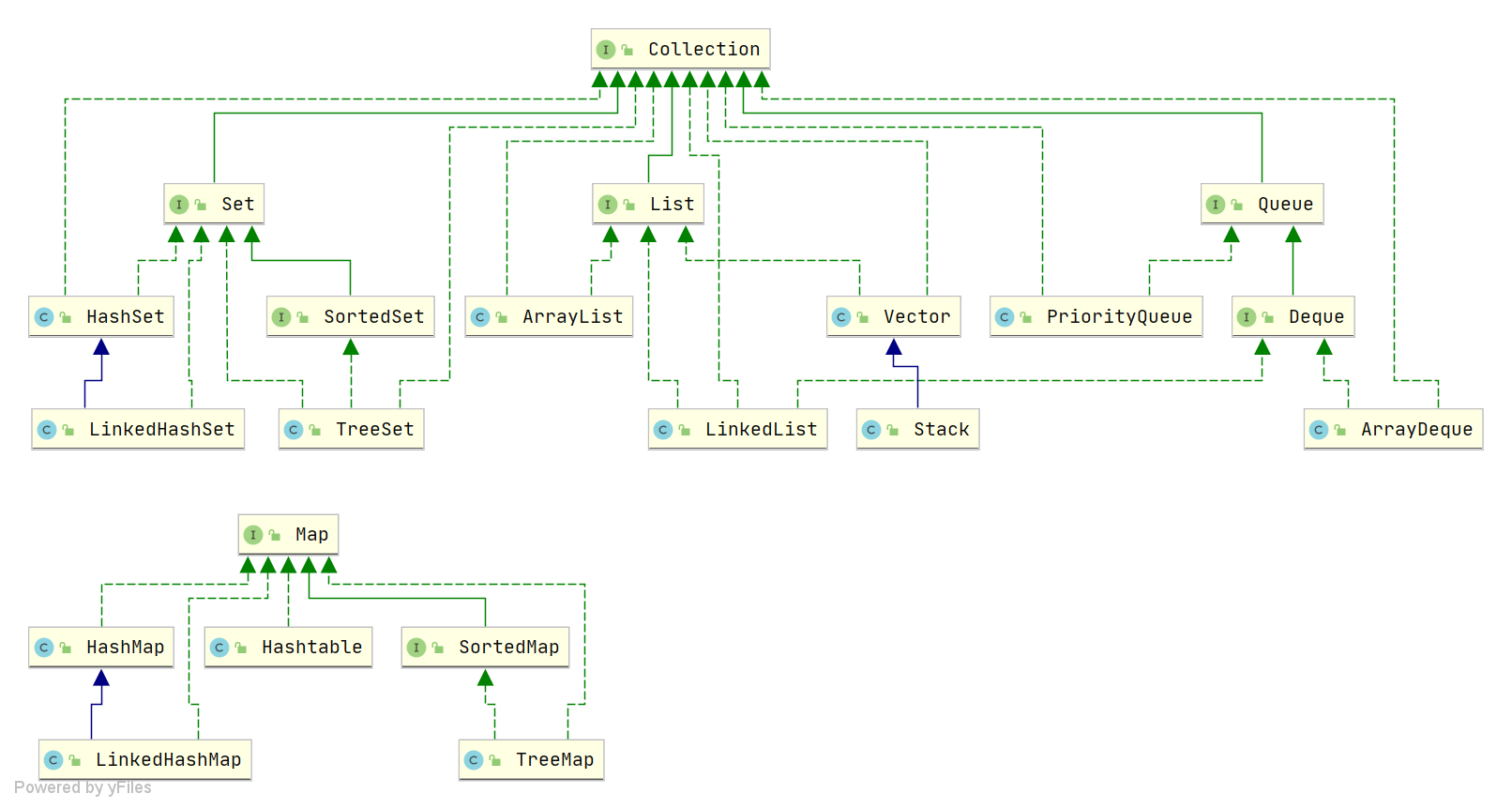
|

|
||||||
|
|
||||||
|
|
||||||
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了`AbstractList`, `NavigableSet`等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
|
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了`AbstractList`, `NavigableSet`等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
|
||||||
|
|
||||||
### 说说 List, Set, Queue, Map 四者的区别?
|
### 说说 List, Set, Queue, Map 四者的区别?
|
||||||
@ -307,7 +306,6 @@ Output:
|
|||||||
|
|
||||||
事实上,`Deque` 还提供有 `push()` 和 `pop()` 等其他方法,可用于模拟栈。
|
事实上,`Deque` 还提供有 `push()` 和 `pop()` 等其他方法,可用于模拟栈。
|
||||||
|
|
||||||
|
|
||||||
### ArrayDeque 与 LinkedList 的区别
|
### ArrayDeque 与 LinkedList 的区别
|
||||||
|
|
||||||
`ArrayDeque` 和 `LinkedList` 都实现了 `Deque` 接口,两者都具有队列的功能,但两者有什么区别呢?
|
`ArrayDeque` 和 `LinkedList` 都实现了 `Deque` 接口,两者都具有队列的功能,但两者有什么区别呢?
|
||||||
|
|||||||
@ -64,7 +64,7 @@ head:
|
|||||||
如果你看过 `HashSet` 源码的话就应该知道:`HashSet` 底层就是基于 `HashMap` 实现的。(`HashSet` 的源码非常非常少,因为除了 `clone()`、`writeObject()`、`readObject()`是 `HashSet` 自己不得不实现之外,其他方法都是直接调用 `HashMap` 中的方法。
|
如果你看过 `HashSet` 源码的话就应该知道:`HashSet` 底层就是基于 `HashMap` 实现的。(`HashSet` 的源码非常非常少,因为除了 `clone()`、`writeObject()`、`readObject()`是 `HashSet` 自己不得不实现之外,其他方法都是直接调用 `HashMap` 中的方法。
|
||||||
|
|
||||||
| `HashMap` | `HashSet` |
|
| `HashMap` | `HashSet` |
|
||||||
| :------------------------------------: | :----------------------------------------------------------: |
|
| :------------------------------------: | :----------------------------------------------------------------------------------------------------------------------: |
|
||||||
| 实现了 `Map` 接口 | 实现 `Set` 接口 |
|
| 实现了 `Map` 接口 | 实现 `Set` 接口 |
|
||||||
| 存储键值对 | 仅存储对象 |
|
| 存储键值对 | 仅存储对象 |
|
||||||
| 调用 `put()`向 map 中添加元素 | 调用 `add()`方法向 `Set` 中添加元素 |
|
| 调用 `put()`向 map 中添加元素 | 调用 `add()`方法向 `Set` 中添加元素 |
|
||||||
|
|||||||
@ -5,7 +5,6 @@ tag:
|
|||||||
- Java并发
|
- Java并发
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
自己在项目中使用 `CompletableFuture` 比较多,看到很多开源框架中也大量使用到了 `CompletableFuture` 。
|
自己在项目中使用 `CompletableFuture` 比较多,看到很多开源框架中也大量使用到了 `CompletableFuture` 。
|
||||||
|
|
||||||
因此,专门写一篇文章来介绍这个 Java 8 才被引入的一个非常有用的用于异步编程的类。
|
因此,专门写一篇文章来介绍这个 Java 8 才被引入的一个非常有用的用于异步编程的类。
|
||||||
|
|||||||
@ -149,7 +149,7 @@ AQS 使用一个 Volatile 的 int 类型的成员变量来表示同步状态,
|
|||||||
解释一下几个方法和属性值的含义:
|
解释一下几个方法和属性值的含义:
|
||||||
|
|
||||||
| 方法和属性值 | 含义 |
|
| 方法和属性值 | 含义 |
|
||||||
| :----------- | :----------------------------------------------------------- |
|
| :----------- | :----------------------------------------------------------------------------------------------- |
|
||||||
| waitStatus | 当前节点在队列中的状态 |
|
| waitStatus | 当前节点在队列中的状态 |
|
||||||
| thread | 表示处于该节点的线程 |
|
| thread | 表示处于该节点的线程 |
|
||||||
| prev | 前驱指针 |
|
| prev | 前驱指针 |
|
||||||
@ -187,7 +187,7 @@ private volatile int state;
|
|||||||
下面提供了几个访问这个字段的方法:
|
下面提供了几个访问这个字段的方法:
|
||||||
|
|
||||||
| 方法名 | 描述 |
|
| 方法名 | 描述 |
|
||||||
| :----------------------------------------------------------- | :---------------------- |
|
| :----------------------------------------------------------------- | :---------------------- |
|
||||||
| protected final int getState() | 获取 State 的值 |
|
| protected final int getState() | 获取 State 的值 |
|
||||||
| protected final void setState(int newState) | 设置 State 的值 |
|
| protected final void setState(int newState) | 设置 State 的值 |
|
||||||
| protected final boolean compareAndSetState(int expect, int update) | 使用 CAS 方式更新 State |
|
| protected final boolean compareAndSetState(int expect, int update) | 使用 CAS 方式更新 State |
|
||||||
@ -205,7 +205,7 @@ private volatile int state;
|
|||||||
从架构图中可以得知,AQS 提供了大量用于自定义同步器实现的 Protected 方法。自定义同步器实现的相关方法也只是为了通过修改 State 字段来实现多线程的独占模式或者共享模式。自定义同步器需要实现以下方法(ReentrantLock 需要实现的方法如下,并不是全部):
|
从架构图中可以得知,AQS 提供了大量用于自定义同步器实现的 Protected 方法。自定义同步器实现的相关方法也只是为了通过修改 State 字段来实现多线程的独占模式或者共享模式。自定义同步器需要实现以下方法(ReentrantLock 需要实现的方法如下,并不是全部):
|
||||||
|
|
||||||
| 方法名 | 描述 |
|
| 方法名 | 描述 |
|
||||||
| :------------------------------------------ | :----------------------------------------------------------- |
|
| :------------------------------------------ | :--------------------------------------------------------------------------------------------------------------------- |
|
||||||
| protected boolean isHeldExclusively() | 该线程是否正在独占资源。只有用到 Condition 才需要去实现它。 |
|
| protected boolean isHeldExclusively() | 该线程是否正在独占资源。只有用到 Condition 才需要去实现它。 |
