mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-10 00:41:37 +08:00
commit
5678155022
4
.husky/pre-commit
Executable file
4
.husky/pre-commit
Executable file
@ -0,0 +1,4 @@
|
||||
#!/bin/sh
|
||||
. "$(dirname "$0")/_/husky.sh"
|
||||
|
||||
pnpm nano-staged
|
||||
20
.markdownlint.json
Normal file
20
.markdownlint.json
Normal file
@ -0,0 +1,20 @@
|
||||
{
|
||||
"default": true,
|
||||
"MD003": {
|
||||
"style": "atx"
|
||||
},
|
||||
"MD004": {
|
||||
"style": "dash"
|
||||
},
|
||||
"MD013": false,
|
||||
"MD024": {
|
||||
"allow_different_nesting": true
|
||||
},
|
||||
"MD035": {
|
||||
"style": "---"
|
||||
},
|
||||
"MD040": false,
|
||||
"MD045": false,
|
||||
"MD046": false,
|
||||
"MD049": false
|
||||
}
|
||||
4
.markdownlintignore
Normal file
4
.markdownlintignore
Normal file
@ -0,0 +1,4 @@
|
||||
**/node_modules/**
|
||||
|
||||
# markdown snippets
|
||||
*.snippet.md
|
||||
15
.prettierignore
Normal file
15
.prettierignore
Normal file
@ -0,0 +1,15 @@
|
||||
# Vuepress Cache
|
||||
**/.vuepress/.cache/**
|
||||
# Vuepress Temp
|
||||
**/.vuepress/.temp/**
|
||||
# Vuepress Output
|
||||
dist/
|
||||
|
||||
# Node modules
|
||||
node_modules/
|
||||
|
||||
# pnpm lock file
|
||||
pnpm-lock.yaml
|
||||
|
||||
index.html
|
||||
sw.js
|
||||
@ -2,7 +2,11 @@ import { navbar } from "vuepress-theme-hope";
|
||||
|
||||
export default navbar([
|
||||
{ text: "面试指南", icon: "java", link: "/home.md" },
|
||||
{ text: "知识星球", icon: "code", link: "/about-the-author/zhishixingqiu-two-years.md" },
|
||||
{
|
||||
text: "知识星球",
|
||||
icon: "code",
|
||||
link: "/about-the-author/zhishixingqiu-two-years.md",
|
||||
},
|
||||
{ text: "开源项目", icon: "github", link: "/open-source-project/" },
|
||||
{ text: "技术书籍", icon: "book", link: "/books/" },
|
||||
{
|
||||
|
||||
@ -1,8 +1,11 @@
|
||||
import { getDirname, path } from "@vuepress/utils";
|
||||
import { hopeTheme } from "vuepress-theme-hope";
|
||||
|
||||
import navbar from "./navbar.js";
|
||||
import sidebar from "./sidebar/index.js";
|
||||
|
||||
const __dirname = getDirname(import.meta.url);
|
||||
|
||||
export default hopeTheme({
|
||||
logo: "/logo.png",
|
||||
hostname: "https://javaguide.cn/",
|
||||
@ -50,7 +53,19 @@ export default hopeTheme({
|
||||
align: true,
|
||||
codetabs: true,
|
||||
container: true,
|
||||
include: true,
|
||||
figure: true,
|
||||
include: {
|
||||
resolvePath: (file, cwd) => {
|
||||
if (file.startsWith("@"))
|
||||
return path.resolve(
|
||||
__dirname,
|
||||
"../snippets",
|
||||
file.replace("@", "./")
|
||||
);
|
||||
|
||||
return path.resolve(cwd, file);
|
||||
},
|
||||
},
|
||||
tasklist: true,
|
||||
},
|
||||
feed: {
|
||||
|
||||
@ -7,18 +7,18 @@ tag:
|
||||
|
||||
不知不觉已经入职一个多月了,在入职之前我没有在某个公司实习过或者工作过,所以很多东西刚入职工作的我来说还是比较新颖的。学校到职场的转变,带来了角色的转变,其中的差别因人而异。对我而言,在学校的时候课堂上老师课堂上教的东西,自己会根据自己的兴趣选择性接受,甚至很多课程你不想去上的话,还可以逃掉。到了公司就不一样了,公司要求你会的技能你不得不学,除非你不想干了。在学校的时候大部分人编程的目的都是为了通过考试或者找到一份好工作,真正靠自己兴趣支撑起来的很少,到了工作岗位之后我们编程更多的是因为工作的要求,相比于学校的来说会一般会更有挑战而且压力更大。在学校的时候,我们最重要的就是对自己负责,我们不断学习知识去武装自己,但是到了公司之后我们不光要对自己负责,更要对公司负责,毕竟公司出钱请你过来,不是让你一直 on beach 的。
|
||||
|
||||
刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
|
||||
刚来公司的时候,因为公司要求,我换上了 Mac 电脑。由于之前一直用的是 Windows 系统,所以非常不习惯。刚开始用 Mac 系统的时候笨手笨脚,自己会很明显的感觉自己的编程效率降低了至少 3 成。当时内心还是挺不爽的,心里也总是抱怨为什么不直接用 Windows 系统或者 Linux 系统。不过也挺奇怪,大概一个星期之后,自己就开始慢慢适应使用 Mac 进行编程,甚至非常喜欢。我这里不想对比 Mac 和 Windows 编程体验哪一个更好,我觉得还是因人而异,相同价位的 Mac 的配置相比于 Windows 确实要被甩几条街。不过 Mac 的编程和使用体验确实不错,当然你也可以选择使用 Linux 进行日常开发,相信一定很不错。 另外,Mac 不能玩一些主流网络游戏,对于一些克制不住自己想玩游戏的朋友是一个不错的选择。
|
||||
|
||||
不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8周的培训,除了工作需要用到的基本技术比如ES6、SpringBoot等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如Weekend Trip、 City Tour、Cake time等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
|
||||
不得不说 ThoughtWorks 的培训机制还是很不错的。应届生入职之后一般都会安排培训,与往年不同的是,今年的培训多了中国本地班(TWU-C)。作为本地班的第一期学员,说句心里话还是很不错。8 周的培训,除了工作需要用到的基本技术比如 ES6、SpringBoot 等等之外,还会增加一些新员工基本技能的培训比如如何高效开会、如何给别人正确的提 Feedback、如何对代码进行重构、如何进行 TDD 等等。培训期间不定期的有活动,比如 Weekend Trip、 City Tour、Cake time 等等。最后三周还会有一个实际的模拟项目,这个项目基本和我们正式工作的实际项目差不多,我个人感觉很不错。目前这个项目已经正式完成了一个迭代,我觉得在做项目的过程中,收获最大的不是项目中使用的技术,而是如何进行团队合作、如何正确使用 Git 团队协同开发、一个完成的迭代是什么样子的、做项目的过程中可能遇到那些问题、一个项目运作的完整流程等等。
|
||||
|
||||
ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责5-6个人。Trainer不定期都会给我们最近表现的 Feedback( 反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
|
||||
ThoughtWorks 非常提倡分享、提倡帮助他人成长,这一点在公司的这段时间深有感触。培训期间,我们每个人会有一个 Trainer 负责,Trainer 就是日常带我们上课和做项目的同事,一个 Trainer 大概会负责 5-6 个人。Trainer 不定期都会给我们最近表现的 Feedback( 反馈) ,我个人觉得这个并不是这是走走形式,Trainer 们都很负责,很多时候都是在下班之后找我们聊天。同事们也都很热心,如果你遇到问题,向别人询问,其他人如果知道的话一般都会毫无保留的告诉你,如果遇到大部分都不懂的问题,甚至会组织一次技术 Session 分享。上周五我在我们小组内进行了一次关于 Feign 远程调用的技术分享,因为 team 里面大家对这部分知识都不太熟悉,但是后面的项目进展大概率会用到这部分知识。我刚好研究了这部分内容,所以就分享给了组内的其他同事,以便于项目更好的进行。
|
||||
|
||||
另外,ThoughtWorks 也是一家非常提倡 Feedback( 反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
|
||||
另外,ThoughtWorks 也是一家非常提倡 Feedback( 反馈) 文化的公司,反馈是告诉人们我们对他们的表现的看法以及他们应该如何更好地做到这一点。刚开始我并没有太在意,慢慢地自己确实感觉到正确的进行反馈对他人会有很大的帮助。因为人在做很多事情的时候,会很难发现别人很容易看到的一些小问题。就比如一个很有趣的现象一样,假如我们在做项目的时候没有测试这个角色,如果你完成了自己的模块,并且自己对这个模块测试了很多遍,你发现已经没啥问题了。但是,到了实际使用的时候会很大概率出现你之前从来没有注意的问题。解释这个问题的说法是:每个人的视野或多或少都是有盲点的,这与我们的关注点息息相关。对于自己做的东西,很多地方自己测试很多遍都不会发现,但是如果让其他人帮你进行测试的话,就很大可能会发现很多显而易见的问题。
|
||||
|
||||

|
||||
|
||||
工作之后,平时更新公众号、专栏还有维护 Github 的时间变少了。实际上,很多时候下班回来后,都有自己的时间来干自己的事情,但是自己也总是找工作太累或者时间比较零散的接口来推掉了。到了今天,翻看 Github 突然发现 14 天前别人在 Github 上给我提的 pr 我还没有处理。这一点确实是自己没有做好的地方,没有合理安排好自己的时间。实际上自己有很多想写的东西,后面会慢慢将他们提上日程。工作之后,更加发现下班后的几个小时如何度过确实很重要 ,如果你觉得自己没有完成好自己白天该做的工作的话,下班后你可以继续忙白天没有忙完的工作,如果白天的工作对于你游刃有余的话,下班回来之后,你大可去干自己感兴趣的事情,学习自己感兴趣的技术。做任何事情都要基于自身的基础,切不可好高骛远。
|
||||
|
||||
工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
|
||||
工作之后身边也会有很多厉害的人,多从他人身上学习我觉得是每个职场人都应该做的。这一届和我们一起培训的同事中,有一些技术很厉害的,也有一些技术虽然不是那么厉害,但是组织能力以及团队协作能力特别厉害的。有一个特别厉害的同事,在我们还在学 SpringBoot 各种语法的时候,他自己利用业余时间写了一个简化版的 SpringBoot ,涵盖了 Spring 的一些常用注解比如 `@RestController`、`@Autowried`、`@Pathvairable`、`@RestquestParam`等等(已经联系这位同事,想让他开源一下,后面会第一时间同步到公众号,期待一下吧!)。我觉得这位同事对于编程是真的有兴趣,他好像从初中就开始接触编程了,对于各种底层知识也非常感兴趣,自己写过实现过很多比较底层的东西。他的梦想是在 Github 上造一个 20k Star 以上的轮子。我相信以这位同事的能力一定会达成目标的,在这里祝福这位同事,希望他可以尽快实现这个目标。
|
||||
|
||||
这是我入职一个多月之后的个人感受,很多地方都是一带而过,后面我会抽时间分享自己在公司或者业余学到的比较有用的知识给各位,希望看过的人都能有所收获。
|
||||
@ -31,7 +31,7 @@ tag:
|
||||
|
||||
不知道其他公司的程序员是怎么样的?我感觉技术积累很大程度在乎平时,单纯依靠工作绝大部分情况只会加快自己做需求的熟练度,当然,写多了之后或多或少也会提升你对代码质量的认识(前提是你有这个意识)。
|
||||
|
||||
工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security+JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,Github 地址:https://github.com/Snailclimb/spring-security-jwt-guide 。以次为契机,我还分享了
|
||||
工作之余,我会利用业余时间来学习自己想学的东西。工作中的例子就是我刚进公司的第一个项目用到了 Spring Security+JWT ,因为当时自己对于这个技术不太了解,然后就在工作之外大概花了一周的时间学习写了一个 Demo 分享了出来,Github 地址:<https://github.com/Snailclimb/spring-security-jwt-guide> 。以次为契机,我还分享了
|
||||
|
||||
- [《一问带你区分清楚 Authentication,Authorization 以及 Cookie、Session、Token》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485626&idx=1&sn=3247aa9000693dd692de8a04ccffeec1&chksm=cea24771f9d5ce675ea0203633a95b68bfe412dc6a9d05f22d221161147b76161d1b470d54b3&token=684071313&lang=zh_CN&scene=21#wechat_redirect)
|
||||
- [JWT 身份认证优缺点分析以及常见问题解决方案](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485655&idx=1&sn=583eeeb081ea21a8ec6347c72aa223d6&chksm=cea2471cf9d5ce0aa135f2fb9aa32d98ebb3338292beaccc1aae43d1178b16c0125eb4139ca4&token=1737409938&lang=zh_CN#rd)
|
||||
|
||||
@ -5,7 +5,7 @@ tag:
|
||||
- 个人经历
|
||||
---
|
||||
|
||||
2021-03-21,晚上12点,肝完了我正在做的一个项目的前端的某块功能,我随手打开了[我的 Github 主页](https://github.com/Snailclimb)。
|
||||
2021-03-21,晚上 12 点,肝完了我正在做的一个项目的前端的某块功能,我随手打开了[我的 Github 主页](https://github.com/Snailclimb)。
|
||||
|
||||
好家伙!几天没注意,[JavaGuide](https://github.com/Snailclimb/JavaGuide) 这个项目直接上了 100K star。
|
||||
|
||||
@ -15,7 +15,7 @@ tag:
|
||||
|
||||

|
||||
|
||||
维护这个项目的过程中,也被某些人 diss 过:“md项目,没啥含金量,给国人丢脸!”。
|
||||
维护这个项目的过程中,也被某些人 diss 过:“md 项目,没啥含金量,给国人丢脸!”。
|
||||
|
||||
对于说这类话的人,我觉得对我没啥影响,就持续完善,把 JavaGuide 做的更好吧!其实,国外的很多项目也是纯 MD 啊!就比如外国的朋友发起的 awesome 系列、求职面试系列。无需多说,行动自证!凎!
|
||||
|
||||
@ -29,7 +29,7 @@ tag:
|
||||
|
||||
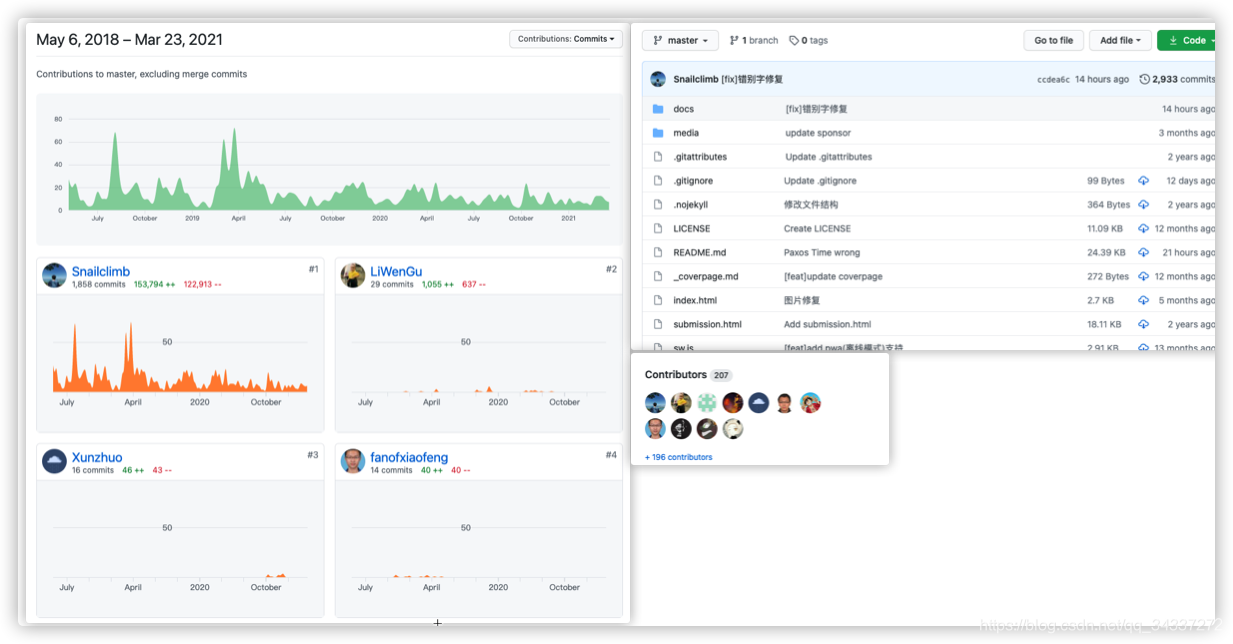
|
||||
|
||||
累计有 **511** 个 **issue** 和 **575** 个 **pr**。所有的 pr 都已经被处理,仅有15 个左右的 issue 我还未抽出时间处理。
|
||||
累计有 **511** 个 **issue** 和 **575** 个 **pr**。所有的 pr 都已经被处理,仅有 15 个左右的 issue 我还未抽出时间处理。
|
||||
|
||||

|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ tag:
|
||||
- 杂谈
|
||||
---
|
||||
|
||||
时间回到 2021-02-25,我在刷哔哩哔哩的时候发现,哔哩哔哩某UP主(某培训机构),擅自将我在知乎的一个回答做成了视频。
|
||||
时间回到 2021-02-25,我在刷哔哩哔哩的时候发现,哔哩哔哩某 UP 主(某培训机构),擅自将我在知乎的一个回答做成了视频。
|
||||
|
||||
原滋原味啊!我艹。甚至,连我开头的自我调侃还加上了!真的牛皮!
|
||||
|
||||
@ -31,7 +31,7 @@ tag:
|
||||
|
||||
其他的视频就不用多看了,是否还是剽窃别人的原创,原封不动地做成视频,大家心里应该有数。
|
||||
|
||||
他们这样做的目的就是一个:**引流到自己的QQ群,然后忽悠你买课程。**
|
||||
他们这样做的目的就是一个:**引流到自己的 QQ 群,然后忽悠你买课程。**
|
||||
|
||||
我并不认为是这完全都是培训机构的问题。培训机构的员工为了流量而做这种恶心的事情,也导致了现在这种事情被越来越频繁地发生。
|
||||
|
||||
|
||||
@ -6,7 +6,7 @@ tag:
|
||||
- 个人经历
|
||||
---
|
||||
|
||||
> 关于初高中的生活,可以看 2020年我写的[我曾经也是网瘾少年](https://javaguide.cn/about-the-author/internet-addiction-teenager.html)这篇文章。
|
||||
> 关于初高中的生活,可以看 2020 年我写的[我曾经也是网瘾少年](https://javaguide.cn/about-the-author/internet-addiction-teenager.html)这篇文章。
|
||||
|
||||
2019 年 6 月份毕业,距今已经过去了 3 年。趁着高考以及应届生毕业之际,简单聊聊自己的大学生活。
|
||||
|
||||
|
||||
@ -45,13 +45,13 @@ category: 走近作者
|
||||
|
||||

|
||||
|
||||
## 为什么自称 Guide哥?
|
||||
## 为什么自称 Guide 哥?
|
||||
|
||||
可能是因为我的项目名字叫做 JavaGuide , 所以导致有很多人称呼我为 **Guide哥**。
|
||||
可能是因为我的项目名字叫做 JavaGuide , 所以导致有很多人称呼我为 **Guide 哥**。
|
||||
|
||||
后面,为了读者更方便称呼,我就将自己的笔名改成了 **Guide哥**。
|
||||
后面,为了读者更方便称呼,我就将自己的笔名改成了 **Guide 哥**。
|
||||
|
||||
我早期写文章用的笔名是 SnailClimb 。很多人不知道这个名字是啥意思,给大家拆解一下就清楚了。SnailClimb=Snail(蜗牛)+Climb(攀登)。我从小就非常喜欢听周杰伦的歌曲,特别是他的《蜗牛》🐌 这首歌曲,另外,当年我高考发挥的算是比较失常,上了大学之后还算是比较“奋青”,所以,我就给自己起的笔名叫做 SnailClimb ,寓意自己要不断向上攀登,嘿嘿😁
|
||||
我早期写文章用的笔名是 SnailClimb 。很多人不知道这个名字是啥意思,给大家拆解一下就清楚了。SnailClimb=Snail(蜗牛)+Climb(攀登)。我从小就非常喜欢听周杰伦的歌曲,特别是他的《蜗牛》🐌 这首歌曲,另外,当年我高考发挥的算是比较失常,上了大学之后还算是比较“奋青”,所以,我就给自己起的笔名叫做 SnailClimb ,寓意自己要不断向上攀登,嘿嘿 😁
|
||||
|
||||

|
||||
|
||||
|
||||
@ -122,7 +122,7 @@ tag:
|
||||
|
||||
最重要的是一定要重视 Markdown 规范,不然内容再好也会显得不专业。
|
||||
|
||||
Markdown 规范请参考:**https://javaguide.cn/javaguide/contribution-guideline.html** (很重要,尽量按照规范来,对你工作中写文档会非常有帮助)
|
||||
Markdown 规范请参考:**<https://javaguide.cn/javaguide/contribution-guideline.html>** (很重要,尽量按照规范来,对你工作中写文档会非常有帮助)
|
||||
|
||||
## 有没有什么写作技巧分享?
|
||||
|
||||
|
||||
@ -138,4 +138,3 @@ star: 2
|
||||
不过, **一定要确定需要再进** 。并且, **三天之内觉得内容不满意可以全额退款** 。
|
||||
|
||||
**星球提供的服务质量还是很高的,非常适合准备面试的同学。我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
|
||||
@ -1,5 +0,0 @@
|
||||
::: center
|
||||
|
||||
[](https://www.yuque.com/snailclimb/rpkqw1/pvak2w?)
|
||||
|
||||
:::
|
||||
@ -16,13 +16,11 @@ head:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
如果你比较喜欢动手,对于理论知识比较抵触的话,推荐你看看[《如何开发一个简单的数据库》](https://cstack.github.io/db_tutorial/) ,这个 project 会手把手教你编写一个简单的数据库。
|
||||
|
||||

|
||||
|
||||
Github上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
||||
Github 上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
||||
|
||||
除了这个用 Java 写的之外,**[db_tutorial](https://github.com/cstack/db_tutorial)** 这个项目是国外的一个大佬用 C 语言写的,朋友们也可以去瞅瞅。
|
||||
|
||||
@ -44,7 +42,7 @@ Github上也已经有大佬用 Java 实现过一个简易的数据库,介绍
|
||||
|
||||

|
||||
|
||||
不管是 MySQL 还是Oracle ,它们总体的架子是差不多的,不同的是其内部的实现比如数据库索引的数据结构、存储引擎的实现方式等等。
|
||||
不管是 MySQL 还是 Oracle ,它们总体的架子是差不多的,不同的是其内部的实现比如数据库索引的数据结构、存储引擎的实现方式等等。
|
||||
|
||||
这本书有些地方还是翻译的比较蹩脚,有能力看英文版的还是建议上手英文版。
|
||||
|
||||
|
||||
@ -18,9 +18,9 @@ icon: "distributed-network"
|
||||
|
||||

|
||||
|
||||
作者专门写了一篇文章来介绍这本书的背后的故事,感兴趣的小伙伴可以自行查阅:https://zhuanlan.zhihu.com/p/487534882 。
|
||||
作者专门写了一篇文章来介绍这本书的背后的故事,感兴趣的小伙伴可以自行查阅:<https://zhuanlan.zhihu.com/p/487534882> 。
|
||||
|
||||
最后,放上这本书的代码仓库和勘误地址:https://github.com/tangwz/DistSysDeepDive 。
|
||||
最后,放上这本书的代码仓库和勘误地址:<https://github.com/tangwz/DistSysDeepDive> 。
|
||||
|
||||
## 《数据密集型应用系统设计》
|
||||
|
||||
@ -32,7 +32,7 @@ icon: "distributed-network"
|
||||
|
||||
书中介绍的大部分概念你可能之前都听过,但是在看了书中的内容之后,你可能会豁然开朗:“哇塞!原来是这样的啊!这不是某技术的原理么?”。
|
||||
|
||||
这本书我之前专门写过知乎回答介绍和推荐,没看过的朋友可以看看:[有哪些你看了以后大呼过瘾的编程书? ](https://www.zhihu.com/question/50408698/answer/2278198495) 。
|
||||
这本书我之前专门写过知乎回答介绍和推荐,没看过的朋友可以看看:[有哪些你看了以后大呼过瘾的编程书?](https://www.zhihu.com/question/50408698/answer/2278198495) 。
|
||||
|
||||
另外,如果你在阅读这本书的时候感觉难度比较大,很多地方读不懂的话,我这里推荐一下《深入理解分布式系统》作者写的[《DDIA 逐章精读》小册](https://ddia.qtmuniao.com)。
|
||||
|
||||
@ -40,7 +40,7 @@ icon: "distributed-network"
|
||||
|
||||

|
||||
|
||||
**[《深入理解分布式事务》](https://book.douban.com/subject/35626925/)** 这本书是的其中一位作者是 Apache ShenYu(incubating)网关创始人、Hmily、RainCat、Myth等分布式事务框架的创始人。
|
||||
**[《深入理解分布式事务》](https://book.douban.com/subject/35626925/)** 这本书是的其中一位作者是 Apache ShenYu(incubating)网关创始人、Hmily、RainCat、Myth 等分布式事务框架的创始人。
|
||||
|
||||
学习分布式事务的时候,可以参考一下这本书。虽有一些小错误以及逻辑不通顺的地方,但对于各种分布式事务解决方案的介绍,总体来说还是不错的。
|
||||
|
||||
|
||||
@ -34,7 +34,7 @@ icon: "java"
|
||||
|
||||
我第一次看的时候还觉得有点枯燥,那时候还在上大二,看了 1/3 就没看下去了。
|
||||
|
||||
**[《Java 8实战》](https://book.douban.com/subject/26772632/)**
|
||||
**[《Java 8 实战》](https://book.douban.com/subject/26772632/)**
|
||||
|
||||

|
||||
|
||||
@ -64,7 +64,7 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
|
||||
|
||||
这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
|
||||
|
||||
在线阅读:[https://redspider.gitbook.io/concurrent/](https://redspider.gitbook.io/concurrent/ ) 。
|
||||
在线阅读:[https://redspider.gitbook.io/concurrent/](https://redspider.gitbook.io/concurrent/) 。
|
||||
|
||||
**[《Java 并发实现原理:JDK 源码剖析》](https://book.douban.com/subject/35013531/)**
|
||||
|
||||
|
||||
@ -18,6 +18,6 @@ category: 计算机书籍
|
||||
|
||||
如果内容对你有帮助的话,欢迎给本项目点个 Star。我会用我的业余时间持续完善这份书单,感谢!
|
||||
|
||||
本项目推荐的大部分书籍的 PDF 版本我已经整理到了云盘里,你可以在公众号“**Github掘金计划**” 后台回复“**书籍**”获取到。
|
||||
本项目推荐的大部分书籍的 PDF 版本我已经整理到了云盘里,你可以在公众号“**Github 掘金计划**” 后台回复“**书籍**”获取到。
|
||||
|
||||

|
||||
@ -8,7 +8,7 @@ icon: "search"
|
||||
|
||||
Elasticsearch 在 Apache Lucene 的基础上开发而成,学习 ES 之前,建议简单了解一下 Lucene 的相关概念。
|
||||
|
||||
**[《Lucene实战》](https://book.douban.com/subject/6440615/)** 是国内为数不多的中文版本讲 Lucene 的书籍,适合用来学习和了解 Lucene 相关的概念和常见操作。
|
||||
**[《Lucene 实战》](https://book.douban.com/subject/6440615/)** 是国内为数不多的中文版本讲 Lucene 的书籍,适合用来学习和了解 Lucene 相关的概念和常见操作。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -127,5 +127,5 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
||||
|
||||
最后再推荐两个相关的文档:
|
||||
|
||||
- **阿里巴巴 Java 开发手册** :https://github.com/alibaba/p3c
|
||||
- **Google Java 编程风格指南:** http://www.hawstein.com/posts/google-java-style.html
|
||||
- **阿里巴巴 Java 开发手册** :<https://github.com/alibaba/p3c>
|
||||
- **Google Java 编程风格指南**: <http://www.hawstein.com/posts/google-java-style.html>
|
||||
|
||||
@ -11,7 +11,7 @@ tag:
|
||||
|
||||
> Leetcode:给定两个非空链表来表示两个非负整数。位数按照逆序方式存储,它们的每个节点只存储单个数字。将两数相加返回一个新的链表。
|
||||
>
|
||||
>你可以假设除了数字 0 之外,这两个数字都不会以零开头。
|
||||
> 你可以假设除了数字 0 之外,这两个数字都不会以零开头。
|
||||
|
||||
示例:
|
||||
|
||||
@ -23,11 +23,11 @@ tag:
|
||||
|
||||
### 问题分析
|
||||
|
||||
Leetcode官方详细解答地址:
|
||||
Leetcode 官方详细解答地址:
|
||||
|
||||
https://leetcode-cn.com/problems/add-two-numbers/solution/
|
||||
https://leetcode-cn.com/problems/add-two-numbers/solution/
|
||||
|
||||
> 要对头结点进行操作时,考虑创建哑节点dummy,使用dummy->next表示真正的头节点。这样可以避免处理头节点为空的边界问题。
|
||||
> 要对头结点进行操作时,考虑创建哑节点 dummy,使用 dummy->next 表示真正的头节点。这样可以避免处理头节点为空的边界问题。
|
||||
|
||||
我们使用变量来跟踪进位,并从包含最低有效位的表头开始模拟逐
|
||||
位相加的过程。
|
||||
@ -36,7 +36,7 @@ Leetcode官方详细解答地址:
|
||||
|
||||
### Solution
|
||||
|
||||
**我们首先从最低有效位也就是列表 l1和 l2 的表头开始相加。注意需要考虑到进位的情况!**
|
||||
**我们首先从最低有效位也就是列表 l1 和 l2 的表头开始相加。注意需要考虑到进位的情况!**
|
||||
|
||||
```java
|
||||
/**
|
||||
@ -76,8 +76,8 @@ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
|
||||
|
||||
## 2. 翻转链表
|
||||
|
||||
|
||||
### 题目描述
|
||||
|
||||
> 剑指 offer:输入一个链表,反转链表后,输出链表的所有元素。
|
||||
|
||||
|
||||
@ -88,7 +88,6 @@ public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
|
||||
|
||||
### Solution
|
||||
|
||||
|
||||
```java
|
||||
public class ListNode {
|
||||
int val;
|
||||
@ -162,18 +161,17 @@ public class Solution {
|
||||
1
|
||||
```
|
||||
|
||||
## 3. 链表中倒数第k个节点
|
||||
## 3. 链表中倒数第 k 个节点
|
||||
|
||||
### 题目描述
|
||||
|
||||
> 剑指offer: 输入一个链表,输出该链表中倒数第k个结点。
|
||||
> 剑指 offer: 输入一个链表,输出该链表中倒数第 k 个结点。
|
||||
|
||||
### 问题分析
|
||||
|
||||
> **链表中倒数第k个节点也就是正数第(L-K+1)个节点,知道了只一点,这一题基本就没问题!**
|
||||
|
||||
首先两个节点/指针,一个节点 node1 先开始跑,指针 node1 跑到 k-1 个节点后,另一个节点 node2 开始跑,当 node1 跑到最后时,node2 所指的节点就是倒数第k个节点也就是正数第(L-K+1)个节点。
|
||||
> **链表中倒数第 k 个节点也就是正数第(L-K+1)个节点,知道了只一点,这一题基本就没问题!**
|
||||
|
||||
首先两个节点/指针,一个节点 node1 先开始跑,指针 node1 跑到 k-1 个节点后,另一个节点 node2 开始跑,当 node1 跑到最后时,node2 所指的节点就是倒数第 k 个节点也就是正数第(L-K+1)个节点。
|
||||
|
||||
### Solution
|
||||
|
||||
@ -221,9 +219,7 @@ public class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 4. 删除链表的倒数第N个节点
|
||||
|
||||
## 4. 删除链表的倒数第 N 个节点
|
||||
|
||||
> Leetcode:给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
|
||||
|
||||
@ -248,8 +244,7 @@ public class Solution {
|
||||
|
||||
### 问题分析
|
||||
|
||||
|
||||
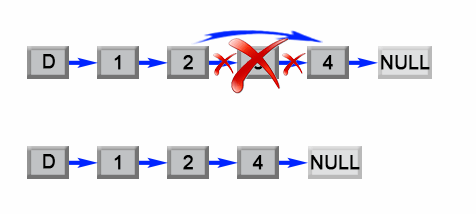
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)个结点,其中 L是列表的长度。只要我们找到列表的长度 L,这个问题就很容易解决。
|
||||
我们注意到这个问题可以容易地简化成另一个问题:删除从列表开头数起的第 (L - n + 1)个结点,其中 L 是列表的长度。只要我们找到列表的长度 L,这个问题就很容易解决。
|
||||
|
||||
|
||||
|
||||
@ -301,14 +296,11 @@ public class Solution {
|
||||
- **时间复杂度 O(L)** :该算法对列表进行了两次遍历,首先计算了列表的长度 LL 其次找到第 (L - n)(L−n) 个结点。 操作执行了 2L-n2L−n 步,时间复杂度为 O(L)O(L)。
|
||||
- **空间复杂度 O(1)** :我们只用了常量级的额外空间。
|
||||
|
||||
|
||||
|
||||
**进阶——一次遍历法:**
|
||||
|
||||
> 链表中倒数第 N 个节点也就是正数第(L-N+1)个节点。
|
||||
|
||||
> 链表中倒数第N个节点也就是正数第(L-N+1)个节点。
|
||||
|
||||
其实这种方法就和我们上面第四题找“链表中倒数第k个节点”所用的思想是一样的。**基本思路就是:** 定义两个节点 node1、node2;node1 节点先跑,node1节点 跑到第 n+1 个节点的时候,node2 节点开始跑.当node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点(L代表总链表长度,也就是倒数第 n+1 个节点)
|
||||
其实这种方法就和我们上面第四题找“链表中倒数第 k 个节点”所用的思想是一样的。**基本思路就是:** 定义两个节点 node1、node2;node1 节点先跑,node1 节点 跑到第 n+1 个节点的时候,node2 节点开始跑.当 node1 节点跑到最后一个节点时,node2 节点所在的位置就是第 (L-n ) 个节点(L 代表总链表长度,也就是倒数第 n+1 个节点)
|
||||
|
||||
```java
|
||||
/**
|
||||
@ -345,25 +337,21 @@ public class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 5. 合并两个排序的链表
|
||||
|
||||
### 题目描述
|
||||
|
||||
> 剑指offer:输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
|
||||
> 剑指 offer:输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
|
||||
|
||||
### 问题分析
|
||||
|
||||
我们可以这样分析:
|
||||
|
||||
1. 假设我们有两个链表 A,B;
|
||||
2. A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
|
||||
3. A2再和B1比较,假设B1小,则,A1指向B1;
|
||||
4. A2再和B2比较
|
||||
就这样循环往复就行了,应该还算好理解。
|
||||
2. A 的头节点 A1 的值与 B 的头结点 B1 的值比较,假设 A1 小,则 A1 为头节点;
|
||||
3. A2 再和 B1 比较,假设 B1 小,则,A1 指向 B1;
|
||||
4. A2 再和 B2 比较
|
||||
就这样循环往复就行了,应该还算好理解。
|
||||
|
||||
考虑通过递归的方式实现!
|
||||
|
||||
@ -400,4 +388,3 @@ public ListNode Merge(ListNode list1,ListNode list2) {
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -9,12 +9,12 @@ tag:
|
||||
|
||||
**题目描述:**
|
||||
|
||||
大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。
|
||||
大家都知道斐波那契数列,现在要求输入一个整数 n,请你输出斐波那契数列的第 n 项。
|
||||
n<=39
|
||||
|
||||
**问题分析:**
|
||||
|
||||
可以肯定的是这一题通过递归的方式是肯定能做出来,但是这样会有一个很大的问题,那就是递归大量的重复计算会导致内存溢出。另外可以使用迭代法,用fn1和fn2保存计算过程中的结果,并复用起来。下面我会把两个方法示例代码都给出来并给出两个方法的运行时间对比。
|
||||
可以肯定的是这一题通过递归的方式是肯定能做出来,但是这样会有一个很大的问题,那就是递归大量的重复计算会导致内存溢出。另外可以使用迭代法,用 fn1 和 fn2 保存计算过程中的结果,并复用起来。下面我会把两个方法示例代码都给出来并给出两个方法的运行时间对比。
|
||||
|
||||
**示例代码:**
|
||||
|
||||
@ -57,24 +57,24 @@ public int Fibonacci(int n) {
|
||||
|
||||
**题目描述:**
|
||||
|
||||
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
|
||||
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
|
||||
|
||||
**问题分析:**
|
||||
|
||||
正常分析法:
|
||||
|
||||
> a.如果两种跳法,1阶或者2阶,那么假定第一次跳的是一阶,那么剩下的是n-1个台阶,跳法是f(n-1);
|
||||
> b.假定第一次跳的是2阶,那么剩下的是n-2个台阶,跳法是f(n-2)
|
||||
> c.由a,b假设可以得出总跳法为: f(n) = f(n-1) + f(n-2)
|
||||
> a.如果两种跳法,1 阶或者 2 阶,那么假定第一次跳的是一阶,那么剩下的是 n-1 个台阶,跳法是 f(n-1);
|
||||
> b.假定第一次跳的是 2 阶,那么剩下的是 n-2 个台阶,跳法是 f(n-2)
|
||||
> c.由 a,b 假设可以得出总跳法为: f(n) = f(n-1) + f(n-2)
|
||||
> d.然后通过实际的情况可以得出:只有一阶的时候 f(1) = 1 ,只有两阶的时候可以有 f(2) = 2
|
||||
|
||||
找规律分析法:
|
||||
|
||||
> f(1) = 1, f(2) = 2, f(3) = 3, f(4) = 5, 可以总结出f(n) = f(n-1) + f(n-2)的规律。但是为什么会出现这样的规律呢?假设现在6个台阶,我们可以从第5跳一步到6,这样的话有多少种方案跳到5就有多少种方案跳到6,另外我们也可以从4跳两步跳到6,跳到4有多少种方案的话,就有多少种方案跳到6,其他的不能从3跳到6什么的啦,所以最后就是f(6) = f(5) + f(4);这样子也很好理解变态跳台阶的问题了。
|
||||
> f(1) = 1, f(2) = 2, f(3) = 3, f(4) = 5, 可以总结出 f(n) = f(n-1) + f(n-2)的规律。但是为什么会出现这样的规律呢?假设现在 6 个台阶,我们可以从第 5 跳一步到 6,这样的话有多少种方案跳到 5 就有多少种方案跳到 6,另外我们也可以从 4 跳两步跳到 6,跳到 4 有多少种方案的话,就有多少种方案跳到 6,其他的不能从 3 跳到 6 什么的啦,所以最后就是 f(6) = f(5) + f(4);这样子也很好理解变态跳台阶的问题了。
|
||||
|
||||
**所以这道题其实就是斐波那契数列的问题。**
|
||||
|
||||
代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
|
||||
代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为 1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
|
||||
|
||||
**示例代码:**
|
||||
|
||||
@ -103,20 +103,20 @@ int jumpFloor(int number) {
|
||||
|
||||
**题目描述:**
|
||||
|
||||
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
|
||||
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级……它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
|
||||
|
||||
**问题分析:**
|
||||
|
||||
假设n>=2,第一步有n种跳法:跳1级、跳2级、到跳n级
|
||||
跳1级,剩下n-1级,则剩下跳法是f(n-1)
|
||||
跳2级,剩下n-2级,则剩下跳法是f(n-2)
|
||||
假设 n>=2,第一步有 n 种跳法:跳 1 级、跳 2 级、到跳 n 级
|
||||
跳 1 级,剩下 n-1 级,则剩下跳法是 f(n-1)
|
||||
跳 2 级,剩下 n-2 级,则剩下跳法是 f(n-2)
|
||||
......
|
||||
跳n-1级,剩下1级,则剩下跳法是f(1)
|
||||
跳n级,剩下0级,则剩下跳法是f(0)
|
||||
所以在n>=2的情况下:
|
||||
跳 n-1 级,剩下 1 级,则剩下跳法是 f(1)
|
||||
跳 n 级,剩下 0 级,则剩下跳法是 f(0)
|
||||
所以在 n>=2 的情况下:
|
||||
f(n)=f(n-1)+f(n-2)+...+f(1)
|
||||
因为f(n-1)=f(n-2)+f(n-3)+...+f(1)
|
||||
所以f(n)=2*f(n-1) 又f(1)=1,所以可得**f(n)=2^(number-1)**
|
||||
因为 f(n-1)=f(n-2)+f(n-3)+...+f(1)
|
||||
所以 f(n)=2\*f(n-1) 又 f(1)=1,所以可得**f(n)=2^(number-1)**
|
||||
|
||||
**示例代码:**
|
||||
|
||||
@ -128,11 +128,11 @@ int JumpFloorII(int number) {
|
||||
|
||||
**补充:**
|
||||
|
||||
java中有三种移位运算符:
|
||||
java 中有三种移位运算符:
|
||||
|
||||
1. “<<” : **左移运算符**,等同于乘2的n次方
|
||||
2. “>>”: **右移运算符**,等同于除2的n次方
|
||||
3. “>>>” : **无符号右移运算符**,不管移动前最高位是0还是1,右移后左侧产生的空位部分都以0来填充。与>>类似。
|
||||
1. “<<” : **左移运算符**,等同于乘 2 的 n 次方
|
||||
2. “>>”: **右移运算符**,等同于除 2 的 n 次方
|
||||
3. “>>>” : **无符号右移运算符**,不管移动前最高位是 0 还是 1,右移后左侧产生的空位部分都以 0 来填充。与>>类似。
|
||||
|
||||
```java
|
||||
int a = 16;
|
||||
@ -140,7 +140,6 @@ int b = a << 2;//左移2,等同于16 * 2的2次方,也就是16 * 4
|
||||
int c = a >> 2;//右移2,等同于16 / 2的2次方,也就是16 / 4
|
||||
```
|
||||
|
||||
|
||||
## 二维数组查找
|
||||
|
||||
**题目描述:**
|
||||
@ -180,11 +179,11 @@ public boolean Find(int target, int [][] array) {
|
||||
|
||||
**题目描述:**
|
||||
|
||||
请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
|
||||
请实现一个函数,将一个字符串中的空格替换成“%20”。例如,当字符串为 We Are Happy.则经过替换之后的字符串为 We%20Are%20Happy。
|
||||
|
||||
**问题分析:**
|
||||
|
||||
这道题不难,我们可以通过循环判断字符串的字符是否为空格,是的话就利用append()方法添加追加“%20”,否则还是追加原字符。
|
||||
这道题不难,我们可以通过循环判断字符串的字符是否为空格,是的话就利用 append()方法添加追加“%20”,否则还是追加原字符。
|
||||
|
||||
或者最简单的方法就是利用:replaceAll(String regex,String replacement)方法了,一行代码就可以解决。
|
||||
|
||||
@ -223,17 +222,14 @@ public String replaceSpace(StringBuffer str) {
|
||||
|
||||
**题目描述:**
|
||||
|
||||
给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
|
||||
给定一个 double 类型的浮点数 base 和 int 类型的整数 exponent。求 base 的 exponent 次方。
|
||||
|
||||
**问题解析:**
|
||||
|
||||
这道题算是比较麻烦和难一点的一个了。我这里采用的是**二分幂**思想,当然也可以采用**快速幂**。
|
||||
更具剑指offer书中细节,该题的解题思路如下:
|
||||
1.当底数为0且指数<0时,会出现对0求倒数的情况,需进行错误处理,设置一个全局变量;
|
||||
2.判断底数是否等于0,由于base为double型,所以不能直接用==判断
|
||||
3.优化求幂函数(二分幂)。
|
||||
当n为偶数,a^n =(a^n/2)*(a^n/2);
|
||||
当n为奇数,a^n = a^[(n-1)/2] * a^[(n-1)/2] * a。时间复杂度O(logn)
|
||||
更具剑指 offer 书中细节,该题的解题思路如下: 1.当底数为 0 且指数<0 时,会出现对 0 求倒数的情况,需进行错误处理,设置一个全局变量; 2.判断底数是否等于 0,由于 base 为 double 型,所以不能直接用==判断 3.优化求幂函数(二分幂)。
|
||||
当 n 为偶数,a^n =(a^n/2)_(a^n/2);
|
||||
当 n 为奇数,a^n = a^[(n-1)/2] _ a^[(n-1)/2] \* a。时间复杂度 O(logn)
|
||||
|
||||
**时间复杂度**:O(logn)
|
||||
|
||||
@ -286,7 +282,7 @@ public class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
当然这一题也可以采用笨方法:累乘。不过这种方法的时间复杂度为O(n),这样没有前一种方法效率高。
|
||||
当然这一题也可以采用笨方法:累乘。不过这种方法的时间复杂度为 O(n),这样没有前一种方法效率高。
|
||||
|
||||
```java
|
||||
// 使用累乘
|
||||
@ -311,11 +307,11 @@ public double powerAnother(double base, int exponent) {
|
||||
**问题解析:**
|
||||
|
||||
这道题有挺多种解法的,给大家介绍一种我觉得挺好理解的方法:
|
||||
我们首先统计奇数的个数假设为n,然后新建一个等长数组,然后通过循环判断原数组中的元素为偶数还是奇数。如果是则从数组下标0的元素开始,把该奇数添加到新数组;如果是偶数则从数组下标为n的元素开始把该偶数添加到新数组中。
|
||||
我们首先统计奇数的个数假设为 n,然后新建一个等长数组,然后通过循环判断原数组中的元素为偶数还是奇数。如果是则从数组下标 0 的元素开始,把该奇数添加到新数组;如果是偶数则从数组下标为 n 的元素开始把该偶数添加到新数组中。
|
||||
|
||||
**示例代码:**
|
||||
|
||||
时间复杂度为O(n),空间复杂度为O(n)的算法
|
||||
时间复杂度为 O(n),空间复杂度为 O(n)的算法
|
||||
|
||||
```java
|
||||
public class Solution {
|
||||
@ -346,26 +342,26 @@ public class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
## 链表中倒数第k个节点
|
||||
## 链表中倒数第 k 个节点
|
||||
|
||||
**题目描述:**
|
||||
|
||||
输入一个链表,输出该链表中倒数第k个结点
|
||||
输入一个链表,输出该链表中倒数第 k 个结点
|
||||
|
||||
**问题分析:**
|
||||
|
||||
**一句话概括:**
|
||||
两个指针一个指针p1先开始跑,指针p1跑到k-1个节点后,另一个节点p2开始跑,当p1跑到最后时,p2所指的指针就是倒数第k个节点。
|
||||
两个指针一个指针 p1 先开始跑,指针 p1 跑到 k-1 个节点后,另一个节点 p2 开始跑,当 p1 跑到最后时,p2 所指的指针就是倒数第 k 个节点。
|
||||
|
||||
**思想的简单理解:**
|
||||
前提假设:链表的结点个数(长度)为n。
|
||||
规律一:要找到倒数第k个结点,需要向前走多少步呢?比如倒数第一个结点,需要走n步,那倒数第二个结点呢?很明显是向前走了n-1步,所以可以找到规律是找到倒数第k个结点,需要向前走n-k+1步。
|
||||
前提假设:链表的结点个数(长度)为 n。
|
||||
规律一:要找到倒数第 k 个结点,需要向前走多少步呢?比如倒数第一个结点,需要走 n 步,那倒数第二个结点呢?很明显是向前走了 n-1 步,所以可以找到规律是找到倒数第 k 个结点,需要向前走 n-k+1 步。
|
||||
|
||||
**算法开始:**
|
||||
|
||||
1. 设两个都指向head的指针p1和p2,当p1走了k-1步的时候,停下来。p2之前一直不动。
|
||||
2. p1的下一步是走第k步,这个时候,p2开始一起动了。至于为什么p2这个时候动呢?看下面的分析。
|
||||
3. 当p1走到链表的尾部时,即p1走了n步。由于我们知道p2是在p1走了k-1步才开始动的,也就是说p1和p2永远差k-1步。所以当p1走了n步时,p2走的应该是在n-(k-1)步。即p2走了n-k+1步,此时巧妙的是p2正好指向的是规律一的倒数第k个结点处。
|
||||
1. 设两个都指向 head 的指针 p1 和 p2,当 p1 走了 k-1 步的时候,停下来。p2 之前一直不动。
|
||||
2. p1 的下一步是走第 k 步,这个时候,p2 开始一起动了。至于为什么 p2 这个时候动呢?看下面的分析。
|
||||
3. 当 p1 走到链表的尾部时,即 p1 走了 n 步。由于我们知道 p2 是在 p1 走了 k-1 步才开始动的,也就是说 p1 和 p2 永远差 k-1 步。所以当 p1 走了 n 步时,p2 走的应该是在 n-(k-1)步。即 p2 走了 n-k+1 步,此时巧妙的是 p2 正好指向的是规律一的倒数第 k 个结点处。
|
||||
这样是不是很好理解了呢?
|
||||
|
||||
**考察内容:**
|
||||
@ -425,7 +421,7 @@ public class Solution {
|
||||
|
||||
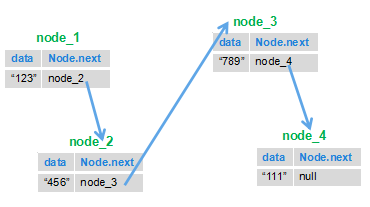
链表的很常规的一道题,这一道题思路不算难,但自己实现起来真的可能会感觉无从下手,我是参考了别人的代码。
|
||||
思路就是我们根据链表的特点,前一个节点指向下一个节点的特点,把后面的节点移到前面来。
|
||||
就比如下图:我们把1节点和2节点互换位置,然后再将3节点指向2节点,4节点指向3节点,这样以来下面的链表就被反转了。
|
||||
就比如下图:我们把 1 节点和 2 节点互换位置,然后再将 3 节点指向 2 节点,4 节点指向 3 节点,这样以来下面的链表就被反转了。
|
||||
|
||||
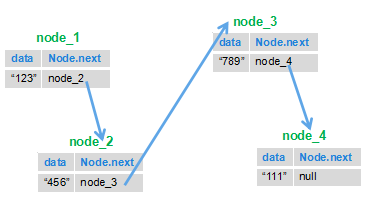
|
||||
|
||||
@ -475,9 +471,9 @@ public class Solution {
|
||||
我们可以这样分析:
|
||||
|
||||
1. 假设我们有两个链表 A,B;
|
||||
2. A的头节点A1的值与B的头结点B1的值比较,假设A1小,则A1为头节点;
|
||||
3. A2再和B1比较,假设B1小,则,A1指向B1;
|
||||
4. A2再和B2比较。。。。。。。
|
||||
2. A 的头节点 A1 的值与 B 的头结点 B1 的值比较,假设 A1 小,则 A1 为头节点;
|
||||
3. A2 再和 B1 比较,假设 B1 小,则,A1 指向 B1;
|
||||
4. A2 再和 B2 比较。。。。。。。
|
||||
就这样循环往复就行了,应该还算好理解。
|
||||
|
||||
**考察内容:**
|
||||
@ -569,17 +565,17 @@ public ListNode Merge(ListNode list1,ListNode list2) {
|
||||
|
||||
**题目描述:**
|
||||
|
||||
用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
|
||||
用两个栈来实现一个队列,完成队列的 Push 和 Pop 操作。 队列中的元素为 int 类型。
|
||||
|
||||
**问题分析:**
|
||||
|
||||
先来回顾一下栈和队列的基本特点:
|
||||
**栈:**后进先出(LIFO)
|
||||
**队列:** 先进先出
|
||||
很明显我们需要根据JDK给我们提供的栈的一些基本方法来实现。先来看一下Stack类的一些基本方法:
|
||||
很明显我们需要根据 JDK 给我们提供的栈的一些基本方法来实现。先来看一下 Stack 类的一些基本方法:
|
||||
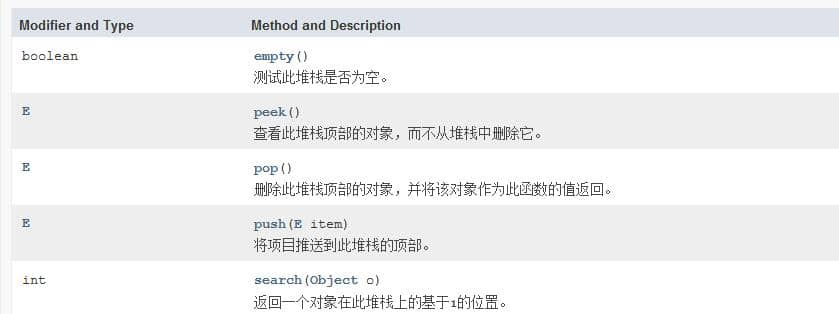
|
||||
|
||||
既然题目给了我们两个栈,我们可以这样考虑当push的时候将元素push进stack1,pop的时候我们先把stack1的元素pop到stack2,然后再对stack2执行pop操作,这样就可以保证是先进先出的。(负[pop]负[pop]得正[先进先出])
|
||||
既然题目给了我们两个栈,我们可以这样考虑当 push 的时候将元素 push 进 stack1,pop 的时候我们先把 stack1 的元素 pop 到 stack2,然后再对 stack2 执行 pop 操作,这样就可以保证是先进先出的。(负[pop]负[pop]得正[先进先出])
|
||||
|
||||
**考察内容:**
|
||||
|
||||
@ -621,34 +617,34 @@ public class Solution {
|
||||
|
||||
**题目描述:**
|
||||
|
||||
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
|
||||
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列 1,2,3,4,5 是某栈的压入顺序,序列 4,5,3,2,1 是该压栈序列对应的一个弹出序列,但 4,3,5,1,2 就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
|
||||
|
||||
**题目分析:**
|
||||
|
||||
这道题想了半天没有思路,参考了Alias的答案,他的思路写的也很详细应该很容易看懂。
|
||||
这道题想了半天没有思路,参考了 Alias 的答案,他的思路写的也很详细应该很容易看懂。
|
||||
作者:Alias
|
||||
https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
|
||||
来源:牛客网
|
||||
|
||||
【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是4,很显然1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
|
||||
【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是 1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是 4,很显然 1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
|
||||
|
||||
举例:
|
||||
|
||||
入栈1,2,3,4,5
|
||||
入栈 1,2,3,4,5
|
||||
|
||||
出栈4,5,3,2,1
|
||||
出栈 4,5,3,2,1
|
||||
|
||||
首先1入辅助栈,此时栈顶1≠4,继续入栈2
|
||||
首先 1 入辅助栈,此时栈顶 1≠4,继续入栈 2
|
||||
|
||||
此时栈顶2≠4,继续入栈3
|
||||
此时栈顶 2≠4,继续入栈 3
|
||||
|
||||
此时栈顶3≠4,继续入栈4
|
||||
此时栈顶 3≠4,继续入栈 4
|
||||
|
||||
此时栈顶4=4,出栈4,弹出序列向后一位,此时为5,,辅助栈里面是1,2,3
|
||||
此时栈顶 4 = 4,出栈 4,弹出序列向后一位,此时为 5,,辅助栈里面是 1,2,3
|
||||
|
||||
此时栈顶3≠5,继续入栈5
|
||||
此时栈顶 3≠5,继续入栈 5
|
||||
|
||||
此时栈顶5=5,出栈5,弹出序列向后一位,此时为3,,辅助栈里面是1,2,3
|
||||
此时栈顶 5=5,出栈 5,弹出序列向后一位,此时为 3,,辅助栈里面是 1,2,3
|
||||
|
||||
….
|
||||
依次执行,最后辅助栈为空。如果不为空说明弹出序列不是该栈的弹出顺序。
|
||||
|
||||
@ -57,7 +57,6 @@ tag:
|
||||
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
|
||||
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
|
||||
|
||||
|
||||
## 编码实战
|
||||
|
||||
### 通过 Java 编程手动实现布隆过滤器
|
||||
@ -245,9 +244,9 @@ Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Red
|
||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom
|
||||
其他还有:
|
||||
|
||||
* redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||
* pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
|
||||
* ......
|
||||
- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||
- pyreBloom(Python 中的快速 Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
|
||||
- ......
|
||||
|
||||
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
|
||||
|
||||
@ -287,7 +286,7 @@ root@21396d02c252:/data# redis-cli
|
||||
|
||||
可选参数:
|
||||
|
||||
* expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以`expansion`。默认扩展值为 2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
|
||||
- expansion:如果创建了一个新的子过滤器,则其大小将是当前过滤器的大小乘以`expansion`。默认扩展值为 2。这意味着每个后续子过滤器将是前一个子过滤器的两倍。
|
||||
|
||||
### 实际使用
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ tag:
|
||||
|
||||
但是,图形结构的元素之间的关系是任意的。
|
||||
|
||||
**何为图呢?** 简单来说,图就是由顶点的有穷非空集合和顶点之间的边组成的集合。通常表示为:**G(V,E)**,其中,G表示一个图,V表示顶点的集合,E表示边的集合。
|
||||
**何为图呢?** 简单来说,图就是由顶点的有穷非空集合和顶点之间的边组成的集合。通常表示为:**G(V,E)**,其中,G 表示一个图,V 表示顶点的集合,E 表示边的集合。
|
||||
|
||||
下图所展示的就是图这种数据结构,并且还是一张有向图。
|
||||
|
||||
@ -25,24 +25,28 @@ tag:
|
||||
## 图的基本概念
|
||||
|
||||
### 顶点
|
||||
|
||||
图中的数据元素,我们称之为顶点,图至少有一个顶点(非空有穷集合)
|
||||
|
||||
对应到好友关系图,每一个用户就代表一个顶点。
|
||||
|
||||
### 边
|
||||
|
||||
顶点之间的关系用边表示。
|
||||
|
||||
对应到好友关系图,两个用户是好友的话,那两者之间就存在一条边。
|
||||
|
||||
### 度
|
||||
|
||||
度表示一个顶点包含多少条边,在有向图中,还分为出度和入度,出度表示从该顶点出去的边的条数,入度表示进入该顶点的边的条数。
|
||||
|
||||
对应到好友关系图,度就代表了某个人的好友数量。
|
||||
|
||||
### 无向图和有向图
|
||||
边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A是B的同学,那么B也肯定是A的同学,那么在表示A和B的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
|
||||
|
||||
有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A是B的爸爸,但B肯定不是A的爸爸,A关注B,B不一定关注A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
|
||||
边表示的是顶点之间的关系,有的关系是双向的,比如同学关系,A 是 B 的同学,那么 B 也肯定是 A 的同学,那么在表示 A 和 B 的关系时,就不用关注方向,用不带箭头的边表示,这样的图就是无向图。
|
||||
|
||||
有的关系是有方向的,比如父子关系,师生关系,微博的关注关系,A 是 B 的爸爸,但 B 肯定不是 A 的爸爸,A 关注 B,B 不一定关注 A。在这种情况下,我们就用带箭头的边表示二者的关系,这样的图就是有向图。
|
||||
|
||||
### 无权图和带权图
|
||||
|
||||
@ -55,16 +59,18 @@ tag:
|
||||
|
||||
|
||||
## 图的存储
|
||||
|
||||
### 邻接矩阵存储
|
||||
|
||||
邻接矩阵将图用二维矩阵存储,是一种较为直观的表示方式。
|
||||
|
||||
如果第i个顶点和第j个顶点之间有关系,且关系权值为n,则 `A[i][j]=n` 。
|
||||
如果第 i 个顶点和第 j 个顶点之间有关系,且关系权值为 n,则 `A[i][j]=n` 。
|
||||
|
||||
在无向图中,我们只关心关系的有无,所以当顶点i和顶点j有关系时,`A[i][j]`=1,当顶点i和顶点j没有关系时,`A[i][j]`=0。如下图所示:
|
||||
在无向图中,我们只关心关系的有无,所以当顶点 i 和顶点 j 有关系时,`A[i][j]`=1,当顶点 i 和顶点 j 没有关系时,`A[i][j]`=0。如下图所示:
|
||||
|
||||
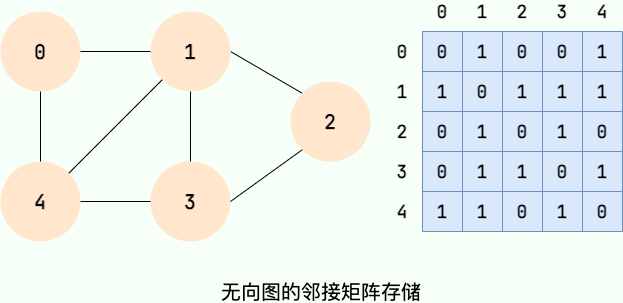
|
||||
|
||||
值得注意的是:**无向图的邻接矩阵是一个对称矩阵,因为在无向图中,顶点i和顶点j有关系,则顶点j和顶点i必有关系。**
|
||||
值得注意的是:**无向图的邻接矩阵是一个对称矩阵,因为在无向图中,顶点 i 和顶点 j 有关系,则顶点 j 和顶点 i 必有关系。**
|
||||
|
||||

