mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs fix]图片403问题修复
This commit is contained in:
parent
ee12b9d103
commit
0d7578c511
@ -1,6 +1,6 @@
|
|||||||
<p style="text-align:center">
|
<p style="text-align:center">
|
||||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||||
<img src="https://img-blog.csdnimg.cn/img_convert/1c00413c65d1995993bf2b0daf7b4f03.png#pic_center" width=""/>
|
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/csdn/1c00413c65d1995993bf2b0daf7b4f03.png" width=""/>
|
||||||
</a>
|
</a>
|
||||||
</p>
|
</p>
|
||||||
<p style="text-align:center">
|
<p style="text-align:center">
|
||||||
@ -21,6 +21,7 @@
|
|||||||
</tbody>
|
</tbody>
|
||||||
</table>
|
</table>
|
||||||
|
|
||||||
|
|
||||||
## Java
|
## Java
|
||||||
|
|
||||||
### Basis
|
### Basis
|
||||||
@ -369,6 +370,4 @@ If you want to follow my updated articles and the dry goods I share in real time
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|||||||
@ -11,7 +11,7 @@
|
|||||||
</p>
|
</p>
|
||||||
<p>
|
<p>
|
||||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||||
<img src="https://img-blog.csdnimg.cn/img_convert/1c00413c65d1995993bf2b0daf7b4f03.png#pic_center" width="" />
|
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/csdn/1c00413c65d1995993bf2b0daf7b4f03.png" width="" />
|
||||||
</a>
|
</a>
|
||||||
</p>
|
</p>
|
||||||
<p>
|
<p>
|
||||||
@ -26,6 +26,7 @@
|
|||||||
</p>
|
</p>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|
||||||
> 1. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java 面试指北 》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) (质量很高,专为面试打造,配合 JavaGuide 食用)。
|
> 1. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java 面试指北 》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) (质量很高,专为面试打造,配合 JavaGuide 食用)。
|
||||||
> 1. **知识星球** :专属面试小册/一对一交流/简历修改/专属求职指南,欢迎加入 [JavaGuide 知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看星球的详细介绍,一定一定一定确定自己真的需要再加入,一定一定要看完详细介绍之后再加我)。
|
> 1. **知识星球** :专属面试小册/一对一交流/简历修改/专属求职指南,欢迎加入 [JavaGuide 知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看星球的详细介绍,一定一定一定确定自己真的需要再加入,一定一定要看完详细介绍之后再加我)。
|
||||||
> 2. **转载须知** :以下所有文章如非文首说明为转载皆为我(Guide 哥)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
> 2. **转载须知** :以下所有文章如非文首说明为转载皆为我(Guide 哥)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
||||||
@ -33,8 +34,6 @@
|
|||||||
<div align="center">
|
<div align="center">
|
||||||
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/gongzhonghaoxuanchuan.png" style="margin: 0 auto;" />
|
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/gongzhonghaoxuanchuan.png" style="margin: 0 auto;" />
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|
||||||
## 项目相关
|
## 项目相关
|
||||||
|
|
||||||
* [项目介绍](./docs/javaguide/intro.md)
|
* [项目介绍](./docs/javaguide/intro.md)
|
||||||
|
|||||||
@ -9,23 +9,23 @@ tag:
|
|||||||
|
|
||||||
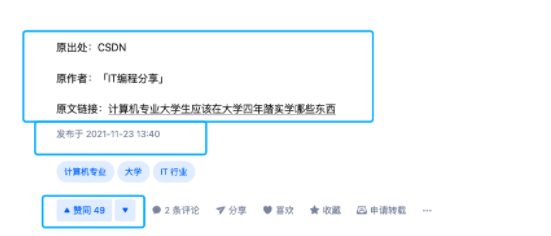
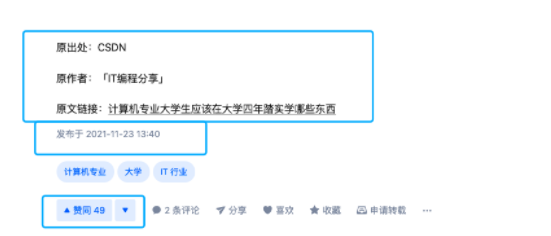
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
|
听朋友说我的文章在知乎又被盗了,原封不动地被别人用来引流。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
而且!!!这还不是最气的。
|
而且!!!这还不是最气的。
|
||||||
|
|
||||||
这人还在文末注明的原出处还不是我的。。。
|
这人还在文末注明的原出处还不是我的。。。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
|
也就是说 CSDN 有另外一位抄袭狗盗了我的这篇文章并声明了原创,知乎抄袭狗又原封不动地搬运了这位 CSDN 抄袭狗的文章。
|
||||||
|
|
||||||
真可谓离谱他妈给离谱开门,离谱到家了。
|
真可谓离谱他妈给离谱开门,离谱到家了。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
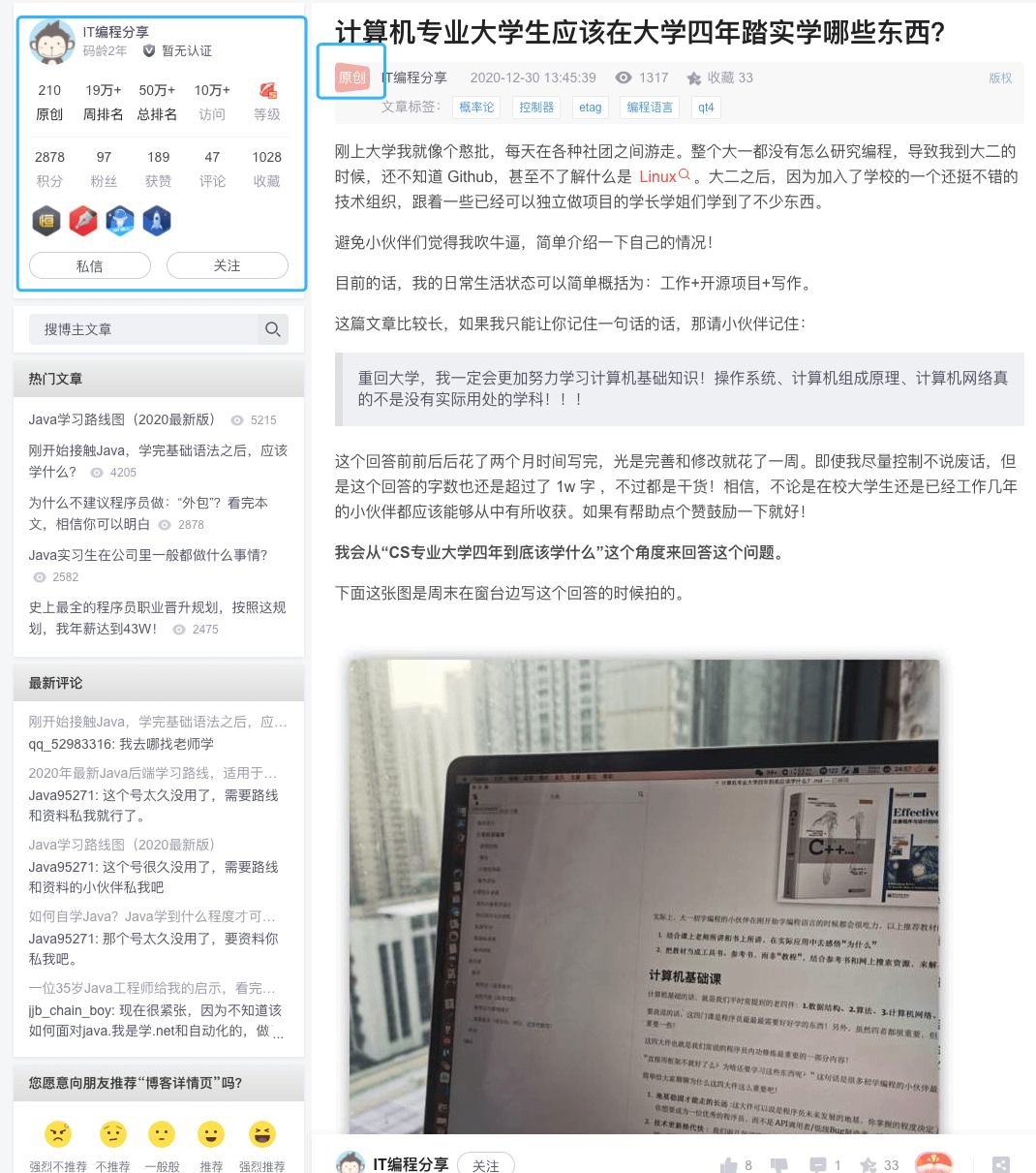
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
|
我打开知乎抄袭狗注明的原出处链接,好家伙,一模一样的内容,还表明了原创。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
|
看了一下 CSDN 这位抄袭狗的文章,好家伙,把我高赞回答搬运了一个遍。。。真是很勤奋了。。。
|
||||||
|
|
||||||
@ -33,7 +33,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
|
|||||||
|
|
||||||
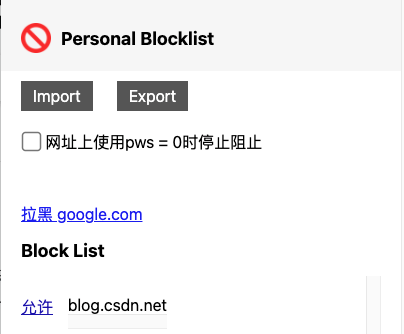
像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
|
像我自己平时用 Google 搜索的时候,都是直接屏蔽掉 CSDN 这个站点的。只需要下载一个叫做 Personal Blocklist 的 Chrome 插件,然后将 blog.csdn.net 添加进黑名单就可以了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
|
我的文章基本被盗完了,关键是我自己发没有什么流量,反而是盗我文章的那些人比我这个原作者流量还大。
|
||||||
|
|
||||||
@ -43,7 +43,7 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
|
|||||||
|
|
||||||
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
|
看看 CSDN 热榜上的文章都是一些什么垃圾,不是各种广告就是一些毫无质量的拼凑文。
|
||||||
|
|
||||||
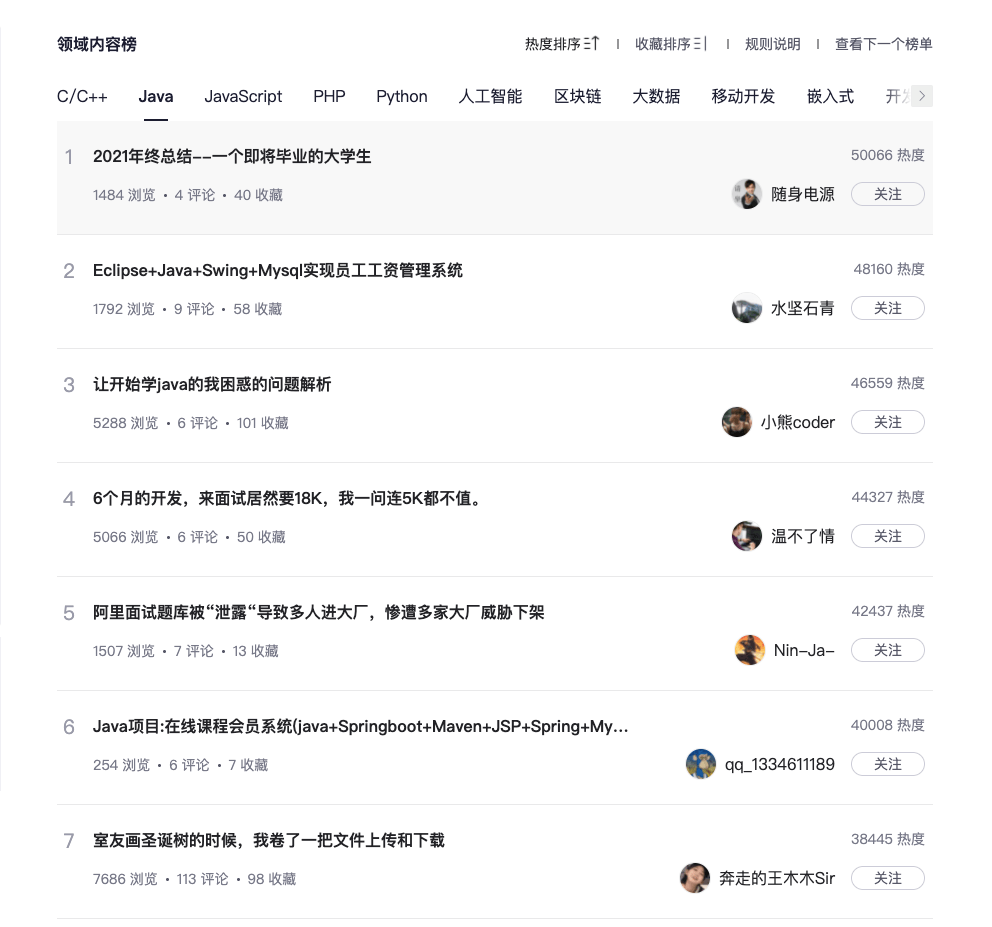
|
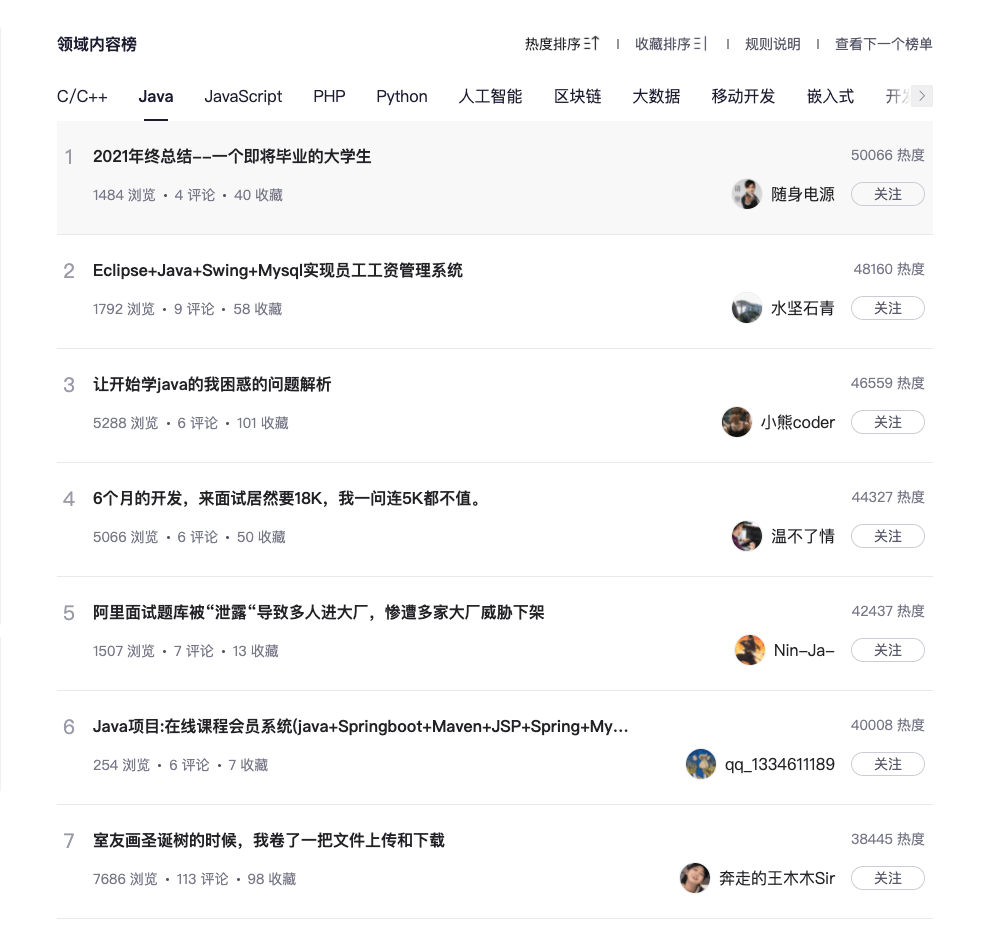
|
||||||
|
|
||||||
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
|
当然了,也有极少部分的高质量文章,比如涛哥、二哥、冰河、微观技术等博主的文章。
|
||||||
|
|
||||||
@ -51,7 +51,6 @@ CSDN 我就不想多说了,就一大型文章垃圾场,都是各种不规范
|
|||||||
|
|
||||||
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
|
今天提到的这篇被盗的文章曾经就被一个培训机构拿去做成了视频用来引流。
|
||||||
|
|
||||||
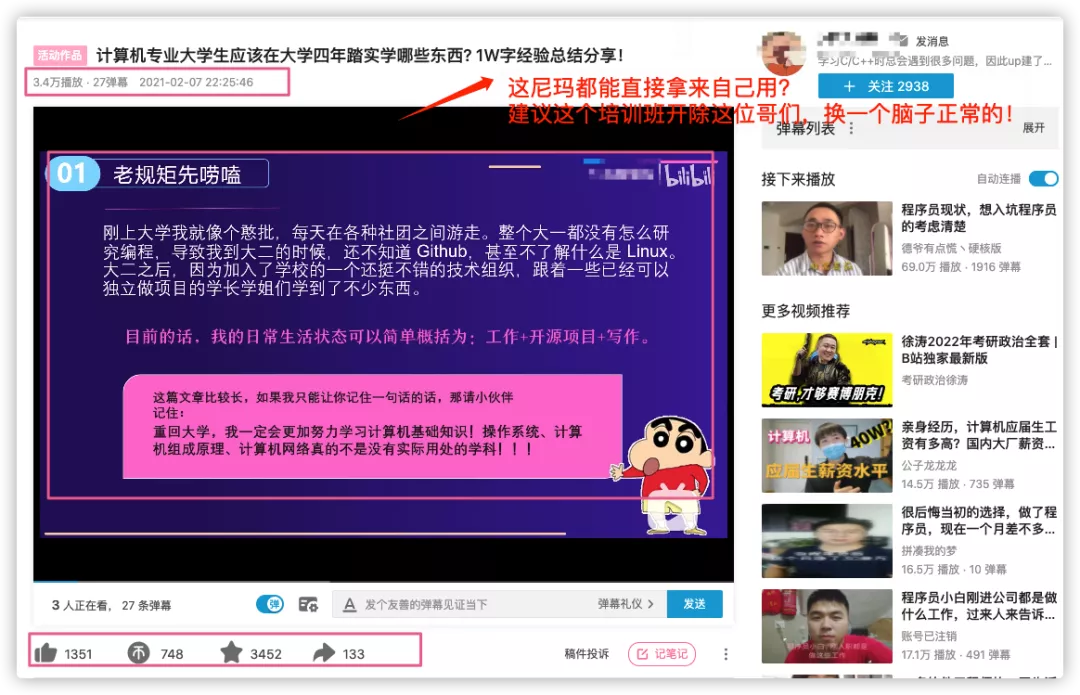
|
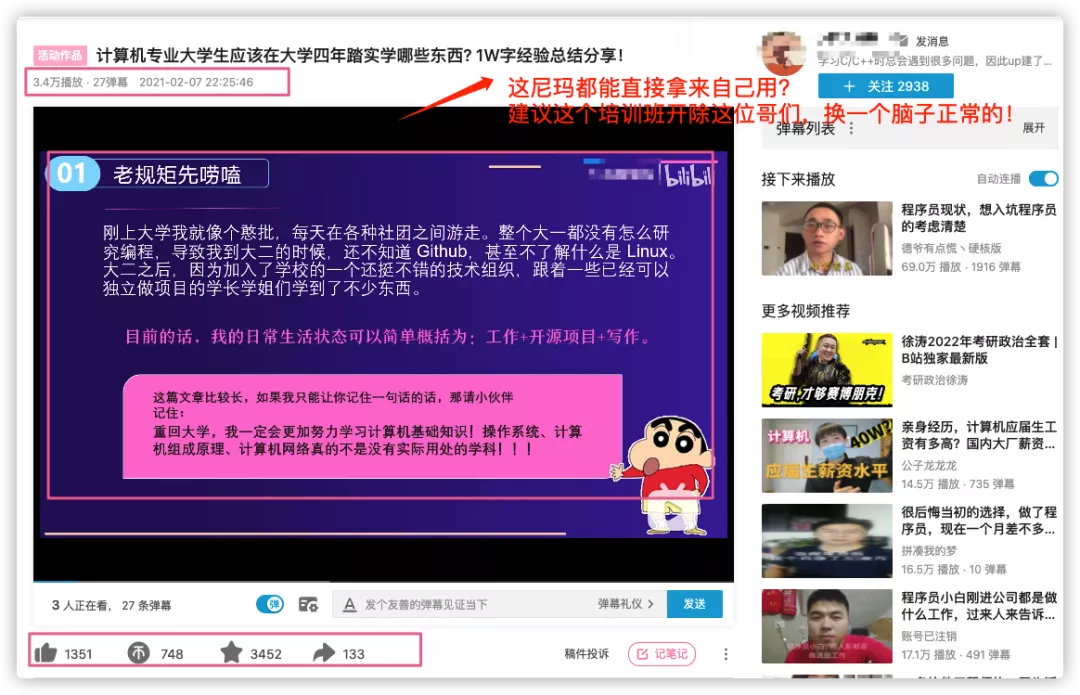
|
||||||
|
|
||||||
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
|
作为个体,咱也没啥办法,只能遇到一个举报一个。。。
|
||||||
|
|
||||||
|
|||||||
@ -13,7 +13,7 @@ tag:
|
|||||||
|
|
||||||
其实,这个真没啥好嘚瑟的。因为,教程类的含金量其实是比较低的,Star 数量比较多主要也是因为受众面比较广,大家觉得不错,点个 star 就相当于收藏了。很多特别优秀的框架,star 数量可能只有几 K。所以,单纯看 star 数量没啥意思,就当看个笑话吧!
|
其实,这个真没啥好嘚瑟的。因为,教程类的含金量其实是比较低的,Star 数量比较多主要也是因为受众面比较广,大家觉得不错,点个 star 就相当于收藏了。很多特别优秀的框架,star 数量可能只有几 K。所以,单纯看 star 数量没啥意思,就当看个笑话吧!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
维护这个项目的过程中,也被某些人 diss 过:“md项目,没啥含金量,给国人丢脸!”。
|
维护这个项目的过程中,也被某些人 diss 过:“md项目,没啥含金量,给国人丢脸!”。
|
||||||
|
|
||||||
@ -27,11 +27,11 @@ tag:
|
|||||||
|
|
||||||
到今天(2021-03-23)为止,这个仓库已经累计有 **2933** 次 commit,累计有 **207** 位朋友参与到了项目中来。
|
到今天(2021-03-23)为止,这个仓库已经累计有 **2933** 次 commit,累计有 **207** 位朋友参与到了项目中来。
|
||||||
|
|
||||||
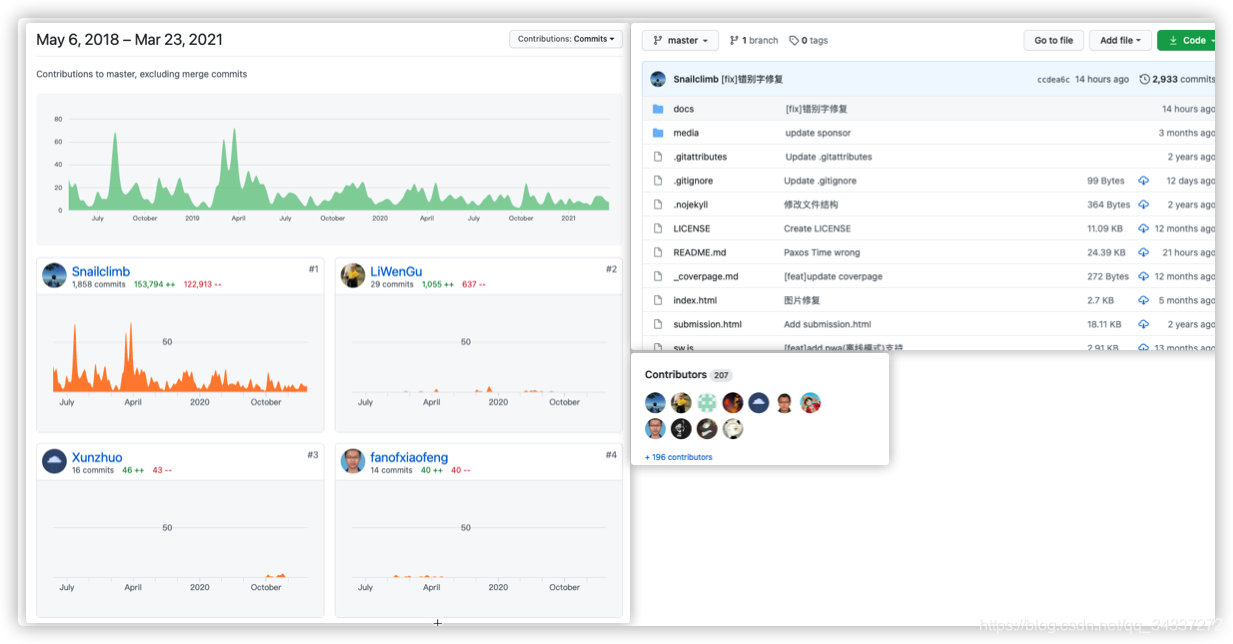
|

|
||||||
|
|
||||||
累计有 **511** 个 **issue** 和 **575** 个 **pr**。所有的 pr 都已经被处理,仅有15 个左右的 issue 我还未抽出时间处理。
|
累计有 **511** 个 **issue** 和 **575** 个 **pr**。所有的 pr 都已经被处理,仅有15 个左右的 issue 我还未抽出时间处理。
|
||||||
|
|
||||||
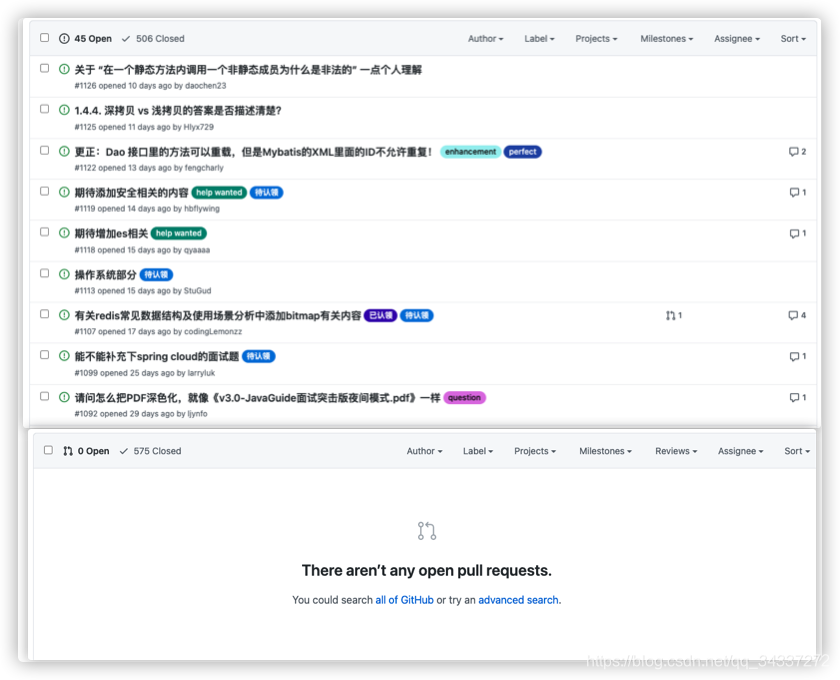
|

|
||||||
|
|
||||||
其实,相比于 star 数量,你看看仓库的 issue 和 pr 更能说明你的项目是否有价值。
|
其实,相比于 star 数量,你看看仓库的 issue 和 pr 更能说明你的项目是否有价值。
|
||||||
|
|
||||||
|
|||||||
@ -61,7 +61,7 @@ tag:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
如果他们把账号注销了,我或许还能考虑放一手。但是,文章是肯定不会删的。
|
如果他们把账号注销了,我或许还能考虑放一手。但是,文章是肯定不会删的。
|
||||||
|
|
||||||
|
|||||||
@ -113,11 +113,7 @@ star: 2
|
|||||||
|
|
||||||
**这里再送一个 30 元的新人优惠券,数量有限(续费半价)。**
|
**这里再送一个 30 元的新人优惠券,数量有限(续费半价)。**
|
||||||
|
|
||||||
<div align="center">
|

|
||||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
|
||||||
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/xingqiu/xingqiuyouhuijuanheyi.png" style="margin: 0 auto; " />
|
|
||||||
</a>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
**进入星球之后,记得添加微信,我会发你详细的星球使用指南。**
|
**进入星球之后,记得添加微信,我会发你详细的星球使用指南。**
|
||||||
|
|
||||||
@ -126,5 +122,4 @@ star: 2
|
|||||||
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/IMG_3007.jpg" style="margin: 0 auto; " />
|
||||||
</a>
|
</a>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
**真诚欢迎准备面试的小伙伴加入星球一起交流!真心希望能够帮助到更多小伙伴!**
|
**真诚欢迎准备面试的小伙伴加入星球一起交流!真心希望能够帮助到更多小伙伴!**
|
||||||
|
|||||||
@ -26,7 +26,7 @@ head:
|
|||||||
|
|
||||||
另外,去年新出的一本国产的操作系统书籍也很不错:**[《现代操作系统:原理与实现》](https://book.douban.com/subject/35208251/)** (夏老师和陈老师团队的力作,值得推荐)。
|
另外,去年新出的一本国产的操作系统书籍也很不错:**[《现代操作系统:原理与实现》](https://book.douban.com/subject/35208251/)** (夏老师和陈老师团队的力作,值得推荐)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如果你比较喜欢动手,对于理论知识比较抵触的话,我推荐你看看 **[《30 天自制操作系统》](https://book.douban.com/subject/11530329/)** ,这本书会手把手教你编写一个操作系统。
|
如果你比较喜欢动手,对于理论知识比较抵触的话,我推荐你看看 **[《30 天自制操作系统》](https://book.douban.com/subject/11530329/)** ,这本书会手把手教你编写一个操作系统。
|
||||||
|
|
||||||
@ -163,7 +163,7 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||||||
|
|
||||||
视频的话,推荐北京大学的国家精品课程—**[程序设计与算法(二)算法基础](https://www.icourse163.org/course/PKU-1001894005)**,讲的非常好!
|
视频的话,推荐北京大学的国家精品课程—**[程序设计与算法(二)算法基础](https://www.icourse163.org/course/PKU-1001894005)**,讲的非常好!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这个课程把七种基本的通用算法(枚举、二分、递归、分治、动态规划、搜索、贪心)都介绍到了。各种复杂算法问题的解决,都可能用到这些基本的思想。并且,这个课程的一部分的例题和 ACM 国际大学生程序设计竞赛中的中等题相当,如果你能够解决这些问题,那你的算法能力将超过绝大部分的高校计算机专业本科毕业生。
|
这个课程把七种基本的通用算法(枚举、二分、递归、分治、动态规划、搜索、贪心)都介绍到了。各种复杂算法问题的解决,都可能用到这些基本的思想。并且,这个课程的一部分的例题和 ACM 国际大学生程序设计竞赛中的中等题相当,如果你能够解决这些问题,那你的算法能力将超过绝大部分的高校计算机专业本科毕业生。
|
||||||
|
|
||||||
@ -187,7 +187,7 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||||||
|
|
||||||
类似的还有 **[《数据结构与算法分析 :C 语言描述》](https://book.douban.com/subject/1139426/)** 、**[《数据结构与算法分析:C++ 描述》](https://book.douban.com/subject/1971825/)**
|
类似的还有 **[《数据结构与算法分析 :C 语言描述》](https://book.douban.com/subject/1139426/)** 、**[《数据结构与算法分析:C++ 描述》](https://book.douban.com/subject/1971825/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
视频的话推荐你看浙江大学的国家精品课程—**[《数据结构》](https://www.icourse163.org/course/ZJU-93001#/info)** 。
|
视频的话推荐你看浙江大学的国家精品课程—**[《数据结构》](https://www.icourse163.org/course/ZJU-93001#/info)** 。
|
||||||
|
|
||||||
@ -262,7 +262,7 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||||||
|
|
||||||
总的来说,这门课对于各位程序员的职业发展来说,相对不那么重要,但是从难度上来说,学习这门课可以对编程思想有一个较好的巩固。学习资源的话,除了课堂上的幻灯片课件以外,还可以把 《编译原理》 这本书作为参考书,用以辅助自己学不懂的地方(大家口中的龙书,想要啃下来还是有一定难度的)。
|
总的来说,这门课对于各位程序员的职业发展来说,相对不那么重要,但是从难度上来说,学习这门课可以对编程思想有一个较好的巩固。学习资源的话,除了课堂上的幻灯片课件以外,还可以把 《编译原理》 这本书作为参考书,用以辅助自己学不懂的地方(大家口中的龙书,想要啃下来还是有一定难度的)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
其他书籍推荐:
|
其他书籍推荐:
|
||||||
|
|
||||||
@ -271,4 +271,4 @@ Github 上就有一些名校的计算机网络试验/Project:
|
|||||||
|
|
||||||
我上面推荐的书籍的难度还是比较高的,真心很难坚持看完。这里强烈推荐[哈工大的编译原理视频课程](https://www.icourse163.org/course/HIT-1002123007),真心不错,还是国家精品课程,关键还是又漂亮有温柔的美女老师讲的!
|
我上面推荐的书籍的难度还是比较高的,真心很难坚持看完。这里强烈推荐[哈工大的编译原理视频课程](https://www.icourse163.org/course/HIT-1002123007),真心不错,还是国家精品课程,关键还是又漂亮有温柔的美女老师讲的!
|
||||||
|
|
||||||
|

|
||||||
@ -14,13 +14,13 @@ head:
|
|||||||
|
|
||||||
[《数据库系统原理》](https://www.icourse163.org/course/BNU-1002842007)这个课程的老师讲的非常详细,而且每一小节的作业设计的也与所讲知识很贴合,后面还有很多配套实验。
|
[《数据库系统原理》](https://www.icourse163.org/course/BNU-1002842007)这个课程的老师讲的非常详细,而且每一小节的作业设计的也与所讲知识很贴合,后面还有很多配套实验。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
如果你比较喜欢动手,对于理论知识比较抵触的话,推荐你看看[《如何开发一个简单的数据库》](https://cstack.github.io/db_tutorial/) ,这个 project 会手把手教你编写一个简单的数据库。
|
如果你比较喜欢动手,对于理论知识比较抵触的话,推荐你看看[《如何开发一个简单的数据库》](https://cstack.github.io/db_tutorial/) ,这个 project 会手把手教你编写一个简单的数据库。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Github上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
Github上也已经有大佬用 Java 实现过一个简易的数据库,介绍的挺详细的,感兴趣的朋友可以去看看。地址:[https://github.com/alchemystar/Freedom](https://github.com/alchemystar/Freedom) 。
|
||||||
|
|
||||||
@ -66,7 +66,7 @@ Github上也已经有大佬用 Java 实现过一个简易的数据库,介绍
|
|||||||
|
|
||||||
另外,强推一波 **[《MySQL 是怎样运行的》](https://book.douban.com/subject/35231266/)** 这本书,内容很适合拿来准备面试。讲的很细节,但又不枯燥,内容非常良心!
|
另外,强推一波 **[《MySQL 是怎样运行的》](https://book.douban.com/subject/35231266/)** 这本书,内容很适合拿来准备面试。讲的很细节,但又不枯燥,内容非常良心!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## PostgreSQL
|
## PostgreSQL
|
||||||
|
|
||||||
|
|||||||
@ -68,7 +68,7 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
|
|||||||
|
|
||||||
**[《Java 并发实现原理:JDK 源码剖析》](https://book.douban.com/subject/35013531/)**
|
**[《Java 并发实现原理:JDK 源码剖析》](https://book.douban.com/subject/35013531/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这本书是 2020 年新出的,所以,现在知道的人还不是很多。
|
这本书是 2020 年新出的,所以,现在知道的人还不是很多。
|
||||||
|
|
||||||
@ -80,7 +80,7 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
|
|||||||
|
|
||||||
**[《深入理解 Java 虚拟机》](https://book.douban.com/subject/34907497/)**
|
**[《深入理解 Java 虚拟机》](https://book.douban.com/subject/34907497/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这本书就一句话形容:**国产书籍中的战斗机,实实在在的优秀!** (真心希望国内能有更多这样的优质书籍出现!加油!💪)
|
这本书就一句话形容:**国产书籍中的战斗机,实实在在的优秀!** (真心希望国内能有更多这样的优质书籍出现!加油!💪)
|
||||||
|
|
||||||
@ -114,8 +114,6 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
|
|||||||
2. 《字节码与类的加载篇》
|
2. 《字节码与类的加载篇》
|
||||||
3. 《性能监控与调优篇》
|
3. 《性能监控与调优篇》
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
第 2 个是你假笨大佬的 **[《JVM 参数【Memory 篇】》](https://club.perfma.com/course/438755/list)** 教程,很厉害了!
|
第 2 个是你假笨大佬的 **[《JVM 参数【Memory 篇】》](https://club.perfma.com/course/438755/list)** 教程,很厉害了!
|
||||||
|
|
||||||
|

|
||||||
@ -155,7 +153,7 @@ _这本书还是非常适合我们用来学习 Java 多线程的。这本书的
|
|||||||
|
|
||||||
**[《Spring 5 高级编程》](https://book.douban.com/subject/30452637/)**
|
**[《Spring 5 高级编程》](https://book.douban.com/subject/30452637/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
对于 Spring5 的新特性介绍的比较详细,也说不上好。另外,感觉全书翻译的有一点蹩脚的味道,还有一点枯燥。全书的内容比较多,我一般拿来当做工具书参考。
|
对于 Spring5 的新特性介绍的比较详细,也说不上好。另外,感觉全书翻译的有一点蹩脚的味道,还有一点枯燥。全书的内容比较多,我一般拿来当做工具书参考。
|
||||||
|
|
||||||
@ -213,11 +211,11 @@ O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是
|
|||||||
|
|
||||||
目前我觉得能推荐的只有李运华老师的 **[《从零开始学架构》](https://book.douban.com/subject/30335935/)** 和 余春龙老师的 **[《软件架构设计:大型网站技术架构与业务架构融合之道》](https://book.douban.com/subject/30443578/ "《软件架构设计:大型网站技术架构与业务架构融合之道》")** 。
|
目前我觉得能推荐的只有李运华老师的 **[《从零开始学架构》](https://book.douban.com/subject/30335935/)** 和 余春龙老师的 **[《软件架构设计:大型网站技术架构与业务架构融合之道》](https://book.douban.com/subject/30443578/ "《软件架构设计:大型网站技术架构与业务架构融合之道》")** 。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
《从零开始学架构》这本书对应的有一个极客时间的专栏—《从零开始学架构》,里面的很多内容都是这个专栏里面的,两者买其一就可以了。我看了很小一部分,内容挺全面的,是一本真正在讲如何做架构的书籍。
|
《从零开始学架构》这本书对应的有一个极客时间的专栏—《从零开始学架构》,里面的很多内容都是这个专栏里面的,两者买其一就可以了。我看了很小一部分,内容挺全面的,是一本真正在讲如何做架构的书籍。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
事务与锁、分布式(CAP、分布式事务......)、高并发、高可用 《软件架构设计:大型网站技术架构与业务架构融合之道》 这本书都有介绍到。
|
事务与锁、分布式(CAP、分布式事务......)、高并发、高可用 《软件架构设计:大型网站技术架构与业务架构融合之道》 这本书都有介绍到。
|
||||||
|
|
||||||
@ -225,10 +223,12 @@ O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是
|
|||||||
|
|
||||||
**《JavaGuide 面试突击版》**
|
**《JavaGuide 面试突击版》**
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
[JavaGuide](https://javaguide.cn/) 的面试版本,涵盖了 Java 后端方面的大部分知识点比如 集合、JVM、多线程还有数据库 MySQL 等内容。
|
[JavaGuide](https://javaguide.cn/) 的面试版本,涵盖了 Java 后端方面的大部分知识点比如 集合、JVM、多线程还有数据库 MySQL 等内容。
|
||||||
|
|
||||||
公众号后台回复 :“**面试突击**” 即可免费获取,无任何套路。
|
公众号后台回复 :“**面试突击**” 即可免费获取,无任何套路。
|
||||||
|
|
||||||

|

|
||||||
|
|||||||
@ -16,12 +16,12 @@ Elasticsearch 在 Apache Lucene 的基础上开发而成,学习 ES 之前,
|
|||||||
|
|
||||||
极客时间的[《Elasticsearch 核心技术与实战》](http://gk.link/a/10bcT "《Elasticsearch 核心技术与实战》")这门课程基于 Elasticsearch 7.1 版本讲解,还算比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!
|
极客时间的[《Elasticsearch 核心技术与实战》](http://gk.link/a/10bcT "《Elasticsearch 核心技术与实战》")这门课程基于 Elasticsearch 7.1 版本讲解,还算比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如果你想看书的话,可以考虑一下 **[《Elasticsearch 实战》](https://book.douban.com/subject/30380439/)** 这本书。不过,需要说明的是,这本书中的 Elasticsearch 版本比较老,你可以将其作为一个参考书籍来看,有一些原理性的东西可以在上面找找答案。
|
如果你想看书的话,可以考虑一下 **[《Elasticsearch 实战》](https://book.douban.com/subject/30380439/)** 这本书。不过,需要说明的是,这本书中的 Elasticsearch 版本比较老,你可以将其作为一个参考书籍来看,有一些原理性的东西可以在上面找找答案。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的 **[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)** 这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
|
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的 **[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)** 这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
|
||||||
|
|
||||||