|
||||||
| protected boolean tryAcquire(int arg) | 独占方式。arg 为获取锁的次数,尝试获取资源,成功则返回 True,失败则返回 False。 |
|
| protected boolean tryAcquire(int arg) | 独占方式。arg 为获取锁的次数,尝试获取资源,成功则返回 True,失败则返回 False。 |
|
||||||
| protected boolean tryRelease(int arg) | 独占方式。arg 为释放锁的次数,尝试释放资源,成功则返回 True,失败则返回 False。 |
|
| protected boolean tryRelease(int arg) | 独占方式。arg 为释放锁的次数,尝试释放资源,成功则返回 True,失败则返回 False。 |
|
||||||
@ -242,7 +242,6 @@ private volatile int state;
|
|||||||
> return false;
|
> return false;
|
||||||
> }
|
> }
|
||||||
> ```
|
> ```
|
||||||
>
|
|
||||||
|
|
||||||
为了帮助大家理解 ReentrantLock 和 AQS 之间方法的交互过程,以非公平锁为例,我们将加锁和解锁的交互流程单独拎出来强调一下,以便于对后续内容的理解。
|
为了帮助大家理解 ReentrantLock 和 AQS 之间方法的交互过程,以非公平锁为例,我们将加锁和解锁的交互流程单独拎出来强调一下,以便于对后续内容的理解。
|
||||||
|
|
||||||
@ -927,7 +926,7 @@ private volatile int state;
|
|||||||
除了上边 ReentrantLock 的可重入性的应用,AQS 作为并发编程的框架,为很多其他同步工具提供了良好的解决方案。下面列出了 JUC 中的几种同步工具,大体介绍一下 AQS 的应用场景:
|
除了上边 ReentrantLock 的可重入性的应用,AQS 作为并发编程的框架,为很多其他同步工具提供了良好的解决方案。下面列出了 JUC 中的几种同步工具,大体介绍一下 AQS 的应用场景:
|
||||||
|
|
||||||
| 同步工具 | 同步工具与 AQS 的关联 |
|
| 同步工具 | 同步工具与 AQS 的关联 |
|
||||||
| :--------------------- | :----------------------------------------------------------- |
|
| :--------------------- | :---------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||||
| ReentrantLock | 使用 AQS 保存锁重复持有的次数。当一个线程获取锁时,ReentrantLock 记录当前获得锁的线程标识,用于检测是否重复获取,以及错误线程试图解锁操作时异常情况的处理。 |
|
| ReentrantLock | 使用 AQS 保存锁重复持有的次数。当一个线程获取锁时,ReentrantLock 记录当前获得锁的线程标识,用于检测是否重复获取,以及错误线程试图解锁操作时异常情况的处理。 |
|
||||||
| Semaphore | 使用 AQS 同步状态来保存信号量的当前计数。tryRelease 会增加计数,acquireShared 会减少计数。 |
|
| Semaphore | 使用 AQS 同步状态来保存信号量的当前计数。tryRelease 会增加计数,acquireShared 会减少计数。 |
|
||||||
| CountDownLatch | 使用 AQS 同步状态来表示计数。计数为 0 时,所有的 Acquire 操作(CountDownLatch 的 await 方法)才可以通过。 |
|
| CountDownLatch | 使用 AQS 同步状态来表示计数。计数为 0 时,所有的 Acquire 操作(CountDownLatch 的 await 方法)才可以通过。 |
|
||||||
|
|||||||
@ -6,7 +6,6 @@ tag:
|
|||||||
- Java基础
|
- Java基础
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
IO 模型这块确实挺难理解的,需要太多计算机底层知识。写这篇文章用了挺久,就非常希望能把我所知道的讲出来吧!希望朋友们能有收获!为了写这篇文章,还翻看了一下《UNIX 网络编程》这本书,太难了,我滴乖乖!心痛~
|
IO 模型这块确实挺难理解的,需要太多计算机底层知识。写这篇文章用了挺久,就非常希望能把我所知道的讲出来吧!希望朋友们能有收获!为了写这篇文章,还翻看了一下《UNIX 网络编程》这本书,太难了,我滴乖乖!心痛~
|
||||||
|
|
||||||
_个人能力有限。如果文章有任何需要补充/完善/修改的地方,欢迎在评论区指出,共同进步!_
|
_个人能力有限。如果文章有任何需要补充/完善/修改的地方,欢迎在评论区指出,共同进步!_
|
||||||
@ -129,4 +128,3 @@ AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO
|
|||||||
- 10 分钟看懂, Java NIO 底层原理:https://www.cnblogs.com/crazymakercircle/p/10225159.html
|
- 10 分钟看懂, Java NIO 底层原理:https://www.cnblogs.com/crazymakercircle/p/10225159.html
|
||||||
- IO 模型知多少 | 理论篇:https://www.cnblogs.com/sheng-jie/p/how-much-you-know-about-io-models.html
|
- IO 模型知多少 | 理论篇:https://www.cnblogs.com/sheng-jie/p/how-much-you-know-about-io-models.html
|
||||||
- 《UNIX 网络编程 卷 1;套接字联网 API 》6.2 节 IO 模型
|
- 《UNIX 网络编程 卷 1;套接字联网 API 》6.2 节 IO 模型
|
||||||
|
|
||||||
|
|||||||
@ -95,7 +95,7 @@ ClassFile {
|
|||||||
常量池中每一项常量都是一个表,这 14 种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
|
常量池中每一项常量都是一个表,这 14 种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
|
||||||
|
|
||||||
| 类型 | 标志(tag) | 描述 |
|
| 类型 | 标志(tag) | 描述 |
|
||||||
|:--------------------------------:| :---------: | :--------------------: |
|
| :------------------------------: | :---------: | :--------------------: |
|
||||||
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
||||||
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
||||||
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
||||||
|
|||||||
@ -316,7 +316,7 @@ HotSpot VM 中的垃圾回收器,以及适用场景
|
|||||||
JVM 的参数非常之多,这里只列举比较重要的几个,通过各种各样的搜索引擎也可以得知这些信息。
|
JVM 的参数非常之多,这里只列举比较重要的几个,通过各种各样的搜索引擎也可以得知这些信息。
|
||||||
|
|
||||||
| 参数名称 | 含义 | 默认值 | 说明 |
|
| 参数名称 | 含义 | 默认值 | 说明 |
|
||||||
| -------------------------- | ------------------------------------------------------------ | --------------------- | ------------------------------------------------------------ |
|
| -------------------------- | -------------------------------------------------------------- | --------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
|
||||||
| -Xms | 初始堆大小 | 物理内存的 1/64(<1GB) | 默认(MinHeapFreeRatio 参数可以调整)空余堆内存小于 40%时,JVM 就会增大堆直到-Xmx 的最大限制. |
|
| -Xms | 初始堆大小 | 物理内存的 1/64(<1GB) | 默认(MinHeapFreeRatio 参数可以调整)空余堆内存小于 40%时,JVM 就会增大堆直到-Xmx 的最大限制. |
|
||||||
| -Xmx | 最大堆大小 | 物理内存的 1/4(<1GB) | 默认(MaxHeapFreeRatio 参数可以调整)空余堆内存大于 70%时,JVM 会减少堆直到 -Xms 的最小限制 |