|
||||
|
||||
@ -74,7 +80,7 @@ tag:
|
||||
|
||||
针对上面邻接矩阵比较浪费内存空间的问题,诞生了图的另外一种存储方法—**邻接表** 。
|
||||
|
||||
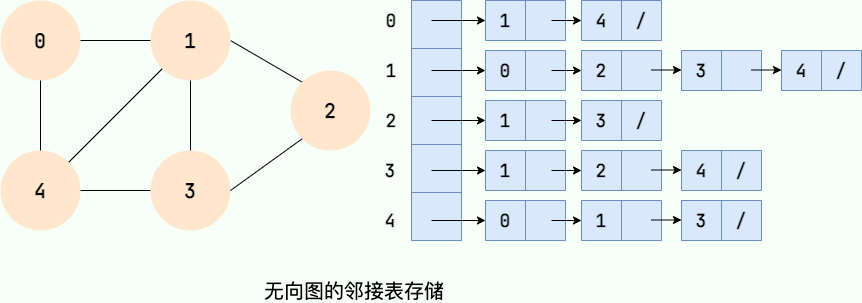
邻接链表使用一个链表来存储某个顶点的所有后继相邻顶点。对于图中每个顶点Vi,把所有邻接于Vi的顶点Vj链成一个单链表,这个单链表称为顶点Vi的 **邻接表**。如下图所示:
|
||||
邻接链表使用一个链表来存储某个顶点的所有后继相邻顶点。对于图中每个顶点 Vi,把所有邻接于 Vi 的顶点 Vj 链成一个单链表,这个单链表称为顶点 Vi 的 **邻接表**。如下图所示:
|
||||
|
||||
|
||||
|
||||
@ -82,38 +88,40 @@ tag:
|
||||
|
||||
大家可以数一数邻接表中所存储的元素的个数以及图中边的条数,你会发现:
|
||||
|
||||
- 在无向图中,邻接表元素个数等于边的条数的两倍,如左图所示的无向图中,边的条数为7,邻接表存储的元素个数为14。
|
||||
- 在有向图中,邻接表元素个数等于边的条数,如右图所示的有向图中,边的条数为8,邻接表存储的元素个数为8。
|
||||
- 在无向图中,邻接表元素个数等于边的条数的两倍,如左图所示的无向图中,边的条数为 7,邻接表存储的元素个数为 14。
|
||||
- 在有向图中,邻接表元素个数等于边的条数,如右图所示的有向图中,边的条数为 8,邻接表存储的元素个数为 8。
|
||||
|
||||
## 图的搜索
|
||||
|
||||
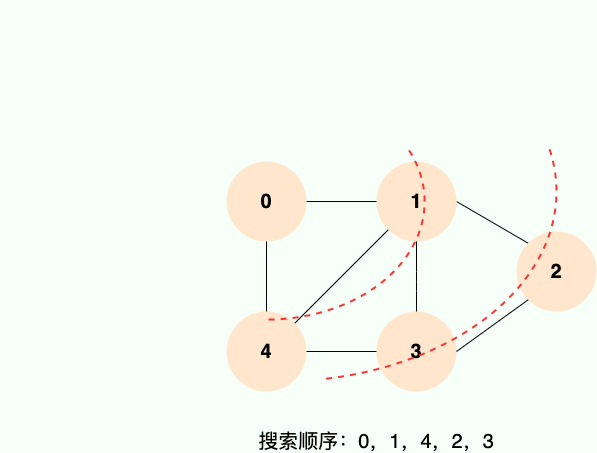
### 广度优先搜索
|
||||
|
||||
广度优先搜索就像水面上的波纹一样一层一层向外扩展,如下图所示:
|
||||
|
||||
|
||||
|
||||
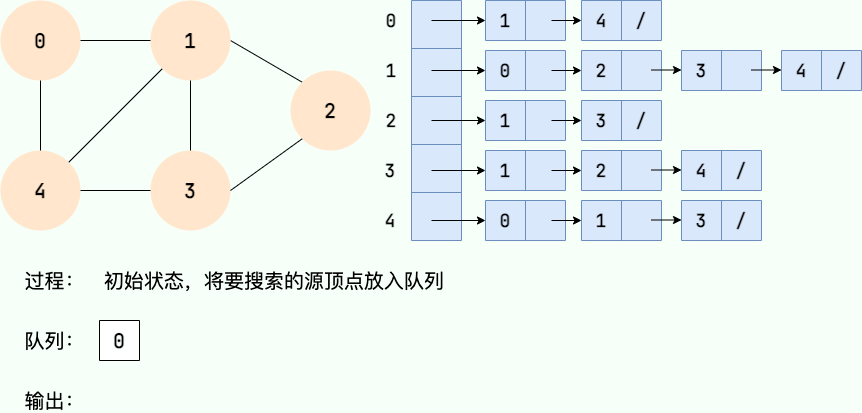
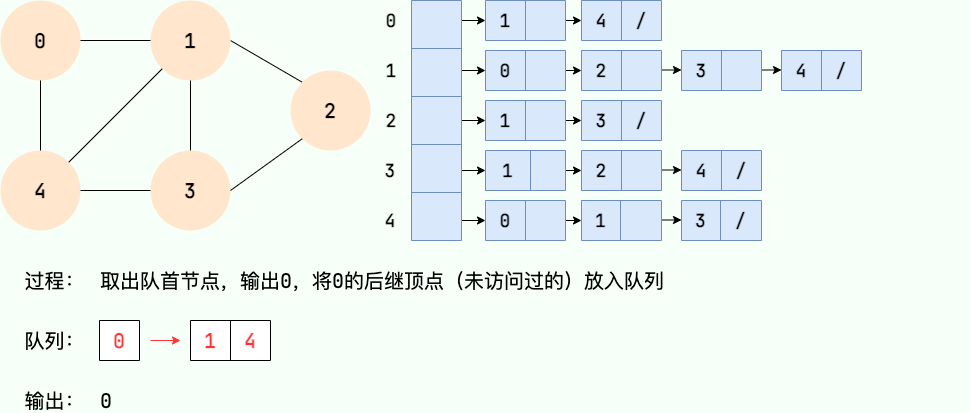
**广度优先搜索的具体实现方式用到了之前所学过的线性数据结构——队列** 。具体过程如下图所示:
|
||||
|
||||
**第1步:**
|
||||
**第 1 步:**
|
||||
|
||||
|
||||
|
||||
**第2步:**
|
||||
**第 2 步:**
|
||||
|
||||
|
||||
|
||||
**第3步:**
|
||||
**第 3 步:**
|
||||
|
||||
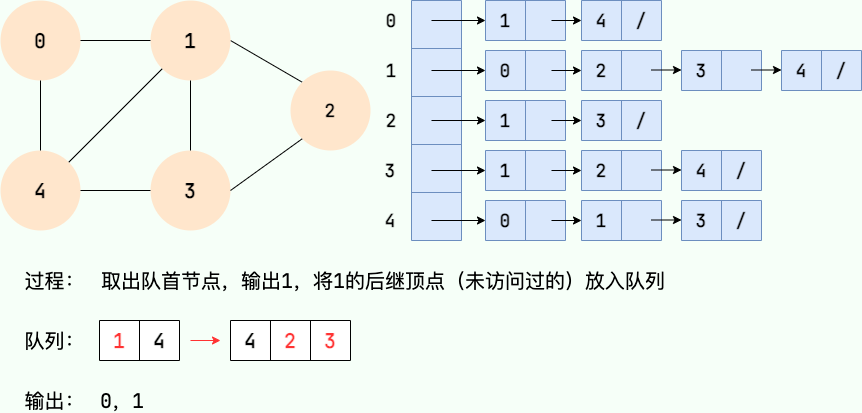
|
||||
|
||||
**第4步:**
|
||||
**第 4 步:**
|
||||
|
||||
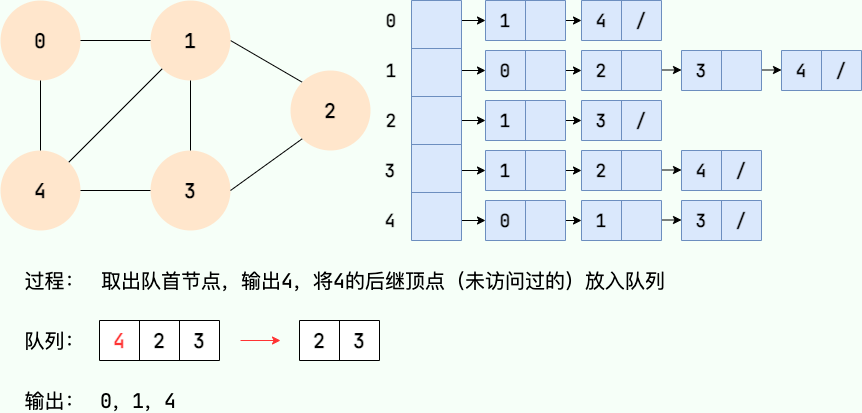
|
||||
|
||||
**第5步:**
|
||||
**第 5 步:**
|
||||
|
||||
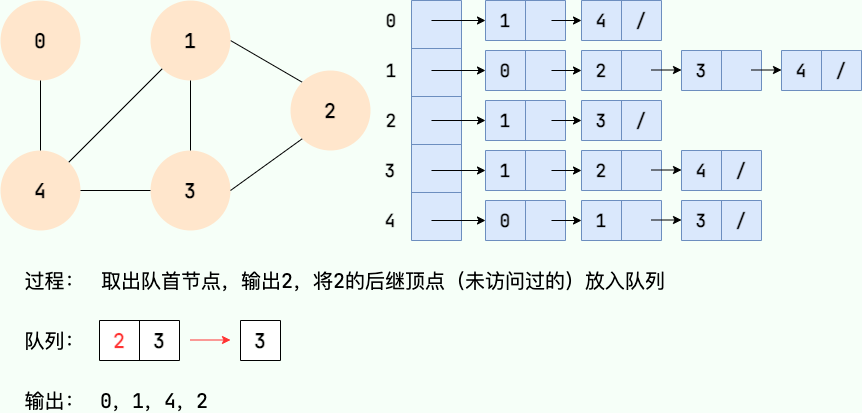
|
||||
|
||||
**第6步:**
|
||||
**第 6 步:**
|
||||
|
||||
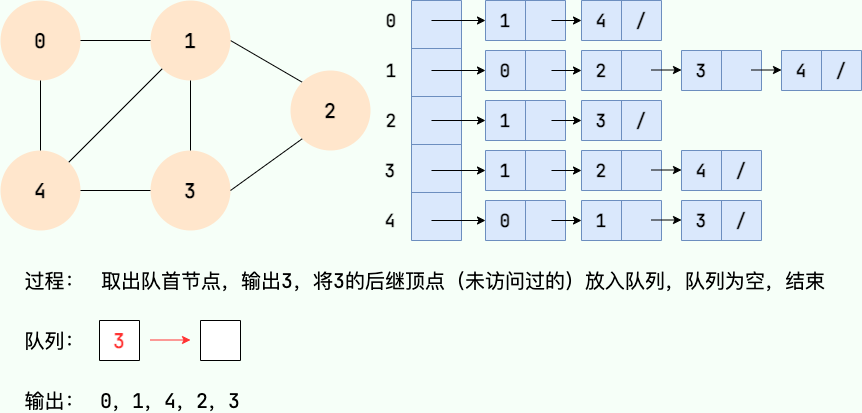
|
||||
|
||||
@ -123,30 +131,28 @@ tag:
|
||||
|
||||
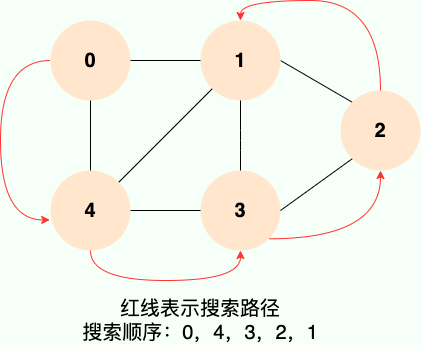
|
||||
|
||||
|
||||
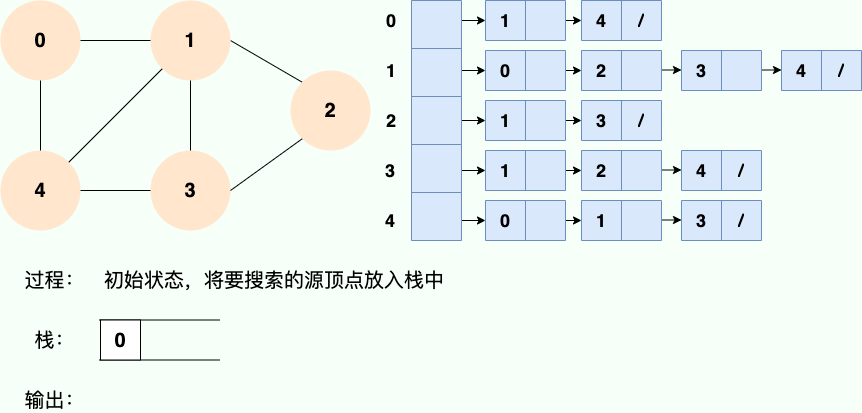
**和广度优先搜索类似,深度优先搜索的具体实现用到了另一种线性数据结构——栈** 。具体过程如下图所示:
|
||||
|
||||
**第1步:**
|
||||
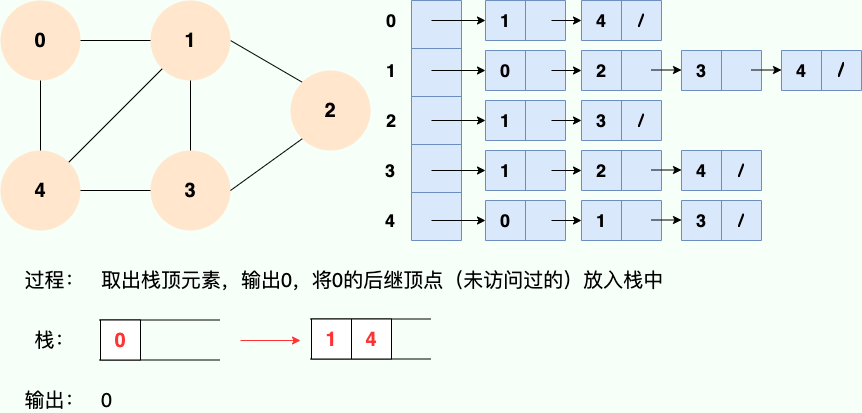
**第 1 步:**
|
||||
|
||||
|
||||
|
||||
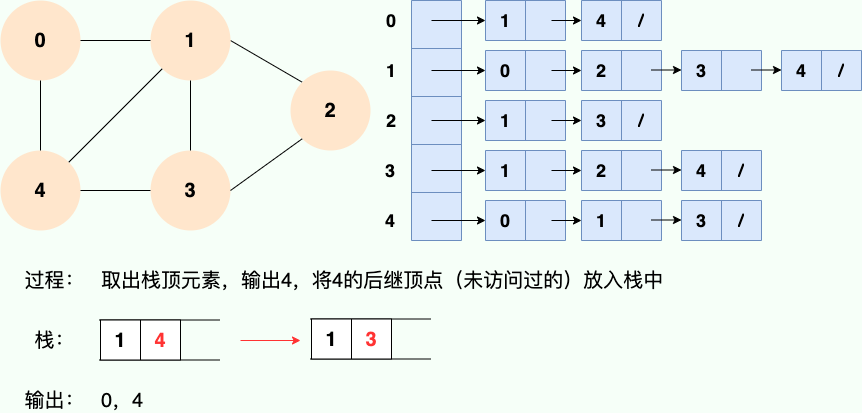
**第2步:**
|
||||
**第 2 步:**
|
||||
|
||||
|
||||
|
||||
**第3步:**
|
||||
**第 3 步:**
|
||||
|
||||
|
||||
|
||||
**第4步:**
|
||||
**第 4 步:**
|
||||
|
||||
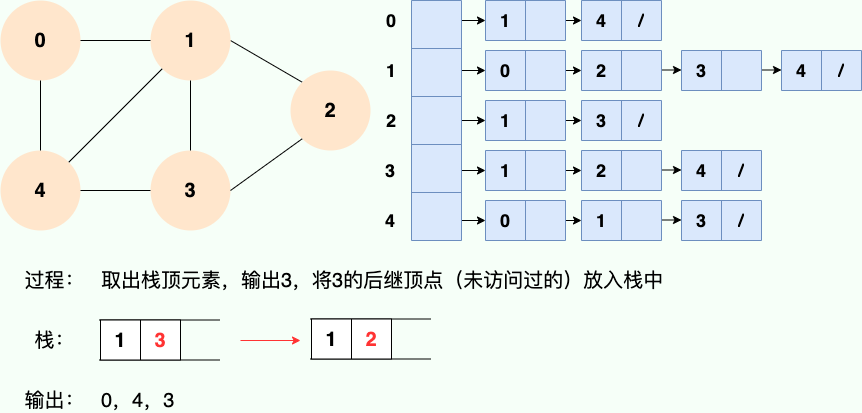
|
||||
|
||||
**第5步:**
|
||||
**第 5 步:**
|
||||
|
||||

|
||||
|
||||
**第6步:**
|
||||
**第 6 步:**
|
||||
|
||||
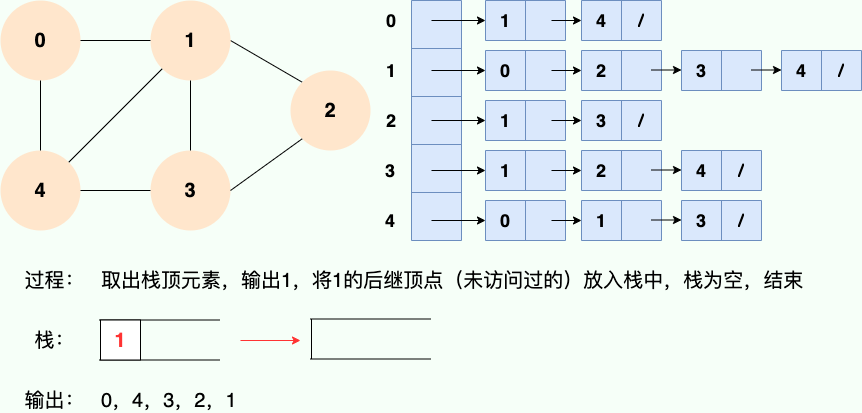
|
||||
|
||||
|
||||
@ -23,11 +23,12 @@ tag:
|
||||
|
||||

|
||||
|
||||
第1个和第2个是堆。第1个是最大堆,每个节点都比子树中所有节点大。第2个是最小堆,每个节点都比子树中所有节点小。
|
||||
第 1 个和第 2 个是堆。第 1 个是最大堆,每个节点都比子树中所有节点大。第 2 个是最小堆,每个节点都比子树中所有节点小。
|
||||
|
||||
第3个不是,第三个中,根结点1比2和15小,而15却比3大,19比5大,不满足堆的性质。
|
||||
第 3 个不是,第三个中,根结点 1 比 2 和 15 小,而 15 却比 3 大,19 比 5 大,不满足堆的性质。
|
||||
|
||||
## 堆的用途
|
||||
|
||||
当我们只关心所有数据中的最大值或者最小值,存在多次获取最大值或者最小值,多次插入或删除数据时,就可以使用堆。
|
||||
|
||||
有小伙伴可能会想到用有序数组,初始化一个有序数组时间复杂度是 `O(nlog(n))`,查找最大值或者最小值时间复杂度都是 `O(1)`,但是,涉及到更新(插入或删除)数据时,时间复杂度为 `O(n)`,即使是使用复杂度为 `O(log(n))` 的二分法找到要插入或者删除的数据,在移动数据时也需要 `O(n)` 的时间复杂度。
|
||||
@ -39,25 +40,30 @@ tag:
|
||||
## 堆的分类
|
||||
|
||||
堆分为 **最大堆** 和 **最小堆**。二者的区别在于节点的排序方式。
|
||||
|
||||
- **最大堆** :堆中的每一个节点的值都大于等于子树中所有节点的值
|
||||
- **最小堆** :堆中的每一个节点的值都小于等于子树中所有节点的值
|
||||
|
||||
如下图所示,图1是最大堆,图2是最小堆
|
||||
如下图所示,图 1 是最大堆,图 2 是最小堆
|
||||
|
||||

|
||||
|
||||
|
||||
## 堆的存储
|
||||
之前介绍树的时候说过,由于完全二叉树的优秀性质,利用数组存储二叉树即节省空间,又方便索引(若根结点的序号为1,那么对于树中任意节点i,其左子节点序号为 `2*i`,右子节点序号为 `2*i+1`)。
|
||||
|
||||
之前介绍树的时候说过,由于完全二叉树的优秀性质,利用数组存储二叉树即节省空间,又方便索引(若根结点的序号为 1,那么对于树中任意节点 i,其左子节点序号为 `2*i`,右子节点序号为 `2*i+1`)。
|
||||
|
||||
为了方便存储和索引,(二叉)堆可以用完全二叉树的形式进行存储。存储的方式如下图所示:
|
||||
|
||||

|
||||
|
||||
## 堆的操作
|
||||
|
||||
堆的更新操作主要包括两种 : **插入元素** 和 **删除堆顶元素**。操作过程需要着重掌握和理解。
|
||||
|
||||
> 在进入正题之前,再重申一遍,堆是一个公平的公司,有能力的人自然会走到与他能力所匹配的位置
|
||||
|
||||
### 插入元素
|
||||
|
||||
> 插入元素,作为一个新入职的员工,初来乍到,这个员工需要从基层做起
|
||||
|
||||
**1.将要插入的元素放到最后**
|
||||
@ -85,20 +91,16 @@ tag:
|
||||
|
||||
> 在堆这个公司中,会出现老大离职的现象,老大离职之后,他的位置就空出来了
|
||||
|
||||
首先删除堆顶元素,使得数组中下标为1的位置空出。
|
||||
|
||||
|
||||
首先删除堆顶元素,使得数组中下标为 1 的位置空出。
|
||||
|
||||

|
||||
|
||||
|
||||
> 那么他的位置由谁来接替呢,当然是他的直接下属了,谁能力强就让谁上呗
|
||||
|
||||
比较根结点的左子节点和右子节点,也就是下标为2,3的数组元素,将较大的元素填充到根结点(下标为1)的位置。
|
||||
比较根结点的左子节点和右子节点,也就是下标为 2,3 的数组元素,将较大的元素填充到根结点(下标为 1)的位置。
|
||||
|
||||

|
||||
|
||||
|
||||
> 这个时候又空出一个位置了,老规矩,谁有能力谁上
|
||||
|
||||
一直循环比较空出位置的左右子节点,并将较大者移至空位,直到堆的最底部
|
||||
@ -108,6 +110,7 @@ tag:
|
||||
这个时候已经完成了自底向上的堆化,没有元素可以填补空缺了,但是,我们可以看到数组中出现了“气泡”,这会导致存储空间的浪费。接下来我们试试自顶向下堆化。
|
||||
|
||||
#### 自顶向下堆化
|
||||
|
||||
自顶向下的堆化用一个词形容就是“石沉大海”,那么第一件事情,就是把石头抬起来,从海面扔下去。这个石头就是堆的最后一个元素,我们将最后一个元素移动到堆顶。
|
||||
|
||||

|
||||
@ -118,14 +121,11 @@ tag:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
### 堆的操作总结
|
||||
|
||||
- **插入元素** :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
|
||||
- **删除堆顶元素** :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
|
||||
|
||||
|
||||
## 堆排序
|
||||
|
||||
堆排序的过程分为两步:
|
||||
@ -137,22 +137,22 @@ tag:
|
||||
|
||||
如果你已经足够了解堆化的过程,那么建堆的过程掌握起来就比较容易了。建堆的过程就是一个对所有非叶节点的自顶向下堆化过程。
|
||||
|
||||
首先要了解哪些是非叶节点,最后一个节点的父结点及它之前的元素,都是非叶节点。也就是说,如果节点个数为n,那么我们需要对n/2到1的节点进行自顶向下(沉底)堆化。
|
||||
首先要了解哪些是非叶节点,最后一个节点的父结点及它之前的元素,都是非叶节点。也就是说,如果节点个数为 n,那么我们需要对 n/2 到 1 的节点进行自顶向下(沉底)堆化。
|
||||
|
||||
具体过程如下图:
|
||||
|
||||

|
||||
|
||||
将初始的无序数组抽象为一棵树,图中的节点个数为6,所以4,5,6节点为叶节点,1,2,3节点为非叶节点,所以要对1-3号节点进行自顶向下(沉底)堆化,注意,顺序是从后往前堆化,从3号节点开始,一直到1号节点。
|
||||
3号节点堆化结果:
|
||||
将初始的无序数组抽象为一棵树,图中的节点个数为 6,所以 4,5,6 节点为叶节点,1,2,3 节点为非叶节点,所以要对 1-3 号节点进行自顶向下(沉底)堆化,注意,顺序是从后往前堆化,从 3 号节点开始,一直到 1 号节点。
|
||||
3 号节点堆化结果:
|
||||
|
||||

|
||||
|
||||
2号节点堆化结果:
|
||||
2 号节点堆化结果:
|
||||
|
||||

|
||||
|
||||
1号节点堆化结果:
|
||||
1 号节点堆化结果:
|
||||
|
||||

|
||||
|
||||
|
||||
@ -10,13 +10,12 @@ tag:
|
||||
|
||||
1. 每个节点非红即黑;
|
||||
2. 根节点总是黑色的;
|
||||
3. 每个叶子节点都是黑色的空节点(NIL节点);
|
||||
3. 每个叶子节点都是黑色的空节点(NIL 节点);
|
||||
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
|
||||
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
|
||||
|
||||
**红黑树的应用** :TreeMap、TreeSet以及JDK1.8的HashMap底层都用到了红黑树。
|
||||
**红黑树的应用** :TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。
|
||||
|
||||
**为什么要用红黑树?** 简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||
|
||||
**相关阅读** :[《红黑树深入剖析及Java实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||
|
||||
**相关阅读** :[《红黑树深入剖析及 Java 实现》](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||
|
||||
@ -38,7 +38,7 @@ tag:
|
||||
|
||||
**二叉树** 的分支通常被称作“**左子树**”或“**右子树**”。并且,**二叉树** 的分支具有左右次序,不能随意颠倒。
|
||||
|
||||
**二叉树** 的第 i 层至多拥有 `2^(i-1)` 个节点,深度为 k 的二叉树至多总共有 `2^(k+1)-1` 个节点(满二叉树的情况),至少有 2^(k) 个节点(关于节点的深度的定义国内争议比较多,我个人比较认可维基百科对[节点深度的定义](https://zh.wikipedia.org/wiki/%E6%A0%91_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)#/%E6%9C%AF%E8%AF%AD))。
|
||||
**二叉树** 的第 i 层至多拥有 `2^(i-1)` 个节点,深度为 k 的二叉树至多总共有 `2^(k+1)-1` 个节点(满二叉树的情况),至少有 2^(k) 个节点(关于节点的深度的定义国内争议比较多,我个人比较认可维基百科对[节点深度的定义](<https://zh.wikipedia.org/wiki/%E6%A0%91_(%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)#/%E6%9C%AF%E8%AF%AD>))。
|
||||
|
||||

|
||||
|
||||
@ -48,8 +48,6 @@ tag:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 完全二叉树
|
||||
|
||||
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 **完全二叉树** 。
|
||||
|
||||
@ -5,8 +5,6 @@ tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
|
||||
|
||||
## HTTP:超文本传输协议
|
||||
|
||||
**超文本传输协议(HTTP,HyperText Transfer Protocol)** 是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
|
||||
@ -5,7 +5,6 @@ tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
|
||||
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
|
||||
|
||||

