mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs add]Redis 为什么用跳表实现有序集合
This commit is contained in:
parent
c720d99925
commit
2620a095fb
@ -325,6 +325,7 @@ export default sidebar({
|
|||||||
"3-commonly-used-cache-read-and-write-strategies",
|
"3-commonly-used-cache-read-and-write-strategies",
|
||||||
"redis-data-structures-01",
|
"redis-data-structures-01",
|
||||||
"redis-data-structures-02",
|
"redis-data-structures-02",
|
||||||
|
"redis-skiplist",
|
||||||
"redis-persistence",
|
"redis-persistence",
|
||||||
"redis-memory-fragmentation",
|
"redis-memory-fragmentation",
|
||||||
"redis-common-blocking-problems-summary",
|
"redis-common-blocking-problems-summary",
|
||||||
|
|||||||
@ -104,6 +104,12 @@ tag:
|
|||||||
|
|
||||||
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
|
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
|
||||||
|
|
||||||
|
先来看一张图(来源于《图解 HTTP》):
|
||||||
|
|
||||||
|
<img src="https://oss.javaguide.cn/github/javaguide/url%E8%BE%93%E5%85%A5%E5%88%B0%E5%B1%95%E7%A4%BA%E5%87%BA%E6%9D%A5%E7%9A%84%E8%BF%87%E7%A8%8B.jpg" style="zoom:50%" />
|
||||||
|
|
||||||
|
上图有一个错误需要注意:是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
|
||||||
|
|
||||||
总体来说分为以下几个步骤:
|
总体来说分为以下几个步骤:
|
||||||
|
|
||||||
1. 在浏览器中输入指定网页的 URL。
|
1. 在浏览器中输入指定网页的 URL。
|
||||||
|
|||||||
@ -187,7 +187,7 @@ MAC 地址具有可携带性、永久性,身份证号永久地标识一个人
|
|||||||
|
|
||||||
最后,记住,MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
|
最后,记住,MAC 地址有一个特殊地址:FF-FF-FF-FF-FF-FF(全 1 地址),该地址表示广播地址。
|
||||||
|
|
||||||
### ARP 协议解决了什么问题地位如何?
|
### ARP 协议解决了什么问题?
|
||||||
|
|
||||||
ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,它解决的是网络层地址和链路层地址之间的转换问题。因为一个 IP 数据报在物理上传输的过程中,总是需要知道下一跳(物理上的下一个目的地)该去往何处,但 IP 地址属于逻辑地址,而 MAC 地址才是物理地址,ARP 协议解决了 IP 地址转 MAC 地址的一些问题。
|
||||||
|
|
||||||
|
|||||||
@ -54,6 +54,7 @@ URL(Uniform Resource Locators),即统一资源定位器。网络上的所
|
|||||||
|
|
||||||
- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
|
- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
|
||||||
- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
|
- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
|
||||||
|
- [HTTP 常见状态码总结(应用层)](https://javaguide.cn/cs-basics/network/http-status-codes.html)
|
||||||
|
|
||||||
## 传输层
|
## 传输层
|
||||||
|
|
||||||
|
|||||||
@ -395,7 +395,7 @@ struct sdshdr {
|
|||||||
|
|
||||||
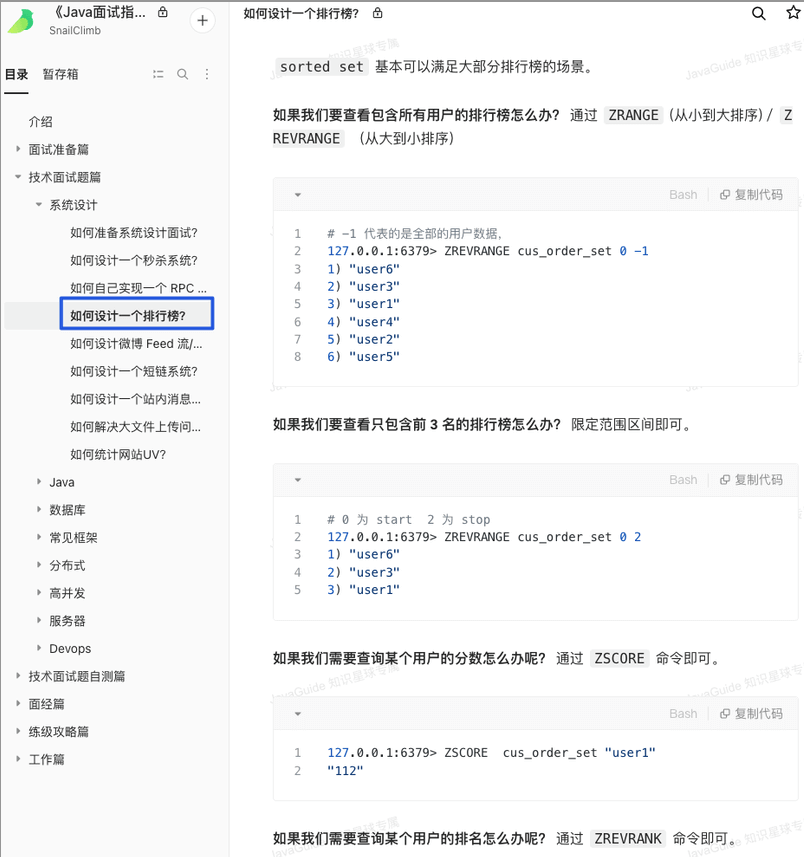
### 使用 Redis 实现一个排行榜怎么做?
|
### 使用 Redis 实现一个排行榜怎么做?
|
||||||
|
|
||||||
Redis 中有一个叫做 `Sorted Set` 的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
Redis 中有一个叫做 `Sorted Set` (有序集合)的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||||
|
|
||||||
相关的一些 Redis 命令: `ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
相关的一些 Redis 命令: `ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||||
|
|
||||||
@ -405,6 +405,10 @@ Redis 中有一个叫做 `Sorted Set` 的数据类型经常被用在各种排行
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### Redis 为什么用跳表实现有序集合?
