mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Merge pull request #1220 from 2293736867/master
multi-thread/2020最新Java并发进阶常见面试题总结 排版修正
This commit is contained in:
commit
07cc257b74
@ -12,7 +12,7 @@
|
|||||||
- [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
|
- [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
|
||||||
- [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
|
- [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
|
||||||
- [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
|
- [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
|
||||||
- [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
|
- [1.3.2. synchronized 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
|
||||||
- [1.3.3.总结](#133总结)
|
- [1.3.3.总结](#133总结)
|
||||||
- [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
|
- [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
|
||||||
- [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
|
- [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
|
||||||
@ -86,7 +86,7 @@
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
synchronized void method() {
|
synchronized void method() {
|
||||||
//业务代码
|
//业务代码
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -94,7 +94,7 @@ synchronized void method() {
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
synchronized static void method() {
|
synchronized static void method() {
|
||||||
//业务代码
|
//业务代码
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -102,7 +102,7 @@ synchronized static void method() {
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
synchronized(this) {
|
synchronized(this) {
|
||||||
//业务代码
|
//业务代码
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -167,11 +167,11 @@ public class Singleton {
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
public class SynchronizedDemo {
|
public class SynchronizedDemo {
|
||||||
public void method() {
|
public void method() {
|
||||||
synchronized (this) {
|
synchronized (this) {
|
||||||
System.out.println("synchronized 代码块");
|
System.out.println("synchronized 代码块");
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
@ -194,13 +194,13 @@ public class SynchronizedDemo {
|
|||||||
|
|
||||||
在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
|
在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
|
||||||
|
|
||||||
#### 1.3.2. `synchronized` 修饰方法的的情况
|
#### 1.3.2. synchronized 修饰方法的的情况
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public class SynchronizedDemo2 {
|
public class SynchronizedDemo2 {
|
||||||
public synchronized void method() {
|
public synchronized void method() {
|
||||||
System.out.println("synchronized 方法");
|
System.out.println("synchronized 方法");
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
@ -277,7 +277,7 @@ JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
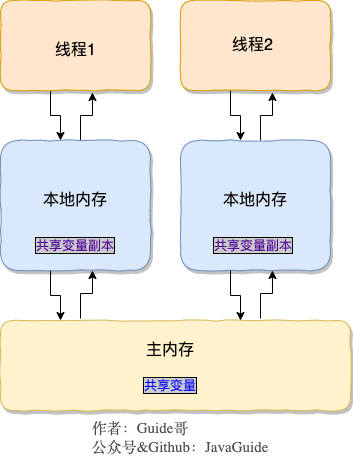
要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
|
要解决这个问题,就需要把变量声明为 **`volatile`** ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
|
||||||
|
|
||||||
所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
|
所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
|
||||||
|
|
||||||
@ -293,7 +293,7 @@ JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、
|
|||||||
|
|
||||||
`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
|
`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
|
||||||
|
|
||||||
- **`volatile` 关键字**是线程同步的**轻量级实现**,所以**`volatile `性能肯定比` synchronized `关键字要好**。但是**`volatile` 关键字只能用于变量而 `synchronized` 关键字可以修饰方法以及代码块**。
|
- **`volatile` 关键字**是线程同步的**轻量级实现**,所以 **`volatile `性能肯定比` synchronized `关键字要好** 。但是 **`volatile` 关键字只能用于变量而 `synchronized` 关键字可以修饰方法以及代码块** 。
|
||||||
- **`volatile` 关键字能保证数据的可见性,但不能保证数据的原子性。`synchronized` 关键字两者都能保证。**
|
- **`volatile` 关键字能保证数据的可见性,但不能保证数据的原子性。`synchronized` 关键字两者都能保证。**
|
||||||
- **`volatile`关键字主要用于解决变量在多个线程之间的可见性,而 `synchronized` 关键字解决的是多个线程之间访问资源的同步性。**
|
- **`volatile`关键字主要用于解决变量在多个线程之间的可见性,而 `synchronized` 关键字解决的是多个线程之间访问资源的同步性。**
|
||||||
|
|
||||||
@ -379,13 +379,12 @@ Thread Name= 9 formatter = yy-M-d ah:mm
|
|||||||
上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
|
上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
|
private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
|
||||||
@Override
|
@Override
|
||||||
protected SimpleDateFormat initialValue()
|
protected SimpleDateFormat initialValue(){
|
||||||
{
|
return new SimpleDateFormat("yyyyMMdd HHmm");
|
||||||
return new SimpleDateFormat("yyyyMMdd HHmm");
|
}
|
||||||
}
|
};
|
||||||
};
|
|
||||||
```
|
```
|
||||||
|
|
||||||
### 3.3. ThreadLocal 原理
|
### 3.3. ThreadLocal 原理
|
||||||
@ -394,13 +393,13 @@ Thread Name= 9 formatter = yy-M-d ah:mm
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
public class Thread implements Runnable {
|
public class Thread implements Runnable {
|
||||||
......
