mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]进一步完善jvm类加载器部分的内容
This commit is contained in:
parent
1742c14080
commit
5af33e9c33
@ -196,11 +196,17 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **IO 多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本)。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
|
- **多路复用(Multiplexing)**:HTTP/2.0 在同一连接上可以同时传输多个请求和响应(可以看作是 HTTP/1.1 中长链接的升级版本),互不干扰。HTTP/1.1 则使用串行方式,每个请求和响应都需要独立的连接,而浏览器为了控制资源会有 6-8 个 TCP 连接都限制。。这使得 HTTP/2.0 在处理多个请求时更加高效,减少了网络延迟和提高了性能。
|
||||||
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
|
- **二进制帧(Binary Frames)**:HTTP/2.0 使用二进制帧进行数据传输,而 HTTP/1.1 则使用文本格式的报文。二进制帧更加紧凑和高效,减少了传输的数据量和带宽消耗。
|
||||||
- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,减少了网络开销。
|
- **头部压缩(Header Compression)**:HTTP/1.1 支持`Body`压缩,`Header`不支持压缩。HTTP/2.0 支持对`Header`压缩,使用了专门为`Header`压缩而设计的 HPACK 算法,减少了网络开销。
|
||||||
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
|
- **服务器推送(Server Push)**:HTTP/2.0 支持服务器推送,可以在客户端请求一个资源时,将其他相关资源一并推送给客户端,从而减少了客户端的请求次数和延迟。而 HTTP/1.1 需要客户端自己发送请求来获取相关资源。
|
||||||
|
|
||||||
|
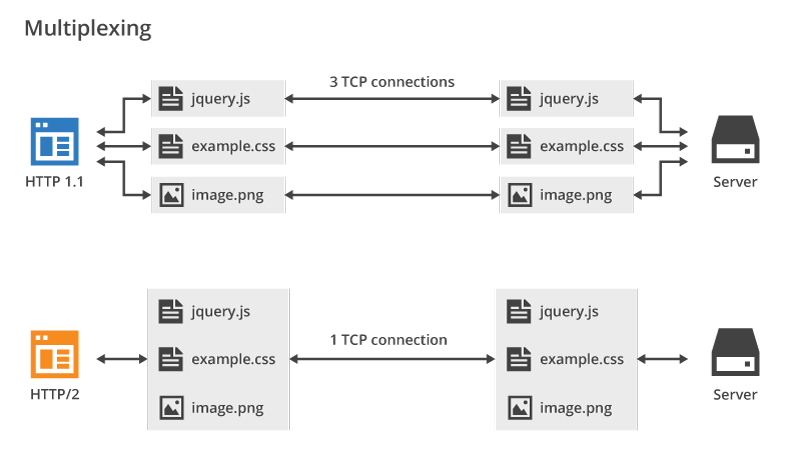
HTTP/2.0 多路复用效果图(图源: [HTTP/2 For Web Developers](https://blog.cloudflare.com/http-2-for-web-developers/)):
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
可以看到,HTTP/2.0 的多路复用使得不同的请求可以共用一个 TCP 连接,避免建立多个连接带来不必要的额外开销,而 HTTP/1.1 中的每个请求都会建立一个单独的连接