|
| -Xmx | 最大堆大小 | 物理内存的 1/4(<1GB) | 默认(MaxHeapFreeRatio 参数可以调整)空余堆内存大于 70%时,JVM 会减少堆直到 -Xms 的最小限制 |
|
||||||
| -Xmn | 年轻代大小(1.4or later) | | 注意:此处的大小是(eden+ 2 survivor space).与 jmap -heap 中显示的 New gen 是不同的。整个堆大小=年轻代大小 + 老年代大小 + 持久代(永久代)大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun 官方推荐配置为整个堆的 3/8 |
|
| -Xmn | 年轻代大小(1.4or later) | | 注意:此处的大小是(eden+ 2 survivor space).与 jmap -heap 中显示的 New gen 是不同的。整个堆大小=年轻代大小 + 老年代大小 + 持久代(永久代)大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun 官方推荐配置为整个堆的 3/8 |
|
||||||
@ -342,7 +342,7 @@ JVM 的参数非常之多,这里只列举比较重要的几个,通过各种
|
|||||||
|
|
||||||
### 4.1 调整最大堆内存和最小堆内存
|
### 4.1 调整最大堆内存和最小堆内存
|
||||||
|
|
||||||
-Xmx –Xms:指定 java 堆最大值(默认值是物理内存的 1/4(<1GB))和初始 java 堆最小值(默认值是物理内存的 1/64(<1GB))
|
-Xmx –Xms:指定 java 堆最大值(默认值是物理内存的 1/4(<1GB))和初始 java 堆最小值(默认值是物理内存的 1/64(<1GB))
|
||||||
|
|
||||||
默认(MinHeapFreeRatio 参数可以调整)空余堆内存小于 40%时,JVM 就会增大堆直到-Xmx 的最大限制.,默认(MaxHeapFreeRatio 参数可以调整)空余堆内存大于 70%时,JVM 会减少堆直到 -Xms 的最小限制。简单点来说,你不停地往堆内存里面丢数据,等它剩余大小小于 40%了,JVM 就会动态申请内存空间不过会小于-Xmx,如果剩余大小大于 70%,又会动态缩小不过不会小于–Xms。就这么简单
|
默认(MinHeapFreeRatio 参数可以调整)空余堆内存小于 40%时,JVM 就会增大堆直到-Xmx 的最大限制.,默认(MaxHeapFreeRatio 参数可以调整)空余堆内存大于 70%时,JVM 会减少堆直到 -Xms 的最小限制。简单点来说,你不停地往堆内存里面丢数据,等它剩余大小小于 40%了,JVM 就会动态申请内存空间不过会小于-Xmx,如果剩余大小大于 70%,又会动态缩小不过不会小于–Xms。就这么简单
|
||||||
|
|
||||||
|
|||||||
@ -115,5 +115,3 @@ Oracle 的 HotSpot VM 便附带两个用 C++ 实现的 JIT compiler:C1 及 C2
|
|||||||
- Guide to Java10 : <https://www.baeldung.com/java-10-overview>
|
- Guide to Java10 : <https://www.baeldung.com/java-10-overview>
|
||||||
|
|
||||||
- 4 Class Data Sharing : https://docs.oracle.com/javase/10/vm/class-data-sharing.htm#JSJVM-GUID-7EAA3411-8CF0-4D19-BD05-DF5E1780AA91
|
- 4 Class Data Sharing : https://docs.oracle.com/javase/10/vm/class-data-sharing.htm#JSJVM-GUID-7EAA3411-8CF0-4D19-BD05-DF5E1780AA91
|
||||||
|
|
||||||
|
|
||||||
@ -106,7 +106,7 @@ if (o instanceof String s) {
|
|||||||
记录类型变更历史:
|
记录类型变更历史:
|
||||||
|
|
||||||
| JDK 版本 | 更新类型 | JEP | 更新内容 |
|
| JDK 版本 | 更新类型 | JEP | 更新内容 |
|
||||||
| ---------- | ----------------- | -------------------------------------------- | ------------------------------------------------------------ |
|
| ---------- | ----------------- | -------------------------------------------- | ------------------------------------------------------------------------- |
|
||||||
| Java SE 14 | Preview | [JEP 359](https://openjdk.java.net/jeps/359) | 引入 `record` 关键字,`record` 提供一种紧凑的语法来定义类中的不可变数据。 |
|
| Java SE 14 | Preview | [JEP 359](https://openjdk.java.net/jeps/359) | 引入 `record` 关键字,`record` 提供一种紧凑的语法来定义类中的不可变数据。 |
|
||||||
| Java SE 15 | Second Preview | [JEP 384](https://openjdk.org/jeps/384) | 支持在局部方法和接口中使用 `record`。 |
|
| Java SE 15 | Second Preview | [JEP 384](https://openjdk.org/jeps/384) | 支持在局部方法和接口中使用 `record`。 |
|
||||||
| Java SE 16 | Permanent Release | [JEP 395](https://openjdk.org/jeps/395) | 非静态内部类可以定义非常量的静态成员。 |
|
| Java SE 16 | Permanent Release | [JEP 395](https://openjdk.org/jeps/395) | 非静态内部类可以定义非常量的静态成员。 |
|
||||||
|
|||||||
@ -3,11 +3,10 @@
|
|||||||
随着 Java 8 的普及度越来越高,很多人都提到面试中关于 Java 8 也是非常常问的知识点。应各位要求和需要,我打算对这部分知识做一个总结。本来准备自己总结的,后面看到 Github 上有一个相关的仓库,地址:
|
随着 Java 8 的普及度越来越高,很多人都提到面试中关于 Java 8 也是非常常问的知识点。应各位要求和需要,我打算对这部分知识做一个总结。本来准备自己总结的,后面看到 Github 上有一个相关的仓库,地址:
|
||||||
[https://github.com/winterbe/java8-tutorial](https://github.com/winterbe/java8-tutorial)。这个仓库是英文的,我对其进行了翻译并添加和修改了部分内容,下面是正文。
|
[https://github.com/winterbe/java8-tutorial](https://github.com/winterbe/java8-tutorial)。这个仓库是英文的,我对其进行了翻译并添加和修改了部分内容,下面是正文。
|
||||||
|
|
||||||
------
|
---
|
||||||
|
|
||||||
欢迎阅读我对 Java 8 的介绍。本教程将逐步指导您完成所有新语言功能。 在简短的代码示例的基础上,您将学习如何使用默认接口方法,lambda 表达式,方法引用和可重复注释。 在本文的最后,您将熟悉最新的 API 更改,如流,函数式接口(Functional Interfaces),Map 类的扩展和新的 Date API。 没有大段枯燥的文字,只有一堆注释的代码片段。
|
欢迎阅读我对 Java 8 的介绍。本教程将逐步指导您完成所有新语言功能。 在简短的代码示例的基础上,您将学习如何使用默认接口方法,lambda 表达式,方法引用和可重复注释。 在本文的最后,您将熟悉最新的 API 更改,如流,函数式接口(Functional Interfaces),Map 类的扩展和新的 Date API。 没有大段枯燥的文字,只有一堆注释的代码片段。
|
||||||
|
|
||||||
|
|
||||||
### 接口的默认方法(Default Methods for Interfaces)
|
### 接口的默认方法(Default Methods for Interfaces)
|
||||||
|
|
||||||
Java 8 使我们能够通过使用 `default` 关键字向接口添加非抽象方法实现。 此功能也称为[虚拟扩展方法](http://stackoverflow.com/a/24102730)。
|
Java 8 使我们能够通过使用 `default` 关键字向接口添加非抽象方法实现。 此功能也称为[虚拟扩展方法](http://stackoverflow.com/a/24102730)。
|
||||||
@ -126,6 +125,7 @@ public interface Converter<F, T> {