|
||||||
|
|
||||||
|
这道面试题很多大厂比较喜欢问,难度还是有点大的,我单独写了一篇文章来详细回答这个问题:[Redis 为什么用跳表实现有序集合](./redis-skiplist.md)。
|
||||||
|
|
||||||
### Set 的应用场景是什么?
|
### Set 的应用场景是什么?
|
||||||
|
|
||||||
Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
|
Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
|
||||||
|
|||||||
@ -1,3 +1,10 @@
|
|||||||
|
---
|
||||||
|
title: Redis为什么用跳表实现有序集合
|
||||||
|
category: 数据库
|
||||||
|
tag:
|
||||||
|
- Redis
|
||||||
|
---
|
||||||
|
|
||||||
## 前言
|
## 前言
|
||||||
|
|
||||||
近几年针对 Redis 面试时会涉及常见数据结构的底层设计,其中就有这么一道比较有意思的面试题:“Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
|
近几年针对 Redis 面试时会涉及常见数据结构的底层设计,其中就有这么一道比较有意思的面试题:“Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?”。
|
||||||
@ -6,7 +13,7 @@
|
|||||||
|
|
||||||
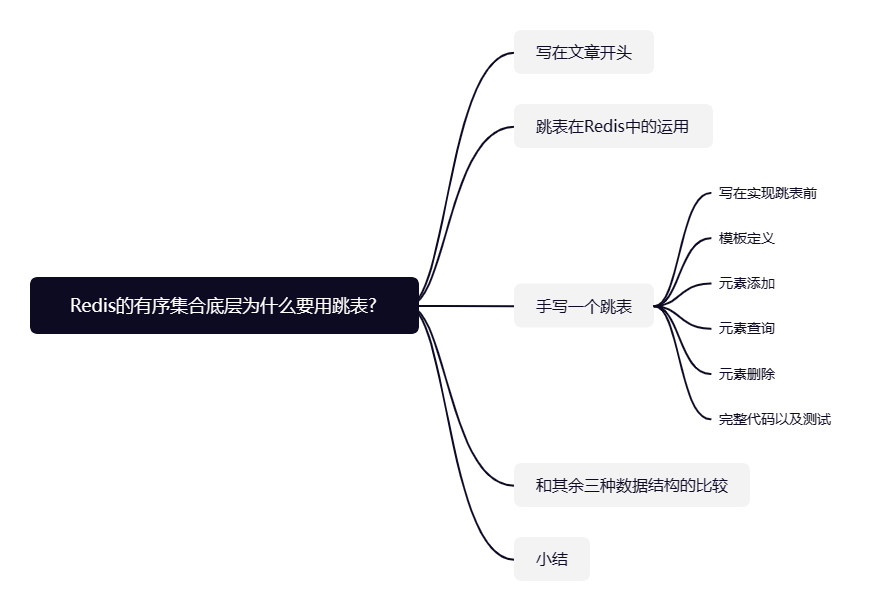
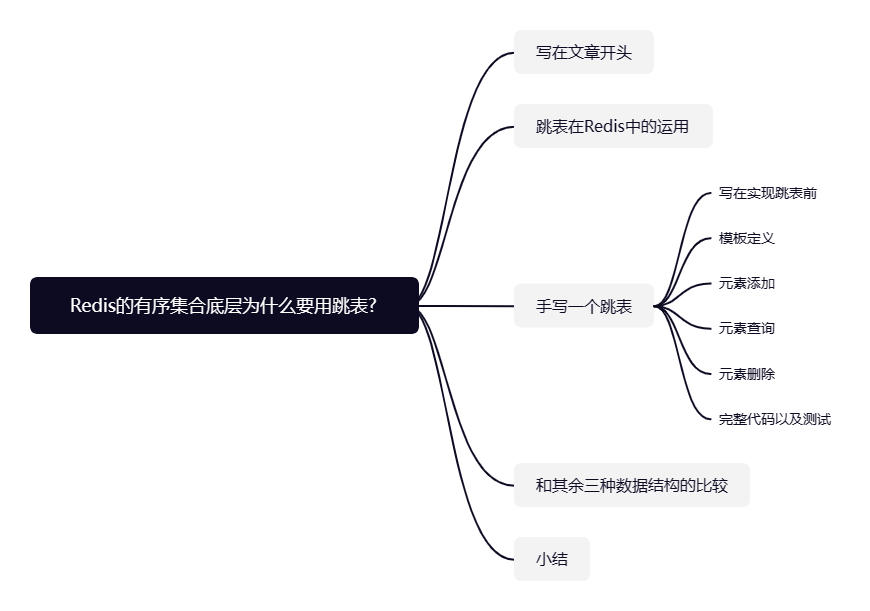
本文整体脉络如下图所示,笔者会从有序集合的基本使用结合跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握。
