mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]markdown格式规范
This commit is contained in:
parent
eb51143b87
commit
6469d6c097
1
.gitignore
vendored
1
.gitignore
vendored
@ -15,3 +15,4 @@ packages/*/lib/
|
|||||||
traversal-folder-replace-string.py
|
traversal-folder-replace-string.py
|
||||||
format-markdown.py
|
format-markdown.py
|
||||||
package-lock.json
|
package-lock.json
|
||||||
|
lintmd-config.json
|
||||||
|
|||||||
@ -90,7 +90,7 @@ MySQL 字段类型比较多,我这里会挑选一些日常开发使用很频
|
|||||||
|
|
||||||
MySQL 中的整数类型可以使用可选的 UNSIGNED 属性来表示不允许负值的无符号整数。使用 UNSIGNED 属性可以将正整数的上限提高一倍,因为它不需要存储负数值。
|
MySQL 中的整数类型可以使用可选的 UNSIGNED 属性来表示不允许负值的无符号整数。使用 UNSIGNED 属性可以将正整数的上限提高一倍,因为它不需要存储负数值。
|
||||||
|
|
||||||
例如, TINYINT UNSIGNED 类型的取值范围是 0 ~ 255,而普通的 TINYINT 类型的值范围是 -128 ~ 127。INT UNSIGNED 类型的取值范围是 0 ~ 4,294,967,295,而普通的 TINYINT 类型的值范围是 2,147,483,648 ~ 2,147,483,647。
|
例如, TINYINT UNSIGNED 类型的取值范围是 0 ~ 255,而普通的 TINYINT 类型的值范围是 -128 ~ 127。INT UNSIGNED 类型的取值范围是 0 ~ 4,294,967,295,而普通的 INT 类型的值范围是 2,147,483,648 ~ 2,147,483,647。
|
||||||
|
|
||||||
对于从 0 开始递增的 ID 列,使用 UNSIGNED 属性可以非常适合,因为不允许负值并且可以拥有更大的上限范围,提供了更多的 ID 值可用。
|
对于从 0 开始递增的 ID 列,使用 UNSIGNED 属性可以非常适合,因为不允许负值并且可以拥有更大的上限范围,提供了更多的 ID 值可用。
|
||||||
|
|
||||||
|
|||||||
@ -27,7 +27,7 @@ head:
|
|||||||
7. 高效性(通过 Just In Time 编译器等技术的优化,Java 语言的运行效率还是非常不错的);
|
7. 高效性(通过 Just In Time 编译器等技术的优化,Java 语言的运行效率还是非常不错的);
|
||||||
8. 支持网络编程并且很方便;
|
8. 支持网络编程并且很方便;
|
||||||
9. 编译与解释并存;
|
9. 编译与解释并存;
|
||||||
10. ......
|
10. ……
|
||||||
|
|
||||||
> **🐛 修正(参见:[issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))**:C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
|
> **🐛 修正(参见:[issue#544](https://github.com/Snailclimb/JavaGuide/issues/544))**:C++11 开始(2011 年的时候),C++就引入了多线程库,在 windows、linux、macos 都可以使用`std::thread`和`std::async`来创建线程。参考链接:http://www.cplusplus.com/reference/thread/thread/?kw=thread
|
||||||
|
|
||||||
@ -70,7 +70,7 @@ JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编
|
|||||||
|
|
||||||
### 什么是字节码?采用字节码的好处是什么?
|
### 什么是字节码?采用字节码的好处是什么?
|
||||||
|
|
||||||
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和C、 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
在 Java 中,JVM 可以理解的代码就叫做字节码(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以, Java 程序运行时相对来说还是高效的(不过,和 C、 C++,Rust,Go 等语言还是有一定差距的),而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
||||||
|
|
||||||
**Java 程序从源代码到运行的过程如下图所示**:
|
**Java 程序从源代码到运行的过程如下图所示**:
|
||||||
|
|
||||||
@ -185,7 +185,7 @@ JDK 9 引入了一种新的编译模式 **AOT(Ahead of Time Compilation)** 。
|
|||||||
- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
|
- Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
|
||||||
- Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
|
- Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
|
||||||
- C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
|
- C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 基本语法
|
## 基本语法
|
||||||
|
|
||||||
@ -320,7 +320,7 @@ System.out.println("左移 10 位后的数据对应的二进制字符 " + Intege
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
初始数据:-1
|
初始数据:-1
|
||||||
初始数据对应的二进制字符串:11111111111111111111111111111111
|
初始数据对应的二进制字符串:11111111111111111111111111111111
|
||||||
左移 10 位后的数据 -1024
|
左移 10 位后的数据 -1024
|
||||||
@ -384,7 +384,7 @@ System.out.println("左移 10 位后的数据对应的二进制字符 " + Intege
|
|||||||
|
|
||||||
运行结果:
|
运行结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
0
|
0
|
||||||
xixi
|
xixi
|
||||||
1
|
1
|
||||||
@ -681,16 +681,13 @@ System.out.println(l + 1 == Long.MIN_VALUE); // true
|
|||||||
- **生存时间**:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
|
- **生存时间**:从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
|
||||||
- **默认值**:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被 `final` 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
|
- **默认值**:从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被 `final` 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
|
||||||
|
|
||||||
> 问:为什么成员变量有默认值?
|
**为什么成员变量有默认值?**
|
||||||
>
|
|
||||||
> 答:
|
1. 先不考虑变量类型,如果没有默认值会怎样?变量存储的是内存地址对应的任意随机值,程序读取该值运行会出现意外。
|
||||||
>
|
|
||||||
> 1. 先不考虑变量类型,如果没有默认值会怎样?变量存储的是内存地址对应的任意随机值,程序读取该值运行会出现意外。
|
2. 默认值有两种设置方式:手动和自动,根据第一点,没有手动赋值一定要自动赋值。成员变量在运行时可借助反射等方法手动赋值,而局部变量不行。
|
||||||
>
|
|
||||||
> 2. 默认值有两种设置方式:手动和自动,根据第一点,没有手动赋值一定要自动赋值。成员变量在运行时可借助反射等方法手动赋值,而局部变量不行。
|
3. 对于编译器(javac)来说,局部变量没赋值很好判断,可以直接报错。而成员变量可能是运行时赋值,无法判断,误报“没默认值”又会影响用户体验,所以采用自动赋默认值。
|
||||||
>
|
|
||||||
> 3. 对于编译器(javac)来说,局部变量没赋值很好判断,可以直接报错。而成员变量可能是运行时赋值,无法判断,误报“没默认值”又会影响用户体验,所以采用自动赋默认值。
|
|
||||||
>
|
|
||||||
|
|
||||||
成员变量与局部变量代码示例:
|
成员变量与局部变量代码示例:
|
||||||
|
|
||||||
@ -776,7 +773,7 @@ public class StringExample {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
字符型常量占用的字节数为:2
|
字符型常量占用的字节数为:2
|
||||||
字符串常量占用的字节数为:13
|
字符串常量占用的字节数为:13
|
||||||
```
|
```
|
||||||
@ -1022,7 +1019,7 @@ public class VariableLengthArgument {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
ab
|
ab
|
||||||
a
|
a
|
||||||
b
|
b
|
||||||
|
|||||||
@ -115,7 +115,7 @@ System.out.println(str1.equals(str3));
|
|||||||
|
|
||||||
输出结果:
|
输出结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
false
|
false
|
||||||
true
|
true
|
||||||
true
|
true
|
||||||
@ -432,8 +432,8 @@ public boolean equals(Object anObject) {
|
|||||||
|
|
||||||
> ⚠️ 注意:该方法在 **Oracle OpenJDK8** 中默认是 "使用线程局部状态来实现 Marsaglia's xor-shift 随机数生成", 并不是 "地址" 或者 "地址转换而来", 不同 JDK/VM 可能不同在 **Oracle OpenJDK8** 中有六种生成方式 (其中第五种是返回地址), 通过添加 VM 参数: -XX:hashCode=4 启用第五种。参考源码:
|
> ⚠️ 注意:该方法在 **Oracle OpenJDK8** 中默认是 "使用线程局部状态来实现 Marsaglia's xor-shift 随机数生成", 并不是 "地址" 或者 "地址转换而来", 不同 JDK/VM 可能不同在 **Oracle OpenJDK8** 中有六种生成方式 (其中第五种是返回地址), 通过添加 VM 参数: -XX:hashCode=4 启用第五种。参考源码:
|
||||||
>
|
>
|
||||||
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp(1127行)
|
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp(1127 行)
|
||||||
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp(537行开始)
|
> - https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp(537 行开始)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public native int hashCode();
|
public native int hashCode();
|
||||||
|
|||||||
@ -49,7 +49,7 @@ head:
|
|||||||
- `ArithmeticException`(算术错误)
|
- `ArithmeticException`(算术错误)
|
||||||
- `SecurityException` (安全错误比如权限不够)
|
- `SecurityException` (安全错误比如权限不够)
|
||||||
- `UnsupportedOperationException`(不支持的操作错误比如重复创建同一用户)
|
- `UnsupportedOperationException`(不支持的操作错误比如重复创建同一用户)
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -81,7 +81,7 @@ try {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Try to do something
|
Try to do something
|
||||||
Catch Exception -> RuntimeException
|
Catch Exception -> RuntimeException
|
||||||
Finally
|
Finally
|
||||||
@ -117,7 +117,7 @@ public static int f(int value) {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
0
|
0
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -142,7 +142,7 @@ try {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Try to do something
|
Try to do something
|
||||||
Catch Exception -> RuntimeException
|
Catch Exception -> RuntimeException
|
||||||
```
|
```
|
||||||
@ -219,7 +219,7 @@ catch (IOException e) {
|
|||||||
- 抛出的异常信息一定要有意义。
|
- 抛出的异常信息一定要有意义。
|
||||||
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出`NumberFormatException`而不是其父类`IllegalArgumentException`。
|
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出`NumberFormatException`而不是其父类`IllegalArgumentException`。
|
||||||
- 使用日志打印异常之后就不要再抛出异常了(两者不要同时存在一段代码逻辑中)。
|
- 使用日志打印异常之后就不要再抛出异常了(两者不要同时存在一段代码逻辑中)。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 泛型
|
## 泛型
|
||||||
|
|
||||||
@ -323,7 +323,7 @@ printArray( stringArray );
|
|||||||
- 自定义接口通用返回结果 `CommonResult<T>` 通过参数 `T` 可根据具体的返回类型动态指定结果的数据类型
|
- 自定义接口通用返回结果 `CommonResult<T>` 通过参数 `T` 可根据具体的返回类型动态指定结果的数据类型
|
||||||
- 定义 `Excel` 处理类 `ExcelUtil<T>` 用于动态指定 `Excel` 导出的数据类型
|
- 定义 `Excel` 处理类 `ExcelUtil<T>` 用于动态指定 `Excel` 导出的数据类型
|
||||||
- 构建集合工具类(参考 `Collections` 中的 `sort`, `binarySearch` 方法)。
|
- 构建集合工具类(参考 `Collections` 中的 `sort`, `binarySearch` 方法)。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 反射
|
## 反射
|
||||||
|
|
||||||
|
|||||||
@ -150,7 +150,7 @@ public class StaticDemo {
|
|||||||
|
|
||||||
静态代码块的格式是
|
静态代码块的格式是
|
||||||
|
|
||||||
```
|
```plain
|
||||||
static {
|
static {
|
||||||
语句体;
|
语句体;
|
||||||
}
|
}
|
||||||
@ -282,19 +282,19 @@ public class Test {
|
|||||||
|
|
||||||
上述代码输出:
|
上述代码输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
静态代码块!--非静态代码块!--默认构造方法!--静态方法中的内容! --静态方法中的代码块!--
|
静态代码块!--非静态代码块!--默认构造方法!--静态方法中的内容! --静态方法中的代码块!--
|
||||||
```
|
```
|
||||||
|
|
||||||
当只执行 `Test.test();` 时输出:
|
当只执行 `Test.test();` 时输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
静态代码块!--静态方法中的内容! --静态方法中的代码块!--
|
静态代码块!--静态方法中的内容! --静态方法中的代码块!--
|
||||||
```
|
```
|
||||||
|
|
||||||
当只执行 `Test test = new Test();` 时输出:
|
当只执行 `Test test = new Test();` 时输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
静态代码块!--非静态代码块!--默认构造方法!--
|
静态代码块!--非静态代码块!--默认构造方法!--
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -248,7 +248,7 @@ smsService.send("java");
|
|||||||
|
|
||||||
运行上述代码之后,控制台打印出:
|
运行上述代码之后,控制台打印出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
before method send
|
before method send
|
||||||
send message:java
|
send message:java
|
||||||
after method send
|
after method send
|
||||||
|
|||||||
@ -170,7 +170,7 @@ public class Main {
|
|||||||
|
|
||||||
输出内容:
|
输出内容:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
publicMethod
|
publicMethod
|
||||||
privateMethod
|
privateMethod
|
||||||
I love JavaGuide
|
I love JavaGuide
|
||||||
|
|||||||
@ -58,7 +58,7 @@ SLF4J (Simple Logging Facade for Java)是 Java 的一个日志门面(接
|
|||||||
|
|
||||||
新建一个 Java 项目 `service-provider-interface` 目录结构如下:(注意直接新建 Java 项目就好了,不用新建 Maven 项目,Maven 项目会涉及到一些编译配置,如果有私服的话,直接 deploy 会比较方便,但是没有的话,在过程中可能会遇到一些奇怪的问题。)
|
新建一个 Java 项目 `service-provider-interface` 目录结构如下:(注意直接新建 Java 项目就好了,不用新建 Maven 项目,Maven 项目会涉及到一些编译配置,如果有私服的话,直接 deploy 会比较方便,但是没有的话,在过程中可能会遇到一些奇怪的问题。)
|
||||||
|
|
||||||
```
|
```plain
|
||||||
│ service-provider-interface.iml
|
│ service-provider-interface.iml
|
||||||
│
|
│
|
||||||
├─.idea
|
├─.idea
|
||||||
@ -171,7 +171,7 @@ public class Main {
|
|||||||
|
|
||||||
新建项目 `service-provider` 目录结构如下:
|
新建项目 `service-provider` 目录结构如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
│ service-provider.iml
|
│ service-provider.iml
|
||||||
│
|
│
|
||||||
├─.idea
|
├─.idea
|
||||||
@ -290,7 +290,7 @@ public class TestJavaSPI {
|
|||||||
|
|
||||||
`ServiceLoader` 是 JDK 提供的一个工具类, 位于`package java.util;`包下。
|
`ServiceLoader` 是 JDK 提供的一个工具类, 位于`package java.util;`包下。
|
||||||
|
|
||||||
```
|
```plain
|
||||||
A facility to load implementations of a service.
|
A facility to load implementations of a service.
