mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
048d5a9f50
71
README.md
71
README.md
@ -1,6 +1,6 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
**[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
|
||||
**[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广。不懂怎么使用云服务器的朋友可以看这篇[阿里云服务器使用经验](docs/tools/阿里云服务器使用经验.md))。
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||
@ -35,9 +35,10 @@
|
||||
- [JVM](#jvm)
|
||||
- [I/O](#io)
|
||||
- [Java 8](#java-8)
|
||||
- [编程规范](#编程规范)
|
||||
- [优雅 Java 代码必备实践(Java编程规范)](#优雅-java-代码必备实践java编程规范)
|
||||
- [网络](#网络)
|
||||
- [操作系统](#操作系统)
|
||||
|
||||
- [Linux相关](#linux相关)
|
||||
- [数据结构与算法](#数据结构与算法)
|
||||
- [数据结构](#数据结构)
|
||||
@ -45,12 +46,18 @@
|
||||
- [数据库](#数据库)
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [数据库扩展](#数据库扩展)
|
||||
- [系统设计](#系统设计)
|
||||
- [常用框架(Spring/SpringBoot、Zookeeper ... )](#常用框架)
|
||||
- [数据通信(消息队列、Dubbo ... )](#数据通信)
|
||||
- [数据通信/中间件(消息队列、RPC ... )](#数据通信中间件)
|
||||
- [权限认证](#权限认证)
|
||||
- [分布式 & 微服务](#分布式--微服务)
|
||||
- [API 网关](#api-网关)
|
||||
- [配置中心](#配置中心)
|
||||
- [唯一 id 生成](#唯一-id-生成)
|
||||
- [服务治理:服务注册与发现、服务路由控制](#服务治理服务注册与发现服务路由控制)
|
||||
- [架构](#架构)
|
||||
- [设计模式(工厂模式、单例模式 ... )](#设计模式)
|
||||
- [网站架构](#网站架构)
|
||||
- [面试指南](#面试指南)
|
||||
- [备战面试](#备战面试)
|
||||
- [常见面试题总结](#常见面试题总结)
|
||||
@ -110,9 +117,9 @@
|
||||
* [Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
* [Java8 forEach 指南](docs/java/What's%20New%20in%20JDK8/Java8foreach指南.md)
|
||||
|
||||
### 编程规范
|
||||
### 优雅 Java 代码必备实践(Java编程规范)
|
||||
|
||||
- [Java 编程规范](docs/java/Java编程规范.md)
|
||||
* [Java 编程规范以及优雅Java代码实践总结](docs/java/Java编程规范.md)
|
||||
|
||||
## 网络
|
||||
|
||||
@ -159,6 +166,11 @@
|
||||
* [Redis 总结](docs/database/Redis/Redis.md)
|
||||
* [Redlock分布式锁](docs/database/Redis/Redlock分布式锁.md)
|
||||
* [如何做可靠的分布式锁,Redlock真的可行么](docs/database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
|
||||
* [几种常见的 Redis 集群以及使用场景](docs/database/Redis/redis集群以及应用场景.md)
|
||||
|
||||
### 数据库扩展
|
||||
|
||||
代办......
|
||||
|
||||
## 系统设计
|
||||
|
||||
@ -178,15 +190,16 @@
|
||||
- [ZooKeeper 相关概念总结](docs/system-design/framework/ZooKeeper.md)
|
||||
- [ZooKeeper 数据模型和常见命令](docs/system-design/framework/ZooKeeper数据模型和常见命令.md)
|
||||
|
||||
### 数据通信
|
||||
### 数据通信/中间件
|
||||
|
||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
|
||||
|
||||
#### Dubbo
|
||||
#### RPC
|
||||
|
||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
|
||||
- [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/data-communication/why-use-rpc.md)
|
||||
|
||||
#### 消息中间件
|
||||
#### 消息队列
|
||||
|
||||
- [消息队列总结](docs/system-design/data-communication/message-queue.md)
|
||||
- [RabbitMQ 入门](docs/system-design/data-communication/rabbitmq.md)
|
||||
@ -200,16 +213,37 @@
|
||||
- **[JWT 优缺点分析以及常见问题解决方案](docs/system-design/authority-certification/JWT-advantages-and-disadvantages.md)**
|
||||
- **[适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)**
|
||||
|
||||
### 分布式 & 微服务
|
||||
|
||||
- [分布式应该学什么](docs/system-design/website-architecture/分布式.md)
|
||||
|
||||
#### API 网关
|
||||
|
||||
网关主要用于请求转发、安全认证、协议转换、容灾。
|
||||
|
||||
- [浅析如何设计一个亿级网关(API Gateway)](docs/system-design/micro-service/API网关.md)
|
||||
|
||||
#### 配置中心
|
||||
|
||||
代办......
|
||||
|
||||
#### 唯一 id 生成
|
||||
|
||||
[分布式id生成方案总结](docs/system-design/micro-service/分布式id生成方案总结.md)
|
||||
|
||||
#### 服务治理:服务注册与发现、服务路由控制
|
||||
|
||||
代办......
|
||||
|
||||
### 架构
|
||||
|
||||
- [8 张图读懂大型网站技术架构](docs/system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](docs/system-design/website-architecture/关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
### 设计模式
|
||||
|
||||
- [设计模式系列文章](docs/system-design/设计模式.md)
|
||||
|
||||
### 网站架构
|
||||
|
||||
- [一文读懂分布式应该学什么](docs/system-design/website-architecture/分布式.md)
|
||||
- [8 张图读懂大型网站技术架构](docs/system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](docs/system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
## 面试指南
|
||||
|
||||
### 备战面试
|
||||
@ -239,6 +273,7 @@
|
||||
|
||||
- [Java学习路线和方法推荐](docs/questions/java-learning-path-and-methods.md)
|
||||
- [Java培训四个月能学会吗?](docs/questions/java-training-4-month.md)
|
||||
- [新手学习Java,有哪些Java相关的博客,专栏,和技术学习网站推荐?](docs/questions/java-learning-website-blog.md)
|
||||
|
||||
## 工具
|
||||
|
||||
@ -248,9 +283,13 @@
|
||||
|
||||
### Docker
|
||||
|
||||
* [Docker 入门](docs/tools/Docker.md)
|
||||
* [Docker 基本概念解读](docs/tools/Docker.md)
|
||||
* [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
||||
|
||||
### 其他
|
||||
|
||||
- [阿里云服务器使用经验](docs/tools/阿里云服务器使用经验.md)
|
||||
|
||||
## 资源
|
||||
|
||||
### 书单
|
||||
|
||||
149
docs/database/Redis/redis集群以及应用场景.md
Normal file
149
docs/database/Redis/redis集群以及应用场景.md
Normal file
@ -0,0 +1,149 @@
|
||||
相关阅读:
|
||||
|
||||
- [史上最全Redis高可用技术解决方案大全](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484850&idx=1&sn=3238360bfa8105cf758dcf7354af2814&chksm=cea24a79f9d5c36fb2399aafa91d7fb2699b5006d8d037fe8aaf2e5577ff20ae322868b04a87&token=1082669959&lang=zh_CN&scene=21#wechat_redirect)
|
||||
|
||||
# Redis 集群以及应用
|
||||
|
||||
## 集群
|
||||
### 主从复制
|
||||
#### 主从链(拓扑结构)
|
||||

|
||||
|
||||

|
||||
|
||||
#### 复制模式
|
||||
- 全量复制:master 全部同步到 slave
|
||||
- 部分复制:slave 数据丢失进行备份
|
||||
|
||||
#### 问题点
|
||||
- 同步故障
|
||||
- 复制数据延迟(不一致)
|
||||
- 读取过期数据(Slave 不能删除数据)
|
||||
- 从节点故障
|
||||
- 主节点故障
|
||||
- 配置不一致
|
||||
- maxmemory 不一致:丢失数据
|
||||
- 优化参数不一致:内存不一致.
|
||||
- 避免全量复制
|
||||
- 选择小主节点(分片)、低峰期间操作.
|
||||
- 如果节点运行 id 不匹配(如主节点重启、运行 id 发送变化),此时要执行全量复制,应该配合哨兵和集群解决.
|
||||
- 主从复制挤压缓冲区不足产生的问题(网络中断,部分复制无法满足),可增大复制缓冲区( rel_backlog_size 参数).
|
||||
- 复制风暴
|
||||
|
||||
### 哨兵机制
|
||||
#### 拓扑图
|
||||

|
||||
|
||||
#### 节点下线
|
||||
- 客观下线
|
||||
- 所有 Sentinel 节点对 Redis 节点失败要达成共识,即超过 quorum 个统一.
|
||||
- 主管下线
|
||||
- 即 Sentinel 节点对 Redis 节点失败的偏见,超出超时时间认为 Master 已经宕机.
|
||||
#### leader选举
|
||||
- 选举出一个 Sentinel 作为 Leader:集群中至少有三个 Sentinel 节点,但只有其中一个节点可完成故障转移.通过以下命令可以进行失败判定或领导者选举.
|
||||
- 选举流程
|
||||
1. 每个主观下线的 Sentinel 节点向其他 Sentinel 节点发送命令,要求设置它为领导者.
|
||||
1. 收到命令的 Sentinel 节点如果没有同意通过其他 Sentinel 节点发送的命令,则同意该请求,否则拒绝.
|
||||
1. 如果该 Sentinel 节点发现自己的票数已经超过 Sentinel 集合半数且超过 quorum,则它成为领导者.
|
||||
1. 如果此过程有多个 Sentinel 节点成为领导者,则等待一段时间再重新进行选举.
|
||||
#### 故障转移
|
||||
- 转移流程
|
||||
1. Sentinel 选出一个合适的 Slave 作为新的 Master(slaveof no one 命令).
|
||||
1. 向其余 Slave 发出通知,让它们成为新 Master 的 Slave( parallel-syncs 参数).
|
||||
1. 等待旧 Master 复活,并使之称为新 Master 的 Slave.
|
||||
1. 向客户端通知 Master 变化.
|
||||
- 从 Slave 中选择新 Master 节点的规则(slave 升级成 master 之后)
|
||||
1. 选择 slave-priority 最高的节点.
|
||||
1. 选择复制偏移量最大的节点(同步数据最多).
|
||||
1. 选择 runId 最小的节点.
|
||||
#### 读写分离
|
||||
#### 定时任务
|
||||
- 每 1s 每个 Sentinel 对其他 Sentinel 和 Redis 执行 ping,进行心跳检测.
|
||||
- 每 2s 每个 Sentinel 通过 Master 的 Channel 交换信息(pub - sub).
|
||||
- 每 10s 每个 Sentinel 对 Master 和 Slave 执行 info,目的是发现 Slave 节点、确定主从关系.
|
||||
|
||||
### 分布式集群(Cluster)
|
||||
#### 拓扑图
|
||||
|
||||

|
||||
|
||||
#### 通讯
|
||||
##### 集中式
|
||||
> 将集群元数据(节点信息、故障等等)几种存储在某个节点上.
|
||||
- 优势
|
||||
1. 元数据的更新读取具有很强的时效性,元数据修改立即更新
|
||||
- 劣势
|
||||
1. 数据集中存储
|
||||
##### Gossip
|
||||

|
||||
|
||||
- [Gossip 协议](https://www.jianshu.com/p/8279d6fd65bb)
|
||||
|
||||
#### 寻址分片
|
||||
##### hash取模
|
||||
- hash(key)%机器数量
|
||||
- 问题
|
||||
1. 机器宕机,造成数据丢失,数据读取失败
|
||||
1. 伸缩性
|
||||
##### 一致性hash
|
||||
- 
|
||||
|
||||
- 问题
|
||||
1. 一致性哈希算法在节点太少时,容易因为节点分布不均匀而造成缓存热点的问题。
|
||||
- 解决方案
|
||||
- 可以通过引入虚拟节点机制解决:即对每一个节点计算多个 hash,每个计算结果位置都放置一个虚拟节点。这样就实现了数据的均匀分布,负载均衡。
|
||||
##### hash槽
|
||||
- CRC16(key)%16384
|
||||
-
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 使用场景
|
||||
### 热点数据
|
||||
### 会话维持 session
|
||||
### 分布式锁 SETNX
|
||||
### 表缓存
|
||||
### 消息队列 list
|
||||
### 计数器 string
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 缓存设计
|
||||
### 更新策略
|
||||
- LRU、LFU、FIFO 算法自动清除:一致性最差,维护成本低.
|
||||
- 超时自动清除(key expire):一致性较差,维护成本低.
|
||||
- 主动更新:代码层面控制生命周期,一致性最好,维护成本高.
|
||||
### 更新一致性
|
||||
- 读请求:先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应.
|
||||
- 写请求:先删除缓存,然后再更新数据库(避免大量地写、却又不经常读的数据导致缓存频繁更新).