|
本文整体脉络如下图所示,笔者会从有序集合的基本使用结合跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 跳表在 Redis 中的运用
|
## 跳表在 Redis 中的运用
|
||||||
|
|
||||||
@ -75,7 +82,7 @@ zset-max-ziplist-entries 128
|
|||||||
|
|
||||||
可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
|
可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
假如我们需要查询元素 6,其工作流程如下:
|
假如我们需要查询元素 6,其工作流程如下:
|
||||||
|
|
||||||
@ -85,7 +92,7 @@ zset-max-ziplist-entries 128
|
|||||||
|
|
||||||
相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
|
相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
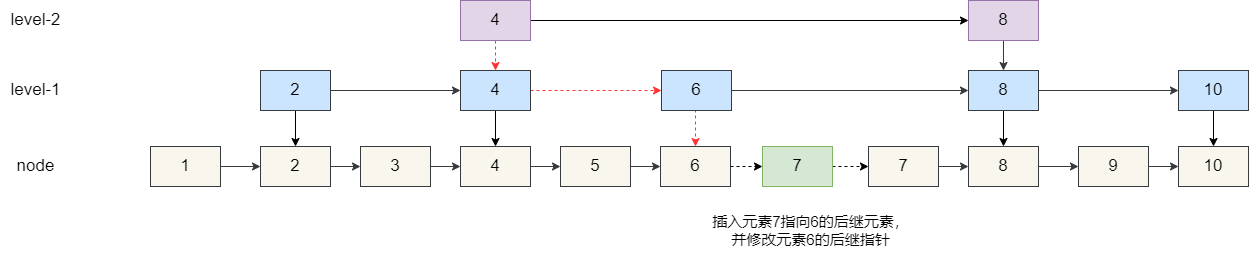
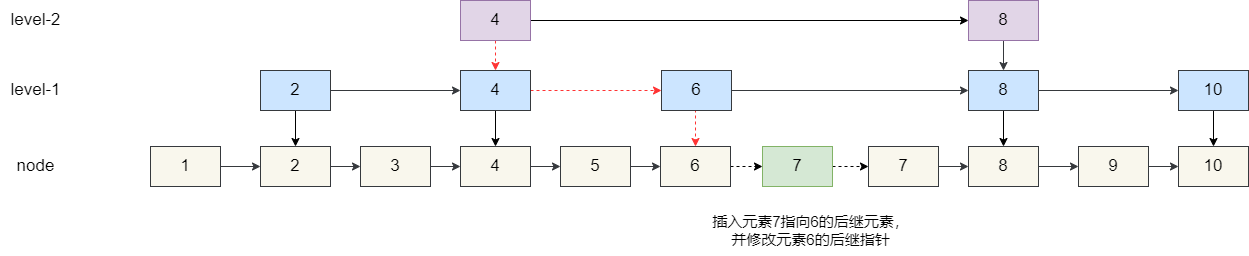
对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
|
对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
|
||||||
|
|
||||||
@ -95,7 +102,7 @@ zset-max-ziplist-entries 128
|
|||||||
4. 继续比较 6 的后继节点为索引 8,大于元素 7,索引继续向下。
|
4. 继续比较 6 的后继节点为索引 8,大于元素 7,索引继续向下。
|