|
||||||
|
|
||||||
### HTTP/2.0 和 HTTP/3.0 有什么区别?
|
### HTTP/2.0 和 HTTP/3.0 有什么区别?
|
||||||
|
|
||||||

|

|
||||||
@ -211,6 +217,12 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||||||
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
|
- **错误恢复**:HTTP/3.0 具有更好的错误恢复机制,当出现丢包、延迟等网络问题时,可以更快地进行恢复和重传。而 HTTP/2.0 则需要依赖于 TCP 的错误恢复机制。
|
||||||
- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
|
- **安全性**:HTTP/2.0 和 HTTP/3.0 在安全性上都有较高的要求,支持加密通信,但在实现上有所不同。HTTP/2.0 使用 TLS 协议进行加密,而 HTTP/3.0 基于 QUIC 协议,包含了内置的加密和身份验证机制,可以提供更强的安全性。
|
||||||
|
|
||||||
|
HTTP/1.0、HTTP/2.0 和 HTTP/3.0 的协议栈比较:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
关于 HTTP/1.0 -> HTTP/3.0 更详细的演进介绍,推荐阅读[HTTP1 到 HTTP3 的工程优化](https://dbwu.tech/posts/http_evolution/)。
|
||||||
|
|
||||||
### HTTP 是不保存状态的协议, 如何保存用户状态?
|
### HTTP 是不保存状态的协议, 如何保存用户状态?
|
||||||
|
|
||||||
HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们如何保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
|
HTTP 是一种不保存状态,即无状态(stateless)协议。也就是说 HTTP 协议自身不对请求和响应之间的通信状态进行保存。那么我们如何保存用户状态呢?Session 机制的存在就是为了解决这个问题,Session 的主要作用就是通过服务端记录用户的状态。典型的场景是购物车,当你要添加商品到购物车的时候,系统不知道是哪个用户操作的,因为 HTTP 协议是无状态的。服务端给特定的用户创建特定的 Session 之后就可以标识这个用户并且跟踪这个用户了(一般情况下,服务器会在一定时间内保存这个 Session,过了时间限制,就会销毁这个 Session)。
|
||||||
|
|||||||
@ -7,7 +7,7 @@ tag:
|
|||||||
|
|
||||||
> 作者: 听风 原文地址: <https://www.cnblogs.com/huchong/p/10219318.html>。
|
> 作者: 听风 原文地址: <https://www.cnblogs.com/huchong/p/10219318.html>。
|
||||||
>
|
>
|
||||||
> JavaGuide 已获得作者授权,并对原文内容进行了完善。
|
> JavaGuide 已获得作者授权,并对原文内容进行了完善补充。
|
||||||
|
|
||||||
## 数据库命名规范
|
## 数据库命名规范
|
||||||
|
|
||||||
@ -29,10 +29,7 @@ InnoDB 支持事务,支持行级锁,更好的恢复性,高并发下性能
|
|||||||
|
|
||||||
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
|
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
|
||||||
|
|
||||||
参考文章:
|
推荐阅读一下我写的这篇文章:[MySQL 字符集详解](../character-set.md) 。
|
||||||
|
|
||||||
- [MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
|
|
||||||
- [MySQL 字符集详解](../character-set.md)
|
|
||||||
|
|
||||||
### 所有表和字段都需要添加注释
|
### 所有表和字段都需要添加注释
|
||||||
|
|
||||||
@ -135,18 +132,19 @@ MySQL 内存临时表不支持 TEXT、BLOB 这样的大数据类型,如果查
|
|||||||
|
|
||||||
