> T min(T[] values) {
- if (values == null || values.length == 0) return null;
- T min = values[0];
- for (int i = 1; i < values.length; i++) {
- if (min.compareTo(values[i]) > 0) min = values[i];
- }
- return min;
-}
-```
-
-测试:
-
-```java
-int minInteger = min(new Integer[]{1, 2, 3});//result:1
-double minDouble = min(new Double[]{1.2, 2.2, -1d});//result:-1d
-String typeError = min(new String[]{"1","3"});//报错
-```
-### 0.0.2. 使用数组实现栈
-
-**自己实现一个栈,要求这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。**
-
-提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用`Arrays.copyOf()`进行扩容;
-
-```java
-public class MyStack {
- private int[] storage;//存放栈中元素的数组
- private int capacity;//栈的容量
- private int count;//栈中元素数量
- private static final int GROW_FACTOR = 2;
-
- //不带初始容量的构造方法。默认容量为8
- public MyStack() {
- this.capacity = 8;
- this.storage=new int[8];
- this.count = 0;
- }
-
- //带初始容量的构造方法
- public MyStack(int initialCapacity) {
- if (initialCapacity < 1)
- throw new IllegalArgumentException("Capacity too small.");
-
- this.capacity = initialCapacity;
- this.storage = new int[initialCapacity];
- this.count = 0;
- }
-
- //入栈
- public void push(int value) {
- if (count == capacity) {
- ensureCapacity();
- }
- storage[count++] = value;
- }
-
- //确保容量大小
- private void ensureCapacity() {
- int newCapacity = capacity * GROW_FACTOR;
- storage = Arrays.copyOf(storage, newCapacity);
- capacity = newCapacity;
- }
-
- //返回栈顶元素并出栈
- private int pop() {
- if (count == 0)
- throw new IllegalArgumentException("Stack is empty.");
- count--;
- return storage[count];
- }
-
- //返回栈顶元素不出栈
- private int peek() {
- if (count == 0){
- throw new IllegalArgumentException("Stack is empty.");
- }else {
- return storage[count-1];
- }
- }
-
- //判断栈是否为空
- private boolean isEmpty() {
- return count == 0;
- }
-
- //返回栈中元素的个数
- private int size() {
- return count;
- }
-
-}
-
-```
-
-验证
-
-```java
-MyStack myStack = new MyStack(3);
-myStack.push(1);
-myStack.push(2);
-myStack.push(3);
-myStack.push(4);
-myStack.push(5);
-myStack.push(6);
-myStack.push(7);
-myStack.push(8);
-System.out.println(myStack.peek());//8
-System.out.println(myStack.size());//8
-for (int i = 0; i < 8; i++) {
- System.out.println(myStack.pop());
-}
-System.out.println(myStack.isEmpty());//true
-myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
-```
-
-
-
diff --git a/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md b/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md
deleted file mode 100644
index 7c367e11..00000000
--- a/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md
+++ /dev/null
@@ -1,441 +0,0 @@
-
-
-- [1. LRU 缓存介绍](#1-lru-%e7%bc%93%e5%ad%98%e4%bb%8b%e7%bb%8d)
-- [2. ConcurrentLinkedQueue简单介绍](#2-concurrentlinkedqueue%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
-- [3. ReadWriteLock简单介绍](#3-readwritelock%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
-- [4. ScheduledExecutorService 简单介绍](#4-scheduledexecutorservice-%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
-- [5. 徒手撸一个线程安全的 LRU 缓存](#5-%e5%be%92%e6%89%8b%e6%92%b8%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
- - [5.1. 实现方法](#51-%e5%ae%9e%e7%8e%b0%e6%96%b9%e6%b3%95)
- - [5.2. 原理](#52-%e5%8e%9f%e7%90%86)
- - [5.3. put方法具体流程分析](#53-put%e6%96%b9%e6%b3%95%e5%85%b7%e4%bd%93%e6%b5%81%e7%a8%8b%e5%88%86%e6%9e%90)
- - [5.4. 源码](#54-%e6%ba%90%e7%a0%81)
-- [6. 实现一个线程安全并且带有过期时间的 LRU 缓存](#6-%e5%ae%9e%e7%8e%b0%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e5%b9%b6%e4%b8%94%e5%b8%a6%e6%9c%89%e8%bf%87%e6%9c%9f%e6%97%b6%e9%97%b4%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
-
-
-
-最近被读者问到“不用LinkedHashMap的话,如何实现一个线程安全的 LRU 缓存?网上的代码太杂太乱,Guide哥哥能不能帮忙写一个?”。
-
-*划重点,手写一个 LRU 缓存在面试中还是挺常见的!*
-
-很多人就会问了:“网上已经有这么多现成的缓存了!为什么面试官还要我们自己实现一个呢?” 。咳咳咳,当然是为了面试需要。哈哈!开个玩笑,我个人觉得更多地是为了学习吧!今天Guide哥教大家:
-
-1. 实现一个线程安全的 LRU 缓存
-2. 实现一个线程安全并且带有过期时间的 LRU 缓存
-
-考虑到了线程安全性我们使用了 `ConcurrentHashMap` 、`ConcurrentLinkedQueue` 这两个线程安全的集合。另外,还用到 `ReadWriteLock`(读写锁)。为了实现带有过期时间的缓存,我们用到了 `ScheduledExecutorService`来做定时任务执行。
-
-如果有任何不对或者需要完善的地方,请帮忙指出!
-
-### 1. LRU 缓存介绍
-
-**LRU (Least Recently Used,最近最少使用)是一种缓存淘汰策略。**
-
-LRU缓存指的是当缓存大小已达到最大分配容量的时候,如果再要去缓存新的对象数据的话,就需要将缓存中最近访问最少的对象删除掉以便给新来的数据腾出空间。
-
-### 2. ConcurrentLinkedQueue简单介绍
-
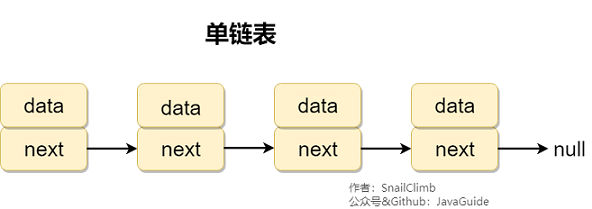
-**ConcurrentLinkedQueue是一个基于单向链表的无界无锁线程安全的队列,适合在高并发环境下使用,效率比较高。** 我们在使用的时候,可以就把它理解为我们经常接触的数据结构——队列,不过是增加了多线程下的安全性保证罢了。**和普通队列一样,它也是按照先进先出(FIFO)的规则对接点进行排序。** 另外,队列元素中不可以放置null元素。
-
-`ConcurrentLinkedQueue` 整个继承关系如下图所示:
-
-
-
-`ConcurrentLinkedQueue中`最主要的两个方法是:`offer(value)`和`poll()`,分别实现队列的两个重要的操作:入队和出队(`offer(value)`等价于 `add(value)`)。
-
-我们添加一个元素到队列的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。
-
-
-
-利用`ConcurrentLinkedQueue`队列先进先出的特性,每当我们 `put`/`get`(缓存被使用)元素的时候,我们就将这个元素存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。
-
-### 3. ReadWriteLock简单介绍
-
-`ReadWriteLock` 是一个接口,位于`java.util.concurrent.locks`包下,里面只有两个方法分别返回读锁和写锁:
-
-```java
-public interface ReadWriteLock {
- /**
- * 返回读锁
- */
- Lock readLock();
-
- /**
- * 返回写锁
- */
- Lock writeLock();
-}
-```
-
-`ReentrantReadWriteLock` 是`ReadWriteLock`接口的具体实现类。
-
-**读写锁还是比较适合缓存这种读多写少的场景。读写锁可以保证多个线程和同时读取,但是只有一个线程可以写入。**
-
-读写锁的特点是:写锁和写锁互斥,读锁和写锁互斥,读锁之间不互斥。也就说:同一时刻只能有一个线程写,但是可以有多个线程
-读。读写之间是互斥的,两者不能同时发生(当进行写操作时,同一时刻其他线程的读操作会被阻塞;当进行读操作时,同一时刻所有线程的写操作会被阻塞)。
-
-另外,**同一个线程持有写锁时是可以申请读锁,但是持有读锁的情况下不可以申请写锁。**
-
-### 4. ScheduledExecutorService 简单介绍
-
-`ScheduledExecutorService` 是一个接口,`ScheduledThreadPoolExecutor` 是其主要实现类。
-
-
-
-**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目用到的比较少,因为有其他方案选择比如`quartz`。但是,在一些需求比较简单的场景下还是非常有用的!
-
-**`ScheduledThreadPoolExecutor` 使用的任务队列 `DelayQueue` 封装了一个 `PriorityQueue`,`PriorityQueue` 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行,如果执行所需时间相同则先提交的任务将被先执行。**
-
-### 5. 徒手撸一个线程安全的 LRU 缓存
-
-#### 5.1. 实现方法
-
- `ConcurrentHashMap` + `ConcurrentLinkedQueue` +`ReadWriteLock`
-
-#### 5.2. 原理
-
-`ConcurrentHashMap` 是线程安全的Map,我们可以利用它缓存 key,value形式的数据。`ConcurrentLinkedQueue`是一个线程安全的基于链表的队列(先进先出),我们可以用它来维护 key 。每当我们put/get(缓存被使用)元素的时候,我们就将这个元素对应的 key 存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。当我们的缓存容量不够的时候,我们直接移除队列头部对应的key以及这个key对应的缓存即可!
-
-另外,我们用到了`ReadWriteLock`(读写锁)来保证线程安全。
-
-#### 5.3. put方法具体流程分析
-
-为了方便大家理解,我将代码中比较重要的 `put(key,value)`方法的原理图画了出来,如下图所示:
-
-
-
-
-
-#### 5.4. 源码
-
-```java
-/**
- * @author shuang.kou
- *
- * 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock实现线程安全的 LRU 缓存
- * 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
- */
-public class MyLruCache {
-
- /**
- * 缓存的最大容量
- */
- private final int maxCapacity;
-
- private ConcurrentHashMap cacheMap;
- private ConcurrentLinkedQueue keys;
- /**
- * 读写锁
- */
- private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- private Lock writeLock = readWriteLock.writeLock();
- private Lock readLock = readWriteLock.readLock();
-
- public MyLruCache(int maxCapacity) {
- if (maxCapacity < 0) {
- throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
- }
- this.maxCapacity = maxCapacity;
- cacheMap = new ConcurrentHashMap<>(maxCapacity);
- keys = new ConcurrentLinkedQueue<>();
- }
-
- public V put(K key, V value) {
- // 加写锁
- writeLock.lock();
- try {
- //1.key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- moveToTailOfQueue(key);
- cacheMap.put(key, value);
- return value;
- }
- //2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
- if (cacheMap.size() == maxCapacity) {
- System.out.println("maxCapacity of cache reached");
- removeOldestKey();
- }
- //3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
- keys.add(key);
- cacheMap.put(key, value);
- return value;
- } finally {
- writeLock.unlock();
- }
- }
-
- public V get(K key) {
- //加读锁
- readLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在的话就将key移动到队列的尾部
- moveToTailOfQueue(key);
- return cacheMap.get(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- readLock.unlock();
- }
- }
-
- public V remove(K key) {
- writeLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在移除队列和Map中对应的Key
- keys.remove(key);
- return cacheMap.remove(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- writeLock.unlock();
- }
- }
-
- /**
- * 将元素添加到队列的尾部(put/get的时候执行)
- */
- private void moveToTailOfQueue(K key) {
- keys.remove(key);
- keys.add(key);
- }
-
- /**
- * 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
- */
- private void removeOldestKey() {
- K oldestKey = keys.poll();
- if (oldestKey != null) {
- cacheMap.remove(oldestKey);
- }
- }
-
- public int size() {
- return cacheMap.size();
- }
-
-}
-```
-
-**非并发环境测试:**
-
-```java
-MyLruCache myLruCache = new MyLruCache<>(3);
-myLruCache.put(1, "Java");
-System.out.println(myLruCache.get(1));// Java
-myLruCache.remove(1);
-System.out.println(myLruCache.get(1));// null
-myLruCache.put(2, "C++");
-myLruCache.put(3, "Python");
-System.out.println(myLruCache.get(2));//C++
-myLruCache.put(4, "C");
-myLruCache.put(5, "PHP");
-System.out.println(myLruCache.get(2));// C++
-```
-
-**并发环境测试:**
-
-我们初始化了一个固定容量为 10 的线程池和count为10的`CountDownLatch`。我们将1000000次操作分10次添加到线程池,然后我们等待线程池执行完成这10次操作。
-
-
-```java
-int threadNum = 10;
-int batchSize = 100000;
-//init cache
-MyLruCache myLruCache = new MyLruCache<>(batchSize * 10);
-//init thread pool with 10 threads
-ExecutorService fixedThreadPool = Executors.newFixedThreadPool(threadNum);
-//init CountDownLatch with 10 count
-CountDownLatch latch = new CountDownLatch(threadNum);
-AtomicInteger atomicInteger = new AtomicInteger(0);
-long startTime = System.currentTimeMillis();
-for (int t = 0; t < threadNum; t++) {
- fixedThreadPool.submit(() -> {
- for (int i = 0; i < batchSize; i++) {
- int value = atomicInteger.incrementAndGet();
- myLruCache.put("id" + value, value);
- }
- latch.countDown();
- });
-}
-//wait for 10 threads to complete the task
-latch.await();
-fixedThreadPool.shutdown();
-System.out.println("Cache size:" + myLruCache.size());//Cache size:1000000
-long endTime = System.currentTimeMillis();
-long duration = endTime - startTime;
-System.out.println(String.format("Time cost:%dms", duration));//Time cost:511ms
-```
-
-### 6. 实现一个线程安全并且带有过期时间的 LRU 缓存
-
-实际上就是在我们上面时间的LRU缓存的基础上加上一个定时任务去删除缓存,单纯利用 JDK 提供的类,我们实现定时任务的方式有很多种:
-
-1. `Timer` :不被推荐,多线程会存在问题。
-2. `ScheduledExecutorService` :定时器线程池,可以用来替代 `Timer`
-3. `DelayQueue` :延时队列
-4. `quartz` :一个很火的开源任务调度框架,很多其他框架都是基于 `quartz` 开发的,比如当当网的`elastic-job `就是基于`quartz`二次开发之后的分布式调度解决方案
-5. ......
