mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Update rocketmq-questions.md
修改两处拼写错误,RockeMQ -> RocketMQ.
This commit is contained in:
parent
c183e05b5e
commit
0110397c6d
@ -891,13 +891,13 @@ RocketMQ 内部主要是使用基于 mmap 实现的零拷贝(其实就是调用
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
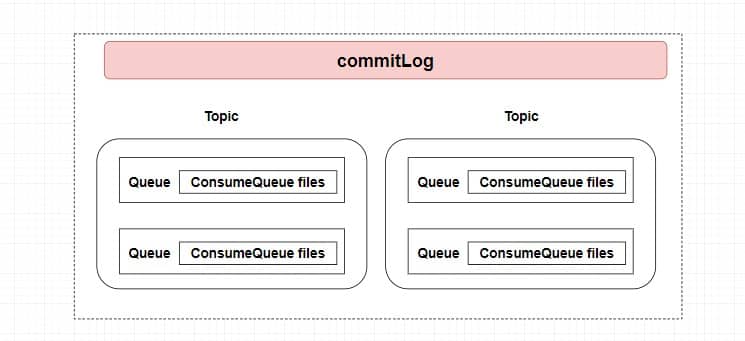
`RocketMQ` 采用的是 **混合型的存储结构** ,即为 `Broker` 单个实例下所有的队列共用一个日志数据文件来存储消息。有意思的是在同样高并发的 `Kafka` 中会为每个 `Topic` 分配一个存储文件。这就有点类似于我们有一大堆书需要装上书架,`RockeMQ` 是不分书的种类直接成批的塞上去的,而 `Kafka` 是将书本放入指定的分类区域的。
|
`RocketMQ` 采用的是 **混合型的存储结构** ,即为 `Broker` 单个实例下所有的队列共用一个日志数据文件来存储消息。有意思的是在同样高并发的 `Kafka` 中会为每个 `Topic` 分配一个存储文件。这就有点类似于我们有一大堆书需要装上书架,`RocketMQ` 是不分书的种类直接成批的塞上去的,而 `Kafka` 是将书本放入指定的分类区域的。
|
||||||
|
|
||||||
而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
|
而 `RocketMQ` 为什么要这么做呢?原因是 **提高数据的写入效率** ,不分 `Topic` 意味着我们有更大的几率获取 **成批** 的消息进行数据写入,但也会带来一个麻烦就是读取消息的时候需要遍历整个大文件,这是非常耗时的。
|
||||||
|
|
||||||
所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号\*索引固定⻓度 20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
|
所以,在 `RocketMQ` 中又使用了 `ConsumeQueue` 作为每个队列的索引文件来 **提升读取消息的效率**。我们可以直接根据队列的消息序号,计算出索引的全局位置(索引序号\*索引固定⻓度 20),然后直接读取这条索引,再根据索引中记录的消息的全局位置,找到消息。
|
||||||
|
|
||||||
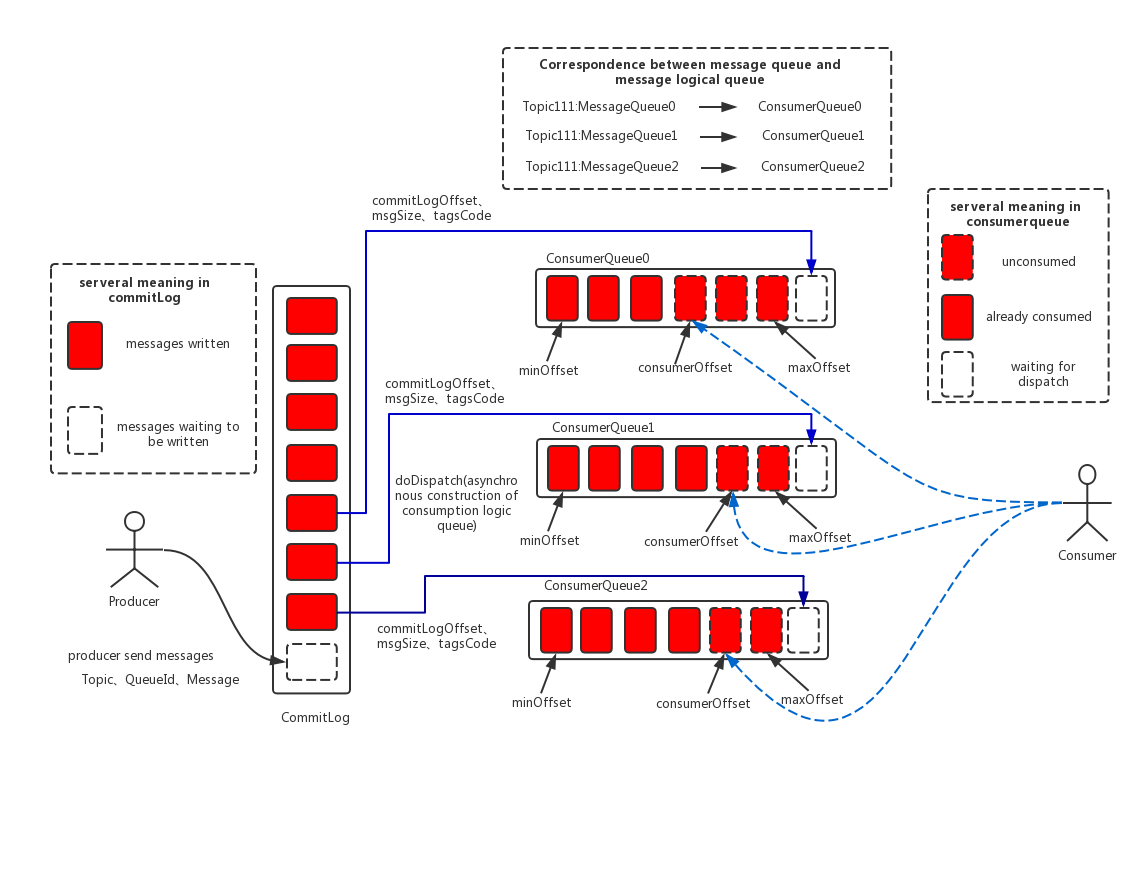
讲到这里,你可能对 `RockeMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
|
讲到这里,你可能对 `RocketMQ` 的存储架构还有些模糊,没事,我们结合着图来理解一下。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user