|

|
||||||
@ -16,7 +16,7 @@ head:
|
|||||||
|
|
||||||
**[《重构》](https://book.douban.com/subject/30468597/)**
|
**[《重构》](https://book.douban.com/subject/30468597/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
必看书籍!无需多言。编程书籍领域的瑰宝。
|
必看书籍!无需多言。编程书籍领域的瑰宝。
|
||||||
|
|
||||||
@ -26,7 +26,7 @@ head:
|
|||||||
|
|
||||||
**[《Clean Code》](https://book.douban.com/subject/4199741/)**
|
**[《Clean Code》](https://book.douban.com/subject/4199741/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
《Clean Code》是 Bob 大叔的一本经典著作,强烈建议小伙伴们一定要看看。
|
《Clean Code》是 Bob 大叔的一本经典著作,强烈建议小伙伴们一定要看看。
|
||||||
|
|
||||||
@ -34,7 +34,7 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
|||||||
|
|
||||||
**[《Effective Java 》](https://book.douban.com/subject/30412517/)**
|
**[《Effective Java 》](https://book.douban.com/subject/30412517/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
《Effective Java 》这本书是 Java 领域国宝级别的书,非常经典。Java 程序员必看!
|
《Effective Java 》这本书是 Java 领域国宝级别的书,非常经典。Java 程序员必看!
|
||||||
|
|
||||||
@ -42,7 +42,7 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
|||||||
|
|
||||||
**[《代码大全》](https://book.douban.com/subject/1477390/)**
|
**[《代码大全》](https://book.douban.com/subject/1477390/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
其实,《代码大全(第 2 版)》这本书我本身是不太想推荐给大家了。但是,看在它的豆瓣评分这么高的份上,还是拿出来说说吧!
|
其实,《代码大全(第 2 版)》这本书我本身是不太想推荐给大家了。但是,看在它的豆瓣评分这么高的份上,还是拿出来说说吧!
|
||||||
|
|
||||||
@ -54,11 +54,11 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
|||||||
|
|
||||||
**[《编写可读代码的艺术》](https://book.douban.com/subject/10797189/)**
|
**[《编写可读代码的艺术》](https://book.douban.com/subject/10797189/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
《编写可读代码的艺术》这本书要表达的意思和《Clean Code》很像,你看它俩的目录就可以看出来了。
|
《编写可读代码的艺术》这本书要表达的意思和《Clean Code》很像,你看它俩的目录就可以看出来了。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
在我看来,如果你看过 《Clean Code》 的话,就不需要再看这本书了。当然,如果你有时间和精力,也可以快速过一遍。
|
在我看来,如果你看过 《Clean Code》 的话,就不需要再看这本书了。当然,如果你有时间和精力,也可以快速过一遍。
|
||||||
|
|
||||||
@ -66,13 +66,13 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
|||||||
|
|
||||||
在实践中学习的效果肯定会更好!推荐小伙伴们都抓紧学起来啊!
|
在实践中学习的效果肯定会更好!推荐小伙伴们都抓紧学起来啊!
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 程序员职业素养
|
## 程序员职业素养
|
||||||
|
|
||||||
**[《The Clean Coder》](https://book.douban.com/subject/26919457/)**
|
**[《The Clean Coder》](https://book.douban.com/subject/26919457/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
《 The Clean Coder》是 Bob 大叔的又一经典著作。
|
《 The Clean Coder》是 Bob 大叔的又一经典著作。
|
||||||
|
|
||||||
@ -84,7 +84,7 @@ Bob 大叔将自己对整洁代码的理解浓缩在了这本书中,真可谓
|
|||||||
|
|
||||||
**[《架构整洁之道》](https://book.douban.com/subject/30333919/)**
|
**[《架构整洁之道》](https://book.douban.com/subject/30333919/)**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
你没看错,《架构整洁之道》这本书又是 Bob 大叔的经典之作。
|
你没看错,《架构整洁之道》这本书又是 Bob 大叔的经典之作。
|
||||||
|
|
||||||
|
|||||||
@ -23,7 +23,7 @@ tag:
|
|||||||
|
|
||||||
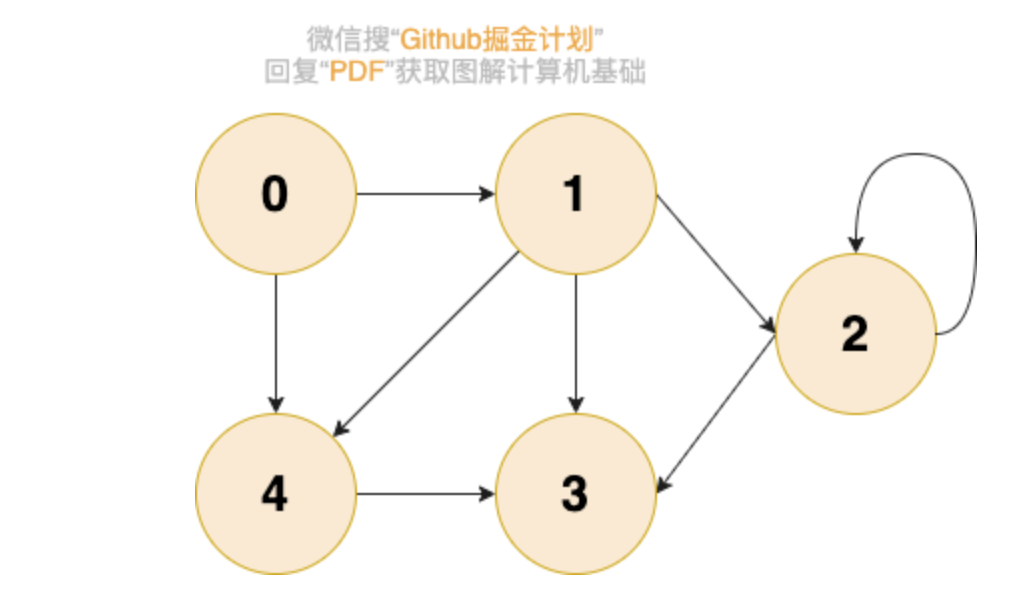
下图所展示的就是图这种数据结构,并且还是一张有向图。
|
下图所展示的就是图这种数据结构,并且还是一张有向图。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
图在我们日常生活中的例子很多!比如我们在社交软件上好友关系就可以用图来表示。
|
图在我们日常生活中的例子很多!比如我们在社交软件上好友关系就可以用图来表示。
|
||||||
|
|
||||||
|
|||||||
@ -8,7 +8,7 @@ tag:
|
|||||||
|
|
||||||
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
|
本文是我在大二学习计算机网络期间整理, 大部分内容都来自于谢希仁老师的[《计算机网络》第七版 ](https://www.elias.ltd/usr/local/etc/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C%EF%BC%88%E7%AC%AC7%E7%89%88%EF%BC%89%E8%B0%A2%E5%B8%8C%E4%BB%81.pdf)这本书。为了内容更容易理解,我对之前的整理进行了一波重构,并配上了一些相关的示意图便于理解。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
|
相关问题:[如何评价谢希仁的计算机网络(第七版)? - 知乎](https://www.zhihu.com/question/327872966) 。
|
||||||
|
|
||||||
@ -21,11 +21,11 @@ tag:
|
|||||||
3. **主机(host)** :连接在因特网上的计算机。
|
3. **主机(host)** :连接在因特网上的计算机。
|
||||||
4. **ISP(Internet Service Provider)** :因特网服务提供者(提供商)。
|
4. **ISP(Internet Service Provider)** :因特网服务提供者(提供商)。
|
||||||
|
|
||||||
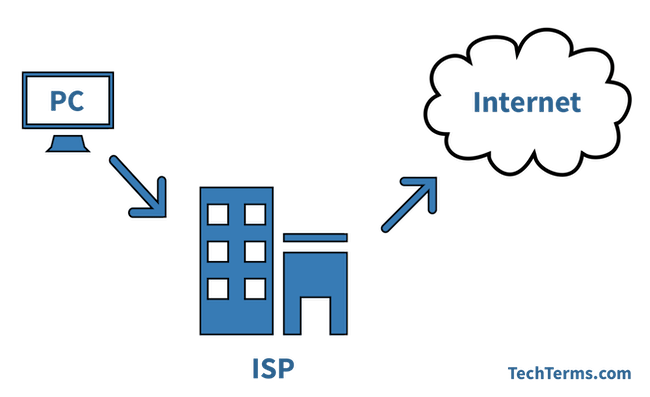
|
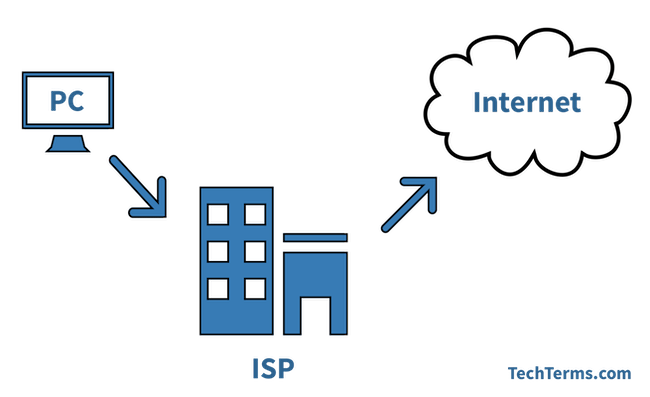
|
||||||
|
|
||||||
5. **IXP(Internet eXchange Point)** : 互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
|
5. **IXP(Internet eXchange Point)** : 互联网交换点 IXP 的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。
|
||||||
|
|
||||||
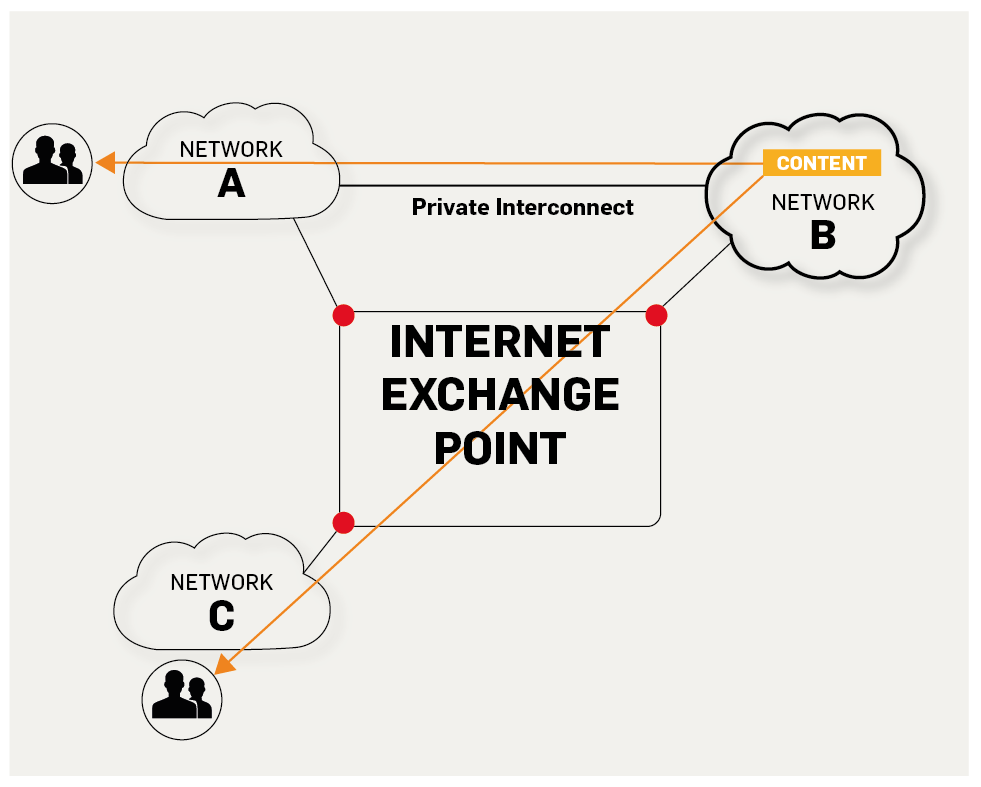
|
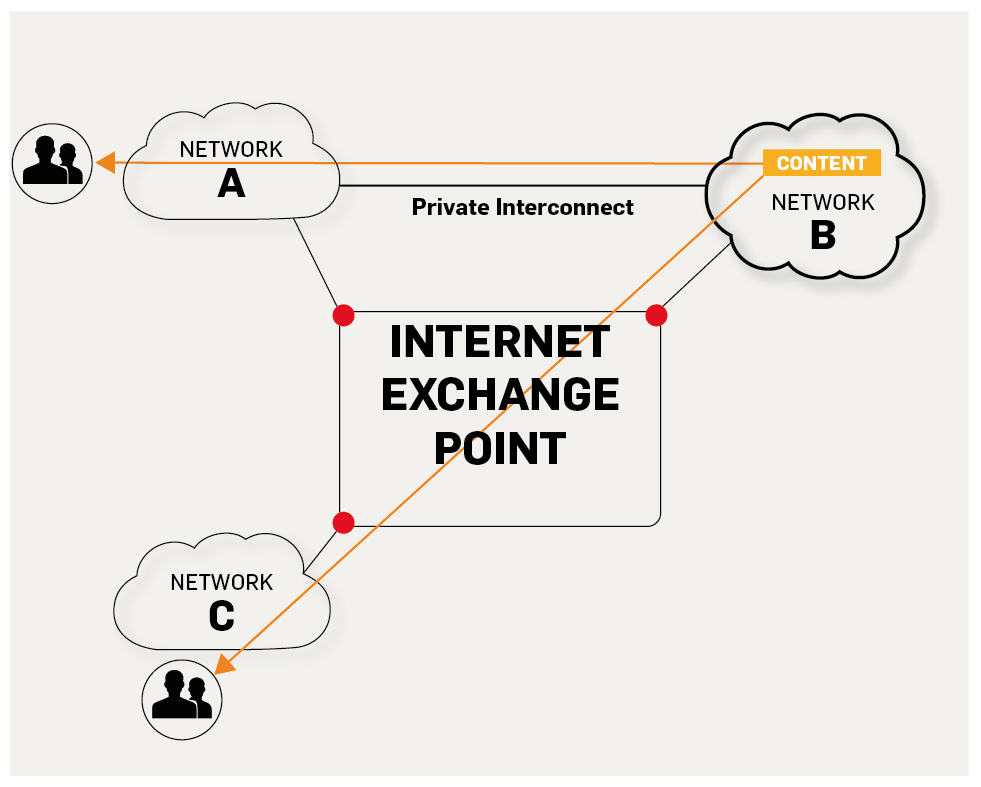
|
||||||
|
|
||||||
<p style="text-align:center;font-size:13px;color:gray">https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive</p>
|
<p style="text-align:center;font-size:13px;color:gray">https://labs.ripe.net/Members/fergalc/ixp-traffic-during-stratos-skydive</p>
|
||||||
|
|
||||||
@ -34,20 +34,20 @@ tag:
|
|||||||
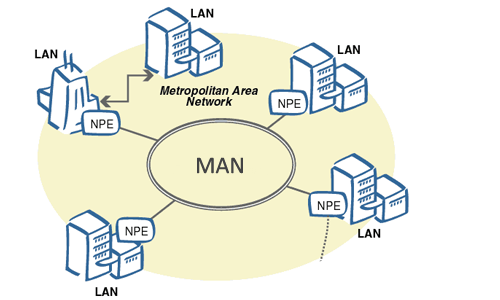
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
|
8. **城域网 MAN(Metropolitan Area Network)**:用来将多个局域网进行互连。
|
||||||
9. **局域网 LAN(Local Area Network)** : 学校或企业大多拥有多个互连的局域网。
|
9. **局域网 LAN(Local Area Network)** : 学校或企业大多拥有多个互连的局域网。
|
||||||
|
|
||||||
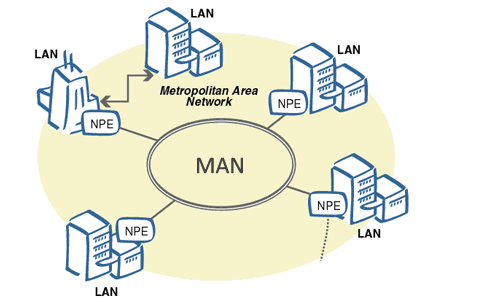
|
|
||||||
|
|
||||||
<p style="text-align:center;font-size:13px;color:gray">http://conexionesmanwman.blogspot.com/</p>
|
<p style="text-align:center;font-size:13px;color:gray">http://conexionesmanwman.blogspot.com/</p>
|
||||||
|
|
||||||
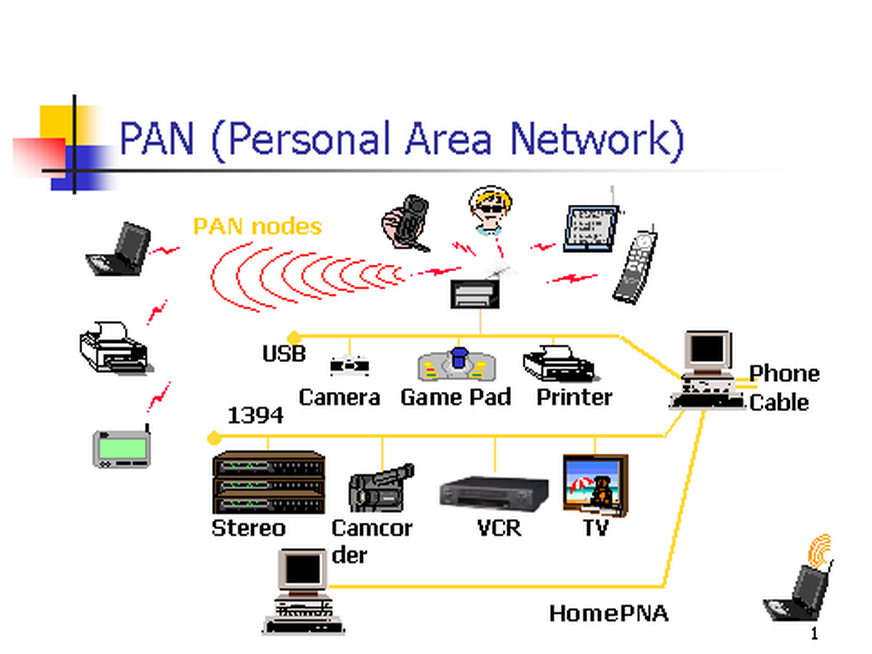
10. **个人区域网 PAN(Personal Area Network)** :在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
|
10. **个人区域网 PAN(Personal Area Network)** :在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络 。
|
||||||
|
|
||||||
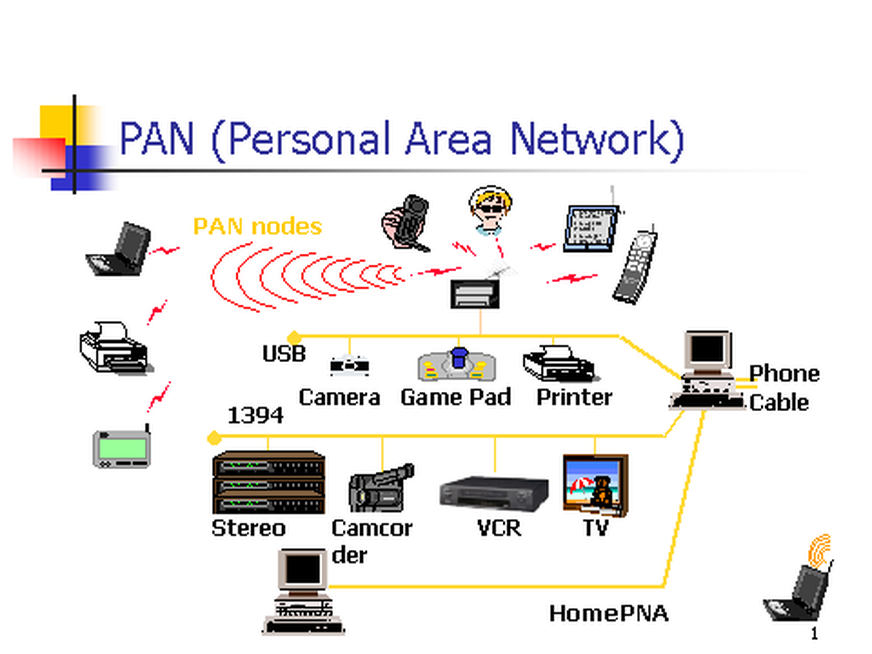
|
|
||||||
|
|
||||||
<p style="text-align:center;font-size:13px;color:gray">https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/</p>
|
<p style="text-align:center;font-size:13px;color:gray">https://www.itrelease.com/2018/07/advantages-and-disadvantages-of-personal-area-network-pan/</p>
|
||||||
|
|
||||||
12. **分组(packet )** :因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
|
12. **分组(packet )** :因特网中传送的数据单元。由首部 header 和数据段组成。分组又称为包,首部可称为包头。
|
||||||
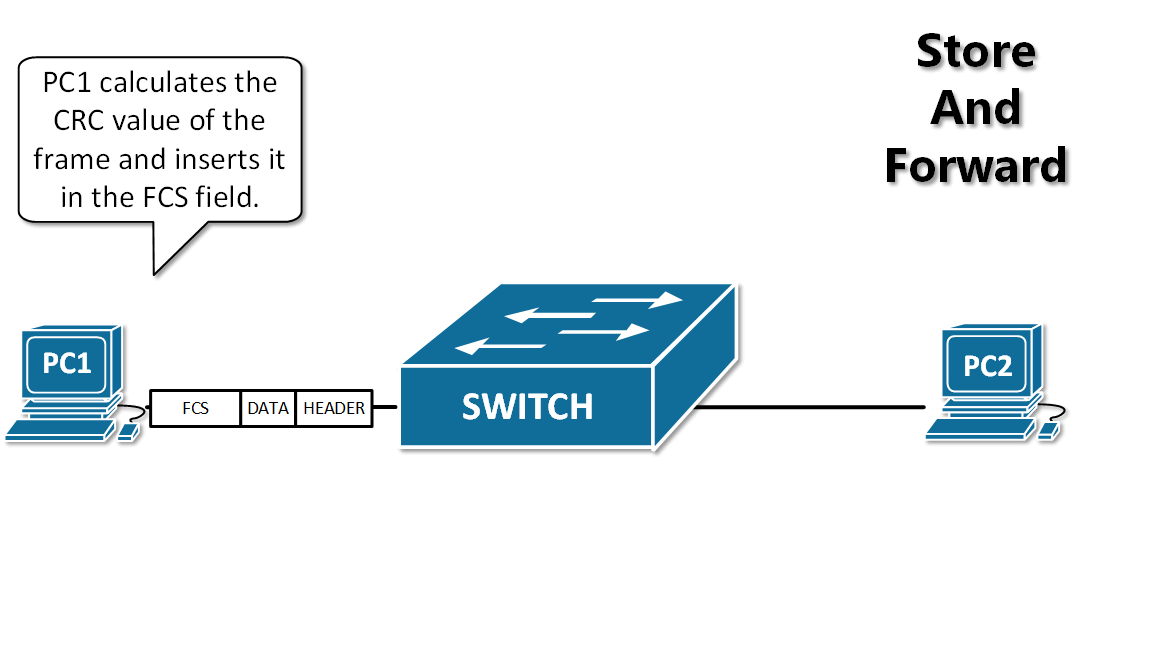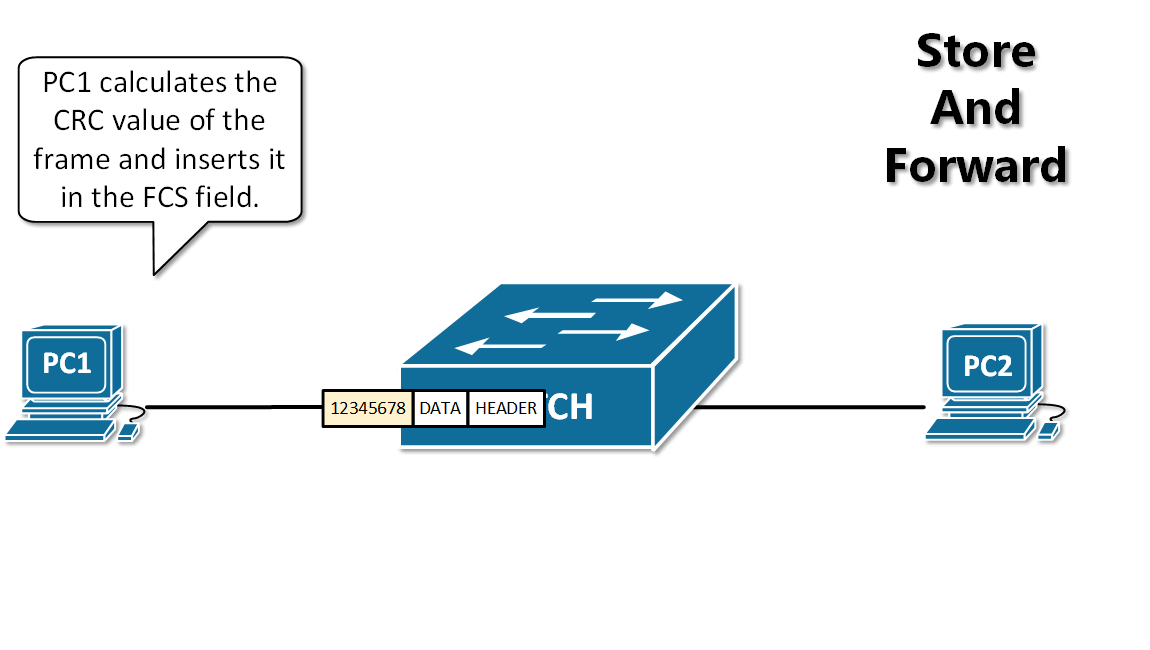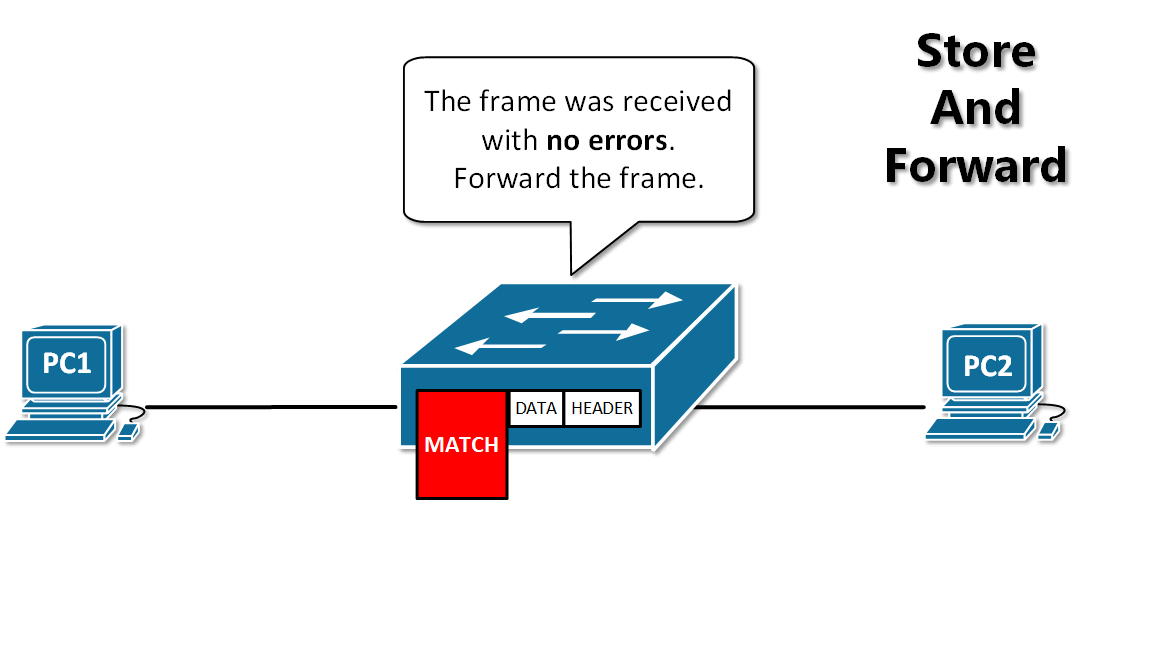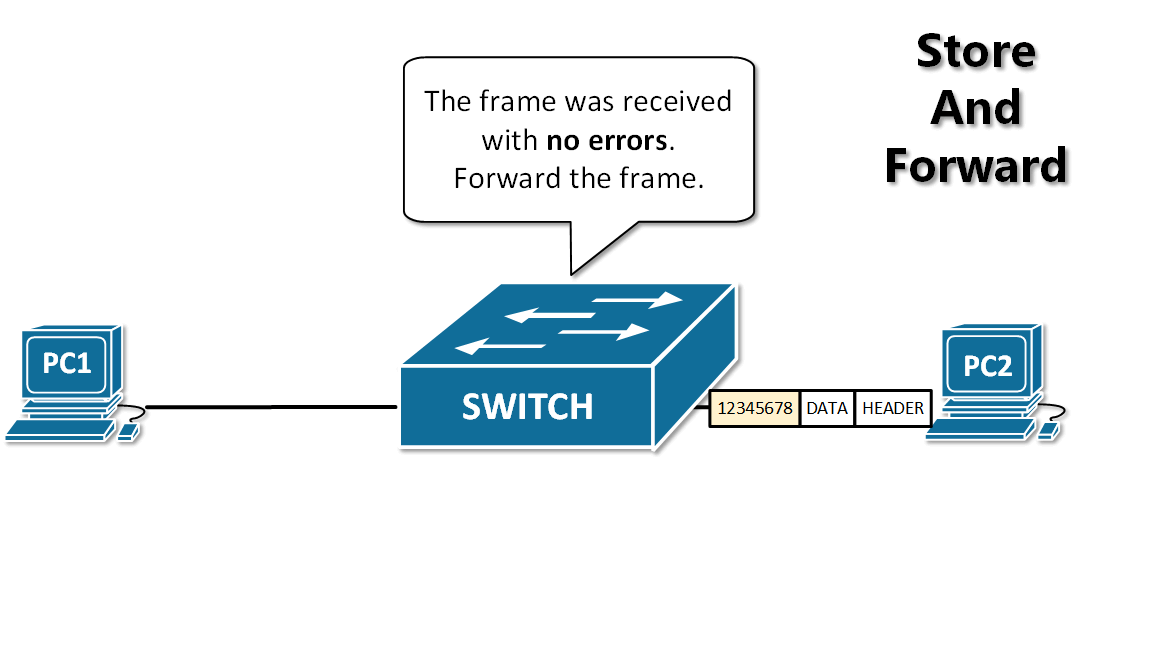
13. **存储转发(store and forward )** :路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
|
13. **存储转发(store and forward )** :路由器收到一个分组,先检查分组是否正确,并过滤掉冲突包错误。确定包正确后,取出目的地址,通过查找表找到想要发送的输出端口地址,然后将该包发送出去。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
14. **带宽(bandwidth)** :在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
|
14. **带宽(bandwidth)** :在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为 b/s。
|
||||||
15. **吞吐量(throughput )** :表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
|
15. **吞吐量(throughput )** :表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
|
||||||
@ -65,13 +65,13 @@ tag:
|
|||||||
9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
|
9. 网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
|
||||||
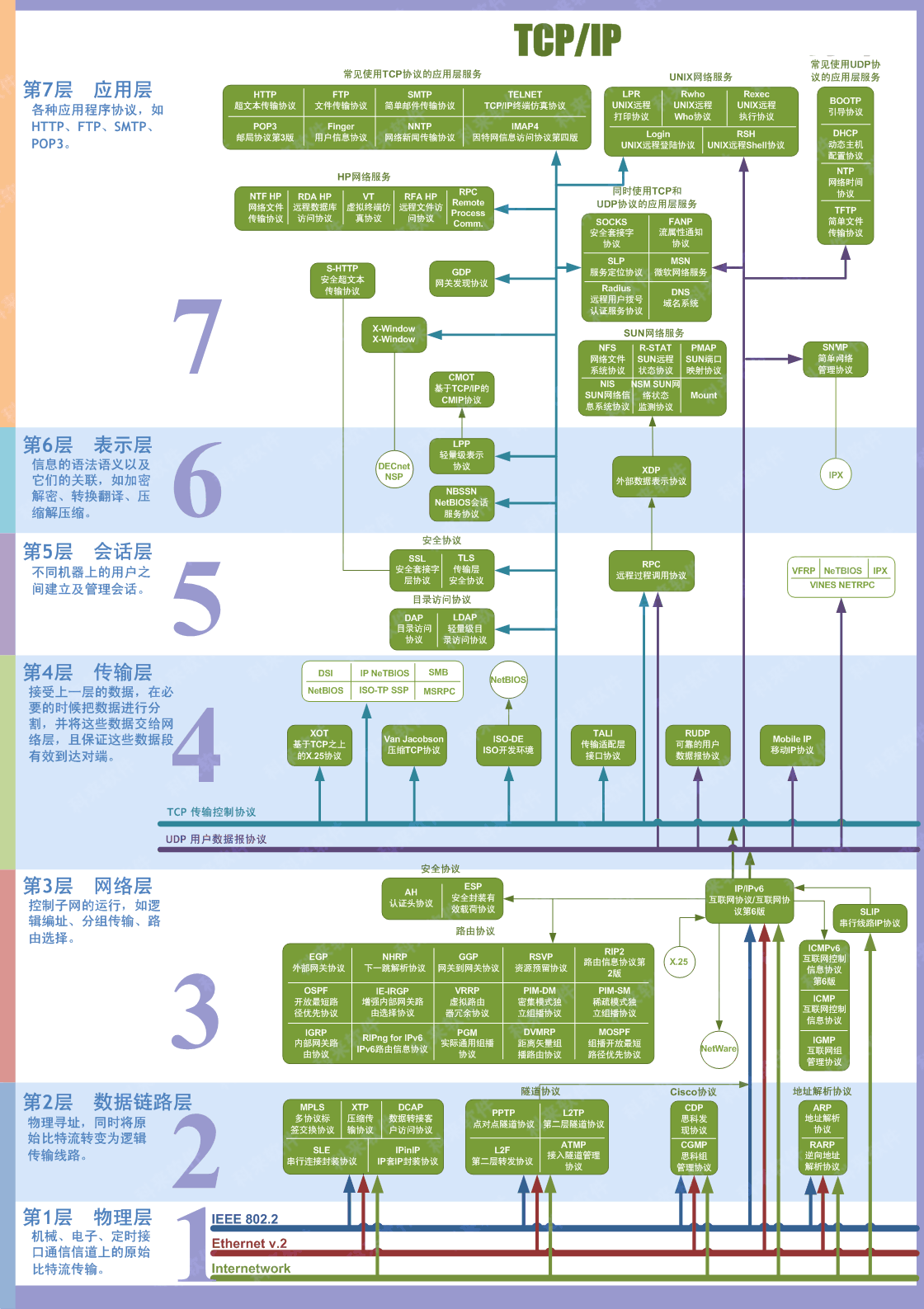
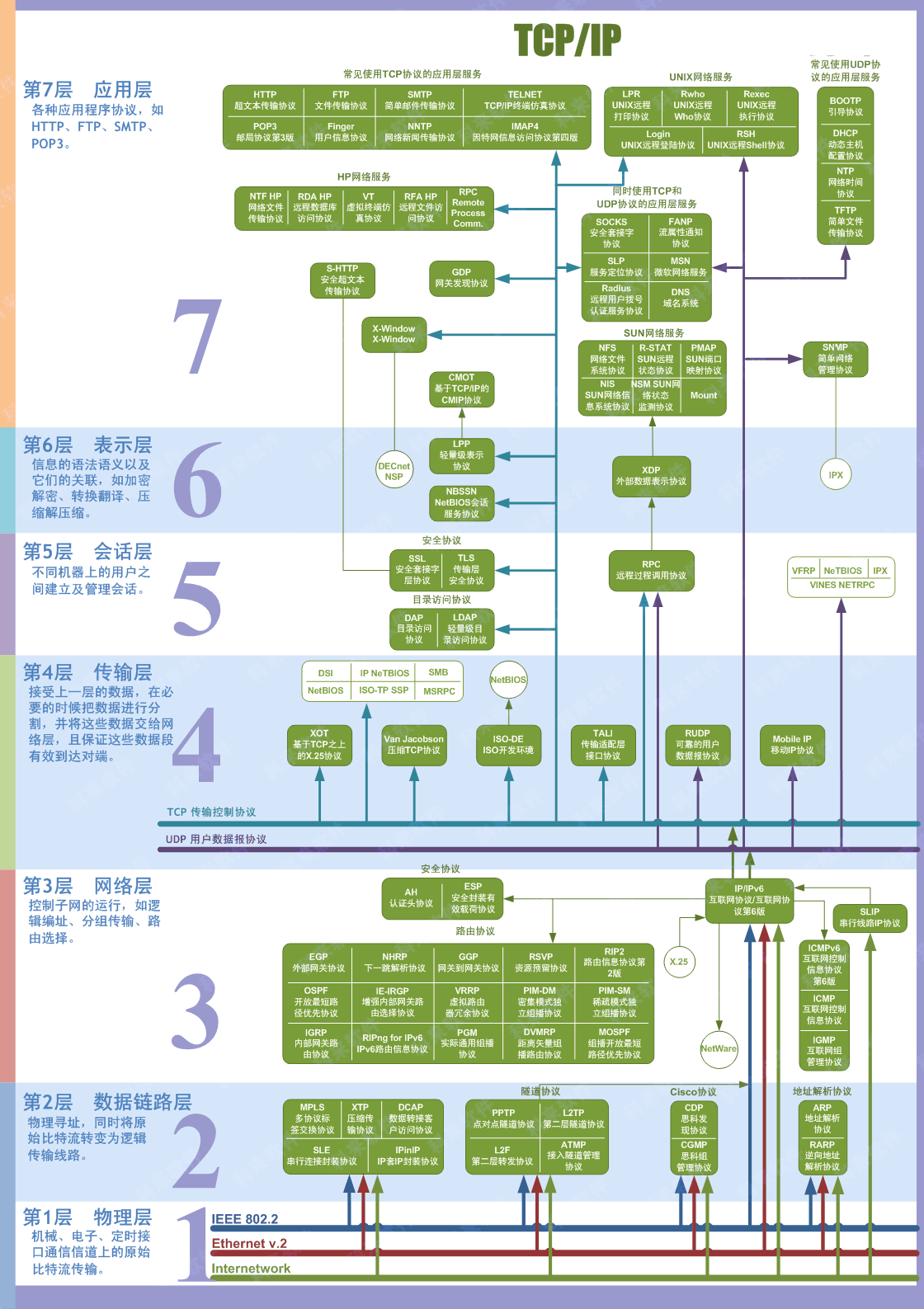
10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
|
10. **五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是 TCP 和 UDP 协议,网络层最重要的协议是 IP 协议。**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
|
下面的内容会介绍计算机网络的五层体系结构:**物理层+数据链路层+网络层(网际层)+运输层+应用层**。
|
||||||
|
|
||||||
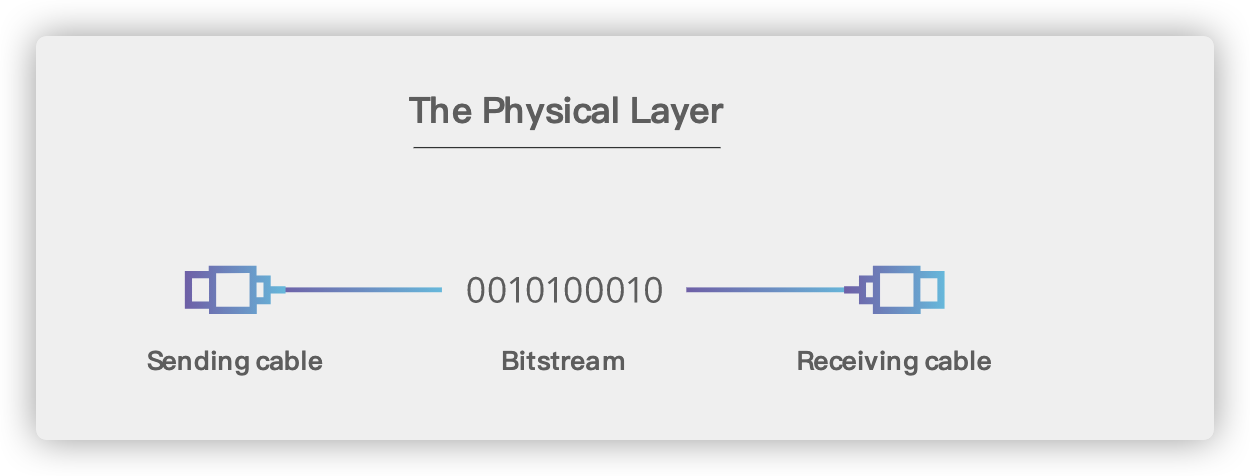
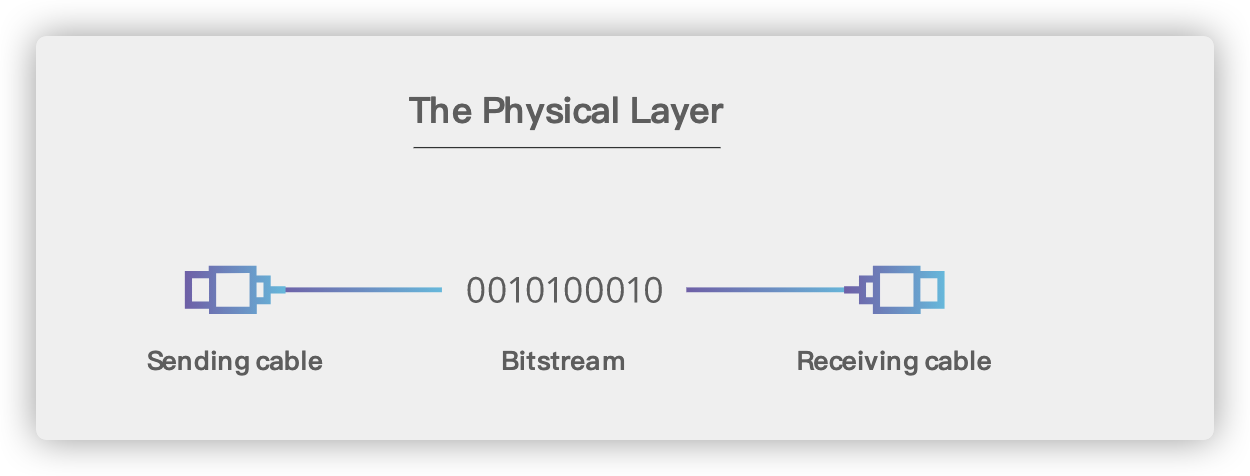
## 2. 物理层(Physical Layer)
|
## 2. 物理层(Physical Layer)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 2.1. 基本术语
|
### 2.1. 基本术语
|
||||||
|
|
||||||
@ -82,11 +82,11 @@ tag:
|
|||||||
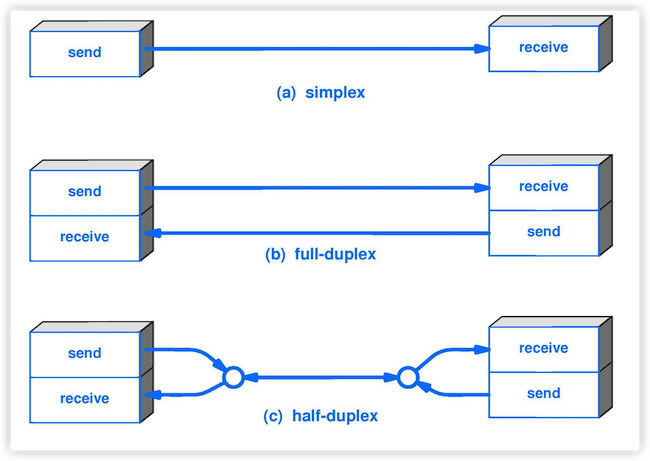
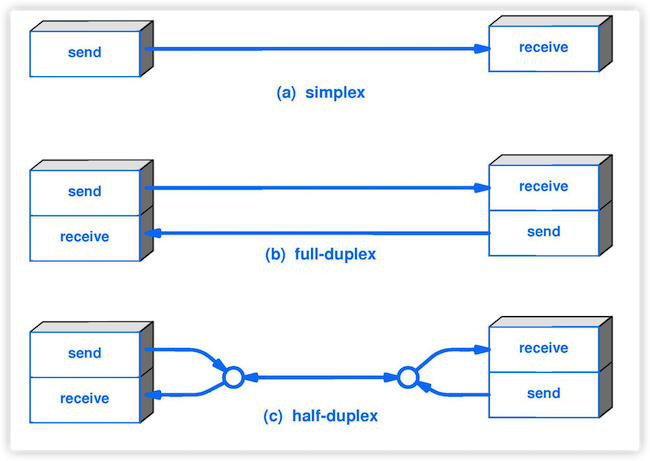
5. **半双工(half duplex )** :通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
|
5. **半双工(half duplex )** :通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
|
||||||
6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
|
6. **全双工(full duplex)** : 通信的双方可以同时发送和接收信息。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
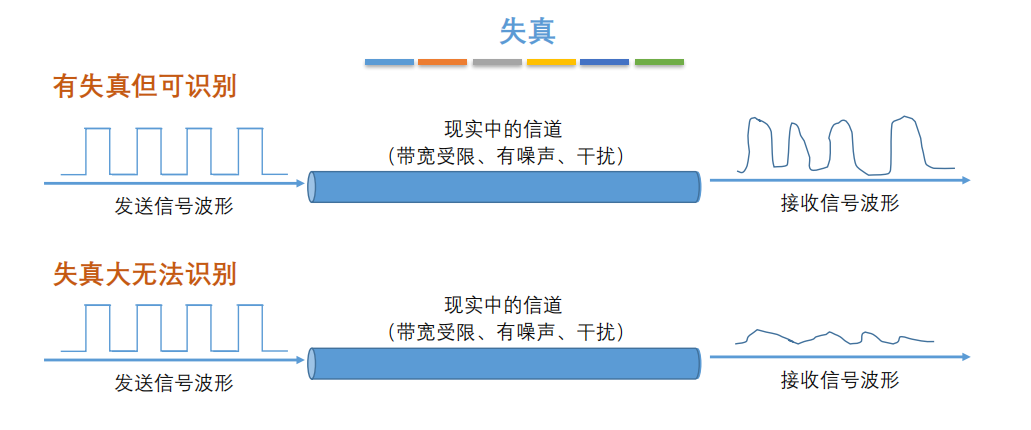
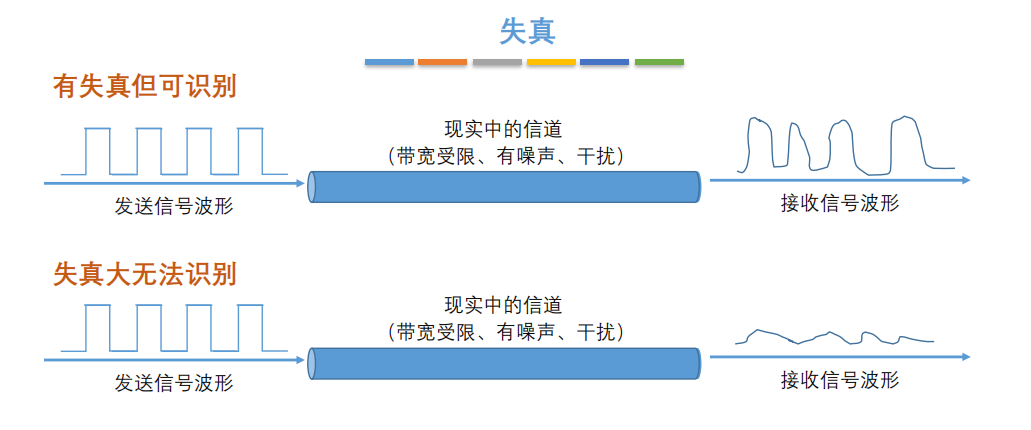
7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
|
7. **失真**:失去真实性,主要是指接受到的信号和发送的信号不同,有磨损和衰减。影响失真程度的因素:1.码元传输速率 2.信号传输距离 3.噪声干扰 4.传输媒体质量
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
|
8. **奈氏准则** : 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
|
||||||
9. **香农定理** :在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
|
9. **香农定理** :在带宽受限且有噪声的信道中,为了不产生误差,信息的数据传输速率有上限值。
|
||||||
@ -96,7 +96,7 @@ tag:
|
|||||||
13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
|
13. **信噪比(signal-to-noise ratio )** : 指信号的平均功率和噪声的平均功率之比,记为 S/N。信噪比(dB)=10\*log10(S/N)。
|
||||||
14. **信道复用(channel multiplexing )** :指多个用户共享同一个信道。(并不一定是同时)。
|
14. **信道复用(channel multiplexing )** :指多个用户共享同一个信道。(并不一定是同时)。
|
||||||
|
|
||||||
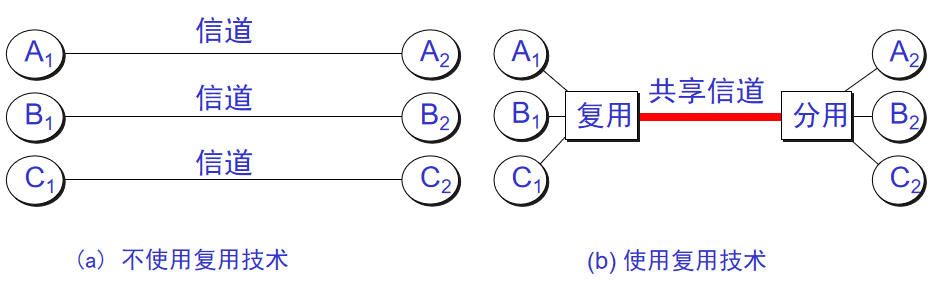
|
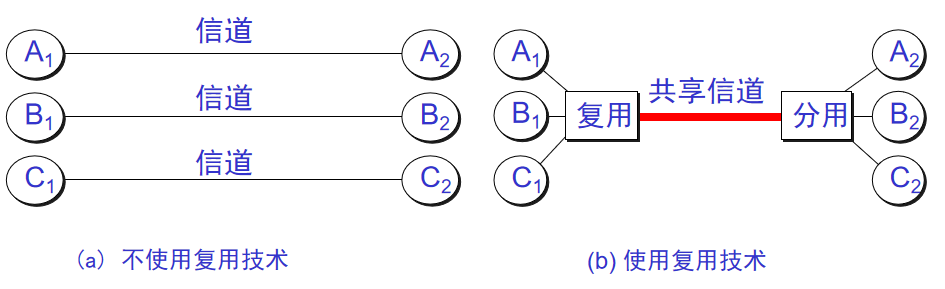
|
||||||
|
|
||||||
15. **比特率(bit rate )** :单位时间(每秒)内传送的比特数。
|
15. **比特率(bit rate )** :单位时间(每秒)内传送的比特数。
|
||||||
16. **波特率(baud rate)** :单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
|
16. **波特率(baud rate)** :单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
|
||||||
@ -138,7 +138,7 @@ tag:
|
|||||||
|
|
||||||
## 3. 数据链路层(Data Link Layer)
|
## 3. 数据链路层(Data Link Layer)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 3.1. 基本术语
|
### 3.1. 基本术语
|
||||||
|
|
||||||
@ -149,10 +149,10 @@ tag:
|
|||||||
5. **MTU(Maximum Transfer Uint )** :最大传送单元。帧的数据部分的的长度上限。
|
5. **MTU(Maximum Transfer Uint )** :最大传送单元。帧的数据部分的的长度上限。
|
||||||
6. **误码率 BER(Bit Error Rate )** :在一段时间内,传输错误的比特占所传输比特总数的比率。
|
6. **误码率 BER(Bit Error Rate )** :在一段时间内,传输错误的比特占所传输比特总数的比率。
|
||||||
7. **PPP(Point-to-Point Protocol )** :点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
|
7. **PPP(Point-to-Point Protocol )** :点对点协议。即用户计算机和 ISP 进行通信时所使用的数据链路层协议。以下是 PPP 帧的示意图:
|
||||||
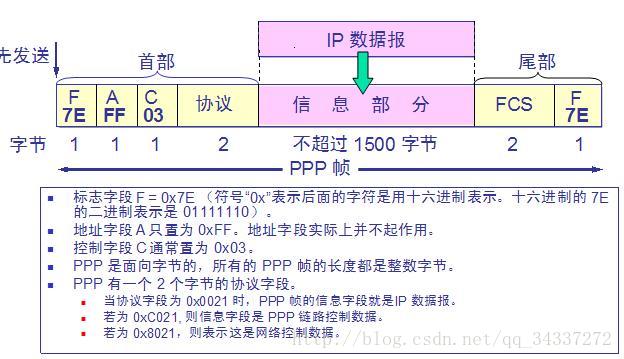
|
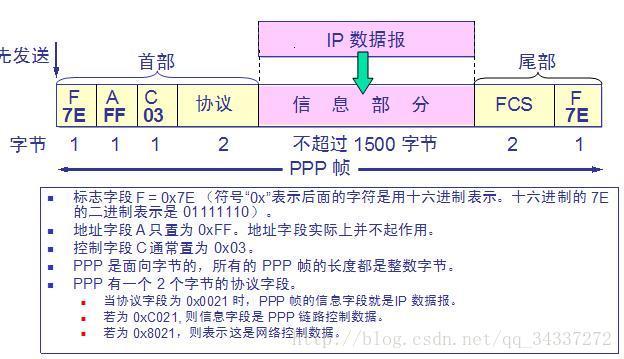
|
||||||
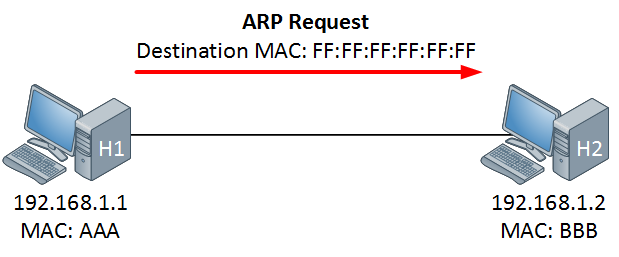
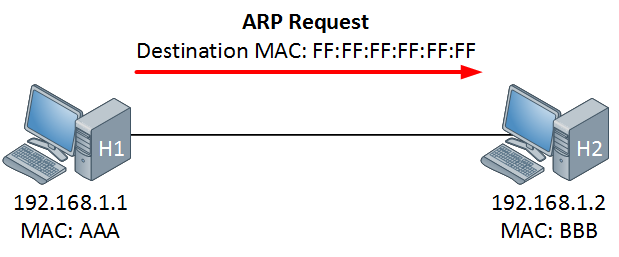
8. **MAC 地址(Media Access Control 或者 Medium Access Control)** :意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
|
8. **MAC 地址(Media Access Control 或者 Medium Access Control)** :意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。在 OSI 模型中,第三层网络层负责 IP 地址,第二层数据链路层则负责 MAC 地址。因此一个主机会有一个 MAC 地址,而每个网络位置会有一个专属于它的 IP 地址 。地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处。”
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
9. **网桥(bridge)** :一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
|
9. **网桥(bridge)** :一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
|
||||||
10. **交换机(switch )** :广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
|
10. **交换机(switch )** :广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
|
||||||
@ -181,7 +181,7 @@ tag:
|
|||||||
|
|
||||||
## 4. 网络层(Network Layer)
|
## 4. 网络层(Network Layer)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 4.1. 基本术语
|
### 4.1. 基本术语
|
||||||
|
|
||||||
@ -209,7 +209,7 @@ tag:
|
|||||||
|
|
||||||
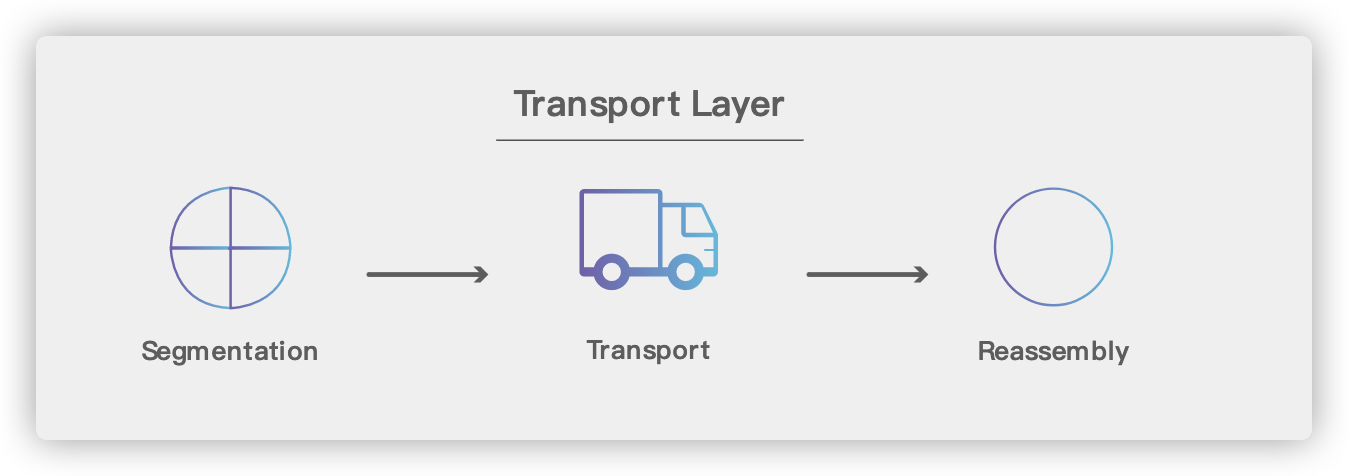
## 5. 传输层(Transport Layer)
|
## 5. 传输层(Transport Layer)
|
||||||
|
|
||||||
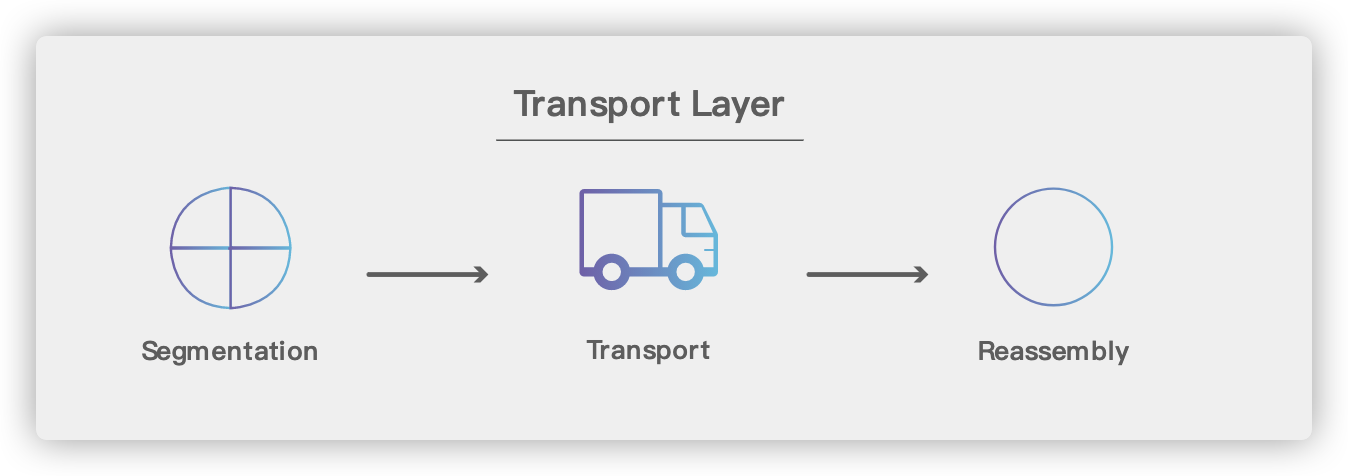
|
|
||||||
|
|
||||||
### 5.1. 基本术语
|
### 5.1. 基本术语
|
||||||
|
|
||||||
@ -219,7 +219,7 @@ tag:
|
|||||||
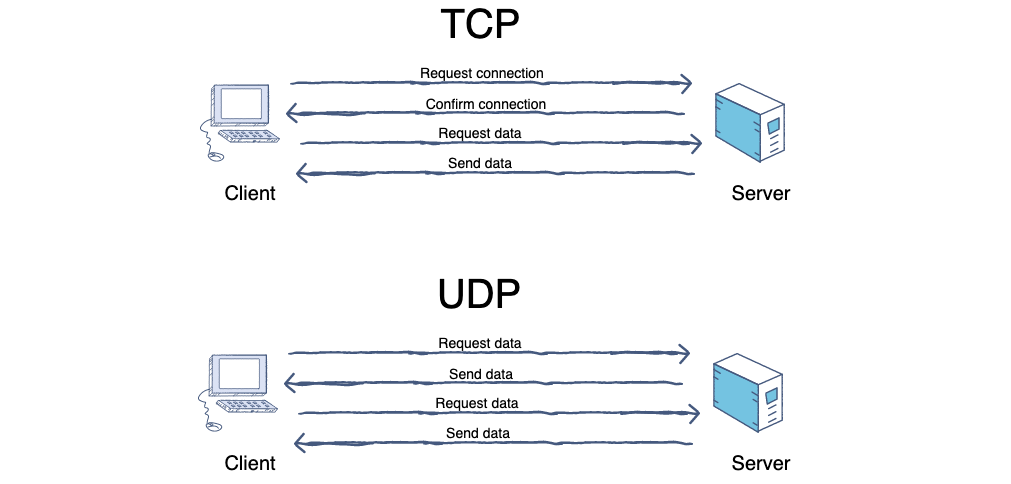
4. **TCP(Transmission Control Protocol)** :传输控制协议。
|
4. **TCP(Transmission Control Protocol)** :传输控制协议。
|
||||||
5. **UDP(User Datagram Protocol)** :用户数据报协议。
|
5. **UDP(User Datagram Protocol)** :用户数据报协议。
|
||||||
|
|
||||||
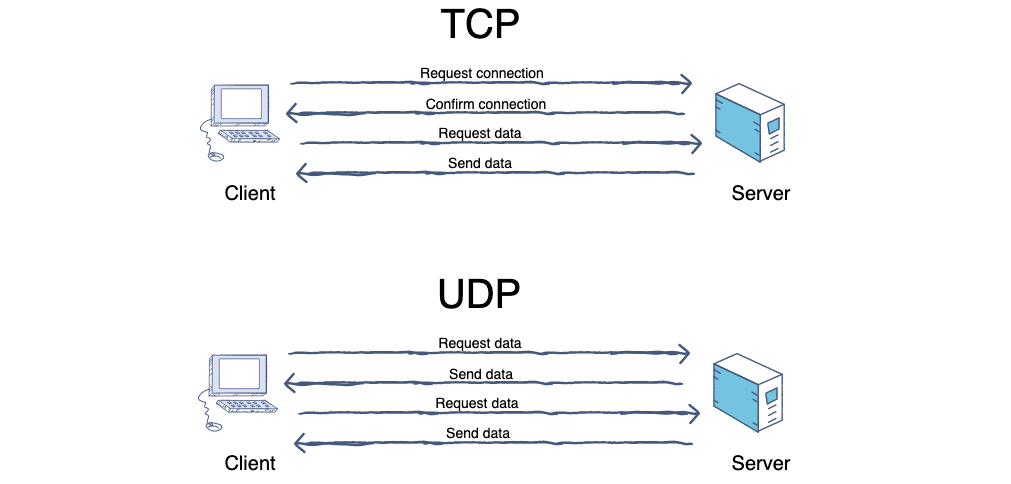
|
|
||||||
|
|
||||||
6. **端口(port)** :端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
|
6. **端口(port)** :端口的目的是为了确认对方机器的哪个进程在与自己进行交互,比如 MSN 和 QQ 的端口不同,如果没有端口就可能出现 QQ 进程和 MSN 交互错误。端口又称协议端口号。
|
||||||
7. **停止等待协议(stop-and-wait)** :指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
|
7. **停止等待协议(stop-and-wait)** :指发送方每发送完一个分组就停止发送,等待对方确认,在收到确认之后在发送下一个分组。
|
||||||
@ -262,44 +262,44 @@ tag:
|
|||||||
|
|
||||||
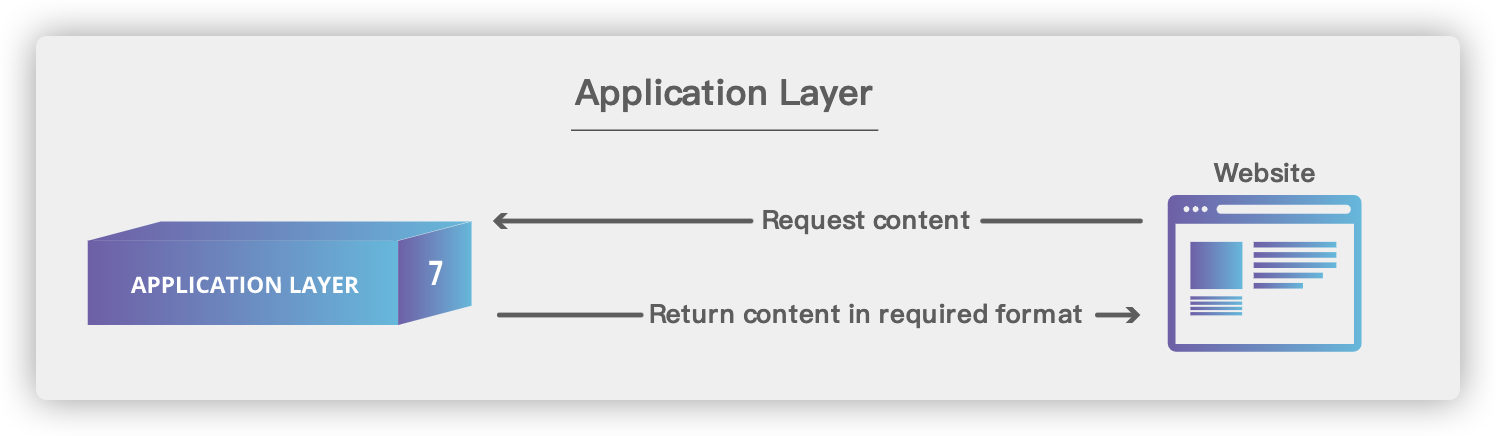
## 6. 应用层(Application Layer)
|
## 6. 应用层(Application Layer)
|
||||||
|
|
||||||
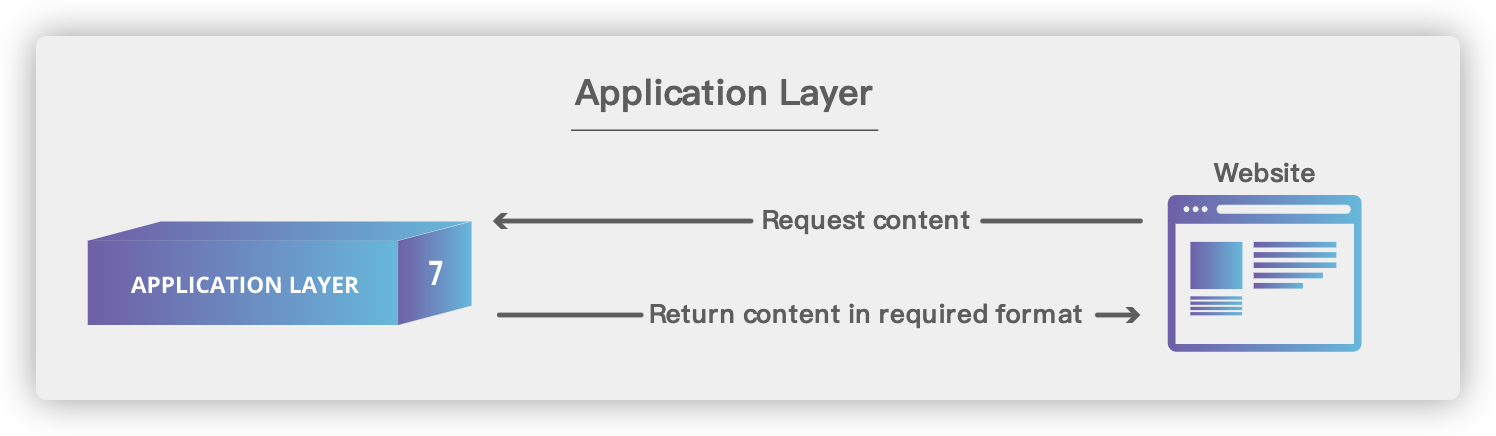
|
|
||||||
|
|
||||||
### 6.1. 基本术语
|
### 6.1. 基本术语
|
||||||
|
|
||||||
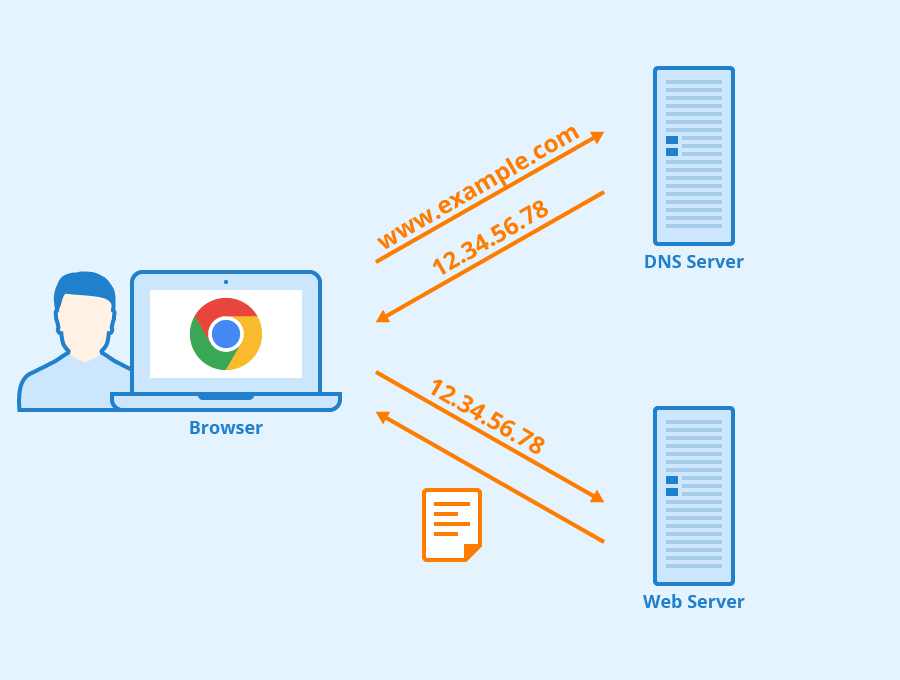
1. **域名系统(DNS)** :域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
|
1. **域名系统(DNS)** :域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。我们可以将其理解为专为互联网设计的电话薄。
|
||||||
|
|
||||||
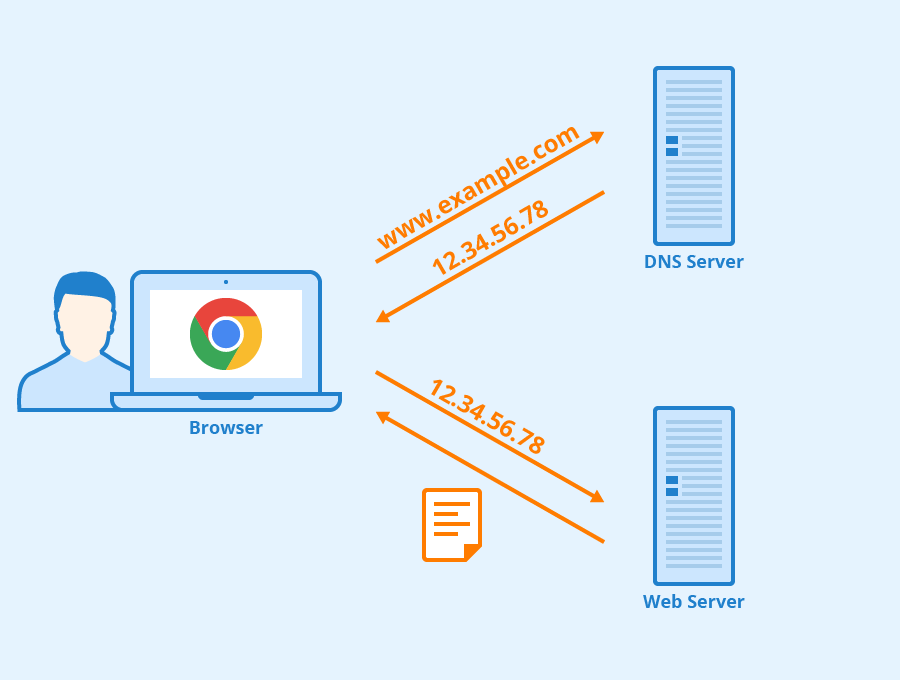
|
|
||||||
|
|
||||||
<p style="text-align:right;font-size:12px">https://www.seobility.net/en/wiki/HTTP_headers</p>
|
<p style="text-align:right;font-size:12px">https://www.seobility.net/en/wiki/HTTP_headers</p>
|
||||||
|
|
||||||
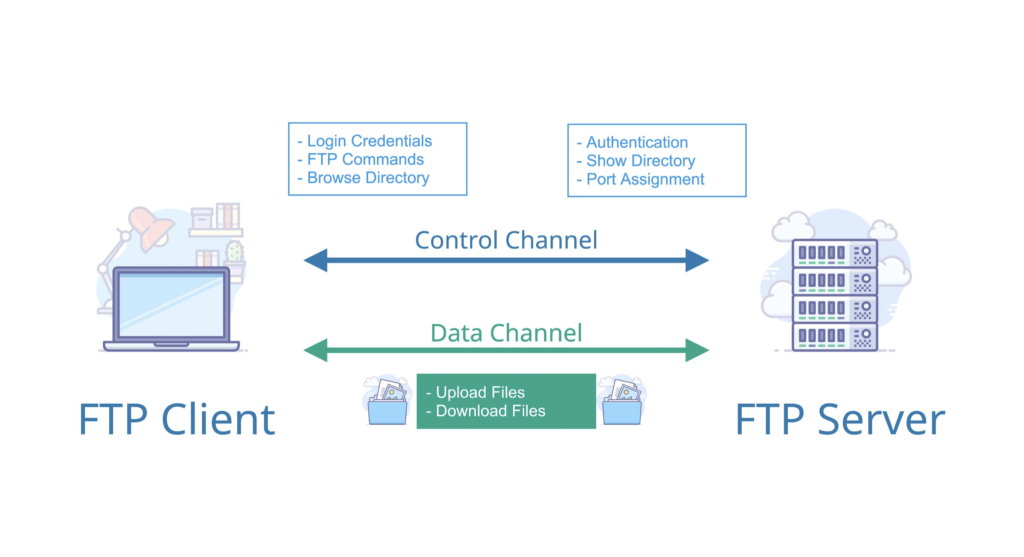
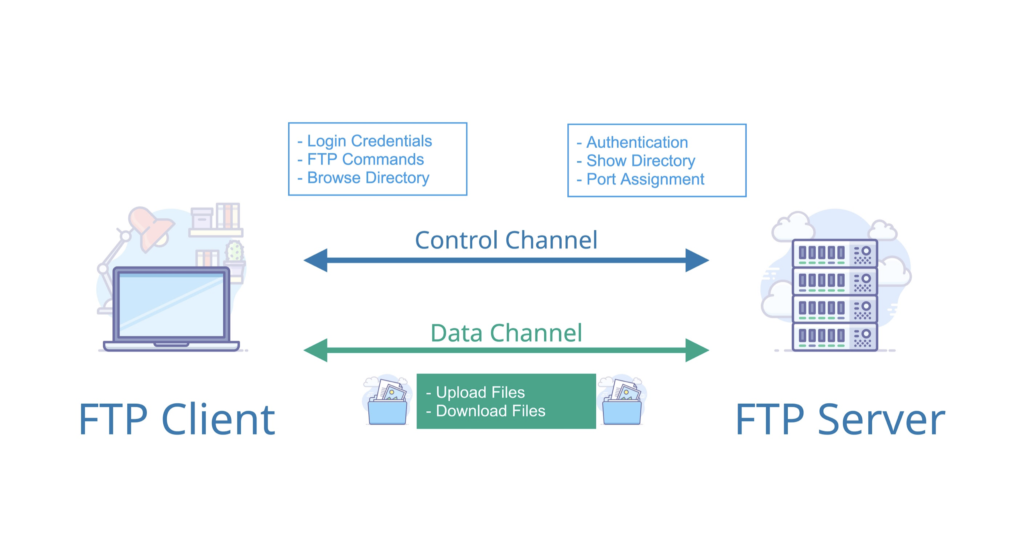
2. **文件传输协议(FTP)** :FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
|
2. **文件传输协议(FTP)** :FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。 "下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用 Internet 语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
3. **简单文件传输协议(TFTP)** :TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
|
3. **简单文件传输协议(TFTP)** :TFTP(Trivial File Transfer Protocol,简单文件传输协议)是 TCP/IP 协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为 69。
|
||||||
4. **远程终端协议(TELNET)** :Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
|
4. **远程终端协议(TELNET)** :Telnet 协议是 TCP/IP 协议族中的一员,是 Internet 远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用 telnet 程序,用它连接到服务器。终端使用者可以在 telnet 程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个 telnet 会话,必须输入用户名和密码来登录服务器。Telnet 是常用的远程控制 Web 服务器的方法。
|
||||||
5. **万维网(WWW)** :WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
|
5. **万维网(WWW)** :WWW 是环球信息网的缩写,(亦作“Web”、“WWW”、“'W3'”,英文全称为“World Wide Web”),中文名字为“万维网”,"环球网"等,常简称为 Web。分为 Web 客户端和 Web 服务器程序。WWW 可以让 Web 客户端(常用浏览器)访问浏览 Web 服务器上的页面。是一个由许多互相链接的超文本组成的系统,通过互联网访问。在这个系统中,每个有用的事物,称为一样“资源”;并且由一个全局“统一资源标识符”(URI)标识;这些资源通过超文本传输协议(Hypertext Transfer Protocol)传送给用户,而后者通过点击链接来获得资源。万维网联盟(英语:World Wide Web Consortium,简称 W3C),又称 W3C 理事会。1994 年 10 月在麻省理工学院(MIT)计算机科学实验室成立。万维网联盟的创建者是万维网的发明者蒂姆·伯纳斯-李。万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
|
||||||
6. **万维网的大致工作工程:**
|
6. **万维网的大致工作工程:**
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
7. **统一资源定位符(URL)** :统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
|
7. **统一资源定位符(URL)** :统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的 URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
|
||||||
8. **超文本传输协议(HTTP)** :超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
|
8. **超文本传输协议(HTTP)** :超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法。1960 年美国人 Ted Nelson 构思了一种通过计算机处理文本信息的方法,并称之为超文本(hypertext),这成为了 HTTP 超文本传输协议标准架构的发展根基。
|
||||||
|
|
||||||
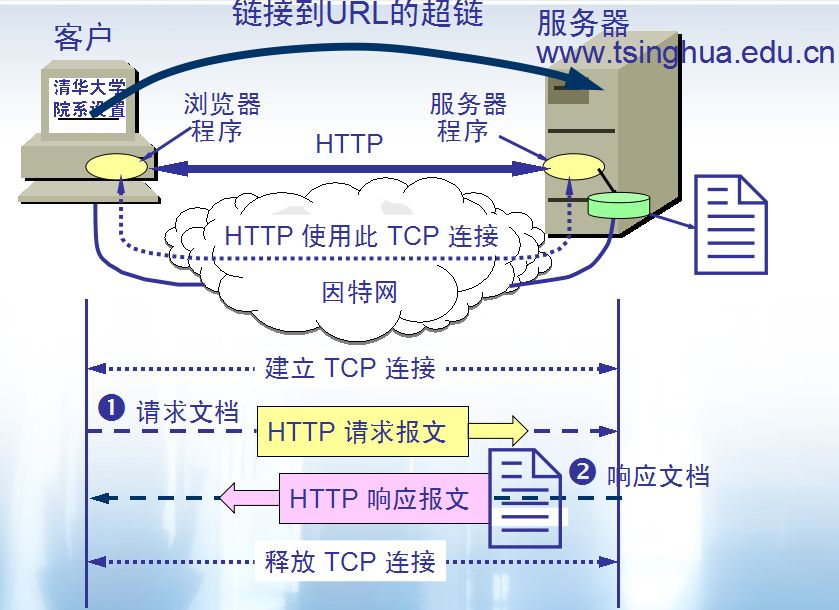
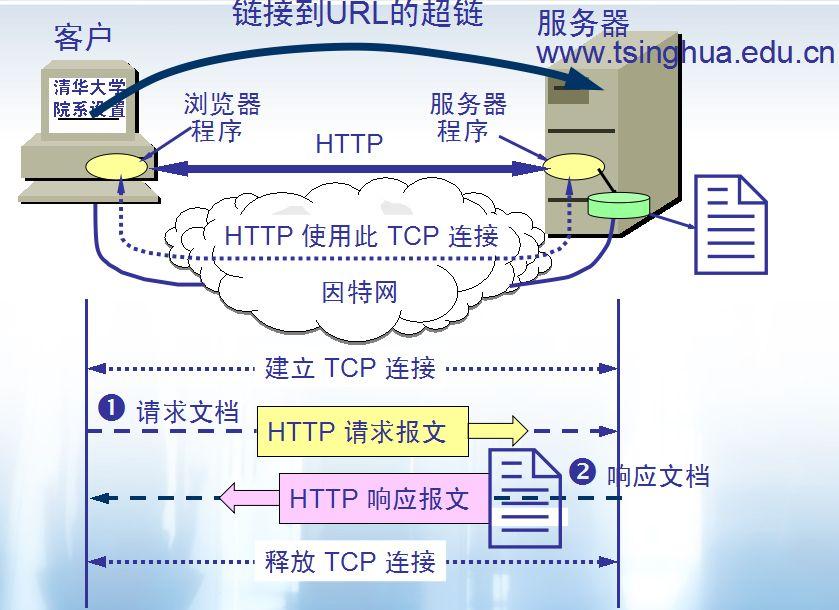
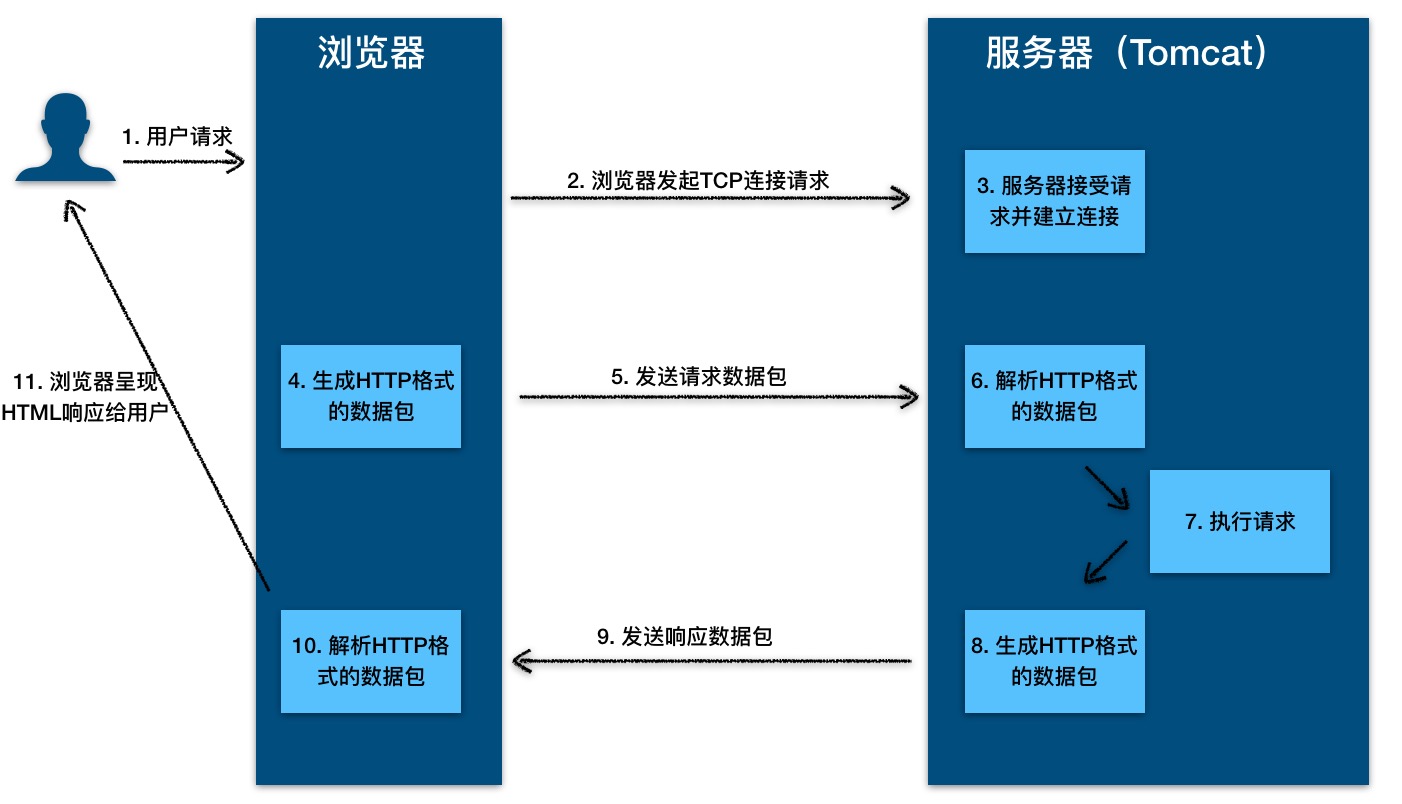
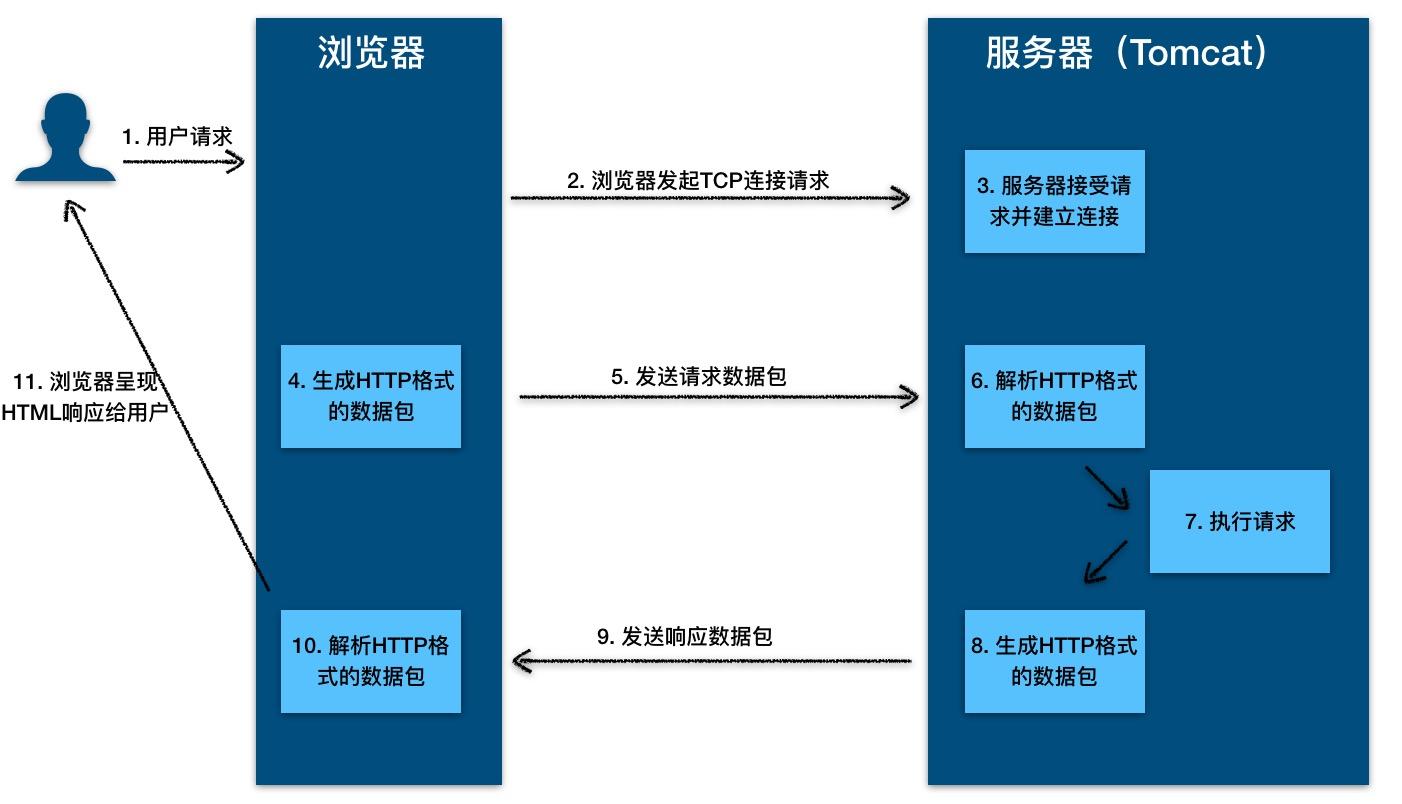
HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
|
HTTP 协议的本质就是一种浏览器与服务器之间约定好的通信格式。HTTP 的原理如下图所示:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
10. **代理服务器(Proxy Server)** : 代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
|
10. **代理服务器(Proxy Server)** : 代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。 代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按 URL 的地址再次去互联网访问该资源。代理服务器可在客户端或服务器工作,也可以在中间系统工作。
|
||||||
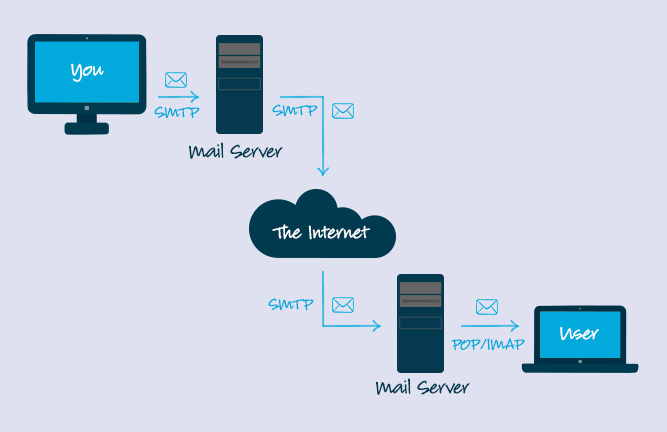
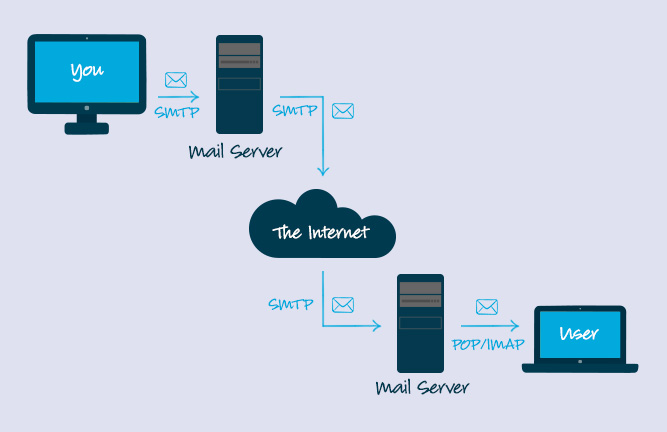
11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
|
11. **简单邮件传输协议(SMTP)** : SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。 SMTP 协议属于 TCP/IP 协议簇,它帮助每台计算机在发送或中转信件时找到下一个目的地。 通过 SMTP 协议所指定的服务器,就可以把 E-mail 寄到收信人的服务器上了,整个过程只要几分钟。SMTP 服务器则是遵循 SMTP 协议的发送邮件服务器,用来发送或中转发出的电子邮件。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
<p style="text-align:right;font-size:12px">https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/</p>
|
<p style="text-align:right;font-size:12px">https://www.campaignmonitor.com/resources/knowledge-base/what-is-the-code-that-makes-bcc-or-cc-operate-in-an-email/</p>
|
||||||
|
|
||||||
11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
|
11. **搜索引擎** :搜索引擎(Search Engine)是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
12. **垂直搜索引擎** :垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
|
12. **垂直搜索引擎** :垂直搜索引擎是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索是相对通用搜索引擎的信息量大、查询不准确、深度不够等提出来的新的搜索引擎服务模式,通过针对某一特定领域、某一特定人群或某一特定需求提供的有一定价值的信息和相关服务。其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,垂直搜索引擎则显得更加专注、具体和深入。
|
||||||
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
|
13. **全文索引** :全文索引技术是目前搜索引擎的关键技术。试想在 1M 大小的文件中搜索一个词,可能需要几秒,在 100M 的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
|
||||||
|
|||||||
@ -21,7 +21,7 @@ tag:
|
|||||||
|
|
||||||
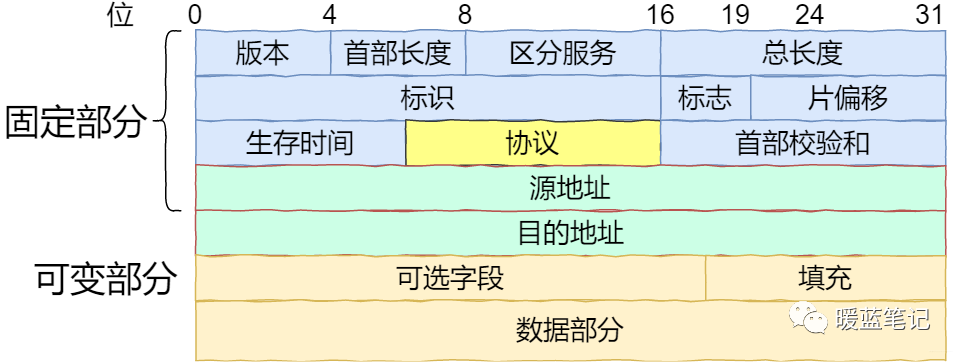
**IP 头部格式** :
|
**IP 头部格式** :
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### IP 欺骗技术是什么?
|
### IP 欺骗技术是什么?
|
||||||
|
|
||||||
@ -33,7 +33,7 @@ IP 欺骗技术就是**伪造**某台主机的 IP 地址的技术。通过 IP
|
|||||||
|
|
||||||
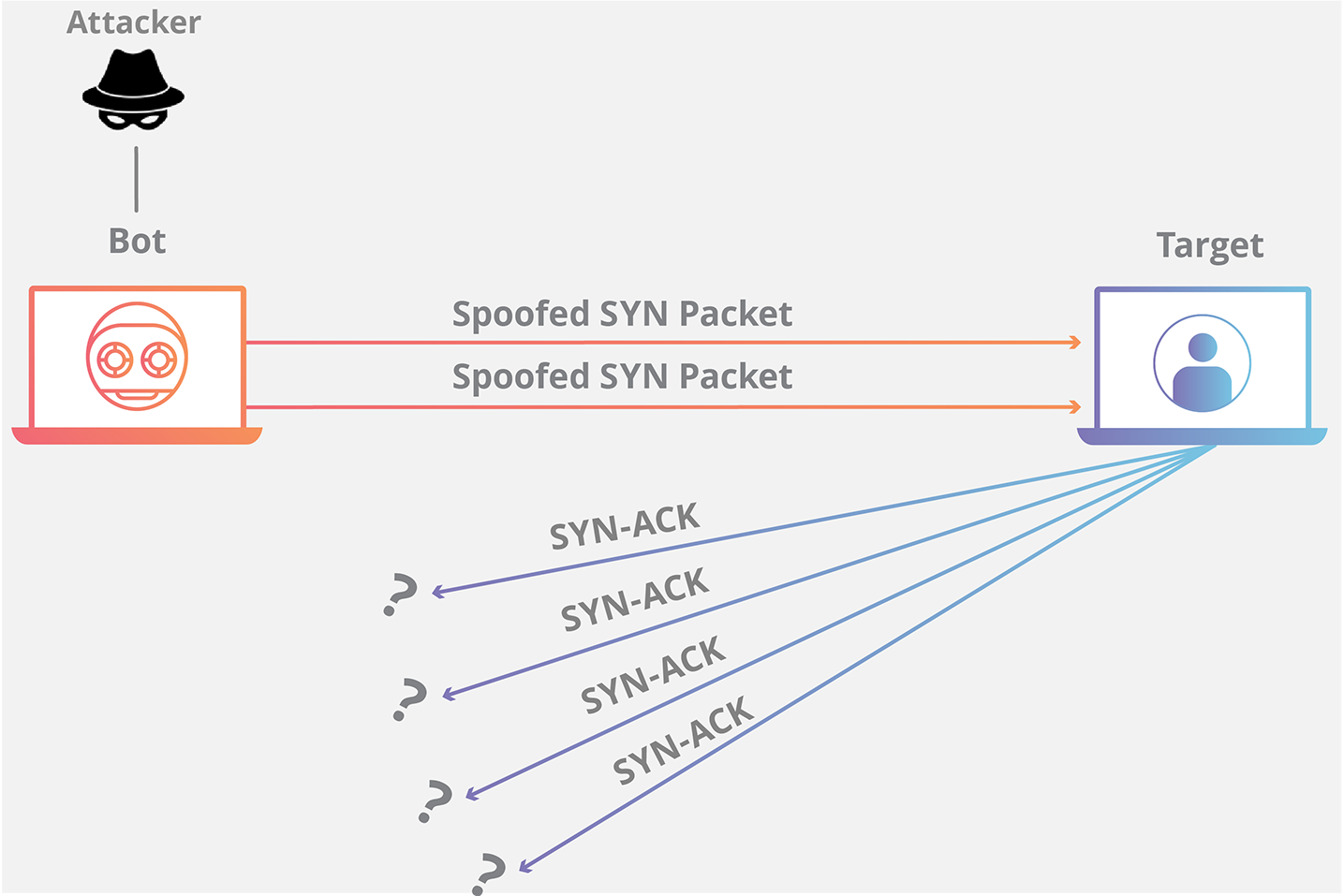
这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
|
这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 如何缓解 IP 欺骗?
|
### 如何缓解 IP 欺骗?
|
||||||
|
|
||||||
@ -48,13 +48,13 @@ SYN Flood 是互联网上最原始、最经典的 DDoS(Distributed Denial of S
|
|||||||
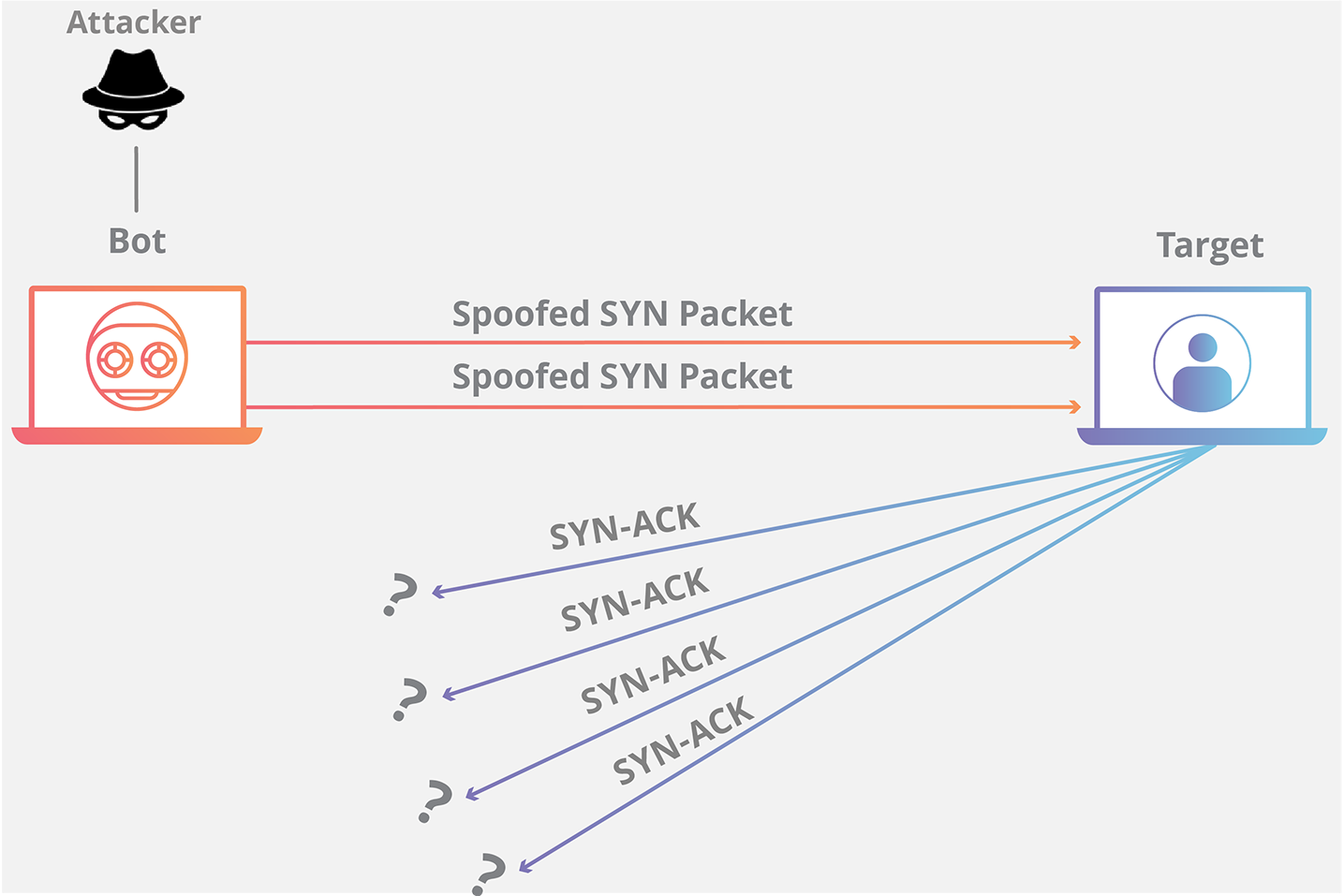
SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
|
SYN Flood 利用了 TCP 协议的三次握手机制,攻击者通常利用工具或者控制僵尸主机向服务器发送海量的变源 IP 地址或变源端口的 TCP SYN 报文,服务器响应了这些报文后就会生成大量的半连接,当系统资源被耗尽后,服务器将无法提供正常的服务。
|
||||||
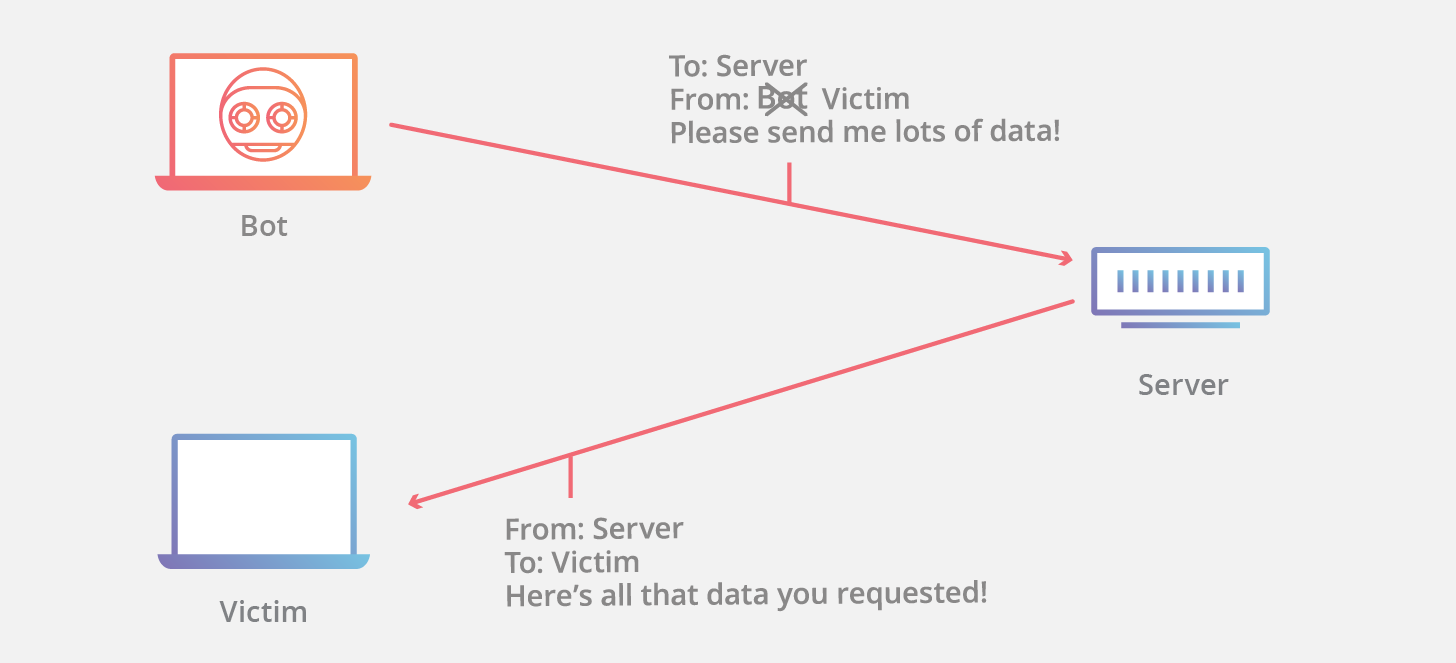
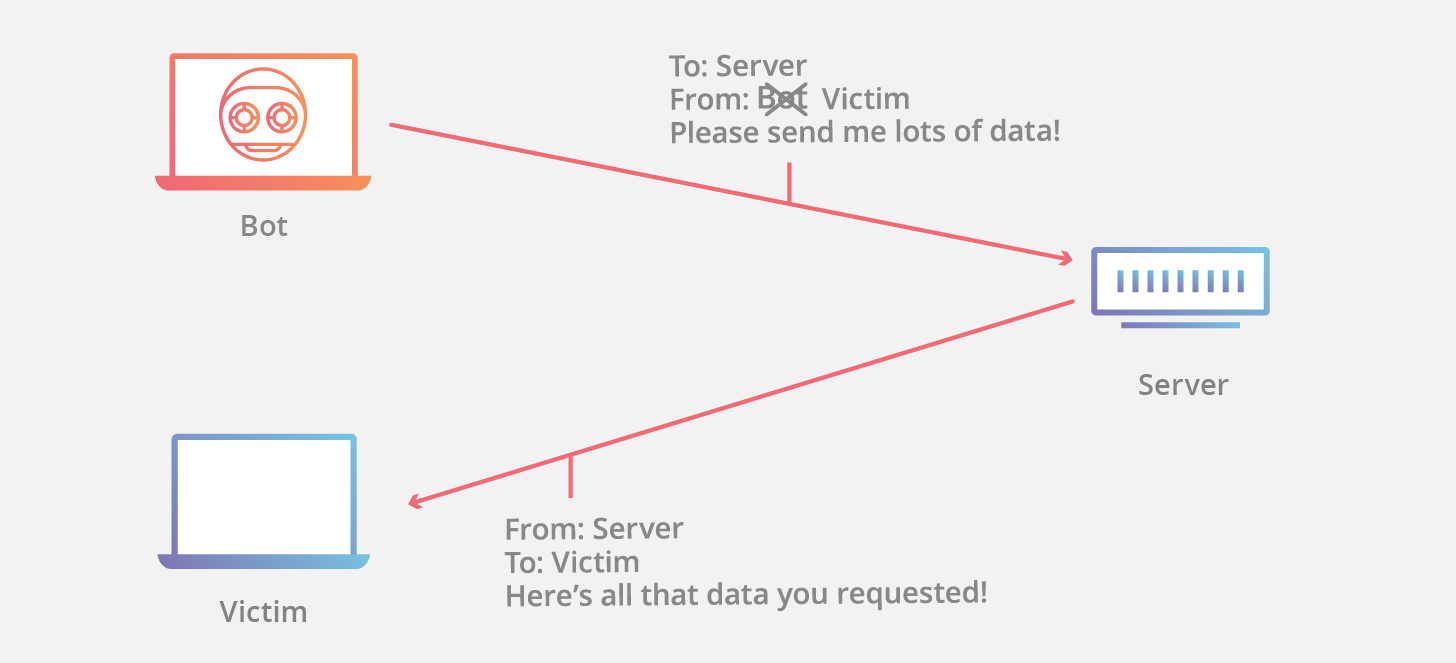
增加服务器性能,提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪,防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
|
增加服务器性能,提供更多的连接能力对于 SYN Flood 的海量报文来说杯水车薪,防御 SYN Flood 的关键在于判断哪些连接请求来自于真实源,屏蔽非真实源的请求以保障正常的业务请求能得到服务。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### TCP SYN Flood 攻击原理是什么?
|
### TCP SYN Flood 攻击原理是什么?
|
||||||
|
|
||||||
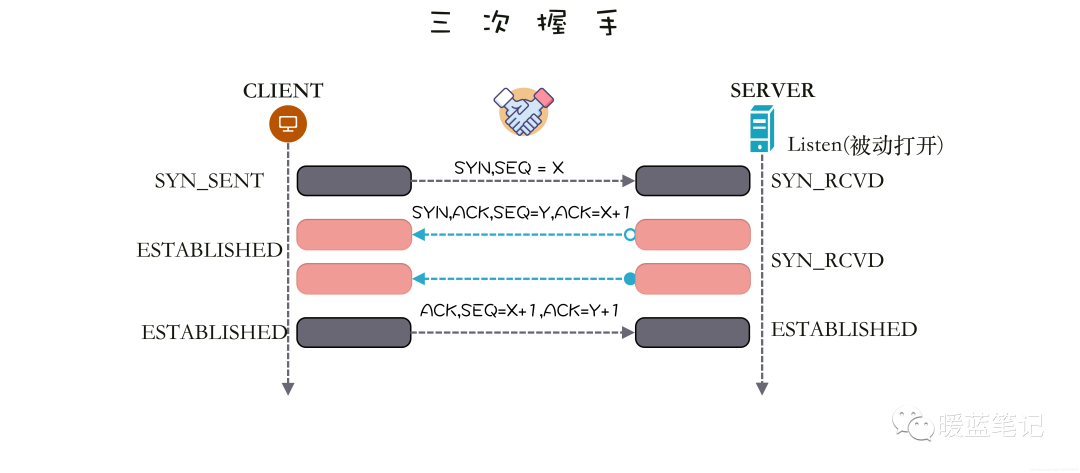
**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
|
**TCP SYN Flood** 攻击利用的是 **TCP** 的三次握手(**SYN -> SYN/ACK -> ACK**),假设连接发起方是 A,连接接受方是 B,即 B 在某个端口(**Port**)上监听 A 发出的连接请求,过程如下图所示,左边是 A,右边是 B。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
|
A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收数据的准备;B 收到后反馈 **SYN-ACK**(Synchronization-Acknowledgement) 消息给 A,这个消息的目的有两个:
|
||||||
|
|
||||||
@ -71,7 +71,7 @@ A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收
|
|||||||
|
|
||||||
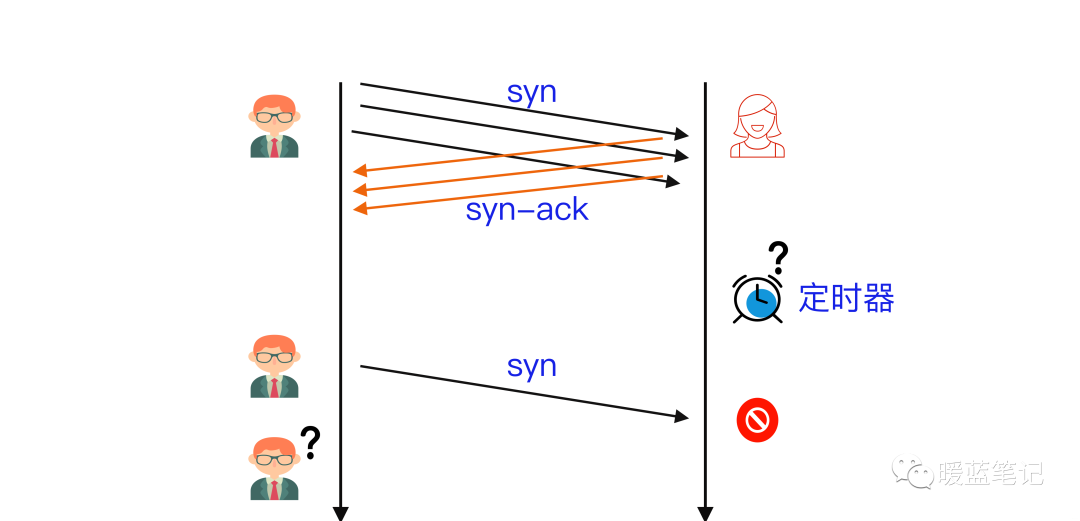
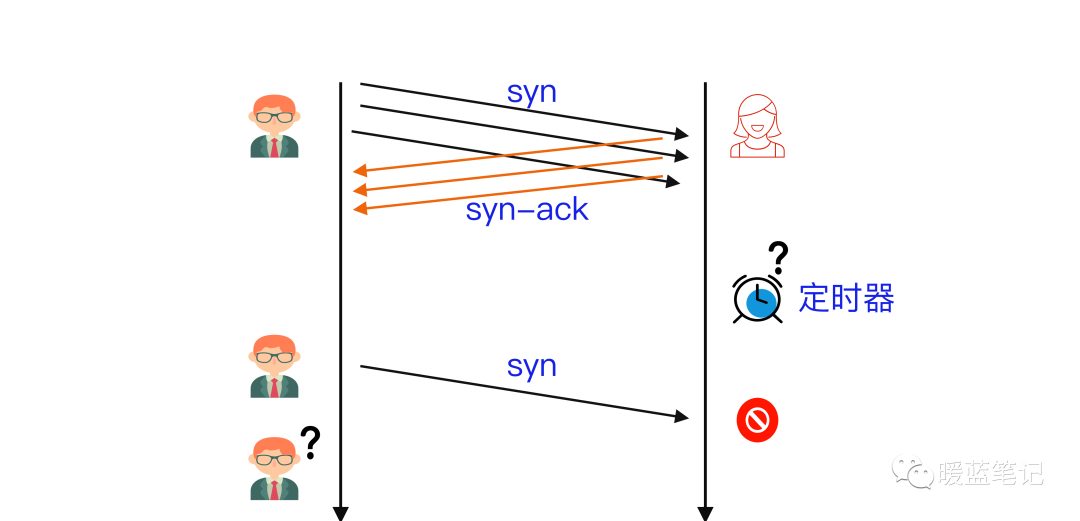
假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
|
假设 B 通过某 **TCP** 端口提供服务,B 在收到 A 的 **SYN** 消息时,积极的反馈了 **SYN-ACK** 消息,使连接进入**半开状态**,因为 B 不确定自己发给 A 的 **SYN-ACK** 消息或 A 反馈的 ACK 消息是否会丢在半路,所以会给每个待完成的半开连接都设一个**Timer**,如果超过时间还没有收到 A 的 **ACK** 消息,则重新发送一次 **SYN-ACK** 消息给 A,直到重试超过一定次数时才会放弃。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
|
B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接,那么当 B 面临海量的连接 A 时,如上图所示,**SYN Flood** 攻击就形成了。攻击方 A 可以控制肉鸡向 B 发送大量 SYN 消息但不响应 ACK 消息,或者干脆伪造 SYN 消息中的 **Source IP**,使 B 反馈的 **SYN-ACK** 消息石沉大海,导致 B 被大量注定不能完成的半开连接占据,直到资源耗尽,停止响应正常的连接请求。
|
||||||
|
|
||||||
@ -118,7 +118,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
|
|||||||
|
|
||||||
由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
|
由于目标服务器利用资源检查并响应每个接收到的 **UDP** 数据包的结果,当接收到大量 **UDP** 数据包时,目标的资源可能会迅速耗尽,导致对正常流量的拒绝服务。
|
||||||
|
|
||||||
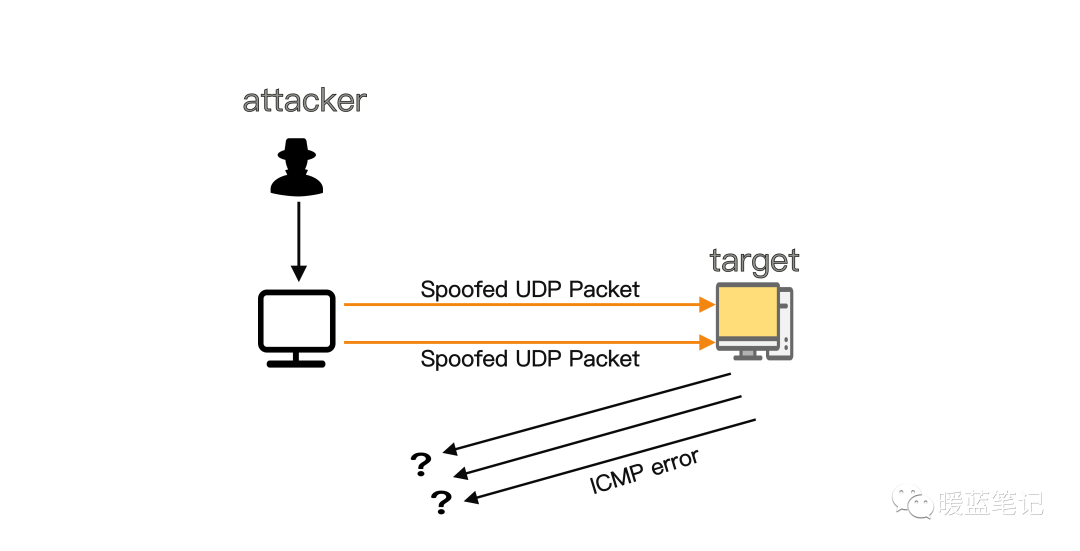
|

