mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]Redis持久化的内容单独提取成一篇文章
This commit is contained in:
parent
3729b6f417
commit
1f9ffd17b3
@ -228,7 +228,9 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
- [3种常用的缓存读写策略详解](./docs/database/redis/3-commonly-used-cache-read-and-write-strategies.md)
|
||||
- [Redis 5 种基本数据结构详解](./docs/database/redis/redis-data-structures-01.md)
|
||||
- [Redis 3 种特殊数据结构详解](./docs/database/redis/redis-data-structures-02.md)
|
||||
- [Redis 持久化机制详解](./docs/database/redis/redis-persistence.md)
|
||||
- [Redis 内存碎片详解](./docs/database/redis/redis-memory-fragmentation.md)
|
||||
- [Redis 常见阻塞原因总结](./docs/database/redis/redis-common-blocking-problems-summary.md)
|
||||
- [Redis 集群详解](./docs/database/redis/redis-cluster.md)
|
||||
|
||||
### MongoDB
|
||||
|
||||
@ -289,6 +289,7 @@ export const sidebarConfig = sidebar({
|
||||
"3-commonly-used-cache-read-and-write-strategies",
|
||||
"redis-data-structures-01",
|
||||
"redis-data-structures-02",
|
||||
"redis-persistence",
|
||||
"redis-memory-fragmentation",
|
||||
"redis-common-blocking-problems-summary",
|
||||
"redis-cluster",
|
||||
|
||||
@ -9,32 +9,29 @@ tag:
|
||||
>
|
||||
> 原文地址:https://www.weiweiblog.cn/13string/
|
||||
|
||||
|
||||
## 1. KMP 算法
|
||||
|
||||
谈到字符串问题,不得不提的就是 KMP 算法,它是用来解决字符串查找的问题,可以在一个字符串(S)中查找一个子串(W)出现的位置。KMP 算法把字符匹配的时间复杂度缩小到 O(m+n) ,而空间复杂度也只有O(m)。因为“暴力搜索”的方法会反复回溯主串,导致效率低下,而KMP算法可以利用已经部分匹配这个有效信息,保持主串上的指针不回溯,通过修改子串的指针,让模式串尽量地移动到有效的位置。
|
||||
谈到字符串问题,不得不提的就是 KMP 算法,它是用来解决字符串查找的问题,可以在一个字符串(S)中查找一个子串(W)出现的位置。KMP 算法把字符匹配的时间复杂度缩小到 O(m+n) ,而空间复杂度也只有 O(m)。因为“暴力搜索”的方法会反复回溯主串,导致效率低下,而 KMP 算法可以利用已经部分匹配这个有效信息,保持主串上的指针不回溯,通过修改子串的指针,让模式串尽量地移动到有效的位置。
|
||||
|
||||
具体算法细节请参考:
|
||||
|
||||
- **字符串匹配的KMP算法:** http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
|
||||
- **从头到尾彻底理解KMP:** https://blog.csdn.net/v_july_v/article/details/7041827
|
||||
- **如何更好的理解和掌握 KMP 算法?:** https://www.zhihu.com/question/21923021
|
||||
- **KMP 算法详细解析:** https://blog.sengxian.com/algorithms/kmp
|
||||
- **图解 KMP 算法:** http://blog.jobbole.com/76611/
|
||||
- **汪都能听懂的KMP字符串匹配算法【双语字幕】:** https://www.bilibili.com/video/av3246487/?from=search&seid=17173603269940723925
|
||||