|
//......
|
||||||
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
|
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
|
||||||
ThreadLocal.ThreadLocalMap threadLocals = null;
|
ThreadLocal.ThreadLocalMap threadLocals = null;
|
||||||
|
|
||||||
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
|
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
|
||||||
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||||
......
|
//......
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -409,17 +408,17 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
|||||||
`ThreadLocal`类的`set()`方法
|
`ThreadLocal`类的`set()`方法
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public void set(T value) {
|
public void set(T value) {
|
||||||
Thread t = Thread.currentThread();
|
Thread t = Thread.currentThread();
|
||||||
ThreadLocalMap map = getMap(t);
|
ThreadLocalMap map = getMap(t);
|
||||||
if (map != null)
|
if (map != null)
|
||||||
map.set(this, value);
|
map.set(this, value);
|
||||||
else
|
else
|
||||||
createMap(t, value);
|
createMap(t, value);
|
||||||
}
|
}
|
||||||
ThreadLocalMap getMap(Thread t) {
|
ThreadLocalMap getMap(Thread t) {
|
||||||
return t.threadLocals;
|
return t.threadLocals;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
|
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
|
||||||
@ -428,7 +427,7 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
|
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
|
||||||
......
|
//......
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -445,15 +444,15 @@ ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
|
|||||||
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
|
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
|
||||||
|
|
||||||
```java
|
```java
|
||||||
static class Entry extends WeakReference<ThreadLocal<?>> {
|
static class Entry extends WeakReference<ThreadLocal<?>> {
|
||||||
/** The value associated with this ThreadLocal. */
|
/** The value associated with this ThreadLocal. */
|
||||||
Object value;
|
Object value;
|
||||||
|
|
||||||
Entry(ThreadLocal<?> k, Object v) {
|
Entry(ThreadLocal<?> k, Object v) {
|
||||||
super(k);
|
super(k);
|
||||||
value = v;
|
value = v;
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
**弱引用介绍:**
|
**弱引用介绍:**
|
||||||
@ -478,7 +477,7 @@ ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
|
|||||||
|
|
||||||
### 4.2. 实现 Runnable 接口和 Callable 接口的区别
|
### 4.2. 实现 Runnable 接口和 Callable 接口的区别
|
||||||
|
|
||||||
`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
|
`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口** 不会返回结果或抛出检查异常,但是 **`Callable` 接口** 可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口** ,这样代码看起来会更加简洁。
|
||||||
|
|
||||||
工具类 `Executors` 可以实现 `Runnable` 对象和 `Callable` 对象之间的相互转换。(`Executors.callable(Runnable task`)或 `Executors.callable(Runnable task,Object resule)`)。
|
工具类 `Executors` 可以实现 `Runnable` 对象和 `Callable` 对象之间的相互转换。(`Executors.callable(Runnable task`)或 `Executors.callable(Runnable task,Object resule)`)。
|
||||||
|
|
||||||
@ -513,31 +512,31 @@ public interface Callable<V> {
|
|||||||
1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
|
1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
|
||||||
2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
|
2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
|
||||||
|
|
||||||
我们以**`AbstractExecutorService`**接口中的一个 `submit` 方法为例子来看看源代码:
|
我们以** `AbstractExecutorService` **接口中的一个 `submit` 方法为例子来看看源代码:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public Future<?> submit(Runnable task) {
|
public Future<?> submit(Runnable task) {
|
||||||
if (task == null) throw new NullPointerException();
|
if (task == null) throw new NullPointerException();
|
||||||
RunnableFuture<Void> ftask = newTaskFor(task, null);
|
RunnableFuture<Void> ftask = newTaskFor(task, null);
|
||||||
execute(ftask);
|
execute(ftask);
|
||||||
return ftask;
|
return ftask;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
上面方法调用的 `newTaskFor` 方法返回了一个 `FutureTask` 对象。
|
上面方法调用的 `newTaskFor` 方法返回了一个 `FutureTask` 对象。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
|
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
|
||||||
return new FutureTask<T>(runnable, value);
|
return new FutureTask<T>(runnable, value);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
我们再来看看`execute()`方法:
|
我们再来看看`execute()`方法:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public void execute(Runnable command) {
|
public void execute(Runnable command) {
|
||||||
...