|
||||||
|
|
||||||
### 如何缓解 UDP Flooding?
|
### 如何缓解 UDP Flooding?
|
||||||
|
|
||||||
@ -130,7 +130,7 @@ B 为帮助 A 能顺利连接,需要**分配内核资源**维护半开连接
|
|||||||
|
|
||||||
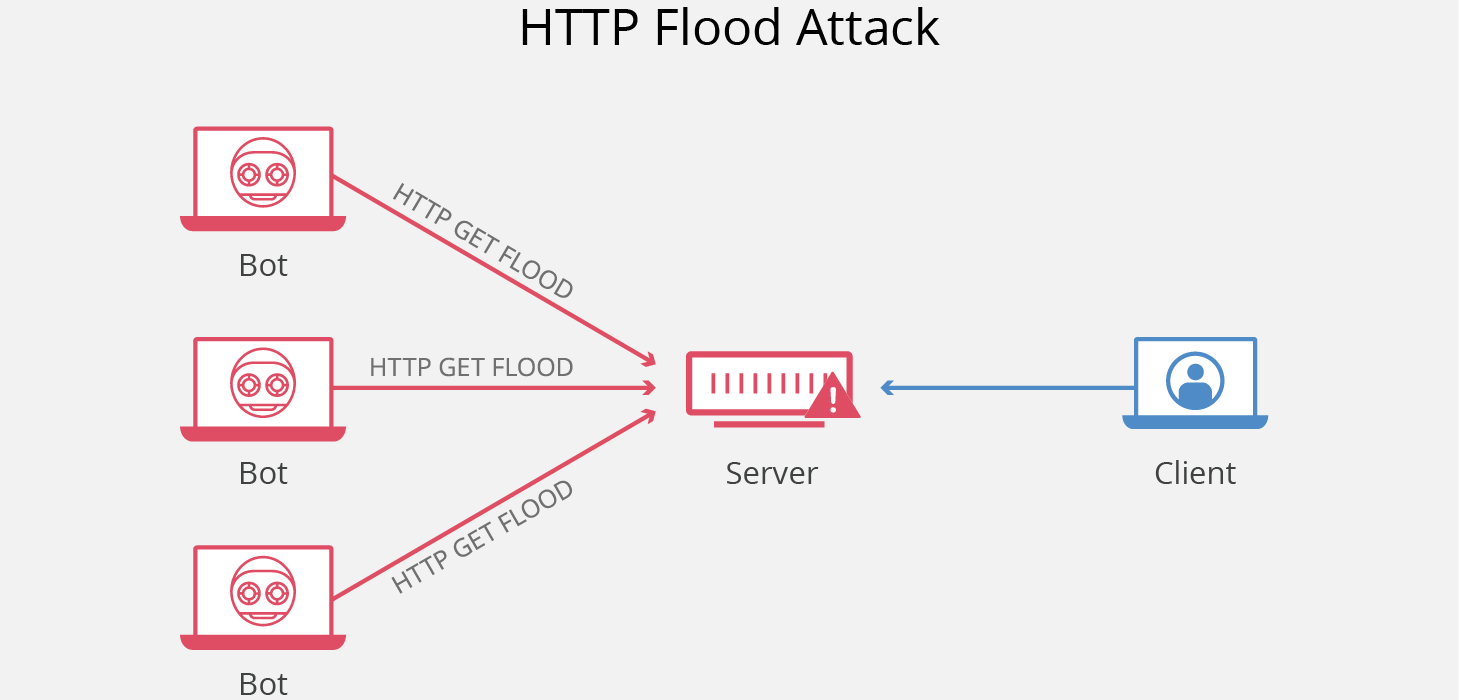
HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
|
HTTP Flood 是一种大规模的 DDoS(Distributed Denial of Service,分布式拒绝服务)攻击,旨在利用 HTTP 请求使目标服务器不堪重负。目标因请求而达到饱和,且无法响应正常流量后,将出现拒绝服务,拒绝来自实际用户的其他请求。
|
||||||
|
|
||||||
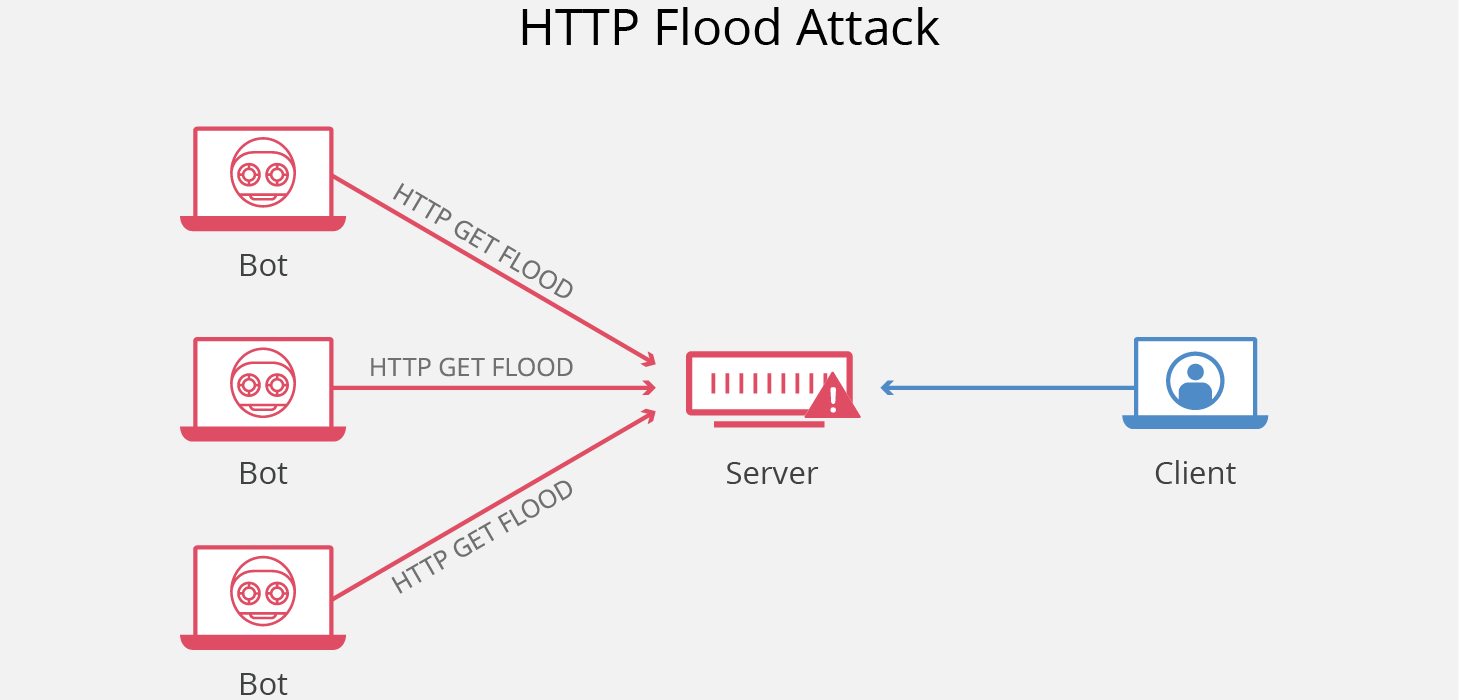
|
|
||||||
|
|
||||||
### HTTP Flood 的攻击原理是什么?
|
### HTTP Flood 的攻击原理是什么?
|
||||||
|
|
||||||
@ -157,7 +157,7 @@ HTTP 洪水攻击有两种:
|
|||||||
|
|
||||||
### DNS Flood 的攻击原理是什么?
|
### DNS Flood 的攻击原理是什么?
|
||||||
|
|
||||||
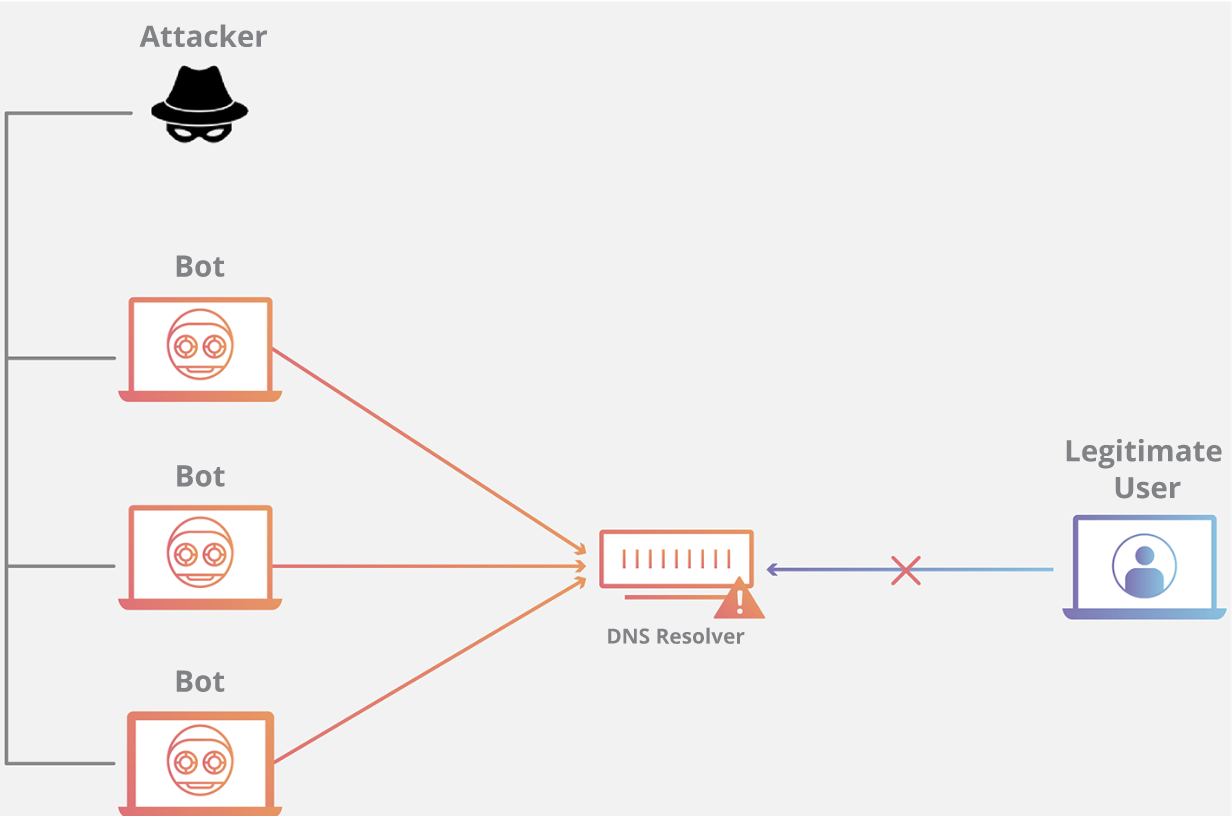
|
|
||||||
|
|
||||||
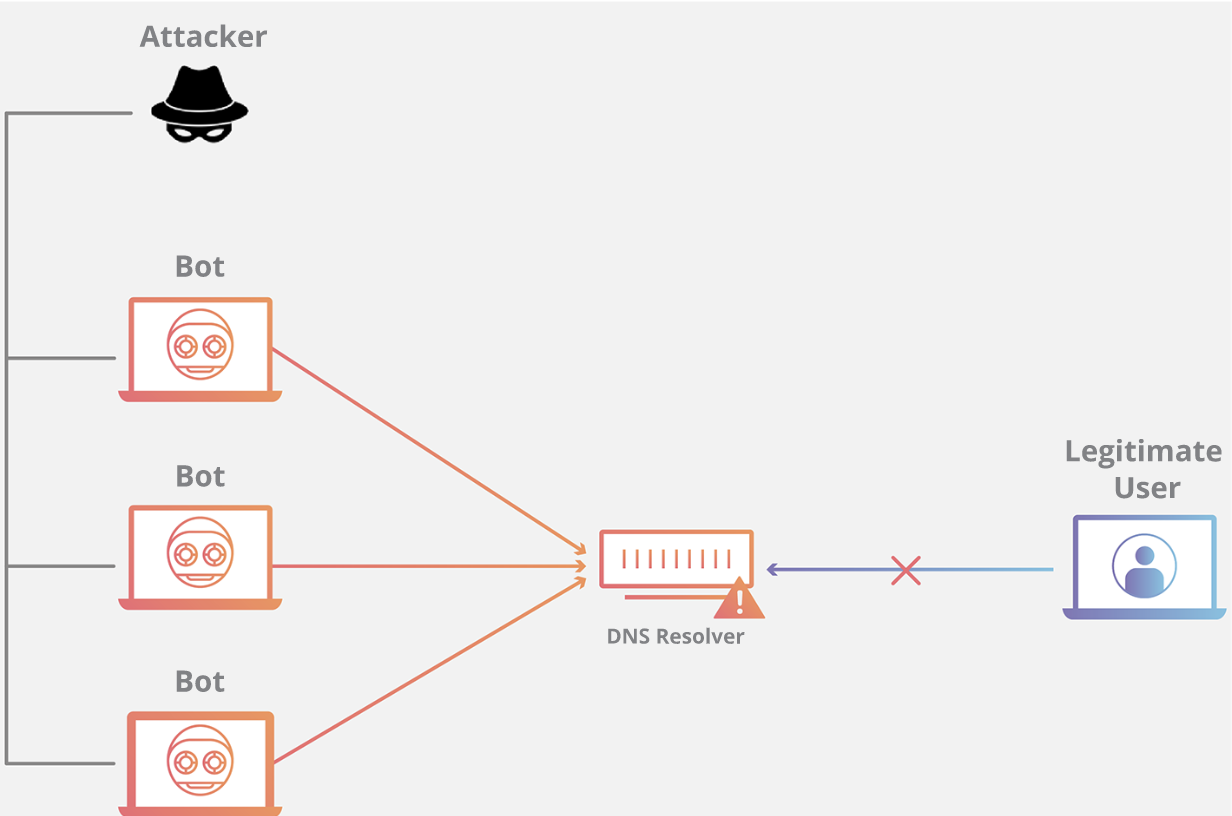
域名系统的功能是将易于记忆的名称(例如example.com)转换成难以记住的网站服务器地址(例如192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
|
域名系统的功能是将易于记忆的名称(例如example.com)转换成难以记住的网站服务器地址(例如192.168.0.1),因此成功攻击 DNS 基础设施将导致大多数人无法使用互联网。DNS Flood攻击是一种相对较新的基于 DNS 的攻击,这种攻击是在高带宽[物联网(IoT)](https://www.cloudflare.com/learning/ddos/glossary/internet-of-things-iot/)[僵尸网络](https://www.cloudflare.com/learning/ddos/what-is-a-ddos-botnet/)(如 [Mirai](https://www.cloudflare.com/learning/ddos/glossary/mirai-botnet/))兴起后激增的。DNS Flood攻击使用 IP 摄像头、DVR 盒和其他 IoT 设备的高带宽连接直接淹没主要提供商的 DNS 服务器。来自 IoT 设备的大量请求淹没 DNS 提供商的服务,阻止合法用户访问提供商的 DNS 服务器。
|
||||||
|
|
||||||
@ -210,13 +210,13 @@ $ nc 127.0.0.1 8000
|
|||||||
|
|
||||||
该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
|
该命令会尝试与上面的服务建立连接,在其中一个窗口输入一些字符,就会通过 TCP 连接发送给另一个窗口并打印出来。
|
||||||
|
|
||||||
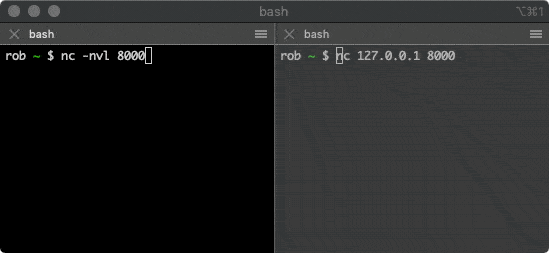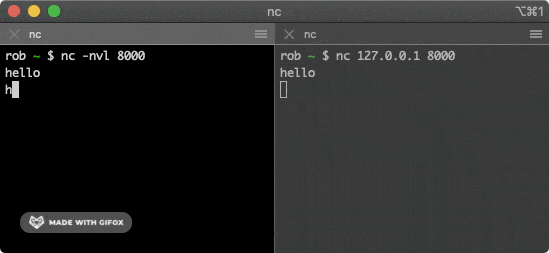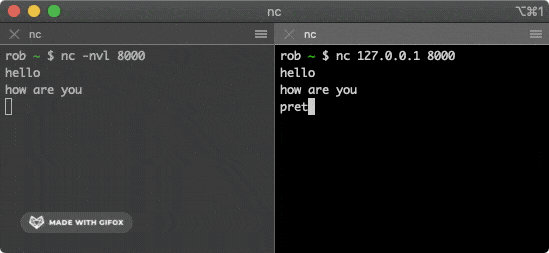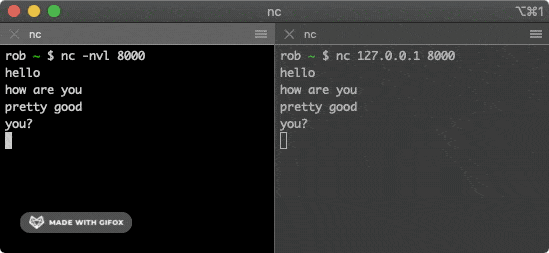
|