|
|||||||
Integer converted = converter.convert("123");
|
Integer converted = converter.convert("123");
|
||||||
System.out.println(converted.getClass()); //class java.lang.Integer
|
System.out.println(converted.getClass()); //class java.lang.Integer
|
||||||
```
|
```
|
||||||
|
|
||||||
Java 8 允许您通过`::`关键字传递方法或构造函数的引用。 上面的示例显示了如何引用静态方法。 但我们也可以引用对象方法:
|
Java 8 允许您通过`::`关键字传递方法或构造函数的引用。 上面的示例显示了如何引用静态方法。 但我们也可以引用对象方法:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ -158,6 +158,7 @@ class Person {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
接下来我们指定一个用来创建 Person 对象的对象工厂接口:
|
接下来我们指定一个用来创建 Person 对象的对象工厂接口:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ -172,6 +173,7 @@ interface PersonFactory<P extends Person> {
|
|||||||
PersonFactory<Person> personFactory = Person::new;
|
PersonFactory<Person> personFactory = Person::new;
|
||||||
Person person = personFactory.create("Peter", "Parker");
|
Person person = personFactory.create("Peter", "Parker");
|
||||||
```
|
```
|
||||||
|
|
||||||
我们只需要使用 `Person::new` 来获取 Person 类构造函数的引用,Java 编译器会自动根据`PersonFactory.create`方法的参数类型来选择合适的构造函数。
|
我们只需要使用 `Person::new` 来获取 Person 类构造函数的引用,Java 编译器会自动根据`PersonFactory.create`方法的参数类型来选择合适的构造函数。
|
||||||
|
|
||||||
### Lambda 表达式作用域(Lambda Scopes)
|
### Lambda 表达式作用域(Lambda Scopes)
|
||||||
@ -333,8 +335,6 @@ public interface Function<T, R> {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```java
|
```java
|
||||||
Function<String, Integer> toInteger = Integer::valueOf;
|
Function<String, Integer> toInteger = Integer::valueOf;
|
||||||
Function<String, String> backToString = toInteger.andThen(String::valueOf);
|
Function<String, String> backToString = toInteger.andThen(String::valueOf);
|
||||||
@ -464,8 +464,6 @@ forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda
|
|||||||
.forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "BBB1", "AAA2", "AAA1"
|
.forEach(System.out::println);// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "BBB1", "AAA2", "AAA1"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Match(匹配)
|
### Match(匹配)
|
||||||
|
|
||||||
Stream 提供了多种匹配操作,允许检测指定的 Predicate 是否匹配整个 Stream。所有的匹配操作都是 **最终操作** ,并返回一个 boolean 类型的值。
|
Stream 提供了多种匹配操作,允许检测指定的 Predicate 是否匹配整个 Stream。所有的匹配操作都是 **最终操作** ,并返回一个 boolean 类型的值。
|
||||||
@ -493,8 +491,6 @@ Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配
|
|||||||
System.out.println(noneStartsWithZ); // true
|
System.out.println(noneStartsWithZ); // true
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Count(计数)
|
### Count(计数)
|
||||||
|
|
||||||
计数是一个 **最终操作**,返回 Stream 中元素的个数,**返回值类型是 long**。
|
计数是一个 **最终操作**,返回 Stream 中元素的个数,**返回值类型是 long**。
|
||||||
@ -524,8 +520,6 @@ Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配
|
|||||||
reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
|
reduced.ifPresent(System.out::println);//aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**译者注:** 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于`Integer sum = integers.reduce(0, (a, b) -> a+b);`也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
|
**译者注:** 这个方法的主要作用是把 Stream 元素组合起来。它提供一个起始值(种子),然后依照运算规则(BinaryOperator),和前面 Stream 的第一个、第二个、第 n 个元素组合。从这个意义上说,字符串拼接、数值的 sum、min、max、average 都是特殊的 reduce。例如 Stream 的 sum 就相当于`Integer sum = integers.reduce(0, (a, b) -> a+b);`也有没有起始值的情况,这时会把 Stream 的前面两个元素组合起来,返回的是 Optional。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ -678,8 +672,6 @@ Java 8在 `java.time` 包下包含一个全新的日期和时间API。新的Date
|
|||||||
|
|
||||||
- jdk1.8 中新增了 LocalDate 与 LocalDateTime 等类来解决日期处理方法,同时引入了一个新的类 DateTimeFormatter 来解决日期格式化问题。可以使用 Instant 代替 Date,LocalDateTime 代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
|
- jdk1.8 中新增了 LocalDate 与 LocalDateTime 等类来解决日期处理方法,同时引入了一个新的类 DateTimeFormatter 来解决日期格式化问题。可以使用 Instant 代替 Date,LocalDateTime 代替 Calendar,DateTimeFormatter 代替 SimpleDateFormat。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### Clock
|
### Clock
|
||||||
|
|
||||||
Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
|
Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 `System.currentTimeMillis()` 来获取当前的微秒数。某一个特定的时间点也可以使用 `Instant` 类来表示,`Instant` 类也可以用来创建旧版本的`java.util.Date` 对象。
|
||||||
|
|||||||
@ -80,7 +80,6 @@ module my.module {
|
|||||||
|
|
||||||
G1 还是在 Java 7 中被引入的,经过两个版本优异的表现成为成为默认垃圾回收器。
|
G1 还是在 Java 7 中被引入的,经过两个版本优异的表现成为成为默认垃圾回收器。
|
||||||
|
|
||||||
|
|
||||||
## 快速创建不可变集合
|
## 快速创建不可变集合
|
