diff --git a/docs/high-performance/deep-pagination-optimization.md b/docs/high-performance/deep-pagination-optimization.md
index 25c555fe..8fa69f4a 100644
--- a/docs/high-performance/deep-pagination-optimization.md
+++ b/docs/high-performance/deep-pagination-optimization.md
@@ -18,20 +18,18 @@ head:
# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
```
+
## 深度分页问题的原因
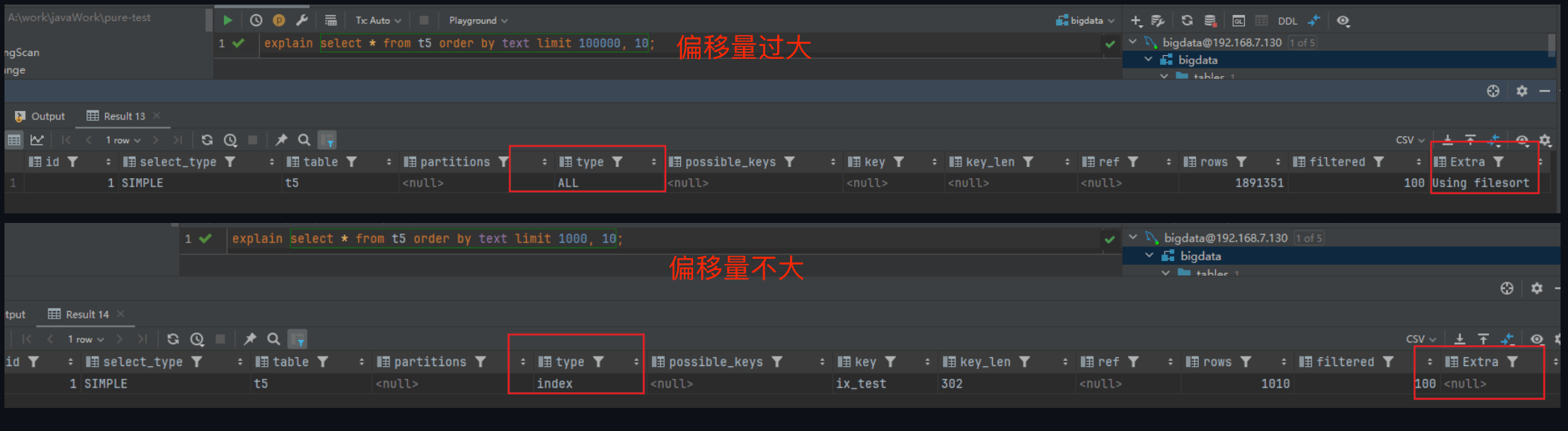
-**全表扫描**:当OFFSET值较大时,MySQL可能会选择执行全表扫描而不是使用索引。
-
-
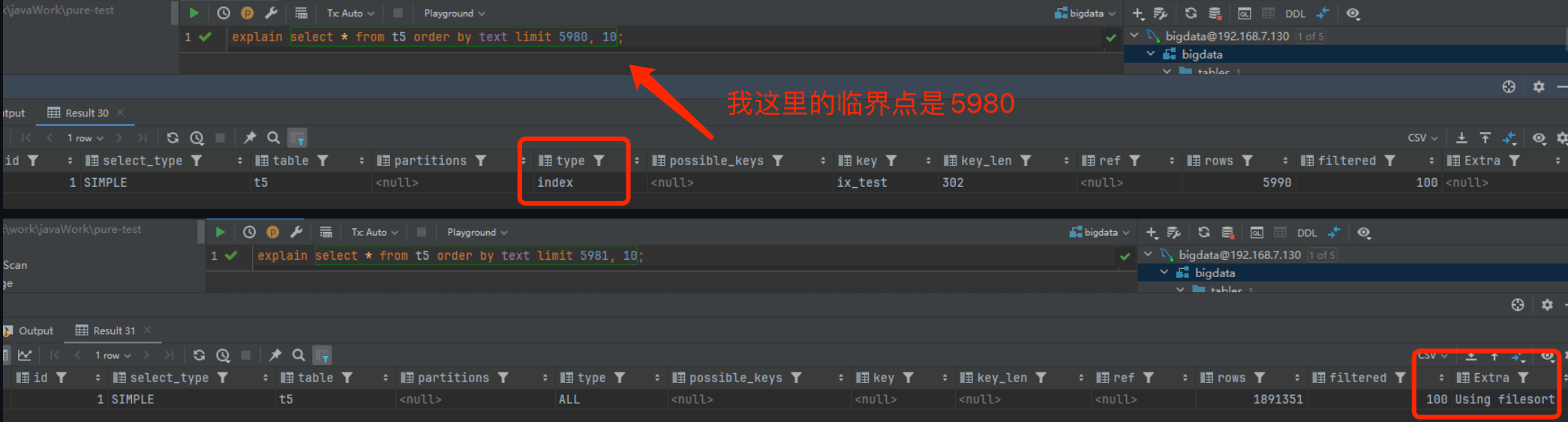
-具体的临界点每个机器不一样,我的机器上是5980,为什么产生呢?
-
-
-MySQL数据库的查询优化器是采用了基于代价的,而查询代价的估算是基于CPU代价和IO代价。
-如果MySQL在查询代价估算中,认为全表扫描方式比走索引扫描的方式效率更高的话,就会放弃索引,直接全表扫描。
-这就是为什么在大分页的SQL查询中,明明给该字段加了索引,但是MySQL却走了全表扫描的原因。
+当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。这是因为扫描索引和跳过大量记录可能比直接全表扫描更耗费资源。
+
+不同机器上这个查询偏移量过大的临界点可能不同,取决于多个因素,包括硬件配置(如 CPU 性能、磁盘速度)、表的大小、索引的类型和统计信息等。
+
+
+MySQL 的查询优化器采用基于成本的策略来选择最优的查询执行计划。它会根据 CPU 和 I/O 的成本来决定是否使用索引扫描或全表扫描。如果优化器认为全表扫描的成本更低,它就会放弃使用索引。不过,即使偏移量很大,如果查询中使用了覆盖索引(covering index),MySQL 仍然可能会使用索引,避免回表操作。
## 深度分页优化建议
diff --git a/docs/system-design/framework/spring/spring-design-patterns-summary.md b/docs/system-design/framework/spring/spring-design-patterns-summary.md
index 37d50e8b..dfbce7e8 100644
--- a/docs/system-design/framework/spring/spring-design-patterns-summary.md
+++ b/docs/system-design/framework/spring/spring-design-patterns-summary.md
@@ -346,7 +346,6 @@ Spring 框架中用到了哪些设计模式?
- 《Spring 技术内幕》
-
--
-
-
-