|
||||||
|
|
||||||
> 嗅探流量
|
> 嗅探流量
|
||||||
|
|
||||||
编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
|
编写一个攻击程序,使用 Python 网络库 `scapy` 来读取两个终端窗口之间交换的数据,并将其打印到终端上。代码比较长,下面为一部份,完整代码后台回复 TCP 攻击,代码的核心是调用 `scapy` 的嗅探方法:
|
||||||
|
|
||||||
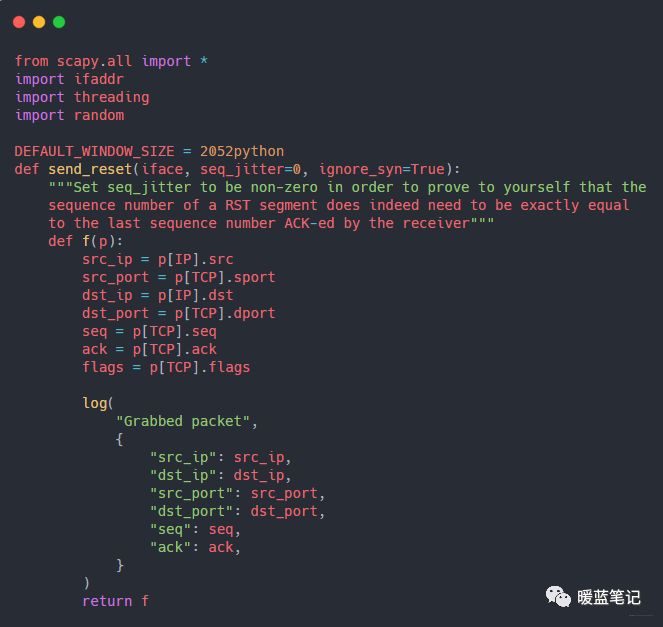
|

|
||||||
|
|
||||||
这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
|
这段代码告诉 `scapy` 在 `lo0` 网络接口上嗅探数据包,并记录所有 TCP 连接的详细信息。
|
||||||
|
|
||||||
@ -252,7 +252,7 @@ $ nc 127.0.0.1 8000
|
|||||||
|
|
||||||
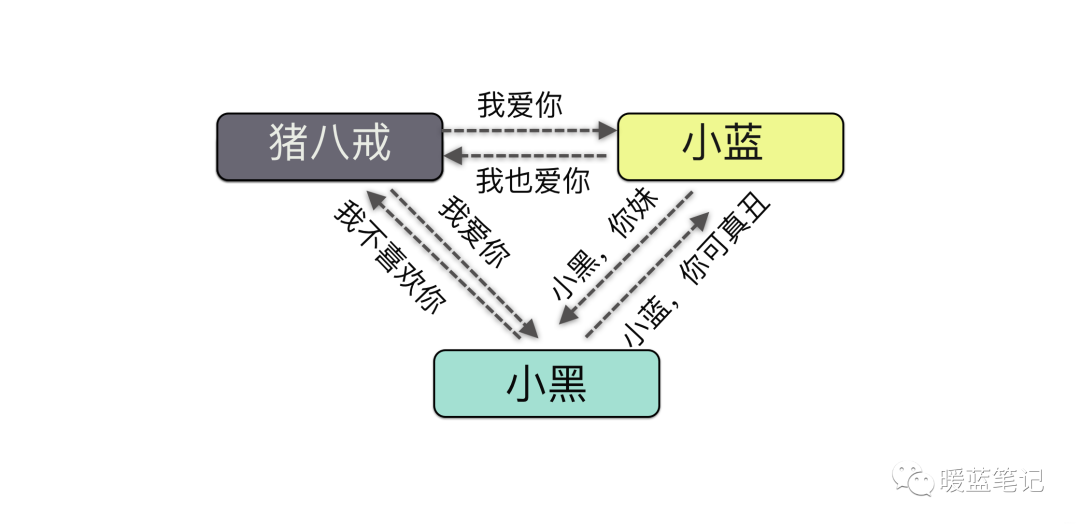
攻击中间人攻击英文名叫 Man-in-the-MiddleAttack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
|
攻击中间人攻击英文名叫 Man-in-the-MiddleAttack,简称「MITM 攻击」。指攻击者与通讯的两端分别创建独立的联系,并交换其所收到的数据,使通讯的两端认为他们正在通过一个私密的连接与对方 直接对话,但事实上整个会话都被攻击者完全控制。我们画一张图:
|
||||||
|
|
||||||
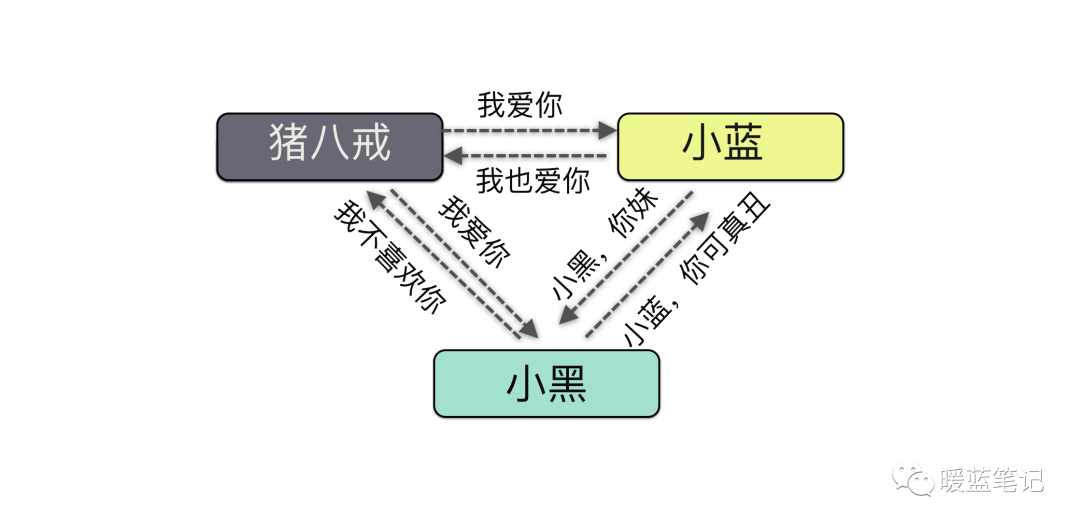
|
|
||||||
|
|
||||||
从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
|
从这张图可以看到,中间人其实就是攻击者。通过这种原理,有很多实现的用途,比如说,你在手机上浏览不健康网站的时候,手机就会提示你,此网站可能含有病毒,是否继续访问还是做其他的操作等等。
|
||||||
|
|
||||||
@ -292,7 +292,7 @@ $ nc 127.0.0.1 8000
|
|||||||
|
|
||||||
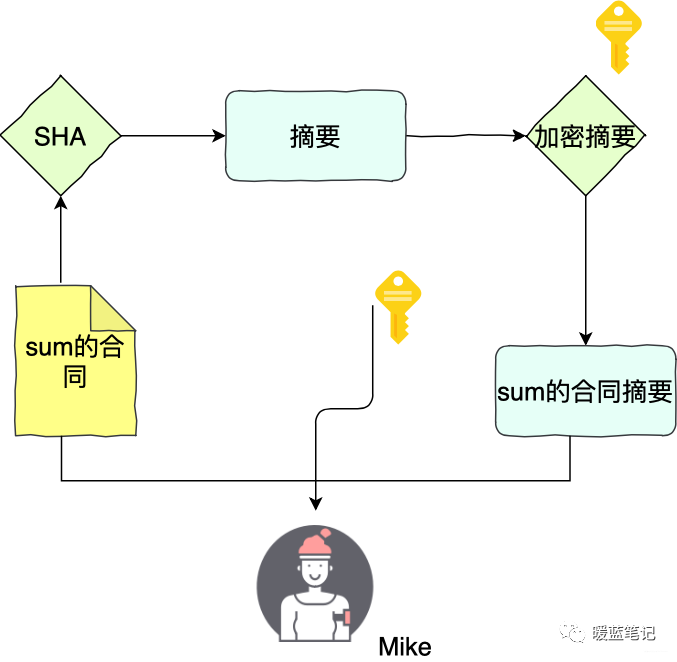
同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
|
同样的,举个例子。Sum 和 Mike 两个人签合同。Sum 首先用 **SHA** 算法计算合同的摘要,然后用自己私钥将摘要加密,得到数字签名。Sum 将合同原文、签名,以及公钥三者都交给 Mike
|
||||||
|
|
||||||
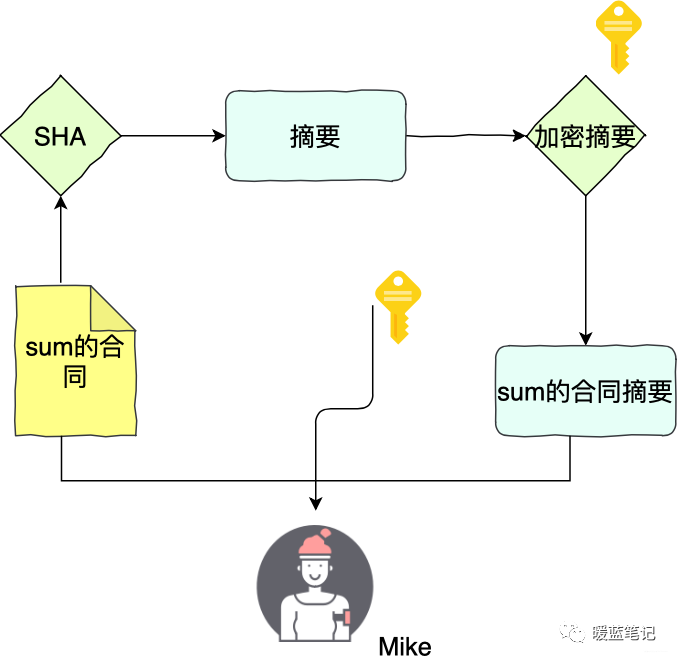
|
|
||||||
|
|
||||||
如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
|
如果 Sum 想要证明合同是 Mike 的,那么就要使用 Mike 的公钥,将这个签名解密得到摘要 x,然后 Mike 计算原文的 sha 摘要 Y,随后对比 x 和 y,如果两者相等,就认为数据没有被篡改
|
||||||
|
|
||||||
@ -308,7 +308,7 @@ $ nc 127.0.0.1 8000
|
|||||||
|
|
||||||
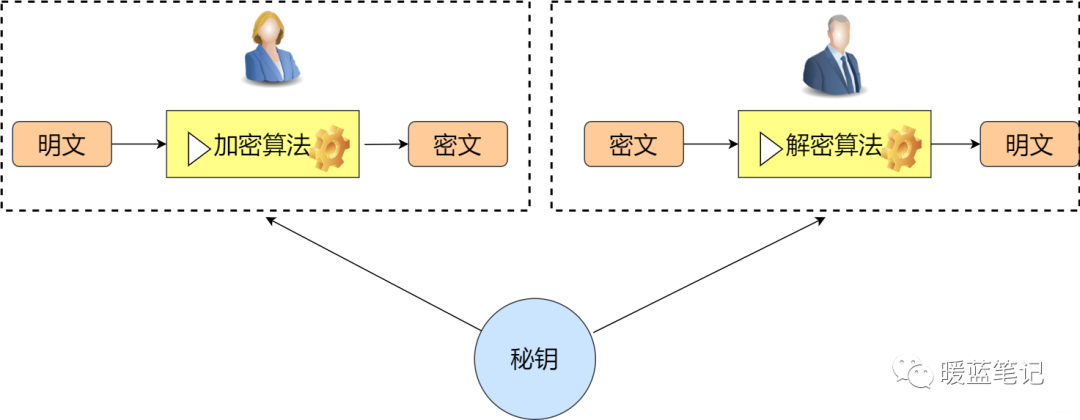
对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
|
对称加密,顾名思义,加密方与解密方使用同一钥匙(秘钥)。具体一些就是,发送方通过使用相应的加密算法和秘钥,对将要发送的信息进行加密;对于接收方而言,使用解密算法和相同的秘钥解锁信息,从而有能力阅读信息。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
#### 常见的对称加密算法有哪些?
|
#### 常见的对称加密算法有哪些?
|
||||||
|
|
||||||
@ -316,7 +316,7 @@ $ nc 127.0.0.1 8000
|
|||||||
|
|
||||||
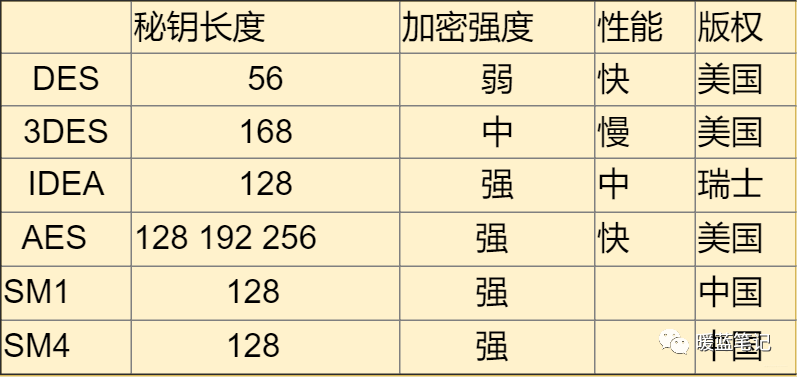
DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
|
DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实际用于算法,其余 8 位可以被用于奇偶校验,并在算法中被丢弃。因此,**DES** 的有效密钥长度为 56 位,通常称 **DES** 的密钥长度为 56 位。假设秘钥为 56 位,采用暴力破 Jie 的方式,其秘钥个数为 2 的 56 次方,那么每纳秒执行一次解密所需要的时间差不多 1 年的样子。当然,没人这么干。**DES** 现在已经不是一种安全的加密方法,主要因为它使用的 56 位密钥过短。
|
||||||
|
|
||||||
|
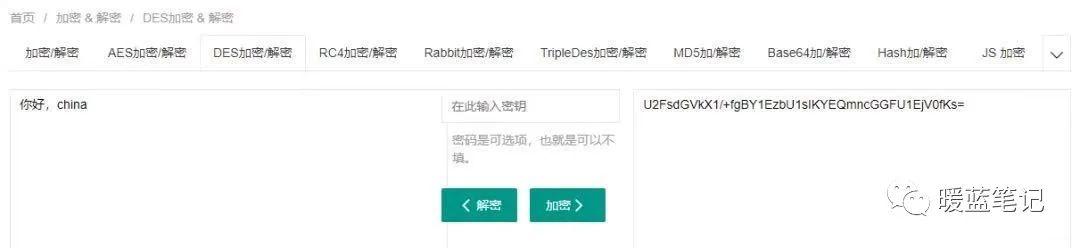
|
||||||
|
|
||||||
**IDEA**
|
**IDEA**
|
||||||
|
|
||||||
@ -332,13 +332,13 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
|
|||||||
|
|
||||||
**总结** :
|
**总结** :
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
#### 常见的非对称加密算法有哪些?
|
#### 常见的非对称加密算法有哪些?
|
||||||
|
|
||||||
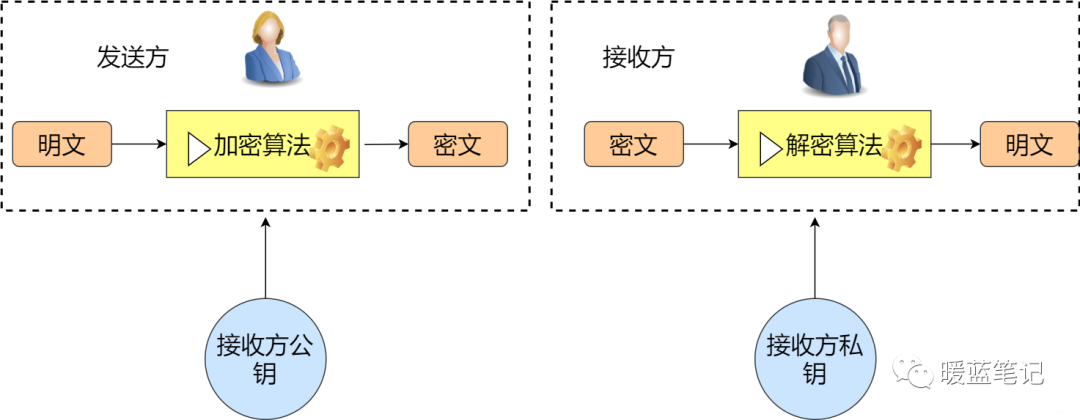
在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
|
在对称加密中,发送方与接收方使用相同的秘钥。那么在非对称加密中则是发送方与接收方使用的不同的秘钥。其主要解决的问题是防止在秘钥协商的过程中发生泄漏。比如在对称加密中,小蓝将需要发送的消息加密,然后告诉你密码是 123balala,ok,对于其他人而言,很容易就能劫持到密码是 123balala。那么在非对称的情况下,小蓝告诉所有人密码是 123balala,对于中间人而言,拿到也没用,因为没有私钥。所以,非对称密钥其实主要解决了密钥分发的难题。如下图
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 docker 集群也会使用相关非对称加密算法。
|
其实我们经常都在使用非对称加密,比如使用多台服务器搭建大数据平台 hadoop,为了方便多台机器设置免密登录,是不是就会涉及到秘钥分发。再比如搭建 docker 集群也会使用相关非对称加密算法。
|
||||||
|
|
||||||
@ -351,7 +351,7 @@ DES 使用的密钥表面上是 64 位的,然而只有其中的 56 位被实
|
|||||||
|
|
||||||
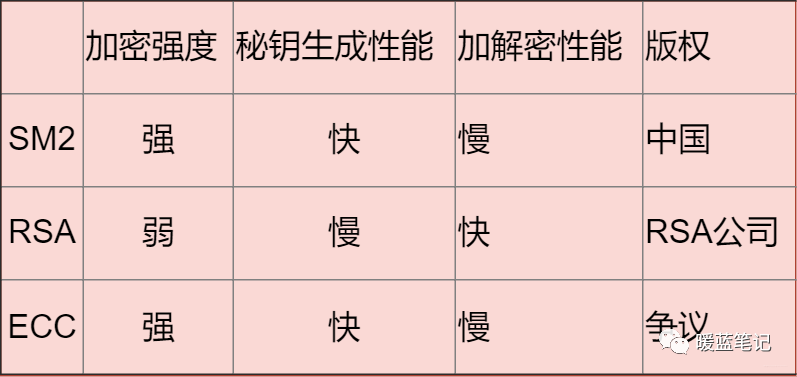
总结:
|
总结:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
#### 常见的散列算法有哪些?
|
#### 常见的散列算法有哪些?
|
||||||
|
|
||||||
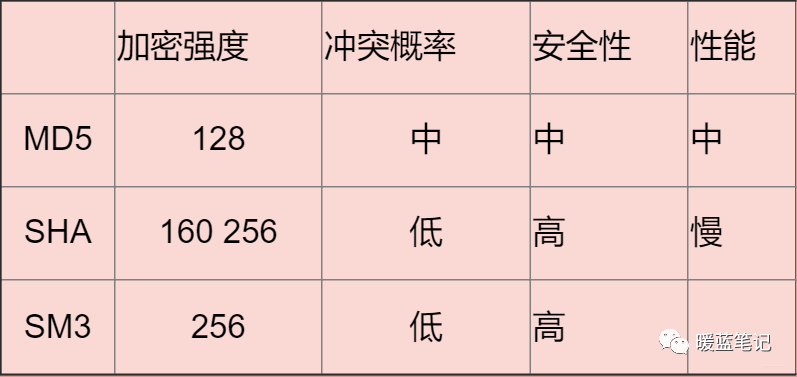
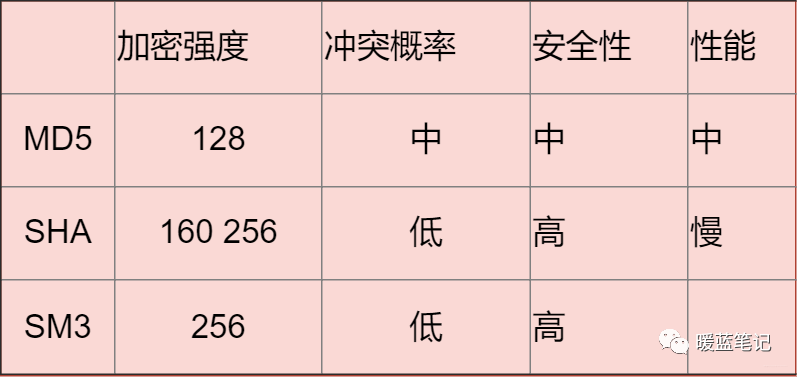
@ -371,7 +371,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
|||||||
|
|
||||||
**总结** :
|
**总结** :
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则散列算法。** 因为这段时间有这方面需求,就看了一些这方面的资料,入坑信息安全,就怕以后洗发水都不用买。谢谢大家查看!
|
**大部分情况下使用对称加密,具有比较不错的安全性。如果需要分布式进行秘钥分发,考虑非对称。如果不需要可逆计算则散列算法。** 因为这段时间有这方面需求,就看了一些这方面的资料,入坑信息安全,就怕以后洗发水都不用买。谢谢大家查看!
|
||||||
|
|
||||||
@ -383,7 +383,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
|||||||
|
|
||||||
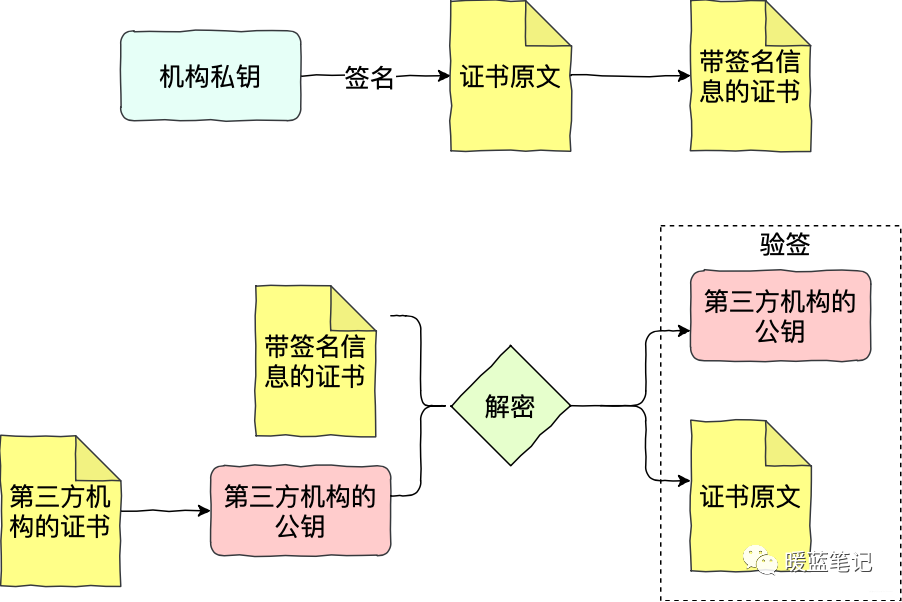
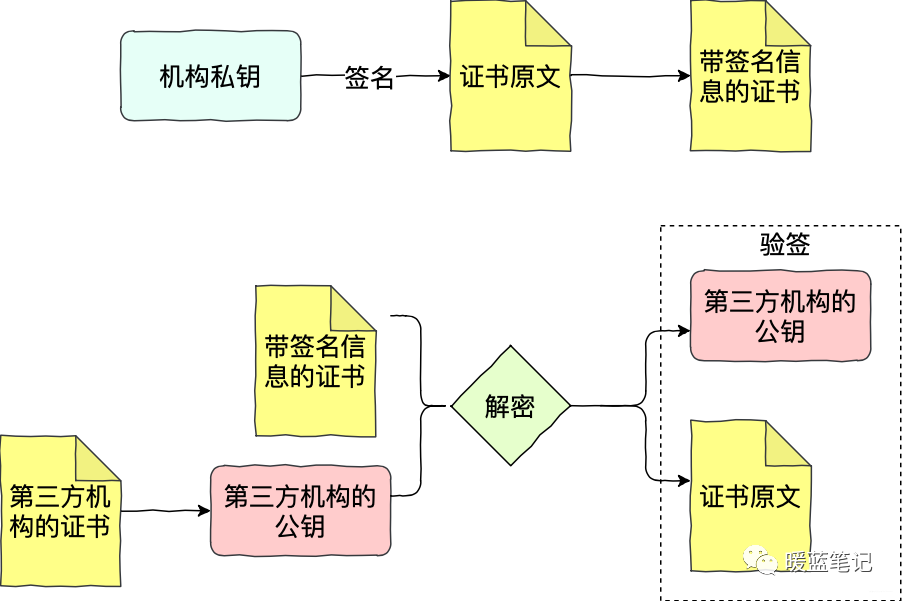
证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike ,而是提供由第三方机构,含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那 ik,信任关系成立
|
证书之所以会有信用,是因为证书的签发方拥有信用。所以如果 Sum 想让 Mike 承认自己的公钥,Sum 不会直接将公钥给 Mike ,而是提供由第三方机构,含有公钥的证书。如果 Mike 也信任这个机构,法律都认可,那 ik,信任关系成立
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
|
如上图所示,Sum 将自己的申请提交给机构,产生证书的原文。机构用自己的私钥签名 Sum 的申请原文(先根据原文内容计算摘要,再用私钥加密),得到带有签名信息的证书。Mike 拿到带签名信息的证书,通过第三方机构的公钥进行解密,获得 Sum 证书的摘要、证书的原文。有了 Sum 证书的摘要和原文,Mike 就可以进行验签。验签通过,Mike 就可以确认 Sum 的证书的确是第三方机构签发的。
|
||||||
|
|
||||||
@ -391,7 +391,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
|||||||
|
|
||||||
为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险
|
为了让这个信任条更加稳固,就需要环环相扣,打造更长的信任链,避免单点信任风险
|
||||||
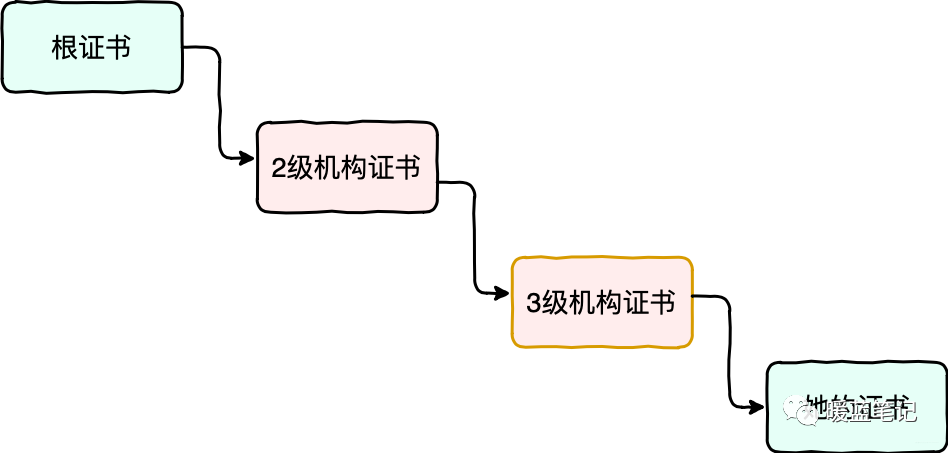
|
|
||||||
|

|
||||||
|
|
||||||
上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
|
上图中,由信誉最好的根证书机构提供根证书,然后根证书机构去签发二级机构的证书;二级机构去签发三级机构的证书;最后有由三级机构去签发 Sum 证书。
|
||||||
|
|
||||||
@ -407,7 +407,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
|||||||
|
|
||||||
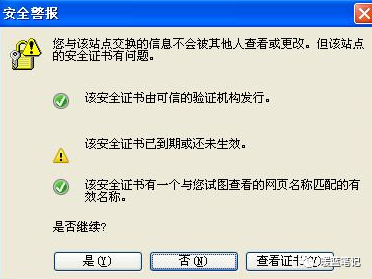
既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
|
既然知道了中间人攻击的原理也知道了他的危险,现在我们看看如何避免。相信我们都遇到过下面这种状况:
|
||||||
|
|
||||||
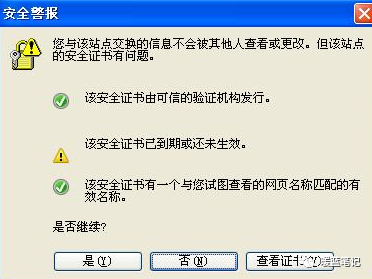
|
|
||||||
|
|
||||||
出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
|
出现这个界面的很多情况下,都是遇到了中间人攻击的现象,需要对安全证书进行及时地监测。而且大名鼎鼎的 github 网站,也曾遭遇过中间人攻击:
|
||||||
|
|
||||||
|
|||||||
@ -38,7 +38,7 @@ ER 图由下面 3 个要素组成:
|
|||||||
|
|
||||||
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
|
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
|
||||||
|
|
||||||
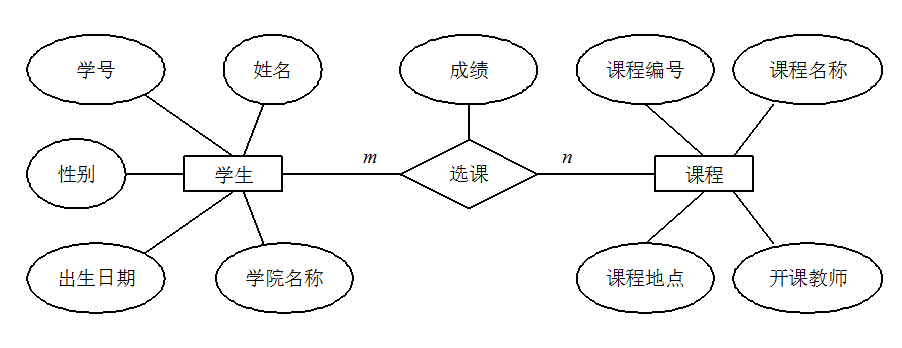
|

|
||||||
|
|
||||||
## 数据库范式了解吗?
|
## 数据库范式了解吗?
|
||||||
|
|
||||||
@ -56,7 +56,7 @@ ER 图由下面 3 个要素组成:
|
|||||||
|
|
||||||
2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
|
2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
|
||||||
|
|
||||||
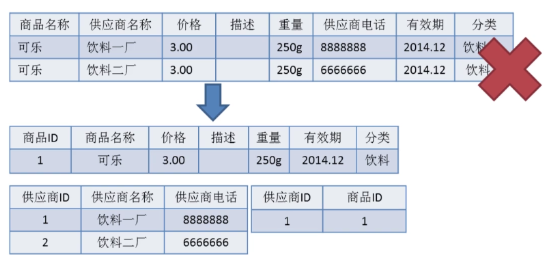
|

|
||||||
|
|
||||||
一些重要的概念:
|
一些重要的概念:
|
||||||
|
|
||||||
@ -105,7 +105,7 @@ ER 图由下面 3 个要素组成:
|
|||||||
|
|
||||||
阿里巴巴 Java 开发手册里要求禁止使用存储过程。
|
阿里巴巴 Java 开发手册里要求禁止使用存储过程。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## drop、delete 与 truncate 区别?
|
## drop、delete 与 truncate 区别?
|
||||||
|
|
||||||
|
|||||||
@ -41,7 +41,7 @@ ASCII 字符集至今为止共定义了 128 个字符,其中有 33 个控制
|
|||||||
|
|
||||||
由于,ASCII 码可以表示的字符实在是太少了。后来,人们对其进行了扩展得到了 **ASCII 扩展字符集** 。ASCII 扩展字符集使用 8 位(bits)表示一个字符,所以,ASCII 扩展字符集可以定义 256(2^8)个字符。
|
由于,ASCII 码可以表示的字符实在是太少了。后来,人们对其进行了扩展得到了 **ASCII 扩展字符集** 。ASCII 扩展字符集使用 8 位(bits)表示一个字符,所以,ASCII 扩展字符集可以定义 256(2^8)个字符。
|
||||||
|
|
||||||
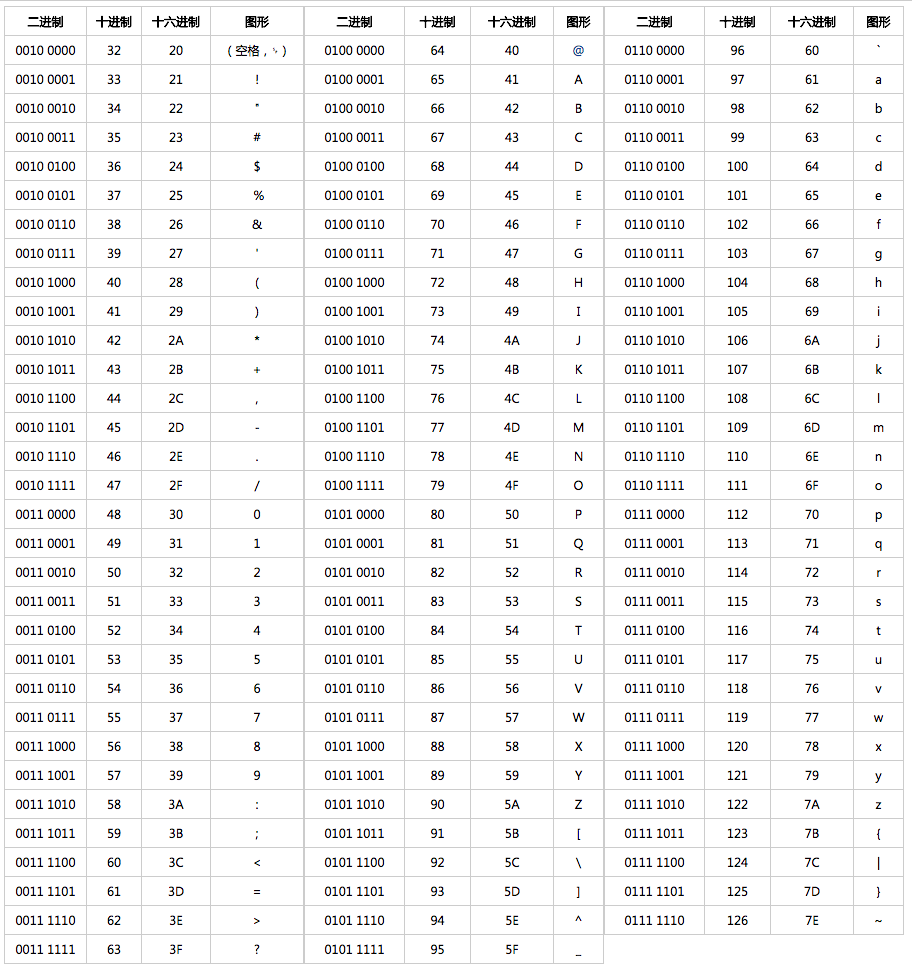
|

|
||||||
|
|
||||||
### GB2312
|
### GB2312
|
||||||
|
|
||||||
@ -75,7 +75,7 @@ BIG5 主要针对的是繁体中文,收录了 13000 多个汉字。
|
|||||||
|
|
||||||
你可以通过这个网站在线进行编码和解码:https://www.haomeili.net/HanZi/ZiFuBianMaZhuanHuan
|
你可以通过这个网站在线进行编码和解码:https://www.haomeili.net/HanZi/ZiFuBianMaZhuanHuan
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这样我们就搞懂了乱码的本质: **编码和解码时用了不同或者不兼容的字符集** 。
|
这样我们就搞懂了乱码的本质: **编码和解码时用了不同或者不兼容的字符集** 。
|
||||||
|
|
||||||
|
|||||||
@ -7,7 +7,7 @@ tag:
|
|||||||
---
|
---
|
||||||
|
|
||||||
> 作者:飞天小牛肉
|
> 作者:飞天小牛肉
|
||||||
>
|
>
|
||||||
> 原文:https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ
|
> 原文:https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ
|
||||||
|
|
||||||
众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
|
众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
|
||||||
@ -16,17 +16,17 @@ tag:
|
|||||||
|
|
||||||
下面举个例子来看下,如下所示创建一张表:
|
下面举个例子来看下,如下所示创建一张表:
|
||||||
|
|
||||||