|
...
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
### 4.4. 如何创建线程池
|
### 4.4. 如何创建线程池
|
||||||
@ -550,8 +549,11 @@ public interface Callable<V> {
|
|||||||
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
|
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
|
||||||
|
|
||||||
**方式一:通过构造方法实现**
|
**方式一:通过构造方法实现**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**方式二:通过 Executor 框架的工具类 Executors 来实现**
|
**方式二:通过 Executor 框架的工具类 Executors 来实现**
|
||||||
|
|
||||||
我们可以创建三种类型的 ThreadPoolExecutor:
|
我们可以创建三种类型的 ThreadPoolExecutor:
|
||||||
|
|
||||||
- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||||
@ -559,6 +561,7 @@ public interface Callable<V> {
|
|||||||
- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
||||||
|
|
||||||
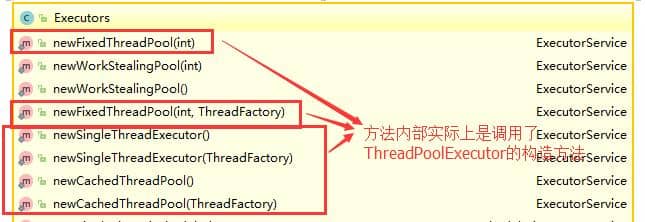
对应 Executors 工具类中的方法如图所示:
|
对应 Executors 工具类中的方法如图所示:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 4.5 ThreadPoolExecutor 类分析
|
### 4.5 ThreadPoolExecutor 类分析
|
||||||
@ -566,30 +569,30 @@ public interface Callable<V> {
|
|||||||
`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
|
`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么),这里就不贴代码讲了,比较简单。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
/**
|
/**
|
||||||
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
|
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
|
||||||
*/
|
*/
|
||||||
public ThreadPoolExecutor(int corePoolSize,
|
public ThreadPoolExecutor(int corePoolSize,
|
||||||
int maximumPoolSize,
|
int maximumPoolSize,
|
||||||
long keepAliveTime,
|
long keepAliveTime,
|
||||||
TimeUnit unit,
|
TimeUnit unit,
|
||||||
BlockingQueue<Runnable> workQueue,
|
BlockingQueue<Runnable> workQueue,
|
||||||
ThreadFactory threadFactory,
|
ThreadFactory threadFactory,
|
||||||
RejectedExecutionHandler handler) {
|
RejectedExecutionHandler handler) {
|
||||||
if (corePoolSize < 0 ||
|
if (corePoolSize < 0 ||
|
||||||
maximumPoolSize <= 0 ||
|
maximumPoolSize <= 0 ||
|
||||||
maximumPoolSize < corePoolSize ||
|
maximumPoolSize < corePoolSize ||
|
||||||
keepAliveTime < 0)
|
keepAliveTime < 0)
|
||||||
throw new IllegalArgumentException();
|
throw new IllegalArgumentException();
|
||||||
if (workQueue == null || threadFactory == null || handler == null)
|
if (workQueue == null || threadFactory == null || handler == null)
|
||||||
throw new NullPointerException();
|
throw new NullPointerException();
|
||||||
this.corePoolSize = corePoolSize;
|
this.corePoolSize = corePoolSize;
|
||||||
this.maximumPoolSize = maximumPoolSize;
|
this.maximumPoolSize = maximumPoolSize;
|
||||||
this.workQueue = workQueue;
|
this.workQueue = workQueue;
|
||||||
this.keepAliveTime = unit.toNanos(keepAliveTime);
|
this.keepAliveTime = unit.toNanos(keepAliveTime);
|
||||||
this.threadFactory = threadFactory;
|
this.threadFactory = threadFactory;
|
||||||
this.handler = handler;
|
this.handler = handler;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
**下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。**
|
**下面这些对创建 非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。**
|
||||||
@ -615,8 +618,9 @@ public interface Callable<V> {
|
|||||||
|
|
||||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
|
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
|
||||||
|
|
||||||
- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
- **`ThreadPoolExecutor.AbortPolicy`:** 抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||||
- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
- **`ThreadPoolExecutor.CallerRunsPolicy`:**
|
||||||
|
调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||||
- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
|
- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
|
||||||
- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
