mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]添加 MySQL 基础架构介绍
This commit is contained in:
parent
afa4da721d
commit
5a81e5c8ae
@ -7,7 +7,7 @@ tag:
|
||||
|
||||
> 本文来自[木木匠](https://github.com/kinglaw1204)投稿。
|
||||
|
||||
本篇文章会分析下一个 sql 语句在 MySQL 中的执行流程,包括 sql 的查询在 MySQL 内部会怎么流转,sql 语句的更新是怎么完成的。
|
||||
本篇文章会分析下一个 SQL 语句在 MySQL 中的执行流程,包括 SQL 的查询在 MySQL 内部会怎么流转,SQL 语句的更新是怎么完成的。
|
||||
|
||||
在分析之前我会先带着你看看 MySQL 的基础架构,知道了 MySQL 由那些组件组成以及这些组件的作用是什么,可以帮助我们理解和解决这些问题。
|
||||
|
||||
@ -23,14 +23,14 @@ tag:
|
||||
- **查询缓存:** 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
|
||||
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
|
||||
- **优化器:** 按照 MySQL 认为最优的方案去执行。
|
||||
<!-- - **执行器:** 执行语句,然后从存储引擎返回数据。 -->
|
||||
- **执行器:** 执行语句,然后从存储引擎返回数据。 -
|
||||
|
||||
|
||||
|
||||
简单来说 MySQL 主要分为 Server 层和存储引擎层:
|
||||
|
||||
- **Server 层**:主要包括连接器、查询缓存、分析器、优化器、执行器等,所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图,函数等,还有一个通用的日志模块 binlog 日志模块。
|
||||
- **存储引擎**: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始就被当做默认存储引擎了。**
|
||||
- **存储引擎**: 主要负责数据的存储和读取,采用可以替换的插件式架构,支持 InnoDB、MyISAM、Memory 等多个存储引擎,其中 InnoDB 引擎有自有的日志模块 redolog 模块。**现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5 版本开始就被当做默认存储引擎了。**
|
||||
|
||||
### 1.2 Server 层基本组件介绍
|
||||
|
||||
@ -44,7 +44,7 @@ tag:
|
||||
|
||||
查询缓存主要用来缓存我们所执行的 SELECT 语句以及该语句的结果集。
|
||||
|
||||
连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 sql 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询预计,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
|
||||
连接建立后,执行查询语句的时候,会先查询缓存,MySQL 会先校验这个 SQL 是否执行过,以 Key-Value 的形式缓存在内存中,Key 是查询预计,Value 是结果集。如果缓存 key 被命中,就会直接返回给客户端,如果没有命中,就会执行后续的操作,完成后也会把结果缓存起来,方便下一次调用。当然在真正执行缓存查询的时候还是会校验用户的权限,是否有该表的查询条件。
|
||||
|
||||
MySQL 查询不建议使用缓存,因为查询缓存失效在实际业务场景中可能会非常频繁,假如你对一个表更新的话,这个表上的所有的查询缓存都会被清空。对于不经常更新的数据来说,使用缓存还是可以的。
|
||||
|
||||
@ -58,7 +58,7 @@ MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用
|
||||
|
||||
**第一步,词法分析**,一条 SQL 语句有多个字符串组成,首先要提取关键字,比如 select,提出查询的表,提出字段名,提出查询条件等等。做完这些操作后,就会进入第二步。
|