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -777,7 +777,7 @@ public static void main(String[] args) {
|
|||||||
|
|
||||||
输出结果:
|
输出结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
a == b is false
|
a == b is false
|
||||||
c == d is true
|
c == d is true
|
||||||
```
|
```
|
||||||
|
|||||||
@ -152,7 +152,7 @@ private void memoryTest() {
|
|||||||
|
|
||||||
先看结果输出:
|
先看结果输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
addr: 2433733895744
|
addr: 2433733895744
|
||||||
addr3: 2433733894944
|
addr3: 2433733894944
|
||||||
16843009
|
16843009
|
||||||
@ -275,7 +275,7 @@ public static void main(String[] args){
|
|||||||
|
|
||||||
运行结果:
|
运行结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
subThread change flag to:false
|
subThread change flag to:false
|
||||||
detected flag changed
|
detected flag changed
|
||||||
main thread end
|
main thread end
|
||||||
@ -341,7 +341,7 @@ public class Main {
|
|||||||
|
|
||||||
输出结果:
|
输出结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
value before putInt: 0
|
value before putInt: 0
|
||||||
value after putInt: 42
|
value after putInt: 42
|
||||||
value after putInt: 42
|
value after putInt: 42
|
||||||
@ -417,7 +417,7 @@ public void objTest() throws Exception{
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
打印结果分别为 1、1、0,说明通过`allocateInstance`方法创建对象过程中,不会调用类的构造方法。使用这种方式创建对象时,只用到了`Class`对象,所以说如果想要跳过对象的初始化阶段或者跳过构造器的安全检查,就可以使用这种方法。在上面的例子中,如果将 A 类的构造函数改为`private`类型,将无法通过构造函数和反射创建对象(可以通过构造函数对象setAccessible后创建对象),但`allocateInstance`方法仍然有效。
|
打印结果分别为 1、1、0,说明通过`allocateInstance`方法创建对象过程中,不会调用类的构造方法。使用这种方式创建对象时,只用到了`Class`对象,所以说如果想要跳过对象的初始化阶段或者跳过构造器的安全检查,就可以使用这种方法。在上面的例子中,如果将 A 类的构造函数改为`private`类型,将无法通过构造函数和反射创建对象(可以通过构造函数对象 setAccessible 后创建对象),但`allocateInstance`方法仍然有效。
|
||||||
|
|
||||||
#### 典型应用
|
#### 典型应用
|
||||||
|
|
||||||
@ -510,7 +510,7 @@ private void increment(int x){
|
|||||||
|
|
||||||
运行代码会依次输出:
|
运行代码会依次输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
1 2 3 4 5 6 7 8 9
|
1 2 3 4 5 6 7 8 9
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -600,7 +600,7 @@ public static void main(String[] args) {
|
|||||||
|
|
||||||
程序输出为:
|
程序输出为:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
park main mainThread
|
park main mainThread
|
||||||
subThread try to unpark mainThread
|
subThread try to unpark mainThread
|
||||||
unpark mainThread success
|
unpark mainThread success
|
||||||
@ -653,7 +653,7 @@ private void staticTest() throws Exception {
|
|||||||
|
|
||||||
运行结果:
|
运行结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
false
|
false
|
||||||
Hydra
|
Hydra
|
||||||
```
|
```
|
||||||
@ -662,7 +662,7 @@ Hydra
|
|||||||
|
|
||||||
在上面的代码中首先创建一个`User`对象,这是因为如果一个类没有被初始化,那么它的静态属性也不会被初始化,最后获取的字段属性将是`null`。所以在获取静态属性前,需要调用`shouldBeInitialized`方法,判断在获取前是否需要初始化这个类。如果删除创建 User 对象的语句,运行结果会变为:
|
在上面的代码中首先创建一个`User`对象,这是因为如果一个类没有被初始化,那么它的静态属性也不会被初始化,最后获取的字段属性将是`null`。所以在获取静态属性前,需要调用`shouldBeInitialized`方法,判断在获取前是否需要初始化这个类。如果删除创建 User 对象的语句,运行结果会变为:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
true
|
true
|
||||||
null
|
null
|
||||||
```
|
```
|
||||||
|
|||||||
@ -64,7 +64,7 @@ public static void swap(int a, int b) {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
a = 20
|
a = 20
|
||||||
b = 10
|
b = 10
|
||||||
num1 = 10
|
num1 = 10
|
||||||
@ -99,7 +99,7 @@ num2 = 20
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
1
|
1
|
||||||
0
|
0
|
||||||
```
|
```
|
||||||
@ -143,7 +143,7 @@ public static void swap(Person person1, Person person2) {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
person1:小李
|
person1:小李
|
||||||
person2:小张
|
person2:小张
|
||||||
xiaoZhang:小张
|
xiaoZhang:小张
|
||||||
@ -184,7 +184,7 @@ int main()
|
|||||||
|
|
||||||
输出结果:
|
输出结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
invoke before: 10
|
invoke before: 10
|
||||||
incr before: 10
|
incr before: 10
|
||||||
incr after: 11
|
incr after: 11
|
||||||
|
|||||||
@ -48,7 +48,7 @@ System.out.println(listOfStrings);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
[null, java]
|
[null, java]
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -64,7 +64,7 @@ System.out.println(listOfStrings);
|
|||||||
|
|
||||||
## ArrayList 核心源码解读
|
## ArrayList 核心源码解读
|
||||||
|
|
||||||
这里以 JDK1.8为例,分析一下 `ArrayList` 的底层源码。
|
这里以 JDK1.8 为例,分析一下 `ArrayList` 的底层源码。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public class ArrayList<E> extends AbstractList<E>
|
public class ArrayList<E> extends AbstractList<E>
|
||||||
@ -823,7 +823,7 @@ public class ArraycopyTest {
|
|||||||
|
|
||||||
结果:
|
结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
0 1 99 2 3 0 0 0 0 0
|
0 1 99 2 3 0 0 0 0 0
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -872,7 +872,7 @@ public class ArrayscopyOfTest {
|
|||||||
|
|
||||||
结果:
|
结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
10
|
10
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -933,7 +933,7 @@ public class EnsureCapacityTest {
|
|||||||
|
|
||||||
运行结果:
|
运行结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
使用ensureCapacity方法前:2158
|
使用ensureCapacity方法前:2158
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -955,7 +955,7 @@ public class EnsureCapacityTest {
|
|||||||
|
|
||||||
运行结果:
|
运行结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
使用ensureCapacity方法后:1773
|
使用ensureCapacity方法后:1773
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -7,7 +7,7 @@ tag:
|
|||||||
|
|
||||||
> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
|
> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
|
||||||
|
|
||||||
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap ` 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
|
上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap` 了,作为线程安全的 HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
|
||||||
|
|
||||||
## 1. ConcurrentHashMap 1.7
|
## 1. ConcurrentHashMap 1.7
|
||||||
|
|
||||||
|
|||||||
@ -36,7 +36,7 @@ JDK1.5 引入了 `Java.util.concurrent`(JUC)包,其中提供了很多线
|
|||||||
1. 内存占用:每次写操作都需要复制一份原始数据,会占用额外的内存空间,在数据量比较大的情况下,可能会导致内存资源不足。
|
1. 内存占用:每次写操作都需要复制一份原始数据,会占用额外的内存空间,在数据量比较大的情况下,可能会导致内存资源不足。
|
||||||
2. 写操作开销:每一次写操作都需要复制一份原始数据,然后再进行修改和替换,所以写操作的开销相对较大,在写入比较频繁的场景下,性能可能会受到影响。
|
2. 写操作开销:每一次写操作都需要复制一份原始数据,然后再进行修改和替换,所以写操作的开销相对较大,在写入比较频繁的场景下,性能可能会受到影响。
|
||||||
3. 数据一致性问题:修改操作不会立即反映到最终结果中,还需要等待复制完成,这可能会导致一定的数据一致性问题。
|
3. 数据一致性问题:修改操作不会立即反映到最终结果中,还需要等待复制完成,这可能会导致一定的数据一致性问题。
|
||||||
4. ......
|
4. ……
|
||||||
|
|
||||||
## CopyOnWriteArrayList 源码分析
|
## CopyOnWriteArrayList 源码分析
|
||||||
|
|
||||||
@ -305,7 +305,7 @@ System.out.println("列表清空后为:" + list);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
列表更新后为:[Java, Golang]
|
列表更新后为:[Java, Golang]
|
||||||
列表插入元素后为:[PHP, Java, Golang]
|
列表插入元素后为:[PHP, Java, Golang]
|
||||||
列表大小为:3
|
列表大小为:3
|
||||||
|
|||||||
@ -19,7 +19,7 @@ public interface Delayed extends Comparable<Delayed> {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
默认情况下, `DelayQueue` 会按照到期时间升序编排任务。只有当元素过期时(`getDelay()`方法返回值小于等于0),才能从队列中取出。
|
默认情况下, `DelayQueue` 会按照到期时间升序编排任务。只有当元素过期时(`getDelay()`方法返回值小于等于 0),才能从队列中取出。
|
||||||
|
|
||||||
## DelayQueue 发展史
|
## DelayQueue 发展史
|
||||||
|
|
||||||
@ -353,7 +353,7 @@ public E peek() {
|
|||||||
|
|
||||||
## 参考文献
|
## 参考文献
|
||||||
|
|
||||||
- 《深入理解高并发编程:JDK核心技术》:
|
- 《深入理解高并发编程:JDK 核心技术》:
|
||||||
- 一口气说出Java 6种延时队列的实现方法(面试官也得服):<https://www.jb51.net/article/186192.htm>
|
- 一口气说出 Java 6 种延时队列的实现方法(面试官也得服):<https://www.jb51.net/article/186192.htm>
|
||||||
- 图解DelayQueue源码(java 8)——延时队列的小九九: <https://blog.csdn.net/every__day/article/details/113810985>
|
- 图解 DelayQueue 源码(java 8)——延时队列的小九九: <https://blog.csdn.net/every__day/article/details/113810985>
|
||||||
<!-- @include: @article-footer.snippet.md -->
|
<!-- @include: @article-footer.snippet.md -->
|
||||||
|
|||||||
@ -217,7 +217,7 @@ HashMap 中有四个构造方法,它们分别如下:
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
> 值得注意的是上述四个构造方法中,都初始化了负载因子 loadFactor,由于HashMap中没有 capacity 这样的字段,即使指定了初始化容量 initialCapacity ,也只是通过 tableSizeFor 将其扩容到与 initialCapacity 最接近的2的幂次方大小,然后暂时赋值给 threshold ,后续通过 resize 方法将 threshold 赋值给 newCap 进行 table 的初始化。
|
> 值得注意的是上述四个构造方法中,都初始化了负载因子 loadFactor,由于 HashMap 中没有 capacity 这样的字段,即使指定了初始化容量 initialCapacity ,也只是通过 tableSizeFor 将其扩容到与 initialCapacity 最接近的 2 的幂次方大小,然后暂时赋值给 threshold ,后续通过 resize 方法将 threshold 赋值给 newCap 进行 table 的初始化。
|
||||||
|
|
||||||
**putMapEntries 方法:**
|
**putMapEntries 方法:**
|
||||||
|
|
||||||
@ -409,7 +409,7 @@ final Node<K,V> getNode(int hash, Object key) {
|
|||||||
|
|
||||||
### resize 方法
|
### resize 方法
|
||||||
|
|
||||||
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。resize方法实际上是将 table 初始化和 table 扩容 进行了整合,底层的行为都是给 table 赋值一个新的数组。
|
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。resize 方法实际上是将 table 初始化和 table 扩容 进行了整合,底层的行为都是给 table 赋值一个新的数组。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
final Node<K,V>[] resize() {
|
final Node<K,V>[] resize() {
|
||||||
|
|||||||
@ -141,7 +141,7 @@ System.out.println(list); /* [1, 3, 5, 7, 9] */
|
|||||||
|
|
||||||
- 使用普通的 for 循环
|
- 使用普通的 for 循环
|
||||||
- 使用 fail-safe 的集合类。`java.util`包下面的所有的集合类都是 fail-fast 的,而`java.util.concurrent`包下面的所有的类都是 fail-safe 的。
|
- 使用 fail-safe 的集合类。`java.util`包下面的所有的集合类都是 fail-fast 的,而`java.util.concurrent`包下面的所有的类都是 fail-safe 的。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 集合去重
|
## 集合去重
|
||||||
|
|
||||||
|
|||||||
@ -147,7 +147,7 @@ System.out.println(listOfStrings);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
[null, java]
|
[null, java]
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -191,7 +191,7 @@ System.out.println(listOfStrings);
|
|||||||
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
|
- 尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
|
||||||
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
|
- 指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,因此需要移动平均 n/2 个元素,时间复杂度为 O(n)。
|
||||||
|
|
||||||
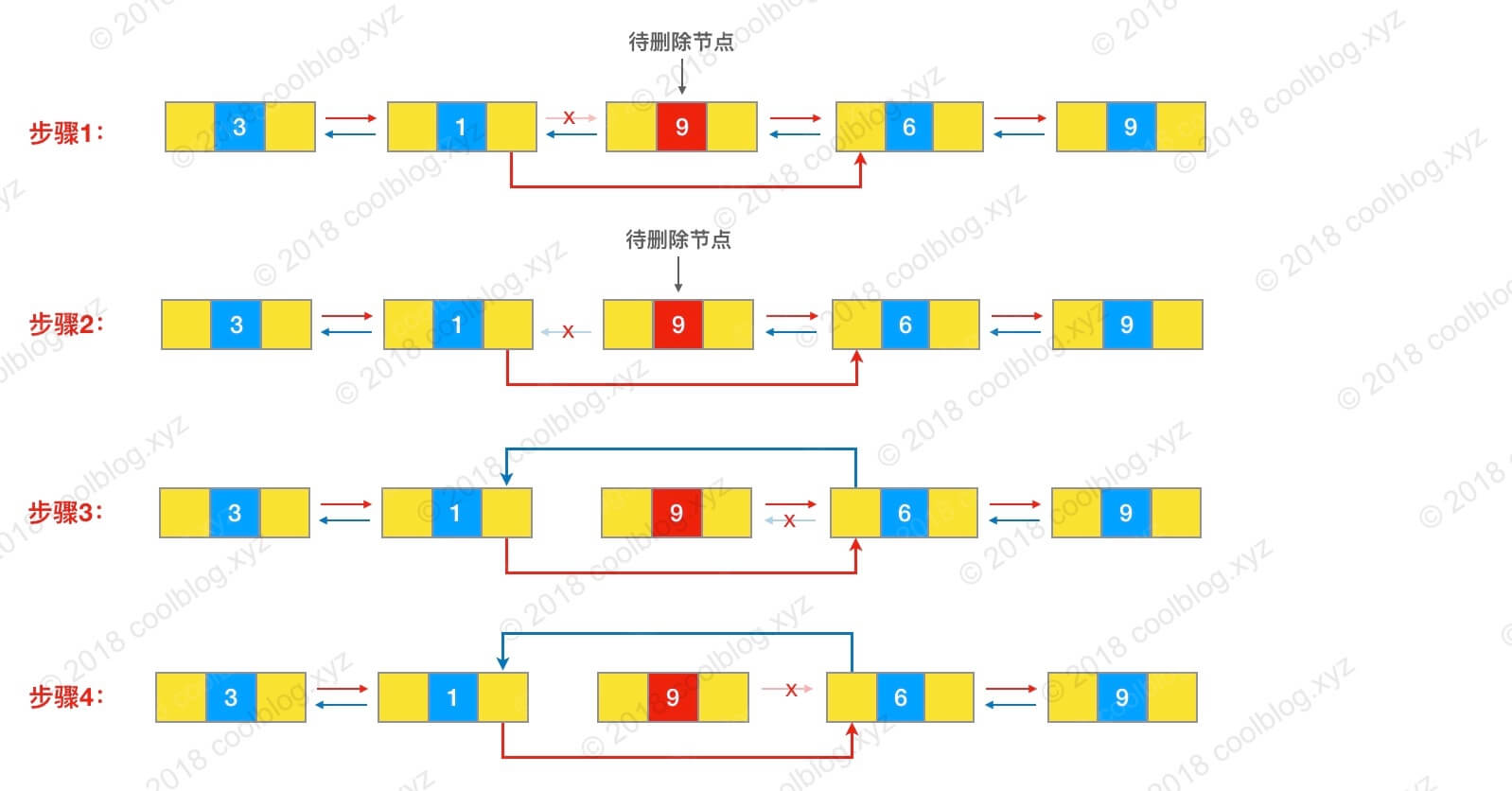
这里简单列举一个例子:假如我们要删除节点9 的话,需要先遍历链表找到该节点。然后,再执行相应节点指针指向的更改,具体的源码可以参考:[LinkedList 源码分析](./linkedlist-source-code.md) 。
|
这里简单列举一个例子:假如我们要删除节点 9 的话,需要先遍历链表找到该节点。然后,再执行相应节点指针指向的更改,具体的源码可以参考:[LinkedList 源码分析](./linkedlist-source-code.md) 。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -299,7 +299,7 @@ System.out.println(arrayList);
|
|||||||
|
|
||||||
Output:
|
Output:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
原始数组:
|
原始数组:
|
||||||
[-1, 3, 3, -5, 7, 4, -9, -7]
|
[-1, 3, 3, -5, 7, 4, -9, -7]
|
||||||
Collections.reverse(arrayList):
|
Collections.reverse(arrayList):
|
||||||
@ -377,7 +377,7 @@ public class Person implements Comparable<Person> {
|
|||||||
|
|
||||||
Output:
|
Output:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
5-小红
|
5-小红
|
||||||
10-王五
|
10-王五
|
||||||
20-李四
|
20-李四
|
||||||
@ -476,7 +476,7 @@ Java 中常用的阻塞队列实现类有以下几种:
|
|||||||
3. `PriorityBlockingQueue`:支持优先级排序的无界阻塞队列。元素必须实现`Comparable`接口或者在构造函数中传入`Comparator`对象,并且不能插入 null 元素。
|
3. `PriorityBlockingQueue`:支持优先级排序的无界阻塞队列。元素必须实现`Comparable`接口或者在构造函数中传入`Comparator`对象,并且不能插入 null 元素。
|
||||||
4. `SynchronousQueue`:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,`SynchronousQueue`通常用于线程之间的直接传递数据。
|
4. `SynchronousQueue`:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,`SynchronousQueue`通常用于线程之间的直接传递数据。
|
||||||
5. `DelayQueue`:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
|
5. `DelayQueue`:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
|
||||||
6. ......
