mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]完善MySQL索引详解
添加索引类型总结、完善正确使用索引的一些建议
This commit is contained in:
parent
be1b16ffcf
commit
01d8de7380
@ -84,9 +84,36 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
|
||||
>
|
||||
> InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“**聚簇索引(聚集索引)**”,而其余的索引都作为 **辅助索引** ,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
|
||||
|
||||
## 索引类型
|
||||
## 索引类型总结
|
||||
|
||||
### 主键索引(Primary Key)
|
||||
按照数据结构维度划分:
|
||||
|
||||
- BTree 索引:MySQL 里默认和最常用的索引类型。只有叶子节点存储 value,非叶子节点只有指针和 key。存储引擎 MyISAM 和 InnoDB 实现 BTree 索引都是使用 B+Tree,但二者实现方式不一样(前面已经介绍了)。
|
||||
- 哈希索引:类似键值对的形式,一次即可定位。
|
||||
- RTree 索引:一般不会使用,仅支持 geometry 数据类型,优势在于范围查找,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
|
||||
- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
|
||||
|
||||
按照底层存储方式角度划分:
|
||||
|
||||
- 聚簇索引(聚集索引):索引结构和数据一起存放的索引,InnoDB 中的主键索引就属于聚簇索引。
|
||||
- 非聚簇索引(非聚集索引):索引结构和数据分开存放的索引,二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。
|
||||
|
||||
按照应用维度划分:
|
||||
|
||||
- 主键索引:加速查询 + 列值唯一(不可以有 NULL)+ 表中只有一个。
|
||||
- 普通索引:仅加速查询。
|
||||
- 唯一索引:加速查询 + 列值唯一(可以有 NULL)。
|
||||
- 覆盖索引:一个索引包含(或者说覆盖)所有需要查询的字段的值。
|
||||
- 联合索引:多列值组成一个索引,专门用于组合搜索,其效率大于索引合并。
|
||||
- 全文索引:对文本的内容进行分词,进行搜索。目前只有 `CHAR`、`VARCHAR` ,`TEXT` 列上可以创建全文索引。一般不会使用,效率较低,通常使用搜索引擎如 ElasticSearch 代替。
|
||||
|
||||
MySQL 8.x 中实现的索引新特性:
|
||||
|
||||
- 隐藏索引:也称为不可见索引,不会被优化器使用,但是仍然需要维护,通常会软删除和灰度发布的场景中使用。主键不能设置为隐藏(包括显式设置或隐式设置)。
|
||||
- 降序索引:之前的版本就支持通过 desc 来指定索引为降序,但实际上创建的仍然是常规的升序索引。直到 MySQL 8.x 版本才开始真正支持降序索引。另外,在 MySQL 8.x 版本中,不再对 GROUP BY 语句进行隐式排序。
|
||||
- 函数索引:从 MySQL 8.0.13 版本开始支持在索引中使用函数或者表达式的值,也就是在索引中可以包含函数或者表达式。
|
||||
|
||||
## 主键索引(Primary Key)
|
||||
|
||||
数据表的主键列使用的就是主键索引。
|
||||
|
||||
@ -96,7 +123,7 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
|
||||
|
||||
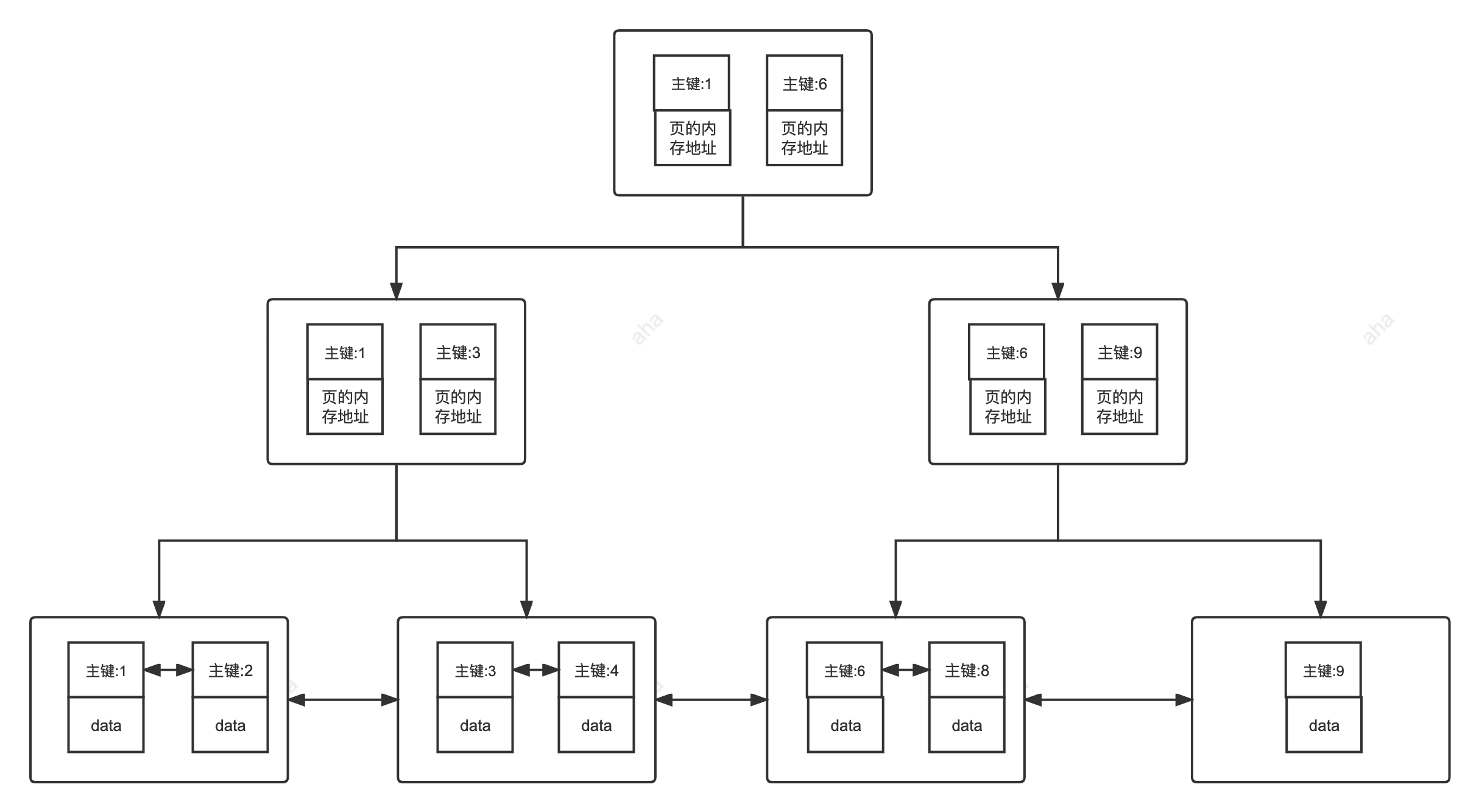