- **KMP字符串匹配算法1:** https://www.bilibili.com/video/av11866460?from=search&seid=12730654434238709250
|
||||
- [从头到尾彻底理解 KMP:](https://blog.csdn.net/v_july_v/article/details/7041827)
|
||||
- [如何更好的理解和掌握 KMP 算法?](https://www.zhihu.com/question/21923021)
|
||||
- [KMP 算法详细解析](https://blog.sengxian.com/algorithms/kmp)
|
||||
- [图解 KMP 算法](http://blog.jobbole.com/76611/)
|
||||
- [汪都能听懂的 KMP 字符串匹配算法【双语字幕】](https://www.bilibili.com/video/av3246487/?from=search&seid=17173603269940723925)
|
||||
- [KMP 字符串匹配算法 1](https://www.bilibili.com/video/av11866460?from=search&seid=12730654434238709250)
|
||||
|
||||
**除此之外,再来了解一下BM算法!**
|
||||
|
||||
> BM算法也是一种精确字符串匹配算法,它采用从右向左比较的方法,同时应用到了两种启发式规则,即坏字符规则 和好后缀规则 ,来决定向右跳跃的距离。基本思路就是从右往左进行字符匹配,遇到不匹配的字符后从坏字符表和好后缀表找一个最大的右移值,将模式串右移继续匹配。
|
||||
《字符串匹配的KMP算法》:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
|
||||
**除此之外,再来了解一下 BM 算法!**
|
||||
|
||||
> BM 算法也是一种精确字符串匹配算法,它采用从右向左比较的方法,同时应用到了两种启发式规则,即坏字符规则 和好后缀规则 ,来决定向右跳跃的距离。基本思路就是从右往左进行字符匹配,遇到不匹配的字符后从坏字符表和好后缀表找一个最大的右移值,将模式串右移继续匹配。
|
||||
> 《字符串匹配的 KMP 算法》:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
|
||||
|
||||
## 2. 替换空格
|
||||
|
||||
> 剑指offer:请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
|
||||
> 剑指 offer:请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为 We Are Happy.则经过替换之后的字符串为 We%20Are%20Happy。
|
||||
|
||||
这里我提供了两种方法:①常规方法;②利用 API 解决。
|
||||
这里我提供了两种方法:① 常规方法;② 利用 API 解决。
|
||||
|
||||
```java
|
||||
//https://www.weiweiblog.cn/replacespace/
|
||||
@ -65,7 +62,7 @@ public class Solution {
|
||||
* 第二种方法:利用API替换掉所用空格,一行代码解决问题
|
||||
*/
|
||||
public static String replaceSpace2(StringBuffer str) {
|
||||
|
||||
|
||||
return str.toString().replaceAll("\\s", "%20");
|
||||
}
|
||||
}
|
||||
@ -80,7 +77,7 @@ str.toString().replace(" ","%20");
|
||||
|
||||
## 3. 最长公共前缀
|
||||
|
||||
> Leetcode: 编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
|
||||
> Leetcode: 编写一个函数来查找字符串数组中的最长公共前缀。如果不存在公共前缀,返回空字符串 ""。
|
||||
|
||||
示例 1:
|
||||
|
||||
@ -97,8 +94,7 @@ str.toString().replace(" ","%20");
|
||||
解释: 输入不存在公共前缀。
|
||||
```
|
||||
|
||||
|
||||
思路很简单!先利用Arrays.sort(strs)为数组排序,再将数组第一个元素和最后一个元素的字符从前往后对比即可!
|
||||
思路很简单!先利用 Arrays.sort(strs)为数组排序,再将数组第一个元素和最后一个元素的字符从前往后对比即可!