||||||
5. 最终我们来到 6 的原始节点,发现其后继节点为 7,指针没有继续向下的空间,自此我们可知元素 6 就是小于插入元素 7 的最大值,于是便将元素 7 插入。
|
5. 最终我们来到 6 的原始节点,发现其后继节点为 7,指针没有继续向下的空间,自此我们可知元素 6 就是小于插入元素 7 的最大值,于是便将元素 7 插入。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
这里我们又面临一个问题,我们是否需要为元素 7 建立索引,索引多高合适?
|
这里我们又面临一个问题,我们是否需要为元素 7 建立索引,索引多高合适?
|
||||||
|
|
||||||
@ -143,7 +150,7 @@ r=n/2^k
|
|||||||
|
|
||||||
我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
|
我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
最后我们再来说说删除,假设我们这里要删除元素 10,我们必须定位到当前跳表**各层**元素小于 10 的最大值,索引执行步骤为:
|
最后我们再来说说删除,假设我们这里要删除元素 10,我们必须定位到当前跳表**各层**元素小于 10 的最大值,索引执行步骤为:
|
||||||
|
|
||||||
@ -153,7 +160,7 @@ r=n/2^k
|
|||||||
4. 1 级索引完成定位后,指针向下,后继节点为 9,指针推进。
|
4. 1 级索引完成定位后,指针向下,后继节点为 9,指针推进。
|
||||||
5. 9 的后继节点为 10,同理需要让其指向 null,将 10 删除。
|
5. 9 的后继节点为 10,同理需要让其指向 null,将 10 删除。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 模板定义
|
### 模板定义
|
||||||
|
|
||||||