-
-最终我们选择了 `ScheduledExecutorService`,主要原因是它易用(基于`DelayQueue`做了很多封装)并且基本能满足我们的大部分需求。
-
-我们在我们上面实现的线程安全的 LRU 缓存基础上,简单稍作修改即可!我们增加了一个方法:
-
-```java
-private void removeAfterExpireTime(K key, long expireTime) {
- scheduledExecutorService.schedule(() -> {
- //过期后清除该键值对
- cacheMap.remove(key);
- keys.remove(key);
- }, expireTime, TimeUnit.MILLISECONDS);
-}
-```
-我们put元素的时候,如果通过这个方法就能直接设置过期时间。
-
-
-**完整源码如下:**
-
-```java
-/**
- * @author shuang.kou
- *
- * 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock+ScheduledExecutorService实现线程安全的 LRU 缓存
- * 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
- */
-public class MyLruCacheWithExpireTime {
-
- /**
- * 缓存的最大容量
- */
- private final int maxCapacity;
-
- private ConcurrentHashMap cacheMap;
- private ConcurrentLinkedQueue keys;
- /**
- * 读写锁
- */
- private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
- private Lock writeLock = readWriteLock.writeLock();
- private Lock readLock = readWriteLock.readLock();
-
- private ScheduledExecutorService scheduledExecutorService;
-
- public MyLruCacheWithExpireTime(int maxCapacity) {
- if (maxCapacity < 0) {
- throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
- }
- this.maxCapacity = maxCapacity;
- cacheMap = new ConcurrentHashMap<>(maxCapacity);
- keys = new ConcurrentLinkedQueue<>();
- scheduledExecutorService = Executors.newScheduledThreadPool(3);
- }
-
- public V put(K key, V value, long expireTime) {
- // 加写锁
- writeLock.lock();
- try {
- //1.key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- moveToTailOfQueue(key);
- cacheMap.put(key, value);
- return value;
- }
- //2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
- if (cacheMap.size() == maxCapacity) {
- System.out.println("maxCapacity of cache reached");
- removeOldestKey();
- }
- //3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
- keys.add(key);
- cacheMap.put(key, value);
- if (expireTime > 0) {
- removeAfterExpireTime(key, expireTime);
- }
- return value;
- } finally {
- writeLock.unlock();
- }
- }
-
- public V get(K key) {
- //加读锁
- readLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在的话就将key移动到队列的尾部
- moveToTailOfQueue(key);
- return cacheMap.get(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- readLock.unlock();
- }
- }
-
- public V remove(K key) {
- writeLock.lock();
- try {
- //key是否存在于当前缓存
- if (cacheMap.containsKey(key)) {
- // 存在移除队列和Map中对应的Key
- keys.remove(key);
- return cacheMap.remove(key);
- }
- //不存在于当前缓存中就返回Null
- return null;
- } finally {
- writeLock.unlock();
- }
- }
-
- /**
- * 将元素添加到队列的尾部(put/get的时候执行)
- */
- private void moveToTailOfQueue(K key) {
- keys.remove(key);
- keys.add(key);
- }
-
- /**
- * 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
- */
- private void removeOldestKey() {
- K oldestKey = keys.poll();
- if (oldestKey != null) {
- cacheMap.remove(oldestKey);
- }
- }
-
- private void removeAfterExpireTime(K key, long expireTime) {
- scheduledExecutorService.schedule(() -> {
- //过期后清除该键值对
- cacheMap.remove(key);
- keys.remove(key);
- }, expireTime, TimeUnit.MILLISECONDS);
- }
-
- public int size() {
- return cacheMap.size();
- }
-
-}
-
-```
-
-**测试效果:**
-
-```java
-MyLruCacheWithExpireTime myLruCache = new MyLruCacheWithExpireTime<>(3);
-myLruCache.put(1,"Java",3000);
-myLruCache.put(2,"C++",3000);
-myLruCache.put(3,"Python",1500);
-System.out.println(myLruCache.size());//3
-Thread.sleep(2000);
-System.out.println(myLruCache.size());//2
-```
diff --git a/docs/java/jvm/JDK监控和故障处理工具总结.md b/docs/java/jvm/JDK监控和故障处理工具总结.md
index d5cb29de..c8263de0 100644
--- a/docs/java/jvm/JDK监控和故障处理工具总结.md
+++ b/docs/java/jvm/JDK监控和故障处理工具总结.md
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [JDK 监控和故障处理工具总结](#jdk-监控和故障处理工具总结)
@@ -325,13 +323,3 @@ VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java
-
-
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/jvm/JVM垃圾回收.md b/docs/java/jvm/JVM垃圾回收.md
index 95363151..f6ede785 100644
--- a/docs/java/jvm/JVM垃圾回收.md
+++ b/docs/java/jvm/JVM垃圾回收.md
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [JVM 垃圾回收](#jvm-垃圾回收)
@@ -334,7 +332,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
- +
### 3.3 标记-整理算法
@@ -401,7 +399,7 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
```
-**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用Parallel Scavenge收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
**新生代采用复制算法,老年代采用标记-整理算法。**

@@ -473,16 +471,6 @@ G1 收集器的运作大致分为以下几个步骤:
- https://my.oschina.net/hosee/blog/644618
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
diff --git a/docs/java/jvm/Java内存区域.md b/docs/java/jvm/Java内存区域.md
index 0cae9f0a..42dc7b7c 100644
--- a/docs/java/jvm/Java内存区域.md
+++ b/docs/java/jvm/Java内存区域.md
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [Java 内存区域详解](#java-内存区域详解)
@@ -492,13 +490,3 @@ i4=i5+i6 true
-
-
- 深入解析String#intern
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/jvm/类加载器.md b/docs/java/jvm/类加载器.md
index 1d0a826f..37394a92 100644
--- a/docs/java/jvm/类加载器.md
+++ b/docs/java/jvm/类加载器.md
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [回顾一下类加载过程](#回顾一下类加载过程)
@@ -134,13 +132,5 @@ protected Class loadClass(String name, boolean resolve)
-
-
-### 公众号
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/jvm/类加载过程.md b/docs/java/jvm/类加载过程.md
index 9330c581..947e1ad1 100644
--- a/docs/java/jvm/类加载过程.md
+++ b/docs/java/jvm/类加载过程.md
@@ -1,7 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
-
- [类的生命周期](#类的生命周期)
diff --git a/docs/java/jvm/类文件结构.md b/docs/java/jvm/类文件结构.md
index d766aa80..8620fab9 100644
--- a/docs/java/jvm/类文件结构.md
+++ b/docs/java/jvm/类文件结构.md
@@ -212,13 +212,3 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
-
-
- 《实战 Java 虚拟机》
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md b/docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
similarity index 100%
rename from docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
rename to docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
diff --git a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md b/docs/java/multi-thread/2020最新Java并发进阶常见面试题总结.md
similarity index 100%
rename from docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
rename to docs/java/multi-thread/2020最新Java并发进阶常见面试题总结.md
diff --git a/docs/java/Multithread/AQS.md b/docs/java/multi-thread/AQS原理以及AQS同步组件总结.md
similarity index 100%
rename from docs/java/Multithread/AQS.md
rename to docs/java/multi-thread/AQS原理以及AQS同步组件总结.md
diff --git a/docs/java/Multithread/Atomic.md b/docs/java/multi-thread/Atomic原子类总结.md
similarity index 100%
rename from docs/java/Multithread/Atomic.md
rename to docs/java/multi-thread/Atomic原子类总结.md
diff --git a/docs/java/Multithread/ThreadLocal(未完成).md b/docs/java/multi-thread/ThreadLocal(未完成).md
similarity index 100%
rename from docs/java/Multithread/ThreadLocal(未完成).md
rename to docs/java/multi-thread/ThreadLocal(未完成).md
diff --git a/docs/java/Multithread/images/ThreadLocal内部类.png b/docs/java/multi-thread/images/ThreadLocal内部类.png
similarity index 100%
rename from docs/java/Multithread/images/ThreadLocal内部类.png
rename to docs/java/multi-thread/images/ThreadLocal内部类.png
diff --git a/docs/java/Multithread/images/interview-questions/synchronized关键字.png b/docs/java/multi-thread/images/interview-questions/synchronized关键字.png
similarity index 100%
rename from docs/java/Multithread/images/interview-questions/synchronized关键字.png
rename to docs/java/multi-thread/images/interview-questions/synchronized关键字.png
diff --git a/docs/java/multi-thread/images/java线程池学习总结/CachedThreadPool-execute.png b/docs/java/multi-thread/images/java线程池学习总结/CachedThreadPool-execute.png
new file mode 100644
index 00000000..8b2ede8a
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/CachedThreadPool-execute.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/Executors工具类.png b/docs/java/multi-thread/images/java线程池学习总结/Executors工具类.png
new file mode 100644
index 00000000..87658aa3
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/Executors工具类.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/Executor框架的使用示意图.png b/docs/java/multi-thread/images/java线程池学习总结/Executor框架的使用示意图.png
new file mode 100644
index 00000000..5cc148dd
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/Executor框架的使用示意图.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/FixedThreadPool.png b/docs/java/multi-thread/images/java线程池学习总结/FixedThreadPool.png
new file mode 100644
index 00000000..fc1c7034
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/FixedThreadPool.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor执行周期任务步骤.png b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor执行周期任务步骤.png
new file mode 100644
index 00000000..c56521d2
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor执行周期任务步骤.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor机制.png b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor机制.png
new file mode 100644
index 00000000..bae0dc5b
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor机制.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/SingleThreadExecutor.png b/docs/java/multi-thread/images/java线程池学习总结/SingleThreadExecutor.png
new file mode 100644
index 00000000..c933674f
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/SingleThreadExecutor.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/threadpoolexecutor构造函数.png b/docs/java/multi-thread/images/java线程池学习总结/threadpoolexecutor构造函数.png
new file mode 100644
index 00000000..30c29859
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/threadpoolexecutor构造函数.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/任务的执行相关接口.png b/docs/java/multi-thread/images/java线程池学习总结/任务的执行相关接口.png
new file mode 100644
index 00000000..6aebd60b
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/任务的执行相关接口.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/图解线程池实现原理.png b/docs/java/multi-thread/images/java线程池学习总结/图解线程池实现原理.png
new file mode 100644
index 00000000..bc661944
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/图解线程池实现原理.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/线程池各个参数之间的关系.png b/docs/java/multi-thread/images/java线程池学习总结/线程池各个参数之间的关系.png
new file mode 100644
index 00000000..d609943b
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/线程池各个参数之间的关系.png differ
diff --git a/docs/java/Multithread/images/thread-local/1.png b/docs/java/multi-thread/images/thread-local/1.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/1.png
rename to docs/java/multi-thread/images/thread-local/1.png
diff --git a/docs/java/Multithread/images/thread-local/10.png b/docs/java/multi-thread/images/thread-local/10.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/10.png
rename to docs/java/multi-thread/images/thread-local/10.png
diff --git a/docs/java/Multithread/images/thread-local/11.png b/docs/java/multi-thread/images/thread-local/11.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/11.png
rename to docs/java/multi-thread/images/thread-local/11.png
diff --git a/docs/java/Multithread/images/thread-local/12.png b/docs/java/multi-thread/images/thread-local/12.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/12.png
rename to docs/java/multi-thread/images/thread-local/12.png
diff --git a/docs/java/Multithread/images/thread-local/13.png b/docs/java/multi-thread/images/thread-local/13.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/13.png
rename to docs/java/multi-thread/images/thread-local/13.png
diff --git a/docs/java/Multithread/images/thread-local/14.png b/docs/java/multi-thread/images/thread-local/14.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/14.png
