diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index bdd5072d..7f20ff19 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -127,11 +127,14 @@ SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTE
+
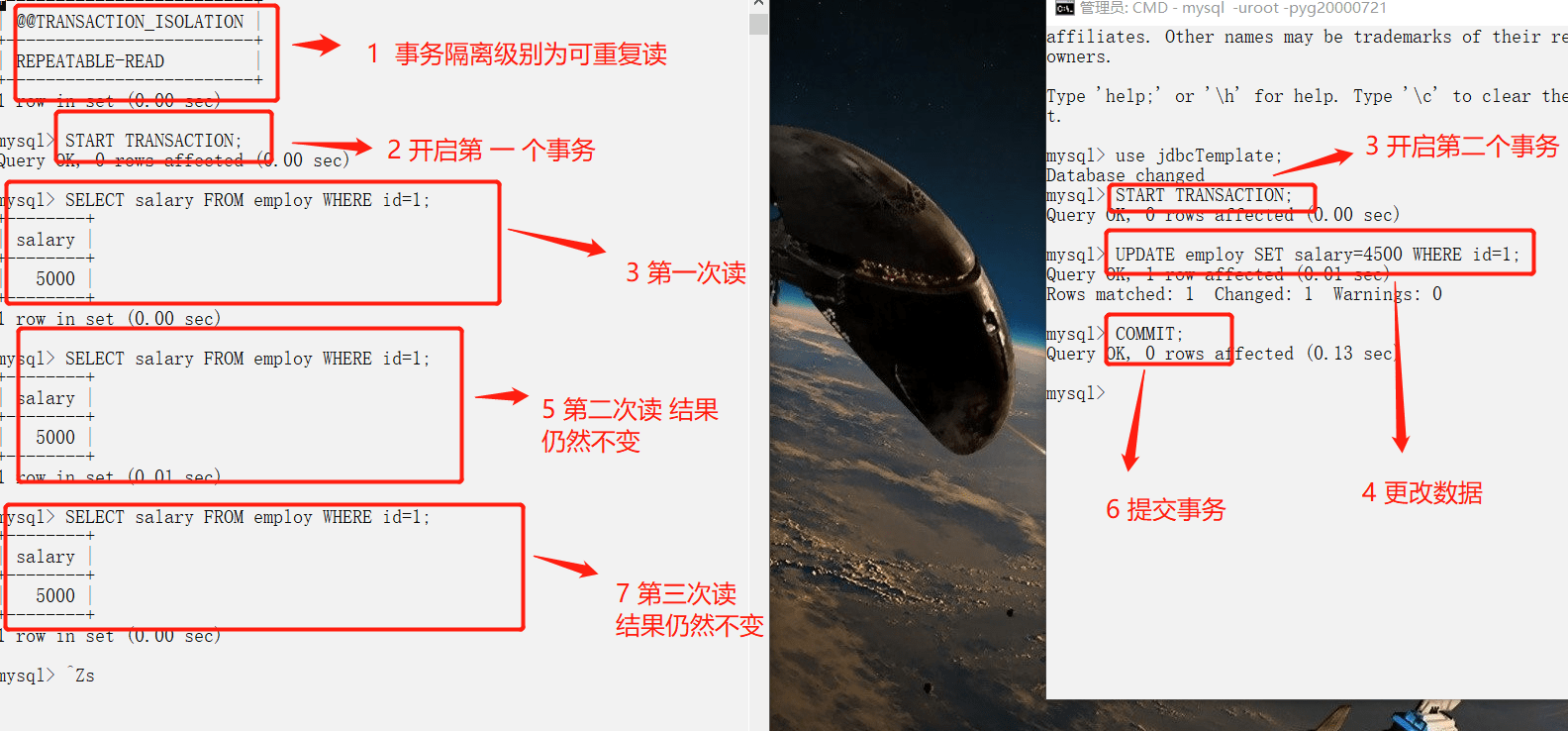
#### 幻读
##### 演示幻读出现的情况
-
+
+

+