mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]缓存开源项目模块添加 OHC
This commit is contained in:
parent
36f59d4dbf
commit
0e974419b5
@ -97,7 +97,7 @@ tag:
|
||||
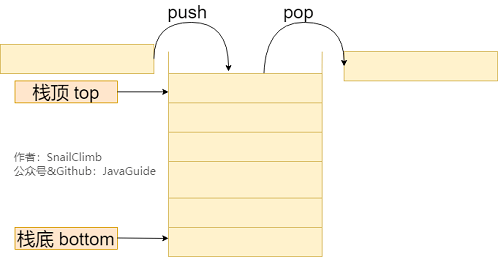
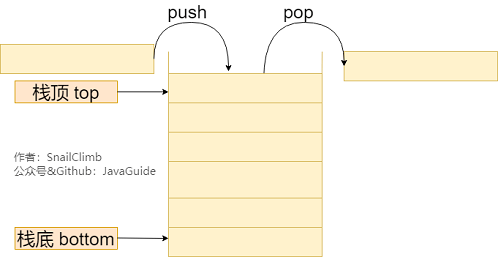
插入删除:O(1)//顶端插入和删除元素
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
### 3.2. 栈的常见应用常见应用场景
|
||||
|
||||
@ -107,7 +107,7 @@ tag:
|
||||
|
||||
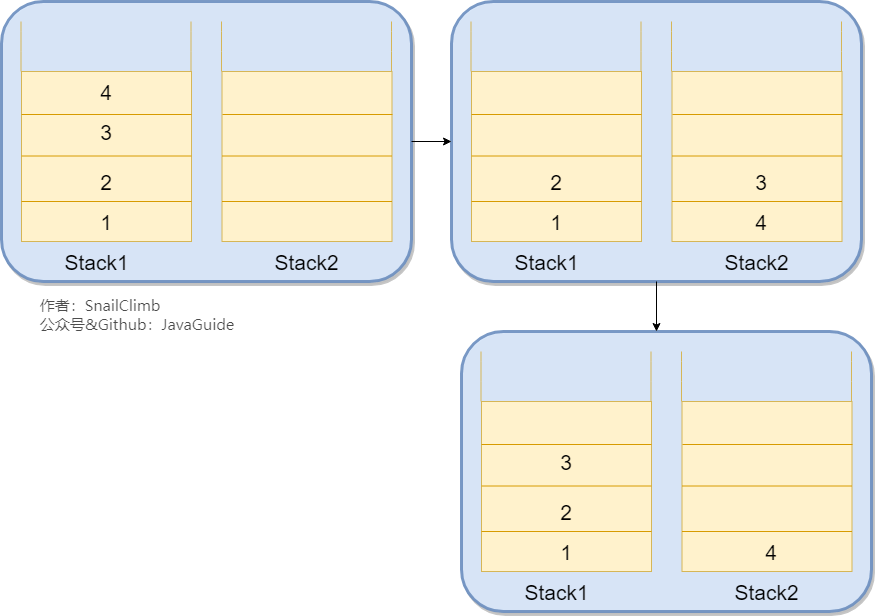
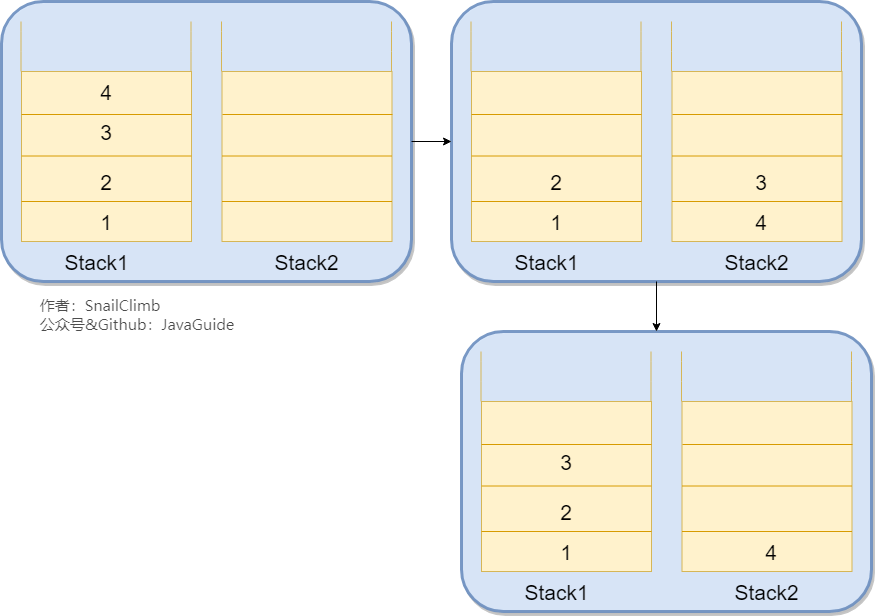
我们只需要使用两个栈(Stack1 和 Stack2)和就能实现这个功能。比如你按顺序查看了 1,2,3,4 这四个页面,我们依次把 1,2,3,4 这四个页面压入 Stack1 中。当你想回头看 2 这个页面的时候,你点击回退按钮,我们依次把 4,3 这两个页面从 Stack1 弹出,然后压入 Stack2 中。假如你又想回到页面 3,你点击前进按钮,我们将 3 页面从 Stack2 弹出,然后压入到 Stack1 中。示例图如下:
|
||||
|
||||
|
||||
|
||||
|
||||
#### 3.2.2. 检查符号是否成对出现
|
||||
|
||||
|
||||
@ -15,7 +15,7 @@ tag:
|
||||
|
||||
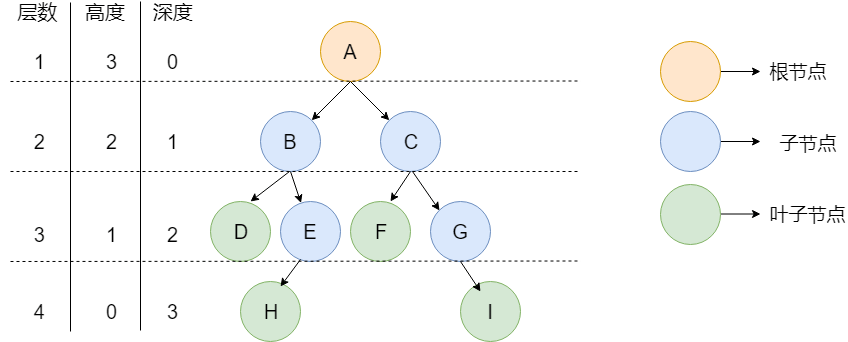
下图就是一颗树,并且是一颗二叉树。
|
||||
|
||||

|
||||
|
||||
|
||||
如上图所示,通过上面这张图说明一下树中的常用概念:
|
||||
|
||||
|
||||
@ -311,7 +311,7 @@ CREATE TABLE IF NOT EXISTS user_info_vip(
|
||||
uid INT(11) UNIQUE NOT NULL COMMENT '用户ID',
|
||||
nick_name VARCHAR(64) COMMENT'昵称',
|
||||
achievement INT(11) DEFAULT 0 COMMENT '成就值',
|
||||
level INT(11) COMMENT '用户等级',
|
||||
`level` INT(11) COMMENT '用户等级',
|
||||
job VARCHAR(32) COMMENT '职业方向',
|
||||
register_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '注册时间'
|
||||
)CHARACTER SET UTF8
|
||||
|
||||
@ -31,7 +31,7 @@ tag:
|
||||
|
||||
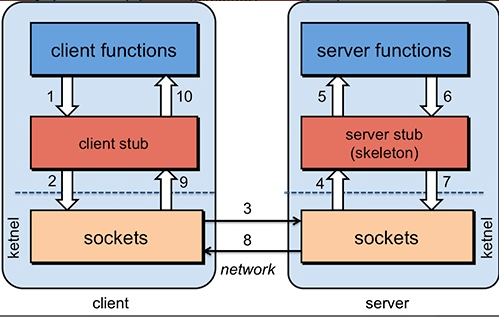
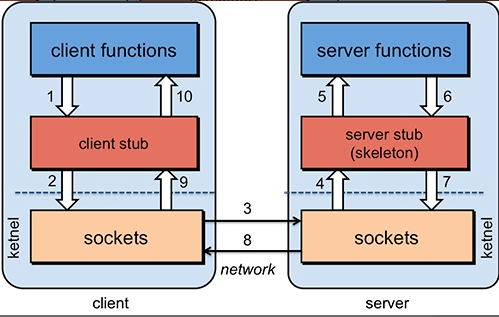
