mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
1d30b7e1de
@ -68,23 +68,25 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
private int size;
|
||||
|
||||
/**
|
||||
* 带初始容量参数的构造函数。(用户自己指定容量)
|
||||
* 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
|
||||
*/
|
||||
public ArrayList(int initialCapacity) {
|
||||
if (initialCapacity > 0) {
|
||||
//创建initialCapacity大小的数组
|
||||
//如果传入的参数大于0,创建initialCapacity大小的数组
|
||||
this.elementData = new Object[initialCapacity];
|
||||
} else if (initialCapacity == 0) {
|
||||
//创建空数组
|
||||
//如果传入的参数等于0,创建空数组
|
||||
this.elementData = EMPTY_ELEMENTDATA;
|
||||
} else {
|
||||
//其他情况,抛出异常
|
||||
throw new IllegalArgumentException("Illegal Capacity: "+
|
||||
initialCapacity);
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
*默认构造函数,DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
|
||||
*默认无参构造函数
|
||||
*DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
|
||||
*/
|
||||
public ArrayList() {
|
||||
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
|
||||
@ -94,16 +96,16 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
|
||||
*/
|
||||
public ArrayList(Collection<? extends E> c) {
|
||||
//
|
||||
//将指定集合转换为数组
|
||||
elementData = c.toArray();
|
||||
//如果指定集合元素个数不为0
|
||||
//如果elementData数组的长度不为0
|
||||
if ((size = elementData.length) != 0) {
|
||||
// c.toArray 可能返回的不是Object类型的数组所以加上下面的语句用于判断,
|
||||
//这里用到了反射里面的getClass()方法
|
||||
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
|
||||
if (elementData.getClass() != Object[].class)
|
||||
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
|
||||
elementData = Arrays.copyOf(elementData, size, Object[].class);
|
||||
} else {
|
||||
// 用空数组代替
|
||||
// 其他情况,用空数组代替
|
||||
this.elementData = EMPTY_ELEMENTDATA;
|
||||
}
|
||||
}
|
||||
@ -127,13 +129,14 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
* @param minCapacity 所需的最小容量
|
||||
*/
|
||||
public void ensureCapacity(int minCapacity) {
|
||||
//如果是true,minExpand的值为0,如果是false,minExpand的值为10
|
||||
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
|
||||
// any size if not default element table
|
||||
? 0
|
||||
// larger than default for default empty table. It's already
|
||||
// supposed to be at default size.
|
||||
: DEFAULT_CAPACITY;
|
||||
|
||||
//如果最小容量大于已有的最大容量
|
||||
if (minCapacity > minExpand) {
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
@ -141,7 +144,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
//得到最小扩容量
|
||||
private void ensureCapacityInternal(int minCapacity) {
|
||||
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
|
||||
// 获取默认的容量和传入参数的较大值
|
||||
// 获取“默认的容量”和“传入参数”两者之间的最大值
|
||||
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
|
||||
}
|
||||
|
||||
|
||||
@ -9,16 +9,16 @@
|
||||
* [1.1.3 如何选用集合?](#-1)
|
||||
* [1.1.4 为什么要使用集合?](#-1)
|
||||
* [1.2 Iterator迭代器接口](#Iterator)
|
||||
* [1.2.1 为什么要使用迭代器](#1.2.1为什么要使用迭代器)
|
||||
* [1.3 Collection子接口之List](#CollectionList)
|
||||
* [ 1.3.1 Arraylist 与 LinkedList 区别?](#ArraylistLinkedList)
|
||||
* [**补充内容:RandomAccess接口**](#:RandomAccess)
|
||||
* [补充内容:双向链表和双向循环链表](#:)
|
||||
* [1.3.2 ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?](#ArrayListVectorArraylistVector)
|
||||
* [1.3.3 说一说 ArrayList 的扩容机制吧](#ArrayList)
|
||||
* [1.3.2 说一说 ArrayList 的扩容机制吧](#ArrayList)
|
||||
* [1.4 Collection子接口之Set](#CollectionSet)
|
||||
* [1.4.1 comparable 和 Comparator的区别](#comparableComparator)
|
||||
* [Comparator定制排序](#Comparator)
|
||||
* [重写compareTo方法实现按年龄来排序](#compareTo)
|
||||
* [1.4.2 无序性和不可重复性的含义是什么](#1.4.2无序性和不可重复性的含义是什么)
|
||||
* [1.4.3 比较HashSet 、LinkedHashSet和TreeSet三者的异同 ](#1.4.3比较HashSet、LinkedHashSet和TreeSet三者的异同 )
|
||||
* [1.5 Map接口](#Map-1)
|
||||
* [1.5.1 HashMap 和 Hashtable 的区别](#HashMapHashtable)
|
||||
* [1.5.2 HashMap 和 HashSet区别](#HashMapHashSet)
