mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
04ebec50b5
@ -78,7 +78,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **TCP(Transmisson Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
|
- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
|
||||||
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
|
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
|
||||||
|
|
||||||
### 网络层(Network layer)
|
### 网络层(Network layer)
|
||||||
|
|||||||
@ -237,7 +237,7 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
|
|||||||
|
|
||||||
### 文件权限
|
### 文件权限
|
||||||
|
|
||||||
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
|
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(executable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
|
||||||
|
|
||||||
通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
|
通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
|
||||||
|
|
||||||
|
|||||||
@ -385,7 +385,7 @@ c. WHERE 子句
|
|||||||
-- 运算符:
|
-- 运算符:
|
||||||
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
|
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
|
||||||
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
|
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
|
||||||
is/is not 加上ture/false/unknown,检验某个值的真假
|
is/is not 加上true/false/unknown,检验某个值的真假
|
||||||
<=>与<>功能相同,<=>可用于null比较
|
<=>与<>功能相同,<=>可用于null比较
|
||||||
d. GROUP BY 子句, 分组子句
|
d. GROUP BY 子句, 分组子句
|
||||||
GROUP BY 字段/别名 [排序方式]
|
GROUP BY 字段/别名 [排序方式]
|
||||||
@ -792,7 +792,7 @@ default();
|
|||||||
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
|
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
|
||||||
函数体
|
函数体
|
||||||
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
|
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
|
||||||
- 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
|
- 一个函数应该属于某个数据库,可以使用db_name.function_name的形式执行当前函数所属数据库,否则为当前数据库。
|
||||||
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
|
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
|
||||||
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
|
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
|
||||||
- 多条语句应该使用 begin...end 语句块包含。
|
- 多条语句应该使用 begin...end 语句块包含。
|
||||||
|
|||||||
@ -164,7 +164,7 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
|
|||||||
|
|
||||||
不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
|
不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
|
||||||
|
|
||||||
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Bloking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
|
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
# 超时时间为 10s
|
# 超时时间为 10s
|
||||||
|
|||||||
@ -858,7 +858,7 @@ ORDER BY level_cnt DESC
|
|||||||
|
|
||||||
**解释**:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002
|
**解释**:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002
|
||||||
|
|
||||||
**思路**:这题的难点和易错点在于`UNOIN`和`ORDER BY` 同时使用的问题
|
**思路**:这题的难点和易错点在于`UNION`和`ORDER BY` 同时使用的问题
|
||||||
|
|
||||||
有以下几种情况:使用`union`和多个`order by`不加括号,报错!
|
有以下几种情况:使用`union`和多个`order by`不加括号,报错!
|
||||||
|
|
||||||
|
|||||||
@ -1127,7 +1127,7 @@ MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储
|
|||||||
|
|
||||||
> 注意:在 MySQL 中,分号 `;` 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。
|
> 注意:在 MySQL 中,分号 `;` 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。
|
||||||
>
|
>
|
||||||
> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delemiter`。`new_delemiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
|
> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delimiter`。`new_delimiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
|
||||||
|
|
||||||
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
|
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
|
||||||
|
|
||||||
|
|||||||
@ -925,7 +925,7 @@ emmm,是不是有一点复杂 🤣,看英文图片和英文文档的时候
|
|||||||
2. 消息队列的作用(异步,解耦,削峰)
|
2. 消息队列的作用(异步,解耦,削峰)
|
||||||
3. 消息队列带来的一系列问题(消息堆积、重复消费、顺序消费、分布式事务等等)
|
3. 消息队列带来的一系列问题(消息堆积、重复消费、顺序消费、分布式事务等等)
|
||||||
4. 消息队列的两种消息模型——队列和主题模式
|
4. 消息队列的两种消息模型——队列和主题模式
|
||||||
5. 分析了 `RocketMQ` 的技术架构(`NameServer`、`Broker`、`Producer`、`Comsumer`)
|
5. 分析了 `RocketMQ` 的技术架构(`NameServer`、`Broker`、`Producer`、`Consumer`)
|
||||||
6. 结合 `RocketMQ` 回答了消息队列副作用的解决方案
|
6. 结合 `RocketMQ` 回答了消息队列副作用的解决方案
|
||||||
7. 介绍了 `RocketMQ` 的存储机制和刷盘策略。
|
7. 介绍了 `RocketMQ` 的存储机制和刷盘策略。
|
||||||
|
|
||||||
|
|||||||
@ -215,7 +215,7 @@ public class ArrayList<E> extends AbstractList<E>
|
|||||||
newCapacity = minCapacity;
|
newCapacity = minCapacity;
|
||||||
//再检查新容量是否超出了ArrayList所定义的最大容量,
|
//再检查新容量是否超出了ArrayList所定义的最大容量,
|
||||||
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
|
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
|
||||||
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
||||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||||
newCapacity = hugeCapacity(minCapacity);
|
newCapacity = hugeCapacity(minCapacity);
|
||||||
// minCapacity is usually close to size, so this is a win:
|
// minCapacity is usually close to size, so this is a win:
|
||||||
|
|||||||
@ -623,7 +623,7 @@ public ReentrantReadWriteLock(boolean fair) {
|
|||||||
|
|
||||||
### StampedLock 是什么?
|
### StampedLock 是什么?
|
||||||
|
|
||||||
`StampedLock` 是 JDK 1.8 引入的性能更好的读写锁,不可重入且不支持条件变量 `Conditon`。
|
`StampedLock` 是 JDK 1.8 引入的性能更好的读写锁,不可重入且不支持条件变量 `Condition`。
|
||||||
|
|
||||||
不同于一般的 `Lock` 类,`StampedLock` 并不是直接实现 `Lock`或 `ReadWriteLock`接口,而是基于 **CLH 锁** 独立实现的(AQS 也是基于这玩意)。
|
不同于一般的 `Lock` 类,`StampedLock` 并不是直接实现 `Lock`或 `ReadWriteLock`接口,而是基于 **CLH 锁** 独立实现的(AQS 也是基于这玩意)。
|
||||||
|
|
||||||
@ -678,7 +678,7 @@ public long tryOptimisticRead() {
|
|||||||
|
|
||||||
和 `ReentrantReadWriteLock` 一样,`StampedLock` 同样适合读多写少的业务场景,可以作为 `ReentrantReadWriteLock`的替代品,性能更好。
|
和 `ReentrantReadWriteLock` 一样,`StampedLock` 同样适合读多写少的业务场景,可以作为 `ReentrantReadWriteLock`的替代品,性能更好。
|
||||||
|
|
||||||
不过,需要注意的是`StampedLock`不可重入,不支持条件变量 `Conditon`,对中断操作支持也不友好(使用不当容易导致 CPU 飙升)。如果你需要用到 `ReentrantLock` 的一些高级性能,就不太建议使用 `StampedLock` 了。
|
不过,需要注意的是`StampedLock`不可重入,不支持条件变量 `Condition`,对中断操作支持也不友好(使用不当容易导致 CPU 飙升)。如果你需要用到 `ReentrantLock` 的一些高级性能,就不太建议使用 `StampedLock` 了。
|
||||||
|
|
||||||
另外,`StampedLock` 性能虽好,但使用起来相对比较麻烦,一旦使用不当,就会出现生产问题。强烈建议你在使用`StampedLock` 之前,看看 [StampedLock 官方文档中的案例](https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/locks/StampedLock.html)。
|
另外,`StampedLock` 性能虽好,但使用起来相对比较麻烦,一旦使用不当,就会出现生产问题。强烈建议你在使用`StampedLock` 之前,看看 [StampedLock 官方文档中的案例](https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/locks/StampedLock.html)。
|
||||||
|
|
||||||
|
|||||||
@ -598,7 +598,7 @@ private void cancelAcquire(Node node) {
|
|||||||
compareAndSetNext(pred, predNext, null);
|
compareAndSetNext(pred, predNext, null);
|
||||||
} else {
|
} else {
|
||||||
int ws;
|
int ws;
|
||||||
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
|
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SIGNAL看是否成功
|
||||||
// 如果1和2中有一个为true,再判断当前节点的线程是否为null
|
// 如果1和2中有一个为true,再判断当前节点的线程是否为null
|
||||||
// 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
|
// 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
|
||||||
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
|
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
|
||||||
|
|||||||
@ -367,7 +367,7 @@ private void loadFileIntoMemory(File xmlFile) throws IOException {
|
|||||||
FileInputStream fis = new FileInputStream(xmlFile);
|
FileInputStream fis = new FileInputStream(xmlFile);
|
||||||
// 创建 FileChannel 对象
|
// 创建 FileChannel 对象
|
||||||
FileChannel fc = fis.getChannel();
|
FileChannel fc = fis.getChannel();
|
||||||
// FileChannle.map() 将文件映射到直接内存并返回 MappedByteBuffer 对象
|
// FileChannel.map() 将文件映射到直接内存并返回 MappedByteBuffer 对象
|
||||||
MappedByteBuffer mmb = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());
|
MappedByteBuffer mmb = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());
|
||||||
xmlFileBuffer = new byte[(int)fc.size()];
|
xmlFileBuffer = new byte[(int)fc.size()];
|
||||||
mmb.get(xmlFileBuffer);
|
mmb.get(xmlFileBuffer);
|
||||||
|
|||||||
@ -119,7 +119,7 @@ JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参
|
|||||||
|
|
||||||
```c
|
```c
|
||||||
void MetaspaceGC::initialize() {
|
void MetaspaceGC::initialize() {
|
||||||
// Set the high-water mark to MaxMetapaceSize during VM initializaton since
|
// Set the high-water mark to MaxMetapaceSize during VM initialization since
|
||||||
// we can't do a GC during initialization.
|
// we can't do a GC during initialization.
