mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-14 05:21:42 +08:00
Update MySQL数据库索引.md
This commit is contained in:
parent
55cb730b49
commit
496f4cb8a3
@ -22,20 +22,37 @@
|
||||
|
||||
## 索引的底层数据结构
|
||||
|
||||
### Hash & B+树
|
||||
### Hash表 & B+树
|
||||
|
||||
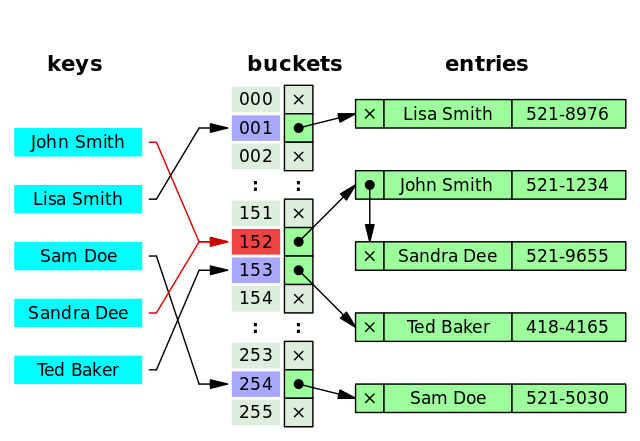
Hash 索引指的就是 Hash 表,最大的优点就是能够在很短的时间内,根据 Hash 函数定位到数据所在的位置,也就是说 Hash 索引检索指定数据的时间复杂度可以接近 0(1)。
|
||||
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
|
||||
|
||||
但是,MySQL 并没有使用 Hash 索引而是使用 B+树作为索引的数据结构。**为什么呢?**
|
||||
**为何能够通过 key 快速取出 value呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 value 对应的 index,找到了 index 也就找到了对应的 value。
|
||||
|
||||
**1.Hash 冲突问题** :知道 HashMap 或 HashTable 的同学,相信都知道它们最大的缺点就是 Hash 冲突了。不过对于数据库来说这还不算最大的缺点。
|
||||
```java
|
||||
hash = hashfunc(key)
|
||||
index = hash % array_size
|
||||
```
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
|
||||
|
||||
|
||||
|
||||
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
|
||||
|
||||
既然哈希表这么快,**为什么MySQL 没有使用其作为索引的数据结构呢?**
|
||||
|
||||
**1.Hash 冲突问题** :我们上面也提到过Hash 冲突了,不过对于数据库来说这还不算最大的缺点。
|
||||
|
||||
**2.Hash 索引不支持顺序和范围查询(Hash 索引不支持顺序和范围查询是它最大的缺点:** 假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。
|
||||
|
||||
试想一种情况:
|
||||
|
||||
```java
|
||||
SELECT * FROM tb1 WHERE id < 500;
|
||||
SELECT * FROM tb1 WHERE id < 500;Copy to clipboardErrorCopied
|
||||
```
|
||||
|
||||
在这种范围查询中,优势非常大,直接遍历比 500 小的叶子节点就够了。而 Hash 索引是根据 hash 算法来定位的,难不成还要把 1 - 499 的数据,每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了。
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user