|
||||
### 缓存粒度
|
||||
- 通用性:全量属性更好.
|
||||
- 占用空间:部分属性更好.
|
||||
- 代码维护成本.
|
||||
|
||||
### 缓存穿透
|
||||
> 当大量的请求无命中缓存、直接请求到后端数据库(业务代码的 bug、或恶意攻击),同时后端数据库也没有查询到相应的记录、无法添加缓存.
|
||||
这种状态会一直维持,流量一直打到存储层上,无法利用缓存、还会给存储层带来巨大压力.
|
||||
>
|
||||
#### 解决方案
|
||||
1. 请求无法命中缓存、同时数据库记录为空时在缓存添加该 key 的空对象(设置过期时间),缺点是可能会在缓存中添加大量的空值键(比如遭到恶意攻击或爬虫),而且缓存层和存储层数据短期内不一致;
|
||||
1. 使用布隆过滤器在缓存层前拦截非法请求、自动为空值添加黑名单(同时可能要为误判的记录添加白名单).但需要考虑布隆过滤器的维护(离线生成/ 实时生成).
|
||||
### 缓存雪崩
|
||||
> 缓存崩溃时请求会直接落到数据库上,很可能由于无法承受大量的并发请求而崩溃,此时如果只重启数据库,或因为缓存重启后没有数据,新的流量进来很快又会把数据库击倒
|
||||
>
|
||||
#### 出现后应对
|
||||
- 事前:Redis 高可用,主从 + 哨兵,Redis Cluster,避免全盘崩溃.
|
||||
- 事中:本地 ehcache 缓存 + hystrix 限流 & 降级,避免数据库承受太多压力.
|
||||
- 事后:Redis 持久化,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据.
|
||||
#### 请求过程
|
||||
1. 用户请求先访问本地缓存,无命中后再访问 Redis,如果本地缓存和 Redis 都没有再查数据库,并把数据添加到本地缓存和 Redis;
|
||||
1. 由于设置了限流,一段时间范围内超出的请求走降级处理(返回默认值,或给出友情提示).
|
||||
|
||||
|
||||
|
||||
@ -30,7 +30,7 @@
|
||||
|
||||
|
||||
1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性:** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
|
||||
2. **一致性:** 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||
3. **隔离性:** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
|
||||
21
docs/database/数据库连接池.md
Normal file
21
docs/database/数据库连接池.md
Normal file
@ -0,0 +1,21 @@
|
||||
- 公众号和Github待发文章:[数据库:数据库连接池原理详解与自定义连接池实现](https://www.fangzhipeng.com/javainterview/2019/07/15/mysql-connector-pool.html)
|
||||
- [基于JDBC的数据库连接池技术研究与应用](http://blog.itpub.net/9403012/viewspace-111794/)
|
||||
- [数据库连接池技术详解](https://juejin.im/post/5b7944c6e51d4538c86cf195)
|
||||
|
||||
数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存
|
||||
|
||||
连接池是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
|
||||
|
||||
操作过数据库的朋友应该都知道数据库连接池这个概念,它几乎每天都在和我们打交道,但是你真的了解 **数据库连接池** 吗?
|
||||
|
||||
### 没有数据库连接池之前
|
||||
|
||||
我相信你一定听过这样一句话:**Java语言中,JDBC(Java DataBase Connection)是应用程序与数据库沟通的桥梁**。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -338,9 +338,9 @@ hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返
|
||||
|
||||
### 为什么要有 hashCode
|
||||
|
||||
**我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
**我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
|
||||
通过我们可以看出:`hashCode()` 的作用就是**获取哈希码**,也称为散列码;它实际上是返回一个int整数。这个**哈希码的作用**是确定该对象在哈希表中的索引位置。**`hashCode() `在散列表中才有用,在其它情况下没用。**在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
|
||||
通过我们可以看出:`hashCode()` 的作用就是**获取哈希码**,也称为散列码;它实际上是返回一个int整数。这个**哈希码的作用**是确定该对象在哈希表中的索引位置。**`hashCode() `在散列表中才有用,在其它情况下没用**。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
|
||||
|
||||
### hashCode()与equals()的相关规定
|
||||
|
||||
@ -419,7 +419,7 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
- **public string getMessage()**:返回异常发生时的简要描述
|
||||
- **public string toString()**:返回异常发生时的详细信息
|
||||
- **public string getLocalizedMessage()**:返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以声称本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
|
||||
- **public string getLocalizedMessage()**:返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
|
||||
- **public void printStackTrace()**:在控制台上打印Throwable对象封装的异常信息
|
||||
|
||||
### 异常处理总结
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
根据各位建议加上了这部分内容,我暂时只是给出了两个资源,后续可能会对重要的点进行总结,然后更新在这里,如果你总结过这类东西,欢迎与我联系!
|
||||
讲真的,下面推荐的文章或者资源建议阅读 3 遍以上。
|
||||
|
||||
### 团队
|
||||
|
||||
@ -8,3 +8,23 @@
|
||||
### 个人
|
||||
|
||||
- **程序员你为什么这么累:** <https://xwjie.github.io/rule/>
|
||||
|
||||
### 如何写出优雅的 Java 代码
|
||||
|
||||
1. 使用 IntelliJ IDEA 作为您的集成开发环境 (IDE)
|
||||
1. 使用 JDK 8 或更高版本
|
||||
1. 使用 Maven/Gradle
|
||||
1. 使用 Lombok
|
||||
1. 编写单元测试
|
||||
1. 重构:常见,但也很慢
|
||||
1. 注意代码规范
|
||||
1. 定期联络客户,以获取他们的反馈
|
||||
|
||||
上述建议的详细内容:[八点建议助您写出优雅的Java代码](docs/八点建议助您写出优雅的Java代码.md)。
|
||||
|
||||
更多代码优化相关内容推荐:
|
||||
|
||||
- [业务复杂=if else?刚来的大神竟然用策略+工厂彻底干掉了他们!](https://juejin.im/post/5dad23685188251d2c4ea2b6)
|
||||
- [一些不错的 Java 实践!推荐阅读3遍以上!](http://lrwinx.github.io/2017/03/04/%E7%BB%86%E6%80%9D%E6%9E%81%E6%81%90-%E4%BD%A0%E7%9C%9F%E7%9A%84%E4%BC%9A%E5%86%99java%E5%90%97/)
|
||||
- [[解锁新姿势] 兄dei,你代码需要优化了](https://juejin.im/post/5dafbc02e51d4524a0060bdd)
|
||||
- [消灭 Java 代码的“坏味道”](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485599&idx=1&sn=d83ff4e6b1ee951a0a33508a10980ea3&chksm=cea24754f9d5ce426d18b435a8c373ddc580c06c7d6a45cc51377361729c31c7301f1bbc3b78&token=1328169465&lang=zh_CN#rd)
|
||||
@ -358,7 +358,7 @@ class Person {
|
||||
|
||||
}
|
||||
```
|
||||
上述代码首先创建了一个 Person 对象,然后把 Person 对象设置进 AtomicReference 对象中,然后调用 compareAndSet 方法,该方法就是通过通过 CAS 操作设置 ar。如果 ar 的值为 person 的话,则将其设置为 updatePerson。实现原理与 AtomicInteger 类中的 compareAndSet 方法相同。运行上面的代码后的输出结果如下:
|
||||
上述代码首先创建了一个 Person 对象,然后把 Person 对象设置进 AtomicReference 对象中,然后调用 compareAndSet 方法,该方法就是通过 CAS 操作设置 ar。如果 ar 的值为 person 的话,则将其设置为 updatePerson。实现原理与 AtomicInteger 类中的 compareAndSet 方法相同。运行上面的代码后的输出结果如下:
|
||||
|
||||
```
|
||||
Daisy
|
||||
|
||||
@ -39,7 +39,7 @@
|
||||
- [LocalDate\(本地日期\)](#localdate本地日期)
|
||||
- [LocalDateTime\(本地日期时间\)](#localdatetime本地日期时间)
|
||||
- [Annotations\(注解\)](#annotations注解)
|
||||
- [Whete to go from here?](#whete-to-go-from-here)
|
||||
- [Where to go from here?](#where-to-go-from-here)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@
|
||||
## HashMap 简介
|
||||
HashMap 主要用来存放键值对,它基于哈希表的Map接口实现</font>,是常用的Java集合之一。
|
||||
|
||||
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
|
||||
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考 `treeifyBin`方法。
|
||||
|
||||
## 底层数据结构分析
|
||||
### JDK1.8之前
|
||||
|
||||
@ -331,20 +331,29 @@ passwd命令用于设置用户的认证信息,包括用户密码、密码过
|
||||
### 4.8 其他常用命令
|
||||
|
||||
- **`pwd`:** 显示当前所在位置
|
||||
|
||||
- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
|
||||
|
||||
- **`grep 要搜索的字符串 要搜索的文件 --color`:** 搜索命令,--color代表高亮显示
|
||||
|
||||
- **`ps -ef`/`ps -aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括redis字符串的进程),也可使用 `pgrep redis -a`。
|
||||
|
||||
注意:如果直接用ps((Process Status))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。
|
||||
|
||||
- **`kill -9 进程的pid`:** 杀死进程(-9 表示强制终止。)
|
||||
|
||||
先用ps查找进程,然后用kill杀掉
|
||||
|
||||
- **网络通信命令:**
|
||||
- 查看当前系统的网卡信息:ifconfig
|
||||
- 查看与某台机器的连接情况:ping
|
||||
- 查看当前系统的端口使用:netstat -an
|
||||
|
||||
- **net-tools 和 iproute2 :**
|
||||
`net-tools`起源于BSD的TCP/IP工具箱,后来成为老版本Linux内核中配置网络功能的工具。但自2001年起,Linux社区已经对其停止维护。同时,一些Linux发行版比如Arch Linux和CentOS/RHEL 7则已经完全抛弃了net-tools,只支持`iproute2`。linux ip命令类似于ifconfig,但功能更强大,旨在替代它。更多详情请阅读[如何在Linux中使用IP命令和示例](https://linoxide.com/linux-command/use-ip-command-linux)
|
||||
|
||||
- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定5分钟后关机,同时送出警告信息给登入用户。
|
||||
|
||||
- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
|
||||
|
||||
## 公众号
|
||||
|
||||
@ -16,7 +16,7 @@
|
||||
|
||||
**下面的学习路线以及方法是笔主根据个人学习经历总结改进后得出,我相信照着这条学习路线来你的学习效率会非常高。**
|
||||
|
||||
学习某个知识点的过程中如果不知道看什么书的话,可以查看这篇文章 :[Java 学习必备书籍推荐终极版!](../data/java-recommended-books.md "Java 学习必备书籍推荐终极版!")。
|
||||
学习某个知识点的过程中如果不知道看什么书的话,可以查看这篇文章 :[Java 学习必备书籍推荐终极版!](https://github.com/Snailclimb/JavaGuide/blob/master/docs/data/java-recommended-books.md)。
|
||||
|
||||
另外,很重要的一点:**建议使用 Intellij IDEA 进行编码,可以单独抽点时间学习 Intellij IDEA 的使用。**
|
||||
|
||||
|
||||
54
docs/questions/java-learning-website-blog.md
Normal file
54
docs/questions/java-learning-website-blog.md
Normal file
@ -0,0 +1,54 @@
|
||||
## 推荐两个视频学习网站
|
||||
|
||||
### 慕课网
|
||||
|
||||
第一个推荐的学习网站应该是慕课网(慕课网私聊我打钱哈!),在我初学的时候,这个网站对我的帮助挺大的,里面有很多免费的课程,也有很多付费的课程。如果你没有特殊的需求,一般免费课程就够自己学的了。
|
||||
|
||||

|
||||
|
||||
### 哔哩哔哩
|
||||
|
||||
想不到弹幕追番/原创视频小站也被推荐了吧!不得不说哔哩哔哩上面的学习资源还是很多的,现在有很多年轻人都在上面学习呢!哈哈哈 大部分年轻人最爱的小破站可是受到过央视表扬的。被誉为年轻人学习的首要阵地,哔哩哔哩干杯!