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
|
||||
|
||||
|
||||
|
||||
|
||||
1. 服务消费端(client)以本地调用的方式调用远程服务;
|
||||
1. 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):`RpcRequest`;
|
||||
@ -82,7 +82,7 @@ Motan 是新浪微博开源的一款 RPC 框架,据说在新浪微博正支撑
|
||||
|
||||
### gRPC
|
||||
|
||||
|
||||
|
||||
|
||||
gRPC 是 Google 开源的一个高性能、通用的开源 RPC 框架。其由主要面向移动应用开发并基于 HTTP/2 协议标准而设计(支持双向流、消息头压缩等功能,更加节省带宽),基于 ProtoBuf 序列化协议开发,并且支持众多开发语言。
|
||||
|
||||
@ -114,11 +114,11 @@ Dubbo 不论是从功能完善程度、生态系统还是社区活跃度来说
|
||||
|
||||
下图展示了 Dubbo 的生态系统。
|
||||
|
||||

|
||||

|
||||
|
||||
Dubbo 也是 Spring Cloud Alibaba 里面的一个组件。
|
||||
|
||||

|
||||

|
||||
|
||||
但是,Dubbo 和 Motan 主要是给 Java 语言使用。虽然,Dubbo 和 Motan 目前也能兼容部分语言,但是不太推荐。如果需要跨多种语言调用的话,可以考虑使用 gRPC。
|
||||
|
||||
|
||||
@ -39,7 +39,7 @@ Kafka 主要有两大应用场景:
|
||||
|
||||
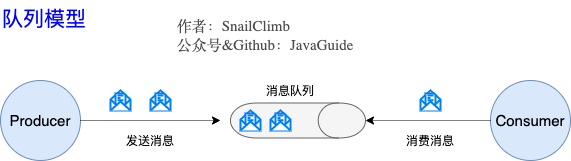
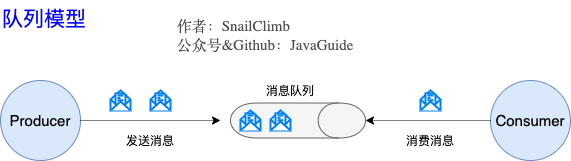
#### 队列模型:早期的消息模型
|
||||
|
||||
|
||||
|
||||
|
||||
**使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。** 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
|
||||
|
||||
@ -186,7 +186,7 @@ if (sendResult.getRecordMetadata() != null) {
|
||||
|
||||
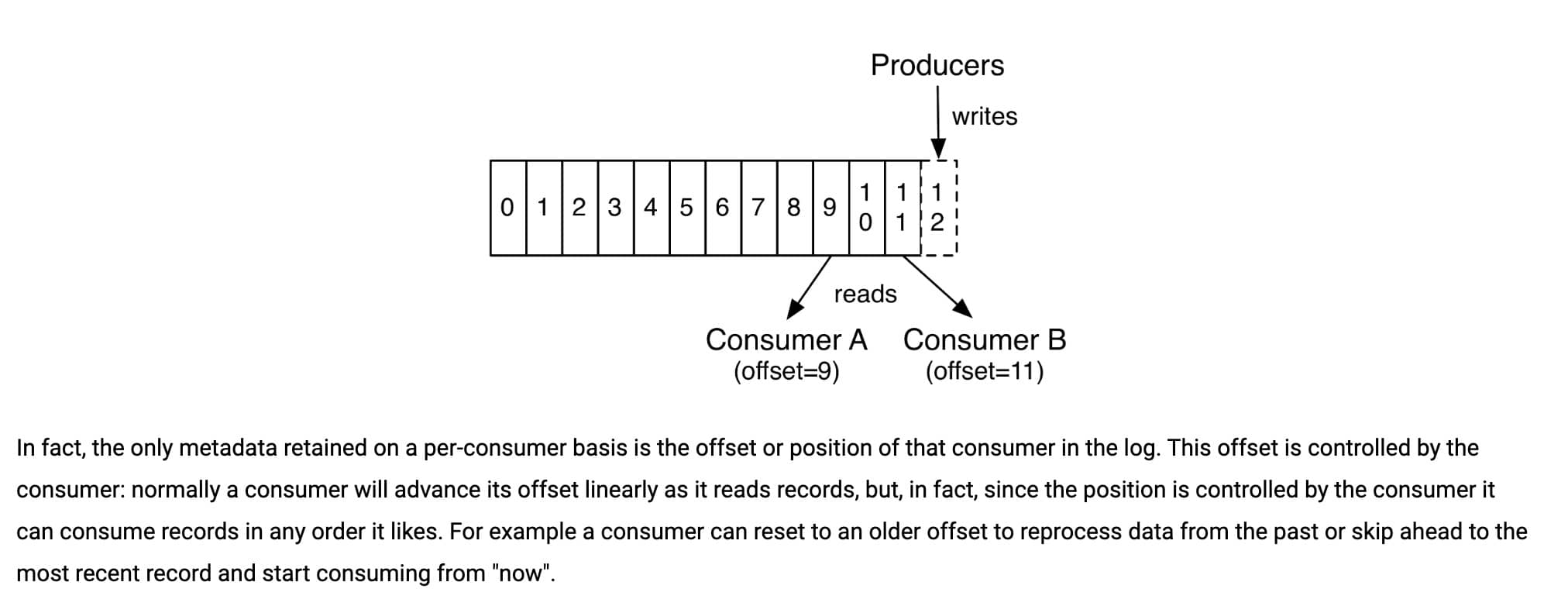
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
|
||||
|
||||
|
||||
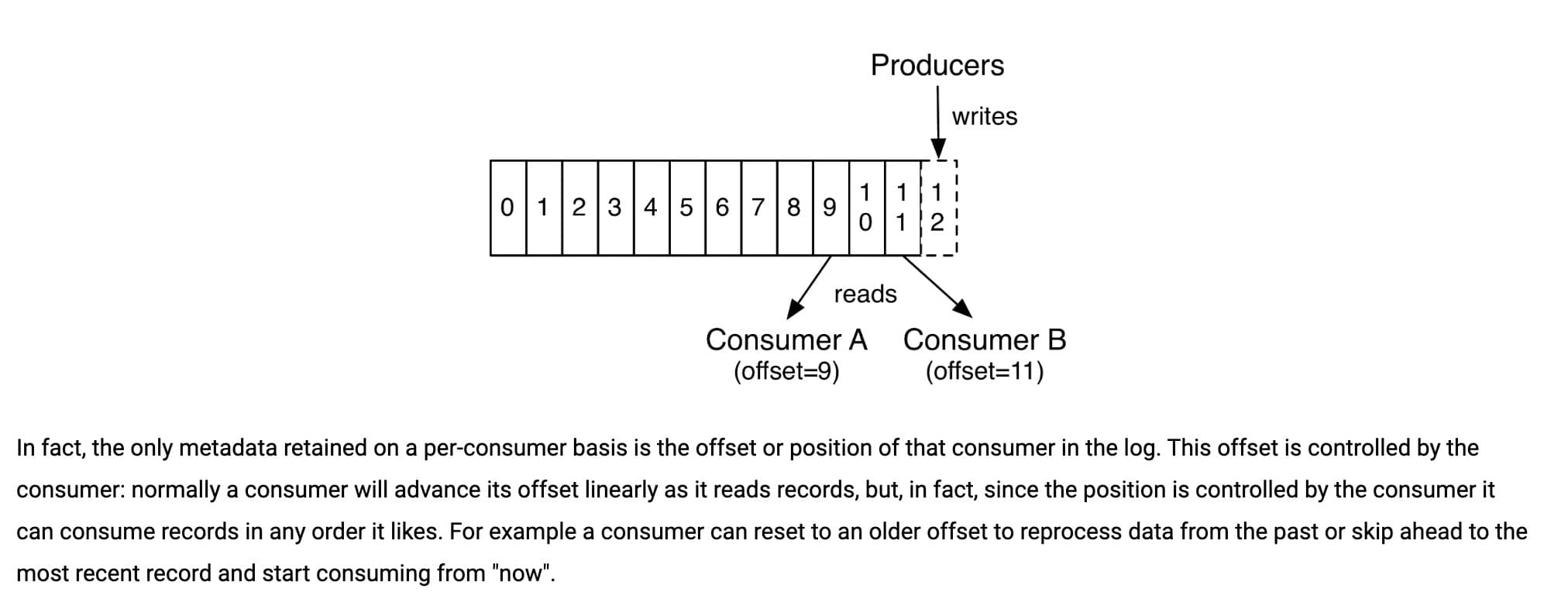
|
||||
|
||||
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
|
||||
|
||||
|
||||
@ -69,7 +69,7 @@ tag:
|
||||
|
||||
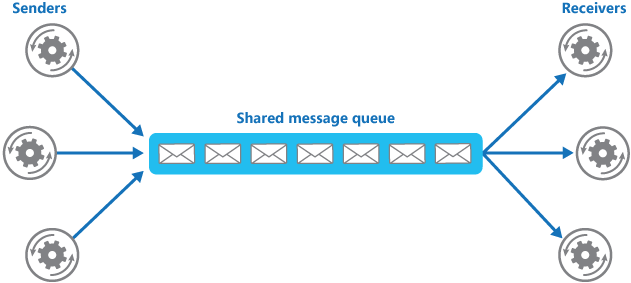
