mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-14 05:21:42 +08:00
[docs update]mysql 索引内容部分描述完善
This commit is contained in:
parent
d145d61f35
commit
1816abea3b
@ -7,12 +7,18 @@ tag:
|
||||
|
||||
> 感谢[WT-AHA](https://github.com/WT-AHA)对本文的完善,相关 PR:https://github.com/Snailclimb/JavaGuide/pull/1648 。
|
||||
|
||||
## 何为索引?有什么作用?
|
||||
但凡经历过几场面试的小伙伴,应该都清楚,数据库索引这个知识点在面试中出现的频率高到离谱。
|
||||
|
||||
**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B 树, B+树和 Hash。**
|
||||
除了对于准备面试来说非常重要之外,善用索引对 SQL 的性能提升非常明显,是一个性价比较高的 SQL 优化手段。
|
||||
|
||||
## 索引介绍
|
||||
|
||||
**索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。**
|
||||
|
||||
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
|
||||
|
||||
索引底层数据结构存在很多种类型,常见的索引结构有: B 树, B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyIsam,都使用了 B+树作为索引结构。
|
||||
|
||||
## 索引的优缺点
|
||||
|
||||
**优点** :
|
||||
@ -31,11 +37,11 @@ tag:
|
||||
|
||||
## 索引的底层数据结构
|
||||
|
||||
### Hash表
|
||||
### Hash 表
|
||||
|
||||
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
|
||||
|
||||
**为何能够通过 key 快速取出 value呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
|
||||
**为何能够通过 key 快速取出 value 呢?** 原因在于 **哈希算法**(也叫散列算法)。通过哈希算法,我们可以快速找到 key 对应的 index,找到了 index 也就找到了对应的 value。
|
||||
|
||||
```java
|
||||
hash = hashfunc(key)
|
||||
@ -44,17 +50,13 @@ index = hash % array_size
|
||||
|
||||

|
||||
|
||||
但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
|
||||
但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
|
||||
|
||||
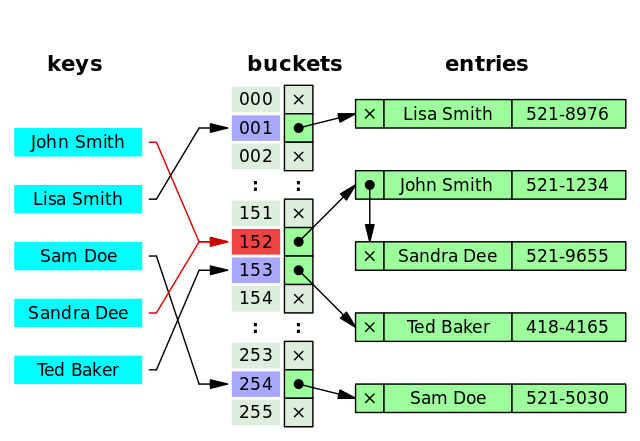
|
||||
|
||||
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
|
||||
|
||||
既然哈希表这么快,**为什么MySQL 没有使用其作为索引的数据结构呢?**
|
||||
|
||||
**1.Hash 冲突问题** :我们上面也提到过Hash 冲突了,不过对于数据库来说这还不算最大的缺点。
|
||||
|
||||