|
||||
|
||||
```java
|
||||
public class Main {
|
||||
@ -160,12 +156,10 @@ public class Main {
|
||||
|
||||
### 4.1. 最长回文串
|
||||
|
||||
> LeetCode: 给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。在构造过程中,请注意区分大小写。比如`"Aa"`不能当做一个回文字符串。注
|
||||
意:假设字符串的长度不会超过 1010。
|
||||
> LeetCode: 给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。在构造过程中,请注意区分大小写。比如`"Aa"`不能当做一个回文字符串。注
|
||||
> 意:假设字符串的长度不会超过 1010。
|
||||
|
||||
|
||||
|
||||
> 回文串:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。——百度百科 地址:https://baike.baidu.com/item/%E5%9B%9E%E6%96%87%E4%B8%B2/1274921?fr=aladdin
|
||||
> 回文串:“回文串”是一个正读和反读都一样的字符串,比如“level”或者“noon”等等就是回文串。——百度百科 地址:https://baike.baidu.com/item/%E5%9B%9E%E6%96%87%E4%B8%B2/1274921?fr=aladdin
|
||||
|
||||
示例 1:
|
||||
|
||||
@ -185,7 +179,7 @@ public class Main {
|
||||
- 字符出现次数为双数的组合
|
||||
- **字符出现次数为偶数的组合+单个字符中出现次数最多且为奇数次的字符** (参见 **[issue665](https://github.com/Snailclimb/JavaGuide/issues/665)** )
|
||||
|
||||
统计字符出现的次数即可,双数才能构成回文。因为允许中间一个数单独出现,比如“abcba”,所以如果最后有字母落单,总长度可以加 1。首先将字符串转变为字符数组。然后遍历该数组,判断对应字符是否在hashset中,如果不在就加进去,如果在就让count++,然后移除该字符!这样就能找到出现次数为双数的字符个数。
|
||||
统计字符出现的次数即可,双数才能构成回文。因为允许中间一个数单独出现,比如“abcba”,所以如果最后有字母落单,总长度可以加 1。首先将字符串转变为字符数组。然后遍历该数组,判断对应字符是否在 hashset 中,如果不在就加进去,如果在就让 count++,然后移除该字符!这样就能找到出现次数为双数的字符个数。
|
||||
|
||||
```java
|
||||
//https://leetcode-cn.com/problems/longest-palindrome/description/
|
||||
@ -210,7 +204,6 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 4.2. 验证回文串
|
||||
|
||||
> LeetCode: 给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。 说明:本题中,我们将空字符串定义为有效的回文串。
|
||||
@ -255,10 +248,9 @@ class Solution {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 4.3. 最长回文子串
|
||||
|
||||
> Leetcode: LeetCode: 最长回文子串 给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为1000。
|
||||
> Leetcode: LeetCode: 最长回文子串 给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
|
||||
|
||||
示例 1:
|
||||
|
||||
@ -308,10 +300,10 @@ class Solution {
|
||||
### 4.4. 最长回文子序列
|
||||
|
||||
> LeetCode: 最长回文子序列
|
||||
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
|
||||
**最长回文子序列和上一题最长回文子串的区别是,子串是字符串中连续的一个序列,而子序列是字符串中保持相对位置的字符序列,例如,"bbbb"可以是字符串"bbbab"的子序列但不是子串。**
|
||||
> 给定一个字符串 s,找到其中最长的回文子序列。可以假设 s 的最大长度为 1000。
|
||||
> **最长回文子序列和上一题最长回文子串的区别是,子串是字符串中连续的一个序列,而子序列是字符串中保持相对位置的字符序列,例如,"bbbb"可以是字符串"bbbab"的子序列但不是子串。**
|
||||
|
||||
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
|
||||
给定一个字符串 s,找到其中最长的回文子序列。可以假设 s 的最大长度为 1000。
|
||||
|
||||
示例 1:
|
||||
|
||||
@ -321,6 +313,7 @@ class Solution {
|
||||
输出:
|
||||
4
|
||||
```
|
||||
|
||||
一个可能的最长回文子序列为 "bbbb"。
|
||||
|
||||
示例 2:
|
||||
@ -334,7 +327,7 @@ class Solution {
|
||||
|
||||
一个可能的最长回文子序列为 "bb"。
|
||||
|
||||
**动态规划:** dp[i][j] = dp[i+1][j-1] + 2 if s.charAt(i) == s.charAt(j) otherwise, dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])
|