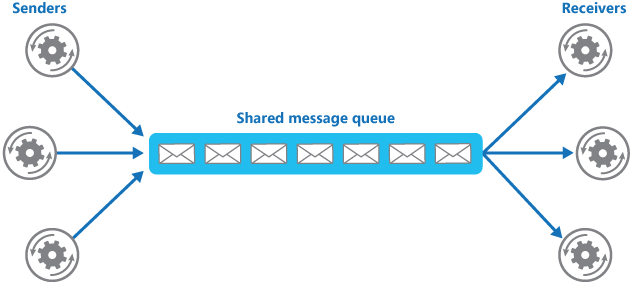
使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
|
||||
|
||||
|
||||
|
||||
|
||||
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
|
||||
|
||||
|
||||
@ -484,13 +484,19 @@ Java 8 中,锁粒度更细,`synchronized` 只锁定当前链表或红黑二
|
||||
public static final Object NULL = new Object();
|
||||
```
|
||||
|
||||
最后,再分享一下 `ConcurrentHashMap` 作者本人 (Doug Lea)对于这个问题的回答:
|
||||
|
||||
> The main reason that nulls aren't allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can't be accommodated. The main one is that if `map.get(key)` returns `null`, you can't detect whether the key explicitly maps to `null` vs the key isn't mapped. In a non-concurrent map, you can check this via `map.contains(key)`, but in a concurrent one, the map might have changed between calls.
|
||||
|
||||
翻译过来之后的,大致意思还是单线程下可以容忍歧义,而多线程下无法容忍。
|
||||
|
||||
### ConcurrentHashMap 能保证复合操作的原子性吗?
|
||||
|
||||
`ConcurrentHashMap` 是线程安全的,意味着它可以保证多个线程同时对它进行读写操作时,不会出现数据不一致的情况。但是,这并不意味着它可以保证所有的复合操作都是原子性的。
|
||||
`ConcurrentHashMap` 是线程安全的,意味着它可以保证多个线程同时对它进行读写操作时,不会出现数据不一致的情况,也不会导致 JDK1.7 及之前版本的 `HashMap` 多线程操作导致死循环问题。但是,这并不意味着它可以保证所有的复合操作都是原子性的,一定不要搞混了!
|
||||
|
||||
复合操作是指由多个基本操作(如`put`、`get`、`remove`、`containsKey`等)组成的操作,例如先判断某个键是否存在`containsKey(key)`,然后根据结果进行插入或更新`put(key, value)`。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
|
||||
|
||||
假设有两个线程 A 和 B 同时对 `ConcurrentHashMap` 进行复合操作,如下:
|
||||
例如,有两个线程 A 和 B 同时对 `ConcurrentHashMap` 进行复合操作,如下:
|
||||
|
||||
```java
|
||||
// 线程 A
