mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]完善对分库分表的介绍
This commit is contained in:
parent
a82fc5ce6b
commit
392632a739
@ -196,14 +196,22 @@ MySQL 主从同步延时是指从库的数据落后于主库的数据,这种
|
|||||||
- 数据库中的数据占用的空间越来越大,备份时间越来越长。
|
- 数据库中的数据占用的空间越来越大,备份时间越来越长。
|
||||||
- 应用的并发量太大。
|
- 应用的并发量太大。
|
||||||
|
|
||||||
|
不过,分库分表的成本太高,如非必要尽量不要采用。而且,并不一定是单表千万级数据量就要分表,毕竟每张表包含的字段不同,它们在不错的性能下能够存放的数据量也不同,还是要具体情况具体分析。
|
||||||
|
|
||||||
|
之前看过一篇文章分析 “[InnoDB 中高度为 3 的 B+ 树最多可以存多少数据](https://juejin.cn/post/7165689453124517896)”,写的挺不错,感兴趣的可以看看。
|
||||||
|
|
||||||
### 常见的分片算法有哪些?
|
### 常见的分片算法有哪些?
|
||||||
|
|
||||||
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
|
分片算法主要解决了数据被水平分片之后,数据究竟该存放在哪个表的问题。
|
||||||
|
|
||||||
- **哈希分片**:求指定 key(比如 id) 的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。
|
常见的分片算法有:
|
||||||
- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
|
||||||
|
- **哈希分片**:求指定分片键的哈希,然后根据哈希值确定数据应被放置在哪个表中。哈希分片比较适合随机读写的场景,不太适合经常需要范围查询的场景。哈希分片可以使每个表的数据分布相对均匀,但对动态伸缩(例如新增一个表或者库)不友好。
|
||||||
|
- **范围分片**:按照特定的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个表, `300000~599999` 的分到第二个表。范围分片适合需要经常进行范围查找且数据分布均匀的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
||||||
|
- **映射表分片**:使用一个单独的表(称为映射表)来存储分片键和分片位置的对应关系。映射表分片策略可以支持任何类型的分片算法,如哈希分片、范围分片等。映射表分片策略是可以灵活地调整分片规则,不需要修改应用程序代码或重新分布数据。不过,这种方式需要维护额外的表,还增加了查询的开销和复杂度。
|
||||||
|
- **一致性哈希分片**:将哈希空间组织成一个环形结构,将分片键和节点(数据库或表)都映射到这个环上,然后根据顺时针的规则确定数据或请求应该分配到哪个节点上,解决了传统哈希对动态伸缩不友好的问题。
|
||||||
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
|
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
|
||||||
- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
|
- **融合算法分片**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
|
||||||
- ……
|
- ……
|
||||||
|
|
||||||
### 分库分表会带来什么问题呢?
|
### 分库分表会带来什么问题呢?
|
||||||
@ -214,7 +222,7 @@ MySQL 主从同步延时是指从库的数据落后于主库的数据,这种
|
|||||||
|
|
||||||
- **join 操作**:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。不过,很多大厂的资深 DBA 都是建议尽量不要使用 join 操作。因为 join 的效率低,并且会对分库分表造成影响。对于需要用到 join 操作的地方,可以采用多次查询业务层进行数据组装的方法。不过,这种方法需要考虑业务上多次查询的事务性的容忍度。
|
- **join 操作**:同一个数据库中的表分布在了不同的数据库中,导致无法使用 join 操作。这样就导致我们需要手动进行数据的封装,比如你在一个数据库中查询到一个数据之后,再根据这个数据去另外一个数据库中找对应的数据。不过,很多大厂的资深 DBA 都是建议尽量不要使用 join 操作。因为 join 的效率低,并且会对分库分表造成影响。对于需要用到 join 操作的地方,可以采用多次查询业务层进行数据组装的方法。不过,这种方法需要考虑业务上多次查询的事务性的容忍度。
|
||||||
- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。这个时候,我们就需要引入分布式事务了。关于分布式事务常见解决方案总结,网站上也有对应的总结:<https://javaguide.cn/distributed-system/distributed-transaction.html> 。
|
- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。这个时候,我们就需要引入分布式事务了。关于分布式事务常见解决方案总结,网站上也有对应的总结:<https://javaguide.cn/distributed-system/distributed-transaction.html> 。
|
||||||
- **分布式 ID**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 ID 了。关于分布式 ID 的详细介绍&实现方案总结,网站上也有对应的总结:<https://javaguide.cn/distributed-system/distributed-id.html> 。
|
- **分布式 ID**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 ID 了。关于分布式 ID 的详细介绍&实现方案总结,可以看我写的这篇文章:[分布式 ID 介绍&实现方案总结](https://javaguide.cn/distributed-system/distributed-id.html)。
|
||||||
- **跨库聚合查询问题**:分库分表会导致常规聚合查询操作,如 group by,order by 等变得异常复杂。这是因为这些操作需要在多个分片上进行数据汇总和排序,而不是在单个数据库上进行。为了实现这些操作,需要编写复杂的业务代码,或者使用中间件来协调分片间的通信和数据传输。这样会增加开发和维护的成本,以及影响查询的性能和可扩展性。
|
- **跨库聚合查询问题**:分库分表会导致常规聚合查询操作,如 group by,order by 等变得异常复杂。这是因为这些操作需要在多个分片上进行数据汇总和排序,而不是在单个数据库上进行。为了实现这些操作,需要编写复杂的业务代码,或者使用中间件来协调分片间的通信和数据传输。这样会增加开发和维护的成本,以及影响查询的性能和可扩展性。
|
||||||
- ……
|
- ……
|
||||||
|
|
||||||
|
|||||||
@ -88,7 +88,7 @@ JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编
|
|||||||
|
|
||||||
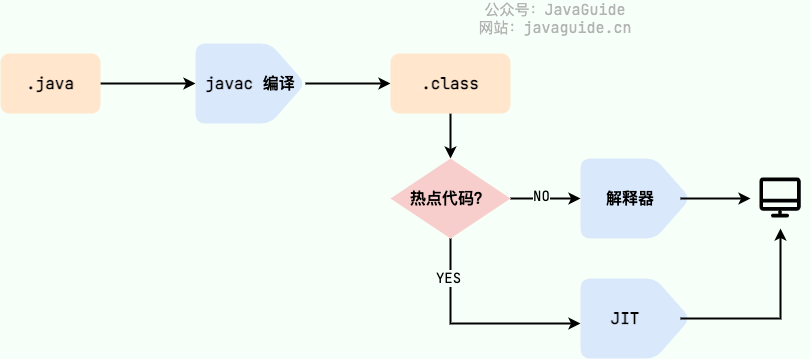
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 **JIT(Just in Time Compilation)** 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
|
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 **JIT(Just in Time Compilation)** 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
|
||||||
|
|
||||||
> 🌈 拓展:[有关JIT的实现细节: JVM C1、C2编译器](https://mp.weixin.qq.com/s/4haTyXUmh8m-dBQaEzwDJw)
|
> 🌈 拓展:[有关 JIT 的实现细节: JVM C1、C2 编译器](https://mp.weixin.qq.com/s/4haTyXUmh8m-dBQaEzwDJw)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user