||||
|
||||
**第二步,语法分析**,主要就是判断你输入的 sql 是否正确,是否符合 MySQL 的语法。
|
||||
**第二步,语法分析**,主要就是判断你输入的 SQL 是否正确,是否符合 MySQL 的语法。
|
||||
|
||||
完成这 2 步之后,MySQL 就准备开始执行了,但是如何执行,怎么执行是最好的结果呢?这个时候就需要优化器上场了。
|
||||
|
||||
@ -76,7 +76,7 @@ MySQL 没有命中缓存,那么就会进入分析器,分析器主要是用
|
||||
|
||||
### 2.1 查询语句
|
||||
|
||||
说了以上这么多,那么究竟一条 sql 语句是如何执行的呢?其实我们的 sql 可以分为两种,一种是查询,一种是更新(增加,更新,删除)。我们先分析下查询语句,语句如下:
|
||||
说了以上这么多,那么究竟一条 SQL 语句是如何执行的呢?其实我们的 SQL 可以分为两种,一种是查询,一种是更新(增加,更新,删除)。我们先分析下查询语句,语句如下:
|
||||
|
||||
```sql
|
||||
select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
@ -84,9 +84,9 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
|
||||
结合上面的说明,我们分析下这个语句的执行流程:
|
||||
|
||||
* 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 sql 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
||||
* 通过分析器进行词法分析,提取 sql 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 sql 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
||||
* 接下来就是优化器进行确定执行方案,上面的 sql 语句,可以有两种执行方案:
|
||||
* 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
||||
* 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
||||
* 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
|
||||
|
||||
a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
|
||||
b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
|
||||
@ -96,7 +96,7 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
|
||||
### 2.2 更新语句
|
||||
|
||||
以上就是一条查询 sql 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?sql 语句如下:
|
||||
以上就是一条查询 SQL 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?SQL 语句如下:
|
||||
|
||||
```
|
||||
update tb_student A set A.age='19' where A.name=' 张三 ';
|
||||
|
||||
@ -30,19 +30,36 @@ MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录
|
||||
|
||||
由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是**3306**。
|
||||
|
||||
## 存储引擎
|
||||
## MySQL 基础架构
|
||||
|
||||
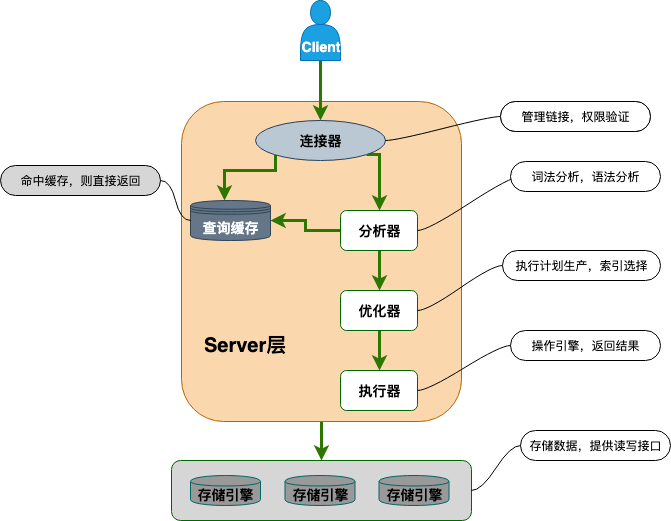
下图是 MySQL 的一个简要架构图,从下图你可以很清晰的看到客户端的一条 SQL 语句在 MySQL 内部是如何执行的。
|
||||
|
||||

|
||||
|
||||
从上图可以看出, MySQL 主要由下面几部分构成:
|
||||
|
||||
- **连接器:** 身份认证和权限相关(登录 MySQL 的时候)。
|
||||
- **查询缓存:** 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
|
||||
- **分析器:** 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
|
||||
- **优化器:** 按照 MySQL 认为最优的方案去执行。
|
||||
- **执行器:** 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
|
||||
- **插件式存储引擎** : 主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。
|
||||
|
||||
## MySQL 存储引擎
|
||||
|
||||
MySQL 核心在于存储引擎,想要深入学习 MySQL,必定要深入研究 MySQL 存储引擎。
|
||||
|
||||
### MySQL 支持哪些存储引擎?默认使用哪个?
|
||||
|
||||
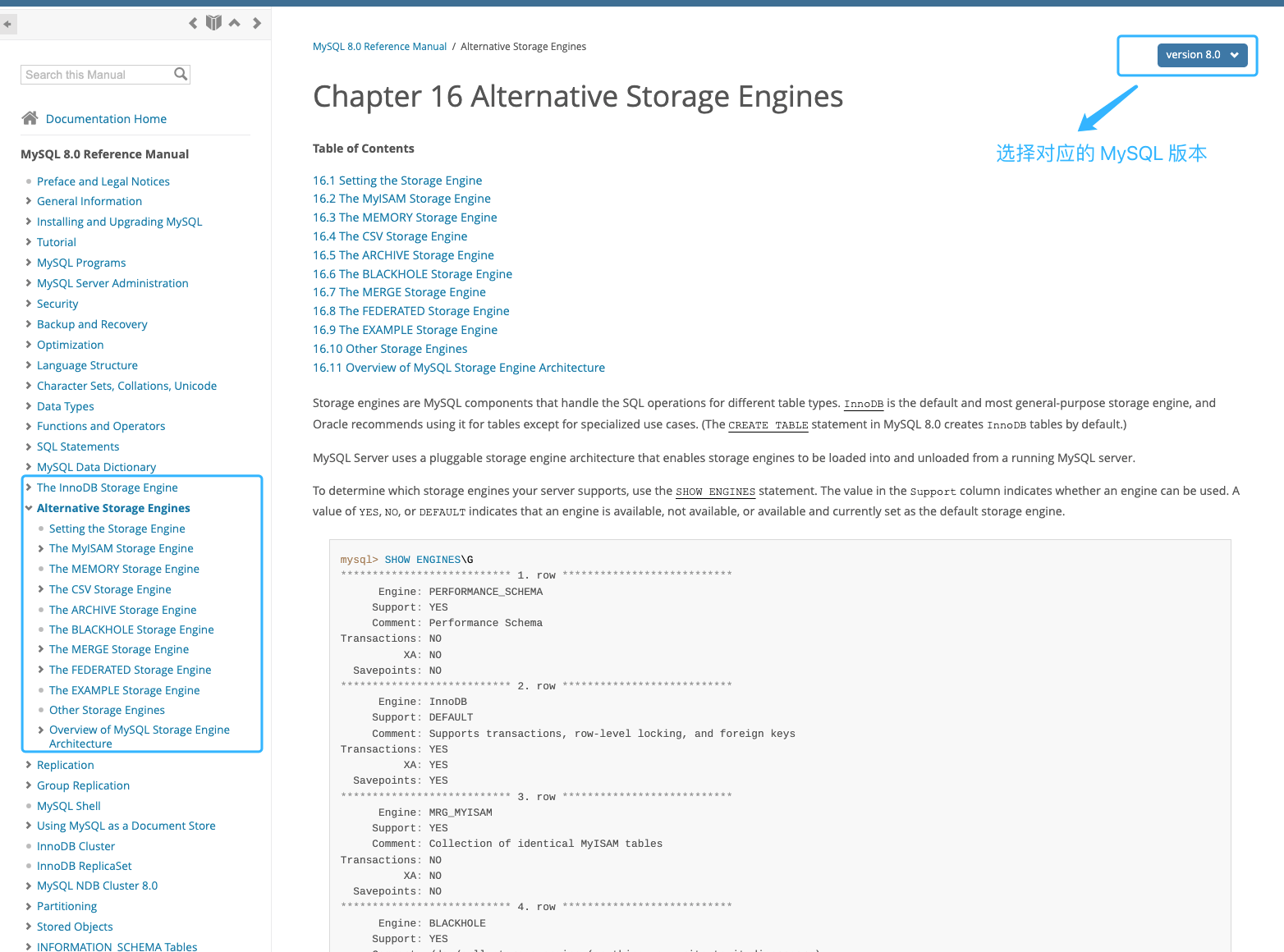
MySQL 支持多种存储引擎,你可以通过 `show engines` 命令来查看 MySQL 支持的所有存储引擎。
|
||||
|
||||

|
||||

|
||||
|
||||
从上图我们可以查看出, MySQL 当前默认的存储引擎是 InnoDB。并且,所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
|
||||
|
||||
我这里使用的 MySQL 版本是 8.x,不同的 MySQL 版本之间可能会有差别。
|
||||
|
||||
MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎。5.5 版本之后,MySQL 引入了 InnoDB(事务性数据库引擎),MySQL 5.5 版本后默认的存储引擎为 InnoDB。
|
||||
MySQL 5.5.5 之前,MyISAM 是 MySQL 的默认存储引擎。5.5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
|
||||
|
||||
你可以通过 `select version()` 命令查看你的 MySQL 版本。
|
||||
|
||||
@ -58,13 +75,26 @@ MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎。5.5 版本之
|
||||
|
||||
你也可以通过 `show variables like '%storage_engine%'` 命令直接查看 MySQL 当前默认的存储引擎。
|
||||
|
||||