rename to docs/java/multi-thread/images/thread-local/14.png
diff --git a/docs/java/Multithread/images/thread-local/15.png b/docs/java/multi-thread/images/thread-local/15.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/15.png
rename to docs/java/multi-thread/images/thread-local/15.png
diff --git a/docs/java/Multithread/images/thread-local/16.png b/docs/java/multi-thread/images/thread-local/16.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/16.png
rename to docs/java/multi-thread/images/thread-local/16.png
diff --git a/docs/java/Multithread/images/thread-local/17.png b/docs/java/multi-thread/images/thread-local/17.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/17.png
rename to docs/java/multi-thread/images/thread-local/17.png
diff --git a/docs/java/Multithread/images/thread-local/18.png b/docs/java/multi-thread/images/thread-local/18.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/18.png
rename to docs/java/multi-thread/images/thread-local/18.png
diff --git a/docs/java/Multithread/images/thread-local/19.png b/docs/java/multi-thread/images/thread-local/19.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/19.png
rename to docs/java/multi-thread/images/thread-local/19.png
diff --git a/docs/java/Multithread/images/thread-local/2.png b/docs/java/multi-thread/images/thread-local/2.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/2.png
rename to docs/java/multi-thread/images/thread-local/2.png
diff --git a/docs/java/Multithread/images/thread-local/20.png b/docs/java/multi-thread/images/thread-local/20.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/20.png
rename to docs/java/multi-thread/images/thread-local/20.png
diff --git a/docs/java/Multithread/images/thread-local/21.png b/docs/java/multi-thread/images/thread-local/21.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/21.png
rename to docs/java/multi-thread/images/thread-local/21.png
diff --git a/docs/java/Multithread/images/thread-local/22.png b/docs/java/multi-thread/images/thread-local/22.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/22.png
rename to docs/java/multi-thread/images/thread-local/22.png
diff --git a/docs/java/Multithread/images/thread-local/23.png b/docs/java/multi-thread/images/thread-local/23.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/23.png
rename to docs/java/multi-thread/images/thread-local/23.png
diff --git a/docs/java/Multithread/images/thread-local/24.png b/docs/java/multi-thread/images/thread-local/24.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/24.png
rename to docs/java/multi-thread/images/thread-local/24.png
diff --git a/docs/java/Multithread/images/thread-local/25.png b/docs/java/multi-thread/images/thread-local/25.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/25.png
rename to docs/java/multi-thread/images/thread-local/25.png
diff --git a/docs/java/Multithread/images/thread-local/26.png b/docs/java/multi-thread/images/thread-local/26.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/26.png
rename to docs/java/multi-thread/images/thread-local/26.png
diff --git a/docs/java/Multithread/images/thread-local/27.png b/docs/java/multi-thread/images/thread-local/27.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/27.png
rename to docs/java/multi-thread/images/thread-local/27.png
diff --git a/docs/java/Multithread/images/thread-local/28.png b/docs/java/multi-thread/images/thread-local/28.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/28.png
rename to docs/java/multi-thread/images/thread-local/28.png
diff --git a/docs/java/Multithread/images/thread-local/29.png b/docs/java/multi-thread/images/thread-local/29.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/29.png
rename to docs/java/multi-thread/images/thread-local/29.png
diff --git a/docs/java/Multithread/images/thread-local/3.png b/docs/java/multi-thread/images/thread-local/3.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/3.png
rename to docs/java/multi-thread/images/thread-local/3.png
diff --git a/docs/java/Multithread/images/thread-local/30.png b/docs/java/multi-thread/images/thread-local/30.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/30.png
rename to docs/java/multi-thread/images/thread-local/30.png
diff --git a/docs/java/Multithread/images/thread-local/31.png b/docs/java/multi-thread/images/thread-local/31.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/31.png
rename to docs/java/multi-thread/images/thread-local/31.png
diff --git a/docs/java/Multithread/images/thread-local/4.png b/docs/java/multi-thread/images/thread-local/4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/4.png
rename to docs/java/multi-thread/images/thread-local/4.png
diff --git a/docs/java/Multithread/images/thread-local/5.png b/docs/java/multi-thread/images/thread-local/5.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/5.png
rename to docs/java/multi-thread/images/thread-local/5.png
diff --git a/docs/java/Multithread/images/thread-local/6.png b/docs/java/multi-thread/images/thread-local/6.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/6.png
rename to docs/java/multi-thread/images/thread-local/6.png
diff --git a/docs/java/Multithread/images/thread-local/7.png b/docs/java/multi-thread/images/thread-local/7.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/7.png
rename to docs/java/multi-thread/images/thread-local/7.png
diff --git a/docs/java/Multithread/images/thread-local/8.png b/docs/java/multi-thread/images/thread-local/8.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/8.png
rename to docs/java/multi-thread/images/thread-local/8.png
diff --git a/docs/java/Multithread/images/thread-local/9.png b/docs/java/multi-thread/images/thread-local/9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/9.png
rename to docs/java/multi-thread/images/thread-local/9.png
diff --git a/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png b/docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
rename to docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
diff --git a/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png b/docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
rename to docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
diff --git a/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png b/docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
rename to docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
diff --git a/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png b/docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
rename to docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
diff --git a/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png b/docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
rename to docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
diff --git a/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png b/docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
rename to docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
diff --git a/docs/java/Multithread/images/threadlocal数据结构.png b/docs/java/multi-thread/images/threadlocal数据结构.png
similarity index 100%
rename from docs/java/Multithread/images/threadlocal数据结构.png
rename to docs/java/multi-thread/images/threadlocal数据结构.png
diff --git a/docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png b/docs/java/multi-thread/images/多线程学习指南/Java并发编程的艺术.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png
rename to docs/java/multi-thread/images/多线程学习指南/Java并发编程的艺术.png
diff --git a/docs/java/Multithread/images/多线程学习指南/javaguide-并发.png b/docs/java/multi-thread/images/多线程学习指南/javaguide-并发.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/javaguide-并发.png
rename to docs/java/multi-thread/images/多线程学习指南/javaguide-并发.png
diff --git a/docs/java/Multithread/images/多线程学习指南/java并发编程之美.png b/docs/java/multi-thread/images/多线程学习指南/java并发编程之美.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/java并发编程之美.png
rename to docs/java/multi-thread/images/多线程学习指南/java并发编程之美.png
diff --git a/docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png b/docs/java/multi-thread/images/多线程学习指南/实战Java高并发程序设计.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png
rename to docs/java/multi-thread/images/多线程学习指南/实战Java高并发程序设计.png
diff --git a/docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png b/docs/java/multi-thread/images/多线程学习指南/深入浅出Java多线程.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png
rename to docs/java/multi-thread/images/多线程学习指南/深入浅出Java多线程.png
diff --git a/docs/java/Multithread/java线程池学习总结.md b/docs/java/multi-thread/java线程池学习总结.md
similarity index 96%
rename from docs/java/Multithread/java线程池学习总结.md
rename to docs/java/multi-thread/java线程池学习总结.md
index 54f4b650..6a946dd0 100644
--- a/docs/java/Multithread/java线程池学习总结.md
+++ b/docs/java/multi-thread/java线程池学习总结.md
@@ -97,7 +97,7 @@ public class ScheduledThreadPoolExecutor
implements ScheduledExecutorService
```
-
+
#### 3) 异步计算的结果(`Future`)
@@ -107,7 +107,7 @@ public class ScheduledThreadPoolExecutor
### 2.3 Executor 框架的使用示意图
-
+
1. **主线程首先要创建实现 `Runnable` 或者 `Callable` 接口的任务对象。**
2. **把创建完成的实现 `Runnable`/`Callable`接口的 对象直接交给 `ExecutorService` 执行**: `ExecutorService.execute(Runnable command)`)或者也可以把 `Runnable` 对象或`Callable` 对象提交给 `ExecutorService` 执行(`ExecutorService.submit(Runnable task)`或 `ExecutorService.submit(Callable task)`)。
@@ -167,7 +167,7 @@ public class ScheduledThreadPoolExecutor
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
-
+
**`ThreadPoolExecutor` 饱和策略定义:**
@@ -198,7 +198,7 @@ public class ScheduledThreadPoolExecutor
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
**方式一:通过`ThreadPoolExecutor`构造函数实现(推荐)**
-
+
**方式二:通过 Executor 框架的工具类 Executors 来实现**
我们可以创建三种类型的 ThreadPoolExecutor:
@@ -207,7 +207,7 @@ public class ScheduledThreadPoolExecutor
- **CachedThreadPool**
对应 Executors 工具类中的方法如图所示:
-
+
## 四 (重要)ThreadPoolExecutor 使用示例
@@ -388,7 +388,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
-
+
@@ -705,7 +705,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
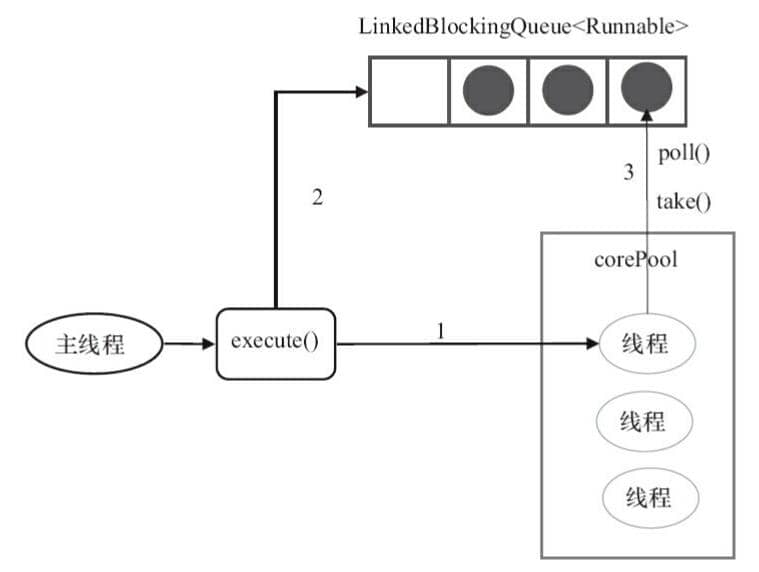
`FixedThreadPool` 的 `execute()` 方法运行示意图(该图片来源:《Java 并发编程的艺术》):
-
+
**上图说明:**
@@ -755,7 +755,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.2.2 执行任务过程介绍
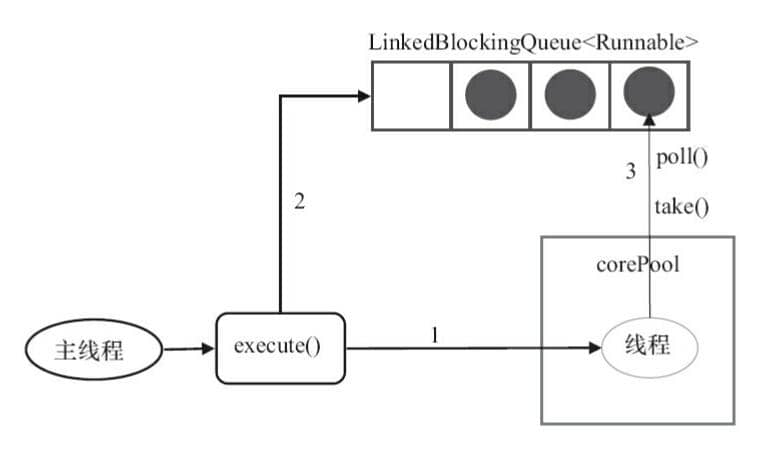
**`SingleThreadExecutor` 的运行示意图(该图片来源:《Java 并发编程的艺术》):**
-
+
**上图说明;**
@@ -799,7 +799,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.3.2 执行任务过程介绍
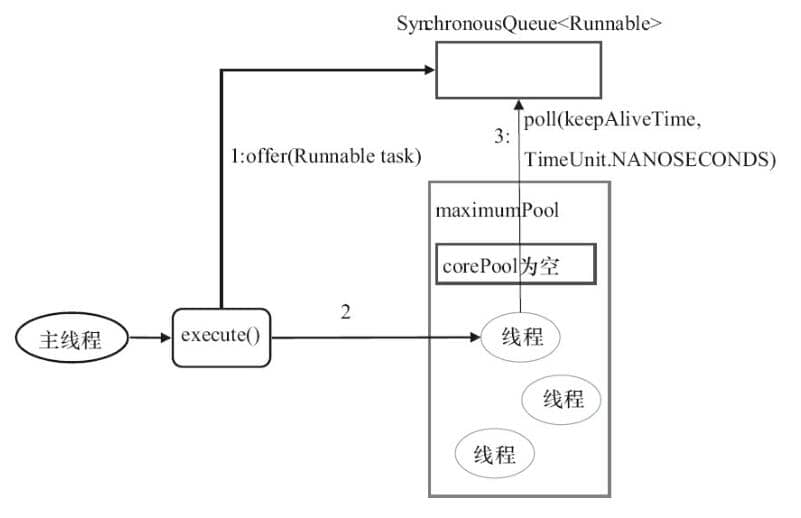
**CachedThreadPool 的 execute()方法的执行示意图(该图片来源:《Java 并发编程的艺术》):**
-
+
**上图说明:**
@@ -830,7 +830,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.2 运行机制
-
+
**`ScheduledThreadPoolExecutor` 的执行主要分为两大部分:**
@@ -845,7 +845,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.3 ScheduledThreadPoolExecutor 执行周期任务的步骤
-
+
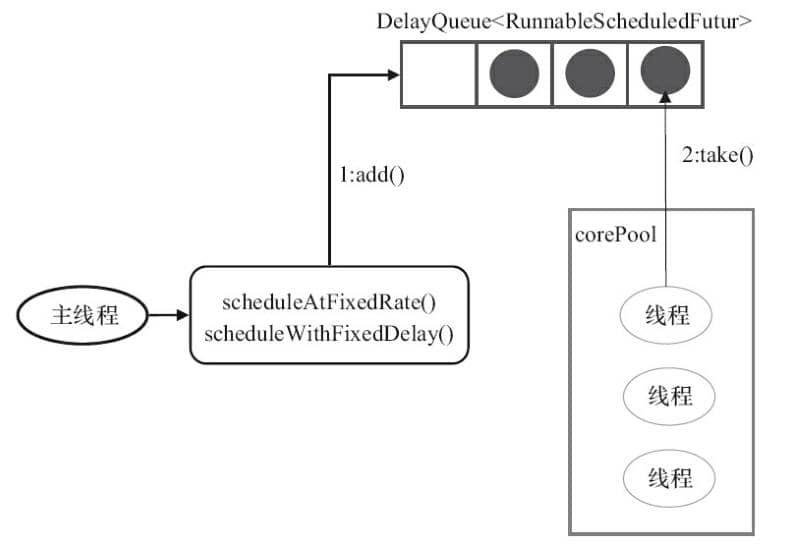
1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask`的 time 大于等于当前系统的时间;
2. 线程 1 执行这个 `ScheduledFutureTask`;
diff --git a/docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md b/docs/java/multi-thread/synchronized在JDK1.6之后的底层优化.md
similarity index 100%
rename from docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md
rename to docs/java/multi-thread/synchronized在JDK1.6之后的底层优化.md
diff --git a/docs/java/Multithread/ThreadLocal.md b/docs/java/multi-thread/万字详解ThreadLocal关键字.md
similarity index 100%
rename from docs/java/Multithread/ThreadLocal.md
rename to docs/java/multi-thread/万字详解ThreadLocal关键字.md
diff --git a/docs/java/Multithread/创建线程的几种方式总结.md b/docs/java/multi-thread/创建线程的几种方式总结.md
