mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-10 00:41:37 +08:00
commit
60d2075884
@ -29,7 +29,7 @@ tag:
|
||||
|
||||
简单来说 MySQL 主要分为 Server 层和存储引擎层:
|
||||
|
||||
- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binglog 日志模块。
|
||||
- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binlog 日志模块。
|
||||
- **存储引擎**: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了。**
|
||||
|
||||
### 1.2 Server 层基本组件介绍
|
||||
@ -114,10 +114,10 @@ update tb_student A set A.age='19' where A.name=' 张三 ';
|
||||
|
||||
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
|
||||
|
||||
* **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 bingog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
|
||||
* **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
|
||||
* **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
|
||||
|
||||
如果采用 redo log 两阶段提交的方式就不一样了,写完 binglog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binglog 也已经写完了,这个时候发生了异常重启会怎么样呢?
|
||||
如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢?
|
||||
这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
|
||||
|
||||
* 判断 redo log 是否完整,如果判断是完整的,就立即提交。
|
||||
|
||||
@ -210,7 +210,7 @@ tag:
|
||||
|
||||
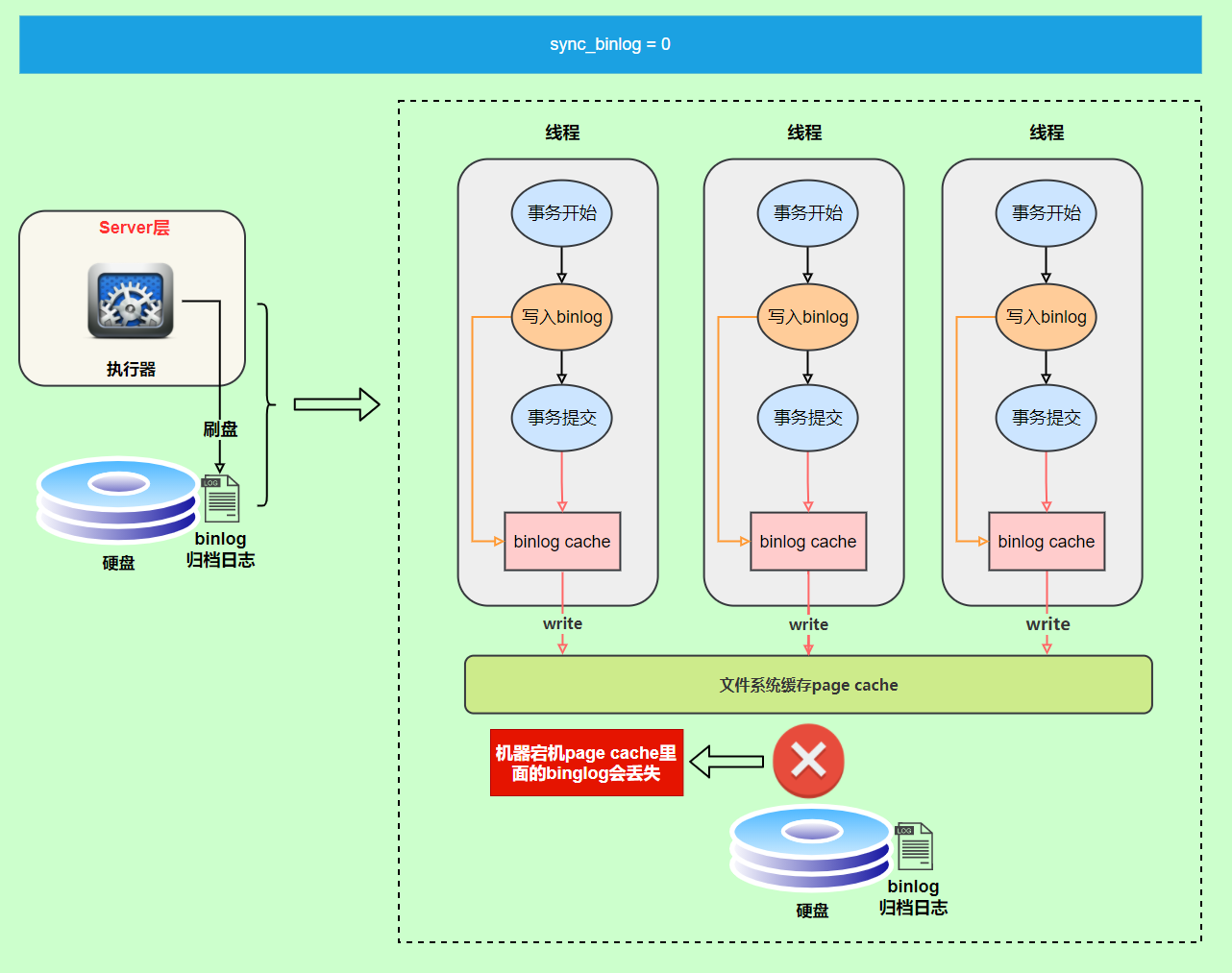
|
||||
|
||||
虽然性能得到提升,但是机器宕机,`page cache`里面的 binglog 会丢失。
|
||||
虽然性能得到提升,但是机器宕机,`page cache`里面的 binlog 会丢失。
|
||||
|
||||
为了安全起见,可以设置为`1`,表示每次提交事务都会执行`fsync`,就如同**binlog 日志刷盘流程**一样。
|
||||
|
||||
|
||||
@ -34,7 +34,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
**区别** :
|
||||
|
||||