|
||||
|
||||
### 如何查看某个表的存储引擎?
|
||||

|
||||
|
||||
如果你只想查看数据库中某个表使用的存储引擎的话,可以使用 `show table status from db_name where name='table_name'`命令。
|
||||
|
||||

|
||||

|
||||
|
||||
如果你想要深入了解每个存储引擎以及它们之间的区别,推荐你去阅读以下 MySQL 官方文档对应的介绍(面试不会问这么细,了解即可):
|
||||
|
||||
- InnoDB 存储引擎详细介绍:https://dev.mysql.com/doc/refman/8.0/en/innodb-storage-engine.html 。
|
||||
- 其他存储引擎详细介绍:https://dev.mysql.com/doc/refman/8.0/en/storage-engines.html 。
|
||||
|
||||
|
||||
|
||||
### MySQL 存储引擎架构了解吗?
|
||||
|
||||
MySQL 存储引擎采用的是插件式架构,支持多种存储引擎,我们甚至可以为不同的数据库表设置不同的存储引擎以适应不同场景的需要。**存储引擎是基于表的,而不是数据库。**
|
||||
|
||||
并且,你还可以根据 MySQL 定义的存储引擎实现标准接口来编写一个属于自己的存储引擎。这些非官方提供的存储引擎可以称为第三方存储引擎,区别于官方存储引擎。像目前最常用的 InnoDB 其实刚开始就是一个第三方存储引擎,后面由于过于优秀,其被 Oracle 直接收购了。
|
||||
|
||||
MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地址:https://dev.mysql.com/doc/internals/en/custom-engine.html 。
|
||||
|
||||
### MyISAM 和 InnoDB 的区别是什么?
|
||||
|
||||
@ -74,7 +104,7 @@ MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风
|
||||
|
||||
虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
|
||||
|
||||
5.5 版本之后,MySQL 引入了 InnoDB(事务性数据库引擎),MySQL 5.5 版本后默认的存储引擎为 InnoDB。小伙子,一定要记好这个 InnoDB ,你每次使用 MySQL 数据库都是用的这个存储引擎吧?
|
||||
MySQL 5.5.5 之前,MyISAM 是 MySQL 的默认存储引擎。5.5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。
|
||||
|
||||
言归正传!咱们下面还是来简单对比一下两者:
|
||||
|
||||
@ -100,7 +130,7 @@ MyISAM 不支持,而 InnoDB 支持。
|
||||
|
||||
阿里的《Java 开发手册》也是明确规定禁止使用外键的。
|
||||
|
||||

|
||||

|
||||
|
||||
不过,在代码中进行约束的话,对程序员的能力要求更高,具体是否要采用外键还是要根据你的项目实际情况而定。
|
||||
|
||||
@ -138,7 +168,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
|
||||
|
||||
## 查询缓存
|
||||
## MySQL 查询缓存
|
||||
|
||||
执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
|
||||
|
||||
@ -166,32 +196,39 @@ set global query_cache_size=600000;
|
||||
select sql_no_cache count(*) from usr;
|
||||
```
|
||||
|
||||
## 事务
|
||||
## MySQL 事务
|
||||
|
||||
### 何为事务?
|
||||
### 何谓事务?
|
||||
|
||||
一言蔽之,**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
|
||||
我们设想一个场景,这个场景中我们需要插入多条相关联的数据到数据库,不幸的是,这个过程可能会遇到下面这些问题:
|
||||
|
||||
**可以简单举一个例子不?**
|
||||
- 数据库中途突然因为某些原因挂掉了。
|
||||
- 客户端突然因为网络原因连接不上数据库了。
|
||||
- 并发访问数据库时,多个线程同时写入数据库,覆盖了彼此的更改。
|
||||
- ......
