mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs fix]403图片修复
This commit is contained in:
parent
f718447610
commit
6bc82a7634
@ -15,19 +15,19 @@ tag:
|
||||
|
||||
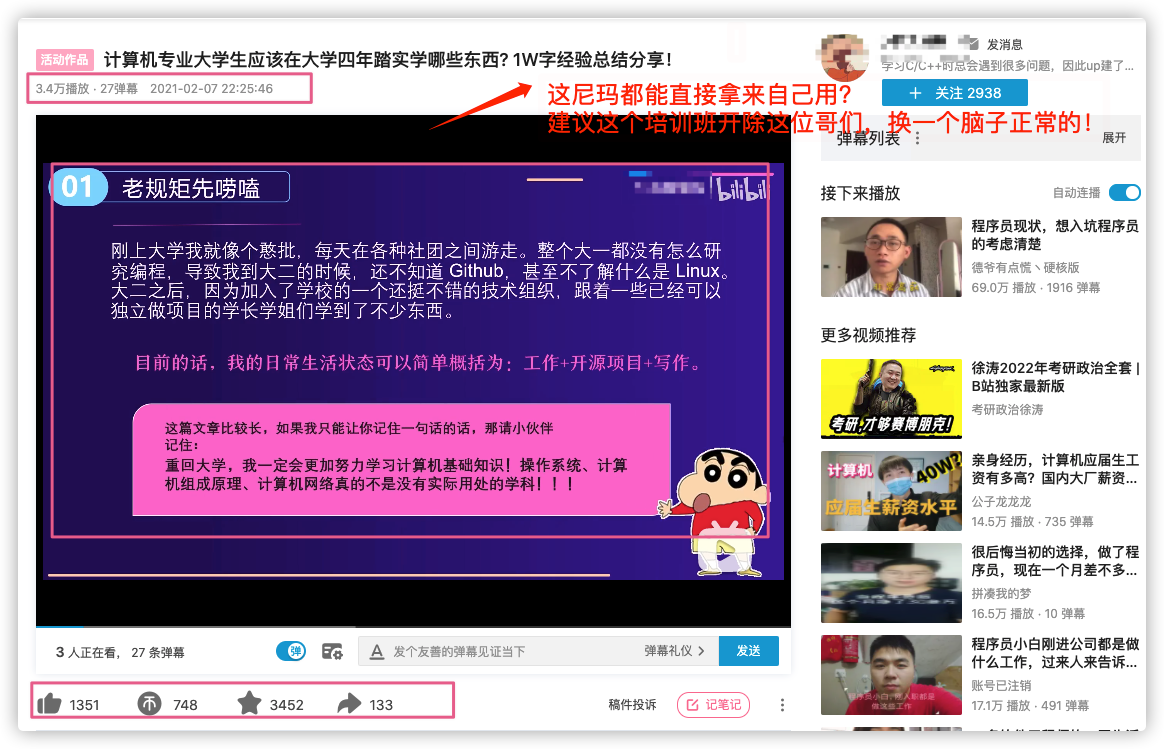
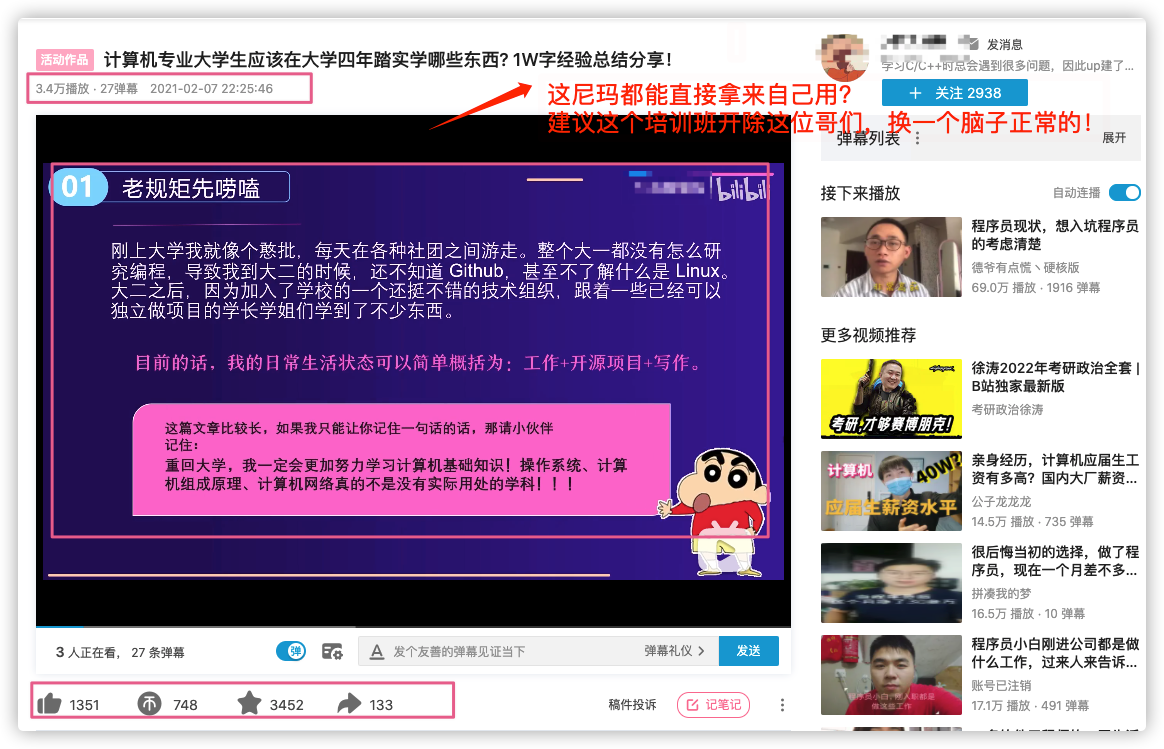
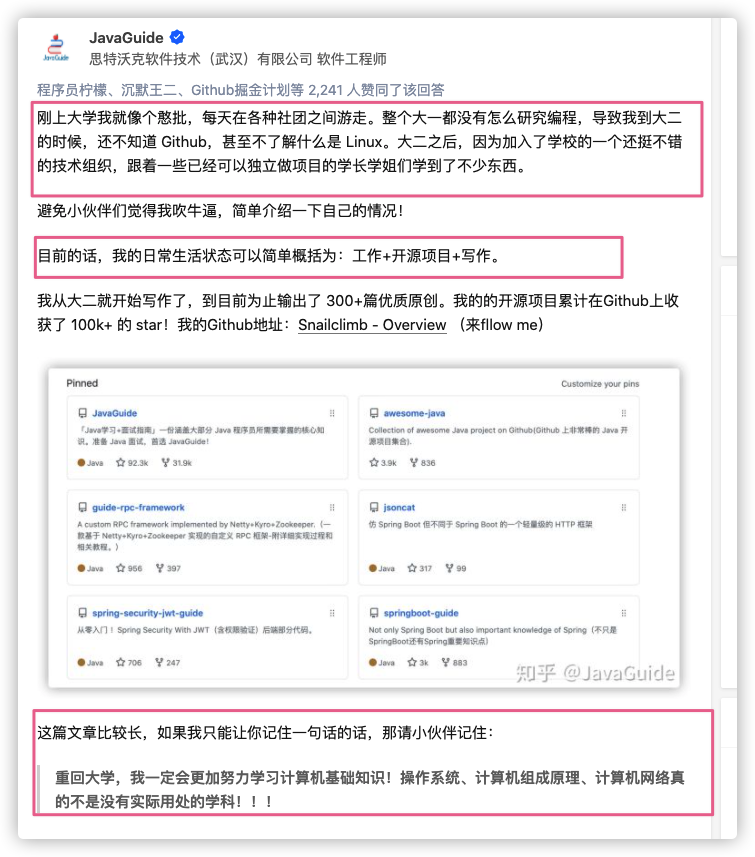
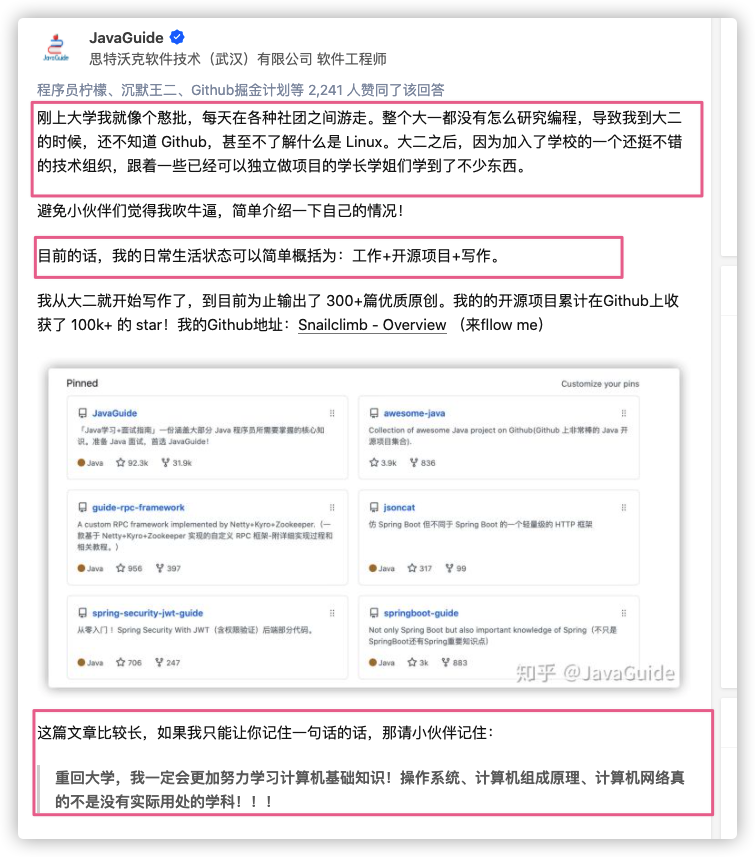
麻烦这个培训机构看到这篇文章之后可以考虑换一个人做类似恶心的事情哈!这人完全没脑子啊!
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
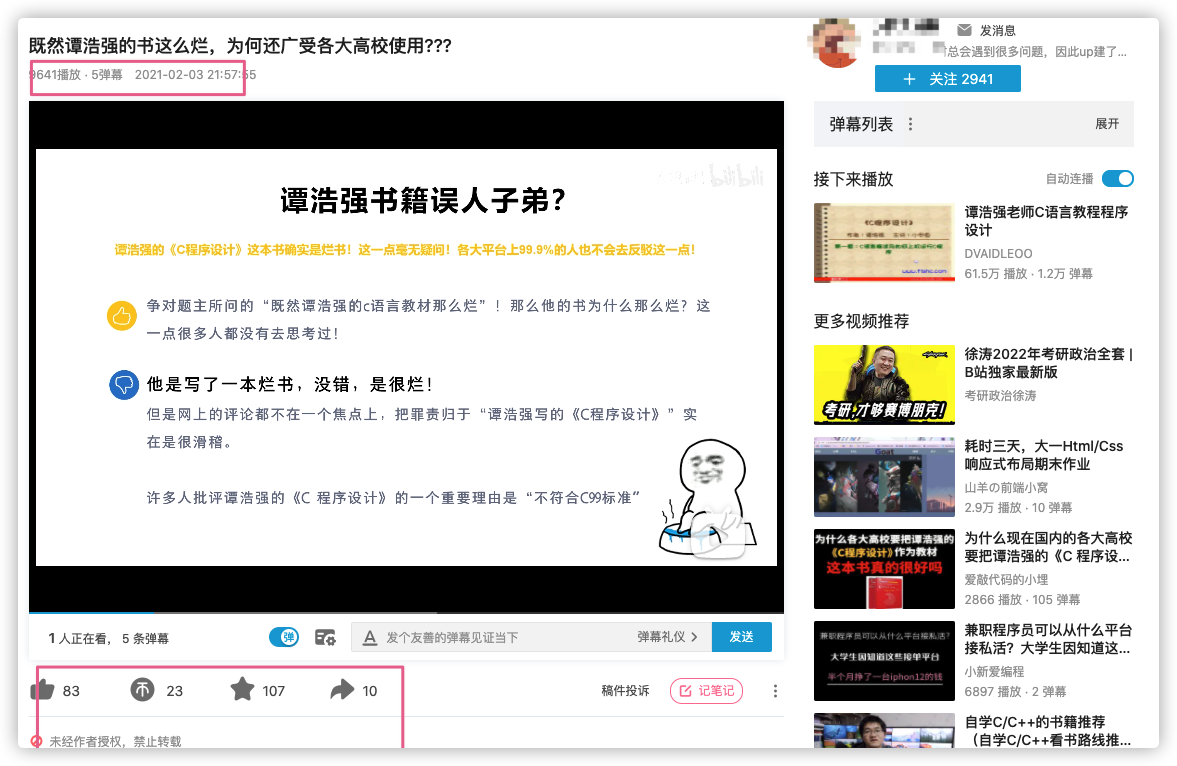
我随便找了一个视频看,发现也还是盗用别人的原创。
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
其他的视频就不用多看了,是否还是剽窃别人的原创,原封不动地做成视频,大家心里应该有数。
|
||||
|
||||
@ -49,7 +49,7 @@ tag:
|
||||
|
||||
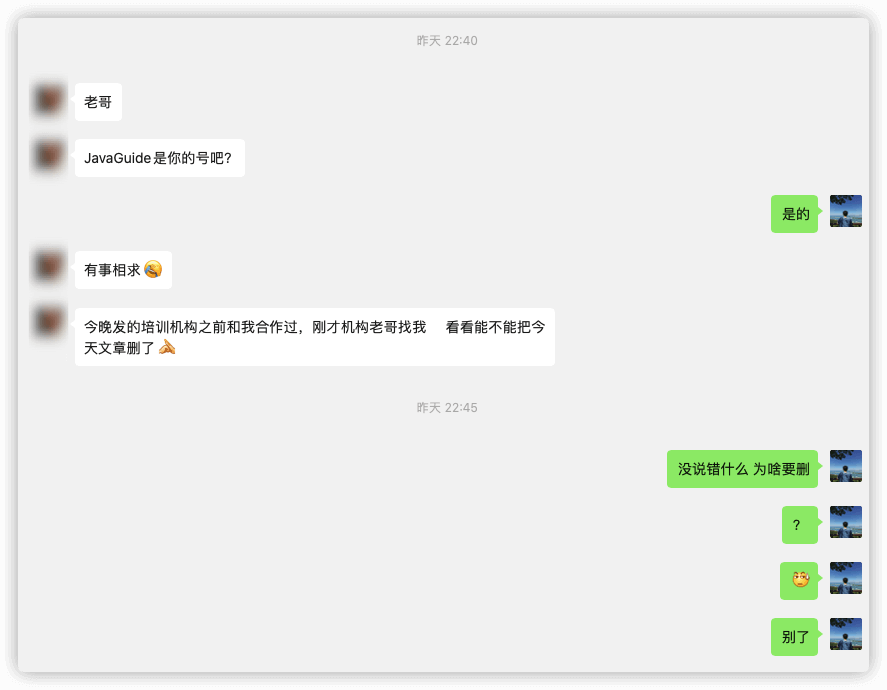
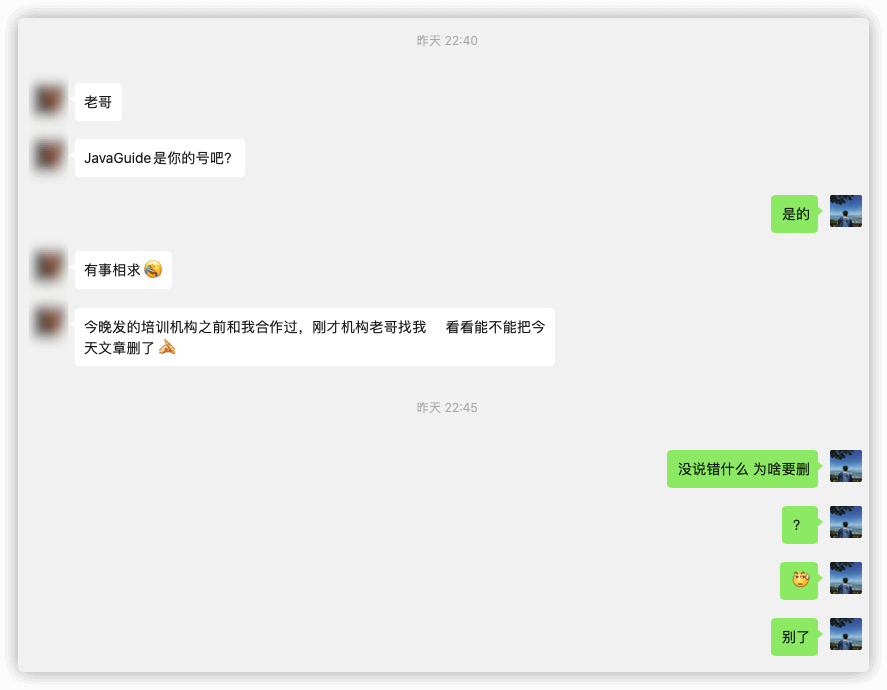
谁能想到,培训机构的人竟然找人来让我删文章了!讲真,这俩人是真的奇葩啊!
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
@ -14,11 +14,11 @@ head:
|
||||
|
||||
[《数据库系统原理》](https://www.icourse163.org/course/BNU-1002842007)这个课程的老师讲的非常详细,而且每一小节的作业设计的也与所讲知识很贴合,后面还有很多配套实验。
|
||||
|
||||

|
||||

|
||||
|
||||
如果你比较喜欢动手,对于理论知识比较抵触的话,推荐你看看[《如何开发一个简单的数据库》](https://cstack.github.io/db_tutorial/) ,这个 project 会手把手教你编写一个简单的数据库。
|
||||
|
||||

|
||||

|
||||
|
||||
GitHub 上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
||||
|
||||
@ -26,7 +26,7 @@ GitHub 上也已经有大佬用 Java 实现过一个简易的数据库,介绍
|
||||
|
||||
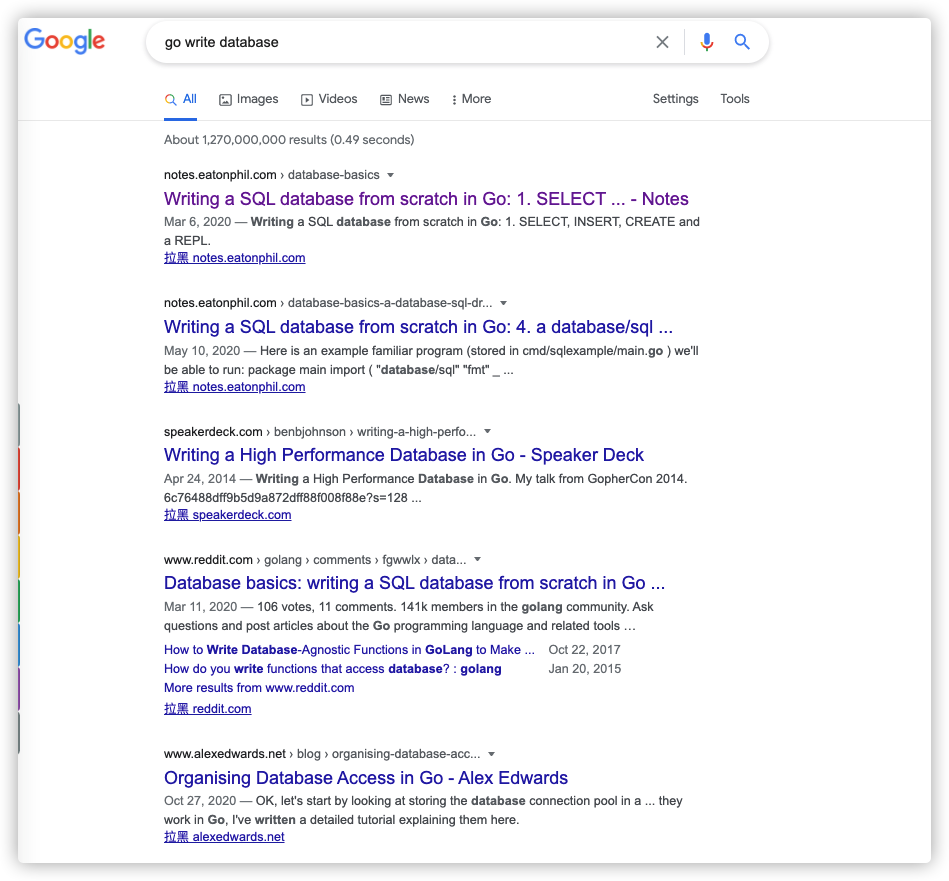
**只要利用好搜索引擎,你可以找到各种语言实现的数据库玩具。**
|
||||
|
||||
|
||||
|
||||
|
||||
**纸上学来终觉浅 绝知此事要躬行!强烈推荐 CS 专业的小伙伴一定要多多实践!!!**
|
||||
|
||||
@ -58,7 +58,7 @@ GitHub 上也已经有大佬用 Java 实现过一个简易的数据库,介绍
|
||||
- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)**:MySQL 领域的经典之作!学习 MySQL 必看!属于进阶内容,主要教你如何更好地使用 MySQL 。既有有理论,又有实践!如果你没时间都看一遍的话,我建议第 5 章(创建高性能的索引)、第 6 章(查询性能优化) 你一定要认真看一下。
|
||||
- **[《MySQL 技术内幕》](https://book.douban.com/subject/24708143/)**:你想深入了解 MySQL 存储引擎的话,看这本书准没错!
|
||||
|
||||