||||
**动态规划:** dp[i][j] = dp[i+1][j-1] + 2 if s.charAt(i) == s.charAt(j) otherwise, dp[i][j] = Math.max(dp[i+1][j], dp[i][j-1])
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
@ -358,19 +351,21 @@ class Solution {
|
||||
## 5. 括号匹配深度
|
||||
|
||||
> 爱奇艺 2018 秋招 Java:
|
||||
>一个合法的括号匹配序列有以下定义:
|
||||
>1. 空串""是一个合法的括号匹配序列
|
||||
>2. 如果"X"和"Y"都是合法的括号匹配序列,"XY"也是一个合法的括号匹配序列
|
||||
>3. 如果"X"是一个合法的括号匹配序列,那么"(X)"也是一个合法的括号匹配序列
|
||||
>4. 每个合法的括号序列都可以由以上规则生成。
|
||||
> 一个合法的括号匹配序列有以下定义:
|
||||
>
|
||||
> 1. 空串""是一个合法的括号匹配序列
|
||||
> 2. 如果"X"和"Y"都是合法的括号匹配序列,"XY"也是一个合法的括号匹配序列
|
||||
> 3. 如果"X"是一个合法的括号匹配序列,那么"(X)"也是一个合法的括号匹配序列
|
||||
> 4. 每个合法的括号序列都可以由以上规则生成。
|
||||
|
||||
> 例如: "","()","()()","((()))"都是合法的括号序列
|
||||
>对于一个合法的括号序列我们又有以下定义它的深度:
|
||||
>1. 空串""的深度是0
|
||||
>2. 如果字符串"X"的深度是x,字符串"Y"的深度是y,那么字符串"XY"的深度为max(x,y)
|
||||
>3. 如果"X"的深度是x,那么字符串"(X)"的深度是x+1
|
||||
> 对于一个合法的括号序列我们又有以下定义它的深度:
|
||||
>
|
||||
> 1. 空串""的深度是 0
|
||||
> 2. 如果字符串"X"的深度是 x,字符串"Y"的深度是 y,那么字符串"XY"的深度为 max(x,y)
|
||||
> 3. 如果"X"的深度是 x,那么字符串"(X)"的深度是 x+1
|
||||
|
||||
> 例如: "()()()"的深度是1,"((()))"的深度是3。牛牛现在给你一个合法的括号序列,需要你计算出其深度。
|
||||
> 例如: "()()()"的深度是 1,"((()))"的深度是 3。牛牛现在给你一个合法的括号序列,需要你计算出其深度。
|
||||
|
||||
```
|
||||
输入描述:
|
||||
@ -396,7 +391,7 @@ import java.util.Scanner;
|
||||
|
||||
/**
|
||||
* https://www.nowcoder.com/test/8246651/summary
|
||||
*
|
||||
*
|
||||
* @author Snailclimb
|
||||
* @date 2018年9月6日
|
||||
* @Description: TODO 求给定合法括号序列的深度
|
||||
@ -422,7 +417,7 @@ public class Main {
|
||||
|
||||
## 6. 把字符串转换成整数
|
||||
|
||||
> 剑指offer: 将一个字符串转换成一个整数(实现Integer.valueOf(string)的功能,但是string不符合数字要求时返回0),要求不能使用字符串转换整数的库函数。 数值为0或者字符串不是一个合法的数值则返回0。
|
||||
> 剑指 offer: 将一个字符串转换成一个整数(实现 Integer.valueOf(string)的功能,但是 string 不符合数字要求时返回 0),要求不能使用字符串转换整数的库函数。 数值为 0 或者字符串不是一个合法的数值则返回 0。
|
||||
|
||||
```java
|
||||
//https://www.weiweiblog.cn/strtoint/
|
||||
|
||||
154
docs/database/redis/redis-persistence.md
Normal file
154
docs/database/redis/redis-persistence.md
Normal file
@ -0,0 +1,154 @@
|
||||
---
|
||||
title: Redis持久化机制详解
|
||||
category: 数据库
|
||||
tag:
|
||||
- Redis
|
||||
head:
|
||||
- - meta
|
||||
- name: keywords
|
||||
content: Redis持久化机制详解
|
||||
- - meta
|
||||
- name: description
|
||||
content: Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)、RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
|
||||
---
|
||||
|
||||
使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
|
||||
|
||||
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
|
||||
|
||||
- 快照(snapshotting,RDB)
|
||||
- 只追加文件(append-only file, AOF)
|
||||
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
|
||||
|
||||
官方文档地址:https://redis.io/topics/persistence 。
|
||||
|
||||