|
||||
|
||||

|
||||
|
||||
## 推荐一些文字类型学习网站/博客
|
||||
|
||||
### 菜鸟教程
|
||||
|
||||
网站地址:https://www.runoob.com/ 。
|
||||
|
||||
对于新手入门来说很不错的网站,大部分教程都是针对的入门级别。优点是网站教程内容比较完善并且内容质量也是有保障的。
|
||||
|
||||

|
||||
|
||||
### w3cschool
|
||||
|
||||
和菜鸟教程类似的一个网站,里面的教程也很齐全。
|
||||
|
||||
|
||||
|
||||
### 一些不错的技术交流社区推荐
|
||||
|
||||
1. **掘金**:https://juejin.im/ 。
|
||||
2. **segmentfault** : https://segmentfault.com/
|
||||
3. **博客园** : https://www.cnblogs.com/
|
||||
4. **慕课网手记** :https://www.imooc.com/article
|
||||
5. **知乎** :https://www.zhihu.com/
|
||||
|
||||
### 一些不错的博客/Github推荐
|
||||
|
||||
- SnailClimb 的 Github :https://github.com/Snailclimb 。(自荐一波哈!主要专注在 Java基础和进阶、Spring、Spiring Boot、Java面试这方面。)
|
||||
- kuke
|
||||
- 徐靖峰个人博客 :https://www.cnkirito.moe/(探讨 Java 生态的知识点,内容覆盖分布式服务治理、微服务、性能调优、各类源码分析)
|
||||
- 田小波:http://www.tianxiaobo.com/ (Java 、Spring 、MyBatis 、Dubbo)
|
||||
- 周立的博客: http://www.itmuch.com/(Spring Cloud、Docker、Kubernetes,及其相关生态的技术)
|
||||
- Hollis: https://www.hollischuang.com/ (Java后端)
|
||||
- 方志朋的专栏 : https://www.fangzhipeng.com/ (Java面试 Java并发 openresty kubernetes Docker 故事 )
|
||||
- 纯洁的微笑 : http://www.ityouknow.com/ (Java、SpringBoot、Spring Cloud)
|
||||
- 芋道源码: http://www.iocoder.cn/ (专注源码)。
|
||||
- 欢迎自荐
|
||||
- ......
|
||||
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@
|
||||
|
||||
## 编程好习惯推荐
|
||||
|
||||
> **下面这些我都总结在了 Github 上,更多内容可以通过这个链接查看:https://github.com/Snailclimb/programmer-advancement。**
|
||||
> **下面这些我都总结在了 Github 上,更多内容可以通过这个链接查看:** https://github.com/Snailclimb/programmer-advancement 。
|
||||
|
||||
### 正确提问
|
||||
|
||||
|
||||
94
docs/system-design/data-communication/why-use-rpc.md
Normal file
94
docs/system-design/data-communication/why-use-rpc.md
Normal file
@ -0,0 +1,94 @@
|
||||
## 什么是 RPC?RPC原理是什么?
|
||||
|
||||
### **什么是 RPC?**
|
||||
|
||||
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求 当然可以,但是可能会比较慢而且一些优化做的并不好。 RPC 的出现就是为了解决这个问题。
|
||||
|
||||
### **RPC原理是什么?**
|
||||
|
||||
我这里这是简单的提一下,详细内容可以查看下面这篇文章:
|
||||
|
||||
http://www.importnew.com/22003.html
|
||||
|
||||
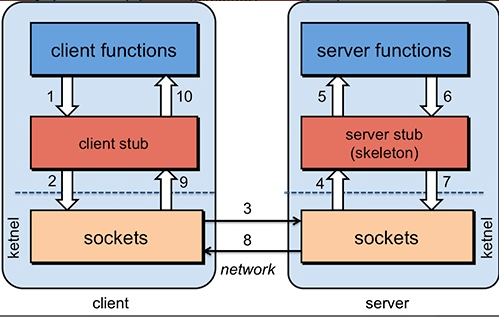
|
||||
|
||||
1. 服务消费方(client)调用以本地调用方式调用服务;
|
||||
2. client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
|
||||
3. client stub找到服务地址,并将消息发送到服务端;
|
||||
4. server stub收到消息后进行解码;
|
||||
5. server stub根据解码结果调用本地的服务;
|
||||
6. 本地服务执行并将结果返回给server stub;
|
||||
7. server stub将返回结果打包成消息并发送至消费方;
|
||||
8. client stub接收到消息,并进行解码;
|
||||
9. 服务消费方得到最终结果。
|
||||
|
||||
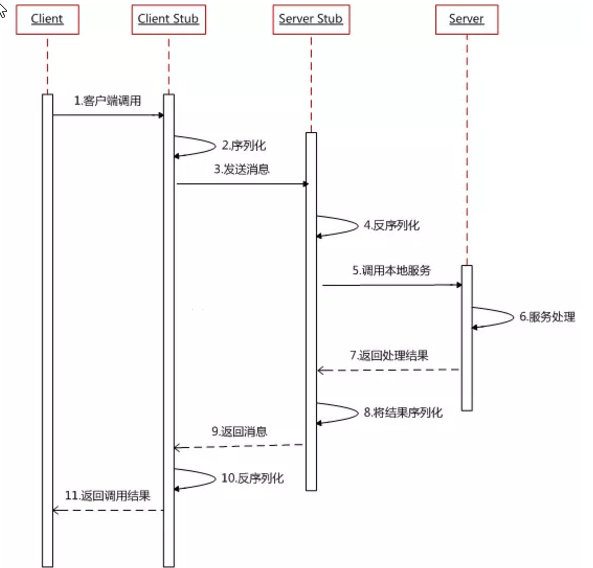
下面再贴一个网上的时序图:
|
||||
|
||||
|
||||
|
||||
### RPC 解决了什么问题?
|
||||
|
||||
从上面对 RPC 介绍的内容中,概括来讲RPC 主要解决了:**让分布式或者微服务系统中不同服务之间的调用像本地调用一样简单。**
|
||||
|
||||
### 常见的 RPC 框架总结?
|
||||
|
||||
- **RMI(JDK自带):** JDK自带的RPC,有很多局限性,不推荐使用。
|
||||
- **Dubbo:** Dubbo是 阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。目前 Dubbo 已经成为 Spring Cloud Alibaba 中的官方组件。
|
||||
- **gRPC** :gRPC是可以在任何环境中运行的现代开源高性能RPC框架。它可以通过可插拔的支持来有效地连接数据中心内和跨数据中心的服务,以实现负载平衡,跟踪,运行状况检查和身份验证。它也适用于分布式计算的最后一英里,以将设备,移动应用程序和浏览器连接到后端服务。
|
||||
|
||||
- **Hessian:** Hessian是一个轻量级的remotingonhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
|
||||
- **Thrift:** Apache Thrift是Facebook开源的跨语言的RPC通信框架,目前已经捐献给Apache基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于thrift研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
|
||||
|
||||
## 既有 HTTP ,为啥用 RPC 进行服务调用?
|
||||
|
||||
###RPC 只是一种设计而已
|
||||
|
||||
RPC 只是一种概念、一种设计,就是为了解决 **不同服务之间的调用问题**, 它一般会包含有 **传输协议** 和 **序列化协议** 这两个。
|
||||
|
||||
实现 RPC 的可以传输协议可以直接建立在 TCP 之上,也可以建立在 HTTP 协议之上。**大部分 RPC 框架都是使用的 TCP 连接(gRPC使用了HTTP2)。**
|
||||
|
||||
### HTTP 和 TCP
|
||||
|
||||
**可能现在很多对计算机网络不太熟悉的朋友已经被搞蒙了,要想真正搞懂,还需要来简单复习一下计算机网络基础知识:**
|
||||
|
||||
> 我们通常谈计算机网络的五层协议的体系结构是指:应用层、传输层、网络层、数据链路层、物理层。
|
||||
>
|
||||
> **应用层(application-layer)的任务是通过应用进程间的交互来完成特定网络应用。**HTTP 属于应用层协议,它会基于TCP/IP通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过 URL 向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。HTTP协议建立在 TCP 协议之上。
|
||||
>
|
||||
> **运输层(transport layer)的主要任务就是负责向两台主机进程之间的通信提供通用的数据传输服务**。TCP是传输层协议,主要解决数据如何在网络中传输。相比于UDP,**TCP** 提供的是**面向连接**的,**可靠的**数据传输服务。
|
||||
|
||||
**主要关键就在 HTTP 使用的 TCP 协议,和我们自定义的 TCP 协议在报文上的区别。**
|
||||
|
||||
**http1.1协议的 TCP 报文包含太多在传输过程中可能无用的信息:**
|
||||
|
||||
```
|
||||
HTTP/1.0 200 OK
|
||||
Content-Type: text/plain
|
||||
Content-Length: 137582
|
||||
Expires: Thu, 05 Dec 1997 16:00:00 GMT
|
||||
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
|
||||
Server: Apache 0.84
|
||||
|
||||
<html>
|
||||
<body>Hello World</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
**使用自定义 TCP 协议进行传输就会避免上面这个问题,极大地减轻了传输数据的开销。**这也就是为什么通常会采用自定义 TCP 协议的 RPC 来进行进行服务调用的真正原因。初次之外,成熟的 RPC 框架还提供好了“服务自动注册与发现”、"智能负载均衡"、“可视化的服务治理和运维”、“运行期流量调度”等等功能,这些也算是选择 RPC 进行服务注册和发现的一方面原因吧!
|
||||
|
||||
**相关阅读:**
|
||||
|
||||
- http://www.ruanyifeng.com/blog/2016/08/http.html (HTTP 协议入门- 阮一峰)
|
||||
|
||||
###一个常见的错误观点
|
||||
|
||||
很多文章中还会提到说 HTTP 协议相较于自定义 TCP 报文协议,增加的开销在于连接的建立与断开,但是这个观点已经被否认,下面截取自知乎中一个回答,原回答地址:https://www.zhihu.com/question/41609070/answer/191965937。
|
||||
|
||||
>首先要否认一点 HTTP 协议相较于自定义 TCP 报文协议,增加的开销在于连接的建立与断开。HTTP 协议是支持连接池复用的,也就是建立一定数量的连接不断开,并不会频繁的创建和销毁连接。二一要说的是 HTTP 也可以使用 Protobuf 这种二进制编码协议对内容进行编码,因此二者最大的区别还是在传输协议上。
|
||||
|
||||
### 题外话
|
||||
|
||||
初次之外,还需要注意的一点是 Spring Cloud Netflix 并没有使用 RPC 框架来进行不同服务之间的调用,而是使用 HTTP 协议进行调用的,速度虽然不比 RPC ,但是使用 HTTP 协议也会带来其他很多好处(这一点,可以自行查阅相关资料了解)。
|
||||
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [控制反转(IoC)和依赖注入(DI)](#控制反转ioc和依赖注入di)
|
||||
@ -350,3 +352,12 @@ Spring 框架中用到了哪些设计模式?