|
||||
@ -42,9 +42,9 @@
|
||||
## 1.1 集合概述
|
||||
### 1.1.1 说说List,Set,Map三者的区别?
|
||||
|
||||
- **List(对付顺序的好帮手):** List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
|
||||
- **Set(注重独一无二的性质):** 不允许重复的集合。不会有多个元素引用相同的对象。
|
||||
- **Map(用Key来搜索的专家):** 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
|
||||
- **List(对付顺序的好帮手):** 存储的元素是有序的、可重复的。
|
||||
- **Set(注重独一无二的性质):** 存储的元素是无序的、不可重复的。
|
||||
- **Map(用Key来搜索的专家):** 使用键值对(kye-value)存储,类似于数学上的函数y=f(x),“x”代表key,"y"代表value,Key是无序的、不可重复的,value是无序的、可重复的,每个键最多映射到一个值。
|
||||
|
||||
### 1.1.2 集合框架底层数据结构总结
|
||||
|
||||
@ -52,14 +52,14 @@
|
||||
|
||||
##### List
|
||||
|
||||
- **Arraylist:** Object数组
|
||||
- **Vector:** Object数组
|
||||
- **Arraylist:** Object[]数组
|
||||
- **Vector:** Object[]数组
|
||||
- **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
|
||||
|
||||
##### Set
|
||||
|
||||
- **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
|
||||
- **LinkedHashSet:** LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的
|
||||
- **LinkedHashSet:** LinkedHashSet 是 HashSet的子类,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的
|
||||
- **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树)
|
||||
|
||||
#### Map
|
||||
@ -81,47 +81,17 @@
|
||||
但是集合提高了数据存储的灵活性,Java集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据
|
||||
|
||||
## 1.2 Iterator迭代器接口
|
||||
### 1.2.1 为什么要使用迭代器
|
||||
Iterator对象称为迭代器(设计模式的一种),迭代器可以对集合进行遍历,但每一个集合内部的数据结构可能是不尽相同的,所以每一个集合存和取都很可能是不一样的,虽然我们可以人为地在每一个类中定义 hasNext() 和 next() 方法,但这样做会让整个集合体系过于臃肿。于是就有了迭代器。
|
||||
|
||||
迭代器是将这样的方法抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做就规定了整个集合体系的遍历方式都是hasNext()和next()方法,使用者不用管怎么实现的,会用即可。迭代器的定义为:提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节。
|
||||
|
||||
## 1.3 Collection子接口之List
|
||||
### 1.3.1 Arraylist 与 LinkedList 区别?
|
||||
### 1.3.1 Arraylist、LinkedList与Vector的区别?
|
||||
|
||||
- **1. 是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
|
||||
|
||||
- **2. 底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
|
||||
|
||||
- **3. 插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度近似为`o(n))`因为需要先移动到指定位置再插入。**
|
||||
|
||||
- **4. 是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
|
||||
|
||||
- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
||||
|
||||
#### **补充内容:RandomAccess接口**
|
||||
|
||||
```java
|
||||
public interface RandomAccess {
|
||||
}
|
||||
```
|
||||
|
||||
查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
|
||||
|
||||
在 `binarySearch()` 方法中,它要判断传入的list 是否 `RamdomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
|
||||
|
||||
```java
|
||||
public static <T>
|
||||
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
|
||||
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
|
||||
return Collections.indexedBinarySearch(list, key);
|
||||
else
|
||||
return Collections.iteratorBinarySearch(list, key);
|
||||
}
|
||||
```
|
||||
|
||||
`ArrayList` 实现了 `RandomAccess` 接口, 而 `LinkedList` 没有实现。为什么呢?我觉得还是和底层数据结构有关!`ArrayList` 底层是数组,而 `LinkedList` 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,`ArrayList` 实现了 `RandomAccess` 接口,就表明了他具有快速随机访问功能。 `RandomAccess` 接口只是标识,并不是说 `ArrayList` 实现 `RandomAccess` 接口才具有快速随机访问功能的!