||||||
|
|
||||||
增加了`List.of()`、`Set.of()`、`Map.of()` 和 `Map.ofEntries()`等工厂方法来创建不可变集合(有点参考 Guava 的味道):
|
增加了`List.of()`、`Set.of()`、`Map.of()` 和 `Map.ofEntries()`等工厂方法来创建不可变集合(有点参考 Guava 的味道):
|
||||||
|
|||||||
@ -125,7 +125,6 @@ public @interface SpringBootConfiguration {
|
|||||||
- `@Configuration`:允许在上下文中注册额外的 bean 或导入其他配置类
|
- `@Configuration`:允许在上下文中注册额外的 bean 或导入其他配置类
|
||||||
- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除`TypeExcludeFilter`和`AutoConfigurationExcludeFilter`。
|
- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除`TypeExcludeFilter`和`AutoConfigurationExcludeFilter`。
|
||||||
|
|
||||||
|
|
||||||
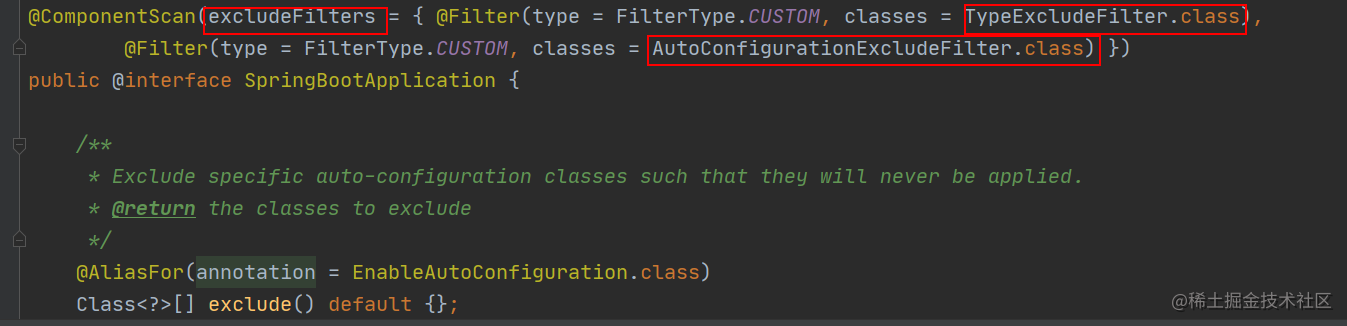
|

|
||||||
|
|
||||||
`@EnableAutoConfiguration` 是实现自动装配的重要注解,我们以这个注解入手。
|
`@EnableAutoConfiguration` 是实现自动装配的重要注解,我们以这个注解入手。
|
||||||
|
|||||||
@ -357,7 +357,7 @@ Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某
|
|||||||
AOP 切面编程设计到的一些专业术语:
|
AOP 切面编程设计到的一些专业术语:
|
||||||
|
|
||||||
| 术语 | 含义 |
|
| 术语 | 含义 |
|
||||||
| :---------------- | :----------------------------------------------------------: |
|
| :---------------- | :-------------------------------------------------------------------: |
|
||||||
| 目标(Target) | 被通知的对象 |
|
| 目标(Target) | 被通知的对象 |
|
||||||
| 代理(Proxy) | 向目标对象应用通知之后创建的代理对象 |
|
| 代理(Proxy) | 向目标对象应用通知之后创建的代理对象 |
|
||||||
| 连接点(JoinPoint) | 目标对象的所属类中,定义的所有方法均为连接点 |
|
| 连接点(JoinPoint) | 目标对象的所属类中,定义的所有方法均为连接点 |
|
||||||
|
|||||||
@ -165,7 +165,6 @@ Spring 框架中,事务管理相关最重要的 3 个接口如下:
|
|||||||
|
|
||||||
**Spring 并不直接管理事务,而是提供了多种事务管理器** 。Spring 事务管理器的接口是: **`PlatformTransactionManager`** 。
|
**Spring 并不直接管理事务,而是提供了多种事务管理器** 。Spring 事务管理器的接口是: **`PlatformTransactionManager`** 。
|
||||||
|
|
||||||
|
|
||||||
通过这个接口,Spring 为各个平台如:JDBC(`DataSourceTransactionManager`)、Hibernate(`HibernateTransactionManager`)、JPA(`JpaTransactionManager`)等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
|
通过这个接口,Spring 为各个平台如:JDBC(`DataSourceTransactionManager`)、Hibernate(`HibernateTransactionManager`)、JPA(`JpaTransactionManager`)等都提供了对应的事务管理器,但是具体的实现就是各个平台自己的事情了。
|
||||||
|
|
||||||
**`PlatformTransactionManager` 接口的具体实现如下:**
|
**`PlatformTransactionManager` 接口的具体实现如下:**
|
||||||
@ -202,8 +201,7 @@ public interface PlatformTransactionManager {
|
|||||||
>
|
>
|
||||||
> 举个例子,我上个项目有发送短信的需求,为此,我们定了一个接口,接口只有两个方法:
|
> 举个例子,我上个项目有发送短信的需求,为此,我们定了一个接口,接口只有两个方法:
|
||||||
>
|
>
|
||||||
> 1.发送短信
|
> 1.发送短信 2.处理发送结果的方法。
|
||||||
> 2.处理发送结果的方法。
|
|
||||||
>
|
>
|
||||||
> 刚开始我们用的是阿里云短信服务,然后我们实现这个接口完成了一个阿里云短信的服务。后来,我们突然又换到了别的短信服务平台,我们这个时候只需要再实现这个接口即可。这样保证了我们提供给外部的行为不变。几乎不需要改变什么代码,我们就轻松完成了需求的转变,提高了代码的灵活性和可扩展性。
|
> 刚开始我们用的是阿里云短信服务,然后我们实现这个接口完成了一个阿里云短信的服务。后来,我们突然又换到了别的短信服务平台,我们这个时候只需要再实现这个接口即可。这样保证了我们提供给外部的行为不变。几乎不需要改变什么代码,我们就轻松完成了需求的转变,提高了代码的灵活性和可扩展性。
|
||||||
>
|
>
|
||||||
@ -612,7 +610,7 @@ public @interface Transactional {
|
|||||||
**`@Transactional` 的常用配置参数总结(只列出了 5 个我平时比较常用的):**
|
**`@Transactional` 的常用配置参数总结(只列出了 5 个我平时比较常用的):**
|
||||||
|
|
||||||
| 属性名 | 说明 |
|
| 属性名 | 说明 |
|
||||||
| :---------- | :----------------------------------------------------------- |
|
| :---------- | :------------------------------------------------------------------------------------------- |
|
||||||
| propagation | 事务的传播行为,默认值为 REQUIRED,可选的值在上面介绍过 |
|
| propagation | 事务的传播行为,默认值为 REQUIRED,可选的值在上面介绍过 |
|
||||||
| isolation | 事务的隔离级别,默认值采用 DEFAULT,可选的值在上面介绍过 |
|
| isolation | 事务的隔离级别,默认值采用 DEFAULT,可选的值在上面介绍过 |
|
||||||
| timeout | 事务的超时时间,默认值为-1(不会超时)。如果超过该时间限制但事务还没有完成,则自动回滚事务。 |
|
| timeout | 事务的超时时间,默认值为-1(不会超时)。如果超过该时间限制但事务还没有完成,则自动回滚事务。 |
|
||||||
|
|||||||
@ -50,4 +50,3 @@ tag:
|
|||||||
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||||
</a>
|
</a>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|||||||
@ -36,7 +36,9 @@ JWT 自身包含了身份验证所需要的所有信息,因此,我们的服
|
|||||||
举个简单的例子:小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
|
举个简单的例子:小壮登录了某网上银行,他来到了网上银行的帖子区,看到一个帖子下面有一个链接写着“科学理财,年盈利率过万”,小壮好奇的点开了这个链接,结果发现自己的账户少了 10000 元。这是这么回事呢?原来黑客在链接中藏了一个请求,这个请求直接利用小壮的身份给银行发送了一个转账请求,也就是通过你的 Cookie 向银行发出请求。
|
||||||
|
|
||||||
```html
|
```html
|
||||||
<a src="http://www.mybank.com/Transfer?bankId=11&money=10000">科学理财,年盈利率过万</a>
|
<a src="http://www.mybank.com/Transfer?bankId=11&money=10000"
|
||||||
|
>科学理财,年盈利率过万</a
|
||||||
|
>
|
||||||
```
|
```
|
||||||
|
|
||||||
CSRF 攻击需要依赖 Cookie ,Session 认证中 Cookie 中的 `SessionID` 是由浏览器发送到服务端的,只要发出请求,Cookie 就会被携带。借助这个特性,即使黑客无法获取你的 `SessionID`,只要让你误点攻击链接,就可以达到攻击效果。