|
6. ……
|
||||||
|
|
||||||
日常开发中,这些队列使用的其实都不多,了解即可。
|
日常开发中,这些队列使用的其实都不多,了解即可。
|
||||||
|
|
||||||
|
|||||||
@ -120,7 +120,7 @@ public class Person {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
person1
|
person1
|
||||||
person4
|
person4
|
||||||
person2
|
person2
|
||||||
@ -356,7 +356,7 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
|
|||||||
|
|
||||||
当遍历不存在阻塞时, parallelStream 的性能是最低的:
|
当遍历不存在阻塞时, parallelStream 的性能是最低的:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Benchmark Mode Cnt Score Error Units
|
Benchmark Mode Cnt Score Error Units
|
||||||
Test.entrySet avgt 5 288.651 ± 10.536 ns/op
|
Test.entrySet avgt 5 288.651 ± 10.536 ns/op
|
||||||
Test.keySet avgt 5 584.594 ± 21.431 ns/op
|
Test.keySet avgt 5 584.594 ± 21.431 ns/op
|
||||||
@ -366,7 +366,7 @@ Test.parallelStream avgt 5 6919.163 ± 1116.139 ns/op
|
|||||||
|
|
||||||
加入阻塞代码`Thread.sleep(10)`后, parallelStream 的性能才是最高的:
|
加入阻塞代码`Thread.sleep(10)`后, parallelStream 的性能才是最高的:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Benchmark Mode Cnt Score Error Units
|
Benchmark Mode Cnt Score Error Units
|
||||||
Test.entrySet avgt 5 1554828440.000 ± 23657748.653 ns/op
|
Test.entrySet avgt 5 1554828440.000 ± 23657748.653 ns/op
|
||||||
Test.keySet avgt 5 1550612500.000 ± 6474562.858 ns/op
|
Test.keySet avgt 5 1550612500.000 ± 6474562.858 ns/op
|
||||||
|
|||||||
@ -141,7 +141,7 @@ four
|
|||||||
|
|
||||||
在正式讨论 `LinkedHashMap` 前,我们先来聊聊 `LinkedHashMap` 节点 `Entry` 的设计,我们都知道 `HashMap` 的 bucket 上的因为冲突转为链表的节点会在符合以下两个条件时会将链表转为红黑树:
|
在正式讨论 `LinkedHashMap` 前,我们先来聊聊 `LinkedHashMap` 节点 `Entry` 的设计,我们都知道 `HashMap` 的 bucket 上的因为冲突转为链表的节点会在符合以下两个条件时会将链表转为红黑树:
|
||||||
|
|
||||||
1. ~~链表上的节点个数达到树化的阈值7,即`TREEIFY_THRESHOLD - 1`。~~
|
1. ~~链表上的节点个数达到树化的阈值 7,即`TREEIFY_THRESHOLD - 1`。~~
|
||||||
2. bucket 的容量达到最小的树化容量即`MIN_TREEIFY_CAPACITY`。
|
2. bucket 的容量达到最小的树化容量即`MIN_TREEIFY_CAPACITY`。
|
||||||
|
|
||||||
> **🐛 修正(参见:[issue#2147](https://github.com/Snailclimb/JavaGuide/issues/2147))**:
|
> **🐛 修正(参见:[issue#2147](https://github.com/Snailclimb/JavaGuide/issues/2147))**:
|
||||||
|
|||||||
@ -9,7 +9,7 @@ tag:
|
|||||||
|
|
||||||
## LinkedList 简介
|
## LinkedList 简介
|
||||||
|
|
||||||
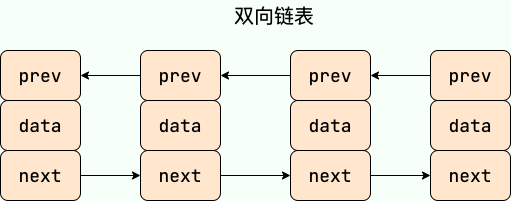
`LinkedList` 是一个基于双向链表实现的集合类,经常被拿来和 `ArrayList` 做比较。关于 `LinkedList` 和`ArrayList`的详细对比,我们 [Java集合常见面试题总结(上)](./java-collection-questions-01.md)有详细介绍到。
|
`LinkedList` 是一个基于双向链表实现的集合类,经常被拿来和 `ArrayList` 做比较。关于 `LinkedList` 和`ArrayList`的详细对比,我们 [Java 集合常见面试题总结(上)](./java-collection-questions-01.md)有详细介绍到。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -505,7 +505,7 @@ System.out.println("清空后的链表:" + list);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
索引为 2 的元素:banana
|
索引为 2 的元素:banana
|
||||||
链表内容:[apple, orange, banana, grape]
|
链表内容:[apple, orange, banana, grape]
|
||||||
链表内容:[orange, banana, grape]
|
链表内容:[orange, banana, grape]
|
||||||
|
|||||||
@ -688,7 +688,7 @@ public class CyclicBarrierExample1 {
|
|||||||
|
|
||||||
运行结果,如下:
|
运行结果,如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
threadnum:0is ready
|
threadnum:0is ready
|
||||||
threadnum:1is ready
|
threadnum:1is ready
|
||||||
threadnum:2is ready
|
threadnum:2is ready
|
||||||
@ -760,7 +760,7 @@ public class CyclicBarrierExample2 {
|
|||||||
|
|
||||||
运行结果,如下:
|
运行结果,如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
threadnum:0is ready
|
threadnum:0is ready
|
||||||
threadnum:1is ready
|
threadnum:1is ready
|
||||||
threadnum:2is ready
|
threadnum:2is ready
|
||||||
|
|||||||
@ -257,7 +257,7 @@ class Person {
|
|||||||
|
|
||||||
上述代码首先创建了一个 `Person` 对象,然后把 `Person` 对象设置进 `AtomicReference` 对象中,然后调用 `compareAndSet` 方法,该方法就是通过 CAS 操作设置 ar。如果 ar 的值为 `person` 的话,则将其设置为 `updatePerson`。实现原理与 `AtomicInteger` 类中的 `compareAndSet` 方法相同。运行上面的代码后的输出结果如下:
|
上述代码首先创建了一个 `Person` 对象,然后把 `Person` 对象设置进 `AtomicReference` 对象中,然后调用 `compareAndSet` 方法,该方法就是通过 CAS 操作设置 ar。如果 ar 的值为 `person` 的话,则将其设置为 `updatePerson`。实现原理与 `AtomicInteger` 类中的 `compareAndSet` 方法相同。运行上面的代码后的输出结果如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Daisy
|
Daisy
|
||||||
20
|
20
|
||||||
```
|
```
|
||||||
@ -312,7 +312,7 @@ public class AtomicStampedReferenceDemo {
|
|||||||
|
|
||||||
输出结果如下:
|
输出结果如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
currentValue=0, currentStamp=0
|
currentValue=0, currentStamp=0
|
||||||
currentValue=666, currentStamp=999, casResult=true
|
currentValue=666, currentStamp=999, casResult=true
|
||||||
currentValue=666, currentStamp=999
|
currentValue=666, currentStamp=999
|
||||||
@ -371,7 +371,7 @@ public class AtomicMarkableReferenceDemo {
|
|||||||
|
|
||||||
输出结果如下:
|
输出结果如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
currentValue=null, currentMark=false
|
currentValue=null, currentMark=false
|
||||||
currentValue=true, currentMark=true, casResult=true
|
currentValue=true, currentMark=true, casResult=true
|
||||||
currentValue=true, currentMark=true
|
currentValue=true, currentMark=true
|
||||||
@ -438,7 +438,7 @@ class User {
|
|||||||
|
|
||||||
输出结果:
|
输出结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
22
|
22
|
||||||
23
|
23
|
||||||
```
|
```
|
||||||
|
|||||||
@ -533,7 +533,7 @@ try {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
任务1开始执行,当前时间:1695088058520
|
任务1开始执行,当前时间:1695088058520
|
||||||
任务2开始执行,当前时间:1695088058521
|
任务2开始执行,当前时间:1695088058521
|
||||||
任务1执行完毕,当前时间:1695088059023
|
任务1执行完毕,当前时间:1695088059023
|
||||||
@ -614,7 +614,7 @@ System.out.println("all futures done...");
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```java
|
```plain
|
||||||
future1 done...
|
future1 done...
|
||||||
future2 done...
|
future2 done...
|
||||||
all futures done...
|
all futures done...
|
||||||
@ -629,14 +629,14 @@ System.out.println(f.get());
|
|||||||
|
|
||||||
输出结果可能是:
|
输出结果可能是:
|
||||||
|
|
||||||
```java
|
```plain
|
||||||
future2 done...
|
future2 done...
|
||||||
efg
|
efg
|
||||||
```
|
```
|
||||||
|
|
||||||
也可能是:
|
也可能是:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
future1 done...
|
future1 done...
|
||||||
abc
|
abc
|
||||||
```
|
```
|
||||||
@ -696,11 +696,11 @@ CompletableFuture.runAsync(() -> {
|
|||||||
- 使用 `exceptionally` 方法可以处理异常并重新抛出,以便异常能够传播到后续阶段,而不是让异常被忽略或终止。
|
- 使用 `exceptionally` 方法可以处理异常并重新抛出,以便异常能够传播到后续阶段,而不是让异常被忽略或终止。
|
||||||
- 使用 `handle` 方法可以处理正常的返回结果和异常,并返回一个新的结果,而不是让异常影响正常的业务逻辑。
|
- 使用 `handle` 方法可以处理正常的返回结果和异常,并返回一个新的结果,而不是让异常影响正常的业务逻辑。
|
||||||
- 使用 `CompletableFuture.allOf` 方法可以组合多个 `CompletableFuture`,并统一处理所有任务的异常,而不是让异常处理过于冗长或重复。
|
- 使用 `CompletableFuture.allOf` 方法可以组合多个 `CompletableFuture`,并统一处理所有任务的异常,而不是让异常处理过于冗长或重复。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
### 合理组合多个异步任务
|
### 合理组合多个异步任务
|
||||||
|
|
||||||
正确使用 `thenCompose()` 、 `thenCombine()` 、`acceptEither()`、`allOf()`、`anyOf() `等方法来组合多个异步任务,以满足实际业务的需求,提高程序执行效率。
|
正确使用 `thenCompose()` 、 `thenCombine()` 、`acceptEither()`、`allOf()`、`anyOf()`等方法来组合多个异步任务,以满足实际业务的需求,提高程序执行效率。
|
||||||
|
|
||||||
实际使用中,我们还可以利用或者参考现成的异步任务编排框架,比如京东的 [asyncTool](https://gitee.com/jd-platform-opensource/asyncTool) 。
|
实际使用中,我们还可以利用或者参考现成的异步任务编排框架,比如京东的 [asyncTool](https://gitee.com/jd-platform-opensource/asyncTool) 。
|
||||||
|
|
||||||
|
|||||||
@ -49,7 +49,7 @@ public class MultiThread {
|
|||||||
|
|
||||||
上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
|
上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
|
||||||
|
|
||||||
```
|
```plain
|
||||||
[5] Attach Listener //添加事件
|
[5] Attach Listener //添加事件
|
||||||
[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
|
[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
|
||||||
[3] Finalizer //调用对象 finalize 方法的线程
|
[3] Finalizer //调用对象 finalize 方法的线程
|
||||||
@ -136,11 +136,11 @@ public class MultiThread {
|
|||||||
|
|
||||||
## 单核 CPU 上运行多个线程效率一定会高吗?
|
## 单核 CPU 上运行多个线程效率一定会高吗?
|
||||||
|
|
||||||
单核CPU同时运行多个线程的效率是否会高,取决于线程的类型和任务的性质。一般来说,有两种类型的线程:CPU密集型和IO密集型。CPU密集型的线程主要进行计算和逻辑处理,需要占用大量的CPU资源。IO密集型的线程主要进行输入输出操作,如读写文件、网络通信等,需要等待IO设备的响应,而不占用太多的CPU资源。
|
单核 CPU 同时运行多个线程的效率是否会高,取决于线程的类型和任务的性质。一般来说,有两种类型的线程:CPU 密集型和 IO 密集型。CPU 密集型的线程主要进行计算和逻辑处理,需要占用大量的 CPU 资源。IO 密集型的线程主要进行输入输出操作,如读写文件、网络通信等,需要等待 IO 设备的响应,而不占用太多的 CPU 资源。
|
||||||
|
|
||||||
在单核CPU上,同一时刻只能有一个线程在运行,其他线程需要等待CPU的时间片分配。如果线程是CPU密集型的,那么多个线程同时运行会导致频繁的线程切换,增加了系统的开销,降低了效率。如果线程是IO密集型的,那么多个线程同时运行可以利用CPU在等待IO时的空闲时间,提高了效率。
|
在单核 CPU 上,同一时刻只能有一个线程在运行,其他线程需要等待 CPU 的时间片分配。如果线程是 CPU 密集型的,那么多个线程同时运行会导致频繁的线程切换,增加了系统的开销,降低了效率。如果线程是 IO 密集型的,那么多个线程同时运行可以利用 CPU 在等待 IO 时的空闲时间,提高了效率。
|
||||||
|
|
||||||
因此,对于单核CPU来说,如果任务是CPU密集型的,那么开很多线程会影响效率;如果任务是IO密集型的,那么开很多线程会提高效率。当然,这里的“很多”也要适度,不能超过系统能够承受的上限。
|
因此,对于单核 CPU 来说,如果任务是 CPU 密集型的,那么开很多线程会影响效率;如果任务是 IO 密集型的,那么开很多线程会提高效率。当然,这里的“很多”也要适度,不能超过系统能够承受的上限。