|
||||||
_capacity_until_GC = MaxMetaspaceSize;
|
_capacity_until_GC = MaxMetaspaceSize;
|
||||||
}
|
}
|
||||||
|
|||||||
@ -168,7 +168,7 @@ public ResponseEntity<List<User>> getAllUsers() {
|
|||||||
```java
|
```java
|
||||||
@PostMapping("/users")
|
@PostMapping("/users")
|
||||||
public ResponseEntity<User> createUser(@Valid @RequestBody UserCreateRequest userCreateRequest) {
|
public ResponseEntity<User> createUser(@Valid @RequestBody UserCreateRequest userCreateRequest) {
|
||||||
return userRespository.save(userCreateRequest);
|
return userRepository.save(userCreateRequest);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|||||||
@ -207,7 +207,7 @@ public OneService getService(status) {
|
|||||||
|
|
||||||
Spring 内置的 `@Autowired` 以及 JDK 内置的 `@Resource` 和 `@Inject` 都可以用于注入 Bean。
|
Spring 内置的 `@Autowired` 以及 JDK 内置的 `@Resource` 和 `@Inject` 都可以用于注入 Bean。
|
||||||
|
|
||||||
| Annotaion | Package | Source |
|
| Annotation | Package | Source |
|
||||||
| ------------ | ---------------------------------- | ------------ |
|
| ------------ | ---------------------------------- | ------------ |
|
||||||
| `@Autowired` | `org.springframework.bean.factory` | Spring 2.5+ |
|
| `@Autowired` | `org.springframework.bean.factory` | Spring 2.5+ |
|
||||||
| `@Resource` | `javax.annotation` | Java JSR-250 |
|
| `@Resource` | `javax.annotation` | Java JSR-250 |
|
||||||
|
|||||||
@ -77,14 +77,14 @@ byte[] result = messageDigest.digest();
|
|||||||
// 将哈希值转换为十六进制字符串
|
// 将哈希值转换为十六进制字符串
|
||||||
String hexString = new HexBinaryAdapter().marshal(result);
|
String hexString = new HexBinaryAdapter().marshal(result);
|
||||||
System.out.println("Original String: " + originalString);
|
System.out.println("Original String: " + originalString);
|
||||||
System.out.println("SHA-256 Hash: " + hexString.toLowerCase());
|
System.out.println("MD5 Hash: " + hexString.toLowerCase());
|
||||||
```
|
```
|
||||||
|
|
||||||
输出:
|
输出:
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
Original String: Java学习 + 面试指南:javaguide.cn
|
Original String: Java学习 + 面试指南:javaguide.cn
|
||||||
SHA-256 Hash: fb246796f5b1b60d4d0268c817c608fa
|
MD5 Hash: fb246796f5b1b60d4d0268c817c608fa
|
||||||
```
|
```
|
||||||
|
|
||||||
### SHA
|
### SHA
|
||||||
|
|||||||
@ -32,9 +32,9 @@ tag:
|
|||||||
|
|
||||||
可以看出, **Trie 树的核心原理其实很简单,就是通过公共前缀来提高字符串匹配效率。**
|
可以看出, **Trie 树的核心原理其实很简单,就是通过公共前缀来提高字符串匹配效率。**
|
||||||
|
|
||||||
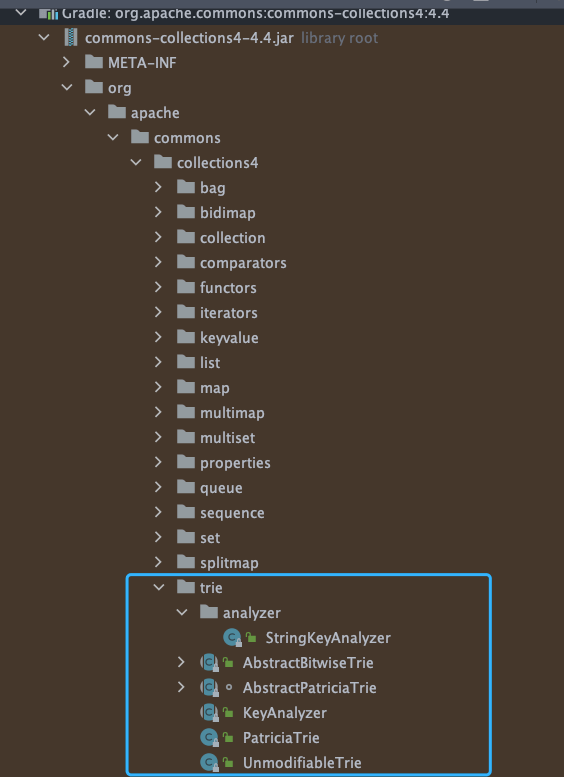
[Apache Commons Collecions](https://mvnrepository.com/artifact/org.apache.commons/commons-collections4) 这个库中就有 Trie 树实现:
|
[Apache Commons Collections](https://mvnrepository.com/artifact/org.apache.commons/commons-collections4) 这个库中就有 Trie 树实现:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
```java
|
```java
|
||||||
Trie<String, String> trie = new PatriciaTrie<>();
|
Trie<String, String> trie = new PatriciaTrie<>();
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user