diff --git a/README.md b/README.md
index 7fe0229b..1e614dda 100644
--- a/README.md
+++ b/README.md
@@ -346,6 +346,8 @@ CAP 也就是 Consistency(一致性)、Availability(可用性)、Partiti
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
+关于 CAP 的详细解读请看:[《BASE理论解读》](docs/system-design/high-availability/BASE理论.md)。
+
#### 限流
限流为了对服务端的接口接受请求的频率进行限制,防止服务挂掉。比如某一接口的请求限制为 100 个每秒, 对超过限制的请求放弃处理或者放到队列中等待处理。限流可以有效应对突发请求过多。相关阅读:[限流算法有哪些?](docs/system-design/high-availability/limit-request.md)
diff --git a/docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md b/docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
index e5561246..59c14848 100644
--- a/docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
+++ b/docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
@@ -1,1119 +1,305 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
+
+- [Java 并发基础常见面试题总结](#java-并发基础常见面试题总结)
+ - [1. 什么是线程和进程?](#1-什么是线程和进程)
+ - [1.1. 何为进程?](#11-何为进程)
+ - [1.2. 何为线程?](#12-何为线程)
+ - [2. 请简要描述线程与进程的关系,区别及优缺点?](#2-请简要描述线程与进程的关系区别及优缺点)
+ - [2.1. 图解进程和线程的关系](#21-图解进程和线程的关系)
+ - [2.2. 程序计数器为什么是私有的?](#22-程序计数器为什么是私有的)
+ - [2.3. 虚拟机栈和本地方法栈为什么是私有的?](#23-虚拟机栈和本地方法栈为什么是私有的)
+ - [2.4. 一句话简单了解堆和方法区](#24-一句话简单了解堆和方法区)
+ - [3. 说说并发与并行的区别?](#3-说说并发与并行的区别)
+ - [4. 为什么要使用多线程呢?](#4-为什么要使用多线程呢)
+ - [5. 使用多线程可能带来什么问题?](#5-使用多线程可能带来什么问题)
+ - [6. 说说线程的生命周期和状态?](#6-说说线程的生命周期和状态)
+ - [7. 什么是上下文切换?](#7-什么是上下文切换)
+ - [8. 什么是线程死锁?如何避免死锁?](#8-什么是线程死锁如何避免死锁)
+ - [8.1. 认识线程死锁](#81-认识线程死锁)
+ - [8.2. 如何避免线程死锁?](#82-如何避免线程死锁)
+ - [9. 说说 sleep() 方法和 wait() 方法区别和共同点?](#9-说说-sleep-方法和-wait-方法区别和共同点)
+ - [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
+ - [公众号](#公众号)
-
+
-
+# Java 并发基础常见面试题总结
-- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
- - [1.synchronized 关键字](#1synchronized-关键字)
- - [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
- - [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
- - [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
- - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
- - [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
- - [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
- - [1.3.3.总结](#133总结)
- - [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
- - [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
- - [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
- - [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
- - [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
- - [2. volatile 关键字](#2-volatile-关键字)
- - [2.1. CPU 缓存模型](#21-cpu-缓存模型)
- - [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
- - [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
- - [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
- - [3. ThreadLocal](#3-threadlocal)
- - [3.1. ThreadLocal 简介](#31-threadlocal-简介)
- - [3.2. ThreadLocal 示例](#32-threadlocal-示例)
- - [3.3. ThreadLocal 原理](#33-threadlocal-原理)
- - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
- - [4. 线程池](#4-线程池)
- - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
- - [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
- - [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
- - [4.4. 如何创建线程池](#44-如何创建线程池)
- - [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
- - [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
- - [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
- - [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
- - [4.7 线程池原理分析](#47-线程池原理分析)
- - [5. Atomic 原子类](#5-atomic-原子类)
- - [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
- - [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
- - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
- - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
- - [6. AQS](#6-aqs)
- - [6.1. AQS 介绍](#61-aqs-介绍)
- - [6.2. AQS 原理分析](#62-aqs-原理分析)
- - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
- - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
- - [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
- - [6.3. AQS 组件总结](#63-aqs-组件总结)
- - [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
- - [7 Reference](#7-reference)
- - [公众号](#公众号)
+## 1. 什么是线程和进程?
-
+### 1.1. 何为进程?
+进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
-# Java 并发进阶常见面试题总结
+在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
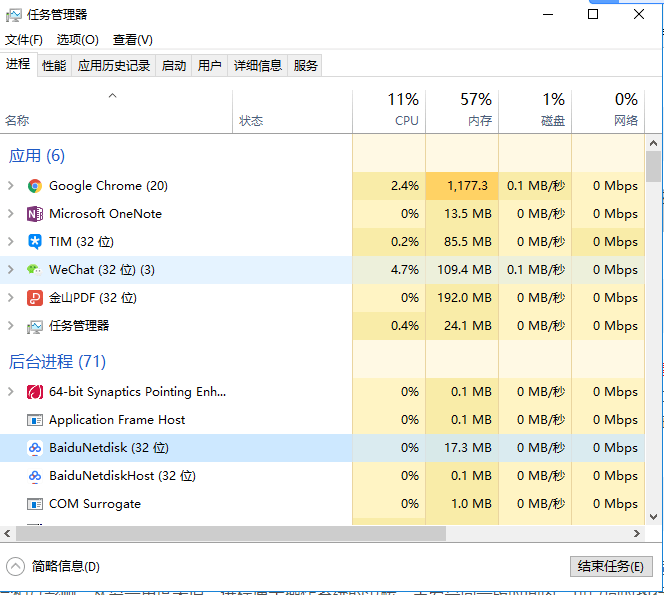
-## 1.synchronized 关键字
+如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
-
+
-### 1.1.说一说自己对于 synchronized 关键字的了解
+### 1.2. 何为线程?