相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
|
相关阅读:[技术分享 | MySQL 默认值选型(是空,还是 NULL)](https://opensource.actionsky.com/20190710-mysql/) 。
|
||||||
|
|
||||||
### 使用 TIMESTAMP(4 个字节) 或 DATETIME 类型 (8 个字节) 存储时间
|
### 一定不要用字符串存储日期
|
||||||
|
|
||||||
TIMESTAMP 存储的时间范围 1970-01-01 00:00:01 ~ 2038-01-19-03:14:07
|
对于日期类型来说, 一定不要用字符串存储日期。可以考虑 DATETIME、TIMESTAMP 和 数值型时间戳。
|
||||||
|
|
||||||
TIMESTAMP 占用 4 字节和 INT 相同,但比 INT 可读性高
|
这三种种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
|
||||||
|
|
||||||
超出 TIMESTAMP 取值范围的使用 DATETIME 类型存储
|
| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
|
||||||
|
| ------------ | -------- | ------------------------------ | ------------------------------------------------------------ | -------------- |
|
||||||
|
| DATETIME | 5~8字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
|
||||||
|
| TIMESTAMP | 4~7字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
|
||||||
|
| 数值型时间戳 | 4字节 | 全数字如1578707612 | 1970-01-01 00:00:01之后的时间 | 否 |
|
||||||
|
|
||||||
**经常会有人用字符串存储日期型的数据(不正确的做法)**
|
MySQL 时间类型选择的详细介绍请看这篇:[MySQL时间类型数据存储建议](https://javaguide.cn/database/mysql/some-thoughts-on-database-storage-time.html)。
|
||||||
|
|
||||||
- 缺点 1:无法用日期函数进行计算和比较
|
|
||||||
- 缺点 2:用字符串存储日期要占用更多的空间
|
|
||||||
|
|
||||||
### 同财务相关的金额类数据必须使用 decimal 类型
|
### 同财务相关的金额类数据必须使用 decimal 类型
|
||||||
|
|
||||||
@ -230,9 +228,13 @@ InnoDB 是按照主键索引的顺序来组织表的
|
|||||||
|
|
||||||
## 数据库 SQL 开发规范
|
## 数据库 SQL 开发规范
|
||||||
|
|
||||||
|
### 尽量不在数据库做运算,复杂运算需移到业务应用里完成
|
||||||
|
|
||||||
|
尽量不在数据库做运算,复杂运算需移到业务应用里完成。这样可以避免数据库的负担过重,影响数据库的性能和稳定性。数据库的主要作用是存储和管理数据,而不是处理数据。
|
||||||
|
|
||||||
### 优化对性能影响较大的 SQL 语句
|
### 优化对性能影响较大的 SQL 语句
|
||||||
|
|
||||||
要找到最需要优化的 SQL 语句。要么是使用最频繁的语句,要么是优化后提高最明显的语句,可以通过查询 MySQL 的慢查询日志来发现需要进行优化的 SQL 语句;
|
要找到最需要优化的 SQL 语句。要么是使用最频繁的语句,要么是优化后提高最明显的语句,可以通过查询 MySQL 的慢查询日志来发现需要进行优化的 SQL 语句。
|
||||||
|
|
||||||
### 充分利用表上已经存在的索引
|
### 充分利用表上已经存在的索引
|
||||||
|
|
||||||
@ -244,9 +246,10 @@ InnoDB 是按照主键索引的顺序来组织表的
|
|||||||
|
|
||||||
### 禁止使用 SELECT \* 必须使用 SELECT <字段列表> 查询
|
### 禁止使用 SELECT \* 必须使用 SELECT <字段列表> 查询
|
||||||
|
|
||||||
- `SELECT *` 消耗更多的 CPU 和 IO 以网络带宽资源
|
