mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-10 00:41:37 +08:00
Merge branch 'Snailclimb:main' into main
This commit is contained in:
commit
11e30decfe
@ -348,7 +348,7 @@ emmm,就两个字—— **幂等** 。在编程中一个*幂等* 操作的特
|
||||
|
||||
|
||||
|
||||
## 什么事回溯消费?
|
||||
## 什么是回溯消费?
|
||||
|
||||
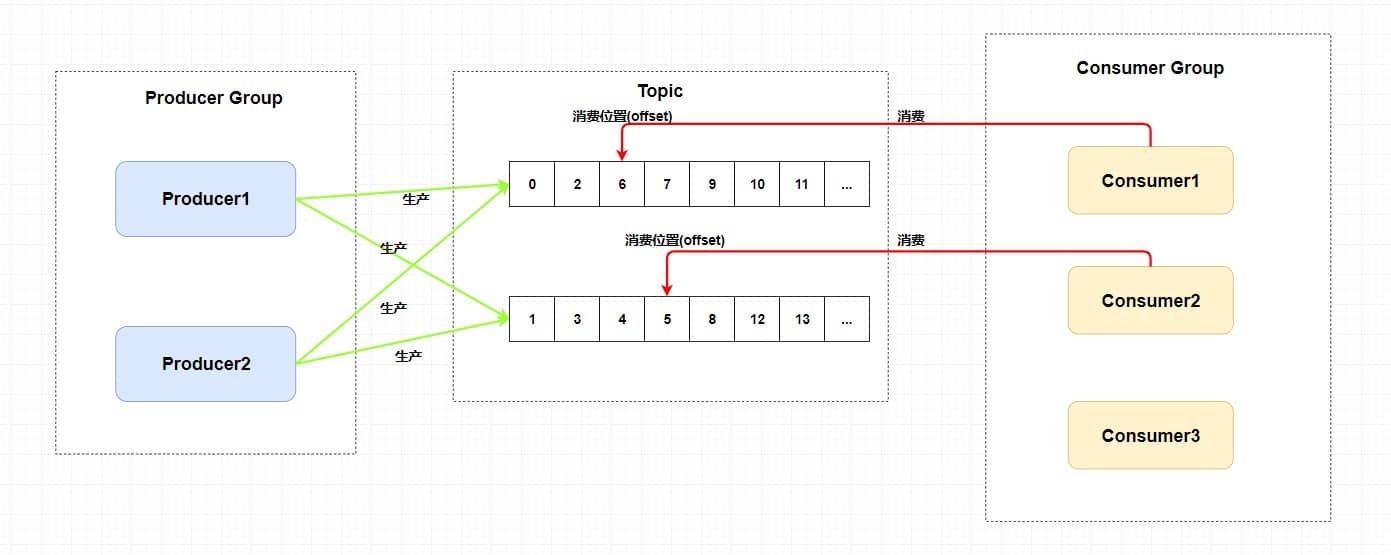
回溯消费是指 `Consumer` 已经消费成功的消息,由于业务上需求需要重新消费,在`RocketMQ` 中, `Broker` 在向`Consumer` 投递成功消息后,**消息仍然需要保留** 。并且重新消费一般是按照时间维度,例如由于 `Consumer` 系统故障,恢复后需要重新消费 1 小时前的数据,那么 `Broker` 要提供一种机制,可以按照时间维度来回退消费进度。`RocketMQ` 支持按照时间回溯消费,时间维度精确到毫秒。
|
||||
|
||||
|
||||
@ -229,7 +229,7 @@ public class DebugInvocationHandler implements InvocationHandler {
|
||||
public class JdkProxyFactory {
|
||||
public static Object getProxy(Object target) {
|
||||
return Proxy.newProxyInstance(
|
||||
target.getClass().getClassLoader(), // 目标类的类加载
|
||||
target.getClass().getClassLoader(), // 目标类的类加载器
|
||||
target.getClass().getInterfaces(), // 代理需要实现的接口,可指定多个
|
||||
new DebugInvocationHandler(target) // 代理对象对应的自定义 InvocationHandler
|
||||
);
|
||||
|
||||
@ -219,8 +219,8 @@ sum.increment();
|
||||
|
||||
理论上来说:
|
||||
|
||||
- 悲观锁通常多用于写比较多的情况下(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如`LongAdder`),也是可以考虑使用乐观锁的,要视实际情况而定。
|
||||
- 乐观锁通常多于写比较少的情况下(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考`java.util.concurrent.atomic`包下面的原子变量类)。
|
||||
- 悲观锁通常多用于写比较多的情况(多写场景,竞争激烈),这样可以避免频繁失败和重试影响性能,悲观锁的开销是固定的。不过,如果乐观锁解决了频繁失败和重试这个问题的话(比如`LongAdder`),也是可以考虑使用乐观锁的,要视实际情况而定。
|
||||
- 乐观锁通常多用于写比较少的情况(多读场景,竞争较少),这样可以避免频繁加锁影响性能。不过,乐观锁主要针对的对象是单个共享变量(参考`java.util.concurrent.atomic`包下面的原子变量类)。
|
||||
|
||||
### 如何实现乐观锁?
|
||||
|
||||
|
||||
@ -32,7 +32,7 @@ JMM(Java 内存模型)主要定义了对于一个共享变量,当另一个线
|
||||
|
||||
现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache。有些 CPU 可能还有 L4 Cache,这里不做讨论,并不常见
|
||||
|
||||
**CPU Cache 的工作方式:** 先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++ 操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++ 运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
|
||||
**CPU Cache 的工作方式:** 先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++ 操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 i++ 运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
|
||||
|
||||
**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议(比如 [MESI 协议](https://zh.wikipedia.org/wiki/MESI%E5%8D%8F%E8%AE%AE))或者其他手段来解决。** 这个缓存一致性协议指的是在 CPU 高速缓存与主内存交互的时候需要遵守的原则和规范。不同的 CPU 中,使用的缓存一致性协议通常也会有所不同。
|
||||
|
||||
|
||||
@ -74,7 +74,7 @@ public class OrdersService {
|
||||
>
|
||||
> 翻译过来的意思是:原子性,隔离性和持久性是数据库的属性,而一致性(在 ACID 意义上)是应用程序的属性。应用可能依赖数据库的原子性和隔离属性来实现一致性,但这并不仅取决于数据库。因此,字母 C 不属于 ACID 。
|
||||
|
||||
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 GitHub 开源,地址:[https://github.com/Vonng/ddiaopen in new window](https://github.com/Vonng/ddia) 。
|
||||
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 GitHub 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
|
||||
|
||||
## 详谈 Spring 对事务的支持
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user