|
||||

|
||||
|
||||
视频的话,你可以看看动力节点的 [《MySQL 数据库教程视频》](https://www.bilibili.com/video/BV1fx411X7BD)。这个视频基本上把 MySQL 的相关一些入门知识给介绍完了。
|
||||
|
||||
|
||||
@ -206,7 +206,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
||||

|
||||
|
||||
- **传输协议**:HTTP/2.0 是基于 TCP 协议实现的,HTTP/3.0 新增了 QUIC(Quick UDP Internet Connections) 协议来实现可靠的传输,提供与 TLS/SSL 相当的安全性,具有较低的连接和传输延迟。你可以将 QUIC 看作是 UDP 的升级版本,在其基础上新增了很多功能比如加密、重传等等。HTTP/3.0 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC。
|
||||
- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
|
||||
- **连接建立**:HTTP/2.0 需要经过经典的 TCP 三次握手过程(由于安全的 HTTPS 连接建立还需要 TLS 握手,共需要大约 3 个 RTT)。由于 QUIC 协议的特性(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
|
||||
- **队头阻塞**:HTTP/2.0 多请求复用一个 TCP 连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。由于 QUIC 协议的特性,HTTP/3.0 在一定程度上解决了队头阻塞(Head-of-Line blocking, 简写:HOL blocking)问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
|
||||
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
|
||||
- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
|
||||
@ -307,5 +307,7 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
|
||||
|
||||
- 《图解 HTTP》
|
||||
- 《计算机网络自顶向下方法》(第七版)
|
||||
- 详解 HTTP/2.0 及 HTTPS 协议:https://juejin.cn/post/7034668672262242318
|
||||
- HTTP 请求头字段大全| HTTP Request Headers:https://www.flysnow.org/tools/table/http-request-headers/
|
||||
- 详解 HTTP/2.0 及 HTTPS 协议:<https://juejin.cn/post/7034668672262242318>
|
||||
- HTTP 请求头字段大全| HTTP Request Headers:<https://www.flysnow.org/tools/table/http-request-headers/>
|
||||
- HTTP1、HTTP2、HTTP3:<https://juejin.cn/post/6855470356657307662>
|
||||
- 如何看待 HTTP/3 ? - 车小胖的回答 - 知乎: <https://www.zhihu.com/question/302412059/answer/533223530>
|
||||
|
||||
@ -41,7 +41,18 @@ tag:
|
||||
|
||||
~~**HTTP 协议是基于 TCP 协议的**,所以发送 HTTP 请求之前首先要建立 TCP 连接也就是要经历 3 次握手。~~
|
||||
|
||||
🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** 。此变化解决了 HTTP/2 中存在的队头阻塞问题。由于 HTTP/2 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。另外,HTTP/2.0 需要经过经典的 TCP 三次握手过程(一般是 3 个 RTT)。由于 QUIC 协议的特性,HTTP/3.0 可以避免 TCP 三次握手的延迟,允许在第一次连接时发送数据(0 个 RTT ,零往返时间)。
|
||||
🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
|
||||
|
||||
HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** 。
|
||||
|
||||
此变化解决了 HTTP/2 中存在的队头阻塞问题。队头阻塞是指在 HTTP/2.0 中,多个 HTTP 请求和响应共享一个 TCP 连接,如果其中一个请求或响应因为网络拥塞或丢包而被阻塞,那么后续的请求或响应也无法发送,导致整个连接的效率降低。这是由于 HTTP/2.0 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。HTTP/3.0 在一定程度上解决了队头阻塞问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
|
||||
|
||||
除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
|
||||
|
||||
1. TCP 三次握手:客户端和服务器交换 SYN 和 ACK 包,建立一个 TCP 连接。这个过程需要 1.5 个 RTT(round-trip time),即一个数据包从发送到接收的时间。
|
||||
2. TLS 握手:客户端和服务器交换密钥和证书,建立一个 TLS 加密层。这个过程需要至少 1 个 RTT(TLS 1.3)或者 2 个 RTT(TLS 1.2)。
|
||||
|
||||
所以,HTTP/2.0 的连接建立就至少需要 2.5 个 RTT(TLS 1.3)或者 3.5 个 RTT(TLS 1.2)。而在 HTTP/3.0 中,使用的 QUIC 协议(TLS 1.3,TLS 1.3 除了支持 1 个 RTT 的握手,还支持 0 个 RTT 的握手)连接建立仅需 0-RTT 或者 1-RTT。这意味着 QUIC 在最佳情况下不需要任何的额外往返时间就可以建立新连接。
|
||||
|
||||
相关证明可以参考下面这两个链接:
|
||||
|
||||
@ -173,5 +184,5 @@ ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,
|
||||
|
||||
- 《图解 HTTP》
|
||||
- 《计算机网络自顶向下方法》(第七版)
|
||||
- 什么是 Internet 协议(IP)?:https://www.cloudflare.com/zh-cn/learning/network-layer/internet-protocol/
|
||||
- What Is NAT and What Are the Benefits of NAT Firewalls?:https://community.fs.com/blog/what-is-nat-and-what-are-the-benefits-of-nat-firewalls.html
|
||||
- 什么是 Internet 协议(IP)?:<https://www.cloudflare.com/zh-cn/learning/network-layer/internet-protocol/>
|
||||
- What Is NAT and What Are the Benefits of NAT Firewalls?:<https://community.fs.com/blog/what-is-nat-and-what-are-the-benefits-of-nat-firewalls.html>
|
||||
|
||||
@ -40,7 +40,7 @@ category: 分布式
|
||||
|
||||
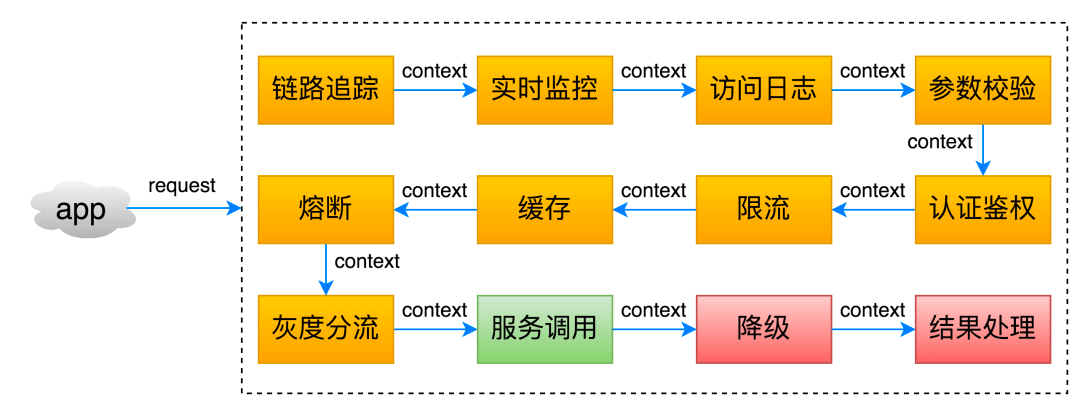
下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
|
||||
|
||||

|
||||
|
||||
|
||||
## 有哪些常见的网关系统?
|
||||
|
||||
@ -50,7 +50,7 @@ Zuul 是 Netflix 开发的一款提供动态路由、监控、弹性、安全的
|
||||
|
||||
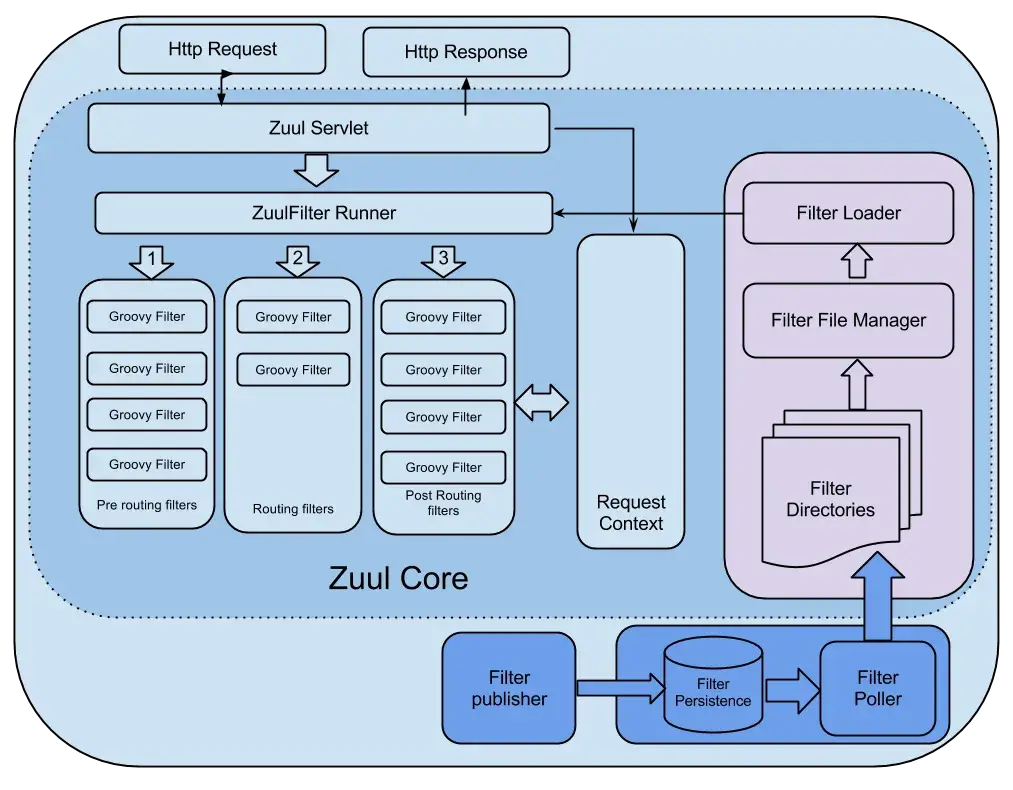
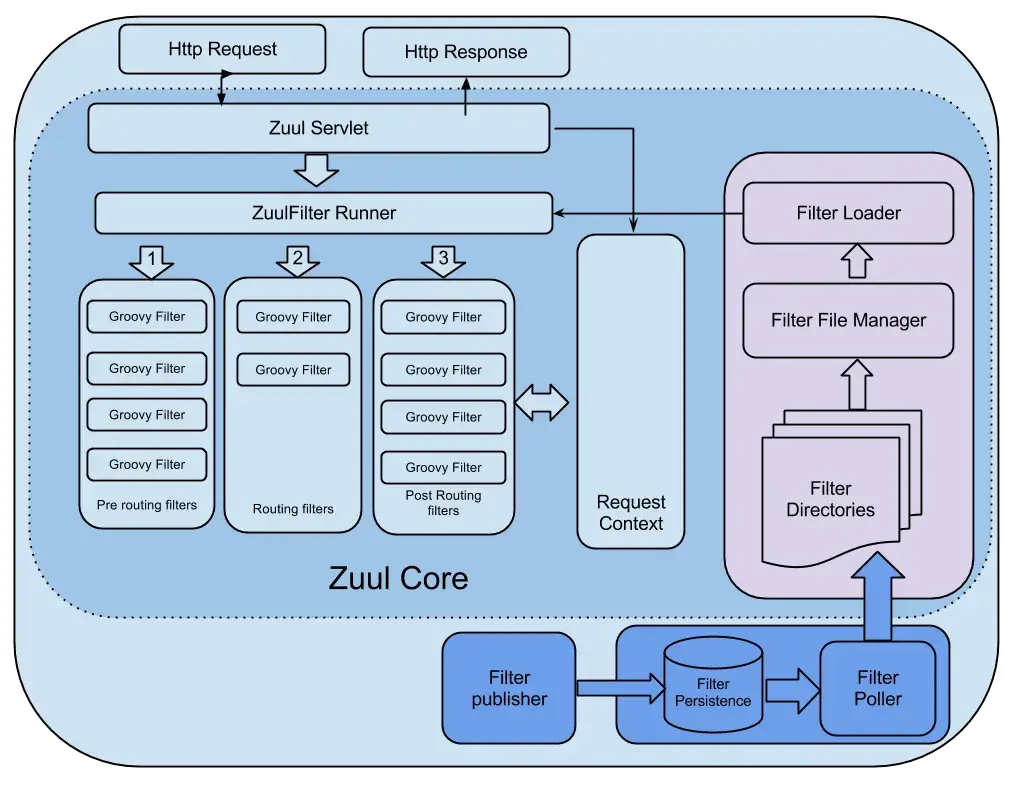
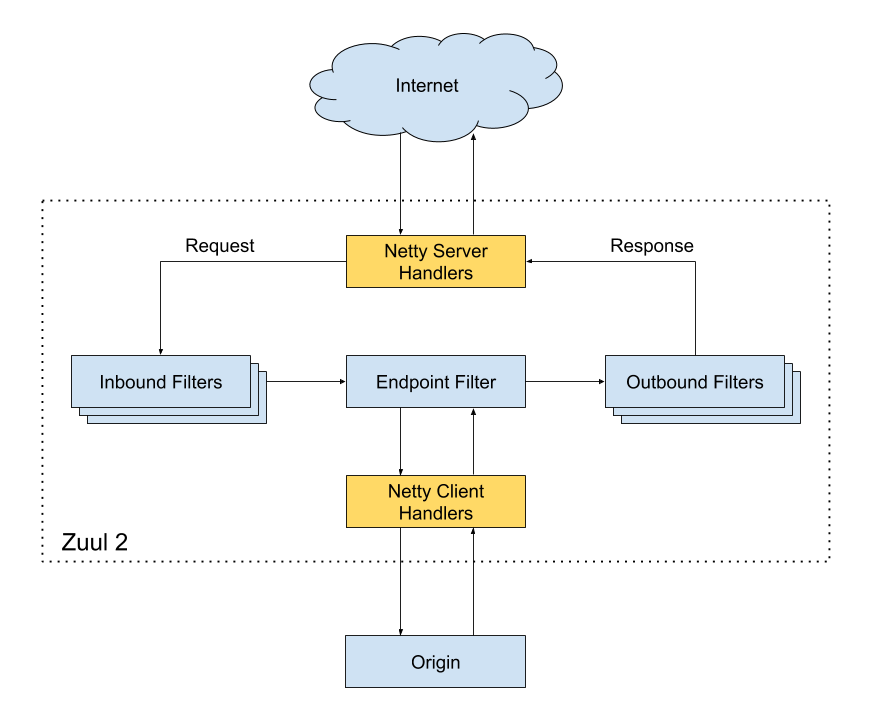
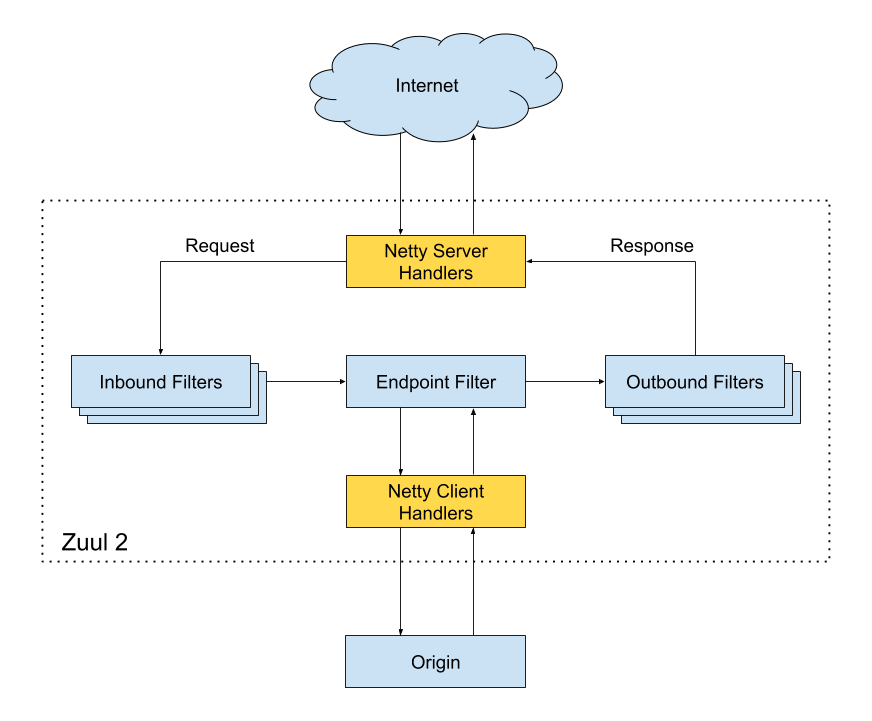
Zuul 核心架构如下:
|
||||
|
||||
|
||||
|
||||
|
||||
Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网关必备的各种功能。
|
||||
|
||||
@ -72,7 +72,7 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网
|
||||
|
||||
[Zuul 1.x](https://netflixtechblog.com/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee) 基于同步 IO,性能较差。[Zuul 2.x](https://netflixtechblog.com/open-sourcing-zuul-2-82ea476cb2b3) 基于 Netty 实现了异步 IO,性能得到了大幅改进。
|
||||
|
||||
|
||||
|
||||
|
||||
- GitHub 地址: <https://github.com/Netflix/zuul>
|
||||
- 官方 Wiki: <https://github.com/Netflix/zuul/wiki>
|
||||
@ -128,7 +128,7 @@ APISIX 是一款基于 Nginx 和 etcd 的高性能、云原生、可扩展的网
|
||||
|
||||
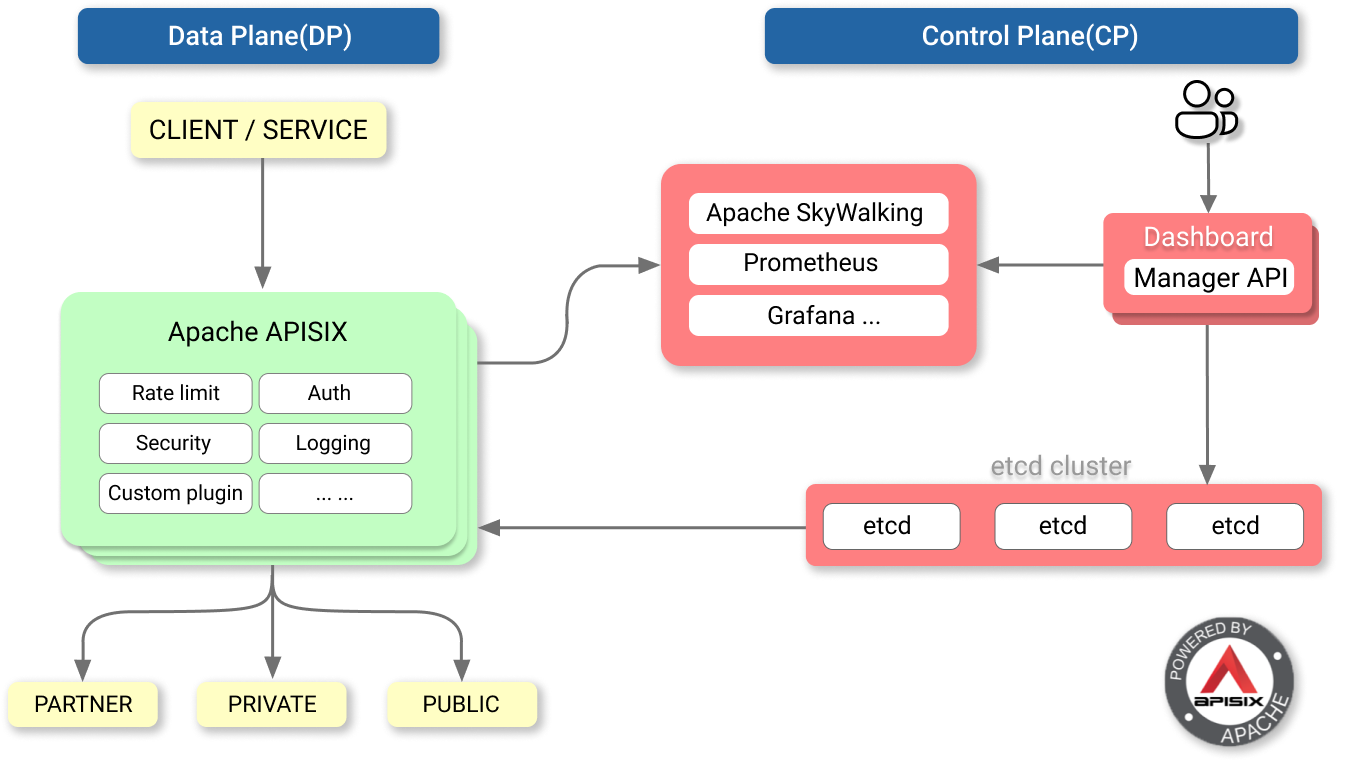
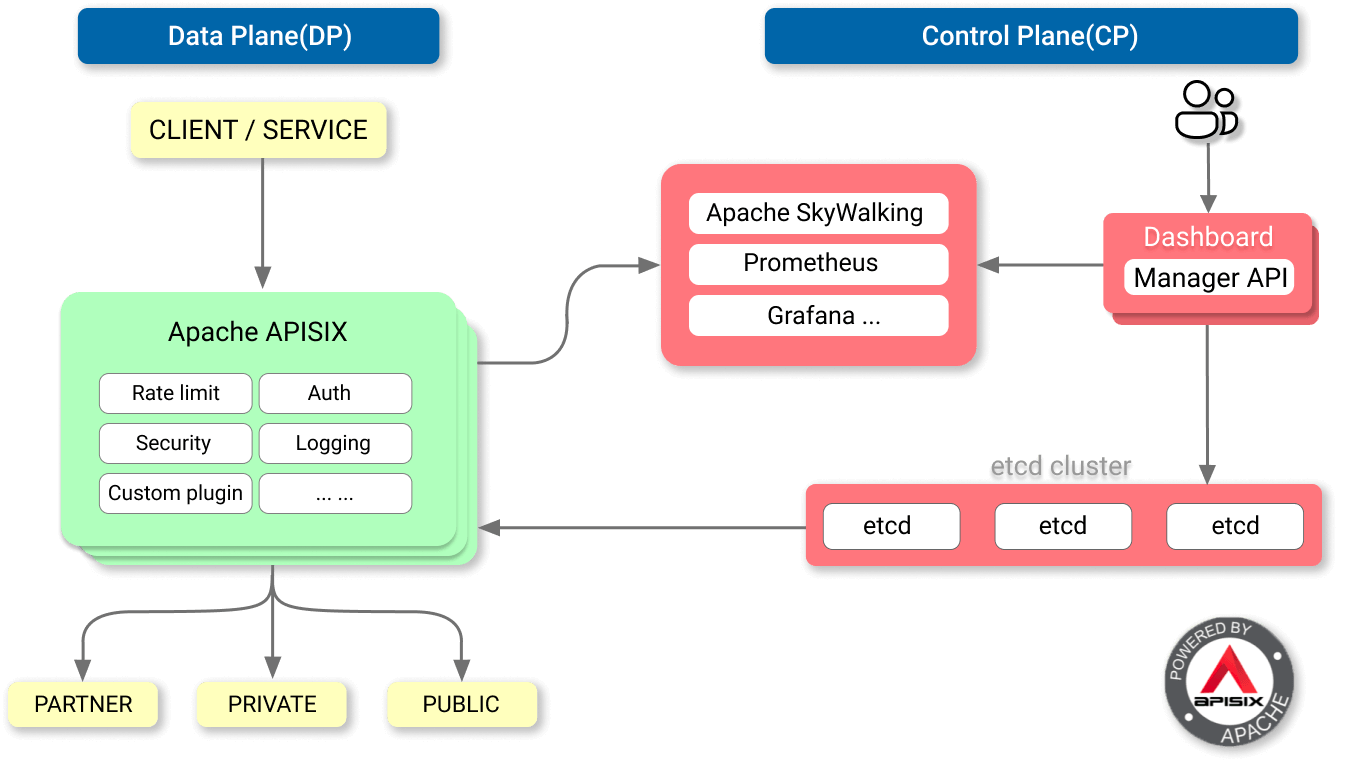
与传统 API 网关相比,APISIX 具有动态路由和插件热加载,特别适合微服务系统下的 API 管理。并且,APISIX 与 SkyWalking(分布式链路追踪系统)、Zipkin(分布式链路追踪系统)、Prometheus(监控系统) 等 DevOps 生态工具对接都十分方便。
|
||||
|
||||
|
||||
|
||||
|
||||
作为 NGINX 和 Kong 的替代项目,APISIX 目前已经是 Apache 顶级开源项目,并且是最快毕业的国产开源项目。国内目前已经有很多知名企业(比如金山、有赞、爱奇艺、腾讯、贝壳)使用 APISIX 处理核心的业务流量。
|
||||
|
||||
@ -141,7 +141,7 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
|
||||
|
||||
> Wasm 是基于堆栈的虚拟机的二进制指令格式,一种低级汇编语言,旨在非常接近已编译的机器代码,并且非常接近本机性能。Wasm 最初是为浏览器构建的,但是随着技术的成熟,在服务器端看到了越来越多的用例。
|
||||
|
||||