|
CSRF 攻击需要依赖 Cookie ,Session 认证中 Cookie 中的 `SessionID` 是由浏览器发送到服务端的,只要发出请求,Cookie 就会被携带。借助这个特性,即使黑客无法获取你的 `SessionID`,只要让你误点攻击链接,就可以达到攻击效果。
|
||||||
@ -172,7 +174,7 @@ JWT 也不是银弹,也有很多缺陷,具体是选择 JWT 还是 Session
|
|||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- JWT 超详细分析:https://learnku.com/articles/17883
|
- JWT 超详细分析:<https://learnku.com/articles/17883>
|
||||||
- How to log out when using JWT:https://medium.com/devgorilla/how-to-log-out-when-using-jwt-a8c7823e8a6
|
- How to log out when using JWT:<https://medium.com/devgorilla/how-to-log-out-when-using-jwt-a8c7823e8a6>
|
||||||
- CSRF protection with JSON Web JWTs:https://medium.com/@agungsantoso/csrf-protection-with-json-web-JWTs-83e0f2fcbcc
|
- CSRF protection with JSON Web JWTs:<https://medium.com/@agungsantoso/csrf-protection-with-json-web-JWTs-83e0f2fcbcc>
|
||||||
- Invalidating JSON Web JWTs:https://stackoverflow.com/questions/21978658/invalidating-json-web-JWTs
|
- Invalidating JSON Web JWTs:<https://stackoverflow.com/questions/21978658/invalidating-json-web-JWTs>
|
||||||
|
|||||||
@ -217,8 +217,6 @@ SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中
|
|||||||
|
|
||||||
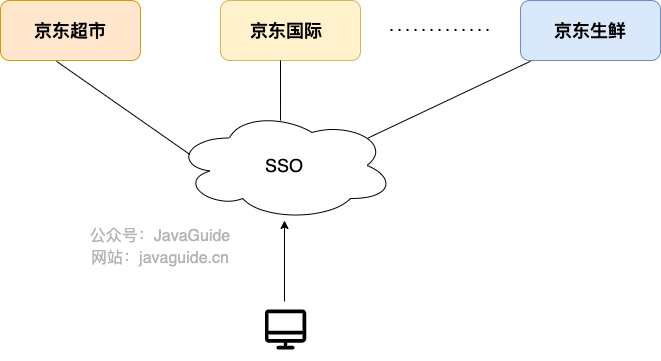
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## SSO 有什么好处?
|
## SSO 有什么好处?
|
||||||
|
|
||||||
- **用户角度** :用户能够做到一次登录多次使用,无需记录多套用户名和密码,省心。
|
- **用户角度** :用户能够做到一次登录多次使用,无需记录多套用户名和密码,省心。
|
||||||
|
|||||||
@ -5,4 +5,4 @@ tag:
|
|||||||
- 安全
|
- 安全
|
||||||
---
|
---
|
||||||
|
|
||||||
数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 * 来代替。
|
数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 \* 来代替。
|
||||||
|
|||||||
@ -64,7 +64,7 @@ SSO 英文全称 Single Sign On,单点登录。SSO 是在多个应用系统中
|
|||||||
对于登录信息的存储,建议采用 Redis,使用 Redis 集群来存储登录信息,既可以保证高可用,又可以线性扩充。同时也可以让 SSO 服务满足负载均衡/可伸缩的需求。
|
对于登录信息的存储,建议采用 Redis,使用 Redis 集群来存储登录信息,既可以保证高可用,又可以线性扩充。同时也可以让 SSO 服务满足负载均衡/可伸缩的需求。
|
||||||
|
|
||||||
| 对象 | 说明 |
|
| 对象 | 说明 |
|
||||||
| --------- | ------------------------------------------------------------ |
|
| --------- | ------------------------------------------------------------------------------------------------------------------ |
|
||||||
| AuthToken | 直接使用 UUID/GUID 即可,如果有验证 AuthToken 合法性需求,可以将 UserName+时间戳加密生成,服务端解密之后验证合法性 |
|
| AuthToken | 直接使用 UUID/GUID 即可,如果有验证 AuthToken 合法性需求,可以将 UserName+时间戳加密生成,服务端解密之后验证合法性 |
|
||||||
| 登录信息 | 通常是将 UserId,UserName 缓存起来 |
|
| 登录信息 | 通常是将 UserId,UserName 缓存起来 |
|
||||||
|
|
||||||
|
|||||||
@ -9,10 +9,13 @@
|
|||||||
"scripts": {
|
"scripts": {
|
||||||
"docs:build": "vuepress build docs",
|
"docs:build": "vuepress build docs",
|
||||||
"docs:dev": "vuepress dev docs",
|
"docs:dev": "vuepress dev docs",
|
||||||
"docs:clean-dev": "vuepress dev docs --clean-cache"
|
"docs:clean-dev": "vuepress dev docs --clean-cache",
|
||||||
|
"lint": "prettier --check --write . && markdownlint **/*.md"
|
||||||
},
|
},
|
||||||
"dependencies": {
|
"dependencies": {
|
||||||
"@vuepress/client": "2.0.0-beta.61",
|
"@vuepress/client": "2.0.0-beta.61",
|
||||||
|
"markdownlint-cli": "0.33.0",
|
||||||
|
"prettier": "2.8.8",
|
||||||
"vue": "3.2.47",
|
"vue": "3.2.47",
|
||||||
"vuepress": "2.0.0-beta.61",
|
"vuepress": "2.0.0-beta.61",
|
||||||
"vuepress-plugin-search-pro": "2.0.0-beta.206",
|
"vuepress-plugin-search-pro": "2.0.0-beta.206",
|
||||||
|
|||||||
89
pnpm-lock.yaml
generated
89
pnpm-lock.yaml
generated
@ -4,6 +4,12 @@ dependencies:
|
|||||||
'@vuepress/client':
|
'@vuepress/client':
|
||||||
specifier: 2.0.0-beta.61
|
specifier: 2.0.0-beta.61
|
||||||
version: 2.0.0-beta.61
|
version: 2.0.0-beta.61
|
||||||
|
markdownlint-cli:
|
||||||
|
specifier: 0.33.0
|
||||||
|
version: 0.33.0
|
||||||
|
prettier:
|
||||||
|
specifier: 2.8.8
|
||||||
|
version: 2.8.8
|
||||||
vue:
|
vue:
|
||||||
specifier: 3.2.47
|
specifier: 3.2.47
|
||||||
version: 3.2.47
|
version: 3.2.47
|
||||||
@ -2716,6 +2722,11 @@ packages:
|
|||||||
engines: {node: ^12.20.0 || >=14}
|
engines: {node: ^12.20.0 || >=14}
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/commander@9.4.1:
|
||||||
|
resolution: {integrity: sha512-5EEkTNyHNGFPD2H+c/dXXfQZYa/scCKasxWcXJaWnNJ99pnQN9Vnmqow+p+PlFPE63Q6mThaZws1T+HxfpgtPw==}
|
||||||
|
engines: {node: ^12.20.0 || >=14}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/comment-regex@1.0.1:
|
/comment-regex@1.0.1:
|
||||||
resolution: {integrity: sha512-IWlN//Yfby92tOIje7J18HkNmWRR7JESA/BK8W7wqY/akITpU5B0JQWnbTjCfdChSrDNb0DrdA9jfAxiiBXyiQ==}
|
resolution: {integrity: sha512-IWlN//Yfby92tOIje7J18HkNmWRR7JESA/BK8W7wqY/akITpU5B0JQWnbTjCfdChSrDNb0DrdA9jfAxiiBXyiQ==}
|
||||||
engines: {node: '>=0.10.0'}
|
engines: {node: '>=0.10.0'}
|
||||||
@ -3120,6 +3131,11 @@ packages:
|
|||||||
engines: {node: '>=0.10.0'}
|
engines: {node: '>=0.10.0'}
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/deep-extend@0.6.0:
|
||||||
|
resolution: {integrity: sha512-LOHxIOaPYdHlJRtCQfDIVZtfw/ufM8+rVj649RIHzcm/vGwQRXFt6OPqIFWsm2XEMrNIEtWR64sY1LEKD2vAOA==}
|
||||||
|
engines: {node: '>=4.0.0'}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/deepmerge@4.3.1:
|
/deepmerge@4.3.1:
|
||||||
resolution: {integrity: sha512-3sUqbMEc77XqpdNO7FRyRog+eW3ph+GYCbj+rK+uYyRMuwsVy0rMiVtPn+QJlKFvWP/1PYpapqYn0Me2knFn+A==}
|
resolution: {integrity: sha512-3sUqbMEc77XqpdNO7FRyRog+eW3ph+GYCbj+rK+uYyRMuwsVy0rMiVtPn+QJlKFvWP/1PYpapqYn0Me2knFn+A==}
|
||||||
engines: {node: '>=0.10.0'}
|
engines: {node: '>=0.10.0'}
|
||||||
@ -3529,6 +3545,11 @@ packages:
|
|||||||
resolution: {integrity: sha512-I0UBV/XOz1XkIJHEUDMZAbzCThU/H8DxmSfmdGcKPnVhu2VfFqr34jr9777IyaTYvxjedWhqVIilEDsCdP5G6g==}
|
resolution: {integrity: sha512-I0UBV/XOz1XkIJHEUDMZAbzCThU/H8DxmSfmdGcKPnVhu2VfFqr34jr9777IyaTYvxjedWhqVIilEDsCdP5G6g==}
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/get-stdin@9.0.0:
|
||||||
|
resolution: {integrity: sha512-dVKBjfWisLAicarI2Sf+JuBE/DghV4UzNAVe9yhEJuzeREd3JhOTE9cUaJTeSa77fsbQUK3pcOpJfM59+VKZaA==}
|
||||||
|
engines: {node: '>=12'}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/get-stream@6.0.1:
|
/get-stream@6.0.1:
|
||||||
resolution: {integrity: sha512-ts6Wi+2j3jQjqi70w5AlN8DFnkSwC+MqmxEzdEALB2qXZYV3X/b1CTfgPLGJNMeAWxdPfU8FO1ms3NUfaHCPYg==}
|
resolution: {integrity: sha512-ts6Wi+2j3jQjqi70w5AlN8DFnkSwC+MqmxEzdEALB2qXZYV3X/b1CTfgPLGJNMeAWxdPfU8FO1ms3NUfaHCPYg==}
|
||||||
engines: {node: '>=10'}
|
engines: {node: '>=10'}
|
||||||
@ -3566,6 +3587,17 @@ packages:
|
|||||||
path-is-absolute: 1.0.1
|
path-is-absolute: 1.0.1
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/glob@8.0.3:
|
||||||
|
resolution: {integrity: sha512-ull455NHSHI/Y1FqGaaYFaLGkNMMJbavMrEGFXG/PGrg6y7sutWHUHrz6gy6WEBH6akM1M414dWKCNs+IhKdiQ==}
|
||||||
|
engines: {node: '>=12'}
|
||||||
|
dependencies:
|
||||||
|
fs.realpath: 1.0.0
|
||||||
|
inflight: 1.0.6
|
||||||
|
inherits: 2.0.4
|
||||||
|
minimatch: 5.1.6
|
||||||
|
once: 1.4.0
|
||||||
|
dev: false
|
||||||
|
|
||||||
/globals@11.12.0:
|
/globals@11.12.0:
|
||||||
resolution: {integrity: sha512-WOBp/EEGUiIsJSp7wcv/y6MO+lV9UoncWqxuFfm8eBwzWNgyfBd6Gz+IeKQ9jCmyhoH99g15M3T+QaVHFjizVA==}
|
resolution: {integrity: sha512-WOBp/EEGUiIsJSp7wcv/y6MO+lV9UoncWqxuFfm8eBwzWNgyfBd6Gz+IeKQ9jCmyhoH99g15M3T+QaVHFjizVA==}
|
||||||
engines: {node: '>=4'}
|
engines: {node: '>=4'}
|
||||||
@ -3739,6 +3771,11 @@ packages:
|
|||||||
resolution: {integrity: sha512-k/vGaX4/Yla3WzyMCvTQOXYeIHvqOKtnqBduzTHpzpQZzAskKMhZ2K+EnBiSM9zGSoIFeMpXKxa4dYeZIQqewQ==}
|
resolution: {integrity: sha512-k/vGaX4/Yla3WzyMCvTQOXYeIHvqOKtnqBduzTHpzpQZzAskKMhZ2K+EnBiSM9zGSoIFeMpXKxa4dYeZIQqewQ==}
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/ini@3.0.1:
|
||||||
|
resolution: {integrity: sha512-it4HyVAUTKBc6m8e1iXWvXSTdndF7HbdN713+kvLrymxTaU4AUBWrJ4vEooP+V7fexnVD3LKcBshjGGPefSMUQ==}
|
||||||
|
engines: {node: ^12.13.0 || ^14.15.0 || >=16.0.0}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/insane@2.6.2:
|
/insane@2.6.2:
|
||||||
resolution: {integrity: sha512-BqEL1CJsjJi+/C/zKZxv31zs3r6zkLH5Nz1WMFb7UBX2KHY2yXDpbFTSEmNHzomBbGDysIfkTX55A0mQZ2CQiw==}
|
resolution: {integrity: sha512-BqEL1CJsjJi+/C/zKZxv31zs3r6zkLH5Nz1WMFb7UBX2KHY2yXDpbFTSEmNHzomBbGDysIfkTX55A0mQZ2CQiw==}
|
||||||
dependencies:
|
dependencies:
|
||||||
@ -4008,6 +4045,10 @@ packages:
|
|||||||
hasBin: true
|
hasBin: true
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/jsonc-parser@3.2.0:
|
||||||
|
resolution: {integrity: sha512-gfFQZrcTc8CnKXp6Y4/CBT3fTc0OVuDofpre4aEeEpSBPV5X5v4+Vmx+8snU7RLPrNHPKSgLxGo9YuQzz20o+w==}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/jsonfile@6.1.0:
|
/jsonfile@6.1.0:
|
||||||
resolution: {integrity: sha512-5dgndWOriYSm5cnYaJNhalLNDKOqFwyDB/rr1E9ZsGciGvKPs8R2xYGCacuf3z6K1YKDz182fd+fY3cn3pMqXQ==}
|
resolution: {integrity: sha512-5dgndWOriYSm5cnYaJNhalLNDKOqFwyDB/rr1E9ZsGciGvKPs8R2xYGCacuf3z6K1YKDz182fd+fY3cn3pMqXQ==}