@ -167,7 +174,7 @@ r=n/2^k
|
|||||||
|
|
||||||
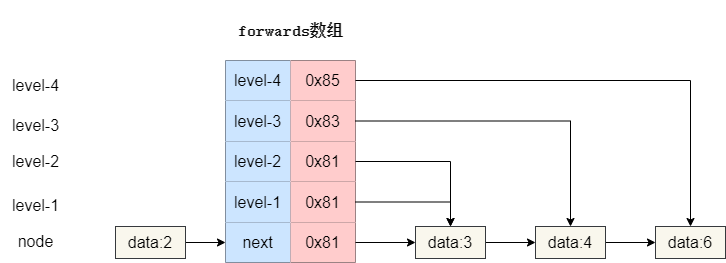
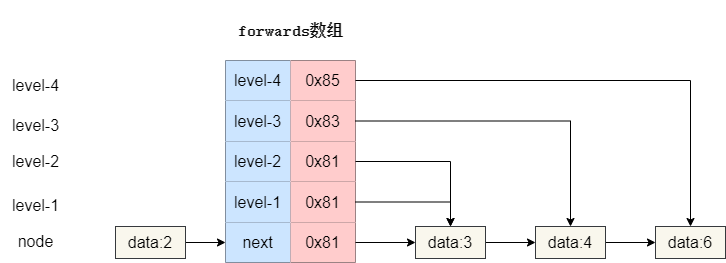
以下图为例,我们**forwards**数组长度为 5,其中**索引 0**记录的是原始链表节点的后继节点地址,而其余自底向上表示从 1 级索引到 4 级索引的后继节点指向。
|
以下图为例,我们**forwards**数组长度为 5,其中**索引 0**记录的是原始链表节点的后继节点地址,而其余自底向上表示从 1 级索引到 4 级索引的后继节点指向。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
于是我们的就有了这样一个代码定义,可以看出笔者对于数组的长度设置为固定的 16**(上文的推算最大高度建议是 16)**,默认**data**为-1,节点最大高度**maxLevel**初始化为 1,注意这个**maxLevel**的值代表原始链表加上索引的总高度。
|
于是我们的就有了这样一个代码定义,可以看出笔者对于数组的长度设置为固定的 16**(上文的推算最大高度建议是 16)**,默认**data**为-1,节点最大高度**maxLevel**初始化为 1,注意这个**maxLevel**的值代表原始链表加上索引的总高度。
|
||||||
|
|
||||||
@ -214,11 +221,11 @@ private int randomLevel() {
|
|||||||
|
|
||||||
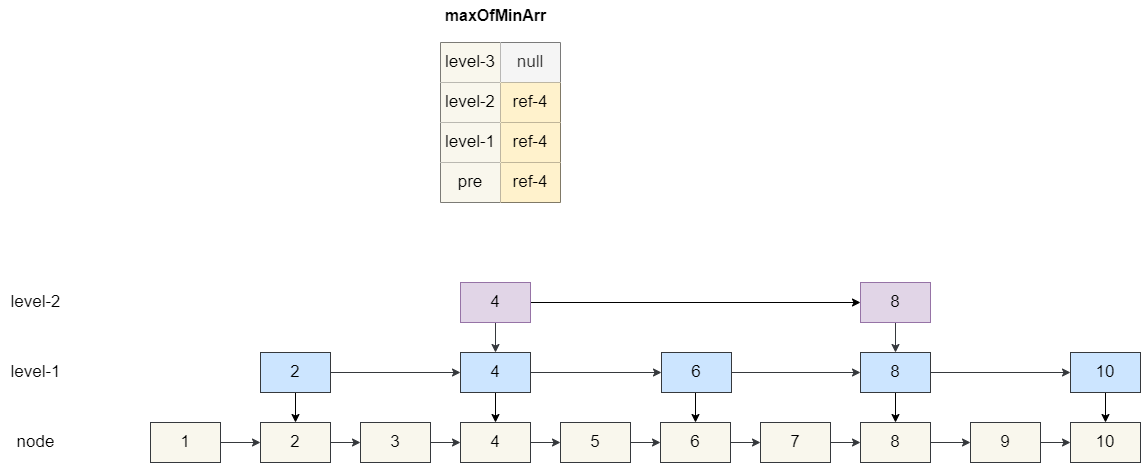
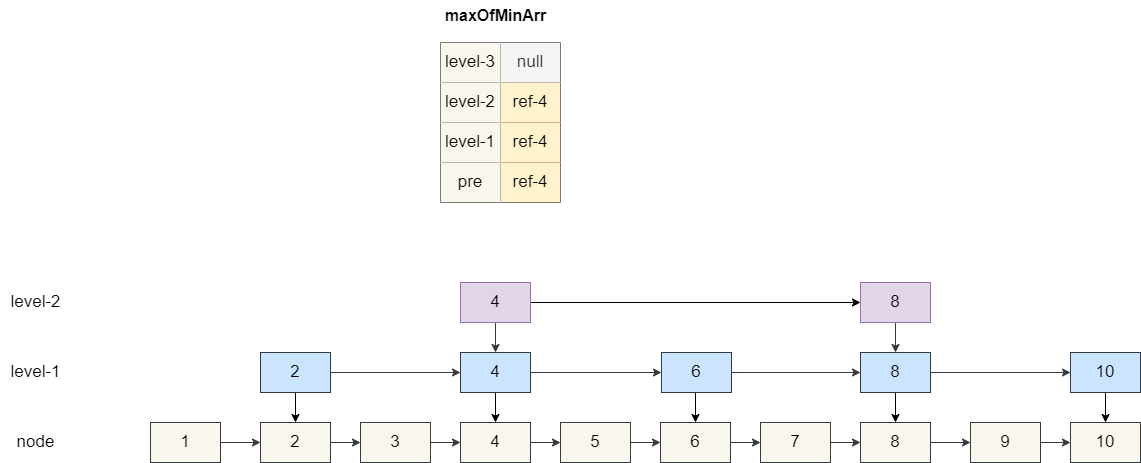
假设我们要插入的**value**为 5,我们的数组查找结果当前节点的前驱节点和 1 级索引、2 级索引的前驱节点都为 4,三级索引为空。
|