|
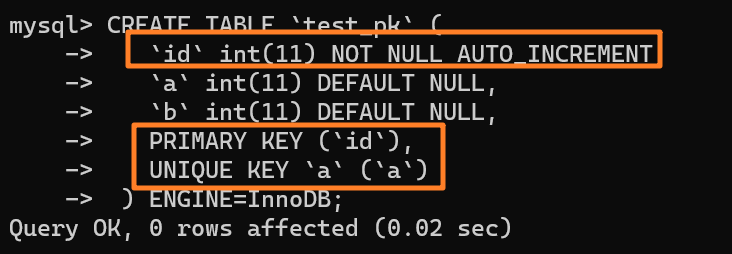
|
||||||
|
|
||||||
## 自增值保存在哪里?
|
## 自增值保存在哪里?
|
||||||
|
|
||||||
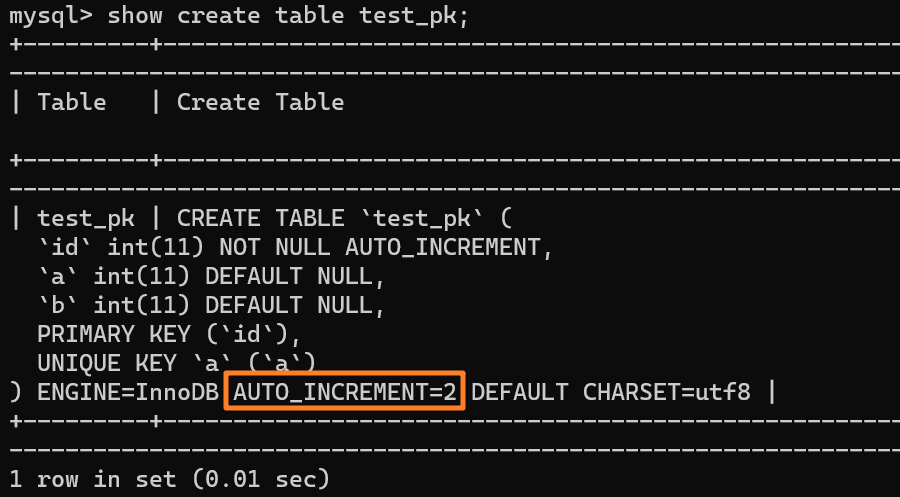
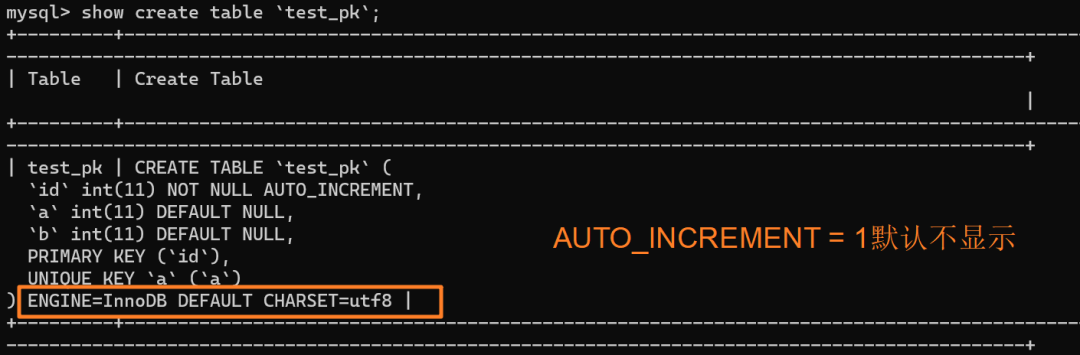
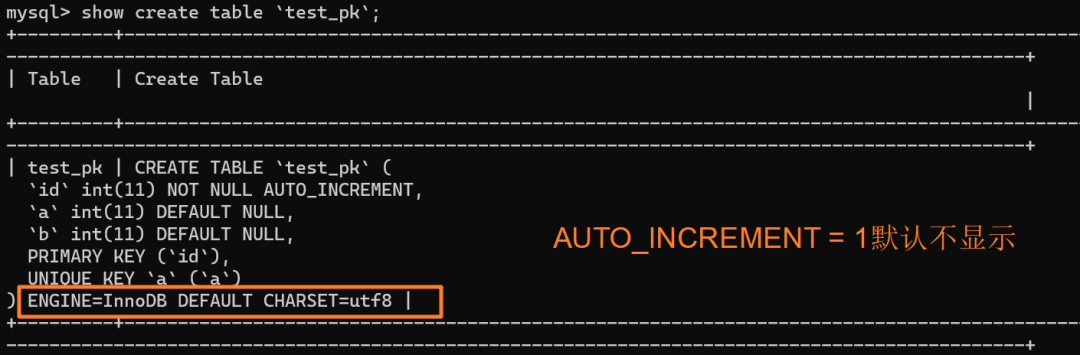
使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
|
使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
|
||||||
|
|
||||||
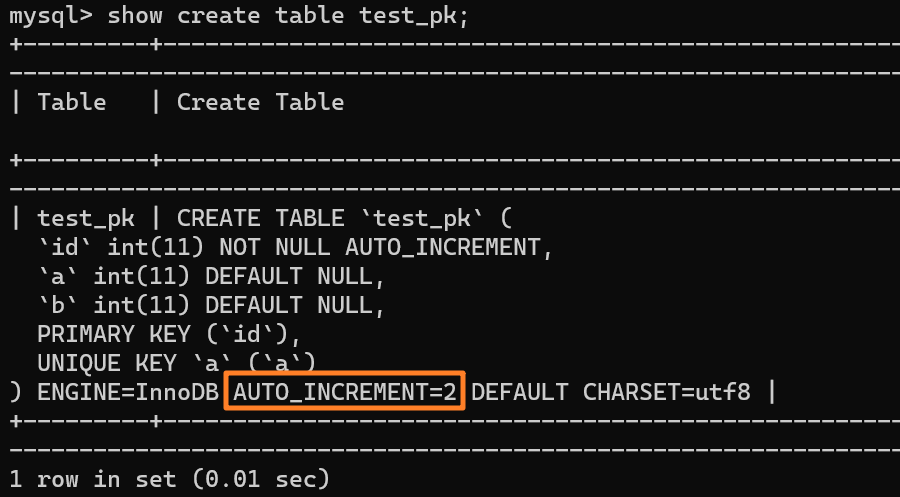
|
|
||||||
|
|
||||||
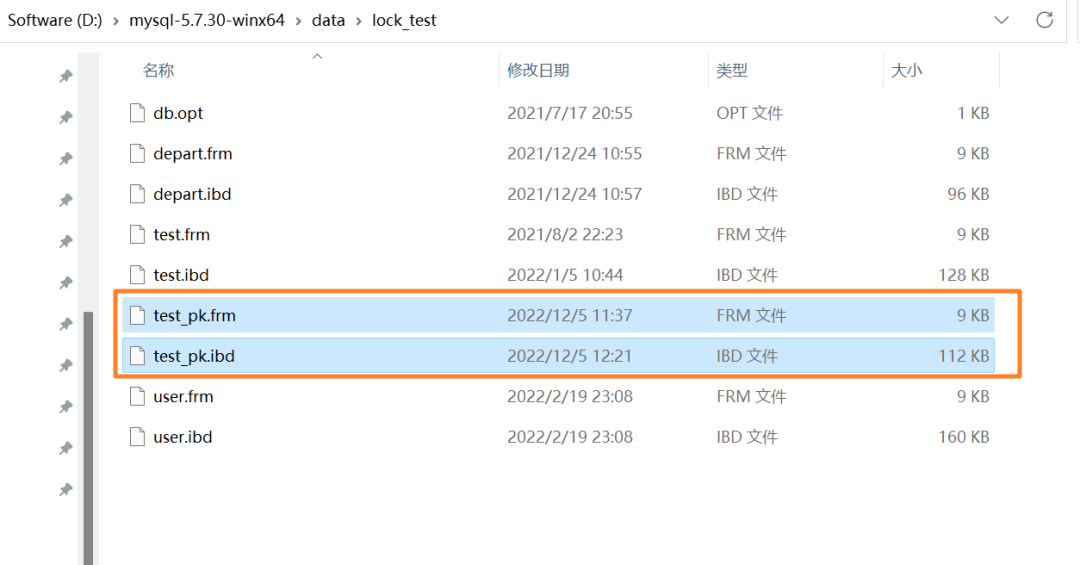
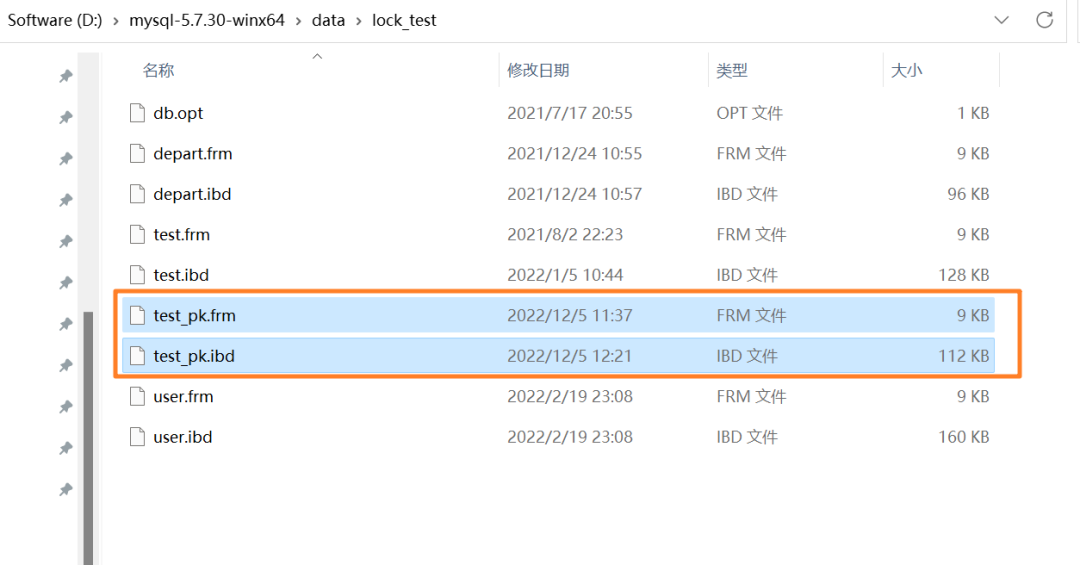
上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
|
上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
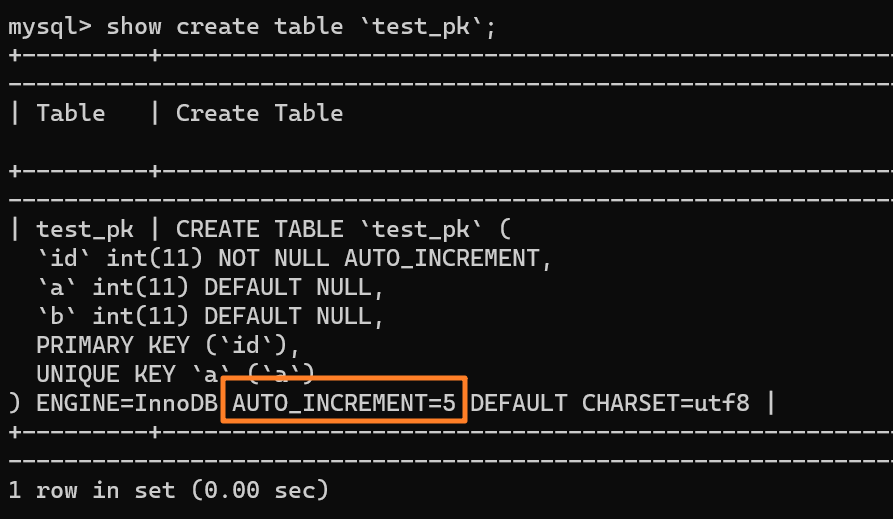
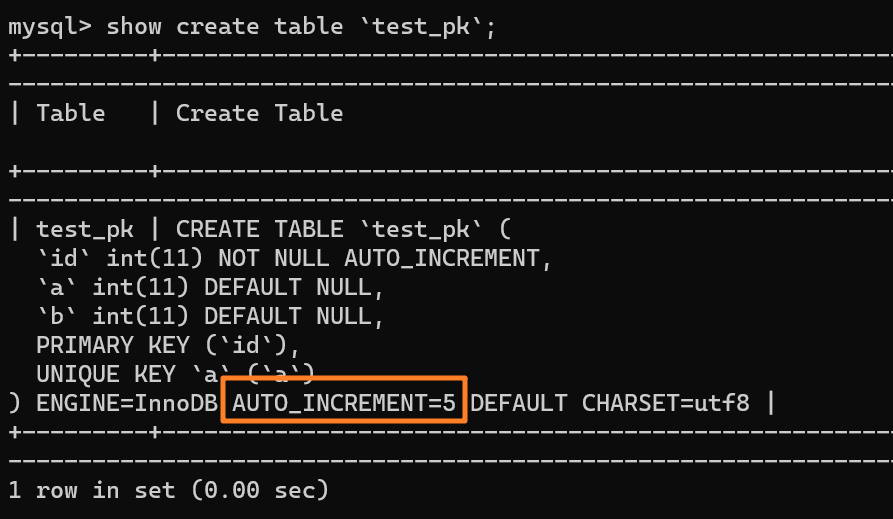
从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
|
从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
|
||||||
|
|
||||||
@ -38,13 +38,13 @@ tag:
|
|||||||
|
|
||||||
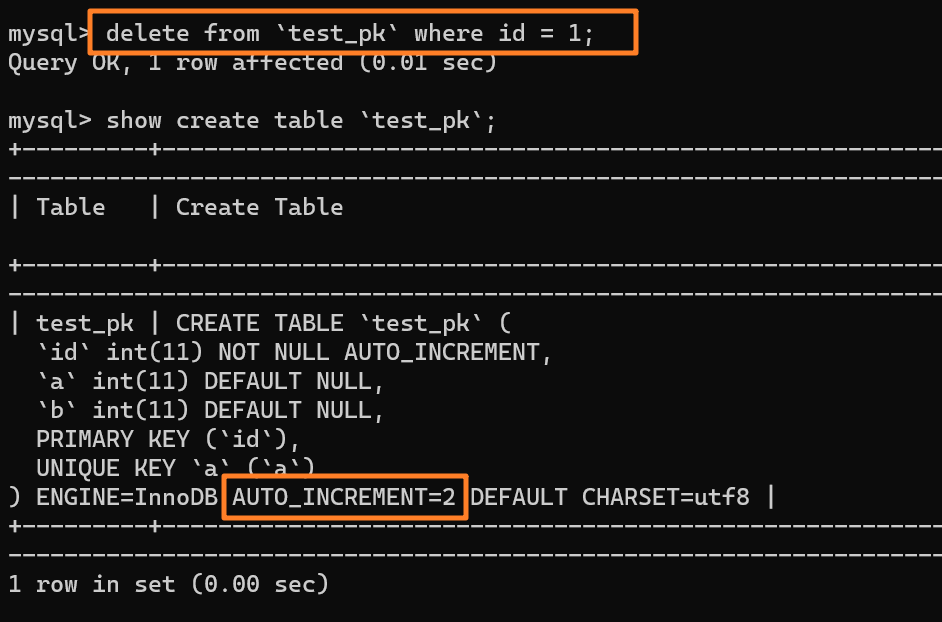
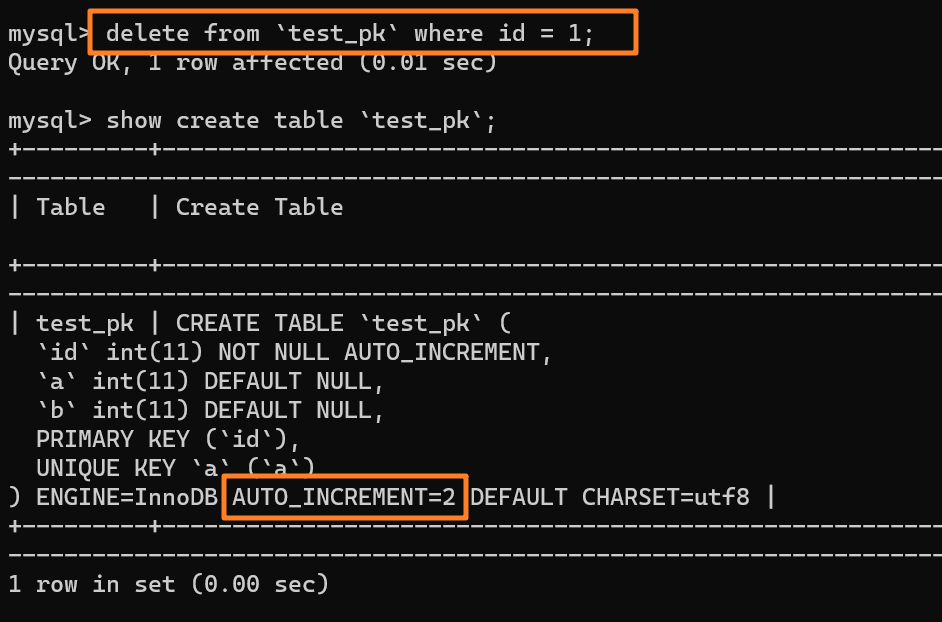
举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
|
举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
|
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
|
以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
|
||||||
|
|
||||||
@ -86,11 +86,11 @@ tag:
|
|||||||
|
|
||||||
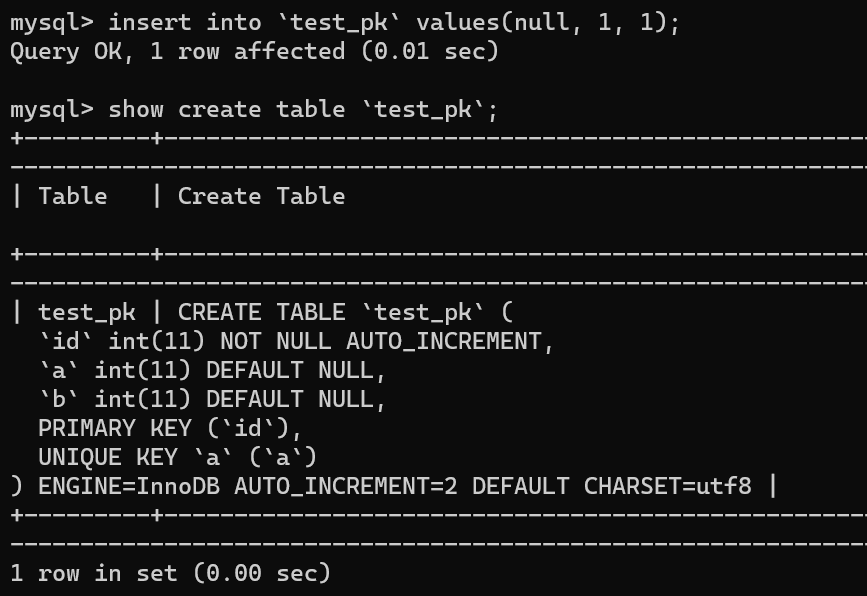
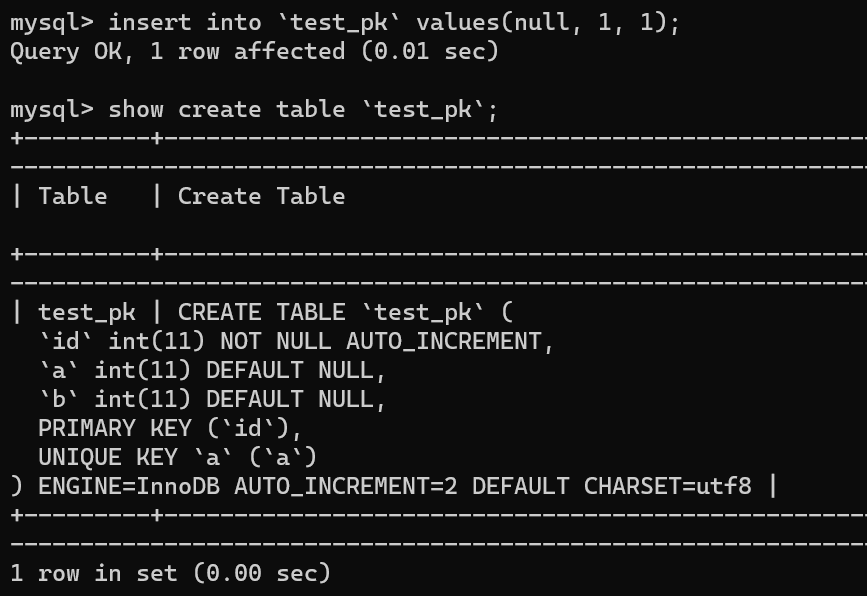
举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
|
举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
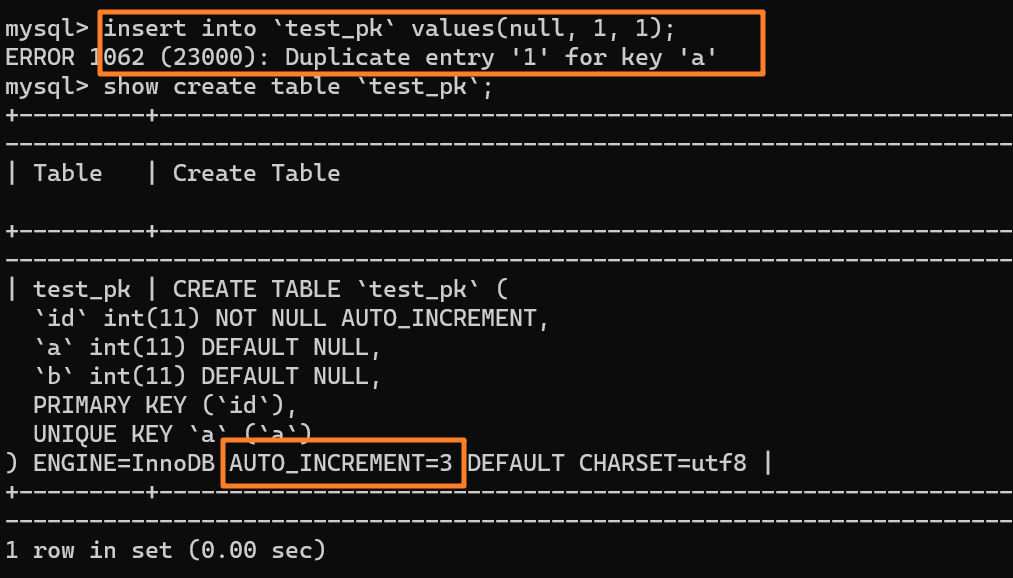
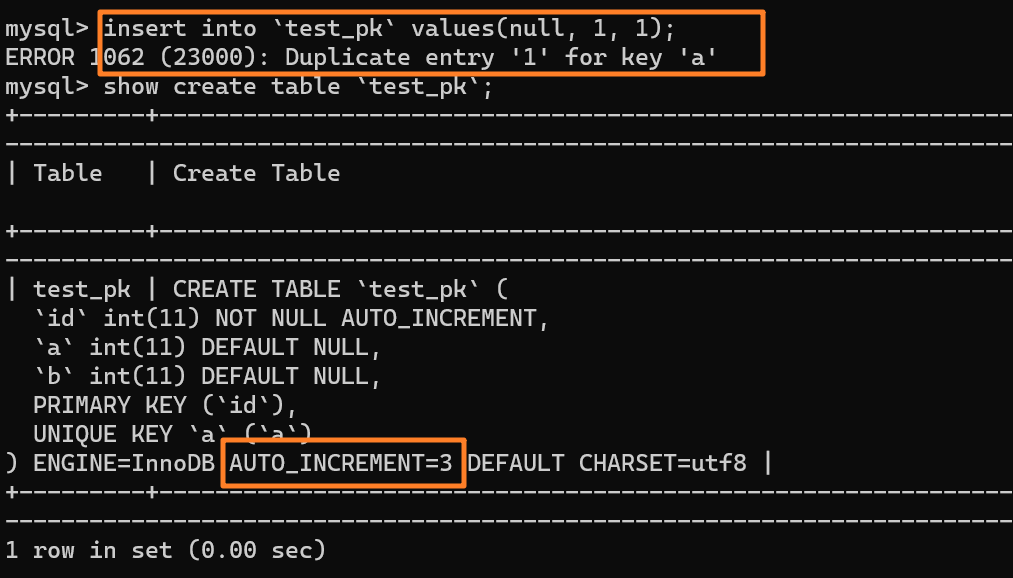
这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
|
这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
|
但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
|
||||||
|
|
||||||
@ -119,27 +119,27 @@ tag:
|
|||||||
|
|
||||||
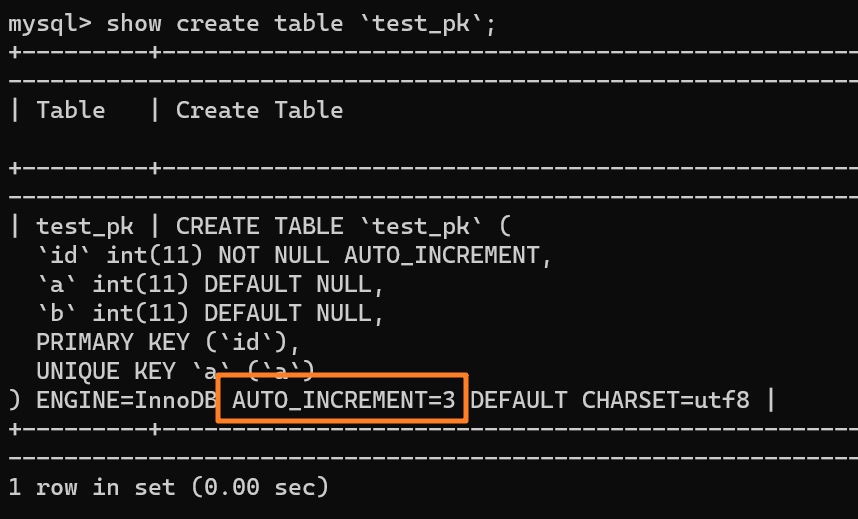
我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
|
我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
|
||||||
|
|
||||||
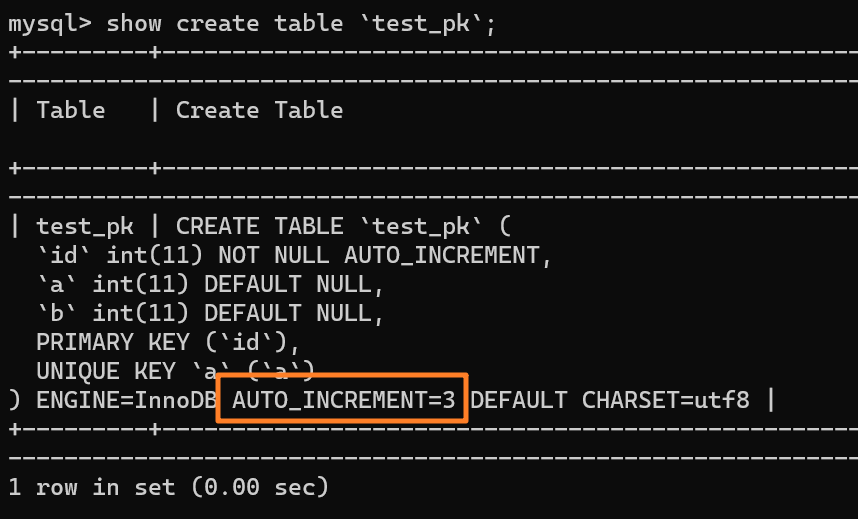
|
|
||||||
|
|
||||||
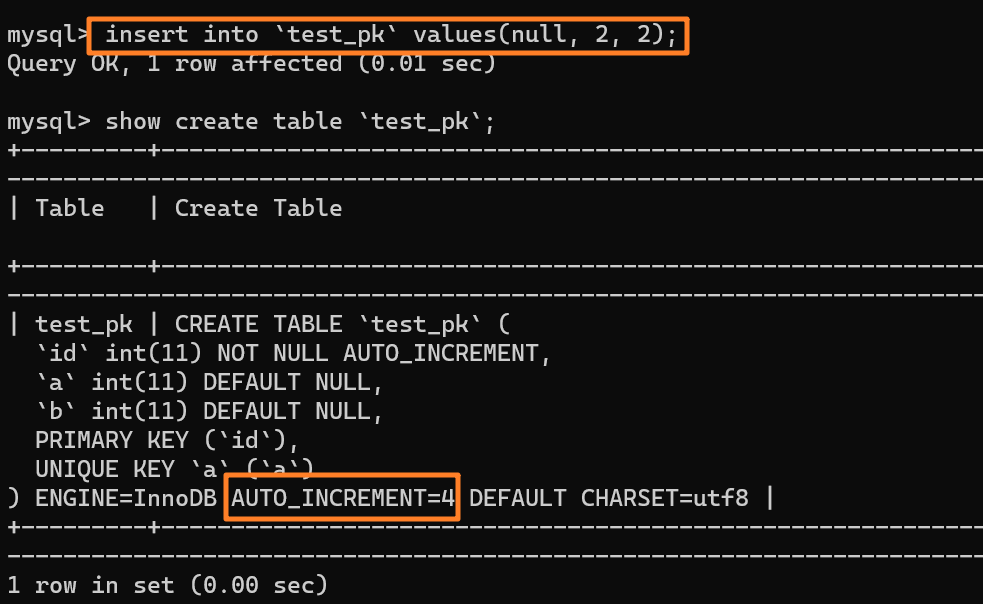
我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
|
我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
|
||||||
|
|
||||||
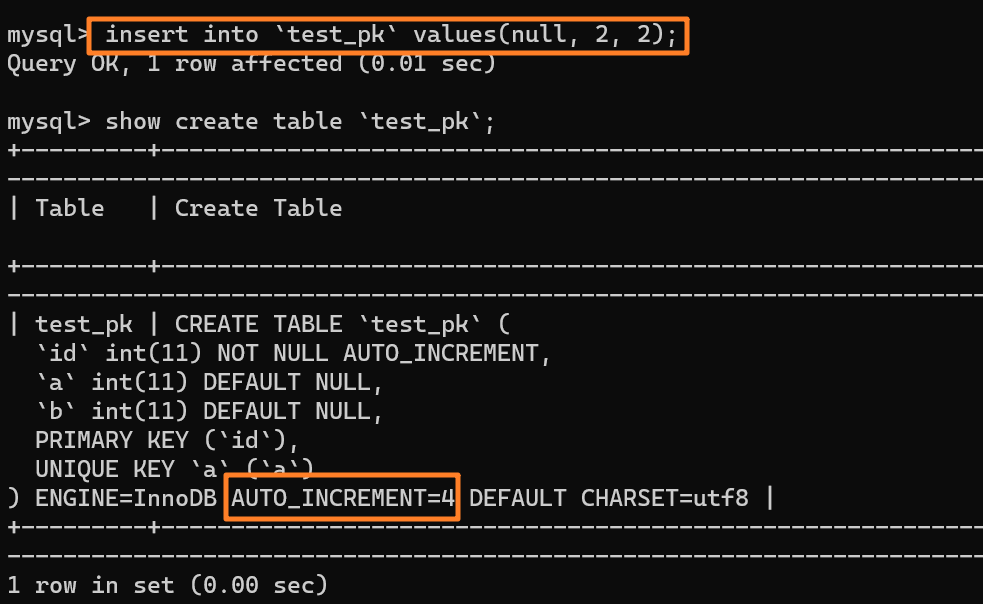
|
|
||||||
|
|
||||||
再去执行这样一段 SQL:
|
再去执行这样一段 SQL:
|
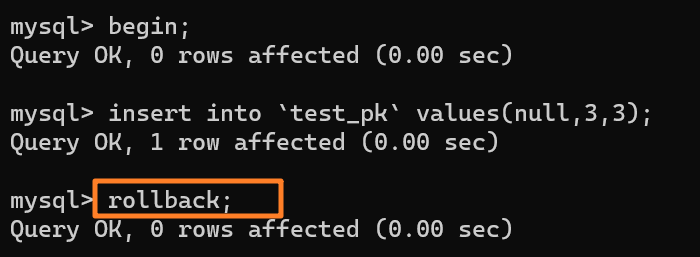
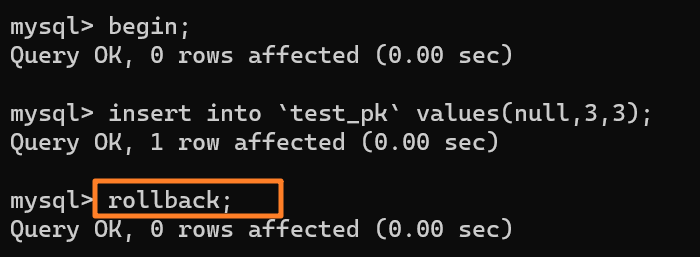
||||||
|
|
||||||
|
|
||||||
|
|
||||||
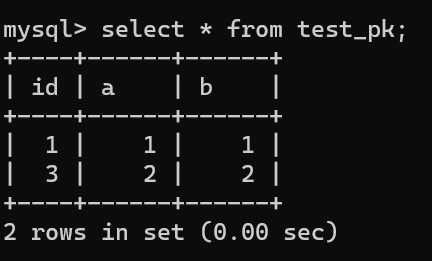
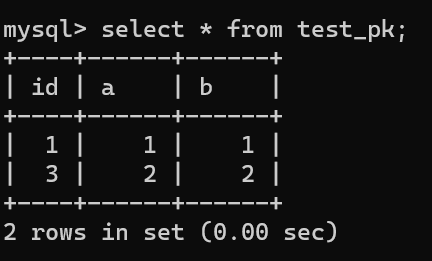
虽然我们插入了一条 (null, 3, 3) 记录,但是使用 rollback 进行回滚了,所以数据库中是没有这条记录的:
|
虽然我们插入了一条 (null, 3, 3) 记录,但是使用 rollback 进行回滚了,所以数据库中是没有这条记录的:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
在这种事务回滚的情况下,自增值并没有同样发生回滚!如下图所示,自增值仍然固执地从 4 增加到了 5:
|
在这种事务回滚的情况下,自增值并没有同样发生回滚!如下图所示,自增值仍然固执地从 4 增加到了 5:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
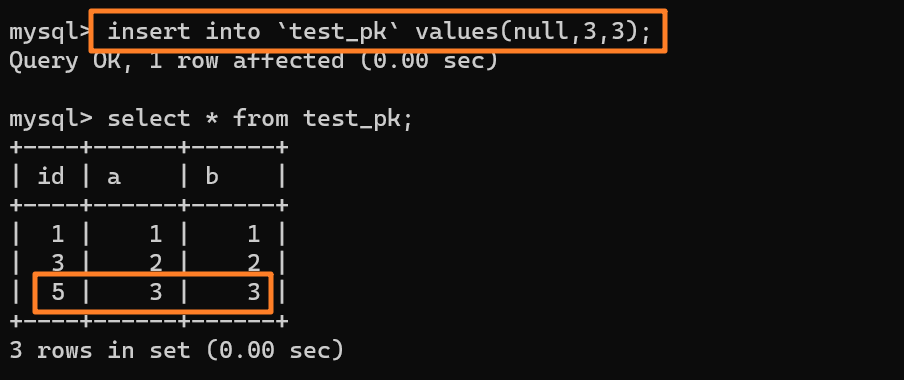
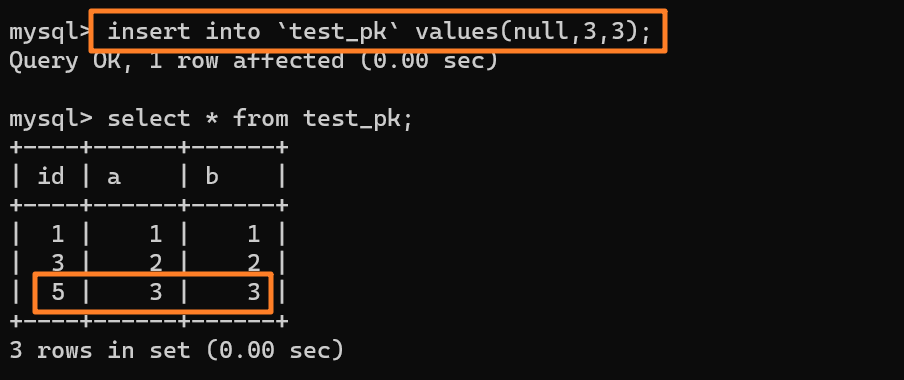
所以这时候我们再去插入一条数据(null, 3, 3)的时候,主键 id 就会被自动赋为 `5` 了:
|
所以这时候我们再去插入一条数据(null, 3, 3)的时候,主键 id 就会被自动赋为 `5` 了:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
那么,为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表的自增值改回去呢?回退回去的话不就不会发生自增 id 不连续了吗?
|
那么,为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表的自增值改回去呢?回退回去的话不就不会发生自增 id 不连续了吗?
|
||||||
|
|
||||||
@ -153,7 +153,7 @@ tag:
|
|||||||
2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。
|
2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。
|
||||||
3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。
|
3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。
|
||||||
|
|
||||||
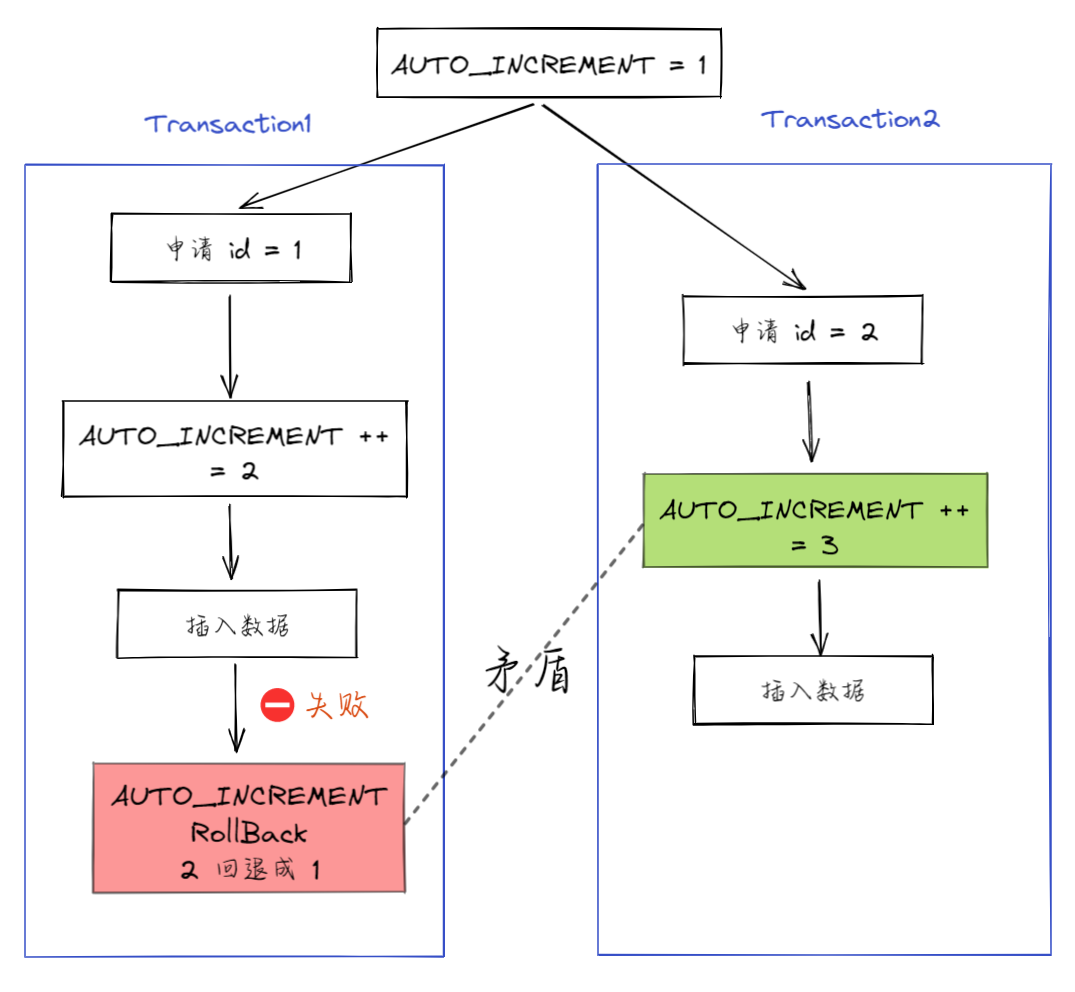
|
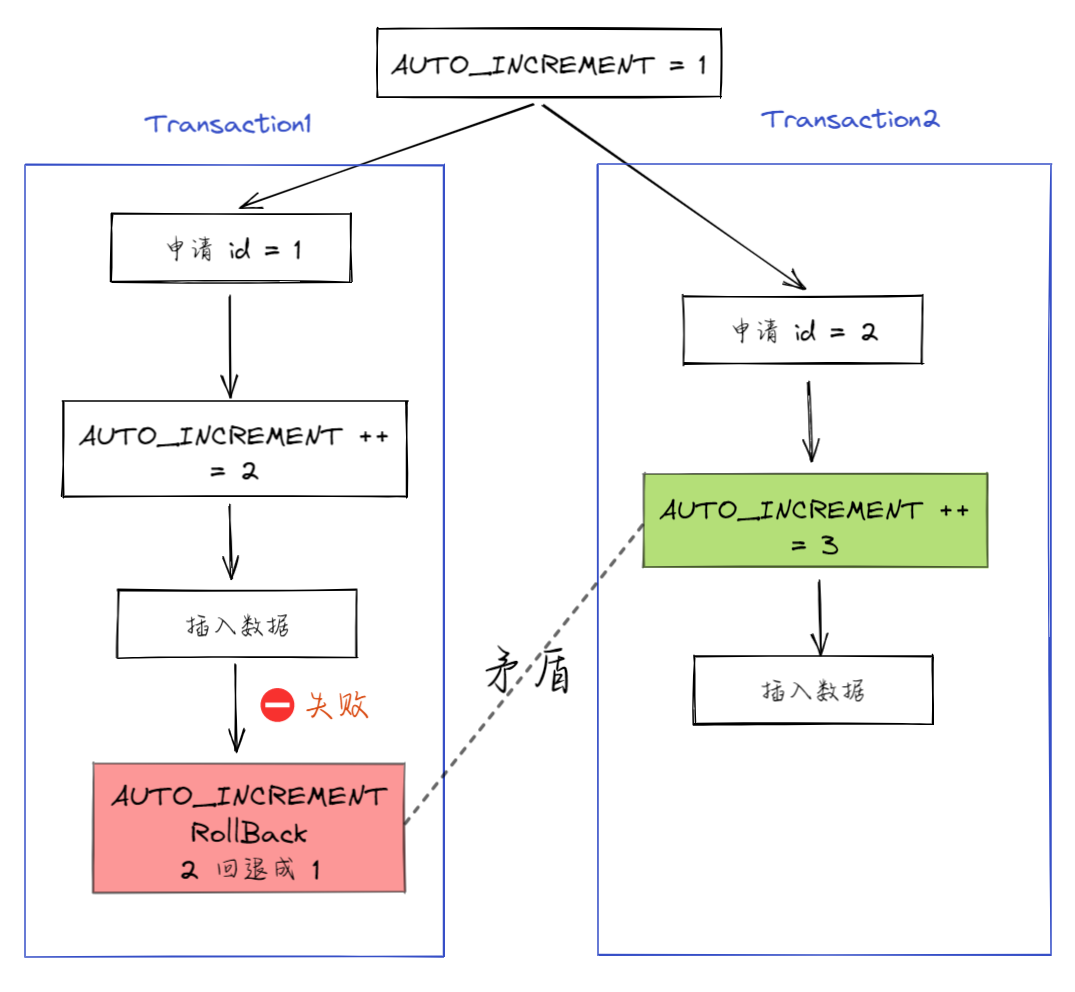
|
||||||
|
|
||||||
而为了解决这个主键冲突,有两种方法:
|
而为了解决这个主键冲突,有两种方法:
|
||||||
|
|
||||||
@ -181,21 +181,21 @@ tag:
|
|||||||
|
|
||||||
举个例子,假设我们现在这个表有下面这些数据:
|
举个例子,假设我们现在这个表有下面这些数据:
|
||||||
|
|
||||||
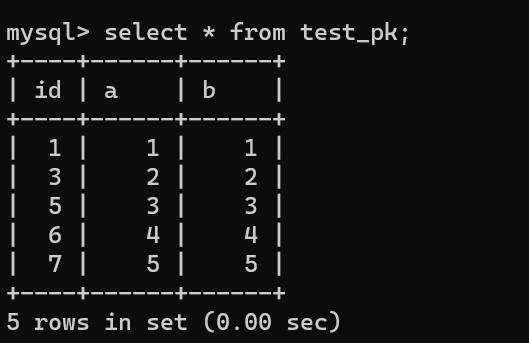
|
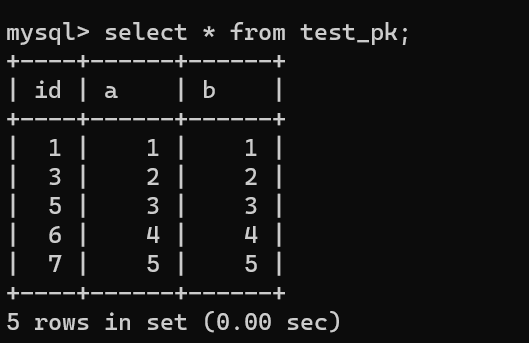
|
||||||
|
|
||||||
我们创建一个和当前表 `test_pk` 有相同结构定义的表 `test_pk2`:
|
我们创建一个和当前表 `test_pk` 有相同结构定义的表 `test_pk2`:
|
||||||
|
|
||||||
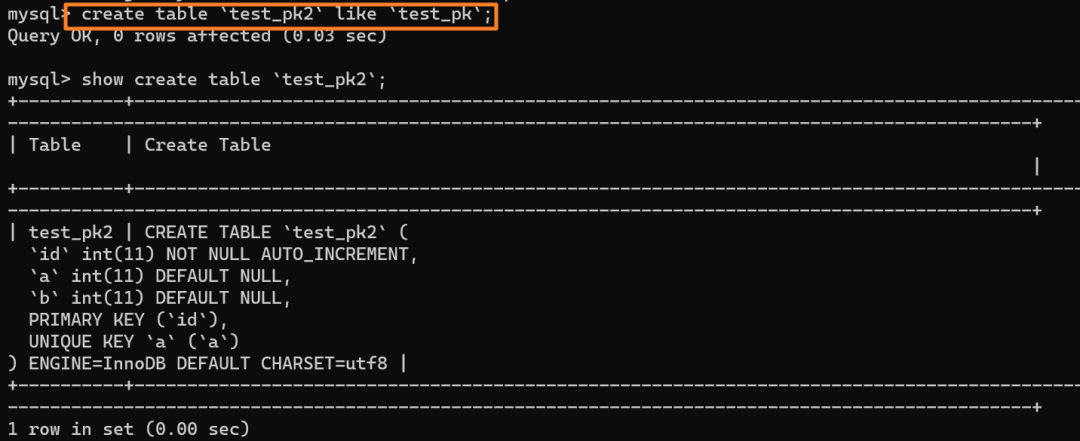
|
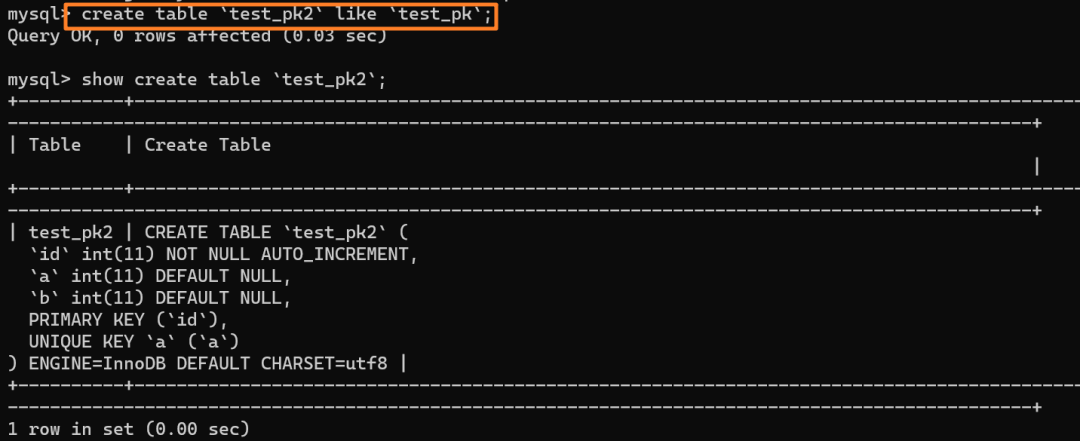
|
||||||
|
|
||||||
然后使用 `insert...select` 往 `teset_pk2` 表中批量插入数据:
|
然后使用 `insert...select` 往 `teset_pk2` 表中批量插入数据:
|
||||||
|
|
||||||

|
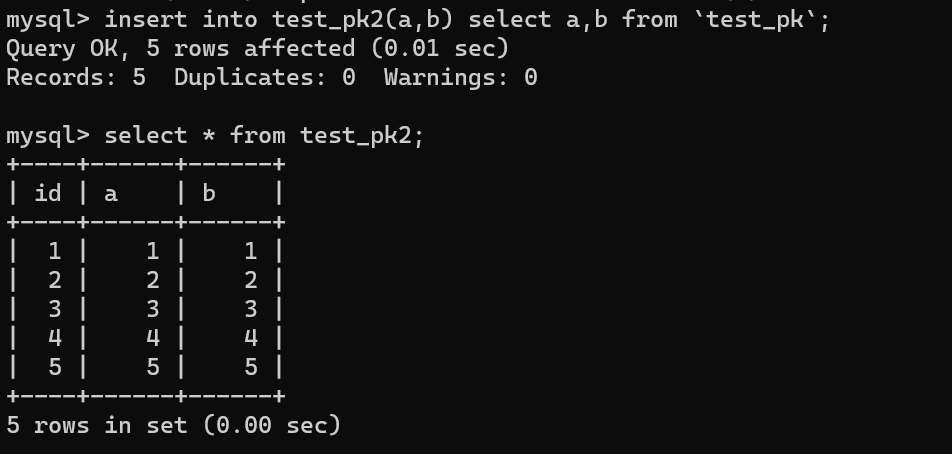
|
||||||
|
|
||||||
可以看到,成功导入了数据。
|
可以看到,成功导入了数据。
|
||||||
|
|
||||||
再来看下 `test_pk2` 的自增值是多少:
|
再来看下 `test_pk2` 的自增值是多少:
|
||||||
|
|
||||||
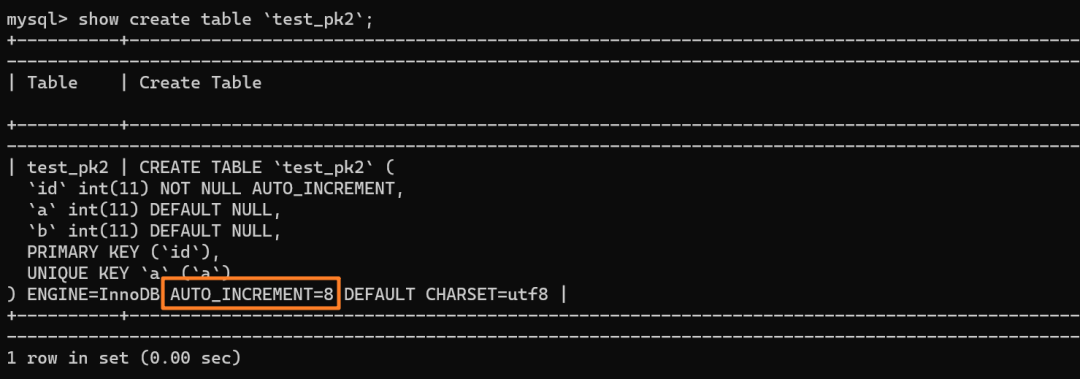
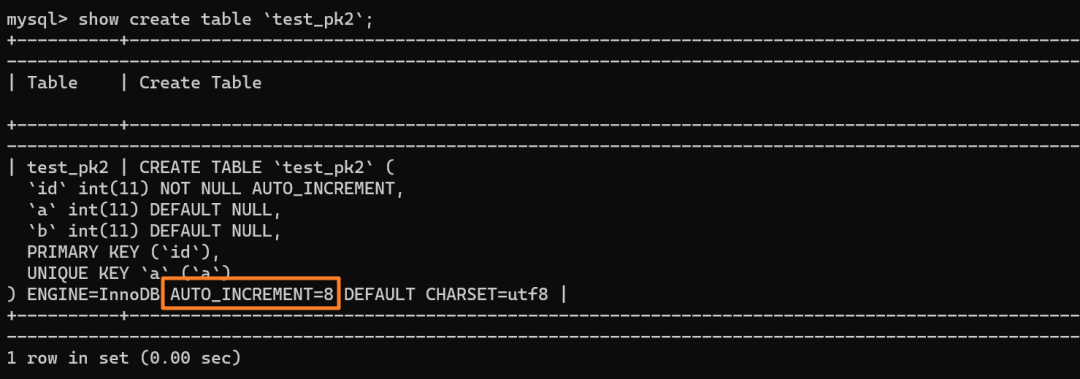
|
|
||||||
|
|
||||||
如上分析,是 8 而不是 6
|
如上分析,是 8 而不是 6
|
||||||
|
|
||||||
@ -207,7 +207,7 @@ tag:
|
|||||||
|
|
||||||
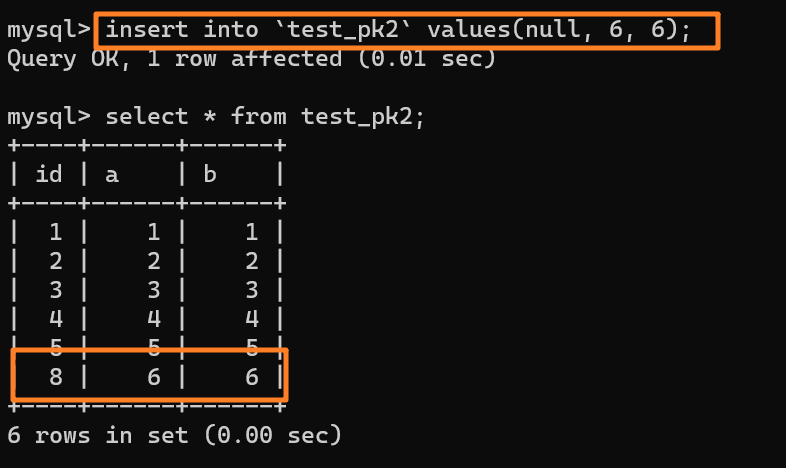
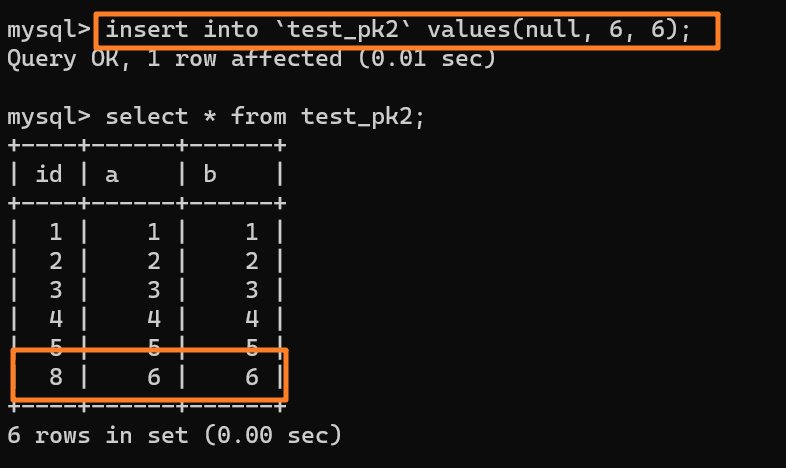
由于这条语句实际只用上了 5 个 id,所以 id=6 和 id=7 就被浪费掉了。之后,再执行 `insert into test_pk2 values(null,6,6)`,实际上插入的数据就是(8,6,6):
|
由于这条语句实际只用上了 5 个 id,所以 id=6 和 id=7 就被浪费掉了。之后,再执行 `insert into test_pk2 values(null,6,6)`,实际上插入的数据就是(8,6,6):
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## 小结
|
## 小结
|
||||||
|
|
||||||
|
|||||||
@ -48,11 +48,11 @@ hash = hashfunc(key)
|
|||||||
index = hash % array_size
|
index = hash % array_size
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
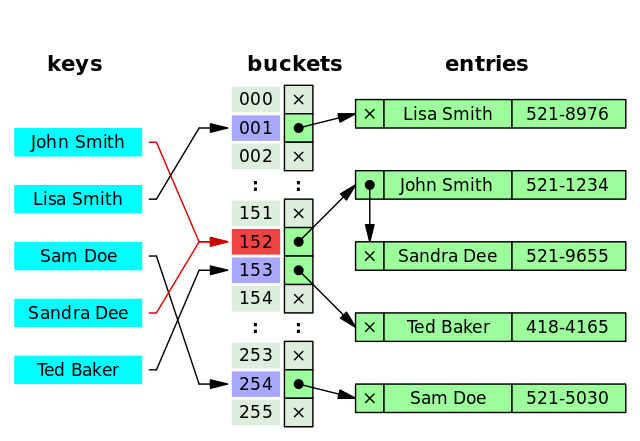
但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
|
但是!哈希算法有个 **Hash 冲突** 问题,也就是说多个不同的 key 最后得到的 index 相同。通常情况下,我们常用的解决办法是 **链地址法**。链地址法就是将哈希冲突数据存放在链表中。就比如 JDK1.8 之前 `HashMap` 就是通过链地址法来解决哈希冲突的。不过,JDK1.8 以后`HashMap`为了减少链表过长的时候搜索时间过长引入了红黑树。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
|
为了减少 Hash 冲突的发生,一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中。
|
||||||
|
|
||||||
@ -184,11 +184,11 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
|||||||
|
|
||||||
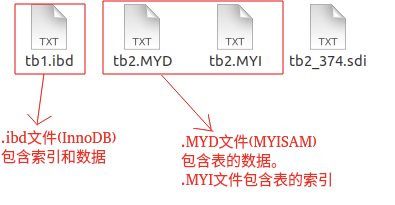
这是 MySQL 的表的文件截图:
|
这是 MySQL 的表的文件截图:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
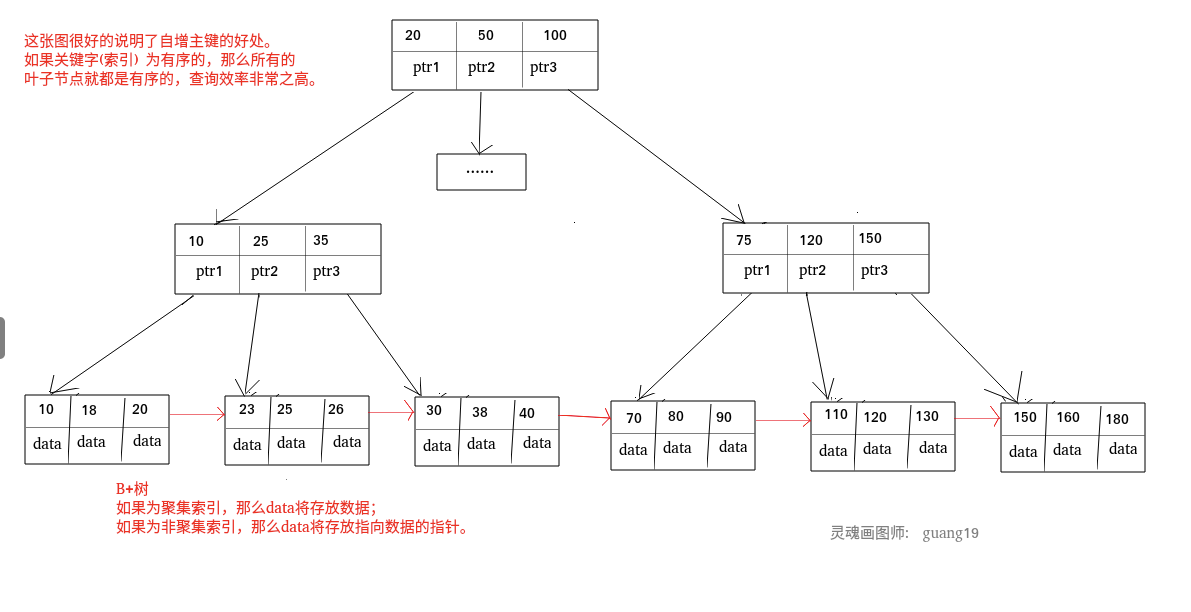
聚簇索引和非聚簇索引:
|
聚簇索引和非聚簇索引:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
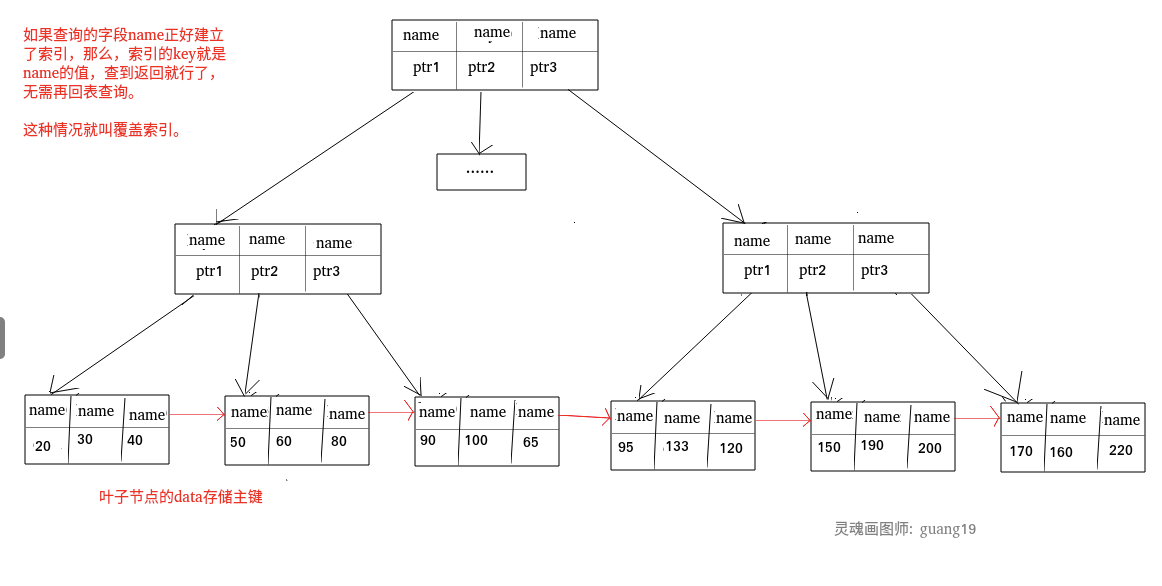
#### 非聚簇索引一定回表查询吗(覆盖索引)?
|
#### 非聚簇索引一定回表查询吗(覆盖索引)?
|
||||||
|
|
||||||
@ -223,7 +223,7 @@ SELECT id FROM table WHERE id=1;
|
|||||||
> 再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
|
> 再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
|
||||||
> 那么直接根据这个索引就可以查到数据,也无需回表。
|
> 那么直接根据这个索引就可以查到数据,也无需回表。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 联合索引
|
### 联合索引
|
||||||
|
|
||||||
|
|||||||
@ -47,7 +47,7 @@ SQL 可以帮助我们:
|
|||||||
|
|
||||||
### 什么是 MySQL?
|
### 什么是 MySQL?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。**
|
**MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。**
|
||||||
|
|
||||||
@ -138,8 +138,6 @@ MySQL 官方文档也有介绍到如何编写一个自定义存储引擎,地
|
|||||||
|
|
||||||
### MyISAM 和 InnoDB 有什么区别?
|
### MyISAM 和 InnoDB 有什么区别?
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
|
MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
|
||||||
|
|
||||||
虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
|
虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
|
||||||
@ -348,7 +346,7 @@ COMMIT;
|
|||||||
|
|
||||||
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 Github 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
|
《Designing Data-Intensive Application(数据密集型应用系统设计)》这本书强推一波,值得读很多遍!豆瓣有接近 90% 的人看了这本书之后给了五星好评。另外,中文翻译版本已经在 Github 开源,地址:[https://github.com/Vonng/ddia](https://github.com/Vonng/ddia) 。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 并发事务带来了哪些问题?
|
### 并发事务带来了哪些问题?
|
||||||
|
|
||||||
|
|||||||
@ -472,7 +472,7 @@ value1
|
|||||||
- 举例 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
- 举例 :各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||||
- 相关命令 :`ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
- 相关命令 :`ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
|
[《Java 面试指北》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
|
||||||
|
|
||||||
|
|||||||
@ -47,7 +47,7 @@ void *zmalloc(size_t size) {
|
|||||||
|
|
||||||
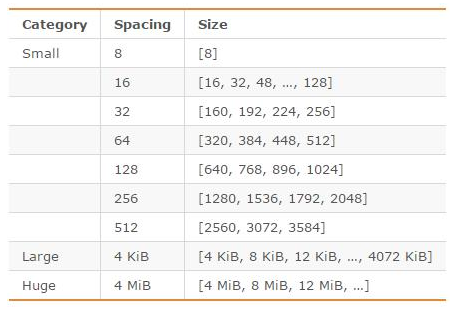
另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节......)来分配内存的。jemalloc 划分的内存单元如下图所示:
|
另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节......)来分配内存的。jemalloc 划分的内存单元如下图所示:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
当程序申请的内存最接近某个固定值时,jemalloc 会给它分配相应大小的空间,就比如说程序需要申请 17 字节的内存,jemalloc 会直接给它分配 32 字节的内存,这样会导致有 15 字节内存的浪费。不过,jemalloc 专门针对内存碎片问题做了优化,一般不会存在过度碎片化的问题。
|
当程序申请的内存最接近某个固定值时,jemalloc 会给它分配相应大小的空间,就比如说程序需要申请 17 字节的内存,jemalloc 会直接给它分配 32 字节的内存,这样会导致有 15 字节内存的浪费。不过,jemalloc 专门针对内存碎片问题做了优化,一般不会存在过度碎片化的问题。
|
||||||
|
|
||||||
|
|||||||
@ -246,7 +246,7 @@ Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行
|
|||||||
|
|
||||||
相关的一些 Redis 命令: `ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
相关的一些 Redis 命令: `ZRANGE` (从小到大排序) 、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
|
[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html) 的「技术面试题篇」就有一篇文章详细介绍如何使用 Sorted Set 来设计制作一个排行榜。
|
||||||
|
|
||||||
|
|||||||
@ -1239,7 +1239,7 @@ SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不
|
|||||||
|
|
||||||
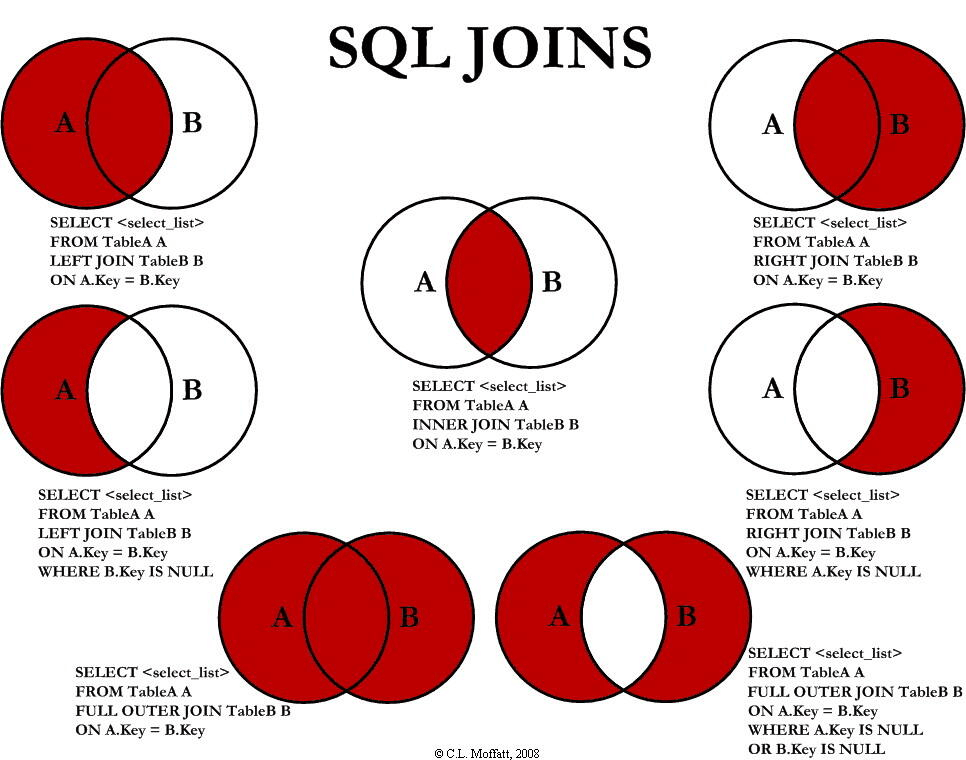
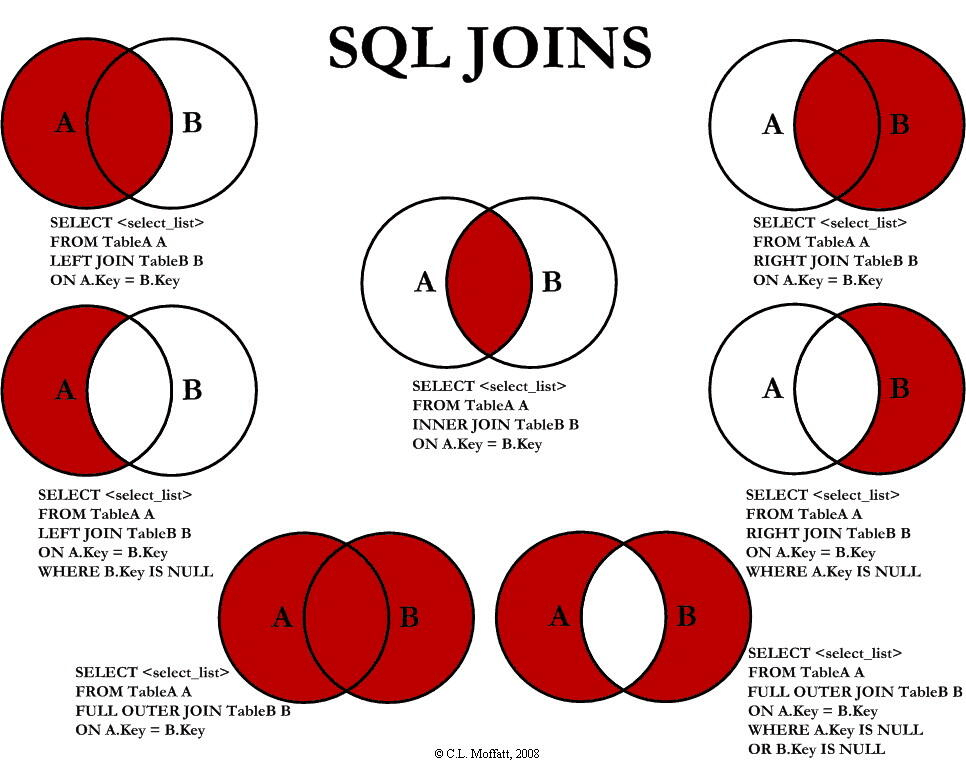
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
|
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIN`
|
如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIN`
|
||||||
|
|
||||||
|
|||||||
@ -28,7 +28,7 @@ SQL(Structured Query Language),标准 SQL 由 ANSI 标准委员会管理,
|
|||||||
|
|
||||||
#### SQL 语法结构
|
#### SQL 语法结构
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
SQL 语法结构包括:
|
SQL 语法结构包括:
|
||||||
|
|
||||||
@ -322,7 +322,7 @@ WHERE cust_id IN (SELECT cust_id
|
|||||||
|
|
||||||
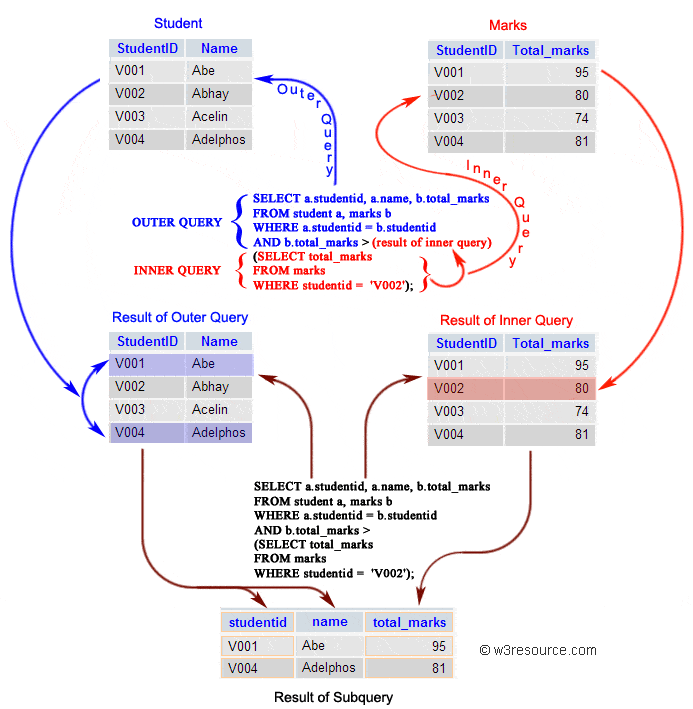
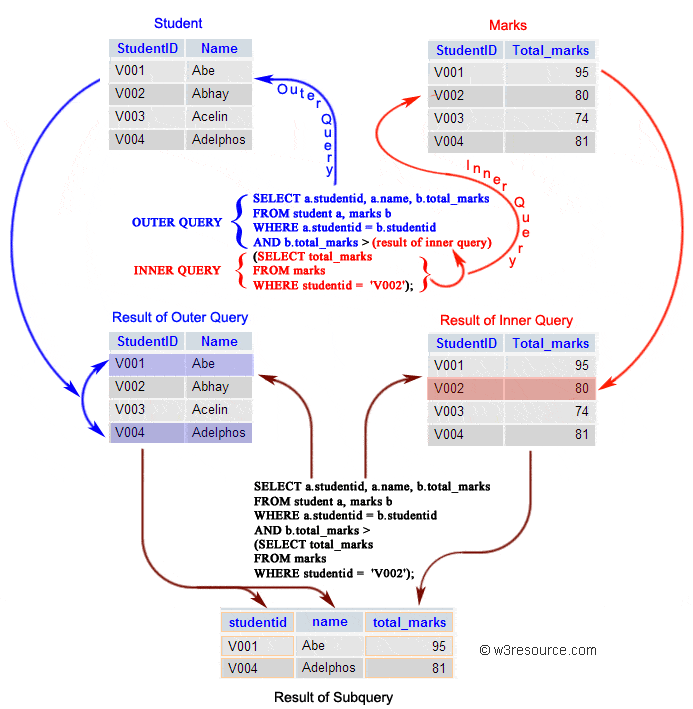
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
内部查询首先在其父查询之前执行,以便可以将内部查询的结果传递给外部查询。执行过程可以参考下图:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### WHERE
|
### WHERE
|
||||||
|
|
||||||
@ -500,7 +500,7 @@ SQL 允许在 `JOIN` 左边加上一些修饰性的关键词,从而形成不
|
|||||||
|
|
||||||
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
|
下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIIN`
|
如果不加任何修饰词,只写 `JOIN`,那么默认为 `INNER JOIIN`
|
||||||
|
|
||||||
@ -728,7 +728,7 @@ DROP PRIMARY KEY;
|
|||||||
- 通过只给用户访问视图的权限,保证数据的安全性;
|
- 通过只给用户访问视图的权限,保证数据的安全性;
|
||||||
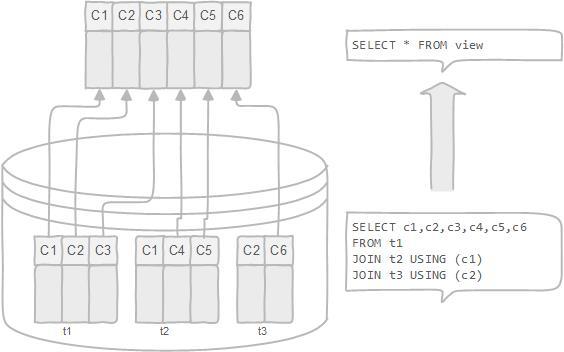
- 更改数据格式和表示。
|
- 更改数据格式和表示。
|
||||||
|
|
||||||
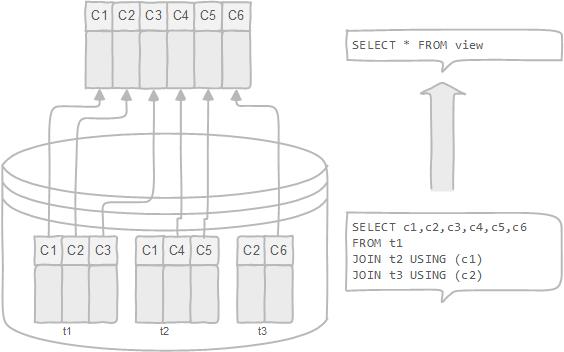
|
|
||||||
|
|
||||||
#### 创建视图
|
#### 创建视图
|
||||||
|
|
||||||
@ -1001,7 +1001,7 @@ SET PASSWORD FOR myuser = 'mypass';
|
|||||||
|
|
||||||
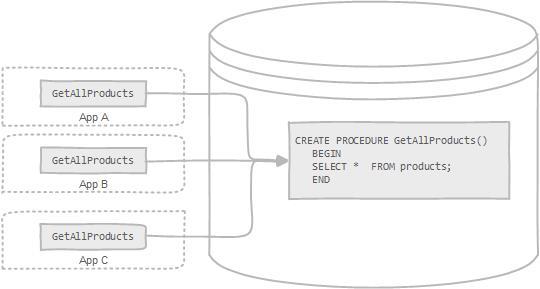
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
|
存储过程可以看成是对一系列 SQL 操作的批处理。存储过程可以由触发器,其他存储过程以及 Java, Python,PHP 等应用程序调用。
|
||||||
|
|
||||||
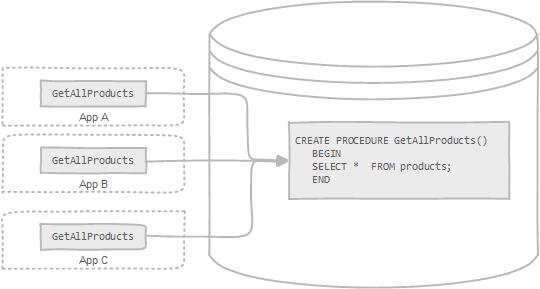
|
|
||||||
|
|
||||||
使用存储过程的好处:
|
使用存储过程的好处:
|
||||||
|
|
||||||
@ -1018,7 +1018,7 @@ SET PASSWORD FOR myuser = 'mypass';
|
|||||||
|
|
||||||
需要注意的是:**阿里巴巴《Java 开发手册》强制禁止使用存储过程。因为存储过程难以调试和扩展,更没有移植性。**
|
需要注意的是:**阿里巴巴《Java 开发手册》强制禁止使用存储过程。因为存储过程难以调试和扩展,更没有移植性。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
至于到底要不要在项目中使用,还是要看项目实际需求,权衡好利弊即可!
|
至于到底要不要在项目中使用,还是要看项目实际需求,权衡好利弊即可!
|
||||||
|
|
||||||
|
|||||||
@ -41,7 +41,7 @@ icon: "gateway"
|
|||||||
|
|
||||||
下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
|
下图来源于[百亿规模 API 网关服务 Shepherd 的设计与实现 - 美团技术团队 - 2021](https://mp.weixin.qq.com/s/iITqdIiHi3XGKq6u6FRVdg)这篇文章。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## 有哪些常见的网关系统?
|
## 有哪些常见的网关系统?
|
||||||
|
|
||||||
@ -73,7 +73,7 @@ Zuul 主要通过过滤器(类似于 AOP)来过滤请求,从而实现网
|
|||||||
|
|
||||||
[Zuul 1.x](https://netflixtechblog.com/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee) 基于同步 IO,性能较差。[Zuul 2.x](https://netflixtechblog.com/open-sourcing-zuul-2-82ea476cb2b3) 基于 Netty 实现了异步 IO,性能得到了大幅改进。
|
[Zuul 1.x](https://netflixtechblog.com/announcing-zuul-edge-service-in-the-cloud-ab3af5be08ee) 基于同步 IO,性能较差。[Zuul 2.x](https://netflixtechblog.com/open-sourcing-zuul-2-82ea476cb2b3) 基于 Netty 实现了异步 IO,性能得到了大幅改进。
|
||||||
|
|
||||||
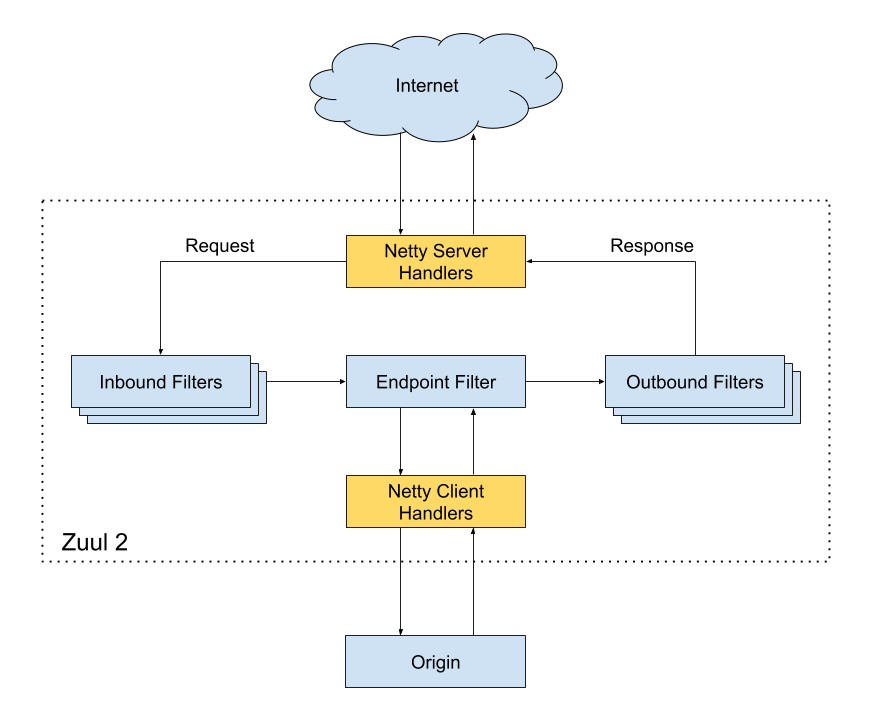
|
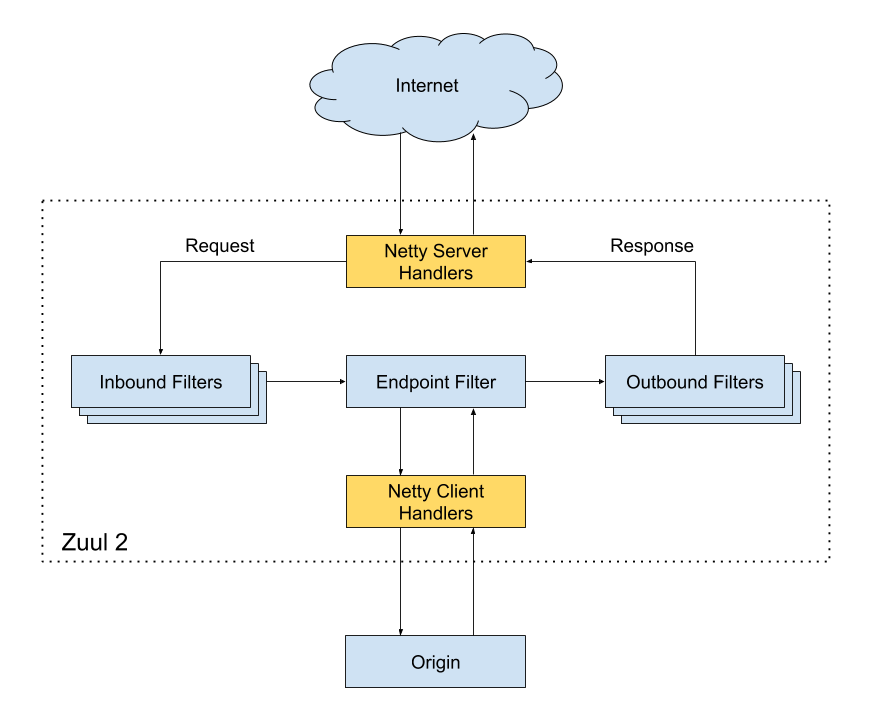
|
||||||
|
|
||||||
- Github 地址 : https://github.com/Netflix/zuul
|
- Github 地址 : https://github.com/Netflix/zuul
|
||||||
- 官方 Wiki : https://github.com/Netflix/zuul/wiki
|
- 官方 Wiki : https://github.com/Netflix/zuul/wiki
|
||||||
@ -129,7 +129,7 @@ APISIX 是一款基于 Nginx 和 etcd 的高性能、云原生、可扩展的网
|
|||||||
|
|
||||||
与传统 API 网关相比,APISIX 具有动态路由和插件热加载,特别适合微服务系统下的 API 管理。并且,APISIX 与 SkyWalking(分布式链路追踪系统)、Zipkin(分布式链路追踪系统)、Prometheus(监控系统) 等 DevOps 生态工具对接都十分方便。
|
与传统 API 网关相比,APISIX 具有动态路由和插件热加载,特别适合微服务系统下的 API 管理。并且,APISIX 与 SkyWalking(分布式链路追踪系统)、Zipkin(分布式链路追踪系统)、Prometheus(监控系统) 等 DevOps 生态工具对接都十分方便。
|
||||||
|
|
||||||
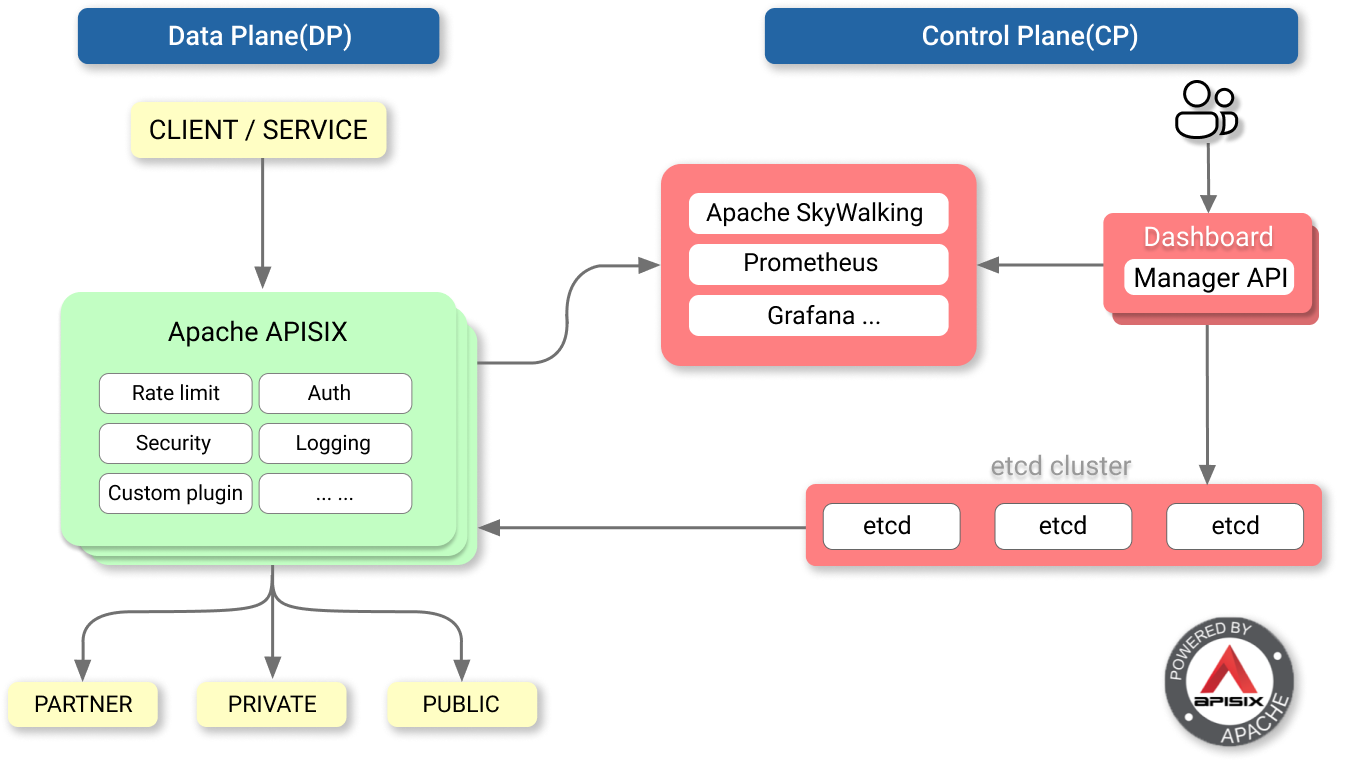
|
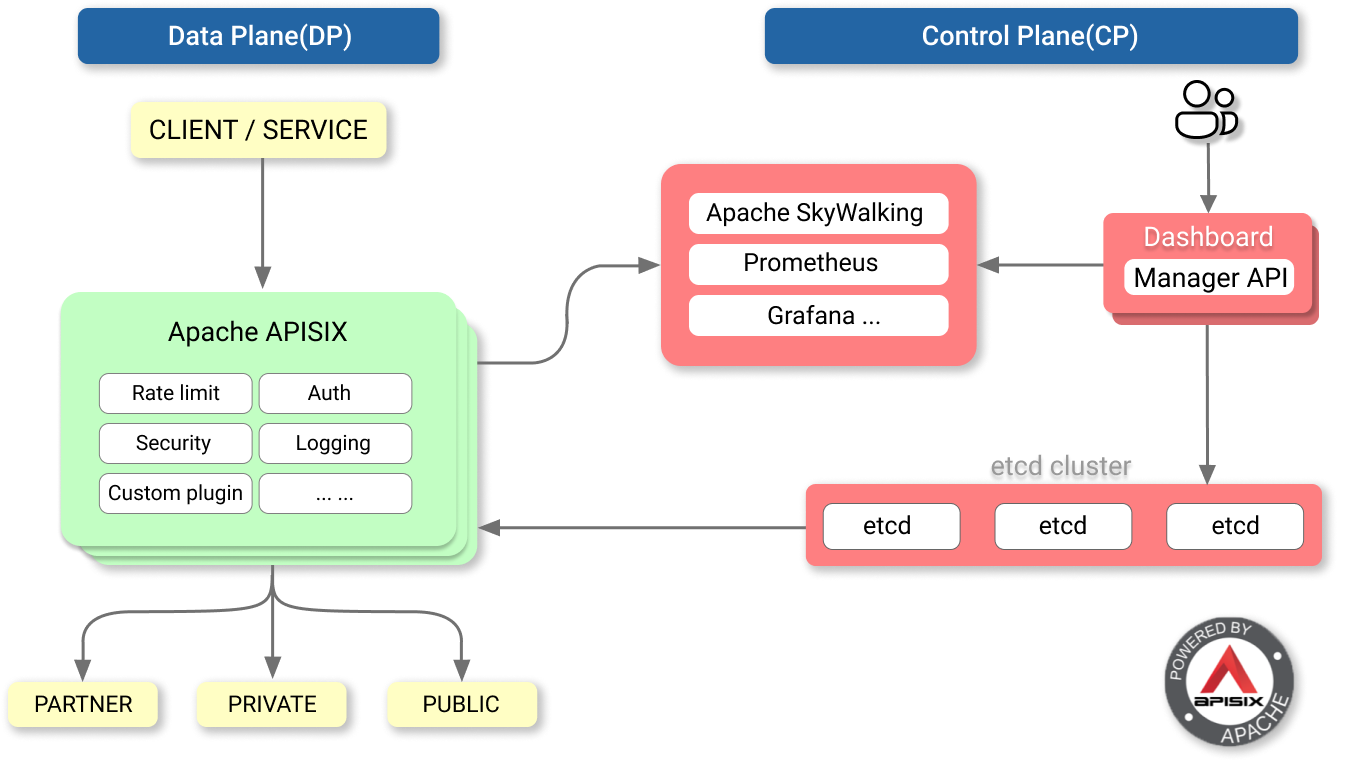
|
||||||
|
|
||||||
作为 NGINX 和 Kong 的替代项目,APISIX 目前已经是 Apache 顶级开源项目,并且是最快毕业的国产开源项目。国内目前已经有很多知名企业(比如金山、有赞、爱奇艺、腾讯、贝壳)使用 APISIX 处理核心的业务流量。
|
作为 NGINX 和 Kong 的替代项目,APISIX 目前已经是 Apache 顶级开源项目,并且是最快毕业的国产开源项目。国内目前已经有很多知名企业(比如金山、有赞、爱奇艺、腾讯、贝壳)使用 APISIX 处理核心的业务流量。
|
||||||
|
|
||||||
@ -142,7 +142,7 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
|
|||||||
|
|
||||||
> Wasm 是基于堆栈的虚拟机的二进制指令格式,一种低级汇编语言,旨在非常接近已编译的机器代码,并且非常接近本机性能。Wasm 最初是为浏览器构建的,但是随着技术的成熟,在服务器端看到了越来越多的用例。
|
> Wasm 是基于堆栈的虚拟机的二进制指令格式,一种低级汇编语言,旨在非常接近已编译的机器代码,并且非常接近本机性能。Wasm 最初是为浏览器构建的,但是随着技术的成熟,在服务器端看到了越来越多的用例。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- Github 地址 :https://github.com/apache/apisix
|
- Github 地址 :https://github.com/apache/apisix
|
||||||
- 官网地址: https://apisix.apache.org/zh/
|
- 官网地址: https://apisix.apache.org/zh/
|
||||||
@ -158,7 +158,7 @@ APISIX 同样支持定制化的插件开发。开发者除了能够使用 Lua
|
|||||||
|
|
||||||
Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apache 顶级开源项目。
|
Shenyu 是一款基于 WebFlux 的可扩展、高性能、响应式网关,Apache 顶级开源项目。
|
||||||
|
|
||||||
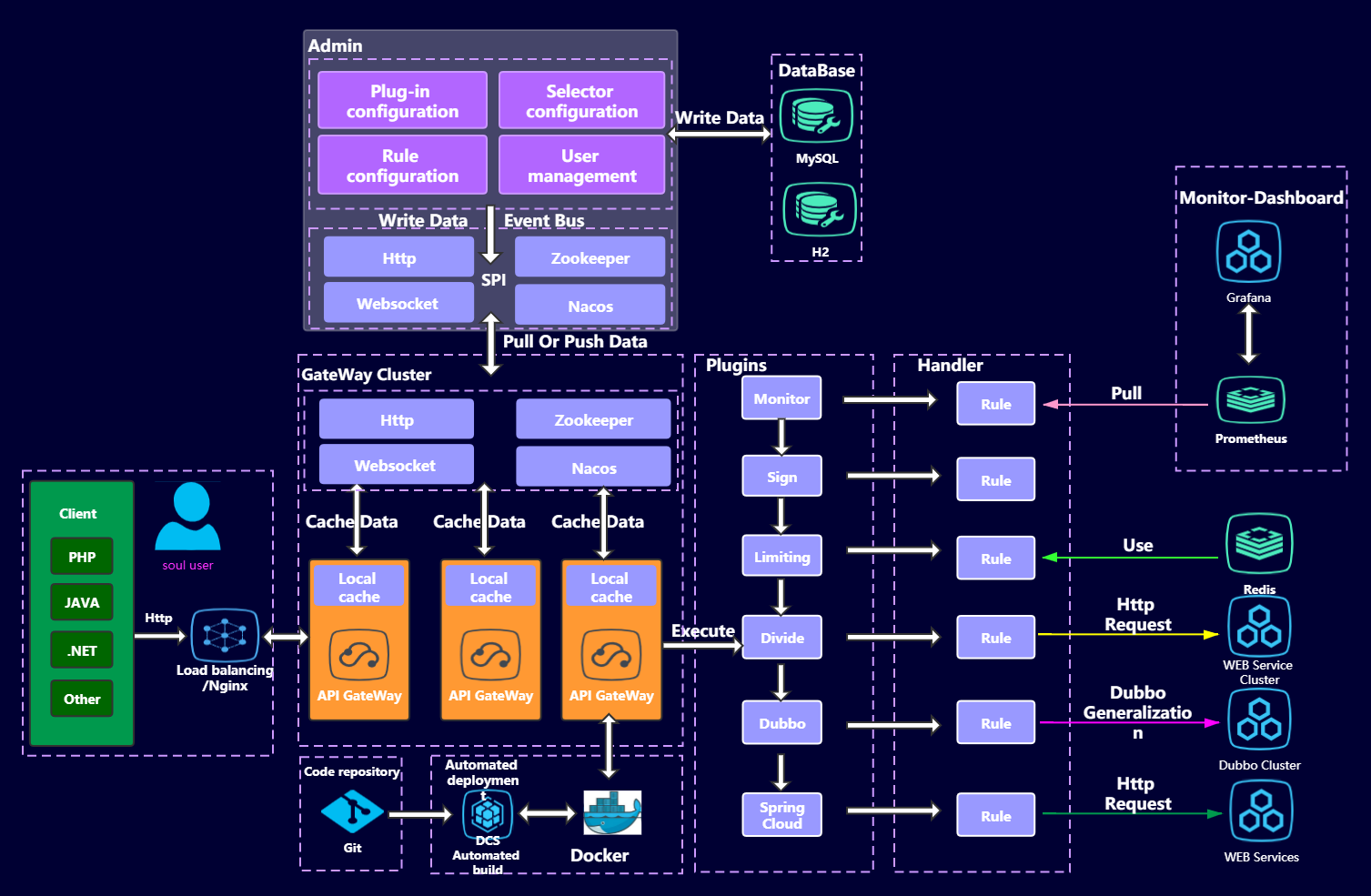
|
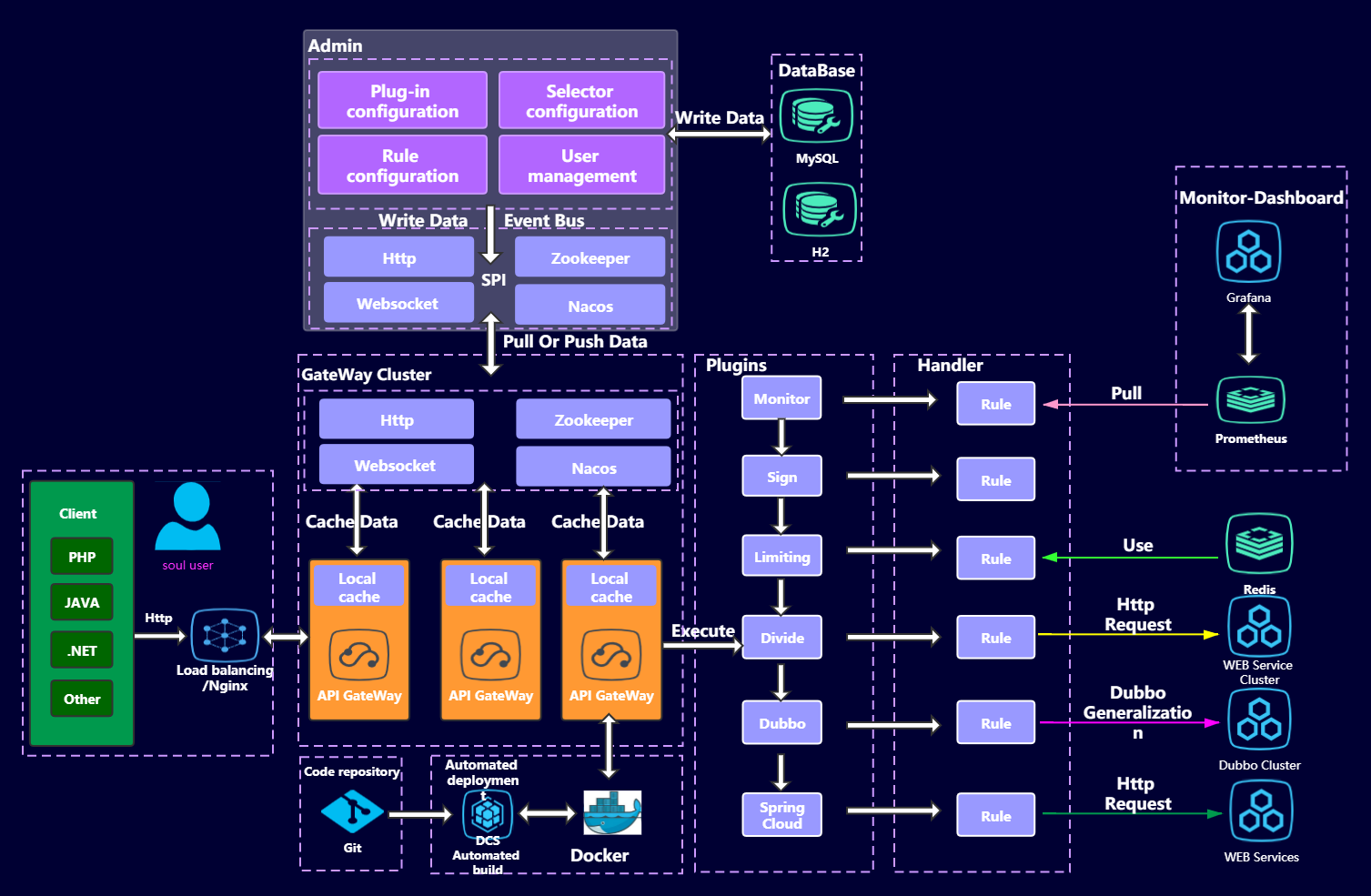
|
||||||
|
|
||||||
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发 、重写、重定向、和路由监控等插件。
|
Shenyu 通过插件扩展功能,插件是 ShenYu 的灵魂,并且插件也是可扩展和热插拔的。不同的插件实现不同的功能。Shenyu 自带了诸如限流、熔断、转发 、重写、重定向、和路由监控等插件。
|
||||||
|
|
||||||
|
|||||||
@ -307,15 +307,13 @@ UidGenerator 官方文档中的介绍如下:
|
|||||||
|
|
||||||
**[Leaf](https://github.com/Meituan-Dianping/Leaf)** 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话: “There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
|
**[Leaf](https://github.com/Meituan-Dianping/Leaf)** 是美团开源的一个分布式 ID 解决方案 。这个项目的名字 Leaf(树叶) 起源于德国哲学家、数学家莱布尼茨的一句话: “There are no two identical leaves in the world”(世界上没有两片相同的树叶) 。这名字起得真心挺不错的,有点文艺青年那味了!
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper 。
|
Leaf 提供了 **号段模式** 和 **Snowflake(雪花算法)** 这两种模式来生成分布式 ID。并且,它支持双号段,还解决了雪花 ID 系统时钟回拨问题。不过,时钟问题的解决需要弱依赖于 Zookeeper 。
|
||||||
|
|
||||||
Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
|
Leaf 的诞生主要是为了解决美团各个业务线生成分布式 ID 的方法多种多样以及不可靠的问题。
|
||||||
|
|
||||||
Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
|
Leaf 对原有的号段模式进行改进,比如它这里增加了双号段避免获取 DB 在获取号段的时候阻塞请求获取 ID 的线程。简单来说,就是我一个号段还没用完之前,我自己就主动提前去获取下一个号段(图片来自于美团官方文章:[《Leaf——美团点评分布式 ID 生成系统》](https://tech.meituan.com/2017/04/21/mt-leaf.html))。
|
||||||
|
|
||||||

