mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-10 00:41:37 +08:00
commit
4313eac5b8
@ -107,7 +107,7 @@ public interface RandomAccess {
|
|||||||
2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
|
2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
|
||||||
3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
|
3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
|
||||||
4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
|
4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
|
||||||
5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
|
5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
|
||||||
|
|
||||||
**HashMap 中带有初始容量的构造函数:**
|
**HashMap 中带有初始容量的构造函数:**
|
||||||
|
|
||||||
@ -218,7 +218,7 @@ static int hash(int h) {
|
|||||||
|
|
||||||
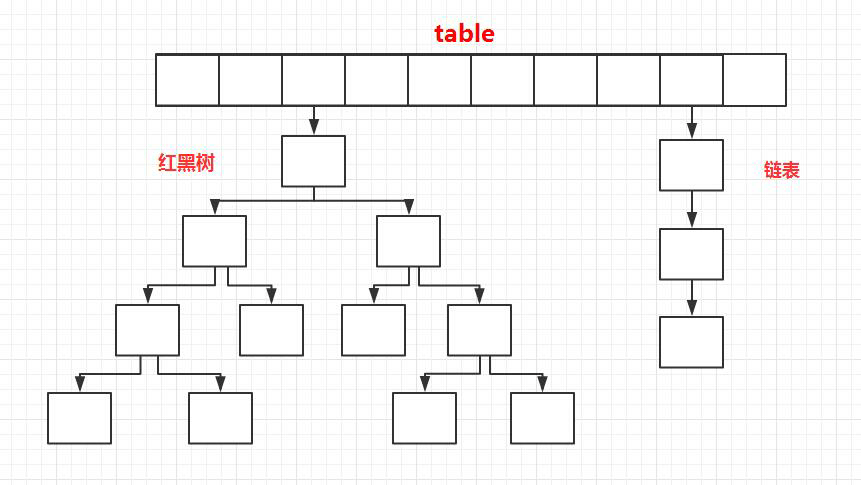
### JDK1.8之后
|
### JDK1.8之后
|
||||||
|
|
||||||
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
|
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -436,7 +436,7 @@ Output:
|
|||||||
|
|
||||||
### Map
|
### Map
|
||||||
|
|
||||||
- **HashMap:** JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
|
- **HashMap:** JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
|
||||||
- **LinkedHashMap:** LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
|
- **LinkedHashMap:** LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
|
||||||
- **Hashtable:** 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
|
- **Hashtable:** 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
|
||||||
- **TreeMap:** 红黑树(自平衡的排序二叉树)
|
- **TreeMap:** 红黑树(自平衡的排序二叉树)
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user