假设我们要插入的**value**为 5,我们的数组查找结果当前节点的前驱节点和 1 级索引、2 级索引的前驱节点都为 4,三级索引为空。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
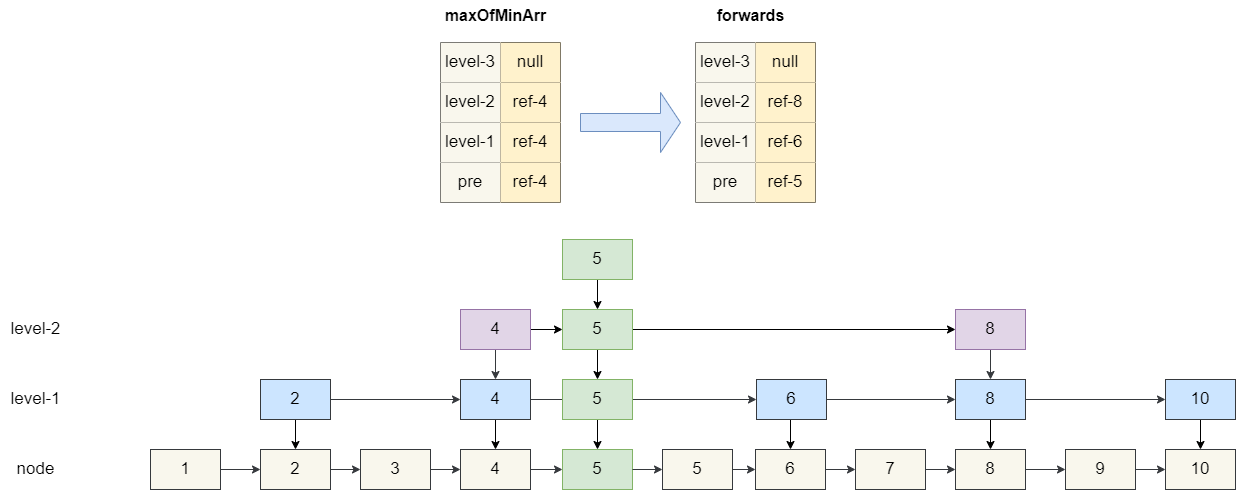
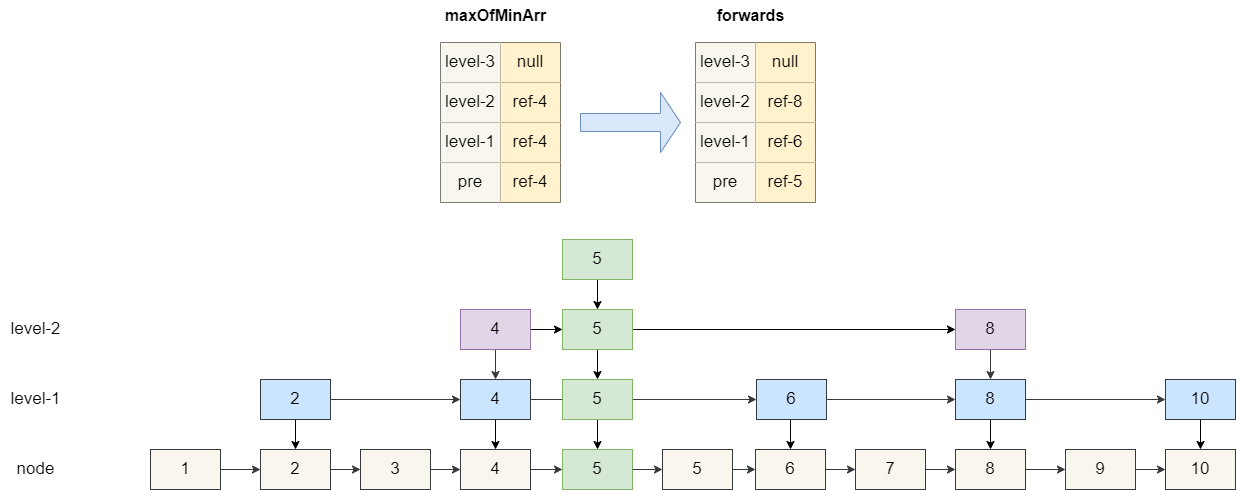
然后我们基于这个数组**maxOfMinArr** 定位到各级的后继节点,让插入的元素 5 指向这些后继节点,而**maxOfMinArr**指向 5,结果如下图:
|
然后我们基于这个数组**maxOfMinArr** 定位到各级的后继节点,让插入的元素 5 指向这些后继节点,而**maxOfMinArr**指向 5,结果如下图:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
转化成代码就是下面这个形式,是不是很简单呢?我们继续:
|
转化成代码就是下面这个形式,是不是很简单呢?我们继续:
|
||||||
|
|
||||||
@ -284,7 +291,7 @@ public void add(int value) {
|
|||||||
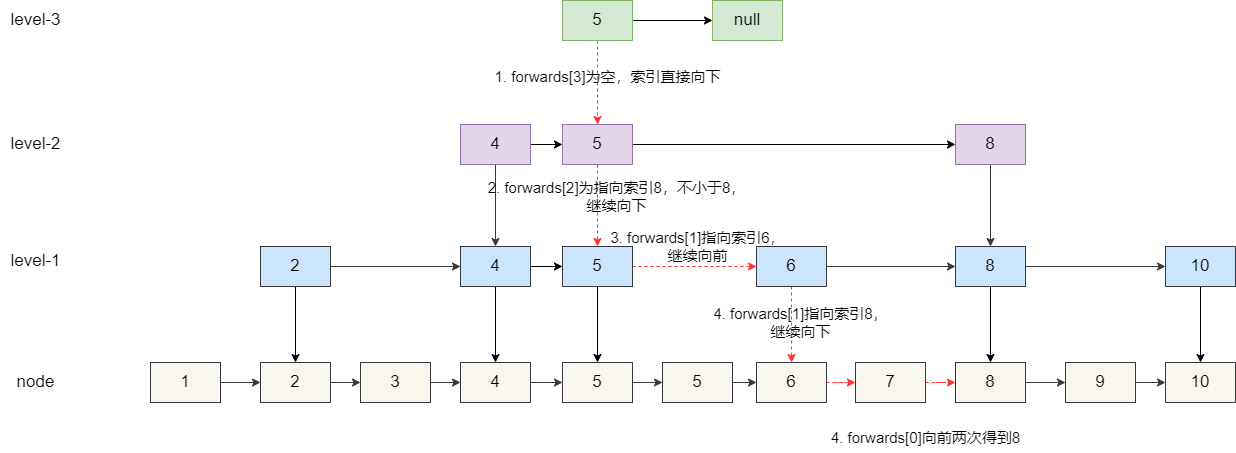
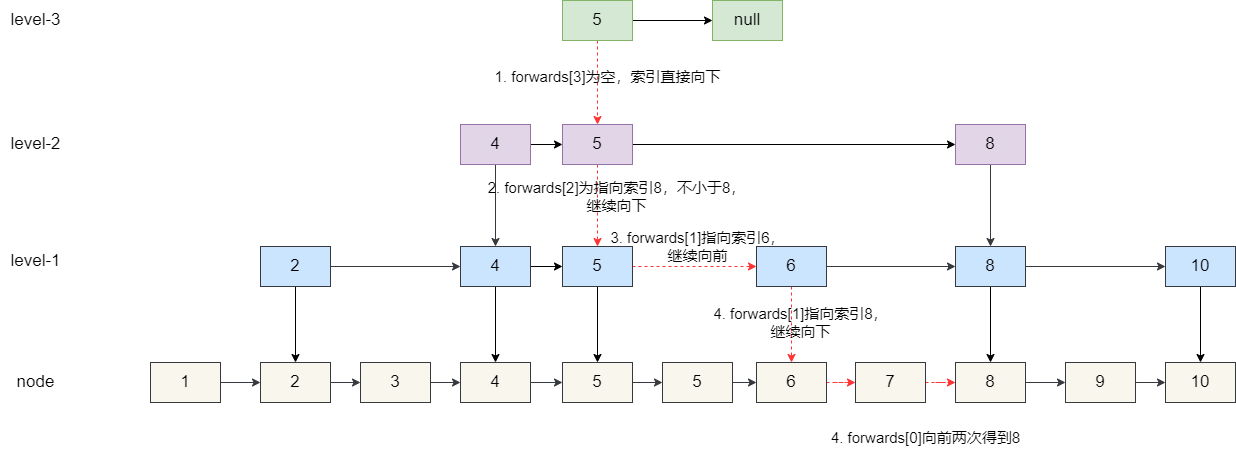
6. 节点 7 后续就是节点 8,继续向前为节点 8,无法继续向下,结束搜寻。
|
6. 节点 7 后续就是节点 8,继续向前为节点 8,无法继续向下,结束搜寻。
|
||||||
7. 判断 7 的前驱,等于 8,查找结束。
|
7. 判断 7 的前驱,等于 8,查找结束。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
|
所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
|
||||||
|
|
||||||
@ -316,7 +323,7 @@ public Node get(int value) {
|
|||||||