|
||||||
|
|
||||||
## 说说线程的生命周期和状态?
|
## 说说线程的生命周期和状态?
|
||||||
|
|
||||||
@ -240,7 +240,7 @@ public class DeadLockDemo {
|
|||||||
|
|
||||||
Output
|
Output
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Thread[线程 1,5,main]get resource1
|
Thread[线程 1,5,main]get resource1
|
||||||
Thread[线程 2,5,main]get resource2
|
Thread[线程 2,5,main]get resource2
|
||||||
Thread[线程 1,5,main]waiting get resource2
|
Thread[线程 1,5,main]waiting get resource2
|
||||||
@ -268,7 +268,7 @@ Thread[线程 2,5,main]waiting get resource1
|
|||||||
|
|
||||||
避免死锁就是在资源分配时,借助于算法(比如银行家算法)对资源分配进行计算评估,使其进入安全状态。
|
避免死锁就是在资源分配时,借助于算法(比如银行家算法)对资源分配进行计算评估,使其进入安全状态。
|
||||||
|
|
||||||
> **安全状态** 指的是系统能够按照某种线程推进顺序(P1、P2、P3.....Pn)来为每个线程分配所需资源,直到满足每个线程对资源的最大需求,使每个线程都可顺利完成。称 `<P1、P2、P3.....Pn>` 序列为安全序列。
|
> **安全状态** 指的是系统能够按照某种线程推进顺序(P1、P2、P3……Pn)来为每个线程分配所需资源,直到满足每个线程对资源的最大需求,使每个线程都可顺利完成。称 `<P1、P2、P3.....Pn>` 序列为安全序列。
|
||||||
|
|
||||||
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
|
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
|
||||||
|
|
||||||
@ -291,7 +291,7 @@ new Thread(() -> {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Thread[线程 1,5,main]get resource1
|
Thread[线程 1,5,main]get resource1
|
||||||
Thread[线程 1,5,main]waiting get resource2
|
Thread[线程 1,5,main]waiting get resource2
|
||||||
Thread[线程 1,5,main]get resource2
|
Thread[线程 1,5,main]get resource2
|
||||||
|
|||||||
@ -608,7 +608,7 @@ public ReentrantReadWriteLock(boolean fair) {
|
|||||||
- 在线程持有读锁的情况下,该线程不能取得写锁(因为获取写锁的时候,如果发现当前的读锁被占用,就马上获取失败,不管读锁是不是被当前线程持有)。
|
- 在线程持有读锁的情况下,该线程不能取得写锁(因为获取写锁的时候,如果发现当前的读锁被占用,就马上获取失败,不管读锁是不是被当前线程持有)。
|
||||||
- 在线程持有写锁的情况下,该线程可以继续获取读锁(获取读锁时如果发现写锁被占用,只有写锁没有被当前线程占用的情况才会获取失败)。
|
- 在线程持有写锁的情况下,该线程可以继续获取读锁(获取读锁时如果发现写锁被占用,只有写锁没有被当前线程占用的情况才会获取失败)。
|
||||||
|
|
||||||
读写锁的源码分析,推荐阅读 [聊聊 Java 的几把 JVM 级锁 - 阿里巴巴中间件 ](https://mp.weixin.qq.com/s/h3VIUyH9L0v14MrQJiiDbw) 这篇文章,写的很不错。
|
读写锁的源码分析,推荐阅读 [聊聊 Java 的几把 JVM 级锁 - 阿里巴巴中间件](https://mp.weixin.qq.com/s/h3VIUyH9L0v14MrQJiiDbw) 这篇文章,写的很不错。
|
||||||
|
|
||||||
### 读锁为什么不能升级为写锁?
|
### 读锁为什么不能升级为写锁?
|
||||||
|
|
||||||
|
|||||||
@ -68,7 +68,7 @@ public class ThreadLocalExample implements Runnable{
|
|||||||
|
|
||||||
输出结果 :
|
输出结果 :
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Thread Name= 0 default Formatter = yyyyMMdd HHmm
|
Thread Name= 0 default Formatter = yyyyMMdd HHmm
|
||||||
Thread Name= 0 formatter = yy-M-d ah:mm
|
Thread Name= 0 formatter = yy-M-d ah:mm
|
||||||
Thread Name= 1 default Formatter = yyyyMMdd HHmm
|
Thread Name= 1 default Formatter = yyyyMMdd HHmm
|
||||||
@ -215,7 +215,7 @@ static class Entry extends WeakReference<ThreadLocal<?>> {
|
|||||||
|
|
||||||
- **`FixedThreadPool`**:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
- **`FixedThreadPool`**:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||||
- **`SingleThreadExecutor`:** 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
- **`SingleThreadExecutor`:** 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
||||||
- **`CachedThreadPool`:** 该方法返回一个可根据实际情况调整线程数量的线程池。初始大小为0。当有新任务提交时,如果当前线程池中没有线程可用,它会创建一个新的线程来处理该任务。如果在一段时间内(默认为60秒)没有新任务提交,核心线程会超时并被销毁,从而缩小线程池的大小。
|
- **`CachedThreadPool`:** 该方法返回一个可根据实际情况调整线程数量的线程池。初始大小为 0。当有新任务提交时,如果当前线程池中没有线程可用,它会创建一个新的线程来处理该任务。如果在一段时间内(默认为 60 秒)没有新任务提交,核心线程会超时并被销毁,从而缩小线程池的大小。
|
||||||
- **`ScheduledThreadPool`**:该方法返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
|
- **`ScheduledThreadPool`**:该方法返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
|
||||||
|
|
||||||
对应 `Executors` 工具类中的方法如图所示:
|
对应 `Executors` 工具类中的方法如图所示:
|
||||||
@ -759,7 +759,7 @@ public final boolean releaseShared(int arg) {
|
|||||||
|
|
||||||
### CountDownLatch 的原理是什么?
|
### CountDownLatch 的原理是什么?
|
||||||
|
|
||||||
`CountDownLatch` 是共享锁的一种实现,它默认构造 AQS 的 `state` 值为 `count`。当线程使用 `countDown()` 方法时,其实使用了`tryReleaseShared`方法以 CAS 的操作来减少 `state`,直至 `state` 为 0 。当调用 `await()` 方法的时候,如果 `state` 不为 0,那就证明任务还没有执行完毕,`await()` 方法就会一直阻塞,也就是说 `await()` 方法之后的语句不会被执行。直到`count` 个线程调用了`countDown()`使state值被减为0,或者调用`await()`的线程被中断,该线程才会从阻塞中被唤醒,`await()` 方法之后的语句得到执行。
|
`CountDownLatch` 是共享锁的一种实现,它默认构造 AQS 的 `state` 值为 `count`。当线程使用 `countDown()` 方法时,其实使用了`tryReleaseShared`方法以 CAS 的操作来减少 `state`,直至 `state` 为 0 。当调用 `await()` 方法的时候,如果 `state` 不为 0,那就证明任务还没有执行完毕,`await()` 方法就会一直阻塞,也就是说 `await()` 方法之后的语句不会被执行。直到`count` 个线程调用了`countDown()`使 state 值被减为 0,或者调用`await()`的线程被中断,该线程才会从阻塞中被唤醒,`await()` 方法之后的语句得到执行。
|
||||||
|
|
||||||
### 用过 CountDownLatch 么?什么场景下用的?
|
### 用过 CountDownLatch 么?什么场景下用的?
|
||||||
|
|
||||||
|
|||||||
@ -125,11 +125,11 @@ public final class NamingThreadFactory implements ThreadFactory {
|
|||||||
|
|
||||||
说到如何给线程池配置参数,美团的骚操作至今让我难忘(后面会提到)!
|
说到如何给线程池配置参数,美团的骚操作至今让我难忘(后面会提到)!
|
||||||
|
|
||||||
我们先来看一下各种书籍和博客上一般推荐的配置线程池参数的方式,可以作为参考!
|
我们先来看一下各种书籍和博客上一般推荐的配置线程池参数的方式,可以作为参考。
|
||||||
|
|
||||||
### 常规操作
|
### 常规操作
|
||||||
|
|
||||||
很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换**成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
|
很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换** 成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
|
||||||
|
|
||||||
> 上下文切换:
|
> 上下文切换:
|
||||||
>
|
>
|
||||||
@ -153,19 +153,19 @@ public final class NamingThreadFactory implements ThreadFactory {
|
|||||||
|
|
||||||
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
|
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
|
||||||
|
|
||||||
> 🌈 拓展一下(参见:[issue#1737](https://github.com/Snailclimb/JavaGuide/issues/1737)):
|
🌈 拓展一下(参见:[issue#1737](https://github.com/Snailclimb/JavaGuide/issues/1737)):
|
||||||
>
|
|
||||||
> 线程数更严谨的计算的方法应该是:`最佳线程数 = N(CPU 核心数)∗(1+WT(线程等待时间)/ST(线程计算时间))`,其中 `WT(线程等待时间)=线程运行总时间 - ST(线程计算时间)`。
|
|
||||||
>
|
|
||||||
> 线程等待时间所占比例越高,需要越多线程。线程计算时间所占比例越高,需要越少线程。
|
|
||||||
>
|
|
||||||
> 我们可以通过 JDK 自带的工具 VisualVM 来查看 `WT/ST` 比例。
|
|
||||||
>
|
|
||||||
> CPU 密集型任务的 `WT/ST` 接近或者等于 0,因此, 线程数可以设置为 N(CPU 核心数)∗(1+0)= N,和我们上面说的 N(CPU 核心数)+1 差不多。
|
|
||||||
>
|
|
||||||
> IO 密集型任务下,几乎全是线程等待时间,从理论上来说,你就可以将线程数设置为 2N(按道理来说,WT/ST 的结果应该比较大,这里选择 2N 的原因应该是为了避免创建过多线程吧)。
|
|
||||||
|
|
||||||
**公示也只是参考,具体还是要根据项目实际线上运行情况来动态调整。我在后面介绍的美团的线程池参数动态配置这种方案就非常不错,很实用!**
|
线程数更严谨的计算的方法应该是:`最佳线程数 = N(CPU 核心数)∗(1+WT(线程等待时间)/ST(线程计算时间))`,其中 `WT(线程等待时间)=线程运行总时间 - ST(线程计算时间)`。
|
||||||
|
|
||||||
|
线程等待时间所占比例越高,需要越多线程。线程计算时间所占比例越高,需要越少线程。
|
||||||
|
|
||||||
|
我们可以通过 JDK 自带的工具 VisualVM 来查看 `WT/ST` 比例。
|
||||||
|
|
||||||
|
CPU 密集型任务的 `WT/ST` 接近或者等于 0,因此, 线程数可以设置为 N(CPU 核心数)∗(1+0)= N,和我们上面说的 N(CPU 核心数)+1 差不多。
|
||||||
|
|
||||||
|
IO 密集型任务下,几乎全是线程等待时间,从理论上来说,你就可以将线程数设置为 2N(按道理来说,WT/ST 的结果应该比较大,这里选择 2N 的原因应该是为了避免创建过多线程吧)。
|
||||||
|
|
||||||
|
**注意**:上面提到的公示也只是参考,实际项目不太可能直接按照公式来设置线程池参数,毕竟不同的业务场景对应的需求不同,具体还是要根据项目实际线上运行情况来动态调整。接下来介绍的美团的线程池参数动态配置这种方案就非常不错,很实用!
|
||||||
|
|
||||||
### 美团的骚操作
|
### 美团的骚操作
|
||||||
|
|
||||||
|
|||||||
@ -315,7 +315,7 @@ public class ThreadPoolExecutorDemo {
|
|||||||
|
|
||||||
**输出结构**:
|
**输出结构**:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
|
pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
|
||||||
pool-1-thread-5 Start. Time = Sun Apr 12 11:14:37 CST 2020
|
pool-1-thread-5 Start. Time = Sun Apr 12 11:14:37 CST 2020
|
||||||
pool-1-thread-2 Start. Time = Sun Apr 12 11:14:37 CST 2020
|
pool-1-thread-2 Start. Time = Sun Apr 12 11:14:37 CST 2020
|
||||||
@ -579,7 +579,7 @@ executorService.shutdown();
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
abc
|
abc
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -604,7 +604,7 @@ executorService.shutdown();
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Exception in thread "main" java.util.concurrent.TimeoutException
|
Exception in thread "main" java.util.concurrent.TimeoutException
|
||||||
at java.util.concurrent.FutureTask.get(FutureTask.java:205)
|
at java.util.concurrent.FutureTask.get(FutureTask.java:205)
|
||||||
```
|
```
|
||||||
|
|||||||
@ -126,7 +126,7 @@ Java 内存模型的抽象示意图如下:
|
|||||||
- 一个变量在同一个时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁。
|
- 一个变量在同一个时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以被同一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会被解锁。
|
||||||
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作初始化变量的值。
|
- 如果对一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行 load 或 assign 操作初始化变量的值。
|
||||||
- 如果一个变量事先没有被 lock 操作锁定,则不允许对它执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定住的变量。
|
- 如果一个变量事先没有被 lock 操作锁定,则不允许对它执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定住的变量。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
### Java 内存区域和 JMM 有何区别?
|
### Java 内存区域和 JMM 有何区别?
|
||||||
|
|
||||||
|
|||||||
@ -24,7 +24,7 @@ tag:
|
|||||||
- `ThreadLocalMap.set()`方法实现原理?
|
- `ThreadLocalMap.set()`方法实现原理?
|
||||||
- `ThreadLocalMap.get()`方法实现原理?
|
- `ThreadLocalMap.get()`方法实现原理?
|
||||||
- 项目中`ThreadLocal`使用情况?遇到的坑?
|
- 项目中`ThreadLocal`使用情况?遇到的坑?