|
||||

|
||||
|
||||
- Github 地址:<https://github.com/apache/apisix>
|
||||
- 官网地址: <https://apisix.apache.org/zh/>
|
||||
@ -157,7 +157,7 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
|
||||
|
||||
Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apache 顶级开源项目。
|
||||
|
||||
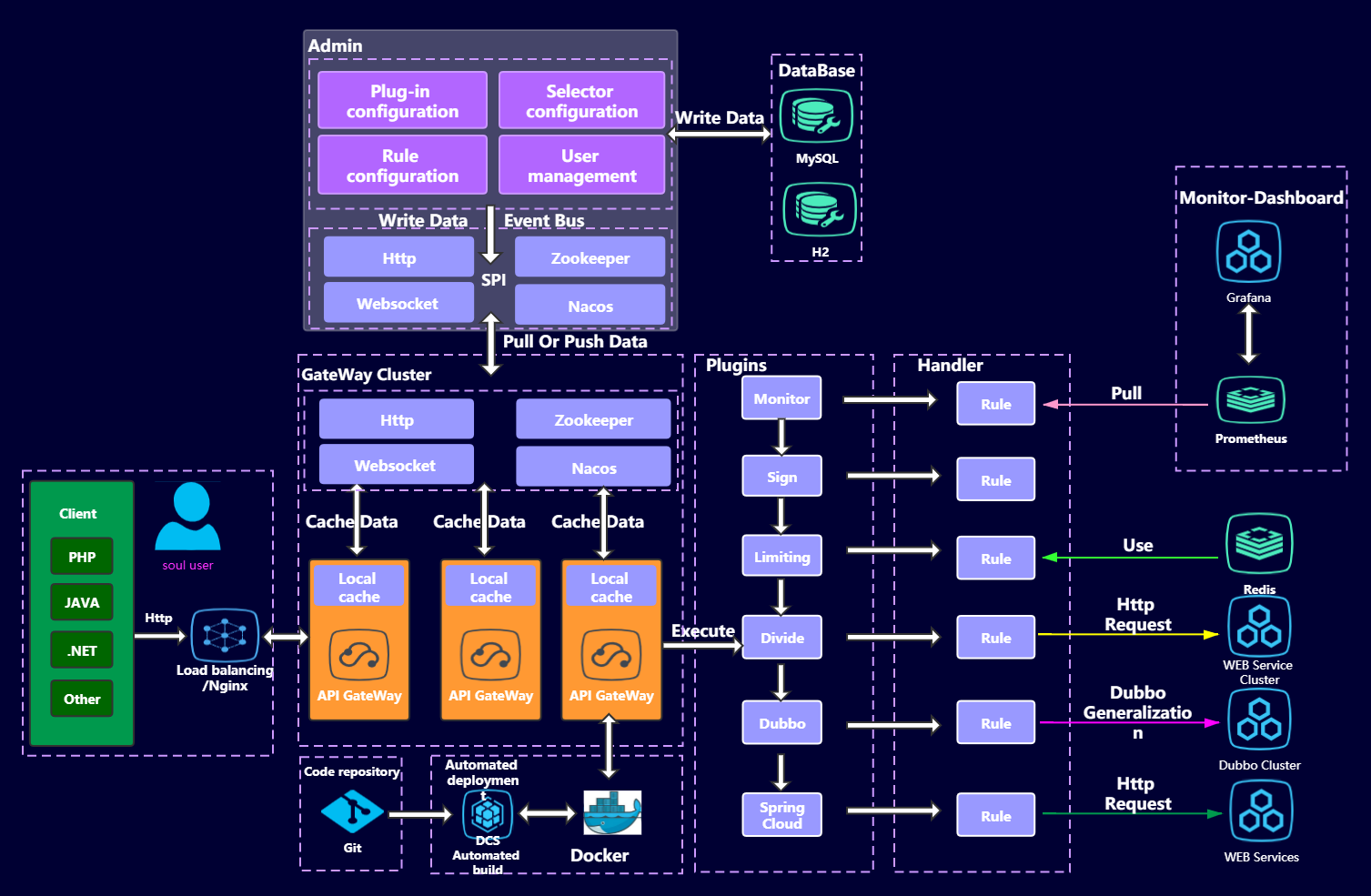
|
||||
|
||||
|
||||
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发、重写、重定向、和路由监控等插件。
|
||||
|
||||
|
||||
@ -312,7 +312,7 @@ Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的
|
||||
|
||||
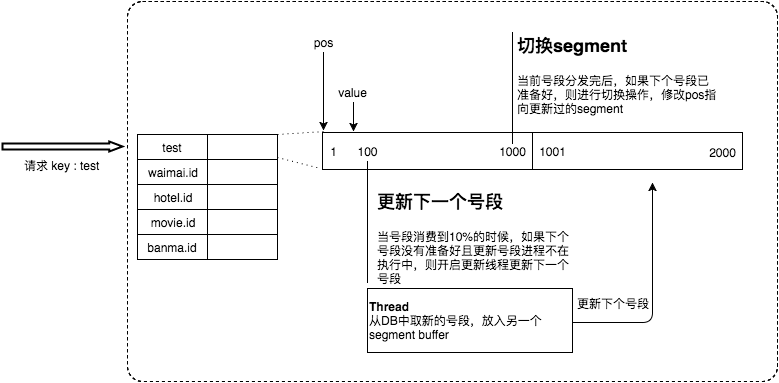
Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
|
||||
|
||||
|
||||

|
||||
|
||||
根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
|
||||
|
||||
@ -324,7 +324,7 @@ Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避
|
||||
|
||||
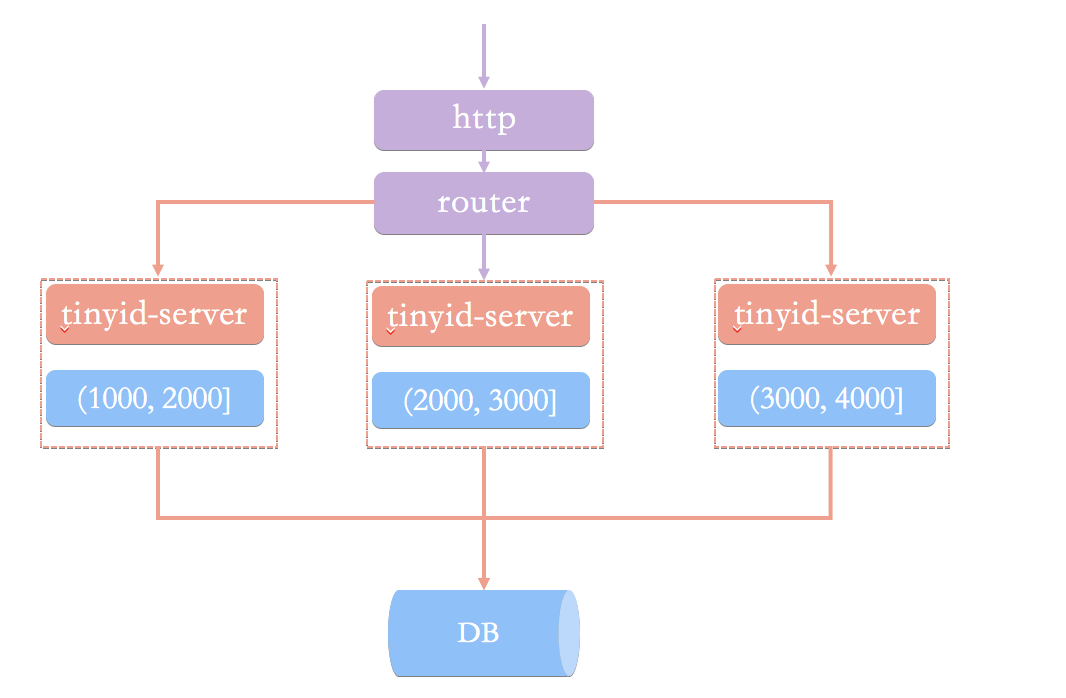
为了搞清楚这个问题,我们先来看看基于数据库号段模式的简单架构方案。(图片来自于 Tinyid 的官方 wiki:[《Tinyid 原理介绍》](https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D))
|
||||
|
||||
|
||||
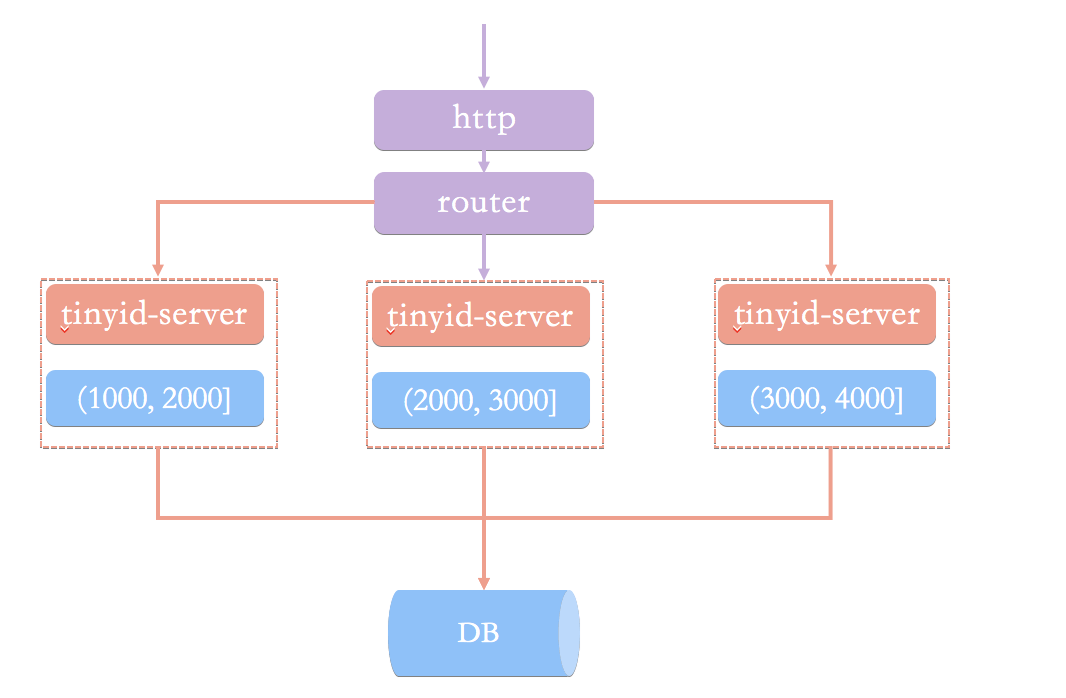
|
||||
|
||||
在这种架构模式下,我们通过 HTTP 请求向发号器服务申请唯一 ID。负载均衡 router 会把我们的请求送往其中的一台 tinyid-server。
|
||||
|
||||
@ -337,7 +337,7 @@ Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避
|
||||
|
||||
Tinyid 的原理比较简单,其架构如下图所示:
|
||||
|
||||

|
||||
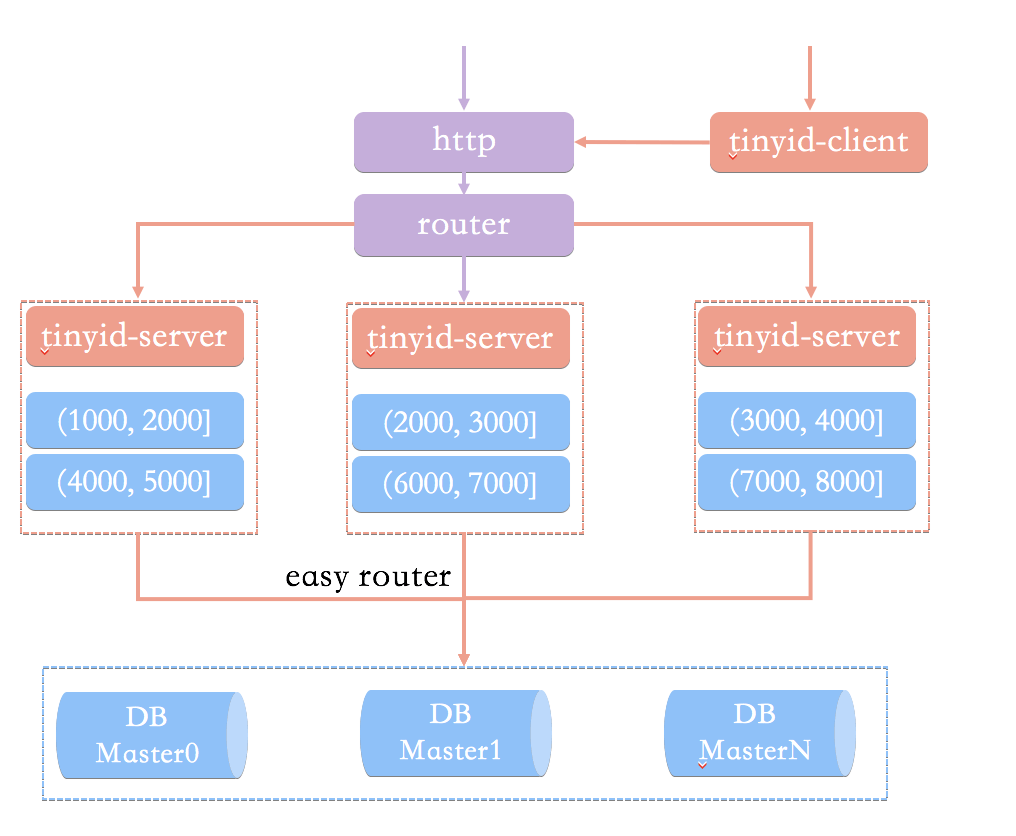
|
||||
|
||||
相比于基于数据库号段模式的简单架构方案,Tinyid 方案主要做了下面这些优化:
|
||||
|
||||
|
||||
@ -38,7 +38,7 @@ NoSQL 数据库 Redis 和 Apache Cassandra、服务网格解决方案 Consul 等
|
||||
|
||||
我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。
|
||||
|
||||
|
||||
|
||||
|
||||
Redis Cluster 是一个典型的分布式系统,分布式系统中的各个节点需要互相通信。既然要相互通信就要遵循一致的通信协议,Redis Cluster 中的各个节点基于 **Gossip 协议** 来进行通信共享信息,每个 Redis 节点都维护了一份集群的状态信息。
|
||||
|
||||
@ -79,7 +79,7 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
|
||||
|
||||
伪代码如下:
|
||||
|
||||