|
- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
|
||||||
|
|
||||||
@ -708,7 +712,6 @@ public class ThreadPoolExecutorDemo {
|
|||||||
System.out.println("Finished all threads");
|
System.out.println("Finished all threads");
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
可以看到我们上面的代码指定了:
|
可以看到我们上面的代码指定了:
|
||||||
@ -752,49 +755,49 @@ pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
|
|||||||
|
|
||||||
现在,我们就分析上面的输出内容来简单分析一下线程池原理。
|
现在,我们就分析上面的输出内容来简单分析一下线程池原理。
|
||||||
|
|
||||||
**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。**在 4.6 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
|
**为了搞懂线程池的原理,我们需要首先分析一下 `execute`方法。** 在 4.6 节中的 Demo 中我们使用 `executor.execute(worker)`来提交一个任务到线程池中去,这个方法非常重要,下面我们来看看它的源码:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
|
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
|
||||||
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
|
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
|
||||||
|
|
||||||
private static int workerCountOf(int c) {
|
private static int workerCountOf(int c) {
|
||||||
return c & CAPACITY;
|
return c & CAPACITY;
|
||||||
|
}
|
||||||
|
|
||||||
|
private final BlockingQueue<Runnable> workQueue;
|
||||||
|
|
||||||
|
public void execute(Runnable command) {
|
||||||
|
// 如果任务为null,则抛出异常。
|
||||||
|
if (command == null)
|
||||||
|
throw new NullPointerException();
|
||||||
|
// ctl 中保存的线程池当前的一些状态信息
|
||||||
|
int c = ctl.get();
|
||||||
|
|
||||||
|
// 下面会涉及到 3 步 操作
|
||||||
|
// 1.首先判断当前线程池中执行的任务数量是否小于 corePoolSize
|
||||||
|
// 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
|
||||||
|
if (workerCountOf(c) < corePoolSize) {
|
||||||
|
if (addWorker(command, true))
|
||||||
|
return;
|
||||||
|
c = ctl.get();
|
||||||
}
|
}
|
||||||
|
// 2.如果当前执行的任务数量大于等于 corePoolSize 的时候就会走到这里
|
||||||
private final BlockingQueue<Runnable> workQueue;
|
// 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去
|
||||||
|
if (isRunning(c) && workQueue.offer(command)) {
|
||||||
public void execute(Runnable command) {
|
int recheck = ctl.get();
|
||||||
// 如果任务为null,则抛出异常。
|
// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
|
||||||
if (command == null)
|
if (!isRunning(recheck) && remove(command))
|
||||||
throw new NullPointerException();
|
|
||||||
// ctl 中保存的线程池当前的一些状态信息
|
|
||||||
int c = ctl.get();
|
|
||||||
|
|
||||||
// 下面会涉及到 3 步 操作
|
|
||||||
// 1.首先判断当前线程池中执行的任务数量是否小于 corePoolSize
|
|
||||||
// 如果小于的话,通过addWorker(command, true)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
|
|
||||||
if (workerCountOf(c) < corePoolSize) {
|
|
||||||
if (addWorker(command, true))
|
|
||||||
return;
|
|
||||||
c = ctl.get();
|
|
||||||
}
|
|
||||||
// 2.如果当前执行的任务数量大于等于 corePoolSize 的时候就会走到这里
|
|
||||||
// 通过 isRunning 方法判断线程池状态,线程池处于 RUNNING 状态才会被并且队列可以加入任务,该任务才会被加入进去
|
|
||||||
if (isRunning(c) && workQueue.offer(command)) {
|
|
||||||
int recheck = ctl.get();
|
|
||||||
// 再次获取线程池状态,如果线程池状态不是 RUNNING 状态就需要从任务队列中移除任务,并尝试判断线程是否全部执行完毕。同时执行拒绝策略。
|
|
||||||
if (!isRunning(recheck) && remove(command))
|
|
||||||
reject(command);
|
|
||||||
// 如果当前线程池为空就新创建一个线程并执行。
|
|
||||||
else if (workerCountOf(recheck) == 0)
|
|
||||||
addWorker(null, false);
|
|
||||||
}
|
|
||||||
//3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
|
|
||||||
//如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
|
|
||||||
else if (!addWorker(command, false))
|
|
||||||
reject(command);
|
reject(command);
|
||||||
|
// 如果当前线程池为空就新创建一个线程并执行。
|
||||||
|
else if (workerCountOf(recheck) == 0)
|
||||||
|
addWorker(null, false);
|
||||||
}
|
}
|
||||||
|
//3. 通过addWorker(command, false)新建一个线程,并将任务(command)添加到该线程中;然后,启动该线程从而执行任务。
|
||||||
|
//如果addWorker(command, false)执行失败,则通过reject()执行相应的拒绝策略的内容。
|
||||||
|
else if (!addWorker(command, false))
|