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
上述的一些问题你是否都已经掌握的很清楚了呢?本文将围绕这些问题使用图文方式来剖析`ThreadLocal`的**点点滴滴**。
|
上述的一些问题你是否都已经掌握的很清楚了呢?本文将围绕这些问题使用图文方式来剖析`ThreadLocal`的**点点滴滴**。
|
||||||
|
|
||||||
|
|||||||
@ -64,7 +64,7 @@ try (InputStream fis = new FileInputStream("input.txt")) {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Number of remaining bytes:11
|
Number of remaining bytes:11
|
||||||
The actual number of bytes skipped:2
|
The actual number of bytes skipped:2
|
||||||
The content read from file:JavaGuide
|
The content read from file:JavaGuide
|
||||||
@ -233,7 +233,7 @@ try (FileReader fileReader = new FileReader("input.txt");) {
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
The actual number of bytes skipped:3
|
The actual number of bytes skipped:3
|
||||||
The content read from file:我是Guide。
|
The content read from file:我是Guide。
|
||||||
```
|
```
|
||||||
@ -296,7 +296,7 @@ BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputS
|
|||||||
|
|
||||||
我使用 `write(int b)` 和 `read()` 方法,分别通过字节流和字节缓冲流复制一个 `524.9 mb` 的 PDF 文件耗时对比如下:
|
我使用 `write(int b)` 和 `read()` 方法,分别通过字节流和字节缓冲流复制一个 `524.9 mb` 的 PDF 文件耗时对比如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
使用缓冲流复制PDF文件总耗时:15428 毫秒
|
使用缓冲流复制PDF文件总耗时:15428 毫秒
|
||||||
使用普通字节流复制PDF文件总耗时:2555062 毫秒
|
使用普通字节流复制PDF文件总耗时:2555062 毫秒
|
||||||
```
|
```
|
||||||
@ -347,7 +347,7 @@ void copy_pdf_to_another_pdf_stream() {
|
|||||||
|
|
||||||
这次我们使用 `read(byte b[])` 和 `write(byte b[], int off, int len)` 方法,分别通过字节流和字节缓冲流复制一个 524.9 mb 的 PDF 文件耗时对比如下:
|
这次我们使用 `read(byte b[])` 和 `write(byte b[], int off, int len)` 方法,分别通过字节流和字节缓冲流复制一个 524.9 mb 的 PDF 文件耗时对比如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
使用缓冲流复制PDF文件总耗时:695 毫秒
|
使用缓冲流复制PDF文件总耗时:695 毫秒
|
||||||
使用普通字节流复制PDF文件总耗时:989 毫秒
|
使用普通字节流复制PDF文件总耗时:989 毫秒
|
||||||
```
|
```
|
||||||
@ -516,7 +516,7 @@ System.out.println("读取之前的偏移量:" + randomAccessFile.getFilePoint
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
读取之前的偏移量:0,当前读取到的字符A,读取之后的偏移量:1
|
读取之前的偏移量:0,当前读取到的字符A,读取之后的偏移量:1
|
||||||
读取之前的偏移量:6,当前读取到的字符G,读取之后的偏移量:7
|
读取之前的偏移量:6,当前读取到的字符G,读取之后的偏移量:7
|
||||||
读取之前的偏移量:0,当前读取到的字符A,读取之后的偏移量:1
|
读取之前的偏移量:0,当前读取到的字符A,读取之后的偏移量:1
|
||||||
|
|||||||
@ -6,13 +6,13 @@ tag:
|
|||||||
- Java基础
|
- Java基础
|
||||||
---
|
---
|
||||||
|
|
||||||
在学习 NIO 之前,需要先了解一下计算机 I/O模型的基础理论知识。还不了解的话,可以参考我写的这篇文章:[Java IO 模型详解](https://javaguide.cn/java/io/io-model.html)。
|
在学习 NIO 之前,需要先了解一下计算机 I/O 模型的基础理论知识。还不了解的话,可以参考我写的这篇文章:[Java IO 模型详解](https://javaguide.cn/java/io/io-model.html)。
|
||||||
|
|
||||||
## NIO 简介
|
## NIO 简介
|
||||||
|
|
||||||
在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。也就是说,当一个线程执行一个 I/O 操作时,它会被阻塞直到操作完成。这种阻塞模型在处理多个并发连接时可能会导致性能瓶颈,因为需要为每个连接创建一个线程,而线程的创建和切换都是有开销的。
|
在传统的 Java I/O 模型(BIO)中,I/O 操作是以阻塞的方式进行的。也就是说,当一个线程执行一个 I/O 操作时,它会被阻塞直到操作完成。这种阻塞模型在处理多个并发连接时可能会导致性能瓶颈,因为需要为每个连接创建一个线程,而线程的创建和切换都是有开销的。
|
||||||
|
|
||||||
为了解决这个问题,在Java1.4 版本引入了一种新的 I/O 模型 — **NIO** (New IO,也称为 Non-blocking IO) 。NIO 弥补了同步阻塞I/O的不足,它在标准 Java 代码中提供了非阻塞、面向缓冲、基于通道的 I/O,可以使用少量的线程来处理多个连接,大大提高了 I/O 效率和并发。
|
为了解决这个问题,在 Java1.4 版本引入了一种新的 I/O 模型 — **NIO** (New IO,也称为 Non-blocking IO) 。NIO 弥补了同步阻塞 I/O 的不足,它在标准 Java 代码中提供了非阻塞、面向缓冲、基于通道的 I/O,可以使用少量的线程来处理多个连接,大大提高了 I/O 效率和并发。
|
||||||
|
|
||||||
下图是 BIO、NIO 和 AIO 处理客户端请求的简单对比图(关于 AIO 的介绍,可以看我写的这篇文章:[Java IO 模型详解](https://javaguide.cn/java/io/io-model.html),不是重点,了解即可)。
|
下图是 BIO、NIO 和 AIO 处理客户端请求的简单对比图(关于 AIO 的介绍,可以看我写的这篇文章:[Java IO 模型详解](https://javaguide.cn/java/io/io-model.html),不是重点,了解即可)。
|
||||||
|
|
||||||
@ -24,9 +24,9 @@ tag:
|
|||||||
|
|
||||||
NIO 主要包括以下三个核心组件:
|
NIO 主要包括以下三个核心组件:
|
||||||
|
|
||||||
- **Buffer(缓冲区)**:NIO 读写数据都是通过缓冲区进行操作的。读操作的时候将 Channel 中的数据填充到 Buffer中,而写操作时将 Buffer中的数据写入到 Channel 中。
|
- **Buffer(缓冲区)**:NIO 读写数据都是通过缓冲区进行操作的。读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
|
||||||
- **Channel(通道)**:Channel 是一个双向的、可读可写的数据传输通道,NIO 通过Channel来实现数据的输入输出。通道是一个抽象的概念,它可以代表文件、套接字或者其他数据源之间的连接。
|
- **Channel(通道)**:Channel 是一个双向的、可读可写的数据传输通道,NIO 通过 Channel 来实现数据的输入输出。通道是一个抽象的概念,它可以代表文件、套接字或者其他数据源之间的连接。
|
||||||
- **Selector(选择器)**:允许一个线程处理多个 Channel,基于事件驱动的 I/O 多路复用模型。所有的 Channel 都可以注册到Selector上,由Selector来分配线程来处理事件。
|
- **Selector(选择器)**:允许一个线程处理多个 Channel,基于事件驱动的 I/O 多路复用模型。所有的 Channel 都可以注册到 Selector 上,由 Selector 来分配线程来处理事件。
|
||||||
|
|
||||||
三者的关系如下图所示(暂时不理解没关系,后文会详细介绍):
|
三者的关系如下图所示(暂时不理解没关系,后文会详细介绍):
|
||||||
|
|
||||||
@ -38,7 +38,7 @@ NIO 主要包括以下三个核心组件:
|
|||||||
|
|
||||||
在传统的 BIO 中,数据的读写是面向流的, 分为字节流和字符流。
|
在传统的 BIO 中,数据的读写是面向流的, 分为字节流和字符流。
|
||||||
|
|
||||||
在Java 1.4 的 NIO库中,所有数据都是用缓冲区处理的,这是新库和之前的 BIO 的一个重要区别,有点类似于 BIO 中的缓冲流。NIO 在读取数据时,它是直接读到缓冲区中的。在写入数据时,写入到缓冲区中。 使用 NIO在读写数据时,都是通过缓冲区进行操作。
|
在 Java 1.4 的 NIO 库中,所有数据都是用缓冲区处理的,这是新库和之前的 BIO 的一个重要区别,有点类似于 BIO 中的缓冲流。NIO 在读取数据时,它是直接读到缓冲区中的。在写入数据时,写入到缓冲区中。 使用 NIO 在读写数据时,都是通过缓冲区进行操作。
|
||||||
|
|
||||||
`Buffer` 的子类如下图所示。其中,最常用的是 `ByteBuffer`,它可以用来存储和操作字节数据。
|
`Buffer` 的子类如下图所示。其中,最常用的是 `ByteBuffer`,它可以用来存储和操作字节数据。
|
||||||
|
|
||||||
@ -61,7 +61,7 @@ public abstract class Buffer {
|
|||||||
这四个成员变量的具体含义如下:
|
这四个成员变量的具体含义如下:
|
||||||
|
|
||||||
1. 容量(`capacity`):`Buffer`可以存储的最大数据量,`Buffer`创建时设置且不可改变;
|
1. 容量(`capacity`):`Buffer`可以存储的最大数据量,`Buffer`创建时设置且不可改变;
|
||||||
2. 界限(`limit`):`Buffer` 中可以读/写数据的边界。写模式下,`limit` 代表最多能写入的数据,一般等于 `capacity`(可以通过`limit(int newLimit) `方法设置);读模式下,`limit` 等于 Buffer 中实际写入的数据大小。
|
2. 界限(`limit`):`Buffer` 中可以读/写数据的边界。写模式下,`limit` 代表最多能写入的数据,一般等于 `capacity`(可以通过`limit(int newLimit)`方法设置);读模式下,`limit` 等于 Buffer 中实际写入的数据大小。
|
||||||
3. 位置(`position`):下一个可以被读写的数据的位置(索引)。从写操作模式到读操作模式切换的时候(flip),`position` 都会归零,这样就可以从头开始读写了。
|
3. 位置(`position`):下一个可以被读写的数据的位置(索引)。从写操作模式到读操作模式切换的时候(flip),`position` 都会归零,这样就可以从头开始读写了。
|
||||||
4. 标记(`mark`):`Buffer`允许将位置直接定位到该标记处,这是一个可选属性;
|
4. 标记(`mark`):`Buffer`允许将位置直接定位到该标记处,这是一个可选属性;
|
||||||
|
|
||||||
@ -75,7 +75,7 @@ public abstract class Buffer {
|
|||||||
|
|
||||||
`Buffer` 对象不能通过 `new` 调用构造方法创建对象 ,只能通过静态方法实例化 `Buffer`。
|
`Buffer` 对象不能通过 `new` 调用构造方法创建对象 ,只能通过静态方法实例化 `Buffer`。
|
||||||
|
|
||||||
这里以 `ByteBuffer `为例进行介绍:
|
这里以 `ByteBuffer`为例进行介绍:
|
||||||
|
|
||||||
~~~java
|
~~~java
|
||||||
// 分配堆内存
|
// 分配堆内存
|
||||||
@ -93,7 +93,7 @@ public static ByteBuffer allocateDirect(int capacity);
|
|||||||
|
|
||||||
- `flip` :将缓冲区从写模式切换到读模式,它会将 `limit` 的值设置为当前 `position` 的值,将 `position` 的值设置为 0。
|
- `flip` :将缓冲区从写模式切换到读模式,它会将 `limit` 的值设置为当前 `position` 的值,将 `position` 的值设置为 0。
|
||||||
- `clear`: 清空缓冲区,将缓冲区从读模式切换到写模式,并将 `position` 的值设置为 0,将 `limit` 的值设置为 `capacity` 的值。
|
- `clear`: 清空缓冲区,将缓冲区从读模式切换到写模式,并将 `position` 的值设置为 0,将 `limit` 的值设置为 `capacity` 的值。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
Buffer 中数据变化的过程:
|
Buffer 中数据变化的过程:
|
||||||
|
|
||||||
@ -170,7 +170,7 @@ Channel 是一个通道,它建立了与数据源(如文件、网络套接字
|
|||||||
|
|
||||||
BIO 中的流是单向的,分为各种 `InputStream`(输入流)和 `OutputStream`(输出流),数据只是在一个方向上传输。通道与流的不同之处在于通道是双向的,它可以用于读、写或者同时用于读写。
|
BIO 中的流是单向的,分为各种 `InputStream`(输入流)和 `OutputStream`(输出流),数据只是在一个方向上传输。通道与流的不同之处在于通道是双向的,它可以用于读、写或者同时用于读写。
|
||||||
|
|
||||||
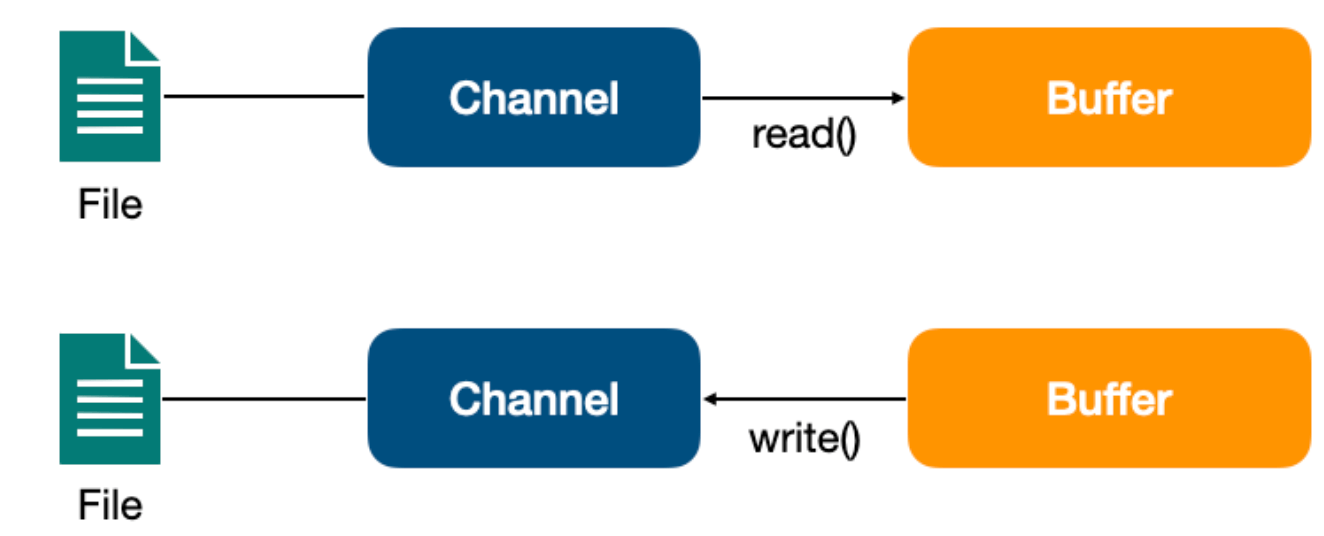
Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中的数据填充到 Buffer中,而写操作时将 Buffer中的数据写入到 Channel 中。
|
Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中的数据填充到 Buffer 中,而写操作时将 Buffer 中的数据写入到 Channel 中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -183,7 +183,7 @@ Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中
|
|||||||
其中,最常用的是以下几种类型的通道:
|
其中,最常用的是以下几种类型的通道:
|
||||||
|
|
||||||
- `FileChannel`:文件访问通道;
|
- `FileChannel`:文件访问通道;
|
||||||
- `SocketChannel`、`ServerSocketChannel`:TCP通信通道;
|
- `SocketChannel`、`ServerSocketChannel`:TCP 通信通道;
|
||||||
- `DatagramChannel`:UDP 通信通道;
|
- `DatagramChannel`:UDP 通信通道;
|
||||||
|
|
||||||
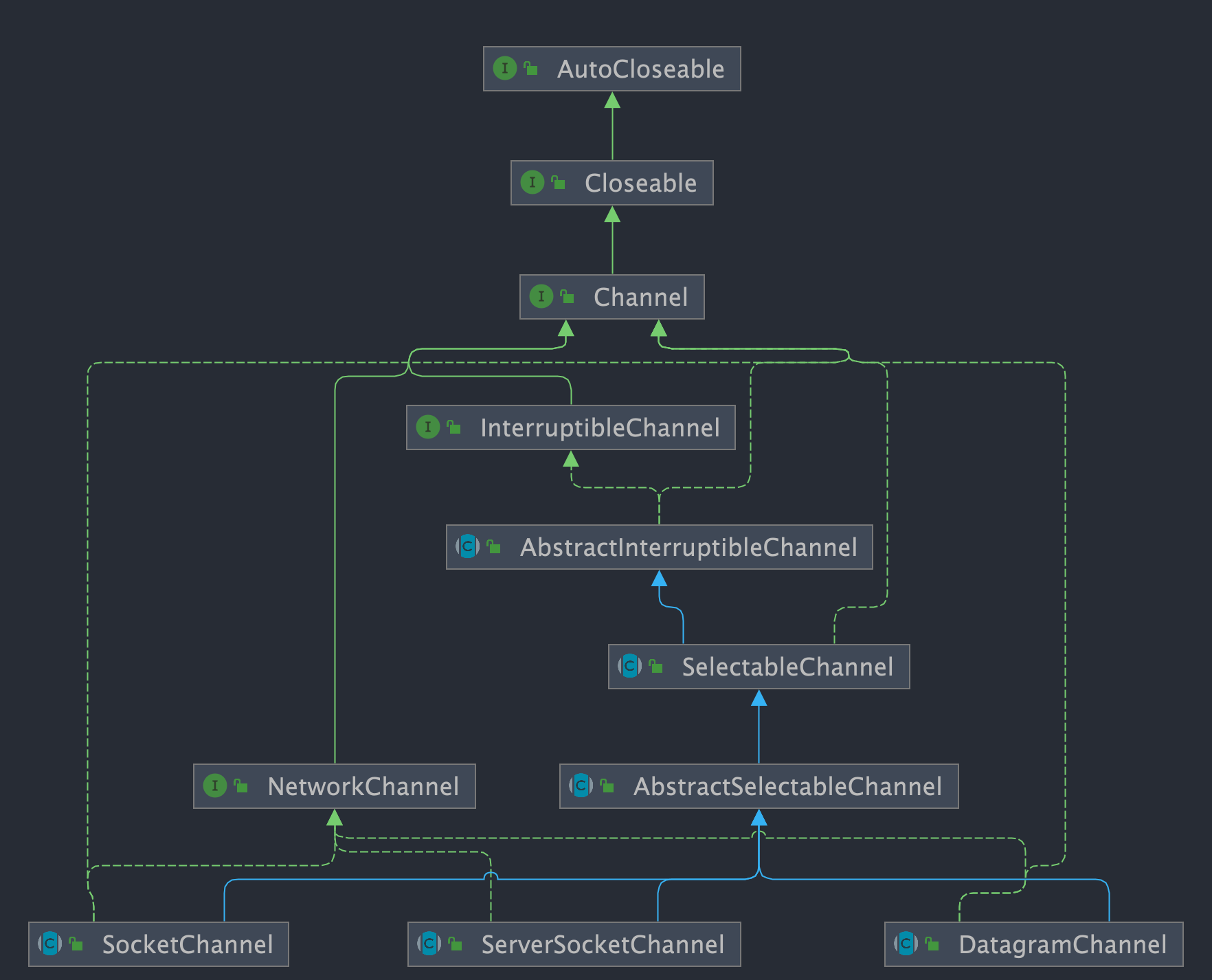
|

|
||||||
@ -205,11 +205,11 @@ channel.read(buffer);
|
|||||||
|
|
||||||
### Selector(选择器)
|
### Selector(选择器)
|
||||||
|
|
||||||
Selector(选择器) 是 NIO中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel上面有新的 TCP 连接接入、读和写事件,这个 Channel就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel加入到就绪集合中。通过 SelectionKey可以获取就绪 Channel的集合,然后对这些就绪的 Channel进行响应的 I/O 操作。
|
Selector(选择器) 是 NIO 中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel 上面有新的 TCP 连接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel 加入到就绪集合中。通过 SelectionKey 可以获取就绪 Channel 的集合,然后对这些就绪的 Channel 进行响应的 I/O 操作。
|
||||||
|
|
||||||
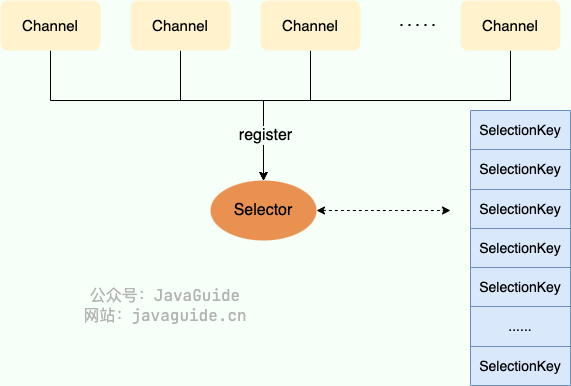
|

|
||||||
|
|
||||||
一个多路复用器 Selector 可以同时轮询多个 Channel,由于 JDK使用了 `epoll()` 代替传统的 `select` 实现,所以它并没有最大连接句柄 `1024/2048` 的限制。这也就意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
|
一个多路复用器 Selector 可以同时轮询多个 Channel,由于 JDK 使用了 `epoll()` 代替传统的 `select` 实现,所以它并没有最大连接句柄 `1024/2048` 的限制。这也就意味着只需要一个线程负责 Selector 的轮询,就可以接入成千上万的客户端。
|
||||||
|
|
||||||
Selector 可以监听以下四种事件类型:
|
Selector 可以监听以下四种事件类型:
|
||||||
|
|
||||||
@ -218,9 +218,9 @@ Selector 可以监听以下四种事件类型:
|
|||||||
3. `SelectionKey.OP_READ`:表示通道准备好进行读取的事件,即有数据可读。
|
3. `SelectionKey.OP_READ`:表示通道准备好进行读取的事件,即有数据可读。
|
||||||
4. `SelectionKey.OP_WRITE`:表示通道准备好进行写入的事件,即可以写入数据。
|
4. `SelectionKey.OP_WRITE`:表示通道准备好进行写入的事件,即可以写入数据。
|
||||||
|
|
||||||
`Selector `是抽象类,可以通过调用此类的 `open()` 静态方法来创建 Selector 实例。Selector 可以同时监控多个 `SelectableChannel` 的 `IO` 状况,是非阻塞 `IO` 的核心。
|
`Selector`是抽象类,可以通过调用此类的 `open()` 静态方法来创建 Selector 实例。Selector 可以同时监控多个 `SelectableChannel` 的 `IO` 状况,是非阻塞 `IO` 的核心。
|
||||||
|
|
||||||
一个Selector 实例有三个 `SelectionKey` 集合:
|
一个 Selector 实例有三个 `SelectionKey` 集合:
|
||||||
|
|
||||||
1. 所有的 `SelectionKey` 集合:代表了注册在该 Selector 上的 `Channel`,这个集合可以通过 `keys()` 方法返回。
|
1. 所有的 `SelectionKey` 集合:代表了注册在该 Selector 上的 `Channel`,这个集合可以通过 `keys()` 方法返回。
|
||||||
2. 被选择的 `SelectionKey` 集合:代表了所有可通过 `select()` 方法获取的、需要进行 `IO` 处理的 Channel,这个集合可以通过 `selectedKeys()` 返回。