|
||||
- <https://juejin.im/post/5a8eb261f265da4e9e307230>
|
||||
- <https://juejin.im/post/5ba28986f265da0abc2b6084>
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
190
docs/system-design/micro-service/API网关.md
Normal file
190
docs/system-design/micro-service/API网关.md
Normal file
@ -0,0 +1,190 @@
|
||||
> 点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
>
|
||||
> 本文授权转载自:[https://github.com/javagrowing/JGrowing/blob/master/服务端开发/浅析如何设计一个亿级网关.md](https://github.com/javagrowing/JGrowing/blob/master/服务端开发/浅析如何设计一个亿级网关.md)。
|
||||
|
||||
## 1.背景
|
||||
|
||||
### 1.1 什么是API网关
|
||||
|
||||
API网关可以看做系统与外界联通的入口,我们可以在网关进行处理一些非业务逻辑的逻辑,比如权限验证,监控,缓存,请求路由等等。
|
||||
|
||||
### 1.2 为什么需要API网关
|
||||
|
||||
- RPC协议转成HTTP。
|
||||
|
||||
由于在内部开发中我们都是以RPC协议(thrift or dubbo)去做开发,暴露给内部服务,当外部服务需要使用这个接口的时候往往需要将RPC协议转换成HTTP协议。
|
||||
|
||||
- 请求路由
|
||||
|
||||
在我们的系统中由于同一个接口新老两套系统都在使用,我们需要根据请求上下文将请求路由到对应的接口。
|
||||
|
||||
- 统一鉴权
|
||||
|
||||
对于鉴权操作不涉及到业务逻辑,那么可以在网关层进行处理,不用下层到业务逻辑。
|
||||
|
||||
- 统一监控
|
||||
|
||||
由于网关是外部服务的入口,所以我们可以在这里监控我们想要的数据,比如入参出参,链路时间。
|
||||
|
||||
- 流量控制,熔断降级
|
||||
|
||||
对于流量控制,熔断降级非业务逻辑可以统一放到网关层。
|
||||
|
||||
有很多业务都会自己去实现一层网关层,用来接入自己的服务,但是对于整个公司来说这还不够。
|
||||
|
||||
### 1.3 统一API网关
|
||||
|
||||
统一的API网关不仅有API网关的所有的特点,还有下面几个好处:
|
||||
|
||||
- 统一技术组件升级
|
||||
|
||||
在公司中如果有某个技术组件需要升级,那么是需要和每个业务线沟通,通常几个月都搞不定。举个例子如果对于入口的安全鉴权有重大安全隐患需要升级,如果速度还是这么慢肯定是不行,那么有了统一的网关升级是很快的。
|
||||
|
||||
- 统一服务接入
|
||||
|
||||
对于某个服务的接入也比较困难,比如公司已经研发出了比较稳定的服务组件,正在公司大力推广,这个周期肯定也特别漫长,由于有了统一网关,那么只需要统一网关统一接入。
|
||||
|
||||
- 节约资源
|
||||
|
||||
不同业务不同部门如果按照我们上面的做法应该会都自己搞一个网关层,用来做这个事,可以想象如果一个公司有100个这种业务,每个业务配备4台机器,那么就需要400台机器。并且每个业务的开发RD都需要去开发这个网关层,去随时去维护,增加人力。如果有了统一网关层,那么也许只需要50台机器就可以做这100个业务的网关层的事,并且业务RD不需要随时关注开发,上线的步骤。
|
||||
|
||||
## 2.统一网关的设计
|
||||
|
||||
### 2.1 异步化请求
|
||||
|
||||
对于我们自己实现的网关层,由于只有我们自己使用,对于吞吐量的要求并不高所以,我们一般同步请求调用即可。
|
||||
|
||||
对于我们统一的网关层,如何用少量的机器接入更多的服务,这就需要我们的异步,用来提高更多的吞吐量。对于异步化一般有下面两种策略:
|
||||
|
||||
- Tomcat/Jetty+NIO+servlet3
|
||||
|
||||
这种策略使用的比较普遍,京东,有赞,Zuul,都选取的是这个策略,这种策略比较适合HTTP。在Servlet3中可以开启异步。
|
||||
|
||||
- Netty+NIO
|
||||
|
||||
Netty为高并发而生,目前唯品会的网关使用这个策略,在唯品会的技术文章中在相同的情况下Netty是每秒30w+的吞吐量,Tomcat是13w+,可以看出是有一定的差距的,但是Netty需要自己处理HTTP协议,这一块比较麻烦。
|
||||
|
||||
对于网关是HTTP请求场景比较多的情况可以采用Servlet,毕竟有更加成熟的处理HTTP协议。如果更加重视吞吐量那么可以采用Netty。
|
||||
|
||||
#### 2.1.1 全链路异步
|
||||
|
||||
对于来的请求我们已经使用异步了,为了达到全链路异步所以我们需要对去的请求也进行异步处理,对于去的请求我们可以利用我们rpc的异步支持进行异步请求所以基本可以达到下图:
|
||||
|
||||
[](https://camo.githubusercontent.com/ea78c61029cee6487f3aa0cecf5443f18d102173/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633837373331356535353761663f773d3133303026683d34383026663d706e6726733d3639323735)
|
||||
|
||||
由在web容器中开启servlet异步,然后进入到网关的业务线程池中进行业务处理,然后进行rpc的异步调用并注册需要回调的业务,最后在回调线程池中进行回调处理。
|
||||
|
||||
### 2.2 链式处理
|
||||
|
||||
在设计模式中有一个模式叫责任链模式,他的作用是避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。通过这种模式将请求的发送者和请求的处理者解耦了。在我们的各个框架中对此模式都有实现,比如servlet里面的filter,springmvc里面的Interceptor。
|
||||
|
||||
在Netflix Zuul中也应用了这种模式,如下图所示:
|
||||
|
||||
[](https://camo.githubusercontent.com/22d9288d6e9137b98aef563ff7a5a76a090a4609/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633837383234303735333733353f773d39363026683d37323026663d706e6726733d3439333134)
|
||||
|
||||
这种模式在网关的设计中我们可以借鉴到自己的网关设计:
|
||||
|
||||
- preFilters:前置过滤器,用来处理一些公共的业务,比如统一鉴权,统一限流,熔断降级,缓存处理等,并且提供业务方扩展。
|
||||
- routingFilters: 用来处理一些泛化调用,主要是做协议的转换,请求的路由工作。
|
||||
- postFilters: 后置过滤器,主要用来做结果的处理,日志打点,记录时间等等。
|
||||
- errorFilters: 错误过滤器,用来处理调用异常的情况。
|
||||
|
||||
这种设计在有赞的网关也有应用。
|
||||
|
||||
### 2.3 业务隔离
|
||||
|
||||
上面在全链路异步的情况下不同业务之间的影响很小,但是如果在提供的自定义FiIlter中进行了某些同步调用,一旦超时频繁那么就会对其他业务产生影响。所以我们需要采用隔离之术,降低业务之间的互相影响。
|
||||
|
||||
#### 2.3.1 信号量隔离
|
||||
|
||||
信号量隔离只是限制了总的并发数,服务还是主线程进行同步调用。这个隔离如果远程调用超时依然会影响主线程,从而会影响其他业务。因此,如果只是想限制某个服务的总并发调用量或者调用的服务不涉及远程调用的话,可以使用轻量级的信号量来实现。有赞的网关由于没有自定义filter所以选取的是信号量隔离。
|
||||
|
||||
#### 2.3.2 线程池隔离
|
||||
|
||||
最简单的就是不同业务之间通过不同的线程池进行隔离,就算业务接口出现了问题由于线程池已经进行了隔离那么也不会影响其他业务。在京东的网关实现之中就是采用的线程池隔离,比较重要的业务比如商品或者订单 都是单独的通过线程池去处理。但是由于是统一网关平台,如果业务线众多,大家都觉得自己的业务比较重要需要单独的线程池隔离,如果使用的是Java语言开发的话那么,在Java中线程是比较重的资源比较受限,如果需要隔离的线程池过多不是很适用。如果使用一些其他语言比如Golang进行开发网关的话,线程是比较轻的资源,所以比较适合使用线程池隔离。
|
||||
|
||||
#### 2.3.3 集群隔离
|
||||
|
||||
如果有某些业务就需要使用隔离但是统一网关又没有线程池隔离那么应该怎么办呢?那么可以使用集群隔离,如果你的某些业务真的很重要那么可以为这一系列业务单独申请一个集群或者多个集群,通过机器之间进行隔离。
|
||||
|
||||
### 2.4 请求限流
|
||||
|
||||
流量控制可以采用很多开源的实现,比如阿里最近开源的Sentinel和比较成熟的Hystrix。
|
||||
|
||||
一般限流分为集群限流和单机限流:
|
||||
|
||||
- 利用统一存储保存当前流量的情况,一般可以采用Redis,这个一般会有一些性能损耗。
|
||||
- 单机限流:限流每台机器我们可以直接利用Guava的令牌桶去做,由于没有远程调用性能消耗较小。
|
||||
|
||||
### 2.5 熔断降级
|
||||
|
||||
这一块也可以参照开源的实现Sentinel和Hystrix,这里不是重点就不多提了。
|
||||
|
||||
### 2.6 泛化调用
|
||||
|
||||
泛化调用指的是一些通信协议的转换,比如将HTTP转换成Thrift。在一些开源的网关中比如Zuul是没有实现的,因为各个公司的内部服务通信协议都不同。比如在唯品会中支持HTTP1,HTTP2,以及二进制的协议,然后转化成内部的协议,淘宝的支持HTTPS,HTTP1,HTTP2这些协议都可以转换成,HTTP,HSF,Dubbo等协议。
|
||||
|
||||
#### 2.6.1泛化调用
|
||||
|
||||
如何去实现泛化调用呢?由于协议很难自动转换,那么其实每个协议对应的接口需要提供一种映射。简单来说就是把两个协议都能转换成共同语言,从而互相转换。
|
||||
|
||||
[](https://camo.githubusercontent.com/d680a88d0dd9063fe53df26705836c4b7a19c121/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633838306163386264623537353f773d3133333826683d39363326663d706e6726733d3830313730)一般来说共同语言有三种方式指定:
|
||||
|
||||
- json:json数据格式比较简单,解析速度快,较轻量级。在Dubbo的生态中有一个HTTP转Dubbo的项目是用JsonRpc做的,将HTTP转化成JsonRpc再转化成Dubbo。
|
||||
|
||||
比如可以将一个 [www.baidu.com/id](http://www.baidu.com/id) = 1 GET 可以映射为json:
|
||||
|
||||
代码块
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
- xml:xml数据比较重,解析比较困难,这里不过多讨论。
|
||||
- 自定义描述语言:一般来说这个成本比较高需要自己定义语言来进行描述并进行解析,但是其扩展性,自定义个性化性都是最高。例:spring自定义了一套自己的SPEL表达式语言
|
||||
|
||||
对于泛化调用如果要自己设计的话JSON基本可以满足,如果对于个性化的需要特别多的话倒是可以自己定义一套语言。
|
||||
|
||||
### 2.7 管理平台
|
||||
|
||||
上面介绍的都是如何实现一个网关的技术关键。这里需要介绍网关的一个业务关键。有了网关之后,需要一个管理平台如何去对我们上面所描述的技术关键进行配置,包括但不限于下面这些配置:
|
||||
|
||||
- 限流
|
||||
- 熔断
|
||||
- 缓存
|
||||
- 日志
|
||||
- 自定义filter
|
||||
- 泛化调用
|
||||
|
||||
## 3.总结
|
||||
|
||||
最后一个合理的标准网关应该按照如下去实现:
|
||||
|
||||
[](https://camo.githubusercontent.com/16eef64bd42ee7b2eb08c36039316fadb4e4d6b3/68747470733a2f2f757365722d676f6c642d63646e2e786974752e696f2f323031382f31302f33312f313636633838343136633463633232373f773d3230313326683d3130303726663d706e6726733d313532363930)
|
||||
|
||||
| --- | 京东 | 唯品会 | 有赞 | 阿里 | Zuul |
|
||||
| -------- | ------------------------------ | ----------------------------- | ----------------------------------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| 实现关键 | servlet3.0 | netty | servlet3.0 | servlet3.0 | servlet3.0 |
|
||||
| 异步情况 | servlet异步,rpc是否异步不清楚 | 全链路异步 | 全链路异步 | 全链路异步 | Zuul1同步阻塞,Zuul2异步非阻塞 |
|
||||
| 限流 | --- | --- | 平滑限流。最初是codis,后续换到每个单机的令牌桶限流。 | 1.基本流控:基于API的QPS做限流。2.运营流控:支持APP流量包,APP+API+USER的流控33.大促流控:APP访问API的权重流控。阿里开源:Sentinel | 提供了jar包:spring-cloud-zuul-ratelimit。1.对请求的目标URL进行限流(例如:某个URL每分钟只允许调用多少次)。2.对客户端的访问IP进行限流(例如:某个IP每分钟只允许请求多少次)3.对某些特定用户或者用户组进行限流(例如:非VIP用户限制每分钟只允许调用100次某个API等)4.多维度混合的限流。此时,就需要实现一些限流规则的编排机制。与、或、非等关系。支持四种存储方式ConcurrentHashMap,Consul,Redis,数据库。 |
|
||||
| 熔断降级 | --- | --- | Hystrix | --- | 只支持服务级别熔断,不支持URL级别。 |
|
||||
| 隔离 | 线程池隔离 | --- | 信号量隔离 | --- | 线程池隔离,信号量隔离 |
|
||||
| 缓存 | redis | --- | 二级缓存,本地缓存+Codis | HDCC 本地缓存,远程缓存,数据库 | 需要自己开发 |
|
||||
| 泛化调用 | --- | http,https,http1,http2,二进制 | dubbo,http,nova | hsf,dubbo,http,https,http2,http1 | 只支持http |
|
||||
|
||||
## 4.参考
|
||||
|
||||
- 京东:http://www.yunweipai.com/archives/23653.html
|
||||
- 有赞网关:https://tech.youzan.com/api-gateway-in-practice/
|
||||
- 唯品会:https://mp.weixin.qq.com/s/gREMe-G7nqNJJLzbZ3ed3A
|
||||
- Zuul:http://www.scienjus.com/api-gateway-and-netflix-zuul/
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
186
docs/system-design/micro-service/分布式id生成方案总结.md
Normal file
186
docs/system-design/micro-service/分布式id生成方案总结.md
Normal file
@ -0,0 +1,186 @@
|
||||
> 点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
>
|
||||
> 本文授权转载自:https://juejin.im/post/5d6fc8eff265da03ef7a324b ,作者:1点25。
|
||||
|
||||
ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID,在互联网企业中,大部分公司使用的都是Mysql,并且因为需要事务支持,所以通常会使用Innodb存储引擎,UUID太长以及无序,所以并不适合在Innodb中来作为主键,自增ID比较合适,但是随着公司的业务发展,数据量将越来越大,需要对数据进行分表,而分表后,每个表中的数据都会按自己的节奏进行自增,很有可能出现ID冲突。这时就需要一个单独的机制来负责生成唯一ID,生成出来的ID也可以叫做**分布式ID**,或**全局ID**。下面来分析各个生成分布式ID的机制。
|
||||
|
||||

|
||||
|
||||
这篇文章并不会分析的特别详细,主要是做一些总结,以后再出一些详细某个方案的文章。
|
||||
|
||||
|
||||
|
||||
## 数据库自增ID
|
||||
|
||||
第一种方案仍然还是基于数据库的自增ID,需要单独使用一个数据库实例,在这个实例中新建一个单独的表:
|
||||
|
||||
表结构如下:
|
||||
|
||||
```sql
|
||||
CREATE DATABASE `SEQID`;
|
||||
|
||||
CREATE TABLE SEQID.SEQUENCE_ID (
|
||||
id bigint(20) unsigned NOT NULL auto_increment,
|
||||
stub char(10) NOT NULL default '',
|
||||
PRIMARY KEY (id),
|
||||
UNIQUE KEY stub (stub)
|
||||
) ENGINE=MyISAM;
|
||||
```
|
||||
|
||||
可以使用下面的语句生成并获取到一个自增ID
|
||||
|
||||
```sql
|
||||
begin;
|
||||
replace into SEQUENCE_ID (stub) VALUES ('anyword');
|
||||
select last_insert_id();
|
||||
commit;
|
||||
```
|
||||
|
||||
stub字段在这里并没有什么特殊的意义,只是为了方便的去插入数据,只有能插入数据才能产生自增id。而对于插入我们用的是replace,replace会先看是否存在stub指定值一样的数据,如果存在则先delete再insert,如果不存在则直接insert。
|
||||
|
||||
这种生成分布式ID的机制,需要一个单独的Mysql实例,虽然可行,但是基于性能与可靠性来考虑的话都不够,**业务系统每次需要一个ID时,都需要请求数据库获取,性能低,并且如果此数据库实例下线了,那么将影响所有的业务系统。**
|
||||
|
||||
为了解决数据库可靠性问题,我们可以使用第二种分布式ID生成方案。
|
||||
|
||||
## 数据库多主模式
|
||||
|
||||
如果我们两个数据库组成一个**主从模式**集群,正常情况下可以解决数据库可靠性问题,但是如果主库挂掉后,数据没有及时同步到从库,这个时候会出现ID重复的现象。我们可以使用**双主模式**集群,也就是两个Mysql实例都能单独的生产自增ID,这样能够提高效率,但是如果不经过其他改造的话,这两个Mysql实例很可能会生成同样的ID。需要单独给每个Mysql实例配置不同的起始值和自增步长。
|
||||
|
||||
第一台Mysql实例配置:
|
||||
|
||||
```sql
|
||||
set @@auto_increment_offset = 1; -- 起始值
|
||||
set @@auto_increment_increment = 2; -- 步长
|
||||
```
|
||||
|
||||
第二台Mysql实例配置:
|
||||
|
||||
```sql
|
||||
set @@auto_increment_offset = 2; -- 起始值
|
||||
set @@auto_increment_increment = 2; -- 步长
|
||||
```
|
||||
|
||||
经过上面的配置后,这两个Mysql实例生成的id序列如下: mysql1,起始值为1,步长为2,ID生成的序列为:1,3,5,7,9,... mysql2,起始值为2,步长为2,ID生成的序列为:2,4,6,8,10,...