||||||
|
reject(command);
|
||||||
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
|
通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
|
||||||
@ -869,15 +872,15 @@ public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
class AtomicIntegerTest {
|
class AtomicIntegerTest {
|
||||||
private AtomicInteger count = new AtomicInteger();
|
private AtomicInteger count = new AtomicInteger();
|
||||||
//使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
|
//使用AtomicInteger之后,不需要对该方法加锁,也可以实现线程安全。
|
||||||
public void increment() {
|
public void increment() {
|
||||||
count.incrementAndGet();
|
count.incrementAndGet();
|
||||||
}
|
}
|
||||||
|
|
||||||
public int getCount() {
|
public int getCount() {
|
||||||
return count.get();
|
return count.get();
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|
||||||
```
|
```
|
||||||
@ -889,18 +892,18 @@ AtomicInteger 线程安全原理简单分析
|
|||||||
AtomicInteger 类的部分源码:
|
AtomicInteger 类的部分源码:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
|
// setup to use Unsafe.compareAndSwapInt for updates(更新操作时提供“比较并替换”的作用)
|
||||||
private static final Unsafe unsafe = Unsafe.getUnsafe();
|
private static final Unsafe unsafe = Unsafe.getUnsafe();
|
||||||
private static final long valueOffset;
|
private static final long valueOffset;
|
||||||
|
|
||||||
static {
|
static {
|
||||||
try {
|
try {
|
||||||
valueOffset = unsafe.objectFieldOffset
|
valueOffset = unsafe.objectFieldOffset
|
||||||
(AtomicInteger.class.getDeclaredField("value"));
|
(AtomicInteger.class.getDeclaredField("value"));
|
||||||
} catch (Exception ex) { throw new Error(ex); }
|
} catch (Exception ex) { throw new Error(ex); }
|
||||||
}
|
}
|
||||||
|
|
||||||
private volatile int value;
|
private volatile int value;
|
||||||
```
|
```
|
||||||
|
|
||||||
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
|
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
|
||||||
@ -949,15 +952,15 @@ private volatile int state;//共享变量,使用volatile修饰保证线程可
|
|||||||
|
|
||||||
//返回同步状态的当前值
|
//返回同步状态的当前值
|
||||||
protected final int getState() {
|
protected final int getState() {
|
||||||
return state;
|
return state;
|
||||||
}
|
}
|
||||||
// 设置同步状态的值
|
//设置同步状态的值
|
||||||
protected final void setState(int newState) {
|
protected final void setState(int newState) {
|
||||||
state = newState;
|
state = newState;
|
||||||
}
|
}
|
||||||
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
|
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
|
||||||
protected final boolean compareAndSetState(int expect, int update) {
|
protected final boolean compareAndSetState(int expect, int update) {
|
||||||
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
|
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -1025,33 +1028,32 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
public class CountDownLatchExample1 {
|
public class CountDownLatchExample1 {
|
||||||
// 处理文件的数量
|
// 处理文件的数量
|
||||||
private static final int threadCount = 6;
|
private static final int threadCount = 6;
|
||||||
|
|
||||||
public static void main(String[] args) throws InterruptedException {
|
public static void main(String[] args) throws InterruptedException {
|
||||||
// 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
|
// 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
|
||||||
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
||||||
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
|
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
|
||||||
for (int i = 0; i < threadCount; i++) {
|
for (int i = 0; i < threadCount; i++) {
|
||||||
final int threadnum = i;
|
final int threadnum = i;
|
||||||
threadPool.execute(() -> {
|
threadPool.execute(() -> {
|
||||||
try {
|
try {
|
||||||
//处理文件的业务操作
|
//处理文件的业务操作
|
||||||
......