|
||||
@ -534,7 +540,7 @@ map.computeIfAbsent(key, k -> value);
|
||||
map.computeIfAbsent(key, k -> anotherValue);
|
||||
```
|
||||
|
||||
不建议使用加锁的同步机制,违背了使用 `ConcurrentHashMap` 的初衷。
|
||||
很多同学可能会说了,这种情况也能加锁同步呀!确实可以,但不建议使用加锁的同步机制,违背了使用 `ConcurrentHashMap` 的初衷。在使用 `ConcurrentHashMap` 的时候,尽量使用这些原子性的复合操作方法来保证原子性。
|
||||
|
||||
## Collections 工具类(不重要)
|
||||
|
||||
|
||||
@ -17,7 +17,7 @@ JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,
|
||||
|
||||
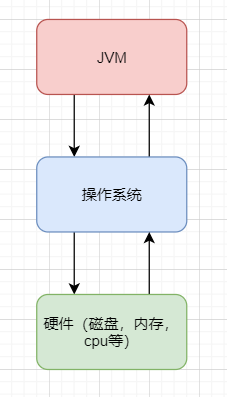
好,其实抛开这么专业的句子不说,就知道 JVM 其实就类似于一台小电脑运行在 windows 或者 linux 这些操作系统环境下即可。它直接和操作系统进行交互,与硬件不直接交互,而操作系统可以帮我们完成和硬件进行交互的工作。
|
||||
|
||||
|
||||
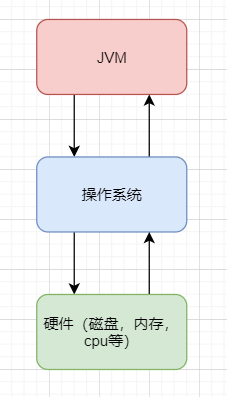
|
||||
|
||||
### 1.1 Java 文件是如何被运行的
|
||||
|
||||
@ -29,7 +29,7 @@ JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,
|
||||
|
||||
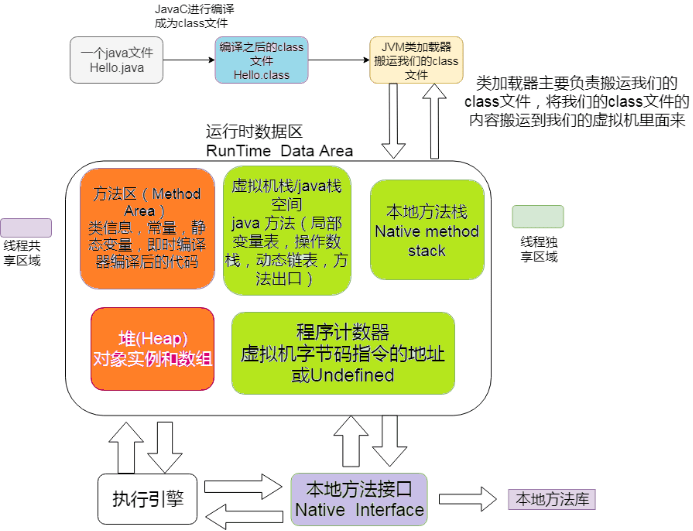
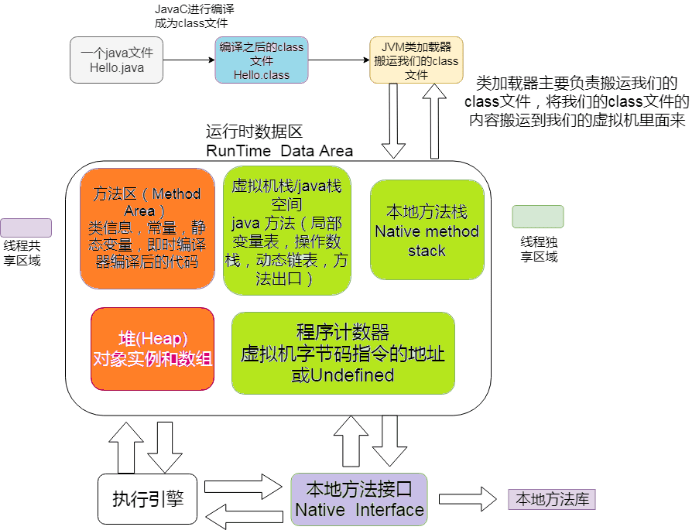
如果 **JVM** 想要执行这个 **.class** 文件,我们需要将其装进一个 **类加载器** 中,它就像一个搬运工一样,会把所有的 **.class** 文件全部搬进 JVM 里面来。
|
||||
|
||||

|
||||

|
||||
|
||||
#### ② 方法区
|
||||
|
||||
@ -51,7 +51,7 @@ JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,
|
||||
|
||||
主要就是完成一个加载工作,类似于一个指针一样的,指向下一行我们需要执行的代码。和栈一样,都是 **线程独享** 的,就是说每一个线程都会有自己对应的一块区域而不会存在并发和多线程的问题。
|
||||
|
||||
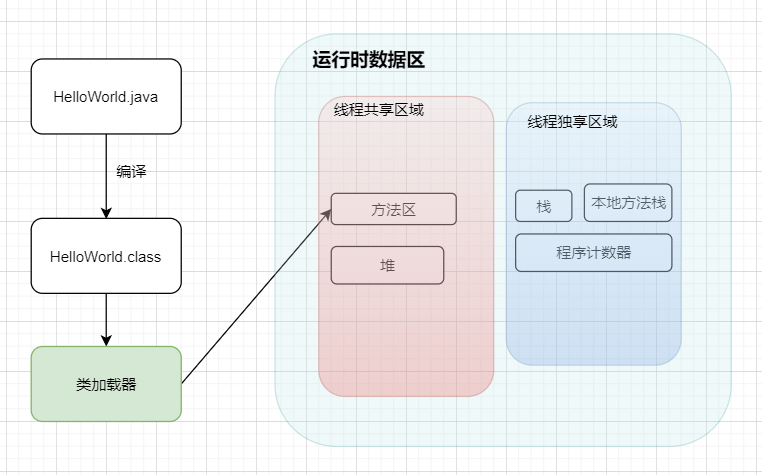
|
||||
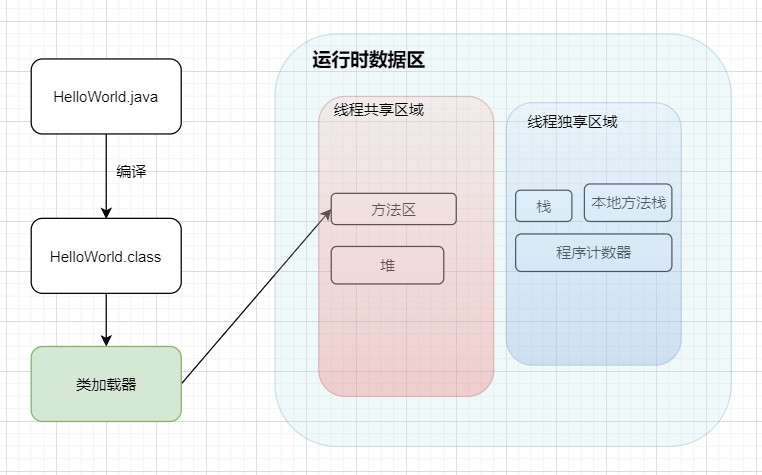
|
||||
|
||||
#### 小总结
|
||||
|
||||
@ -63,11 +63,11 @@ JVM 是 Java Virtual Machine 的缩写,它是一个虚构出来的计算机,
|
||||
|
||||
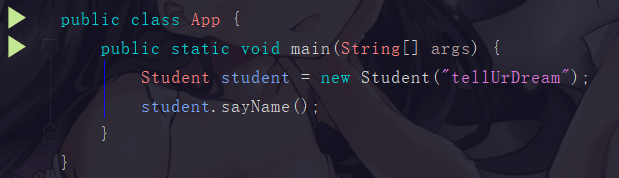