|
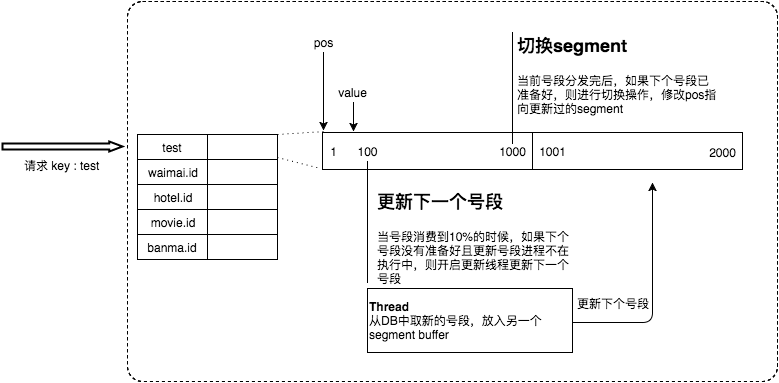
|
||||||
|
|
||||||
根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
|
根据项目 README 介绍,在 4C8G VM 基础上,通过公司 RPC 方式调用,QPS 压测结果近 5w/s,TP999 1ms。
|
||||||
|
|
||||||
|
|||||||
@ -14,7 +14,7 @@
|
|||||||
|
|
||||||
`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
|
`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
|
简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
|
||||||
|
|
||||||
@ -22,15 +22,15 @@
|
|||||||
|
|
||||||
比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
|
比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也 **一样** 提供秒杀服务,这个时候就是 **`Cluster` 集群** 。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
|
但是,我现在换一种方式,我将一个秒杀服务 **拆分成多个子服务** ,比如创建订单服务,增加积分服务,扣优惠券服务等等,**然后我将这些子服务都部署在不同的服务器上** ,这个时候就是 **`Distributed` 分布式** 。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
|
而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
|
比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。`ZooKeeper` 主要就是解决这些问题的。
|
||||||
|
|
||||||
@ -40,7 +40,7 @@
|
|||||||
|
|
||||||
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
|
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
而上述前者就是 `Eureka` 的处理方式,它保证了AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了CP(数据一致性)。
|
而上述前者就是 `Eureka` 的处理方式,它保证了AP(可用性),后者就是我们今天所要讲的 `ZooKeeper` 的处理方式,它保证了CP(数据一致性)。
|
||||||
|
|
||||||
@ -50,7 +50,7 @@
|
|||||||
|
|
||||||
这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
|
这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
|
这个时候就引申出一个概念—— **拜占庭将军问题** 。它意指 **在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**, 所以所有的一致性算法的 **必要前提** 就是安全可靠的消息通道。
|
||||||
|
|
||||||
@ -76,11 +76,11 @@
|
|||||||
|
|
||||||
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
|
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 **回滚事务的 `rollback` 请求**,参与者收到之后将会 **回滚它在第一阶段所做的事务处理** ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。
|
||||||
|
|
||||||
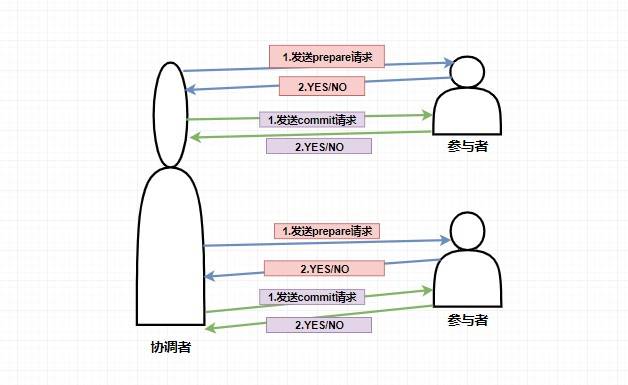
|
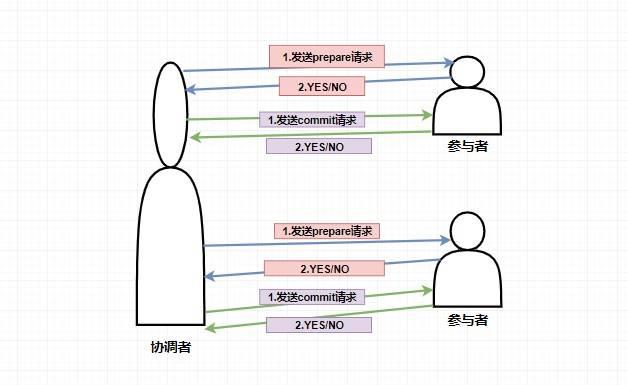
|
||||||
|
|
||||||
个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
|
个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
* **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
|
* **单点故障问题**,如果协调者挂了那么整个系统都处于不可用的状态了。
|
||||||
* **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
|
* **阻塞问题**,即当协调者发送 `prepare` 请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
|
||||||
@ -96,7 +96,7 @@
|
|||||||
2. **PreCommit阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
|
2. **PreCommit阶段**:协调者根据参与者返回的响应来决定是否可以进行下面的 `PreCommit` 操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送 `PreCommit` 预提交请求,**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中** ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 **任何一个 NO** 的信息,或者 **在一定时间内** 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
|
||||||
3. **DoCommit阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
|
3. **DoCommit阶段**:这个阶段其实和 `2PC` 的第二阶段差不多,如果协调者收到了所有参与者在 `PreCommit` 阶段的 YES 响应,那么协调者将会给所有参与者发送 `DoCommit` 请求,**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在 `PreCommit` 阶段 **收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应** ,那么就会进行中断请求的发送,参与者收到中断请求后则会 **通过上面记录的回滚日志** 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
|
||||||
|
|
||||||
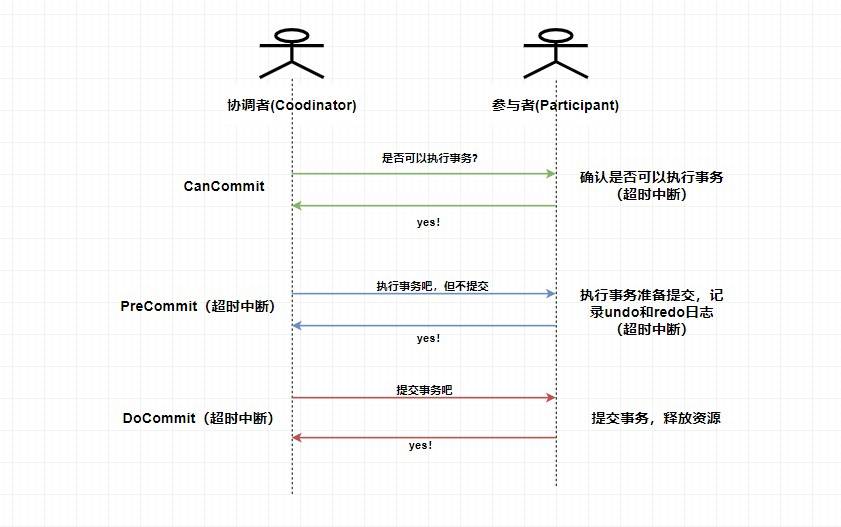
|
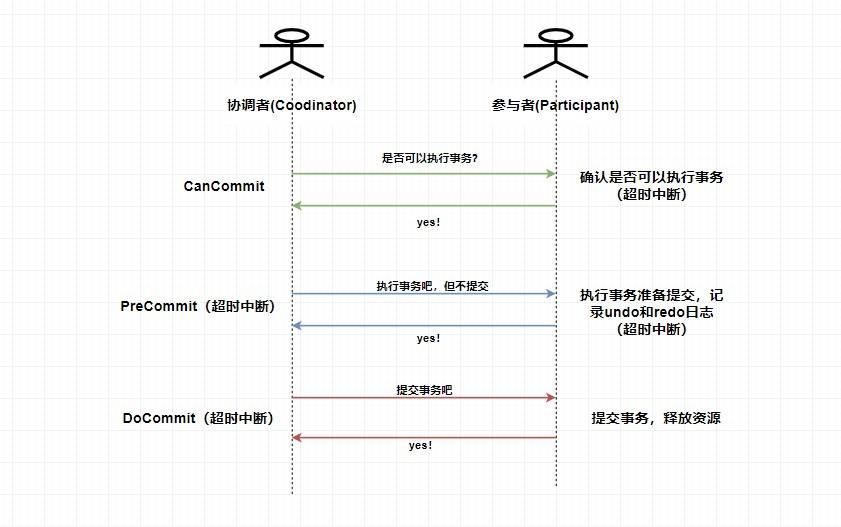
|
||||||
|
|
||||||
> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内为收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
|
> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内为收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
|
||||||
|
|
||||||
@ -117,7 +117,7 @@
|
|||||||
|
|
||||||
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
|
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。
|
||||||
|
|
||||||
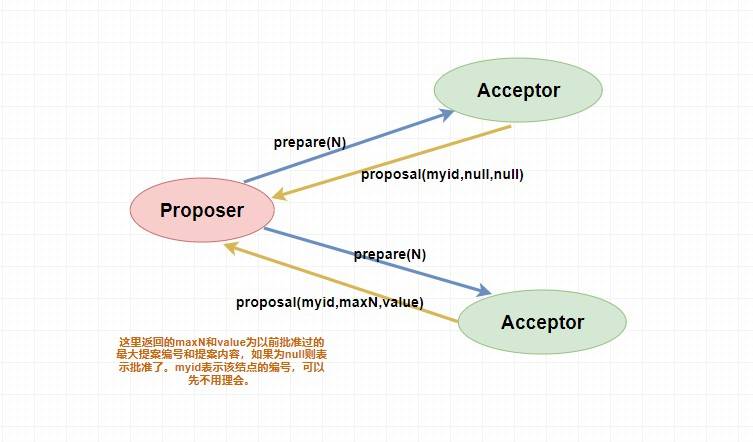
|
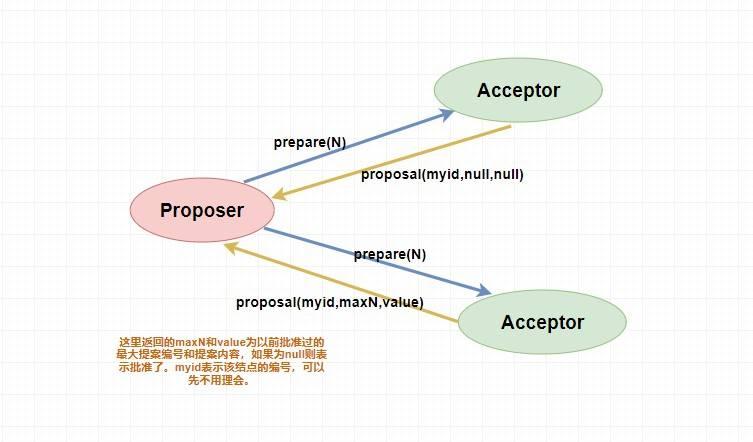
|
||||||
|
|
||||||
#### 4.3.2. accept 阶段
|
#### 4.3.2. accept 阶段
|
||||||
|
|
||||||
@ -125,11 +125,11 @@
|
|||||||
|
|
||||||
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
|
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号 **大于等于** 已经批准过的最大提案编号,那么就 `accept` 该提案(此时执行提案内容但不提交),随后将情况返回给 `Proposer` 。如果不满足则不回应或者返回 NO 。
|
||||||
|
|
||||||

|
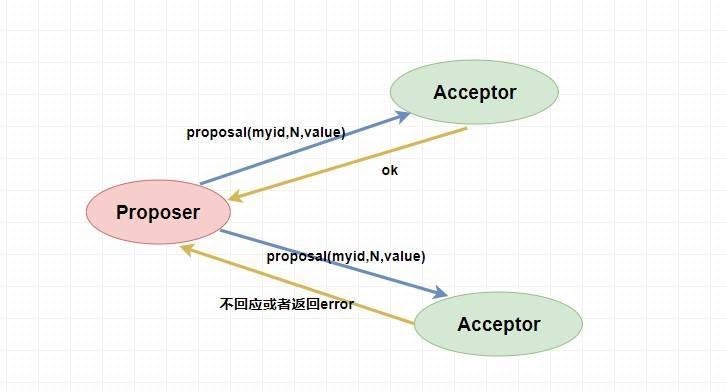
|
||||||
|
|
||||||
当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
|
当 `Proposer` 收到超过半数的 `accept` ,那么它这个时候会向所有的 `acceptor` 发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的 `acceptor` 批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**,而对于前面已经批准过该提案的 `acceptor` 来说 **仅仅需要发送该提案的编号** ,让 `acceptor` 执行提交就行了。
|
||||||
|
|
||||||
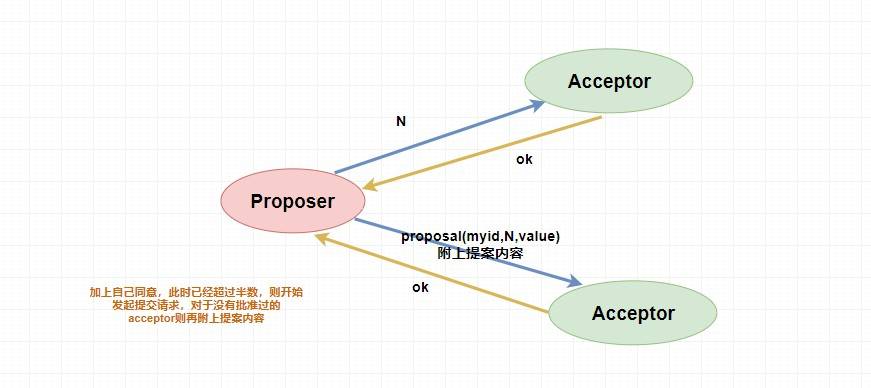
|
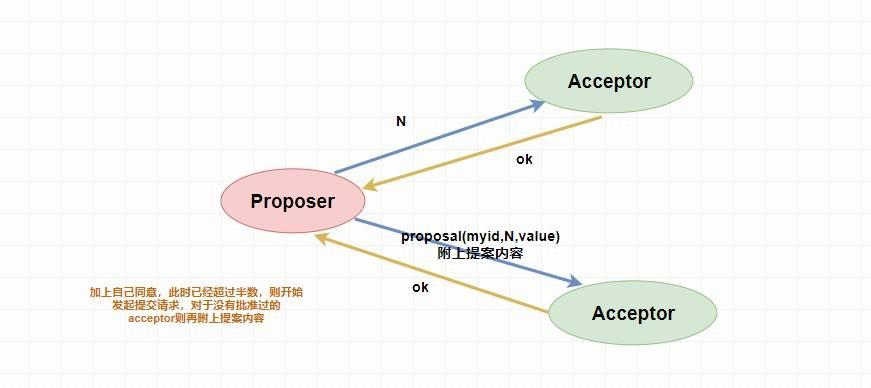
|
||||||
|
|
||||||
而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
|
而如果 `Proposer` 如果没有收到超过半数的 `accept` 那么它将会将 **递增** 该 `Proposal` 的编号,然后 **重新进入 `Prepare` 阶段** 。
|
||||||
|
|
||||||
@ -143,7 +143,7 @@
|
|||||||
|
|
||||||
就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
|
就这样无休无止的永远提案下去,这就是 `paxos` 算法的死循环问题。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
|
那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
|
||||||
|
|
||||||
@ -153,7 +153,7 @@
|
|||||||
|
|
||||||
作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
|
作为一个优秀高效且可靠的分布式协调框架,`ZooKeeper` 在解决分布式数据一致性问题时并没有直接使用 `Paxos` ,而是专门定制了一致性协议叫做 `ZAB(ZooKeeper Atomic Broadcast)` 原子广播协议,该协议能够很好地支持 **崩溃恢复** 。
|
||||||
|
|
||||||
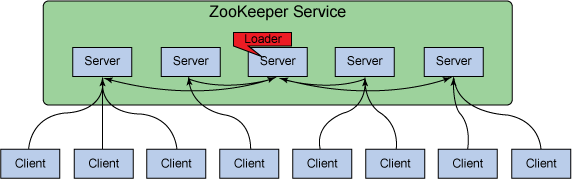
|
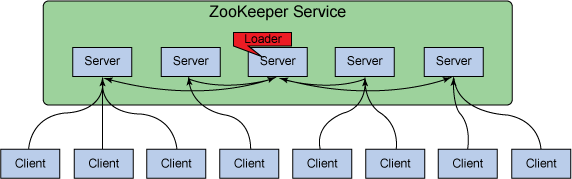
|
||||||
|
|
||||||
### 5.2. `ZAB` 中的三个角色
|
### 5.2. `ZAB` 中的三个角色
|
||||||
|
|
||||||
@ -171,11 +171,11 @@
|
|||||||
|
|
||||||
不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
|
不就是 **在整个集群中保持数据的一致性** 嘛?如果是你,你会怎么做呢?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
|
废话,第一步肯定需要 `Leader` 将写请求 **广播** 出去呀,让 `Leader` 问问 `Followers` 是否同意更新,如果超过半数以上的同意那么就进行 `Follower` 和 `Observer` 的更新(和 `Paxos` 一样)。当然这么说有点虚,画张图理解一下。
|
||||||
|
|
||||||
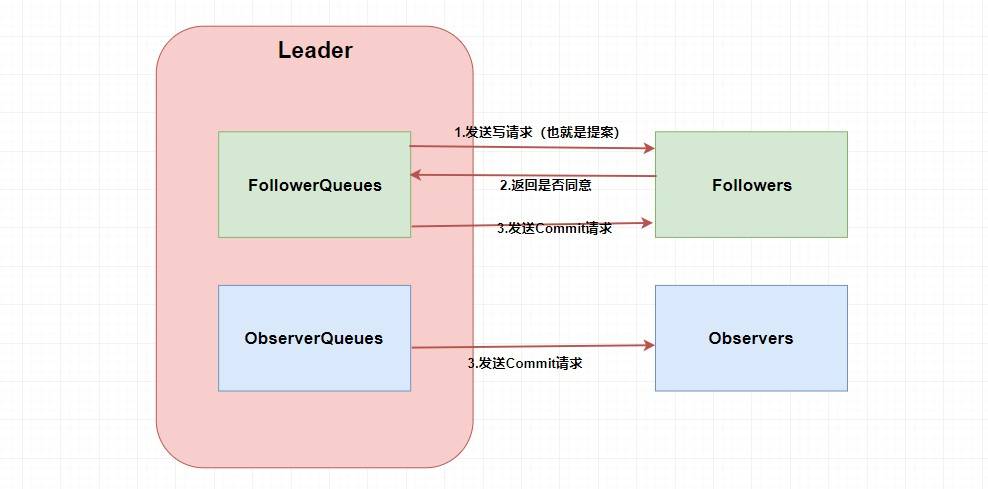
|
|
||||||
|
|
||||||
嗯。。。看起来很简单,貌似懂了🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求A,此时 `Leader` 将请求A广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1因为网络原因没有收到,而 `Leader` 又广播了一个请求B,因为网络原因,F1竟然先收到了请求B然后才收到了请求A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
|
嗯。。。看起来很简单,貌似懂了🤥🤥🤥。这两个 `Queue` 哪冒出来的?答案是 **`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性** 。何为顺序性,比如我现在有一个写请求A,此时 `Leader` 将请求A广播出去,因为只需要半数同意就行,所以可能这个时候有一个 `Follower` F1因为网络原因没有收到,而 `Leader` 又广播了一个请求B,因为网络原因,F1竟然先收到了请求B然后才收到了请求A,这个时候请求处理的顺序不同就会导致数据的不同,从而 **产生数据不一致问题** 。
|
||||||
|
|
||||||
@ -217,7 +217,7 @@
|
|||||||
|
|
||||||
假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
|
假设 `Leader (server2)` 发送 `commit` 请求(忘了请看上面的消息广播模式),他发送给了 `server3`,然后要发给 `server1` 的时候突然挂了。这个时候重新选举的时候我们如果把 `server1` 作为 `Leader` 的话,那么肯定会产生数据不一致性,因为 `server3` 肯定会提交刚刚 `server2` 发送的 `commit` 请求的提案,而 `server1` 根本没收到所以会丢弃。
|
||||||
|
|
||||||
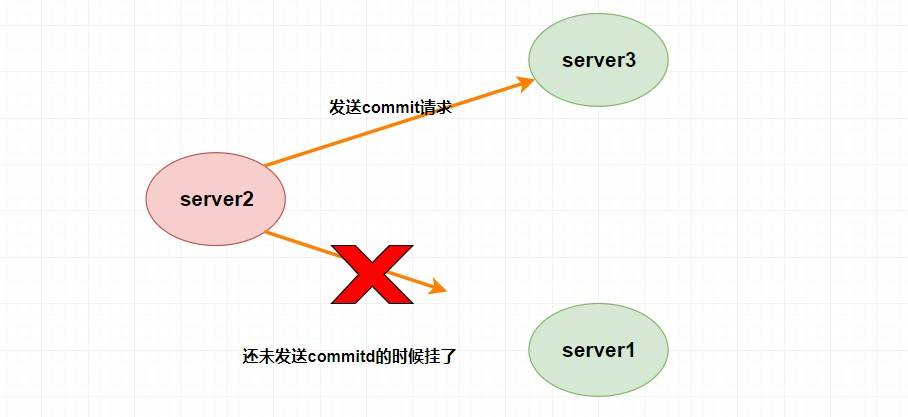
|
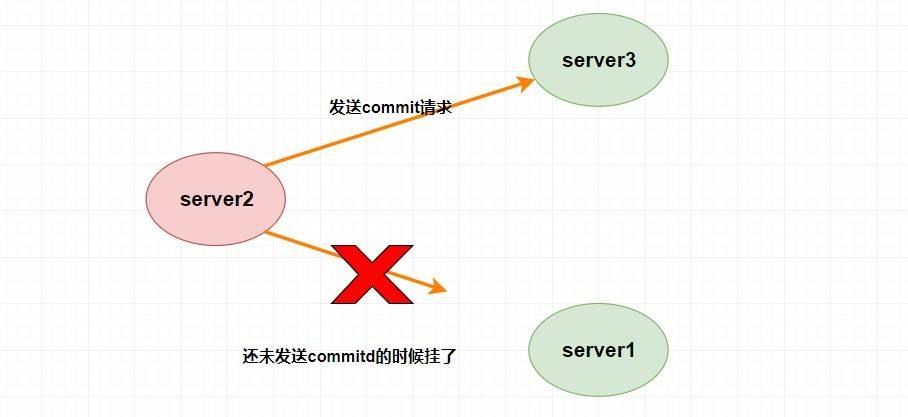
|
||||||
|
|
||||||
那怎么解决呢?
|
那怎么解决呢?
|
||||||
|
|
||||||
@ -227,7 +227,7 @@
|
|||||||
|
|
||||||
假设 `Leader (server2)` 此时同意了提案N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案N1了,这样就会出现数据不一致性问题了,所以 **该提案N1最终需要被抛弃掉** 。
|
假设 `Leader (server2)` 此时同意了提案N1,自身提交了这个事务并且要发送给所有 `Follower` 要 `commit` 的请求,却在这个时候挂了,此时肯定要重新进行 `Leader` 的选举,比如说此时选 `server1` 为 `Leader` (这无所谓)。但是过了一会,这个 **挂掉的 `Leader` 又重新恢复了** ,此时它肯定会作为 `Follower` 的身份进入集群中,需要注意的是刚刚 `server2` 已经同意提交了提案N1,但其他 `server` 并没有收到它的 `commit` 信息,所以其他 `server` 不可能再提交这个提案N1了,这样就会出现数据不一致性问题了,所以 **该提案N1最终需要被抛弃掉** 。
|
||||||
|
|
||||||
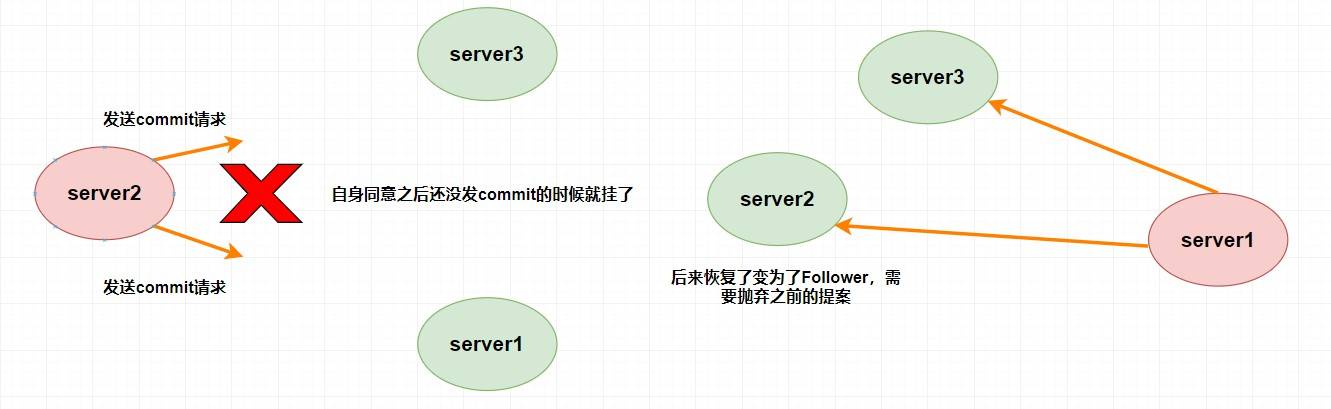
|
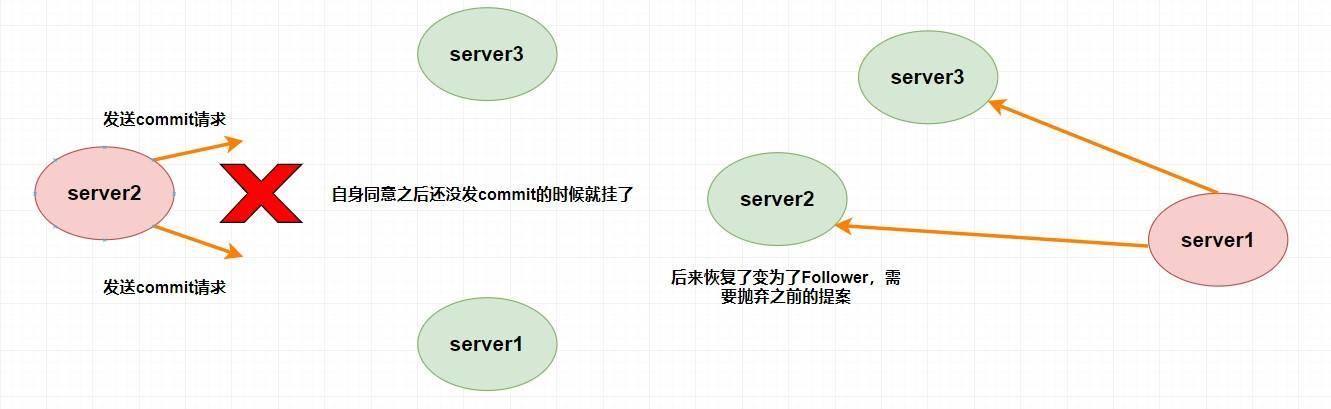
|
||||||
|
|
||||||
## 6. Zookeeper的几个理论知识
|
## 6. Zookeeper的几个理论知识
|
||||||
|
|
||||||
@ -239,7 +239,7 @@
|
|||||||
|
|
||||||
`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
|
`zookeeper` 数据存储结构与标准的 `Unix` 文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是 `zookeeper` 中没有文件系统中目录与文件的概念,而是 **使用了 `znode` 作为数据节点** 。`znode` 是 `zookeeper` 中的最小数据单元,每个 `znode` 上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。
|
||||||
|
|
||||||
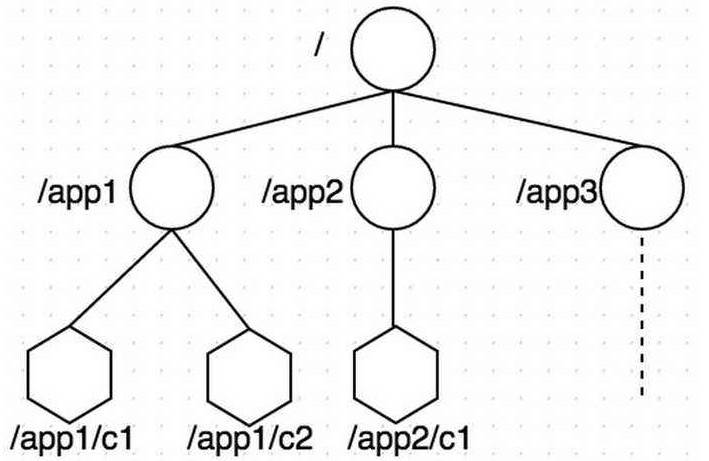
|
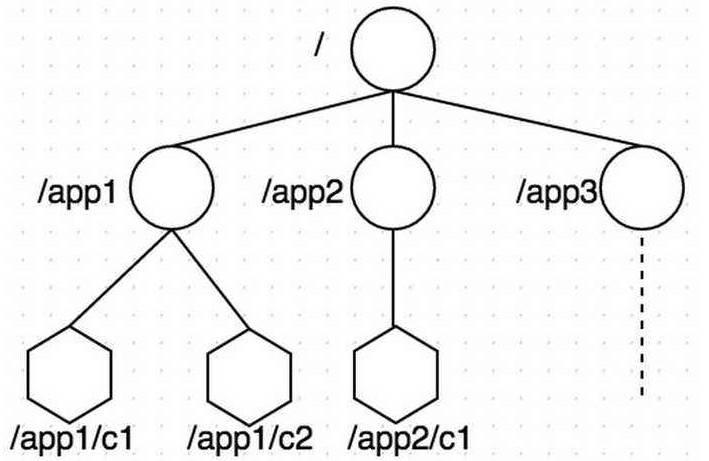
|
||||||
|
|
||||||
每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
|
每个 `znode` 都有自己所属的 **节点类型** 和 **节点状态**。
|
||||||
|
|
||||||
@ -284,13 +284,13 @@
|
|||||||
|
|
||||||
`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
|
`Watcher` 为事件监听器,是 `zk` 非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端 **注册** 指定的 `watcher` ,当服务端符合了 `watcher` 的某些事件或要求则会 **向客户端发送事件通知** ,客户端收到通知后找到自己定义的 `Watcher` 然后 **执行相应的回调方法** 。
|
||||||
|
|
||||||
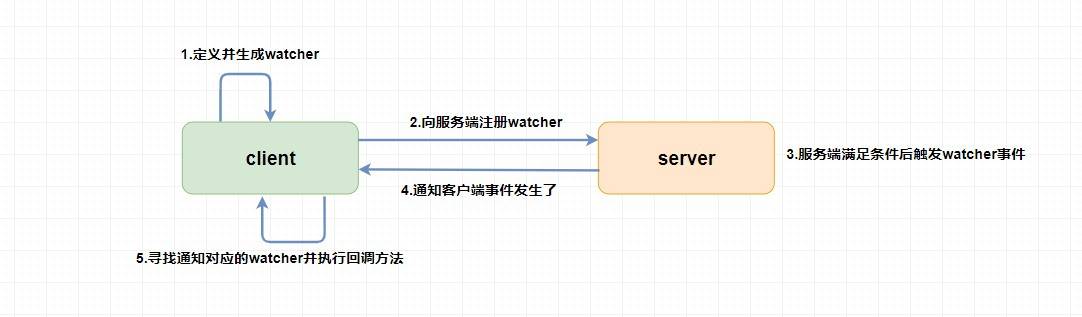
|
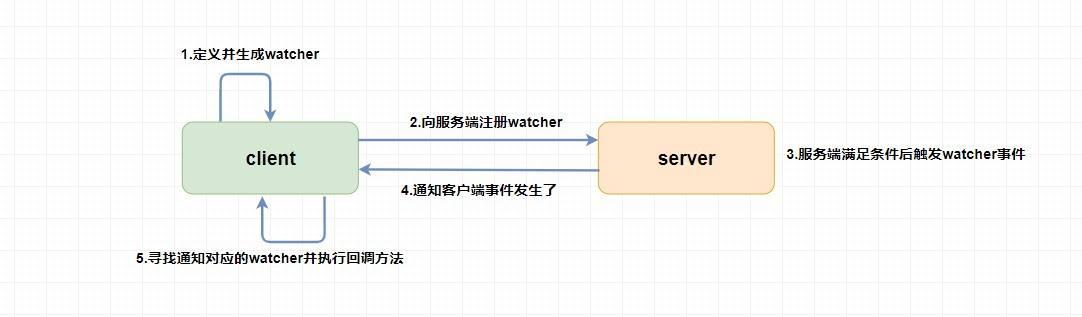
|
||||||
|
|
||||||
## 7. Zookeeper的几个典型应用场景
|
## 7. Zookeeper的几个典型应用场景
|
||||||
|
|
||||||
前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
|
前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 7.1. 选主
|
### 7.1. 选主
|
||||||
|
|
||||||
@ -302,7 +302,7 @@
|
|||||||
|
|
||||||
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
|
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?`master` 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 `watcher` 吗?我们是不是可以 **让其他不是 `master` 的节点监听节点的状态** ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 `master` 挂了,这个时候我们 **触发回调函数进行重新选举** ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 `master` 是否挂了等等。
|
||||||
|
|
||||||
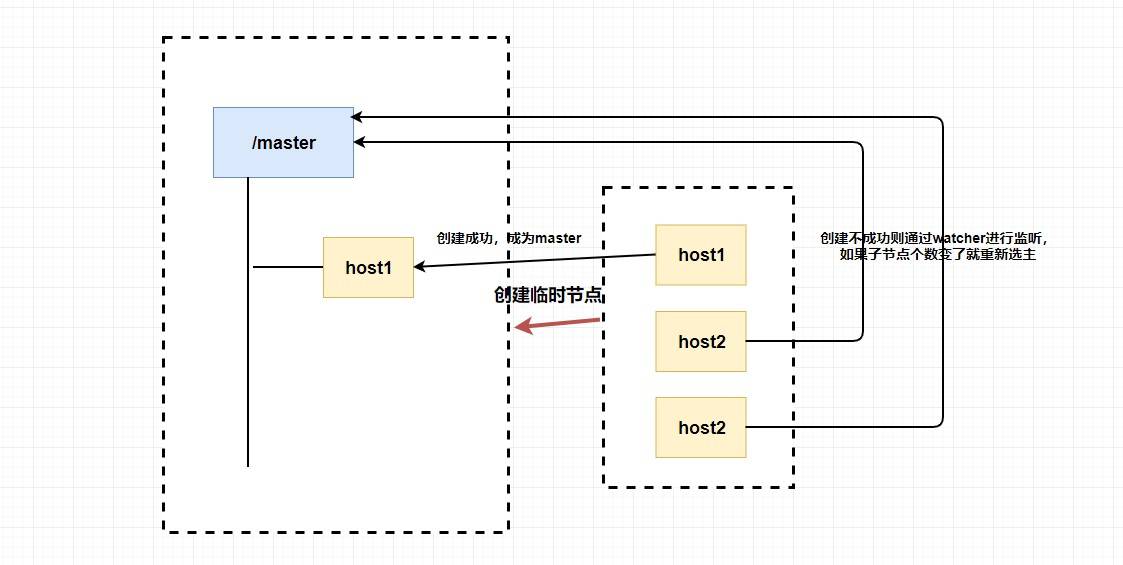
|
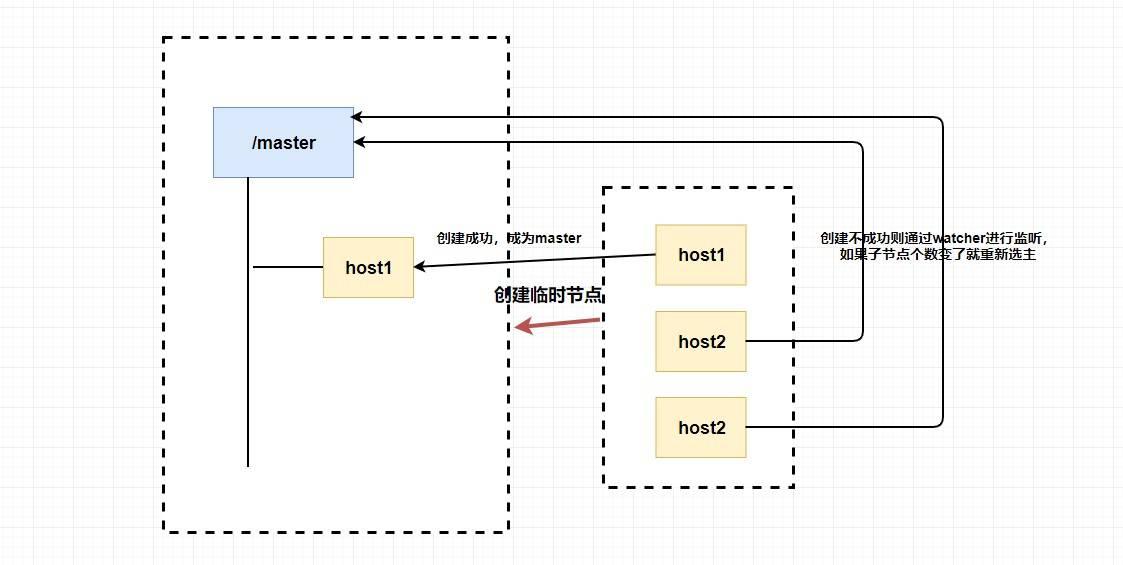
|
||||||
|
|
||||||
总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
|
总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
|
||||||
|
|
||||||
@ -344,13 +344,13 @@
|
|||||||
|
|
||||||
而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
|
而 `zookeeper` 天然支持的 `watcher` 和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的 `watcher` 进行状态监控和回调。
|
||||||
|
|
||||||