-**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
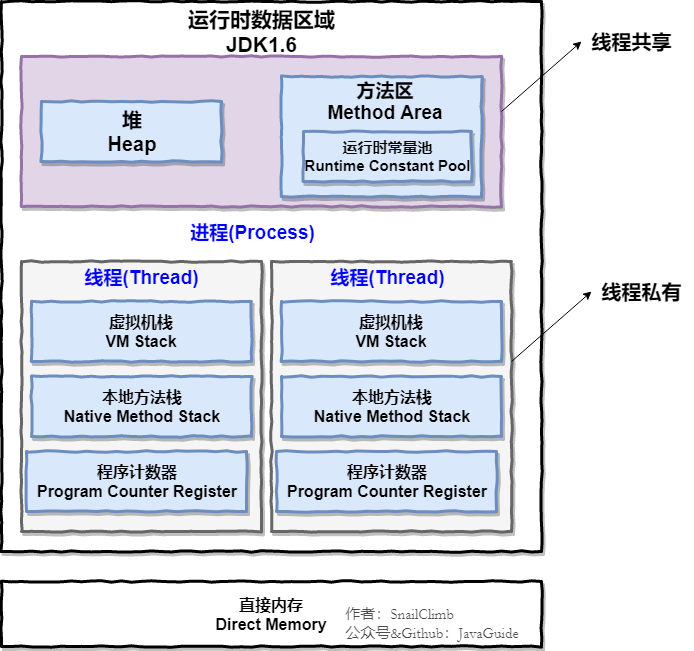
+线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
-
-**为什么呢?**
-
-因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
-
-庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-
-所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 synchronized 关键字。
-
-### 1.2. 说说自己是怎么使用 synchronized 关键字
-
-**synchronized 关键字最主要的三种使用方式:**
-
-**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
```java
-synchronized void method() {
- //业务代码
-}
-```
-
-**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
-
-```java
-synchronized void staic method() {
- //业务代码
-}
-```
-
-**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
-
-```java
-synchronized(this) {
- //业务代码
-}
-```
-
-**总结:**
-
-- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
-- `synchronized` 关键字加到实例方法上是给对象实例上锁。
-- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
-
-下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
-
-面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
-
-**双重校验锁实现对象单例(线程安全)**
-
-```java
-public class Singleton {
-
- private volatile static Singleton uniqueInstance;
-
- private Singleton() {
- }
-
- public static Singleton getUniqueInstance() {
- //先判断对象是否已经实例过,没有实例化过才进入加锁代码
- if (uniqueInstance == null) {
- //类对象加锁
- synchronized (Singleton.class) {
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-
-另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
-
-`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
-
-1. 为 `uniqueInstance` 分配内存空间
-2. 初始化 `uniqueInstance`
-3. 将 `uniqueInstance` 指向分配的内存地址
-
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
-
-使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
-
-### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
-
-先说结论:**构造方法不能使用 synchronized 关键字修饰。**
-
-构造方法本身就属于线程安全的,不存在同步的构造方法一说。
-
-### 1.3. 讲一下 synchronized 关键字的底层原理
-
-**synchronized 关键字底层原理属于 JVM 层面。**
-
-#### 1.3.1. synchronized 同步语句块的情况
-
-```java
-public class SynchronizedDemo {
- public void method() {
- synchronized (this) {
- System.out.println("synchronized 代码块");
+public class MultiThread {
+ public static void main(String[] args) {
+ // 获取 Java 线程管理 MXBean
+ ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
+ // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
+ ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
+ // 遍历线程信息,仅打印线程 ID 和线程名称信息
+ for (ThreadInfo threadInfo : threadInfos) {
+ System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
}
}
}
-
```
-通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
+上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
-
+```
+[5] Attach Listener //添加事件
+[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
+[3] Finalizer //调用对象 finalize 方法的线程
+[2] Reference Handler //清除 reference 线程
+[1] main //main 线程,程序入口
+```
-从上面我们可以看出:
+从上面的输出内容可以看出:**一个 Java 程序的运行是 main 线程和多个其他线程同时运行**。
-**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
+## 2. 请简要描述线程与进程的关系,区别及优缺点?
-当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
+**从 JVM 角度说进程和线程之间的关系**
-> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
->
-> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
+### 2.1. 图解进程和线程的关系
-在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
+下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》](https://github.com/Snailclimb/JavaGuide/blob/3965c02cc0f294b0bd3580df4868d5e396959e2e/Java%E7%9B%B8%E5%85%B3/%E5%8F%AF%E8%83%BD%E6%98%AF%E6%8A%8AJava%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F%E8%AE%B2%E7%9A%84%E6%9C%80%E6%B8%85%E6%A5%9A%E7%9A%84%E4%B8%80%E7%AF%87%E6%96%87%E7%AB%A0.md "《可能是把 Java 内存区域讲的最清楚的一篇文章》")
-在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
+
+
+
-
-