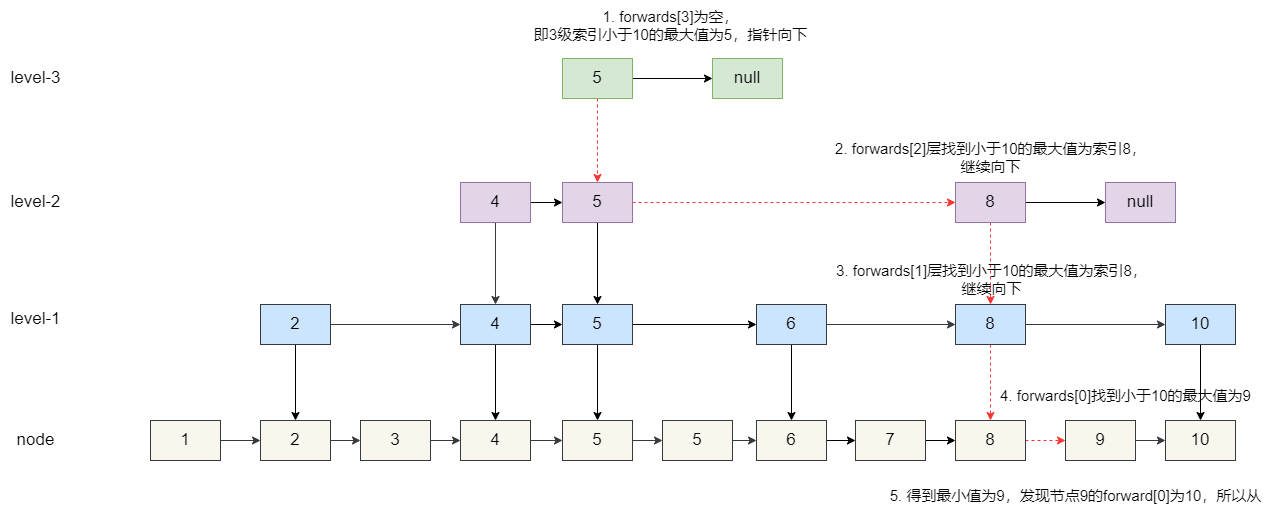
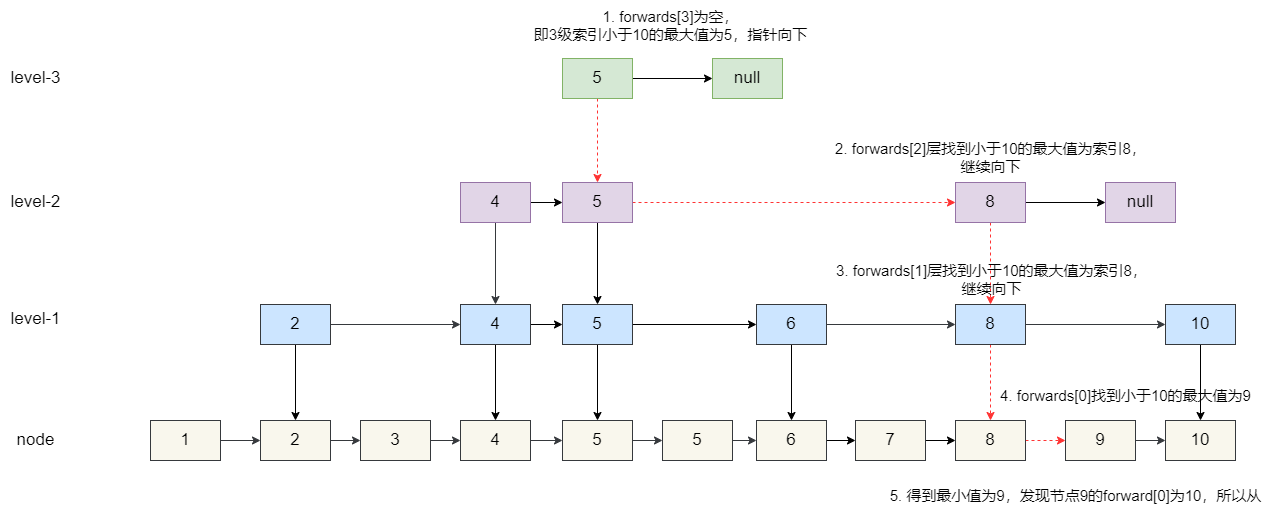
4. 原始节点找到 9。
|
4. 原始节点找到 9。
|
||||||
5. 从最高级索引开始,查看每个小于 10 的节点后继节点是否为 10,如果等于 10,则让这个节点指向 10 的后继节点,将节点 10 及其索引交由 GC 回收。
|
5. 从最高级索引开始,查看每个小于 10 的节点后继节点是否为 10,如果等于 10,则让这个节点指向 10 的后继节点,将节点 10 及其索引交由 GC 回收。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```java
|
```java
|
||||||
/**
|
/**
|
||||||
@ -602,7 +609,7 @@ Node{data=23, maxLevel=1}
|
|||||||
|
|
||||||
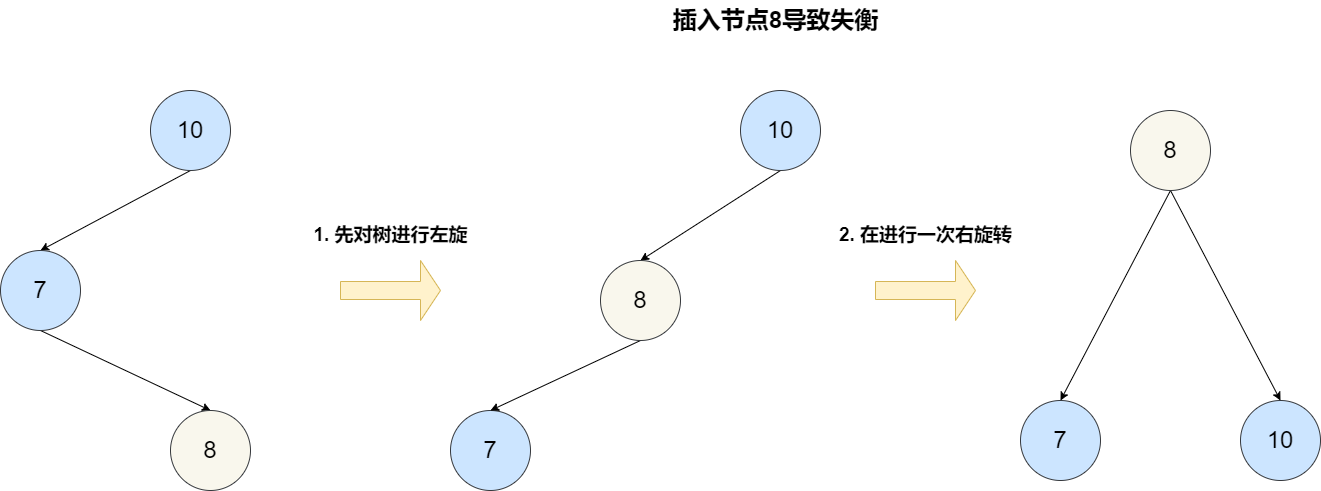
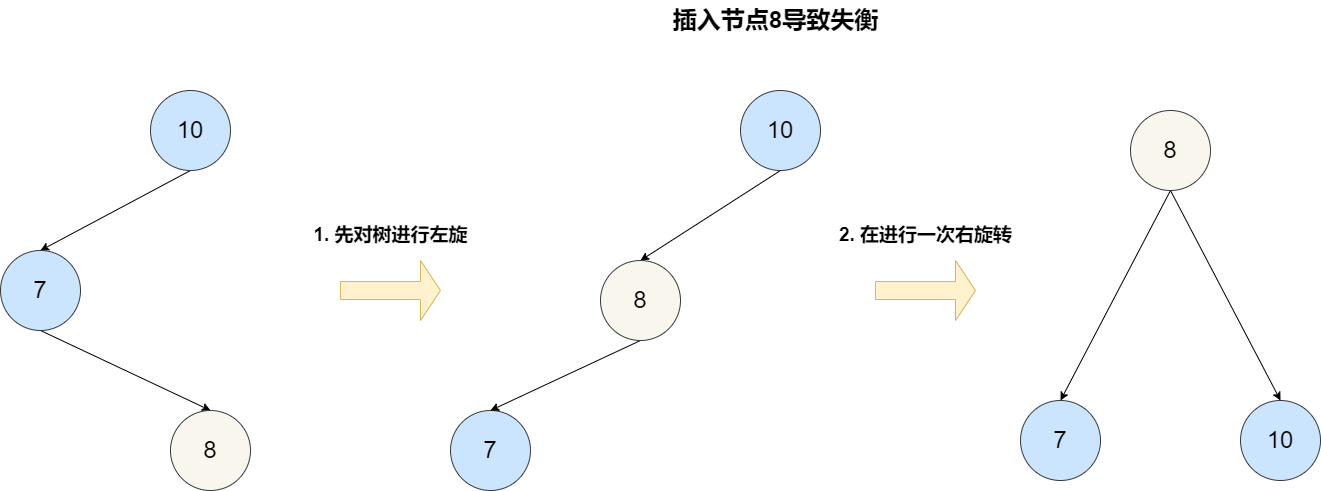
对于范围查询来说,它也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。
|
对于范围查询来说,它也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
跳表诞生的初衷就是为了克服平衡树的一些缺点,跳表的发明者在论文[《Skip lists: a probabilistic alternative to balanced trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)中有详细提到:
|
跳表诞生的初衷就是为了克服平衡树的一些缺点,跳表的发明者在论文[《Skip lists: a probabilistic alternative to balanced trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)中有详细提到:
|
||||||
|
|
||||||
@ -673,7 +680,7 @@ private Node add(Node node, K key, V value) {
|
|||||||
|
|
||||||
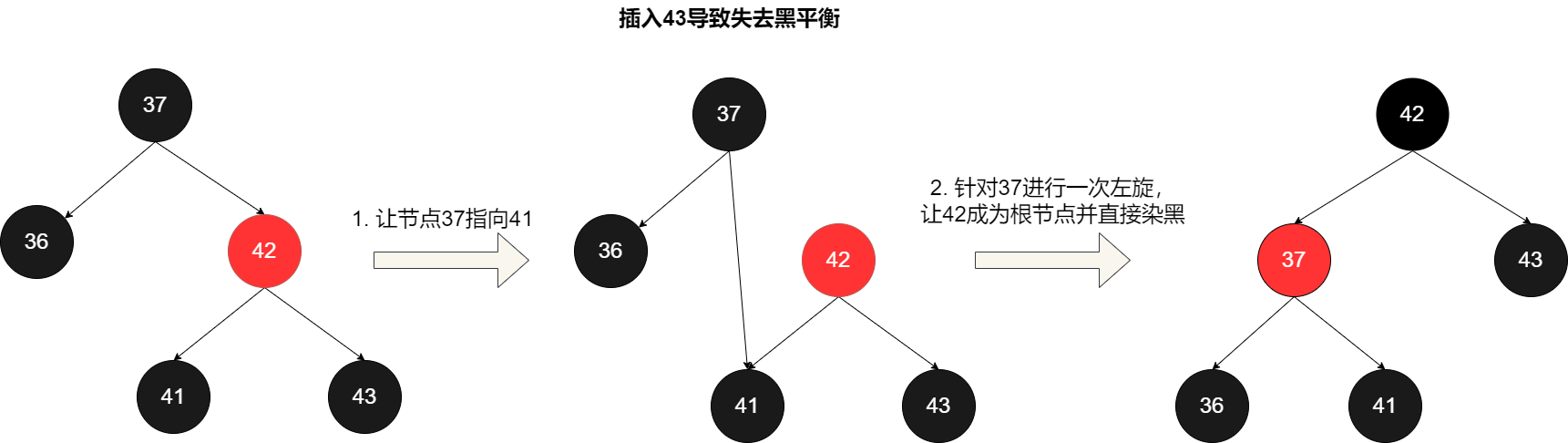
相比较于红黑树来说,跳表的实现也更简单一些。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
|
相比较于红黑树来说,跳表的实现也更简单一些。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
对应红黑树添加的核心代码如下,读者可自行参阅理解:
|
对应红黑树添加的核心代码如下,读者可自行参阅理解:
|
||||||
|
|
||||||
@ -723,7 +730,7 @@ private Node < K, V > add(Node < K, V > node, K key, V val) {
|
|||||||
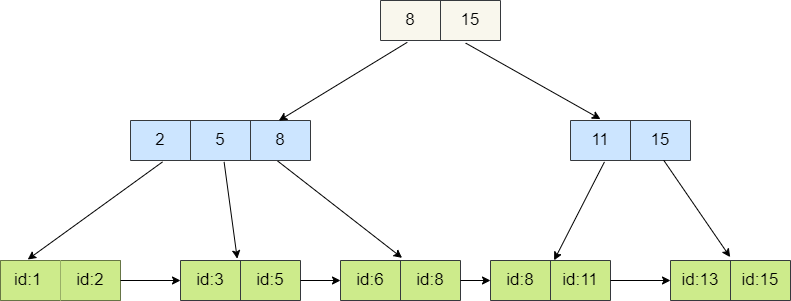
4. **顺序访问**:叶子节点间通过链表指针相连,范围查询表现出色。
|
4. **顺序访问**:叶子节点间通过链表指针相连,范围查询表现出色。
|
||||||
5. **数据均匀分布**:B+树插入时可能会导致数据重新分布,使得数据在整棵树分布更加均匀,保证范围查询和删除效率。
|
5. **数据均匀分布**:B+树插入时可能会导致数据重新分布,使得数据在整棵树分布更加均匀,保证范围查询和删除效率。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
所以,B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
|
所以,B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user