- `SELECT *` 会消耗更多的 CPU。
|
||||||
- `SELECT *` 无法使用覆盖索引
|
- `SELECT *` 无用字段增加网络带宽资源消耗,增加数据传输时间,尤其是大字段(如 varchar、blob、text)。
|
||||||
- `SELECT <字段列表>` 可减少表结构变更带来的影响
|
- `SELECT *` 无法使用 MySQL 优化器覆盖索引的优化(基于 MySQL 优化器的“覆盖索引”策略又是速度极快,效率极高,业界极为推荐的查询优化方式)
|
||||||
|
- `SELECT <字段列表>` 可减少表结构变更带来的影响、
|
||||||
|
|
||||||
### 禁止使用不含字段列表的 INSERT 语句
|
### 禁止使用不含字段列表的 INSERT 语句
|
||||||
|
|
||||||
@ -378,4 +381,9 @@ pt-online-schema-change 它会首先建立一个与原表结构相同的新表
|
|||||||
- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
|
- 程序使用数据库账号只能在一个 DB 下使用,不准跨库
|
||||||
- 程序使用的账号原则上不准有 drop 权限
|
- 程序使用的账号原则上不准有 drop 权限
|
||||||
|
|
||||||
|
## 推荐阅读
|
||||||
|
|
||||||
|
- [技术同学必会的MySQL设计规约,都是惨痛的教训 - 阿里开发者](https://mp.weixin.qq.com/s/XC8e5iuQtfsrEOERffEZ-Q)
|
||||||
|
- [聊聊数据库建表的15个小技巧](https://mp.weixin.qq.com/s/NM-aHaW6TXrnO6la6Jfl5A)
|
||||||
|
|
||||||
<!-- @include: @article-footer.snippet.md -->
|
<!-- @include: @article-footer.snippet.md -->
|
||||||
@ -92,7 +92,7 @@ JVM 中内置了三个重要的 `ClassLoader`:
|
|||||||
|
|
||||||
> 🌈 拓展一下:
|
> 🌈 拓展一下:
|
||||||
>
|
>
|
||||||
> - **`rt.jar`**:rt 代表“RunTime”,`rt.jar`是 Java 基础类库,包含 Java doc 里面看到的所有的类的类文件。也就是说,我们常用内置库 `java.xxx.* `都在里面,比如`java.util.*`、`java.io.*`、`java.nio.*`、`java.lang.*`、`java.sql.*`、`java.math.*`。
|
> - **`rt.jar`**:rt 代表“RunTime”,`rt.jar`是 Java 基础类库,包含 Java doc 里面看到的所有的类的类文件。也就是说,我们常用内置库 `java.xxx.*`都在里面,比如`java.util.*`、`java.io.*`、`java.nio.*`、`java.lang.*`、`java.sql.*`、`java.math.*`。
|
||||||
> - Java 9 引入了模块系统,并且略微更改了上述的类加载器。扩展类加载器被改名为平台类加载器(platform class loader)。Java SE 中除了少数几个关键模块,比如说 `java.base` 是由启动类加载器加载之外,其他的模块均由平台类加载器所加载。
|
> - Java 9 引入了模块系统,并且略微更改了上述的类加载器。扩展类加载器被改名为平台类加载器(platform class loader)。Java SE 中除了少数几个关键模块,比如说 `java.base` 是由启动类加载器加载之外,其他的模块均由平台类加载器所加载。
|
||||||
|
|
||||||
除了这三种类加载器之外,用户还可以加入自定义的类加载器来进行拓展,以满足自己的特殊需求。就比如说,我们可以对 Java 类的字节码( `.class` 文件)进行加密,加载时再利用自定义的类加载器对其解密。
|
除了这三种类加载器之外,用户还可以加入自定义的类加载器来进行拓展,以满足自己的特殊需求。就比如说,我们可以对 Java 类的字节码( `.class` 文件)进行加密,加载时再利用自定义的类加载器对其解密。
|
||||||
@ -273,6 +273,7 @@ protected Class<?> loadClass(String name, boolean resolve)
|
|||||||
- 在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载(每个父类加载器都会走一遍这个流程)。
|