|
||||
|
||||
@ -5,7 +5,7 @@ tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被成功处理。
|
||||
HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被成功处理。
|
||||
|
||||
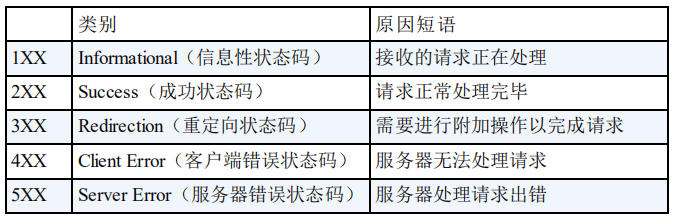
|
||||
|
||||
@ -15,14 +15,14 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被
|
||||
|
||||
### 2xx Success(成功状态码)
|
||||
|
||||
- **200 OK** :请求被成功处理。比如我们发送一个查询用户数据的HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
|
||||
- **200 OK** :请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
|
||||
- **201 Created** :请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
|
||||
- **202 Accepted** :服务端已经接收到了请求,但是还未处理。
|
||||
- **204 No Content** : 服务端已经成功处理了请求,但是没有返回任何内容。
|
||||
|
||||
这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
|
||||
|
||||
[HTTP RFC 2616对204状态码的描述](https://tools.ietf.org/html/rfc2616#section-10.2.5)如下:
|
||||
[HTTP RFC 2616 对 204 状态码的描述](https://tools.ietf.org/html/rfc2616#section-10.2.5)如下:
|
||||
|
||||
> The server has fulfilled the request but does not need to return an
|
||||
> entity-body, and might want to return updated metainformation. The
|
||||
@ -40,7 +40,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被
|
||||
> The 204 response MUST NOT include a message-body, and thus is always
|
||||
> terminated by the first empty line after the header fields.
|
||||
|
||||
简单来说,204状态码描述的是我们向服务端发送 HTTP 请求之后,只关注处理结果是否成功的场景。也就是说我们需要的就是一个结果:true/false。
|
||||
简单来说,204 状态码描述的是我们向服务端发送 HTTP 请求之后,只关注处理结果是否成功的场景。也就是说我们需要的就是一个结果:true/false。
|
||||
|
||||
举个例子:你要追一个女孩子,你问女孩子:“我能追你吗?”,女孩子回答:“好!”。我们把这个女孩子当做是服务端就很好理解 204 状态码了。
|
||||
|
||||
@ -51,15 +51,15 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被
|
||||
|
||||
### 4xx Client Error(客户端错误状态码)
|
||||
|
||||
- **400 Bad Request** : 发送的HTTP请求存在问题。比如请求参数不合法、请求方法错误。
|
||||
- **400 Bad Request** : 发送的 HTTP 请求存在问题。比如请求参数不合法、请求方法错误。
|
||||
- **401 Unauthorized** : 未认证却请求需要认证之后才能访问的资源。
|
||||
- **403 Forbidden** :直接拒绝HTTP请求,不处理。一般用来针对非法请求。
|
||||
- **403 Forbidden** :直接拒绝 HTTP 请求,不处理。一般用来针对非法请求。
|
||||
- **404 Not Found** : 你请求的资源未在服务端找到。比如你请求某个用户的信息,服务端并没有找到指定的用户。
|
||||
- **409 Conflict** : 表示请求的资源与服务端当前的状态存在冲突,请求无法被处理。
|
||||
|
||||
### 5xx Server Error(服务端错误状态码)
|
||||
|
||||
- **500 Internal Server Error** : 服务端出问题了(通常是服务端出Bug了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
|
||||
- **500 Internal Server Error** : 服务端出问题了(通常是服务端出 Bug 了)。比如你服务端处理请求的时候突然抛出异常,但是异常并未在服务端被正确处理。
|
||||
- **502 Bad Gateway** :我们的网关将请求转发到服务端,但是服务端返回的却是一个错误的响应。
|
||||
|
||||
### 参考
|
||||
@ -68,4 +68,3 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被
|
||||
- https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
|
||||
- https://en.wikipedia.org/wiki/List_of_HTTP_status_codes
|
||||
- https://segmentfault.com/a/1190000018264501
|
||||
|
||||
|
||||
@ -39,7 +39,7 @@ HTTPS 协议中,SSL 通道通常使用基于密钥的加密算法,密钥长
|
||||
|
||||
保密性好、信任度高。
|
||||
|
||||
## HTTPS 的核心—SSL/TLS协议
|
||||
## HTTPS 的核心—SSL/TLS 协议
|
||||
|
||||
HTTPS 之所以能达到较高的安全性要求,就是结合了 SSL/TLS 和 TCP 协议,对通信数据进行加密,解决了 HTTP 数据透明的问题。接下来重点介绍一下 SSL/TLS 的工作原理。
|
||||
|
||||
@ -138,6 +138,3 @@ SSL/TLS 介绍到这里,了解信息安全的朋友又会想到一个安全隐
|
||||
- **端口号** :HTTP 默认是 80,HTTPS 默认是 443。
|
||||
- **URL 前缀** :HTTP 的 URL 前缀是 `http://`,HTTPS 的 URL 前缀是 `https://`。
|
||||
- **安全性和资源消耗** : HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。所以说,HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -10,12 +10,12 @@ tag:
|
||||
- 响应状态码
|
||||
- 缓存处理
|
||||
- 连接方式
|
||||
- Host头处理
|
||||
- Host 头处理
|
||||
- 带宽优化
|
||||
|
||||
## 响应状态码
|
||||
|
||||
HTTP/1.0仅定义了16种状态码。HTTP/1.1中新加入了大量的状态码,光是错误响应状态码就新增了24种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
||||
HTTP/1.0 仅定义了 16 种状态码。HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
||||
|
||||
## 缓存处理
|
||||
|
||||
@ -23,7 +23,7 @@ HTTP/1.0仅定义了16种状态码。HTTP/1.1中新加入了大量的状态码
|
||||
|
||||
### HTTP/1.0
|
||||
|
||||
HTTP/1.0提供的缓存机制非常简单。服务器端使用`Expires`标签来标志(时间)一个响应体,在`Expires`标志时间内的请求,都会获得该响应体缓存。服务器端在初次返回给客户端的响应体中,有一个`Last-Modified`标签,该标签标记了被请求资源在服务器端的最后一次修改。在请求头中,使用`If-Modified-Since`标签,该标签标志一个时间,意为客户端向服务器进行问询:“该时间之后,我要请求的资源是否有被修改过?”通常情况下,请求头中的`If-Modified-Since`的值即为上一次获得该资源时,响应体中的`Last-Modified`的值。
|
||||
HTTP/1.0 提供的缓存机制非常简单。服务器端使用`Expires`标签来标志(时间)一个响应体,在`Expires`标志时间内的请求,都会获得该响应体缓存。服务器端在初次返回给客户端的响应体中,有一个`Last-Modified`标签,该标签标记了被请求资源在服务器端的最后一次修改。在请求头中,使用`If-Modified-Since`标签,该标签标志一个时间,意为客户端向服务器进行问询:“该时间之后,我要请求的资源是否有被修改过?”通常情况下,请求头中的`If-Modified-Since`的值即为上一次获得该资源时,响应体中的`Last-Modified`的值。
|
||||
|
||||
如果服务器接收到了请求头,并判断`If-Modified-Since`时间后,资源确实没有修改过,则返回给客户端一个`304 not modified`响应头,表示”缓冲可用,你从浏览器里拿吧!”。
|
||||
|
||||
@ -35,27 +35,27 @@ HTTP/1.0提供的缓存机制非常简单。服务器端使用`Expires`标签来
|
||||
|
||||
### HTTP/1.1
|
||||
|
||||
HTTP/1.1的缓存机制在HTTP/1.0的基础上,大大增加了灵活性和扩展性。基本工作原理和HTTP/1.0保持不变,而是增加了更多细致的特性。其中,请求头中最常见的特性就是`Cache-Control`,详见MDN Web文档 [Cache-Control](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control).
|
||||
HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和扩展性。基本工作原理和 HTTP/1.0 保持不变,而是增加了更多细致的特性。其中,请求头中最常见的特性就是`Cache-Control`,详见 MDN Web 文档 [Cache-Control](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Cache-Control).
|
||||
|
||||
## 连接方式
|
||||
|
||||
**HTTP/1.0 默认使用短连接** ,也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个TCP连接,这样就会导致有大量的“握手报文”和“挥手报文”占用了带宽。
|
||||
**HTTP/1.0 默认使用短连接** ,也就是说,客户端和服务器每进行一次 HTTP 操作,就建立一次连接,任务结束就中断连接。当客户端浏览器访问的某个 HTML 或其他类型的 Web 页中包含有其他的 Web 资源(如 JavaScript 文件、图像文件、CSS 文件等),每遇到这样一个 Web 资源,浏览器就会重新建立一个 TCP 连接,这样就会导致有大量的“握手报文”和“挥手报文”占用了带宽。
|
||||
|
||||
**为了解决 HTTP/1.0 存在的资源浪费的问题, HTTP/1.1 优化为默认长连接模式 。** 采用长连接模式的请求报文会通知服务端:“我向你请求连接,并且连接成功建立后,请不要关闭”。因此,该TCP连接将持续打开,为后续的客户端-服务端的数据交互服务。也就是说在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
|
||||
**为了解决 HTTP/1.0 存在的资源浪费的问题, HTTP/1.1 优化为默认长连接模式 。** 采用长连接模式的请求报文会通知服务端:“我向你请求连接,并且连接成功建立后,请不要关闭”。因此,该 TCP 连接将持续打开,为后续的客户端-服务端的数据交互服务。也就是说在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输 HTTP 数据的 TCP 连接不会关闭,客户端再次访问这个服务器时,会继续使用这一条已经建立的连接。
|
||||
|
||||
如果 TCP 连接一直保持的话也是对资源的浪费,因此,一些服务器软件(如 Apache)还会支持超时时间的时间。在超时时间之内没有新的请求达到,TCP 连接才会被关闭。
|
||||
|
||||
有必要说明的是,HTTP/1.0仍提供了长连接选项,即在请求头中加入`Connection: Keep-alive`。同样的,在HTTP/1.1中,如果不希望使用长连接选项,也可以在请求头中加入`Connection: close`,这样会通知服务器端:“我不需要长连接,连接成功后即可关闭”。
|
||||
有必要说明的是,HTTP/1.0 仍提供了长连接选项,即在请求头中加入`Connection: Keep-alive`。同样的,在 HTTP/1.1 中,如果不希望使用长连接选项,也可以在请求头中加入`Connection: close`,这样会通知服务器端:“我不需要长连接,连接成功后即可关闭”。
|
||||
|
||||
**HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。**
|
||||
|
||||
**实现长连接需要客户端和服务端都支持长连接。**
|
||||
|
||||
## Host头处理
|
||||
## Host 头处理
|
||||
|
||||
域名系统(DNS)允许多个主机名绑定到同一个IP地址上,但是HTTP/1.0并没有考虑这个问题,假设我们有一个资源URL是http://example1.org/home.html,HTTP/1.0的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
|
||||
域名系统(DNS)允许多个主机名绑定到同一个 IP 地址上,但是 HTTP/1.0 并没有考虑这个问题,假设我们有一个资源 URL 是http://example1.org/home.html,HTTP/1.0的请求报文中,将会请求的是`GET /home.html HTTP/1.0`.也就是不会加入主机名。这样的报文送到服务器端,服务器是理解不了客户端想请求的真正网址。
|
||||
|
||||
因此,HTTP/1.1在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
|
||||
因此,HTTP/1.1 在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
|
||||
|
||||
```
|
||||
GET /home.html HTTP/1.1
|
||||
@ -68,37 +68,37 @@ Host: example1.org
|
||||
|
||||
### 范围请求
|
||||
|
||||
HTTP/1.1引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1可以在请求中加入`Range`头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略`Range`头部,也可以返回若干`Range`响应。
|
||||
HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入`Range`头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略`Range`头部,也可以返回若干`Range`响应。
|
||||
|
||||
如果一个响应包含部分数据的话,那么将带有`206 (Partial Content)`状态码。该状态码的意义在于避免了HTTP/1.0代理缓存错误地把该响应认为是一个完整的数据响应,从而把他当作为一个请求的响应缓存。
|
||||
如果一个响应包含部分数据的话,那么将带有`206 (Partial Content)`状态码。该状态码的意义在于避免了 HTTP/1.0 代理缓存错误地把该响应认为是一个完整的数据响应,从而把他当作为一个请求的响应缓存。
|
||||
|
||||
在范围响应中,`Content-Range`头部标志指示出了该数据块的偏移量和数据块的长度。
|
||||
|
||||
### 状态码100
|
||||
### 状态码 100
|
||||
|
||||
HTTP/1.1中新加入了状态码`100`。该状态码的使用场景为,存在某些较大的文件请求,服务器可能不愿意响应这种请求,此时状态码`100`可以作为指示请求是否会被正常响应,过程如下图:
|
||||
HTTP/1.1 中新加入了状态码`100`。该状态码的使用场景为,存在某些较大的文件请求,服务器可能不愿意响应这种请求,此时状态码`100`可以作为指示请求是否会被正常响应,过程如下图:
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
然而在HTTP/1.0中,并没有`100 (Continue)`状态码,要想触发这一机制,可以发送一个`Expect`头部,其中包含一个`100-continue`的值。
|
||||
然而在 HTTP/1.0 中,并没有`100 (Continue)`状态码,要想触发这一机制,可以发送一个`Expect`头部,其中包含一个`100-continue`的值。
|
||||
|
||||
### 压缩
|
||||
|
||||
许多格式的数据在传输时都会做预压缩处理。数据的压缩可以大幅优化带宽的利用。然而,HTTP/1.0对数据压缩的选项提供的不多,不支持压缩细节的选择,也无法区分端到端(end-to-end)压缩或者是逐跳(hop-by-hop)压缩。
|
||||
许多格式的数据在传输时都会做预压缩处理。数据的压缩可以大幅优化带宽的利用。然而,HTTP/1.0 对数据压缩的选项提供的不多,不支持压缩细节的选择,也无法区分端到端(end-to-end)压缩或者是逐跳(hop-by-hop)压缩。
|
||||
|
||||
HTTP/1.1则对内容编码(content-codings)和传输编码(transfer-codings)做了区分。内容编码总是端到端的,传输编码总是逐跳的。
|
||||
HTTP/1.1 则对内容编码(content-codings)和传输编码(transfer-codings)做了区分。内容编码总是端到端的,传输编码总是逐跳的。
|
||||
|
||||
HTTP/1.0包含了`Content-Encoding`头部,对消息进行端到端编码。HTTP/1.1加入了`Transfer-Encoding`头部,可以对消息进行逐跳传输编码。HTTP/1.1还加入了`Accept-Encoding`头部,是客户端用来指示他能处理什么样的内容编码。
|
||||
HTTP/1.0 包含了`Content-Encoding`头部,对消息进行端到端编码。HTTP/1.1 加入了`Transfer-Encoding`头部,可以对消息进行逐跳传输编码。HTTP/1.1 还加入了`Accept-Encoding`头部,是客户端用来指示他能处理什么样的内容编码。
|
||||
|
||||
## 总结
|
||||
|
||||
1. **连接方式** : HTTP 1.0 为短连接,HTTP 1.1 支持长连接。
|
||||
1. **状态响应码** : HTTP/1.1中新加入了大量的状态码,光是错误响应状态码就新增了24种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
||||
1. **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
||||
1. **缓存处理** : 在 HTTP1.0 中主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
|
||||
1. **带宽优化及网络连接的使用** :HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
|
||||
1. **Host头处理** : HTTP/1.1在请求头中加入了`Host`字段。
|
||||
1. **Host 头处理** : HTTP/1.1 在请求头中加入了`Host`字段。
|
||||
|
||||
## 参考资料
|
||||
|
||||
|
||||
@ -5,9 +5,9 @@ tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
> 本文整理完善自[TCP/IP常见攻击手段 - 暖蓝笔记 - 2021](https://mp.weixin.qq.com/s/AZwWrOlLxRSSi-ywBgZ0fA)这篇文章。
|
||||
> 本文整理完善自[TCP/IP 常见攻击手段 - 暖蓝笔记 - 2021](https://mp.weixin.qq.com/s/AZwWrOlLxRSSi-ywBgZ0fA)这篇文章。
|
||||
|
||||
这篇文章的内容主要是介绍 TCP/IP常见攻击手段,尤其是 DDoS 攻击,也会补充一些其他的常见网络攻击手段。
|
||||
这篇文章的内容主要是介绍 TCP/IP 常见攻击手段,尤其是 DDoS 攻击,也会补充一些其他的常见网络攻击手段。
|
||||
|
||||
## IP 欺骗
|
||||
|
||||
@ -153,15 +153,15 @@ HTTP 洪水攻击有两种:
|
||||
|
||||
### DNS Flood 是什么?
|
||||
|
||||
域名系统(DNS)服务器是互联网的“电话簿“;互联网设备通过这些服务器来查找特定 Web 服务器以便访问互联网内容。DNS Flood攻击是一种分布式拒绝服务(DDoS)攻击,攻击者用大量流量淹没某个域的 DNS 服务器,以尝试中断该域的 DNS 解析。如果用户无法找到电话簿,就无法查找到用于调用特定资源的地址。通过中断 DNS 解析,DNS Flood攻击将破坏网站、API 或 Web 应用程序响应合法流量的能力。很难将 DNS Flood攻击与正常的大流量区分开来,因为这些大规模流量往往来自多个唯一地址,查询该域的真实记录,模仿合法流量。
|
||||
域名系统(DNS)服务器是互联网的“电话簿“;互联网设备通过这些服务器来查找特定 Web 服务器以便访问互联网内容。DNS Flood 攻击是一种分布式拒绝服务(DDoS)攻击,攻击者用大量流量淹没某个域的 DNS 服务器,以尝试中断该域的 DNS 解析。如果用户无法找到电话簿,就无法查找到用于调用特定资源的地址。通过中断 DNS 解析,DNS Flood 攻击将破坏网站、API 或 Web 应用程序响应合法流量的能力。很难将 DNS Flood 攻击与正常的大流量区分开来,因为这些大规模流量往往来自多个唯一地址,查询该域的真实记录,模仿合法流量。
|
||||
|
||||
### DNS Flood 的攻击原理是什么?
|
||||
|
||||
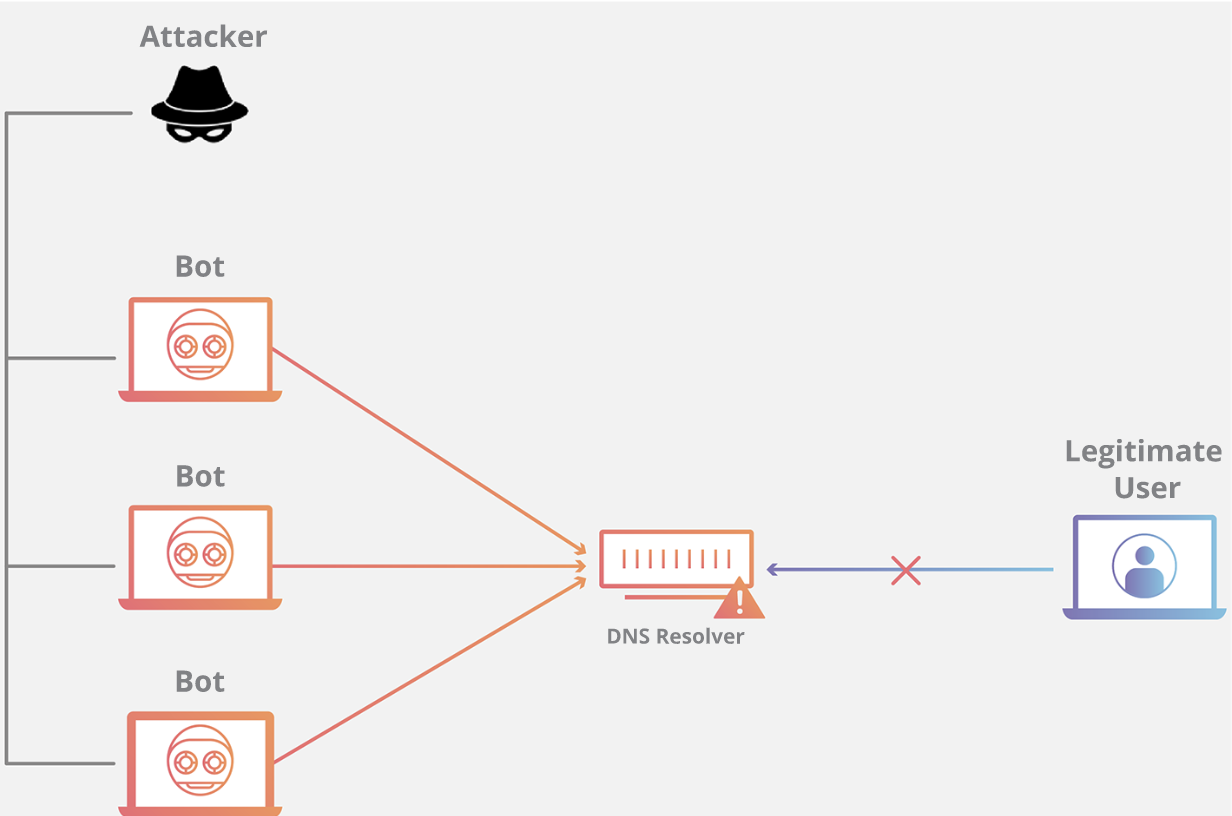
|
||||
|
||||
域名系统的功能是将易于记忆的名称(例如example.com)转换成难以记住的网站服务器地址(例如192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
|
||||
域名系统的功能是将易于记忆的名称(例如 example.com)转换成难以记住的网站服务器地址(例如 192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood 攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood 攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
|
||||
|
||||
DNS Flood攻击不同于 [DNS 放大攻击](https://www.cloudflare.com/zh-cn/learning/ddos/dns-amplification-ddos-attack/)。与 DNS Flood攻击不同,DNS 放大攻击反射并放大不安全 DNS 服务器的流量,以便隐藏攻击的源头并提高攻击的有效性。DNS 放大攻击使用连接带宽较小的设备向不安全的 DNS 服务器发送无数请求。这些设备对非常大的 DNS 记录发出小型请求,但在发出请求时,攻击者伪造返回地址为目标受害者。这种放大效果让攻击者能借助有限的攻击资源来破坏较大的目标。
|
||||
DNS Flood 攻击不同于 [DNS 放大攻击](https://www.cloudflare.com/zh-cn/learning/ddos/dns-amplification-ddos-attack/)。与 DNS Flood 攻击不同,DNS 放大攻击反射并放大不安全 DNS 服务器的流量,以便隐藏攻击的源头并提高攻击的有效性。DNS 放大攻击使用连接带宽较小的设备向不安全的 DNS 服务器发送无数请求。这些设备对非常大的 DNS 记录发出小型请求,但在发出请求时,攻击者伪造返回地址为目标受害者。这种放大效果让攻击者能借助有限的攻击资源来破坏较大的目标。
|
||||
|
||||
### 如何防护 DNS Flood?
|
||||
|
||||
|
||||
@ -133,7 +133,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
||||
### HTTP Header 中常见的字段有哪些?
|
||||
|
||||
| 请求头字段名 | 说明 | 示例 |
|
||||
| :------------------ | :----------------------------------------------------------- | :----------------------------------------------------------- |
|
||||
| :------------------ | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | :----------------------------------------------------------------------------------------- |
|
||||
| Accept | 能够接受的回应内容类型(Content-Types)。 | Accept: text/plain |
|
||||
| Accept-Charset | 能够接受的字符集 | Accept-Charset: utf-8 |
|
||||
| Accept-Datetime | 能够接受的按照时间来表示的版本 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
|
||||
|
||||
@ -96,21 +96,19 @@ tag:
|
||||
|
||||
每个连入互联网的设备或域(如计算机、服务器、路由器等)都被分配一个 **IP 地址(Internet Protocol address)**,作为唯一标识符。每个 IP 地址都是一个字符序列,如 192.168.1.1(IPv4)、2001:0db8:85a3:0000:0000:8a2e:0370:7334(IPv6) 。
|
||||
|
||||
当网络设备发送IP数据包时,数据包中包含了 **源IP地址** 和 **目的IP地址** 。源IP地址用于标识数据包的发送方设备或域,而目的IP地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
|
||||
当网络设备发送 IP 数据包时,数据包中包含了 **源 IP 地址** 和 **目的 IP 地址** 。源 IP 地址用于标识数据包的发送方设备或域,而目的 IP 地址则用于标识数据包的接收方设备或域。这类似于一封邮件中同时包含了目的地地址和回邮地址。
|
||||
|
||||
网络设备根据目的IP地址来判断数据包的目的地,并将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
|
||||
网络设备根据目的 IP 地址来判断数据包的目的地,并将数据包转发到正确的目的地网络或子网络,从而实现了设备间的通信。
|
||||
|
||||
这种基于IP地址的寻址方式是互联网通信的基础,它允许数据包在不同的网络之间传递,从而实现了全球范围内的网络互联互通。IP地址的唯一性和全局性保证了网络中的每个设备都可以通过其独特的IP地址进行标识和寻址。
|
||||
这种基于 IP 地址的寻址方式是互联网通信的基础,它允许数据包在不同的网络之间传递,从而实现了全球范围内的网络互联互通。IP 地址的唯一性和全局性保证了网络中的每个设备都可以通过其独特的 IP 地址进行标识和寻址。
|
||||
|
||||
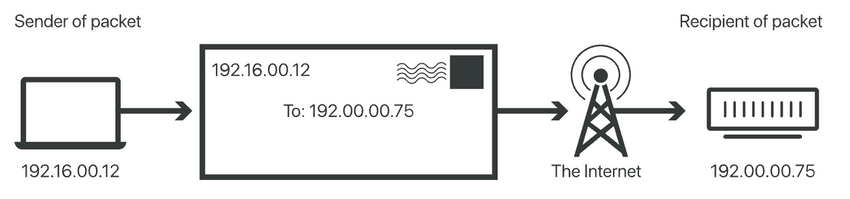
|
||||
|
||||
|
||||
|
||||
### 什么是 IP 地址过滤?
|
||||
|
||||
**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定IP地址或IP地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
|
||||
**IP 地址过滤(IP Address Filtering)** 简单来说就是限制或阻止特定 IP 地址或 IP 地址范围的访问。例如,你有一个图片服务突然被某一个 IP 地址攻击,那我们就可以禁止这个 IP 地址访问图片服务。
|
||||
|
||||
IP地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP地址过滤并不能完全保证网络的安全。
|
||||
IP 地址过滤是一种简单的网络安全措施,实际应用中一般会结合其他网络安全措施,如认证、授权、加密等一起使用。单独使用 IP 地址过滤并不能完全保证网络的安全。
|
||||
|
||||
### IPv4 和 IPv6 有什么区别?
|
||||
|
||||
|
||||
@ -5,7 +5,6 @@ tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
|
||||
为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
|
||||
|
||||
## 建立连接-TCP 三次握手
|
||||
@ -14,16 +13,16 @@ tag:
|
||||
|
||||
建立一个 TCP 连接需要“三次握手”,缺一不可 :
|
||||
|
||||
|
||||
- **一次握手**:客户端发送带有 SYN(SEQ=x) 标志的数据包 -> 服务端,然后客户端进入 **SYN_SEND** 状态,等待服务器的确认;
|
||||
- **二次握手**:服务端发送带有 SYN+ACK(SEQ=y,ACK=x+1) 标志的数据包 –> 客户端,然后服务端进入 **SYN_RECV** 状态
|
||||
- **三次握手**:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务器端都进入**ESTABLISHED** 状态,完成TCP三次握手。
|
||||
- **三次握手**:客户端发送带有 ACK(ACK=y+1) 标志的数据包 –> 服务端,然后客户端和服务器端都进入**ESTABLISHED** 状态,完成 TCP 三次握手。
|
||||
|
||||
**当建立了 3 次握手之后,客户端和服务端就可以传输数据啦!**
|
||||
|
||||
### 为什么要三次握手?
|
||||
|
||||
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
|
||||
|
||||
1. **第一次握手** :Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
|
||||
2. **第二次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
|
||||
3. **第三次握手** :Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
||||
@ -32,7 +31,7 @@ tag:
|
||||
|
||||
更详细的解答可以看这个:[TCP 为什么是三次握手,而不是两次或四次? - 车小胖的回答 - 知乎](https://www.zhihu.com/question/24853633/answer/115173386) 。
|
||||
|
||||
### 第2次握手传回了ACK,为什么还要传回SYN?
|
||||
### 第 2 次握手传回了 ACK,为什么还要传回 SYN?
|
||||
|
||||
服务端传回发送端所发送的 ACK 是为了告诉客户端:“我接收到的信息确实就是你所发送的信号了”,这表明从客户端到服务端的通信是正常的。回传 SYN 则是为了建立并确认从服务端到客户端的通信。
|
||||
|
||||
@ -53,7 +52,7 @@ tag:
|
||||
|
||||
### 为什么要四次挥手?
|
||||
|
||||
TCP是全双工通信,可以双向传输数据。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
|
||||
TCP 是全双工通信,可以双向传输数据。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
|
||||
|
||||
举个例子:A 和 B 打电话,通话即将结束后。
|
||||
|
||||
@ -64,28 +63,22 @@ TCP是全双工通信,可以双向传输数据。任何一方都可以在数
|
||||
|
||||
### 为什么不能把服务器发送的 ACK 和 FIN 合并起来,变成三次挥手?
|
||||
|
||||
|
||||
因为服务器收到客户端断开连接的请求时,可能还有一些数据没有发完,这时先回复 ACK,表示接收到了断开连接的请求。等到数据发完之后再发 FIN,断开服务器到客户端的数据传送。
|
||||
|
||||
### 如果第二次挥手时服务器的 ACK 没有送达客户端,会怎样?
|
||||
|
||||
|
||||
客户端没有收到 ACK 确认,会重新发送 FIN 请求。
|
||||
|
||||
### 为什么第四次挥手客户端需要等待 2\*MSL(报文段最长寿命)时间后才进入 CLOSED 状态?
|
||||
|
||||
|
||||
第四次挥手时,客户端发送给服务器的 ACK 有可能丢失,如果服务端因为某些原因而没有收到 ACK 的话,服务端就会重发 FIN,如果客户端在 2\*MSL 的时间内收到了 FIN,就会重新发送 ACK 并再次等待 2MSL,防止 Server 没有收到 ACK 而不断重发 FIN。
|
||||
|
||||
> **MSL(Maximum Segment Lifetime)** : 一个片段在网络中最大的存活时间,2MSL 就是一个发送和一个回复所需的最大时间。如果直到 2MSL,Client 都没有再次收到 FIN,那么 Client 推断 ACK 已经被成功接收,则结束 TCP 连接。
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
- 《计算机网络(第 7 版)》
|
||||
|
||||
- 《图解 HTTP》
|
||||
|
||||
- TCP and UDP Tutorial:https://www.9tut.com/tcp-and-udp-tutorial
|
||||
|
||||
|
||||
|
||||
@ -10,7 +10,7 @@ tag:
|
||||
1. **基于数据块传输** :应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
|
||||
2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
|
||||
3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
|
||||
4. **超时重传** : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包 )并进行重传。
|
||||
4. **超时重传** : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
|
||||
5. **流量控制** : TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
|
||||
6. **拥塞控制** : 当网络拥塞时,减少数据的发送。
|
||||
|
||||
@ -25,16 +25,16 @@ tag:
|
||||
- 发送端不等同于客户端
|
||||
- 接收端不等同于服务端
|
||||
|
||||
TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同
|
||||
TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客户端和服务端既可能是发送端又可能是服务端。因此,两端各有一个发送缓冲区与接收缓冲区,两端都各自维护一个发送窗口和一个接收窗口。接收窗口大小取决于应用、系统、硬件的限制(TCP 传输速率不能大于应用的数据处理速率)。通信双方的发送窗口和接收窗口的要求相同
|
||||
|
||||
**TCP 发送窗口可以划分成四个部分** :
|
||||
|
||||
1. 已经发送并且确认的TCP段(已经发送并确认);
|
||||
2. 已经发送但是没有确认的TCP段(已经发送未确认);
|
||||
3. 未发送但是接收方准备接收的TCP段(可以发送);
|
||||
4. 未发送并且接收方也并未准备接受的TCP段(不可发送)。
|
||||
1. 已经发送并且确认的 TCP 段(已经发送并确认);
|
||||
2. 已经发送但是没有确认的 TCP 段(已经发送未确认);
|
||||
3. 未发送但是接收方准备接收的 TCP 段(可以发送);
|
||||
4. 未发送并且接收方也并未准备接受的 TCP 段(不可发送)。
|
||||
|
||||
**TCP发送窗口结构图示** :
|
||||
**TCP 发送窗口结构图示** :
|
||||
|
||||
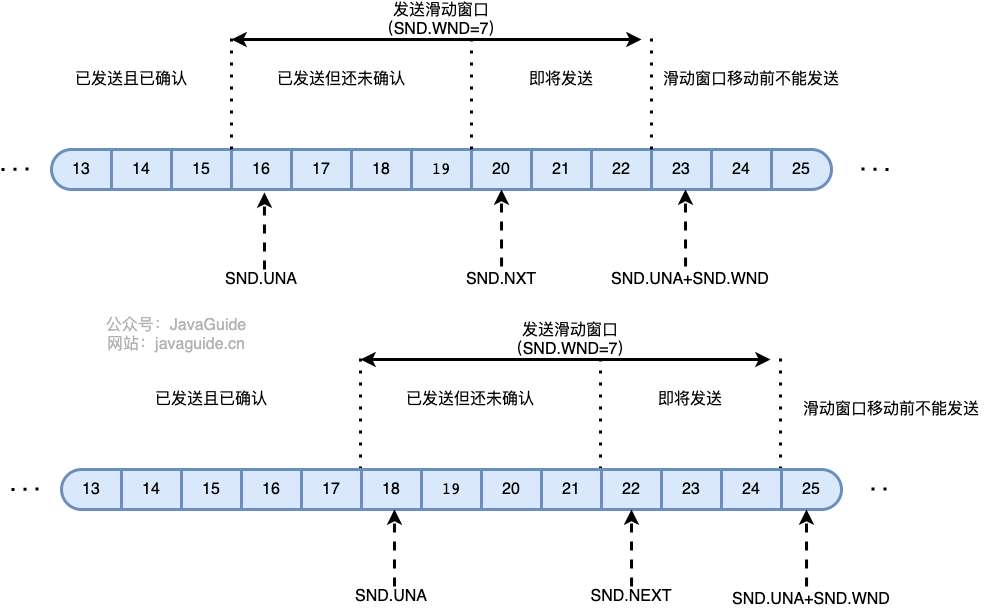
|
||||
|
||||
@ -48,7 +48,7 @@ TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客
|
||||
|
||||
1. 已经接收并且已经确认的 TCP 段(已经接收并确认);
|
||||
2. 等待接收且允许发送方发送 TCP 段(可以接收未确认);
|
||||
3. 不可接收且不允许发送方发送TCP段(不可接收)。
|
||||
3. 不可接收且不允许发送方发送 TCP 段(不可接收)。
|
||||
|
||||
**TCP 接收窗口结构图示** :
|
||||
|
||||
@ -60,7 +60,6 @@ TCP 为全双工(Full-Duplex, FDX)通信,双方可以进行双向通信,客
|
||||
|
||||
## TCP 的拥塞控制是怎么实现的?
|
||||
|
||||
|
||||
在某段时间,若对网络中某一资源的需求超过了该资源所能提供的可用部分,网络的性能就要变坏。这种情况就叫拥塞。拥塞控制就是为了防止过多的数据注入到网络中,这样就可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提,就是网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机,所有的路由器,以及与降低网络传输性能有关的所有因素。相反,流量控制往往是点对点通信量的控制,是个端到端的问题。流量控制所要做到的就是抑制发送端发送数据的速率,以便使接收端来得及接收。
|
||||
|
||||
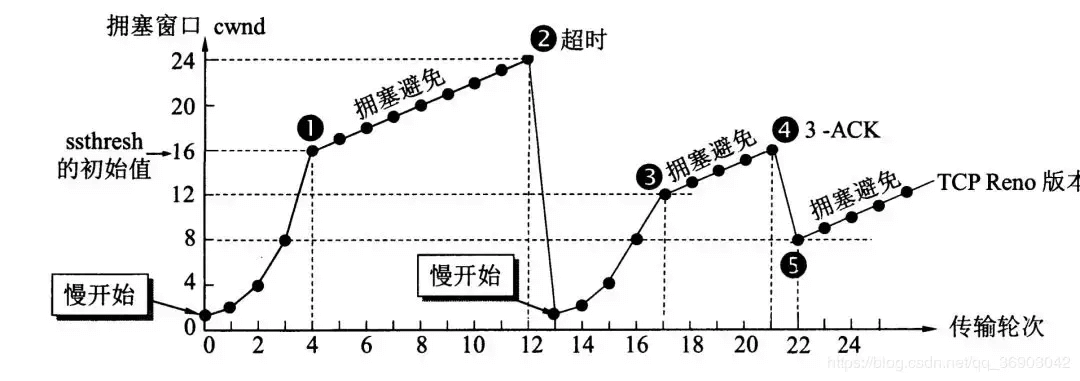
|
||||
@ -100,7 +99,6 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
||||
|
||||
### 连续 ARQ 协议
|
||||
|
||||
|
||||
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
|
||||
|
||||
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
||||
@ -109,11 +107,10 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
||||
|
||||
## Reference
|
||||
|
||||
|
||||
1. 《计算机网络(第 7 版)》
|
||||
2. 《图解 HTTP》
|
||||
3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial )
|
||||
4. [https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md](https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md )
|
||||
5. TCP Flow Control—[https://www.brianstorti.com/tcp-flow-control/](https://www.brianstorti.com/tcp-flow-control/ )
|
||||
3. [https://www.9tut.com/tcp-and-udp-tutorial](https://www.9tut.com/tcp-and-udp-tutorial)
|
||||
4. [https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md](https://github.com/wolverinn/Waking-Up/blob/master/Computer%20Network.md)
|
||||
5. TCP Flow Control—[https://www.brianstorti.com/tcp-flow-control/](https://www.brianstorti.com/tcp-flow-control/)
|
||||
6. TCP 流量控制(Flow Control):https://notfalse.net/24/tcp-flow-control
|
||||
7. TCP之滑动窗口原理 : https://cloud.tencent.com/developer/article/1857363
|
||||
7. TCP 之滑动窗口原理 : https://cloud.tencent.com/developer/article/1857363
|
||||
|
||||
@ -339,7 +339,7 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
|
||||
- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
|
||||
- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
|
||||
- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
|
||||
- `vmstat [间隔时间] [重复次数]` :vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O等系统整体运行状态。
|
||||
- `vmstat [间隔时间] [重复次数]` :vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O 等系统整体运行状态。
|
||||
- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
|
||||
- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
|
||||
- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
|
||||
|
||||
@ -45,8 +45,6 @@ head:
|
||||
|
||||
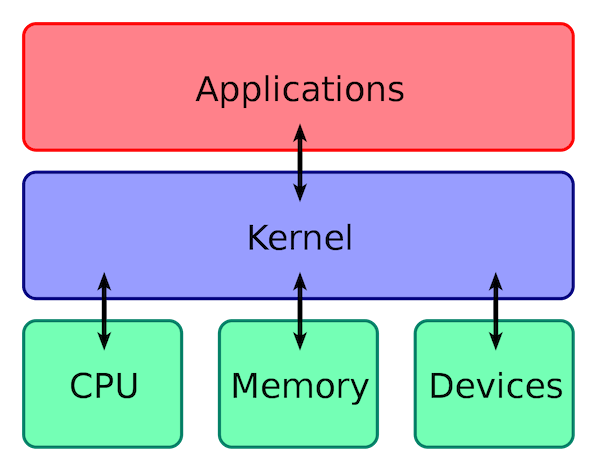
|
||||
|
||||
|
||||
|
||||
### 操作系统主要有哪些功能?
|
||||
|
||||
从资源管理的角度来看,操作系统有 6 大功能:
|
||||
|
||||
@ -115,7 +115,7 @@ ER 图由下面 3 个要素组成:
|
||||
- `truncate` (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
|
||||
- `delete`(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 `where` 子句和`truncate table 表名`作用类似。
|
||||
|
||||
`truncate` 和不带 where``子句的 `delete`、以及 `drop` 都会删除表内的数据,但是 **`truncate` 和 `delete` 只删除数据不删除表的结构(定义),执行 `drop` 语句,此表的结构也会删除,也就是执行 `drop` 之后对应的表不复存在。**
|
||||
`truncate` 和不带 `where`子句的 `delete`、以及 `drop` 都会删除表内的数据,但是 **`truncate` 和 `delete` 只删除数据不删除表的结构(定义),执行 `drop` 语句,此表的结构也会删除,也就是执行`drop` 之后对应的表不复存在。**
|
||||
|
||||
### 属于不同的数据库语言
|
||||
|
||||
|
||||
@ -5,10 +5,9 @@ tag:
|
||||
- 数据库基础
|
||||
---
|
||||
|
||||
|
||||
MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4`**。
|
||||
|
||||
如果使用 **`utf8`** 的话,存储emoji 符号和一些比较复杂的汉字、繁体字就会出错。
|
||||
如果使用 **`utf8`** 的话,存储 emoji 符号和一些比较复杂的汉字、繁体字就会出错。
|
||||
|
||||
为什么会这样呢?这篇文章可以从源头给你解答。
|
||||
|
||||
@ -65,7 +64,7 @@ GB18030 完全兼容 GB2312 和 GBK 字符集,纳入中国国内少数民族
|
||||
|
||||
BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
|
||||
|
||||
### Unicode & UTF-8编码
|
||||
### Unicode & UTF-8 编码
|
||||
|
||||
为了更加适合本国语言,诞生了很多种字符集。
|
||||
|
||||
@ -73,7 +72,7 @@ BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
|
||||
|
||||
就比如说你使用 UTF-8 编码方式打开 GB2312 编码格式的文件就会出现乱码。示例:“牛”这个汉字 GB2312 编码后的十六进制数值为 “C5A3”,而 “C5A3” 用 UTF-8 解码之后得到的却是 “ţ”。
|
||||
|
||||
你可以通过这个网站在线进行编码和解码:https://www.haomeili.net/HanZi/ZiFuBianMaZhuanHuan
|
||||
你可以通过这个网站在线进行编码和解码:<https://www.haomeili.net/HanZi/ZiFuBianMaZhuanHuan>
|
||||
|
||||
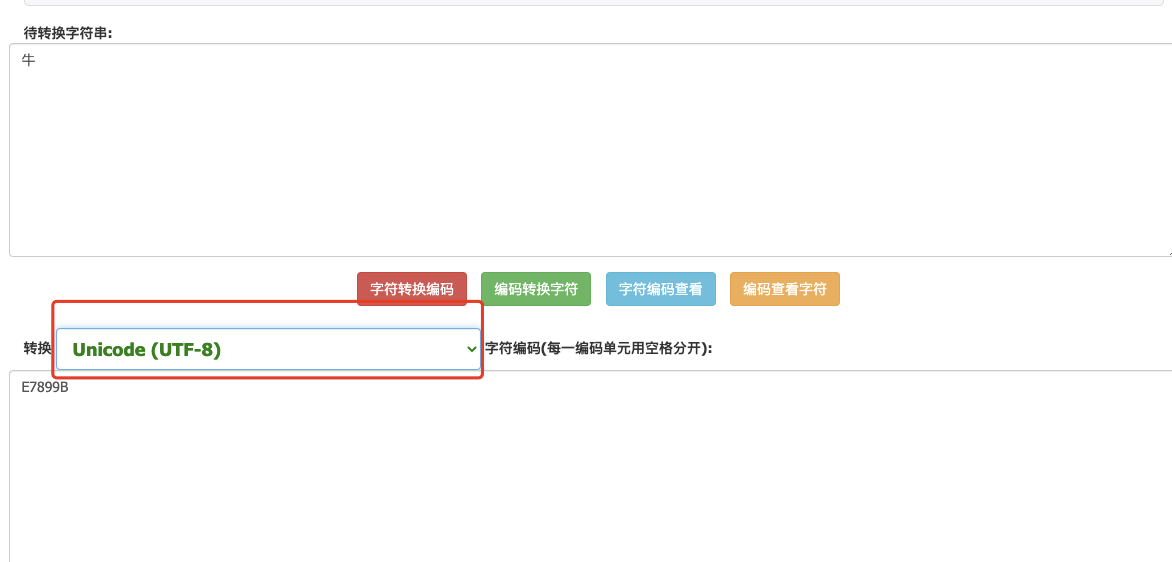
|
||||
|
||||
@ -152,9 +151,9 @@ Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
|
||||
|
||||
## 参考
|
||||
|
||||
- 字符集和字符编码(Charset & Encoding): https://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
|
||||
- 十分钟搞清字符集和字符编码:http://cenalulu.github.io/linux/character-encoding/
|
||||
- Unicode-维基百科:https://zh.wikipedia.org/wiki/Unicode
|
||||
- GB2312-维基百科:https://zh.wikipedia.org/wiki/GB_2312
|
||||
- UTF-8-维基百科:https://zh.wikipedia.org/wiki/UTF-8
|
||||
- GB18030-维基百科: https://zh.wikipedia.org/wiki/GB_18030
|
||||
- 字符集和字符编码(Charset & Encoding): <https://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html>
|
||||
- 十分钟搞清字符集和字符编码:<http://cenalulu.github.io/linux/character-encoding/>
|
||||
- Unicode-维基百科:<https://zh.wikipedia.org/wiki/Unicode>
|
||||
- GB2312-维基百科:<https://zh.wikipedia.org/wiki/GB_2312>
|
||||
- UTF-8-维基百科:<https://zh.wikipedia.org/wiki/UTF-8>
|
||||
- GB18030-维基百科: <https://zh.wikipedia.org/wiki/GB_18030>
|
||||
|
||||
@ -29,7 +29,7 @@ MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三
|
||||
**SQL 与 MongoDB 常见术语对比** :
|
||||
|
||||
| SQL | MongoDB |
|
||||
| ----------------------- | ------------------------------ |
|
||||
| ------------------------ | ------------------------------- |
|
||||
| 表(Table) | 集合(Collection) |
|
||||
| 行(Row) | 文档(Document) |
|
||||
| 列(Col) | 字段(Field) |
|
||||
@ -126,7 +126,7 @@ MongoDB 预留了几个特殊的数据库。
|
||||
|
||||
与 MySQL 一样,MongoDB 采用的也是 **插件式的存储引擎架构** ,支持不同类型的存储引擎,不同的存储引擎解决不同场景的问题。在创建数据库或集合时,可以指定存储引擎。
|
||||
|
||||
> 插件式的存储引擎架构可以实现 Server 层和存储引擎层的解耦,可以支持多种存储引擎,如MySQL既可以支持B-Tree结构的InnoDB存储引擎,还可以支持LSM结构的RocksDB存储引擎。
|
||||
> 插件式的存储引擎架构可以实现 Server 层和存储引擎层的解耦,可以支持多种存储引擎,如 MySQL 既可以支持 B-Tree 结构的 InnoDB 存储引擎,还可以支持 LSM 结构的 RocksDB 存储引擎。
|
||||
|
||||
在存储引擎刚出来的时候,默认是使用 MMAPV1 存储引擎,MongoDB4.x 版本不再支持 MMAPv1 存储引擎。
|
||||
|
||||
@ -141,13 +141,13 @@ MongoDB 预留了几个特殊的数据库。
|
||||
|
||||
目前绝大部分流行的数据库存储引擎都是基于 B/B+ Tree 或者 LSM(Log Structured Merge) Tree 来实现的。对于 NoSQL 数据库来说,绝大部分(比如 HBase、Cassandra、RocksDB)都是基于 LSM 树,MongoDB 不太一样。
|
||||
|
||||
上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
|
||||
上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
|
||||
|
||||
```
|
||||
WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
|
||||
```
|
||||
|
||||
此外,WiredTiger 还支持 [LSM(Log Structured Merge)](https://source.wiredtiger.com/3.1.0/lsm.html) 树作为存储结构,MongoDB 在使用WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
|
||||
此外,WiredTiger 还支持 [LSM(Log Structured Merge)](https://source.wiredtiger.com/3.1.0/lsm.html) 树作为存储结构,MongoDB 在使用 WiredTiger 作为存储引擎时,默认使用的是 B+ 树。
|
||||
|
||||
如果想要了解 MongoDB 使用 B 树的原因,可以看看这篇文章:[为什么 MongoDB 使用 B 树?](https://mp.weixin.qq.com/s/mMWdpbYRiT6LQcdaj4hgXQ)。
|
||||
|
||||
@ -155,13 +155,13 @@ WiredTiger maintains a table's data in memory using a data structure called a B-
|
||||
|
||||
- **root page(根节点)** : B+ 树的根节点。
|
||||
- **internal page(内部节点)** :不实际存储数据的中间索引节点。
|
||||
- **leaf page(叶子节点)**:真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的checksum、块在磁盘上的寻址位置等信息。
|
||||
- **leaf page(叶子节点)**:真正存储数据的叶子节点,包含一个页头(page header)、块头(block header)和真正的数据(key/value),其中页头定义了页的类型、页中实际载荷数据的大小、页中记录条数等信息;块头定义了此页的 checksum、块在磁盘上的寻址位置等信息。
|
||||
|
||||
其整体结构如下图所示:
|
||||
|
||||
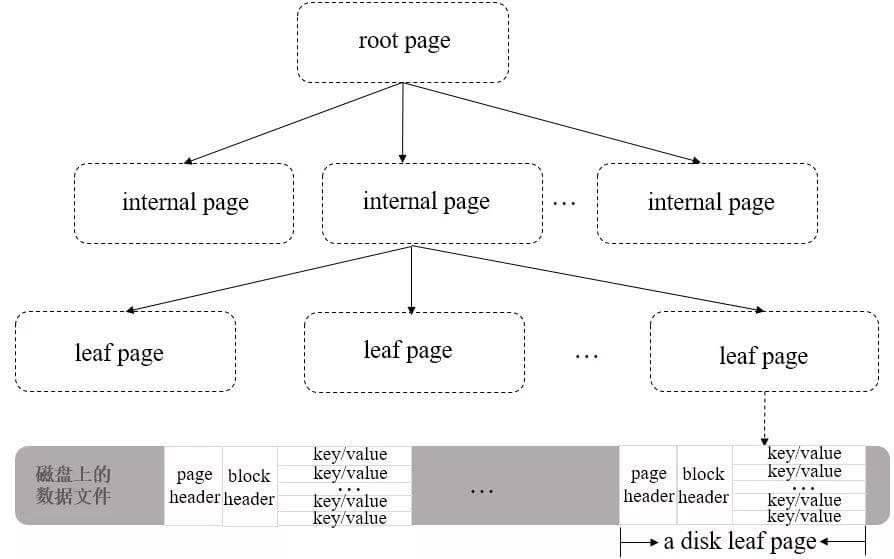
|
||||
|
||||
如果想要深入研究学习 WiredTiger 存储引擎,推荐阅读 MongoDB 中文社区的 [WiredTiger存储引擎系列](https://mongoing.com/archives/category/wiredtiger%e5%ad%98%e5%82%a8%e5%bc%95%e6%93%8e%e7%b3%bb%e5%88%97)。
|
||||
如果想要深入研究学习 WiredTiger 存储引擎,推荐阅读 MongoDB 中文社区的 [WiredTiger 存储引擎系列](https://mongoing.com/archives/category/wiredtiger%e5%ad%98%e5%82%a8%e5%bc%95%e6%93%8e%e7%b3%bb%e5%88%97)。
|
||||
|
||||
## MongoDB 聚合
|
||||
|
||||
@ -197,7 +197,7 @@ MongoDB 聚合管道由多个阶段组成,每个阶段在文档通过管道时
|
||||
**常用阶段操作符** :
|
||||
|
||||
| 操作符 | 简述 |
|
||||
| --------- | ------------------------------------------------------------ |
|
||||
| --------- | ---------------------------------------------------------------------------------------------------- |
|
||||
| \$match | 匹配操作符,用于对文档集合进行筛选 |
|
||||
| \$project | 投射操作符,用于重构每一个文档的字段,可以提取字段,重命名字段,甚至可以对原有字段进行操作后新增字段 |
|
||||
| \$sort | 排序操作符,用于根据一个或多个字段对文档进行排序 |
|
||||
@ -246,7 +246,7 @@ db.orders.aggregate([
|
||||
- **隔离性**(`Isolation`): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。WiredTiger 存储引擎支持读未提交( read-uncommitted )、读已提交( read-committed )和快照( snapshot )隔离,MongoDB 启动时默认选快照隔离。在不同隔离级别下,一个事务的生命周期内,可能出现脏读、不可重复读、幻读等现象。
|
||||
- **持久性**(`Durability`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
关于事务的详细介绍这篇文章就不多说了,感兴趣的可以看看我写的[MySQL常见面试题总结](https://javaguide.cn/database/mysql/mysql-questions-01.html)这篇文章,里面有详细介绍到。
|
||||
关于事务的详细介绍这篇文章就不多说了,感兴趣的可以看看我写的[MySQL 常见面试题总结](https://javaguide.cn/database/mysql/mysql-questions-01.html)这篇文章,里面有详细介绍到。
|
||||
|
||||
MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 MongoDB 事务的时候,通常指的是 **多文档** 。MongoDB 4.0 加入了对多文档 ACID 事务的支持,但只支持复制集部署模式下的 ACID 事务,也就是说事务的作用域限制为一个副本集内。MongoDB 4.2 引入了 **分布式事务** ,增加了对分片集群上多文档事务的支持,并合并了对副本集上多文档事务的现有支持。
|
||||
|
||||
@ -258,8 +258,8 @@ MongoDB 单文档原生支持原子性,也具备事务的特性。当谈论 Mo
|
||||
|
||||
**注意** :
|
||||
|
||||
- 从MongoDB 4.2开始,多文档事务支持副本集和分片集群,其中:主节点使用WiredTiger存储引擎,同时从节点使用WiredTiger存储引擎或In-Memory存储引擎。在MongoDB 4.0中,只有使用WiredTiger存储引擎的副本集支持事务。
|
||||
- 在MongoDB 4.2及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。有关详细信息,请参阅 [在事务中创建集合和索引](https://www.mongodb.com/docs/upcoming/core/transactions/#std-label-transactions-create-collections-indexes)。
|
||||
- 从 MongoDB 4.2 开始,多文档事务支持副本集和分片集群,其中:主节点使用 WiredTiger 存储引擎,同时从节点使用 WiredTiger 存储引擎或 In-Memory 存储引擎。在 MongoDB 4.0 中,只有使用 WiredTiger 存储引擎的副本集支持事务。
|
||||
- 在 MongoDB 4.2 及更早版本中,你无法在事务中创建集合。从 MongoDB 4.4 开始,您可以在事务中创建集合和索引。有关详细信息,请参阅 [在事务中创建集合和索引](https://www.mongodb.com/docs/upcoming/core/transactions/#std-label-transactions-create-collections-indexes)。
|
||||
|
||||
## MongoDB 数据压缩
|
||||
|
||||
@ -281,4 +281,4 @@ WiredTiger 日志也会被压缩,默认使用的也是 Snappy 压缩算法。
|
||||
- 技术干货| MongoDB 事务原理 - MongoDB 中文社区:https://mongoing.com/archives/82187
|
||||
- Transactions - MongoDB 官方文档:https://www.mongodb.com/docs/manual/core/transactions/
|
||||
- WiredTiger Storage Engine - MongoDB 官方文档:https://www.mongodb.com/docs/manual/core/wiredtiger/
|
||||