|
||||
|
||||
### 二级索引(辅助索引)
|
||||
## 二级索引(辅助索引)
|
||||
|
||||
**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
||||
|
||||
@ -140,7 +167,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
||||
|
||||
#### 非聚簇索引介绍
|
||||
|
||||
**非聚簇索引即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引**
|
||||
**非聚簇索引即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。**
|
||||
|
||||
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
|
||||
|
||||
@ -226,6 +253,14 @@ SELECT id FROM table WHERE id=1;
|
||||
|
||||
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。 如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
|
||||
|
||||
### 限制每张表上的索引数量
|
||||
|
||||
索引并不是越多越好,建议单张表索引不超过 5 个!索引可以提高效率同样可以降低效率。
|
||||
|
||||
索引可以增加查询效率,但同样也会降低插入和更新的效率,甚至有些情况下会降低查询效率。
|
||||
|
||||
因为 MySQL 优化器在选择如何优化查询时,会根据统一信息,对每一个可以用到的索引来进行评估,以生成出一个最好的执行计划,如果同时有很多个索引都可以用于查询,就会增加 MySQL 优化器生成执行计划的时间,同样会降低查询性能。
|
||||
|
||||
### 尽可能的考虑建立联合索引而不是单列索引
|
||||
|
||||
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
|
||||
@ -234,7 +269,7 @@ SELECT id FROM table WHERE id=1;
|
||||
|
||||
冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
||||
|
||||
### 考虑在字符串类型的字段上使用前缀索引代替普通索引
|
||||
### 字符串类型的字段使用前缀索引代替普通索引
|
||||
|
||||
前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
|
||||
|
||||
@ -245,11 +280,50 @@ SELECT id FROM table WHERE id=1;
|
||||
- 使用 `SELECT *` 进行查询;
|
||||
- 创建了组合索引,但查询条件未准守最左匹配原则;
|
||||
- 在索引列上进行计算、函数、类型转换等操作;
|
||||
- 以 % 开头的 LIKE 查询比如 `like '%abc';`;
|
||||
- 以 `%` 开头的 LIKE 查询比如 `like '%abc';`;
|
||||
- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
|
||||
- 发生[隐式转换](https://javaguide.cn/database/mysql/index-invalidation-caused-by-implicit-conversion.html);
|
||||
- ......
|
||||
|
||||
### 删除长期未使用的索引
|
||||
|
||||
删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
|
||||