1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
|
||||
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。**
|
||||
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memcached 把数据全部存在内存之中。**
|
||||
3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
|
||||
4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
|
||||
5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的。**
|
||||
|
||||
@ -181,9 +181,9 @@ OK
|
||||
"2"
|
||||
```
|
||||
|
||||
为了提高可用性和并发,我们可以使用 Redis Cluser。Redis Cluser 是 Redis 官方提供的 Redis 集群解决方案(3.0+版本)。
|
||||
为了提高可用性和并发,我们可以使用 Redis Cluster。Redis Cluster 是 Redis 官方提供的 Redis 集群解决方案(3.0+版本)。
|
||||
|
||||
除了 Redis Cluser 之外,你也可以使用开源的 Redis 集群方案[Codis](https://github.com/CodisLabs/codis) (大规模集群比如上百个节点的时候比较推荐)。
|
||||
除了 Redis Cluster 之外,你也可以使用开源的 Redis 集群方案[Codis](https://github.com/CodisLabs/codis) (大规模集群比如上百个节点的时候比较推荐)。
|
||||
|
||||
除了高可用和并发之外,我们知道 Redis 基于内存,我们需要持久化数据,避免重启机器或者机器故障后数据丢失。Redis 支持两种不同的持久化方式:**快照(snapshotting,RDB)**、**只追加文件(append-only file, AOF)**。 并且,Redis 4.0 开始支持 **RDB 和 AOF 的混合持久化**(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
|
||||
|
||||
|
||||
@ -145,6 +145,6 @@ GitHub Actions 有一个官方市场,上面有非常多别人提交的 Actions
|
||||
|
||||
## 后记
|
||||
|
||||
这一篇文章,我毫无保留地把自己这些年总结的 Github 小技巧分享了出来,真心希望对大家有帮助,真心希望大家一定要利用好 Gihub 这个专属程序员的宝藏。
|
||||
这一篇文章,我毫无保留地把自己这些年总结的 Github 小技巧分享了出来,真心希望对大家有帮助,真心希望大家一定要利用好 Github 这个专属程序员的宝藏。
|
||||
|
||||
另外,这篇文章中,我并没有提到 Github 搜索技巧。在我看来,Github 搜索技巧不必要记网上那些文章说的各种命令啥的,真没啥卵用。你会发现你用的最多的还是关键字搜索以及 Github 自带的筛选功能。
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user