一个简单的学生类
|
||||
|
||||

|
||||

|
||||
|
||||
一个 main 方法
|
||||
|
||||
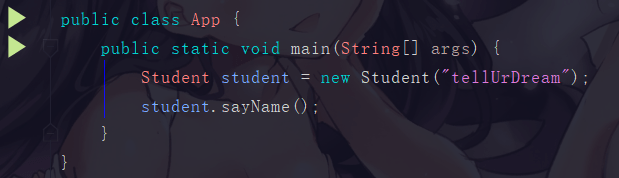
|
||||
|
||||
|
||||
执行 main 方法的步骤如下:
|
||||
|
||||
@ -219,13 +219,13 @@ JVM 内存会划分为堆内存和非堆内存,堆内存中也会划分为**
|
||||
|
||||
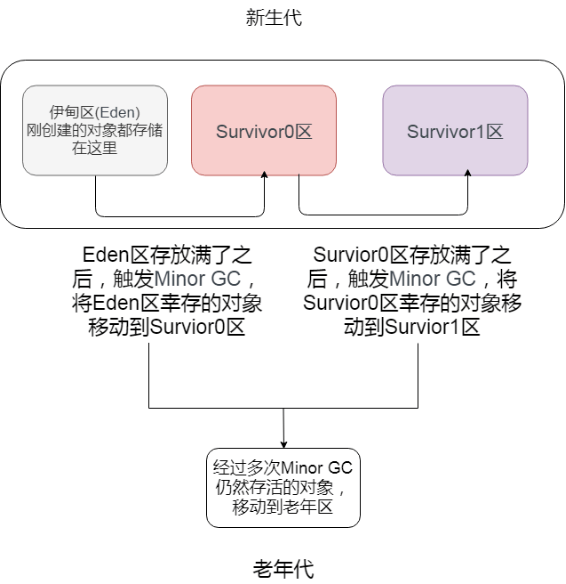
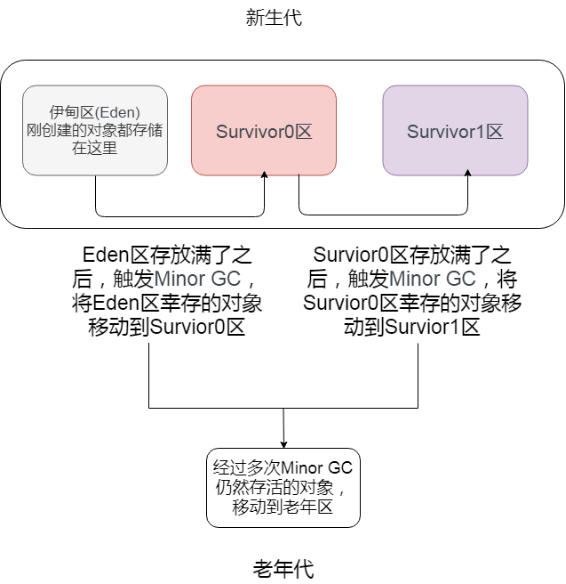
而且当老年区执行了 full gc 之后仍然无法进行对象保存的操作,就会产生 OOM,这时候就是虚拟机中的堆内存不足,原因可能会是堆内存设置的大小过小,这个可以通过参数-Xms、-Xmx 来调整。也可能是代码中创建的对象大且多,而且它们一直在被引用从而长时间垃圾收集无法收集它们。
|
||||
|
||||
|
||||
|
||||
|
||||
补充说明:关于-XX:TargetSurvivorRatio 参数的问题。其实也不一定是要满足-XX:MaxTenuringThreshold 才移动到老年代。可以举个例子:如对象年龄 5 的占 30%,年龄 6 的占 36%,年龄 7 的占 34%,加入某个年龄段(如例子中的年龄 6)后,总占用超过 Survivor 空间\*TargetSurvivorRatio 的时候,从该年龄段开始及大于的年龄对象就要进入老年代(即例子中的年龄 6 对象,就是年龄 6 和年龄 7 晋升到老年代),这时候无需等到 MaxTenuringThreshold 中要求的 15
|
||||
|
||||
#### 3.3.8 如何判断一个对象需要被干掉
|
||||
|
||||
|
||||
|
||||
|
||||
图中程序计数器、虚拟机栈、本地方法栈,3 个区域随着线程的生存而生存的。内存分配和回收都是确定的。随着线程的结束内存自然就被回收了,因此不需要考虑垃圾回收的问题。而 Java 堆和方法区则不一样,各线程共享,内存的分配和回收都是动态的。因此垃圾收集器所关注的都是堆和方法这部分内存。
|
||||
|
||||
@ -253,7 +253,7 @@ finalize()是 Object 类的一个方法、一个对象的 finalize()方法只会
|
||||
|
||||
补充一句:并不提倡在程序中调用 finalize()来进行自救。建议忘掉 Java 程序中该方法的存在。因为它执行的时间不确定,甚至是否被执行也不确定(Java 程序的不正常退出),而且运行代价高昂,无法保证各个对象的调用顺序(甚至有不同线程中调用)。在 Java9 中已经被标记为 **deprecated** ,且 `java.lang.ref.Cleaner`(也就是强、软、弱、幻象引用的那一套)中已经逐步替换掉它,会比 `finalize` 来的更加的轻量及可靠。
|
||||
|
||||

|
||||

|
||||
|
||||
判断一个对象的死亡至少需要两次标记
|
||||
|
||||
@ -264,47 +264,13 @@ finalize()是 Object 类的一个方法、一个对象的 finalize()方法只会
|
||||
|
||||
### 3.4 垃圾回收算法
|
||||
|
||||