删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗。
|
||||
|
||||
MySQL 5.7 可以通过查询 `sys` 库的 `schema_unused_indexes` 视图来查询哪些索引从未被使用。
|
||||
|
||||
### 知道如何分析语句是否走索引查询
|
||||
|
||||
我们可以使用 `EXPLAIN` 命令来分析 SQL 的 **执行计划** ,这样就知道语句是否命中索引了。执行计划是指一条 SQL 语句在经过 MySQL 查询优化器的优化会后,具体的执行方式。
|
||||
|
||||
`EXPLAIN` 并不会真的去执行相关的语句,而是通过 **查询优化器** 对语句进行分析,找出最优的查询方案,并显示对应的信息。
|
||||
|
||||
`EXPLAIN` 的输出格式如下:
|
||||
|
||||
```sql
|
||||
mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
||||
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
|
||||
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|
||||
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
|
||||
| 1 | SIMPLE | cus_order | NULL | ALL | NULL | NULL | NULL | NULL | 997572 | 100.00 | Using filesort |
|
||||
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
|
||||
1 row in set, 1 warning (0.00 sec)
|
||||
```
|
||||
|
||||
各个字段的含义如下:
|
||||
|
||||
| **列名** | **含义** |
|
||||
| ------------- | -------------------------------------------- |
|
||||
| id | SELECT 查询的序列标识符 |
|
||||
| select_type | SELECT 关键字对应的查询类型 |
|
||||
| table | 用到的表名 |
|
||||
| partitions | 匹配的分区,对于未分区的表,值为 NULL |
|
||||
| type | 表的访问方法 |
|
||||
| possible_keys | 可能用到的索引 |
|
||||
| key | 实际用到的索引 |
|
||||
| key_len | 所选索引的长度 |
|
||||
| ref | 当使用索引等值查询时,与索引作比较的列或常量 |
|
||||
| rows | 预计要读取的行数 |
|
||||
| filtered | 按表条件过滤后,留存的记录数的百分比 |
|
||||
| Extra | 附加信息 |
|
||||
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
|
||||
@ -681,7 +681,7 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
||||
| filtered | 按表条件过滤后,留存的记录数的百分比 |
|
||||
| Extra | 附加信息 |
|
||||
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](./mysql-query-execution-plan.md)这篇文章。
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
|
||||
### 读写分离和分库分表了解吗?
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user