similarity index 100%
rename from docs/java/Multithread/创建线程的几种方式总结.md
rename to docs/java/multi-thread/创建线程的几种方式总结.md
diff --git a/docs/java/Multithread/多线程学习指南.md b/docs/java/multi-thread/多线程学习指南.md
similarity index 100%
rename from docs/java/Multithread/多线程学习指南.md
rename to docs/java/multi-thread/多线程学习指南.md
diff --git a/docs/java/Multithread/并发容器总结.md b/docs/java/multi-thread/并发容器总结.md
similarity index 100%
rename from docs/java/Multithread/并发容器总结.md
rename to docs/java/multi-thread/并发容器总结.md
diff --git a/docs/java/Multithread/best-practice-of-threadpool.md b/docs/java/multi-thread/拿来即用的线程池最佳实践.md
similarity index 100%
rename from docs/java/Multithread/best-practice-of-threadpool.md
rename to docs/java/multi-thread/拿来即用的线程池最佳实践.md
diff --git a/docs/java/What's New in JDK8/Java8foreach指南.md b/docs/java/new-features/Java8foreach指南.md
similarity index 100%
rename from docs/java/What's New in JDK8/Java8foreach指南.md
rename to docs/java/new-features/Java8foreach指南.md
diff --git a/docs/java/What's New in JDK8/Java8教程推荐.md b/docs/java/new-features/Java8教程推荐.md
similarity index 100%
rename from docs/java/What's New in JDK8/Java8教程推荐.md
rename to docs/java/new-features/Java8教程推荐.md
diff --git a/docs/java/What's New in JDK8/Java8Tutorial.md b/docs/java/new-features/Java8新特性总结.md
similarity index 100%
rename from docs/java/What's New in JDK8/Java8Tutorial.md
rename to docs/java/new-features/Java8新特性总结.md
diff --git a/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png b/docs/java/new-features/images/一文带你看遍JDK9~14 的重要新特性/java版本发布.png
similarity index 100%
rename from docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png
rename to docs/java/new-features/images/一文带你看遍JDK9~14 的重要新特性/java版本发布.png
diff --git a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md b/docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md
similarity index 99%
rename from docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
rename to docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md
index 5b193cd5..64d70b3a 100644
--- a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
+++ b/docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md
@@ -109,7 +109,7 @@ Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
-
+
### 字符串加强
diff --git a/docs/network/images/七层体系结构图.png b/docs/network/images/七层体系结构图.png
new file mode 100644
index 00000000..a2d24300
Binary files /dev/null and b/docs/network/images/七层体系结构图.png differ
diff --git a/docs/network/images/传输层.png b/docs/network/images/传输层.png
new file mode 100644
index 00000000..192af245
Binary files /dev/null and b/docs/network/images/传输层.png differ
diff --git a/docs/network/images/应用层.png b/docs/network/images/应用层.png
new file mode 100644
index 00000000..31e1e447
Binary files /dev/null and b/docs/network/images/应用层.png differ
diff --git a/docs/network/images/数据链路层.png b/docs/network/images/数据链路层.png
new file mode 100644
index 00000000..c2b51a7c
Binary files /dev/null and b/docs/network/images/数据链路层.png differ
diff --git a/docs/network/images/物理层.png b/docs/network/images/物理层.png
new file mode 100644
index 00000000..abb97926
Binary files /dev/null and b/docs/network/images/物理层.png differ
diff --git a/docs/network/images/网络层.png b/docs/network/images/网络层.png
new file mode 100644
index 00000000..376479d7
Binary files /dev/null and b/docs/network/images/网络层.png differ
diff --git a/docs/network/images/计算机网络概述.png b/docs/network/images/计算机网络概述.png
new file mode 100644
index 00000000..999c2362
Binary files /dev/null and b/docs/network/images/计算机网络概述.png differ
diff --git a/docs/network/images/计算机网络知识点总结/万维网的大致工作工程.png b/docs/network/images/计算机网络知识点总结/万维网的大致工作工程.png
new file mode 100644
index 00000000..6af03daa
Binary files /dev/null and b/docs/network/images/计算机网络知识点总结/万维网的大致工作工程.png differ
diff --git a/docs/network/images/计算机网络第七版.png b/docs/network/images/计算机网络第七版.png
new file mode 100644
index 00000000..1ea61963
Binary files /dev/null and b/docs/network/images/计算机网络第七版.png differ
diff --git a/docs/network/干货:计算机网络知识总结.md b/docs/network/干货:计算机网络知识总结.md
deleted file mode 100644
index a20e6f85..00000000
--- a/docs/network/干货:计算机网络知识总结.md
+++ /dev/null
@@ -1,420 +0,0 @@
-### 1. [计算机概述 ](#一计算机概述)
-### 2. [物理层 ](#二物理层)
-### 3. [数据链路层 ](#三数据链路层 )
-### 4. [网络层 ](#四网络层 )
-### 5. [运输层 ](#五运输层 )
-### 6. [应用层](#六应用层)
-
-
-## 一计算机概述
-### (1),基本术语
-
-#### 结点 (node):
-
- 网络中的结点可以是计算机,集线器,交换机或路由器等。
-#### 链路(link ):
-
- 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-#### 主机(host):
- 连接在因特网上的计算机.
-#### ISP(Internet Service Provider):
- 因特网服务提供者(提供商).
-#### IXP(Internet eXchange Point):
- 互联网交换点IXP的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。.
-#### RFC(Request For Comments)
- 意思是“请求评议”,包含了关于Internet几乎所有的重要的文字资料。
-#### 广域网WAN(Wide Area Network)
- 任务是通过长距离运送主机发送的数据
-#### 城域网MAN(Metropolitan Area Network)
- 用来将多个局域网进行互连
-
-#### 局域网LAN(Local Area Network)
- 学校或企业大多拥有多个互连的局域网
-#### 个人区域网PAN(Personal Area Network)
- 在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络
-#### 端系统(end system):
- 处在因特网边缘的部分即是连接在因特网上的所有的主机.
-#### 分组(packet ):
- 因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
-#### 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
-#### 带宽(bandwidth):
- 在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
-#### 吞吐量(throughput ):
- 表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
-
-### (2),重要知识点总结
-
- 1,计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。
-
- 2,小写字母i开头的internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。
-
- 大写字母I开头的Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用TCP/IP协议作为通信规则,其前身为ARPANET。Internet的推荐译名为因特网,现在一般流行称为互联网。
-
- 3,路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
-
-4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
-
- 5,计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S方式)和对等连接方式(P2P方式)。
-
- 6,客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
-
-7,按照作用范围的不同,计算机网络分为广域网WAN,城域网MAN,局域网LAN,个人区域网PAN。
-
- 8,计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。
-
- 9,网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
-
- 10,五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是TCP和UDP协议,网络层最重要的协议是IP协议。
-
-## 二物理层
-### (1),基本术语
-#### 数据(data):
- 运送消息的实体。
-#### 信号(signal):
- 数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
-#### 码元( code):
- 在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
-#### 单工(simplex ):
- 只能有一个方向的通信而没有反方向的交互。
-#### 半双工(half duplex ):
- 通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
-#### 全双工(full duplex):
- 通信的双方可以同时发送和接收信息。
-#### 奈氏准则:
- 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
-#### 基带信号(baseband signal):
- 来自信源的信号。指没有经过调制的数字信号或模拟信号。
-#### 带通(频带)信号(bandpass signal):
- 把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
-#### 调制(modulation ):
- 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
-#### 信噪比(signal-to-noise ratio ):
- 指信号的平均功率和噪声的平均功率之比,记为S/N。信噪比(dB)=10*log10(S/N)
-#### 信道复用(channel multiplexing ):
- 指多个用户共享同一个信道。(并不一定是同时)
-#### 比特率(bit rate ):
- 单位时间(每秒)内传送的比特数。
-#### 波特率(baud rate):
- 单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
-#### 复用(multiplexing):
- 共享信道的方法
-#### ADSL(Asymmetric Digital Subscriber Line ):
- 非对称数字用户线。
-#### 光纤同轴混合网(HFC网):
- 在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
-
-### (2),重要知识点总结
-
- 1,物理层的主要任务就是确定与传输媒体接口有关的一些特性,如机械特性,电气特性,功能特性,过程特性。
-
- 2,一个数据通信系统可划分为三大部分,即源系统,传输系统,目的系统。源系统包括源点(或源站,信源)和发送器,目的系统包括接收器和终点。
-
- 3,通信的目的是传送消息。如话音,文字,图像等都是消息,数据是运送消息的实体。信号则是数据的电器或电磁的表现。
-
- 4,根据信号中代表消息的参数的取值方式不同,信号可分为模拟信号(或连续信号)和数字信号(或离散信号)。在使用时间域(简称时域)的波形表示数字信号时,代表不同离散数值的基本波形称为码元。
-
- 5,根据双方信息交互的方式,通信可划分为单向通信(或单工通信),双向交替通信(或半双工通信),双向同时通信(全双工通信)。
-
- 6,来自信源的信号称为基带信号。信号要在信道上传输就要经过调制。调制有基带调制和带通调制之分。最基本的带通调制方法有调幅,调频和调相。还有更复杂的调制方法,如正交振幅调制。
-
- 7,要提高数据在信道上的传递速率,可以使用更好的传输媒体,或使用先进的调制技术。但数据传输速率不可能任意被提高。
-
- 8,传输媒体可分为两大类,即导引型传输媒体(双绞线,同轴电缆,光纤)和非导引型传输媒体(无线,红外,大气激光)。
-
- 9,为了有效利用光纤资源,在光纤干线和用户之间广泛使用无源光网络PON。无源光网络无需配备电源,其长期运营成本和管理成本都很低。最流行的无源光网络是以太网无源光网络EPON和吉比特无源光网络GPON。
-
-### (3),最重要的知识点
-#### **①,物理层的任务**
- 透明地传送比特流。也可以将物理层的主要任务描述为确定与传输媒体的接口的一些特性,即:机械特性(接口所用接线器的一些物理属性如形状尺寸),电气特性(接口电缆的各条线上出现的电压的范围),功能特性(某条线上出现的某一电平的电压的意义),过程特性(对于不同功能能的各种可能事件的出现顺序)。
-
-#### 拓展:
- 物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。现有的计算机网络中的硬件设备和传输媒体的种类非常繁多,而且通信手段也有许多不同的方式。物理层的作用正是尽可能地屏蔽掉这些传输媒体和通信手段的差异,使物理层上面的数据链路层感觉不到这些差异,这样就可以使数据链路层只考虑完成本层的协议和服务,而不必考虑网络的具体传输媒体和通信手段是什么。
-
-#### **②,几种常用的信道复用技术**
-
-
-### **③,几种常用的宽带接入技术,主要是ADSL和FTTx**
- 用户到互联网的宽带接入方法有非对称数字用户线ADSL(用数字技术对现有的模拟电话线进行改造,而不需要重新布线。ASDL的快速版本是甚高速数字用户线VDSL。),光纤同轴混合网HFC(是在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网)和FTTx(即光纤到······)。
-
-## 三数据链路层
-### (1),基本术语
-
-#### 链路(link):
- 一个结点到相邻结点的一段物理链路
-#### 数据链路(data link):
- 把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路
-#### 循环冗余检验CRC(Cyclic Redundancy Check):
- 为了保证数据传输的可靠性,CRC是数据链路层广泛使用的一种检错技术
-#### 帧(frame):
- 一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-#### MTU(Maximum Transfer Uint ):
- 最大传送单元。帧的数据部分的的长度上限。
-#### 误码率BER(Bit Error Rate ):
- 在一段时间内,传输错误的比特占所传输比特总数的比率。
-#### PPP(Point-to-Point Protocol ):
- 点对点协议。即用户计算机和ISP进行通信时所使用的数据链路层协议。以下是PPP帧的示意图:
-
-#### MAC地址(Media Access Control或者Medium Access Control):
- 意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。
- 在OSI模型中,第三层网络层负责 IP地址,第二层数据链路层则负责 MAC地址。
- 因此一个主机会有一个MAC地址,而每个网络位置会有一个专属于它的IP地址 。
- 地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处”
-#### 网桥(bridge):
- 一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
-#### 交换机(switch ):
- 广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
-
-
-### (2),重要知识点总结
-
-1,链路是从一个结点到相邻节点的一段物理链路,数据链路则在链路的基础上增加了一些必要的硬件(如网络适配器)和软件(如协议的实现)
-
-2,数据链路层使用的主要是**点对点信道**和**广播信道**两种。
-
-3,数据链路层传输的协议数据单元是帧。数据链路层的三个基本问题是:**封装成帧**,**透明传输**和**差错检测**
-
-4,**循环冗余检验CRC**是一种检错方法,而帧检验序列FCS是添加在数据后面的冗余码
-
-5,**点对点协议PPP**是数据链路层使用最多的一种协议,它的特点是:简单,只检测差错而不去纠正差错,不使用序号,也不进行流量控制,可同时支持多种网络层协议
-
- 6,PPPoE是为宽带上网的主机使用的链路层协议
-
-7,局域网的优点是:具有广播功能,从一个站点可方便地访问全网;便于系统的扩展和逐渐演变;提高了系统的可靠性,可用性和生存性。
-
-8,共向媒体通信资源的方法有二:一是静态划分信道(各种复用技术),而是动态媒体接入控制,又称为多点接入(随即接入或受控接入)
-
-9,计算机与外接局域网通信需要通过通信适配器(或网络适配器),它又称为网络接口卡或网卡。**计算器的硬件地址就在适配器的ROM中**。
-
-10,以太网采用的无连接的工作方式,对发送的数据帧不进行编号,也不要求对方发回确认。目的站收到有差错帧就把它丢掉,其他什么也不做
-
-11,以太网采用的协议是具有冲突检测的**载波监听多点接入CSMA/CD**。协议的特点是:**发送前先监听,边发送边监听,一旦发现总线上出现了碰撞,就立即停止发送。然后按照退避算法等待一段随机时间后再次发送。** 因此,每一个站点在自己发送数据之后的一小段时间内,存在这遭遇碰撞的可能性。以太网上的各站点平等的争用以太网信道
-
-12,以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。
-
-13,使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)
-### (3),最重要的知识点
+
### 3.3 标记-整理算法
@@ -401,7 +399,7 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
```
-**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
+**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用Parallel Scavenge收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
**新生代采用复制算法,老年代采用标记-整理算法。**

@@ -473,16 +471,6 @@ G1 收集器的运作大致分为以下几个步骤:
- https://my.oschina.net/hosee/blog/644618
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
diff --git a/docs/java/jvm/Java内存区域.md b/docs/java/jvm/Java内存区域.md
index 0cae9f0a..42dc7b7c 100644
--- a/docs/java/jvm/Java内存区域.md
+++ b/docs/java/jvm/Java内存区域.md
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [Java 内存区域详解](#java-内存区域详解)
@@ -492,13 +490,3 @@ i4=i5+i6 true
-
-
- 深入解析String#intern
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/jvm/类加载器.md b/docs/java/jvm/类加载器.md
index 1d0a826f..37394a92 100644
--- a/docs/java/jvm/类加载器.md
+++ b/docs/java/jvm/类加载器.md
@@ -1,5 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
- [回顾一下类加载过程](#回顾一下类加载过程)
@@ -134,13 +132,5 @@ protected Class loadClass(String name, boolean resolve)
-
-
-### 公众号