- 在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载(每个父类加载器都会走一遍这个流程)。
|
||||||
- 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器 `loadClass()`方法来加载类)。这样的话,所有的请求最终都会传送到顶层的启动类加载器 `BootstrapClassLoader` 中。
|
- 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器 `loadClass()`方法来加载类)。这样的话,所有的请求最终都会传送到顶层的启动类加载器 `BootstrapClassLoader` 中。
|
||||||
- 只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载(调用自己的 `findClass()` 方法来加载类)。
|
- 只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载(调用自己的 `findClass()` 方法来加载类)。
|
||||||
|
- 如果子类加载器也无法加载这个类,那么它会抛出一个 `ClassNotFoundException` 异常。
|
||||||
|
|
||||||
🌈 拓展一下:
|
🌈 拓展一下:
|
||||||
|
|
||||||
@ -294,13 +295,48 @@ protected Class<?> loadClass(String name, boolean resolve)
|
|||||||
|
|
||||||
> 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器 `loadClass()`方法来加载类)。
|
> 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器 `loadClass()`方法来加载类)。
|
||||||
|
|
||||||
|
重写 `loadClass()`方法之后,我们就可以改变传统双亲委派模型的执行流程。例如,子类加载器可以在委派给父类加载器之前,先自己尝试加载这个类,或者在父类加载器返回之后,再尝试从其他地方加载这个类。具体的规则由我们自己实现,根据项目需求定制化。
|
||||||
|
|
||||||
我们比较熟悉的 Tomcat 服务器为了能够优先加载 Web 应用目录下的类,然后再加载其他目录下的类,就自定义了类加载器 `WebAppClassLoader` 来打破双亲委托机制。这也是 Tomcat 下 Web 应用之间的类实现隔离的具体原理。
|
我们比较熟悉的 Tomcat 服务器为了能够优先加载 Web 应用目录下的类,然后再加载其他目录下的类,就自定义了类加载器 `WebAppClassLoader` 来打破双亲委托机制。这也是 Tomcat 下 Web 应用之间的类实现隔离的具体原理。
|
||||||
|
|
||||||
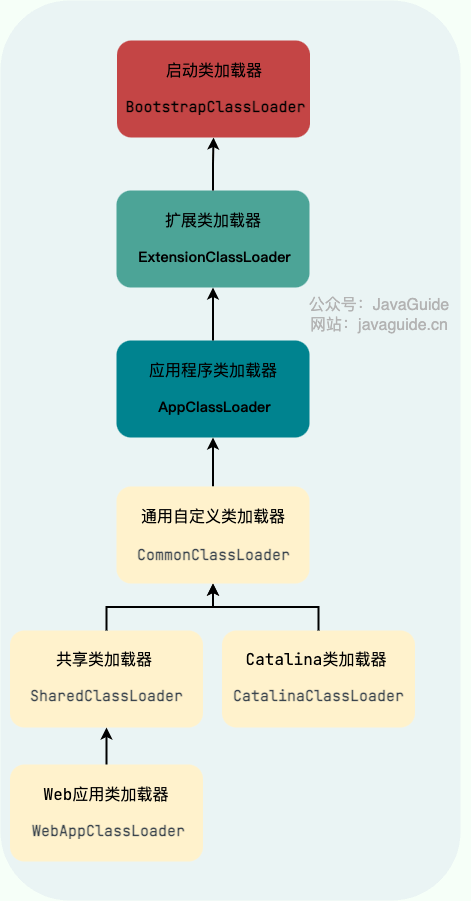
Tomcat 的类加载器的层次结构如下:
|
Tomcat 的类加载器的层次结构如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
感兴趣的小伙伴可以自行研究一下 Tomcat 类加载器的层次结构,这有助于我们搞懂 Tomcat 隔离 Web 应用的原理,推荐资料是[《深入拆解 Tomcat & Jetty》](http://gk.link/a/10Egr)。
|
Tomcat 这四个自定义的类加载器对应的目录如下:
|
||||||
|
|
||||||
|
- `CommonClassLoader`对应`<Tomcat>/common/*`
|
||||||
|
- `CatalinaClassLoader`对应`<Tomcat >/server/*`
|
||||||
|
- `SharedClassLoader`对应 `<Tomcat >/shared/*`
|
||||||
|
- `WebAppClassloader`对应 `<Tomcat >/webapps/<app>/WEB-INF/*`
|
||||||
|
|
||||||
|
从图中的委派关系中可以看出:
|
||||||
|
|
||||||
|
- `CommonClassLoader`作为 `CatalinaClassLoader` 和 `SharedClassLoader` 的父加载器。`CommonClassLoader` 能加载的类都可以被 `CatalinaClassLoader` 和 `SharedClassLoader` 使用。因此,`CommonClassLoader` 是为了实现公共类库(可以被所有 Web 应用和 Tomcat 内部组件使用的类库)的共享和隔离。