|
||||
|
||||
对于这种生成分布式ID的方案,需要单独新增一个生成分布式ID应用,比如DistributIdService,该应用提供一个接口供业务应用获取ID,业务应用需要一个ID时,通过rpc的方式请求DistributIdService,DistributIdService随机去上面的两个Mysql实例中去获取ID。
|
||||
|
||||
实行这种方案后,就算其中某一台Mysql实例下线了,也不会影响DistributIdService,DistributIdService仍然可以利用另外一台Mysql来生成ID。
|
||||
|
||||
但是这种方案的扩展性不太好,如果两台Mysql实例不够用,需要新增Mysql实例来提高性能时,这时就会比较麻烦。
|
||||
|
||||
现在如果要新增一个实例mysql3,要怎么操作呢? 第一,mysql1、mysql2的步长肯定都要修改为3,而且只能是人工去修改,这是需要时间的。 第二,因为mysql1和mysql2是不停在自增的,对于mysql3的起始值我们可能要定得大一点,以给充分的时间去修改mysql1,mysql2的步长。 第三,在修改步长的时候很可能会出现重复ID,要解决这个问题,可能需要停机才行。
|
||||
|
||||
为了解决上面的问题,以及能够进一步提高DistributIdService的性能,如果使用第三种生成分布式ID机制。
|
||||
|
||||
## 号段模式
|
||||
|
||||
我们可以使用号段的方式来获取自增ID,号段可以理解成批量获取,比如DistributIdService从数据库获取ID时,如果能批量获取多个ID并缓存在本地的话,那样将大大提供业务应用获取ID的效率。
|
||||
|
||||
比如DistributIdService每次从数据库获取ID时,就获取一个号段,比如(1,1000],这个范围表示了1000个ID,业务应用在请求DistributIdService提供ID时,DistributIdService只需要在本地从1开始自增并返回即可,而不需要每次都请求数据库,一直到本地自增到1000时,也就是当前号段已经被用完时,才去数据库重新获取下一号段。
|
||||
|
||||
所以,我们需要对数据库表进行改动,如下:
|
||||
|
||||
```sql
|
||||
CREATE TABLE id_generator (
|
||||
id int(10) NOT NULL,
|
||||
current_max_id bigint(20) NOT NULL COMMENT '当前最大id',
|
||||
increment_step int(10) NOT NULL COMMENT '号段的长度',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
||||
```
|
||||
|
||||
这个数据库表用来记录自增步长以及当前自增ID的最大值(也就是当前已经被申请的号段的最后一个值),因为自增逻辑被移到DistributIdService中去了,所以数据库不需要这部分逻辑了。
|
||||
|
||||
这种方案不再强依赖数据库,就算数据库不可用,那么DistributIdService也能继续支撑一段时间。但是如果DistributIdService重启,会丢失一段ID,导致ID空洞。
|
||||
|
||||
为了提高DistributIdService的高可用,需要做一个集群,业务在请求DistributIdService集群获取ID时,会随机的选择某一个DistributIdService节点进行获取,对每一个DistributIdService节点来说,数据库连接的是同一个数据库,那么可能会产生多个DistributIdService节点同时请求数据库获取号段,那么这个时候需要利用乐观锁来进行控制,比如在数据库表中增加一个version字段,在获取号段时使用如下SQL:
|
||||
|
||||
```sql
|
||||
update id_generator set current_max_id=#{newMaxId}, version=version+1 where version = #{version}
|
||||
```
|
||||
|
||||
因为newMaxId是DistributIdService中根据oldMaxId+步长算出来的,只要上面的update更新成功了就表示号段获取成功了。
|
||||
|
||||
为了提供数据库层的高可用,需要对数据库使用多主模式进行部署,对于每个数据库来说要保证生成的号段不重复,这就需要利用最开始的思路,再在刚刚的数据库表中增加起始值和步长,比如如果现在是两台Mysql,那么 mysql1将生成号段(1,1001],自增的时候序列为1,3,4,5,7.... mysql1将生成号段(2,1002],自增的时候序列为2,4,6,8,10...
|
||||
|
||||
更详细的可以参考滴滴开源的TinyId:[github.com/didi/tinyid…](https://github.com/didi/tinyid/wiki/tinyid原理介绍)
|
||||
|
||||
在TinyId中还增加了一步来提高效率,在上面的实现中,ID自增的逻辑是在DistributIdService中实现的,而实际上可以把自增的逻辑转移到业务应用本地,这样对于业务应用来说只需要获取号段,每次自增时不再需要请求调用DistributIdService了。
|
||||
|
||||
## 雪花算法
|
||||
|
||||
上面的三种方法总的来说是基于自增思想的,而接下来就介绍比较著名的雪花算法-snowflake。
|
||||
|
||||
我们可以换个角度来对分布式ID进行思考,只要能让负责生成分布式ID的每台机器在每毫秒内生成不一样的ID就行了。
|
||||
|
||||
snowflake是twitter开源的分布式ID生成算法,是一种算法,所以它和上面的三种生成分布式ID机制不太一样,它不依赖数据库。
|
||||
|
||||
核心思想是:分布式ID固定是一个long型的数字,一个long型占8个字节,也就是64个bit,原始snowflake算法中对于bit的分配如下图:
|
||||
|
||||

|
||||
|
||||
- 第一个bit位是标识部分,在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以固定为0。
|
||||
- 时间戳部分占41bit,这个是毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
|
||||
- 工作机器id占10bit,这里比较灵活,比如,可以使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点。
|
||||
- 序列号部分占12bit,支持同一毫秒内同一个节点可以生成4096个ID
|
||||
|
||||
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
|
||||
|
||||
snowflake算法实现起来并不难,提供一个github上用java实现的:[github.com/beyondfengy…](https://github.com/beyondfengyu/SnowFlake)
|
||||
|
||||
在大厂里,其实并没有直接使用snowflake,而是进行了改造,因为snowflake算法中最难实践的就是工作机器id,原始的snowflake算法需要人工去为每台机器去指定一个机器id,并配置在某个地方从而让snowflake从此处获取机器id。
|
||||
|
||||
但是在大厂里,机器是很多的,人力成本太大且容易出错,所以大厂对snowflake进行了改造。
|
||||
|
||||
### 百度(uid-generator)
|
||||
|
||||
github地址:[uid-generator](https://github.com/baidu/uid-generator)
|
||||
|
||||
uid-generator使用的就是snowflake,只是在生产机器id,也叫做workId时有所不同。
|
||||
|
||||
uid-generator中的workId是由uid-generator自动生成的,并且考虑到了应用部署在docker上的情况,在uid-generator中用户可以自己去定义workId的生成策略,默认提供的策略是:应用启动时由数据库分配。说的简单一点就是:应用在启动时会往数据库表(uid-generator需要新增一个WORKER_NODE表)中去插入一条数据,数据插入成功后返回的该数据对应的自增唯一id就是该机器的workId,而数据由host,port组成。
|
||||
|
||||
对于uid-generator中的workId,占用了22个bit位,时间占用了28个bit位,序列化占用了13个bit位,需要注意的是,和原始的snowflake不太一样,时间的单位是秒,而不是毫秒,workId也不一样,同一个应用每重启一次就会消费一个workId。
|
||||
|
||||
具体可参考[github.com/baidu/uid-g…](https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md)
|
||||
|
||||
### 美团(Leaf)
|
||||
|
||||
github地址:[Leaf](https://github.com/Meituan-Dianping/Leaf)
|
||||
|
||||
美团的Leaf也是一个分布式ID生成框架。它非常全面,即支持号段模式,也支持snowflake模式。号段模式这里就不介绍了,和上面的分析类似。
|
||||
|
||||
Leaf中的snowflake模式和原始snowflake算法的不同点,也主要在workId的生成,Leaf中workId是基于ZooKeeper的顺序Id来生成的,每个应用在使用Leaf-snowflake时,在启动时都会都在Zookeeper中生成一个顺序Id,相当于一台机器对应一个顺序节点,也就是一个workId。
|
||||
|
||||
### 总结
|
||||
|
||||
总得来说,上面两种都是自动生成workId,以让系统更加稳定以及减少人工成功。
|
||||
|
||||
## Redis
|
||||
|
||||
这里额外再介绍一下使用Redis来生成分布式ID,其实和利用Mysql自增ID类似,可以利用Redis中的incr命令来实现原子性的自增与返回,比如:
|
||||
|
||||
```shell
|
||||
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
|
||||
OK
|
||||
127.0.0.1:6379> incr seq_id // 增加1,并返回
|
||||
(integer) 2
|
||||
127.0.0.1:6379> incr seq_id // 增加1,并返回
|
||||
(integer) 3
|
||||
```
|
||||
|
||||
使用redis的效率是非常高的,但是要考虑持久化的问题。Redis支持RDB和AOF两种持久化的方式。
|
||||
|
||||
RDB持久化相当于定时打一个快照进行持久化,如果打完快照后,连续自增了几次,还没来得及做下一次快照持久化,这个时候Redis挂掉了,重启Redis后会出现ID重复。
|
||||
|
||||
AOF持久化相当于对每条写命令进行持久化,如果Redis挂掉了,不会出现ID重复的现象,但是会由于incr命令过得,导致重启恢复数据时间过长。
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
@ -1,33 +1,8 @@
|
||||
**本文只是对Docker的概念做了较为详细的介绍,并不涉及一些像Docker环境的安装以及Docker的一些常见操作和命令。**
|
||||
**本文只是对 Docker 的概念做了较为详细的介绍,并不涉及一些像 Docker 环境的安装以及 Docker 的一些常见操作和命令。**
|
||||
|
||||
<!-- TOC -->
|
||||
## 一 认识容器
|
||||
|
||||
- [一 先从认识容器开始](#一-先从认识容器开始)
|
||||
- [1.1 什么是容器?](#11-什么是容器)
|
||||
- [先来看看容器较为官方的解释](#先来看看容器较为官方的解释)
|
||||
- [再来看看容器较为通俗的解释](#再来看看容器较为通俗的解释)
|
||||
- [1.2 图解物理机,虚拟机与容器](#12-图解物理机虚拟机与容器)
|
||||
- [二 再来谈谈 Docker 的一些概念](#二-再来谈谈-docker-的一些概念)
|
||||
- [2.1 什么是 Docker?](#21-什么是-docker)
|
||||
- [2.2 Docker 思想](#22-docker-思想)
|
||||
- [2.3 Docker 容器的特点](#23-docker-容器的特点)
|
||||
- [2.4 为什么要用 Docker ?](#24-为什么要用-docker-)
|
||||
- [三 容器 VS 虚拟机](#三-容器-vs-虚拟机)
|
||||
- [3.1 两者对比图](#31-两者对比图)
|
||||
- [3.2 容器与虚拟机总结](#32-容器与虚拟机总结)
|
||||
- [3.3 容器与虚拟机两者是可以共存的](#33-容器与虚拟机两者是可以共存的)
|
||||
- [四 Docker基本概念](#四-docker基本概念)
|
||||
- [4.1 镜像(Image):一个特殊的文件系统](#41-镜像image一个特殊的文件系统)
|
||||
- [4.2 容器(Container):镜像运行时的实体](#42-容器container镜像运行时的实体)
|
||||
- [4.3仓库(Repository):集中存放镜像文件的地方](#43仓库repository集中存放镜像文件的地方)
|
||||
- [五 最后谈谈:Build Ship and Run](#五-最后谈谈build-ship-and-run)