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/jvm/类加载过程.md b/docs/java/jvm/类加载过程.md
index 9330c581..947e1ad1 100644
--- a/docs/java/jvm/类加载过程.md
+++ b/docs/java/jvm/类加载过程.md
@@ -1,7 +1,3 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
-
- [类的生命周期](#类的生命周期)
diff --git a/docs/java/jvm/类文件结构.md b/docs/java/jvm/类文件结构.md
index d766aa80..8620fab9 100644
--- a/docs/java/jvm/类文件结构.md
+++ b/docs/java/jvm/类文件结构.md
@@ -212,13 +212,3 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
-
-
- 《实战 Java 虚拟机》
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md b/docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
similarity index 100%
rename from docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
rename to docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md
diff --git a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md b/docs/java/multi-thread/2020最新Java并发进阶常见面试题总结.md
similarity index 100%
rename from docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
rename to docs/java/multi-thread/2020最新Java并发进阶常见面试题总结.md
diff --git a/docs/java/Multithread/AQS.md b/docs/java/multi-thread/AQS原理以及AQS同步组件总结.md
similarity index 100%
rename from docs/java/Multithread/AQS.md
rename to docs/java/multi-thread/AQS原理以及AQS同步组件总结.md
diff --git a/docs/java/Multithread/Atomic.md b/docs/java/multi-thread/Atomic原子类总结.md
similarity index 100%
rename from docs/java/Multithread/Atomic.md
rename to docs/java/multi-thread/Atomic原子类总结.md
diff --git a/docs/java/Multithread/ThreadLocal(未完成).md b/docs/java/multi-thread/ThreadLocal(未完成).md
similarity index 100%
rename from docs/java/Multithread/ThreadLocal(未完成).md
rename to docs/java/multi-thread/ThreadLocal(未完成).md
diff --git a/docs/java/Multithread/images/ThreadLocal内部类.png b/docs/java/multi-thread/images/ThreadLocal内部类.png
similarity index 100%
rename from docs/java/Multithread/images/ThreadLocal内部类.png
rename to docs/java/multi-thread/images/ThreadLocal内部类.png
diff --git a/docs/java/Multithread/images/interview-questions/synchronized关键字.png b/docs/java/multi-thread/images/interview-questions/synchronized关键字.png
similarity index 100%
rename from docs/java/Multithread/images/interview-questions/synchronized关键字.png
rename to docs/java/multi-thread/images/interview-questions/synchronized关键字.png
diff --git a/docs/java/multi-thread/images/java线程池学习总结/CachedThreadPool-execute.png b/docs/java/multi-thread/images/java线程池学习总结/CachedThreadPool-execute.png
new file mode 100644
index 00000000..8b2ede8a
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/CachedThreadPool-execute.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/Executors工具类.png b/docs/java/multi-thread/images/java线程池学习总结/Executors工具类.png
new file mode 100644
index 00000000..87658aa3
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/Executors工具类.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/Executor框架的使用示意图.png b/docs/java/multi-thread/images/java线程池学习总结/Executor框架的使用示意图.png
new file mode 100644
index 00000000..5cc148dd
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/Executor框架的使用示意图.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/FixedThreadPool.png b/docs/java/multi-thread/images/java线程池学习总结/FixedThreadPool.png
new file mode 100644
index 00000000..fc1c7034
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/FixedThreadPool.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor执行周期任务步骤.png b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor执行周期任务步骤.png
new file mode 100644
index 00000000..c56521d2
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor执行周期任务步骤.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor机制.png b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor机制.png
new file mode 100644
index 00000000..bae0dc5b
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/ScheduledThreadPoolExecutor机制.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/SingleThreadExecutor.png b/docs/java/multi-thread/images/java线程池学习总结/SingleThreadExecutor.png
new file mode 100644
index 00000000..c933674f
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/SingleThreadExecutor.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/threadpoolexecutor构造函数.png b/docs/java/multi-thread/images/java线程池学习总结/threadpoolexecutor构造函数.png
new file mode 100644
index 00000000..30c29859
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/threadpoolexecutor构造函数.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/任务的执行相关接口.png b/docs/java/multi-thread/images/java线程池学习总结/任务的执行相关接口.png
new file mode 100644
index 00000000..6aebd60b
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/任务的执行相关接口.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/图解线程池实现原理.png b/docs/java/multi-thread/images/java线程池学习总结/图解线程池实现原理.png
new file mode 100644
index 00000000..bc661944
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/图解线程池实现原理.png differ
diff --git a/docs/java/multi-thread/images/java线程池学习总结/线程池各个参数之间的关系.png b/docs/java/multi-thread/images/java线程池学习总结/线程池各个参数之间的关系.png
new file mode 100644
index 00000000..d609943b
Binary files /dev/null and b/docs/java/multi-thread/images/java线程池学习总结/线程池各个参数之间的关系.png differ
diff --git a/docs/java/Multithread/images/thread-local/1.png b/docs/java/multi-thread/images/thread-local/1.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/1.png
rename to docs/java/multi-thread/images/thread-local/1.png
diff --git a/docs/java/Multithread/images/thread-local/10.png b/docs/java/multi-thread/images/thread-local/10.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/10.png
rename to docs/java/multi-thread/images/thread-local/10.png
diff --git a/docs/java/Multithread/images/thread-local/11.png b/docs/java/multi-thread/images/thread-local/11.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/11.png
rename to docs/java/multi-thread/images/thread-local/11.png
diff --git a/docs/java/Multithread/images/thread-local/12.png b/docs/java/multi-thread/images/thread-local/12.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/12.png
rename to docs/java/multi-thread/images/thread-local/12.png
diff --git a/docs/java/Multithread/images/thread-local/13.png b/docs/java/multi-thread/images/thread-local/13.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/13.png
rename to docs/java/multi-thread/images/thread-local/13.png
diff --git a/docs/java/Multithread/images/thread-local/14.png b/docs/java/multi-thread/images/thread-local/14.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/14.png
rename to docs/java/multi-thread/images/thread-local/14.png
diff --git a/docs/java/Multithread/images/thread-local/15.png b/docs/java/multi-thread/images/thread-local/15.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/15.png
rename to docs/java/multi-thread/images/thread-local/15.png
diff --git a/docs/java/Multithread/images/thread-local/16.png b/docs/java/multi-thread/images/thread-local/16.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/16.png
rename to docs/java/multi-thread/images/thread-local/16.png
diff --git a/docs/java/Multithread/images/thread-local/17.png b/docs/java/multi-thread/images/thread-local/17.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/17.png
rename to docs/java/multi-thread/images/thread-local/17.png
diff --git a/docs/java/Multithread/images/thread-local/18.png b/docs/java/multi-thread/images/thread-local/18.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/18.png
rename to docs/java/multi-thread/images/thread-local/18.png
diff --git a/docs/java/Multithread/images/thread-local/19.png b/docs/java/multi-thread/images/thread-local/19.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/19.png
rename to docs/java/multi-thread/images/thread-local/19.png
diff --git a/docs/java/Multithread/images/thread-local/2.png b/docs/java/multi-thread/images/thread-local/2.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/2.png
rename to docs/java/multi-thread/images/thread-local/2.png
diff --git a/docs/java/Multithread/images/thread-local/20.png b/docs/java/multi-thread/images/thread-local/20.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/20.png
rename to docs/java/multi-thread/images/thread-local/20.png
diff --git a/docs/java/Multithread/images/thread-local/21.png b/docs/java/multi-thread/images/thread-local/21.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/21.png
rename to docs/java/multi-thread/images/thread-local/21.png
diff --git a/docs/java/Multithread/images/thread-local/22.png b/docs/java/multi-thread/images/thread-local/22.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/22.png
rename to docs/java/multi-thread/images/thread-local/22.png
diff --git a/docs/java/Multithread/images/thread-local/23.png b/docs/java/multi-thread/images/thread-local/23.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/23.png
rename to docs/java/multi-thread/images/thread-local/23.png
diff --git a/docs/java/Multithread/images/thread-local/24.png b/docs/java/multi-thread/images/thread-local/24.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/24.png
rename to docs/java/multi-thread/images/thread-local/24.png
diff --git a/docs/java/Multithread/images/thread-local/25.png b/docs/java/multi-thread/images/thread-local/25.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/25.png
rename to docs/java/multi-thread/images/thread-local/25.png
diff --git a/docs/java/Multithread/images/thread-local/26.png b/docs/java/multi-thread/images/thread-local/26.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/26.png
rename to docs/java/multi-thread/images/thread-local/26.png
diff --git a/docs/java/Multithread/images/thread-local/27.png b/docs/java/multi-thread/images/thread-local/27.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/27.png
rename to docs/java/multi-thread/images/thread-local/27.png
diff --git a/docs/java/Multithread/images/thread-local/28.png b/docs/java/multi-thread/images/thread-local/28.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/28.png
rename to docs/java/multi-thread/images/thread-local/28.png
diff --git a/docs/java/Multithread/images/thread-local/29.png b/docs/java/multi-thread/images/thread-local/29.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/29.png
rename to docs/java/multi-thread/images/thread-local/29.png
diff --git a/docs/java/Multithread/images/thread-local/3.png b/docs/java/multi-thread/images/thread-local/3.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/3.png
rename to docs/java/multi-thread/images/thread-local/3.png
diff --git a/docs/java/Multithread/images/thread-local/30.png b/docs/java/multi-thread/images/thread-local/30.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/30.png
rename to docs/java/multi-thread/images/thread-local/30.png
diff --git a/docs/java/Multithread/images/thread-local/31.png b/docs/java/multi-thread/images/thread-local/31.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/31.png
rename to docs/java/multi-thread/images/thread-local/31.png
diff --git a/docs/java/Multithread/images/thread-local/4.png b/docs/java/multi-thread/images/thread-local/4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/4.png
rename to docs/java/multi-thread/images/thread-local/4.png
diff --git a/docs/java/Multithread/images/thread-local/5.png b/docs/java/multi-thread/images/thread-local/5.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/5.png
rename to docs/java/multi-thread/images/thread-local/5.png
diff --git a/docs/java/Multithread/images/thread-local/6.png b/docs/java/multi-thread/images/thread-local/6.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/6.png
rename to docs/java/multi-thread/images/thread-local/6.png