|
2. 被选择的 `SelectionKey` 集合:代表了所有可通过 `select()` 方法获取的、需要进行 `IO` 处理的 Channel,这个集合可以通过 `selectedKeys()` 返回。
|
||||||
@ -254,7 +254,7 @@ Selector 还提供了一系列和 `select()` 相关的方法:
|
|||||||
- `int select(long timeout)`:可以设置超时时长的 `select()` 操作。
|
- `int select(long timeout)`:可以设置超时时长的 `select()` 操作。
|
||||||
- `int selectNow()`:执行一个立即返回的 `select()` 操作,相对于无参数的 `select()` 方法而言,该方法不会阻塞线程。
|
- `int selectNow()`:执行一个立即返回的 `select()` 操作,相对于无参数的 `select()` 方法而言,该方法不会阻塞线程。
|
||||||
- `Selector wakeup()`:使一个还未返回的 `select()` 方法立刻返回。
|
- `Selector wakeup()`:使一个还未返回的 `select()` 方法立刻返回。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
使用 Selector 实现网络读写的简单示例:
|
使用 Selector 实现网络读写的简单示例:
|
||||||
|
|
||||||
@ -337,7 +337,7 @@ public class NioSelectorExample {
|
|||||||
}
|
}
|
||||||
~~~
|
~~~
|
||||||
|
|
||||||
在示例中,我们创建了一个简单的服务器,监听8080端口,使用 Selector 处理连接、读取和写入事件。当接收到客户端的数据时,服务器将读取数据并将其打印到控制台,然后向客户端回复 "Hello, Client!"。
|
在示例中,我们创建了一个简单的服务器,监听 8080 端口,使用 Selector 处理连接、读取和写入事件。当接收到客户端的数据时,服务器将读取数据并将其打印到控制台,然后向客户端回复 "Hello, Client!"。
|
||||||
|
|
||||||
## NIO 零拷贝
|
## NIO 零拷贝
|
||||||
|
|
||||||
@ -384,7 +384,7 @@ private void loadFileIntoMemory(File xmlFile) throws IOException {
|
|||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- Java NIO浅析:<https://tech.meituan.com/2016/11/04/nio.html>
|
- Java NIO 浅析:<https://tech.meituan.com/2016/11/04/nio.html>
|
||||||
|
|
||||||
- 面试官:Java NIO 了解?https://mp.weixin.qq.com/s/mZobf-U8OSYQfHfYBEB6KA
|
- 面试官:Java NIO 了解?https://mp.weixin.qq.com/s/mZobf-U8OSYQfHfYBEB6KA
|
||||||
|
|
||||||
|
|||||||
@ -60,7 +60,7 @@ ClassFile {
|
|||||||
u4 magic; //Class 文件的标志
|
u4 magic; //Class 文件的标志
|
||||||
```
|
```
|
||||||
|
|
||||||
每个 Class 文件的头 4 个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。Java规范规定魔数为固定值:0xCAFEBABE。如果读取的文件不是以这个魔数开头,Java虚拟机将拒绝加载它。
|
每个 Class 文件的头 4 个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。Java 规范规定魔数为固定值:0xCAFEBABE。如果读取的文件不是以这个魔数开头,Java 虚拟机将拒绝加载它。
|
||||||
|
|
||||||
### Class 文件版本号(Minor&Major Version)
|
### Class 文件版本号(Minor&Major Version)
|
||||||
|
|
||||||
@ -97,11 +97,11 @@ ClassFile {
|
|||||||
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
||||||
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
||||||
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
||||||
| CONSTANT_Long_info | 5 | 长整型字面量 |
|
| CONSTANT_Long_info | 5 | 长整型字面量 |
|
||||||
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
|
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
|
||||||
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
|
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
|
||||||
| CONSTANT_String_info | 8 | 字符串类型字面量 |
|
| CONSTANT_String_info | 8 | 字符串类型字面量 |
|
||||||
| CONSTANT_FieldRef_info | 9 | 字段的符号引用 |
|
| CONSTANT_FieldRef_info | 9 | 字段的符号引用 |
|
||||||
| CONSTANT_MethodRef_info | 10 | 类中方法的符号引用 |
|
| CONSTANT_MethodRef_info | 10 | 类中方法的符号引用 |
|
||||||
| CONSTANT_InterfaceMethodRef_info | 11 | 接口中方法的符号引用 |
|
| CONSTANT_InterfaceMethodRef_info | 11 | 接口中方法的符号引用 |
|
||||||
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
|
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
|
||||||
|
|||||||
@ -73,7 +73,7 @@ tag:
|
|||||||
- `java.lang.IllegalAccessError`:当类试图访问或修改它没有权限访问的字段,或调用它没有权限访问的方法时,抛出该异常。
|
- `java.lang.IllegalAccessError`:当类试图访问或修改它没有权限访问的字段,或调用它没有权限访问的方法时,抛出该异常。
|
||||||
- `java.lang.NoSuchFieldError`:当类试图访问或修改一个指定的对象字段,而该对象不再包含该字段时,抛出该异常。
|
- `java.lang.NoSuchFieldError`:当类试图访问或修改一个指定的对象字段,而该对象不再包含该字段时,抛出该异常。
|
||||||
- `java.lang.NoSuchMethodError`:当类试图访问一个指定的方法,而该方法不存在时,抛出该异常。
|
- `java.lang.NoSuchMethodError`:当类试图访问一个指定的方法,而该方法不存在时,抛出该异常。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
### 准备
|
### 准备
|
||||||
|
|
||||||
|
|||||||
@ -145,7 +145,7 @@ public class PrintClassLoaderTree {
|
|||||||
|
|
||||||
输出结果(JDK 8 ):
|
输出结果(JDK 8 ):
|
||||||
|
|
||||||
```
|
```plain
|
||||||
|--sun.misc.Launcher$AppClassLoader@18b4aac2
|
|--sun.misc.Launcher$AppClassLoader@18b4aac2
|
||||||
|--sun.misc.Launcher$ExtClassLoader@53bd815b
|
|--sun.misc.Launcher$ExtClassLoader@53bd815b
|
||||||
|--null
|
|--null
|
||||||
@ -318,7 +318,7 @@ Tomcat 这四个自定义的类加载器对应的目录如下:
|
|||||||
|
|
||||||
单纯依靠自定义类加载器没办法满足某些场景的要求,例如,有些情况下,高层的类加载器需要加载低层的加载器才能加载的类。
|
单纯依靠自定义类加载器没办法满足某些场景的要求,例如,有些情况下,高层的类加载器需要加载低层的加载器才能加载的类。
|
||||||
|
|
||||||
比如,SPI 中,SPI 的接口(如 `java.sql.Driver`)是由 Java 核心库提供的,由`BootstrapClassLoader` 加载。而 SPI 的实现(如`com.mysql.cj.jdbc.Driver`)是由第三方供应商提供的,它们是由应用程序类加载器或者自定义类加载器来加载的。默认情况下,一个类及其依赖类由同一个类加载器加载。所以,加载SPI 的接口的类加载器(`BootstrapClassLoader`)也会用来加载SPI 的实现。按照双亲委派模型,`BootstrapClassLoader` 是无法找到 SPI 的实现类的,因为它无法委托给子类加载器去尝试加载。
|
比如,SPI 中,SPI 的接口(如 `java.sql.Driver`)是由 Java 核心库提供的,由`BootstrapClassLoader` 加载。而 SPI 的实现(如`com.mysql.cj.jdbc.Driver`)是由第三方供应商提供的,它们是由应用程序类加载器或者自定义类加载器来加载的。默认情况下,一个类及其依赖类由同一个类加载器加载。所以,加载 SPI 的接口的类加载器(`BootstrapClassLoader`)也会用来加载 SPI 的实现。按照双亲委派模型,`BootstrapClassLoader` 是无法找到 SPI 的实现类的,因为它无法委托给子类加载器去尝试加载。
|
||||||
|
|
||||||
再比如,假设我们的项目中有 Spring 的 jar 包,由于其是 Web 应用之间共享的,因此会由 `SharedClassLoader` 加载(Web 服务器是 Tomcat)。我们项目中有一些用到了 Spring 的业务类,比如实现了 Spring 提供的接口、用到了 Spring 提供的注解。所以,加载 Spring 的类加载器(也就是 `SharedClassLoader`)也会用来加载这些业务类。但是业务类在 Web 应用目录下,不在 `SharedClassLoader` 的加载路径下,所以 `SharedClassLoader` 无法找到业务类,也就无法加载它们。
|
再比如,假设我们的项目中有 Spring 的 jar 包,由于其是 Web 应用之间共享的,因此会由 `SharedClassLoader` 加载(Web 服务器是 Tomcat)。我们项目中有一些用到了 Spring 的业务类,比如实现了 Spring 提供的接口、用到了 Spring 提供的注解。所以,加载 Spring 的类加载器(也就是 `SharedClassLoader`)也会用来加载这些业务类。但是业务类在 Web 应用目录下,不在 `SharedClassLoader` 的加载路径下,所以 `SharedClassLoader` 无法找到业务类,也就无法加载它们。
|
||||||
|
|
||||||
|
|||||||
@ -182,14 +182,14 @@ public class DeadLockDemo {
|
|||||||
|
|
||||||
Output
|
Output
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Thread[线程 1,5,main]get resource1
|
Thread[线程 1,5,main]get resource1
|
||||||
Thread[线程 2,5,main]get resource2
|
Thread[线程 2,5,main]get resource2
|
||||||
Thread[线程 1,5,main]waiting get resource2
|
Thread[线程 1,5,main]waiting get resource2
|
||||||
Thread[线程 2,5,main]waiting get resource1
|
Thread[线程 2,5,main]waiting get resource1
|
||||||
```
|
```
|
||||||
|
|
||||||
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过` Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
|
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
|
||||||
|
|
||||||
**通过 `jstack` 命令分析:**
|
**通过 `jstack` 命令分析:**
|
||||||
|
|
||||||
@ -260,7 +260,7 @@ JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监
|
|||||||
|
|
||||||
在使用 JConsole 连接时,远程进程地址如下:
|
在使用 JConsole 连接时,远程进程地址如下:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
外网访问 ip 地址:60001
|
外网访问 ip 地址:60001
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -302,7 +302,7 @@ VisualVM 基于 NetBeans 平台开发,因此他一开始就具备了插件扩
|
|||||||
- **dump 以及分析堆转储快照(jmap、jhat)。**
|
- **dump 以及分析堆转储快照(jmap、jhat)。**
|
||||||
- **方法级的程序运行性能分析,找到被调用最多、运行时间最长的方法。**
|
- **方法级的程序运行性能分析,找到被调用最多、运行时间最长的方法。**
|
||||||
- **离线程序快照:收集程序的运行时配置、线程 dump、内存 dump 等信息建立一个快照,可以将快照发送开发者处进行 Bug 反馈。**
|
- **离线程序快照:收集程序的运行时配置、线程 dump、内存 dump 等信息建立一个快照,可以将快照发送开发者处进行 Bug 反馈。**
|
||||||
- **其他 plugins 的无限的可能性......**
|
- **其他 plugins 的无限的可能性……**
|
||||||
|
|
||||||
这里就不具体介绍 VisualVM 的使用,如果想了解的话可以看:
|
这里就不具体介绍 VisualVM 的使用,如果想了解的话可以看:
|
||||||
|
|
||||||
|
|||||||
@ -109,8 +109,8 @@ public class GCTest {
|
|||||||
|
|
||||||
大对象直接进入老年代的行为是由虚拟机动态决定的,它与具体使用的垃圾回收器和相关参数有关。大对象直接进入老年代是一种优化策略,旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本。
|
大对象直接进入老年代的行为是由虚拟机动态决定的,它与具体使用的垃圾回收器和相关参数有关。大对象直接进入老年代是一种优化策略,旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本。
|
||||||
|
|
||||||
* G1垃圾回收器会根据-XX:G1HeapRegionSize参数设置的堆区域大小和-XX:G1MixedGCLiveThresholdPercent参数设置的阈值,来决定哪些对象会直接进入老年代。
|
* G1 垃圾回收器会根据-XX:G1HeapRegionSize参数设置的堆区域大小和-XX:G1MixedGCLiveThresholdPercent参数设置的阈值,来决定哪些对象会直接进入老年代。
|
||||||
* Parallel Scavenge垃圾回收器中,默认情况下,并没有一个固定的阈值(XX:ThresholdTolerance是动态调整的)来决定何时直接在老年代分配大对象。而是由虚拟机根据当前的堆内存情况和历史数据动态决定。
|
* Parallel Scavenge 垃圾回收器中,默认情况下,并没有一个固定的阈值(XX:ThresholdTolerance是动态调整的)来决定何时直接在老年代分配大对象。而是由虚拟机根据当前的堆内存情况和历史数据动态决定。
|
||||||
|
|
||||||
### 长期存活的对象将进入老年代
|
### 长期存活的对象将进入老年代
|
||||||
|
|
||||||
|
|||||||
@ -73,7 +73,7 @@ GC 调优策略中很重要的一条经验总结是这样说的:
|
|||||||
|
|
||||||
比如下面的参数就是设置老年代与新生代内存的比值为 1。也就是说老年代和新生代所占比值为 1:1,新生代占整个堆栈的 1/2。
|
比如下面的参数就是设置老年代与新生代内存的比值为 1。也就是说老年代和新生代所占比值为 1:1,新生代占整个堆栈的 1/2。
|
||||||
|
|
||||||
```
|
```plain
|
||||||
-XX:NewRatio=1
|
-XX:NewRatio=1
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -125,7 +125,7 @@ void MetaspaceGC::initialize() {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
相关阅读:[issue 更正:MaxMetaspaceSize 如果不指定大小的话,不会耗尽内存 #1204 ](https://github.com/Snailclimb/JavaGuide/issues/1204) 。
|
相关阅读:[issue 更正:MaxMetaspaceSize 如果不指定大小的话,不会耗尽内存 #1204](https://github.com/Snailclimb/JavaGuide/issues/1204) 。
|
||||||
|
|
||||||
## 3.垃圾收集相关
|
## 3.垃圾收集相关
|
||||||
|
|
||||||
|
|||||||
@ -151,7 +151,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||||||
|
|
||||||
1. **`java.lang.OutOfMemoryError: GC Overhead Limit Exceeded`**:当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
|
1. **`java.lang.OutOfMemoryError: GC Overhead Limit Exceeded`**:当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时,就会发生此错误。
|
||||||
2. **`java.lang.OutOfMemoryError: Java heap space`** :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过`-Xmx`参数配置,若没有特别配置,将会使用默认值,详见:[Default Java 8 max heap size](https://stackoverflow.com/questions/28272923/default-xmxsize-in-java-8-max-heap-size))
|
2. **`java.lang.OutOfMemoryError: Java heap space`** :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过`-Xmx`参数配置,若没有特别配置,将会使用默认值,详见:[Default Java 8 max heap size](https://stackoverflow.com/questions/28272923/default-xmxsize-in-java-8-max-heap-size))
|
||||||
3. ......