|
||||||
|
- `CatalinaClassLoader` 和 `SharedClassLoader` 能加载的类则与对方相互隔离。`CatalinaClassLoader` 用于加载 Tomcat 自身的类,为了隔离 Tomcat 本身的类和 Web 应用的类。`SharedClassLoader` 作为 `WebAppClassLoader` 的父加载器,专门来加载 Web 应用之间共享的类比如 Spring、Mybatis。
|
||||||
|
- 每个 Web 应用都会创建一个单独的 `WebAppClassLoader`,并在启动 Web 应用的线程里设置线程上下文加载器为 `WebAppClassLoader`。各个 `WebAppClassLoader` 实例之间相互隔离,进而实现 Web 应用之间的类隔。
|
||||||
|
|
||||||
|
单纯依靠自定义类加载器没办法满足某些场景的要求,例如,有些情况下,高层的类加载器需要加载低层的加载器才能加载的类。
|
||||||
|
|
||||||
|
比如,SPI 中,SPI 的接口(如 `java.sql.Driver`)是由 Java 核心库提供的,由`BootstrapClassLoader` 加载。而 SPI 的实现(如`com.mysql.cj.jdbc.Driver`)是由第三方供应商提供的,它们是由应用程序类加载器或者自定义类加载器来加载的。默认情况下,一个类及其依赖类由同一个类加载器加载。所以,加载SPI 的接口的类加载器(`BootstrapClassLoader`)也会用来加载SPI 的实现。按照双亲委派模型,`BootstrapClassLoader` 是无法找到 SPI 的实现类的,因为它无法委托给子类加载器去尝试加载。
|
||||||
|
|
||||||
|
再比如,假设我们的项目中有 Spring 的 jar 包,由于其是 Web 应用之间共享的,因此会由 `SharedClassLoader` 加载(Web 服务器是 Tomcat)。我们项目中有一些用到了 Spring 的业务类,比如实现了 Spring 提供的接口、用到了 Spring 提供的注解。所以,加载 Spring 的类加载器(也就是 `SharedClassLoader`)也会用来加载这些业务类。但是业务类在 Web 应用目录下,不在 `SharedClassLoader` 的加载路径下,所以 `SharedClassLoader` 无法找到业务类,也就无法加载它们。
|
||||||
|
|
||||||
|
如何解决这个问题呢? 这个时候就需要用到 **线程上下文加载器(`ThreadContextClassLoader`)** 了。
|
||||||
|
|
||||||
|
拿 Spring 这个例子来说,当 Spring 需要加载业务类的时候,它不是用自己的类加载器,而是用当前线程的上下文类加载器。还记得我上面说的吗?每个 Web 应用都会创建一个单独的 `WebAppClassLoader`,并在启动 Web 应用的线程里设置线程上下文加载器为 `WebAppClassLoader`。这样就可以让高层的类加载器(`SharedClassLoader`)借助子类加载器( `WebAppClassLoader`)来加载业务类,破坏了 Java 的类加载委托机制,让应用逆向使用类加载器。
|
||||||
|
|
||||||
|
线程上下文加载器的原理是将一个类加载器保存在线程私有数据里,跟线程绑定,然后在需要的时候取出来使用。这个类加载器通常是由应用程序或者容器(如 Tomcat)设置的。
|
||||||
|
|
||||||
|
`Java.lang.Thread` 中的`getContextClassLoader()`和 `setContextClassLoader(ClassLoader cl)`分别用来获取和设置线程的上下文类加载器。如果没有通过`setContextClassLoader(ClassLoader cl)`进行设置的话,线程将继承其父线程的上下文类加载器。
|
||||||
|
|
||||||
|
Spring 获取线程上下文加载器的代码如下:
|
||||||
|
|
||||||
|
```java
|
||||||
|
cl = Thread.currentThread().getContextClassLoader();
|
||||||
|
```
|
||||||
|
|
||||||
|
感兴趣的小伙伴可以自行深入研究一下 Tomcat 打破双亲委派模型的原理,推荐资料:[《深入拆解 Tomcat & Jetty》](http://gk.link/a/10Egr)。
|
||||||
|
|
||||||
## 推荐阅读
|
## 推荐阅读
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user