|
||||
- [六 总结](#六-总结)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
> **Docker 是世界领先的软件容器平台**,所以想要搞懂Docker的概念我们必须先从容器开始说起。
|
||||
|
||||
## 一 先从认识容器开始
|
||||
**Docker 是世界领先的软件容器平台**,所以想要搞懂 Docker 的概念我们必须先从容器开始说起。
|
||||
|
||||
### 1.1 什么是容器?
|
||||
|
||||
@ -36,34 +11,38 @@
|
||||
**一句话概括容器:容器就是将软件打包成标准化单元,以用于开发、交付和部署。**
|
||||
|
||||
- **容器镜像是轻量的、可执行的独立软件包** ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
|
||||
- **容器化软件适用于基于Linux和Windows的应用,在任何环境中都能够始终如一地运行。**
|
||||
- **容器化软件适用于基于 Linux 和 Windows 的应用,在任何环境中都能够始终如一地运行。**
|
||||
- **容器赋予了软件独立性** ,使其免受外在环境差异(例如,开发和预演环境的差异)的影响,从而有助于减少团队间在相同基础设施上运行不同软件时的冲突。
|
||||
|
||||
#### 再来看看容器较为通俗的解释
|
||||
|
||||
**如果需要通俗的描述容器的话,我觉得容器就是一个存放东西的地方,就像书包可以装各种文具、衣柜可以放各种衣服、鞋架可以放各种鞋子一样。我们现在所说的容器存放的东西可能更偏向于应用比如网站、程序甚至是系统环境。**
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
### 1.2 图解物理机,虚拟机与容器
|
||||
关于虚拟机与容器的对比在后面会详细介绍到,这里只是通过网上的图片加深大家对于物理机、虚拟机与容器这三者的理解。
|
||||
|
||||
关于虚拟机与容器的对比在后面会详细介绍到,这里只是通过网上的图片加深大家对于物理机、虚拟机与容器这三者的理解(下面的图片来源与网络)。
|
||||
|
||||
**物理机**
|
||||

|
||||
|
||||

|
||||
|
||||
**虚拟机:**
|
||||
|
||||

|
||||

|
||||
|
||||
**容器:**
|
||||
|
||||

|
||||

|
||||
|
||||
通过上面这三张抽象图,我们可以大概可以通过类比概括出: **容器虚拟化的是操作系统而不是硬件,容器之间是共享同一套操作系统资源的。虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统。因此容器的隔离级别会稍低一些。**
|
||||
|
||||
---
|
||||
|
||||
> 相信通过上面的解释大家对于容器这个既陌生又熟悉的概念有了一个初步的认识,下面我们就来谈谈Docker的一些概念。
|
||||
**相信通过上面的解释大家对于容器这个既陌生又熟悉的概念有了一个初步的认识,下面我们就来谈谈 Docker 的一些概念。**
|
||||
|
||||
## 二 再来谈谈 Docker 的一些概念
|
||||
|
||||
@ -71,11 +50,10 @@
|
||||
|
||||
### 2.1 什么是 Docker?
|
||||
|
||||
说实话关于Docker是什么并太好说,下面我通过四点向你说明Docker到底是个什么东西。
|
||||
说实话关于 Docker 是什么并太好说,下面我通过四点向你说明 Docker 到底是个什么东西。
|
||||
|
||||
- **Docker 是世界领先的软件容器平台。**
|
||||
- **Docker** 使用 Google 公司推出的 **Go 语言** 进行开发实现,基于 **Linux 内核** 的cgroup,namespace,以及AUFS类的**UnionFS**等技术,**对进程进行封装隔离,属于操作系统层面的虚拟化技术。** 由于隔离的进程独立于宿主和其它的隔离的进
|
||||
程,因此也称其为容器。**Docke最初实现是基于 LXC.**
|
||||
- **Docker** 使用 Google 公司推出的 **Go 语言** 进行开发实现,基于 **Linux 内核** 提供的 CGroup 功能和 name space 来实现的,以及 AUFS 类的 **UnionFS** 等技术,**对进程进行封装隔离,属于操作系统层面的虚拟化技术。** 由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
|
||||
- **Docker 能够自动执行重复性任务,例如搭建和配置开发环境,从而解放了开发人员以便他们专注在真正重要的事情上:构建杰出的软件。**
|
||||
- **用户可以方便地创建和使用容器,把自己的应用放入容器。容器还可以进行版本管理、复制、分享、修改,就像管理普通的代码一样。**
|
||||
|
||||
@ -84,7 +62,7 @@
|
||||
### 2.2 Docker 思想
|
||||
|
||||
- **集装箱**
|
||||
- **标准化:** ①运输方式 ② 存储方式 ③ API接口
|
||||
- **标准化:** ① 运输方式 ② 存储方式 ③ API 接口
|
||||
- **隔离**
|
||||
|
||||
### 2.3 Docker 容器的特点
|
||||
@ -92,9 +70,11 @@
|
||||
- #### 轻量
|
||||
|
||||
在一台机器上运行的多个 Docker 容器可以共享这台机器的操作系统内核;它们能够迅速启动,只需占用很少的计算和内存资源。镜像是通过文件系统层进行构造的,并共享一些公共文件。这样就能尽量降低磁盘用量,并能更快地下载镜像。
|
||||
|
||||
- #### 标准
|
||||
|
||||
Docker 容器基于开放式标准,能够在所有主流 Linux 版本、Microsoft Windows 以及包括 VM、裸机服务器和云在内的任何基础设施上运行。
|
||||
|
||||
- #### 安全
|
||||
|
||||
Docker 赋予应用的隔离性不仅限于彼此隔离,还独立于底层的基础设施。Docker 默认提供最强的隔离,因此应用出现问题,也只是单个容器的问题,而不会波及到整台机器。
|
||||
@ -110,15 +90,15 @@
|
||||
|
||||
---
|
||||
|
||||
> 每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。
|
||||
|
||||
## 三 容器 VS 虚拟机
|
||||
|
||||
简单来说: **容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。**
|
||||
**每当说起容器,我们不得不将其与虚拟机做一个比较。就我而言,对于两者无所谓谁会取代谁,而是两者可以和谐共存。**
|
||||
|
||||
简单来说: **容器和虚拟机具有相似的资源隔离和分配优势,但功能有所不同,因为容器虚拟化的是操作系统,而不是硬件,因此容器更容易移植,效率也更高。**
|
||||
|
||||
### 3.1 两者对比图
|
||||
|
||||
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便.
|
||||
传统虚拟机技术是虚拟出一套硬件后,在其上运行一个完整操作系统,在该系统上再运行所需应用进程;而容器内的应用进程直接运行于宿主的内核,容器内没有自己的内核,而且也没有进行硬件虚拟。因此容器要比传统虚拟机更为轻便.
|
||||
|
||||

|
||||
|
||||
@ -128,9 +108,9 @@
|
||||
|
||||
- **容器是一个应用层抽象,用于将代码和依赖资源打包在一起。** **多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行** 。与虚拟机相比, **容器占用的空间较少**(容器镜像大小通常只有几十兆),**瞬间就能完成启动** 。
|
||||
|
||||
- **虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。** 管理程序允许多个 VM 在一台机器上运行。每个VM都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 **占用大量空间** 。而且 VM **启动也十分缓慢** 。
|
||||
- **虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。** 管理程序允许多个 VM 在一台机器上运行。每个 VM 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此 **占用大量空间** 。而且 VM **启动也十分缓慢** 。
|
||||
|
||||
通过Docker官网,我们知道了这么多Docker的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。**虚拟机更擅长于彻底隔离整个运行环境**。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 **Docker通常用于隔离不同的应用** ,例如前端,后端以及数据库。
|
||||
通过 Docker 官网,我们知道了这么多 Docker 的优势,但是大家也没有必要完全否定虚拟机技术,因为两者有不同的使用场景。**虚拟机更擅长于彻底隔离整个运行环境**。例如,云服务提供商通常采用虚拟机技术隔离不同的用户。而 **Docker 通常用于隔离不同的应用** ,例如前端,后端以及数据库。
|
||||
|
||||
### 3.3 容器与虚拟机两者是可以共存的
|
||||
|
||||
@ -140,11 +120,9 @@
|
||||
|
||||
---
|
||||
|
||||
> Docker中非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。
|
||||
## 四 Docker 基本概念
|
||||
|
||||
## 四 Docker基本概念
|
||||
|
||||
Docker 包括三个基本概念
|
||||
**Docker 中有非常重要的三个基本概念,理解了这三个概念,就理解了 Docker 的整个生命周期。**
|
||||
|
||||
- **镜像(Image)**
|
||||
- **容器(Container)**
|
||||
@ -152,53 +130,125 @@ Docker 包括三个基本概念
|
||||
|
||||
理解了这三个概念,就理解了 Docker 的整个生命周期
|
||||
|
||||

|
||||

|
||||
|
||||
### 4.1 镜像(Image):一个特殊的文件系统
|
||||
|
||||
**操作系统分为内核和用户空间**。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而Docker 镜像(Image),就相当于是一个 root 文件系统。
|
||||
**操作系统分为内核和用户空间**。对于 Linux 而言,内核启动后,会挂载 root 文件系统为其提供用户空间支持。而 Docker 镜像(Image),就相当于是一个 root 文件系统。
|
||||
|
||||
**Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。** 镜像不包含任何动态数据,其内容在构建之后也不会被改变。
|
||||
**Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。** 镜像不包含任何动态数据,其内容在构建之后也不会被改变。
|
||||
|
||||
Docker 设计时,就充分利用 **Union FS**的技术,将其设计为 **分层存储的架构** 。 镜像实际是由多层文件系统联合组成。
|
||||
Docker 设计时,就充分利用 **Union FS**的技术,将其设计为 **分层存储的架构** 。 镜像实际是由多层文件系统联合组成。
|
||||
|
||||
**镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。** 比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
|
||||
**镜像构建时,会一层层构建,前一层是后一层的基础。每一层构建完就不会再发生改变,后一层上的任何改变只发生在自己这一层。** 比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量只包含该层需要添加的东西,任何额外的东西应该在该层构建结束前清理掉。
|
||||
|
||||
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
|
||||
分层存储的特征还使得镜像的复用、定制变的更为容易。甚至可以用之前构建好的镜像作为基础层,然后进一步添加新的层,以定制自己所需的内容,构建新的镜像。
|
||||
|
||||
### 4.2 容器(Container):镜像运行时的实体
|
||||
|
||||
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,**容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等** 。
|
||||
镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的 类 和 实例 一样,镜像是静态的定义,**容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等** 。
|
||||
|
||||
**容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。前面讲过镜像使用的是分层存储,容器也是如此。**
|