|
3. ……
|
||||||
|
|
||||||
### 方法区
|
### 方法区
|
||||||
|
|
||||||
|
|||||||
@ -106,7 +106,7 @@ Oracle 的 HotSpot VM 便附带两个用 C++ 实现的 JIT compiler:C1 及 C2
|
|||||||
|
|
||||||
- **线程-局部管控**:Java 10 中线程管控引入 JVM 安全点的概念,将允许在不运行全局 JVM 安全点的情况下实现线程回调,由线程本身或者 JVM 线程来执行,同时保持线程处于阻塞状态,这种方式使得停止单个线程变成可能,而不是只能启用或停止所有线程
|
- **线程-局部管控**:Java 10 中线程管控引入 JVM 安全点的概念,将允许在不运行全局 JVM 安全点的情况下实现线程回调,由线程本身或者 JVM 线程来执行,同时保持线程处于阻塞状态,这种方式使得停止单个线程变成可能,而不是只能启用或停止所有线程
|
||||||
- **备用存储装置上的堆分配**:Java 10 中将使得 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配
|
- **备用存储装置上的堆分配**:Java 10 中将使得 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
|
|||||||
@ -121,7 +121,7 @@ Consumer<String> consumer = (String i) -> System.out.println(i);
|
|||||||
- **低开销的 Heap Profiling**:Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息
|
- **低开销的 Heap Profiling**:Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息
|
||||||
- **TLS1.3 协议**:Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升
|
- **TLS1.3 协议**:Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升
|
||||||
- **飞行记录器(Java Flight Recorder)**:飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了。
|
- **飞行记录器(Java Flight Recorder)**:飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
|
|||||||
@ -24,7 +24,7 @@ System.out.println(text);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Java
|
Java
|
||||||
Java
|
Java
|
||||||
```
|
```
|
||||||
@ -82,7 +82,7 @@ System.out.println(result);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
1K
|
1K
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -182,7 +182,7 @@ System.out.println(encodedString);
|
|||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
0Hc0lxxASZNvS52WsvnncJOH/mlFhnA8Tc6D/k5DtAX5BSsNVjtPF4R4+yMWXVjrvB2mxVXmChIbki6goFBgAg==
|
0Hc0lxxASZNvS52WsvnncJOH/mlFhnA8Tc6D/k5DtAX5BSsNVjtPF4R4+yMWXVjrvB2mxVXmChIbki6goFBgAg==
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -238,6 +238,6 @@ Java 15 并没有对此特性进行调整,继续预览特性,主要用于接
|
|||||||
- **Nashorn JavaScript 引擎彻底移除**:Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性。在 Java 11 中就已经被弃用,到了 Java 15 就彻底被删除了。
|
- **Nashorn JavaScript 引擎彻底移除**:Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性。在 Java 11 中就已经被弃用,到了 Java 15 就彻底被删除了。
|
||||||
- **DatagramSocket API 重构**
|
- **DatagramSocket API 重构**
|
||||||
- **禁用和废弃偏向锁(Biased Locking)**:偏向锁的引入增加了 JVM 的复杂性大于其带来的性能提升。不过,你仍然可以使用 `-XX:+UseBiasedLocking` 启用偏向锁定,但它会提示 这是一个已弃用的 API。
|
- **禁用和废弃偏向锁(Biased Locking)**:偏向锁的引入增加了 JVM 的复杂性大于其带来的性能提升。不过,你仍然可以使用 `-XX:+UseBiasedLocking` 启用偏向锁定,但它会提示 这是一个已弃用的 API。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
<!-- @include: @article-footer.snippet.md -->
|
<!-- @include: @article-footer.snippet.md -->
|
||||||
@ -69,7 +69,7 @@ public void inc(Integer count) {
|
|||||||
|
|
||||||
引入外部内存访问 API 以允许 Java 程序安全有效地访问 Java 堆之外的外部内存。
|
引入外部内存访问 API 以允许 Java 程序安全有效地访问 Java 堆之外的外部内存。
|
||||||
|
|
||||||
Java 14([ JEP 370](https://openjdk.org/jeps/370)) 的时候,第一次孵化外部内存访问 API,Java 15 中进行了第二次复活([JEP 383](https://openjdk.org/jeps/383)),在 Java 16 中进行了第三次孵化。
|
Java 14([JEP 370](https://openjdk.org/jeps/370)) 的时候,第一次孵化外部内存访问 API,Java 15 中进行了第二次复活([JEP 383](https://openjdk.org/jeps/383)),在 Java 16 中进行了第三次孵化。
|
||||||
|
|
||||||
引入外部内存访问 API 的目的如下:
|
引入外部内存访问 API 的目的如下:
|
||||||
|
|
||||||
|
|||||||
@ -29,7 +29,7 @@ Java 17 将是继 Java 8 以来最重要的长期支持(LTS)版本,是 Jav
|
|||||||
- [JEP 410:Remove the Experimental AOT and JIT Compiler(删除实验性的 AOT 和 JIT 编译器)](https://openjdk.java.net/jeps/410)
|
- [JEP 410:Remove the Experimental AOT and JIT Compiler(删除实验性的 AOT 和 JIT 编译器)](https://openjdk.java.net/jeps/410)
|
||||||
- [JEP 411:Deprecate the Security Manager for Removal(弃用安全管理器以进行删除)](https://openjdk.java.net/jeps/411)
|
- [JEP 411:Deprecate the Security Manager for Removal(弃用安全管理器以进行删除)](https://openjdk.java.net/jeps/411)
|
||||||
- [JEP 412:Foreign Function & Memory API (外部函数和内存 API)](https://openjdk.java.net/jeps/412)(孵化)
|
- [JEP 412:Foreign Function & Memory API (外部函数和内存 API)](https://openjdk.java.net/jeps/412)(孵化)
|
||||||
- [JEP 414:Vector(向量) API ](https://openjdk.java.net/jeps/417)(第二次孵化)
|
- [JEP 414:Vector(向量) API](https://openjdk.java.net/jeps/417)(第二次孵化)
|
||||||
- [JEP 415:Context-Specific Deserialization Filters](https://openjdk.java.net/jeps/415)
|
- [JEP 415:Context-Specific Deserialization Filters](https://openjdk.java.net/jeps/415)
|
||||||
|
|
||||||
这里只对 356、398、413、406、407、409、410、411、412、414 这几个我觉得比较重要的新特性进行详细介绍。
|
这里只对 356、398、413、406、407、409、410、411、412、414 这几个我觉得比较重要的新特性进行详细介绍。
|
||||||
@ -161,7 +161,7 @@ Java 17,删除实验性的提前 (AOT) 和即时 (JIT) 编译器,因为该
|
|||||||
|
|
||||||
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
||||||
|
|
||||||
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。第二轮孵化由[ JEP 419](https://openjdk.org/jeps/419) 提出并集成到了 Java 18 中,预览由 [JEP 424](https://openjdk.org/jeps/424) 提出并集成到了 Java 19 中。
|
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。第二轮孵化由[JEP 419](https://openjdk.org/jeps/419) 提出并集成到了 Java 18 中,预览由 [JEP 424](https://openjdk.org/jeps/424) 提出并集成到了 Java 19 中。
|
||||||
|
|
||||||
在 [Java 19 新特性概览](./java19.md) 中,我有详细介绍到外部函数和内存 API,这里就不再做额外的介绍了。
|
在 [Java 19 新特性概览](./java19.md) 中,我有详细介绍到外部函数和内存 API,这里就不再做额外的介绍了。
|
||||||
|
|
||||||
|
|||||||
@ -13,7 +13,7 @@ Java 18 带来了 9 个新特性:
|
|||||||
- [JEP 408:Simple Web Server(简易的 Web 服务器)](https://openjdk.java.net/jeps/408)
|
- [JEP 408:Simple Web Server(简易的 Web 服务器)](https://openjdk.java.net/jeps/408)
|
||||||
- [JEP 413:Code Snippets in Java API Documentation(Java API 文档中的代码片段)](https://openjdk.java.net/jeps/413)
|
- [JEP 413:Code Snippets in Java API Documentation(Java API 文档中的代码片段)](https://openjdk.java.net/jeps/413)
|
||||||
- [JEP 416:Reimplement Core Reflection with Method Handles(使用方法句柄重新实现反射核心)](https://openjdk.java.net/jeps/416)
|
- [JEP 416:Reimplement Core Reflection with Method Handles(使用方法句柄重新实现反射核心)](https://openjdk.java.net/jeps/416)
|
||||||
- [JEP 417:Vector(向量) API ](https://openjdk.java.net/jeps/417)(第三次孵化)
|
- [JEP 417:Vector(向量) API](https://openjdk.java.net/jeps/417)(第三次孵化)
|
||||||
- [JEP 418:Internet-Address Resolution(互联网地址解析)SPI](https://openjdk.java.net/jeps/418)
|
- [JEP 418:Internet-Address Resolution(互联网地址解析)SPI](https://openjdk.java.net/jeps/418)
|
||||||
- [JEP 419:Foreign Function & Memory API(外部函数和内存 API)](https://openjdk.java.net/jeps/419)(第二次孵化)
|
- [JEP 419:Foreign Function & Memory API(外部函数和内存 API)](https://openjdk.java.net/jeps/419)(第二次孵化)
|
||||||
- [JEP 420:Pattern Matching for switch(switch 模式匹配)](https://openjdk.java.net/jeps/420)(第二次预览)
|
- [JEP 420:Pattern Matching for switch(switch 模式匹配)](https://openjdk.java.net/jeps/420)(第二次预览)
|
||||||
@ -134,7 +134,7 @@ Java 18 定义了一个全新的 SPI(service-provider interface),用于主
|
|||||||
|
|
||||||
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
||||||
|
|
||||||
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。第二轮孵化由[ JEP 419](https://openjdk.org/jeps/419) 提出并集成到了 Java 18 中,预览由 [JEP 424](https://openjdk.org/jeps/424) 提出并集成到了 Java 19 中。
|
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。第二轮孵化由[JEP 419](https://openjdk.org/jeps/419) 提出并集成到了 Java 18 中,预览由 [JEP 424](https://openjdk.org/jeps/424) 提出并集成到了 Java 19 中。
|
||||||
|
|
||||||
在 [Java 19 新特性概览](./java19.md) 中,我有详细介绍到外部函数和内存 API,这里就不再做额外的介绍了。
|
在 [Java 19 新特性概览](./java19.md) 中,我有详细介绍到外部函数和内存 API,这里就不再做额外的介绍了。
|
||||||
|
|
||||||
|
|||||||
@ -25,7 +25,7 @@ JDK 19 只有 7 个新特性:
|
|||||||
|
|
||||||
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
||||||
|
|
||||||
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。第二轮孵化由[ JEP 419](https://openjdk.org/jeps/419) 提出并集成到了 Java 18 中,预览由 [JEP 424](https://openjdk.org/jeps/424) 提出并集成到了 Java 19 中。
|
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。第二轮孵化由[JEP 419](https://openjdk.org/jeps/419) 提出并集成到了 Java 18 中,预览由 [JEP 424](https://openjdk.org/jeps/424) 提出并集成到了 Java 19 中。
|
||||||
|
|
||||||
在没有外部函数和内存 API 之前:
|
在没有外部函数和内存 API 之前:
|
||||||
|
|
||||||
|
|||||||
@ -196,7 +196,7 @@ static String formatterPatternSwitch(Object o) {
|
|||||||
|
|
||||||
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
Java 程序可以通过该 API 与 Java 运行时之外的代码和数据进行互操作。通过高效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不受 JVM 管理的内存),该 API 使 Java 程序能够调用本机库并处理本机数据,而不会像 JNI 那样危险和脆弱。
|
||||||
|
|
||||||
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。Java 18 中进行了第二次孵化,由[ JEP 419](https://openjdk.org/jeps/419) 提出。Java 19 中是第一次预览,由 [JEP 424](https://openjdk.org/jeps/424) 提出。
|
外部函数和内存 API 在 Java 17 中进行了第一轮孵化,由 [JEP 412](https://openjdk.java.net/jeps/412) 提出。Java 18 中进行了第二次孵化,由[JEP 419](https://openjdk.org/jeps/419) 提出。Java 19 中是第一次预览,由 [JEP 424](https://openjdk.org/jeps/424) 提出。
|
||||||
|
|
||||||
JDK 20 中是第二次预览,由 [JEP 434](https://openjdk.org/jeps/434) 提出,这次的改进包括:
|
JDK 20 中是第二次预览,由 [JEP 434](https://openjdk.org/jeps/434) 提出,这次的改进包括:
|
||||||
|
|
||||||
@ -247,7 +247,7 @@ Java 19 引入了结构化并发,一种多线程编程方法,目的是为了
|
|||||||
|
|
||||||
结构化并发非常适合虚拟线程,虚拟线程是 JDK 实现的轻量级线程。许多虚拟线程共享同一个操作系统线程,从而允许非常多的虚拟线程。
|
结构化并发非常适合虚拟线程,虚拟线程是 JDK 实现的轻量级线程。许多虚拟线程共享同一个操作系统线程,从而允许非常多的虚拟线程。
|
||||||
|
|
||||||
JDK 20 中对结构化并发唯一变化是更新为支持在任务范围内创建的线程`StructuredTaskScope`继承范围值 这简化了跨线程共享不可变数据,详见[JEP 429 ](https://openjdk.org/jeps/429)。
|
JDK 20 中对结构化并发唯一变化是更新为支持在任务范围内创建的线程`StructuredTaskScope`继承范围值 这简化了跨线程共享不可变数据,详见[JEP 429](https://openjdk.org/jeps/429)。
|
||||||
|
|
||||||
## JEP 432:向量 API(第五次孵化)
|
## JEP 432:向量 API(第五次孵化)
|
||||||
|
|
||||||
|
|||||||
@ -5,21 +5,19 @@ tag:
|
|||||||
- Java新特性
|
- Java新特性
|
||||||
---
|
---
|
||||||
|
|
||||||
JDK 21 于 2023年9月19日 发布,这是一个非常重要的版本,里程碑式。
|
JDK 21 于 2023 年 9 月 19 日 发布,这是一个非常重要的版本,里程碑式。
|
||||||
|
|
||||||
JDK21是 LTS(长期支持版),至此为止,目前有 JDK8、JDK11、JDK17和 JDK21这四个长期支持版了。
|