diff --git a/docs/java/Multithread/images/thread-local/7.png b/docs/java/multi-thread/images/thread-local/7.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/7.png
rename to docs/java/multi-thread/images/thread-local/7.png
diff --git a/docs/java/Multithread/images/thread-local/8.png b/docs/java/multi-thread/images/thread-local/8.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/8.png
rename to docs/java/multi-thread/images/thread-local/8.png
diff --git a/docs/java/Multithread/images/thread-local/9.png b/docs/java/multi-thread/images/thread-local/9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-local/9.png
rename to docs/java/multi-thread/images/thread-local/9.png
diff --git a/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png b/docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
rename to docs/java/multi-thread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
diff --git a/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png b/docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
rename to docs/java/multi-thread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
diff --git a/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png b/docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
rename to docs/java/multi-thread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
diff --git a/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png b/docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
rename to docs/java/multi-thread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
diff --git a/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png b/docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
rename to docs/java/multi-thread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
diff --git a/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png b/docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
similarity index 100%
rename from docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
rename to docs/java/multi-thread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
diff --git a/docs/java/Multithread/images/threadlocal数据结构.png b/docs/java/multi-thread/images/threadlocal数据结构.png
similarity index 100%
rename from docs/java/Multithread/images/threadlocal数据结构.png
rename to docs/java/multi-thread/images/threadlocal数据结构.png
diff --git a/docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png b/docs/java/multi-thread/images/多线程学习指南/Java并发编程的艺术.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png
rename to docs/java/multi-thread/images/多线程学习指南/Java并发编程的艺术.png
diff --git a/docs/java/Multithread/images/多线程学习指南/javaguide-并发.png b/docs/java/multi-thread/images/多线程学习指南/javaguide-并发.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/javaguide-并发.png
rename to docs/java/multi-thread/images/多线程学习指南/javaguide-并发.png
diff --git a/docs/java/Multithread/images/多线程学习指南/java并发编程之美.png b/docs/java/multi-thread/images/多线程学习指南/java并发编程之美.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/java并发编程之美.png
rename to docs/java/multi-thread/images/多线程学习指南/java并发编程之美.png
diff --git a/docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png b/docs/java/multi-thread/images/多线程学习指南/实战Java高并发程序设计.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png
rename to docs/java/multi-thread/images/多线程学习指南/实战Java高并发程序设计.png
diff --git a/docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png b/docs/java/multi-thread/images/多线程学习指南/深入浅出Java多线程.png
similarity index 100%
rename from docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png
rename to docs/java/multi-thread/images/多线程学习指南/深入浅出Java多线程.png
diff --git a/docs/java/Multithread/java线程池学习总结.md b/docs/java/multi-thread/java线程池学习总结.md
similarity index 96%
rename from docs/java/Multithread/java线程池学习总结.md
rename to docs/java/multi-thread/java线程池学习总结.md
index 54f4b650..6a946dd0 100644
--- a/docs/java/Multithread/java线程池学习总结.md
+++ b/docs/java/multi-thread/java线程池学习总结.md
@@ -97,7 +97,7 @@ public class ScheduledThreadPoolExecutor
implements ScheduledExecutorService
```
-
+
#### 3) 异步计算的结果(`Future`)
@@ -107,7 +107,7 @@ public class ScheduledThreadPoolExecutor
### 2.3 Executor 框架的使用示意图
-
+
1. **主线程首先要创建实现 `Runnable` 或者 `Callable` 接口的任务对象。**
2. **把创建完成的实现 `Runnable`/`Callable`接口的 对象直接交给 `ExecutorService` 执行**: `ExecutorService.execute(Runnable command)`)或者也可以把 `Runnable` 对象或`Callable` 对象提交给 `ExecutorService` 执行(`ExecutorService.submit(Runnable task)`或 `ExecutorService.submit(Callable task)`)。
@@ -167,7 +167,7 @@ public class ScheduledThreadPoolExecutor
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
-
+
**`ThreadPoolExecutor` 饱和策略定义:**
@@ -198,7 +198,7 @@ public class ScheduledThreadPoolExecutor
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
**方式一:通过`ThreadPoolExecutor`构造函数实现(推荐)**
-
+
**方式二:通过 Executor 框架的工具类 Executors 来实现**
我们可以创建三种类型的 ThreadPoolExecutor:
@@ -207,7 +207,7 @@ public class ScheduledThreadPoolExecutor
- **CachedThreadPool**
对应 Executors 工具类中的方法如图所示:
-
+
## 四 (重要)ThreadPoolExecutor 使用示例
@@ -388,7 +388,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
通过下图可以更好的对上面这 3 步做一个展示,下图是我为了省事直接从网上找到,原地址不明。
-
+
@@ -705,7 +705,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
`FixedThreadPool` 的 `execute()` 方法运行示意图(该图片来源:《Java 并发编程的艺术》):
-
+
**上图说明:**
@@ -755,7 +755,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.2.2 执行任务过程介绍
**`SingleThreadExecutor` 的运行示意图(该图片来源:《Java 并发编程的艺术》):**
-
+
**上图说明;**
@@ -799,7 +799,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
#### 5.3.2 执行任务过程介绍
**CachedThreadPool 的 execute()方法的执行示意图(该图片来源:《Java 并发编程的艺术》):**
-
+
**上图说明:**
@@ -830,7 +830,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.2 运行机制
-
+
**`ScheduledThreadPoolExecutor` 的执行主要分为两大部分:**
@@ -845,7 +845,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
### 6.3 ScheduledThreadPoolExecutor 执行周期任务的步骤
-
+
1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask`的 time 大于等于当前系统的时间;
2. 线程 1 执行这个 `ScheduledFutureTask`;
diff --git a/docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md b/docs/java/multi-thread/synchronized在JDK1.6之后的底层优化.md
similarity index 100%
rename from docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md
rename to docs/java/multi-thread/synchronized在JDK1.6之后的底层优化.md
diff --git a/docs/java/Multithread/ThreadLocal.md b/docs/java/multi-thread/万字详解ThreadLocal关键字.md
similarity index 100%
rename from docs/java/Multithread/ThreadLocal.md
rename to docs/java/multi-thread/万字详解ThreadLocal关键字.md
diff --git a/docs/java/Multithread/创建线程的几种方式总结.md b/docs/java/multi-thread/创建线程的几种方式总结.md
similarity index 100%
rename from docs/java/Multithread/创建线程的几种方式总结.md
rename to docs/java/multi-thread/创建线程的几种方式总结.md
diff --git a/docs/java/Multithread/多线程学习指南.md b/docs/java/multi-thread/多线程学习指南.md
similarity index 100%
rename from docs/java/Multithread/多线程学习指南.md
rename to docs/java/multi-thread/多线程学习指南.md
diff --git a/docs/java/Multithread/并发容器总结.md b/docs/java/multi-thread/并发容器总结.md
similarity index 100%
rename from docs/java/Multithread/并发容器总结.md
rename to docs/java/multi-thread/并发容器总结.md
diff --git a/docs/java/Multithread/best-practice-of-threadpool.md b/docs/java/multi-thread/拿来即用的线程池最佳实践.md
similarity index 100%
rename from docs/java/Multithread/best-practice-of-threadpool.md
rename to docs/java/multi-thread/拿来即用的线程池最佳实践.md
diff --git a/docs/java/What's New in JDK8/Java8foreach指南.md b/docs/java/new-features/Java8foreach指南.md
similarity index 100%
rename from docs/java/What's New in JDK8/Java8foreach指南.md
rename to docs/java/new-features/Java8foreach指南.md
diff --git a/docs/java/What's New in JDK8/Java8教程推荐.md b/docs/java/new-features/Java8教程推荐.md
similarity index 100%
rename from docs/java/What's New in JDK8/Java8教程推荐.md
rename to docs/java/new-features/Java8教程推荐.md
diff --git a/docs/java/What's New in JDK8/Java8Tutorial.md b/docs/java/new-features/Java8新特性总结.md
similarity index 100%
rename from docs/java/What's New in JDK8/Java8Tutorial.md
rename to docs/java/new-features/Java8新特性总结.md
diff --git a/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png b/docs/java/new-features/images/一文带你看遍JDK9~14 的重要新特性/java版本发布.png
similarity index 100%
rename from docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png
rename to docs/java/new-features/images/一文带你看遍JDK9~14 的重要新特性/java版本发布.png
diff --git a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md b/docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md
similarity index 99%
rename from docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
rename to docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md
index 5b193cd5..64d70b3a 100644
--- a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
+++ b/docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md
@@ -109,7 +109,7 @@ Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
-
+
### 字符串加强
diff --git a/docs/network/images/七层体系结构图.png b/docs/network/images/七层体系结构图.png
new file mode 100644
index 00000000..a2d24300
Binary files /dev/null and b/docs/network/images/七层体系结构图.png differ
diff --git a/docs/network/images/传输层.png b/docs/network/images/传输层.png
new file mode 100644
index 00000000..192af245
Binary files /dev/null and b/docs/network/images/传输层.png differ
diff --git a/docs/network/images/应用层.png b/docs/network/images/应用层.png
new file mode 100644
index 00000000..31e1e447
Binary files /dev/null and b/docs/network/images/应用层.png differ
diff --git a/docs/network/images/数据链路层.png b/docs/network/images/数据链路层.png
new file mode 100644
index 00000000..c2b51a7c
Binary files /dev/null and b/docs/network/images/数据链路层.png differ
diff --git a/docs/network/images/物理层.png b/docs/network/images/物理层.png
new file mode 100644
index 00000000..abb97926
Binary files /dev/null and b/docs/network/images/物理层.png differ
diff --git a/docs/network/images/网络层.png b/docs/network/images/网络层.png
new file mode 100644
index 00000000..376479d7
Binary files /dev/null and b/docs/network/images/网络层.png differ
diff --git a/docs/network/images/计算机网络概述.png b/docs/network/images/计算机网络概述.png
new file mode 100644
index 00000000..999c2362
Binary files /dev/null and b/docs/network/images/计算机网络概述.png differ
diff --git a/docs/network/images/计算机网络知识点总结/万维网的大致工作工程.png b/docs/network/images/计算机网络知识点总结/万维网的大致工作工程.png
new file mode 100644
index 00000000..6af03daa
Binary files /dev/null and b/docs/network/images/计算机网络知识点总结/万维网的大致工作工程.png differ
diff --git a/docs/network/images/计算机网络第七版.png b/docs/network/images/计算机网络第七版.png
new file mode 100644
index 00000000..1ea61963
Binary files /dev/null and b/docs/network/images/计算机网络第七版.png differ
diff --git a/docs/network/干货:计算机网络知识总结.md b/docs/network/干货:计算机网络知识总结.md
deleted file mode 100644
index a20e6f85..00000000
--- a/docs/network/干货:计算机网络知识总结.md
+++ /dev/null
@@ -1,420 +0,0 @@
-### 1. [计算机概述 ](#一计算机概述)
-### 2. [物理层 ](#二物理层)
-### 3. [数据链路层 ](#三数据链路层 )
-### 4. [网络层 ](#四网络层 )
-### 5. [运输层 ](#五运输层 )
-### 6. [应用层](#六应用层)
-
-
-## 一计算机概述
-### (1),基本术语
-
-#### 结点 (node):
-
- 网络中的结点可以是计算机,集线器,交换机或路由器等。
-#### 链路(link ):
-
- 从一个结点到另一个结点的一段物理线路。中间没有任何其他交点。
-#### 主机(host):
- 连接在因特网上的计算机.
-#### ISP(Internet Service Provider):
- 因特网服务提供者(提供商).
-#### IXP(Internet eXchange Point):
- 互联网交换点IXP的主要作用就是允许两个网络直接相连并交换分组,而不需要再通过第三个网络来转发分组。.
-#### RFC(Request For Comments)
- 意思是“请求评议”,包含了关于Internet几乎所有的重要的文字资料。
-#### 广域网WAN(Wide Area Network)
- 任务是通过长距离运送主机发送的数据
-#### 城域网MAN(Metropolitan Area Network)
- 用来将多个局域网进行互连
-
-#### 局域网LAN(Local Area Network)
- 学校或企业大多拥有多个互连的局域网
-#### 个人区域网PAN(Personal Area Network)
- 在个人工作的地方把属于个人使用的电子设备用无线技术连接起来的网络
-#### 端系统(end system):
- 处在因特网边缘的部分即是连接在因特网上的所有的主机.