|
||||||
dependencies:
|
dependencies:
|
||||||
@ -4185,6 +4226,29 @@ packages:
|
|||||||
uc.micro: 1.0.6
|
uc.micro: 1.0.6
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/markdownlint-cli@0.33.0:
|
||||||
|
resolution: {integrity: sha512-zMK1oHpjYkhjO+94+ngARiBBrRDEUMzooDHBAHtmEIJ9oYddd9l3chCReY2mPlecwH7gflQp1ApilTo+o0zopQ==}
|
||||||
|
engines: {node: '>=14'}
|
||||||
|
hasBin: true
|
||||||
|
dependencies:
|
||||||
|
commander: 9.4.1
|
||||||
|
get-stdin: 9.0.0
|
||||||
|
glob: 8.0.3
|
||||||
|
ignore: 5.2.4
|
||||||
|
js-yaml: 4.1.0
|
||||||
|
jsonc-parser: 3.2.0
|
||||||
|
markdownlint: 0.27.0
|
||||||
|
minimatch: 5.1.6
|
||||||
|
run-con: 1.2.11
|
||||||
|
dev: false
|
||||||
|
|
||||||
|
/markdownlint@0.27.0:
|
||||||
|
resolution: {integrity: sha512-HtfVr/hzJJmE0C198F99JLaeada+646B5SaG2pVoEakLFI6iRGsvMqrnnrflq8hm1zQgwskEgqSnhDW11JBp0w==}
|
||||||
|
engines: {node: '>=14.18.0'}
|
||||||
|
dependencies:
|
||||||
|
markdown-it: 13.0.1
|
||||||
|
dev: false
|
||||||
|
|
||||||
/marked@4.3.0:
|
/marked@4.3.0:
|
||||||
resolution: {integrity: sha512-PRsaiG84bK+AMvxziE/lCFss8juXjNaWzVbN5tXAm4XjeaS9NAHhop+PjQxz2A9h8Q4M/xGmzP8vqNwy6JeK0A==}
|
resolution: {integrity: sha512-PRsaiG84bK+AMvxziE/lCFss8juXjNaWzVbN5tXAm4XjeaS9NAHhop+PjQxz2A9h8Q4M/xGmzP8vqNwy6JeK0A==}
|
||||||
engines: {node: '>= 12'}
|
engines: {node: '>= 12'}
|
||||||
@ -4277,6 +4341,10 @@ packages:
|
|||||||
brace-expansion: 2.0.1
|
brace-expansion: 2.0.1
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/minimist@1.2.8:
|
||||||
|
resolution: {integrity: sha512-2yyAR8qBkN3YuheJanUpWC5U3bb5osDywNB8RzDVlDwDHbocAJveqqj1u8+SVD7jkWT4yvsHCpWqqWqAxb0zCA==}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/mitt@3.0.0:
|
/mitt@3.0.0:
|
||||||
resolution: {integrity: sha512-7dX2/10ITVyqh4aOSVI9gdape+t9l2/8QxHrFmUXu4EEUpdlxl6RudZUPZoc+zuY2hk1j7XxVroIVIan/pD/SQ==}
|
resolution: {integrity: sha512-7dX2/10ITVyqh4aOSVI9gdape+t9l2/8QxHrFmUXu4EEUpdlxl6RudZUPZoc+zuY2hk1j7XxVroIVIan/pD/SQ==}
|
||||||
dev: false
|
dev: false
|
||||||
@ -4522,6 +4590,12 @@ packages:
|
|||||||
source-map-js: 1.0.2
|
source-map-js: 1.0.2
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/prettier@2.8.8:
|
||||||
|
resolution: {integrity: sha512-tdN8qQGvNjw4CHbY+XXk0JgCXn9QiF21a55rBe5LJAU+kDyC4WQn4+awm2Xfk2lQMk5fKup9XgzTZtGkjBdP9Q==}
|
||||||
|
engines: {node: '>=10.13.0'}
|
||||||
|
hasBin: true
|
||||||
|
dev: false
|
||||||
|
|
||||||
/pretty-bytes@5.6.0:
|
/pretty-bytes@5.6.0:
|
||||||
resolution: {integrity: sha512-FFw039TmrBqFK8ma/7OL3sDz/VytdtJr044/QUJtH0wK9lb9jLq9tJyIxUwtQJHwar2BqtiA4iCWSwo9JLkzFg==}
|
resolution: {integrity: sha512-FFw039TmrBqFK8ma/7OL3sDz/VytdtJr044/QUJtH0wK9lb9jLq9tJyIxUwtQJHwar2BqtiA4iCWSwo9JLkzFg==}
|
||||||
engines: {node: '>=6'}
|
engines: {node: '>=6'}
|
||||||
@ -4744,6 +4818,16 @@ packages:
|
|||||||
fsevents: 2.3.2
|
fsevents: 2.3.2
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/run-con@1.2.11:
|
||||||
|
resolution: {integrity: sha512-NEMGsUT+cglWkzEr4IFK21P4Jca45HqiAbIIZIBdX5+UZTB24Mb/21iNGgz9xZa8tL6vbW7CXmq7MFN42+VjNQ==}
|
||||||
|
hasBin: true
|
||||||
|
dependencies:
|
||||||
|
deep-extend: 0.6.0
|
||||||
|
ini: 3.0.1
|
||||||
|
minimist: 1.2.8
|
||||||
|
strip-json-comments: 3.1.1
|
||||||
|
dev: false
|
||||||
|
|
||||||
/run-parallel@1.2.0:
|
/run-parallel@1.2.0:
|
||||||
resolution: {integrity: sha512-5l4VyZR86LZ/lDxZTR6jqL8AFE2S0IFLMP26AbjsLVADxHdhB/c0GUsH+y39UfCi3dzz8OlQuPmnaJOMoDHQBA==}
|
resolution: {integrity: sha512-5l4VyZR86LZ/lDxZTR6jqL8AFE2S0IFLMP26AbjsLVADxHdhB/c0GUsH+y39UfCi3dzz8OlQuPmnaJOMoDHQBA==}
|
||||||
dependencies:
|
dependencies:
|
||||||
@ -5006,6 +5090,11 @@ packages:
|
|||||||
engines: {node: '>=12'}
|
engines: {node: '>=12'}
|
||||||
dev: false
|
dev: false
|
||||||
|
|
||||||
|
/strip-json-comments@3.1.1:
|
||||||
|
resolution: {integrity: sha512-6fPc+R4ihwqP6N/aIv2f1gMH8lOVtWQHoqC4yK6oSDVVocumAsfCqjkXnqiYMhmMwS/mEHLp7Vehlt3ql6lEig==}
|
||||||
|
engines: {node: '>=8'}
|
||||||
|
dev: false
|
||||||
|
|
||||||
/striptags@3.2.0:
|
/striptags@3.2.0:
|
||||||
resolution: {integrity: sha512-g45ZOGzHDMe2bdYMdIvdAfCQkCTDMGBazSw1ypMowwGIee7ZQ5dU0rBJ8Jqgl+jAKIv4dbeE1jscZq9wid1Tkw==}
|
resolution: {integrity: sha512-g45ZOGzHDMe2bdYMdIvdAfCQkCTDMGBazSw1ypMowwGIee7ZQ5dU0rBJ8Jqgl+jAKIv4dbeE1jscZq9wid1Tkw==}
|
||||||
dev: false
|
dev: false
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user