**2.Hash 索引不支持顺序和范围查询(Hash 索引不支持顺序和范围查询是它最大的缺点:** 假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。
|
||||
既然哈希表这么快,**为什么 MySQL 没有使用其作为索引的数据结构呢?** 主要是因为 Hash 索引不支持顺序和范围查询。假如我们要对表中的数据进行排序或者进行范围查询,那 Hash 索引可就不行了。并且,每次 IO 只能取一个。
|
||||
|
||||
试想一种情况:
|
||||
|
||||
@ -78,9 +80,9 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
|
||||
|
||||
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
|
||||
|
||||
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
|
||||
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
|
||||
> MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“**非聚簇索引(非聚集索引)**”。
|
||||
>
|
||||
> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引** ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
|
||||
|
||||
## 索引类型
|
||||
|
||||
@ -90,7 +92,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
一张数据表有只能有一个主键,并且主键不能为 null,不能重复。
|
||||
|
||||
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在null值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
|
||||
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在 null 值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
|
||||
|
||||
|
||||
|
||||
@ -100,7 +102,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
唯一索引,普通索引,前缀索引等索引属于二级索引。
|
||||
|
||||
**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
|
||||
PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
|
||||
|
||||
1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为 NULL,一张表允许创建多个唯一索引。** 建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
|
||||
2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和 NULL。**
|
||||
@ -112,70 +114,78 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
|
||||
|
||||
## 聚集索引与非聚集索引
|
||||
## 聚簇索引与非聚簇索引
|
||||
|
||||
### 聚集索引
|
||||
### 聚簇索引(聚集索引)
|
||||
|
||||