|
||||

|
||||
|
||||
在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是需要可以的设计一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
|
||||
|
||||
|
||||
@ -61,7 +61,7 @@ Basic Paxos 中存在 3 个重要的角色:
|
||||
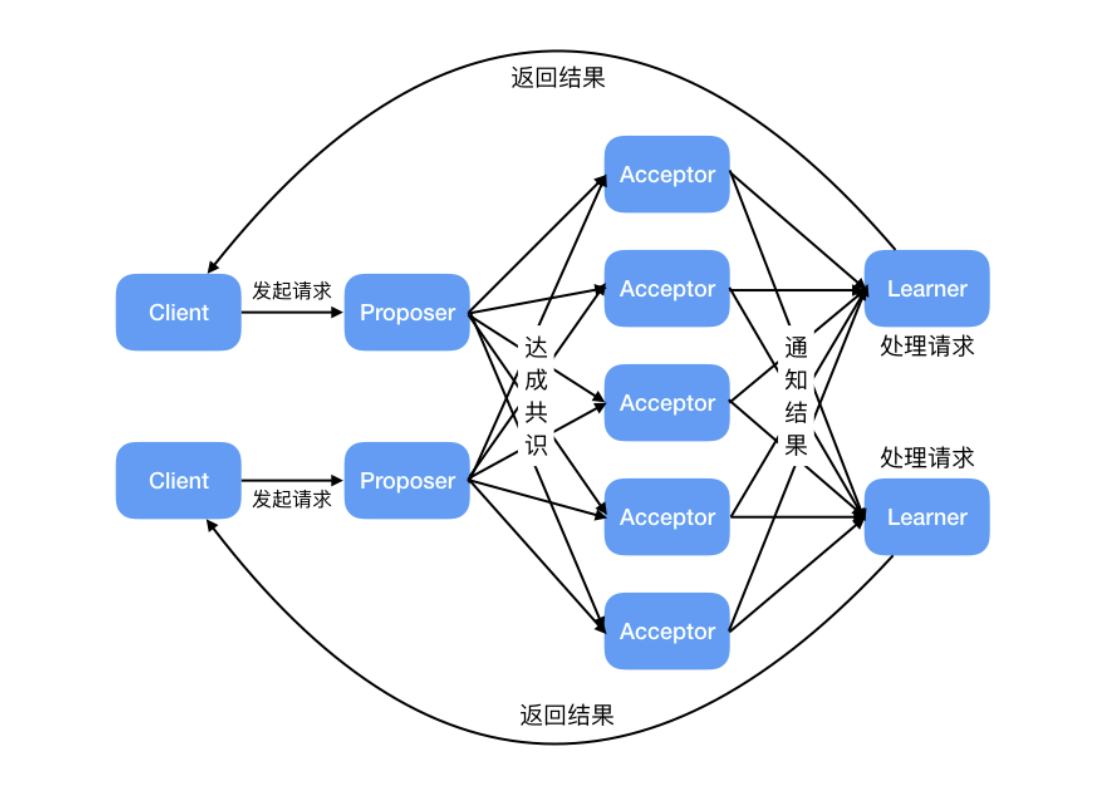
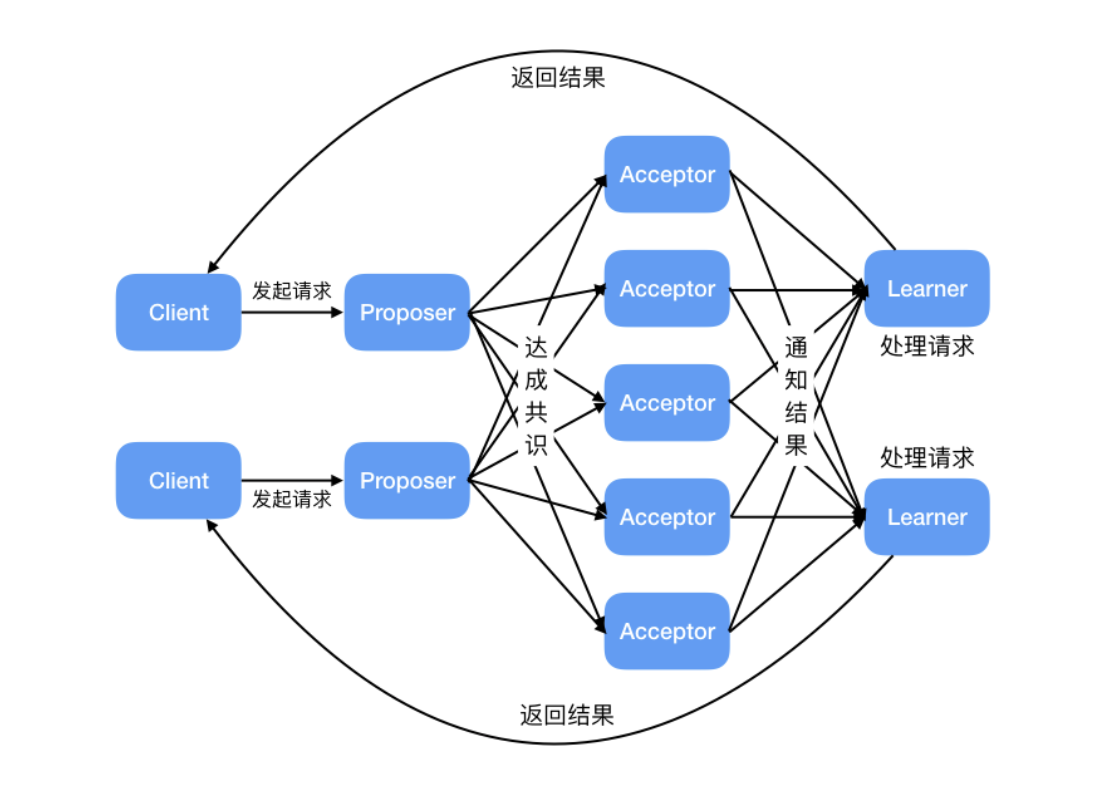
2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
|
||||
3. **学习者(Learner)**:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
|
||||
|
||||
|
||||
|
||||
|
||||
为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。
|
||||
|
||||
|
||||
@ -456,4 +456,4 @@ Kryo 和 FST 这两种序列化方式是 Dubbo 后来才引入的,性能非常
|
||||
|
||||
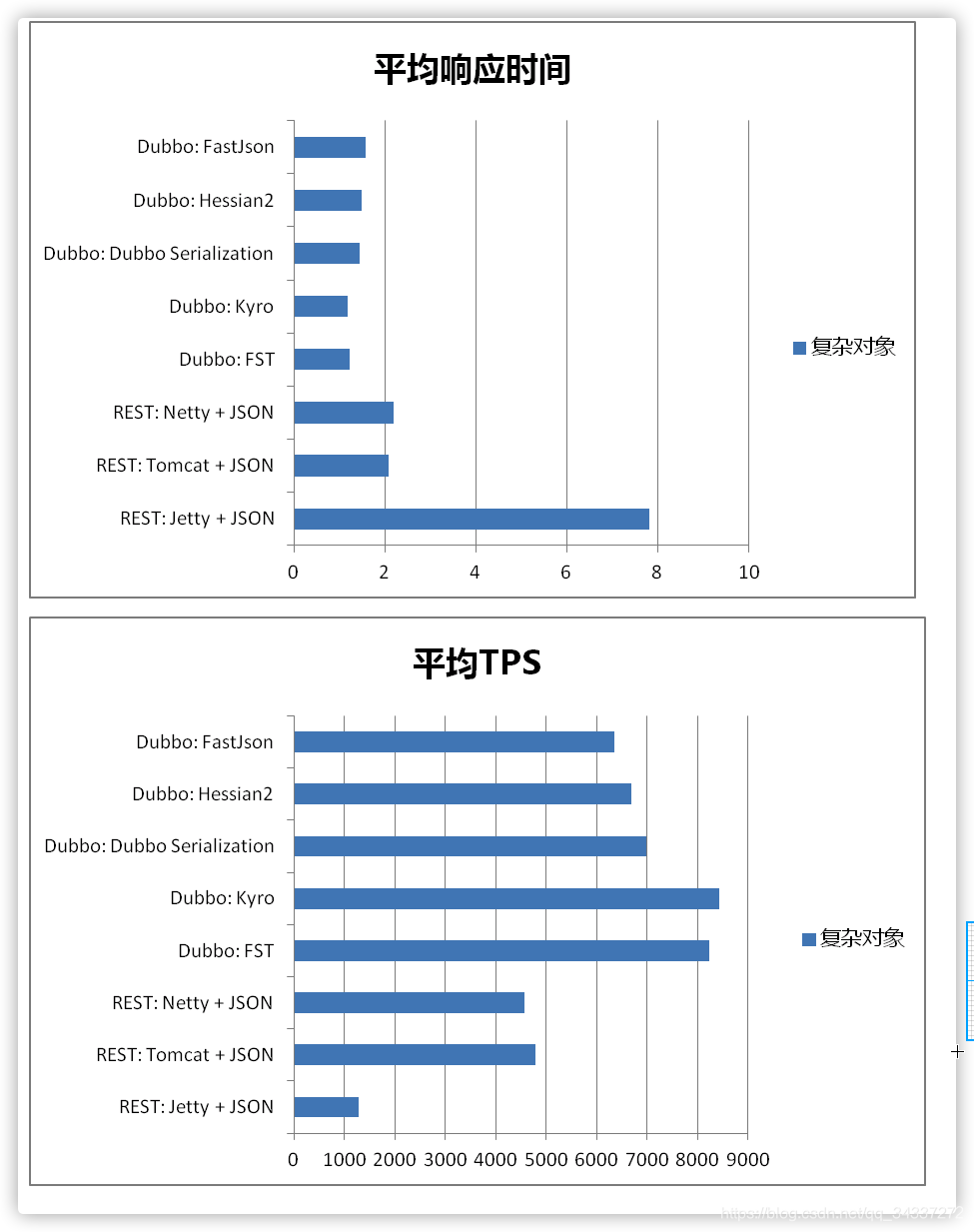
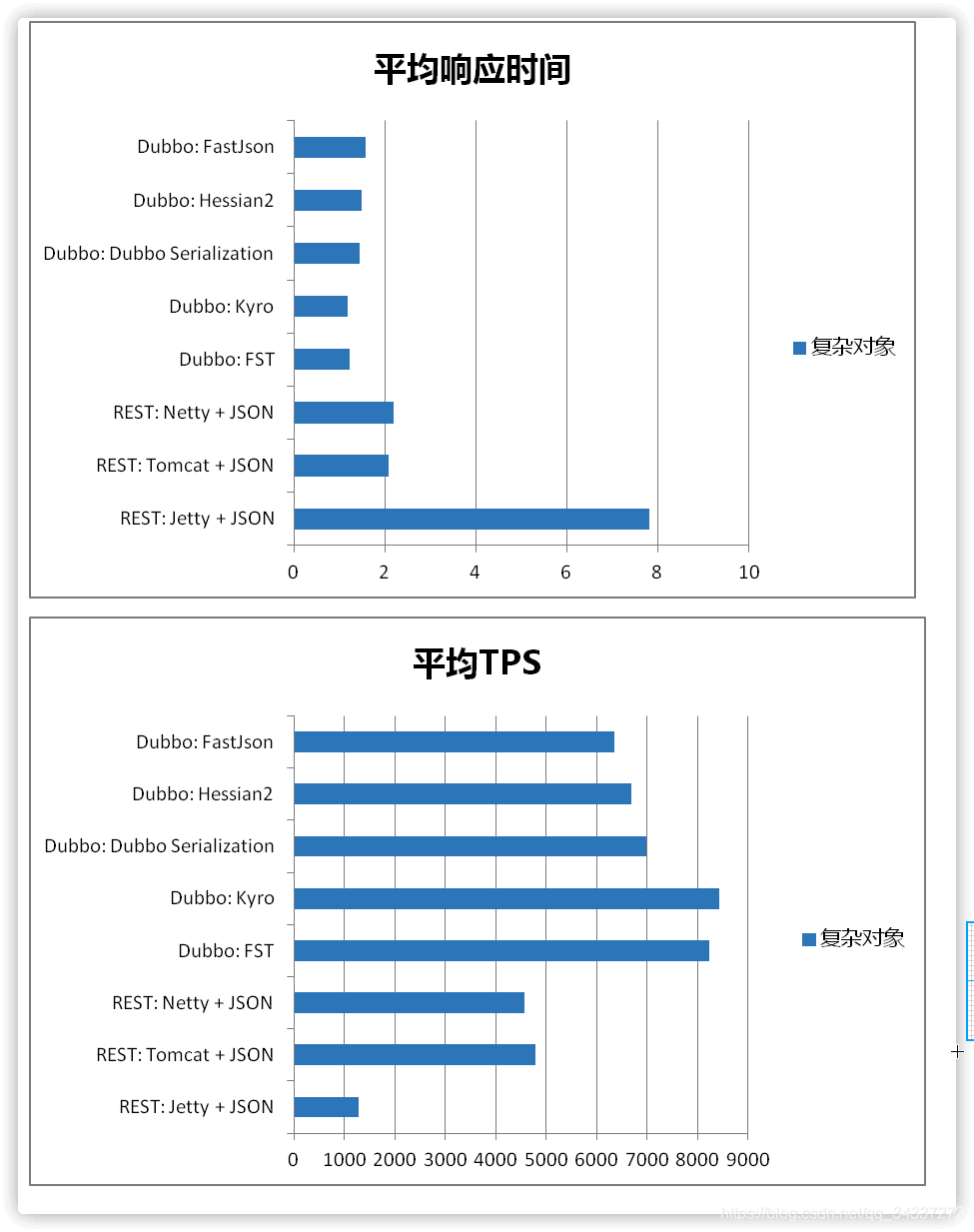
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -178,11 +178,25 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
|
||||
|
||||
### 分库分表有没有什么比较推荐的方案?
|
||||
|
||||
Apache ShardingSphere 是一款分布式的数据库生态系统, 可以将任意数据库转换为分布式数据库,并通过数据分片、弹性伸缩、加密等能力对原有数据库进行增强。
|
||||
|
||||
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
|
||||
|
||||

|
||||
ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理、影子库、数据加密和脱敏等功能。
|
||||
|
||||
ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。
|
||||
ShardingSphere 提供的功能如下:
|
||||
|
||||
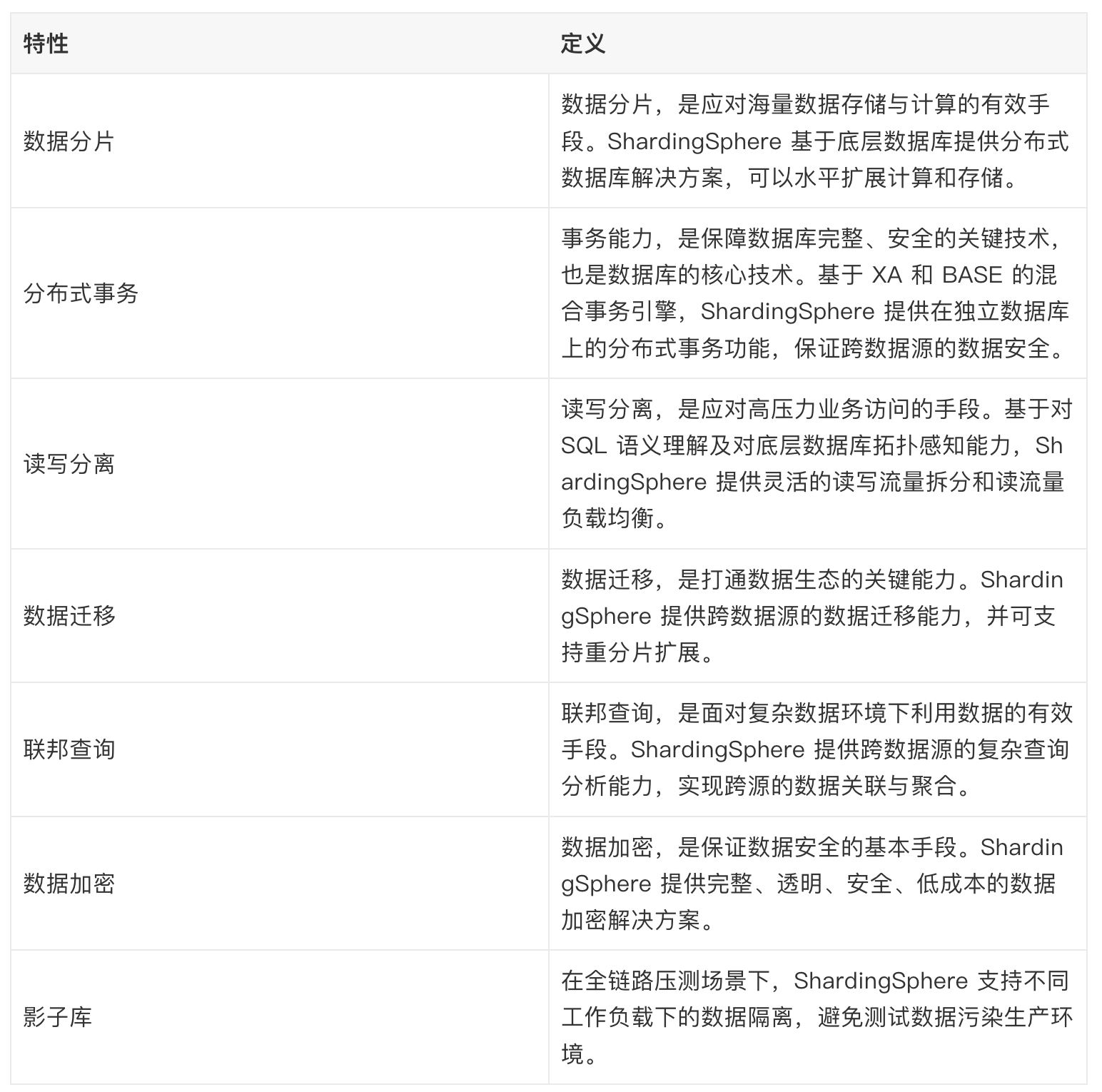
|
||||
|
||||
ShardingSphere 的优势如下(摘自 ShardingSphere 官方文档:<https://shardingsphere.apache.org/document/current/cn/overview/>):
|
||||
|
||||
- 极致性能:驱动程序端历经长年打磨,效率接近原生 JDBC,性能极致。
|
||||
- 生态兼容:代理端支持任何通过 MySQL/PostgreSQL 协议的应用访问,驱动程序端可对接任意实现 JDBC 规范的数据库。
|
||||
- 业务零侵入:面对数据库替换场景,ShardingSphere 可满足业务无需改造,实现平滑业务迁移。
|
||||
- 运维低成本:在保留原技术栈不变前提下,对 DBA 学习、管理成本低,交互友好。
|
||||
- 安全稳定:基于成熟数据库底座之上提供增量能力,兼顾安全性及稳定性。
|
||||
- 弹性扩展:具备计算、存储平滑在线扩展能力,可满足业务多变的需求。
|
||||
- 开放生态:通过多层次(内核、功能、生态)插件化能力,为用户提供可定制满足自身特殊需求的独有系统。
|
||||
|
||||
另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
|
||||
|
||||
|
||||
@ -54,7 +54,7 @@ GitHub 或者码云上面有很多实战类别项目,你可以选择一个来
|
||||
|
||||
如果参加这种赛事能获奖的话,项目含金量非常高。即使没获奖也没啥,也可以写简历上。
|
||||
|
||||

|
||||
|
||||
|
||||
### 参与实际项目
|
||||
|
||||
@ -103,12 +103,12 @@ GitHub 或者码云上面有很多实战类别项目,你可以选择一个来
|
||||
|
||||
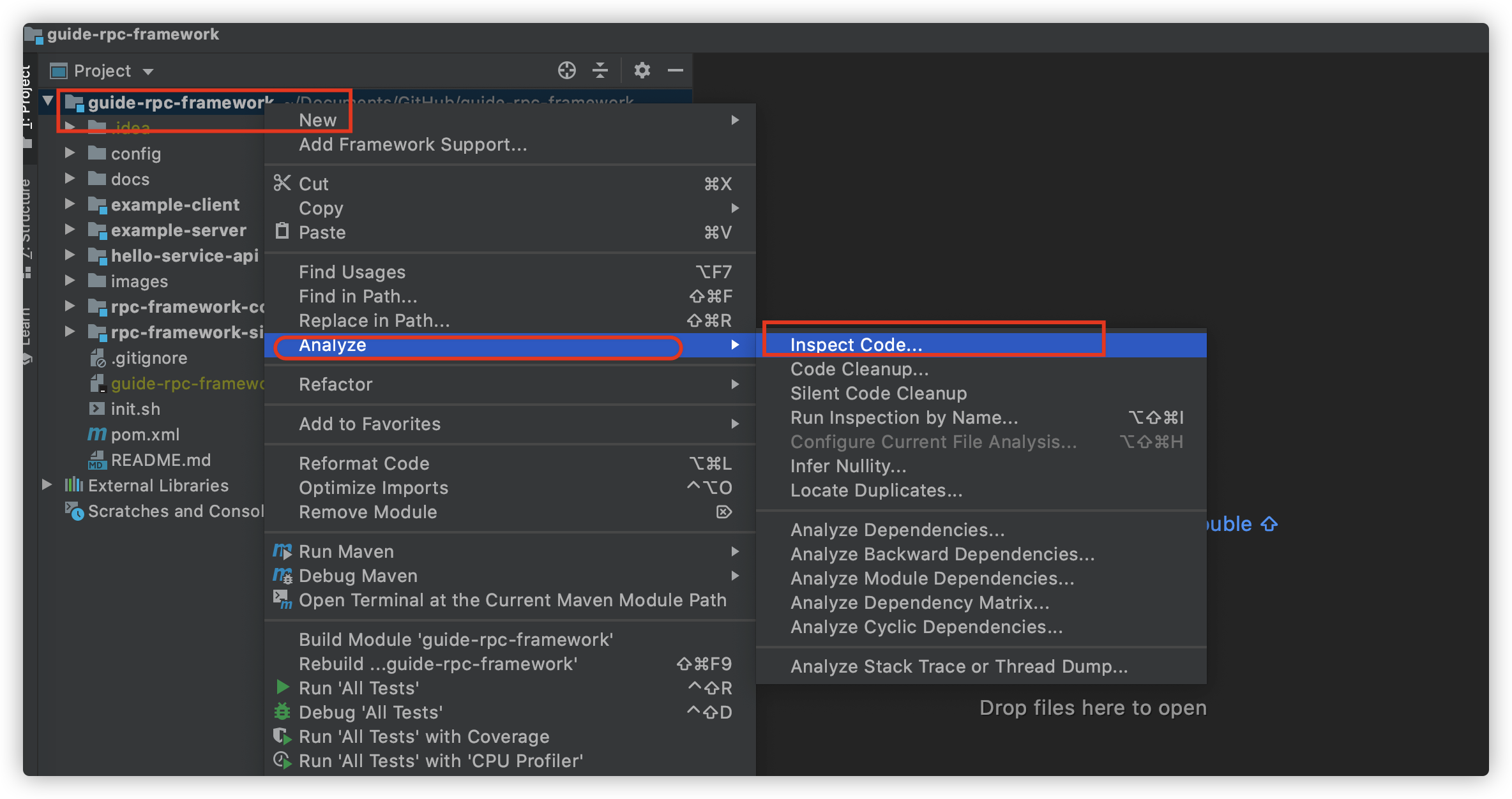
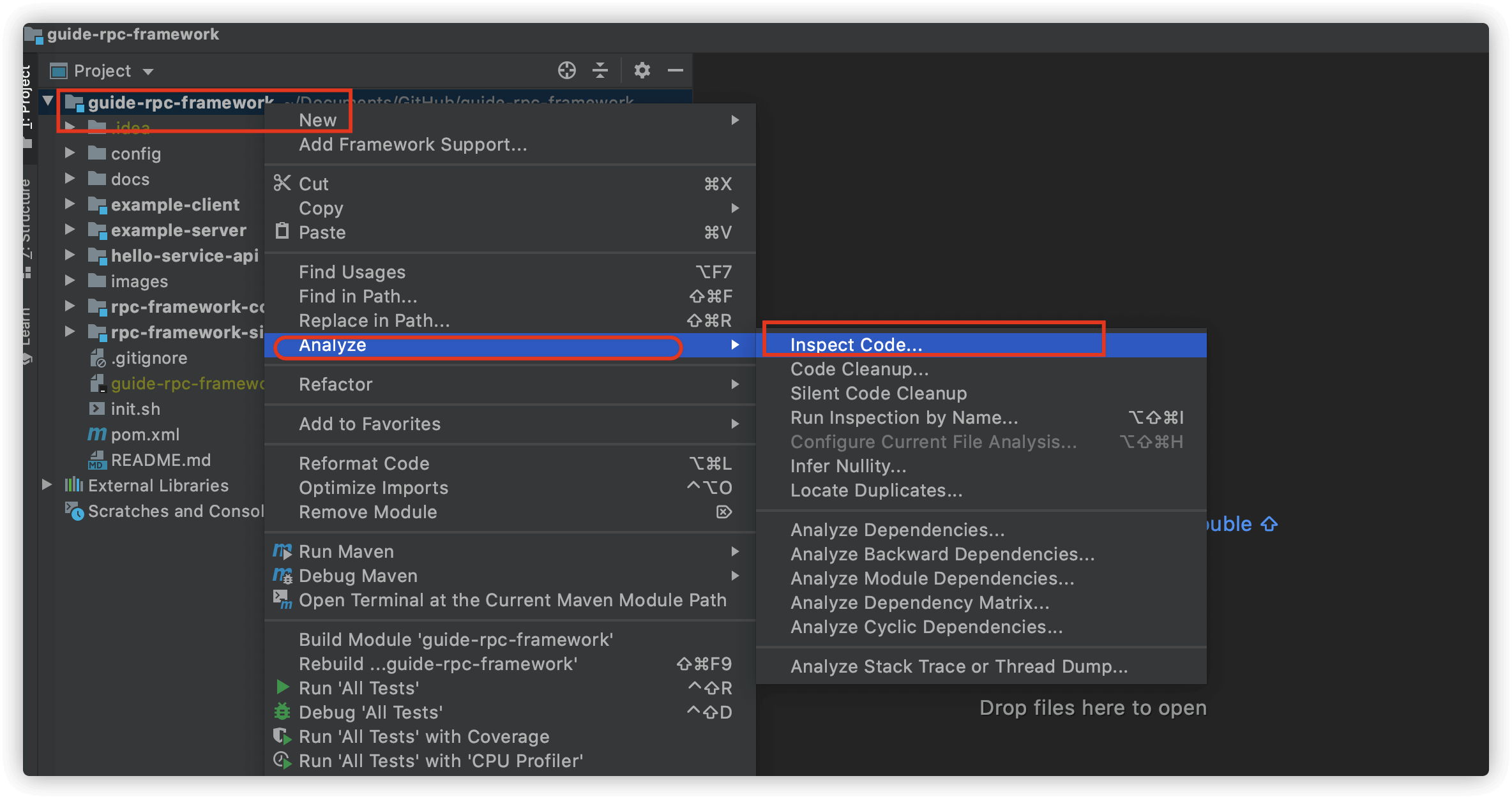
分析你的代码:右键项目-> Analyze->Inspect Code
|
||||
|
||||
|
||||
|
||||
|
||||
扫描完成之后,IDEA 会给出一些可能存在的代码坏味道比如命名问题。
|
||||
|
||||
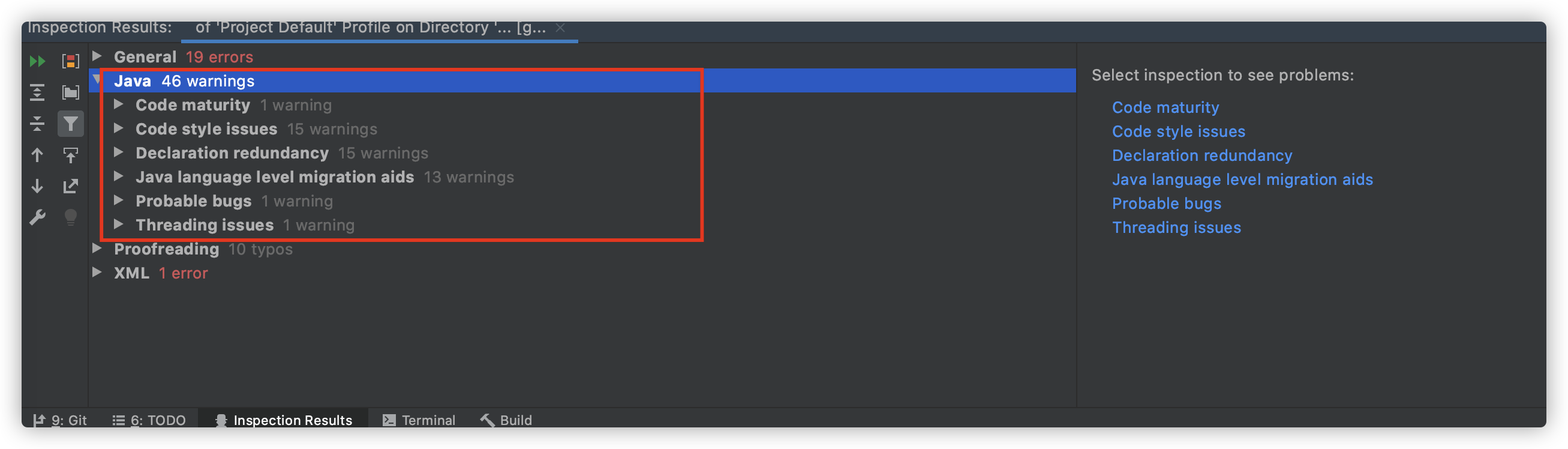
|
||||
|
||||
|
||||
并且,你还可以自定义检查规则。
|
||||
|
||||
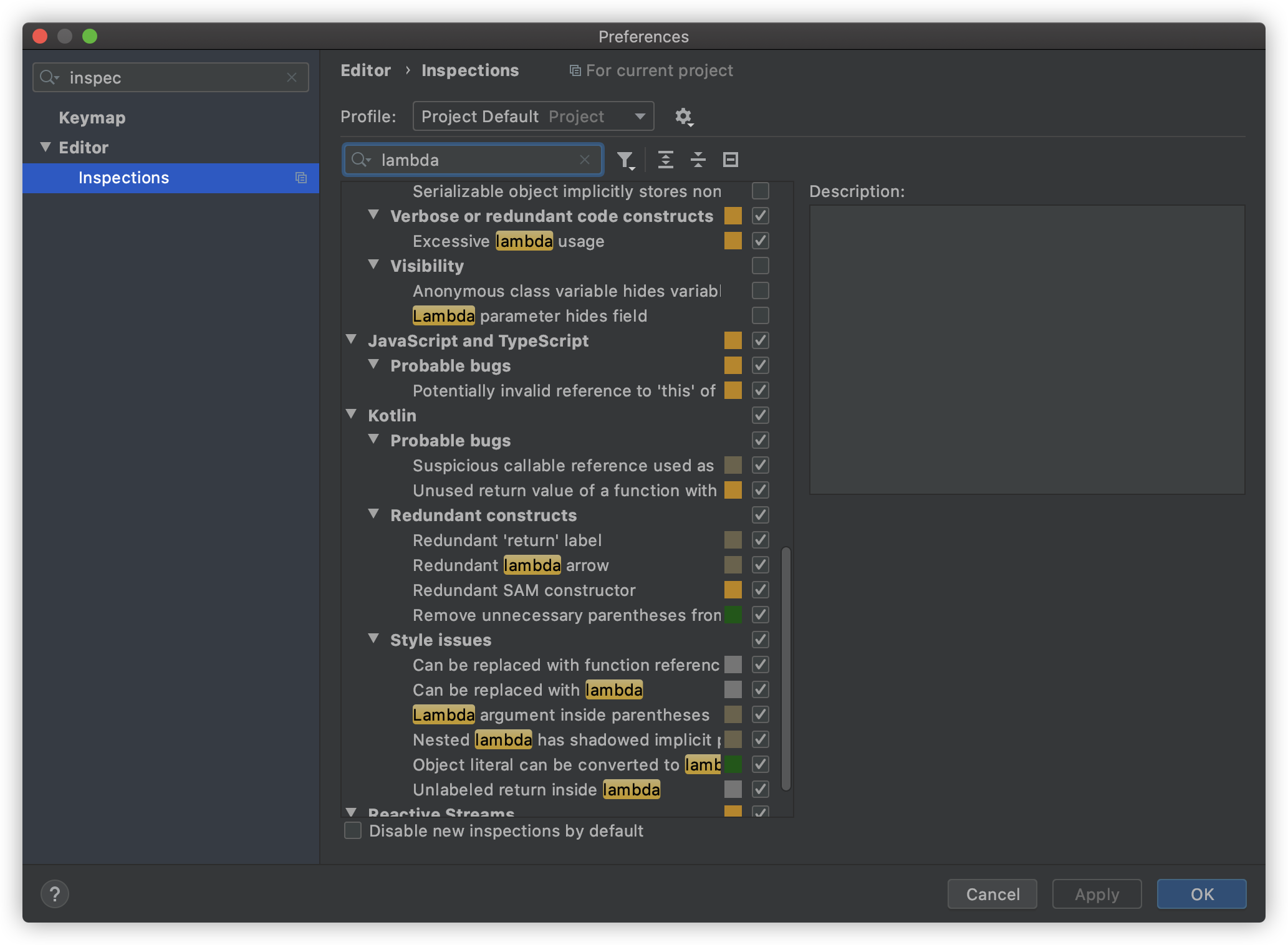
|
||||
|
||||
|
||||
@ -153,8 +153,6 @@ AOT 可以提前编译节省启动时间,那为什么不全部使用这种编
|
||||
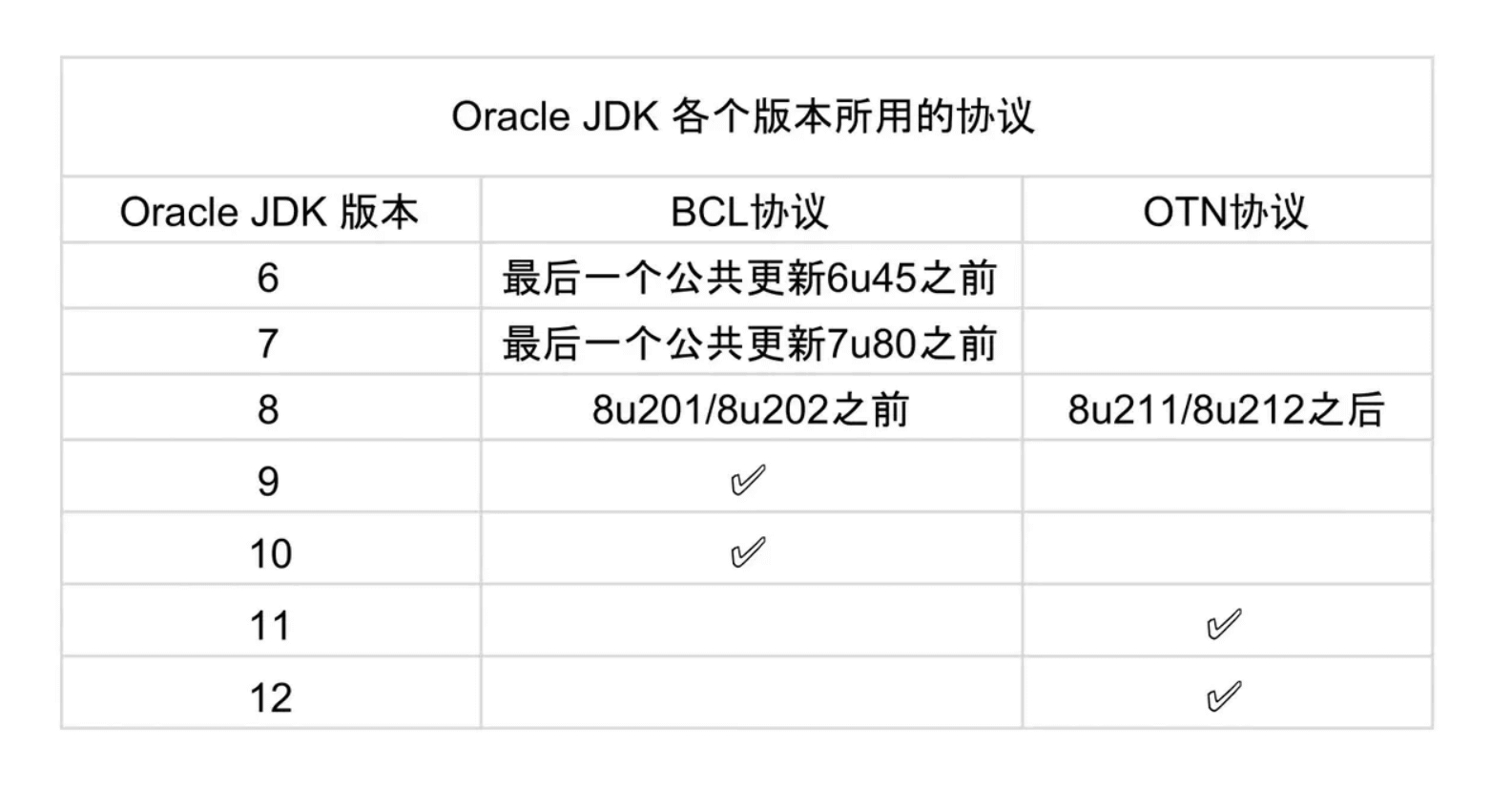
- BCL 协议(Oracle Binary Code License Agreement):可以使用 JDK(支持商用),但是不能进行修改。
|
||||
- OTN 协议(Oracle Technology Network License Agreement):11 及之后新发布的 JDK 用的都是这个协议,可以自己私下用,但是商用需要付费。
|
||||
|
||||
|
||||
|
||||
### Java 和 C++ 的区别?
|
||||
|
||||
我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过 C++,也要记下来。
|
||||
@ -515,7 +513,7 @@ System.out.println(i1==i2);
|
||||
|
||||
记住:**所有整型包装类对象之间值的比较,全部使用 equals 方法比较**。
|
||||
|
||||

|
||||

|
||||
|
||||
### 自动装箱与拆箱了解吗?原理是什么?
|
||||
|
||||
|
||||
@ -92,6 +92,7 @@ icon: "xitongsheji"
|
||||
- [Insomnia](https://insomnia.rest/) :像人类而不是机器人一样调试 API。我平时经常用的,界面美观且轻量,总之很喜欢。
|
||||
- [Postman](https://www.getpostman.com/):API 请求生成器。
|
||||
- [Postwoman](https://github.com/liyasthomas/postwoman "postwoman"):API 请求生成器-一个免费、快速、漂亮的 Postma 替代品。
|
||||
- [Restful Fast Request](https://gitee.com/dromara/fast-request):IDEA 版 Postman,API 调试工具 + API 管理工具 + API 搜索工具。
|
||||
|
||||
## 任务调度
|
||||
|
||||
|
||||
@ -48,7 +48,7 @@ Dijkstra(Dijkstra 算法的作者) 在 1972 年图灵奖获奖感言中也
|
||||
|
||||
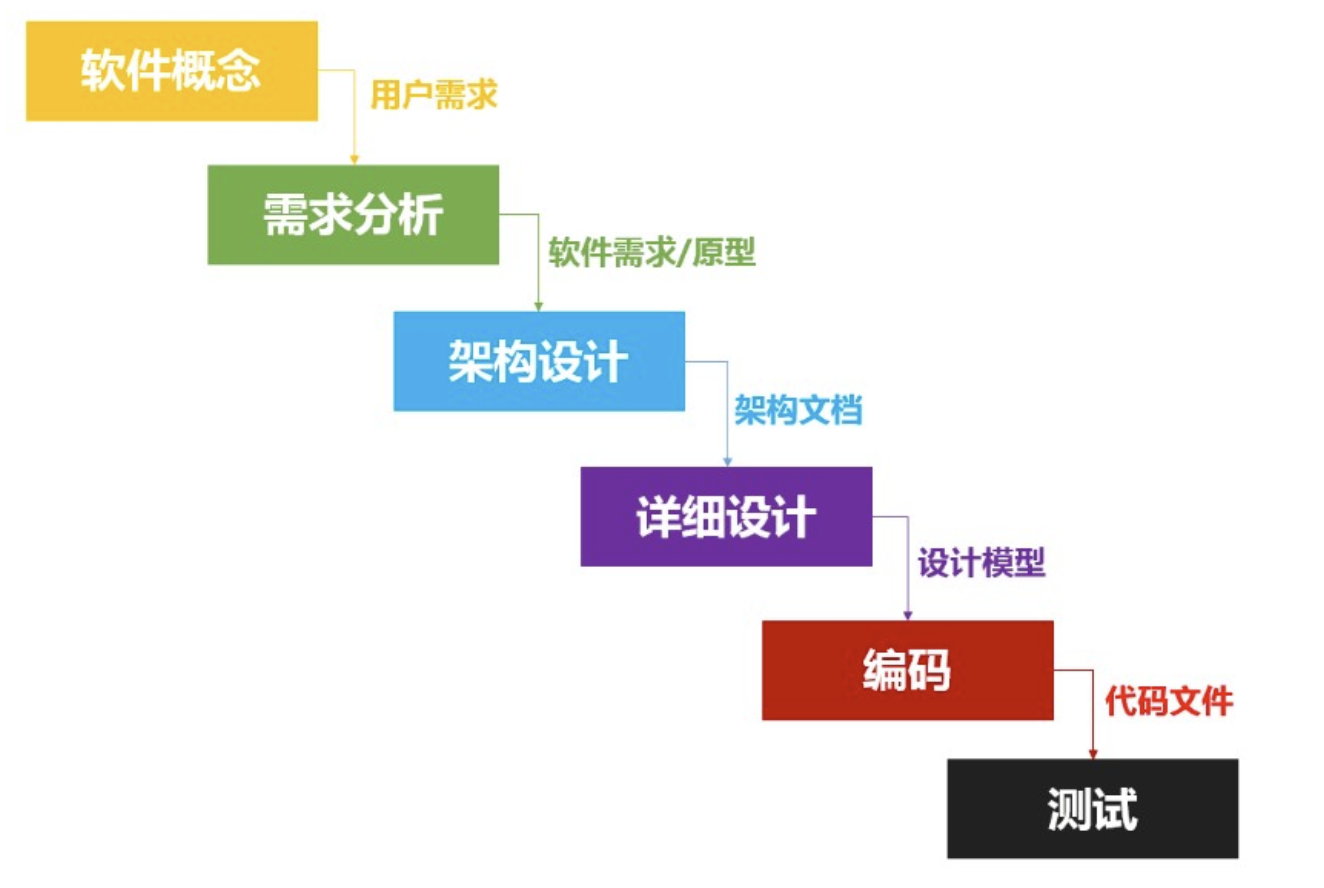
**瀑布模型** 定义了一套完成的软件开发周期,完整地展示了一个软件的的生命周期。
|
||||
|
||||
|
||||

|
||||
|
||||
**敏捷开发模型** 是目前使用的最多的一种软件开发模型。[MBA 智库百科对敏捷开发的描述](https://wiki.mbalib.com/wiki/%E6%95%8F%E6%8D%B7%E5%BC%80%E5%8F%91)是这样的:
|
||||
|
||||
@ -82,7 +82,7 @@ Dijkstra(Dijkstra 算法的作者) 在 1972 年图灵奖获奖感言中也
|
||||
|
||||
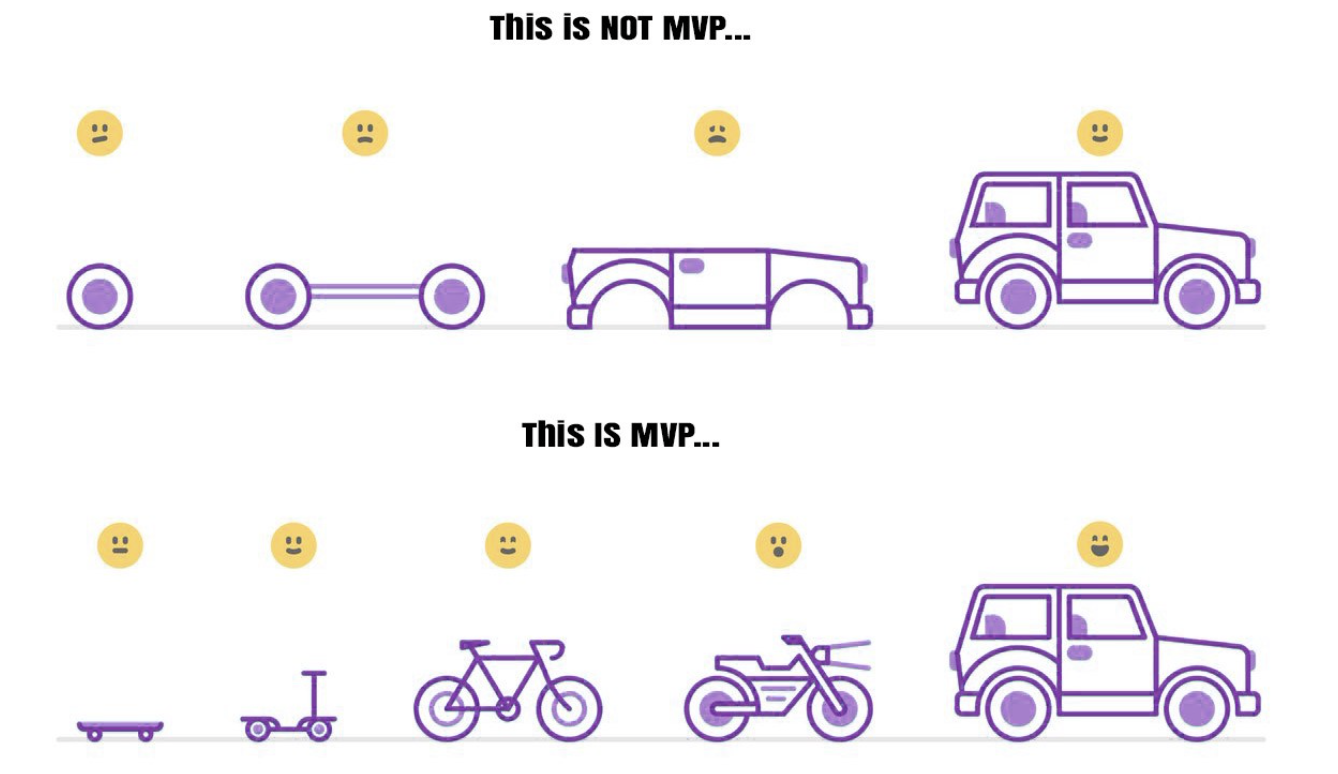
这个最小可行产品,可以理解为刚好能够满足客户需求的产品。下面这张图片把这个思想展示的非常精髓。
|
||||
|
||||
|
||||

|
||||
|
||||
利用最小可行产品,我们可以也可以提早进行市场分析,这对于我们在探索产品不确定性的道路上非常有帮助。可以非常有效地指导我们下一步该往哪里走。
|
||||
|
||||
|
||||
@ -151,7 +151,7 @@ Kafka、Dubbo、ZooKeeper、Netty、Caffeine、Akka 中都有对时间轮的实
|
||||
|
||||
下图是一个有 12 个时间格的时间轮,转完一圈需要 12 s。当我们需要新建一个 3s 后执行的定时任务,只需要将定时任务放在下标为 3 的时间格中即可。当我们需要新建一个 9s 后执行的定时任务,只需要将定时任务放在下标为 9 的时间格中即可。
|
||||
|
||||

|
||||

|
||||
|
||||
那当我们需要创建一个 13s 后执行的定时任务怎么办呢?这个时候可以引入一叫做 **圈数/轮数** 的概念,也就是说这个任务还是放在下标为 3 的时间格中, 不过它的圈数为 2 。
|
||||
|
||||
@ -159,7 +159,7 @@ Kafka、Dubbo、ZooKeeper、Netty、Caffeine、Akka 中都有对时间轮的实
|
||||
|
||||
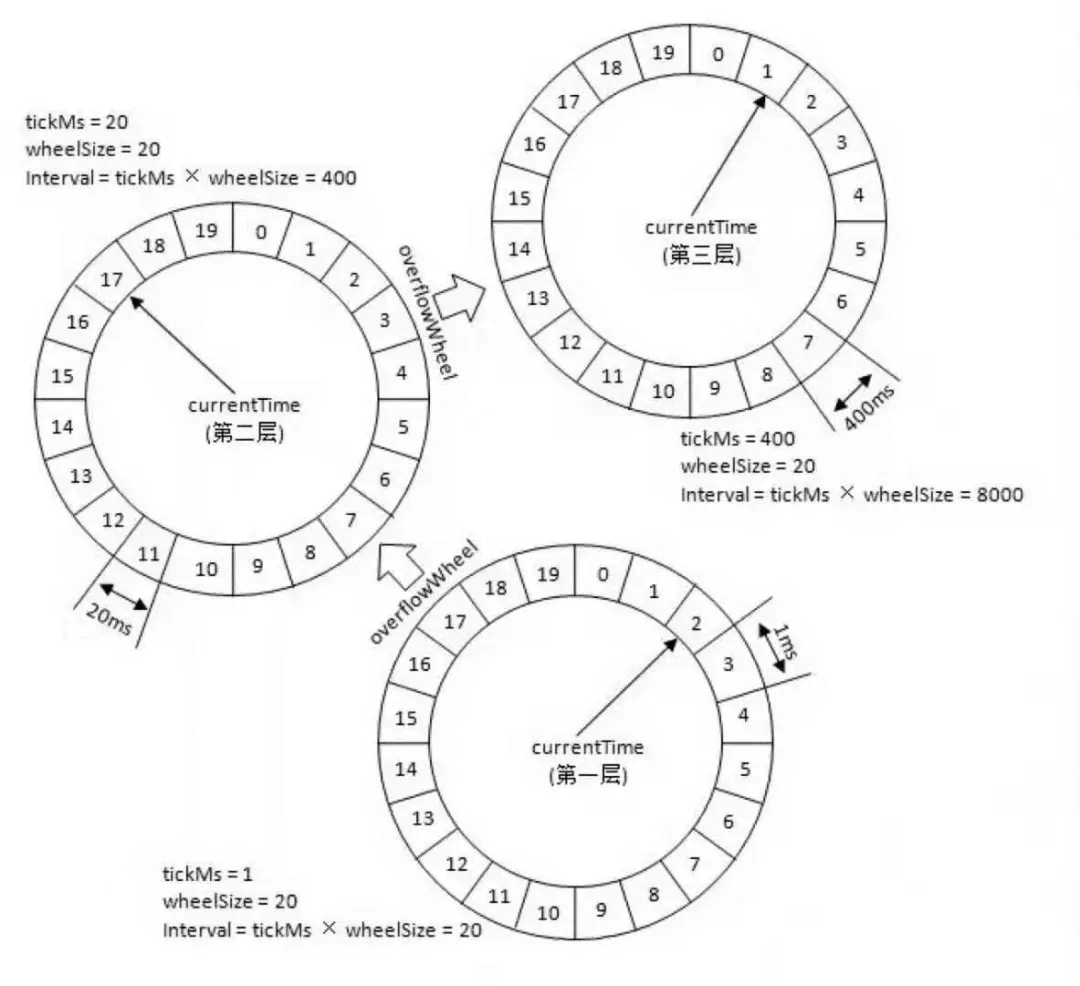
针对下图的时间轮,我来举一个例子便于大家理解。
|
||||
|
||||
|
||||

|
||||
|
||||
上图的时间轮,第 1 层的时间精度为 1 ,第 2 层的时间精度为 20 ,第 3 层的时间精度为 400。假如我们需要添加一个 350s 后执行的任务 A 的话(当前时间是 0s),这个任务会被放在第 2 层(因为第二层的时间跨度为 20\*20=400>350)的第 350/20=17 个时间格子。
|
||||
|
||||
@ -169,8 +169,6 @@ Kafka、Dubbo、ZooKeeper、Netty、Caffeine、Akka 中都有对时间轮的实
|
||||
|
||||
这里在层与层之间的移动也叫做时间轮的升降级。参考手表来理解就好!
|
||||
|
||||

|
||||
|
||||
**时间轮比较适合任务数量比较多的定时任务场景,它的任务写入和执行的时间复杂度都是 0(1)。**
|
||||
|
||||
## 分布式定时任务技术选型
|
||||
@ -187,32 +185,41 @@ Kafka、Dubbo、ZooKeeper、Netty、Caffeine、Akka 中都有对时间轮的实
|
||||
|
||||
### Quartz
|
||||
|
||||
一个很火的开源任务调度框架,完全由`Java`写成。`Quartz` 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 `Quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案。
|
||||
一个很火的开源任务调度框架,完全由Java写成。Quartz 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 Quartz 开发的,比如当当网的`elastic-job`就是基于Quartz二次开发之后的分布式调度解决方案。
|
||||
|
||||
使用 `Quartz` 可以很方便地与 `Spring` 集成,并且支持动态添加任务和集群。但是,`Quartz` 使用起来也比较麻烦,API 繁琐。
|
||||
使用 Quartz 可以很方便地与 Spring集成,并且支持动态添加任务和集群。但是,Quartz 使用起来也比较麻烦,API 繁琐。
|
||||
|
||||
并且,`Quzrtz` 并没有内置 UI 管理控制台,不过你可以使用 [quartzui](https://github.com/zhaopeiym/quartzui) 这个开源项目来解决这个问题。
|
||||
并且,Quartz 并没有内置 UI 管理控制台,不过你可以使用 [quartzui](https://github.com/zhaopeiym/quartzui) 这个开源项目来解决这个问题。
|
||||
|
||||
另外,`Quartz` 虽然也支持分布式任务。但是,它是在数据库层面,通过数据库的锁机制做的,有非常多的弊端比如系统侵入性严重、节点负载不均衡。有点伪分布式的味道。
|
||||
另外,Quartz 虽然也支持分布式任务。但是,它是在数据库层面,通过数据库的锁机制做的,有非常多的弊端比如系统侵入性严重、节点负载不均衡。有点伪分布式的味道。
|
||||
|
||||
**优缺点总结:**
|
||||
|
||||
- 优点:可以与 `Spring` 集成,并且支持动态添加任务和集群。
|
||||
- 优点:可以与 Spring集成,并且支持动态添加任务和集群。
|
||||
- 缺点:分布式支持不友好,没有内置 UI 管理控制台、使用麻烦(相比于其他同类型框架来说)
|
||||
|
||||
### Elastic-Job
|
||||
|
||||
`Elastic-Job` 是当当网开源的一个基于`Quartz`和`ZooKeeper`的分布式调度解决方案,由两个相互独立的子项目 `Elastic-Job-Lite` 和 `Elastic-Job-Cloud` 组成,一般我们只要使用 `Elastic-Job-Lite` 就好。
|
||||
ElasticJob 当当网开源的一个面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。
|
||||
|
||||
ElasticJob-Lite 和 ElasticJob-Cloud 两者的对比如下:
|
||||
|
||||
| ElasticJob-Lite | ElasticJob-Cloud | |
|
||||
| :-------------- | :--------------- | ----------------- |
|
||||
| 无中心化 | 是 | 否 |
|
||||
| 资源分配 | 不支持 | 支持 |
|
||||
| 作业模式 | 常驻 | 常驻 + 瞬时 |
|
||||
| 部署依赖 | ZooKeeper | ZooKeeper + Mesos |
|
||||
|
||||
`ElasticJob` 支持任务在分布式场景下的分片和高可用、任务可视化管理等功能。
|
||||
|
||||

|
||||

|
||||
|
||||
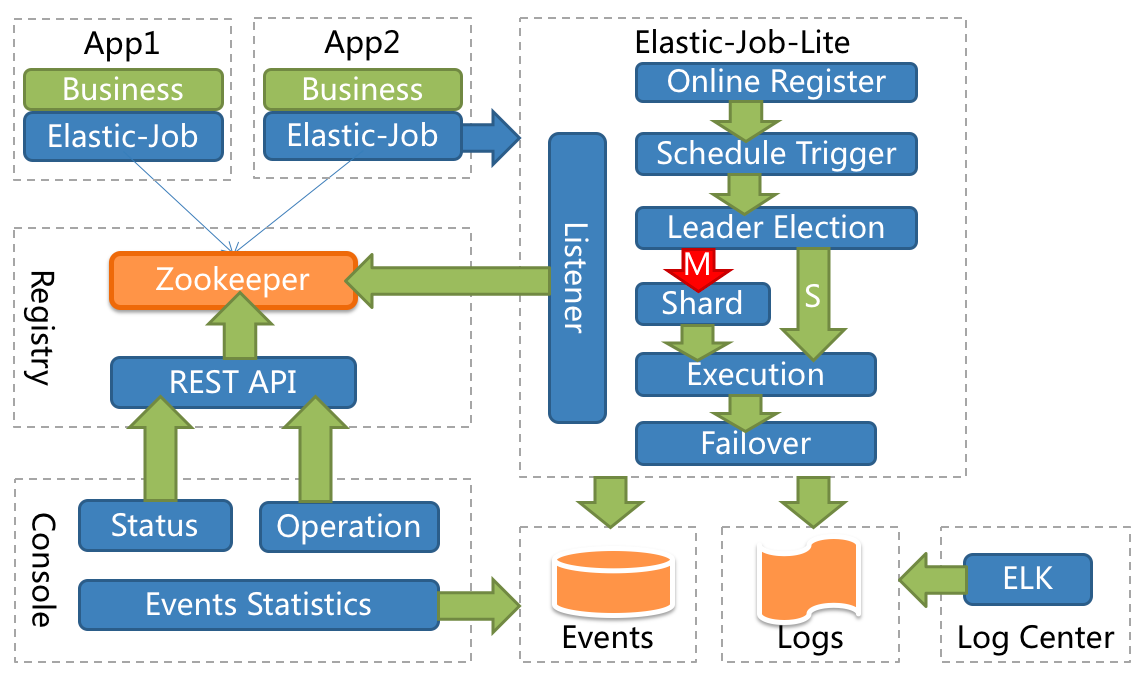
ElasticJob-Lite 的架构设计如下图所示:
|
||||
|
||||
|
||||

|
||||
|
||||
从上图可以看出,`Elastic-Job` 没有调度中心这一概念,而是使用 `ZooKeeper` 作为注册中心,注册中心负责协调分配任务到不同的节点上。
|
||||
从上图可以看出,Elastic-Job没有调度中心这一概念,而是使用 ZooKeeper 作为注册中心,注册中心负责协调分配任务到不同的节点上。
|
||||
|
||||
Elastic-Job 中的定时调度都是由执行器自行触发,这种设计也被称为去中心化设计(调度和处理都是执行器单独完成)。
|
||||
|
||||
@ -236,26 +243,33 @@ public class TestJob implements SimpleJob {
|
||||
|
||||
**优缺点总结:**
|
||||
|
||||
- 优点:可以与 `Spring` 集成、支持分布式、支持集群、性能不错
|
||||
- 优点:可以与 Spring集成、支持分布式、支持集群、性能不错
|
||||
- 缺点:依赖了额外的中间件比如 Zookeeper(复杂度增加,可靠性降低、维护成本变高)
|
||||
|
||||
### XXL-JOB
|
||||
|
||||
`XXL-JOB` 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能,
|
||||
|
||||

|
||||

|
||||
|
||||
根据 `XXL-JOB` 官网介绍,其解决了很多 `Quartz` 的不足。
|
||||
根据 `XXL-JOB` 官网介绍,其解决了很多 Quartz 的不足。
|
||||
|
||||

|
||||
> Quartz作为开源作业调度中的佼佼者,是作业调度的首选。但是集群环境中Quartz采用API的方式对任务进行管理,从而可以避免上述问题,但是同样存在以下问题:
|
||||
>
|
||||
> - 问题一:调用API的的方式操作任务,不人性化;
|
||||
> - 问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
|
||||
> - 问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务;
|
||||
> - 问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大;而XXL-JOB通过执行器实现“协同分配式”运行任务,充分发挥集群优势,负载各节点均衡。
|
||||
>
|
||||
> XXL-JOB弥补了quartz的上述不足之处。
|
||||
|
||||
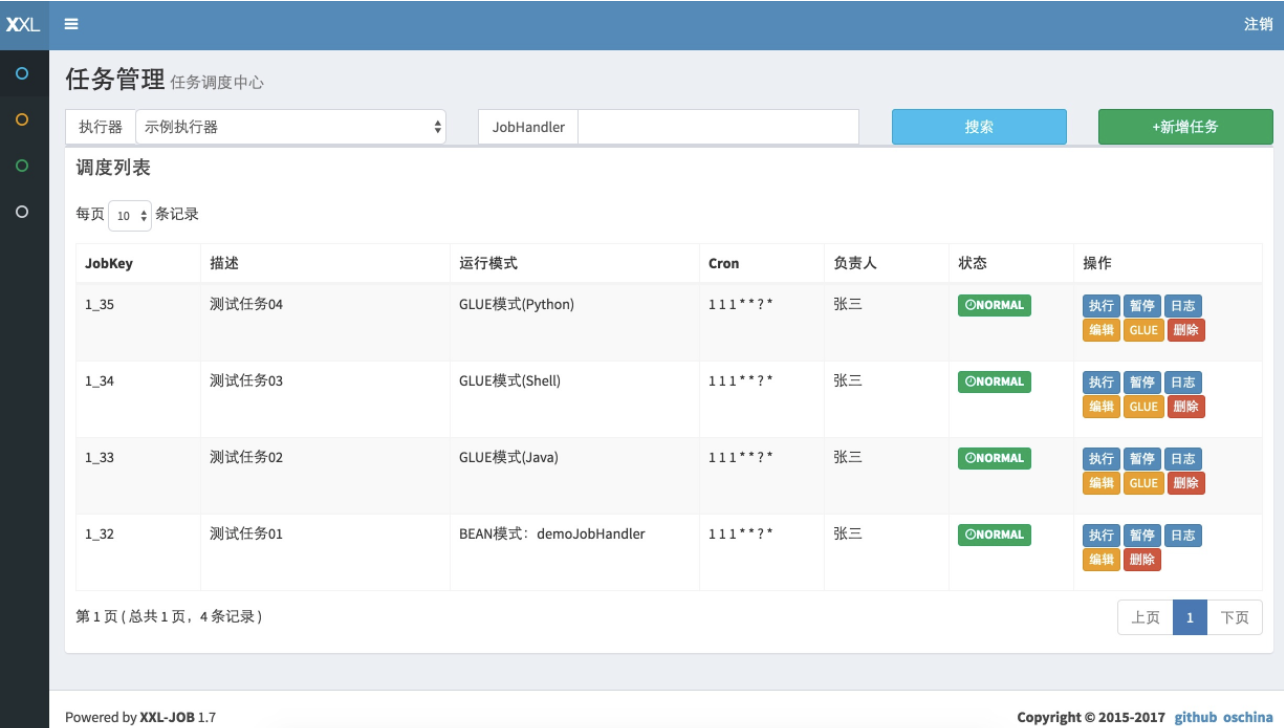
`XXL-JOB` 的架构设计如下图所示:
|
||||
|
||||

|
||||

|
||||
|
||||
从上图可以看出,`XXL-JOB` 由 **调度中心** 和 **执行器** 两大部分组成。调度中心主要负责任务管理、执行器管理以及日志管理。执行器主要是接收调度信号并处理。另外,调度中心进行任务调度时,是通过自研 RPC 来实现的。
|
||||
|
||||
不同于 `Elastic-Job` 的去中心化设计, `XXL-JOB` 的这种设计也被称为中心化设计(调度中心调度多个执行器执行任务)。
|
||||
不同于 Elastic-Job的去中心化设计, `XXL-JOB` 的这种设计也被称为中心化设计(调度中心调度多个执行器执行任务)。
|
||||
|
||||
和 `Quzrtz` 类似 `XXL-JOB` 也是基于数据库锁调度任务,存在性能瓶颈。不过,一般在任务量不是特别大的情况下,没有什么影响的,可以满足绝大部分公司的要求。
|
||||
|
||||
@ -284,7 +298,7 @@ public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||

|
||||
|
||||
**相关地址:**
|
||||
|
||||
@ -306,7 +320,7 @@ public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
|
||||
|
||||
由于 SchedulerX 属于人民币产品,我这里就不过多介绍。PowerJob 官方也对比过其和 QuartZ、XXL-JOB 以及 SchedulerX。
|
||||
|
||||

|
||||

|
||||
|
||||
## 总结
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ tag:
|
||||
|
||||
官网地址:<https://www.docker.com/> 。
|
||||
|
||||
|
||||
|
||||
|
||||
### 为什么要用 Docker?
|
||||
|
||||
@ -46,35 +46,35 @@ Docker 的出现完美地解决了这一问题,我们可以在容器中安装
|
||||
|
||||
接下来对 Docker 进行安装,以 Windows 系统为例,访问 Docker 的官网:
|
||||
|
||||

|
||||
|
||||
|
||||
然后点击`Get Started`:
|
||||
|
||||
|
||||
|
||||
|
||||
在此处点击`Download for Windows`即可进行下载。
|
||||
|
||||
如果你的电脑是`Windows 10 64位专业版`的操作系统,则在安装 Docker 之前需要开启一下`Hyper-V`,开启方式如下。打开控制面板,选择程序:
|
||||
|
||||
|
||||

|
||||
|
||||
点击`启用或关闭Windows功能`:
|
||||
|
||||
|
||||
|
||||
|
||||
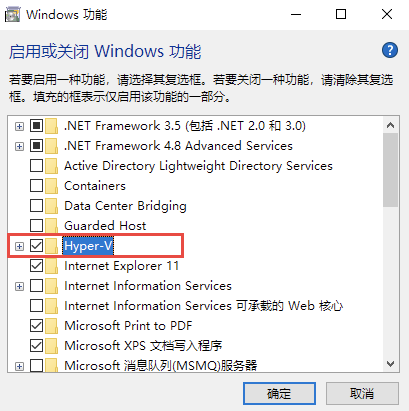
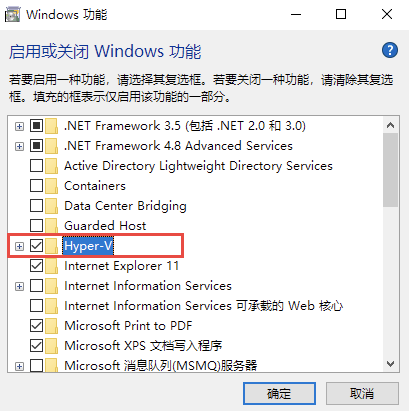
勾选上`Hyper-V`,点击确定即可:
|
||||
|
||||
|
||||
|
||||
|
||||
完成更改后需要重启一下计算机。
|
||||
|
||||
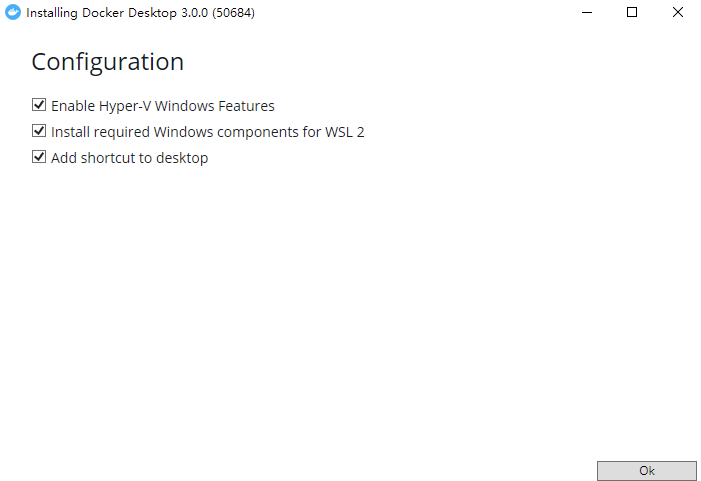
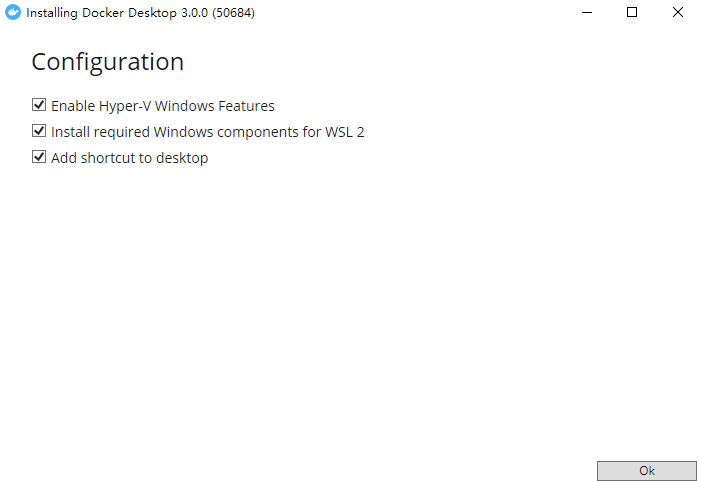
开启了`Hyper-V`后,我们就可以对 Docker 进行安装了,打开安装程序后,等待片刻点击`Ok`即可:
|
||||
|
||||
|
||||
|
||||
|
||||
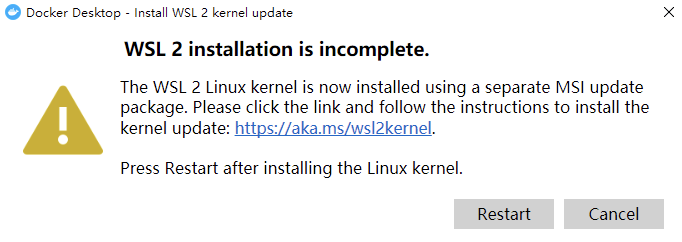
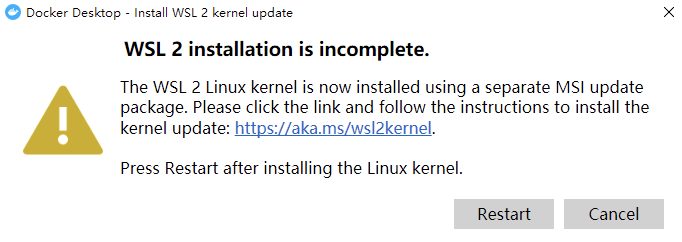
安装完成后,我们仍然需要重启计算机,重启后,若提示如下内容:
|
||||
|
||||
|
||||
|
||||
|
||||
它的意思是询问我们是否使用 WSL2,这是基于 Windows 的一个 Linux 子系统,这里我们取消即可,它就会使用我们之前勾选的`Hyper-V`虚拟机。
|
||||
|
||||
@ -142,21 +142,21 @@ systemctl enable docker
|
||||
|
||||
和 GitHub 一样,Docker 也提供了一个 DockerHub 用于查询各种镜像的地址和安装教程,为此,我们先访问 DockerHub:[https://hub.docker.com/](https://hub.docker.com/)
|
||||
|
||||
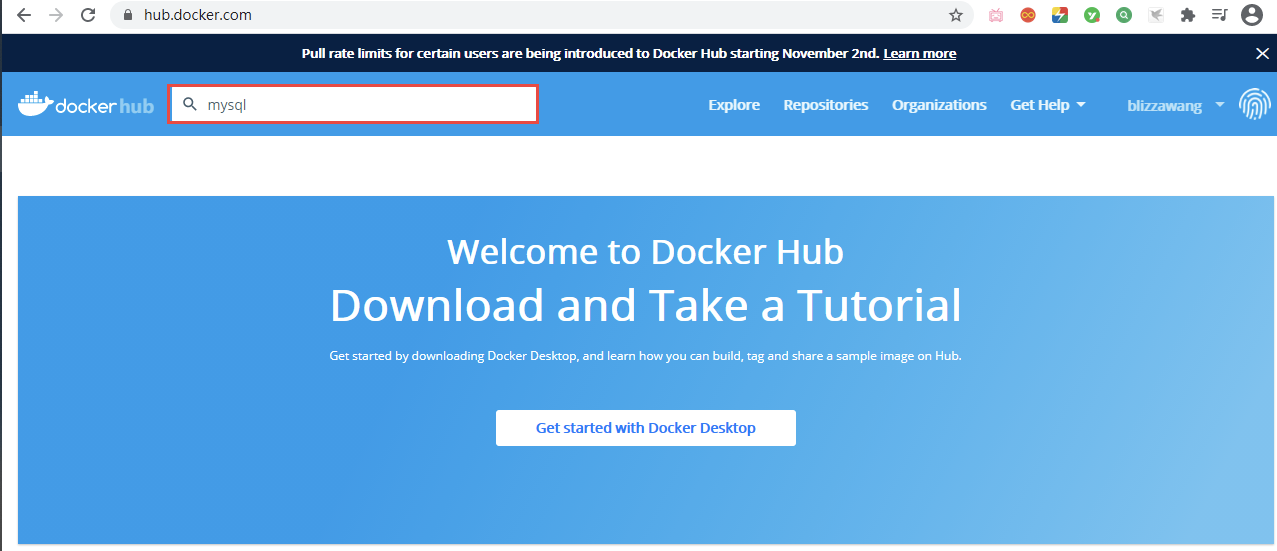
|
||||

|
||||
|
||||
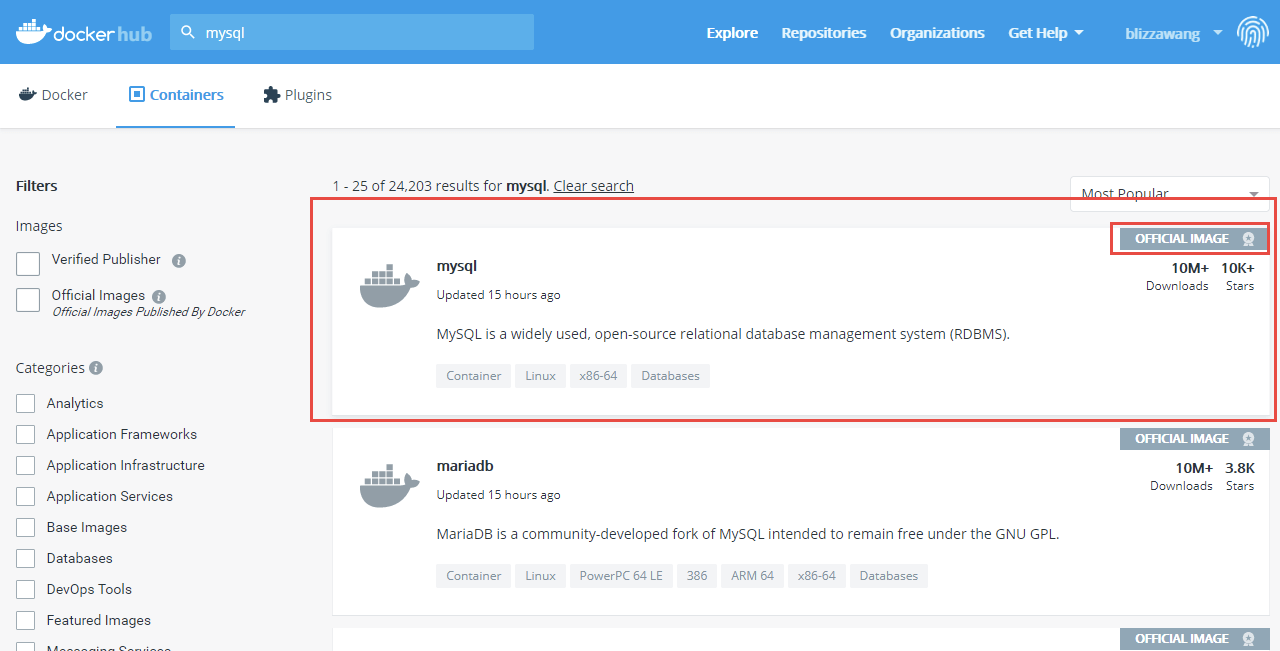
在左上角的搜索框中输入`MySQL`并回车:
|
||||
|
||||
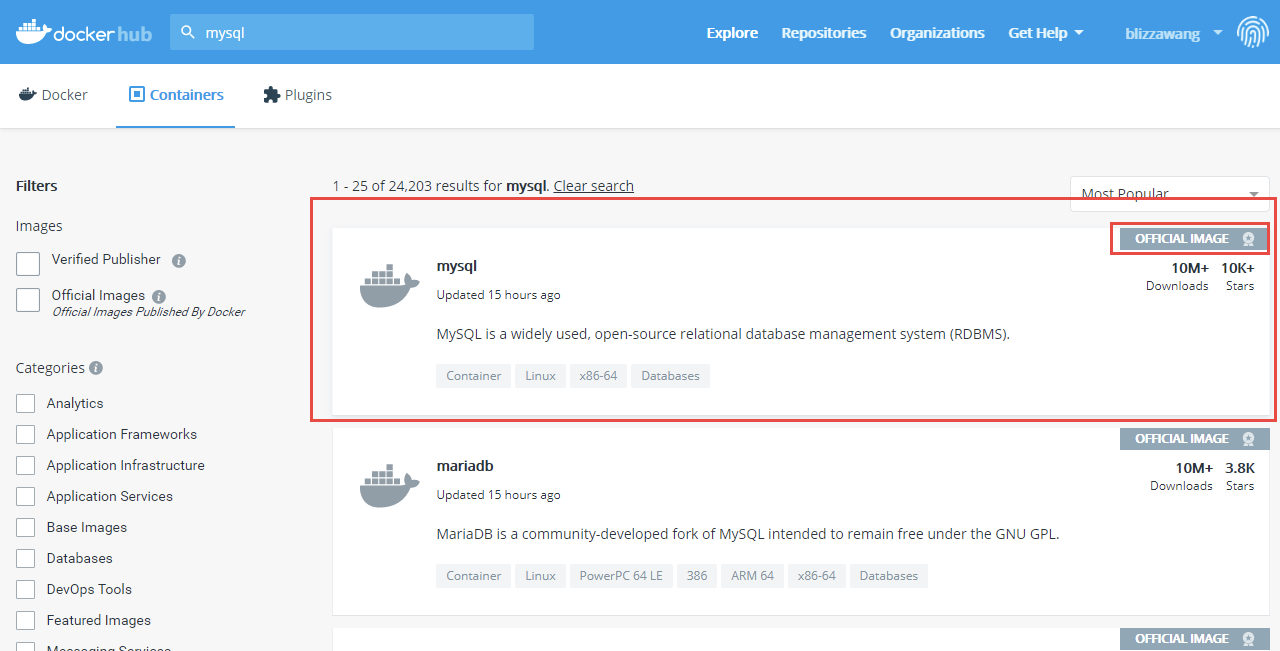
|
||||
|
||||
|
||||
可以看到相关 MySQL 的镜像非常多,若右上角有`OFFICIAL IMAGE`标识,则说明是官方镜像,所以我们点击第一个 MySQL 镜像:
|
||||
|
||||
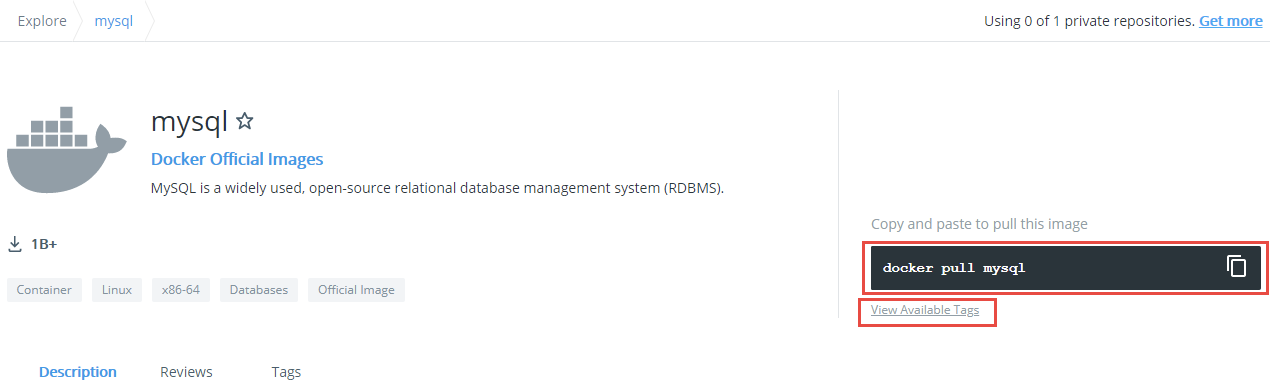
|
||||