不会非常详细的展开,常用的有标记清除,复制,标记整理和分代收集算法
|
||||
|
||||
#### 3.4.1 标记清除算法
|
||||
|
||||
标记清除算法就是分为“标记”和“清除”两个阶段。标记出所有需要回收的对象,标记结束后统一回收。这个套路很简单,也存在不足,后续的算法都是根据这个基础来加以改进的。
|
||||
|
||||
其实它就是把已死亡的对象标记为空闲内存,然后记录在一个空闲列表中,当我们需要 new 一个对象时,内存管理模块会从空闲列表中寻找空闲的内存来分给新的对象。
|
||||
|
||||
不足的方面就是标记和清除的效率比较低下。且这种做法会让内存中的碎片非常多。这个导致了如果我们需要使用到较大的内存块时,无法分配到足够的连续内存。比如下图
|
||||
|
||||

|
||||
|
||||
此时可使用的内存块都是零零散散的,导致了刚刚提到的大内存对象问题
|
||||
|
||||
#### 3.4.2 复制算法
|
||||
|
||||
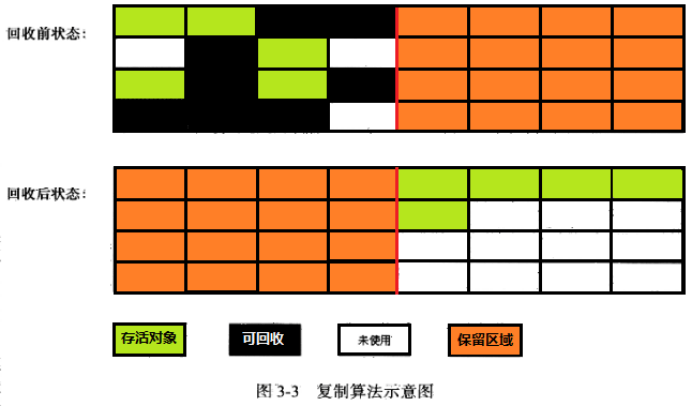
为了解决效率问题,复制算法就出现了。它将可用内存按容量划分成两等分,每次只使用其中的一块。和 survivor 一样也是用 from 和 to 两个指针这样的玩法。fromPlace 存满了,就把存活的对象 copy 到另一块 toPlace 上,然后交换指针的内容。这样就解决了碎片的问题。
|
||||
|
||||
这个算法的代价就是把内存缩水了,这样堆内存的使用效率就会变得十分低下了
|
||||
|
||||
|
||||
|
||||
不过它们分配的时候也不是按照 1:1 这样进行分配的,就类似于 Eden 和 Survivor 也不是等价分配是一个道理。
|
||||
|
||||
#### 3.4.3 标记整理算法
|
||||
|
||||
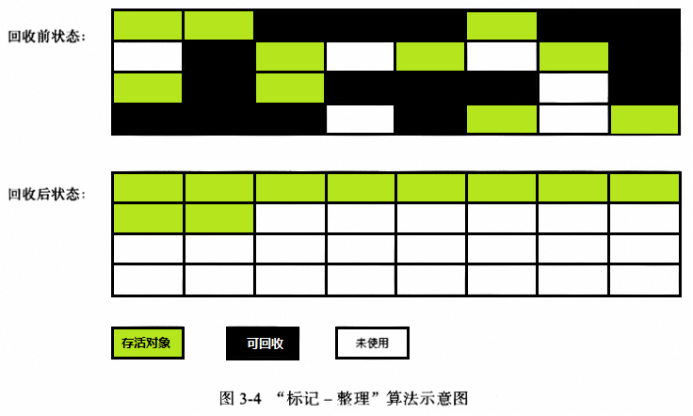
复制算法在对象存活率高的时候会有一定的效率问题,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存
|
||||
|
||||
|
||||
|
||||
#### 3.4.4 分代收集算法
|
||||
|
||||
这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清除”或者“标记-整理”算法来进行回收。
|
||||
|
||||
说白了就是八仙过海各显神通,具体问题具体分析了而已。
|
||||
关于常见垃圾回收算法的详细介绍,建议阅读这篇:[JVM垃圾回收详解(重点)](https://javaguide.cn/java/jvm/jvm-garbage-collection.html)。
|
||||
|
||||
### 3.5 (了解)各种各样的垃圾回收器
|
||||
|
||||
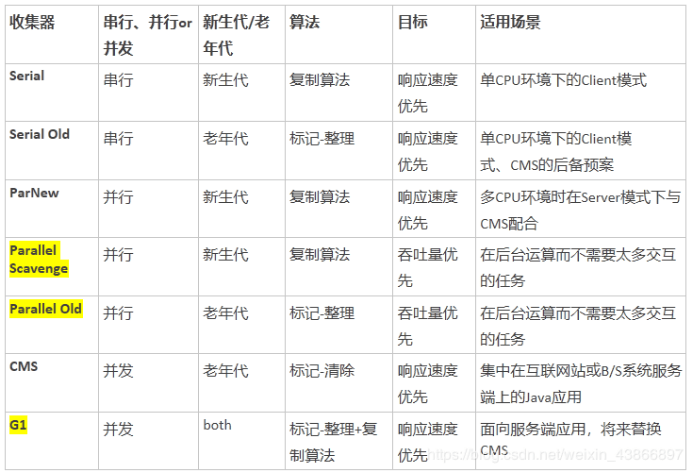
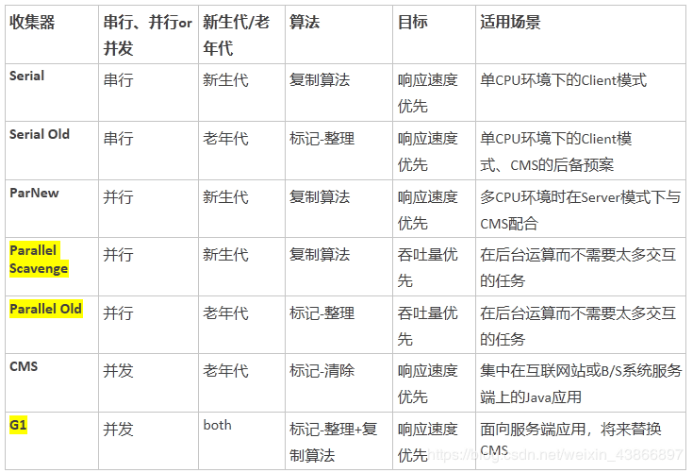
HotSpot VM 中的垃圾回收器,以及适用场景
|
||||
|
||||
|
||||
|
||||
|
||||
到 jdk8 为止,默认的垃圾收集器是 Parallel Scavenge 和 Parallel Old
|
||||
|
||||