||||
**容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 命名空间。前面讲过镜像使用的是分层存储,容器也是如此。**
|
||||
|
||||
**容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。**
|
||||
**容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随容器删除而丢失。**
|
||||
|
||||
按照 Docker 最佳实践的要求,**容器不应该向其存储层内写入任何数据** ,容器存储层要保持无状态化。**所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录**,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, **使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。**
|
||||
按照 Docker 最佳实践的要求,**容器不应该向其存储层内写入任何数据** ,容器存储层要保持无状态化。**所有的文件写入操作,都应该使用数据卷(Volume)、或者绑定宿主目录**,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此, **使用数据卷后,容器可以随意删除、重新 run ,数据却不会丢失。**
|
||||
|
||||
### 4.3 仓库(Repository):集中存放镜像文件的地方
|
||||
|
||||
### 4.3仓库(Repository):集中存放镜像文件的地方
|
||||
镜像构建完成后,可以很容易的在当前宿主上运行,但是, **如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry 就是这样的服务。**
|
||||
|
||||
镜像构建完成后,可以很容易的在当前宿主上运行,但是, **如果需要在其它服务器上使用这个镜像,我们就需要一个集中的存储、分发镜像的服务,Docker Registry就是这样的服务。**
|
||||
一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。所以说:**镜像仓库是 Docker 用来集中存放镜像文件的地方类似于我们之前常用的代码仓库。**
|
||||
|
||||
一个 Docker Registry中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。所以说:**镜像仓库是Docker用来集中存放镜像文件的地方类似于我们之前常用的代码仓库。**
|
||||
通常,**一个仓库会包含同一个软件不同版本的镜像**,而**标签就常用于对应该软件的各个版本** 。我们可以通过`<仓库名>:<标签>`的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签.。
|
||||
|
||||
通常,**一个仓库会包含同一个软件不同版本的镜像**,而**标签就常用于对应该软件的各个版本** 。我们可以通过```<仓库名>:<标签>```的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签.。
|
||||
**这里补充一下 Docker Registry 公开服务和私有 Docker Registry 的概念:**
|
||||
|
||||
**这里补充一下Docker Registry 公开服务和私有 Docker Registry的概念:**
|
||||
**Docker Registry 公开服务** 是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
|
||||
|
||||
**Docker Registry 公开服务** 是开放给用户使用、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
|
||||
最常使用的 Registry 公开服务是官方的 **Docker Hub** ,这也是默认的 Registry,并拥有大量的高质量的官方镜像,网址为:[https://hub.docker.com/](https://hub.docker.com/ "https://hub.docker.com/") 。官方是这样介绍 Docker Hub 的:
|
||||
|
||||
最常使用的 Registry 公开服务是官方的 **Docker Hub** ,这也是默认的 Registry,并拥有大量的高质量的官方镜像,网址为:[https://hub.docker.com/](https://hub.docker.com/) 。在国内访问**Docker Hub** 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [时速云镜像库](https://hub.tenxcloud.com/)、[网易云镜像服务](https://www.163yun.com/product/repo)、[DaoCloud 镜像市场](https://www.daocloud.io/)、[阿里云镜像库](https://www.aliyun.com/product/containerservice?utm_content=se_1292836)等。
|
||||
> Docker Hub 是 Docker 官方提供的一项服务,用于与您的团队查找和共享容器镜像。
|
||||
|
||||
除了使用公开服务外,用户还可以在 **本地搭建私有 Docker Registry** 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
|
||||
比如我们想要搜索自己想要的镜像:
|
||||
|
||||
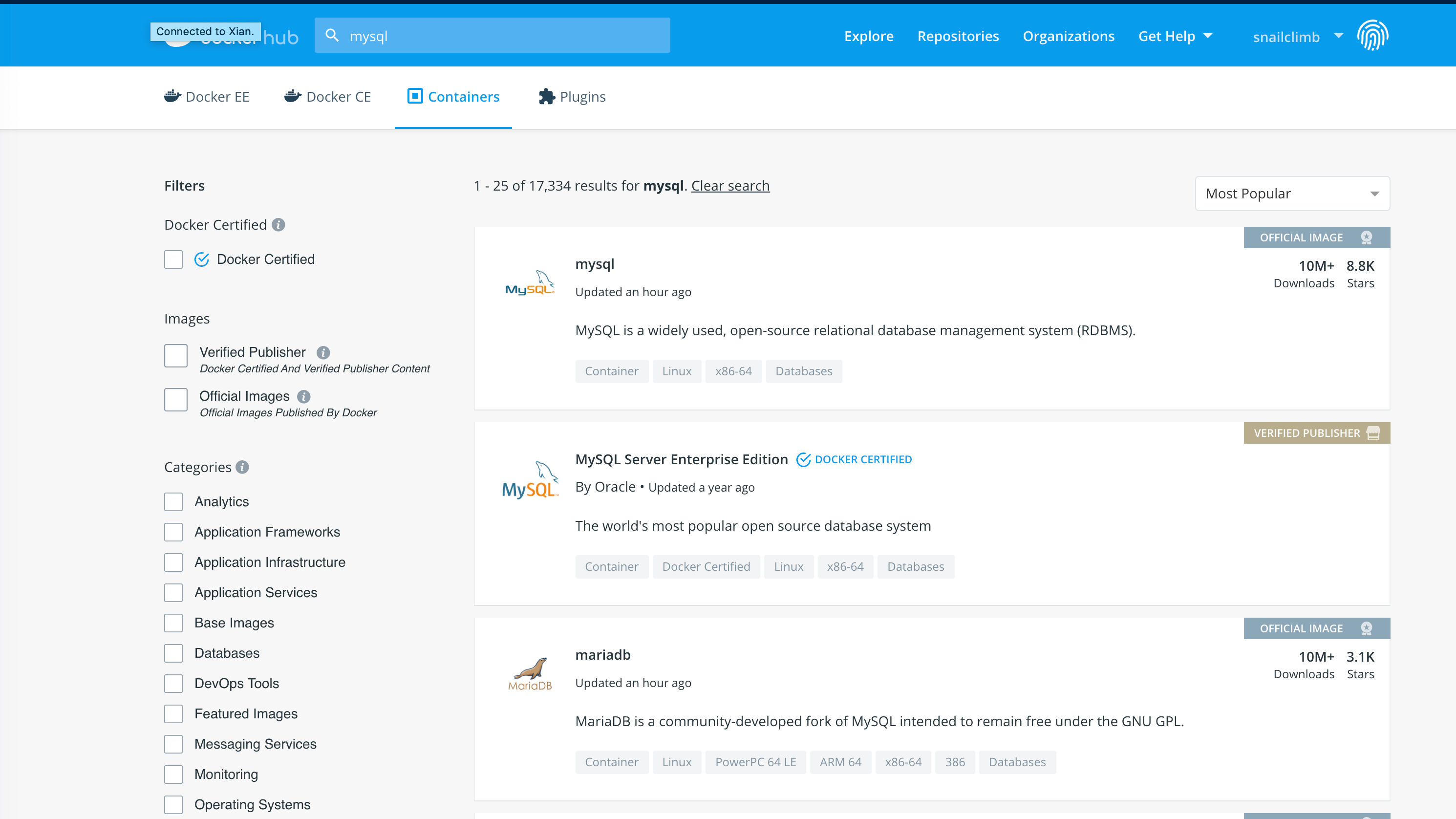
|
||||
|
||||
在 Docker Hub 的搜索结果中,有几项关键的信息有助于我们选择合适的镜像:
|
||||
|
||||
- **OFFICIAL Image** :代表镜像为 Docker 官方提供和维护,相对来说稳定性和安全性较高。
|
||||
- **Stars** :和点赞差不多的意思,类似 GitHub 的 Star。
|
||||
- **Dowloads** :代表镜像被拉取的次数,基本上能够表示镜像被使用的频度。
|
||||
|
||||
当然,除了直接通过 Docker Hub 网站搜索镜像这种方式外,我们还可以通过 `docker search` 这个命令搜索 Docker Hub 中的镜像,搜索的结果是一致的。
|
||||
|
||||
```bash
|
||||
➜ ~ docker search mysql
|
||||
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
|
||||
mysql MySQL is a widely used, open-source relation… 8763 [OK]
|
||||
mariadb MariaDB is a community-developed fork of MyS… 3073 [OK]
|
||||
mysql/mysql-server Optimized MySQL Server Docker images. Create… 650 [OK]
|
||||
```
|
||||
|
||||
在国内访问**Docker Hub** 可能会比较慢国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [时速云镜像库](https://hub.tenxcloud.com/ "时速云镜像库")、[网易云镜像服务](https://www.163yun.com/product/repo "网易云镜像服务")、[DaoCloud 镜像市场](https://www.daocloud.io/ "DaoCloud 镜像市场")、[阿里云镜像库](https://www.aliyun.com/product/containerservice?utm_content=se_1292836 "阿里云镜像库")等。
|
||||
|
||||
除了使用公开服务外,用户还可以在 **本地搭建私有 Docker Registry** 。Docker 官方提供了 Docker Registry 镜像,可以直接使用做为私有 Registry 服务。开源的 Docker Registry 镜像只提供了 Docker Registry API 的服务端实现,足以支持 docker 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。
|
||||
|
||||
---
|
||||
|
||||
> Docker的概念基本上已经讲完,最后我们谈谈:Build, Ship, and Run。
|
||||
## 五 常见命令
|
||||
|
||||
## 五 最后谈谈:Build Ship and Run
|
||||
如果你搜索Docker官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么Build, Ship, and Run到底是在干什么呢?
|
||||
### 5.1 基本命令
|
||||
|
||||
```bash
|
||||
docker version # 查看docker版本
|
||||
docker images # 查看所有已下载镜像,等价于:docker image ls 命令
|
||||
docker container ls # 查看所有容器
|
||||
docker ps #查看正在运行的容器
|
||||
docker image prune # 清理临时的、没有被使用的镜像文件。-a, --all: 删除所有没有用的镜像,而不仅仅是临时文件;
|
||||
```
|
||||
|
||||
### 5.2 拉取镜像
|
||||
|
||||
```bash
|
||||
docker search mysql # 查看mysql相关镜像
|
||||
docker pull mysql:5.7 # 拉取mysql镜像
|
||||
docker image ls # 查看所有已下载镜像
|
||||
```
|
||||
|
||||
### 5.3 删除镜像
|
||||
|
||||
比如我们要删除我们下载的 mysql 镜像。
|
||||
|
||||
通过 `docker rmi [image]` (等价于`docker image rm [image]`)删除镜像之前首先要确保这个镜像没有被容器引用(可以通过标签名称或者镜像 ID删除)。通过我们前面讲的` docker ps`命令即可查看。
|
||||
|
||||
```shell
|
||||
➜ ~ docker ps
|
||||
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
|
||||
c4cd691d9f80 mysql:5.7 "docker-entrypoint.s…" 7 weeks ago Up 12 days 0.0.0.0:3306->3306/tcp, 33060/tcp mysql
|
||||
```
|
||||
|
||||
可以看到 mysql 正在被 id 为 c4cd691d9f80 的容器引用,我们需要首先通过 `docker stop c4cd691d9f80` 或者 `docker stop mysql`暂停这个容器。
|
||||
|
||||
然后查看 mysql 镜像的 id
|
||||
|
||||
```shell
|
||||
➜ ~ docker images
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
mysql 5.7 f6509bac4980 3 months ago 373MB
|
||||
```
|
||||
|
||||
通过 IMAGE ID 或者 REPOSITORY 名字即可删除
|
||||
|
||||
```shell
|
||||
docker rmi f6509bac4980 # 或者 docker rmim mysql
|
||||
```
|
||||
|
||||
## 六 Build Ship and Run
|
||||
|
||||
**Docker 的概念以及常见命令基本上已经讲完,我们再来谈谈:Build, Ship, and Run。**
|
||||
|
||||
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||
|
||||

|
||||
|
||||
@ -206,15 +256,51 @@ Docker 包括三个基本概念
|
||||
- **Ship(运输镜像)** :主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||
- **Run (运行镜像)** :运行的镜像就是一个容器,容器就是运行程序的地方。
|
||||
|
||||
**Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将Docker称为码头工人或码头装卸工,这和Docker的中文翻译搬运工人如出一辙。**
|
||||
**Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。**
|
||||
|
||||
## 六 总结
|
||||
## 七 简单了解一下 Docker 底层原理
|
||||
|
||||
本文主要把Docker中的一些常见概念做了详细的阐述,但是并不涉及Docker的安装、镜像的使用、容器的操作等内容。这部分东西,希望读者自己可以通过阅读书籍与官方文档的形式掌握。如果觉得官方文档阅读起来很费力的话,这里推荐一本书籍《Docker技术入门与实战第二版》。
|
||||
### 7.1 虚拟化技术
|
||||
|
||||
首先,Docker **容器虚拟化**技术为基础的软件,那么什么是虚拟化技术呢?