|
||||
|
||||
**下面再总结一下 list 的遍历方式选择:**
|
||||
|
||||
- 实现了 `RandomAccess` 接口的list,优先选择普通 for 循环 ,其次 foreach,
|
||||
- 未实现 `RandomAccess`接口的list,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
|
||||
- **1. ArrayList是List的主要实现类,底层使用 Object[ ]存储,适用于频繁的查找工作,线程不安全 ;
|
||||
- **2. LinkedList是底层使用双向链表存储,适合频繁的增、删操作,线程不安全;
|
||||
- **3. Vector是List的古老实现类,底层使用 Object[ ]存储,线程安全的。
|
||||
|
||||
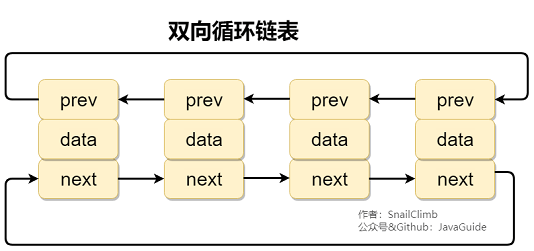
#### 补充内容:双向链表和双向循环链表
|
||||
|
||||
@ -135,18 +105,12 @@ public interface RandomAccess {
|
||||
|
||||
|
||||
|
||||
### 1.3.2 ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?
|
||||
|
||||
`Vector`类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
|
||||
|
||||
`Arraylist`不是同步的,所以在不需要保证线程安全时建议使用Arraylist。
|
||||
|
||||
### 1.3.3 说一说 ArrayList 的扩容机制吧
|
||||
### 1.3.2 说一说 ArrayList 的扩容机制吧
|
||||
|
||||
详见笔主的这篇文章:[通过源码一步一步分析ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList-Grow.md)
|
||||
|
||||
## 1.4 Collection子接口之Set
|
||||
### 1.4.1 comparable 和 Comparator的区别
|
||||
### 1.4.1 comparable 和 Comparator的区别 r
|
||||
|
||||
- comparable接口实际上是出自java.lang包 它有一个 `compareTo(Object obj)`方法用来排序
|
||||
- comparator接口实际上是出自 java.util 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
|
||||
@ -277,12 +241,25 @@ Output:
|
||||
30-张三
|
||||
```
|
||||
|
||||
### 1.4.2 无序性和不可重复性的含义是什么
|
||||
1、什么是无序性?无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
|
||||
|
||||
2、什么是不可重复性?不可重复性是指添加的元素按照equals()判断时 ,返回false,需要同时重写equals()方法和HashCode()方法。
|
||||
|
||||
### 1.4.3 比较HashSet、LinkedHashSet和TreeSet三者的异同
|
||||
HashSet是Set接口的主要实现类 ,HashSet的底层是HashMap,线程不安全的,可以存储null值;
|
||||
|
||||
LinkedHashSet是HashSet的子类,能够按照添加的顺序遍历;
|
||||
|
||||
TreeSet底层使用红黑树,能够按照添加元素的顺序进行遍历,排序的方式有自然排序和定制排序。
|
||||
|
||||
|
||||
## 1.5 Map接口
|
||||
### 1.5.1 HashMap 和 Hashtable 的区别
|
||||
|
||||
1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过`synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
|
||||
1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的,因为HashTable 内部的方法基本都经过`synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
|
||||
2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
|
||||
3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
|
||||
3. **对Null key 和Null value的支持:** HashMap可以存储null的key和value,但null 作为键只能有一个,null作为值可以有多个;HashTable不允许有null键和null值,否则会抛出 NullPointerException。
|
||||
4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
|
||||
5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
|
||||
|
||||
@ -348,9 +325,11 @@ Output:
|
||||
|
||||
**==与equals的区别**
|
||||
|
||||
1. ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
|
||||
2. ==是指对内存地址进行比较 equals()是对字符串的内容进行比较
|
||||
3. ==指引用是否相同 equals()指的是值是否相同
|
||||
对于基本类型来说,== 比较的是值是否相等;
|
||||
|
||||
对于引用类型来说,== 比较的是两个引用是否指向同一个对象地址(两者在内存中存放的地址(堆内存地址)是否指向同一个地方);
|
||||
|
||||
对于引用类型(包括包装类型)来说,equals 如果没有被重写,对比它们的地址是否相等;如果equals()方法被重写(例如String),则比较的是地址里的内容。
|
||||
|
||||
### 1.5.4 HashMap的底层实现
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user