@ -358,17 +324,17 @@ System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 /
|
||||
|
||||
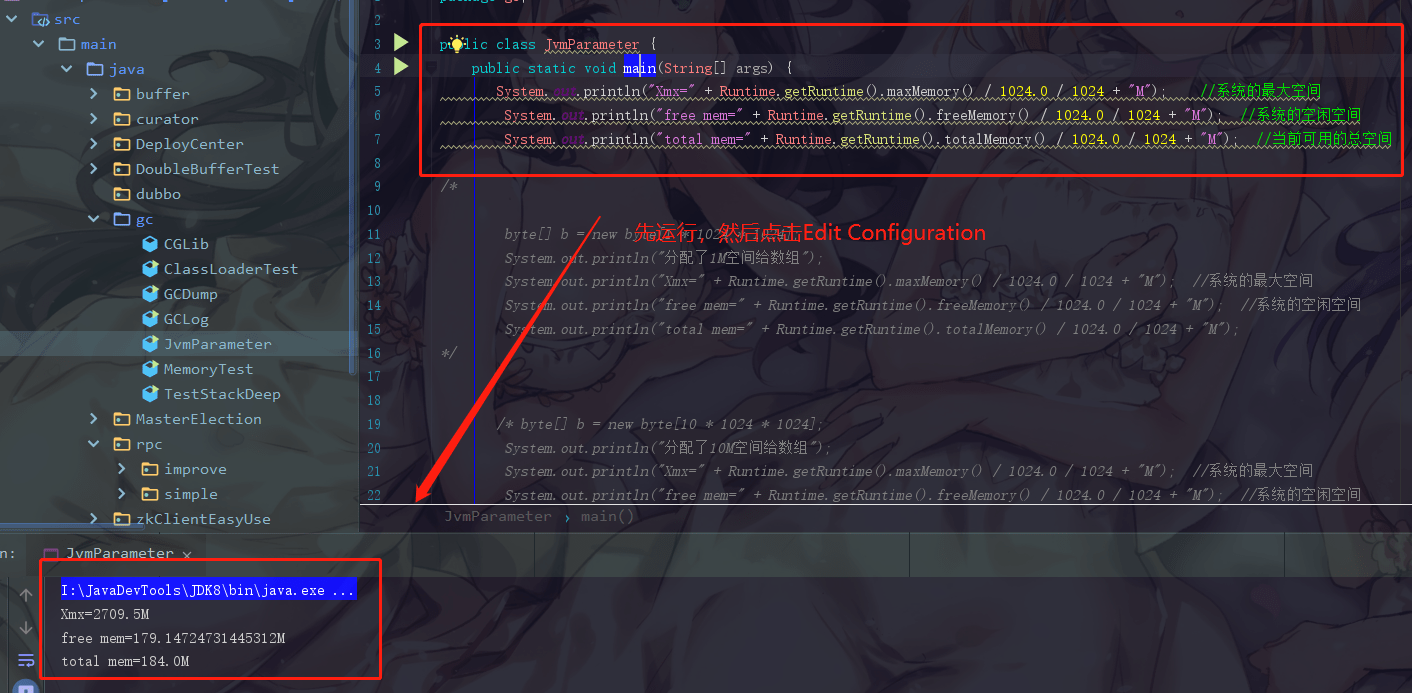
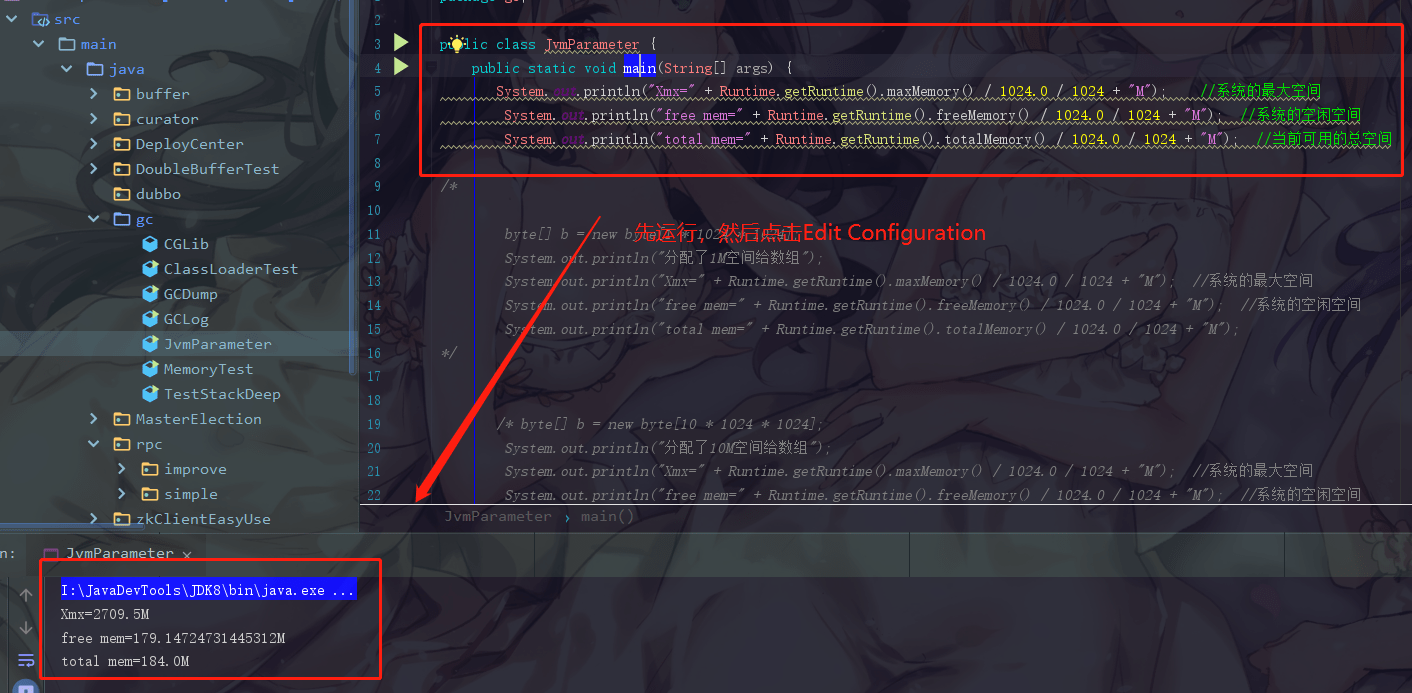
注意:此处设置的是 Java 堆大小,也就是新生代大小 + 老年代大小
|
||||
|
||||
|
||||
|
||||
|
||||
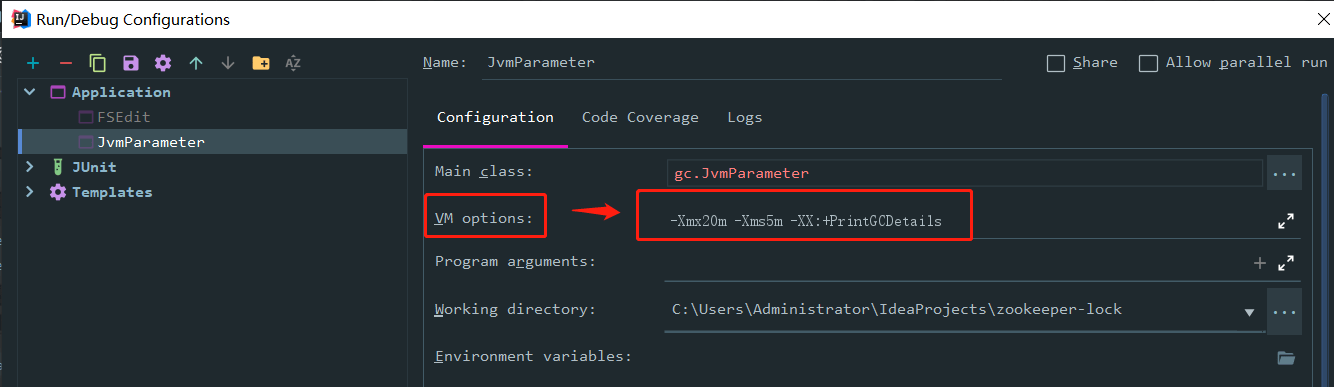
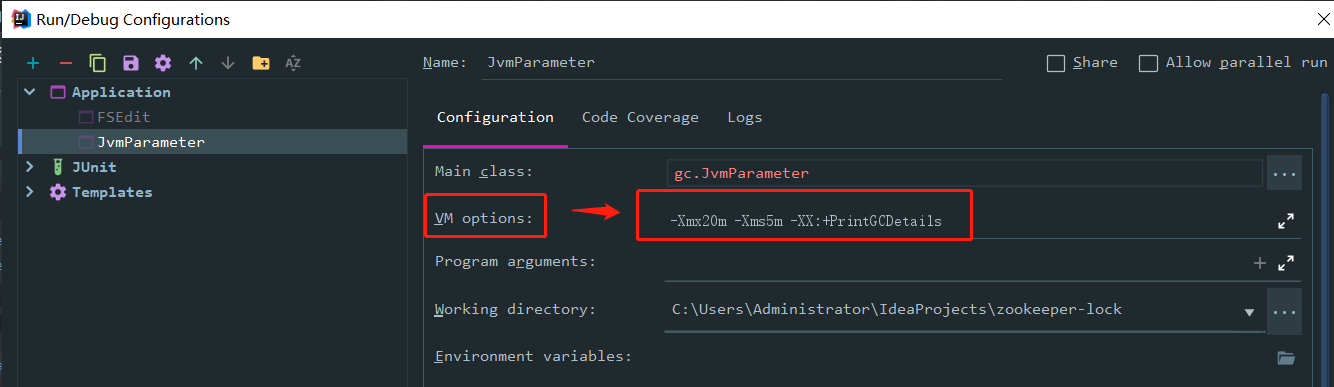
设置一个 VM options 的参数
|
||||
|
||||
-Xmx20m -Xms5m -XX:+PrintGCDetails
|
||||
|
||||
|
||||
|
||||
|
||||
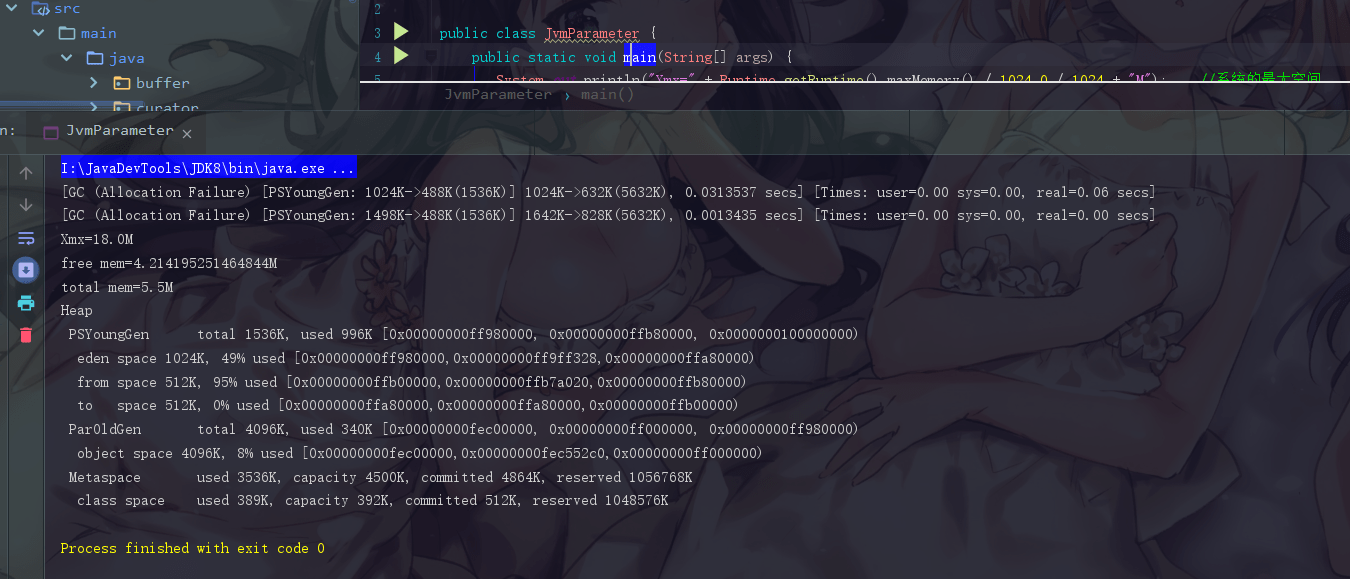
再次启动 main 方法
|
||||
|
||||
|
||||

|
||||
|
||||
这里 GC 弹出了一个 Allocation Failure 分配失败,这个事情发生在 PSYoungGen,也就是年轻代中
|
||||
|
||||
@ -384,7 +350,7 @@ System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 10
|
||||
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
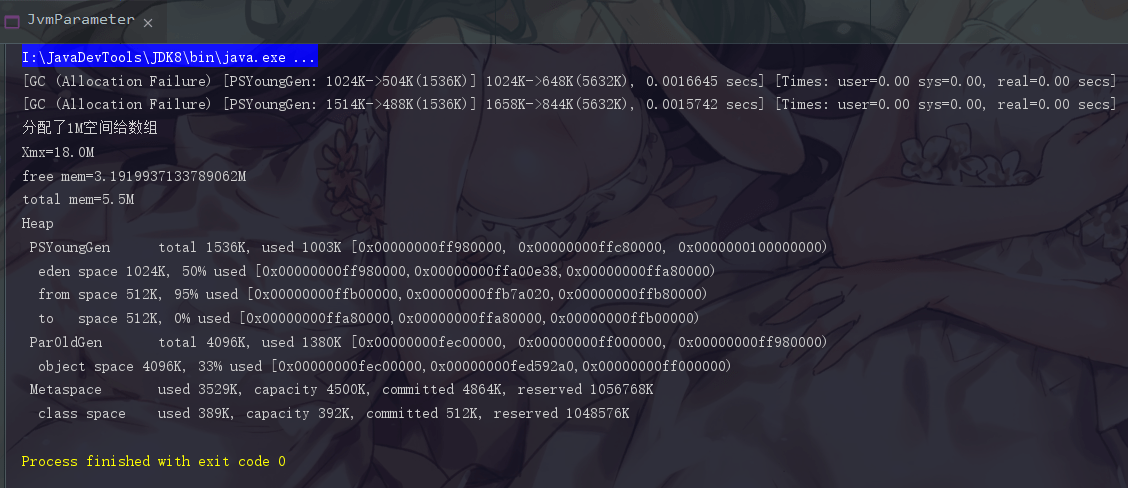
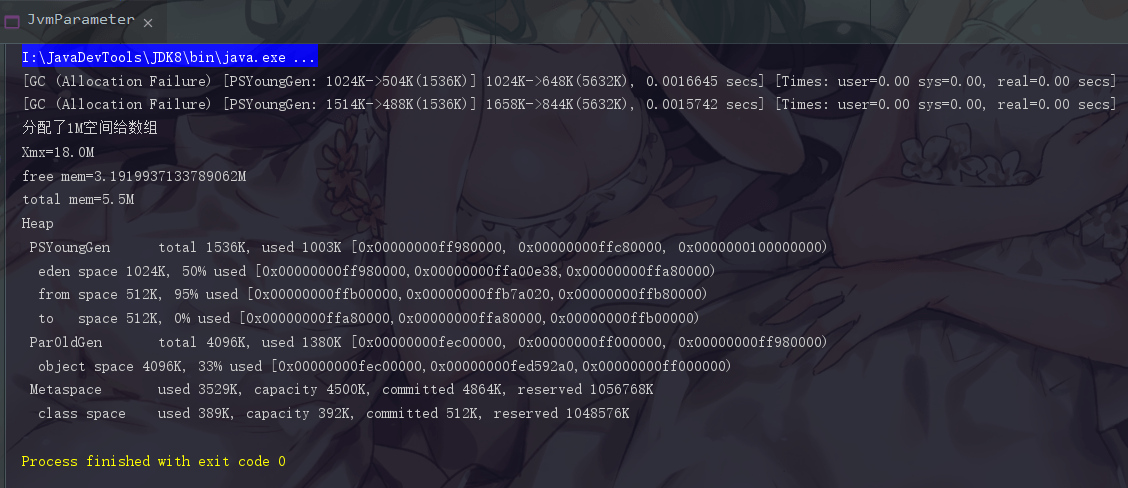
此时 free memory 就又缩水了,不过 total memory 是没有变化的。Java 会尽可能将 total mem 的值维持在最小堆内存大小
|
||||
|
||||
@ -396,7 +362,7 @@ System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 10
|
||||
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
|
||||
```
|
||||
|
||||
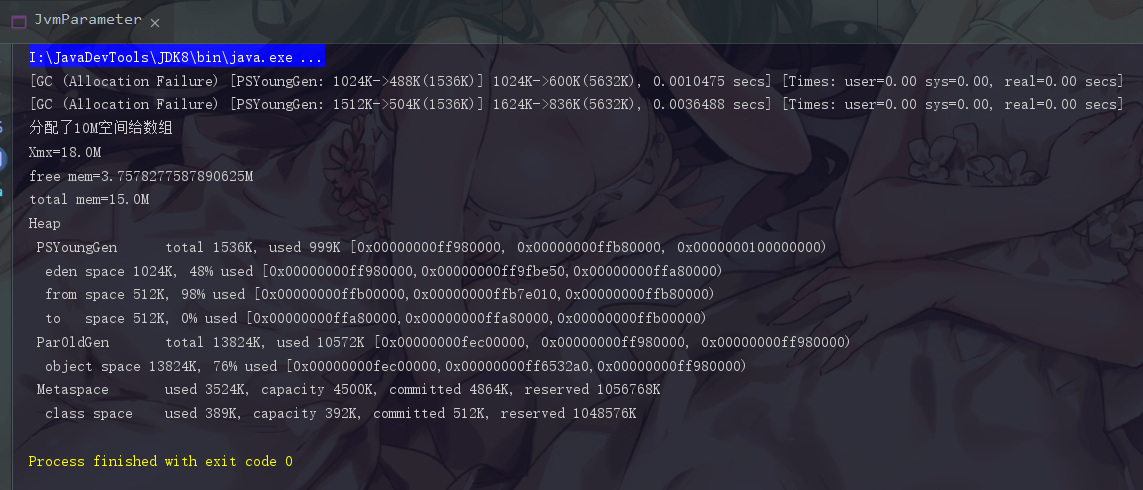
|
||||

|
||||
|
||||
这时候我们创建了一个 10M 的字节数据,这时候最小堆内存是顶不住的。我们会发现现在的 total memory 已经变成了 15M,这就是已经申请了一次内存的结果。
|
||||
|
||||
@ -409,7 +375,7 @@ System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 10
|
||||
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
|
||||
```
|
||||
|
||||
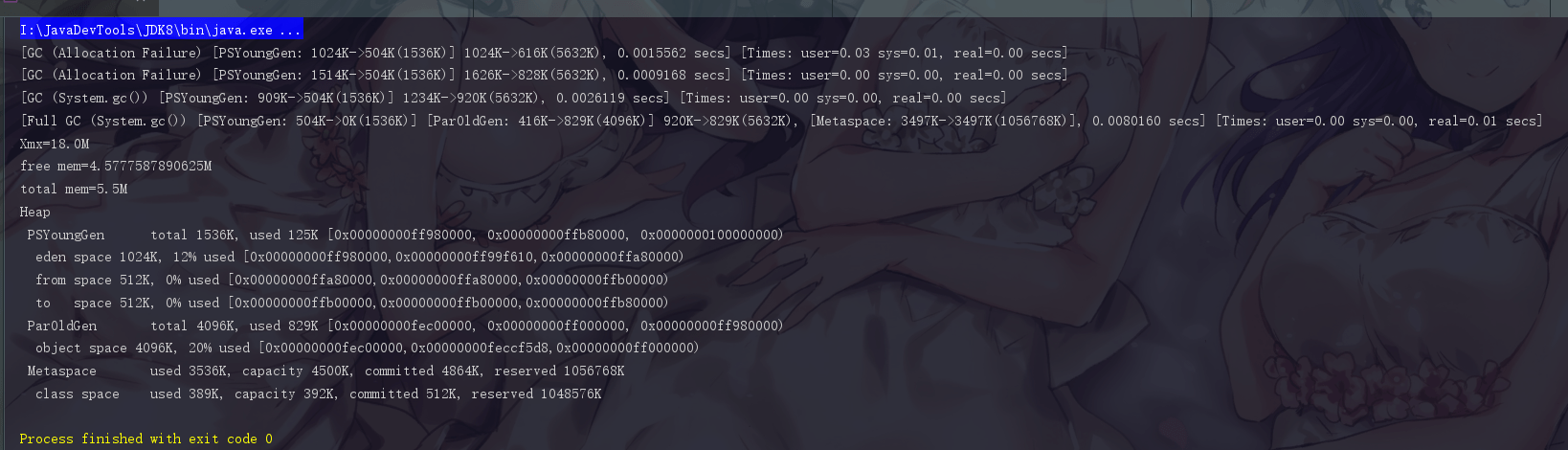
|
||||
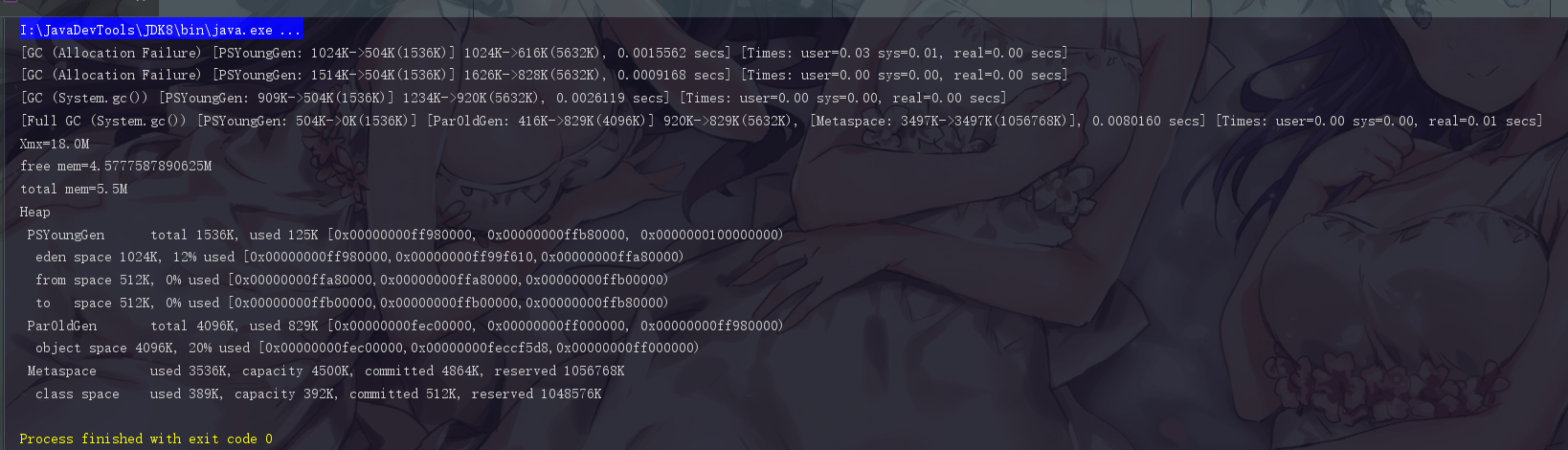
|