|
//......
|
||||||
} catch (InterruptedException e) {
|
} catch (InterruptedException e) {
|
||||||
e.printStackTrace();
|
e.printStackTrace();
|
||||||
} finally {
|
} finally {
|
||||||
//表示一个文件已经被完成
|
//表示一个文件已经被完成
|
||||||
countDownLatch.countDown();
|
countDownLatch.countDown();
|
||||||
|
}
|
||||||
|
|
||||||
|
});
|
||||||
}
|
}
|
||||||
|
countDownLatch.await();
|
||||||
});
|
threadPool.shutdown();
|
||||||
|
System.out.println("finish");
|
||||||
}
|
}
|
||||||
countDownLatch.await();
|
|
||||||
threadPool.shutdown();
|
|
||||||
System.out.println("finish");
|
|
||||||
}
|
|
||||||
|
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -1061,22 +1063,22 @@ public class CountDownLatchExample1 {
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
CompletableFuture<Void> task1 =
|
CompletableFuture<Void> task1 =
|
||||||
CompletableFuture.supplyAsync(()->{
|
CompletableFuture.supplyAsync(()->{
|
||||||
//自定义业务操作
|
//自定义业务操作
|
||||||
});
|
});
|
||||||
......
|
......
|
||||||
CompletableFuture<Void> task6 =
|
CompletableFuture<Void> task6 =
|
||||||
CompletableFuture.supplyAsync(()->{
|
CompletableFuture.supplyAsync(()->{
|
||||||
//自定义业务操作
|
//自定义业务操作
|
||||||
});
|
});
|
||||||
......
|
......
|
||||||
CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
|
CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
|
||||||
|
|
||||||
try {
|
try {
|
||||||
headerFuture.join();
|
headerFuture.join();
|
||||||
} catch (Exception ex) {
|
} catch (Exception ex) {
|
||||||
......
|
//......
|
||||||
}
|
}
|
||||||
System.out.println("all done. ");
|
System.out.println("all done. ");
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -1087,11 +1089,11 @@ System.out.println("all done. ");
|
|||||||
List<String> filePaths = Arrays.asList(...)
|
List<String> filePaths = Arrays.asList(...)
|
||||||
// 异步处理所有文件
|
// 异步处理所有文件
|
||||||
List<CompletableFuture<String>> fileFutures = filePaths.stream()
|
List<CompletableFuture<String>> fileFutures = filePaths.stream()
|
||||||
.map(filePath -> doSomeThing(filePath))
|
.map(filePath -> doSomeThing(filePath))
|
||||||
.collect(Collectors.toList());
|
.collect(Collectors.toList());
|
||||||
// 将他们合并起来
|
// 将他们合并起来
|
||||||
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
|
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
|
||||||
fileFutures.toArray(new CompletableFuture[fileFutures.size()])
|
fileFutures.toArray(new CompletableFuture[fileFutures.size()])
|
||||||
);
|
);
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user