mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
fix typo
This commit is contained in:
parent
b25adb7018
commit
6b71ff4a03
@ -35,15 +35,13 @@ tag:
|
||||
|
||||
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
|
||||
|
||||
**为何能够通过 key 快速取出 value呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 value 对应的 index,找到了 index 也就找到了对应的 value。
|
||||
**为何能够通过 key 快速取出 value呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
|
||||
|
||||
```java
|
||||
hash = hashfunc(key)
|
||||
index = hash % array_size
|
||||
```
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
|
||||
@ -61,7 +59,7 @@ index = hash % array_size
|
||||
试想一种情况:
|
||||
|
||||
```java
|
||||
SELECT * FROM tb1 WHERE id < 500;Copy to clipboardErrorCopied
|
||||
SELECT * FROM tb1 WHERE id < 500;
|
||||
```
|
||||
|
||||
在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
|
||||
@ -111,6 +109,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6 之前只有 MYISAM 引擎支持全文索引,5.6 之后 InnoDB 也支持了全文索引。
|
||||
|
||||
二级索引:
|
||||
|
||||
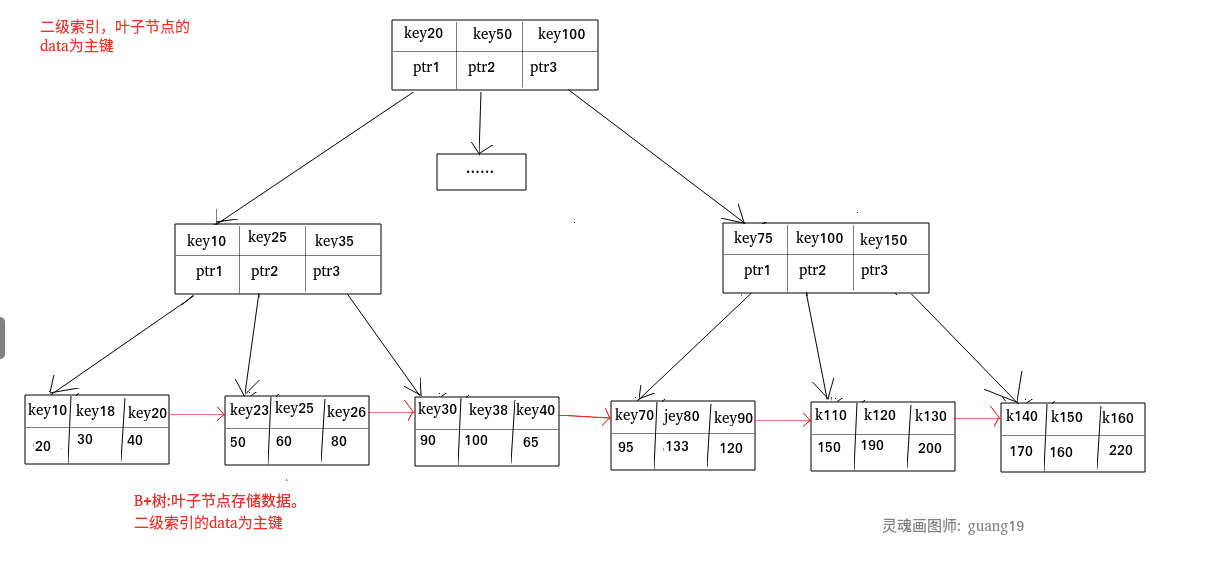
|
||||
|
||||
## 聚集索引与非聚集索引
|
||||
@ -128,9 +127,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
#### 聚集索引的缺点
|
||||
|
||||
1. **依赖于有序的数据** :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
|
||||
而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
|
||||
所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
|
||||
### 非聚集索引
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user