- WiredTiger存储引擎之一:基础数据结构分析:https://mongoing.com/topic/archives-35143
|
||||
- WiredTiger 存储引擎之一:基础数据结构分析:https://mongoing.com/topic/archives-35143
|
||||
|
||||
@ -166,7 +166,7 @@ MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文
|
||||
|
||||
- **Config Servers**:配置服务器,本质上是一个 MongoDB 的副本集,负责存储集群的各种元数据和配置,如分片地址、Chunks 等
|
||||
- **Mongos**:路由服务,不存具体数据,从 Config 获取集群配置讲请求转发到特定的分片,并且整合分片结果返回给客户端。
|
||||
- **Shard**:每个分片是整体数据的一部分子集,从MongoDB3.6版本开始,每个Shard必须部署为副本集(replica set)架构
|
||||
- **Shard**:每个分片是整体数据的一部分子集,从 MongoDB3.6 版本开始,每个 Shard 必须部署为副本集(replica set)架构
|
||||
|
||||
#### 为什么要用分片集群?
|
||||
|
||||
@ -196,12 +196,12 @@ MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文
|
||||
|
||||
选择合适的片键对 sharding 效率影响很大,主要基于如下四个因素(摘自[分片集群使用注意事项 - - 腾讯云文档](https://cloud.tencent.com/document/product/240/44611)):
|
||||
|
||||
- **取值基数** 取值基数建议尽可能大,如果用小基数的片键,因为备选值有限,那么块的总数量就有限,随着数据增多,块的大小会越来越大,导致水平扩展时移动块会非常困难。 例如:选择年龄做一个基数,范围最多只有100个,随着数据量增多,同一个值分布过多时,导致 chunck 的增长超出 chuncksize 的范围,引起 jumbo chunk,从而无法迁移,导致数据分布不均匀,性能瓶颈。
|
||||
- **取值基数** 取值基数建议尽可能大,如果用小基数的片键,因为备选值有限,那么块的总数量就有限,随着数据增多,块的大小会越来越大,导致水平扩展时移动块会非常困难。 例如:选择年龄做一个基数,范围最多只有 100 个,随着数据量增多,同一个值分布过多时,导致 chunck 的增长超出 chuncksize 的范围,引起 jumbo chunk,从而无法迁移,导致数据分布不均匀,性能瓶颈。
|
||||
- **取值分布** 取值分布建议尽量均匀,分布不均匀的片键会造成某些块的数据量非常大,同样有上面数据分布不均匀,性能瓶颈的问题。
|
||||
- **查询带分片** 查询时建议带上分片,使用分片键进行条件查询时,mongos 可以直接定位到具体分片,否则 mongos 需要将查询分发到所有分片,再等待响应返回。
|
||||
- **避免单调递增或递减** 单调递增的 sharding key,数据文件挪动小,但写入会集中,导致最后一篇的数据量持续增大,不断发生迁移,递减同理。
|
||||
|
||||
综上,在选择片键时要考虑以上4个条件,尽可能满足更多的条件,才能降低 MoveChunks 对性能的影响,从而获得最优的性能体验。
|
||||
综上,在选择片键时要考虑以上 4 个条件,尽可能满足更多的条件,才能降低 MoveChunks 对性能的影响,从而获得最优的性能体验。
|
||||
|
||||
#### 分片策略有哪些?
|
||||
|
||||
|
||||
@ -684,7 +684,7 @@ end
|
||||
3. Replace 语法 如果有记录,则执行 before insert, before delete, after delete, after insert
|
||||
```
|
||||
|
||||
### SQL编程
|
||||
### SQL 编程
|
||||
|
||||
```mysql
|
||||
/* SQL编程 */ ------------------
|
||||
@ -953,4 +953,3 @@ OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
|
||||
6. SQL对大小写不敏感
|
||||
7. 清除已有语句:\c
|
||||
```
|
||||
|
||||
|
||||
@ -84,15 +84,16 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
|
||||
结合上面的说明,我们分析下这个语句的执行流程:
|
||||
|
||||
* 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
||||
* 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
||||
* 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
|
||||
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
||||
- 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
||||
- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
|
||||
|
||||
a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
|
||||
b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
|
||||
|
||||
那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
|
||||
|
||||
* 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
|
||||
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
|
||||
|
||||
### 2.2 更新语句
|
||||
|
||||
@ -101,12 +102,13 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
```
|
||||
update tb_student A set A.age='19' where A.name=' 张三 ';
|
||||
```
|
||||
|
||||
我们来给张三修改下年龄,在实际数据库肯定不会设置年龄这个字段的,不然要被技术负责人打的。其实这条语句也基本上会沿着上一个查询的流程走,只不过执行更新的时候肯定要记录日志啦,这就会引入日志模块了,MySQL 自带的日志模块是 **binlog(归档日志)** ,所有的存储引擎都可以使用,我们常用的 InnoDB 引擎还自带了一个日志模块 **redo log(重做日志)**,我们就以 InnoDB 模式下来探讨这个语句的执行流程。流程如下:
|
||||
|
||||
* 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
|
||||
* 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
|
||||
* 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
|
||||
* 更新完成。
|
||||
- 先查询到张三这一条数据,如果有缓存,也是会用到缓存。
|
||||
- 然后拿到查询的语句,把 age 改为 19,然后调用引擎 API 接口,写入这一行数据,InnoDB 引擎把数据保存在内存中,同时记录 redo log,此时 redo log 进入 prepare 状态,然后告诉执行器,执行完成了,随时可以提交。
|
||||
- 执行器收到通知后记录 binlog,然后调用引擎接口,提交 redo log 为提交状态。
|
||||
- 更新完成。
|
||||
|
||||
**这里肯定有同学会问,为什么要用两个日志模块,用一个日志模块不行吗?**
|
||||
|
||||
@ -114,25 +116,25 @@ update tb_student A set A.age='19' where A.name=' 张三 ';
|
||||
|
||||
并不是说只用一个日志模块不可以,只是 InnoDB 引擎就是通过 redo log 来支持事务的。那么,又会有同学问,我用两个日志模块,但是不要这么复杂行不行,为什么 redo log 要引入 prepare 预提交状态?这里我们用反证法来说明下为什么要这么做?
|
||||
|
||||
* **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
|
||||
* **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
|
||||
- **先写 redo log 直接提交,然后写 binlog**,假设写完 redo log 后,机器挂了,binlog 日志没有被写入,那么机器重启后,这台机器会通过 redo log 恢复数据,但是这个时候 binlog 并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
|
||||
- **先写 binlog,然后写 redo log**,假设写完了 binlog,机器异常重启了,由于没有 redo log,本机是无法恢复这一条记录的,但是 binlog 又有记录,那么和上面同样的道理,就会产生数据不一致的情况。
|
||||
|
||||
如果采用 redo log 两阶段提交的方式就不一样了,写完 binlog 后,然后再提交 redo log 就会防止出现上述的问题,从而保证了数据的一致性。那么问题来了,有没有一个极端的情况呢?假设 redo log 处于预提交状态,binlog 也已经写完了,这个时候发生了异常重启会怎么样呢?
|
||||
这个就要依赖于 MySQL 的处理机制了,MySQL 的处理过程如下:
|
||||
|
||||
* 判断 redo log 是否完整,如果判断是完整的,就立即提交。
|
||||
* 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
|
||||
- 判断 redo log 是否完整,如果判断是完整的,就立即提交。
|
||||
- 如果 redo log 只是预提交但不是 commit 状态,这个时候就会去判断 binlog 是否完整,如果完整就提交 redo log, 不完整就回滚事务。
|
||||
|
||||
这样就解决了数据一致性的问题。
|
||||
|
||||
## 三 总结
|
||||
|
||||
* MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
|
||||
* 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
|
||||
* 查询语句的执行流程如下:权限校验(如果命中缓存)--->查询缓存--->分析器--->优化器--->权限校验--->执行器--->引擎
|
||||
* 更新语句执行流程如下:分析器---->权限校验---->执行器--->引擎---redo log(prepare 状态)--->binlog--->redo log(commit状态)
|
||||
- MySQL 主要分为 Server 层和引擎层,Server 层主要包括连接器、查询缓存、分析器、优化器、执行器,同时还有一个日志模块(binlog),这个日志模块所有执行引擎都可以共用,redolog 只有 InnoDB 有。
|
||||
- 引擎层是插件式的,目前主要包括,MyISAM,InnoDB,Memory 等。
|
||||
- 查询语句的执行流程如下:权限校验(如果命中缓存)--->查询缓存--->分析器--->优化器--->权限校验--->执行器--->引擎
|
||||
- 更新语句执行流程如下:分析器---->权限校验---->执行器--->引擎---redo log(prepare 状态)--->binlog--->redo log(commit 状态)
|
||||
|
||||
## 四 参考
|
||||
|
||||
* 《MySQL 实战45讲》
|
||||
* MySQL 5.6参考手册:<https://dev.MySQL.com/doc/refman/5.6/en/>
|
||||
- 《MySQL 实战 45 讲》
|
||||
- MySQL 5.6 参考手册:<https://dev.MySQL.com/doc/refman/5.6/en/>
|
||||
|
||||
@ -40,7 +40,7 @@ tag:
|
||||
|
||||
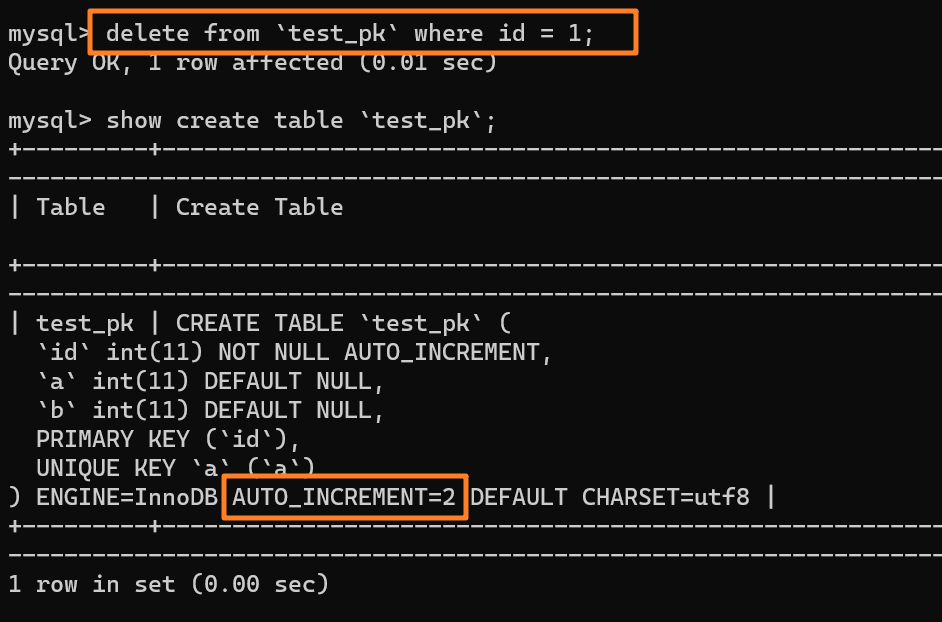
|
||||
|
||||
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
|
||||
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。 也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
|
||||
|
||||
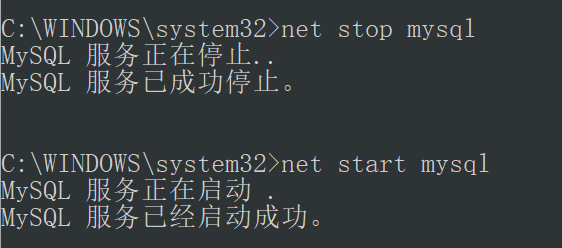
|
||||
|
||||
@ -149,7 +149,7 @@ tag:
|
||||
|
||||
现在有两个并行执行的事务 A 和 B,在申请自增值的时候,为了避免两个事务申请到相同的自增 id,肯定要加锁,然后顺序申请,对吧。
|
||||
|
||||
1. 假设事务 A 申请到了 id = 1, 事务 B 申请到 id=2,那么这时候表 t 的自增值是3,之后继续执行。
|
||||
1. 假设事务 A 申请到了 id = 1, 事务 B 申请到 id=2,那么这时候表 t 的自增值是 3,之后继续执行。
|
||||
2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。
|
||||
3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ head:
|
||||
|
||||
缓存是一个有效且实用的系统性能优化的手段,不论是操作系统还是各种软件和网站或多或少都用到了缓存。
|
||||
|
||||
然而,有经验的 DBA 都建议生产环境中把 MySQL 自带的 Query Cache(查询缓存)给关掉。而且,从 MySQL 5.7.20 开始,就已经默认弃用查询缓存了。在 MySQL 8.0及之后,更是直接删除了查询缓存的功能。
|
||||
然而,有经验的 DBA 都建议生产环境中把 MySQL 自带的 Query Cache(查询缓存)给关掉。而且,从 MySQL 5.7.20 开始,就已经默认弃用查询缓存了。在 MySQL 8.0 及之后,更是直接删除了查询缓存的功能。
|
||||
|
||||
这又是为什么呢?查询缓存真就这么鸡肋么?
|
||||
|
||||
@ -27,7 +27,7 @@ head:
|
||||
|
||||
## MySQL 查询缓存介绍
|
||||
|
||||
MySQL体系架构如下图所示:
|
||||
MySQL 体系架构如下图所示:
|
||||
|
||||
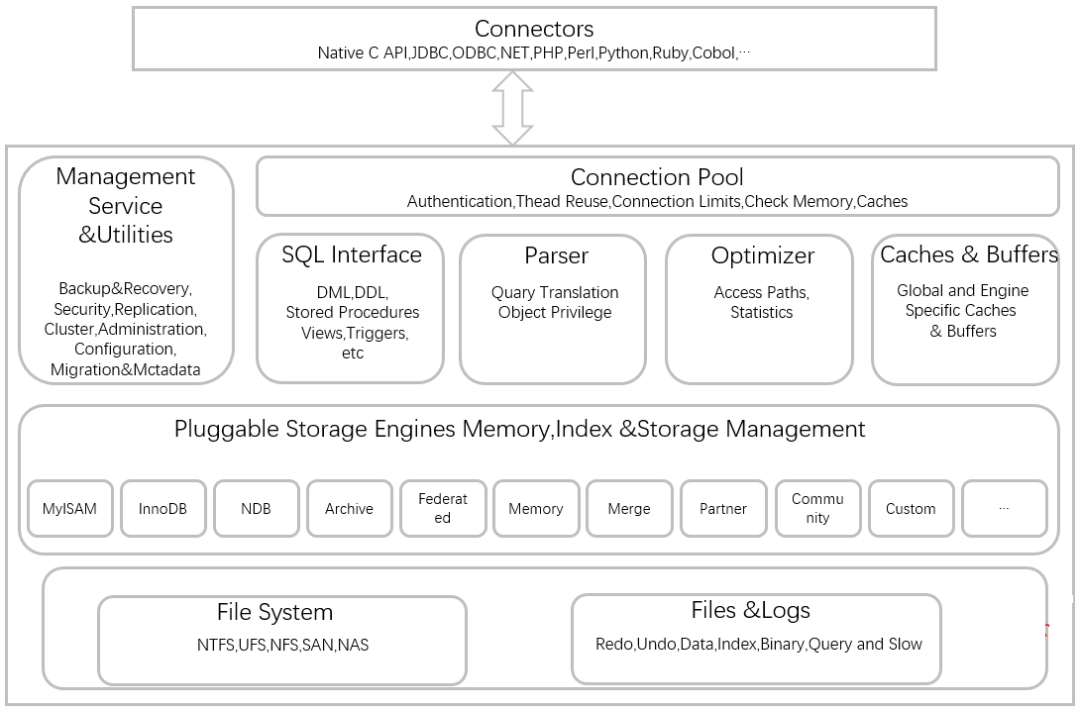
|
||||
|
||||
@ -90,10 +90,10 @@ mysql> show variables like '%query_cache%';
|
||||
|
||||
**建议** :
|
||||
|
||||
- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为10MB到100MB之间的值,而后根据运行使用情况调整。
|
||||
- `query_cache_size`不建议设置的过大。过大的空间不但挤占实例其他内存结构的空间,而且会增加在缓存中搜索的开销。建议根据实例规格,初始值设置为 10MB 到 100MB 之间的值,而后根据运行使用情况调整。
|
||||
- 建议通过调整 `query_cache_size` 的值来开启、关闭查询缓存,因为修改`query_cache_type` 参数需要重启 MySQL Server 生效。
|
||||
|
||||
8.0 版本之前,`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
|
||||
8.0 版本之前,`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
|
||||
|
||||
```properties
|
||||
query_cache_type=1
|
||||
@ -196,11 +196,11 @@ MySQL 中的查询缓存虽然能够提升数据库的查询性能,但是查
|
||||
|
||||
> 根据我们的经验,在高并发压力环境中查询缓存会导致系统性能的下降,甚至僵死。如果你一 定要使用查询缓存,那么不要设置太大内存,而且只有在明确收益的时候才使用(数据库内容修改次数较少)。
|
||||
|
||||
**确实是这样的!实际项目中,更建议使用本地缓存(比如 Caffeine)或者分布式缓存(比如Redis) ,性能更好,更通用一些。**
|
||||
**确实是这样的!实际项目中,更建议使用本地缓存(比如 Caffeine)或者分布式缓存(比如 Redis) ,性能更好,更通用一些。**
|
||||
|
||||
## 参考
|
||||
|
||||
- 《高性能 MySQL》
|
||||
- MySQL缓存机制:https://zhuanlan.zhihu.com/p/55947158
|
||||
- RDS MySQL查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:https://help.aliyun.com/document_detail/41717.html
|
||||
- MySQL 缓存机制:https://zhuanlan.zhihu.com/p/55947158
|
||||
- RDS MySQL 查询缓存(Query Cache)的设置和使用 - 阿里元云数据库 RDS 文档:https://help.aliyun.com/document_detail/41717.html
|
||||
- 8.10.3 The MySQL Query Cache - MySQL 官方文档:https://dev.mysql.com/doc/refman/5.7/en/query-cache.html
|
||||
@ -50,8 +50,8 @@ mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_e
|
||||
|
||||
| **列名** | **含义** |
|
||||
| ------------- | -------------------------------------------- |
|
||||
| id | SELECT查询的序列标识符 |
|
||||
| select_type | SELECT关键字对应的查询类型 |
|
||||
| id | SELECT 查询的序列标识符 |
|
||||
| select_type | SELECT 关键字对应的查询类型 |
|
||||
| table | 用到的表名 |
|
||||
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
|
||||
| type | 表的访问方法 |
|
||||
@ -89,8 +89,7 @@ id 如果相同,从上往下依次执行。id 不同,id 值越大,执行
|
||||
查询用到的表名,每行都有对应的表名,表名除了正常的表之外,也可能是以下列出的值:
|
||||
|
||||
- **`<unionM,N>`** : 本行引用了 id 为 M 和 N 的行的 UNION 结果;
|
||||
- **`<derivedN>`** : 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。
|
||||
-**`<subqueryN>`** : 本行引用了 id 为 N 的表所产生的的物化子查询结果。
|
||||
- **`<derivedN>`** : 本行引用了 id 为 N 的表所产生的的派生表结果。派生表有可能产生自 FROM 语句中的子查询。 -**`<subqueryN>`** : 本行引用了 id 为 N 的表所产生的的物化子查询结果。
|
||||
|
||||
### type(重要)
|
||||
|
||||
|
||||
@ -700,7 +700,7 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
||||
|
||||
- [一树一溪的 MySQL 系列教程](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=Mzg3NTc3NjM4Nw==&action=getalbum&album_id=2372043523518300162&scene=173&from_msgid=2247484308&from_itemidx=1&count=3&nolastread=1#wechat_redirect)
|
||||
- [Yes 的 MySQL 系列教程](https://mp.weixin.qq.com/mp/appmsgalbum?__biz=MzkxNTE3NjQ3MA==&action=getalbum&album_id=1903249596194095112&scene=173&from_msgid=2247490365&from_itemidx=1&count=3&nolastread=1#wechat_redirect)
|
||||
- [写完这篇 我的SQL优化能力直接进入新层次 - 变成派大星 - 2022](https://juejin.cn/post/7161964571853815822)
|
||||
- [写完这篇 我的 SQL 优化能力直接进入新层次 - 变成派大星 - 2022](https://juejin.cn/post/7161964571853815822)
|
||||
- [两万字详解!InnoDB 锁专题! - 捡田螺的小男孩 - 2022](https://juejin.cn/post/7094049650428084232)
|
||||
- [MySQL 的自增主键一定是连续的吗? - 飞天小牛肉 - 2022](https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ)
|
||||
- [深入理解 MySQL 索引底层原理 - 腾讯技术工程 - 2020](https://zhuanlan.zhihu.com/p/113917726)
|
||||
|
||||
@ -73,7 +73,7 @@ SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTE
|
||||
|
||||
### 脏读(读未提交)
|
||||
|
||||
%E5%AE%9E%E4%BE%8B.jpg)
|
||||
%E5%AE%9E%E4%BE%8B.jpg>)
|
||||
|
||||
### 避免脏读(读已提交)
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ NoSQL 数据库代表:HBase 、Cassandra、MongoDB、Redis。
|
||||
## SQL 和 NoSQL 有什么区别?
|
||||
|
||||
| | SQL 数据库 | NoSQL 数据库 |
|
||||
| :----------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| :----------- | -------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 数据存储模型 | 结构化存储,具有固定行和列的表格 | 非结构化存储。文档:JSON 文档,键值:键值对,宽列:包含行和动态列的表,图:节点和边 |
|
||||
| 发展历程 | 开发于 1970 年代,重点是减少数据重复 | 开发于 2000 年代后期,重点是提升可扩展性,减少大规模数据的存储成本 |
|
||||
| 例子 | Oracle、MySQL、Microsoft SQL Server 、PostgreSQL | 文档:MongoDB、CouchDB,键值:Redis 、DynamoDB,宽列:Cassandra 、 HBase,图表:Neo4j 、 Amazon Neptune、Giraph |
|
||||
@ -54,6 +54,6 @@ NoSQL 数据库主要可以分为下面四种类型:
|
||||
|
||||
## 参考
|
||||
|
||||
- NoSQL 是什么?- MongoDB 官方文档:https://www.mongodb.com/zh-cn/nosql-explained
|
||||
- 什么是 NoSQL? - AWS:https://aws.amazon.com/cn/nosql/
|
||||
- NoSQL vs. SQL Databases - MongoDB 官方文档:https://www.mongodb.com/zh-cn/nosql-explained/nosql-vs-sql
|
||||
- NoSQL 是什么?- MongoDB 官方文档:<https://www.mongodb.com/zh-cn/nosql-explained>
|
||||
- 什么是 NoSQL? - AWS:<https://aws.amazon.com/cn/nosql/>
|
||||
- NoSQL vs. SQL Databases - MongoDB 官方文档:<https://www.mongodb.com/zh-cn/nosql-explained/nosql-vs-sql>
|
||||
|
||||
@ -5,12 +5,11 @@ tag:
|
||||
- Redis
|
||||
---
|
||||
|
||||
|
||||
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的3种读写策略**”的时候却一脸懵逼。
|
||||
看到很多小伙伴简历上写了“**熟练使用缓存**”,但是被我问到“**缓存常用的 3 种读写策略**”的时候却一脸懵逼。
|
||||
|
||||
在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单了写一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
|
||||
|
||||
但是,搞懂3种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
|
||||
但是,搞懂 3 种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
|
||||
|
||||
**下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。**
|
||||
|
||||
|
||||
@ -9,7 +9,6 @@ tag:
|
||||
|
||||
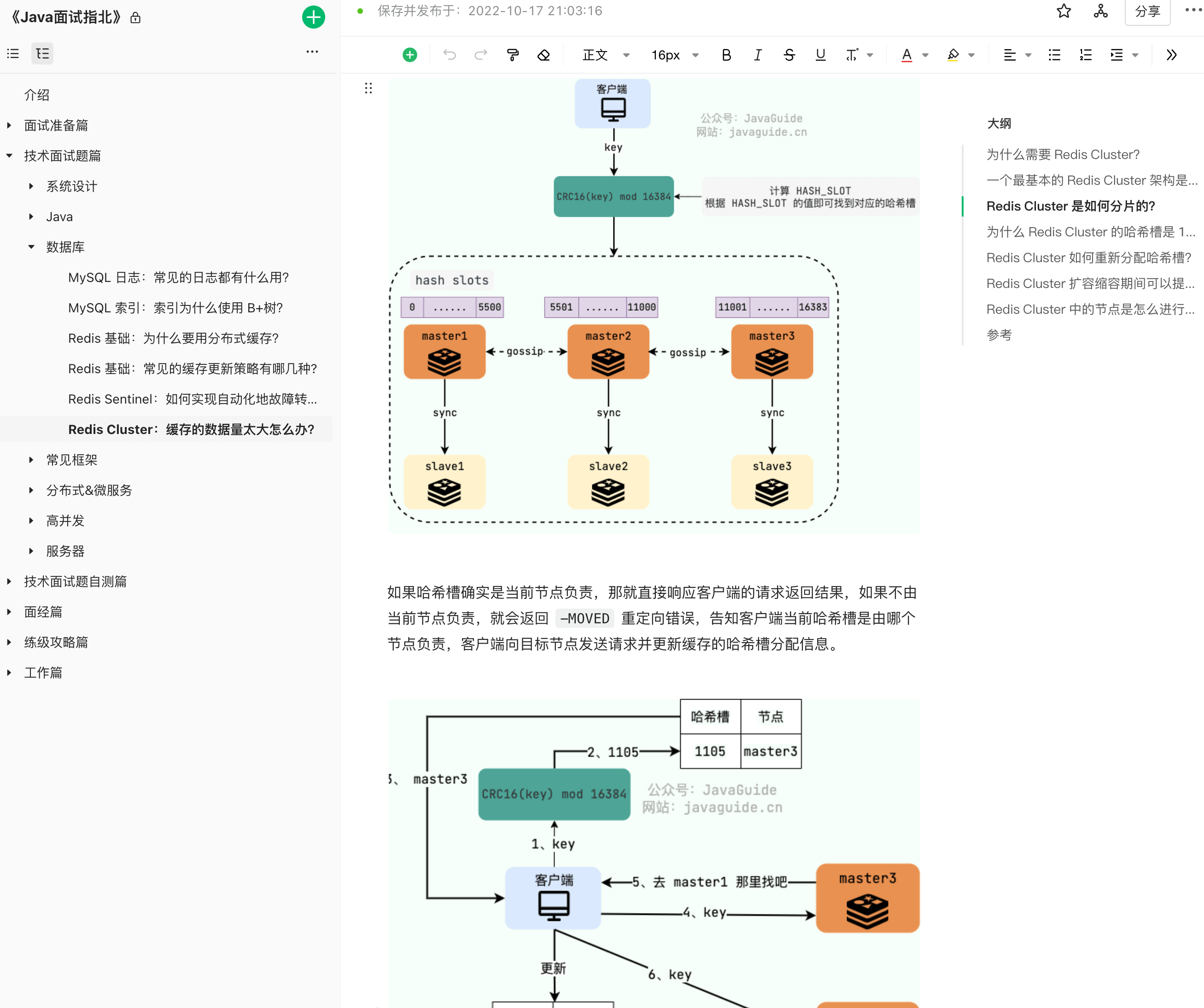
|
||||
|
||||
|
||||
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn) 的补充完善,两者可以配合使用。
|
||||
|
||||

|
||||
|
||||
@ -5,7 +5,7 @@ tag:
|
||||
- Redis
|
||||
---
|
||||
|
||||
> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿Q说代码
|
||||
> 本文整理完善自:https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA ,作者:阿 Q 说代码
|
||||
|
||||
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
|
||||
|
||||
@ -54,7 +54,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
||||
|
||||
当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
|
||||
|
||||
关于 AOF 工作流程的详细介绍可以查看:[Redis持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
|
||||
关于 AOF 工作流程的详细介绍可以查看:[Redis 持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
|
||||
|
||||
### AOF 重写阻塞
|
||||
|
||||
@ -64,7 +64,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
||||
|
||||
阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生**阻塞**。
|
||||
|
||||
相关阅读:[Redis AOF重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
|
||||
相关阅读:[Redis AOF 重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
|
||||
|
||||
## 大 Key
|
||||
|
||||
@ -111,13 +111,13 @@ Redis 集群可以进行节点的动态扩容缩容,这一过程目前还处
|
||||
|
||||
## Swap(内存交换)
|
||||
|
||||
什么是 Swap?Swap 直译过来是交换的意思,Linux中的Swap常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
|
||||
什么是 Swap?Swap 直译过来是交换的意思,Linux 中的 Swap 常被称为内存交换或者交换分区。类似于 Windows 中的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况。因此,Swap 分区的作用就是牺牲硬盘,增加内存,解决 VPS 内存不够用或者爆满的问题。
|
||||
|
||||
Swap 对于Redis来说是非常致命的,Redis保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把Redis使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的Redis性能急剧下降。
|
||||
Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重要前提是所有的数据在内存中。如果操作系统把 Redis 使用的部分内存换出硬盘,由于内存与硬盘读写的速度并几个数量级,会导致发生交换后的 Redis 性能急剧下降。
|
||||
|
||||
识别 Redis 发生 Swap 的检查方法如下:
|
||||
|
||||
1、查询Redis进程号
|
||||
1、查询 Redis 进程号
|
||||
|
||||
```bash
|
||||
reids-cli -p 6383 info server | grep process_id
|
||||
@ -136,19 +136,19 @@ Swap: 0kB
|
||||
.....
|
||||
```
|
||||
|
||||
如果交换量都是0KB或者个别的是4KB,则正常。
|
||||
如果交换量都是 0KB 或者个别的是 4KB,则正常。
|
||||
|
||||
预防内存交换的方法:
|
||||
|
||||
- 保证机器充足的可用内存
|
||||
- 确保所有Redis实例设置最大可用内存(maxmemory),防止极端情况Redis内存不可控的增长
|
||||
- 降低系统使用swap优先级,如`echo 10 > /proc/sys/vm/swappiness`
|
||||
- 确保所有 Redis 实例设置最大可用内存(maxmemory),防止极端情况 Redis 内存不可控的增长
|
||||
- 降低系统使用 swap 优先级,如`echo 10 > /proc/sys/vm/swappiness`
|
||||
|
||||
## CPU 竞争
|
||||
|
||||
Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务部署在一起。当其他进程过度消耗CPU时,将严重影响Redis的吞吐量。
|
||||
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
|
||||
|
||||
可以通过`reids-cli --stat`获取当前Redis使用情况。通过`top`命令获取进程对CPU的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
|
||||
可以通过`reids-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
|
||||
|
||||
## 网络问题
|
||||
|
||||
@ -156,5 +156,5 @@ Redis是典型的CPU密集型应用,不建议和其他多核CPU密集型服务
|
||||
|
||||
## 参考
|
||||
|
||||
- Redis阻塞的6大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
|
||||
- Redis开发与运维笔记-Redis的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
|
||||
- Redis 阻塞的 6 大类场景分析与总结:https://mp.weixin.qq.com/s/eaZCEtTjTuEmXfUubVHjew
|
||||
- Redis 开发与运维笔记-Redis 的噩梦-阻塞:https://mp.weixin.qq.com/s/TDbpz9oLH6ifVv6ewqgSgA
|
||||
|
||||
@ -388,7 +388,7 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| --------------------------------------------- | ------------------------------------------------------------ |
|
||||
| --------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
||||
| ZCARD KEY | 获取指定有序集合的元素数量 |
|
||||
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
|
||||
|
||||
@ -27,7 +27,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------------- | ------------------------------------------------------------ |
|
||||
| ------------------------------------- | ---------------------------------------------------------------- |
|
||||
| SETBIT key offset value | 设置指定 offset 位置的值 |
|
||||
| GETBIT key offset | 获取指定 offset 位置的值 |
|
||||
| BITCOUNT key start end | 获取 start 和 end 之前值为 1 的元素个数 |
|
||||
@ -87,7 +87,7 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
|
||||
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ----------------------------------------- | ------------------------------------------------------------ |
|
||||
| ----------------------------------------- | -------------------------------------------------------------------------------- |
|
||||
| PFADD key element1 element2 ... | 添加一个或多个元素到 HyperLogLog 中 |
|
||||
| PFCOUNT key1 key2 | 获取一个或者多个 HyperLogLog 的唯一计数。 |
|
||||
| PFMERGE destkey sourcekey1 sourcekey2 ... | 将多个 HyperLogLog 合并到 destkey 中,destkey 会结合多个源,算出对应的唯一计数。 |
|
||||
@ -133,7 +133,7 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| ------------------------------------------------ | ---------------------------------------------------------------------------------------------------- |
|
||||
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
|
||||
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
|
||||
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
|
||||
|
||||
@ -248,7 +248,7 @@ struct __attribute__ ((__packed__)) sdshdr64 {
|
||||
通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
|
||||
|
||||
| 类型 | 字节 | 位 |
|
||||
| -------- | ---- | ---- |
|
||||
| -------- | ---- | --- |
|
||||
| sdshdr5 | < 1 | <8 |
|
||||
| sdshdr8 | 1 | 8 |
|
||||
| sdshdr16 | 2 | 16 |
|
||||
@ -371,7 +371,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
||||
|
||||
### 使用 HyperLogLog 统计页面 UV 怎么做?
|
||||
|
||||
使用 HyperLogLog 统计页面 UV主要需要用到下面这两个命令:
|
||||
使用 HyperLogLog 统计页面 UV 主要需要用到下面这两个命令:
|
||||
|
||||
- `PFADD key element1 element2 ...`:添加一个或多个元素到 HyperLogLog 中。
|
||||
- `PFCOUNT key1 key2`:获取一个或者多个 HyperLogLog 的唯一计数。
|
||||
@ -593,4 +593,3 @@ Redis 提供 6 种数据淘汰策略:
|
||||
- 《Redis 设计与实现》
|
||||
- Redis 命令手册:https://www.redis.com.cn/commands.html
|
||||
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
||||
|
||||
|
||||
@ -1204,7 +1204,7 @@ ORDER BY c.cust_name
|
||||
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
||||
|
||||
| 连接类型 | 说明 |
|
||||
| ---------------------------------------- | ------------------------------------------------------------ |
|
||||
| ---------------------------------------- | --------------------------------------------------------------------------------------------- |
|
||||
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
||||
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
||||
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
||||
|
||||
@ -490,7 +490,7 @@ order by c.cust_name;
|
||||
SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不同类型的连接,如下表所示:
|
||||
|
||||
| 连接类型 | 说明 |
|
||||
| ---------------------------------------- | ------------------------------------------------------------ |
|
||||
| ---------------------------------------- | --------------------------------------------------------------------------------------------- |
|
||||
| INNER JOIN 内连接 | (默认连接方式)只有当两个表都存在满足条件的记录时才会返回行。 |
|
||||
| LEFT JOIN / LEFT OUTER JOIN 左(外)连接 | 返回左表中的所有行,即使右表中没有满足条件的行也是如此。 |
|
||||
| RIGHT JOIN / RIGHT OUTER JOIN 右(外)连接 | 返回右表中的所有行,即使左表中没有满足条件的行也是如此。 |
|
||||
@ -919,7 +919,7 @@ SELECT user FROM user;
|
||||
下表说明了可用于`GRANT`和`REVOKE`语句的所有允许权限:
|
||||
|
||||
| **特权** | **说明** | **级别** | | | | | |
|
||||
| ----------------------- | ------------------------------------------------------------ | -------- | ------ | -------- | -------- | ---- | ---- |
|
||||
| ----------------------- | ------------------------------------------------------------------------------------------------------- | -------- | ------ | -------- | -------- | --- | --- |
|
||||
| **全局** | 数据库 | **表** | **列** | **程序** | **代理** | | |
|
||||
| ALL [PRIVILEGES] | 授予除 GRANT OPTION 之外的指定访问级别的所有权限 | | | | | | |
|
||||
| ALTER | 允许用户使用 ALTER TABLE 语句 | X | X | X | | | |
|
||||
@ -1206,5 +1206,5 @@ DROP TRIGGER IF EXISTS trigger_insert_user;
|
||||
|
||||
## 文章推荐
|
||||
|
||||
- [后端程序员必备:SQL高性能优化指南!35+条优化建议立马GET!](https://mp.weixin.qq.com/s/I-ZT3zGTNBZ6egS7T09jyQ)
|
||||
- [后端程序员必备:书写高质量SQL的30条建议](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486461&idx=1&sn=60a22279196d084cc398936fe3b37772&chksm=cea24436f9d5cd20a4fa0e907590f3e700d7378b3f608d7b33bb52cfb96f503b7ccb65a1deed&token=1987003517&lang=zh_CN#rd)
|
||||
- [后端程序员必备:SQL 高性能优化指南!35+条优化建议立马 GET!](https://mp.weixin.qq.com/s/I-ZT3zGTNBZ6egS7T09jyQ)
|
||||
- [后端程序员必备:书写高质量 SQL 的 30 条建议](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486461&idx=1&sn=60a22279196d084cc398936fe3b37772&chksm=cea24436f9d5cd20a4fa0e907590f3e700d7378b3f608d7b33bb52cfb96f503b7ccb65a1deed&token=1987003517&lang=zh_CN#rd)
|
||||
|
||||
@ -75,12 +75,12 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网
|
||||
|
||||
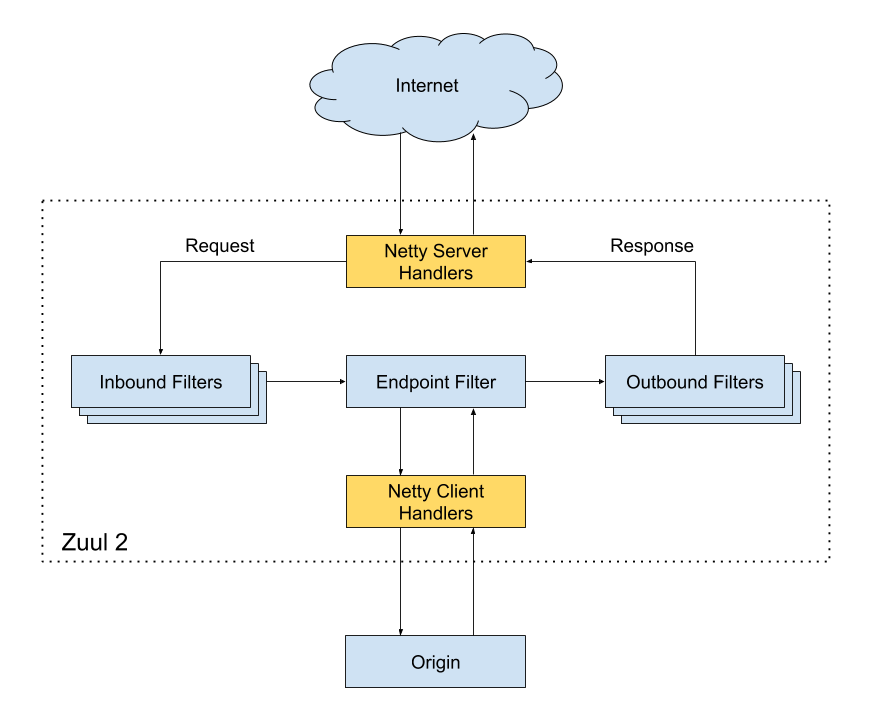
|
||||
|
||||
- Github 地址 : https://github.com/Netflix/zuul
|
||||
- 官方 Wiki : https://github.com/Netflix/zuul/wiki
|
||||
- Github 地址 : <https://github.com/Netflix/zuul>
|
||||
- 官方 Wiki : <https://github.com/Netflix/zuul/wiki>
|
||||
|
||||
### Spring Cloud Gateway
|
||||
|
||||
SpringCloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul **。准确点来说,应该是 Zuul 1.x。SpringCloud Gateway 起步要比 Zuul 2.x 更早。
|
||||
SpringCloud Gateway 属于 Spring Cloud 生态系统中的网关,其诞生的目标是为了替代老牌网关 **Zuul**。准确点来说,应该是 Zuul 1.x。SpringCloud Gateway 起步要比 Zuul 2.x 更早。
|
||||
|
||||
为了提升网关的性能,SpringCloud Gateway 基于 Spring WebFlux 。Spring WebFlux 使用 Reactor 库来实现响应式编程模型,底层基于 Netty 实现同步非阻塞的 I/O。
|
||||
|
||||
@ -90,8 +90,8 @@ Spring Cloud Gateway 不仅提供统一的路由方式,并且基于 Filter 链
|
||||
|
||||
Spring Cloud Gateway 和 Zuul 2.x 的差别不大,也是通过过滤器来处理请求。不过,目前更加推荐使用 Spring Cloud Gateway 而非 Zuul,Spring Cloud 生态对其支持更加友好。
|
||||
|
||||
- Github 地址 : https://github.com/spring-cloud/spring-cloud-gateway
|
||||
- 官网 : https://spring.io/projects/spring-cloud-gateway
|
||||
- Github 地址 : <https://github.com/spring-cloud/spring-cloud-gateway>
|
||||
- 官网 : <https://spring.io/projects/spring-cloud-gateway>
|
||||
|
||||
### Kong
|
||||
|
||||
@ -118,8 +118,8 @@ $ curl -X POST http://kong:8001/services/{service}/plugins \
|
||||
|
||||
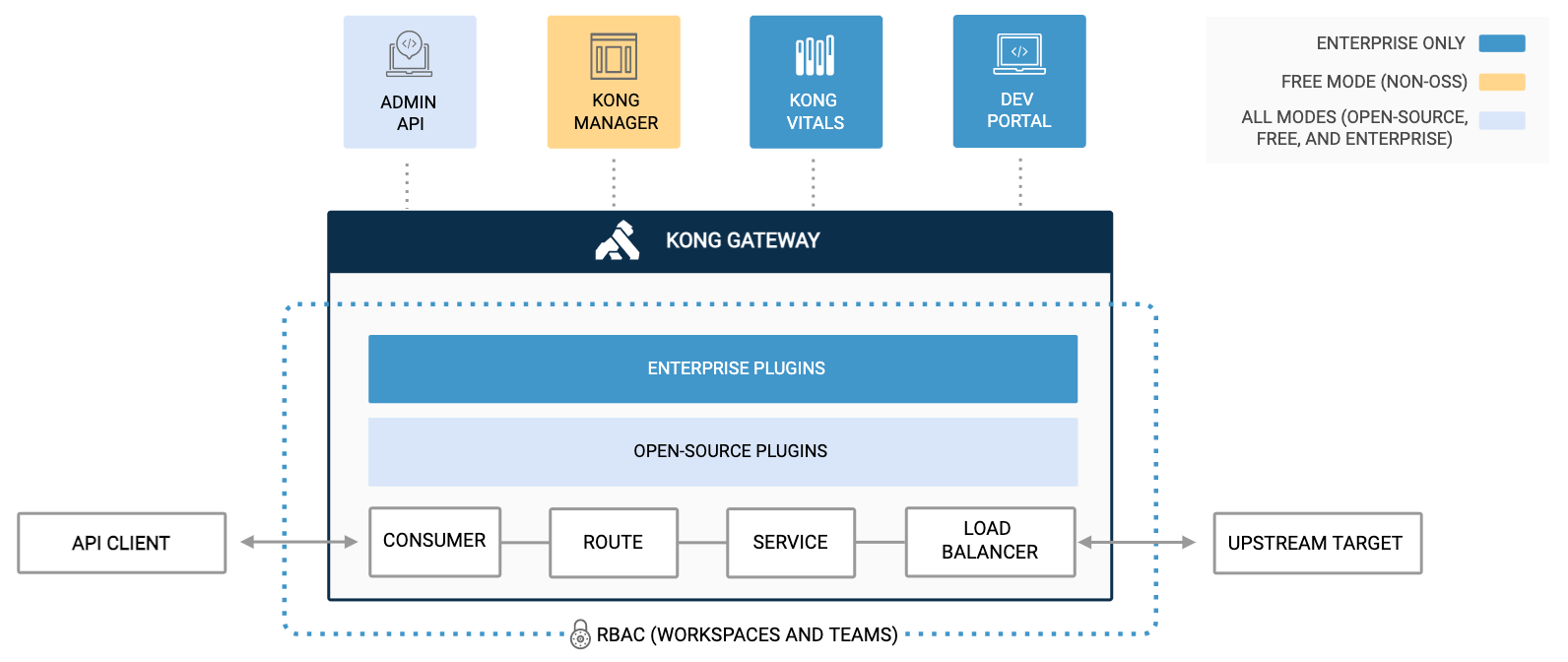
|
||||
|
||||
- Github 地址: https://github.com/Kong/kong
|
||||
- 官网地址 : https://konghq.com/kong
|
||||
- Github 地址: <https://github.com/Kong/kong>
|
||||
- 官网地址 : <https://konghq.com/kong>
|
||||
|
||||
### APISIX
|
||||
|
||||
@ -144,8 +144,8 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
|
||||
|
||||

|
||||
|
||||
- Github 地址 :https://github.com/apache/apisix
|
||||
- 官网地址: https://apisix.apache.org/zh/
|
||||
- Github 地址 :<https://github.com/apache/apisix>
|
||||
- 官网地址: <https://apisix.apache.org/zh/>
|
||||
|
||||
相关阅读:
|
||||
|
||||
@ -162,11 +162,11 @@ Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apac
|
||||
|
||||
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发 、重写、重定向、和路由监控等插件。
|
||||
|
||||
- Github 地址: https://github.com/apache/incubator-shenyu
|
||||
- 官网地址 : https://shenyu.apache.org/
|
||||
- Github 地址: <https://github.com/apache/incubator-shenyu>
|
||||
- 官网地址 : <https://shenyu.apache.org/>
|
||||
|
||||
## 参考
|
||||
|
||||
- Kong 插件开发教程[通俗易懂]:https://cloud.tencent.com/developer/article/2104299
|
||||
- API 网关 Kong 实战:https://xie.infoq.cn/article/10e4dab2de0bdb6f2c3c93da6
|
||||
- Spring Cloud Gateway 原理介绍和应用:https://blog.fintopia.tech/60e27b0e2078082a378ec5ed/
|
||||
- Kong 插件开发教程[通俗易懂]:<https://cloud.tencent.com/developer/article/2104299>
|
||||
- API 网关 Kong 实战:<https://xie.infoq.cn/article/10e4dab2de0bdb6f2c3c93da6>
|
||||
- Spring Cloud Gateway 原理介绍和应用:<https://blog.fintopia.tech/60e27b0e2078082a378ec5ed/>
|
||||
|
||||
@ -12,45 +12,4 @@ icon: "configuration"
|
||||
|
||||

|
||||
|
||||
最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
|
||||
|
||||
为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的知识星球。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面。
|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/image-20220311203414600.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiufuwu.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
|
||||
|
||||
这里再送一个 30 元的新人优惠券(续费半价)。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
进入星球之后,记得添加微信,我会发你详细的星球使用指南。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -84,9 +84,9 @@ COMMIT;
|
||||
|
||||
插入数据这里,我们没有使用 `insert into` 而是使用 `replace into` 来插入数据,具体步骤是这样的:
|
||||
|
||||
1)第一步: 尝试把数据插入到表中。
|
||||
- 第一步: 尝试把数据插入到表中。
|
||||
|
||||
2)第二步: 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
|
||||
- 第二步: 如果主键或唯一索引字段出现重复数据错误而插入失败时,先从表中删除含有重复关键字值的冲突行,然后再次尝试把数据插入到表中。
|
||||
|
||||
这种方式的优缺点也比较明显:
|
||||
|
||||
@ -103,7 +103,7 @@ COMMIT;
|
||||
|
||||
以 MySQL 举例,我们通过下面的方式即可。
|
||||
|
||||
**1.创建一个数据库表。**
|
||||
**1. 创建一个数据库表。**
|
||||
|
||||
```sql
|
||||
CREATE TABLE `sequence_id_generator` (
|
||||
@ -122,7 +122,7 @@ CREATE TABLE `sequence_id_generator` (
|
||||
|
||||
`version` 字段主要用于解决并发问题(乐观锁),`biz_type` 主要用于表示业务类型。
|
||||
|
||||
**2.先插入一行数据。**
|
||||
**2. 先插入一行数据。**
|
||||
|
||||
```sql
|
||||
INSERT INTO `sequence_id_generator` (`id`, `current_max_id`, `step`, `version`, `biz_type`)
|
||||
@ -130,7 +130,7 @@ VALUES
|
||||
(1, 0, 100, 0, 101);
|
||||
```
|
||||
|
||||
**3.通过 SELECT 获取指定业务下的批量唯一 ID**
|
||||
**3. 通过 SELECT 获取指定业务下的批量唯一 ID**
|
||||
|
||||
```sql
|
||||
SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `biz_type` = 101
|
||||
@ -143,7 +143,7 @@ id current_max_id step version biz_type
|
||||
1 0 100 0 101
|
||||
```
|
||||
|
||||
**4.不够用的话,更新之后重新 SELECT 即可。**
|
||||
**4. 不够用的话,更新之后重新 SELECT 即可。**
|
||||
|
||||
```sql
|
||||
UPDATE sequence_id_generator SET current_max_id = 0+100, version=version+1 WHERE version = 0 AND `biz_type` = 101
|
||||
|
||||
@ -95,7 +95,7 @@ OK
|
||||
|
||||
### 如何实现锁的优雅续期?
|
||||
|
||||
对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:https://redis.io/topics/distlock 。
|
||||
对于 Java 开发的小伙伴来说,已经有了现成的解决方案:**[Redisson](https://github.com/redisson/redisson)** 。其他语言的解决方案,可以在 Redis 官方文档中找到,地址:<https://redis.io/topics/distlock> 。
|
||||
|
||||

|
||||
|
||||
@ -394,6 +394,3 @@ private static class LockData
|
||||
## 总结
|
||||
|
||||
这篇文章我们介绍了分布式锁的基本概念以及实现分布式锁的两种常见方式。至于具体选择 Redis 还是 ZooKeeper 来实现分布式锁,还是要看业务的具体需求。如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。如果对可靠性要求比较高的话,建议使用 ZooKeeper 实现分布式锁。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -5,13 +5,13 @@ tag:
|
||||
- ZooKeeper
|
||||
---
|
||||
|
||||
这篇文章简单给演示一下 ZooKeeper 常见命令的使用以及 ZooKeeper Java客户端 Curator 的基本使用。介绍到的内容都是最基本的操作,能满足日常工作的基本需要。
|
||||
这篇文章简单给演示一下 ZooKeeper 常见命令的使用以及 ZooKeeper Java 客户端 Curator 的基本使用。介绍到的内容都是最基本的操作,能满足日常工作的基本需要。
|
||||
|
||||
如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!
|
||||
|
||||
## ZooKeeper 安装
|
||||
|
||||
### 使用Docker 安装 zookeeper
|
||||
### 使用 Docker 安装 zookeeper
|
||||
|
||||
**a.使用 Docker 下载 ZooKeeper**
|
||||
|
||||
@ -27,11 +27,11 @@ docker run -d --name zookeeper -p 2181:2181 zookeeper:3.5.8
|
||||
|
||||
### 连接 ZooKeeper 服务
|
||||
|
||||
**a.进入ZooKeeper容器中**
|
||||
**a.进入 ZooKeeper 容器中**
|
||||
|
||||
先使用 `docker ps` 查看 ZooKeeper 的 ContainerID,然后使用 `docker exec -it ContainerID /bin/bash` 命令进入容器中。
|
||||
|
||||
**b.先进入 bin 目录,然后通过 `./zkCli.sh -server 127.0.0.1:2181`命令连接ZooKeeper 服务**
|
||||
**b.先进入 bin 目录,然后通过 `./zkCli.sh -server 127.0.0.1:2181`命令连接 ZooKeeper 服务**
|
||||
|
||||
```bash
|
||||
root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
|
||||
@ -162,15 +162,15 @@ numChildren = 1
|
||||
|
||||
在后面我会介绍到 Java 客户端 API 的使用以及开源 ZooKeeper 客户端 ZkClient 和 Curator 的使用。
|
||||
|
||||
## ZooKeeper Java客户端 Curator简单使用
|
||||
## ZooKeeper Java 客户端 Curator 简单使用
|
||||
|
||||
Curator 是Netflix公司开源的一套 ZooKeeper Java客户端框架,相比于 Zookeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
|
||||
Curator 是 Netflix 公司开源的一套 ZooKeeper Java 客户端框架,相比于 Zookeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
|
||||
|
||||

|
||||
|
||||
下面我们就来简单地演示一下 Curator 的使用吧!
|
||||
|
||||
Curator4.0+版本对ZooKeeper 3.5.x支持比较好。开始之前,请先将下面的依赖添加进你的项目。
|
||||
Curator4.0+版本对 ZooKeeper 3.5.x 支持比较好。开始之前,请先将下面的依赖添加进你的项目。
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
@ -214,14 +214,14 @@ zkClient.start();
|
||||
|
||||
#### 创建节点
|
||||
|
||||
我们在 [ZooKeeper常见概念解读](./zookeeper-intro.md) 中介绍到,我们通常是将 znode 分为 4 大类:
|
||||
我们在 [ZooKeeper 常见概念解读](./zookeeper-intro.md) 中介绍到,我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点** :一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点** :临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点** :除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001` 、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点** :除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性。
|
||||
|
||||
你在使用的ZooKeeper 的时候,会发现 `CreateMode` 类中实际有 7种 znode 类型 ,但是用的最多的还是上面介绍的 4 种。
|
||||
你在使用的 ZooKeeper 的时候,会发现 `CreateMode` 类中实际有 7 种 znode 类型 ,但是用的最多的还是上面介绍的 4 种。
|
||||
|
||||
**a.创建持久化节点**
|
||||
|
||||
@ -293,8 +293,3 @@ zkClient.setData().forPath("/node1/00001","c++".getBytes());//更新节点数据
|
||||
```java
|
||||
List<String> childrenPaths = zkClient.getChildren().forPath("/node1");
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -125,7 +125,7 @@ Stat 类中包含了一个数据节点的所有状态信息的字段,包括事
|
||||
下面我们来看一下每个 znode 状态信息究竟代表的是什么吧!(下面的内容来源于《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》,因为 Guide 确实也不是特别清楚,要学会参考资料的嘛! ) :
|
||||
|
||||
| znode 状态信息 | 解释 |
|
||||
| -------------- | ------------------------------------------------------------ |
|
||||
| -------------- | --------------------------------------------------------------------------------------------------- |
|
||||
| cZxid | create ZXID,即该数据节点被创建时的事务 id |
|
||||
| ctime | create time,即该节点的创建时间 |
|
||||
| mZxid | modified ZXID,即该节点最终一次更新时的事务 id |
|
||||
@ -202,7 +202,7 @@ Session 有一个属性叫做:`sessionTimeout` ,`sessionTimeout` 代表会
|
||||
ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定一台称为 “**Leader**” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,**Follower** 和 **Observer** 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
|
||||
|
||||
| 角色 | 说明 |
|
||||
| -------- | ------------------------------------------------------------ |
|
||||
| -------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
|
||||
| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
|
||||
| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
|
||||
|
||||
@ -7,7 +7,7 @@ tag:
|
||||
|
||||
> [FrancisQ](https://juejin.im/user/5c33853851882525ea106810) 投稿。
|
||||
|
||||
## 什么是ZooKeeper
|
||||
## 什么是 ZooKeeper
|
||||
|
||||
`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
|
||||
|
||||
@ -39,11 +39,11 @@ tag:
|
||||
|
||||

|
||||
|
||||
而上述前者就是 `Eureka` 的处理方式,它保证了AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了CP(数据一致性)。
|
||||
而上述前者就是 `Eureka` 的处理方式,它保证了 AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了 CP(数据一致性)。
|
||||
|
||||
## 一致性协议和算法
|
||||
|
||||
而为了解决数据一致性问题,在科学家和程序员的不断探索中,就出现了很多的一致性协议和算法。比如 2PC(两阶段提交),3PC(三阶段提交),Paxos算法等等。
|
||||
而为了解决数据一致性问题,在科学家和程序员的不断探索中,就出现了很多的一致性协议和算法。比如 2PC(两阶段提交),3PC(三阶段提交),Paxos 算法等等。
|
||||
|
||||
这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
|
||||
|
||||
@ -57,9 +57,9 @@ tag:
|
||||
|
||||
两阶段提交是一种保证分布式系统数据一致性的协议,现在很多数据库都是采用的两阶段提交协议来完成 **分布式事务** 的处理。
|
||||
|
||||
在介绍2PC之前,我们先来想想分布式事务到底有什么问题呢?
|
||||
在介绍 2PC 之前,我们先来想想分布式事务到底有什么问题呢?
|
||||
|
||||
还拿秒杀系统的下订单和加积分两个系统来举例吧(我想你们可能都吐了🤮🤮🤮),我们此时下完订单会发个消息给积分系统告诉它下面该增加积分了。如果我们仅仅是发送一个消息也不收回复,那么我们的订单系统怎么能知道积分系统的收到消息的情况呢?如果我们增加一个收回复的过程,那么当积分系统收到消息后返回给订单系统一个 `Response` ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。
|
||||
还拿秒杀系统的下订单和加积分两个系统来举例吧(我想你们可能都吐了 🤮🤮🤮),我们此时下完订单会发个消息给积分系统告诉它下面该增加积分了。如果我们仅仅是发送一个消息也不收回复,那么我们的订单系统怎么能知道积分系统的收到消息的情况呢?如果我们增加一个收回复的过程,那么当积分系统收到消息后返回给订单系统一个 `Response` ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。
|
||||
|
||||
所以我们所需要解决的是在分布式系统中,整个调用链中,我们所有服务的数据处理要么都成功要么都失败,即所有服务的 **原子性问题** 。
|
||||
|
||||
@ -79,19 +79,19 @@ tag:
|
||||
|
||||

|
||||
|
||||
* **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
|
||||
* **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
|
||||
* **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
|
||||
- **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
|
||||
- **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
|
||||
- **数据不一致问题**,比如当第二阶段,协调者只发送了一部分的 `commit` 请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
|
||||
|
||||
### 3PC(三阶段提交)
|
||||
|
||||
因为2PC存在的一系列问题,比如单点,容错机制缺陷等等,从而产生了 **3PC(三阶段提交)** 。那么这三阶段又分别是什么呢?
|
||||
因为 2PC 存在的一系列问题,比如单点,容错机制缺陷等等,从而产生了 **3PC(三阶段提交)** 。那么这三阶段又分别是什么呢?
|
||||
|
||||
> 千万不要吧PC理解成个人电脑了,其实他们是 phase-commit 的缩写,即阶段提交。
|
||||
> 千万不要吧 PC 理解成个人电脑了,其实他们是 phase-commit 的缩写,即阶段提交。
|
||||
|
||||
1. **CanCommit阶段**:协调者向所有参与者发送 `CanCommit` 请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
|
||||
2. **PreCommit阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
|
||||
3. **DoCommit阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
|
||||
1. **CanCommit 阶段**:协调者向所有参与者发送 `CanCommit` 请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。
|
||||
2. **PreCommit 阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
|
||||
3. **DoCommit 阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
|
||||
|
||||
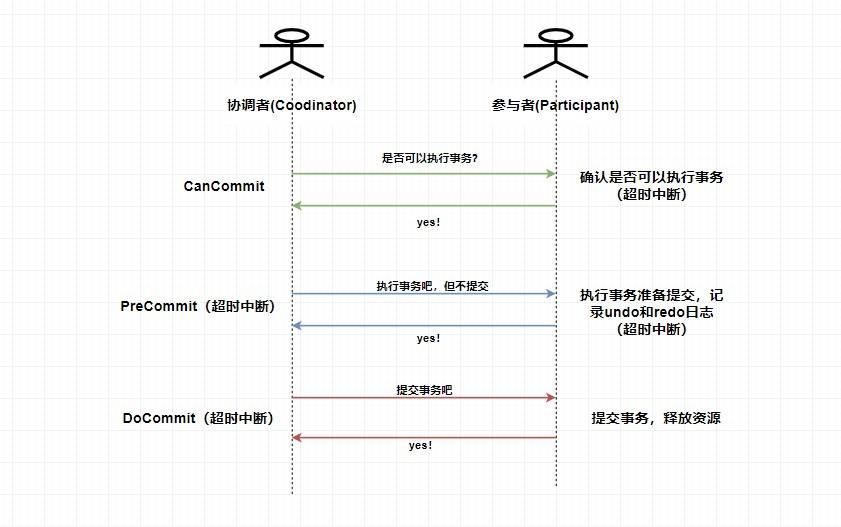
|
||||
|
||||
@ -99,7 +99,7 @@ tag:
|
||||
|
||||
总之,`3PC` 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 `PreCommit` 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
|
||||
|
||||
所以,要解决一致性问题还需要靠 `Paxos` 算法⭐️ ⭐️ ⭐️ 。
|
||||
所以,要解决一致性问题还需要靠 `Paxos` 算法 ⭐️ ⭐️ ⭐️ 。
|
||||
|
||||
### `Paxos` 算法
|
||||
|
||||
@ -109,8 +109,8 @@ tag:
|
||||
|
||||
#### prepare 阶段
|
||||
|
||||
* `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
|
||||
* `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号N记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
|
||||
- `Proposer提案者`:负责提出 `proposal`,每个提案者在提出提案时都会首先获取到一个 **具有全局唯一性的、递增的提案编号 N**,即在整个集群中是唯一的编号 N,然后将该编号赋予其要提出的提案,在**第一阶段是只将提案编号发送给所有的表决者**。
|
||||
- `Acceptor表决者`:每个表决者在 `accept` 某提案后,会将该提案编号 N 记录在本地,这样每个表决者中保存的已经被 accept 的提案中会存在一个**编号最大的提案**,其编号假设为 `maxN`。每个表决者仅会 `accept` 编号大于自己本地 `maxN` 的提案,在批准提案时表决者会将以前接受过的最大编号的提案作为响应反馈给 `Proposer` 。
|
||||
|
||||
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
|
||||
|
||||
@ -134,7 +134,7 @@ tag:
|
||||
|
||||
#### paxos 算法的死循环问题
|
||||
|
||||
其实就有点类似于两个人吵架,小明说我是对的,小红说我才是对的,两个人据理力争的谁也不让谁🤬🤬。
|
||||
其实就有点类似于两个人吵架,小明说我是对的,小红说我才是对的,两个人据理力争的谁也不让谁 🤬🤬。
|
||||
|
||||
比如说,此时提案者 P1 提出一个方案 M1,完成了 `Prepare` 阶段的工作,这个时候 `acceptor` 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 `Prepare` 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 `acceptor` 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 `Prepare` 阶段,然后 `acceptor` ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 `Prepare` 阶段。。。
|
||||
|
||||
@ -156,9 +156,9 @@ tag:
|
||||
|
||||
和介绍 `Paxos` 一样,在介绍 `ZAB` 协议之前,我们首先来了解一下在 `ZAB` 中三个主要的角色,`Leader 领导者`、`Follower跟随者`、`Observer观察者` 。
|
||||
|
||||
* `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
|
||||
* `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
|
||||
* `Observer` :就是没有选举权和被选举权的 `Follower` 。
|
||||
- `Leader` :集群中 **唯一的写请求处理者** ,能够发起投票(投票也是为了进行写请求)。
|
||||
- `Follower`:能够接收客户端的请求,如果是读请求则可以自己处理,**如果是写请求则要转发给 `Leader`** 。在选举过程中会参与投票,**有选举权和被选举权** 。
|
||||
- `Observer` :就是没有选举权和被选举权的 `Follower` 。
|
||||
|
||||
在 `ZAB` 协议中对 `zkServer`(即上面我们说的三个角色的总称) 还有两种模式的定义,分别是 **消息广播** 和 **崩溃恢复** 。
|
||||
|
||||
@ -174,11 +174,11 @@ tag:
|
||||
|
||||
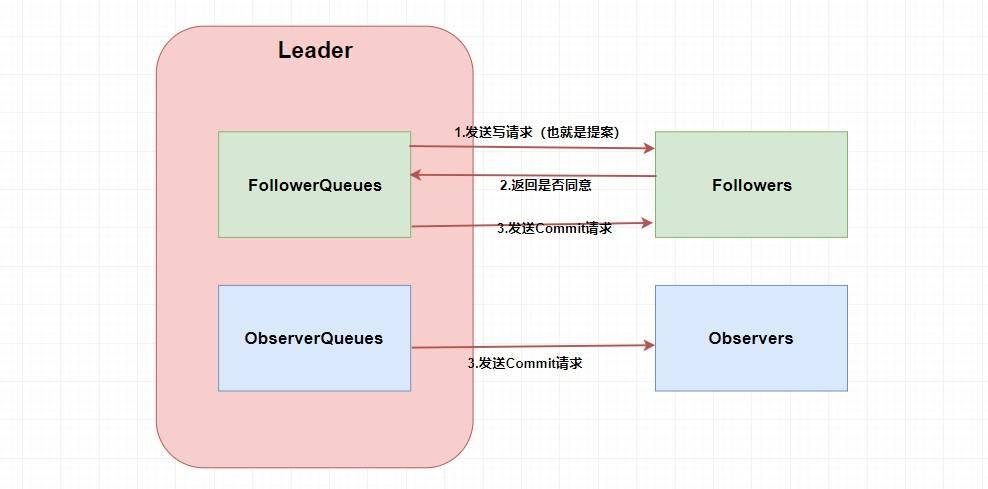
|
||||
|
||||
嗯。。。看起来很简单,貌似懂了🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求A,此时 `Leader` 将请求A广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1因为网络原因没有收到,而 `Leader` 又广播了一个请求B,因为网络原因,F1竟然先收到了请求B然后才收到了请求A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
|
||||
嗯。。。看起来很简单,貌似懂了 🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求 A,此时 `Leader` 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1 因为网络原因没有收到,而 `Leader` 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
|
||||
|
||||
所以在 `Leader` 这端,它为每个其他的 `zkServer` 准备了一个 **队列** ,采用先进先出的方式发送消息。由于协议是 **通过 `TCP`** 来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
|
||||
|
||||
除此之外,在 `ZAB` 中还定义了一个 **全局单调递增的事务ID `ZXID`** ,它是一个64位long型,其中高32位表示 `epoch` 年代,低32位表示事务id。`epoch` 是会根据 `Leader` 的变化而变化的,当一个 `Leader` 挂了,新的 `Leader` 上位的时候,年代(`epoch`)就变了。而低32位可以简单理解为递增的事务id。
|
||||
除此之外,在 `ZAB` 中还定义了一个 **全局单调递增的事务 ID `ZXID`** ,它是一个 64 位 long 型,其中高 32 位表示 `epoch` 年代,低 32 位表示事务 id。`epoch` 是会根据 `Leader` 的变化而变化的,当一个 `Leader` 挂了,新的 `Leader` 上位的时候,年代(`epoch`)就变了。而低 32 位可以简单理解为递增的事务 id。
|
||||
|
||||
定义这个的原因也是为了顺序性,每个 `proposal` 在 `Leader` 中生成后需要 **通过其 `ZXID` 来进行排序** ,才能得到处理。
|
||||
|
||||
@ -188,7 +188,7 @@ tag:
|
||||
|
||||
`Leader` 选举可以分为两个不同的阶段,第一个是我们提到的 `Leader` 宕机需要重新选举,第二则是当 `Zookeeper` 启动时需要进行系统的 `Leader` 初始化选举。下面我先来介绍一下 `ZAB` 是如何进行初始化选举的。
|
||||
|
||||
假设我们集群中有3台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 `server1` ,它会首先 **投票给自己** ,投票内容为服务器的 `myid` 和 `ZXID` ,因为初始化所以 `ZXID` 都为0,此时 `server1` 发出的投票为 (1,0)。但此时 `server1` 的投票仅为1,所以不能作为 `Leader` ,此时还在选举阶段所以整个集群处于 **`Looking` 状态**。
|
||||
假设我们集群中有 3 台机器,那也就意味着我们需要两台以上同意(超过半数)。比如这个时候我们启动了 `server1` ,它会首先 **投票给自己** ,投票内容为服务器的 `myid` 和 `ZXID` ,因为初始化所以 `ZXID` 都为 0,此时 `server1` 发出的投票为 (1,0)。但此时 `server1` 的投票仅为 1,所以不能作为 `Leader` ,此时还在选举阶段所以整个集群处于 **`Looking` 状态**。
|
||||
|
||||
接着 `server2` 启动了,它首先也会将投票选给自己(2,0),并将投票信息广播出去(`server1`也会,只是它那时没有其他的服务器了),`server1` 在收到 `server2` 的投票信息后会将投票信息与自己的作比较。**首先它会比较 `ZXID` ,`ZXID` 大的优先为 `Leader`,如果相同则比较 `myid`,`myid` 大的优先作为 `Leader`**。所以此时`server1` 发现 `server2` 更适合做 `Leader`,它就会将自己的投票信息更改为(2,0)然后再广播出去,之后`server2` 收到之后发现和自己的一样无需做更改,并且自己的 **投票已经超过半数** ,则 **确定 `server2` 为 `Leader`**,`server1` 也会将自己服务器设置为 `Following` 变为 `Follower`。整个服务器就从 `Looking` 变为了正常状态。
|
||||
|
||||
@ -196,7 +196,7 @@ tag:
|
||||
|
||||
还是前面三个 `server` 的例子,如果在整个集群运行的过程中 `server2` 挂了,那么整个集群会如何重新选举 `Leader` 呢?其实和初始化选举差不多。
|
||||
|
||||
首先毫无疑问的是剩下的两个 `Follower` 会将自己的状态 **从 `Following` 变为 `Looking` 状态** ,然后每个 `server` 会向初始化投票一样首先给自己投票(这不过这里的 `zxid` 可能不是0了,这里为了方便随便取个数字)。
|
||||
首先毫无疑问的是剩下的两个 `Follower` 会将自己的状态 **从 `Following` 变为 `Looking` 状态** ,然后每个 `server` 会向初始化投票一样首先给自己投票(这不过这里的 `zxid` 可能不是 0 了,这里为了方便随便取个数字)。
|
||||
|
||||
假设 `server1` 给自己投票为(1,99),然后广播给其他 `server`,`server3` 首先也会给自己投票(3,95),然后也广播给其他 `server`。`server1` 和 `server3` 此时会收到彼此的投票信息,和一开始选举一样,他们也会比较自己的投票和收到的投票(`zxid` 大的优先,如果相同那么就 `myid` 大的优先)。这个时候 `server1` 收到了 `server3` 的投票发现没自己的合适故不变,`server3` 收到 `server1` 的投票结果后发现比自己的合适于是更改投票为(1,99)然后广播出去,最后 `server1` 收到了发现自己的投票已经超过半数就把自己设为 `Leader`,`server3` 也随之变为 `Follower`。
|
||||
|
||||
@ -208,9 +208,9 @@ tag:
|
||||
|
||||
如果只是 `Follower` 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 `Leader` 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
|
||||
|
||||
如果 `Leader` 挂了那就麻烦了,我们肯定需要先暂停服务变为 `Looking` 状态然后进行 `Leader` 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 **确保已经被Leader提交的提案最终能够被所有的Follower提交** 和 **跳过那些已经被丢弃的提案** 。
|
||||
如果 `Leader` 挂了那就麻烦了,我们肯定需要先暂停服务变为 `Looking` 状态然后进行 `Leader` 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 **确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交** 和 **跳过那些已经被丢弃的提案** 。
|
||||
|
||||
确保已经被Leader提交的提案最终能够被所有的Follower提交是什么意思呢?
|
||||
确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交是什么意思呢?
|
||||
|
||||
假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
|
||||
|
||||
@ -222,15 +222,15 @@ tag:
|
||||
|
||||
那么跳过那些已经被丢弃的提案又是什么意思呢?
|
||||
|
||||
假设 `Leader (server2)` 此时同意了提案N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案N1了,这样就会出现数据不一致性问题了,所以 **该提案N1最终需要被抛弃掉** 。
|
||||
假设 `Leader (server2)` 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案 N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 **该提案 N1 最终需要被抛弃掉** 。
|
||||
|
||||
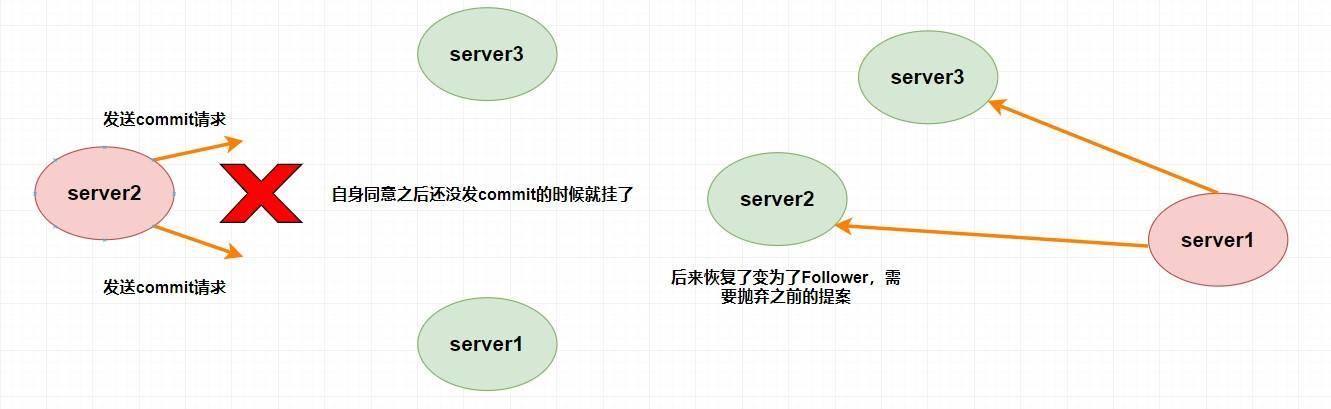
|
||||
|
||||
## Zookeeper的几个理论知识
|
||||
## Zookeeper 的几个理论知识
|
||||
|
||||
了解了 `ZAB` 协议还不够,它仅仅是 `Zookeeper` 内部实现的一种方式,而我们如何通过 `Zookeeper` 去做一些典型的应用场景呢?比如说集群管理,分布式锁,`Master` 选举等等。
|
||||
|
||||
这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型** 、**会话机制**、**ACL**、**Watcher机制** 等等。
|
||||
这就涉及到如何使用 `Zookeeper` 了,但在使用之前我们还需要掌握几个概念。比如 `Zookeeper` 的 **数据模型** 、**会话机制**、**ACL**、**Watcher 机制** 等等。
|
||||
|
||||
### 数据模型
|
||||
|
||||
@ -242,24 +242,24 @@ tag:
|
||||
|
||||
其中节点类型可以分为 **持久节点**、**持久顺序节点**、**临时节点** 和 **临时顺序节点**。
|
||||
|
||||
* 持久节点:一旦创建就一直存在,直到将其删除。
|
||||
* 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
|
||||
* 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||
* 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
|
||||
- 持久节点:一旦创建就一直存在,直到将其删除。
|
||||
- 持久顺序节点:一个父节点可以为其子节点 **维护一个创建的先后顺序** ,这个顺序体现在 **节点名称** 上,是节点名称后自动添加一个由 10 位数字组成的数字串,从 0 开始计数。
|
||||
- 临时节点:临时节点的生命周期是与 **客户端会话** 绑定的,**会话消失则节点消失** 。临时节点 **只能做叶子节点** ,不能创建子节点。
|
||||
- 临时顺序节点:父节点可以创建一个维持了顺序的临时节点(和前面的持久顺序性节点一样)。
|
||||
|
||||
节点状态中包含了很多节点的属性比如 `czxid` 、`mzxid` 等等,在 `zookeeper` 中是使用 `Stat` 这个类来维护的。下面我列举一些属性解释。
|
||||
|
||||
* `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务ID。
|
||||
* `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务ID。
|
||||
* `ctime`:`Created Time`,该节点被创建的时间。
|
||||
* `mtime`: `Modified Time`,该节点最后一次被修改的时间。
|
||||
* `version`:节点的版本号。
|
||||
* `cversion`:**子节点** 的版本号。
|
||||
* `aversion`:节点的 `ACL` 版本号。
|
||||
* `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为0。
|
||||
* `dataLength`:节点数据内容的长度。
|
||||
* `numChildre`:该节点的子节点个数,如果为临时节点为0。
|
||||
* `pzxid`:该节点子节点列表最后一次被修改时的事务ID,注意是子节点的 **列表** ,不是内容。
|
||||
- `czxid`:`Created ZXID`,该数据节点被 **创建** 时的事务 ID。
|
||||
- `mzxid`:`Modified ZXID`,节点 **最后一次被更新时** 的事务 ID。
|
||||
- `ctime`:`Created Time`,该节点被创建的时间。
|
||||
- `mtime`: `Modified Time`,该节点最后一次被修改的时间。
|
||||
- `version`:节点的版本号。
|
||||
- `cversion`:**子节点** 的版本号。
|
||||
- `aversion`:节点的 `ACL` 版本号。
|
||||
- `ephemeralOwner`:创建该节点的会话的 `sessionID` ,如果该节点为持久节点,该值为 0。
|
||||
- `dataLength`:节点数据内容的长度。
|
||||
- `numChildre`:该节点的子节点个数,如果为临时节点为 0。
|
||||
- `pzxid`:该节点子节点列表最后一次被修改时的事务 ID,注意是子节点的 **列表** ,不是内容。
|
||||
|
||||
### 会话
|
||||
|
||||
@ -269,21 +269,21 @@ tag:
|
||||
|
||||
### ACL
|
||||
|
||||
`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了5种权限,它们分别为:
|
||||
`ACL` 为 `Access Control Lists` ,它是一种权限控制。在 `zookeeper` 中定义了 5 种权限,它们分别为:
|
||||
|
||||
* `CREATE` :创建子节点的权限。
|
||||
* `READ`:获取节点数据和子节点列表的权限。
|
||||
* `WRITE`:更新节点数据的权限。
|
||||
* `DELETE`:删除子节点的权限。
|
||||
* `ADMIN`:设置节点 ACL 的权限。
|
||||
- `CREATE` :创建子节点的权限。
|
||||
- `READ`:获取节点数据和子节点列表的权限。
|
||||
- `WRITE`:更新节点数据的权限。
|
||||
- `DELETE`:删除子节点的权限。
|
||||
- `ADMIN`:设置节点 ACL 的权限。
|
||||
|
||||
### Watcher机制
|
||||
### Watcher 机制
|
||||
|
||||
`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
|
||||
|
||||
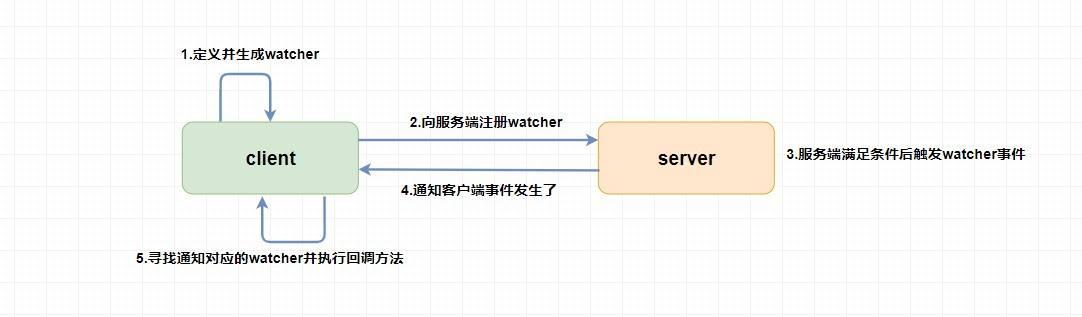
|
||||
|
||||
## Zookeeper的几个典型应用场景
|
||||
## Zookeeper 的几个典型应用场景
|
||||
|
||||
前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
|
||||
|
||||
@ -307,7 +307,7 @@ tag:
|
||||
|
||||
分布式锁的实现方式有很多种,比如 `Redis` 、数据库 、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
|
||||
|
||||
上面我们已经提到过了 **zk在高并发的情况下保证节点创建的全局唯一性**,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
|
||||
上面我们已经提到过了 **zk 在高并发的情况下保证节点创建的全局唯一性**,这玩意一看就知道能干啥了。实现互斥锁呗,又因为能在分布式的情况下,所以能实现分布式锁呗。
|
||||
|
||||
如何实现呢?这玩意其实跟选主基本一样,我们也可以利用临时节点的创建来实现。
|
||||
|
||||
@ -329,9 +329,9 @@ tag:
|
||||
|
||||
### 命名服务
|
||||
|
||||
如何给一个对象设置ID,大家可能都会想到 `UUID`,但是 `UUID` 最大的问题就在于它太长了。。。(太长不一定是好事,嘿嘿嘿)。那么在条件允许的情况下,我们能不能使用 `zookeeper` 来实现呢?
|
||||
如何给一个对象设置 ID,大家可能都会想到 `UUID`,但是 `UUID` 最大的问题就在于它太长了。。。(太长不一定是好事,嘿嘿嘿)。那么在条件允许的情况下,我们能不能使用 `zookeeper` 来实现呢?
|
||||
|
||||
我们之前提到过 `zookeeper` 是通过 **树形结构** 来存储数据节点的,那也就是说,对于每个节点的 **全路径**,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的ID设置可以更加便于理解。
|
||||
我们之前提到过 `zookeeper` 是通过 **树形结构** 来存储数据节点的,那也就是说,对于每个节点的 **全路径**,它必定是唯一的,我们可以使用节点的全路径作为命名方式了。而且更重要的是,路径是我们可以自己定义的,这对于我们对有些有语意的对象的 ID 设置可以更加便于理解。
|
||||
|
||||
### 集群管理和注册中心
|
||||
|
||||
@ -343,7 +343,7 @@ tag:
|
||||
|
||||
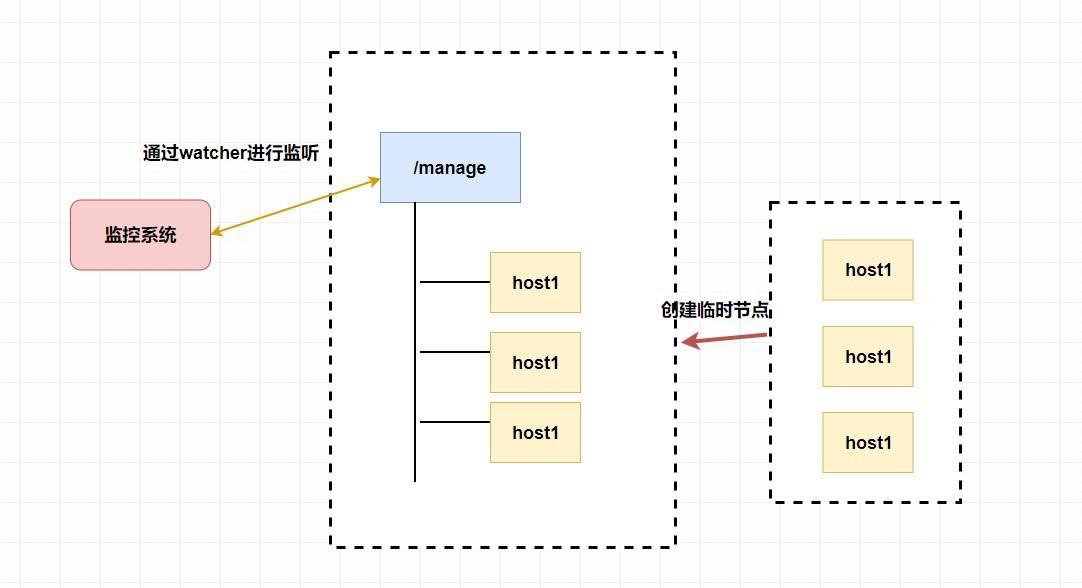
|
||||
|
||||
至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
|
||||
至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP 端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
|
||||
|
||||
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
|
||||
|
||||
@ -351,20 +351,20 @@ tag:
|
||||
|
||||
## 总结
|
||||
|
||||
看到这里的同学实在是太有耐心了👍👍👍不知道大家是否还记得我讲了什么😒。
|
||||
看到这里的同学实在是太有耐心了 👍👍👍 不知道大家是否还记得我讲了什么 😒。
|
||||
|
||||

|
||||
|
||||
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
|
||||
|
||||
* 分布式与集群的区别
|
||||
- 分布式与集群的区别
|
||||
|
||||
* `2PC` 、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
|
||||
- `2PC` 、`3PC` 以及 `paxos` 算法这些一致性框架的原理和实现。
|
||||
|
||||
* `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
|
||||
- `zookeeper` 专门的一致性算法 `ZAB` 原子广播协议的内容(`Leader` 选举、崩溃恢复、消息广播)。
|
||||
|
||||
* `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
|
||||
- `zookeeper` 中的一些基本概念,比如 `ACL`,数据节点,会话,`watcher`机制等等。
|
||||
|
||||
* `zookeeper` 的典型应用场景,比如选主,注册中心等等。
|
||||
- `zookeeper` 的典型应用场景,比如选主,注册中心等等。
|
||||
|
||||
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出🤝🤝🤝。
|
||||
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出 🤝🤝🤝。
|
||||
|
||||
@ -12,42 +12,4 @@ icon: "transanction"
|
||||
|
||||

|
||||
|
||||
最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
|
||||
|
||||
为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的知识星球。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面。
|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/image-20220311203414600.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiufuwu.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
|
||||
|
||||
这里再送一个 30 元的新人优惠券(续费半价)。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
进入星球之后,记得添加微信,我会发你详细的星球使用指南。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -167,4 +167,3 @@ raft 的要求之一就是安全性不依赖于时间:系统不能仅仅因为
|
||||
- https://github.com/OneSizeFitsQuorum/raft-thesis-zh_cn/blob/master/raft-thesis-zh_cn.md
|
||||
- https://github.com/ongardie/dissertation/blob/master/stanford.pdf
|
||||
- https://knowledge-sharing.gitbooks.io/raft/content/chapter5.html
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ tag:
|
||||
|
||||
这篇文章是我根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。欢迎补充!
|
||||
|
||||
## Dubbo基础
|
||||
## Dubbo 基础
|
||||
|
||||
### 什么是 Dubbo?
|
||||
|
||||
@ -19,7 +19,7 @@ tag:
|
||||
|
||||
根据 [Dubbo 官方文档](https://dubbo.apache.org/zh/)的介绍,Dubbo 提供了六大核心能力
|
||||
|
||||
1. 面向接口代理的高性能RPC调用。
|
||||
1. 面向接口代理的高性能 RPC 调用。
|
||||
2. 智能容错和负载均衡。
|
||||
3. 服务自动注册和发现。
|
||||
4. 高度可扩展能力。
|
||||
@ -32,7 +32,7 @@ tag:
|
||||
|
||||
Dubbo 目前已经有接近 34.4 k 的 Star 。
|
||||
|
||||
在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第7名。相比几年前来说,热度和排名有所下降。
|
||||
在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第 7 名。相比几年前来说,热度和排名有所下降。
|
||||
|
||||

|
||||
|
||||
@ -44,7 +44,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
||||
|
||||
分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
|
||||
|
||||
我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
|
||||
我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian 这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
|
||||
|
||||
不过,Dubbo 的出现让上述问题得到了解决。**Dubbo 帮助我们解决了什么问题呢?**
|
||||
|
||||
@ -112,7 +112,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
||||
|
||||
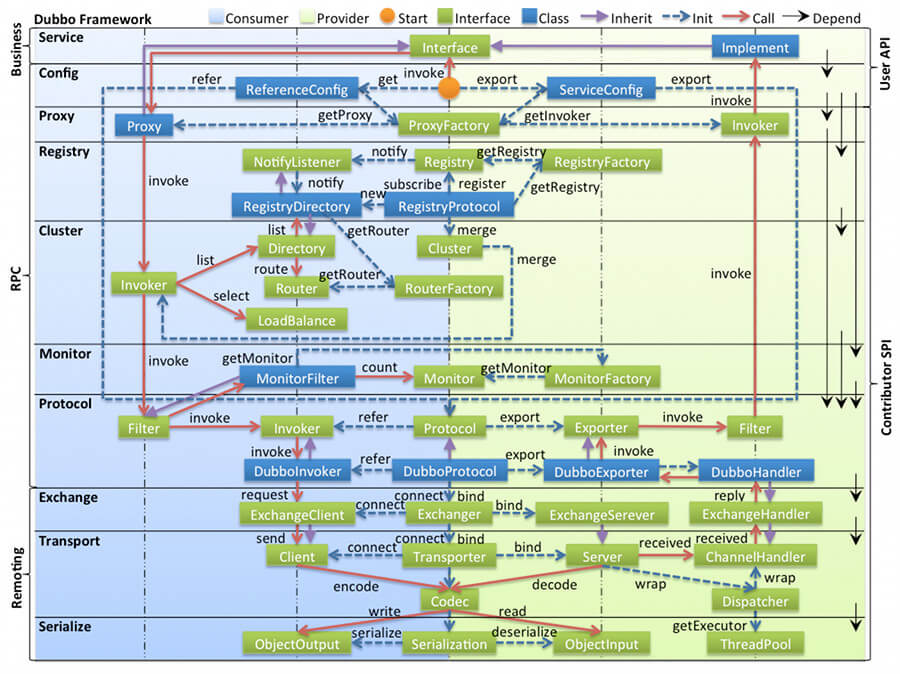
|
||||
|
||||
- **config 配置层**:Dubbo相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
|
||||
- **config 配置层**:Dubbo 相关的配置。支持代码配置,同时也支持基于 Spring 来做配置,以 `ServiceConfig`, `ReferenceConfig` 为中心
|
||||
- **proxy 服务代理层**:调用远程方法像调用本地的方法一样简单的一个关键,真实调用过程依赖代理类,以 `ServiceProxy` 为中心。
|
||||
- **registry 注册中心层**:封装服务地址的注册与发现。
|
||||
- **cluster 路由层**:封装多个提供者的路由及负载均衡,并桥接注册中心,以 `Invoker` 为中心。
|
||||
@ -128,7 +128,7 @@ SPI(Service Provider Interface) 机制被大量用在开源项目中,它
|
||||
|
||||
SPI 的具体原理是这样的:我们将接口的实现类放在配置文件中,我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
|
||||
|
||||
Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java原生的 SPI机制进行了增强,以便更好满足自己的需求。
|
||||
Java 本身就提供了 SPI 机制的实现。不过,Dubbo 没有直接用,而是对 Java 原生的 SPI 机制进行了增强,以便更好满足自己的需求。
|
||||
|
||||
**那我们如何扩展 Dubbo 中的默认实现呢?**
|
||||
|
||||
@ -186,13 +186,13 @@ Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来
|
||||
|
||||
核心系统提供系统所需核心能力,插件模块可以扩展系统的功能。因此, 基于微内核架构的系统,非常易于扩展功能。
|
||||
|
||||
我们常见的一些IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE比如IDEA、VSCode都提供了插件来丰富自己的功能。
|
||||
我们常见的一些 IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE 比如 IDEA、VSCode 都提供了插件来丰富自己的功能。
|
||||
|
||||
正是因为Dubbo基于微内核架构,才使得我们可以随心所欲替换Dubbo的功能点。比如你觉得Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
|
||||
正是因为 Dubbo 基于微内核架构,才使得我们可以随心所欲替换 Dubbo 的功能点。比如你觉得 Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
|
||||
|
||||
通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自己造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件 :**JDK 标准的 SPI 扩展机制** (`java.util.ServiceLoader`)。
|
||||
|
||||
### 关于Dubbo架构的一些自测小问题
|
||||
### 关于 Dubbo 架构的一些自测小问题
|
||||
|
||||
#### 注册中心的作用了解么?
|
||||
|
||||
@ -210,7 +210,6 @@ Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来
|
||||
|
||||
不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
|
||||
|
||||
|
||||
## Dubbo 的负载均衡策略
|
||||
|
||||
### 什么是负载均衡?
|
||||
@ -225,7 +224,7 @@ Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来
|
||||
|
||||
### Dubbo 提供的负载均衡策略有哪些?
|
||||
|
||||
在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 `random` 随机调用。我们还可以自行扩展负载均衡策略(参考Dubbo SPI机制)。
|
||||
在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 `random` 随机调用。我们还可以自行扩展负载均衡策略(参考 Dubbo SPI 机制)。
|
||||
|
||||
在 Dubbo 中,所有负载均衡实现类均继承自 `AbstractLoadBalance`,该类实现了 `LoadBalance` 接口,并封装了一些公共的逻辑。
|
||||
|
||||
@ -252,13 +251,13 @@ public abstract class AbstractLoadBalance implements LoadBalance {
|
||||
|
||||

|
||||
|
||||
官方文档对负载均衡这部分的介绍非常详细,推荐小伙伴们看看,地址:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance ) 。
|
||||
官方文档对负载均衡这部分的介绍非常详细,推荐小伙伴们看看,地址:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#m-zhdocsv27devsourceloadbalance) 。
|
||||
|
||||
#### RandomLoadBalance
|
||||
|
||||
根据权重随机选择(对加权随机算法的实现)。这是Dubbo默认采用的一种负载均衡策略。
|
||||
根据权重随机选择(对加权随机算法的实现)。这是 Dubbo 默认采用的一种负载均衡策略。
|
||||
|
||||
` RandomLoadBalance` 具体的实现原理非常简单,假如有两个提供相同服务的服务器 S1,S2,S1的权重为7,S2的权重为3。
|
||||
` RandomLoadBalance` 具体的实现原理非常简单,假如有两个提供相同服务的服务器 S1,S2,S1 的权重为 7,S2 的权重为 3。
|
||||
|
||||
我们把这些权重值分布在坐标区间会得到:S1->[0, 7) ,S2->[7, 10)。我们生成[0, 10) 之间的随机数,随机数落到对应的区间,我们就选择对应的服务器来处理请求。
|
||||
|
||||
@ -405,37 +404,35 @@ public class RpcStatus {
|
||||
|
||||
`ConsistentHashLoadBalance` 小伙伴们应该也不会陌生,在分库分表、各种集群中就经常使用这个负载均衡策略。
|
||||
|
||||
`ConsistentHashLoadBalance` 即**一致性Hash负载均衡策略**。 `ConsistentHashLoadBalance` 中没有权重的概念,具体是哪个服务提供者处理请求是由你的请求的参数决定的,也就是说相同参数的请求总是发到同一个服务提供者。
|
||||
`ConsistentHashLoadBalance` 即**一致性 Hash 负载均衡策略**。 `ConsistentHashLoadBalance` 中没有权重的概念,具体是哪个服务提供者处理请求是由你的请求的参数决定的,也就是说相同参数的请求总是发到同一个服务提供者。
|
||||
|
||||
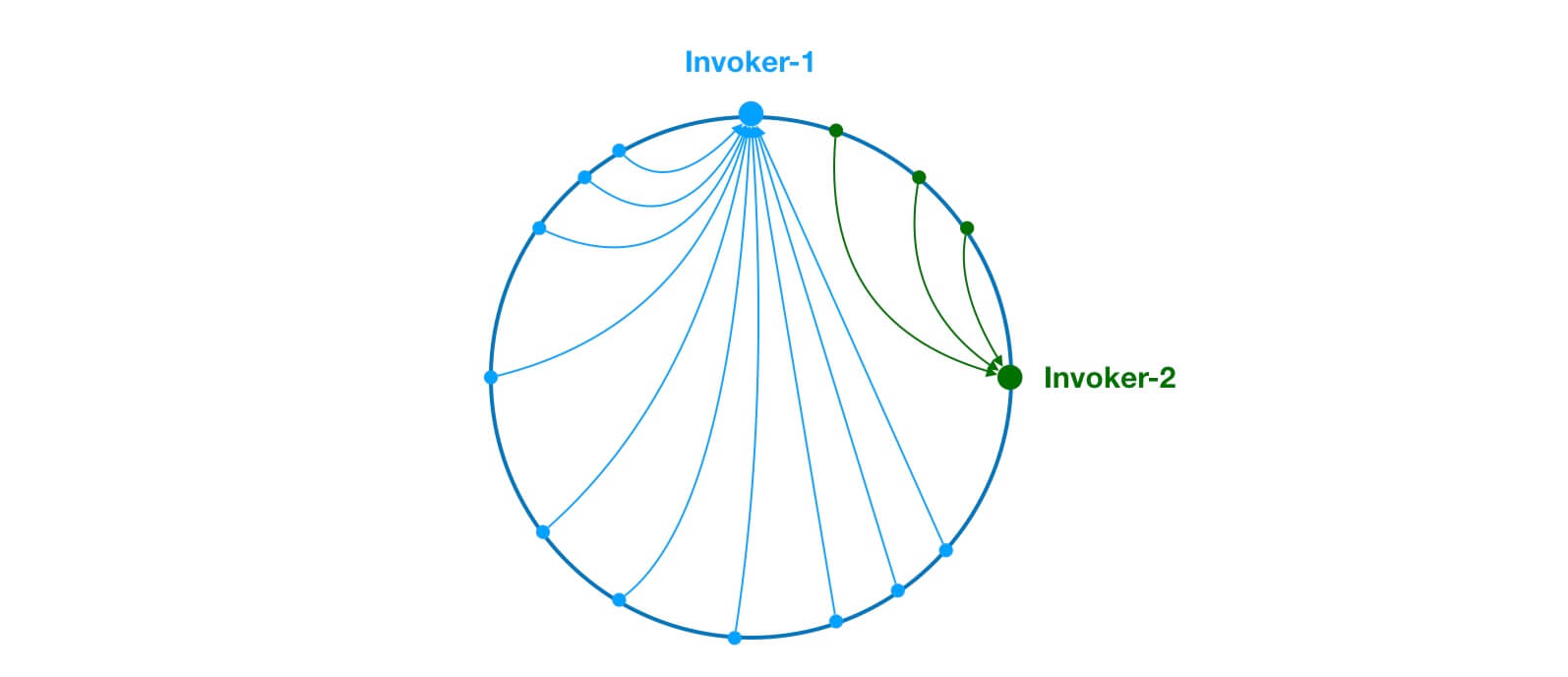
|
||||
|
||||
另外,Dubbo 为了避免数据倾斜问题(节点不够分散,大量请求落到同一节点),还引入了虚拟节点的概念。通过虚拟节点可以让节点更加分散,有效均衡各个节点的请求量。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
官方有详细的源码分析:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance) 。这里还有一个相关的 [PR#5440](https://github.com/apache/dubbo/pull/5440) 来修复老版本中 ConsistentHashLoadBalance 存在的一些Bug。感兴趣的小伙伴,可以多花点时间研究一下。我这里不多分析了,这个作业留给你们!
|
||||
官方有详细的源码分析:[https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance](https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/#23-consistenthashloadbalance) 。这里还有一个相关的 [PR#5440](https://github.com/apache/dubbo/pull/5440) 来修复老版本中 ConsistentHashLoadBalance 存在的一些 Bug。感兴趣的小伙伴,可以多花点时间研究一下。我这里不多分析了,这个作业留给你们!
|
||||
|
||||
#### RoundRobinLoadBalance
|
||||
|
||||
加权轮询负载均衡。
|
||||
|
||||
轮询就是把请求依次分配给每个服务提供者。加权轮询就是在轮询的基础上,让更多的请求落到权重更大的服务提供者上。比如假如有两个提供相同服务的服务器 S1,S2,S1的权重为7,S2的权重为3。
|
||||
轮询就是把请求依次分配给每个服务提供者。加权轮询就是在轮询的基础上,让更多的请求落到权重更大的服务提供者上。比如假如有两个提供相同服务的服务器 S1,S2,S1 的权重为 7,S2 的权重为 3。
|
||||
|
||||
如果我们有 10 次请求,那么 7 次会被 S1处理,3次被 S2处理。
|
||||
如果我们有 10 次请求,那么 7 次会被 S1 处理,3 次被 S2 处理。
|
||||
|
||||
但是,如果是 `RandomLoadBalance` 的话,很可能存在10次请求有9次都被 S1 处理的情况(概率性问题)。
|
||||
但是,如果是 `RandomLoadBalance` 的话,很可能存在 10 次请求有 9 次都被 S1 处理的情况(概率性问题)。
|
||||
|
||||
Dubbo 中的 `RoundRobinLoadBalance` 的代码实现被修改重建了好几次,Dubbo-2.6.5 版本的 `RoundRobinLoadBalance` 为平滑加权轮询算法。
|
||||
|
||||
## Dubbo序列化协议
|
||||
## Dubbo 序列化协议
|
||||
|
||||
### Dubbo 支持哪些序列化方式呢?
|
||||
|
||||
|
||||
|
||||
Dubbo 支持多种序列化方式:JDK自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf等等。
|
||||
Dubbo 支持多种序列化方式:JDK 自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf 等等。
|
||||
|
||||
Dubbo 默认使用的序列化方式是 hessian2。
|
||||
|
||||
@ -448,13 +445,12 @@ Dubbo 默认使用的序列化方式是 hessian2。
|
||||
|
||||
JSON 序列化由于性能问题,我们一般也不会考虑使用。
|
||||
|
||||
像 Protostuff,ProtoBuf、hessian2这些都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
|
||||
像 Protostuff,ProtoBuf、hessian2 这些都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
|
||||
|
||||
Kryo和FST这两种序列化方式是 Dubbo 后来才引入的,性能非常好。不过,这两者都是专门针对 Java 语言的。Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。(文章地址:[https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/](https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/))
|
||||
Kryo 和 FST 这两种序列化方式是 Dubbo 后来才引入的,性能非常好。不过,这两者都是专门针对 Java 语言的。Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。(文章地址:[https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/](https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/))
|
||||
|
||||

|
||||
|
||||
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ tag:
|
||||
- rpc
|
||||
---
|
||||
|
||||
> 本文来自[小白debug](https://juejin.cn/user/4001878057422087)投稿,原文:https://juejin.cn/post/7121882245605883934 。
|
||||
> 本文来自[小白 debug](https://juejin.cn/user/4001878057422087)投稿,原文:https://juejin.cn/post/7121882245605883934 。
|
||||
|
||||
我想起了我刚工作的时候,第一次接触 RPC 协议,当时就很懵,我 HTTP 协议用的好好的,为什么还要用 RPC 协议?
|
||||
|
||||
|
||||
@ -11,39 +11,35 @@ tag:
|
||||
|
||||
**RPC(Remote Procedure Call)** 即远程过程调用,通过名字我们就能看出 RPC 关注的是远程调用而非本地调用。
|
||||
|
||||
**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP还是UDP)、序列化方式等等方面。
|
||||
|
||||
**为什么要 RPC ?** 因为,两个不同的服务器上的服务提供的方法不在一个内存空间,所以,需要通过网络编程才能传递方法调用所需要的参数。并且,方法调用的结果也需要通过网络编程来接收。但是,如果我们自己手动网络编程来实现这个调用过程的话工作量是非常大的,因为,我们需要考虑底层传输方式(TCP 还是 UDP)、序列化方式等等方面。
|
||||
|
||||
**RPC 能帮助我们做什么呢?** 简单来说,通过 RPC 可以帮助我们调用远程计算机上某个服务的方法,这个过程就像调用本地方法一样简单。并且!我们不需要了解底层网络编程的具体细节。
|
||||
|
||||
|
||||
举个例子:两个不同的服务 A、B 部署在两台不同的机器上,服务 A 如果想要调用服务 B 中的某个方法的话就可以通过 RPC 来做。
|
||||
|
||||
一言蔽之:**RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。**
|
||||
|
||||
## RPC 的原理是什么?
|
||||
|
||||
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC的 核心功能看作是下面👇 5 个部分实现的:
|
||||
|
||||
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 5 个部分实现的:
|
||||
|
||||
1. **客户端(服务消费端)** :调用远程方法的一端。
|
||||
1. **客户端 Stub(桩)** : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
|
||||
1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket或者性能以及封装更加优秀的 Netty(推荐)。
|
||||
1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
|
||||
1. **服务端 Stub(桩)** :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
|
||||
1. **服务端(服务提供端)** :提供远程方法的一端。
|
||||
|
||||
具体原理图如下,后面我会串起来将整个RPC的过程给大家说一下。
|
||||
|
||||
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
|
||||
|
||||
|
||||
|
||||
1. 服务消费端(client)以本地调用的方式调用远程服务;
|
||||
1. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
|
||||
1. 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
|
||||
1. 服务端 Stub(桩)收到消息将消息反序列化为Java对象: `RpcRequest`;
|
||||
1. 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象: `RpcRequest`;
|
||||
1. 服务端 Stub(桩)根据`RpcRequest`中的类、方法、方法参数等信息调用本地的方法;
|
||||
1. 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:`RpcResponse`(序列化)发送至消费方;
|
||||
1. 客户端 Stub(client stub)接收到消息并将消息反序列化为Java对象:`RpcResponse` ,这样也就得到了最终结果。over!
|
||||
1. 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象:`RpcResponse` ,这样也就得到了最终结果。over!
|
||||
|
||||
相信小伙伴们看完上面的讲解之后,已经了解了 RPC 的原理。
|
||||
|
||||
@ -53,7 +49,7 @@ tag:
|
||||
|
||||
## 有哪些常见的 RPC 框架?
|
||||
|
||||
我们这里说的 RPC 框架指的是可以让客户端直接调用服务端方法,就像调用本地方法一样简单的框架,比如我下面介绍的 Dubbo、Motan、gRPC这些。 如果需要和 HTTP 协议打交道,解析和封装 HTTP 请求和响应。这类框架并不能算是“RPC 框架”,比如Feign。
|
||||
我们这里说的 RPC 框架指的是可以让客户端直接调用服务端方法,就像调用本地方法一样简单的框架,比如我下面介绍的 Dubbo、Motan、gRPC 这些。 如果需要和 HTTP 协议打交道,解析和封装 HTTP 请求和响应。这类框架并不能算是“RPC 框架”,比如 Feign。
|
||||
|
||||
### Dubbo
|
||||
|
||||
@ -114,7 +110,7 @@ Apache Thrift 是 Facebook 开源的跨语言的 RPC 通信框架,目前已经
|
||||
|
||||
gRPC 和 Thrift 虽然支持跨语言的 RPC 调用,但是它们只提供了最基本的 RPC 框架功能,缺乏一系列配套的服务化组件和服务治理功能的支撑。
|
||||
|
||||
Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说都是最优秀的。而且,Dubbo在国内有很多成功的案例比如当当网、滴滴等等,是一款经得起生产考验的成熟稳定的 RPC 框架。最重要的是你还能找到非常多的 Dubbo 参考资料,学习成本相对也较低。
|
||||
Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说都是最优秀的。而且,Dubbo 在国内有很多成功的案例比如当当网、滴滴等等,是一款经得起生产考验的成熟稳定的 RPC 框架。最重要的是你还能找到非常多的 Dubbo 参考资料,学习成本相对也较低。
|
||||
|
||||
下图展示了 Dubbo 的生态系统。
|
||||
|
||||
@ -141,4 +137,3 @@ Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
|
||||
## 既然有了 HTTP 协议,为什么还要有 RPC ?
|
||||
|
||||
[HTTP 和 RPC 详细对比](http&rpc.md) 。
|
||||
|
||||
|
||||
@ -9,45 +9,4 @@ category: 高可用
|
||||
|
||||

|
||||
|
||||
最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
|
||||
|
||||
为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的知识星球。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面。
|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/image-20220311203414600.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiufuwu.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
|
||||
|
||||
这里再送一个 30 元的新人优惠券(续费半价)。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
|
||||
进入星球之后,记得添加微信,我会发你详细的星球使用指南。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -63,7 +63,7 @@ category: 高可用
|
||||
|
||||
**响应时间就是用户发出请求到用户收到系统处理结果所需要的时间。** 重要吗?实在太重要!
|
||||
|
||||
比较出名的 2-5-8 原则是这样描述的:通常来说,2到5秒,页面体验会比较好,5到8秒还可以接受,8秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
|
||||
比较出名的 2-5-8 原则是这样描述的:通常来说,2 到 5 秒,页面体验会比较好,5 到 8 秒还可以接受,8 秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
|
||||
|
||||
但是,在某些场景下我们也并不需要太看重 2-5-8 原则 ,比如我觉得系统导出导入大数据量这种就不需要,系统生成系统报告这种也不需要。
|
||||
|
||||
@ -85,15 +85,15 @@ category: 高可用
|
||||
理清他们的概念,就很容易搞清楚他们之间的关系了。
|
||||
|
||||
- **QPS(TPS)** = 并发数/平均响应时间
|
||||
- **并发数** = QPS*平均响应时间
|
||||
- **并发数** = QPS\*平均响应时间
|
||||
|
||||
书中是这样描述 QPS 和 TPS 的区别的。
|
||||
|
||||
> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器2次,一次访问,产生一个“T”,产生2个“Q”。
|
||||
> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
|
||||
|
||||
### 3.4 性能计数器
|
||||
|
||||
**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU使用、磁盘与网络I/O等情况。**
|
||||
**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU 使用、磁盘与网络 I/O 等情况。**
|
||||
|
||||
### 四 几种常见的性能测试
|
||||
|
||||
@ -127,13 +127,13 @@ category: 高可用
|
||||
|
||||
1. Jmeter :Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
2. LoadRunner:一款商业的性能测试工具。
|
||||
3. Galtling :一款基于Scala 开发的高性能服务器性能测试工具。
|
||||
3. Galtling :一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. ab :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
|
||||
### 5.2 前端常用
|
||||
|
||||
1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是Web 调试的利器。
|
||||
2. HttpWatch: 可用于录制HTTP请求信息的工具。
|
||||
1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
|
||||
2. HttpWatch: 可用于录制 HTTP 请求信息的工具。
|
||||
|
||||
## 六 常见的性能优化策略
|
||||
|
||||
|
||||
@ -38,7 +38,7 @@ category: 高可用
|
||||
|
||||
没有银弹!超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
|
||||
|
||||
更上一层,参考[美团的Java线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
|
||||
更上一层,参考[美团的 Java 线程池参数动态配置](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)思想,我们也可以将超时弄成可配置化的参数而不是固定的,比较简单的一种办法就是将超时的值放在配置中心中。这样的话,我们就可以根据系统或者服务的状态动态调整超时值了。
|
||||
|
||||
## 重试机制
|
||||
|
||||
@ -66,6 +66,5 @@ category: 高可用
|
||||
|
||||
## 参考
|
||||
|
||||
- 微服务之间调用超时的设置治理:https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx
|
||||
- 超时、重试和抖动回退:https://aws.amazon.com/cn/builders-library/timeouts-retries-and-backoff-with-jitter/
|
||||
|
||||
- 微服务之间调用超时的设置治理:<https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx>
|
||||
- 超时、重试和抖动回退:<https://aws.amazon.com/cn/builders-library/timeouts-retries-and-backoff-with-jitter/>
|
||||
|
||||
@ -63,7 +63,7 @@ head:
|
||||
|
||||
### 如何找到最合适的 CDN 节点?
|
||||
|
||||
GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个CDN节点之间相互协作,最常用的是基于 DNS 的 GSLB。
|
||||
GSLB (Global Server Load Balance,全局负载均衡)是 CDN 的大脑,负责多个 CDN 节点之间相互协作,最常用的是基于 DNS 的 GSLB。
|
||||
|
||||
CDN 会通过 GSLB 找到最合适的 CDN 节点,更具体点来说是下面这样的:
|
||||
|
||||
@ -94,7 +94,7 @@ CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
|
||||
|
||||
时间戳防盗链的 URL 通常会有两个参数一个是签名字符串,一个是过期时间。签名字符串一般是通过对用户设定的加密字符串、请求路径、过期时间通过 MD5 哈希算法取哈希的方式获得。
|
||||
|
||||
时间戳防盗链 URL示例:
|
||||
时间戳防盗链 URL 示例:
|
||||
|
||||
```
|
||||
http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
|
||||
@ -120,9 +120,6 @@ http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTim
|
||||
|
||||
## 参考
|
||||
|
||||
- 时间戳防盗链 - 七牛云 CDN:https://developer.qiniu.com/fusion/kb/1670/timestamp-hotlinking-prevention
|
||||
- CDN是个啥玩意?一文说个明白:https://mp.weixin.qq.com/s/Pp0C8ALUXsmYCUkM5QnkQw
|
||||
- 《透视 HTTP 协议》- 37 | CDN:加速我们的网络服务:http://gk.link/a/11yOG
|
||||
|
||||
|
||||
|
||||
- 时间戳防盗链 - 七牛云 CDN:<https://developer.qiniu.com/fusion/kb/1670/timestamp-hotlinking-prevention>
|
||||
- CDN 是个啥玩意?一文说个明白:<https://mp.weixin.qq.com/s/Pp0C8ALUXsmYCUkM5QnkQw>
|
||||
- 《透视 HTTP 协议》- 37 | CDN:加速我们的网络服务:<http://gk.link/a/11yOG>
|
||||
|
||||
@ -211,7 +211,7 @@ public class CustomLoadBalancerConfiguration {
|
||||
}
|
||||
```
|
||||
|
||||
关于Spring Cloud Load Balancer更详细更新的介绍,推荐大家看看官方文档:https://docs.spring.io/spring-cloud-commons/docs/current/reference/html/#spring-cloud-loadbalancer ,一切以官方文档为主。
|
||||
关于 Spring Cloud Load Balancer 更详细更新的介绍,推荐大家看看官方文档:<https://docs.spring.io/spring-cloud-commons/docs/current/reference/html/#spring-cloud-loadbalancer> ,一切以官方文档为主。
|
||||
|
||||
轮询策略基本可以满足绝大部分项目的需求,我们的实际项目中如果没有特殊需求的话,通常使用的就是默认的轮询策略。并且,Ribbon 和 Spring Cloud Load Balancer 都支持自定义负载均衡策略。
|
||||
|
||||
@ -231,6 +231,6 @@ Spring Cloud 2020.0.0 版本移除了 Netflix 除 Eureka 外的所有组件。Sp
|
||||
|
||||
## 参考
|
||||
|
||||
- 干货 | eBay 的 4 层软件负载均衡实现:https://mp.weixin.qq.com/s/bZMxLTECOK3mjdgiLbHj-g
|
||||
- HTTP Load Balancing(Nginx 官方文档):https://docs.nginx.com/nginx/admin-guide/load-balancer/http-load-balancer/
|
||||
- 深入浅出负载均衡 - vivo 互联网技术:https://www.cnblogs.com/vivotech/p/14859041.html
|
||||
- 干货 | eBay 的 4 层软件负载均衡实现:<https://mp.weixin.qq.com/s/bZMxLTECOK3mjdgiLbHj-g>
|
||||
- HTTP Load Balancing(Nginx 官方文档):<https://docs.nginx.com/nginx/admin-guide/load-balancer/http-load-balancer/>
|
||||
- 深入浅出负载均衡 - vivo 互联网技术:<https://www.cnblogs.com/vivotech/p/14859041.html>
|
||||
|
||||
@ -20,7 +20,7 @@ Kafka 主要有两大应用场景:
|
||||
1. **消息队列** :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
|
||||
2. **数据处理:** 构建实时的流数据处理程序来转换或处理数据流。
|
||||
|
||||
### 和其他消息队列相比,Kafka的优势在哪里?
|
||||
### 和其他消息队列相比,Kafka 的优势在哪里?
|
||||
|
||||
我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它跟 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
|
||||
|
||||
@ -61,7 +61,7 @@ Kafka 主要有两大应用场景:
|
||||
|
||||
> **RocketMQ 的消息模型和 Kafka 基本是完全一样的。唯一的区别是 Kafka 中没有队列这个概念,与之对应的是 Partition(分区)。**
|
||||
|
||||
### 什么是Producer、Consumer、Broker、Topic、Partition?
|
||||
### 什么是 Producer、Consumer、Broker、Topic、Partition?
|
||||
|
||||
Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这些消息的消费者可以订阅这些 **Topic(主题)**,如下图所示:
|
||||
|
||||
@ -95,8 +95,6 @@ Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这
|
||||
|
||||
> **要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。** 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
|
||||
|
||||
|
||||
|
||||
下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/zookeeper-kafka.jpg" style="zoom:50%;" />
|
||||
@ -146,7 +144,7 @@ Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data
|
||||
|
||||
所以,我们不能默认在调用`send`方法发送消息之后消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 `send` 方法发送消息实际上是异步的操作,我们可以通过 `get()`方法获取调用结果,但是这样也让它变为了同步操作,示例代码如下:
|
||||
|
||||
> **详细代码见我的这篇文章:[Kafka系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
|
||||
> **详细代码见我的这篇文章:[Kafka 系列第三篇!10 分钟学会如何在 Spring Boot 程序中使用 Kafka 作为消息队列?](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486269&idx=2&sn=ec00417ad641dd8c3d145d74cafa09ce&chksm=cea244f6f9d5cde0c8eb233fcc4cf82e11acd06446719a7af55230649863a3ddd95f78d111de&token=1633957262&lang=zh_CN#rd)**
|
||||
|
||||
```java
|
||||
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
|
||||
@ -158,15 +156,15 @@ if (sendResult.getRecordMetadata() != null) {
|
||||
|
||||
但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
|
||||
|
||||
````java
|
||||
```java
|
||||
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
|
||||
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
|
||||
ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
|
||||
````
|
||||
```
|
||||
|
||||
如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
|
||||
|
||||
**另外这里推荐为 Producer 的`retries `(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了**
|
||||
**另外这里推荐为 Producer 的`retries `(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你 3 次一下子就重试完了**
|
||||
|
||||
#### 消费者丢失消息的情况
|
||||
|
||||
@ -180,7 +178,7 @@ if (sendResult.getRecordMetadata() != null) {
|
||||
|
||||
#### Kafka 弄丢了消息
|
||||
|
||||
我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
|
||||
我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
|
||||
|
||||
**试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。**
|
||||
|
||||
@ -188,7 +186,7 @@ if (sendResult.getRecordMetadata() != null) {
|
||||
|
||||
解决办法就是我们设置 **acks = all**。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
|
||||
|
||||
acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。当我们配置 **acks = all** 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个 Broker 接收到了消息. 该模式的延迟会很高.
|
||||
acks 的默认值即为 1,代表我们的消息被 leader 副本接收之后就算被成功发送。当我们配置 **acks = all** 表示只有所有 ISR 列表的副本全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个 Broker 接收到了消息. 该模式的延迟会很高.
|
||||
|
||||
**设置 replication.factor >= 3**
|
||||
|
||||
@ -202,25 +200,25 @@ acks 的默认值即为1,代表我们的消息被leader副本接收之后就
|
||||
|
||||
**设置 unclean.leader.election.enable = false**
|
||||
|
||||
> **Kafka 0.11.0.0版本开始 unclean.leader.election.enable 参数的默认值由原来的true 改为false**
|
||||
> **Kafka 0.11.0.0 版本开始 unclean.leader.election.enable 参数的默认值由原来的 true 改为 false**
|
||||
|
||||
我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 **unclean.leader.election.enable = false** 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
|
||||
|
||||
### Kafka 如何保证消息不重复消费
|
||||
|
||||
**kafka出现消息重复消费的原因:**
|
||||
**kafka 出现消息重复消费的原因:**
|
||||
|
||||
- 服务端侧已经消费的数据没有成功提交 offset(根本原因)。
|
||||
- Kafka 侧 由于服务端处理业务时间长或者网络链接等等原因让 Kafka 认为服务假死,触发了分区 rebalance。
|
||||
|
||||
**解决方案:**
|
||||
|
||||
- 消费消息服务做幂等校验,比如 Redis 的set、MySQL 的主键等天然的幂等功能。这种方法最有效。
|
||||
- 将 **`enable.auto.commit`** 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:**什么时候提交offset合适?**
|
||||
* 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
|
||||
* 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
|
||||
- 消费消息服务做幂等校验,比如 Redis 的 set、MySQL 的主键等天然的幂等功能。这种方法最有效。
|
||||
- 将 **`enable.auto.commit`** 参数设置为 false,关闭自动提交,开发者在代码中手动提交 offset。那么这里会有个问题:**什么时候提交 offset 合适?**
|
||||
- 处理完消息再提交:依旧有消息重复消费的风险,和自动提交一样
|
||||
- 拉取到消息即提交:会有消息丢失的风险。允许消息延时的场景,一般会采用这种方式。然后,通过定时任务在业务不繁忙(比如凌晨)的时候做数据兜底。
|
||||
|
||||
### Reference
|
||||
|
||||
- Kafka 官方文档: https://kafka.apache.org/documentation/
|
||||
- 极客时间—《Kafka核心技术与实战》第11节:无消息丢失配置怎么实现?
|
||||
- 极客时间—《Kafka 核心技术与实战》第 11 节:无消息丢失配置怎么实现?
|
||||
|
||||
@ -130,7 +130,7 @@ AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的
|
||||
### JMS vs AMQP
|
||||
|
||||
| 对比方向 | JMS | AMQP |
|
||||
| :----------: | :-------------------------------------- | :----------------------------------------------------------- |
|
||||
| :----------: | :-------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 定义 | Java API | 协议 |
|
||||
| 跨语言 | 否 | 是 |
|
||||
| 跨平台 | 否 | 是 |
|
||||
@ -260,7 +260,7 @@ Pulsar 更新记录(可以直观看到项目是否还在维护):https://gi
|
||||
> 参考《Java 工程师面试突击第 1 季-中华石杉老师》
|
||||
|
||||
| 对比方向 | 概要 |
|
||||
| -------- | ------------------------------------------------------------ |
|
||||
| -------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 吞吐量 | 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。 |
|
||||
| 可用性 | 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 Kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
|
||||
| 时效性 | RabbitMQ 基于 Erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级,其他几个都是 ms 级。 |
|
||||
|
||||
@ -8,7 +8,7 @@ tag:
|
||||
|
||||
## 一 RabbitMQ 介绍
|
||||
|
||||
这部分参考了 《RabbitMQ实战指南》这本书的第 1 章和第 2 章。
|
||||
这部分参考了 《RabbitMQ 实战指南》这本书的第 1 章和第 2 章。
|
||||
|
||||
### 1.1 RabbitMQ 简介
|
||||
|
||||
@ -16,20 +16,20 @@ RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,
|
||||
|
||||
RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性、扩展性、可靠性和高可用性等方面的卓著表现是分不开的。RabbitMQ 的具体特点可以概括为以下几点:
|
||||
|
||||
- **可靠性:** RabbitMQ使用一些机制来保证消息的可靠性,如持久化、传输确认及发布确认等。
|
||||
- **可靠性:** RabbitMQ 使用一些机制来保证消息的可靠性,如持久化、传输确认及发布确认等。
|
||||
- **灵活的路由:** 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能,RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器。这个后面会在我们讲 RabbitMQ 核心概念的时候详细介绍到。
|
||||
- **扩展性:** 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中节点。
|
||||
- **扩展性:** 多个 RabbitMQ 节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中节点。
|
||||
- **高可用性:** 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队列仍然可用。
|
||||
- **支持多种协议:** RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP、MQTT 等多种消息中间件协议。
|
||||
- **多语言客户端:** RabbitMQ几乎支持所有常用语言,比如 Java、Python、Ruby、PHP、C#、JavaScript等。
|
||||
- **易用的管理界面:** RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
|
||||
- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI机制。
|
||||
- **多语言客户端:** RabbitMQ 几乎支持所有常用语言,比如 Java、Python、Ruby、PHP、C#、JavaScript 等。
|
||||
- **易用的管理界面:** RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
|
||||
- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI 机制。
|
||||
|
||||
### 1.2 RabbitMQ 核心概念
|
||||
|
||||
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
|
||||
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ 就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
|
||||
|
||||
下面再来看看图1—— RabbitMQ 的整体模型架构。
|
||||
下面再来看看图 1—— RabbitMQ 的整体模型架构。
|
||||
|
||||
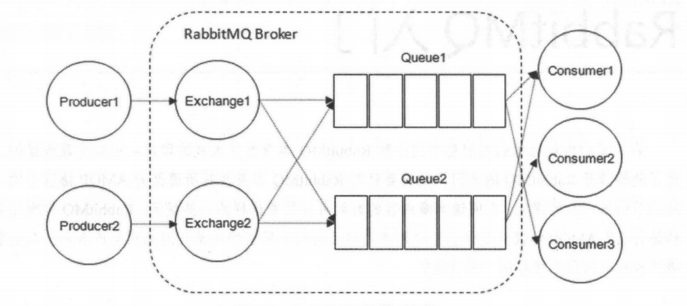
|
||||
|
||||
@ -46,9 +46,9 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
|
||||
|
||||
在 RabbitMQ 中,消息并不是直接被投递到 **Queue(消息队列)** 中的,中间还必须经过 **Exchange(交换器)** 这一层,**Exchange(交换器)** 会把我们的消息分配到对应的 **Queue(消息队列)** 中。
|
||||
|
||||
**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将RabbitMQ中的交换器看作一个简单的实体。
|
||||
**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将 RabbitMQ 中的交换器看作一个简单的实体。
|
||||
|
||||
**RabbitMQ 的 Exchange(交换器) 有4种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的Exchange转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
|
||||
**RabbitMQ 的 Exchange(交换器) 有 4 种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的 Exchange 转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
|
||||
|
||||
Exchange(交换器) 示意图如下:
|
||||
|
||||
@ -62,13 +62,13 @@ Binding(绑定) 示意图:
|
||||
|
||||
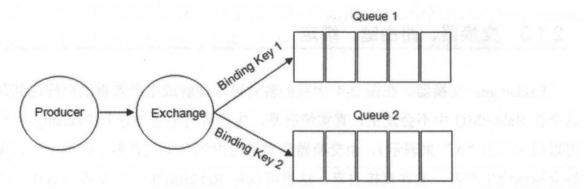
|
||||
|
||||
生产者将消息发送给交换器时,需要一个RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
|
||||
生产者将消息发送给交换器时,需要一个 RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如 fanout 类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
|
||||
|
||||
#### 1.2.3 Queue(消息队列)
|
||||
|
||||
**Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
|
||||
|
||||
**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是topic实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
|
||||
**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是 topic 实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
|
||||
|
||||
**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
|
||||
|
||||
@ -76,35 +76,35 @@ Binding(绑定) 示意图:
|
||||
|
||||
#### 1.2.4 Broker(消息中间件的服务节点)
|
||||
|
||||
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者RabbitMQ服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
|
||||
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者 RabbitMQ 服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
|
||||
|
||||
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。
|
||||
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从 Broker 中消费数据的整个流程。
|
||||
|
||||
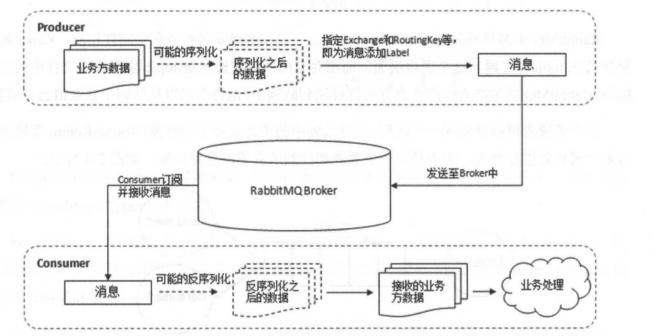
|
||||
|
||||
这样图1中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
|
||||
这样图 1 中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
|
||||
|
||||
#### 1.2.5 Exchange Types(交换器类型)
|
||||
|
||||
RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
|
||||
RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP 规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
|
||||
|
||||
##### ① fanout
|
||||
|
||||
fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
|
||||
fanout 类型的 Exchange 路由规则非常简单,它会把所有发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
|
||||
|
||||
##### ② direct
|
||||
|
||||
direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
|
||||
direct 类型的 Exchange 路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
|
||||
|
||||
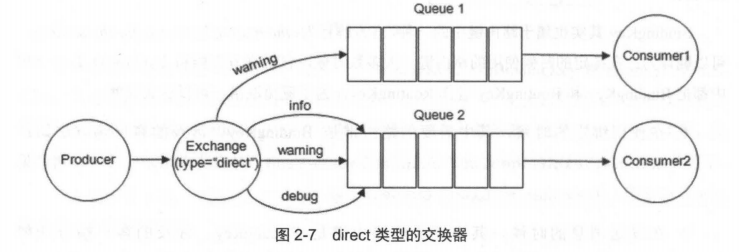
|
||||
|
||||
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
|
||||
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到 Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
|
||||
|
||||
direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
|
||||
|
||||
##### ③ topic
|
||||
|
||||
前面讲到direct类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
|
||||
前面讲到 direct 类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic 类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
|
||||
|
||||
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
|
||||
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
|
||||
@ -122,13 +122,13 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
|
||||
|
||||
##### ④ headers(不推荐)
|
||||
|
||||
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
|
||||
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时指定一组键值对,当发送消息到交换器时,RabbitMQ 会获取到该消息的 headers(也是一个键值对的形式),对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
|
||||
|
||||
## 二 安装 RabbitMQ
|
||||
|
||||
通过 Docker 安装非常方便,只需要几条命令就好了,我这里是只说一下常规安装方法。
|
||||
|
||||
前面提到了 RabbitMQ 是由 Erlang语言编写的,也正因如此,在安装RabbitMQ 之前需要安装 Erlang。
|
||||
前面提到了 RabbitMQ 是由 Erlang 语言编写的,也正因如此,在安装 RabbitMQ 之前需要安装 Erlang。
|
||||
|
||||
注意:在安装 RabbitMQ 的时候需要注意 RabbitMQ 和 Erlang 的版本关系,如果不注意的话会导致出错,两者对应关系如下:
|
||||
|
||||
@ -146,7 +146,7 @@ headers 类型的交换器不依赖于路由键的匹配规则来路由消息,
|
||||
|
||||
erlang 官网下载:[https://www.erlang.org/downloads](https://www.erlang.org/downloads)
|
||||
|
||||
**2 解压 erlang 安装包**
|
||||
**2 解压 erlang 安装包**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]#tar -xvzf otp_src_19.3.tar.gz
|
||||
@ -164,7 +164,7 @@ erlang 官网下载:[https://www.erlang.org/downloads](https://www.erlang.org/
|
||||
[root@SnailClimb local]#yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
|
||||
```
|
||||
|
||||
**5 进入erlang 安装包解压文件对 erlang 进行安装环境的配置**
|
||||
**5 进入 erlang 安装包解压文件对 erlang 进行安装环境的配置**
|
||||
|
||||
新建一个文件夹
|
||||
|
||||
@ -191,11 +191,13 @@ make && make install
|
||||
```shell
|
||||
[root@SnailClimb otp_src_19.3]# ./bin/erl
|
||||
```
|
||||
|
||||
运行下面的语句输出“hello world”
|
||||
|
||||
```erlang
|
||||
io:format("hello world~n", []).
|
||||
```
|
||||
|
||||

|
||||
|
||||
大功告成,我们的 erlang 已经安装完成。
|
||||
@ -231,25 +233,28 @@ export ERL_HOME PATH
|
||||
|
||||
### 2.2 安装 RabbitMQ
|
||||
|
||||
**1. 下载rpm**
|
||||
**1. 下载 rpm**
|
||||
|
||||
```shell
|
||||
wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
||||
```
|
||||
|
||||
或者直接在官网下载
|
||||
|
||||
[https://www.rabbitmq.com/install-rpm.html](https://www.rabbitmq.com/install-rpm.html)
|
||||
|
||||
**2. 安装rpm**
|
||||
**2. 安装 rpm**
|
||||
|
||||
```shell
|
||||
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
|
||||
```
|
||||
|
||||
紧接着执行:
|
||||
|
||||
```shell
|
||||
yum install rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
||||
```
|
||||
|
||||
中途需要你输入"y"才能继续安装。
|
||||
|
||||
**3 开启 web 管理插件**
|
||||
@ -278,9 +283,9 @@ service rabbitmq-server status
|
||||
|
||||
**7. 访问 RabbitMQ 控制台**
|
||||
|
||||
浏览器访问:http://你的ip地址:15672/
|
||||
浏览器访问:http://你的 ip 地址:15672/
|
||||
|
||||
默认用户名和密码:guest/guest; 但是需要注意的是:guest用户只是被容许从localhost访问。官网文档描述如下:
|
||||
默认用户名和密码:guest/guest; 但是需要注意的是:guest 用户只是被容许从 localhost 访问。官网文档描述如下:
|
||||
|
||||
```shell
|
||||
“guest” user can only connect via localhost
|
||||
@ -302,7 +307,6 @@ Setting permissions for user "root" in vhost "/" ...
|
||||
|
||||
```
|
||||
|
||||
再次访问:http://你的ip地址:15672/ ,输入用户名和密码:root root
|
||||
再次访问:http://你的 ip 地址:15672/ ,输入用户名和密码:root root
|
||||
|
||||
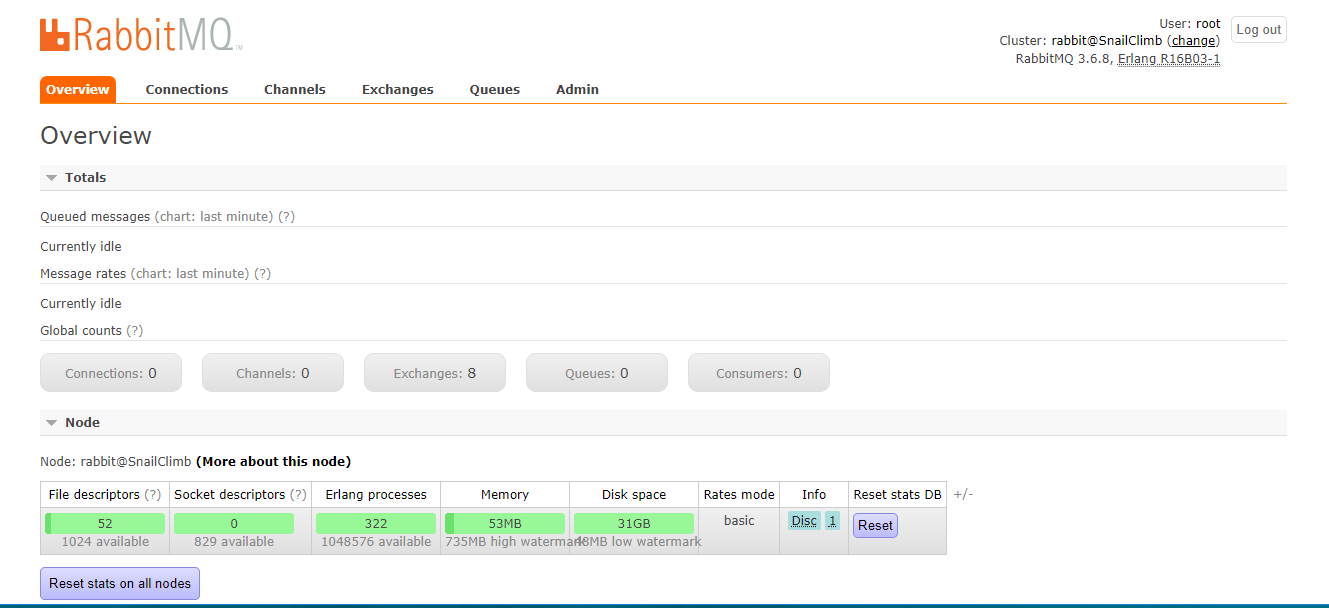
|
||||
|
||||
|
||||
@ -16,9 +16,9 @@ head:
|
||||
|
||||
## RabbitMQ 是什么?
|
||||
|
||||
RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
|
||||
RabbitMQ 是一个在 AMQP(Advanced Message Queuing Protocol )基础上实现的,可复用的企业消息系统。它可以用于大型软件系统各个模块之间的高效通信,支持高并发,支持可扩展。它支持多种客户端如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP 等,支持 AJAX,持久化,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。
|
||||
|
||||
RabbitMQ是使用Erlang编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个Broker构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
|
||||
RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP, SMTP, STOMP,也正是如此,使的它变的非常重量级,更适合于企业级的开发。它同时实现了一个 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队,对路由(Routing)、负载均衡(Load balance)或者数据持久化都有很好的支持。
|
||||
|
||||
PS:也可能直接问什么是消息队列?消息队列就是一个使用队列来通信的组件。
|
||||
|
||||
@ -83,12 +83,12 @@ DLX,全称为 `Dead-Letter-Exchange`,死信交换器,死信邮箱。当消
|
||||
|
||||
延迟队列指的是存储对应的延迟消息,消息被发送以后,并不想让消费者立刻拿到消息,而是等待特定时间后,消费者才能拿到这个消息进行消费。
|
||||
|
||||
RabbitMQ本身是没有延迟队列的,要实现延迟消息,一般有两种方式:
|
||||
RabbitMQ 本身是没有延迟队列的,要实现延迟消息,一般有两种方式:
|
||||
|
||||
1. 通过RabbitMQ本身队列的特性来实现,需要使用RabbitMQ的死信交换机(Exchange)和消息的存活时间TTL(Time To Live)。
|
||||
2. 在RabbitMQ 3.5.7及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖Erlang/OPT 18.0及以上。
|
||||
1. 通过 RabbitMQ 本身队列的特性来实现,需要使用 RabbitMQ 的死信交换机(Exchange)和消息的存活时间 TTL(Time To Live)。
|
||||
2. 在 RabbitMQ 3.5.7 及以上的版本提供了一个插件(rabbitmq-delayed-message-exchange)来实现延迟队列功能。同时,插件依赖 Erlang/OPT 18.0 及以上。
|
||||
|
||||
也就是说,AMQP 协议以及RabbitMQ本身没有直接支持延迟队列的功能,但是可以通过TTL和DLX模拟出延迟队列的功能。
|
||||
也就是说,AMQP 协议以及 RabbitMQ 本身没有直接支持延迟队列的功能,但是可以通过 TTL 和 DLX 模拟出延迟队列的功能。
|
||||
|
||||
## 什么是优先级队列?
|
||||
|
||||
|
||||
@ -24,9 +24,9 @@ tag:
|
||||
|
||||
你可能会反驳我,应用之间的通信又不是只能由消息队列解决,好好的通信为什么中间非要插一个消息队列呢?我不能直接进行通信吗?
|
||||
|
||||
很好👍,你又提出了一个概念,**同步通信**。就比如现在业界使用比较多的 `Dubbo` 就是一个适用于各个系统之间同步通信的 `RPC` 框架。
|
||||
很好 👍,你又提出了一个概念,**同步通信**。就比如现在业界使用比较多的 `Dubbo` 就是一个适用于各个系统之间同步通信的 `RPC` 框架。
|
||||
|
||||
我来举个🌰吧,比如我们有一个购票系统,需求是用户在购买完之后能接收到购买完成的短信。
|
||||
我来举个 🌰 吧,比如我们有一个购票系统,需求是用户在购买完之后能接收到购买完成的短信。
|
||||
|
||||
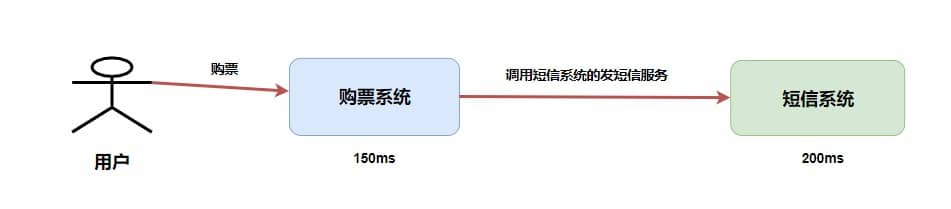
|
||||
|
||||
@ -36,11 +36,11 @@ tag:
|
||||
|
||||

|
||||
|
||||
这样整个系统的调用链又变长了,整个时间就变成了550ms。
|
||||
这样整个系统的调用链又变长了,整个时间就变成了 550ms。
|
||||
|
||||
当我们在学生时代需要在食堂排队的时候,我们和食堂大妈就是一个同步的模型。
|
||||
|
||||
我们需要告诉食堂大妈:“姐姐,给我加个鸡腿,再加个酸辣土豆丝,帮我浇点汁上去,多打点饭哦😋😋😋” 咦~~~ 为了多吃点,真恶心。
|
||||
我们需要告诉食堂大妈:“姐姐,给我加个鸡腿,再加个酸辣土豆丝,帮我浇点汁上去,多打点饭哦 😋😋😋” 咦~~~ 为了多吃点,真恶心。
|
||||
|
||||
然后大妈帮我们打饭配菜,我们看着大妈那颤抖的手和掉落的土豆丝不禁咽了咽口水。
|
||||
|
||||
@ -104,7 +104,7 @@ tag:
|
||||
|
||||
比如,本来好好的两个系统之间的调用,我中间加了个消息队列,如果消息队列挂了怎么办呢?是不是 **降低了系统的可用性** ?
|
||||
|
||||
那这样是不是要保证HA(高可用)?是不是要搞集群?那么我 **整个系统的复杂度是不是上升了** ?
|
||||
那这样是不是要保证 HA(高可用)?是不是要搞集群?那么我 **整个系统的复杂度是不是上升了** ?
|
||||
|
||||
抛开上面的问题不讲,万一我发送方发送失败了,然后执行重试,这样就可能产生重复的消息。
|
||||
|
||||
@ -114,7 +114,7 @@ tag:
|
||||
|
||||
那么,又 **如何解决重复消费消息的问题** 呢?
|
||||
|
||||
如果我们此时的消息需要保证严格的顺序性怎么办呢?比如生产者生产了一系列的有序消息(对一个id为1的记录进行删除增加修改),但是我们知道在发布订阅模型中,对于主题是无顺序的,那么这个时候就会导致对于消费者消费消息的时候没有按照生产者的发送顺序消费,比如这个时候我们消费的顺序为修改删除增加,如果该记录涉及到金额的话是不是会出大事情?
|
||||
如果我们此时的消息需要保证严格的顺序性怎么办呢?比如生产者生产了一系列的有序消息(对一个 id 为 1 的记录进行删除增加修改),但是我们知道在发布订阅模型中,对于主题是无顺序的,那么这个时候就会导致对于消费者消费消息的时候没有按照生产者的发送顺序消费,比如这个时候我们消费的顺序为修改删除增加,如果该记录涉及到金额的话是不是会出大事情?
|
||||
|
||||
那么,又 **如何解决消息的顺序消费问题** 呢?
|
||||
|
||||
@ -126,13 +126,13 @@ tag:
|
||||
|
||||
那么,又如何 **解决消息堆积的问题** 呢?
|
||||
|
||||
可用性降低,复杂度上升,又带来一系列的重复消费,顺序消费,分布式事务,消息堆积的问题,这消息队列还怎么用啊😵?
|
||||
可用性降低,复杂度上升,又带来一系列的重复消费,顺序消费,分布式事务,消息堆积的问题,这消息队列还怎么用啊 😵?
|
||||
|
||||

|
||||
|
||||
别急,办法总是有的。
|
||||
|
||||
## RocketMQ是什么?
|
||||
## RocketMQ 是什么?
|
||||
|
||||

|
||||
|
||||
@ -140,7 +140,7 @@ tag:
|
||||
|
||||
别急别急,话说你现在清楚 `MQ` 的构造吗,我还没讲呢,我们先搞明白 `MQ` 的内部构造,再来看看如何解决上面的一系列问题吧,不过你最好带着问题去阅读和了解喔。
|
||||
|
||||
`RocketMQ` 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 `Java` 语言开发的分布式的消息系统,由阿里巴巴团队开发,在2016年底贡献给 `Apache`,成为了 `Apache` 的一个顶级项目。 在阿里内部,`RocketMQ` 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有不可思议的万亿级消息通过 `RocketMQ` 流转。
|
||||
`RocketMQ` 是一个 **队列模型** 的消息中间件,具有**高性能、高可靠、高实时、分布式** 的特点。它是一个采用 `Java` 语言开发的分布式的消息系统,由阿里巴巴团队开发,在 2016 年底贡献给 `Apache`,成为了 `Apache` 的一个顶级项目。 在阿里内部,`RocketMQ` 很好地服务了集团大大小小上千个应用,在每年的双十一当天,更有不可思议的万亿级消息通过 `RocketMQ` 流转。
|
||||
|
||||
废话不多说,想要了解 `RocketMQ` 历史的同学可以自己去搜寻资料。听完上面的介绍,你只要知道 `RocketMQ` 很快、很牛、而且经历过双十一的实践就行了!
|
||||
|
||||
@ -178,7 +178,7 @@ tag:
|
||||
|
||||
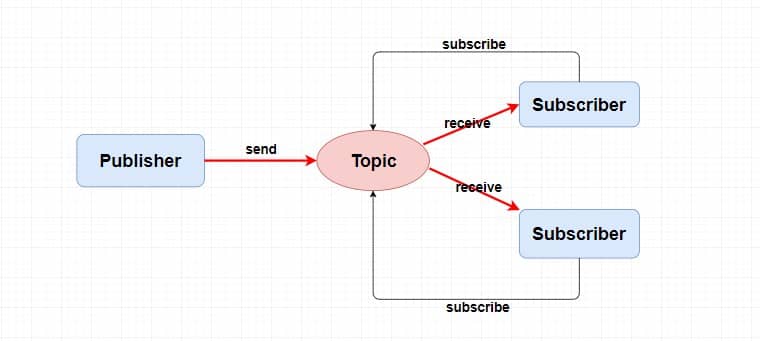
|
||||
|
||||
### RocketMQ中的消息模型
|
||||
### RocketMQ 中的消息模型
|
||||
|
||||
`RocketMQ` 中的消息模型就是按照 **主题模型** 所实现的。你可能会好奇这个 **主题** 到底是怎么实现的呢?你上面也没有讲到呀!
|
||||
|
||||
@ -218,7 +218,7 @@ tag:
|
||||
|
||||
所以总结来说,`RocketMQ` 通过**使用在一个 `Topic` 中配置多个队列并且每个队列维护每个消费者组的消费位置** 实现了 **主题模式/发布订阅模式** 。
|
||||
|
||||
## RocketMQ的架构图
|
||||
## RocketMQ 的架构图
|
||||
|
||||
讲完了消息模型,我们理解起 `RocketMQ` 的技术架构起来就容易多了。
|
||||
|
||||
@ -236,13 +236,13 @@ tag:
|
||||
|
||||
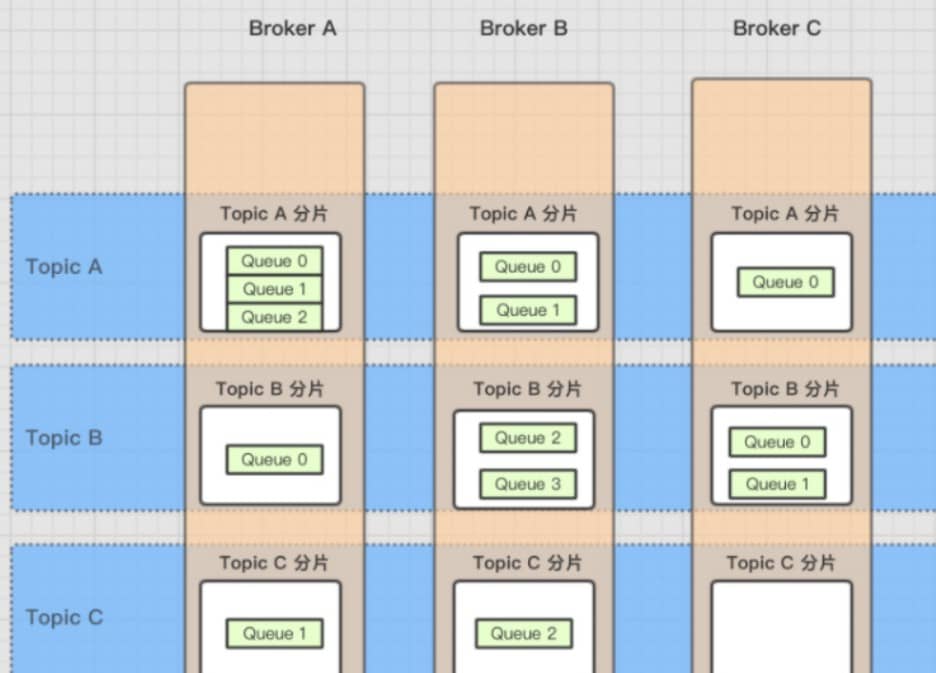
|
||||
|
||||
> 所以说我们需要配置多个Broker。
|
||||
> 所以说我们需要配置多个 Broker。
|
||||
|
||||
- `NameServer`: 不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。
|
||||
- `NameServer`: 不知道你们有没有接触过 `ZooKeeper` 和 `Spring Cloud` 中的 `Eureka` ,它其实也是一个 **注册中心** ,主要提供两个功能:**Broker 管理** 和 **路由信息管理** 。说白了就是 `Broker` 会将自己的信息注册到 `NameServer` 中,此时 `NameServer` 就存放了很多 `Broker` 的信息(Broker 的路由表),消费者和生产者就从 `NameServer` 中获取路由表然后照着路由表的信息和对应的 `Broker` 进行通信(生产者和消费者定期会向 `NameServer` 去查询相关的 `Broker` 的信息)。
|
||||
|
||||
- `Producer`: 消息发布的角色,支持分布式集群方式部署。说白了就是生产者。
|
||||
|
||||
- `Consumer`: 消息消费的角色,支持分布式集群方式部署。支持以push推,pull拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
|
||||
- `Consumer`: 消息消费的角色,支持分布式集群方式部署。支持以 push 推,pull 拉两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制。说白了就是消费者。
|
||||
|
||||
听完了上面的解释你可能会觉得,这玩意好简单。不就是这样的么?
|
||||
|
||||
@ -260,11 +260,11 @@ tag:
|
||||
|
||||
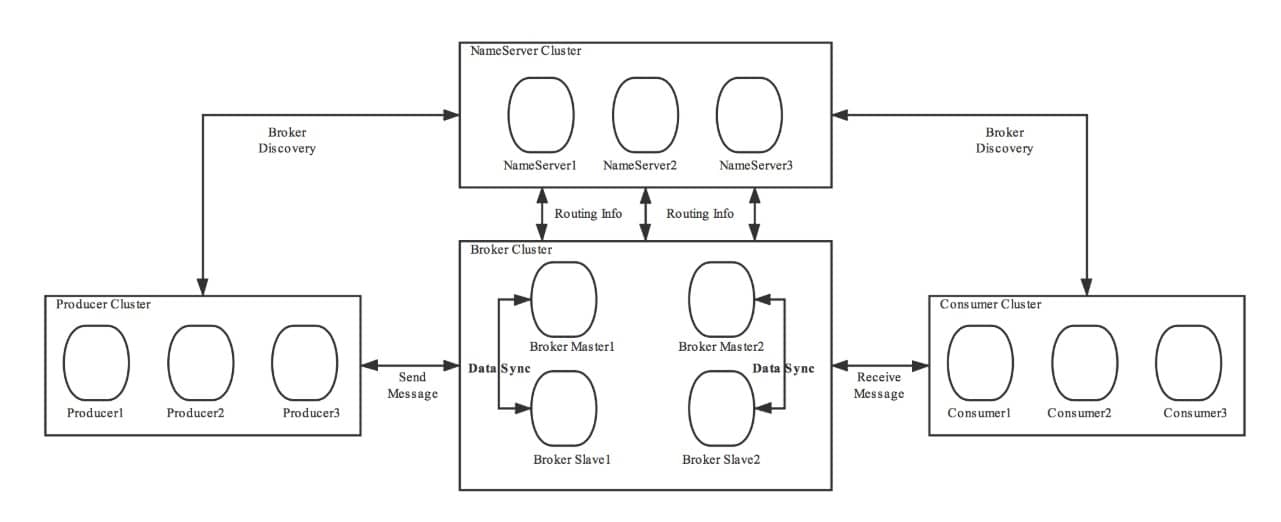
|
||||
|
||||
其实和我们最开始画的那张乞丐版的架构图也没什么区别,主要是一些细节上的差别。听我细细道来🤨。
|
||||
其实和我们最开始画的那张乞丐版的架构图也没什么区别,主要是一些细节上的差别。听我细细道来 🤨。
|
||||
|
||||
第一、我们的 `Broker` **做了集群并且还进行了主从部署** ,由于消息分布在各个 `Broker` 上,一旦某个 `Broker` 宕机,则该`Broker` 上的消息读写都会受到影响。所以 `Rocketmq` 提供了 `master/slave` 的结构,` salve` 定时从 `master` 同步数据(同步刷盘或者异步刷盘),如果 `master` 宕机,**则 `slave` 提供消费服务,但是不能写入消息** (后面我还会提到哦)。
|
||||
|
||||
第二、为了保证 `HA` ,我们的 `NameServer` 也做了集群部署,但是请注意它是 **去中心化** 的。也就意味着它没有主节点,你可以很明显地看出 `NameServer` 的所有节点是没有进行 `Info Replicate` 的,在 `RocketMQ` 中是通过 **单个Broker和所有NameServer保持长连接** ,并且在每隔30秒 `Broker` 会向所有 `Nameserver` 发送心跳,心跳包含了自身的 `Topic` 配置信息,这个步骤就对应这上面的 `Routing Info` 。
|
||||
第二、为了保证 `HA` ,我们的 `NameServer` 也做了集群部署,但是请注意它是 **去中心化** 的。也就意味着它没有主节点,你可以很明显地看出 `NameServer` 的所有节点是没有进行 `Info Replicate` 的,在 `RocketMQ` 中是通过 **单个 Broker 和所有 NameServer 保持长连接** ,并且在每隔 30 秒 `Broker` 会向所有 `Nameserver` 发送心跳,心跳包含了自身的 `Topic` 配置信息,这个步骤就对应这上面的 `Routing Info` 。
|
||||
|
||||
第三、在生产者需要向 `Broker` 发送消息的时候,**需要先从 `NameServer` 获取关于 `Broker` 的路由信息**,然后通过 **轮询** 的方法去向每个队列中生产数据以达到 **负载均衡** 的效果。
|
||||
|
||||
@ -298,11 +298,11 @@ tag:
|
||||
|
||||
那么,怎么解决呢?
|
||||
|
||||
其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash取模法** 来保证同一个订单在同一个队列中就行了。
|
||||
其实很简单,我们需要处理的仅仅是将同一语义下的消息放入同一个队列(比如这里是同一个订单),那我们就可以使用 **Hash 取模法** 来保证同一个订单在同一个队列中就行了。
|
||||
|
||||
### 重复消费
|
||||
|
||||
emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。比如说,这个时候我们有一个订单的处理积分的系统,每当来一个消息的时候它就负责为创建这个订单的用户的积分加上相应的数值。可是有一次,消息队列发送给订单系统 FrancisQ 的订单信息,其要求是给 FrancisQ 的积分加上 500。但是积分系统在收到 FrancisQ 的订单信息处理完成之后返回给消息队列处理成功的信息的时候出现了网络波动(当然还有很多种情况,比如Broker意外重启等等),这条回应没有发送成功。
|
||||
emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。比如说,这个时候我们有一个订单的处理积分的系统,每当来一个消息的时候它就负责为创建这个订单的用户的积分加上相应的数值。可是有一次,消息队列发送给订单系统 FrancisQ 的订单信息,其要求是给 FrancisQ 的积分加上 500。但是积分系统在收到 FrancisQ 的订单信息处理完成之后返回给消息队列处理成功的信息的时候出现了网络波动(当然还有很多种情况,比如 Broker 意外重启等等),这条回应没有发送成功。
|
||||
|
||||
那么,消息队列没收到积分系统的回应会不会尝试重发这个消息?问题就来了,我再发这个消息,万一它又给 FrancisQ 的账户加上 500 积分怎么办呢?
|
||||
|
||||
@ -312,11 +312,11 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||
不过最主要的还是需要 **根据特定场景使用特定的解决方案** ,你要知道你的消息消费是否是完全不可重复消费还是可以忍受重复消费的,然后再选择强校验和弱校验的方式。毕竟在 CS 领域还是很少有技术银弹的说法。
|
||||
|
||||
而在整个互联网领域,幂等不仅仅适用于消息队列的重复消费问题,这些实现幂等的方法,也同样适用于,**在其他场景中来解决重复请求或者重复调用的问题** 。比如将HTTP服务设计成幂等的,**解决前端或者APP重复提交表单数据的问题** ,也可以将一个微服务设计成幂等的,解决 `RPC` 框架自动重试导致的 **重复调用问题** 。
|
||||
而在整个互联网领域,幂等不仅仅适用于消息队列的重复消费问题,这些实现幂等的方法,也同样适用于,**在其他场景中来解决重复请求或者重复调用的问题** 。比如将 HTTP 服务设计成幂等的,**解决前端或者 APP 重复提交表单数据的问题** ,也可以将一个微服务设计成幂等的,解决 `RPC` 框架自动重试导致的 **重复调用问题** 。
|
||||
|
||||
## 分布式事务
|
||||
|
||||
如何解释分布式事务呢?事务大家都知道吧?**要么都执行要么都不执行** 。在同一个系统中我们可以轻松地实现事务,但是在分布式架构中,我们有很多服务是部署在不同系统之间的,而不同服务之间又需要进行调用。比如此时我下订单然后增加积分,如果保证不了分布式事务的话,就会出现A系统下了订单,但是B系统增加积分失败或者A系统没有下订单,B系统却增加了积分。前者对用户不友好,后者对运营商不利,这是我们都不愿意见到的。
|
||||
如何解释分布式事务呢?事务大家都知道吧?**要么都执行要么都不执行** 。在同一个系统中我们可以轻松地实现事务,但是在分布式架构中,我们有很多服务是部署在不同系统之间的,而不同服务之间又需要进行调用。比如此时我下订单然后增加积分,如果保证不了分布式事务的话,就会出现 A 系统下了订单,但是 B 系统增加积分失败或者 A 系统没有下订单,B 系统却增加了积分。前者对用户不友好,后者对运营商不利,这是我们都不愿意见到的。
|
||||
|
||||
那么,如何去解决这个问题呢?
|
||||
|
||||
@ -328,11 +328,11 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||
在第一步发送的 half 消息 ,它的意思是 **在事务提交之前,对于消费者来说,这个消息是不可见的** 。
|
||||
|
||||
> 那么,如何做到写入消息但是对用户不可见呢?RocketMQ事务消息的做法是:如果消息是half消息,将备份原消息的主题与消息消费队列,然后 **改变主题** 为RMQ_SYS_TRANS_HALF_TOPIC。由于消费组未订阅该主题,故消费端无法消费half类型的消息,**然后RocketMQ会开启一个定时任务,从Topic为RMQ_SYS_TRANS_HALF_TOPIC中拉取消息进行消费**,根据生产者组获取一个服务提供者发送回查事务状态请求,根据事务状态来决定是提交或回滚消息。
|
||||
> 那么,如何做到写入消息但是对用户不可见呢?RocketMQ 事务消息的做法是:如果消息是 half 消息,将备份原消息的主题与消息消费队列,然后 **改变主题** 为 RMQ_SYS_TRANS_HALF_TOPIC。由于消费组未订阅该主题,故消费端无法消费 half 类型的消息,**然后 RocketMQ 会开启一个定时任务,从 Topic 为 RMQ_SYS_TRANS_HALF_TOPIC 中拉取消息进行消费**,根据生产者组获取一个服务提供者发送回查事务状态请求,根据事务状态来决定是提交或回滚消息。
|
||||
|
||||
你可以试想一下,如果没有从第5步开始的 **事务反查机制** ,如果出现网路波动第4步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题,他就像一个无头苍蝇一样。在 `RocketMQ` 中就是使用的上述的事务反查来解决的,而在 `Kafka` 中通常是直接抛出一个异常让用户来自行解决。
|
||||
你可以试想一下,如果没有从第 5 步开始的 **事务反查机制** ,如果出现网路波动第 4 步没有发送成功,这样就会产生 MQ 不知道是不是需要给消费者消费的问题,他就像一个无头苍蝇一样。在 `RocketMQ` 中就是使用的上述的事务反查来解决的,而在 `Kafka` 中通常是直接抛出一个异常让用户来自行解决。
|
||||
|
||||
你还需要注意的是,在 `MQ Server` 指向系统B的操作已经和系统A不相关了,也就是说在消息队列中的分布式事务是——**本地事务和存储消息到消息队列才是同一个事务**。这样也就产生了事务的**最终一致性**,因为整个过程是异步的,**每个系统只要保证它自己那一部分的事务就行了**。
|
||||
你还需要注意的是,在 `MQ Server` 指向系统 B 的操作已经和系统 A 不相关了,也就是说在消息队列中的分布式事务是——**本地事务和存储消息到消息队列才是同一个事务**。这样也就产生了事务的**最终一致性**,因为整个过程是异步的,**每个系统只要保证它自己那一部分的事务就行了**。
|
||||
|
||||
## 消息堆积问题
|
||||
|
||||
@ -350,9 +350,9 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||
## 回溯消费
|
||||
|
||||
回溯消费是指 `Consumer` 已经消费成功的消息,由于业务上需求需要重新消费,在`RocketMQ` 中, `Broker` 在向`Consumer` 投递成功消息后,**消息仍然需要保留** 。并且重新消费一般是按照时间维度,例如由于 `Consumer` 系统故障,恢复后需要重新消费1小时前的数据,那么 `Broker` 要提供一种机制,可以按照时间维度来回退消费进度。`RocketMQ` 支持按照时间回溯消费,时间维度精确到毫秒。
|
||||
回溯消费是指 `Consumer` 已经消费成功的消息,由于业务上需求需要重新消费,在`RocketMQ` 中, `Broker` 在向`Consumer` 投递成功消息后,**消息仍然需要保留** 。并且重新消费一般是按照时间维度,例如由于 `Consumer` 系统故障,恢复后需要重新消费 1 小时前的数据,那么 `Broker` 要提供一种机制,可以按照时间维度来回退消费进度。`RocketMQ` 支持按照时间回溯消费,时间维度精确到毫秒。
|
||||
|
||||
这是官方文档的解释,我直接照搬过来就当科普了😁😁😁。
|
||||
这是官方文档的解释,我直接照搬过来就当科普了 😁😁😁。
|
||||
|
||||
## RocketMQ 的刷盘机制
|
||||
|
||||
@ -395,7 +395,7 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||

|
||||
|
||||
但是这种复制方式同样也会带来一个问题,那就是无法保证 **严格顺序** 。在上文中我们提到了如何保证的消息顺序性是通过将一个语义的消息发送在同一个队列中,使用 `Topic` 下的队列来保证顺序性的。如果此时我们主节点A负责的是订单A的一系列语义消息,然后它挂了,这样其他节点是无法代替主节点A的,如果我们任意节点都可以存入任何消息,那就没有顺序性可言了。
|
||||
但是这种复制方式同样也会带来一个问题,那就是无法保证 **严格顺序** 。在上文中我们提到了如何保证的消息顺序性是通过将一个语义的消息发送在同一个队列中,使用 `Topic` 下的队列来保证顺序性的。如果此时我们主节点 A 负责的是订单 A 的一系列语义消息,然后它挂了,这样其他节点是无法代替主节点 A 的,如果我们任意节点都可以存入任何消息,那就没有顺序性可言了。
|
||||
|
||||
而在 `RocketMQ` 中采用了 `Dledger` 解决这个问题。他要求在写入消息的时候,要求**至少消息复制到半数以上的节点之后**,才给客⼾端返回写⼊成功,并且它是⽀持通过选举来动态切换主节点的。这里我就不展开说明了,读者可以自己去了解。
|
||||
|
||||
@ -407,9 +407,9 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||
但是,在 `Topic` 中的 **队列是以什么样的形式存在的?队列中的消息又是如何进行存储持久化的呢?** 还未解决,其实这里涉及到了 `RocketMQ` 是如何设计它的存储结构了。我首先想大家介绍 `RocketMQ` 消息存储架构中的三大角色——`CommitLog` 、`ConsumeQueue` 和 `IndexFile` 。
|
||||
|
||||
- `CommitLog`: **消息主体以及元数据的存储主体**,存储 `Producer` 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是**顺序写入日志文件**,当文件满了,写入下一个文件。
|
||||
- `ConsumeQueue`: 消息消费队列,**引入的目的主要是提高消息消费的性能**(我们再前面也讲了),由于`RocketMQ` 是基于主题 `Topic` 的订阅模式,消息消费是针对主题进行的,如果要遍历 `commitlog` 文件中根据 `Topic` 检索消息是非常低效的。`Consumer` 即可根据 `ConsumeQueue` 来查找待消费的消息。其中,`ConsumeQueue`(逻辑消费队列)**作为消费消息的索引**,保存了指定 `Topic` 下的队列消息在 `CommitLog` 中的**起始物理偏移量 `offset` **,消息大小 `size` 和消息 `Tag` 的 `HashCode` 值。**`consumequeue` 文件可以看成是基于 `topic` 的 `commitlog` 索引文件**,故 `consumequeue` 文件夹的组织方式如下:topic/queue/file三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样 `consumequeue` 文件采取定长设计,每一个条目共20个字节,分别为8字节的 `commitlog` 物理偏移量、4字节的消息长度、8字节tag `hashcode`,单个文件由30W个条目组成,可以像数组一样随机访问每一个条目,每个 `ConsumeQueue`文件大小约5.72M;
|
||||
- `IndexFile`: `IndexFile`(索引文件)提供了一种可以通过key或时间区间来查询消息的方法。这里只做科普不做详细介绍。
|
||||
- `CommitLog`: **消息主体以及元数据的存储主体**,存储 `Producer` 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认 1G ,文件名长度为 20 位,左边补零,剩余为起始偏移量,比如 00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G=1073741824;当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是**顺序写入日志文件**,当文件满了,写入下一个文件。
|
||||
- `ConsumeQueue`: 消息消费队列,**引入的目的主要是提高消息消费的性能**(我们再前面也讲了),由于`RocketMQ` 是基于主题 `Topic` 的订阅模式,消息消费是针对主题进行的,如果要遍历 `commitlog` 文件中根据 `Topic` 检索消息是非常低效的。`Consumer` 即可根据 `ConsumeQueue` 来查找待消费的消息。其中,`ConsumeQueue`(逻辑消费队列)**作为消费消息的索引**,保存了指定 `Topic` 下的队列消息在 `CommitLog` 中的**起始物理偏移量 `offset` **,消息大小 `size` 和消息 `Tag` 的 `HashCode` 值。**`consumequeue` 文件可以看成是基于 `topic` 的 `commitlog` 索引文件**,故 `consumequeue` 文件夹的组织方式如下:topic/queue/file 三层组织结构,具体存储路径为:$HOME/store/consumequeue/{topic}/{queueId}/{fileName}。同样 `consumequeue` 文件采取定长设计,每一个条目共 20 个字节,分别为 8 字节的 `commitlog` 物理偏移量、4 字节的消息长度、8 字节 tag `hashcode`,单个文件由 30W 个条目组成,可以像数组一样随机访问每一个条目,每个 `ConsumeQueue`文件大小约 5.72M;
|
||||
- `IndexFile`: `IndexFile`(索引文件)提供了一种可以通过 key 或时间区间来查询消息的方法。这里只做科普不做详细介绍。
|
||||
|
||||
总结来说,整个消息存储的结构,最主要的就是 `CommitLoq` 和 `ConsumeQueue` 。而 `ConsumeQueue` 你可以大概理解为 `Topic` 中的队列。
|
||||
|
||||
@ -419,23 +419,23 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||
而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
|
||||
|
||||
所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号*索引固定⻓度20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
|
||||
所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号\*索引固定⻓度 20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
|
||||
|
||||
讲到这里,你可能对 `RockeMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
|
||||
|
||||
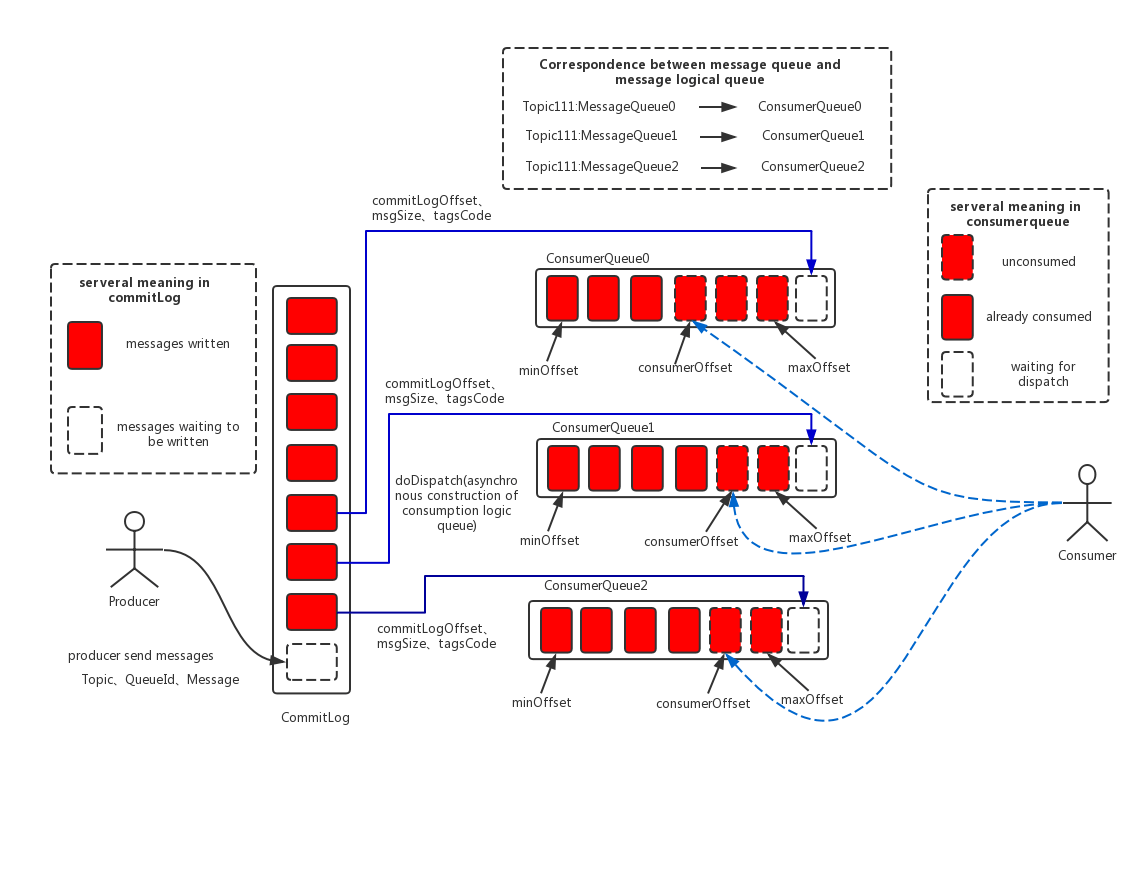
|
||||
|
||||
emmm,是不是有一点复杂🤣,看英文图片和英文文档的时候就不要怂,硬着头皮往下看就行。
|
||||
emmm,是不是有一点复杂 🤣,看英文图片和英文文档的时候就不要怂,硬着头皮往下看就行。
|
||||
|
||||
> 如果上面没看懂的读者一定要认真看下面的流程分析!
|
||||
|
||||
首先,在最上面的那一块就是我刚刚讲的你现在可以直接 **把 `ConsumerQueue` 理解为 `Queue`**。
|
||||
|
||||
在图中最左边说明了红色方块代表被写入的消息,虚线方块代表等待被写入的。左边的生产者发送消息会指定 `Topic` 、`QueueId` 和具体消息内容,而在 `Broker` 中管你是哪门子消息,他直接 **全部顺序存储到了 CommitLog**。而根据生产者指定的 `Topic` 和 `QueueId` 将这条消息本身在 `CommitLog` 的偏移(offset),消息本身大小,和tag的hash值存入对应的 `ConsumeQueue` 索引文件中。而在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置(我在架构那里提到了,忘了的同学可以回去看一下),而消费者拉取消息进行消费的时候只需要根据 `ConsumeOffset` 获取下一个未被消费的消息就行了。
|
||||
在图中最左边说明了红色方块代表被写入的消息,虚线方块代表等待被写入的。左边的生产者发送消息会指定 `Topic` 、`QueueId` 和具体消息内容,而在 `Broker` 中管你是哪门子消息,他直接 **全部顺序存储到了 CommitLog**。而根据生产者指定的 `Topic` 和 `QueueId` 将这条消息本身在 `CommitLog` 的偏移(offset),消息本身大小,和 tag 的 hash 值存入对应的 `ConsumeQueue` 索引文件中。而在每个队列中都保存了 `ConsumeOffset` 即每个消费者组的消费位置(我在架构那里提到了,忘了的同学可以回去看一下),而消费者拉取消息进行消费的时候只需要根据 `ConsumeOffset` 获取下一个未被消费的消息就行了。
|
||||
|
||||
上述就是我对于整个消息存储架构的大概理解(这里不涉及到一些细节讨论,比如稀疏索引等等问题),希望对你有帮助。
|
||||
|
||||
因为有一个知识点因为写嗨了忘讲了,想想在哪里加也不好,所以我留给大家去思考🤔🤔一下吧。
|
||||
因为有一个知识点因为写嗨了忘讲了,想想在哪里加也不好,所以我留给大家去思考 🤔🤔 一下吧。
|
||||
|
||||

|
||||
|
||||
@ -443,7 +443,7 @@ emmm,是不是有一点复杂🤣,看英文图片和英文文档的时候就
|
||||
|
||||
## 总结
|
||||
|
||||
总算把这篇博客写完了。我讲的你们还记得吗😅?
|
||||
总算把这篇博客写完了。我讲的你们还记得吗 😅?
|
||||
|
||||
这篇文章中我主要想大家介绍了
|
||||
|
||||
@ -457,4 +457,4 @@ emmm,是不是有一点复杂🤣,看英文图片和英文文档的时候就
|
||||
|
||||
等等。。。
|
||||
|
||||
> 如果喜欢可以点赞哟👍👍👍。
|
||||
> 如果喜欢可以点赞哟 👍👍👍。
|
||||
|
||||
@ -110,6 +110,7 @@ class Broker {
|
||||
```
|
||||
|
||||
问题:
|
||||
|
||||
1. 没有实现真正执行消息存储落盘
|
||||
2. 没有实现 NameServer 去作为注册中心,定位服务
|
||||
3. 使用 LinkedBlockingQueue 作为消息队列,注意,参数是无限大,在真正 RocketMQ 也是如此是无限大,理论上不会出现对进来的数据进行抛弃,但是会有内存泄漏问题(阿里巴巴开发手册也因为这个问题,建议我们使用自制线程池)
|
||||
@ -129,40 +130,40 @@ class Broker {
|
||||
#### 2.1.2 同步落盘怎么才能快
|
||||
|
||||
1. 使用 FileChannel + DirectBuffer 池,使用堆外内存,加快内存拷贝
|
||||
2. 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询index 文件来定位,从而减少文件IO随机读写的性能损耗
|
||||
2. 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询 index 文件来定位,从而减少文件 IO 随机读写的性能损耗
|
||||
|
||||
#### 2.1.3 消息堆积的问题
|
||||
|
||||
1. 后台定时任务每隔72小时,删除旧的没有使用过的消息信息
|
||||
2. 根据不同的业务实现不同的丢弃任务,具体参考线程池的 AbortPolicy,例如FIFO/LRU等(RocketMQ没有此策略)
|
||||
1. 后台定时任务每隔 72 小时,删除旧的没有使用过的消息信息
|
||||
2. 根据不同的业务实现不同的丢弃任务,具体参考线程池的 AbortPolicy,例如 FIFO/LRU 等(RocketMQ 没有此策略)
|
||||
3. 消息定时转移,或者对某些重要的 TAG 型(支付型)消息真正落库
|
||||
|
||||
#### 2.1.4 定时消息的实现
|
||||
|
||||
1. 实际 RocketMQ 没有实现任意精度的定时消息,它只支持某些特定的时间精度的定时消息
|
||||
2. 实现定时消息的原理是:创建特定时间精度的 MessageQueue,例如生产者需要定时1s之后被消费者消费,你只需要将此消息发送到特定的 Topic,例如:MessageQueue-1 表示这个 MessageQueue 里面的消息都会延迟一秒被消费,然后 Broker 会在 1s 后发送到消费者消费此消息,使用 newSingleThreadScheduledExecutor 实现
|
||||
2. 实现定时消息的原理是:创建特定时间精度的 MessageQueue,例如生产者需要定时 1s 之后被消费者消费,你只需要将此消息发送到特定的 Topic,例如:MessageQueue-1 表示这个 MessageQueue 里面的消息都会延迟一秒被消费,然后 Broker 会在 1s 后发送到消费者消费此消息,使用 newSingleThreadScheduledExecutor 实现
|
||||
|
||||
#### 2.1.5 顺序消息的实现
|
||||
|
||||
1. 与定时消息同原理,生产者生产消息时指定特定的 MessageQueue ,消费者消费消息时,消费特定的 MessageQueue,其实单机版的消息中心在一个 MessageQueue 就天然支持了顺序消息
|
||||
2. 注意:同一个 MessageQueue 保证里面的消息是顺序消费的前提是:消费者是串行的消费该 MessageQueue,因为就算 MessageQueue 是顺序的,但是当并行消费时,还是会有顺序问题,但是串行消费也同时引入了两个问题:
|
||||
>1. 引入锁来实现串行
|
||||
>2. 前一个消费阻塞时后面都会被阻塞
|
||||
> 1. 引入锁来实现串行
|
||||
> 2. 前一个消费阻塞时后面都会被阻塞
|
||||
|
||||
#### 2.1.6 分布式消息的实现
|
||||
|
||||
1. 需要前置知识:2PC
|
||||
2. RocketMQ4.3 起支持,原理为2PC,即两阶段提交,prepared->commit/rollback
|
||||
3. 生产者发送事务消息,假设该事务消息 Topic 为 Topic1-Trans,Broker 得到后首先更改该消息的 Topic 为 Topic1-Prepared,该 Topic1-Prepared 对消费者不可见。然后定时回调生产者的本地事务A执行状态,根据本地事务A执行状态,来是否将该消息修改为 Topic1-Commit 或 Topic1-Rollback,消费者就可以正常找到该事务消息或者不执行等
|
||||
2. RocketMQ4.3 起支持,原理为 2PC,即两阶段提交,prepared->commit/rollback
|
||||
3. 生产者发送事务消息,假设该事务消息 Topic 为 Topic1-Trans,Broker 得到后首先更改该消息的 Topic 为 Topic1-Prepared,该 Topic1-Prepared 对消费者不可见。然后定时回调生产者的本地事务 A 执行状态,根据本地事务 A 执行状态,来是否将该消息修改为 Topic1-Commit 或 Topic1-Rollback,消费者就可以正常找到该事务消息或者不执行等
|
||||
|
||||
>注意,就算是事务消息最后回滚了也不会物理删除,只会逻辑删除该消息
|
||||
> 注意,就算是事务消息最后回滚了也不会物理删除,只会逻辑删除该消息
|
||||
|
||||
#### 2.1.7 消息的 push 实现
|
||||
|
||||
1. 注意,RocketMQ 已经说了自己会有低延迟问题,其中就包括这个消息的 push 延迟问题
|
||||
2. 因为这并不是真正的将消息主动的推送到消费者,而是 Broker 定时任务每5s将消息推送到消费者
|
||||
3. pull模式需要我们手动调用consumer拉消息,而push模式则只需要我们提供一个listener即可实现对消息的监听,而实际上,RocketMQ的push模式是基于pull模式实现的,它没有实现真正的push。
|
||||
4. push方式里,consumer把轮询过程封装了,并注册MessageListener监听器,取到消息后,唤醒MessageListener的consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。
|
||||
2. 因为这并不是真正的将消息主动的推送到消费者,而是 Broker 定时任务每 5s 将消息推送到消费者
|
||||
3. pull 模式需要我们手动调用 consumer 拉消息,而 push 模式则只需要我们提供一个 listener 即可实现对消息的监听,而实际上,RocketMQ 的 push 模式是基于 pull 模式实现的,它没有实现真正的 push。
|
||||
4. push 方式里,consumer 把轮询过程封装了,并注册 MessageListener 监听器,取到消息后,唤醒 MessageListener 的 consumeMessage()来消费,对用户而言,感觉消息是被推送过来的。
|
||||
|
||||
#### 2.1.8 消息重复发送的避免
|
||||
|
||||
@ -186,6 +187,7 @@ class Broker {
|
||||
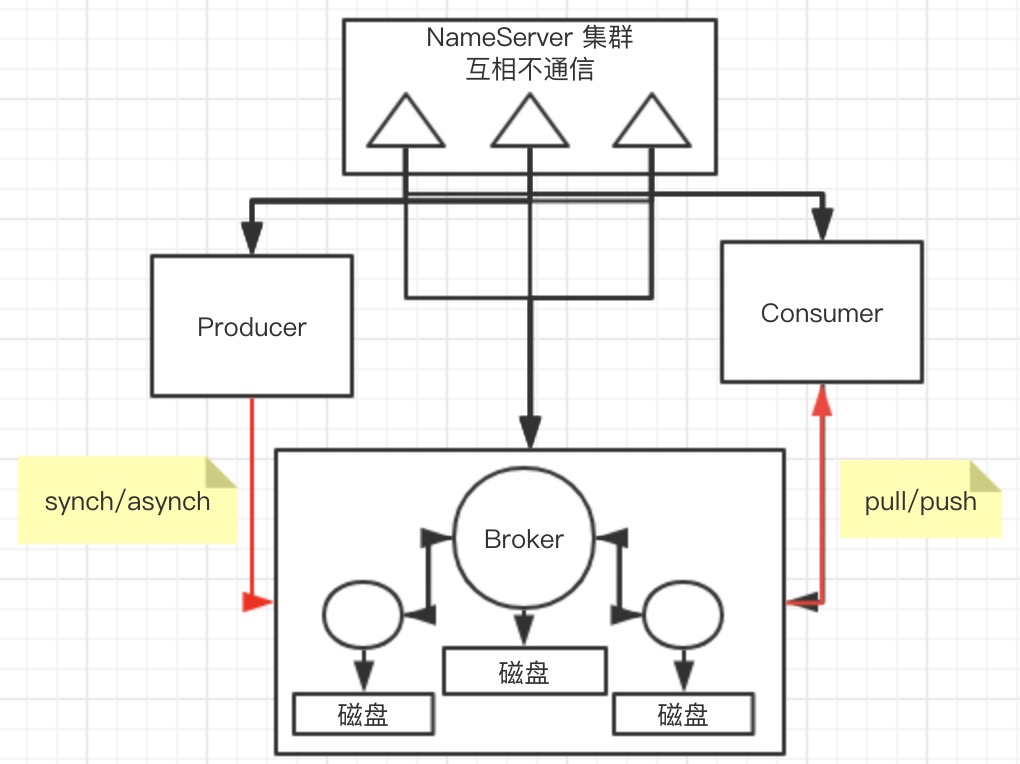
|
||||
|
||||
加分项咯
|
||||
|
||||
1. 包括组件通信间使用 Netty 的自定义协议
|
||||
2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
|
||||
3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时,在 Broker 端就使用过滤服务器进行过滤)
|
||||
@ -194,8 +196,8 @@ class Broker {
|
||||
|
||||
## 3 参考
|
||||
|
||||
1. 《RocketMQ技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
|
||||
3. 十分钟入门RocketMQ:https://developer.aliyun.com/article/66101
|
||||
4. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
|
||||
5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
|
||||
6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
|
||||
1. 《RocketMQ 技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
|
||||
2. 十分钟入门 RocketMQ:https://developer.aliyun.com/article/66101
|
||||
3. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
|
||||
4. 滴滴出行基于 RocketMQ 构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
|
||||
5. 基于《RocketMQ 技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
|
||||
|
||||
@ -61,7 +61,7 @@ hintManager.setMasterRouteOnly();
|
||||
|
||||
落实到项目本身的话,常用的方式有两种:
|
||||
|
||||
**1.代理方式**
|
||||
**1. 代理方式**
|
||||
|
||||
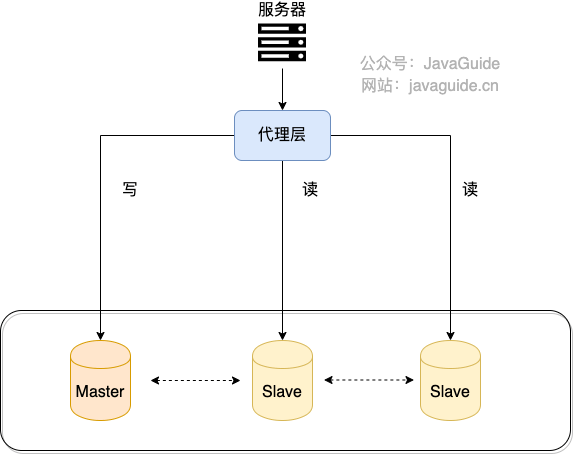
|
||||
|
||||
@ -69,7 +69,7 @@ hintManager.setMasterRouteOnly();
|
||||
|
||||
提供类似功能的中间件有 **MySQL Router**(官方)、**Atlas**(基于 MySQL Proxy)、**MaxScale**、**MyCat**。
|
||||
|
||||
**2.组件方式**
|
||||
**2. 组件方式**
|
||||
|
||||
在这种方式中,我们可以通过引入第三方组件来帮助我们读写请求。
|
||||
|
||||
@ -159,7 +159,7 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
|
||||
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
|
||||
|
||||
- **哈希分片** :求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
|
||||
- **范围分片** :按照特性的范围区间(比如时间区间、ID区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
||||
- **范围分片** :按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
||||
- **地理位置分片** :很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
|
||||
- **融合算法** :灵活组合多种分片算法,比如将哈希分片和范围分片组合。
|
||||
- ......
|
||||
@ -210,4 +210,3 @@ ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere
|
||||
- **分库** 就是将数据库中的数据分散到不同的数据库上。**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
|
||||
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
|
||||
- ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
|
||||
|
||||
|
||||
@ -19,42 +19,4 @@ head:
|
||||
|
||||

|
||||
|
||||
最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
|
||||
|
||||
为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的知识星球。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面。
|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/image-20220311203414600.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiufuwu.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
|
||||
|
||||
这里再送一个 30 元的新人优惠券(续费半价)。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
进入星球之后,记得添加微信,我会发你详细的星球使用指南。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -12,7 +12,7 @@ tag:
|
||||
>
|
||||
> **原文地址:** https://mp.weixin.qq.com/s/6hUU6SZsxGPWAIIByq93Rw
|
||||
|
||||
我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别****人沟通,都显得特别专业**。每次遇到这类人,我都在想,他们到底是怎么做到的?
|
||||
我想你肯定遇到过这样一类程序员:**他们无论是写代码,还是写文档,又或是和别\*\***人沟通,都显得特别专业\*\*。每次遇到这类人,我都在想,他们到底是怎么做到的?
|
||||
|
||||
随着工作时间的增长,渐渐地我也总结出一些经验,他们身上都保持着一些看似很微小的优秀习惯,但正是因为这些习惯,体现出了一个优秀程序员的基本素养。
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ tag:
|
||||
>
|
||||
> **原文地址** :https://mp.weixin.qq.com/s/8lMGzBzXine-NAsqEaIE4g
|
||||
|
||||
### 建议1:刻意加强需求评审能力
|
||||
### 建议 1:刻意加强需求评审能力
|
||||
|
||||
先从需求评审开始说。在互联网公司,需求评审是开发工作的主要入口。
|
||||
|
||||
@ -38,7 +38,7 @@ tag:
|
||||
|
||||
所以,**普通程序员要想成长为更高级别的开发,一定要加强需求评审能力的培养**。
|
||||
|
||||
### 建议2:主动思考效率
|
||||
### 建议 2:主动思考效率
|
||||
|
||||
普通的程序员,按部就班的去写代码,有活儿来我就干,没活儿的时候我就呆着。很少去深度思考现有的这些代码为什么要这么写,这么写的好处是啥,有哪些地方存在瓶颈,我是否可以把它优化一些。
|
||||
|
||||
@ -50,7 +50,7 @@ tag:
|
||||
|
||||
所以,**第二个建议就是要主动思考一下现有工作中哪些地方效率有改进的空间,想到了就主动去改进它!**
|
||||
|
||||
### 建议3:加强内功能力
|
||||
### 建议 3:加强内功能力
|
||||
|
||||
哪些算是内功呢,我想内功修炼的读者们肯定也都很熟悉的了,指的就是大家学校里都学过的操作系统、网络等这些基础。
|
||||
|
||||
@ -64,7 +64,7 @@ tag:
|
||||
|
||||
所以,**还建议多多锻炼底层技术内功能力**。如果你不知道怎么练,那就坚持看「开发内功修炼」公众号。
|
||||
|
||||
### 建议4:思考性能
|
||||
### 建议 4:思考性能
|
||||
|
||||
普通程序员往往就是把需求开发完了就不管了,只要需求实现了,测试通过了就可以交付了。将来流量会有多大,没想过。自己的服务 QPS 能支撑多少,不清楚。
|
||||
|
||||
@ -76,7 +76,7 @@ tag:
|
||||
|
||||
所以,**第四个建议就是一定要多多主动你所负责业务的性能,并多多进行优化和改进**。我想这个建议的重要程度非常之高。但这是需要你具备深厚的内功才可以办的到的,否则如果你连网络是怎么工作的都不清楚,谈何优化!
|
||||
|
||||
### 建议5:重视线上
|
||||
### 建议 5:重视线上
|
||||
|
||||
普通程序员往往对线上的事情很少去关注,手里记录的服务器就是自己的开发机和发布机,线上机器有几台,流量多大,最近有没有波动这些可能都不清楚。
|
||||
|
||||
@ -88,7 +88,7 @@ tag:
|
||||
|
||||
所以,**飞哥给的第五个建议就是要多多观察线上运行情况**。只有多多关注线上,当线上出故障的时候,你才能承担的起快速排出线上问题的重任。
|
||||
|
||||
### 建议6:关注全局
|
||||
### 建议 6:关注全局
|
||||
|
||||
普通程序员是你分配给我哪个模块,我就干哪个模块,给自己的工作设定了非常小的一个边界,自己所有的眼光都聚集在这个小框框内。
|
||||
|
||||
@ -98,8 +98,8 @@ tag:
|
||||
|
||||
所以,**建议要有大局观,不仅仅是你负责的模块,整个项目其实你都应该去关注**。而不是连自己组内同学做的是啥都不知道。
|
||||
|
||||
### 建议7:归纳总结能力
|
||||
### 建议 7:归纳总结能力
|
||||
|
||||
普通程序员往往是工作的事情做完就拉到,很少回头去对自己的技术,对业务进行归纳和总结。
|
||||
|
||||
而高级的程序员往往都会在一件比较大的事情做完之后总结一下,做个ppt,写个博客啥的记录下来。这样既对自己的工作是一个归纳,也可以分享给其它同学,促进团队的共同成长。
|
||||
而高级的程序员往往都会在一件比较大的事情做完之后总结一下,做个 ppt,写个博客啥的记录下来。这样既对自己的工作是一个归纳,也可以分享给其它同学,促进团队的共同成长。
|
||||
|
||||
@ -11,7 +11,7 @@ tag:
|
||||
> **内容概览** :
|
||||
>
|
||||
> 1. 个人介绍,是对自己的一个更为清晰、深入和全面的认识契机。
|
||||
>2. 简历是充分展示自己的浓缩精华,也是重新审视自己和过往经历的契机。不仅仅是简要介绍技能和经验,更要最大程度凸显自己的优势领域(差异化)。
|
||||
> 2. 简历是充分展示自己的浓缩精华,也是重新审视自己和过往经历的契机。不仅仅是简要介绍技能和经验,更要最大程度凸显自己的优势领域(差异化)。
|
||||
> 3. 我个人是不赞成海投的,而倾向于定向投。找准方向投,虽然目标更少,但更有效率。
|
||||
> 4. 技术探索,一定要先理解原理。原理不懂,就会浮于表层,不能真正掌握它。技术原理探究要掌握到什么程度?数据结构与算法设计、考量因素、技术机制、优化思路。要在脑中回放,直到一切细节而清晰可见。如果能够清晰有条理地表述出来,就更好了。技术原理探究,一定要看源码。看了源码与没看源码是有区别的。没看源码,虽然说得出来,但终是隔了一层纸;看了源码,才捅破了那层纸,有了自己的理解,也就能说得更加有底气了。当然,也可能是我缺乏演戏的本领。
|
||||
> 5. 要善于从失败中学习。正是在杭州四个月空档期的持续学习、思考、积累和提炼,以及面试失败的反思、不断调整对策、完善准备、改善原有的短板,采取更为合理的方式,才在回武汉的短短两个周内拿到比较满意的 offer 。
|
||||
|
||||
@ -12,7 +12,7 @@ tag:
|
||||
>
|
||||
> **原文地址** :https://www.cnblogs.com/scada/p/14259332.html
|
||||
|
||||
------
|
||||
---
|
||||
|
||||
## 前言
|
||||
|
||||
@ -20,7 +20,7 @@ tag:
|
||||
|
||||
近 8 年有些事情做对了,也有更多事情做错了,在这里记录一下,希望能够给后人一些帮助吧,也欢迎私信交流。文笔不好,见谅,有些细节记不清了,如果有出入,就当是我编的这个故事吧。
|
||||
|
||||
*PS:有几个问题先在这里解释一下,评论就不一一回复了*
|
||||
_PS:有几个问题先在这里解释一下,评论就不一一回复了_
|
||||
|
||||
1. 关于差生,我本人在科大时确实成绩偏下,差生主要讲这一点,没其他意思。
|
||||
2. 因为买房是我人生中的大事,我认为需要记录和总结一下,本文中会有买房,房价之类的信息出现,您如果对房价,炒房等反感的话,请您停止阅读,并且我再这里为浪费您的时间先道个歉。
|
||||
|
||||
@ -30,17 +30,17 @@ tag:
|
||||
|
||||
## 工作情况
|
||||
|
||||
我在腾讯内部没有转过岗,但是做过的项目也还是比较丰富的,包括:BUGLY、分布式调用链(Huskie)、众包系统(SOHO),EPC度量系统。其中一些是对外的,一些是内部系统,可能有些大家不知道。还是比较感谢这些项目经历,既有纯业务的系统,也有偏框架的系统,让我学到了不少知识。
|
||||
我在腾讯内部没有转过岗,但是做过的项目也还是比较丰富的,包括:BUGLY、分布式调用链(Huskie)、众包系统(SOHO),EPC 度量系统。其中一些是对外的,一些是内部系统,可能有些大家不知道。还是比较感谢这些项目经历,既有纯业务的系统,也有偏框架的系统,让我学到了不少知识。
|
||||
|
||||
接下来,简单介绍一下每个项目吧,毕竟每一个项目都付出了很多心血的:
|
||||
|
||||
BUGLY,这是一个终端Crash联网上报的系统,很多APP都接入了。Huskie,这是一个基于zipkin搭建的分布式调用链跟踪项目。SOHO,这是一个众包系统,主要是将数据标准和语音采集任务众包出去,让人家做。EPC度量系统,这是研发效能度量系统,主要是度量研发效能情况的。这里我谈一下对于业务开发的理解和认识,很多人可能都跟我最开始一样,有一个疑惑,整天做业务开发如何成长?换句话说,就是说整天做CRUD,如何成长?我开始也有这样的疑惑,后来我转变了观念。
|
||||
BUGLY,这是一个终端 Crash 联网上报的系统,很多 APP 都接入了。Huskie,这是一个基于 zipkin 搭建的分布式调用链跟踪项目。SOHO,这是一个众包系统,主要是将数据标准和语音采集任务众包出去,让人家做。EPC 度量系统,这是研发效能度量系统,主要是度量研发效能情况的。这里我谈一下对于业务开发的理解和认识,很多人可能都跟我最开始一样,有一个疑惑,整天做业务开发如何成长?换句话说,就是说整天做 CRUD,如何成长?我开始也有这样的疑惑,后来我转变了观念。
|
||||
|
||||
我觉得对于系统的复杂度,可以粗略的分为技术复杂度和业务复杂度,对于业务系统,就是业务复杂度高一些,对于框架系统就是技术复杂度偏高一些。解决这两种复杂度,都具有很大的挑战。
|
||||
|
||||
此前做过的众包系统,就是各种业务逻辑,搞过去,搞过来,其实这就是业务复杂度高。为了解决这个问题,我们开始探索和实践领域驱动(DDD),确实带来了一些帮助,不至于系统那么混乱了。同时,我觉得这个过程中,自己对于DDD的感悟,对于我后来的项目系统划分和设计以及开发都带来了帮助。
|
||||
此前做过的众包系统,就是各种业务逻辑,搞过去,搞过来,其实这就是业务复杂度高。为了解决这个问题,我们开始探索和实践领域驱动(DDD),确实带来了一些帮助,不至于系统那么混乱了。同时,我觉得这个过程中,自己对于 DDD 的感悟,对于我后来的项目系统划分和设计以及开发都带来了帮助。
|
||||
|
||||
当然DDD不是银弹,我也不是吹嘘它有多好,只是了解了它后,有时候设计和开发时,能换一种思路。
|
||||
当然 DDD 不是银弹,我也不是吹嘘它有多好,只是了解了它后,有时候设计和开发时,能换一种思路。
|
||||
|
||||
可以发现,其实平时咱们做业务,想做好,其实也没那么容易,如果可以多探索多实践,将一些好的方法或思想或架构引入进来,与个人和业务都会有有帮助。
|
||||
|
||||
@ -52,19 +52,19 @@ BUGLY,这是一个终端Crash联网上报的系统,很多APP都接入了。H
|
||||
|
||||
PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎不发了)
|
||||
|
||||
印象比较深的是两次五星获得经历。第一次五星是工作的第二年,那一年是在做众包项目,因为项目本身难度不大,因此我把一些精力投入到了团队的基础建设中,帮团队搭建了java以及golang的项目脚手架,又做了几次中心技术分享,最终Leader觉得我表现比较突出,因此给了我五星。看来,主动一些,与个人与团队都是有好处的,最终也能获得一些回报。
|
||||
印象比较深的是两次五星获得经历。第一次五星是工作的第二年,那一年是在做众包项目,因为项目本身难度不大,因此我把一些精力投入到了团队的基础建设中,帮团队搭建了 java 以及 golang 的项目脚手架,又做了几次中心技术分享,最终 Leader 觉得我表现比较突出,因此给了我五星。看来,主动一些,与个人与团队都是有好处的,最终也能获得一些回报。
|
||||
|
||||
第二次五星,就是与EPC有关了。说一个搞笑的事,我也是后来才知道的,项目初期,总监去汇报时,给老板演示系统,加载了很久指标才刷出来,总监很不好意思的说正在优化;过了一段时间,又去汇报演示,结果又很尴尬的刷了很久才出来,总监无赖表示还是在优化。没想到,自己曾经让总监这么丢脸,哈哈。好吧,说一下结果,最终,我自己写了一个查询引擎替换了Mondrian,之后再也没有出现那种尴尬的情况了。随之而来,也给了好绩效鼓励。做EPC度量项目,我觉得自己成长很大,比如抗压能力,当你从零到一搭建一个系统时,会有一个先扛住再优化的过程,此外如果你的项目很重要,尤其是数据相关,那么任何一点问题,都可能让你神经紧绷,得想尽办法降低风险和故障。此外,另一个不同的感受就是,以前得项目,我大多是开发者,而这个系统,我是Owner负责人,当你Owner一个系统时,你得时刻负责,同时还需要思考系统的规划和方向,此外还需要分配好需求和把控进度,角色体验跟以前完全不一样。
|
||||
第二次五星,就是与 EPC 有关了。说一个搞笑的事,我也是后来才知道的,项目初期,总监去汇报时,给老板演示系统,加载了很久指标才刷出来,总监很不好意思的说正在优化;过了一段时间,又去汇报演示,结果又很尴尬的刷了很久才出来,总监无赖表示还是在优化。没想到,自己曾经让总监这么丢脸,哈哈。好吧,说一下结果,最终,我自己写了一个查询引擎替换了 Mondrian,之后再也没有出现那种尴尬的情况了。随之而来,也给了好绩效鼓励。做 EPC 度量项目,我觉得自己成长很大,比如抗压能力,当你从零到一搭建一个系统时,会有一个先扛住再优化的过程,此外如果你的项目很重要,尤其是数据相关,那么任何一点问题,都可能让你神经紧绷,得想尽办法降低风险和故障。此外,另一个不同的感受就是,以前得项目,我大多是开发者,而这个系统,我是 Owner 负责人,当你 Owner 一个系统时,你得时刻负责,同时还需要思考系统的规划和方向,此外还需要分配好需求和把控进度,角色体验跟以前完全不一样。
|
||||
|
||||
## 谈谈EPC
|
||||
## 谈谈 EPC
|
||||
|
||||
很多人都骂EPC,或者笑EPC,作为度量平台核心开发者之一,我来谈谈客观的看法。
|
||||
很多人都骂 EPC,或者笑 EPC,作为度量平台核心开发者之一,我来谈谈客观的看法。
|
||||
|
||||
其实EPC初衷是好的,希望通过全方位多维度的研效指标,来度量研发效能各环节的质量,进而反推业务,提升研发效能。然而,最终在实践的过程中,才发现,客观条件并不支持(工具还没建设好);此外,一味的追求指标数据,使得下面的人想方设法让指标好看,最终违背了初衷。
|
||||
其实 EPC 初衷是好的,希望通过全方位多维度的研效指标,来度量研发效能各环节的质量,进而反推业务,提升研发效能。然而,最终在实践的过程中,才发现,客观条件并不支持(工具还没建设好);此外,一味的追求指标数据,使得下面的人想方设法让指标好看,最终违背了初衷。
|
||||
|
||||
为什么,说EPC好了,其实如果你仔细了解下EPC,你就会发现,他是一套相当完善且比较先进的指标度量体系。覆盖了需求,代码,缺陷,测试,持续集成,运营部署各个环节。
|
||||
为什么,说 EPC 好了,其实如果你仔细了解下 EPC,你就会发现,他是一套相当完善且比较先进的指标度量体系。覆盖了需求,代码,缺陷,测试,持续集成,运营部署各个环节。
|
||||
|
||||
此外,这个过程中,虽然一些人和一些业务做弊,但绝大多数业务还是做出了改变的,比如微视那边的人反馈是,以前的代码写的跟屎一样,当有了EPC后,代码质量好了很多。虽然最后微视还是亡了,但是大厦将倾,EPC是救不了的,亡了也更不能怪EPC。
|
||||
此外,这个过程中,虽然一些人和一些业务做弊,但绝大多数业务还是做出了改变的,比如微视那边的人反馈是,以前的代码写的跟屎一样,当有了 EPC 后,代码质量好了很多。虽然最后微视还是亡了,但是大厦将倾,EPC 是救不了的,亡了也更不能怪 EPC。
|
||||
|
||||
## 谈谈嫡系
|
||||
|
||||
@ -74,7 +74,7 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
|
||||
|
||||
但另一方面,后来我负责了团队内很重要的事情,应该是中心内都算很重要的事,我独自负责一个方向,直接向总监汇报,似乎又有点像。
|
||||
|
||||
网上也有其他说法,一针见血,是不是嫡系,就看钱到不到位,这么说也有道理。我在7级时,就发了股票,自我感觉,还是不错的。我当时以为不出意外的话,我以后的钱途和发展是不是就会一帆风顺。不出意外就出了意外,第二年,EPC不达预期,部门总经理和总监都被换了,中心来了一个新的的总监。
|
||||
网上也有其他说法,一针见血,是不是嫡系,就看钱到不到位,这么说也有道理。我在 7 级时,就发了股票,自我感觉,还是不错的。我当时以为不出意外的话,我以后的钱途和发展是不是就会一帆风顺。不出意外就出了意外,第二年,EPC 不达预期,部门总经理和总监都被换了,中心来了一个新的的总监。
|
||||
|
||||
好吧,又要重新建立信任了。再到后来,是不是嫡系已经不重要了,因为大环境不好,又加上裁员,大家主动的被动的差不多都走了。
|
||||
|
||||
@ -87,7 +87,7 @@ PS:还好以前有奖杯,不然一点念想都没了。(现在腾讯似乎
|
||||
先说一些可量化的吧,我觉得有:
|
||||
|
||||
- 级别上,升上了九级,高级工程师。虽然大家都在说腾讯职级缩水,但是有没有高工的能力自己其实是知道的,我个人感觉,通过我这几年的努力,我算是达到了我当时认为的我需要在高工时达到的状态;
|
||||
- 绩效上,自我评价,个人不是一个特别卷的人,或者说不会为了卷而卷。但是,如果我认定我应该把它做好得,我的Owner意识,以及负责态度,我觉得还是可以的。最终在腾讯四年的绩效也还算过的去。再谈一些其他软技能方面:
|
||||
- 绩效上,自我评价,个人不是一个特别卷的人,或者说不会为了卷而卷。但是,如果我认定我应该把它做好得,我的 Owner 意识,以及负责态度,我觉得还是可以的。最终在腾讯四年的绩效也还算过的去。再谈一些其他软技能方面:
|
||||
|
||||
**1、文档能力**
|
||||
|
||||
|
||||
@ -159,7 +159,7 @@ OD 同学能拿到 A 吗?不知道,我入职晚,都没有经历一个完
|
||||
|
||||
## 投简历,找面试官求虐
|
||||
|
||||
20年11月初的一天,在同事们讨论“某某被其他公司高薪挖去了,钱景无限”的消息。
|
||||
20 年 11 月初的一天,在同事们讨论“某某被其他公司高薪挖去了,钱景无限”的消息。
|
||||
|
||||
我忽然惊觉,自己来到华为半年多,除了熟悉内部的系统和流程,好像没有什么成长和进步?
|
||||
|
||||
@ -332,6 +332,6 @@ blabla 有少量的基础问题和一面有重复,还有几个和大数据相
|
||||
|
||||
## 文末的絮叨
|
||||
|
||||
**入职鹅厂已经1月有余。不同的岗位,不同的工作内容,也是不同的挑战。**
|
||||
**入职鹅厂已经 1 月有余。不同的岗位,不同的工作内容,也是不同的挑战。**
|
||||
|
||||
感受比较深的是,作为程序员,还是要自我驱动,努力提升个人技术能力,横向纵向都要扩充,这样才能走得长远。
|
||||
@ -1,4 +1,3 @@
|
||||
|
||||
# 程序人生
|
||||
|
||||
::: tip 这是一则或许对你有用的小广告
|
||||
@ -32,9 +31,9 @@
|
||||
- [斩获 20+ 大厂 offer 的面试经验分享](./interview/the-experience-of-get-offer-from-over-20-big-companies.md)
|
||||
- [一位大龄程序员所经历的面试的历炼和思考](./interview/the-experience-and-thinking-of-an-interview-experienced-by-an-older-programmer.md)
|
||||
- [从面试官和候选者的角度谈如何准备技术初试](./interview/technical-preliminary-preparation.md)
|
||||
- [包装严重的IT行业,作为面试官,我是如何甄别应聘者的包装程度](./interview/screen-candidates-for-packaging.md)
|
||||
- [普通人的春招总结(阿里、腾讯offer)](./interview/summary-of-spring-recruitment.md)
|
||||
- [2021校招我的个人经历和经验](./interview/my-personal-experience-in-2021.md)
|
||||
- [包装严重的 IT 行业,作为面试官,我是如何甄别应聘者的包装程度](./interview/screen-candidates-for-packaging.md)
|
||||
- [普通人的春招总结(阿里、腾讯 offer)](./interview/summary-of-spring-recruitment.md)
|
||||
- [2021 校招我的个人经历和经验](./interview/my-personal-experience-in-2021.md)
|
||||
- [如何在技术初试中考察程序员的技术能力](./interview/how-to-examine-the-technical-ability-of-programmers-in-the-first-test-of-technology.md)
|
||||
- [阿里技术面试的一些秘密](./interview/some-secrets-about-alibaba-interview.md)
|
||||
|
||||
|
||||
@ -77,7 +77,7 @@ tag:
|
||||
|
||||
另外就是,技术岗的绩效考核不同于销售或者运营岗,很容易指标化。
|
||||
|
||||
需求吞吐量、BUG数、线上事故... 的确有一大堆研发效能指标,但这些指标在绩效考核时是否会被参考?具体又该如何分配比重?本身就是一个扯不清楚的难题。
|
||||
需求吞吐量、BUG 数、线上事故... 的确有一大堆研发效能指标,但这些指标在绩效考核时是否会被参考?具体又该如何分配比重?本身就是一个扯不清楚的难题。
|
||||
|
||||
最终决定你绩效结果的还是你领导的主观判断。你所见到的 360 环评,以及弄一些指标排序,这些都只是将绩效结果合理化的一种方式,并非关键所在。
|
||||
|
||||
@ -89,7 +89,7 @@ tag:
|
||||
|
||||
下面我再展开聊聊,大家最最关心的 A 和 C,它们背后的逻辑。
|
||||
|
||||
## 绩效被打A和C的逻辑是什么?
|
||||
## 绩效被打 A 和 C 的逻辑是什么?
|
||||
|
||||
“铆足了劲拿不到 A,一不留神居然拿了个 C”,这是绝大多数打工人最真实的职场现状。
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ title: JavaGuide(Java学习&&面试指南)
|
||||
|
||||
[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)
|
||||
|
||||
<!-- @include: ./banner.snippet.md -->
|
||||
<!-- @include: @banner.snippet.md -->
|
||||
|
||||
## 项目相关
|
||||
|
||||
@ -91,7 +91,7 @@ title: JavaGuide(Java学习&&面试指南)
|
||||
|
||||
### JVM (必看 :+1:)
|
||||
|
||||
JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
|
||||
JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.com/javase/specs/jvms/se8/html/index.html) 和周志明老师的[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/34907497/) (强烈建议阅读多遍!)。
|
||||
|
||||
- **[Java 内存区域](./java/jvm/memory-area.md)**
|
||||
- **[JVM 垃圾回收](./java/jvm/jvm-garbage-collection.md)**
|
||||
@ -167,8 +167,8 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
|
||||
**常见算法问题总结** :
|
||||
|
||||
- [几道常见的字符串算法题总结 ](./cs-basics/algorithms/string-algorithm-problems.md)
|
||||
- [几道常见的链表算法题总结 ](./cs-basics/algorithms/linkedlist-algorithm-problems.md)
|
||||
- [几道常见的字符串算法题总结](./cs-basics/algorithms/string-algorithm-problems.md)
|
||||
- [几道常见的链表算法题总结](./cs-basics/algorithms/linkedlist-algorithm-problems.md)
|
||||
- [剑指 offer 部分编程题](./cs-basics/algorithms/the-sword-refers-to-offer.md)
|
||||
- [十大经典排序算法](./cs-basics/algorithms/10-classical-sorting-algorithms.md)
|
||||
|
||||
|
||||
@ -19,39 +19,4 @@ category: 知识星球
|
||||
|
||||

|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/image-20220311203414600.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiufuwu.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
**我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!**
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)。
|
||||
|
||||
这里再送一个 30 元的新人优惠券(续费半价)。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
进入星球之后,记得添加微信,我会发你详细的星球使用指南。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -71,7 +71,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
|
||||
|
||||
## 有没有还不错的项目推荐?
|
||||
|
||||
**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
|
||||
**[《Java 面试指北》](../zhuanlan/java-mian-shi-zhi-bei.md)** 的「面试准备篇」中有一篇文章专门整理了一些比较高质量的实战项目,非常适合用来学习或者作为项目经验。
|
||||
|
||||
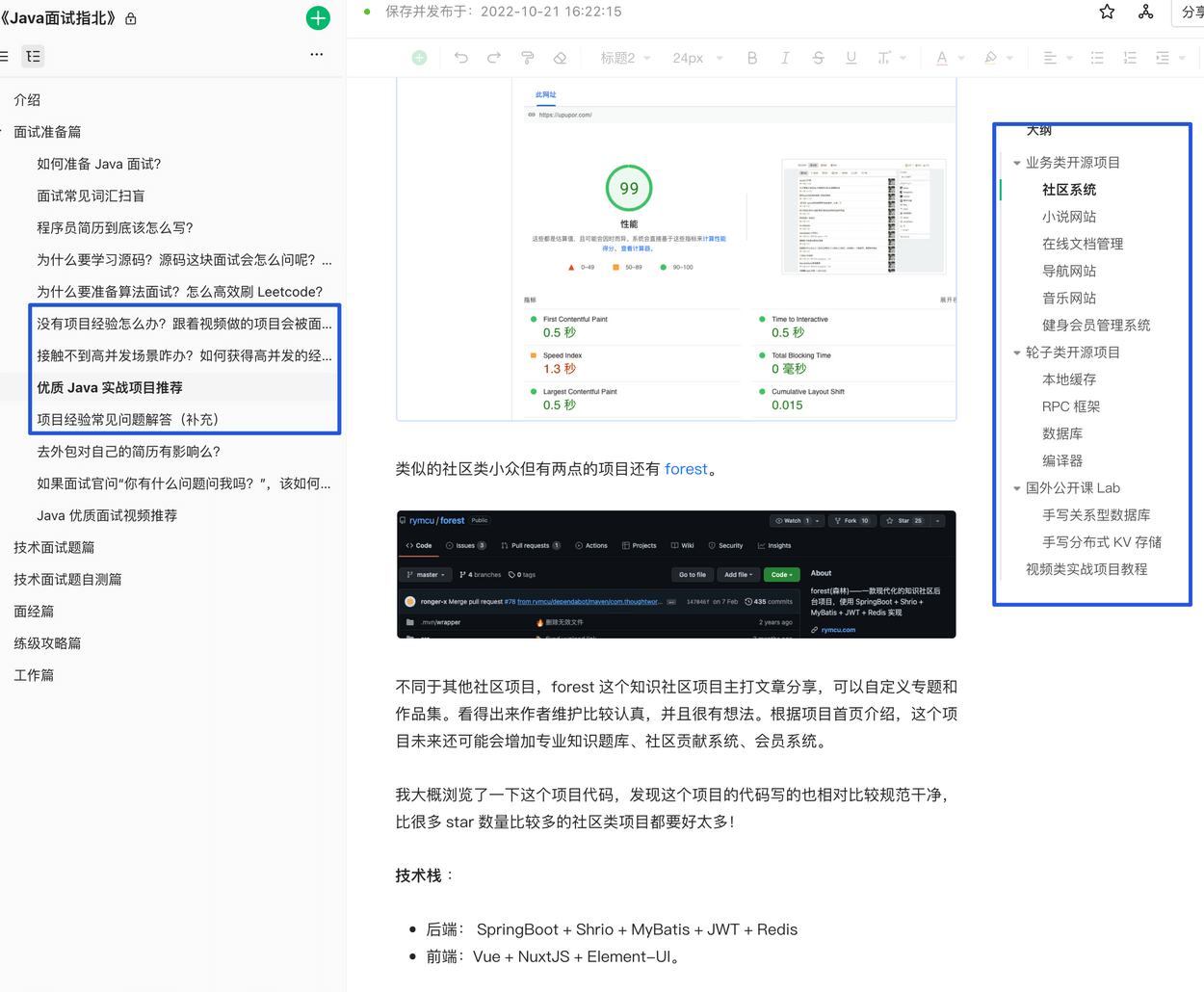
|
||||
|
||||
@ -96,7 +96,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
|
||||
5. **安全** : 项目是否存在安全问题?
|
||||
6. ......
|
||||
|
||||
另外,我在星球分享过常见的性能优化方向实践案例,涉及到多线程、异步、索引、缓存等方向,强烈推荐你看看:https://t.zsxq.com/06EqfeMZZ 。
|
||||
另外,我在星球分享过常见的性能优化方向实践案例,涉及到多线程、异步、索引、缓存等方向,强烈推荐你看看:<https://t.zsxq.com/06EqfeMZZ> 。
|
||||
|
||||
最后,**再给大家推荐一个 IDEA 优化代码的小技巧,超级实用!**
|
||||
|
||||
@ -111,4 +111,3 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
|
||||
并且,你还可以自定义检查规则。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -15,24 +15,4 @@ category: 知识星球
|
||||
|
||||
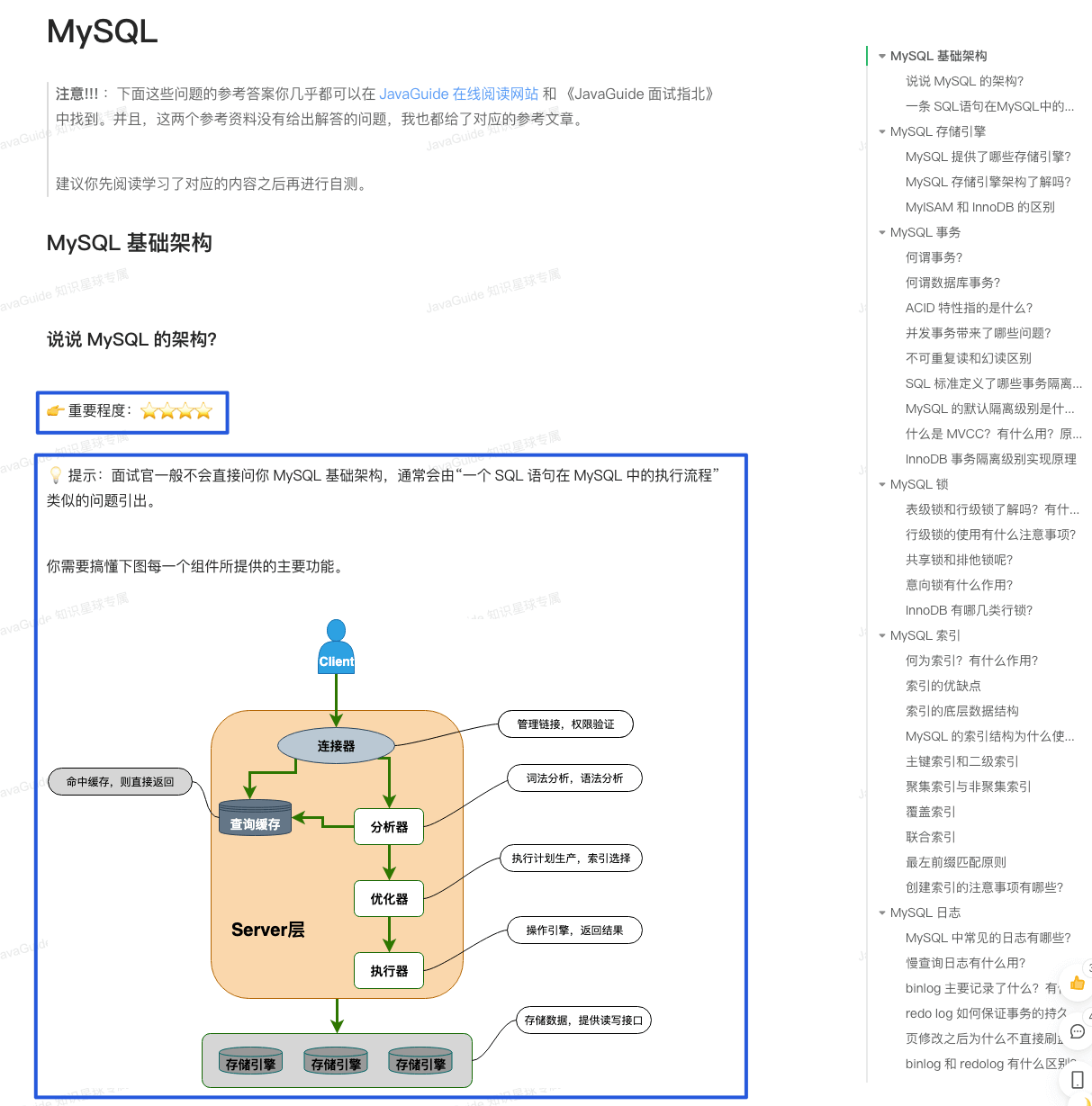
|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://www.yuque.com/docs/share/8a30ffb5-83f3-40f9-baf9-38de68b906dc),干货非常多,学习氛围非常好!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
|
||||
|
||||
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiufuwu.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
我有自己的原则,不割韭菜,用心做内容,真心希望帮助到你!
|
||||
|
||||
如果你感兴趣的话,不妨花 3 分钟左右看看星球的详细介绍: [JavaGuide 知识星球详细介绍](https://www.yuque.com/docs/share/8a30ffb5-83f3-40f9-baf9-38de68b906dc)(文末有优惠券)。
|
||||
|
||||
<div align="center">
|
||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||
<img src="https://oss.javaguide.cn/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
||||
</a>
|
||||
</div>
|
||||
<!-- @include: @planet.snippet.md -->
|
||||
|
||||
@ -61,15 +61,15 @@ category: 知识星球
|
||||
|
||||
- **目标企业的官网/公众号** :最及时最权威的获取招聘信息的途径。
|
||||
- **招聘网站** :[BOSS 直聘](https://www.zhipin.com/)、[智联招聘](https://www.zhaopin.com/)、[拉勾招聘](https://www.lagou.com/)......。
|
||||
- **牛客网** :每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址:https://www.nowcoder.com/jobs/recommend/campus 。
|
||||
- **超级简历** :超级简历目前整合了各大企业的校园招聘入口,地址:https://www.wondercv.com/jobs/。如果你是校招的话,点击“校招网申”就可以直接跳转到各大企业的校园招聘入口的整合页面了。
|
||||
- **牛客网** :每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址:<https://www.nowcoder.com/jobs/recommend/campus> 。
|
||||
- **超级简历** :超级简历目前整合了各大企业的校园招聘入口,地址:<https://www.wondercv.com/jobs/。如果你是校招的话,点击“校招网申”就可以直接跳转到各大企业的校园招聘入口的整合页面了。>
|
||||
- **认识的朋友** :如果你有认识的朋友在目标企业工作的话,你也可以找他们了解招聘信息,并且可以让他们帮你内推。
|
||||
- **宣讲会** :宣讲会也是一个不错的途径,不过,好的企业通常只会去比较好的学校,可以留意一下意向公司的宣讲会安排或者直接去到一所比较好的学校参加宣讲会。像我当时校招就去参加了几场宣讲会。不过,我是在荆州上学,那边没什么比较好的学校,一般没有公司去开宣讲会。所以,我当时是直接跑到武汉来了,参加了武汉理工大学以及华中科技大学的几场宣讲会。总体感觉还是很不错的!
|
||||
- **其他** :校园就业信息网、学校论坛、班级 or 年级 QQ 群。
|
||||
|
||||
校招的话,建议以官网为准,有宣讲会、靠谱一点的内推的话更好。社招的话,可以多留意一下各大招聘网站比如 BOSS直聘、拉勾上的职位信息,也可以找被熟人内推,获得面试机会的概率更大一些,进度一般也更快一些。
|
||||
校招的话,建议以官网为准,有宣讲会、靠谱一点的内推的话更好。社招的话,可以多留意一下各大招聘网站比如 BOSS 直聘、拉勾上的职位信息,也可以找被熟人内推,获得面试机会的概率更大一些,进度一般也更快一些。
|
||||
|
||||
一般是只能投递一个岗位,不过,也有极少数投递不同部门两个岗位的情况,这个应该不会有影响,但你的前一次面试情况可能会被记录,也就是说就算你投递成功两个岗位,第一个岗位面试失败的话,对第二个岗位也会有影响,很可能直接就被pass。
|
||||
一般是只能投递一个岗位,不过,也有极少数投递不同部门两个岗位的情况,这个应该不会有影响,但你的前一次面试情况可能会被记录,也就是说就算你投递成功两个岗位,第一个岗位面试失败的话,对第二个岗位也会有影响,很可能直接就被 pass。
|
||||
|
||||
## 多花点时间完善简历
|
||||
|
||||
|
||||
@ -825,8 +825,6 @@ public class Example {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 静态方法和实例方法有何不同?
|
||||
|
||||
**1、调用方式**
|
||||
@ -898,7 +896,7 @@ public class Person {
|
||||
综上:**重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变。**
|
||||
|
||||
| 区别点 | 重载方法 | 重写方法 |
|
||||
| :--------- | :------- | :----------------------------------------------------------- |
|
||||
| :--------- | :------- | :--------------------------------------------------------------- |
|
||||
| 发生范围 | 同一个类 | 子类 |
|
||||
| 参数列表 | 必须修改 | 一定不能修改 |
|
||||
| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
|
||||
|
||||
@ -511,11 +511,11 @@ JDK 自带的序列化方式一般不会用 ,因为序列化效率低并且存
|
||||
|
||||
- **不支持跨语言调用** : 如果调用的是其他语言开发的服务的时候就不支持了。
|
||||
- **性能差** :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
|
||||
- **存在安全问题** :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:[应用安全:JAVA反序列化漏洞之殇](https://cryin.github.io/blog/secure-development-java-deserialization-vulnerability/) 。
|
||||
- **存在安全问题** :序列化和反序列化本身并不存在问题。但当输入的反序列化的数据可被用户控制,那么攻击者即可通过构造恶意输入,让反序列化产生非预期的对象,在此过程中执行构造的任意代码。相关阅读:[应用安全:JAVA 反序列化漏洞之殇](https://cryin.github.io/blog/secure-development-java-deserialization-vulnerability/) 。
|
||||
|
||||
## I/O
|
||||
|
||||
关于I/O的详细解读,请看下面这几篇文章,里面涉及到的知识点和面试题更全面。
|
||||
关于 I/O 的详细解读,请看下面这几篇文章,里面涉及到的知识点和面试题更全面。
|
||||
|
||||
- [Java IO 基础知识总结](../io/io-basis.md)
|
||||
- [Java IO 设计模式总结](../io/io-design-patterns.md)
|
||||
@ -569,8 +569,3 @@ for (String s : strs) {
|
||||
Java 中最常用的语法糖主要有泛型、自动拆装箱、变长参数、枚举、内部类、增强 for 循环、try-with-resources 语法、lambda 表达式等。
|
||||
|
||||
关于这些语法糖的详细解读,请看这篇文章 [Java 语法糖详解](./syntactic-sugar.md) 。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user