|
||||
|
||||
简单点来说,虚拟化技术可以这样定义:
|
||||
|
||||
> 虚拟化技术是一种资源管理技术,是将计算机的各种[实体资源](https://zh.wikipedia.org/wiki/資源_(計算機科學 "实体资源"))([CPU](https://zh.wikipedia.org/wiki/CPU "CPU")、[内存](https://zh.wikipedia.org/wiki/内存 "内存")、[磁盘空间](https://zh.wikipedia.org/wiki/磁盘空间 "磁盘空间")、[网络适配器](https://zh.wikipedia.org/wiki/網路適配器 "网络适配器")等),予以抽象、转换后呈现出来并可供分割、组合为一个或多个电脑配置环境。由此,打破实体结构间的不可切割的障碍,使用户可以比原本的配置更好的方式来应用这些电脑硬件资源。这些资源的新虚拟部分是不受现有资源的架设方式,地域或物理配置所限制。一般所指的虚拟化资源包括计算能力和数据存储。
|
||||
|
||||
###7.2 Docker 基于 LXC 虚拟容器技术
|
||||
|
||||
Docker 技术是基于 LXC(Linux container- Linux 容器)虚拟容器技术的。
|
||||
|
||||
> LXC,其名称来自 Linux 软件容器(Linux Containers)的缩写,一种操作系统层虚拟化(Operating system–level virtualization)技术,为 Linux 内核容器功能的一个用户空间接口。它将应用软件系统打包成一个软件容器(Container),内含应用软件本身的代码,以及所需要的操作系统核心和库。通过统一的名字空间和共用 API 来分配不同软件容器的可用硬件资源,创造出应用程序的独立沙箱运行环境,使得 Linux 用户可以容易的创建和管理系统或应用容器。
|
||||
|
||||
LXC 技术主要是借助 Linux 内核中提供的 CGroup 功能和 name space 来实现的,通过 LXC 可以为软件提供一个独立的操作系统运行环境。
|
||||
|
||||
**cgroup 和 namespace 介绍:**
|
||||
|
||||
- **namespace 是 Linux 内核用来隔离内核资源的方式。** 通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
|
||||
|
||||
(以上关于 namespace 介绍内容来自https://www.cnblogs.com/sparkdev/p/9365405.html ,更多关于 namespace 的呢内容可以查看这篇文章 )。
|
||||
|
||||
- **CGroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组 (process groups) 所使用的物力资源 (如 cpu memory i/o 等等) 的机制。**
|
||||
|
||||
(以上关于 CGroup 介绍内容来自 https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html ,更多关于 CGroup 的呢内容可以查看这篇文章 )。
|
||||
|
||||
**cgroup 和 namespace 两者对比:**
|
||||
|
||||
两者都是将进程进行分组,但是两者的作用还是有本质区别。namespace 是为了隔离进程组之间的资源,而 cgroup 是为了对一组进程进行统一的资源监控和限制。
|
||||
|
||||
## 八 总结
|
||||
|
||||
本文主要把 Docker 中的一些常见概念做了详细的阐述,但是并不涉及 Docker 的安装、镜像的使用、容器的操作等内容。这部分东西,希望读者自己可以通过阅读书籍与官方文档的形式掌握。如果觉得官方文档阅读起来很费力的话,这里推荐一本书籍《Docker 技术入门与实战第二版》。
|
||||
|
||||
## 九 推荐阅读
|
||||
|
||||
- [10 分钟看懂 Docker 和 K8S](https://zhuanlan.zhihu.com/p/53260098 "10分钟看懂Docker和K8S")
|
||||
- [从零开始入门 K8s:详解 K8s 容器基本概念](https://www.infoq.cn/article/te70FlSyxhltL1Cr7gzM "从零开始入门 K8s:详解 K8s 容器基本概念")
|
||||
|
||||
## 十 参考
|
||||
|
||||
- [Linux Namespace 和 Cgroup](https://segmentfault.com/a/1190000009732550 "Linux Namespace和Cgroup")
|
||||
- [LXC vs Docker: Why Docker is Better](https://www.upguard.com/articles/docker-vs-lxc "LXC vs Docker: Why Docker is Better")
|
||||
- [CGroup 介绍、应用实例及原理描述](https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html "CGroup 介绍、应用实例及原理描述")
|
||||
|
||||
149
docs/tools/阿里云服务器使用经验.md
Normal file
149
docs/tools/阿里云服务器使用经验.md
Normal file
@ -0,0 +1,149 @@
|
||||
最近很多阿里云双 11 做活动,优惠力度还挺大的,很多朋友都买以最低的价格买到了自己的云服务器。不论是作为学习机还是部署自己的小型网站或者服务来说都是很不错的!
|
||||
|
||||
但是,很多朋友都不知道如何正确去使用。下面我简单分享一下自己的使用经验。
|
||||
|
||||
总结一下,主要涉及下面几个部分,对于新手以及没有这么使用过云服务的朋友还是比较友好的:
|
||||
|
||||
1. 善用阿里云镜像市场节省安装 Java 环境的时间,相关说明都在根目录下的 readme.txt. 文件里面;
|
||||
2. 本地通过 SSH 连接阿里云服务器很容易,配置好 Host地址,通过 root 用户加上实例密码直接连接即可。
|
||||
3. 本地连接 MySQL 数据库需要简单配置一下安全组和并且允许 root 用户在任何地方进行远程登录。
|
||||
4. 通过 Alibaba Cloud Toolkit 部署 Spring Boot 项目到阿里云服务器真的很方便。
|
||||
|
||||
**[活动地址](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
|
||||
|
||||
### 善用阿里云镜像市场节省安装环境的时间
|
||||
|
||||
基本的购买流程这里就不多说了,另外这里需要注意的是:其实 Java 环境是不需要我们手动安装配置的,阿里云提供的镜像市场有一些常用的环境。
|
||||
|
||||
> 阿里云镜像市场是指阿里云建立的、由镜像服务商向用户提供其镜像及相关服务的网络平台。这些镜像在操作系统上整合了具体的软件环境和功能,比如Java、PHP运行环境、控制面板等,供有相关需求的用户开通实例时选用。
|
||||
|
||||
具体如何在购买云服务器的时候通过镜像创建实例或者已有ECS用户如何使用镜像可以查看官方详细的介绍,地址:
|
||||
|
||||
https://help.aliyun.com/knowledge_detail/41987.html?spm=a2c4g.11186631.2.1.561e2098dIdCGZ
|
||||
|
||||
### 当我们成功购买服务器之后如何通过 SSH 连接呢?
|
||||
|
||||
创建好 ECS 后,你绑定的手机会收到短信,会告知你初始密码的。你可以登录管理控制台对密码进行修改,修改密码需要在管理控制台重启服务器才能生效。
|
||||
|
||||
你也可以在阿里云 ECS 控制台重置实例密码,如下图所示。
|
||||
|
||||

|
||||
|
||||
**第一种连接方式是直接在阿里云服务器管理的网页上连接**。如上图所示, 点击远程连接,然后输入远程连接密码,这个并不是你重置实例密码得到的密码,如果忘记了直接修改远程连接密码即可。
|
||||
|
||||
**第二种方式是在本地通过命令或者软件连接。** 推荐使用这种方式,更加方便。
|
||||
|
||||
**Windows 推荐使用 Xshell 连接,具体方式如下:**
|
||||
|
||||
> Window电脑在家,这里直接用找到的一些图片给大家展示一个。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
接着点开,输入账号:root,命名输入刚才设置的密码,点ok就可以了
|
||||
|
||||
|
||||
|
||||
**Mac 或者 Linux 系统都可以直接使用 ssh 命令进行连接,非常方便。**
|
||||
|
||||
成功连接之后,控制台会打印出如下消息。
|
||||
|
||||
```shell
|
||||
➜ ~ ssh root@47.107.159.12 -p 22
|
||||
root@47.107.159.12's password:
|
||||
Last login: Wed Oct 30 09:31:31 2019 from 220.249.123.170
|
||||
|
||||
Welcome to Alibaba Cloud Elastic Compute Service !
|
||||
|
||||
欢迎使用 Tomcat8 JDK8 Mysql5.7 环境
|
||||
|
||||
使用说明请参考 /root/readme.txt 文件
|
||||
```
|
||||
|
||||
我当时选择是阿里云提供好的 Java 环境,自动就提供了 Tomcat、 JDK8 、Mysql5.7,所以不需要我们再进行安装配置了,节省了很多时间。另外,需要注意的是:**一定要看 /readme.txt ,Tomcat、 JDK8 、Mysql5.7相关配置以及安装路径等说明都在里面。**
|
||||
|
||||
### 如何连接数据库?
|
||||
|
||||
**如需外网远程访问mysql 请参考以上网址 设置mysql及阿里云安全组**。
|
||||
|
||||

|
||||
|
||||
Mysql为了安全性,在默认情况下用户只允许在本地登录,但是可以使用 SSH 方式连接。如果我们不想通过 SSH 方式连接的话就需要对 MySQL 进行简单的配置。
|
||||
|
||||
```shell
|
||||
#允许root用户在任何地方进行远程登录,并具有所有库任何操作权限:
|
||||
# *.*代表所有库表 “%”代表所有IP地址
|
||||
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY "自定义密码" WITH GRANT OPTION;
|
||||
Query OK, 0 rows affected, 1 warning (0.00 sec)
|
||||
#刷新权限。
|
||||
mysql>flush privileges;
|
||||
#退出mysql
|
||||
mysql>exit
|
||||
#重启MySQL生效
|
||||
[root@snailclimb]# systemctl restart mysql
|
||||
```
|
||||
|
||||
这样的话,我们就能在本地进行连接了。Windows 推荐使用Navicat或者SQLyog。
|
||||
|
||||
> Window电脑在家,这里用 Mac 上的MySQL可视化工具Sequel Pro给大家演示一下。
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Screen Shot 2019-10-30 at 11.02.26 AM.png" style="zoom:50%;" />
|
||||
|
||||
### 如何把一个Spring Boot 项目部署到服务器上呢?
|
||||
|
||||
默认大家都是用 IDEA 进行开发。另外,你要有一个简单的 Spring Boot Web 项目。如果还不了解 Spring Boot 的话,一个简单的 Spring Boot 版 "Hello World "项目,地址如下:
|
||||
|
||||
https://github.com/Snailclimb/springboot-guide/blob/master/docs/start/springboot-hello-world.md 。
|
||||
|
||||
**1.下载一个叫做 Alibaba Cloud Toolkit 的插件。**
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Alibaba-Cloud-Toolkit.png" style="zoom:50%;" />
|
||||
|
||||
**2.进入 Preference 配置一个 Access Key ID 和 Access Key Secret。**
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Screen Shot 2019-10-30 at 10.10.23 AM.png" style="zoom:50%;" />
|
||||
|
||||
**3.部署项目到 ECS 上。**
|
||||
|
||||
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/deploy-to-ecs2.png" style="zoom:50%;" />
|
||||
|
||||
按照上面这样填写完基本配置之后,然后点击 run 运行即可。运行成功,控制台会打印出如下信息:
|
||||
|
||||
```shell
|
||||
[INFO] Deployment File is Uploading...
|
||||
[INFO] IDE Version:IntelliJ IDEA 2019.2
|
||||
[INFO] Alibaba Cloud Toolkit Version:2019.9.1
|
||||
[INFO] Start upload hello-world-0.0.1-SNAPSHOT.jar
|
||||
[INFO][##################################################] 100% (18609645/18609645)
|
||||
[INFO] Succeed to upload, 18609645 bytes have been uploaded.
|
||||
[INFO] Upload Deployment File to OSS Success
|
||||
[INFO] Target Deploy ECS: { 172.18.245.148 / 47.107.159.12 }
|
||||
[INFO] Command: { source /etc/profile; cd /springboot; }
|
||||
Tip: The deployment package will be temporarily stored in Alibaba Cloud Security OSS and will be
|
||||
deleted after the deployment is complete. Please be assured that no one can access it except you.
|
||||
|
||||
[INFO] Create Deploy Directory Success.
|
||||
|
||||
[INFO] Deployment File is Downloading...
|
||||
[INFO] Download Deployment File from OSS Success
|
||||
|
||||
[INFO] File Upload Total time: 16.676 s
|
||||
```
|
||||
|
||||
通过控制台答应出的信息可以看出:通过这个插件会自动把这个 Spring Boot 项目打包成一个 jar 包,然后上传到你的阿里云服务器中指定的文件夹中,你只需要登录你的阿里云服务器,然后通过 `java -jar hello-world-0.0.1-SNAPSHOT.jar`命令运行即可。
|
||||
|
||||
```shell
|
||||
[root@snailclimb springboot]# ll
|
||||
total 18176
|
||||
-rw-r--r-- 1 root root 18609645 Oct 30 08:25 hello-world-0.0.1-SNAPSHOT.jar
|
||||
[root@snailclimb springboot]# java -jar hello-world-0.0.1-SNAPSHOT.jar
|
||||
```
|
||||
|
||||
然后你就可以在本地访问访问部署在你的阿里云 ECS 上的服务了。
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Screen Shot 2019-10-30 at 10.32.06 AM.png" style="zoom:50%;" />
|
||||
|
||||
**[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
|
||||
Loading…
x
Reference in New Issue
Block a user