|
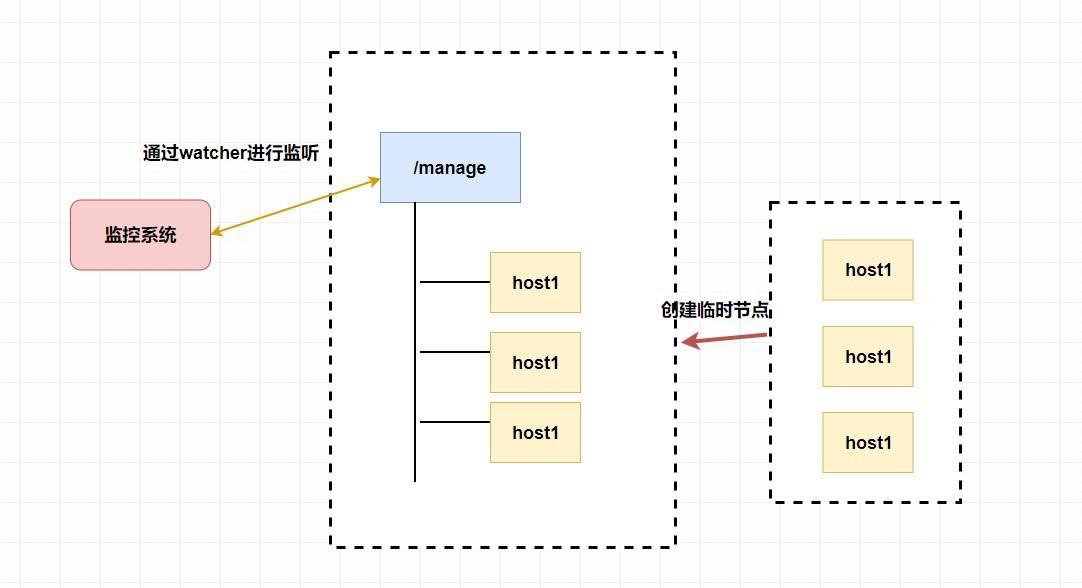
|
||||||
|
|
||||||
至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
|
至于注册中心也很简单,我们同样也是让 **服务提供者** 在 `zookeeper` 中创建一个临时节点并且将自己的 `ip、port、调用方式` 写入节点,当 **服务消费者** 需要进行调用的时候会 **通过注册中心找到相应的服务的地址列表(IP端口什么的)** ,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
|
||||||
|
|
||||||
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
|
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得 `Eureka` 会先试错,然后再更新)。
|
||||||
|
|
||||||
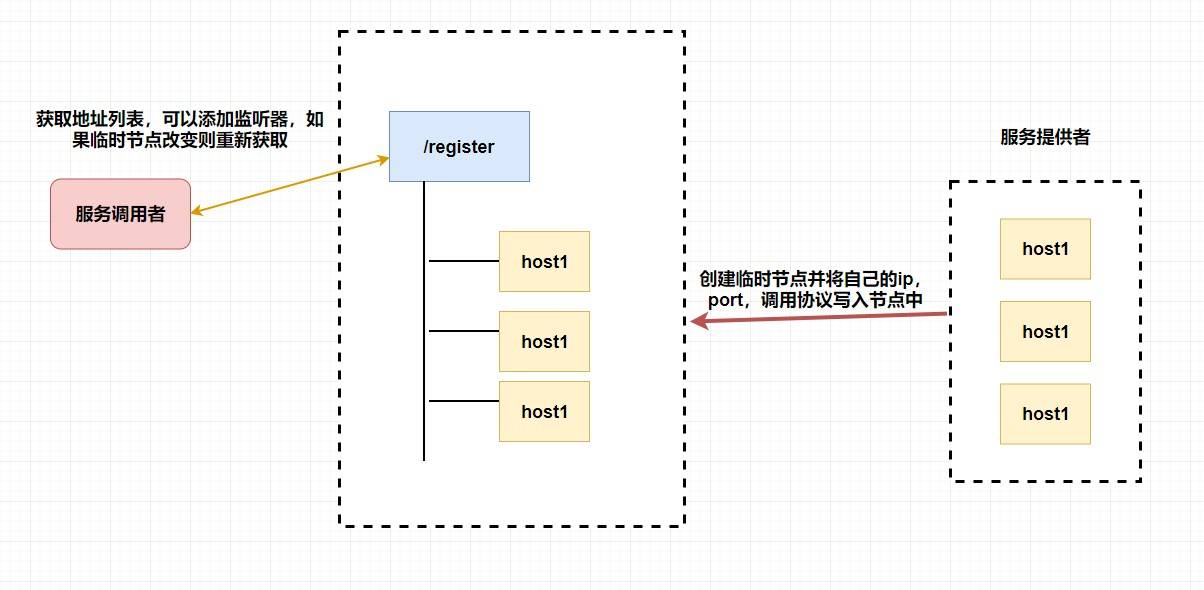
|
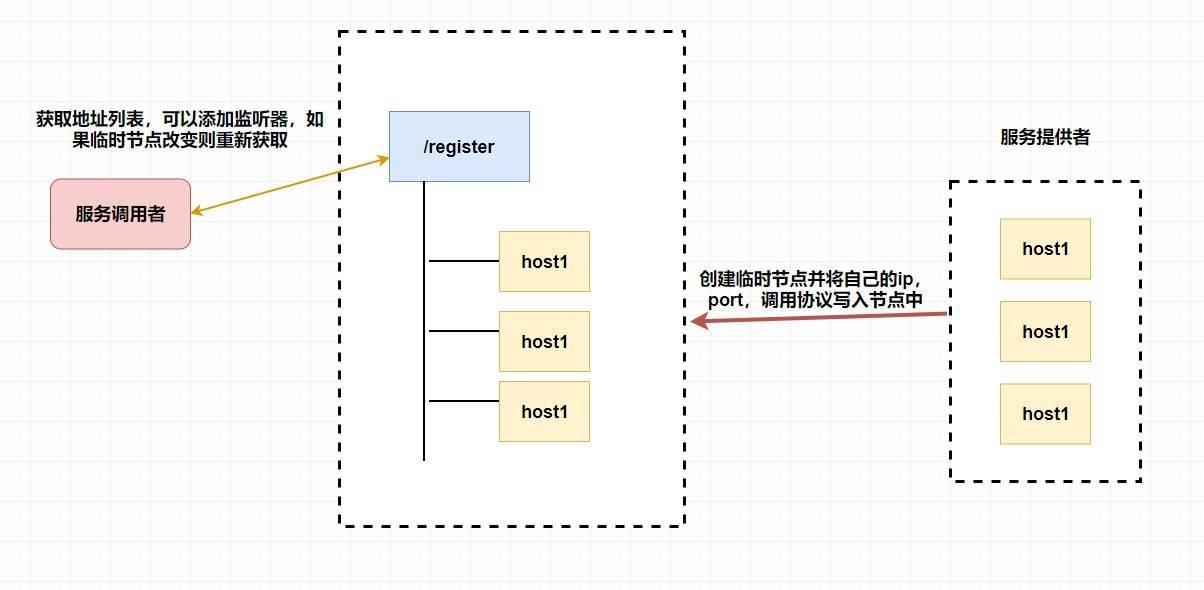
|
||||||
|
|
||||||
## 8. 总结
|
## 8. 总结
|
||||||
|
|
||||||
@ -358,7 +358,7 @@
|
|||||||
|
|
||||||
不知道大家是否还记得我讲了什么😒。
|
不知道大家是否还记得我讲了什么😒。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
|
这篇文章中我带大家入门了 `zookeeper` 这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
|
||||||
|
|
||||||
|
|||||||
@ -170,9 +170,7 @@ src
|
|||||||
xxx=com.xxx.XxxLoadBalance
|
xxx=com.xxx.XxxLoadBalance
|
||||||
```
|
```
|
||||||
|
|
||||||
其他还有很多可供扩展的选择,你可以在[官方文档@SPI扩展实现](https://dubbo.apache.org/zh/docs/v2.7/dev/impls/)这里找到。
|
其他还有很多可供扩展的选择,你可以在[官方文档](https://cn.dubbo.apache.org/zh-cn/overview/home/)中找到。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Dubbo 的微内核架构了解吗?
|
### Dubbo 的微内核架构了解吗?
|
||||||
|
|
||||||
@ -435,7 +433,7 @@ Dubbo 中的 `RoundRobinLoadBalance` 的代码实现被修改重建了好几次
|
|||||||
|
|
||||||
### Dubbo 支持哪些序列化方式呢?
|
### Dubbo 支持哪些序列化方式呢?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
Dubbo 支持多种序列化方式:JDK自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf等等。
|
Dubbo 支持多种序列化方式:JDK自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf等等。
|
||||||
|
|
||||||
@ -458,5 +456,5 @@ Kryo和FST这两种序列化方式是 Dubbo 后来才引入的,性能非常好
|
|||||||
|
|
||||||
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
|
Dubbo 官方文档中还有一个关于这些[序列化协议的性能对比图](https://dubbo.apache.org/zh/docs/v2.7/user/serialization/#m-zhdocsv27userserialization)可供参考。
|
||||||
|
|
||||||

|
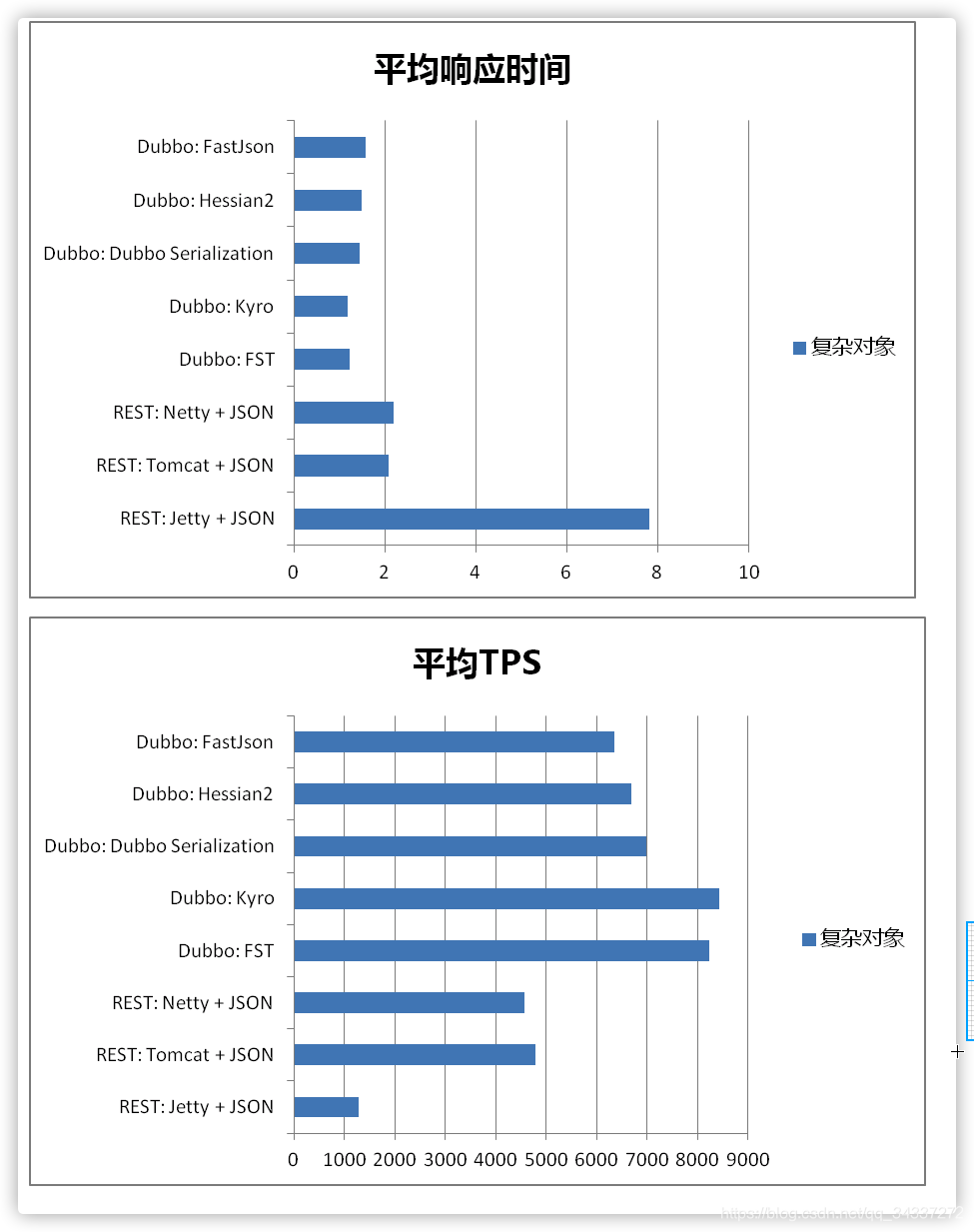
|
||||||
|
|
||||||
|
|||||||
@ -26,7 +26,7 @@ Gossip 协议最早是在 ACM 上的一篇 1987 年发表的论文 [《Epidemic
|
|||||||
|
|
||||||
1、我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。
|
1、我们经常使用的分布式缓存 Redis 的官方集群解决方案(3.0 版本引入) Redis Cluster 就是基于 Gossip 协议来实现集群中各个节点数据的最终一致性。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Redis Cluster 中的每个 Redis 节点都维护了一份集群的状态信息,各个节点利用 Gossip 协议传递的信息就是集群的状态信息。
|
Redis Cluster 中的每个 Redis 节点都维护了一份集群的状态信息,各个节点利用 Gossip 协议传递的信息就是集群的状态信息。
|
||||||
|
|
||||||
@ -66,7 +66,7 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
|
|||||||
|
|
||||||
伪代码如下:
|
伪代码如下:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是需要可以的设计一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
|
在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是需要可以的设计一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
|
||||||
|
|
||||||
@ -89,7 +89,7 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
|
|||||||
|
|
||||||
伪代码如下:
|
伪代码如下:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
谣言传播比较适合节点数量比较多的情况,不过,这种模式下要尽量避免传播的信息包不能太大,避免网络消耗太大。
|
谣言传播比较适合节点数量比较多的情况,不过,这种模式下要尽量避免传播的信息包不能太大,避免网络消耗太大。
|
||||||
|
|
||||||
|
|||||||
@ -60,7 +60,7 @@ Basic Paxos 中存在 3 个重要的角色:
|
|||||||
2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
|
2. **接受者(Acceptor)**:也可以叫做投票员(voter),负责对提议者的提案进行投票,同时需要记住自己的投票历史;
|
||||||
3. **学习者(Learner)**:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
|
3. **学习者(Learner)**:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
|
||||||
|
|
||||||

|
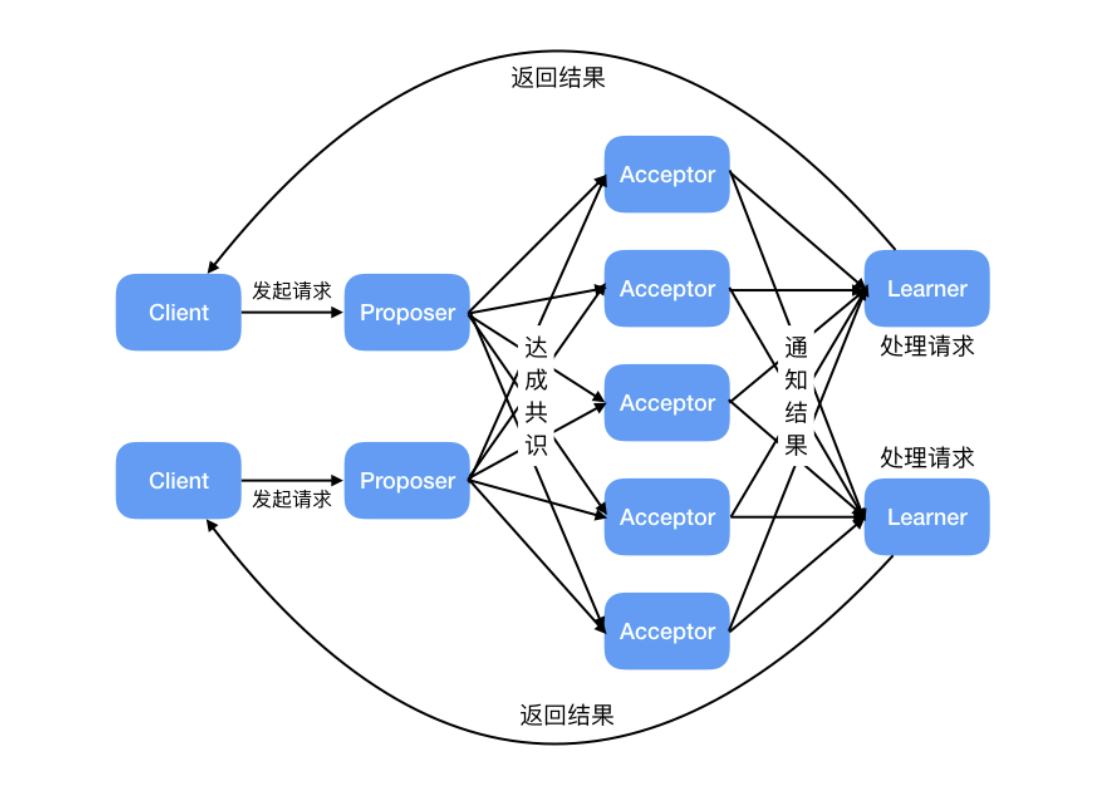
|
||||||
|
|
||||||
为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。
|
为了减少实现该算法所需的节点数,一个节点可以身兼多个角色。并且,一个提案被选定需要被半数以上的 Acceptor 接受。这样的话,Basic Paxos 算法还具备容错性,在少于一半的节点出现故障时,集群仍能正常工作。
|
||||||
|
|
||||||
|
|||||||
@ -9,8 +9,6 @@ category: 高可用
|
|||||||
|
|
||||||
现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
|
现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## 常见限流算法有哪些?
|
## 常见限流算法有哪些?
|
||||||
|
|
||||||
简单介绍 4 种非常好理解并且容易实现的限流算法!
|
简单介绍 4 种非常好理解并且容易实现的限流算法!
|
||||||
@ -204,7 +202,7 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
|
|||||||
|
|
||||||
> ShenYu 地址: https://github.com/apache/incubator-shenyu
|
> ShenYu 地址: https://github.com/apache/incubator-shenyu
|
||||||
|
|
||||||
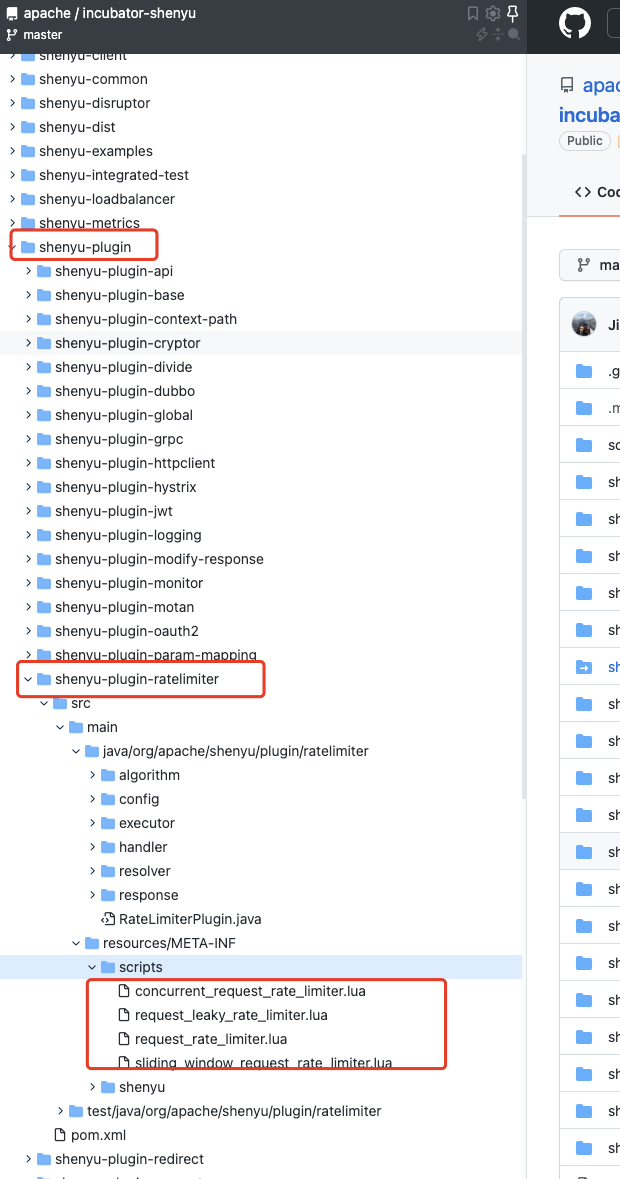
|

|
||||||
|
|
||||||
## 相关阅读
|
## 相关阅读
|
||||||
|
|
||||||
|
|||||||
@ -83,7 +83,7 @@ RocketMQ 、 Kafka、Pulsar 、QMQ 都提供了事务相关的功能。事务允
|
|||||||
|
|
||||||
详细介绍可以查看 [分布式事务详解(付费)](https://javaguide.cn/distributed-system/distributed-transaction.html) 这篇文章。
|
详细介绍可以查看 [分布式事务详解(付费)](https://javaguide.cn/distributed-system/distributed-transaction.html) 这篇文章。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## 使用消息队列会带来哪些问题?
|
## 使用消息队列会带来哪些问题?
|
||||||
|
|
||||||
|
|||||||
@ -181,7 +181,7 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
|
|||||||
|
|
||||||
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
|
ShardingSphere 项目(包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar)是当当捐入 Apache 的,目前主要由京东数科的一些巨佬维护。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。
|
ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。
|
||||||
|
|
||||||
|
|||||||
@ -36,11 +36,11 @@ tag:
|
|||||||
|
|
||||||
Brendan Gregg 之前是 Netflix 公司的高级性能架构师,在 Netflix 工作近 7 年。2022 年 4 月,他离开了 Netflix 去了 Intel,担任院士职位。
|
Brendan Gregg 之前是 Netflix 公司的高级性能架构师,在 Netflix 工作近 7 年。2022 年 4 月,他离开了 Netflix 去了 Intel,担任院士职位。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
总体上,他已经在系统性能领域深耕超过 10 年,[Brendan Gregg 的过往履历](https://www.linkedin.com/in/brendangregg/)可以在 linkedin 上看到。在这 10 年间,除了书籍以外,Brendan Gregg 还产出了超过上百份和系统性能相关的技术文档,演讲视频/ppt,还有各种工具软件,相关内容都整整齐齐地分享在[他的技术博客](http://www.brendangregg.com/)上,可以说他是一个非常高产的技术大牛。
|
总体上,他已经在系统性能领域深耕超过 10 年,[Brendan Gregg 的过往履历](https://www.linkedin.com/in/brendangregg/)可以在 linkedin 上看到。在这 10 年间,除了书籍以外,Brendan Gregg 还产出了超过上百份和系统性能相关的技术文档,演讲视频/ppt,还有各种工具软件,相关内容都整整齐齐地分享在[他的技术博客](http://www.brendangregg.com/)上,可以说他是一个非常高产的技术大牛。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
上图来自 Brendan Gregg 的新书《BPF Performance Tools: Linux System and Application Observability》。从这个图可以看出,Brendan Gregg 对系统性能领域的掌握程度,已经深挖到了硬件、操作系统和应用的每一个角落,可以说是 360 度无死角,整个计算机系统对他来说几乎都是透明的。波波认为,Brendan Gregg 是名副其实的,世界级的,系统性能领域的大神级人物。
|
上图来自 Brendan Gregg 的新书《BPF Performance Tools: Linux System and Application Observability》。从这个图可以看出,Brendan Gregg 对系统性能领域的掌握程度,已经深挖到了硬件、操作系统和应用的每一个角落,可以说是 360 度无死角,整个计算机系统对他来说几乎都是透明的。波波认为,Brendan Gregg 是名副其实的,世界级的,系统性能领域的大神级人物。
|
||||||
|
|
||||||
@ -52,7 +52,7 @@ Brendan Gregg 之前是 Netflix 公司的高级性能架构师,在 Netflix 工
|
|||||||
|
|
||||||
到 2014 年底,Kafka 在社区已经非常成功,有了一个比较大的用户群,于是 Jay Kreps 就和几个早期作者一起离开了 Linkedin,成立了[Confluent 公司](https://tech.163.com/14/1107/18/AAFG92LD00094ODU.html),开始了 Kafka 和周边产品的企业化服务道路。今年(2020.4 月),Confluent 公司已经获得 E 轮 2.5 亿美金融资,公司估值达到 45 亿美金。从 Kafka 诞生到现在,Jay Kreps 差不多在这个产品和公司上投入了整整 10 年。
|
到 2014 年底,Kafka 在社区已经非常成功,有了一个比较大的用户群,于是 Jay Kreps 就和几个早期作者一起离开了 Linkedin,成立了[Confluent 公司](https://tech.163.com/14/1107/18/AAFG92LD00094ODU.html),开始了 Kafka 和周边产品的企业化服务道路。今年(2020.4 月),Confluent 公司已经获得 E 轮 2.5 亿美金融资,公司估值达到 45 亿美金。从 Kafka 诞生到现在,Jay Kreps 差不多在这个产品和公司上投入了整整 10 年。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
上图是 Confluent 创始人三人组,一个非常有意思的组合,一个中国人(左),一个印度人(右),中间的 Jay Kreps 是美国人。
|
上图是 Confluent 创始人三人组,一个非常有意思的组合,一个中国人(左),一个印度人(右),中间的 Jay Kreps 是美国人。
|
||||||
|
|
||||||
@ -64,11 +64,11 @@ Brendan Gregg 之前是 Netflix 公司的高级性能架构师,在 Netflix 工
|
|||||||
|
|
||||||
介绍到这里,有些同学可能会反驳说:波波你讲的这些大牛都是学历背景好,功底扎实起点高,所以他们才更能成功。其实不然,这里我再要介绍一位技术媒体界的大 V 叫 Brad Traversy,大家可以看[他的 Linkedin 简历](https://www.linkedin.com/in/bradtraversy/),背景很一般,学历差不多是一个非正规的社区大学(相当于大专),没有正规大厂工作经历,有限几份工作一直是在做网站外包。
|
介绍到这里,有些同学可能会反驳说:波波你讲的这些大牛都是学历背景好,功底扎实起点高,所以他们才更能成功。其实不然,这里我再要介绍一位技术媒体界的大 V 叫 Brad Traversy,大家可以看[他的 Linkedin 简历](https://www.linkedin.com/in/bradtraversy/),背景很一般,学历差不多是一个非正规的社区大学(相当于大专),没有正规大厂工作经历,有限几份工作一直是在做网站外包。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
但是!!!Brad Traversy 目前是技术媒体领域的一个大 V,当前[他在 Youtube 上的频道](https://www.youtube.com/c/TraversyMedia)有 138 万多的订阅量,10 年累计输出 Web 开发和编程相关教学视频超过 800 个。Brad Traversy 也是 [Udemy](https://www.udemy.com/user/brad-traversy/) 上的一个成功讲师,目前已经在 Udemy 上累计输出课程 19 门,购课学生数量近 42 万。
|
但是!!!Brad Traversy 目前是技术媒体领域的一个大 V,当前[他在 Youtube 上的频道](https://www.youtube.com/c/TraversyMedia)有 138 万多的订阅量,10 年累计输出 Web 开发和编程相关教学视频超过 800 个。Brad Traversy 也是 [Udemy](https://www.udemy.com/user/brad-traversy/) 上的一个成功讲师,目前已经在 Udemy 上累计输出课程 19 门,购课学生数量近 42 万。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Brad Traversy 目前是自由职业者,他的 Youtube 广告+Udemy 课程的收入相当不错。
|
Brad Traversy 目前是自由职业者,他的 Youtube 广告+Udemy 课程的收入相当不错。
|
||||||
|
|
||||||
@ -76,7 +76,7 @@ Brad Traversy 目前是自由职业者,他的 Youtube 广告+Udemy 课程的
|
|||||||
|
|
||||||
到结婚后的第一个孩子诞生,他才开始担起责任做出改变,然后凭借对技术的一腔热情,开始在 Youtube 平台上持续输出免费课程。从此他找到了适合自己的战略目标,然后人生开始发生各种积极的变化。。。如果大家对 Brad Traversy 的过往经历感兴趣,推荐观看他在 Youtube 上的自述视频[《My Struggles & Success》](https://www.youtube.com/watch?v=zA9krklwADI)。
|
到结婚后的第一个孩子诞生,他才开始担起责任做出改变,然后凭借对技术的一腔热情,开始在 Youtube 平台上持续输出免费课程。从此他找到了适合自己的战略目标,然后人生开始发生各种积极的变化。。。如果大家对 Brad Traversy 的过往经历感兴趣,推荐观看他在 Youtube 上的自述视频[《My Struggles & Success》](https://www.youtube.com/watch?v=zA9krklwADI)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
我粗略浏览了[Brad Traversy 在 Youtube 上的所有视频](https://www.youtube.com/c/TraversyMedia/videos),10 年总计输出 800+视频,平均每年 80+。第一个视频提交于 2010 年 8 月,刚开始几年几乎没有订阅量,2017 年 1 月订阅量才到 50k,这中间差不多隔了 6 年。2017.10 月订阅量猛增到 200k,2018 年 3 月订阅量到 300k。当前 2021.1 月,订阅量达到 138 万。可以认为从 2017 开始,也就是在积累了 6 ~ 7 年后,他的订阅量开始出现拐点。**如果把这些数据画出来,将会是一条非常漂亮的复利曲线**。
|
我粗略浏览了[Brad Traversy 在 Youtube 上的所有视频](https://www.youtube.com/c/TraversyMedia/videos),10 年总计输出 800+视频,平均每年 80+。第一个视频提交于 2010 年 8 月,刚开始几年几乎没有订阅量,2017 年 1 月订阅量才到 50k,这中间差不多隔了 6 年。2017.10 月订阅量猛增到 200k,2018 年 3 月订阅量到 300k。当前 2021.1 月,订阅量达到 138 万。可以认为从 2017 开始,也就是在积累了 6 ~ 7 年后,他的订阅量开始出现拐点。**如果把这些数据画出来,将会是一条非常漂亮的复利曲线**。
|
||||||
|
|
||||||
@ -108,13 +108,13 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
|
|||||||
|
|
||||||
普通人通常走一步算一步,很少长远规划。牛人通 常是先有远大目标,然后采用倒推法,将大目标细化到每年/月/周的详细落地计划。Brendan Gregg,Jay Kreps 和 Brad Traversy 三人都是以终为始的典型。
|
普通人通常走一步算一步,很少长远规划。牛人通 常是先有远大目标,然后采用倒推法,将大目标细化到每年/月/周的详细落地计划。Brendan Gregg,Jay Kreps 和 Brad Traversy 三人都是以终为始的典型。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
上面总结了几位技术大牛的成长模式,其中一个重点就是:这些大牛的成长都是通过 **持续有价值产出(Persistent Valuable Output)** 来驱动的。持续产出为啥如此重要,这个还要从下面的学习金字塔说起。
|
上面总结了几位技术大牛的成长模式,其中一个重点就是:这些大牛的成长都是通过 **持续有价值产出(Persistent Valuable Output)** 来驱动的。持续产出为啥如此重要,这个还要从下面的学习金字塔说起。
|
||||||
|
|
||||||
## 三、学习金字塔和刻意训练
|
## 三、学习金字塔和刻意训练
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
学习金字塔是美国缅因州国家训练实验室的研究成果,它认为:
|
学习金字塔是美国缅因州国家训练实验室的研究成果,它认为:
|
||||||
|
|
||||||
@ -134,11 +134,11 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
|
|||||||
|
|
||||||
明白这个道理之后,心智成熟和自律的人就会对自己进行持续地 **刻意训练** 。这个刻意训练包括对身体的训练,比如波波现在每天坚持跑步 3km,走 3km,每天做 60 个仰卧起坐,5 分钟平板撑等等,每天保持让身体燃烧一定量的卡路里。刻意训练也包括对大脑的训练,比如波波现在每天做项目写代码 coding(训练脑+手),平均每天在 B 站上输出十分钟免费视频(训练脑+口头表达),另外有定期总结输出公众号文章(训练脑+文字表达),还有每天打半小时左右的平衡球(下图)或古墓丽影游戏(训练小脑+手),每天保持让大脑燃烧一定量的卡路里,并保持一定强度(适度不适感)。
|
明白这个道理之后,心智成熟和自律的人就会对自己进行持续地 **刻意训练** 。这个刻意训练包括对身体的训练,比如波波现在每天坚持跑步 3km,走 3km,每天做 60 个仰卧起坐,5 分钟平板撑等等,每天保持让身体燃烧一定量的卡路里。刻意训练也包括对大脑的训练,比如波波现在每天做项目写代码 coding(训练脑+手),平均每天在 B 站上输出十分钟免费视频(训练脑+口头表达),另外有定期总结输出公众号文章(训练脑+文字表达),还有每天打半小时左右的平衡球(下图)或古墓丽影游戏(训练小脑+手),每天保持让大脑燃烧一定量的卡路里,并保持一定强度(适度不适感)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
关于刻意训练的专业原理和方法论,推荐看书籍《刻意练习》。
|
关于刻意训练的专业原理和方法论,推荐看书籍《刻意练习》。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
注意,如果你平时从来不做举重锻炼的,那么某天突然做举重会很不适应甚至受伤。脑部训练也是一样的,如果你从来没有做过视频输出,那么刚开始做会很不适应,做出来的视频质量会很差。不过没有关系,任何训练都是一个循序渐进,不断强化的过程。等大脑相关区域的"肌肉"长出来以后,会逐步进入正循环,后面会越来越顺畅,相关"肌肉"会越来越发达。所以,和健身一样,健脑也不能遇到困难就放弃,需要循序渐进(Incremental)+持续地(Persistent)刻意训练。
|
注意,如果你平时从来不做举重锻炼的,那么某天突然做举重会很不适应甚至受伤。脑部训练也是一样的,如果你从来没有做过视频输出,那么刚开始做会很不适应,做出来的视频质量会很差。不过没有关系,任何训练都是一个循序渐进,不断强化的过程。等大脑相关区域的"肌肉"长出来以后,会逐步进入正循环,后面会越来越顺畅,相关"肌肉"会越来越发达。所以,和健身一样,健脑也不能遇到困难就放弃,需要循序渐进(Incremental)+持续地(Persistent)刻意训练。
|
||||||
|
|
||||||
@ -148,7 +148,7 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
|
|||||||
|
|
||||||
## 四、战略思维的诞生
|
## 四、战略思维的诞生
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
一般毕业生刚进入企业工作的时候,思考大都是以天/星期/月为单位的,基本上都是今天学个什么技术,明天学个什么语言,很少会去思考一年甚至更长的目标。这是个眼前漆黑看不到的懵懂时期,捕捉到机会点的能力和概率都非常小。
|
一般毕业生刚进入企业工作的时候,思考大都是以天/星期/月为单位的,基本上都是今天学个什么技术,明天学个什么语言,很少会去思考一年甚至更长的目标。这是个眼前漆黑看不到的懵懂时期,捕捉到机会点的能力和概率都非常小。
|
||||||
|
|
||||||
@ -204,4 +204,4 @@ Brendan Gregg,Jay Kreps 和 Brad Traversy 三个人走的技术路线各不相
|
|||||||
>
|
>
|
||||||
> 实现战略目标,就像种树一样。刚开始只是一个小根芽,树干还没有长出来;树干长出来了,枝叶才能慢慢长出来;树枝长出来,然后才能开花和结果。刚开始种树的时候,只管栽培灌溉,别老是纠结枝什么时候长出来,花什么时候开,果实什么时候结出来。纠结有什么好处呢?只要你坚持投入栽培,还怕没有枝叶花实吗?
|
> 实现战略目标,就像种树一样。刚开始只是一个小根芽,树干还没有长出来;树干长出来了,枝叶才能慢慢长出来;树枝长出来,然后才能开花和结果。刚开始种树的时候,只管栽培灌溉,别老是纠结枝什么时候长出来,花什么时候开,果实什么时候结出来。纠结有什么好处呢?只要你坚持投入栽培,还怕没有枝叶花实吗?
|
||||||
|
|
||||||

|

|
||||||
@ -9,11 +9,10 @@ title: JavaGuide(Java学习&&面试指南)
|
|||||||
- **转载须知** :以下所有文章如非文首说明为转载皆为 JavaGuide 原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
- **转载须知** :以下所有文章如非文首说明为转载皆为 JavaGuide 原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!
|
||||||
:::
|
:::
|
||||||
|
|
||||||
|
|
||||||
<div align="center">
|
<div align="center">
|
||||||
<p>
|
<p>
|
||||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||||
<img src="https://img-blog.csdnimg.cn/img_convert/1c00413c65d1995993bf2b0daf7b4f03.png#pic_center" width="" />
|
<img src="https://guide-blog-images.oss-cn-shenzhen.aliyuncs.com/github/javaguide/csdn/1c00413c65d1995993bf2b0daf7b4f03.png" width="" />
|
||||||
</a>
|
</a>
|
||||||
</p>
|
</p>
|
||||||
<p>
|
<p>
|
||||||
@ -28,6 +27,7 @@ title: JavaGuide(Java学习&&面试指南)
|
|||||||
</p>
|
</p>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
|
||||||
<div style="text-align:center">
|
<div style="text-align:center">
|
||||||
<p>
|
<p>
|
||||||
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
<a href="https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html">
|
||||||
|
|||||||
@ -49,7 +49,7 @@ Github 或者码云上面有很多实战类别项目,你可以选择一个来
|
|||||||
|
|
||||||
如果参加这种赛事能获奖的话,项目含金量非常高。即使没获奖也没啥,也可以写简历上。
|
如果参加这种赛事能获奖的话,项目含金量非常高。即使没获奖也没啥,也可以写简历上。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 参与实际项目
|
### 参与实际项目
|
||||||
|
|
||||||
|
|||||||
@ -57,39 +57,19 @@ category: 知识星球
|
|||||||
|
|
||||||
## 知道如何获取招聘信息
|
## 知道如何获取招聘信息
|
||||||
|
|
||||||
**1、目标企业的官网/公众号**
|
下面是常见的获取招聘信息的渠道:
|
||||||
|
|
||||||
最及时最权威的获取秋招信息的途径。
|
- **目标企业的官网/公众号** :最及时最权威的获取招聘信息的途径。
|
||||||
|
- **招聘网站** :[BOSS 直聘](https://www.zhipin.com/)、[智联招聘](https://www.zhaopin.com/)、[拉勾招聘](https://www.lagou.com/)......。
|
||||||
|
- **牛客网** :每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。地址:https://www.nowcoder.com/jobs/recommend/campus 。
|
||||||
|
- **超级简历** :超级简历目前整合了各大企业的校园招聘入口,地址:https://www.wondercv.com/jobs/。如果你是校招的话,点击“校招网申”就可以直接跳转到各大企业的校园招聘入口的整合页面了。
|
||||||
|
- **认识的朋友** :如果你有认识的朋友在目标企业工作的话,你也可以找他们了解招聘信息,并且可以让他们帮你内推。
|
||||||
|
- **宣讲会** :宣讲会也是一个不错的途径,不过,好的企业通常只会去比较好的学校,可以留意一下意向公司的宣讲会安排或者直接去到一所比较好的学校参加宣讲会。像我当时校招就去参加了几场宣讲会。不过,我是在荆州上学,那边没什么比较好的学校,一般没有公司去开宣讲会。所以,我当时是直接跑到武汉来了,参加了武汉理工大学以及华中科技大学的几场宣讲会。总体感觉还是很不错的!
|
||||||
|
- **其他** :校园就业信息网、学校论坛、班级 or 年级 QQ 群。
|
||||||
|
|
||||||
**2、招聘网站**
|
校招的话,建议以官网为准,有宣讲会、靠谱一点的内推的话更好。社招的话,可以多留意一下各大招聘网站比如 BOSS直聘、拉勾上的职位信息,也可以找被熟人内推,获得面试机会的概率更大一些,进度一般也更快一些。
|
||||||
|
|
||||||
[BOSS 直聘](https://www.zhipin.com/)、[智联招聘](https://www.zhaopin.com/)、[拉勾招聘](https://www.lagou.com/)......。
|
一般是只能投递一个岗位,不过,也有极少数投递不同部门两个岗位的情况,这个应该不会有影响,但你的前一次面试情况可能会被记录,也就是说就算你投递成功两个岗位,第一个岗位面试失败的话,对第二个岗位也会有影响,很可能直接就被pass。
|
||||||
|
|
||||||
**3、牛客网**
|
|
||||||
|
|
||||||
每年秋招/春招,都会有大批量的公司会到牛客网发布招聘信息,并且还会有大量的公司员工来到这里发内推的帖子。
|
|
||||||
|
|
||||||
地址:https://www.nowcoder.com/jobs/recommend/campus 。
|
|
||||||
|
|
||||||
**4、超级简历**
|
|
||||||
|
|
||||||
超级简历目前整合了各大企业的校园招聘入口,地址:https://www.wondercv.com/jobs/。
|
|
||||||
|
|
||||||
如果你是校招的话,点击“校招网申”就可以直接跳转到各大企业的校园招聘入口的整合页面了。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**5、认识的朋友**
|
|
||||||
|
|
||||||
如果你有认识的朋友在目标企业工作的话,你也可以找他们了解秋招信息,并且可以让他们帮你内推。
|
|
||||||
|
|
||||||
**6、宣讲会现场**
|
|
||||||
|
|
||||||
Guide 当时也参加了几场宣讲会。不过,我是在荆州上学,那边没什么比较好的学校,一般没有公司去开宣讲会。所以,我当时是直接跑到武汉来了,参加了武汉理工大学以及华中科技大学的几场宣讲会。总体感觉还是很不错的!
|
|
||||||
|
|
||||||
**7、其他**
|
|
||||||
|
|
||||||
校园就业信息网、学校论坛、班级 or 年级 QQ 群
|
|
||||||
|
|
||||||
## 多花点时间完善简历
|
## 多花点时间完善简历
|
||||||
|
|
||||||
@ -99,15 +79,15 @@ Guide 当时也参加了几场宣讲会。不过,我是在荆州上学,那
|
|||||||
|
|
||||||
**1.个人介绍没太多实用的信息。**
|
**1.个人介绍没太多实用的信息。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
技术博客、Github 以及在校获奖经历的话,能写就尽量写在这里。 你可以参考下面 👇 的模板进行修改:
|
技术博客、Github 以及在校获奖经历的话,能写就尽量写在这里。 你可以参考下面 👇 的模板进行修改:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**2.项目经历过于简单,完全没有质量可言**
|
**2.项目经历过于简单,完全没有质量可言**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
每一个项目经历真的就一两句话可以描述了么?还是自己不想写?还是说不是自己做的,不敢多写。
|
每一个项目经历真的就一两句话可以描述了么?还是自己不想写?还是说不是自己做的,不敢多写。
|
||||||
|
|
||||||
@ -122,11 +102,11 @@ Guide 当时也参加了几场宣讲会。不过,我是在荆州上学,那
|
|||||||
|
|
||||||
**3.计算机二级这个证书对于计算机专业完全不用写了,没有含金量的。**
|
**3.计算机二级这个证书对于计算机专业完全不用写了,没有含金量的。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**4.技能介绍问题太大。**
|
**4.技能介绍问题太大。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- 技术名词最好规范大小写比较好,比如 java->Java ,spring boot -> Spring Boot 。这个虽然有些面试官不会介意,但是很多面试官都会在意这个细节的。
|
- 技术名词最好规范大小写比较好,比如 java->Java ,spring boot -> Spring Boot 。这个虽然有些面试官不会介意,但是很多面试官都会在意这个细节的。
|
||||||
- 技能介绍太杂,没有亮点。不需要全才,某个领域做得好就行了!
|
- 技能介绍太杂,没有亮点。不需要全才,某个领域做得好就行了!
|
||||||
@ -196,7 +176,7 @@ Guide 当时也参加了几场宣讲会。不过,我是在荆州上学,那
|
|||||||
- 降级
|
- 降级
|
||||||
- 熔断
|
- 熔断
|
||||||
|
|
||||||
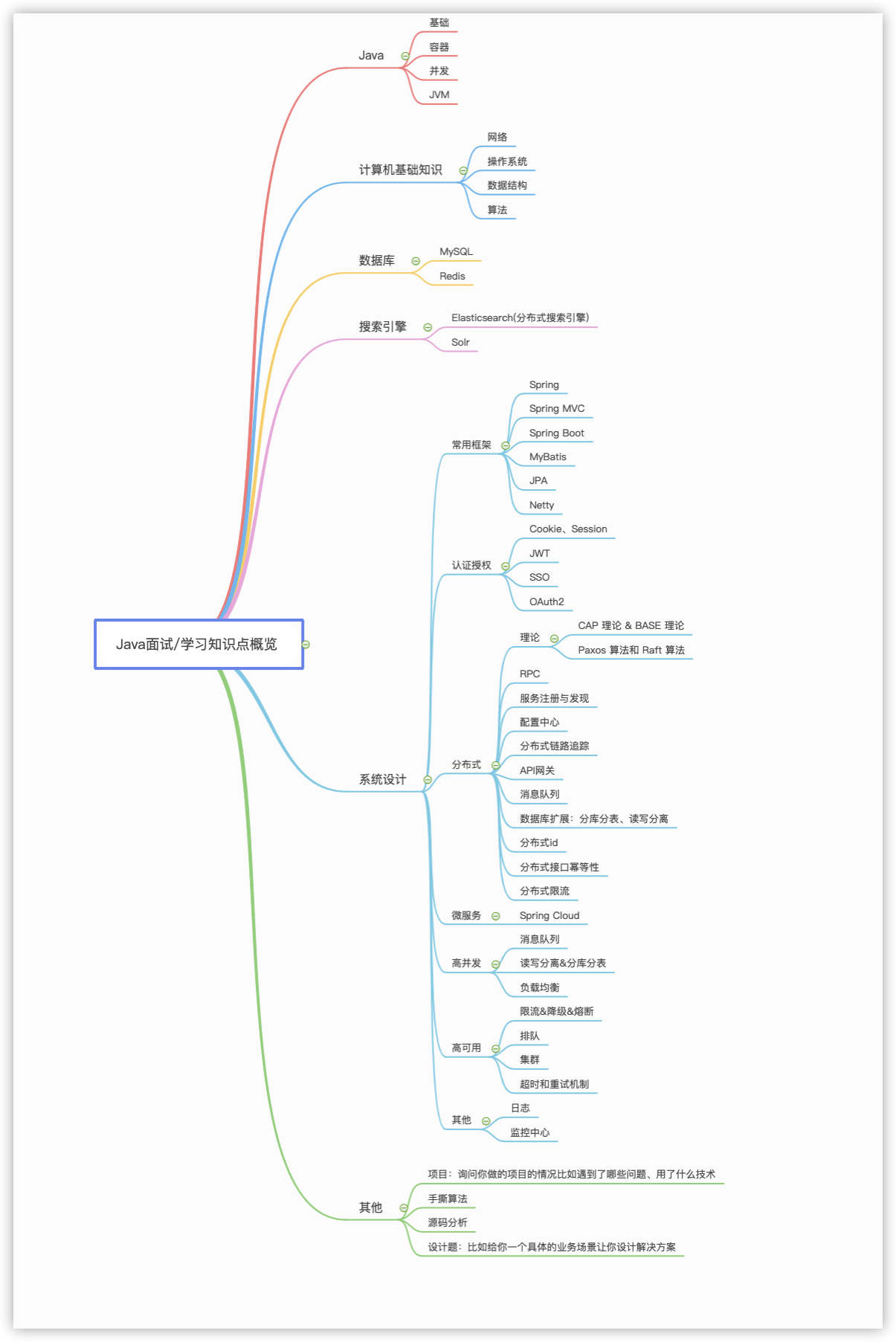
|

|
||||||
|
|
||||||
不同类型的公司对于技能的要求侧重点是不同的比如腾讯、字节可能更重视计算机基础比如网络、操作系统这方面的内容。阿里、美团这种可能更重视你的项目经历、实战能力。
|
不同类型的公司对于技能的要求侧重点是不同的比如腾讯、字节可能更重视计算机基础比如网络、操作系统这方面的内容。阿里、美团这种可能更重视你的项目经历、实战能力。
|
||||||
|
|
||||||
|
|||||||
@ -761,7 +761,7 @@ System.out.println(i1==i2);
|
|||||||
|
|
||||||
记住:**所有整型包装类对象之间值的比较,全部使用 equals 方法比较**。
|
记住:**所有整型包装类对象之间值的比较,全部使用 equals 方法比较**。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 自动装箱与拆箱了解吗?原理是什么?
|
### 自动装箱与拆箱了解吗?原理是什么?
|
||||||
|
|
||||||
|
|||||||
@ -535,7 +535,7 @@ randomAccessFile.write(new byte[]{'H', 'I', 'J', 'K'});
|
|||||||
|
|
||||||
`RandomAccessFile` 可以帮助我们合并文件分片,示例代码如下:
|
`RandomAccessFile` 可以帮助我们合并文件分片,示例代码如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
我在[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中详细介绍了大文件的上传问题。
|
我在[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中详细介绍了大文件的上传问题。
|
||||||
|
|
||||||
|
|||||||
@ -25,7 +25,7 @@ I/O(**I**nput/**O**utpu) 即**输入/输出** 。
|
|||||||
|
|
||||||
根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。
|
根据冯.诺依曼结构,计算机结构分为 5 大部分:运算器、控制器、存储器、输入设备、输出设备。
|
||||||
|
|
||||||
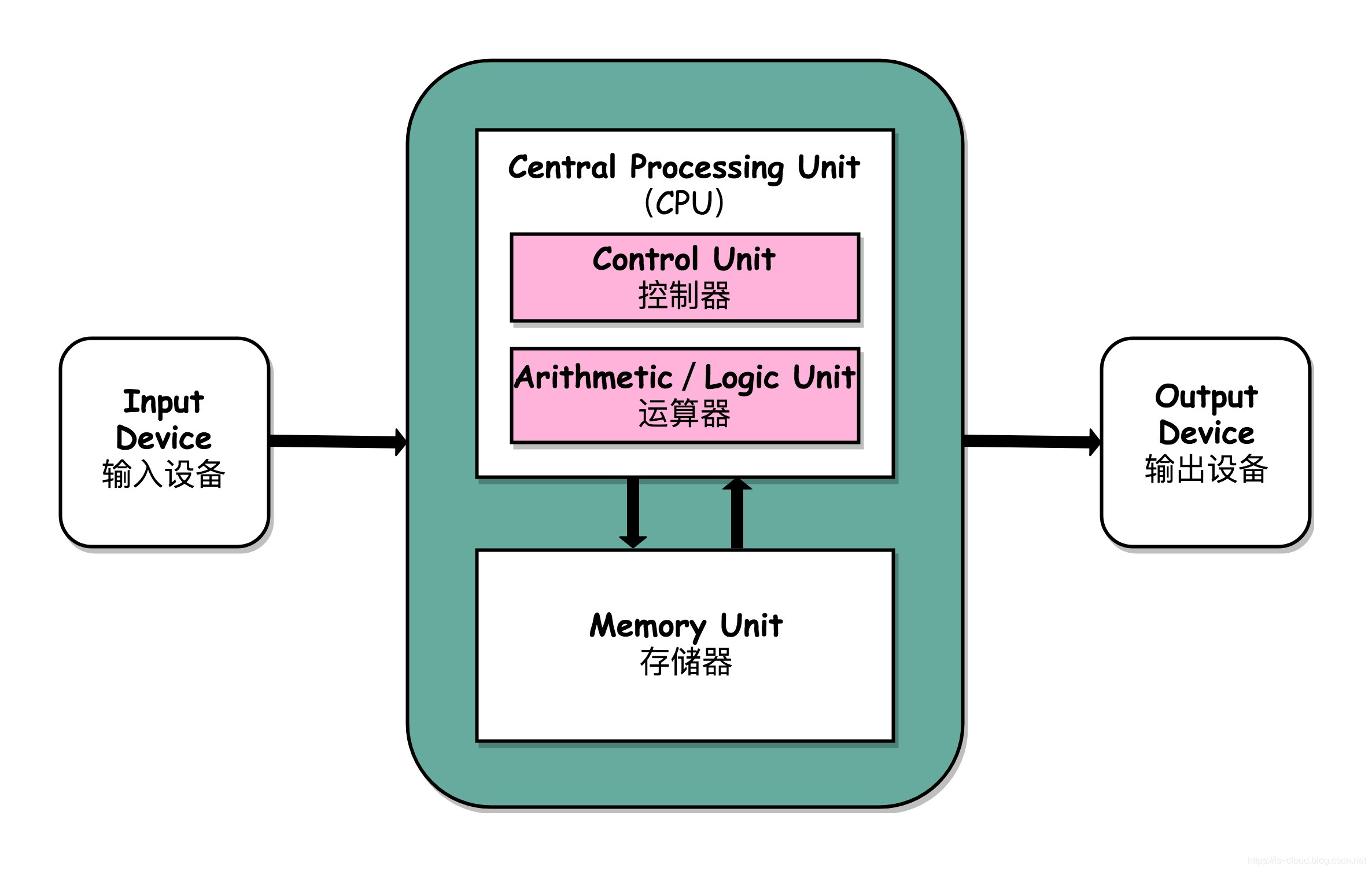
|