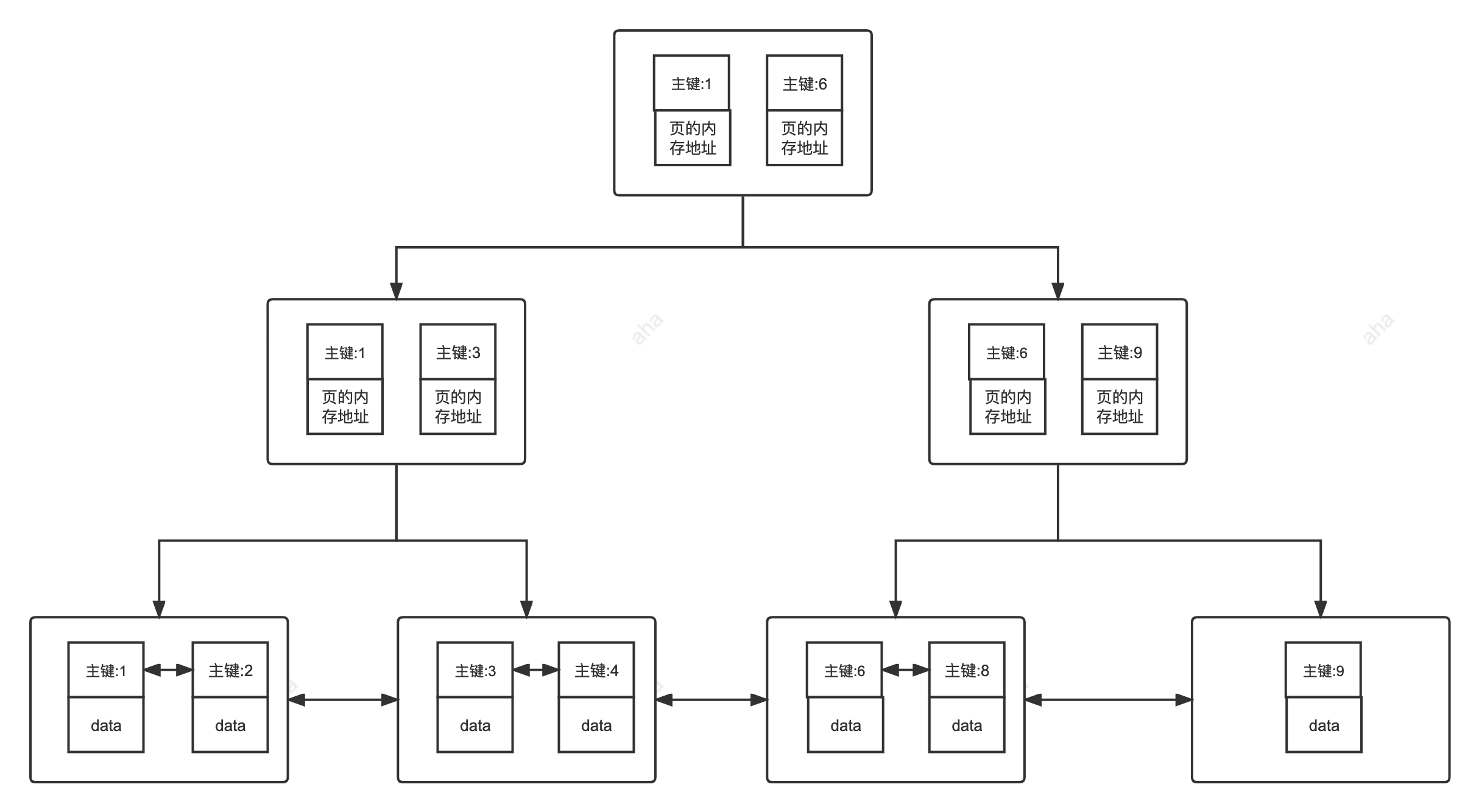
**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
|
||||
#### 聚簇索引介绍
|
||||
|
||||
**聚簇索引即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。**
|
||||
|
||||
在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
|
||||
#### 聚集索引的优点
|
||||
#### 聚簇索引的优缺点
|
||||
|
||||
聚集索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
|
||||
**优点** :
|
||||
|
||||
#### 聚集索引的缺点
|
||||
- **查询速度非常快** :聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
|
||||
- **对排序查找和范围查找优化** :聚簇索引对于主键的排序查找和范围查找速度非常快。
|
||||
|
||||
1. **依赖于有序的数据** :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
**缺点** :
|
||||
|
||||
### 非聚集索引
|
||||
- **依赖于有序的数据** :因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
- **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
|
||||
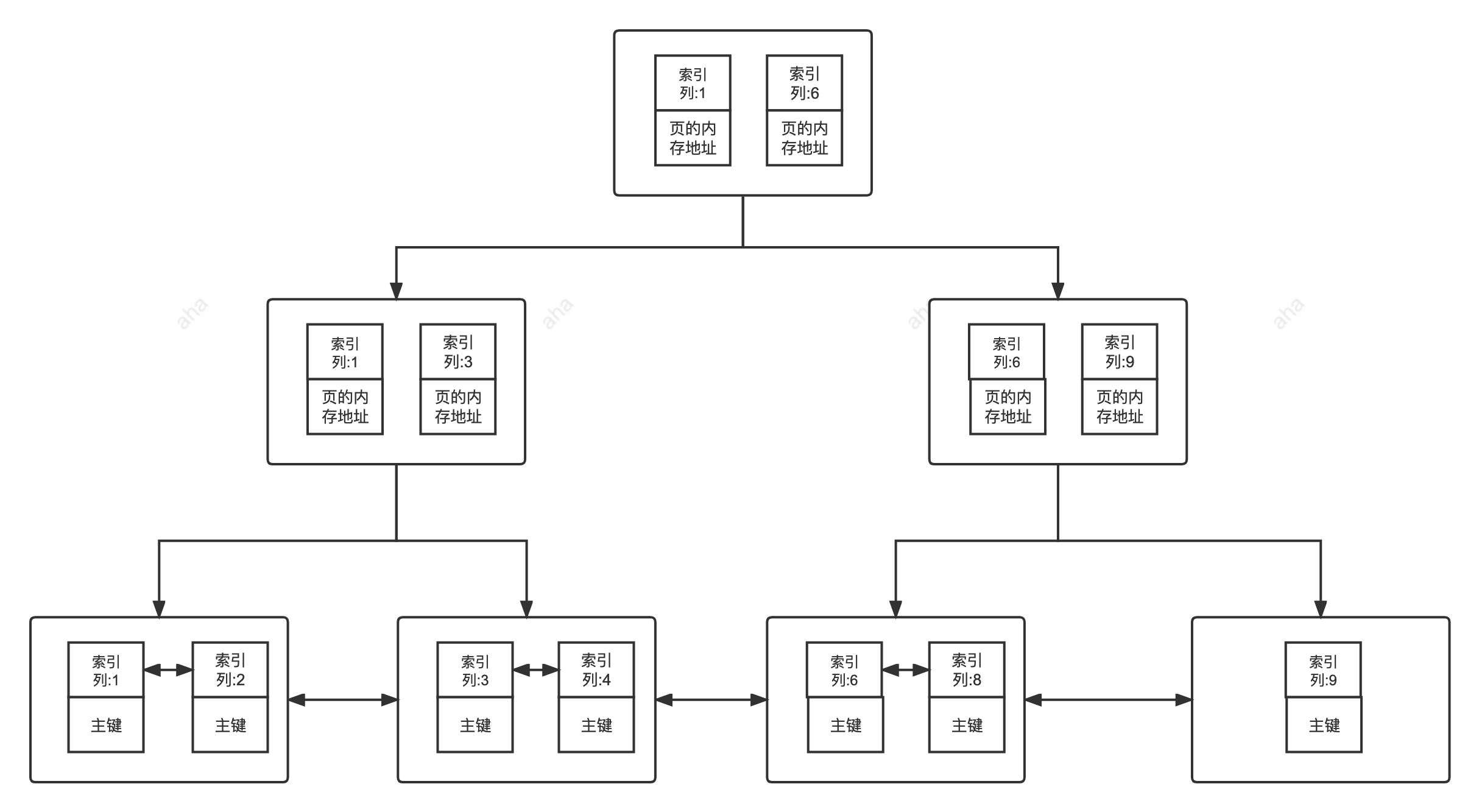
**非聚集索引即索引结构和数据分开存放的索引。**
|
||||
### 非聚簇索引(非聚集索引)
|
||||
|
||||
**二级索引属于非聚集索引。**
|
||||
#### 非聚簇索引介绍
|
||||
|
||||
非聚集索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
|
||||
**非聚簇索引即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引**
|
||||
|
||||
#### 非聚集索引的优点
|
||||
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
|
||||
|
||||
**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
|
||||
#### 非聚簇索引的优缺点
|
||||
|
||||
#### 非聚集索引的缺点
|
||||
**优点** :
|
||||
|
||||
1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
|
||||
2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
更新代价比聚簇索引要小 。非聚簇索引的更新代价就没有聚簇索引那么大了,非聚簇索引的叶子节点是不存放数据的
|
||||
|
||||
**缺点** :
|
||||
|
||||
- **依赖于有序的数据** :跟聚簇索引一样,非聚簇索引也依赖于有序的数据
|
||||
- **可能会二次查询(回表)** :这应该是非聚簇索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
|
||||
这是 MySQL 的表的文件截图:
|
||||
|
||||
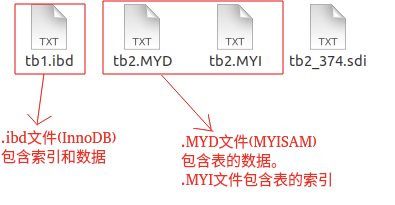
|
||||
|
||||
聚集索引和非聚集索引:
|
||||
聚簇索引和非聚簇索引:
|
||||
|
||||
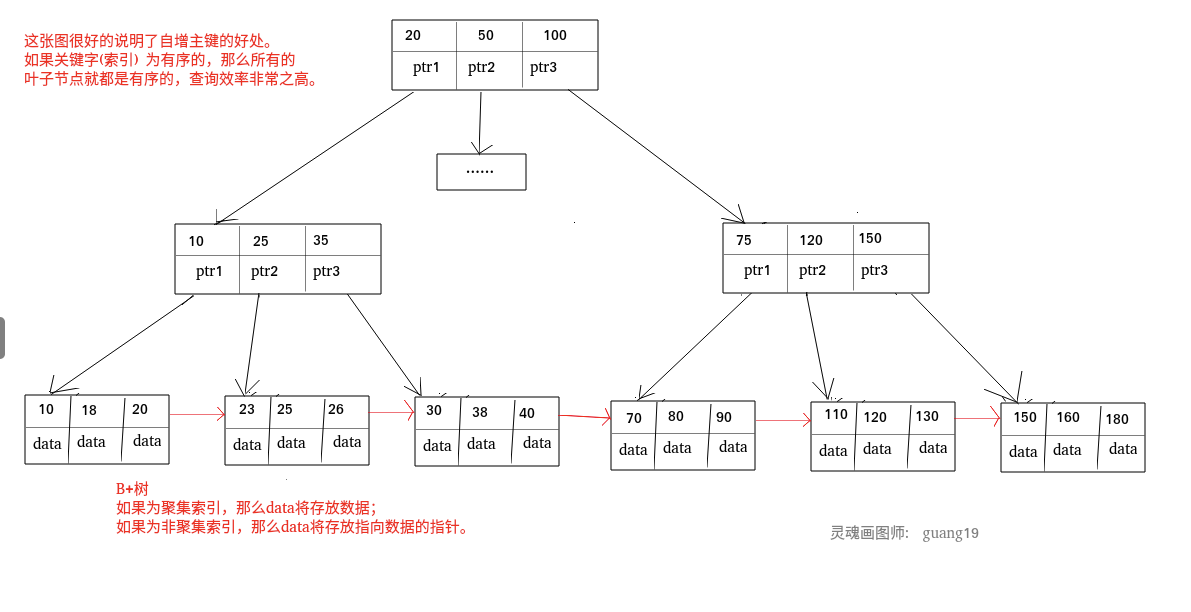
|
||||
|
||||
### 非聚集索引一定回表查询吗(覆盖索引)?
|
||||
#### 非聚簇索引一定回表查询吗(覆盖索引)?
|
||||
|
||||
**非聚集索引不一定回表查询。**
|
||||
**非聚簇索引不一定回表查询。**
|
||||
|
||||
> 试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
|
||||
试想一种情况,用户准备使用 SQL 查询用户名,而用户名字段正好建立了索引。
|
||||
|
||||
```text
|
||||
```sql
|
||||
SELECT name FROM table WHERE name='guang19';
|
||||
```
|
||||
|
||||
> 那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
|
||||
那么这个索引的 key 本身就是 name,查到对应的 name 直接返回就行了,无需回表查询。
|
||||
|
||||
**即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,
|
||||
因为它的主键索引的叶子节点存放的是指针。但是如果 SQL 查的就是主键呢?**
|
||||
即使是 MYISAM 也是这样,虽然 MYISAM 的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是!**如果 SQL 查的就是主键呢?**
|
||||
|
||||
```text
|
||||
```sql
|
||||
SELECT id FROM table WHERE id=1;
|
||||
```
|
||||
|
||||
主键索引本身的 key 就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
|
||||
|
||||
## 覆盖索引
|
||||
## 覆盖索引和联合索引
|
||||
|
||||
### 覆盖索引
|
||||
|
||||
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
|
||||
|
||||
@ -186,15 +196,13 @@ SELECT id FROM table WHERE id=1;
|
||||
> 再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
|
||||
> 那么直接根据这个索引就可以查到数据,也无需回表。
|
||||
|
||||
覆盖索引:
|
||||
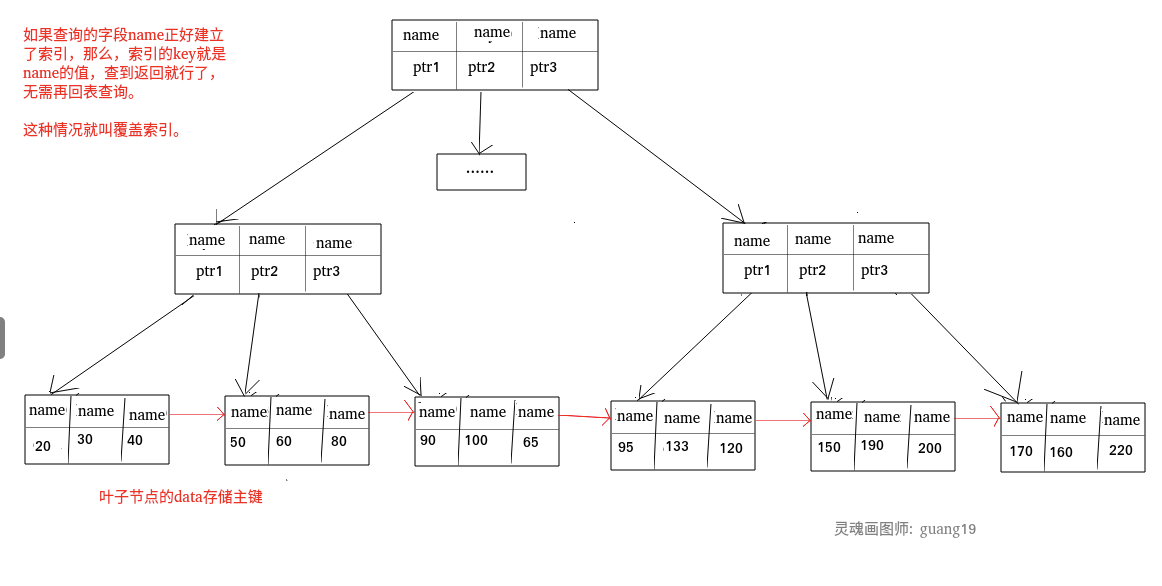
|
||||
|
||||

|
||||
|
||||
## 联合索引
|
||||
### 联合索引
|
||||
|
||||
使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
|
||||
|
||||
## 最左前缀匹配原则
|
||||
### 最左前缀匹配原则
|
||||
|
||||
最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询,如 **`>`**、**`<`**、**`between`** 和 **`以%开头的like查询`** 等条件,才会停止匹配。
|
||||
|
||||
@ -202,11 +210,11 @@ SELECT id FROM table WHERE id=1;
|
||||
|
||||
## 索引下推
|
||||
|
||||
索引下推是 **MySQL 5.6** 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
|
||||
**索引下推(Index Condition Pushdown)** 是 **MySQL 5.6** 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
|