|
||||
|
||||
## RDB 持久化
|
||||
|
||||
### 什么是 RDB 持久化?
|
||||
|
||||
Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
|
||||
|
||||
快照持久化是 Redis 默认采用的持久化方式,在 `redis.conf` 配置文件中默认有此下配置:
|
||||
|
||||
```clojure
|
||||
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
|
||||
|
||||
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
|
||||
|
||||
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
|
||||
```
|
||||
|
||||
### RDB 创建快照时会阻塞主线程吗?
|
||||
|
||||
Redis 提供了两个命令来生成 RDB 快照文件:
|
||||
|
||||
- `save` : 同步保存操作,会阻塞 Redis 主线程;
|
||||
- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
|
||||
|
||||
> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
|
||||
|
||||
## AOF 持久化
|
||||
|
||||
### 什么是 AOF 持久化?
|
||||
|
||||
与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了),可以通过 `appendonly` 参数开启:
|
||||
|
||||
```bash
|
||||
appendonly yes
|
||||
```
|
||||
|
||||
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再根据 `appendfsync` 配置来决定何时将其同步到硬盘中的 AOF 文件。
|
||||
|
||||
AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 `appendonly.aof`。
|
||||
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||
|
||||
```bash
|
||||
appendfsync always #每次有数据修改发生时都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
|
||||
appendfsync everysec #每秒钟调用fsync函数同步一次AOF文件
|
||||
appendfsync no #让操作系统决定何时进行同步,一般为30秒一次
|
||||
```
|
||||
|
||||
为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
|
||||
|
||||
从 Redis 7.0.0 开始,Redis 使用了 **Multi Part AOF** 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 Multi Part AOF 中,AOF 文件被分为三种类型,分别为:
|
||||
|
||||
- BASE:表示基础 AOF 文件,它一般由子进程通过重写产生,该文件最多只有一个。
|
||||
- INCR:表示增量 AOF 文件,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个。
|
||||
- HISTORY:表示历史 AOF 文件,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。
|
||||
|
||||
Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
|
||||
|
||||
**相关 issue** :[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
|
||||
|
||||
### AOF 工作基本流程是怎样的?
|
||||
|
||||
AOF 持久化功能的实现可以简单分为 4 步:
|
||||
|
||||
1. 命令写入(append):所有的写命令会追加到 AOF 缓冲区中。
|
||||
2. 文件同步(sync):AOF 缓冲区根据对应的 fsync 策略向硬盘做同步操作。
|
||||
3. 文件重写(rewrite):随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
|
||||
4. 重启加载(load):当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
|
||||
|
||||
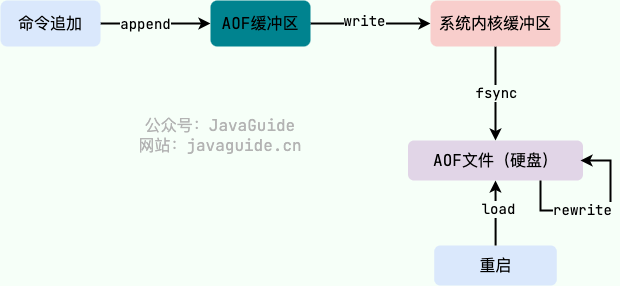
|
||||
|
||||
### AOF 为什么是在执行完命令之后记录日志?
|
||||
|
||||
关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复),而 Redis AOF 持久化机制是在执行完命令之后再记录日志。
|
||||
|
||||
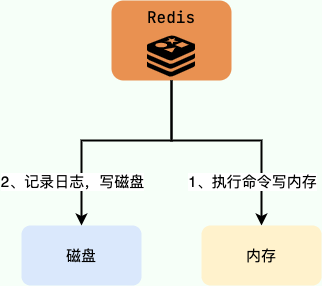
|
||||
|
||||
**为什么是在执行完命令之后记录日志呢?**
|
||||
|
||||
- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
|
||||
- 在命令执行完之后再记录,不会阻塞当前的命令执行。
|
||||
|
||||
这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
|
||||
|
||||
- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
|
||||
- 可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)。
|
||||
|
||||
### AOF 重写了解吗?
|
||||
|
||||
当 AOF 变得太大时,Redis 能够在后台自动重写 AOF 产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
|
||||
|
||||
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
|
||||
|
||||
在执行 `BGREWRITEAOF` 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
|
||||
|
||||
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
|
||||
**相关 issue** :[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
|
||||
|
||||
## Redis 4.0 对于持久化机制做了什么优化?
|
||||
|
||||
由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
|
||||
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
|
||||
官方文档地址:https://redis.io/topics/persistence
|
||||
|
||||

|
||||
|
||||
## 如何选择 RDB 和 AOF?
|
||||
|
||||
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
|
||||
|
||||
**RDB 比 AOF 优秀的地方** :
|
||||
|
||||
- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会必 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
|
||||
|
||||
**AOF 比 RDB 优秀的地方** :
|
||||
|
||||
- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
|
||||
- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
|
||||
- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
|
||||
|
||||
**综上** :
|
||||
|
||||
- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
|
||||
- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
|
||||
- 如果保存的数据要求安全性比较高的话,建议同时开启 RDB 和 AOF 持久化或者开启 RDB 和 AOF 混合持久化。
|
||||
@ -508,154 +508,21 @@ typedef struct redisDb {
|
||||
|
||||
Redis 提供 6 种数据淘汰策略:
|
||||
|
||||
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
|
||||
2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
|
||||
3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
|
||||
4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
|
||||
5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
|
||||
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最近最少使用的数据淘汰。
|
||||
2. **volatile-ttl**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选将要过期的数据淘汰。
|
||||
3. **volatile-random**:从已设置过期时间的数据集(`server.db[i].expires`)中任意选择数据淘汰。
|
||||
4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
|
||||
5. **allkeys-random**:从数据集(`server.db[i].dict`)中任意选择数据淘汰。
|
||||
6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
|
||||
|
||||
4.0 版本后增加以下两种:
|
||||
|
||||
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
|
||||
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
|
||||
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最不经常使用的数据淘汰。
|
||||
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key。
|
||||
|
||||
## Redis 持久化机制
|
||||
|
||||
### 怎么保证 Redis 挂掉之后再重启数据可以进行恢复?
|
||||
|
||||
使用缓存的时候,我们经常需要对内容中的数据进行持久化也就是将内存中的数据写入到硬盘里面。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
|
||||
|
||||
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
|
||||
|
||||
- 快照(snapshotting,RDB)
|
||||
- 只追加文件(append-only file, AOF)
|
||||
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
|
||||
|
||||
### 什么是 RDB 持久化?
|
||||
|
||||
Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
|
||||
|
||||
快照持久化是 Redis 默认采用的持久化方式,在 `redis.conf` 配置文件中默认有此下配置:
|
||||
|
||||
```clojure
|
||||
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发bgsave命令创建快照。
|
||||
|
||||
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发bgsave命令创建快照。
|
||||
|
||||
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发bgsave命令创建快照。
|
||||
```
|
||||
|
||||
### RDB 创建快照时会阻塞主线程吗?
|
||||
|
||||
Redis 提供了两个命令来生成 RDB 快照文件:
|
||||
|
||||
- `save` : 同步保存操作,会阻塞 Redis 主线程;
|
||||
- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
|
||||
|
||||
> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
|
||||
|
||||
### 什么是 AOF 持久化?
|
||||
|
||||
与快照持久化相比,AOF 持久化的实时性更好。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了),可以通过 appendonly 参数开启:
|
||||
|
||||
```bash
|
||||
appendonly yes
|
||||
```
|
||||
|
||||
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到AOF 缓冲区 `server.aof_buf` 中,然后再根据 `appendfsync` 配置来决定何时将其同步到硬盘中的 AOF 文件。
|
||||
|
||||
AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 `appendonly.aof`。
|
||||
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||
|
||||
```bash
|
||||
appendfsync always #每次有数据修改发生时都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
|
||||
appendfsync everysec #每秒钟调用fsync函数同步一次AOF文件
|
||||
appendfsync no #让操作系统决定何时进行同步,一般为30秒一次
|
||||
```
|
||||
|
||||
为了兼顾数据和写入性能,可以考虑 `appendfsync everysec` 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
|
||||
|
||||
从 Redis 7.0.0 开始,Redis 使用了 **Multi Part AOF** 机制。顾名思义,Multi Part AOF 就是将原来的单个 AOF 文件拆分成多个 AOF 文件。在 Multi Part AOF 中,AOF 文件被分为三种类型,分别为:
|
||||
|
||||
- BASE:表示基础 AOF 文件,它一般由子进程通过重写产生,该文件最多只有一个。
|
||||
- INCR:表示增量 AOF 文件,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个。
|
||||
- HISTORY:表示历史 AOF 文件,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。
|
||||
|
||||
Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
|
||||
|
||||
**相关 issue** :[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
|
||||
|
||||
### AOF工作基本流程是怎样的?
|
||||
|
||||
AOF 持久化功能的实现可以简单分为 4 步:
|
||||
|
||||
1. 命令写入(append):所有的写命令会追加到 AOF 缓冲区中。
|
||||
2. 文件同步(sync):AOF缓冲区根据对应的 fsync 策略向硬盘做同步操作。
|
||||
3. 文件重写(rewrite):随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
|
||||
4. 重启加载(load):当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
|
||||
|
||||

|
||||
|
||||
### AOF 为什么是在执行完命令之后记录日志?
|
||||
|
||||
关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复),而 Redis AOF 持久化机制是在执行完命令之后再记录日志。
|
||||
|
||||

|
||||
|
||||
**为什么是在执行完命令之后记录日志呢?**
|
||||
|
||||
- 避免额外的检查开销,AOF 记录日志不会对命令进行语法检查;
|
||||
- 在命令执行完之后再记录,不会阻塞当前的命令执行。
|
||||
|
||||
这样也带来了风险(我在前面介绍 AOF 持久化的时候也提到过):
|
||||
|
||||
- 如果刚执行完命令 Redis 就宕机会导致对应的修改丢失;
|
||||
- 可能会阻塞后续其他命令的执行(AOF 记录日志是在 Redis 主线程中进行的)。
|
||||
|
||||
### AOF 重写了解吗?
|
||||
|
||||
当 AOF 变得太大时,Redis 能够在后台自动重写 AOF 产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
|
||||
|
||||
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
|
||||
|
||||
在执行 `BGREWRITEAOF` 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
|
||||
|
||||
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
|
||||
**相关 issue** :[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
|
||||
|
||||
### Redis 4.0 对于持久化机制做了什么优化?
|
||||
|
||||
由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
|
||||
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
|
||||
官方文档地址:https://redis.io/topics/persistence
|
||||
|
||||