|
||||
|
||||
右边提供了下载 MySQL 镜像的指令为`docker pull MySQL`,但该指令始终会下载 MySQL 镜像的最新版本。
|
||||
|
||||
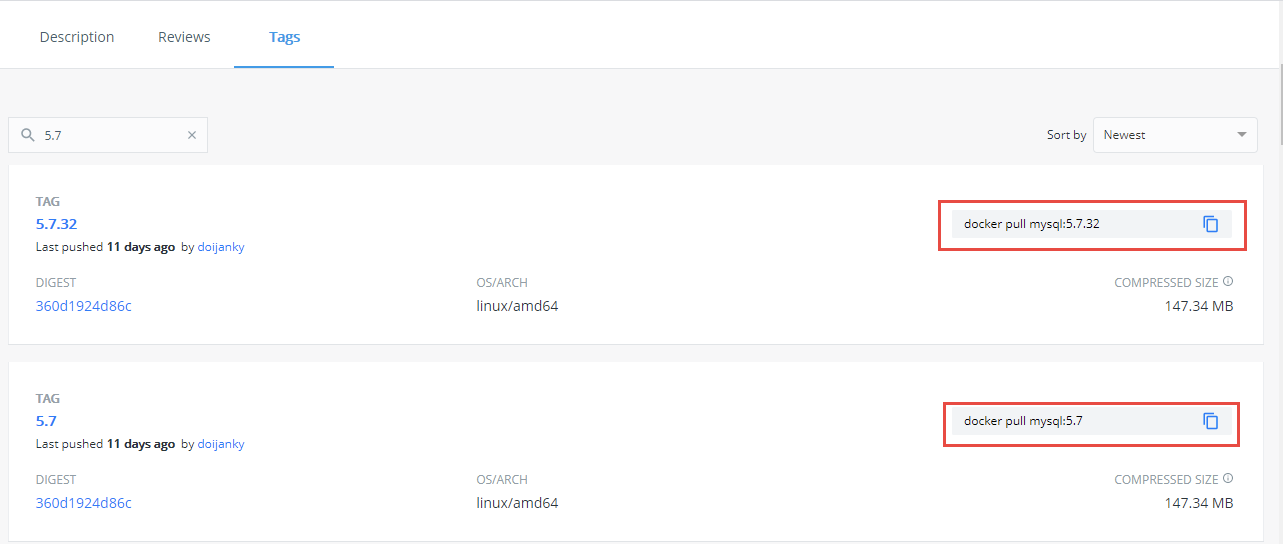
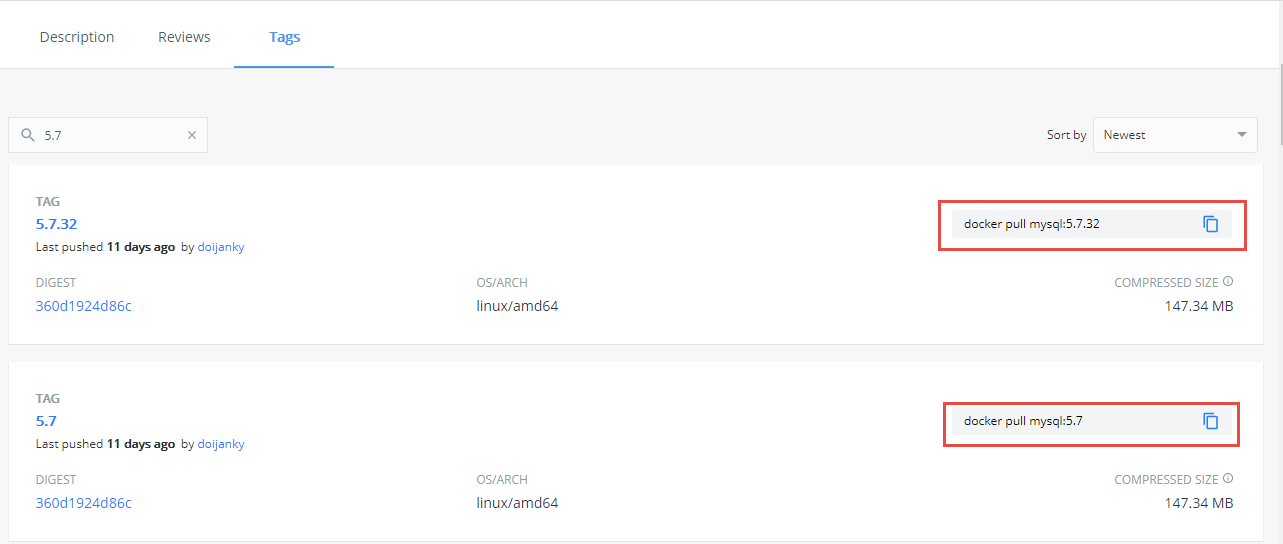
若是想下载指定版本的镜像,则点击下面的`View Available Tags`:
|
||||
|
||||
|
||||
|
||||
|
||||
这里就可以看到各种版本的镜像,右边有下载的指令,所以若是想下载 5.7.32 版本的 MySQL 镜像,则执行:
|
||||
|
||||
@ -164,17 +164,13 @@ systemctl enable docker
|
||||
docker pull MySQL:5.7.32
|
||||
```
|
||||
|
||||
然而下载镜像的过程是非常慢的,所以我们需要配置一下镜像源加速下载,访问`阿里云`官网:
|
||||
然而下载镜像的过程是非常慢的,所以我们需要配置一下镜像源加速下载,访问`阿里云`官网,点击控制台:
|
||||
|
||||

|
||||
|
||||
点击控制台:
|
||||
|
||||
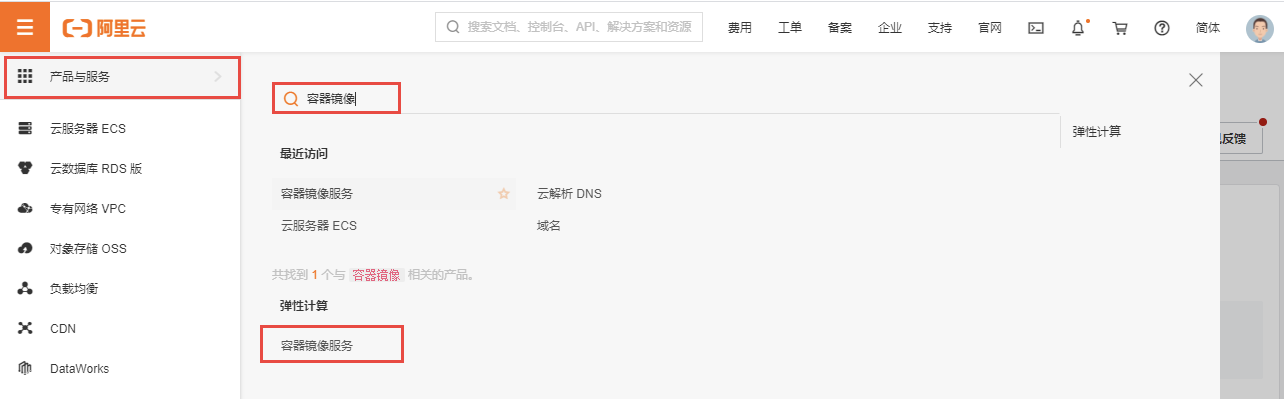
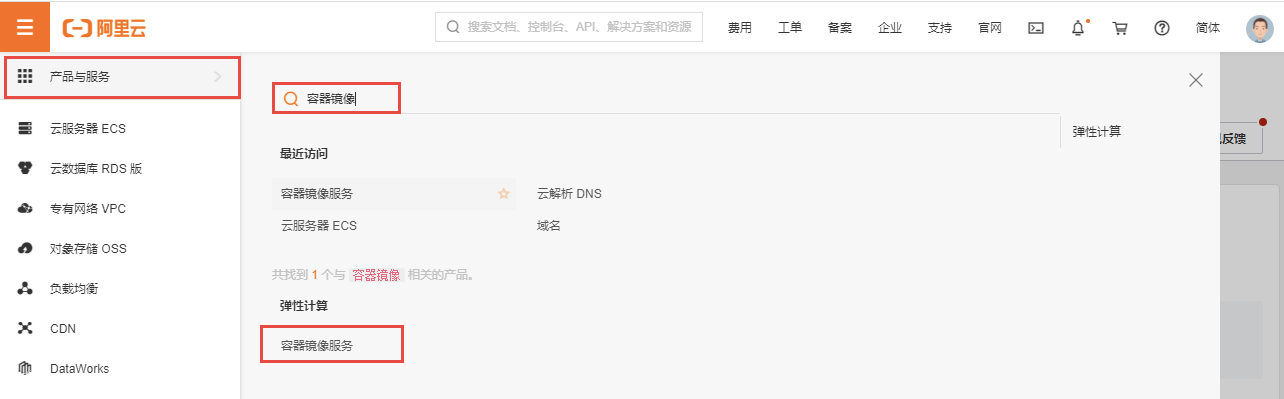
|
||||
|
||||
|
||||
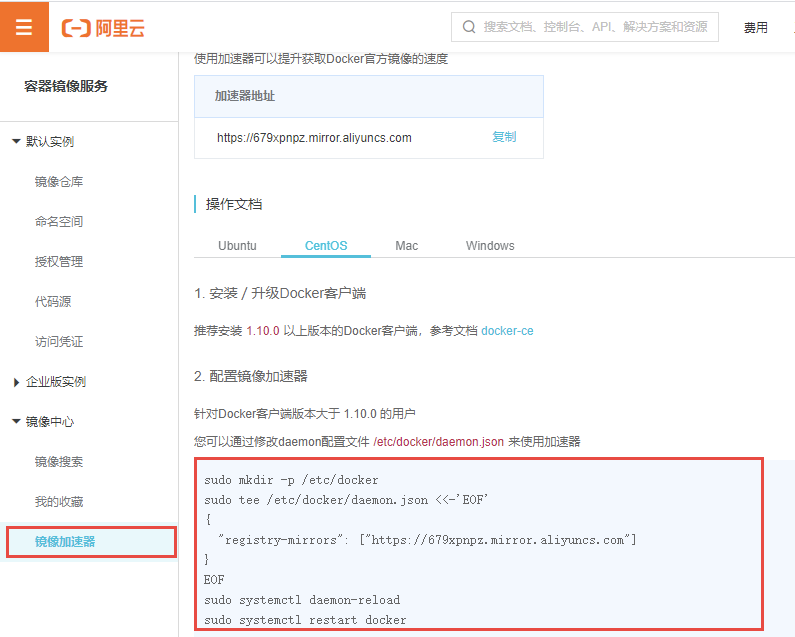
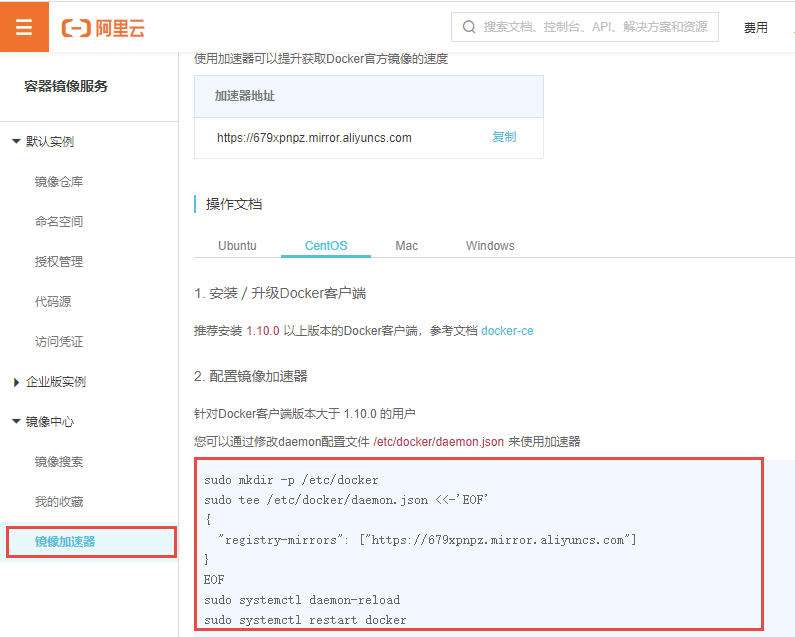
然后点击左上角的菜单,在弹窗的窗口中,将鼠标悬停在产品与服务上,并在右侧搜索容器镜像服务,最后点击容器镜像服务:
|
||||
|
||||
|
||||
|
||||
|
||||
点击左侧的镜像加速器,并依次执行右侧的配置指令即可。
|
||||
|
||||
@ -246,7 +242,7 @@ docker pull MySQL:5.7
|
||||
docker search MySQL
|
||||
```
|
||||
|
||||

|
||||

|
||||
|
||||
不过该指令只能查看 MySQL 相关的镜像信息,而不能知道有哪些版本,若想知道版本,则只能这样查询:
|
||||
|
||||
@ -254,11 +250,9 @@ docker search MySQL
|
||||
docker search MySQL:5.5
|
||||
```
|
||||
|
||||

|
||||
|
||||
若是查询的版本不存在,则结果为空:
|
||||
|
||||

|
||||
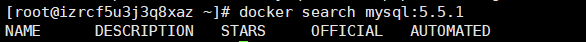
|
||||
|
||||
删除镜像使用指令:
|
||||
|
||||
@ -317,7 +311,7 @@ docker pull tomcat:8.0-jre8
|
||||
|
||||
下载完成后就可以运行了,运行后查看一下当前运行的容器:`docker ps` 。
|
||||
|
||||

|
||||

|
||||
|
||||
其中`CONTAINER_ID`为容器的 id,`IMAGE`为镜像名,`COMMAND`为容器内执行的命令,`CREATED`为容器的创建时间,`STATUS`为容器的状态,`PORTS`为容器内服务监听的端口,`NAMES`为容器的名称。
|
||||
|
||||
@ -331,7 +325,7 @@ docker run -p 8080:8080 tomcat:8.0-jre8
|
||||
|
||||
此时外部就可以访问 Tomcat 了:
|
||||
|
||||
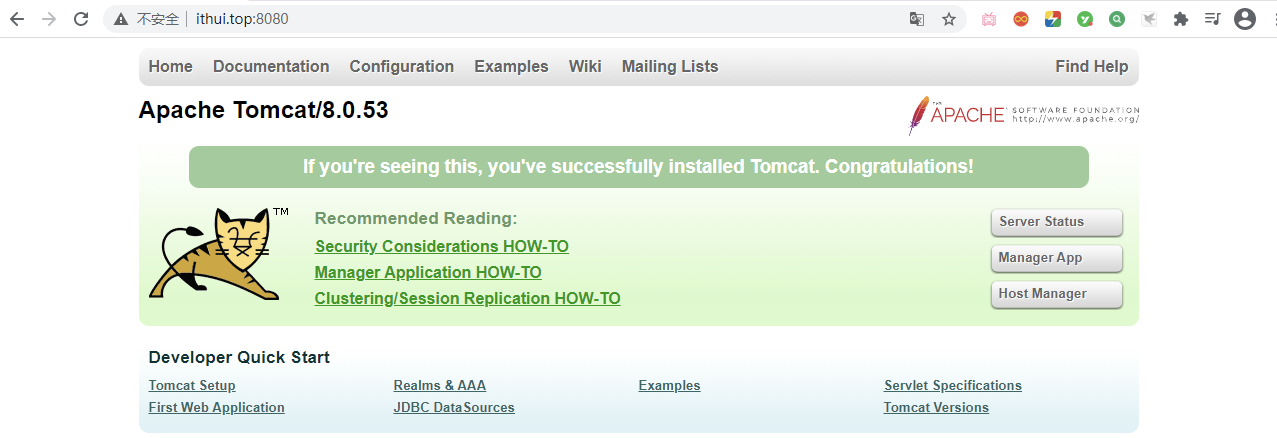
|
||||
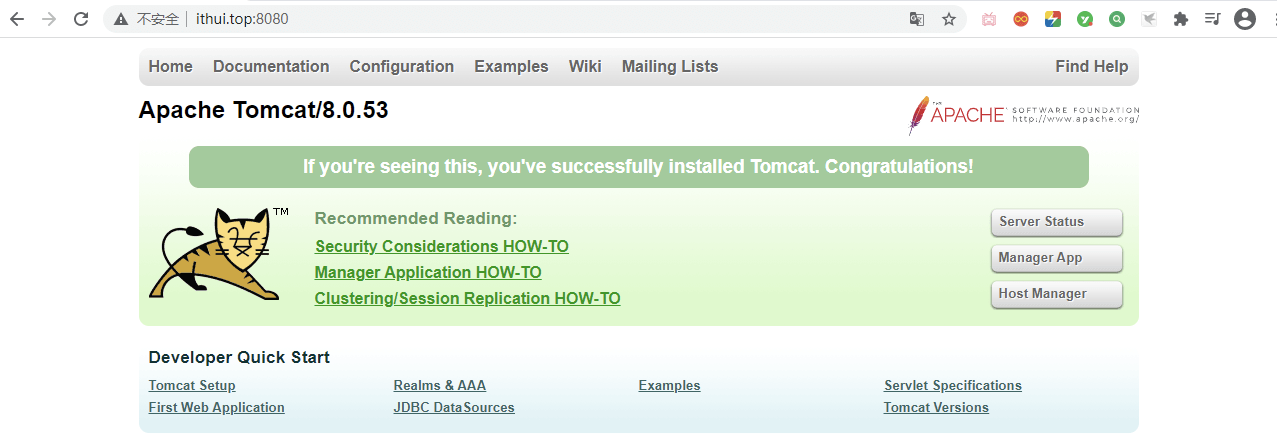
|
||||
|
||||
若是这样进行映射:
|
||||
|
||||
@ -361,9 +355,7 @@ docker run -d -p 8080:8080 --name tomcat01 tomcat:8.0-jre8
|
||||
docker ps -a
|
||||
```
|
||||
|
||||
该参数会将运行和非运行的容器全部列举出来:
|
||||
|
||||

|
||||
该参数会将运行和非运行的容器全部列举出来。
|
||||
|
||||
`-q`参数将只查询正在运行的容器 id:`docker ps -q` 。
|
||||
|
||||
@ -471,16 +463,12 @@ docker logs -ft 289cc00dc5ed
|
||||
docker top 289cc00dc5ed
|
||||
```
|
||||
|
||||

|
||||
|
||||
若是想与容器进行交互,则使用指令:
|
||||
|
||||
```shell
|
||||
docker exec -it 289cc00dc5ed bash
|
||||
```
|
||||
|
||||

|
||||
|
||||
此时终端将会进入容器内部,执行的指令都将在容器中生效,在容器内只能执行一些比较简单的指令,如:ls、cd 等,若是想退出容器终端,重新回到 CentOS 中,则执行`exit`即可。
|
||||
|
||||
现在我们已经能够进入容器终端执行相关操作了,那么该如何向 tomcat 容器中部署一个项目呢?
|
||||
@ -515,7 +503,7 @@ docker cp 289cc00dc5ed:/usr/local/tomcat/webapps/test.html ./
|
||||
docker inspect 923c969b0d91
|
||||
```
|
||||
|
||||
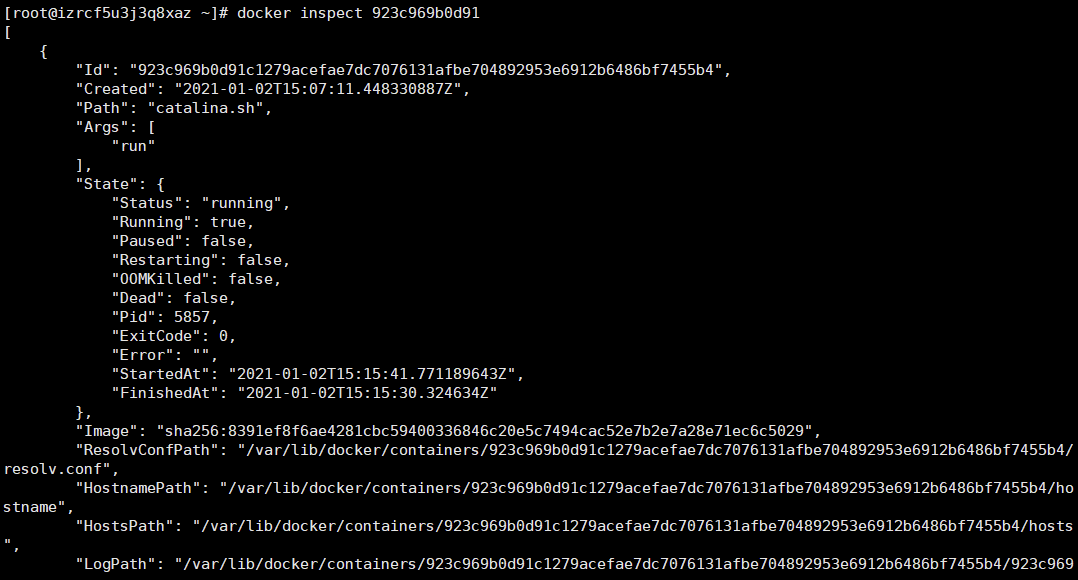
|
||||
|
||||
|
||||
## Docker 数据卷
|
||||
|
||||
@ -529,7 +517,7 @@ docker run -d -p 8080:8080 --name tomcat01 -v /opt/apps:/usr/local/tomcat/webapp
|
||||
|
||||
然而此时访问 tomcat 会发现无法访问:
|
||||
|
||||
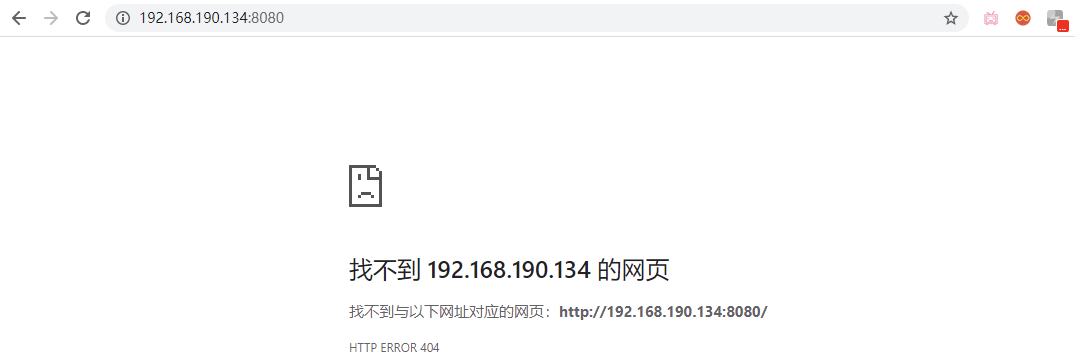
|
||||
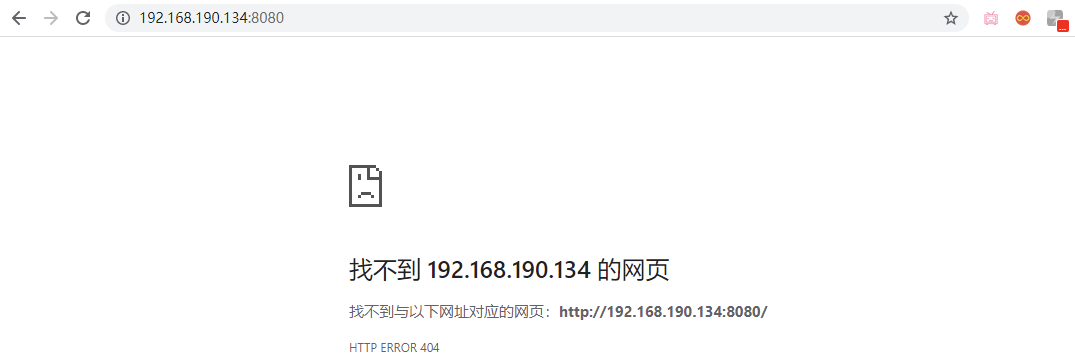
|
||||
|
||||
这就说明我们的数据卷设置成功了,Docker 会将容器内的`webapps`目录与`/opt/apps`目录进行同步,而此时`/opt/apps`目录是空的,导致`webapps`目录也会变成空目录,所以就访问不到了。
|
||||
|
||||
@ -572,7 +560,7 @@ public class HelloServlet extends HttpServlet {
|
||||
|
||||
这是一个非常简单的 Servlet,我们将其打包上传到`/opt/apps`中,那么容器内肯定就会同步到该文件,此时进行访问:
|
||||
|
||||

|
||||

|
||||
|
||||
这种方式设置的数据卷称为自定义数据卷,因为数据卷的目录是由我们自己设置的,Docker 还为我们提供了另外一种设置数据卷的方式:
|
||||
|
||||
|
||||
@ -243,7 +243,7 @@ docker rmi f6509bac4980 # 或者 docker rmi mysql
|
||||
|
||||
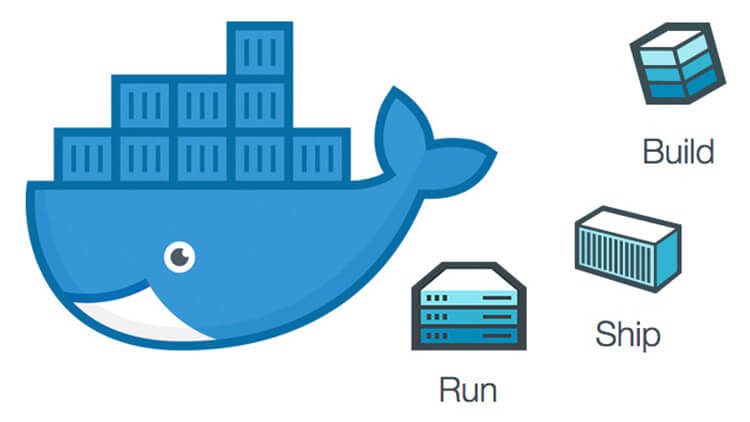
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||
|
||||

|
||||
|
||||
|
||||
- **Build(构建镜像)**:镜像就像是集装箱包括文件以及运行环境等等资源。
|
||||
- **Ship(运输镜像)**:主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||
|
||||
@ -11,7 +11,7 @@ category: 知识星球
|
||||
|
||||
不过,正常面试全是场景题的情况还是极少的,面试官一般会在面试中穿插一两个系统设计和场景题来考察你。
|
||||
|
||||

|
||||

|
||||
|
||||
于是,我总结了这份《后端面试高频系统设计&场景题》,包含了常见的系统设计案例比如短链系统、秒杀系统以及高频的场景题比如海量数据去重、第三方授权登录。
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user