||||
|
||||
## 创建索引的注意事项
|
||||
## 正确使用索引的一些建议
|
||||
|
||||
**1.选择合适的字段创建索引:**
|
||||
### 选择合适的字段创建索引
|
||||
|
||||
- **不为 NULL 的字段** :索引字段的数据应该尽量不为 NULL,因为对于数据为 NULL 的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为 NULL,建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代。
|
||||
- **被频繁查询的字段** :我们创建索引的字段应该是查询操作非常频繁的字段。
|
||||
@ -214,59 +222,34 @@ SELECT id FROM table WHERE id=1;
|
||||
- **频繁需要排序的字段** :索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
|
||||
- **被经常频繁用于连接的字段** :经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
|
||||
|
||||
**2.被频繁更新的字段应该慎重建立索引。**
|
||||
### 被频繁更新的字段应该慎重建立索引
|
||||
|
||||
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
|
||||
如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
|
||||
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
|
||||
|
||||
**3.尽可能的考虑建立联合索引而不是单列索引。**
|
||||
### 尽可能的考虑建立联合索引而不是单列索引
|
||||
|
||||
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
|
||||
|
||||
**4.注意避免冗余索引** 。
|
||||
### 注意避免冗余索引
|
||||
|
||||
冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
||||
|
||||
**5.考虑在字符串类型的字段上使用前缀索引代替普通索引。**
|
||||
### 考虑在字符串类型的字段上使用前缀索引代替普通索引
|
||||
|
||||
前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
|
||||
|
||||
## 使用索引的一些建议
|
||||
### 避免索引失效
|
||||
|
||||
- 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
|
||||
- 避免 where 子句中对字段施加函数,这会造成无法命中索引。
|
||||
- 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
|
||||
- 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
|
||||
- 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
|
||||
索引失效也是慢查询的主要原因之一,常见的导致索引失效的情况有下面这些:
|
||||
|
||||
## MySQL 如何为表字段添加索引?
|
||||
- 使用 `SELECT *` 进行查询;
|
||||
- 创建了组合索引,但查询条件未准守最左匹配原则;
|
||||
- 在索引列上进行计算、函数、类型转换等操作;
|
||||
- 以 % 开头的 LIKE 查询比如 `like '%abc';`;
|
||||
- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
|
||||
- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
|
||||
- ......
|
||||
|
||||
1.添加 PRIMARY KEY(主键索引)
|
||||
### 删除长期未使用的索引
|
||||
|
||||
```sql
|
||||
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
|
||||
```
|
||||
|
||||
2.添加 UNIQUE(唯一索引)
|
||||
|
||||
```sqlite
|
||||
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
|
||||
```
|
||||
|
||||
3.添加 INDEX(普通索引)
|
||||
|
||||
```sql
|
||||
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
|
||||
```
|
||||
|
||||
4.添加 FULLTEXT(全文索引)
|
||||
|
||||
```sql
|
||||
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
|
||||
```
|
||||
|
||||
5.添加多列索引
|
||||
|
||||
```sql
|
||||
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
|
||||
```
|
||||
删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
|
||||
|
||||
@ -175,6 +175,10 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
|
||||
|
||||
## MySQL 索引
|
||||
|
||||
MySQL 索引相关的问题比较多,对于面试和工作都比较重要,于是,我单独抽了一篇文章专门来总结 MySQL 索引相关的知识点和问题: [MySQL索引详解](./mysql-index) 。
|
||||
|
||||
## MySQL 查询缓存
|
||||
|
||||
执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 8.7 KiB After Width: | Height: | Size: 8.7 KiB |
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 数据库读写分离和分库分表
|
||||
title:
|
||||
category: 高性能
|
||||
head:
|
||||
- - meta
|
||||
@ -10,10 +10,6 @@ head:
|
||||
content: 读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上。 这样的话,就能够小幅提升写性能,大幅提升读性能。 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。分库就是将数据库中的数据分散到不同的数据库上。分表就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
|
||||
---
|
||||
|
||||
相信很多小伙伴们对于这两个概念已经比较熟悉了,这篇文章全程都是大白话的形式,希望能够给你带来不一样的感受。
|
||||
|
||||
如果你之前不太了解这两个概念,那我建议你搞懂之后,可以把自己对于读写分离以及分库分表的理解讲给你的同事/朋友听听。
|
||||
|
||||
## 读写分离
|
||||
|
||||
### 什么是读写分离?
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user