JDK21 是 LTS(长期支持版),至此为止,目前有 JDK8、JDK11、JDK17 和 JDK21 这四个长期支持版了。
|
||||||
|
|
||||||
JDK 21 共有 15 个新特性:
|
JDK 21 共有 15 个新特性:
|
||||||
|
|
||||||
- [JEP 430:String Templates(字符串模板)](https://openjdk.org/jeps/430)(预览)
|
- [JEP 430:String Templates(字符串模板)](https://openjdk.org/jeps/430)(预览)
|
||||||
- [JEP 431:Sequenced Collections(序列化集合)](https://openjdk.org/jeps/431)
|
- [JEP 431:Sequenced Collections(序列化集合)](https://openjdk.org/jeps/431)
|
||||||
|
|
||||||
- [JEP 439:Generational ZGC(分代ZGC)](https://openjdk.org/jeps/439)
|
- [JEP 439:Generational ZGC(分代 ZGC)](https://openjdk.org/jeps/439)
|
||||||
|
|
||||||
- [JEP 440:Record Patterns(记录模式)](https://openjdk.org/jeps/440)
|
- [JEP 440:Record Patterns(记录模式)](https://openjdk.org/jeps/440)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## JEP 430:字符串模板(预览)
|
## JEP 430:字符串模板(预览)
|
||||||
|
|
||||||
String Templates(字符串模板) 目前仍然是 JDK 21 中的一个预览功能。
|
String Templates(字符串模板) 目前仍然是 JDK 21 中的一个预览功能。
|
||||||
@ -67,8 +65,8 @@ String message = STR."Greetings \{name}!";
|
|||||||
Java 目前支持三种模板处理器:
|
Java 目前支持三种模板处理器:
|
||||||
|
|
||||||
- STR:自动执行字符串插值,即将模板中的每个嵌入式表达式替换为其值(转换为字符串)。
|
- STR:自动执行字符串插值,即将模板中的每个嵌入式表达式替换为其值(转换为字符串)。
|
||||||
- FMT:和STR类似,但是它还可以接受格式说明符,这些格式说明符出现在嵌入式表达式的左边,用来控制输出的样式
|
- FMT:和 STR 类似,但是它还可以接受格式说明符,这些格式说明符出现在嵌入式表达式的左边,用来控制输出的样式
|
||||||
- RAW:不会像STR和FMT模板处理器那样自动处理字符串模板,而是返回一个 `StringTemplate` 对象,这个对象包含了模板中的文本和表达式的信息
|
- RAW:不会像 STR 和 FMT 模板处理器那样自动处理字符串模板,而是返回一个 `StringTemplate` 对象,这个对象包含了模板中的文本和表达式的信息
|
||||||
|
|
||||||
```java
|
```java
|
||||||
String name = "Lokesh";
|
String name = "Lokesh";
|
||||||
@ -84,7 +82,7 @@ StringTemplate st = RAW."Greetings \{name}.";
|
|||||||
String message = STR.process(st);
|
String message = STR.process(st);
|
||||||
```
|
```
|
||||||
|
|
||||||
除了JDK自带的三种模板处理器外,你还可以实现 `StringTemplate.Processor` 接口来创建自己的模板处理器。
|
除了 JDK 自带的三种模板处理器外,你还可以实现 `StringTemplate.Processor` 接口来创建自己的模板处理器。
|
||||||
|
|
||||||
我们可以使用局部变量、静态/非静态字段甚至方法作为嵌入表达式:
|
我们可以使用局部变量、静态/非静态字段甚至方法作为嵌入表达式:
|
||||||
|
|
||||||
@ -119,22 +117,22 @@ String time = STR."The current time is \{
|
|||||||
|
|
||||||
## JEP431:序列化集合
|
## JEP431:序列化集合
|
||||||
|
|
||||||
JDK 21引入了一种新的集合类型:**Sequenced Collections(序列化集合)**。
|
JDK 21 引入了一种新的集合类型:**Sequenced Collections(序列化集合)**。
|
||||||
|
|
||||||
## JEP 439:分代ZGC
|
## JEP 439:分代 ZGC
|
||||||
|
|
||||||
JDK21中对 ZGC 进行了功能扩展,增加了分代 GC 功能。不过,默认是关闭的,需要通过配置打开:
|
JDK21 中对 ZGC 进行了功能扩展,增加了分代 GC 功能。不过,默认是关闭的,需要通过配置打开:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
// 启用分代ZGC
|
// 启用分代ZGC
|
||||||
java -XX:+UseZGC -XX:+ZGenerational ...
|
java -XX:+UseZGC -XX:+ZGenerational ...
|
||||||
```
|
```
|
||||||
|
|
||||||
在未来的版本中,官方会把 ZGenerational 设为默认值,即默认打开 ZGC 的分代 GC。在更晚的版本中,非分代ZGC就被移除。
|
在未来的版本中,官方会把 ZGenerational 设为默认值,即默认打开 ZGC 的分代 GC。在更晚的版本中,非分代 ZGC 就被移除。
|
||||||
|
|
||||||
> In a future release we intend to make Generational ZGC the default, at which point -XX:-ZGenerational will select non-generational ZGC. In an even later release we intend to remove non-generational ZGC, at which point the ZGenerational option will become obsolete.
|
> In a future release we intend to make Generational ZGC the default, at which point -XX:-ZGenerational will select non-generational ZGC. In an even later release we intend to remove non-generational ZGC, at which point the ZGenerational option will become obsolete.
|
||||||
>
|
>
|
||||||
> 在将来的版本中,我们打算将Generational ZGC作为默认选项,此时-XX:-ZGenerational将选择非分代ZGC。在更晚的版本中,我们打算移除非分代ZGC,此时ZGenerational选项将变得过时。
|
> 在将来的版本中,我们打算将 Generational ZGC 作为默认选项,此时-XX:-ZGenerational 将选择非分代 ZGC。在更晚的版本中,我们打算移除非分代 ZGC,此时 ZGenerational 选项将变得过时。
|
||||||
|
|
||||||
分代 ZGC 可以显著减少垃圾回收过程中的停顿时间,并提高应用程序的响应性能。这对于大型 Java 应用程序和高并发场景下的性能优化非常有价值。
|
分代 ZGC 可以显著减少垃圾回收过程中的停顿时间,并提高应用程序的响应性能。这对于大型 Java 应用程序和高并发场景下的性能优化非常有价值。
|
||||||
|
|
||||||
@ -147,4 +145,4 @@ java -XX:+UseZGC -XX:+ZGenerational ...
|
|||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- Java 21 String Templates:<https://howtodoinjava.com/java/java-string-templates/>
|
- Java 21 String Templates:<https://howtodoinjava.com/java/java-string-templates/>
|
||||||
-
|
|
||||||
|
|||||||
@ -642,7 +642,7 @@ public class MapAndFlatMapExample {
|
|||||||
|
|
||||||
运行结果:
|
运行结果:
|
||||||
|
|
||||||
```
|
```plain
|
||||||
Using map:
|
Using map:
|
||||||
[[APPLE, BANANA, CHERRY], [ORANGE, GRAPE, PEAR], [KIWI, MELON, PINEAPPLE]]
|
[[APPLE, BANANA, CHERRY], [ORANGE, GRAPE, PEAR], [KIWI, MELON, PINEAPPLE]]
|
||||||
|
|
||||||
|
|||||||
@ -66,7 +66,7 @@ Collections.sort(names, new Comparator<String>() {
|
|||||||
});
|
});
|
||||||
```
|
```
|
||||||
|
|
||||||
只需要给静态方法` Collections.sort` 传入一个 List 对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给 `sort` 方法。
|
只需要给静态方法`Collections.sort` 传入一个 List 对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给 `sort` 方法。
|
||||||
|
|
||||||
在 Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8 提供了更简洁的语法,lambda 表达式:
|
在 Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8 提供了更简洁的语法,lambda 表达式:
|
||||||
|
|
||||||
@ -398,7 +398,7 @@ optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b"
|
|||||||
|
|
||||||
## Streams(流)
|
## Streams(流)
|
||||||
|
|
||||||
`java.util.Stream` 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回 Stream 本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如` java.util.Collection` 的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。
|
`java.util.Stream` 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回 Stream 本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如`java.util.Collection` 的子类,List 或者 Set, Map 不支持。Stream 的操作可以串行执行或者并行执行。
|
||||||
|
|
||||||
首先看看 Stream 是怎么用,首先创建实例代码需要用到的数据 List:
|
首先看看 Stream 是怎么用,首先创建实例代码需要用到的数据 List:
|
||||||
|
|
||||||
@ -572,7 +572,7 @@ long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
|
|||||||
System.out.println(String.format("sequential sort took: %d ms", millis));
|
System.out.println(String.format("sequential sort took: %d ms", millis));
|
||||||
```
|
```
|
||||||
|
|
||||||
```
|
```plain
|
||||||
1000000
|
1000000
|
||||||
sequential sort took: 709 ms//串行排序所用的时间
|
sequential sort took: 709 ms//串行排序所用的时间
|
||||||
```
|
```
|
||||||
@ -884,7 +884,7 @@ Hint[] hints2 = Person.class.getAnnotationsByType(Hint.class);
|
|||||||
System.out.println(hints2.length); // 2
|
System.out.println(hints2.length); // 2
|
||||||
```
|
```
|
||||||
|
|
||||||
即便我们没有在 `Person`类上定义 `@Hints`注解,我们还是可以通过 `getAnnotation(Hints.class) `来获取 `@Hints`注解,更加方便的方法是使用 `getAnnotationsByType` 可以直接获取到所有的`@Hint`注解。
|
即便我们没有在 `Person`类上定义 `@Hints`注解,我们还是可以通过 `getAnnotation(Hints.class)`来获取 `@Hints`注解,更加方便的方法是使用 `getAnnotationsByType` 可以直接获取到所有的`@Hint`注解。
|
||||||
另外 Java 8 的注解还增加到两种新的 target 上了:
|
另外 Java 8 的注解还增加到两种新的 target 上了:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
|
|||||||
@ -5,7 +5,7 @@ tag:
|
|||||||
- Java新特性
|
- Java新特性
|
||||||
---
|
---
|
||||||
|
|
||||||
**Java 9** 发布于 2017 年 9 月 21 日 。作为 Java 8 之后 3 年半才发布的新版本,Java 9 带来了很多重大的变化其中最重要的改动是 Java 平台模块系统的引入,其他还有诸如集合、`Stream` 流......。
|
**Java 9** 发布于 2017 年 9 月 21 日 。作为 Java 8 之后 3 年半才发布的新版本,Java 9 带来了很多重大的变化其中最重要的改动是 Java 平台模块系统的引入,其他还有诸如集合、`Stream` 流……。
|
||||||
|
|
||||||
你可以在 [Archived OpenJDK General-Availability Releases](http://jdk.java.net/archive/) 上下载自己需要的 JDK 版本!官方的新特性说明文档地址:https://openjdk.java.net/projects/jdk/ 。
|
你可以在 [Archived OpenJDK General-Availability Releases](http://jdk.java.net/archive/) 上下载自己需要的 JDK 版本!官方的新特性说明文档地址:https://openjdk.java.net/projects/jdk/ 。
|
||||||
|
|
||||||
@ -29,14 +29,14 @@ JShell 是 Java 9 新增的一个实用工具。为 Java 提供了类似于 Pyth
|
|||||||
|
|
||||||
1. 降低了输出第一行 Java 版"Hello World!"的门槛,能够提高新手的学习热情。
|
1. 降低了输出第一行 Java 版"Hello World!"的门槛,能够提高新手的学习热情。
|
||||||
2. 在处理简单的小逻辑,验证简单的小问题时,比 IDE 更有效率(并不是为了取代 IDE,对于复杂逻辑的验证,IDE 更合适,两者互补)。
|
2. 在处理简单的小逻辑,验证简单的小问题时,比 IDE 更有效率(并不是为了取代 IDE,对于复杂逻辑的验证,IDE 更合适,两者互补)。
|
||||||
3. ......
|
3. ……
|
||||||
|
|
||||||
**JShell 的代码和普通的可编译代码,有什么不一样?**
|
**JShell 的代码和普通的可编译代码,有什么不一样?**
|
||||||
|
|
||||||
1. 一旦语句输入完成,JShell 立即就能返回执行的结果,而不再需要编辑器、编译器、解释器。
|
1. 一旦语句输入完成,JShell 立即就能返回执行的结果,而不再需要编辑器、编译器、解释器。
|
||||||
2. JShell 支持变量的重复声明,后面声明的会覆盖前面声明的。
|
2. JShell 支持变量的重复声明,后面声明的会覆盖前面声明的。
|
||||||
3. JShell 支持独立的表达式比如普通的加法运算 `1 + 1`。
|
3. JShell 支持独立的表达式比如普通的加法运算 `1 + 1`。
|
||||||
4. ......
|
4. ……
|
||||||
|
|
||||||
## 模块化系统
|
## 模块化系统
|
||||||
|
|
||||||
@ -230,7 +230,7 @@ System.out.println(currentProcess.info());
|
|||||||
|
|
||||||
`Flow` 中包含了 `Flow.Publisher`、`Flow.Subscriber`、`Flow.Subscription` 和 `Flow.Processor` 等 4 个核心接口。Java 9 还提供了`SubmissionPublisher` 作为`Flow.Publisher` 的一个实现。
|
`Flow` 中包含了 `Flow.Publisher`、`Flow.Subscriber`、`Flow.Subscription` 和 `Flow.Processor` 等 4 个核心接口。Java 9 还提供了`SubmissionPublisher` 作为`Flow.Publisher` 的一个实现。
|
||||||
|
|
||||||
关于 Java 9 响应式流更详细的解读,推荐你看 [Java 9 揭秘(17. Reactive Streams )- 林本托 ](https://www.cnblogs.com/IcanFixIt/p/7245377.html) 这篇文章。
|
关于 Java 9 响应式流更详细的解读,推荐你看 [Java 9 揭秘(17. Reactive Streams )- 林本托](https://www.cnblogs.com/IcanFixIt/p/7245377.html) 这篇文章。
|
||||||
|
|
||||||
## 变量句柄
|
## 变量句柄
|
||||||
|
|
||||||
@ -248,7 +248,7 @@ System.out.println(currentProcess.info());
|
|||||||
- **I/O 流的新特性**:增加了新的方法来读取和复制 `InputStream` 中包含的数据。
|
- **I/O 流的新特性**:增加了新的方法来读取和复制 `InputStream` 中包含的数据。
|
||||||
- **改进应用的安全性能**:Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 SHA3-512。
|
- **改进应用的安全性能**:Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 SHA3-512。
|
||||||
- **改进方法句柄(Method Handle)**:方法句柄从 Java7 开始引入,Java9 在类`java.lang.invoke.MethodHandles` 中新增了更多的静态方法来创建不同类型的方法句柄。
|
- **改进方法句柄(Method Handle)**:方法句柄从 Java7 开始引入,Java9 在类`java.lang.invoke.MethodHandles` 中新增了更多的静态方法来创建不同类型的方法句柄。
|
||||||
- ......
|
- ……
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user