-#### 分组(packet ):
- 因特网中传送的数据单元。由首部header和数据段组成。分组又称为包,首部可称为包头。
-#### 存储转发(store and forward ):
- 路由器收到一个分组,先存储下来,再检查其首部,查找转发表,按照首部中的目的地址,找到合适的接口转发出去。
-#### 带宽(bandwidth):
- 在计算机网络中,表示在单位时间内从网络中的某一点到另一点所能通过的“最高数据率”。常用来表示网络的通信线路所能传送数据的能力。单位是“比特每秒”,记为b/s。
-#### 吞吐量(throughput ):
- 表示在单位时间内通过某个网络(或信道、接口)的数据量。吞吐量更经常地用于对现实世界中的网络的一种测量,以便知道实际上到底有多少数据量能够通过网络。吞吐量受网络的带宽或网络的额定速率的限制。
-
-### (2),重要知识点总结
-
- 1,计算机网络(简称网络)把许多计算机连接在一起,而互联网把许多网络连接在一起,是网络的网络。
-
- 2,小写字母i开头的internet(互联网)是通用名词,它泛指由多个计算机网络相互连接而成的网络。在这些网络之间的通信协议(即通信规则)可以是任意的。
-
- 大写字母I开头的Internet(互联网)是专用名词,它指全球最大的,开放的,由众多网络相互连接而成的特定的互联网,并采用TCP/IP协议作为通信规则,其前身为ARPANET。Internet的推荐译名为因特网,现在一般流行称为互联网。
-
- 3,路由器是实现分组交换的关键构件,其任务是转发收到的分组,这是网络核心部分最重要的功能。分组交换采用存储转发技术,表示把一个报文(要发送的整块数据)分为几个分组后再进行传送。在发送报文之前,先把较长的报文划分成为一个个更小的等长数据段。在每个数据端的前面加上一些由必要的控制信息组成的首部后,就构成了一个分组。分组又称为包。分组是在互联网中传送的数据单元,正是由于分组的头部包含了诸如目的地址和源地址等重要控制信息,每一个分组才能在互联网中独立的选择传输路径,并正确地交付到分组传输的终点。
-
-4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
-
- 5,计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S方式)和对等连接方式(P2P方式)。
-
- 6,客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
-
-7,按照作用范围的不同,计算机网络分为广域网WAN,城域网MAN,局域网LAN,个人区域网PAN。
-
- 8,计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。
-
- 9,网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
-
- 10,五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是TCP和UDP协议,网络层最重要的协议是IP协议。
-
-## 二物理层
-### (1),基本术语
-#### 数据(data):
- 运送消息的实体。
-#### 信号(signal):
- 数据的电气的或电磁的表现。或者说信号是适合在传输介质上传输的对象。
-#### 码元( code):
- 在使用时间域(或简称为时域)的波形来表示数字信号时,代表不同离散数值的基本波形。
-#### 单工(simplex ):
- 只能有一个方向的通信而没有反方向的交互。
-#### 半双工(half duplex ):
- 通信的双方都可以发送信息,但不能双方同时发送(当然也就不能同时接收)。
-#### 全双工(full duplex):
- 通信的双方可以同时发送和接收信息。
-#### 奈氏准则:
- 在任何信道中,码元的传输的效率是有上限的,传输速率超过此上限,就会出现严重的码间串扰问题,使接收端对码元的判决(即识别)成为不可能。
-#### 基带信号(baseband signal):
- 来自信源的信号。指没有经过调制的数字信号或模拟信号。
-#### 带通(频带)信号(bandpass signal):
- 把基带信号经过载波调制后,把信号的频率范围搬移到较高的频段以便在信道中传输(即仅在一段频率范围内能够通过信道),这里调制过后的信号就是带通信号。
-#### 调制(modulation ):
- 对信号源的信息进行处理后加到载波信号上,使其变为适合在信道传输的形式的过程。
-#### 信噪比(signal-to-noise ratio ):
- 指信号的平均功率和噪声的平均功率之比,记为S/N。信噪比(dB)=10*log10(S/N)
-#### 信道复用(channel multiplexing ):
- 指多个用户共享同一个信道。(并不一定是同时)
-#### 比特率(bit rate ):
- 单位时间(每秒)内传送的比特数。
-#### 波特率(baud rate):
- 单位时间载波调制状态改变的次数。针对数据信号对载波的调制速率。
-#### 复用(multiplexing):
- 共享信道的方法
-#### ADSL(Asymmetric Digital Subscriber Line ):
- 非对称数字用户线。
-#### 光纤同轴混合网(HFC网):
- 在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网
-
-### (2),重要知识点总结
-
- 1,物理层的主要任务就是确定与传输媒体接口有关的一些特性,如机械特性,电气特性,功能特性,过程特性。
-
- 2,一个数据通信系统可划分为三大部分,即源系统,传输系统,目的系统。源系统包括源点(或源站,信源)和发送器,目的系统包括接收器和终点。
-
- 3,通信的目的是传送消息。如话音,文字,图像等都是消息,数据是运送消息的实体。信号则是数据的电器或电磁的表现。
-
- 4,根据信号中代表消息的参数的取值方式不同,信号可分为模拟信号(或连续信号)和数字信号(或离散信号)。在使用时间域(简称时域)的波形表示数字信号时,代表不同离散数值的基本波形称为码元。
-
- 5,根据双方信息交互的方式,通信可划分为单向通信(或单工通信),双向交替通信(或半双工通信),双向同时通信(全双工通信)。
-
- 6,来自信源的信号称为基带信号。信号要在信道上传输就要经过调制。调制有基带调制和带通调制之分。最基本的带通调制方法有调幅,调频和调相。还有更复杂的调制方法,如正交振幅调制。
-
- 7,要提高数据在信道上的传递速率,可以使用更好的传输媒体,或使用先进的调制技术。但数据传输速率不可能任意被提高。
-
- 8,传输媒体可分为两大类,即导引型传输媒体(双绞线,同轴电缆,光纤)和非导引型传输媒体(无线,红外,大气激光)。
-
- 9,为了有效利用光纤资源,在光纤干线和用户之间广泛使用无源光网络PON。无源光网络无需配备电源,其长期运营成本和管理成本都很低。最流行的无源光网络是以太网无源光网络EPON和吉比特无源光网络GPON。
-
-### (3),最重要的知识点
-#### **①,物理层的任务**
- 透明地传送比特流。也可以将物理层的主要任务描述为确定与传输媒体的接口的一些特性,即:机械特性(接口所用接线器的一些物理属性如形状尺寸),电气特性(接口电缆的各条线上出现的电压的范围),功能特性(某条线上出现的某一电平的电压的意义),过程特性(对于不同功能能的各种可能事件的出现顺序)。
-
-#### 拓展:
- 物理层考虑的是怎样才能在连接各种计算机的传输媒体上传输数据比特流,而不是指具体的传输媒体。现有的计算机网络中的硬件设备和传输媒体的种类非常繁多,而且通信手段也有许多不同的方式。物理层的作用正是尽可能地屏蔽掉这些传输媒体和通信手段的差异,使物理层上面的数据链路层感觉不到这些差异,这样就可以使数据链路层只考虑完成本层的协议和服务,而不必考虑网络的具体传输媒体和通信手段是什么。
-
-#### **②,几种常用的信道复用技术**
-
-
-### **③,几种常用的宽带接入技术,主要是ADSL和FTTx**
- 用户到互联网的宽带接入方法有非对称数字用户线ADSL(用数字技术对现有的模拟电话线进行改造,而不需要重新布线。ASDL的快速版本是甚高速数字用户线VDSL。),光纤同轴混合网HFC(是在目前覆盖范围很广的有线电视网的基础上开发的一种居民宽带接入网)和FTTx(即光纤到······)。
-
-## 三数据链路层
-### (1),基本术语
-
-#### 链路(link):
- 一个结点到相邻结点的一段物理链路
-#### 数据链路(data link):
- 把实现控制数据运输的协议的硬件和软件加到链路上就构成了数据链路
-#### 循环冗余检验CRC(Cyclic Redundancy Check):
- 为了保证数据传输的可靠性,CRC是数据链路层广泛使用的一种检错技术
-#### 帧(frame):
- 一个数据链路层的传输单元,由一个数据链路层首部和其携带的封包所组成协议数据单元。
-#### MTU(Maximum Transfer Uint ):
- 最大传送单元。帧的数据部分的的长度上限。
-#### 误码率BER(Bit Error Rate ):
- 在一段时间内,传输错误的比特占所传输比特总数的比率。
-#### PPP(Point-to-Point Protocol ):
- 点对点协议。即用户计算机和ISP进行通信时所使用的数据链路层协议。以下是PPP帧的示意图:
-
-#### MAC地址(Media Access Control或者Medium Access Control):
- 意译为媒体访问控制,或称为物理地址、硬件地址,用来定义网络设备的位置。
- 在OSI模型中,第三层网络层负责 IP地址,第二层数据链路层则负责 MAC地址。
- 因此一个主机会有一个MAC地址,而每个网络位置会有一个专属于它的IP地址 。
- 地址是识别某个系统的重要标识符,“名字指出我们所要寻找的资源,地址指出资源所在的地方,路由告诉我们如何到达该处”
-#### 网桥(bridge):
- 一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
-#### 交换机(switch ):
- 广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
-
-
-### (2),重要知识点总结
-
-1,链路是从一个结点到相邻节点的一段物理链路,数据链路则在链路的基础上增加了一些必要的硬件(如网络适配器)和软件(如协议的实现)
-
-2,数据链路层使用的主要是**点对点信道**和**广播信道**两种。
-
-3,数据链路层传输的协议数据单元是帧。数据链路层的三个基本问题是:**封装成帧**,**透明传输**和**差错检测**
-
-4,**循环冗余检验CRC**是一种检错方法,而帧检验序列FCS是添加在数据后面的冗余码
-
-5,**点对点协议PPP**是数据链路层使用最多的一种协议,它的特点是:简单,只检测差错而不去纠正差错,不使用序号,也不进行流量控制,可同时支持多种网络层协议
-
- 6,PPPoE是为宽带上网的主机使用的链路层协议
-
-7,局域网的优点是:具有广播功能,从一个站点可方便地访问全网;便于系统的扩展和逐渐演变;提高了系统的可靠性,可用性和生存性。
-
-8,共向媒体通信资源的方法有二:一是静态划分信道(各种复用技术),而是动态媒体接入控制,又称为多点接入(随即接入或受控接入)
-
-9,计算机与外接局域网通信需要通过通信适配器(或网络适配器),它又称为网络接口卡或网卡。**计算器的硬件地址就在适配器的ROM中**。
-
-10,以太网采用的无连接的工作方式,对发送的数据帧不进行编号,也不要求对方发回确认。目的站收到有差错帧就把它丢掉,其他什么也不做
-
-11,以太网采用的协议是具有冲突检测的**载波监听多点接入CSMA/CD**。协议的特点是:**发送前先监听,边发送边监听,一旦发现总线上出现了碰撞,就立即停止发送。然后按照退避算法等待一段随机时间后再次发送。** 因此,每一个站点在自己发送数据之后的一小段时间内,存在这遭遇碰撞的可能性。以太网上的各站点平等的争用以太网信道
-
-12,以太网的适配器具有过滤功能,它只接收单播帧,广播帧和多播帧。
-
-13,使用集线器可以在物理层扩展以太网(扩展后的以太网仍然是一个网络)
-### (3),最重要的知识点
 -
-  -
-  -
-  -## 公众号
+### 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
diff --git a/docs/dataStructures-algorithms/Backtracking-NQueens.md b/docs/dataStructures-algorithms/Backtracking-NQueens.md
deleted file mode 100644
index 1e1367d3..00000000
--- a/docs/dataStructures-algorithms/Backtracking-NQueens.md
+++ /dev/null
@@ -1,145 +0,0 @@
-# N皇后
-[51. N皇后](https://leetcode-cn.com/problems/n-queens/)
-### 题目描述
-> n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
->
-
->
-上图为 8 皇后问题的一种解法。
->
-给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
->
-每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
-
-示例:
-
-```
-输入: 4
-输出: [
- [".Q..", // 解法 1
- "...Q",
- "Q...",
- "..Q."],
-
- ["..Q.", // 解法 2
- "Q...",
- "...Q",
- ".Q.."]
-]
-解释: 4 皇后问题存在两个不同的解法。
-```
-
-### 问题分析
-约束条件为每个棋子所在的行、列、对角线都不能有另一个棋子。
-
-使用一维数组表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
-每行只存储一个元素,然后递归到下一行,这样就不用判断行了,只需要判断列和对角线。
-### Solution1
-当result[row] = column时,即row行的棋子在column列。
-
-对于[0, row-1]的任意一行(i 行),若 row 行的棋子和 i 行的棋子在同一列,则有result[i] == column;
-若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
-
-布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
-```java
-public List
-## 公众号
+### 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
diff --git a/docs/dataStructures-algorithms/Backtracking-NQueens.md b/docs/dataStructures-algorithms/Backtracking-NQueens.md
deleted file mode 100644
index 1e1367d3..00000000
--- a/docs/dataStructures-algorithms/Backtracking-NQueens.md
+++ /dev/null
@@ -1,145 +0,0 @@
-# N皇后
-[51. N皇后](https://leetcode-cn.com/problems/n-queens/)
-### 题目描述
-> n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
->
-
->
-上图为 8 皇后问题的一种解法。
->
-给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
->
-每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
-
-示例:
-
-```
-输入: 4
-输出: [
- [".Q..", // 解法 1
- "...Q",
- "Q...",
- "..Q."],
-
- ["..Q.", // 解法 2
- "Q...",
- "...Q",
- ".Q.."]