|
||||||
|
|
||||||
输入设备(比如键盘)和输出设备(比如显示器)都属于外部设备。网卡、硬盘这种既可以属于输入设备,也可以属于输出设备。
|
输入设备(比如键盘)和输出设备(比如显示器)都属于外部设备。网卡、硬盘这种既可以属于输入设备,也可以属于输出设备。
|
||||||
|
|
||||||
|
|||||||
@ -1,12 +1,11 @@
|
|||||||
---
|
---
|
||||||
|
title: 类文件结构详解
|
||||||
category: Java
|
category: Java
|
||||||
tag:
|
tag:
|
||||||
- JVM
|
- JVM
|
||||||
---
|
---
|
||||||
|
|
||||||
# 类文件结构详解
|
## 回顾一下字节码
|
||||||
|
|
||||||
## 一 概述
|
|
||||||
|
|
||||||
在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
||||||
|
|
||||||
@ -16,7 +15,7 @@ Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行
|
|||||||
|
|
||||||
可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。
|
可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。
|
||||||
|
|
||||||
## 二 Class 文件结构总结
|
## Class 文件结构总结
|
||||||
|
|
||||||
根据 Java 虚拟机规范,Class 文件通过 `ClassFile` 定义,有点类似 C 语言的结构体。
|
根据 Java 虚拟机规范,Class 文件通过 `ClassFile` 定义,有点类似 C 语言的结构体。
|
||||||
|
|
||||||
@ -45,7 +44,7 @@ ClassFile {
|
|||||||
|
|
||||||
通过分析 `ClassFile` 的内容,我们便可以知道 class 文件的组成。
|
通过分析 `ClassFile` 的内容,我们便可以知道 class 文件的组成。
|
||||||
|
|
||||||
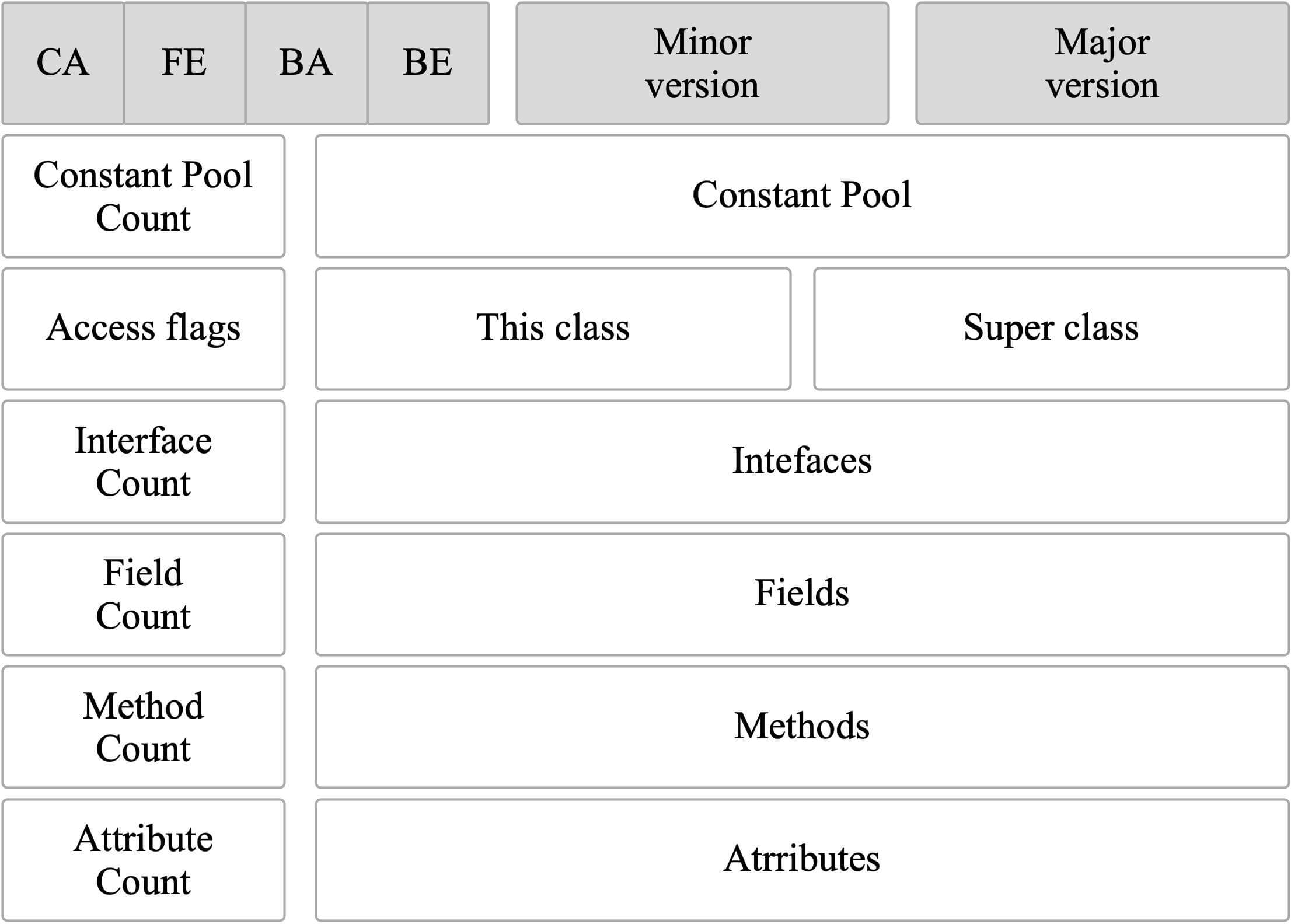
|

|
||||||
|
|
||||||
下面这张图是通过 IDEA 插件 `jclasslib` 查看的,你可以更直观看到 Class 文件结构。
|
下面这张图是通过 IDEA 插件 `jclasslib` 查看的,你可以更直观看到 Class 文件结构。
|
||||||
|
|
||||||
@ -55,7 +54,7 @@ ClassFile {
|
|||||||
|
|
||||||
下面详细介绍一下 Class 文件结构涉及到的一些组件。
|
下面详细介绍一下 Class 文件结构涉及到的一些组件。
|
||||||
|
|
||||||
### 2.1 魔数(Magic Number)
|
### 魔数(Magic Number)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u4 magic; //Class 文件的标志
|
u4 magic; //Class 文件的标志
|
||||||
@ -65,7 +64,7 @@ ClassFile {
|
|||||||
|
|
||||||
程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
|
程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
|
||||||
|
|
||||||
### 2.2 Class 文件版本号(Minor&Major Version)
|
### Class 文件版本号(Minor&Major Version)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 minor_version;//Class 的小版本号
|
u2 minor_version;//Class 的小版本号
|
||||||
@ -78,7 +77,7 @@ ClassFile {
|
|||||||
|
|
||||||
高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
|
高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
|
||||||
|
|
||||||
### 2.3 常量池(Constant Pool)
|
### 常量池(Constant Pool)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 constant_pool_count;//常量池的数量
|
u2 constant_pool_count;//常量池的数量
|
||||||
@ -114,7 +113,11 @@ ClassFile {
|
|||||||
|
|
||||||
`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
|
`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
|
||||||
|
|
||||||
### 2.4 访问标志(Access Flags)
|
### 访问标志(Access Flags)
|
||||||
|
|
||||||
|
```java
|
||||||
|
u2 access_flags;//Class 的访问标记
|
||||||
|
```
|
||||||
|
|
||||||
在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 `public` 或者 `abstract` 类型,如果是类的话是否声明为 `final` 等等。
|
在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 `public` 或者 `abstract` 类型,如果是类的话是否声明为 `final` 等等。
|
||||||
|
|
||||||
@ -122,7 +125,7 @@ ClassFile {
|
|||||||
|
|
||||||
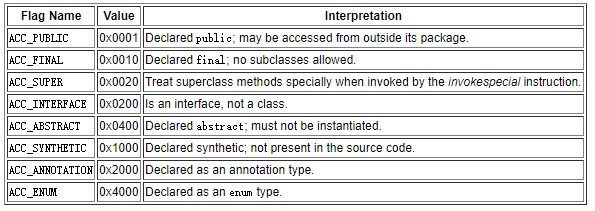
|

|
||||||
|
|
||||||
我们定义了一个 Employee 类
|
我们定义了一个 `Employee` 类
|
||||||
|
|
||||||
```java
|
```java
|
||||||
package top.snailclimb.bean;
|
package top.snailclimb.bean;
|
||||||
@ -135,7 +138,7 @@ public class Employee {
|
|||||||
|
|
||||||
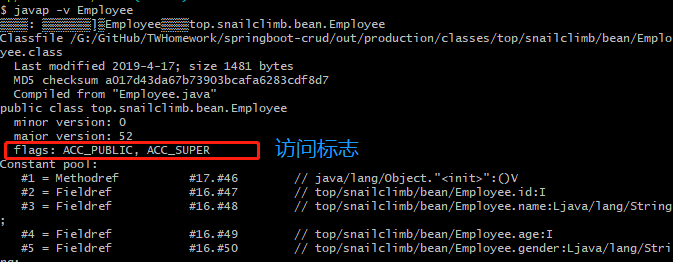
|

|
||||||
|
|
||||||
### 2.5 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合
|
### 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 this_class;//当前类
|
u2 this_class;//当前类
|
||||||
@ -144,11 +147,13 @@ public class Employee {
|
|||||||
u2 interfaces[interfaces_count];//一个类可以实现多个接口
|
u2 interfaces[interfaces_count];//一个类可以实现多个接口
|
||||||
```
|
```
|
||||||
|
|
||||||
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。
|
Java 类的继承关系由类索引、父类索引和接口索引集合三项确定。类索引、父类索引和接口索引集合按照顺序排在访问标志之后,
|
||||||
|
|
||||||
|
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 Java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。
|
||||||
|
|
||||||
接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。
|
接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。
|
||||||
|
|
||||||
### 2.6 字段表集合(Fields)
|
### 字段表集合(Fields)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 fields_count;//Class 文件的字段的个数
|
u2 fields_count;//Class 文件的字段的个数
|
||||||
@ -173,7 +178,7 @@ public class Employee {
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 2.7 方法表集合(Methods)
|
### 方法表集合(Methods)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 methods_count;//Class 文件的方法的数量
|
u2 methods_count;//Class 文件的方法的数量
|
||||||
@ -194,7 +199,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
|
|||||||
|
|
||||||
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
|
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
|
||||||
|
|
||||||
### 2.8 属性表集合(Attributes)
|
### 属性表集合(Attributes)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 attributes_count;//此类的属性表中的属性数
|
u2 attributes_count;//此类的属性表中的属性数
|
||||||
@ -205,7 +210,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
|
|||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- <https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html>
|
|
||||||
- <https://coolshell.cn/articles/9229.html>
|
|
||||||
- <https://blog.csdn.net/luanlouis/article/details/39960815>
|
|
||||||
- 《实战 Java 虚拟机》
|
- 《实战 Java 虚拟机》
|
||||||
|
- Chapter 4. The class File Format - Java Virtual Machine Specification:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-4.html
|
||||||
|
- 实例分析JAVA CLASS的文件结构:<https://coolshell.cn/articles/9229.html>
|
||||||
|
- 《Java虚拟机原理图解》 1.2.2、Class文件中的常量池详解(上):<https://blog.csdn.net/luanlouis/article/details/39960815>
|
||||||
|
|||||||
@ -119,7 +119,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
**JDK 8 版本之后 PermGen(永久) 已被 Metaspace(元空间) 取代,元空间使用的是直接内存** (我会在方法区这部分内容详细介绍到)。
|
**JDK 8 版本之后 PermGen(永久) 已被 Metaspace(元空间) 取代,元空间使用的是本地内存。** (我会在方法区这部分内容详细介绍到)。
|
||||||
|
|
||||||
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
|
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
|
||||||
|
|
||||||
@ -165,9 +165,9 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
|||||||
|
|
||||||
下图来自《深入理解 Java 虚拟机》第 3 版 2.2.5
|
下图来自《深入理解 Java 虚拟机》第 3 版 2.2.5
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
|
1、整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
|
||||||
|
|
||||||
> 当元空间溢出时会得到如下错误: `java.lang.OutOfMemoryError: MetaSpace`
|
> 当元空间溢出时会得到如下错误: `java.lang.OutOfMemoryError: MetaSpace`
|
||||||
|
|
||||||
@ -188,7 +188,7 @@ JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参
|
|||||||
|
|
||||||
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
|
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
|
||||||
|
|
||||||
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。下面是一些常用参数:
|
JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是本地内存。下面是一些常用参数:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
|
-XX:MetaspaceSize=N //设置 Metaspace 的初始(和最小大小)
|
||||||
@ -248,11 +248,17 @@ JDK1.7 之前,字符串常量池存放在永久代。JDK1.7 字符串常量池
|
|||||||
|
|
||||||
### 直接内存
|
### 直接内存
|
||||||
|
|
||||||
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
|
直接内存是一种特殊的内存缓冲区,并不在 Java 堆或方法区中分配的,而是通过 JNI 的方式在本地内存上分配的。
|
||||||
|
|
||||||
|
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 `OutOfMemoryError` 错误出现。
|
||||||
|
|
||||||
JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)**与**缓存区(Buffer)**的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
|
JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)**与**缓存区(Buffer)**的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
|
||||||
|
|
||||||
本机直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
||||||
|
|
||||||
|
类似的概念还有 **堆外内存** 。在一些文章中将直接内存等价于堆外内,个人觉得不是特别准确。
|
||||||
|
|
||||||
|
堆外内存就是把内存对象分配在堆(新生代+老年代+永久代)以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
|
||||||
|
|
||||||
## HotSpot 虚拟机对象探秘
|
## HotSpot 虚拟机对象探秘
|
||||||
|
|
||||||
|
|||||||
@ -9,7 +9,7 @@ tag:
|
|||||||
|
|
||||||
下面这张图是 Oracle 官方给出的 Oracle JDK 支持的时间线。
|
下面这张图是 Oracle 官方给出的 Oracle JDK 支持的时间线。
|
||||||
|
|
||||||
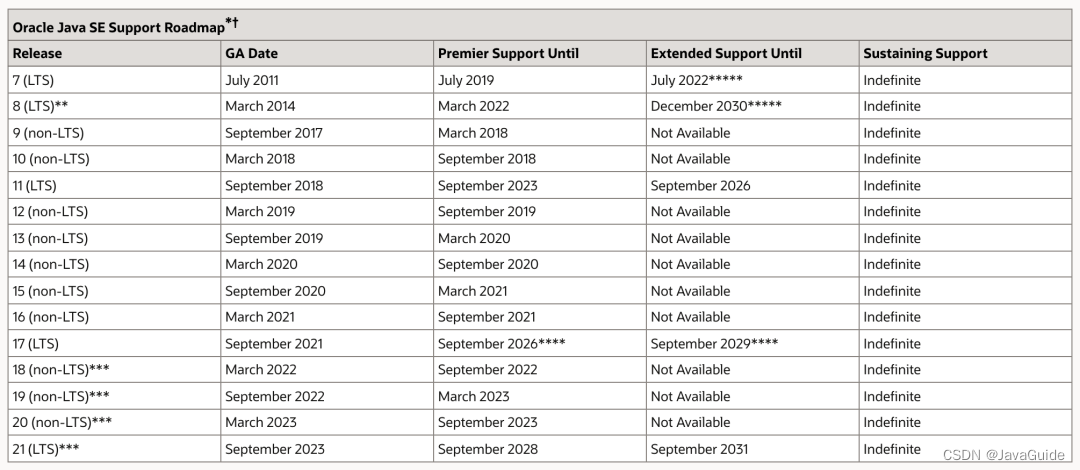
|

|
||||||
|
|
||||||
**概览(精选了一部分)** :
|
**概览(精选了一部分)** :
|
||||||
|
|
||||||
|
|||||||
@ -11,7 +11,7 @@ Java 17 在 2021 年 9 月 14 日正式发布,是一个长期支持(LTS)
|
|||||||
|
|
||||||
17 最多可以支持到 2029 年 9 月份。
|
17 最多可以支持到 2029 年 9 月份。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Java 17 将是继 Java 8 以来最重要的长期支持(LTS)版本,是 Java 社区八年努力的成果。Spring 6.x 和 Spring Boot 3.x 最低支持的就是 Java 17。
|
Java 17 将是继 Java 8 以来最重要的长期支持(LTS)版本,是 Java 社区八年努力的成果。Spring 6.x 和 Spring Boot 3.x 最低支持的就是 Java 17。
|
||||||
|
|
||||||
|
|||||||
@ -803,7 +803,7 @@ System.out.println(formatterOfYyyy.format(rightNow));
|
|||||||
|
|
||||||
从下图可以更清晰的看到具体的错误,并且 IDEA 已经智能地提示更倾向于使用 `yyyy` 而不是 `YYYY` 。
|
从下图可以更清晰的看到具体的错误,并且 IDEA 已经智能地提示更倾向于使用 `yyyy` 而不是 `YYYY` 。
|
||||||
|
|
||||||
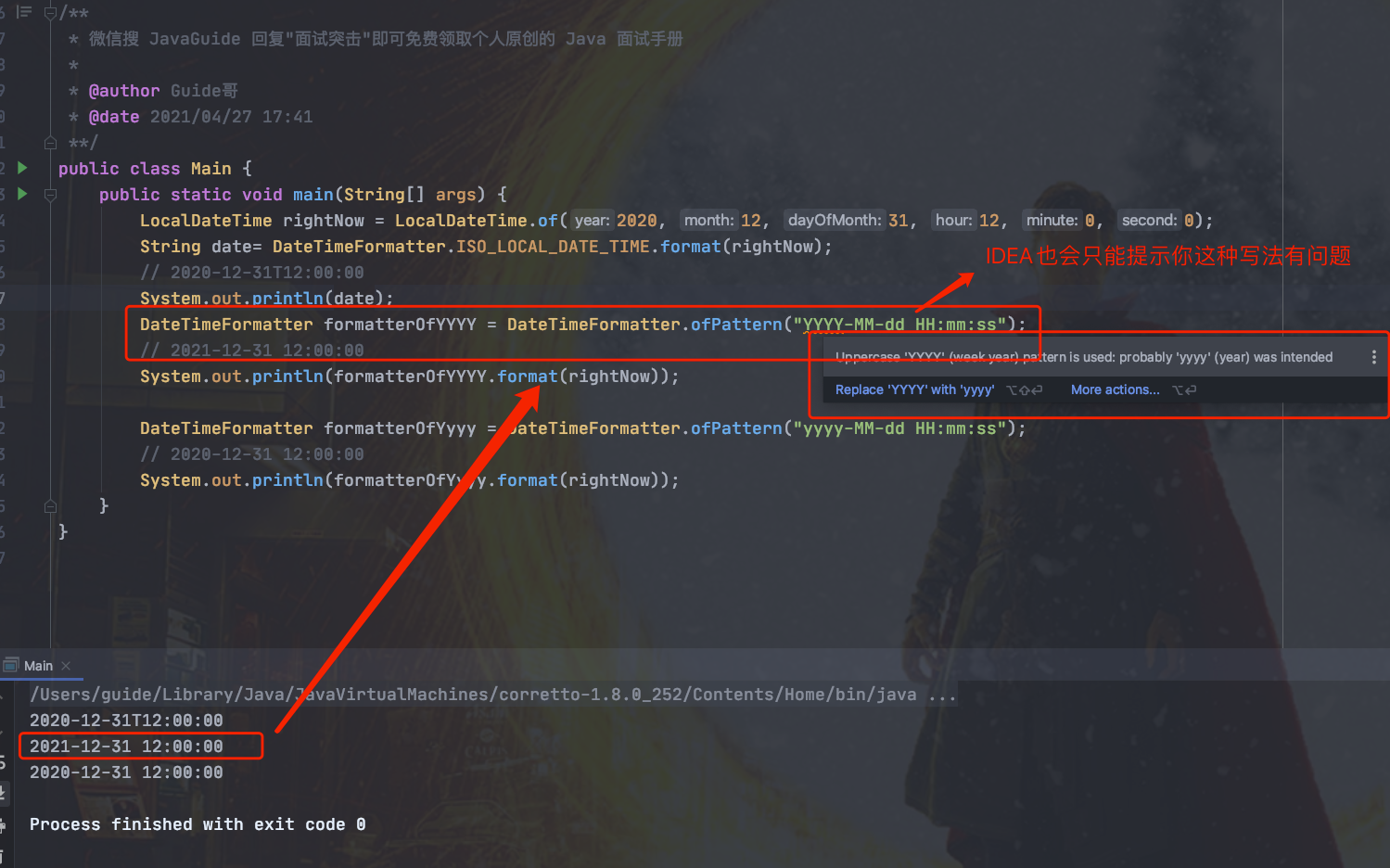
|

|
||||||
|
|
||||||
### LocalDateTime(本地日期时间)
|
### LocalDateTime(本地日期时间)
|
||||||
|
|
||||||
|
|||||||
@ -3,7 +3,7 @@ title: RestFul API 简明教程
|
|||||||
category: 代码质量
|
category: 代码质量
|
||||||
---
|
---
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这篇文章简单聊聊后端程序员必备的 RESTful API 相关的知识。
|
这篇文章简单聊聊后端程序员必备的 RESTful API 相关的知识。
|
||||||
|
|
||||||
@ -11,13 +11,13 @@ category: 代码质量
|
|||||||
|
|
||||||
## 何为 API?
|
## 何为 API?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**API(Application Programming Interface)** 翻译过来是应用程序编程接口的意思。
|
**API(Application Programming Interface)** 翻译过来是应用程序编程接口的意思。
|
||||||
|
|
||||||
我们在进行后端开发的时候,主要的工作就是为前端或者其他后端服务提供 API 比如查询用户数据的 API 。
|
我们在进行后端开发的时候,主要的工作就是为前端或者其他后端服务提供 API 比如查询用户数据的 API 。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
但是, API 不仅仅代表后端系统暴露的接口,像框架中提供的方法也属于 API 的范畴。
|
但是, API 不仅仅代表后端系统暴露的接口,像框架中提供的方法也属于 API 的范畴。
|
||||||
|
|
||||||
@ -66,7 +66,7 @@ POST /classes:新建一个班级
|
|||||||
|
|
||||||
## RESTful API 规范
|
## RESTful API 规范
|
||||||
|
|
||||||
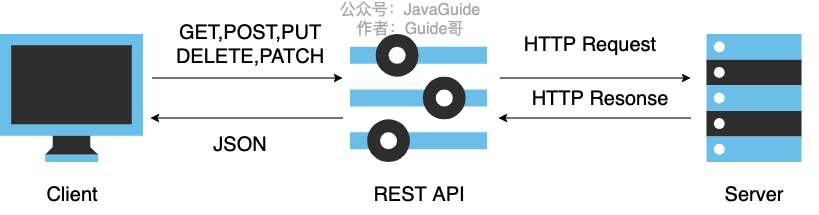
|

|
||||||
|
|
||||||
### 动作
|
### 动作
|
||||||
|
|
||||||
|
|||||||
@ -48,7 +48,7 @@ Dijkstra(Dijkstra算法的作者) 在 1972年图灵奖获奖感言中也提
|
|||||||
|
|
||||||
**瀑布模型** 定义了一套完成的软件开发周期,完整地展示了一个软件的的生命周期。
|
**瀑布模型** 定义了一套完成的软件开发周期,完整地展示了一个软件的的生命周期。
|
||||||
|
|
||||||
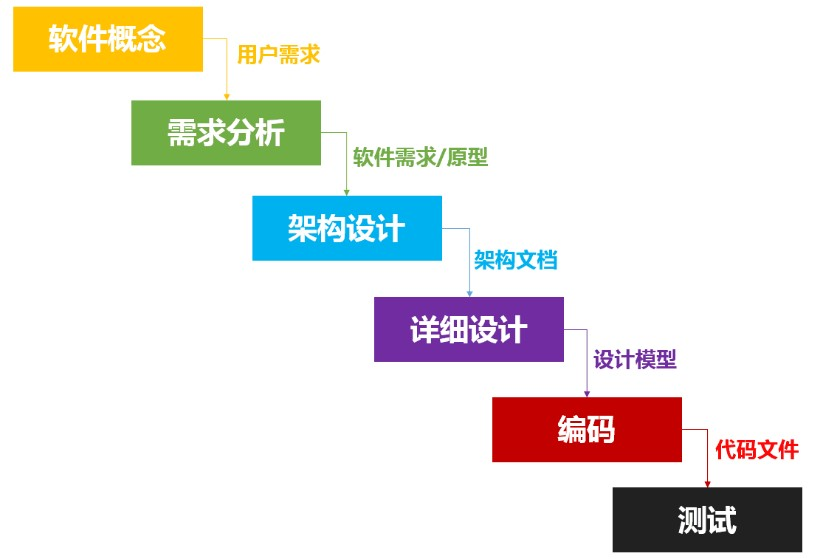
|
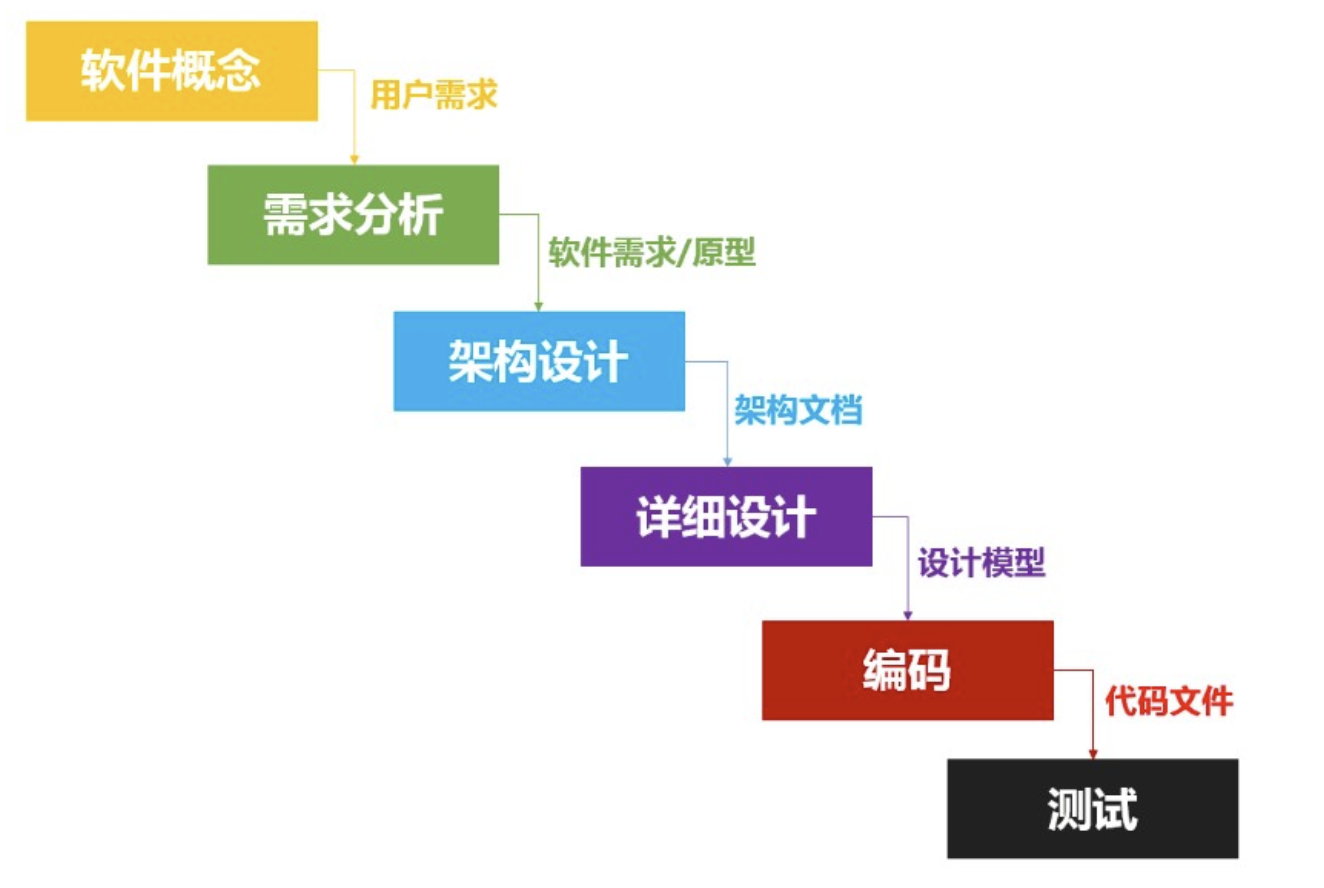
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -84,7 +84,7 @@ Dijkstra(Dijkstra算法的作者) 在 1972年图灵奖获奖感言中也提
|
|||||||
|
|
||||||
这个最小可行产品,可以理解为刚好能够满足客户需求的产品。下面这张图片把这个思想展示的非常精髓。
|
这个最小可行产品,可以理解为刚好能够满足客户需求的产品。下面这张图片把这个思想展示的非常精髓。
|
||||||
|
|
||||||
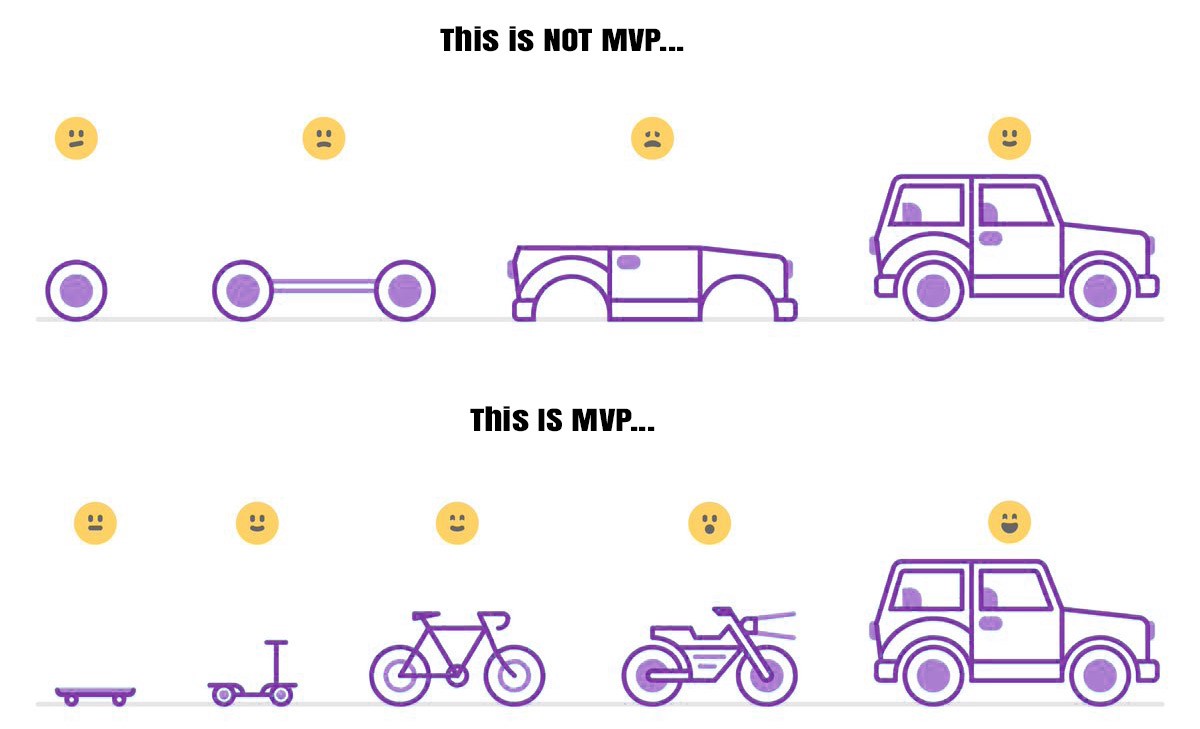
|
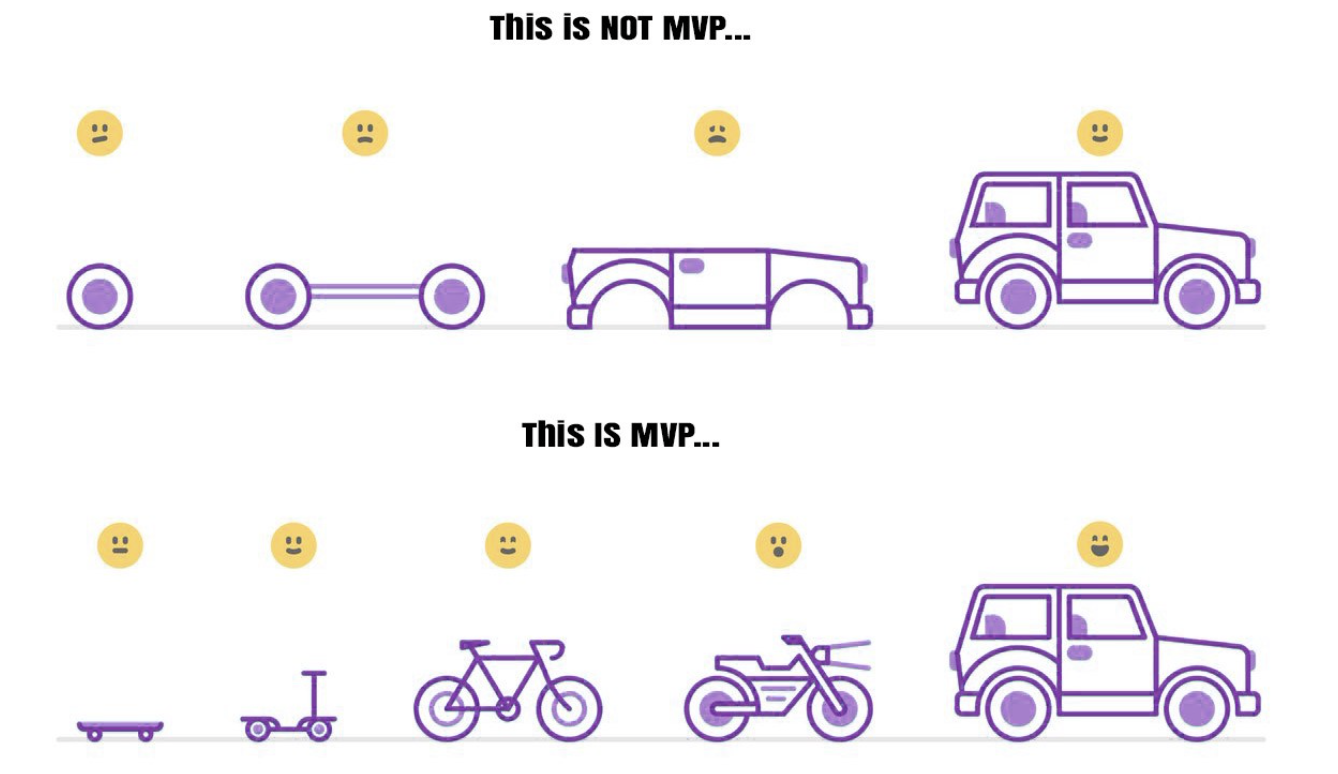
|
||||||
|
|
||||||
利用最小可行产品,我们可以也可以提早进行市场分析,这对于我们在探索产品不确定性的道路上非常有帮助。可以非常有效地指导我们下一步该往哪里走。
|
利用最小可行产品,我们可以也可以提早进行市场分析,这对于我们在探索产品不确定性的道路上非常有帮助。可以非常有效地指导我们下一步该往哪里走。
|
||||||
|
|
||||||
|
|||||||
@ -125,7 +125,8 @@ public @interface SpringBootConfiguration {
|
|||||||
- `@Configuration`:允许在上下文中注册额外的 bean 或导入其他配置类
|
- `@Configuration`:允许在上下文中注册额外的 bean 或导入其他配置类
|
||||||
- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除`TypeExcludeFilter`和`AutoConfigurationExcludeFilter`。
|
- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描启动类所在的包下所有的类 ,可以自定义不扫描某些 bean。如下图所示,容器中将排除`TypeExcludeFilter`和`AutoConfigurationExcludeFilter`。
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
`@EnableAutoConfiguration` 是实现自动装配的重要注解,我们以这个注解入手。
|
`@EnableAutoConfiguration` 是实现自动装配的重要注解,我们以这个注解入手。
|
||||||
|
|
||||||
|
|||||||
@ -17,7 +17,7 @@ Spring 是一款开源的轻量级 Java 开发框架,旨在提高开发人员
|
|||||||
|
|
||||||
我们一般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发,比如说 Spring 支持 IoC(Inversion of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程)、可以很方便地对数据库进行访问、可以很方便地集成第三方组件(电子邮件,任务,调度,缓存等等)、对单元测试支持比较好、支持 RESTful Java 应用程序的开发。
|
我们一般说 Spring 框架指的都是 Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发,比如说 Spring 支持 IoC(Inversion of Control:控制反转) 和 AOP(Aspect-Oriented Programming:面向切面编程)、可以很方便地对数据库进行访问、可以很方便地集成第三方组件(电子邮件,任务,调度,缓存等等)、对单元测试支持比较好、支持 RESTful Java 应用程序的开发。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
Spring 最核心的思想就是不重新造轮子,开箱即用,提高开发效率。
|
Spring 最核心的思想就是不重新造轮子,开箱即用,提高开发效率。
|
||||||
|
|
||||||
@ -147,7 +147,7 @@ Spring 时代我们一般通过 XML 文件来配置 Bean,后来开发人员觉
|
|||||||
|
|
||||||
下图简单地展示了 IoC 容器如何使用配置元数据来管理对象。
|
下图简单地展示了 IoC 容器如何使用配置元数据来管理对象。
|
||||||
|
|
||||||
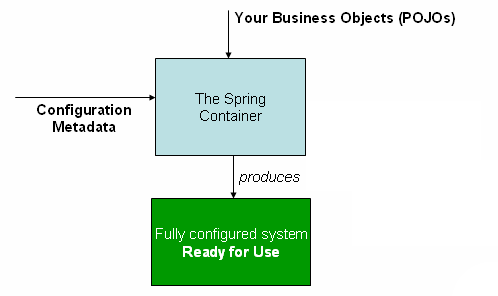
|

|
||||||
|
|
||||||
`org.springframework.beans`和 `org.springframework.context` 这两个包是 IoC 实现的基础,如果想要研究 IoC 相关的源码的话,可以去看看
|
`org.springframework.beans`和 `org.springframework.context` 这两个包是 IoC 实现的基础,如果想要研究 IoC 相关的源码的话,可以去看看
|
||||||
|
|
||||||
@ -350,7 +350,7 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
|
|||||||
|
|
||||||
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 **JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
|
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 **JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
当然你也可以使用 **AspectJ** !Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
|
当然你也可以使用 **AspectJ** !Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
|
||||||
|
|
||||||
@ -421,7 +421,7 @@ MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心
|
|||||||
|
|
||||||
网上有很多人说 MVC 不是设计模式,只是软件设计规范,我个人更倾向于 MVC 同样是众多设计模式中的一种。**[java-design-patterns](https://github.com/iluwatar/java-design-patterns)** 项目中就有关于 MVC 的相关介绍。
|
网上有很多人说 MVC 不是设计模式,只是软件设计规范,我个人更倾向于 MVC 同样是众多设计模式中的一种。**[java-design-patterns](https://github.com/iluwatar/java-design-patterns)** 项目中就有关于 MVC 的相关介绍。
|
||||||
|
|
||||||
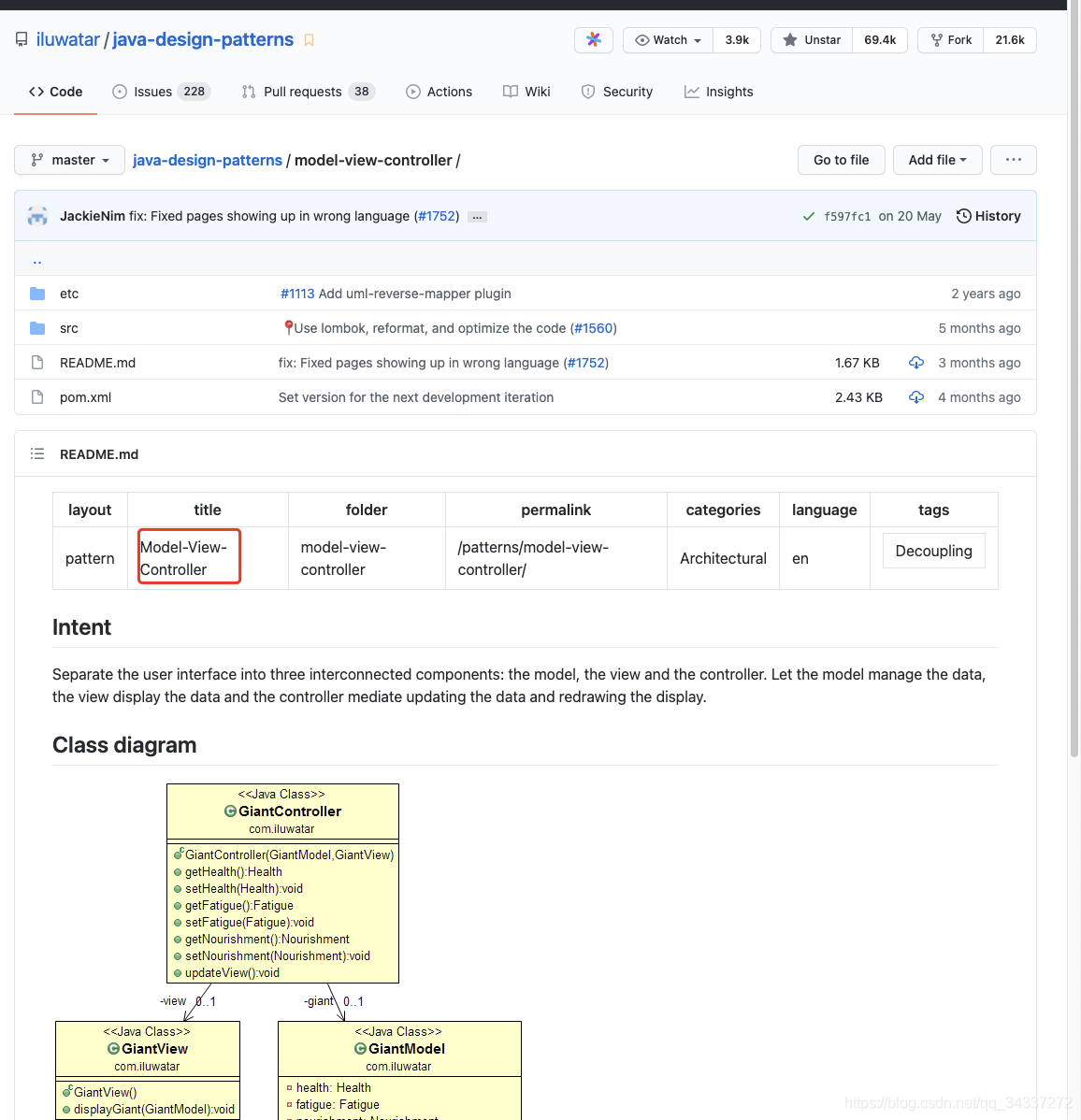
|

|
||||||
|
|
||||||
想要真正理解 Spring MVC,我们先来看看 Model 1 和 Model 2 这两个没有 Spring MVC 的时代。
|
想要真正理解 Spring MVC,我们先来看看 Model 1 和 Model 2 这两个没有 Spring MVC 的时代。
|
||||||
|
|
||||||
@ -469,7 +469,7 @@ MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring
|
|||||||
|
|
||||||
> SpringMVC 工作原理的图解我没有自己画,直接图省事在网上找了一个非常清晰直观的,原出处不明。
|
> SpringMVC 工作原理的图解我没有自己画,直接图省事在网上找了一个非常清晰直观的,原出处不明。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**流程说明(重要):**
|
**流程说明(重要):**
|
||||||
|
|
||||||
|
|||||||
@ -115,8 +115,6 @@ executor.shutdown();
|
|||||||
|
|
||||||
### Spring Task
|
### Spring Task
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
我们直接通过 Spring 提供的 `@Scheduled` 注解即可定义定时任务,非常方便!
|
我们直接通过 Spring 提供的 `@Scheduled` 注解即可定义定时任务,非常方便!
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ -171,7 +169,7 @@ Kafka、Dubbo、ZooKeeper、Netty 、Caffeine 、Akka 中都有对时间轮的
|
|||||||
|
|
||||||
这里在层与层之间的移动也叫做时间轮的升降级。参考手表来理解就好!
|
这里在层与层之间的移动也叫做时间轮的升降级。参考手表来理解就好!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**时间轮比较适合任务数量比较多的定时任务场景,它的任务写入和执行的时间复杂度都是 0(1)。**
|
**时间轮比较适合任务数量比较多的定时任务场景,它的任务写入和执行的时间复杂度都是 0(1)。**
|
||||||
|
|
||||||
@ -189,8 +187,6 @@ Kafka、Dubbo、ZooKeeper、Netty 、Caffeine 、Akka 中都有对时间轮的
|
|||||||
|
|
||||||
### Quartz
|
### Quartz
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
一个很火的开源任务调度框架,完全由`Java`写成。`Quartz` 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 `Quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案。
|
一个很火的开源任务调度框架,完全由`Java`写成。`Quartz` 可以说是 Java 定时任务领域的老大哥或者说参考标准,其他的任务调度框架基本都是基于 `Quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案。
|
||||||
|
|
||||||
使用 `Quartz` 可以很方便地与 `Spring` 集成,并且支持动态添加任务和集群。但是,`Quartz` 使用起来也比较麻烦,API 繁琐。
|
使用 `Quartz` 可以很方便地与 `Spring` 集成,并且支持动态添加任务和集群。但是,`Quartz` 使用起来也比较麻烦,API 繁琐。
|
||||||
@ -206,13 +202,11 @@ Kafka、Dubbo、ZooKeeper、Netty 、Caffeine 、Akka 中都有对时间轮的
|
|||||||
|
|
||||||
### Elastic-Job
|
### Elastic-Job
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
`Elastic-Job` 是当当网开源的一个基于`Quartz`和`ZooKeeper`的分布式调度解决方案,由两个相互独立的子项目 `Elastic-Job-Lite` 和 `Elastic-Job-Cloud` 组成,一般我们只要使用 `Elastic-Job-Lite` 就好。
|
`Elastic-Job` 是当当网开源的一个基于`Quartz`和`ZooKeeper`的分布式调度解决方案,由两个相互独立的子项目 `Elastic-Job-Lite` 和 `Elastic-Job-Cloud` 组成,一般我们只要使用 `Elastic-Job-Lite` 就好。
|
||||||
|
|
||||||
`ElasticJob` 支持任务在分布式场景下的分片和高可用、任务可视化管理等功能。
|
`ElasticJob` 支持任务在分布式场景下的分片和高可用、任务可视化管理等功能。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
ElasticJob-Lite 的架构设计如下图所示:
|
ElasticJob-Lite 的架构设计如下图所示:
|
||||||
|
|
||||||
@ -247,15 +241,13 @@ public class TestJob implements SimpleJob {
|
|||||||
|
|
||||||
### XXL-JOB
|
### XXL-JOB
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
`XXL-JOB` 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能,
|
`XXL-JOB` 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能,
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
根据 `XXL-JOB` 官网介绍,其解决了很多 `Quartz` 的不足。
|
根据 `XXL-JOB` 官网介绍,其解决了很多 `Quartz` 的不足。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
`XXL-JOB` 的架构设计如下图所示:
|
`XXL-JOB` 的架构设计如下图所示:
|
||||||
|
|
||||||
@ -292,7 +284,7 @@ public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**相关地址:**
|
**相关地址:**
|
||||||
|
|
||||||
@ -306,8 +298,6 @@ public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
|
|||||||
|
|
||||||
### PowerJob
|
### PowerJob
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
非常值得关注的一个分布式任务调度框架,分布式任务调度领域的新星。目前,已经有很多公司接入比如 OPPO、京东、中通、思科。
|
非常值得关注的一个分布式任务调度框架,分布式任务调度领域的新星。目前,已经有很多公司接入比如 OPPO、京东、中通、思科。
|
||||||
|
|
||||||
这个框架的诞生也挺有意思的,PowerJob 的作者当时在阿里巴巴实习过,阿里巴巴那会使用的是内部自研的 SchedulerX(阿里云付费产品)。实习期满之后,PowerJob 的作者离开了阿里巴巴。想着说自研一个 SchedulerX,防止哪天 SchedulerX 满足不了需求,于是 PowerJob 就诞生了。
|
这个框架的诞生也挺有意思的,PowerJob 的作者当时在阿里巴巴实习过,阿里巴巴那会使用的是内部自研的 SchedulerX(阿里云付费产品)。实习期满之后,PowerJob 的作者离开了阿里巴巴。想着说自研一个 SchedulerX,防止哪天 SchedulerX 满足不了需求,于是 PowerJob 就诞生了。
|
||||||
|
|||||||
@ -21,11 +21,11 @@ tag:
|
|||||||
|
|
||||||
认证 :
|
认证 :
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
授权:
|
授权:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
这两个一般在我们的系统中被结合在一起使用,目的就是为了保护我们系统的安全性。
|
这两个一般在我们的系统中被结合在一起使用,目的就是为了保护我们系统的安全性。
|
||||||
|
|
||||||
@ -193,7 +193,7 @@ Session-Cookie 方案在单体环境是一个非常好的身份认证方案。
|
|||||||
|
|
||||||
但是,我们使用 `Token` 的话就不会存在这个问题,在我们登录成功获得 `Token` 之后,一般会选择存放在 `localStorage` (浏览器本地存储)中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 `Token`,这样就不会出现 CSRF 漏洞的问题。因为,即使有个你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 `Token` 的,所以这个请求将是非法的。
|
但是,我们使用 `Token` 的话就不会存在这个问题,在我们登录成功获得 `Token` 之后,一般会选择存放在 `localStorage` (浏览器本地存储)中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 `Token`,这样就不会出现 CSRF 漏洞的问题。因为,即使有个你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 `Token` 的,所以这个请求将是非法的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
需要注意的是:不论是 `Cookie` 还是 `Token` 都无法避免 **跨站脚本攻击(Cross Site Scripting)XSS** 。
|
需要注意的是:不论是 `Cookie` 还是 `Token` 都无法避免 **跨站脚本攻击(Cross Site Scripting)XSS** 。
|
||||||
|
|
||||||
@ -241,7 +241,7 @@ OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了
|
|||||||
|
|
||||||
下图是 [Slack OAuth 2.0 第三方登录](https://api.slack.com/legacy/oauth)的示意图:
|
下图是 [Slack OAuth 2.0 第三方登录](https://api.slack.com/legacy/oauth)的示意图:
|
||||||
|
|
||||||
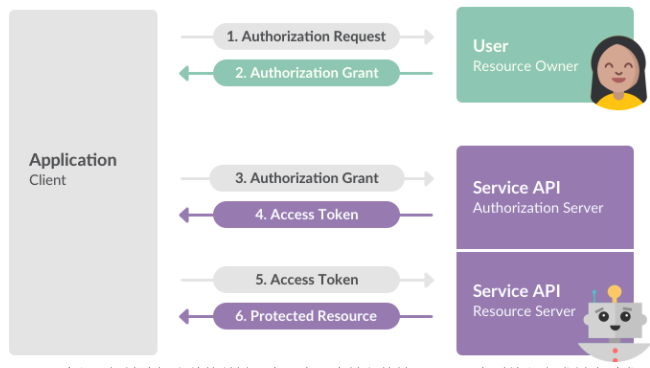
|

|
||||||
|
|
||||||
**推荐阅读:**
|
**推荐阅读:**
|
||||||
|
|
||||||
|
|||||||
@ -38,7 +38,7 @@ Docker 的出现完美地解决了这一问题,我们可以在容器中安装
|
|||||||
|
|
||||||
另外,[《Docker 从入门到实践》](https://yeasy.gitbook.io/docker_practice/introduction/why) 这本开源书籍中也已经给出了使用 Docker 的原因。
|
另外,[《Docker 从入门到实践》](https://yeasy.gitbook.io/docker_practice/introduction/why) 这本开源书籍中也已经给出了使用 Docker 的原因。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## Docker 的安装
|
## Docker 的安装
|
||||||
|
|
||||||
|
|||||||
@ -245,7 +245,7 @@ docker rmi f6509bac4980 # 或者 docker rmi mysql
|
|||||||
|
|
||||||
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **Build(构建镜像)** : 镜像就像是集装箱包括文件以及运行环境等等资源。
|
- **Build(构建镜像)** : 镜像就像是集装箱包括文件以及运行环境等等资源。
|
||||||
- **Ship(运输镜像)** :主机和仓库间运输,这里的仓库就像是超级码头一样。
|
- **Ship(运输镜像)** :主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||||
|
|||||||
@ -62,7 +62,7 @@ Gradle 官方文档是这样介绍的 Gradle Wrapper 的:
|
|||||||
|
|
||||||
Gradle Wrapper 的工作流程图如下(图源[Gradle Wrapper 官方文档介绍](https://docs.gradle.org/current/userguide/gradle_wrapper.html)):
|
Gradle Wrapper 的工作流程图如下(图源[Gradle Wrapper 官方文档介绍](https://docs.gradle.org/current/userguide/gradle_wrapper.html)):
|
||||||
|
|
||||||
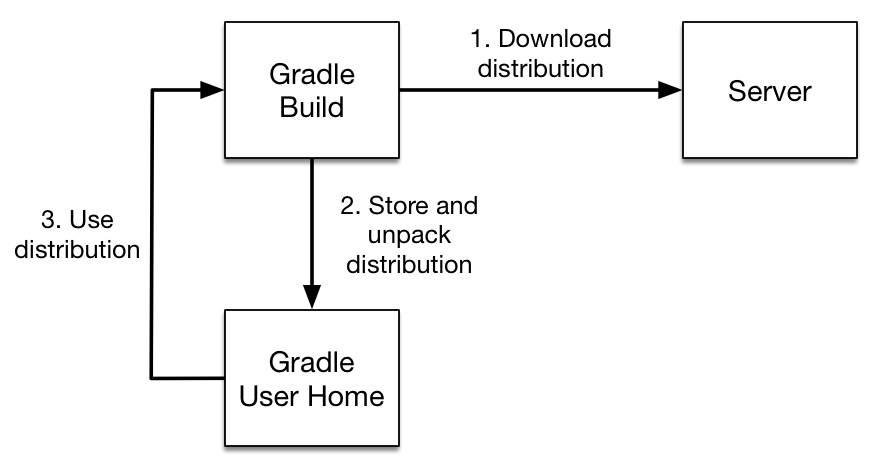
|

|
||||||
|
|
||||||
整个流程主要分为下面 3 步:
|
整个流程主要分为下面 3 步:
|
||||||
|
|
||||||
@ -272,11 +272,11 @@ Gradle 插件主要分为两类:
|
|||||||
|
|
||||||
Gradle 构建的生命周期有三个阶段:**初始化阶段,配置阶段**和**运行阶段**。
|
Gradle 构建的生命周期有三个阶段:**初始化阶段,配置阶段**和**运行阶段**。
|
||||||
|
|
||||||
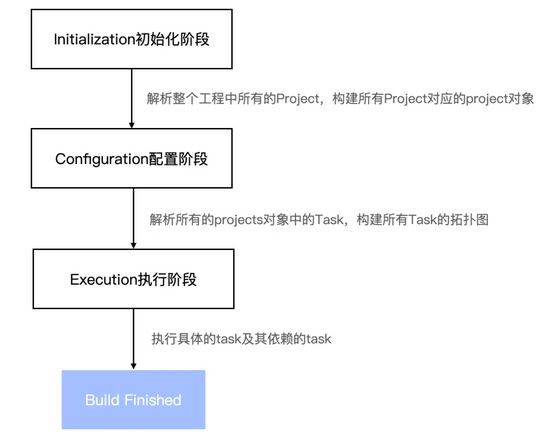
|

|
||||||
|
|
||||||
在初始化阶段与配置阶段之间、配置阶段结束之后、执行阶段结束之后,我们都可以加一些定制化的 Hook。
|
在初始化阶段与配置阶段之间、配置阶段结束之后、执行阶段结束之后,我们都可以加一些定制化的 Hook。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 初始化阶段
|
### 初始化阶段
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user