|
||||
|
||||
### 如何选择 RDB 和 AOF?
|
||||
|
||||
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
|
||||
|
||||
**RDB 比 AOF 优秀的地方** :
|
||||
|
||||
- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会必 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
|
||||
|
||||
**AOF 比 RDB 优秀的地方** :
|
||||
|
||||
- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
|
||||
- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
|
||||
- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
|
||||
|
||||
综上:
|
||||
|
||||
- Redis 保存的数据丢失一些也没什么影响的话,可以选择使用 RDB。
|
||||
- 不建议单独使用 AOF,因为时不时地创建一个 RDB 快照可以进行数据库备份、更快的重启以及解决 AOF 引擎错误。
|
||||
- 如果保存的数据要求安全性比较高的话,建议同时开启 RDB 和 AOF 持久化或者开启 RDB 和 AOF 混合持久化。
|
||||
Redis 持久化机制(RDB 持久化、AOF 持久化、RDB 和 AOF 的混合持久化) 相关的问题比较多,也比较重要,于是我单独抽了一篇文章来总结 Redis 持久化机制相关的知识点和问题: [Redis 持久化机制详解](./redis-persistence.md) 。
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
@ -183,23 +183,19 @@ class Broker {
|
||||
|
||||
#### 2.1.11 其它
|
||||
|
||||
![][1]
|
||||
|
||||
|
||||
加分项咯
|
||||
1. 包括组件通信间使用 Netty 的自定义协议
|
||||
2. 消息重试负载均衡策略(具体参考 Dubbo 负载均衡策略)
|
||||
3. 消息过滤器(Producer 发送消息到 Broker,Broker 存储消息信息,Consumer 消费时请求 Broker 端从磁盘文件查询消息文件时,在 Broker 端就使用过滤服务器进行过滤)
|
||||
4. Broker 同步双写和异步双写中 Master 和 Slave 的交互
|
||||
5. Broker 在 4.5.0 版本更新中引入了基于 Raft 协议的多副本选举,之前这是商业版才有的特性 [ISSUE-1046][2]
|
||||
5. Broker 在 4.5.0 版本更新中引入了基于 Raft 协议的多副本选举,之前这是商业版才有的特性。
|
||||
|
||||
## 3 参考
|
||||
|
||||
1. 《RocketMQ技术内幕》:https://blog.csdn.net/prestigeding/article/details/85233529
|
||||
2. 关于 RocketMQ 对 MappedByteBuffer 的一点优化:https://lishoubo.github.io/2017/09/27/MappedByteBuffer%E7%9A%84%E4%B8%80%E7%82%B9%E4%BC%98%E5%8C%96/
|
||||
3. 十分钟入门RocketMQ:https://developer.aliyun.com/article/66101
|
||||
4. 分布式事务的种类以及 RocketMQ 支持的分布式消息:https://www.infoq.cn/article/2018/08/rocketmq-4.3-release
|
||||
5. 滴滴出行基于RocketMQ构建企业级消息队列服务的实践:https://yq.aliyun.com/articles/664608
|
||||
6. 基于《RocketMQ技术内幕》源码注释:https://github.com/LiWenGu/awesome-rocketmq
|
||||
|
||||
[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/RocketMQ%E6%B5%81%E7%A8%8B.png
|
||||
[2]: http://rocketmq.apache.org/release_notes/release-notes-4.5.0/
|
||||
|
||||
@ -229,7 +229,9 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
- [3种常用的缓存读写策略详解](./database/redis/3-commonly-used-cache-read-and-write-strategies.md)
|
||||
- [Redis 5 种基本数据结构详解](./database/redis/redis-data-structures-01.md)
|
||||
- [Redis 3 种特殊数据结构详解](./database/redis/redis-data-structures-02.md)
|
||||
- [Redis 持久化机制详解](./database/redis/redis-persistence.md)
|
||||
- [Redis 内存碎片详解](./database/redis/redis-memory-fragmentation.md)
|
||||
- [Redis 常见阻塞原因总结](./database/redis/redis-common-blocking-problems-summary.md)
|
||||
- [Redis 集群详解](./database/redis/redis-cluster.md)
|
||||
|
||||
### MongoDB
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user