-]
-解释: 4 皇后问题存在两个不同的解法。
-```
-
-### 问题分析
-约束条件为每个棋子所在的行、列、对角线都不能有另一个棋子。
-
-使用一维数组表示一种解法,下标(index)表示行,值(value)表示该行的Q(皇后)在哪一列。
-每行只存储一个元素,然后递归到下一行,这样就不用判断行了,只需要判断列和对角线。
-### Solution1
-当result[row] = column时,即row行的棋子在column列。
-
-对于[0, row-1]的任意一行(i 行),若 row 行的棋子和 i 行的棋子在同一列,则有result[i] == column;
-若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
-
-布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
-```java
-public List +
**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
-
+
**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
- +
**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
@@ -32,7 +32,7 @@
### 经典
-
+
**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
@@ -32,7 +32,7 @@
### 经典
- +
**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
@@ -42,7 +42,7 @@
> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
-
+
**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
@@ -42,7 +42,7 @@
> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
- +
**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
@@ -50,15 +50,13 @@
很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
-
-
-
+
**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
@@ -50,15 +50,13 @@
很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
-
-
- +
**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
-
+
**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
- +
**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
@@ -80,15 +78,13 @@
-
+
**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
@@ -80,15 +78,13 @@
- +
**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
-
-
-
+
**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
-
-
- +
diff --git a/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md b/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md
index 2b7ef230..0ed56e12 100644
--- a/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md
+++ b/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md
@@ -83,14 +83,14 @@ JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-### CAS与synchronized的使用情景
+### CAS与`synchronized`的使用情景
> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
-1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
+1. 对于资源竞争较少(线程冲突较轻)的情况,使用`synchronized`同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
+补充: Java并发编程这个领域中`synchronized`关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。`synchronized`的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
## 公众号
diff --git a/docs/github-trending/2018-12.md b/docs/github-trending/2018-12.md
deleted file mode 100644
index 3637e93e..00000000
--- a/docs/github-trending/2018-12.md
+++ /dev/null
@@ -1,78 +0,0 @@
-本文数据统计于 1.1 号凌晨,由 SnailClimb 整理。
-
-### 1. JavaGuide
-
-- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
-- **star**: 18.2k
-- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
-
-### 2. mall
-
-- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
-- **star**: 3.3k
-- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
-
-### 3. advanced-java
-
-- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
-- **star**: 3.3k
-- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
-
-### 4. matrix
-
-- **Github地址**:[https://github.com/Tencent/matrix](https://github.com/Tencent/matrix)
-- **star**: 2.5k
-- **介绍**: Matrix 是一款微信研发并日常使用的 APM(Application Performance Manage),当前主要运行在 Android 平台上。 Matrix 的目标是建立统一的应用性能接入框架,通过各种性能监控方案,对性能监控项的异常数据进行采集和分析,输出相应的问题分析、定位与优化建议,从而帮助开发者开发出更高质量的应用。
-
-### 5. miaosha
-
-- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
-- **star**: 2.4k
-- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
-
-### 6. arthas
-
-- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
-- **star**: 8.2k
-- **介绍**: Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
-
-### 7 spring-boot
-
-- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
-- **star:** 32.6k
-- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
-
- **关于Spring Boot官方的介绍:**
-
- > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
-
-### 8. tutorials
-
-- **Github地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
-- **star**: 10k
-- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖Java生态系统中单一且定义明确的开发领域。 当然,它们的重点是Spring Framework - Spring,Spring Boot和Spring Securiyt。 除了Spring之外,还有以下技术:核心Java,Jackson,HttpClient,Guava。
-
-### 9. qmq
-
-- **Github地址**:[https://github.com/qunarcorp/qmq](https://github.com/qunarcorp/qmq)
-- **star**: 1.1k
-- **介绍**: QMQ是去哪儿网内部广泛使用的消息中间件,自2012年诞生以来在去哪儿网所有业务场景中广泛的应用,包括跟交易息息相关的订单场景; 也包括报价搜索等高吞吐量场景。
-
-
-### 10. symphony
-
-- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
-- **star**: 9k
-- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
-
-### 11. incubator-dubbo
-
-- **Github地址**:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo)
-- **star**: 23.6k
-- **介绍**: 阿里开源的一个基于Java的高性能开源RPC框架。
-
-### 12. apollo
-
-- **Github地址**:[https://github.com/ctripcorp/apollo](https://github.com/ctripcorp/apollo)
-- **star**: 10k
-- **介绍**: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
diff --git a/docs/github-trending/2019-1.md b/docs/github-trending/2019-1.md
deleted file mode 100644
index aa1de92f..00000000
--- a/docs/github-trending/2019-1.md
+++ /dev/null
@@ -1,76 +0,0 @@
-### 1. JavaGuide
-
-- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
-- **star**: 22.8k
-- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
-
-### 2. advanced-java
-
-- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
-- **star**: 7.9k
-- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
-
-### 3. fescar
-
-- **Github地址**:[https://github.com/alibaba/fescar](https://github.com/alibaba/fescar)
-- **star**: 4.6k
-- **介绍**: 具有 **高性能** 和 **易用性** 的 **微服务架构** 的 **分布式事务** 的解决方案。(特点:高性能且易于使用,旨在实现简单并快速的事务提交与回滚。
-
-### 4. mall
-
-- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
-- **star**: 5.6 k
-- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
-
-### 5. miaosha
-
-- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
-- **star**: 4.4k
-- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
-
-### 6. flink
-
-- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
-- **star**: 7.1 k
-- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
-
-### 7. cim
-
-- **Github地址**:[https://github.com/crossoverJie/cim](https://github.com/crossoverJie/cim)
-- **star**: 1.8 k
-- **介绍**: cim(cross IM) 适用于开发者的即时通讯系统。
-
-### 8. symphony
-
-- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
-- **star**: 10k
-- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
-
-### 9. spring-boot
-
-- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
-- **star:** 32.6k
-- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
-
- **关于Spring Boot官方的介绍:**
-
- > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
-
-### 10. arthas
-
-- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
-- **star**: 9.5k
-- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
-
-**概览:**
-
-当你遇到以下类似问题而束手无策时,`Arthas`可以帮助你解决:
-
-0. 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
-1. 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
-2. 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
-3. 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
-4. 是否有一个全局视角来查看系统的运行状况?
-5. 有什么办法可以监控到JVM的实时运行状态?
-
-`Arthas`支持JDK 6+,支持Linux/Mac/Winodws,采用命令行交互模式,同时提供丰富的 `Tab` 自动补全功能,进一步方便进行问题的定位和诊断。
diff --git a/docs/github-trending/2019-12.md b/docs/github-trending/2019-12.md
deleted file mode 100644
index 9a8f79ed..00000000
--- a/docs/github-trending/2019-12.md
+++ /dev/null
@@ -1,144 +0,0 @@
-# 年末将至,值得你关注的16个Java 开源项目!
-
-Star 的数量统计于 2019-12-29。
-
-### 1.JavaGuide
-
-Guide 哥大三开始维护的,目前算是纯 Java 类型项目中 Star 数量最多的项目了。但是,本仓库的价值远远(+N次 )比不上像 Spring Boot、Elasticsearch 等等这样非常非常非常优秀的项目。希望以后我也有能力为这些项目贡献一些有价值的代码。
-
-- **Github 地址**:
+
diff --git a/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md b/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md
index 2b7ef230..0ed56e12 100644
--- a/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md
+++ b/docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md
@@ -83,14 +83,14 @@ JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
-### CAS与synchronized的使用情景
+### CAS与`synchronized`的使用情景
> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
-1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
+1. 对于资源竞争较少(线程冲突较轻)的情况,使用`synchronized`同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
+补充: Java并发编程这个领域中`synchronized`关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。`synchronized`的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
## 公众号
diff --git a/docs/github-trending/2018-12.md b/docs/github-trending/2018-12.md
deleted file mode 100644
index 3637e93e..00000000
--- a/docs/github-trending/2018-12.md
+++ /dev/null
@@ -1,78 +0,0 @@
-本文数据统计于 1.1 号凌晨,由 SnailClimb 整理。
-
-### 1. JavaGuide
-
-- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
-- **star**: 18.2k
-- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
-
-### 2. mall
-
-- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
-- **star**: 3.3k
-- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
-
-### 3. advanced-java
-
-- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
-- **star**: 3.3k
-- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
-
-### 4. matrix
-
-- **Github地址**:[https://github.com/Tencent/matrix](https://github.com/Tencent/matrix)
-- **star**: 2.5k
-- **介绍**: Matrix 是一款微信研发并日常使用的 APM(Application Performance Manage),当前主要运行在 Android 平台上。 Matrix 的目标是建立统一的应用性能接入框架,通过各种性能监控方案,对性能监控项的异常数据进行采集和分析,输出相应的问题分析、定位与优化建议,从而帮助开发者开发出更高质量的应用。
-
-### 5. miaosha
-
-- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
-- **star**: 2.4k
-- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
-
-### 6. arthas
-
-- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
-- **star**: 8.2k
-- **介绍**: Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
-
-### 7 spring-boot
-
-- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
-- **star:** 32.6k
-- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
-
- **关于Spring Boot官方的介绍:**
-
- > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
-
-### 8. tutorials
-
-- **Github地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
-- **star**: 10k
-- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖Java生态系统中单一且定义明确的开发领域。 当然,它们的重点是Spring Framework - Spring,Spring Boot和Spring Securiyt。 除了Spring之外,还有以下技术:核心Java,Jackson,HttpClient,Guava。
-
-### 9. qmq
-
-- **Github地址**:[https://github.com/qunarcorp/qmq](https://github.com/qunarcorp/qmq)
-- **star**: 1.1k
-- **介绍**: QMQ是去哪儿网内部广泛使用的消息中间件,自2012年诞生以来在去哪儿网所有业务场景中广泛的应用,包括跟交易息息相关的订单场景; 也包括报价搜索等高吞吐量场景。
-
-
-### 10. symphony
-
-- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
-- **star**: 9k
-- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
-
-### 11. incubator-dubbo
-
-- **Github地址**:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo)
-- **star**: 23.6k
-- **介绍**: 阿里开源的一个基于Java的高性能开源RPC框架。
-
-### 12. apollo
-
-- **Github地址**:[https://github.com/ctripcorp/apollo](https://github.com/ctripcorp/apollo)
-- **star**: 10k
-- **介绍**: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
diff --git a/docs/github-trending/2019-1.md b/docs/github-trending/2019-1.md
deleted file mode 100644
index aa1de92f..00000000
--- a/docs/github-trending/2019-1.md
+++ /dev/null
@@ -1,76 +0,0 @@
-### 1. JavaGuide
-
-- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
-- **star**: 22.8k
-- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
-
-### 2. advanced-java
-
-- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
-- **star**: 7.9k
-- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
-
-### 3. fescar
-
-- **Github地址**:[https://github.com/alibaba/fescar](https://github.com/alibaba/fescar)
-- **star**: 4.6k
-- **介绍**: 具有 **高性能** 和 **易用性** 的 **微服务架构** 的 **分布式事务** 的解决方案。(特点:高性能且易于使用,旨在实现简单并快速的事务提交与回滚。
-
-### 4. mall
-
-- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
-- **star**: 5.6 k
-- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
-
-### 5. miaosha
-
-- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
-- **star**: 4.4k
-- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
-
-### 6. flink
-
-- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
-- **star**: 7.1 k
-- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
-
-### 7. cim
-
-- **Github地址**:[https://github.com/crossoverJie/cim](https://github.com/crossoverJie/cim)
-- **star**: 1.8 k
-- **介绍**: cim(cross IM) 适用于开发者的即时通讯系统。
-
-### 8. symphony
-
-- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
-- **star**: 10k
-- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
-
-### 9. spring-boot
-
-- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
-- **star:** 32.6k
-- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
-
- **关于Spring Boot官方的介绍:**
-
- > Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
-
-### 10. arthas
-
-- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
-- **star**: 9.5k
-- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
-
-**概览:**
-
-当你遇到以下类似问题而束手无策时,`Arthas`可以帮助你解决:
-
-0. 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
-1. 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
-2. 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
-3. 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
-4. 是否有一个全局视角来查看系统的运行状况?
-5. 有什么办法可以监控到JVM的实时运行状态?
-
-`Arthas`支持JDK 6+,支持Linux/Mac/Winodws,采用命令行交互模式,同时提供丰富的 `Tab` 自动补全功能,进一步方便进行问题的定位和诊断。
diff --git a/docs/github-trending/2019-12.md b/docs/github-trending/2019-12.md
deleted file mode 100644
index 9a8f79ed..00000000
--- a/docs/github-trending/2019-12.md
+++ /dev/null
@@ -1,144 +0,0 @@
-# 年末将至,值得你关注的16个Java 开源项目!
-
-Star 的数量统计于 2019-12-29。
-
-### 1.JavaGuide
-
-Guide 哥大三开始维护的,目前算是纯 Java 类型项目中 Star 数量最多的项目了。但是,本仓库的价值远远(+N次 )比不上像 Spring Boot、Elasticsearch 等等这样非常非常非常优秀的项目。希望以后我也有能力为这些项目贡献一些有价值的代码。
-
-- **Github 地址**: