mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-07-28 12:22:17 +08:00
[docs update]补充完善消息队列应用场景&spi机制
This commit is contained in:
parent
c9746ff2df
commit
52cce06e41
@ -553,15 +553,19 @@ Redis 通过 **IO 多路复用程序** 来监听来自客户端的大量连接
|
||||
|
||||
### Redis6.0 之前为什么不使用多线程?
|
||||
|
||||
虽然说 Redis 是单线程模型,但是,实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
|
||||
虽然说 Redis 是单线程模型,但实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
|
||||
|
||||
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”。
|
||||
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主线程之外的其他线程来“异步处理”,从而减少对主线程的影响。
|
||||
|
||||
为此,Redis 4.0 之后新增了`UNLINK`(可以看作是 `DEL` 的异步版本)、`FLUSHALL ASYNC`(清空所有数据库的所有 key,不仅仅是当前 `SELECT` 的数据库)、`FLUSHDB ASYNC`(清空当前 `SELECT` 数据库中的所有 key)等异步命令。
|
||||
为此,Redis 4.0 之后新增了几个异步命令:
|
||||
|
||||
- `UNLINK`:可以看作是 `DEL` 命令的异步版本。
|
||||
- `FLUSHALL ASYNC`:用于清空所有数据库的所有键,不限于当前 `SELECT` 的数据库。
|
||||
- `FLUSHDB ASYNC`:用于清空当前 `SELECT` 数据库中的所有键。
|
||||
|
||||
|
||||
|
||||
大体上来说,Redis 6.0 之前主要还是单线程处理。
|
||||
总的来说,直到 Redis 6.0 之前,Redis 的主要操作仍然是单线程处理的。
|
||||
|
||||
**那 Redis6.0 之前为什么不使用多线程?** 我觉得主要原因有 3 点:
|
||||
|
||||
|
||||
@ -41,15 +41,17 @@ tag:
|
||||
|
||||
## 消息队列有什么用?
|
||||
|
||||
通常来说,使用消息队列能为我们的系统带来下面三点好处:
|
||||
通常来说,使用消息队列主要能为我们的系统带来下面三点好处:
|
||||
|
||||
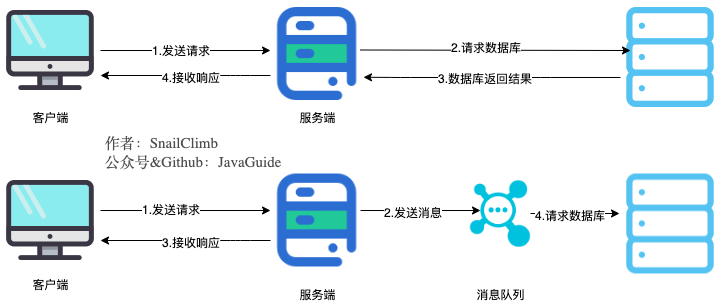
1. **通过异步处理提高系统性能(减少响应所需时间)**
|
||||
2. **削峰/限流**
|
||||
3. **降低系统耦合性。**
|
||||
1. 通过异步处理提高系统性能(减少响应所需时间)
|
||||
2. 削峰/限流
|
||||
3. 降低系统耦合性
|
||||
|
||||
除了这三点之外,消息队列还有其他的一些应用场景,例如实现分布式事务、顺序保证和数据流处理。
|
||||
|
||||
如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
|
||||
|
||||
### 通过异步处理提高系统性能(减少响应所需时间)
|
||||
### 通过异步处理提高系统性能(减少响应时间)
|
||||
|
||||
|
||||
|
||||
@ -93,6 +95,18 @@ RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允
|
||||
|
||||

|
||||
|
||||
### 顺序保证
|
||||
|
||||
在很多应用场景中,处理数据的顺序至关重要。消息队列保证数据按照特定的顺序被处理,适用于那些对数据顺序有严格要求的场景。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持顺序消息。
|
||||
|
||||
### 延时/定时处理
|
||||
|
||||
消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持定时/延时消息。
|
||||
|
||||
### 数据流处理
|
||||
|
||||
针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
|
||||
|
||||
## 使用消息队列会带来哪些问题?
|
||||
|
||||
- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
|
||||
|
||||
@ -14,15 +14,9 @@ head:
|
||||
|
||||
> 本文来自 [Kingshion](https://github.com/jjx0708) 投稿。欢迎更多朋友参与到 JavaGuide 的维护工作,这是一件非常有意义的事情。详细信息请看:[JavaGuide 贡献指南](https://javaguide.cn/javaguide/contribution-guideline.html) 。
|
||||
|
||||
在面向对象的设计原则中,一般推荐模块之间基于接口编程,通常情况下调用方模块是不会感知到被调用方模块的内部具体实现。一旦代码里面涉及具体实现类,就违反了开闭原则。如果需要替换一种实现,就需要修改代码。
|
||||
面向对象设计鼓励模块间基于接口而非具体实现编程,以降低模块间的耦合,遵循依赖倒置原则,并支持开闭原则(对扩展开放,对修改封闭)。然而,直接依赖具体实现会导致在替换实现时需要修改代码,违背了开闭原则。为了解决这个问题,SPI 应运而生,它提供了一种服务发现机制,允许在程序外部动态指定具体实现。这与控制反转(IoC)的思想相似,将组件装配的控制权移交给了程序之外。
|
||||
|
||||
为了实现在模块装配的时候不用在程序里面动态指明,这就需要一种服务发现机制。Java SPI 就是提供了这样一个机制:**为某个接口寻找服务实现的机制。这有点类似 IoC 的思想,将装配的控制权移交到了程序之外。**
|
||||
|
||||
java 也经常会制定一些规范,除了提供默认实现之外,也支持第三方提供其自己对于某规范的实现,例如 JDBC( Java 数据库连接)驱动管理、日志框架、图片处理服务等。以 JDBC 为例,JDBC 4.0 及其之后的版本使用 SPI 机制来自动发现和加载数据库驱动。开发者只需要将 JDBC 驱动的 JAR 包放在类路径下,无需通过 Class.forName() 来显式加载驱动类。
|
||||
|
||||
但是以上机制存在一个特定于 java 的问题,即双亲委派模型不能很好地处理那些由Java核心库直接加载,但又必须由加载到JVM中的第三方类实现的情况。因为核心类加载器不会去加载那些位于应用程序类路径(classpath)上的类,这就导致了一个问题:如何允许核心 Java API 能够加载由应用程序类加载器加载的类或接口的实现?
|
||||
|
||||
java 设计了一种机制来解决该问题,这就是 SPI 。
|
||||
SPI 机制也解决了 Java 类加载体系中双亲委派模型带来的限制。[双亲委派模型](https://javaguide.cn/java/jvm/classloader.html)虽然保证了核心库的安全性和一致性,但也限制了核心库或扩展库加载应用程序类路径上的类(通常由第三方实现)。SPI 允许核心或扩展库定义服务接口,第三方开发者提供并部署实现,SPI 服务加载机制则在运行时动态发现并加载这些实现。例如,JDBC 4.0 及之后版本利用 SPI 自动发现和加载数据库驱动,开发者只需将驱动 JAR 包放置在类路径下即可,无需使用`Class.forName()`显式加载驱动类。
|
||||
|
||||
## SPI 介绍
|
||||
|
||||
@ -338,9 +332,9 @@ public void reload() {
|
||||
}
|
||||
```
|
||||
|
||||
其解决第三方类加载的机制其实就蕴含在 `ClassLoader cl = Thread.currentThread().getContextClassLoader();` 中,`cl` 就是**线程上下文类加载器**(Thread Context ClassLoader)。这是每个线程持有的类加载器,JDK的设计允许应用程序或容器(如Web应用服务器)设置这个类加载器,以便核心类库能够通过它来加载应用程序类。
|
||||
其解决第三方类加载的机制其实就蕴含在 `ClassLoader cl = Thread.currentThread().getContextClassLoader();` 中,`cl` 就是**线程上下文类加载器**(Thread Context ClassLoader)。这是每个线程持有的类加载器,JDK 的设计允许应用程序或容器(如 Web 应用服务器)设置这个类加载器,以便核心类库能够通过它来加载应用程序类。
|
||||
|
||||
线程上下文类加载器默认情况下是应用程序类加载器(Application ClassLoader),它负责加载classpath上的类。当核心库需要加载应用程序提供的类时,它可以使用线程上下文类加载器来完成。这样,即使是由引导类加载器加载的核心库代码,也能够加载并使用由应用程序类加载器加载的类。
|
||||
线程上下文类加载器默认情况下是应用程序类加载器(Application ClassLoader),它负责加载 classpath 上的类。当核心库需要加载应用程序提供的类时,它可以使用线程上下文类加载器来完成。这样,即使是由引导类加载器加载的核心库代码,也能够加载并使用由应用程序类加载器加载的类。
|
||||
|
||||
根据代码的调用顺序,在 `reload()` 方法中是通过一个内部类 `LazyIterator` 实现的。先继续往下面看。
|
||||
|
||||
|
||||
@ -90,7 +90,7 @@ public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneabl
|
||||
static final int MIN_TREEIFY_CAPACITY = 64;
|
||||
// 存储元素的数组,总是2的幂次倍
|
||||
transient Node<k,v>[] table;
|
||||
// 存放具体元素的集
|
||||
// 一个包含了映射中所有键值对的集合视图
|
||||
transient Set<map.entry<k,v>> entrySet;
|
||||
// 存放元素的个数,注意这个不等于数组的长度。
|
||||
transient int size;
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user