||||
|
||||
此时我们手动执行了一次 fullgc,此时 total memory 的内存空间又变回 5.5M 了,此时又是把申请的内存释放掉的结果。
|
||||
|
||||
|
||||
@ -140,18 +140,19 @@ icon: "xitongsheji"
|
||||
|
||||
- [Caffeine](https://github.com/ben-manes/caffeine) : 一款强大的本地缓存解决方案,性能非常强大。
|
||||
- [Redis](https://github.com/redis/redis):一个使用 C 语言开发的内存数据库,分布式缓存首选。
|
||||
- [OHC](https://github.com/snazy/ohc) :Java 堆外缓存解决方案(项目从 2021 年开始就不再进行维护了)。
|
||||
|
||||
### 消息队列
|
||||
|
||||
**分布式队列**:
|
||||
|
||||
- [RocketMQ](https://github.com/apache/rocketmq "RocketMQ"):阿里巴巴开源的一款高性能、高吞吐量的分布式消息中间件。
|
||||
- [Kafaka](https://github.com/apache/kafka "Kafaka"): Kafka 是一种分布式的,基于发布 / 订阅的消息系统。关于它的入门可以查看:[Kafka 入门看这一篇就够了](https://github.com/Snailclimb/JavaGuide/blob/master/docs/system-design/data-communication/Kafka入门看这一篇就够了.md "Kafka入门看这一篇就够了")
|
||||
- [Kafaka](https://github.com/apache/kafka "Kafaka"): Kafka 是一种分布式的,基于发布 / 订阅的消息系统。
|
||||
- [RabbitMQ](https://github.com/rabbitmq "RabbitMQ") :由 erlang 开发的基于 AMQP(Advanced Message Queue 高级消息队列协议)协议实现的消息队列。
|
||||
|
||||
**内存队列**:
|
||||
|
||||
- [Disruptor](https://github.com/LMAX-Exchange/disruptor):Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与 I/O 操作处于同样的数量级)。相关阅读:[《高性能内存队列——Disruptor》](https://tech.meituan.com/2016/11/18/disruptor.html) 。
|
||||
- [Disruptor](https://github.com/LMAX-Exchange/disruptor):Disruptor 是英国外汇交易公司 LMAX 开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与 I/O 操作处于同样的数量级)。
|
||||
|
||||
### 读写分离和分库分表
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user