|
||||
|
||||
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
|
||||
上面的任何一个问题都可能会导致数据的不一致性。为了保证数据的一致性,系统必须能够处理这些问题。事务就是我们抽象出来简化这些问题的首选机制。事务的概念起源于数据库,目前,已经成为一个比较广泛的概念。
|
||||
|
||||
**何为事务?** 一言蔽之,**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
|
||||
|
||||
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作,这两个操作必须都成功或者都失败。
|
||||
|
||||
1. 将小明的余额减少 1000 元
|
||||
2. 将小红的余额增加 1000 元。
|
||||
|
||||
事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。
|
||||
事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
|
||||
|
||||
这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
|
||||

|
||||
|
||||
### 何为数据库事务?
|
||||
### 何谓数据库事务?
|
||||
|
||||
大多数情况下,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
|
||||
|
||||
数据库事务在我们日常开发中接触的最多了。如果你的项目属于单体架构的话,你接触到的往往就是数据库事务了。
|
||||
|
||||
平时,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
|
||||
|
||||
**那数据库事务有什么作用呢?**
|
||||
|
||||
简单来说:数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:**要么全部执行成功,要么全部不执行** 。
|
||||
简单来说,数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:**要么全部执行成功,要么全部不执行** 。
|
||||
|
||||
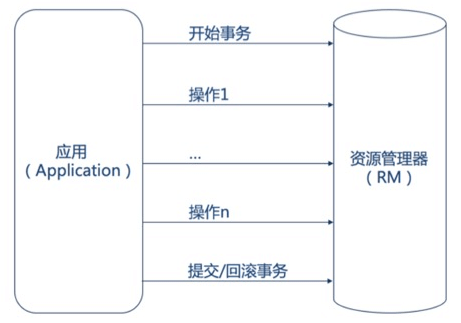
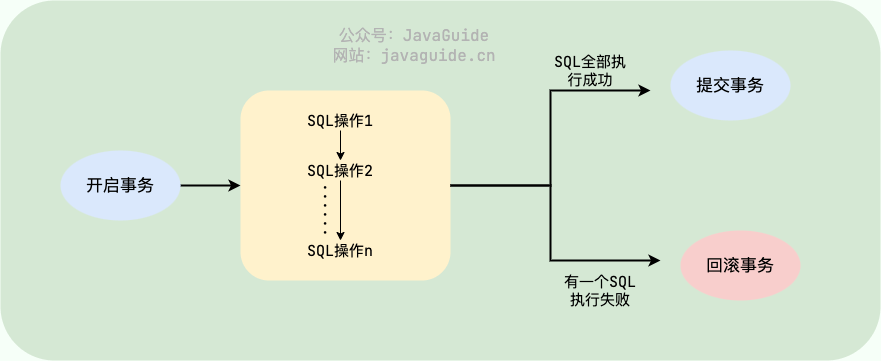
```sql
|
||||
# 开启一个事务
|
||||
@ -202,30 +239,35 @@ SQL1,SQL2...
|
||||
COMMIT;
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
另外,关系型数据库(例如:`MySQL`、`SQL Server`、`Oracle` 等)事务都有 **ACID** 特性:
|
||||
|
||||
|
||||
|
||||
### 何为 ACID 特性呢?
|
||||
|
||||
|
||||
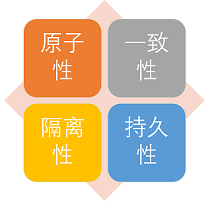
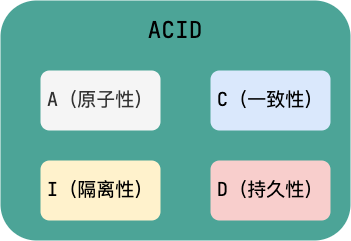
1. **原子性**(`Atomicity`) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性**(`Consistency`): 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||
3. **隔离性**(`Isolation`): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性**(`Durability`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
4. **持久性**(`Durabilily`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
**数据事务的实现原理呢?**
|
||||
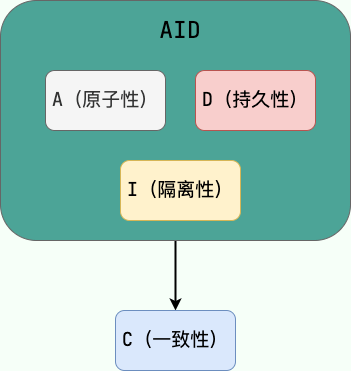
🌈 这里要额外补充一点:**只有保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。也就是说 A、I、D 是手段,C 是目的!** 想必大家也和我一样,被 ACID 这个概念被误导了很久! 我也是看周志明老师的公开课[《周志明的软件架构课》](https://time.geekbang.org/opencourse/intro/100064201)才搞清楚的(多看好书!!!)。
|
||||
|
||||
我们这里以 MySQL 的 InnoDB 引擎为例来简单说一下。
|
||||
|
||||
|
||||
MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
|
||||
另外,DDIA 也就是 [《Designing Data-Intensive Application(数据密集型应用系统设计)》](https://book.douban.com/subject/30329536/) 的作者在他的这本书中如是说:
|
||||
|
||||
MySQL InnoDB 引擎通过 **锁机制**、**MVCC** 等手段来保证事务的隔离性( 默认支持的隔离级别是 **`REPEATABLE-READ`** )。
|
||||
> Atomicity, isolation, and durability are properties of the database, whereas consis‐
|
||||
> tency (in the ACID sense) is a property of the application. The application may rely
|
||||
> on the database’s atomicity and isolation properties in order to achieve consistency,
|
||||
> but it’s not up to the database alone.
|
||||
>
|
||||
> 翻译过来的意思是:原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母 C 不属于 ACID 。
|
||||
|
||||
保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
|
||||
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 Github 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
|
||||
|
||||
### 并发事务带来哪些问题?
|
||||

|
||||
|
||||
### 并发事务带来了哪些问题?
|
||||
|
||||
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
|
||||
|
||||
@ -234,18 +276,16 @@ MySQL InnoDB 引擎通过 **锁机制**、**MVCC** 等手段来保证事务的
|
||||
- **不可重复读(Unrepeatable read):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
|
||||
- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
|
||||
|
||||
**不可重复读和幻读区别:**
|
||||
**不可重复读和幻读区别** :不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次查询同一条查询语句(DQL)时,记录发现记录增多或减少了。
|
||||
|
||||
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次查询同一条查询语句(DQL)时,记录发现记录增多或减少了。
|
||||
|
||||
### 事务隔离级别有哪些?
|
||||
### SQL 标准定义了哪些事务隔离级别?
|
||||
|
||||
SQL 标准定义了四个隔离级别:
|
||||
|
||||
- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
|
||||
- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
|
||||
- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
|
||||
- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
|
||||
- **READ-UNCOMMITTED(读取未提交)** : 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
|
||||
- **READ-COMMITTED(读取已提交)** : 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
|
||||
- **REPEATABLE-READ(可重复读)** : 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
|
||||
- **SERIALIZABLE(可串行化)** : 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
|
||||
|
||||
---
|
||||
|
||||
@ -279,7 +319,7 @@ mysql> SELECT @@tx_isolation;
|
||||
|
||||
关于 MySQL 事务的详细介绍,可以看看我写的这篇文章:[MySQL 事务隔离级别详解](https://javaguide.cn/database/mysql/transaction-isolation-level.html)。
|
||||
|
||||
## 锁机制与 InnoDB 锁算法
|
||||
## MySQL 锁机制与 InnoDB 锁算法
|
||||
|
||||
**MyISAM 和 InnoDB 存储引擎使用的锁:**
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user